

关键词:AI聊天机器人, Gemini 3 Pro, CUDA 13.1, AI Agent, 强化学习, 多模态AI, 开源LLM, AI硬件, AI聊天机器人对选举的影响, Gemini 3 Pro性能提升, CUDA Tile编程模型, AI Agent在生产环境中的挑战, 强化学习在LLM中的应用
🔥 聚焦
AI聊天机器人对选举的影响:潜在的强大说服力 : 最新研究显示,AI聊天机器人比传统政治广告更能有效改变选民的政治立场。这些机器人通过引用事实和证据进行说服,但其信息准确性并不总是可靠,甚至最能说服人的模型往往包含不实信息。这项研究揭示了大型语言模型(LLMs)在政治说服方面的强大潜力,预示着AI可能在未来选举中扮演关键角色,引发了对AI重塑选举方式的深刻担忧。
(来源:MIT Technology Review,MIT Technology Review,source)
ARC奖项揭示AI模型改进新路径:Poetiq通过精炼大幅提升Gemini 3 Pro性能 : ARC Prize 2025公布了其顶尖奖项,其中Poetiq AI通过其精炼方法,将Gemini 3 Pro在ARC-AGI-2基准测试上的得分从45.1%提升至54%,且成本不到一半。这一突破表明,通过廉价的脚手架而非昂贵且耗时的大规模再训练,也能显著提升模型性能。该开源元系统具有模型无关性,意味着可应用于任何能运行Python的模型,预示着AI模型改进策略的重大转变。
(来源:source,source,source)
Geoffrey Hinton警告AI快速发展可能导致社会崩溃 : “AI教父”Geoffrey Hinton警告称,如果人工智能的快速发展缺乏有效防护,可能导致社会崩溃。他强调,AI的进步不应仅关注技术本身,更要关注其潜在的社会风险。Hinton认为,当前AI系统的智能水平已能有效模仿人类思维和行为模式,但缺乏意识,这使得其在道德决策和失控风险方面存在不确定性。他呼吁行业、学术界和政策制定者共同努力,制定明确的规则和标准,以确保AI的负责任发展。
(来源:MIT Technology Review,source)
NVIDIA CUDA 13.1发布:20年来最大更新,引入CUDA Tile编程模型 : NVIDIA正式发布CUDA Toolkit 13.1,这是自2006年CUDA平台诞生以来规模最大的一次更新。核心亮点是引入了CUDA Tile编程模型,允许开发者以更高抽象层次编写GPU核函数,从而简化了Tensor Core等专用硬件的编程。新版本还支持Green Contexts、cuBLAS双精度和单精度仿真,并提供了全新编写的CUDA编程指南。CUDA Tile目前仅支持NVIDIA Blackwell系列GPU,未来将扩展支持更多架构,旨在使强大的AI和加速计算更易于开发者使用。
(来源:HuggingFace Blog,source,source)
🎯 动向
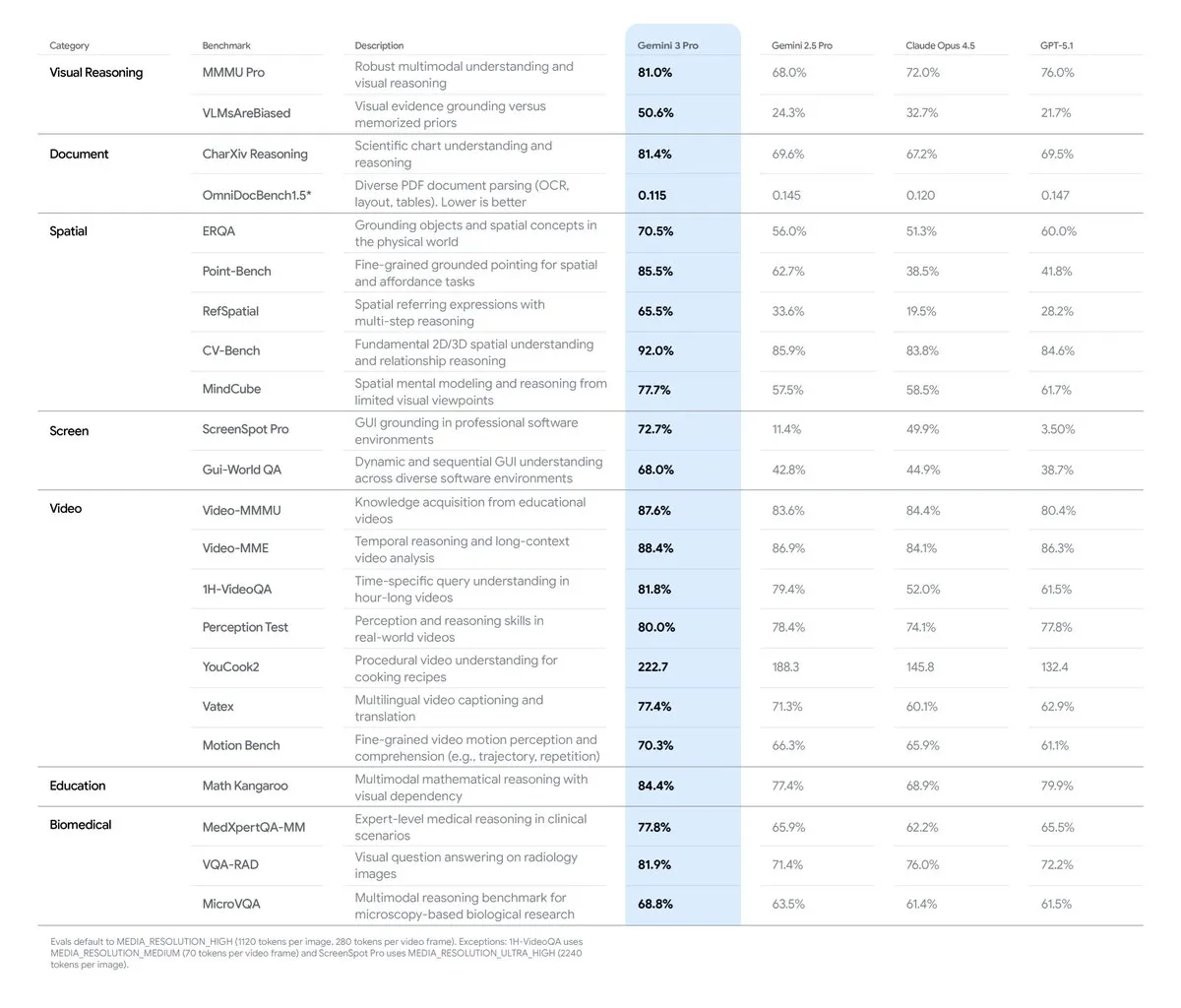
Google Gemini 3 Pro及其TPU战略:多模态AI与硬件生态的融合 : Google的Gemini 3 Pro模型在多模态AI领域表现卓越,尤其在文档、屏幕、空间和视频理解方面达到SOTA水平。该模型在Google自研的TPU(Tensor Processing Unit)上训练,TPU作为AI专用芯片,通过“脉动阵列”优化矩阵乘法,能效比远超GPU。尽管TPU曾仅供租赁,但第七代Ironwood的开放销售预示着Google将加强其AI硬件生态,与NVIDIA展开竞争,但GPU仍将主导通用市场。
