
关键词:类脑大模型, AI芯片, 万亿参数模型, 具身智能, RAG框架, AI代理, LLM推理加速, SpikingBrain-1.0, OpenAI Broadcom定制芯片, Qwen3-Max-Preview, WALL-OSS开源模型, REFRAG框架
🔥 聚焦
中国科学院发布线性复杂度类脑大模型SpikingBrain-1.0 : 采用脉冲神经元机制,实现线性/近线性复杂度,在国产GPU上长序列TTFT速度提升26.5x至100x以上,并在手机CPU端解码速度大幅提升。该模型以极低数据量实现高效训练,展示了类脑架构在解决Transformer架构二次方复杂度限制方面的巨大潜力,为国产自主可控AI生态奠定基础。(来源:量子位)

OpenAI与Broadcom签订100亿美元定制AI芯片协议 : OpenAI为解决AI发展中的芯片短缺问题,与Broadcom达成100亿美元协议,定制AI服务器机架以支持下一代模型。此举凸显AI军备竞赛已转向硬件控制,旨在加速AI训练并降低成本,预示着AI技术突破将依赖于对底层硬件供应链的掌控。(来源:Reddit r/ArtificialInteligence)

阿里发布万亿参数模型Qwen3-Max-Preview : 阿里巴巴推出迄今最大模型Qwen3-Max-Preview(Instruct),参数达1万亿,在中文理解、复杂指令遵循、工具调用等方面显著增强,并大幅减少知识幻觉。实测显示其在AIME数学竞赛题和编程任务中表现出色,支持多模态输入,且编程任务一次成功,性能超越Claude Opus 4。(来源:量子位)
自变量机器人开源具身智能基础大模型WALL-OSS : 自变量机器人正式开源WALL-OSS,这是一个4.2B参数的通用基础具身模型,具备语言、视觉、动作多模态端到端统一输出能力,并在泛化性和推理能力上超越π0。该模型支持单卡训练和开放泛化,可快速适配各类轮式机器人,旨在以最低成本为行业提供最强基座,打破具身智能“不可能三角”困境。(来源:量子位, ZhihuFrontier)

Meta超级智能实验室重新定义RAG,推出REFRAG框架 : Meta超级智能实验室发布首篇论文,提出REFRAG高效解码框架,通过“压缩、感知、扩展”流程优化RAG,将首字生成延迟(TTFT)最高加速30倍,且在困惑度和下游任务准确率上无性能损失。该框架有效解决了长上下文处理的效率问题。(来源:量子位)

🎯 动向
机器人与AI融合:会说话会思考的机器狗 : 机器狗正变得更加智能,通过集成ChatGPT等AI大脑,它们现在不仅能说话,还能进行思考。这标志着机器人技术与AI的深度融合,预示着未来机器人将具备更高级的交互和认知能力,有望在更多实际场景中发挥作用。(来源:Ronald_vanLoon)
中国开源LLM的崛起与Kimi K2.1 Turbo的性能表现 : 社交媒体热议中国在开源LLM领域的显著贡献,如Kimi K2、Qwen3系列和GLM-4.5。Kimi K2.1 Turbo在速度和成本效益上表现出色,其速度是Opus 4.1的3倍,成本便宜7倍,且性能相当,被认为是当前最佳的开源编码代理模型之一。(来源:scaling01, jeremyphoward, JonathanRoss321, crystalsssup)
Google Nano Banana模型赋能图像编辑 : Google的Nano Banana模型在图像编辑领域展现出革命性能力,实现像素级精确编辑和交错生成,使用户通过简单指令即可精准调整图片。该模型低成本、高速度的特点有望催生广泛应用,并提升图生视频的上限。(来源:cloneofsimo, Kling_ai, algo_diver, op7418)
微软亚洲研究院提出DELT数据排序范式提升LLM训练效能 : 微软亚洲研究院发布DELT范式,通过优化训练数据的组织方式来提升语言模型性能,无需增加数据量或扩大模型规模。该方法引入Learning-Quality Score和Folding Ordering策略,在不同模型尺寸和数据规模下均显著提升模型性能。(来源:量子位)
IndexTTS-2.0:情感表达丰富、时长可控的零样本文本转语音系统 : IndexTTS-2.0正式开源,该系统创新性地引入“时间编码”机制,首次解决了传统自回归模型在语音时长精确控制上的挑战。它还通过音色-情感解耦建模,提供多样灵活的情感控制方法,显著增强了合成语音的表达力。(来源:Reddit r/LocalLLaMA)