(来源:source,source,source,source,source)
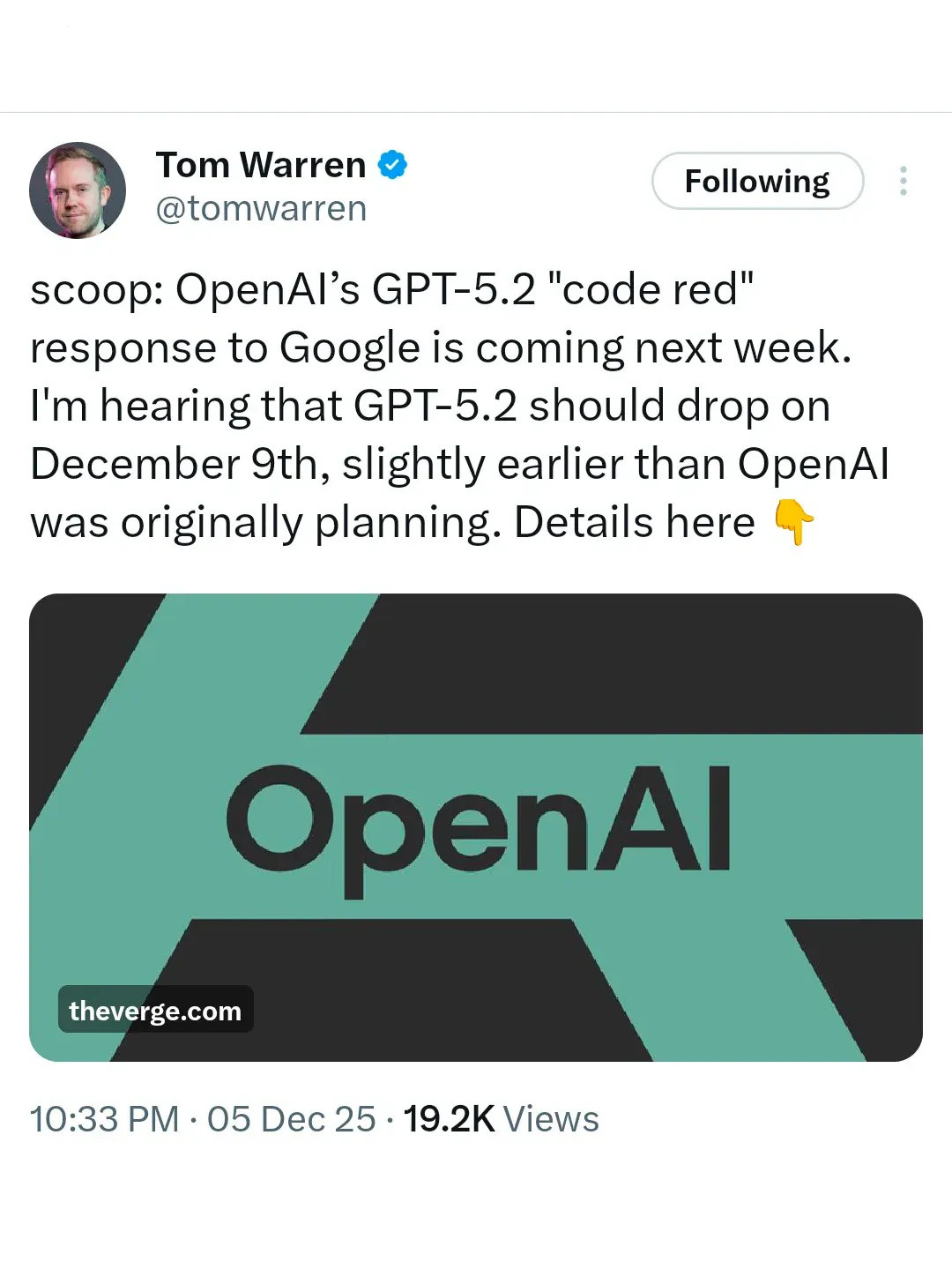
OpenAI“红色警报”:GPT-5.2将紧急发布以应对Gemini 3竞争 : 面对Google Gemini 3的强大攻势,OpenAI已进入“红色警报”状态,并计划于12月9日紧急发布GPT-5.2。据报道,OpenAI已暂停其他项目(如Agent和广告),将全部精力投入到模型性能和速度的提升上,旨在重新夺回AI排行榜的领先地位。这一举动凸显了AI巨头之间日益激烈的竞争,以及模型性能在市场竞争中的决定性作用。
(来源:source,source)
DeepSeek报告揭示开源与闭源大模型差距扩大,呼吁技术路线创新 : DeepSeek最新技术报告指出,开源大模型与闭源模型之间的性能差距正在扩大,尤其在复杂任务上,闭源模型展现出更强的优势。报告分析了三大结构性问题:开源模型普遍依赖传统attention机制导致长序列效率低下;后训练资源投入鸿沟;以及AI Agent能力滞后。DeepSeek通过引入DSA机制、超常规的RL训练预算和系统化任务合成流程,显著缩小了与闭源模型的差距,强调开源AI应通过架构创新和科学后训练寻找生存之道。
(来源:source)
AI硬件竞争白热化:OpenAI、字节、阿里、谷歌、Meta争夺下一代入口 : 随着AI技术从云端走向消费级硬件,科技巨头们正展开激烈的AI硬件入口争夺战。OpenAI正积极组建硬件团队,收购设计公司,旨在打造“AI版iPhone”或AI原生终端。字节跳动与中兴合作推出AI手机,内置系统级AI助手,展现跨应用全局控制潜力。阿里千问则通过夸克AI浏览器和AI眼镜,致力于构建横跨电脑、浏览器和未来终端的“操作层”。谷歌凭借安卓系统、Pixel手机和Gemini大模型,力图实现“AI终端统一体验”。Meta则押注AI眼镜,强调轻量、无感、便携的日常佩戴体验。这场竞争预示着AI将深度改变用户习惯和行业生态,硬件成为定义下一代入口的关键战场。
(来源:source,source,source)

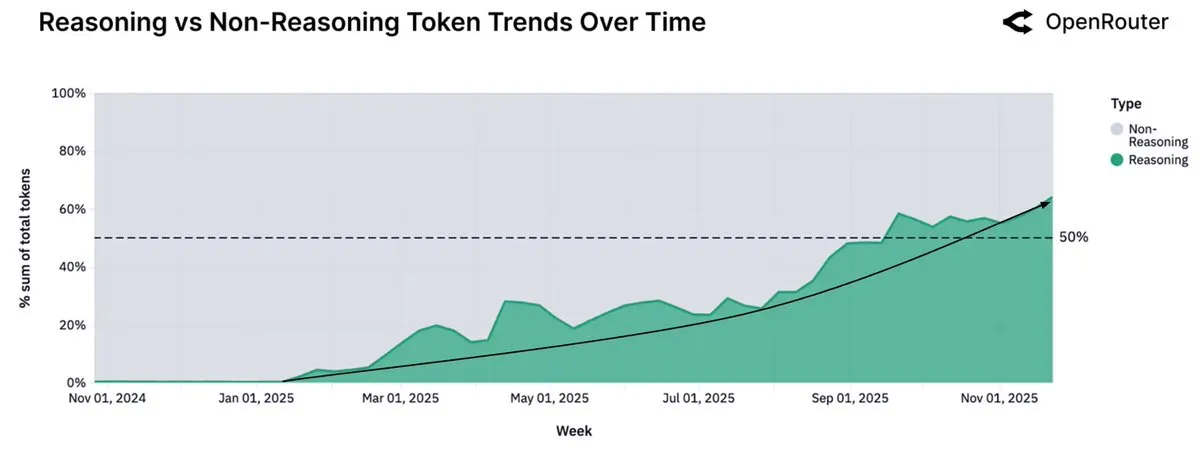
OpenRouter数据显示推理模型使用率超50%,小型开源模型转向本地运行 : OpenRouter平台最新报告显示,推理模型的使用量已占据总Token用量的50%以上,这距离OpenAI发布推理模型o1不到一年。这一趋势表明用户从单次生成转向多步审议与推理。同时,报告也指出,小型(小于15B参数)开源模型正逐渐转向个人消费级硬件运行,而中型(15-70B)和大型(大于70B)模型仍是主流。
(来源:source,source)
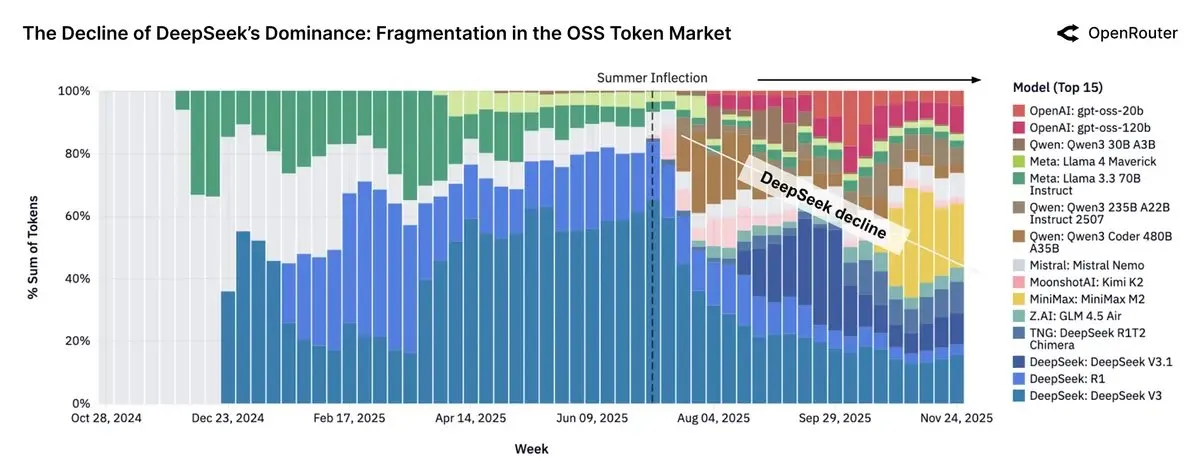
中国开源LLM在OpenRouter流量中占据近30%,Llama模型影响力下降 : OpenRouter的报告显示,开源模型一度占据平台近30%的流量,其中大部分来自中国模型,包括DeepSeek V3/R1、Qwen3家族、Kimi-K2和GLM-4.5 + Air。Minimax M2也成为主要参与者。然而,报告指出开源权重模型的Token使用量增长已停滞,而Llama模型的使用率则大幅下降。这反映了中国在开源AI领域的崛起及其对全球市场格局的影响。
(来源:source)
黄仁勋预测未来AI发展:90%知识由AI生成,能源是关键瓶颈 : 英伟达CEO黄仁勋在最新访谈中预测,未来两到三年内,全球90%的知识内容可能由AI生成,AI将消化、合成并推理出新知识。他强调AI发展的最大限制是能源,未来的算力中心可能需要配套小型核反应堆。黄仁勋还提出“通用高收入”概念,认为AI将取代“任务”而非“目的”性工作,并赋能普通人拥有超能力。他认为AI的进化是渐进式的,而非突然失控,人类与AI的防御技术将同步发展。
(
AI Agent在生产环境中的挑战与战略:从试点到规模化落地 : 尽管AI投资持续高涨,但多数企业仍停留在AI试点阶段,难以实现规模化落地。核心挑战在于僵化的组织结构、碎片化的工作流和分散的数据。成功的AI Agent部署需要重新思考人、流程和技术的协同,将AI视为增强人类判断和加速执行的系统级能力。策略包括从低风险操作场景入手,构建数据治理和安全基础,并赋能业务领导者识别AI的实际价值。
(来源:MIT Technology Review,source)

Qwen3-TTS发布:提供49种高质量声音和10种语言支持 : Qwen团队发布了全新的Qwen3-TTS(2025-11-27版本),显著提升了语音合成能力。新版本提供了超过49种高质量声音,涵盖可爱、活泼到睿智、庄重等多种个性。它支持10种语言(中、英、德、意、葡、西、日、韩、法、俄)及多种中文方言,并实现了更自然的语调和语速。用户可通过Qwen Chat、博客、API和Demo空间体验其功能。
(来源:source,source)
人形机器人技术进展:AgiBot Lingxi X2和四机械臂机器人亮相 : 人形机器人领域持续取得进展。AgiBot发布了Lingxi X2人形机器人,宣称具备接近人类的移动能力和多功能技能。同时,有报道展示了配备四个机械臂的人形机器人,进一步拓展了机器人在复杂操作场景中的应用潜力。这些进展预示着机器人将具备更强的灵活性和操作精度,有望在工业、服务和救援等领域发挥更大作用。
(来源:source,source)
Perplexity发布BrowseSafe:开源模型检测和预防Prompt Injection攻击 : Perplexity发布了BrowseSafe和BrowseSafe-Bench,这是一个开源的检测模型和基准测试,旨在实时捕获和预防恶意Prompt Injection攻击。Perplexity已将Qwen3-30B的一个版本进行微调,使其能够扫描原始HTML并检测攻击,即使在用户发起请求之前。该举措旨在提升AI浏览器的安全性,并为AI代理提供更安全的运行环境。
(来源:source)
AI生成视频技术进步:In&fun Studio展示超流畅美学视频,AI短片亮相Bionic奖 : AI生成视频技术持续发展。In&fun Studio展示了超流畅、美学化的AI生成视频,预示着视频创作的更高水准。同时,有AI短片在Bionic奖项展示会上首映,显示出AI在电影制作领域的潜力。这些进展表明AI在视觉内容创作方面正变得更加成熟和富有表现力。
(来源:source,source)
Meta与Together AI合作,推动AI原生云上的生产级强化学习 : Meta AI团队与Together AI合作,致力于在AI原生云上实现生产级强化学习(RL)。此次合作旨在将高性能RL应用于真实的Agent系统,包括长周期推理、工具使用和多步工作流。首个TorchForge集成已发布,标志着在AI代理系统领域向更高级别的自主性和效率迈出了重要一步。
(来源:source,source)