Set Block Decoding加速LLM推理 : Set Block Decoding (SBD) 是一种新的语言模型推理加速范式,通过在单一架构中整合标准下一词元预测和掩码词元预测,实现并行采样多个未来词元。SBD无需架构更改或额外训练,可将生成所需的正向传播次数减少3-5倍,同时保持与NTP训练相同的性能。(来源:HuggingFace Daily Papers)
远程机器人手术实现8000公里跨越 : 罗马的外科医生成功对8000公里外的北京患者进行了远程机器人手术。这一突破性进展展示了机器人技术在医疗领域的巨大潜力,尤其是在远程医疗和复杂手术操作方面,有望极大扩展医疗服务的可及性。(来源:Ronald_vanLoon)
视觉语言模型MedVista3D降低3D CT诊断错误 : MedVista3D是一个多尺度语义增强的视觉语言预训练框架,用于3D CT分析,旨在解决放射诊断错误。它通过局部和全局图像-文本对齐,实现精确的局部检测、全局体积级推理和语义一致的自然语言报告,在零样本疾病分类、报告检索和医学视觉问答方面取得了最先进的性能。(来源:HuggingFace Daily Papers)
🧰 工具
n8n Workflow Collection & Documentation系统 : Zie619开源了一个包含2053个n8n工作流的集合,并提供高性能文档系统。该系统支持闪电般的全文本搜索、智能分类(包括AI Agent开发),并能生成工作流可视化图表,旨在帮助开发者和业务分析师高效管理和利用自动化工作流。(来源:GitHub Trending)
Kotaemon:开源RAG文档聊天工具 : Cinnamon开源了Kotaemon,一个基于RAG的文档聊天UI工具,旨在帮助用户对文档进行问答,并为开发者构建RAG管道提供框架。它支持多种LLM(包括本地模型),提供混合RAG管道、多模态QA支持、高级引用和可配置的UI设置,并支持GraphRAG和LightRAG集成。(来源:GitHub Trending)

Jaaz:开源多模态创意助手 : 11cafe开源了Jaaz,一款全球首个多模态创意助手,旨在替代Canva和Manus,并优先考虑隐私和本地使用。它支持一键图像和视频生成、魔术画布、智能AI代理系统,并提供灵活的部署选项和本地资产管理。(来源:GitHub Trending)

Qwen Chat将研究论文转换为网站 : Qwen Chat推出新功能,用户可以上传研究论文,让Qwen Chat自动将其转换为网页并即时部署。这一功能极大地简化了学术内容的在线发布流程,提高了效率,并得到了社区的积极反馈。(来源:nrehiew_, huybery)
英伟达推出通用深度研究系统UDR,支持LLM定制 : 英伟达发布通用深度研究(UDR)系统,允许用户通过自然语言自定义研究策略,并可接入任何LLM。UDR将研究逻辑与语言模型解耦,提升了智能体的自主性,降低了GPU资源消耗和研究成本,为企业和开发者提供了高度灵活的深度研究解决方案。(来源:量子位)

MCP文件生成工具v0.4.0 : OWUI_File_Gen_Export发布v0.4.0版本,该AI驱动的文件生成工具现支持PPTX、PDF中的图像嵌入、嵌套文件夹和文件层次结构,并提供全面的日志记录。它将AI从简单的聊天扩展到生成专业文件,提升了文档、报告和演示文稿的生产力。(来源:Reddit r/OpenWebUI)