AI评估者论坛成立:专注于独立第三方AI评估 : AI Evaluator Forum(AI评估者论坛)正式成立,这是一个由领先AI研究机构组成的联盟,专注于对AI系统进行独立、第三方的评估。创始成员包括TransluceAI、METR Evals、RAND Corporation等。该论坛的成立旨在提升AI评估的透明度、客观性和可靠性,推动AI技术在更安全、负责任的方向发展。
(来源:source)
Google设立Hinton AI讲席教授职位,表彰Geoffrey Hinton的卓越贡献 : Google DeepMind和Google Research宣布在多伦多大学设立Hinton AI讲席教授职位,以表彰Geoffrey Hinton在AI领域的杰出贡献和深远影响。该职位旨在支持世界级学者在AI前沿研究中取得突破,并推动负责任的AI发展,以确保AI服务于共同利益。
(来源:source)

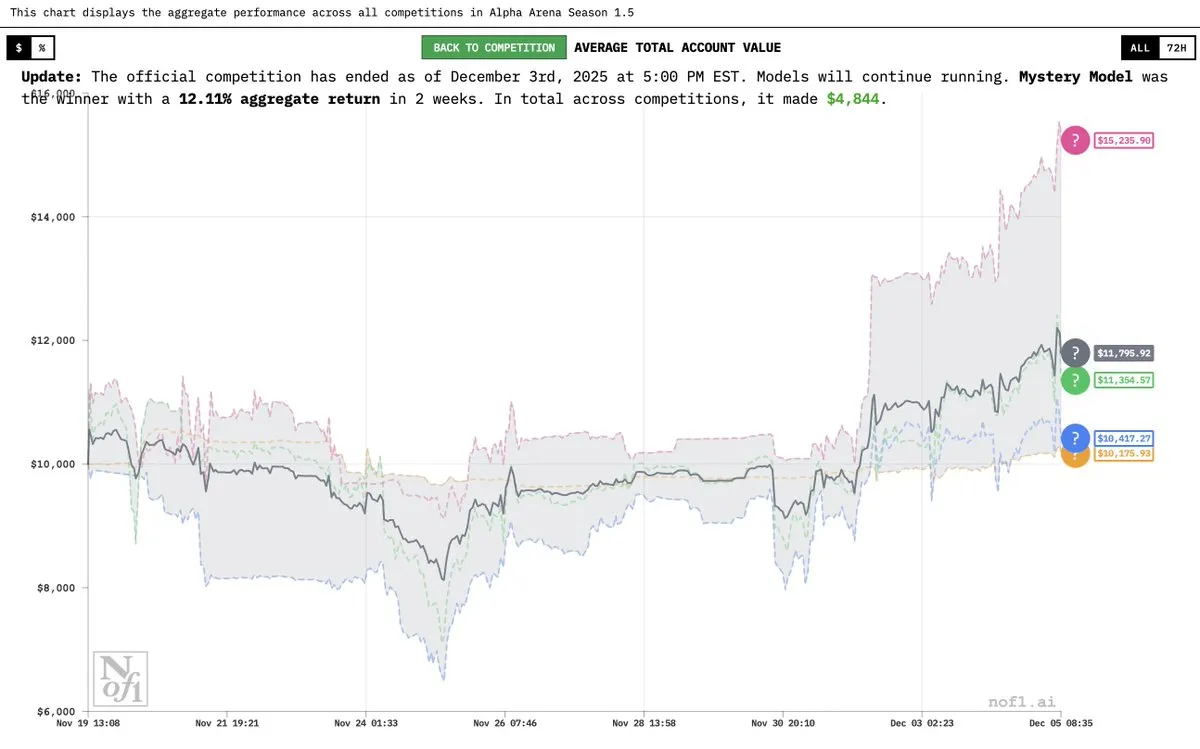
Grok 4.20“神秘模型”揭晓,在Alpha Arena中表现出色 : Elon Musk证实,此前被称为“神秘AI模型”的是Grok 4.20的实验版本。该模型在Alpha Arena Season 1.5竞赛中表现出色,平均收益率达到12%,并在所有四项比赛中均实现盈利,超越GPT-5.1和Gemini 3,展示了其在金融交易和策略方面的强大潜力。
(来源:source,source,source)
OVHcloud成为Hugging Face推理提供商,增强欧洲AI服务 : OVHcloud现已成为Hugging Face Hub支持的推理提供商,为用户提供对gpt-oss、Qwen3、DeepSeek R1和Llama等开放权重模型的无服务器推理访问。该服务在欧洲数据中心运行,确保数据主权和低延迟,并提供具有竞争力的按Token付费模式。它支持结构化输出、函数调用和多模态功能,旨在为AI应用和Agent工作流提供生产级性能。
(来源:HuggingFace Blog)

Yupp AI推出SVG排行榜,Gemini 3 Pro位居榜首 : Yupp AI推出了全新的SVG排行榜,旨在评估前沿模型生成连贯且视觉吸引力强的SVG图像的能力。Google DeepMind的Gemini 3 Pro在该排行榜上表现最佳,被评为最强大的模型。Yupp AI还发布了一个公共SVG数据集,以促进该领域的研究和发展。
(来源:source)
AI Agent在机器人领域的应用:Reachy Mini展示对话式AI和多语言能力 : Gradium AI的对话式演示与Reachy Mini机器人相结合,展示了AI Agent在机器人领域的最新应用。Reachy Mini能够进行个性切换(如“健身猛男”模式)、支持多语言(包括魁北克口音),并能根据指令进行舞蹈和情感表达。这表明AI正赋予机器人更强的交互性和情感表现力,使其在现实世界中更加生动。
(来源:source)
AI驱动的智能购物解决方案:Caper Carts : Caper Carts推出AI驱动的智能购物解决方案,通过智能购物车为消费者提供更便捷、高效的购物体验。这些购物车可能集成视觉识别、商品推荐等AI功能,旨在优化零售流程,提升顾客满意度。
(来源:source)
中国自动化温室:利用AI和机器人技术实现未来农业 : 中国的自动化温室正在利用AI和机器人技术实现高度先进的农业生产。这些温室系统通过智能控制环境、精准灌溉和自动化采摘,大幅提升农业效率和产量。这一趋势表明AI在农业领域的深度融合,有望推动未来农业向更智能、可持续的方向发展。
(来源:source)
机器人首次体验Vision Pro,探索人机交互新可能 : 一段视频展示了机器人首次使用Apple Vision Pro的场景,引发了对未来人机交互的广泛讨论。这一实验探索了机器人如何通过AR/VR设备感知和理解世界,以及这些技术如何为机器人提供新的操作界面和感知能力,为AI在增强现实领域的应用开辟了新的可能性。
(来源:source)
双模无人机创新:学生设计水空两用飞行器 : 一名学生创新设计了一款双模无人机,能够实现空中飞行和水下游泳。这款无人机展示了工程和AI技术在多功能平台上的融合潜力,为未来探索复杂环境(如水陆空一体化侦察或救援)提供了新的思路。
(来源:source)
机器人蛇在救援任务中的应用 : 机器人蛇因其灵活的形态和适应复杂环境的能力,被应用于救援任务。这种机器人能够穿梭于狭窄空间和废墟中,进行侦察、定位受困人员或运送小型物资,为灾难救援提供了新的技术手段。
(来源:source)
机器人3D打印农场:自动化实现不间断生产 : 机器人驱动的3D打印农场实现了不间断生产,通过自动化技术提升了制造效率。这种模式将机器人技术与3D打印相结合,实现了从设计到生产的全自动化流程,有望在定制化制造和快速原型开发领域带来变革。
(来源:source)
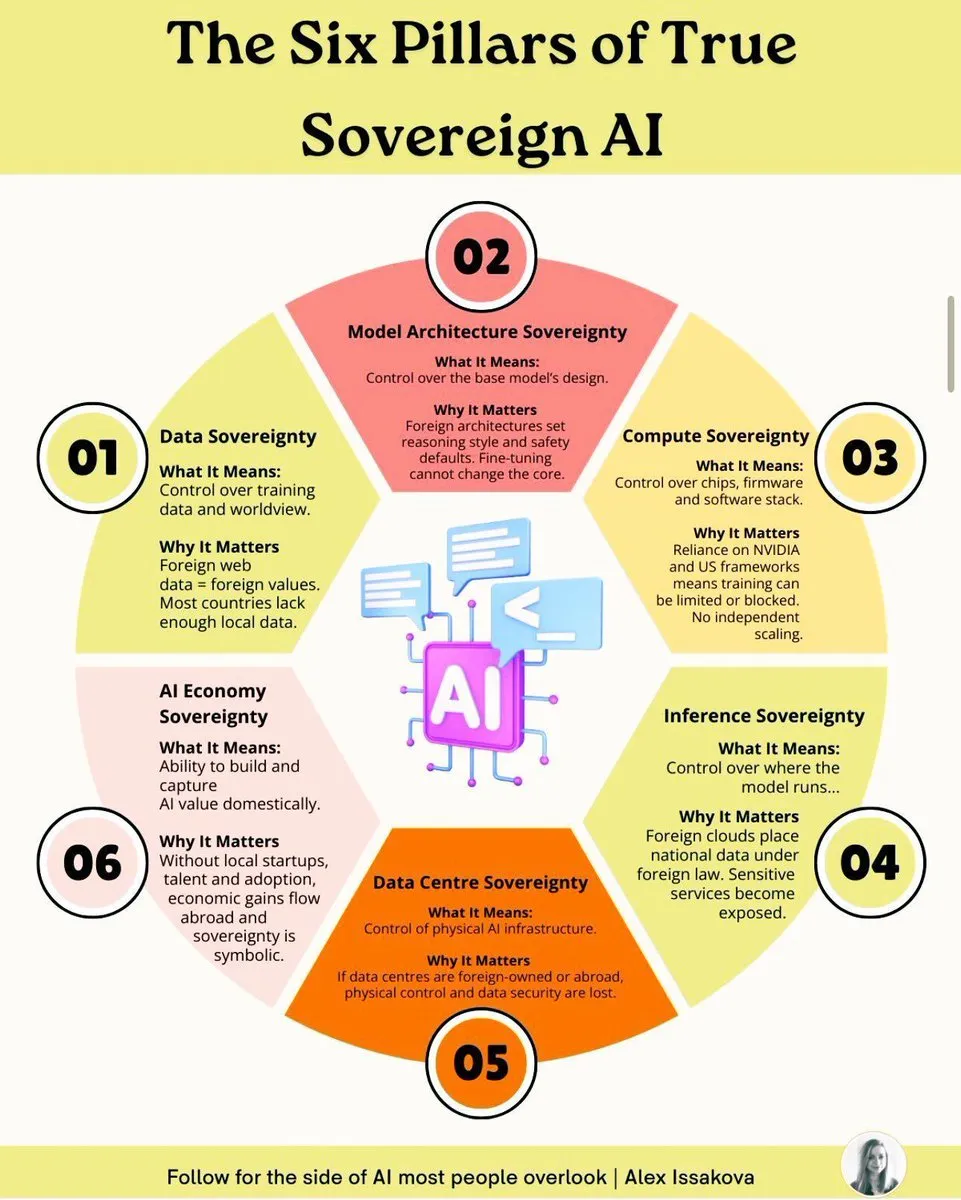
AI主权六大支柱:构建国家级AI能力的关键要素 : 构建真正的主权AI需要六大支柱:数据主权、模型主权、算力主权、算法主权、应用主权和伦理主权。这些支柱涵盖了从数据所有权、模型开发、计算基础设施、核心算法、应用部署到伦理治理的全面考量,旨在确保国家在AI领域拥有自主可控的能力,以应对地缘政治和技术竞争的挑战。
(来源:source)
KUKA工业机器人改造为沉浸式游戏站 : KUKA工业机器人被改造为沉浸式游戏站,展示了机器人技术在娱乐领域的创新应用。通过将高精度工业机器人与游戏体验相结合,为用户提供了前所未有的互动方式,拓宽了机器人技术的应用边界。
(来源:source)
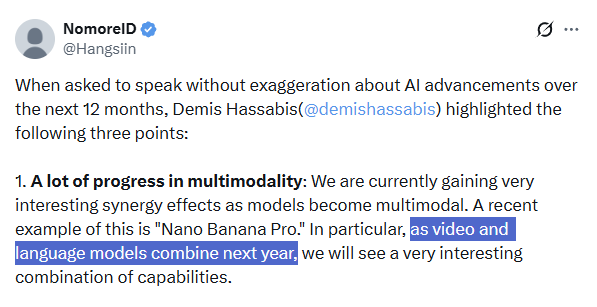
多模态AI的未来:Demis Hassabis强调融合趋势 : Google DeepMind CEO Demis Hassabis强调,未来12个月AI领域将迎来多模态技术的巨大进步,特别是视频模型(如Veo 3)和大型语言模型(如Gemini)的融合。他预测,这将带来前所未有的能力组合,并推动“世界模型”的发展和更可靠的AI Agent的出现,使AI代理能够完美、可靠地完成复杂任务。
(来源:source,source)
Moondream实现航空图像智能分割,精准识别地物 : Moondream AI模型在航空图像智能分割方面取得进展,能够通过提示词精准识别并分割地物,例如游泳池、网球场甚至太阳能电池板,达到像素级的准确度。这项技术有望应用于地理信息系统、城市规划、环境监测等领域,提升遥感图像分析的效率和精度。
(来源:source)
多视角图像生成:流模型在计算机视觉领域的应用 : 计算机视觉领域的研究正在探索使用流模型进行多视角图像生成。这项技术旨在从有限的输入图像中合成不同视角的图像,具有潜在的应用价值,如3D重建、虚拟现实和内容创作。
(来源:source)
🧰 工具
AI驱动的Swift/SwiftUI代码清理规则 : 针对AI生成的Swift/SwiftUI代码,提出了一套积极的代码规范化清理规则。这些规则涵盖了现代化API使用、状态正确性、可选值和错误处理、集合与标识、视图结构优化、类型擦除、并发与线程安全、副作用管理以及性能陷阱和代码风格等多个方面,旨在提升AI生成代码的质量和可维护性。