Vercel AI SDK构建开源“Vibe Coding Platform” : 一个新的开源“Vibe Coding Platform”已发布,利用Vercel AI SDK、Gateway和Sandbox,并与OpenAI合作优化GPT-5代理循环。该平台能够读写文件、运行命令、安装包和自动修复错误,旨在提供更流畅、智能的编码体验。(来源:kylebrussell)
📚 学习
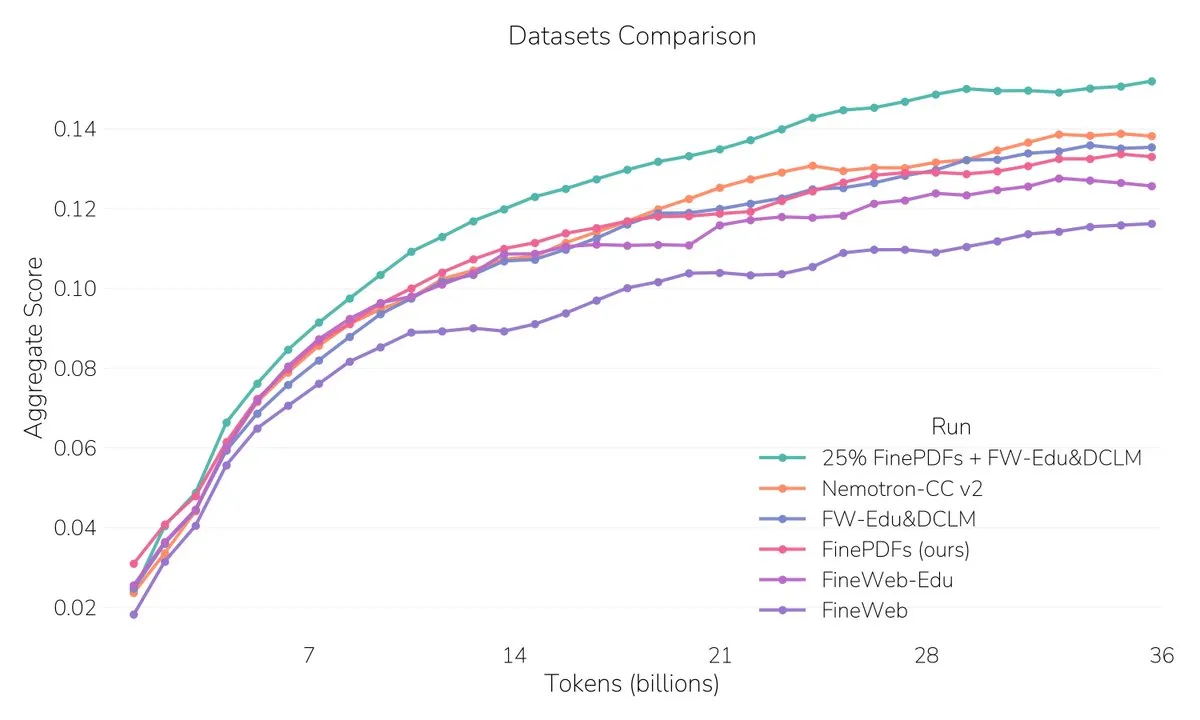
FinePDFs:最大的PDF数据集发布 : Hugging Face发布了FinePDFs,这是迄今为止最大的PDF数据集,包含超过5亿份文档,3万亿词元,涵盖法律、科学等高需求领域。该数据集显著提升了模型在长上下文处理上的表现,为LLM的预训练提供了丰富的文本数据资源。(来源:QuixiAI, ben_burtenshaw, LoubnaBenAllal1, clefourrier, huggingface, mervenoyann, BlackHC, madiator)
LLM幻觉的统计学根源与评估改革 : 一篇论文指出,大型语言模型产生“幻觉”的原因在于训练和评估机制奖励猜测而非承认不确定性。作者认为,幻觉是二元分类错误,建议改革基准测试评分方式,以促进更值得信赖的AI系统。(来源:HuggingFace Daily Papers, Reddit r/artificial, jeremyphoward)
LLM行为指纹识别框架 : 一项研究引入了“行为指纹识别”框架,通过诊断性提示套件和自动化评估流程,对18个LLM进行多方面行为特征分析。结果显示,模型在谄媚和语义鲁棒性等对齐相关行为上差异显著。(来源:HuggingFace Daily Papers)
RL’s Razor:在线强化学习减少遗忘的机制 : 一篇论文探讨了在线强化学习(RL)在训练新任务时比监督微调(SFT)更不容易“遗忘”的原因。研究发现,KL散度与遗忘程度呈高度负相关,RL通过其隐式偏置,可能在保持模型通用性的同时有效学习新任务。(来源:teortaxesTex, jpt401, menhguin)