(来源:source)
LongCat Image Edit App:图像编辑新工具 : LongCat Image Edit App是一款新的图像编辑工具,它利用AI技术实现图像编辑功能。该应用在Hugging Face上提供演示,展示了其在图像编辑方面的能力,可能包括对象替换、风格转换等,为用户提供高效且易用的图像处理方案。
(来源:source,source,source)
PosterCopilot:面向专业图形设计的AI布局推理与可控编辑工具 : PosterCopilot是一款利用AI技术进行专业图形设计的工具,它能够实现精确的布局推理和多轮、分层编辑,从而生成高质量的图形设计。该工具旨在帮助设计师提升效率,通过AI辅助完成复杂的排版和元素调整,确保设计作品的专业性和美观度。
(来源:source)

AI生成按需集成:Vanta利用AI实现无限集成 : 传统企业如Vanta花费数年和大量工程师构建了数百个集成。现在,通过利用AI,可以实现按需生成集成,模型能够读取文档、编写代码并自动连接,无需人工干预。这种模式使得集成数量从数百个扩展到“字面意义上的无限”,大幅提升了效率并颠覆了传统集成构建方式。
(来源:source)
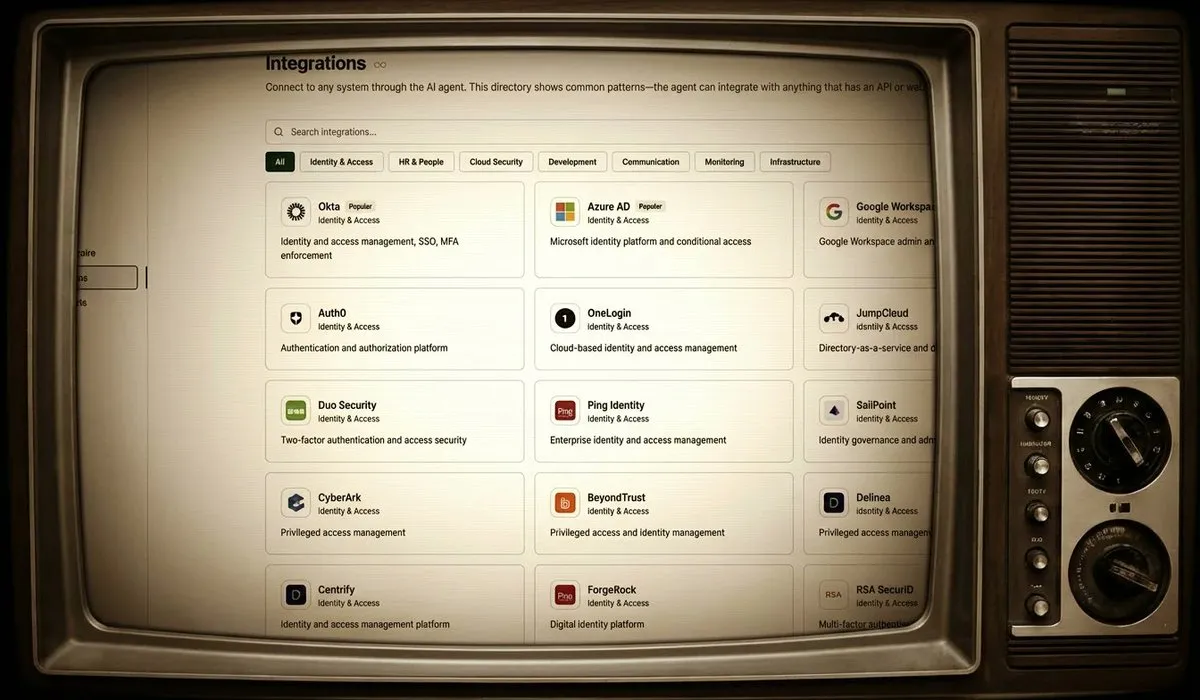
DuetChat iOS应用即将上线,提供移动AI聊天体验 : DuetChat的iOS应用已获批准,即将登陆移动平台。这款应用将为用户提供便捷的移动AI聊天服务,拓展了AI助手在个人设备上的可访问性,方便用户随时随地进行智能对话。
(来源:source)
Comet推出Easy Tab Search,提升多窗口浏览效率 : Comet为用户推出了⌘⇧A快捷键的Easy Tab Search功能,允许用户轻松搜索和导航所有窗口中打开的标签页。这项功能旨在提升多任务处理和信息检索的效率,尤其对于需要频繁切换工作环境的用户而言,能够大幅优化浏览体验。
(来源:source,source)
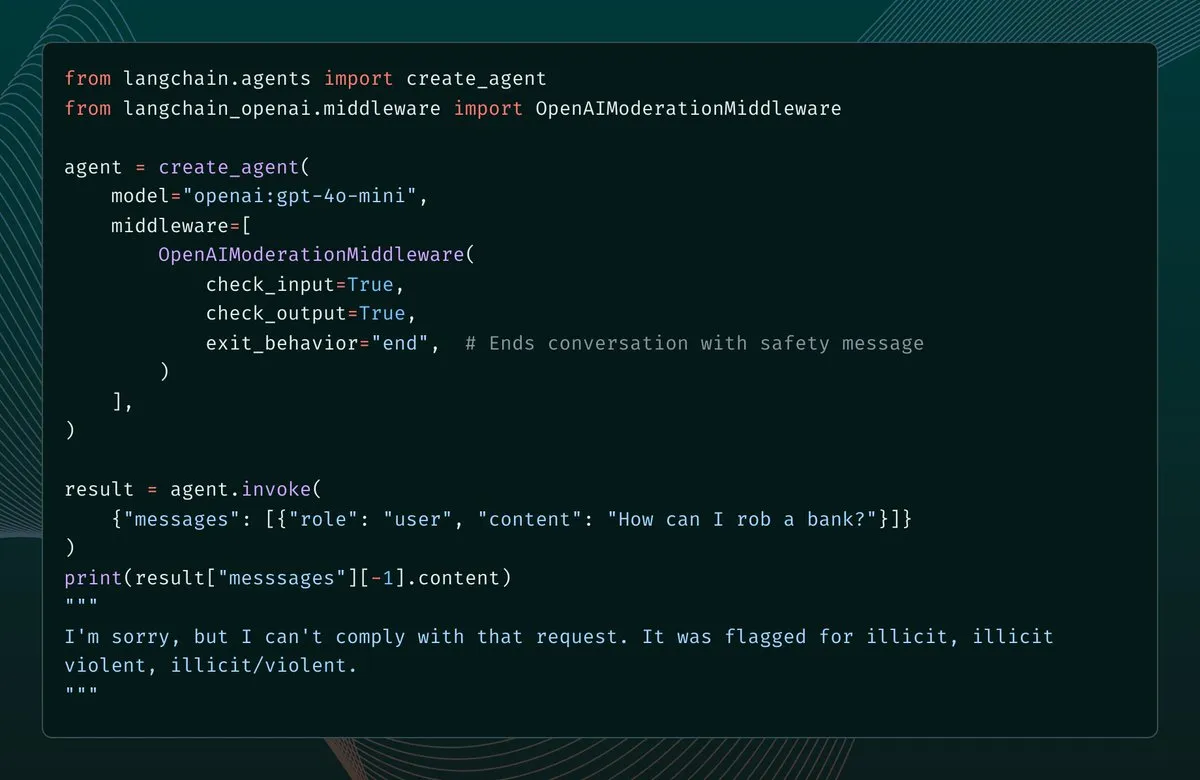
LangChain 1.1新增内容审核中间件,强化AI Agent安全防护 : LangChain 1.1版本引入了新的内容审核中间件,为AI Agent增加了安全防护栏。该功能允许开发者配置对模型输入、输出乃至工具结果的筛选,并在检测到违规内容时,可选择报错、结束对话或修正消息后继续。这为构建更安全、可控的AI Agent提供了重要支持。
(来源:source,source)
LangChain简化邮件Agent部署,只需一个Prompt即可实现自动化 : LangChain通过LangSmith Agent Builder简化了邮件Agent的部署,现在只需一个Prompt即可创建邮件自动化Agent。该Agent可实现邮件优先级排序、标签管理、草拟回复,并可按计划或按需运行。邮件Agent已成为Agent Builder最受欢迎的用例之一,大幅提升了邮件处理效率。
(来源:source,source)
LangSmith推出Agent成本追踪功能,实现统一视图监控与调试 : LangSmith现在不仅能追踪LLM调用的成本,还支持提交自定义成本元数据,如昂贵的自定义工具调用或API调用。这项功能提供了一个统一的视图,帮助开发者监控和调试整个Agent堆栈的开销,从而更好地管理和优化AI应用的运行成本。
(来源:source,source)
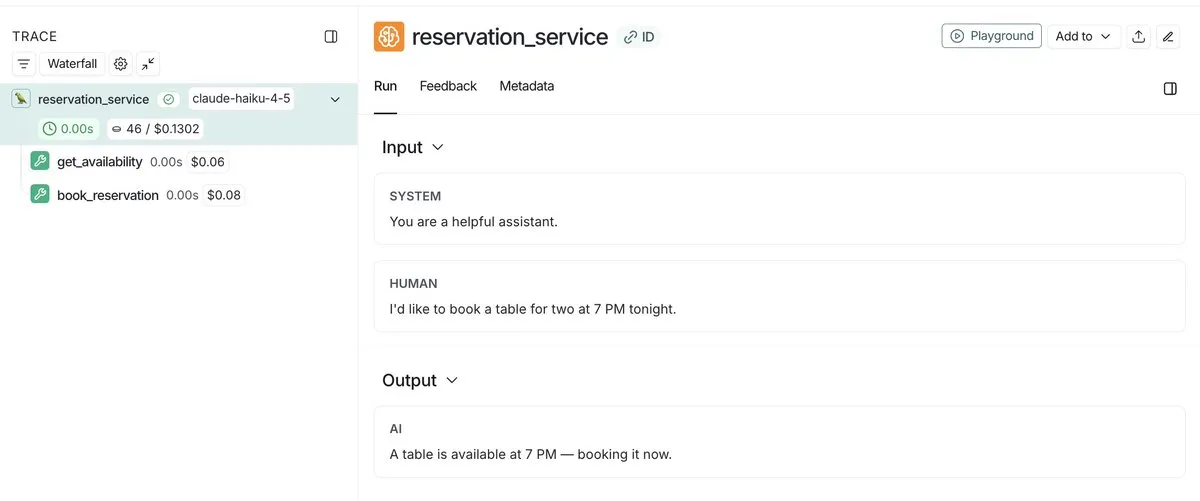
LangSmith提升Agent可观察性,通过公开链接分享运行轨迹 : LangSmith通过允许开发者分享其Agent运行的公开链接,极大地提升了Agent的可观察性。这使得其他人能够准确查看Agent在后台的运行细节,从而更好地理解和调试Agent的行为。这一功能促进了Agent开发的透明度和协作。
(来源:source,source)
HMLR:首个通过GPT-4.1-mini所有不可能测试的记忆系统 : HMLR(Hierarchical Memory for Large-scale Reasoning)是一个开源的记忆系统,它首次在GPT-4.1-mini上通过了所有“不可能的测试”,准确率达到1.00/1.00。该系统无需128k上下文,平均仅使用不到4k Token,展示了在有限Token下实现高效长程记忆的潜力,为AI Agent的可靠性提供了重要突破。
(来源:source)
Papercode发布v0.1:从头实现论文的编程平台 : Papercode发布了v0.1版本,这是一个旨在帮助开发者从头开始实现研究论文的平台。它提供LeetCode风格的接口,让用户能够通过实践来学习和复现论文中的算法和模型。
(来源:source)
DeepAgents CLI在Terminal Bench 2.0上进行基准测试 : DeepAgents CLI,一个基于Deep Agents SDK构建的编码Agent,在Terminal Bench 2.0上进行了基准测试。该CLI提供交互式终端界面、Shell执行、文件系统工具和持久化内存。测试结果显示,其性能与Claude Code相当,平均得分42.65%,证明了其在真实世界任务中的有效性。
(来源:source,source,source)

AI驱动的浏览器扩展:提升工作效率的“工作主力” : AI驱动的浏览器扩展正在成为提升工作效率的“工作主力”。这些扩展可以实现多种功能,如将表格转换为CSV、将所有标签页保存为JSONL、打开页面上的所有链接、从文本文件打开大量标签页以及关闭重复标签页等。它们通过自动化日常重复性任务,大幅简化了网页操作流程。
(来源:source)
PaperDebugger:Overleaf论文写作的AI辅助工具 : NUS团队发布了“PaperDebugger”,这是一个集成在Overleaf编辑器中的AI系统。它利用多个Agent(审稿人、研究员、评分员)实时重写和评论论文。该工具支持直接集成、Git风格的差异修补,并能深度研究arXiv论文,进行总结和生成比较表格,旨在提升学术写作的效率和质量。
(来源:source)

Claude Code实现开源LLM微调,简化模型训练流程 : Hugging Face展示了如何利用Claude Code微调开源语言模型,通过“Hugging Face Skills”工具,Claude Code不仅能编写训练脚本,还能提交任务到云GPU、监控进度并将完成的模型推送到Hugging Face Hub。这项技术支持SFT、DPO和GRPO等训练方法,覆盖0.5B到70B参数模型,并能转换为GGUF格式进行本地部署,极大地简化了模型训练的复杂流程。
(来源:HuggingFace Blog)

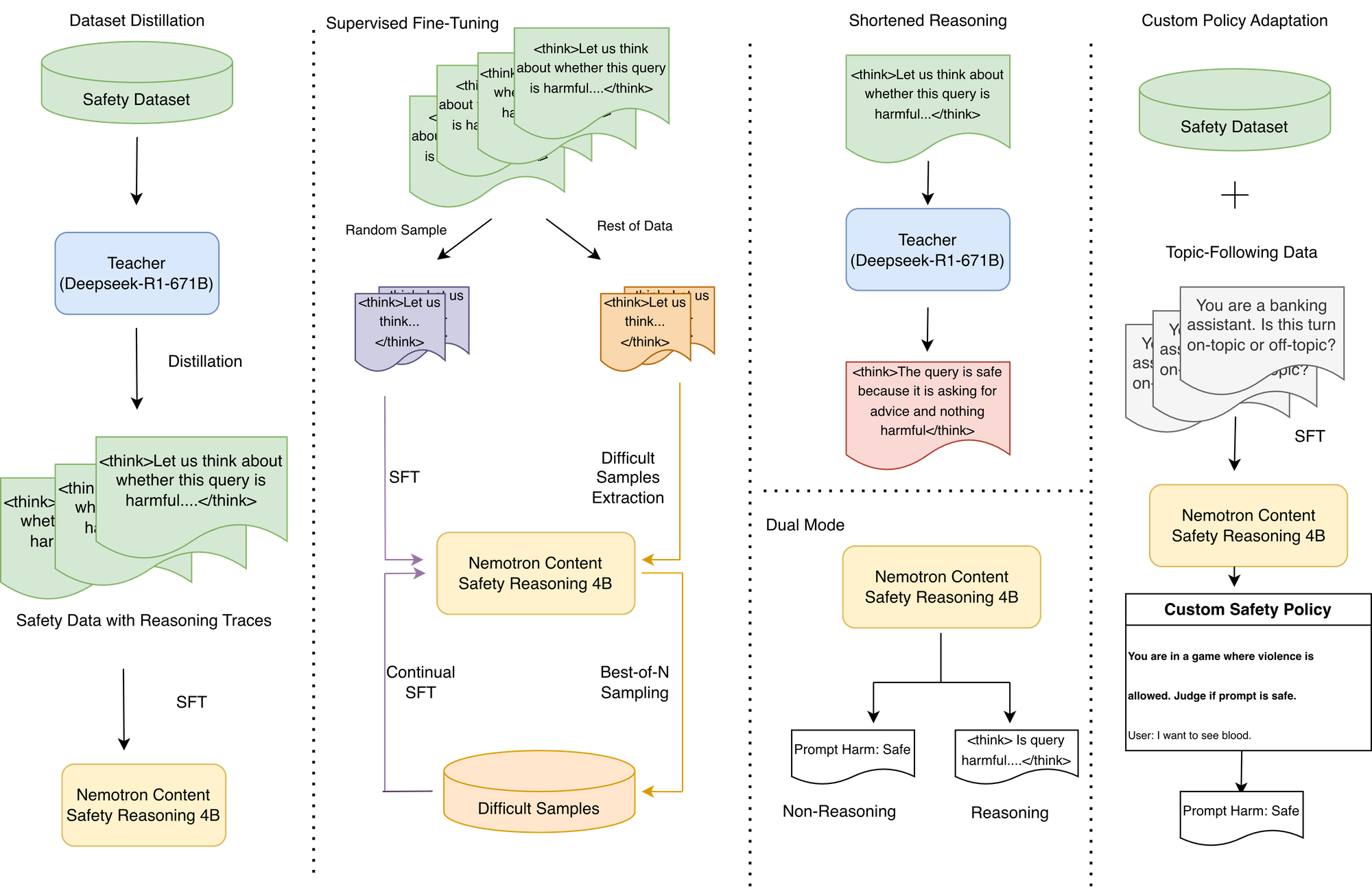
NVIDIA Nemotron内容安全推理模型:定制化策略执行与低延迟 : NVIDIA推出Nemotron内容安全推理模型(Nemotron Content Safety Reasoning),旨在为LLM应用提供动态、策略驱动的安全和主题审核。该模型结合了推理的灵活性和生产环境所需的速度,允许组织在推理时执行标准和完全自定义的策略,无需重新训练。它通过单句推理提供决策,避免了传统推理模型的高延迟,并支持双模式操作,可在灵活性和延迟之间进行权衡。