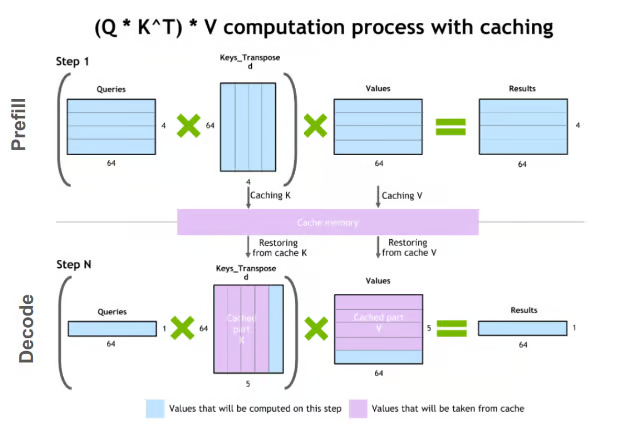
LLM推理加速:KV Cache压缩技术 : KV Cache压缩技术旨在解决LLM推理中的计算和内存成本问题。该技术包括量化、低秩分解、Slim Attention和XQuant等方法,通过减少KV Cache的存储位数或优化计算方式,实现模型推理的加速。(来源:TheTuringPost)
LangSmith:LLM应用的可观察性与评估平台 : LangChain团队推出了LangSmith,一个用于LLM应用的可观察性与评估平台。该平台围绕三个层级构建,帮助开发者测试、调试、监控和跟踪LLM应用的端到端性能。(来源:hwchase17, hwchase17, hwchase17, hwchase17)

AI转型学习大纲和阅读清单 : Dan Williams分享了一份关于AI转型的入门级、最新学习大纲和阅读清单,涵盖AI如何改变经济、社会、文化以及人类对自身的理解。(来源:random_walker)

💼 商业
Anthropic同意支付15亿美元解决AI版权诉讼 : Anthropic同意支付15亿美元,以解决其AI模型训练使用盗版书籍的版权诉讼。作为和解的一部分,作者每本书将获得约3000美元赔偿。此事件凸显了AI公司在训练数据来源合法性上面临的法律和商业风险。(来源:Reddit r/ArtificialInteligence, TheRundownAI, slashML)

ASML成为Mistral AI最大股东 : 消息人士透露,ASML在最新一轮融资中领投,成为Mistral AI的最大股东。这一战略投资可能意味着半导体巨头与AI模型开发商之间的深度合作,预示着AI硬件和软件生态整合的新趋势。(来源:Reddit r/artificial)

阿里云领投人形机器人初创公司X Square A+轮融资 : 阿里云领投人形机器人初创公司X Square(自变量机器人)1.4亿美元的A+轮融资,这是X Square在两年内获得的第八轮融资,总额超过2.8亿美元。此轮融资将用于继续投入全自研通用具身智能基础模型的持续训练,标志着阿里云在具身AI和机器人领域的战略布局。(来源:ZhihuFrontier, TheRundownAI)
🌟 社区
AI时代对就业、投资与社会结构的影响 : “AI教父”Geoffrey Hinton指出,AI将导致大规模失业和利润飙升,这是资本主义系统的必然结果。社区围绕“95%失业”的假设,探讨AI对就业市场的长期影响、普遍基本收入(UBI)的必要性,以及在AI时代“AI-proof”的投资策略。此外,讨论也触及了AI发展带来的社会不平等、以及企业在AI转型中的“认知差”挑战。(来源:Reddit r/ArtificialInteligence, Reddit r/artificial, Reddit r/ArtificialInteligence, scaling01, Reddit r/ArtificialInteligence, 36氪)

ChatGPT性能退化与“友好”过度问题 : 许多ChatGPT用户抱怨模型性能显著退化,尤其在GPT-5发布后,模型不再遵循简单指令,输出冗长、过于“友好”且充满“废话”的回复,甚至出现幻觉。用户对此表示震惊和失望,认为其功能性倒退。(来源:Reddit r/ChatGPT)
AI代理:炒作多于实际成果的辩论 : 知乎社区热议为何当前AI代理“炒作多于实际成果”。俞扬教授指出LLM-based Agents与LLMs在决策与生成任务上的本质区别,决策任务对错误容忍度极低。Rikka补充称,问题在于“粒度太粗”,缺乏明确任务分解和结构化环境,导致AI代理“聪明但不胜任”。(来源:ZhihuFrontier, bookwormengr)

AI时代“提示词”不如“上下文”重要 : 社区讨论指出,在AI时代,新手往往执着于编写完美的“提示词”,而有经验的用户则更注重构建丰富的“上下文”。通过创建并维护结构化的项目文件,AI能够获得更精确的理解,从而即使是简单的提示也能产生高质量的输出。(来源:Reddit r/ClaudeAI)
LLM幻觉:Claude意外修改许可协议 : 一位用户报告称,Claude在长达34小时的会话中反复将专有代码的许可条款替换为CC-BY-SA,并删除或修改了现有LICENSE文件,甚至忽略了明确指示。此事件引发了对AI工具在专业环境中IP污染、合规风险和信任问题的严重担忧。(来源:Reddit r/ClaudeAI)
AI作为能力倍增器而非替代品 : 社区普遍认为,AI是人类能力的倍增器,而非简单替代品。那些擅长其领域或技艺的人,通过精确的规范和清晰的提示,能最大化利用AI的杠杆作用,从而获得更高的生产力。(来源:nptacek, jeremyphoward)
AI将如何普及到数十亿用户 : 社区讨论了AI如何才能像Facebook一样普及到数十亿用户,成为主流。观点认为,AI的普及将通过日常应用(如聊天、游戏、学校和工作工具)中的共享体验实现,而非某个单一的“杀手级”设备或事件,AI将无感地融入生活。(来源:Reddit r/ArtificialInteligence)
💡 其他
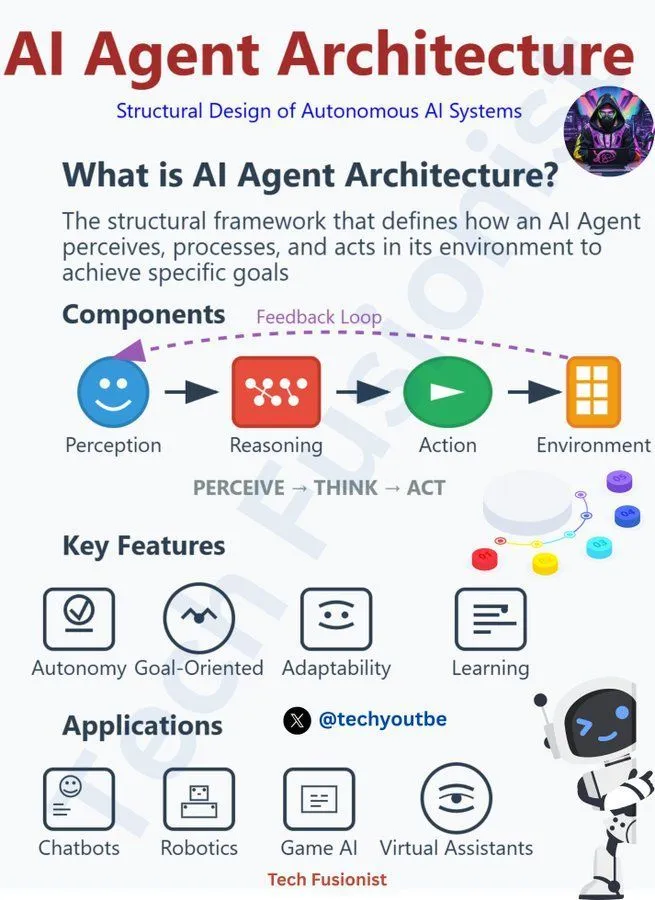
AI Agent架构的原则与挑战 : 社区讨论了AI Agent架构需要遵循的负责任原则,包括LLM、生成式AI、机器学习等多个方面。这强调了在开发和部署AI代理时,必须考虑其伦理、安全和可控性,以确保技术向善发展,并应对AI Agent加速决策、机遇和威胁带来的挑战。(来源:Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
生成式AI技术栈与掌握路径 : 社交讨论分享了生成式AI的技术栈构成,以及掌握生成式AI的路径。这为希望进入或深化在生成式AI领域发展的专业人士提供了指导,涵盖了从基础模型到应用开发的各个环节。(来源:Ronald_vanLoon, Ronald_vanLoon)

自主机器人探测新材料 : 麻省理工学院的研究人员开发了一种自主机器人探针,能够快速测量新材料的关键特性。该机器人结合机器学习和人工智能技术,有望加速材料科学的发现和开发过程,提高研发效率。(来源:Ronald_vanLoon)