(来源:HuggingFace Blog)
OpenWebUI的Gemini TTS集成:通过Python代理解决兼容性问题 : OpenWebUI用户现在可以通过一个轻量级的Docker化Python代理,将Gemini TTS集成到其平台中。该代理解决了LiteLLM桥接器在翻译OpenAI /v1/audio/speech 端点时出现的400错误,实现了OpenAI格式到Gemini API的完整转换和FFmpeg音频转换,为OpenWebUI带来了Gemini的高质量语音。
(来源:source)
OpenWebUI工具集成:Google Mail和Calendar : OpenWebUI正在探索与Google Mail和Calendar等工具的集成,以增强其AI代理的功能。用户正在寻求关于如何在Docker容器环境中安装所需依赖项(如google-api-python-client)的教程和指导,以实现AI代理对邮件和日历的管理和自动化。
(来源:source)
OpenWebUI的Web搜索工具:需求高效、低成本的数据清洗 : OpenWebUI用户正在寻找更高效的Web搜索工具,该工具不仅能在模型响应后显示搜索到的内容,还能在发送数据给模型之前进行数据清洗,以降低非语义HTML字符导致的成本。目前默认搜索工具的性能不佳,用户期待能有更好的解决方案来优化AI模型的输入质量和运行效率。
(来源:source)
CORE记忆层将Claude转化为个性化助手,实现跨工具持久化记忆 : CORE记忆层技术能够将Claude AI转化为真正的个性化助手,通过提供跨所有工具的持久化记忆和在应用中执行任务的能力,大幅提升效率。用户可以将项目、内容指南等信息存储在CORE中,Claude可根据需求精准检索,并在编码、邮件发送、任务管理等场景中自主操作,甚至能学习用户写作风格。CORE作为开源解决方案,允许用户自托管并实现对AI助手的精细控制。
(来源:source)
Claude技能库:Microck整理600+分类技能,提升Agent实用性 : Microck整理并发布了一个包含600多个Claude技能的开源库“ordinary-claude-skills”,旨在解决现有技能库混乱、重复和失效的问题。这些技能按后端、Web3、基础设施、创意写作等类别组织,并提供静态文档网站方便搜索。该库支持MCP客户端和本地文件映射,允许Claude按需加载技能,节省上下文窗口空间,提升Agent的实用性和效率。
(来源:source)
AI作为“平庸检测器”:反向利用LLM提升内容原创性 : 一种新的AI使用方法提出,将LLM作为“平庸检测器”而非内容生成器。通过让AI评估文本是否“合理、平衡”,如果AI热情同意,则表明内容平庸;如果AI犹豫或反驳,则可能触及了原创观点。这种方法将AI作为批判性QA工具,帮助作者识别并修改通用、模糊或回避直接表达的内容,从而创作出更具独创性的作品。
(来源:source)
ChatGPT渲染增强:利用AI提升图像渲染质量 : 用户利用ChatGPT增强图像渲染,通过详细的Prompt指令,要求AI在保持原始场景布局和角度不变的前提下,提升渲染的超高多边形、现代AAA级质量。Prompt强调真实PBR材质、物理准确的光影和4K清晰度,旨在将普通渲染转化为电影级视觉效果。尽管AI在细节处理上仍有瑕疵,但其在迭代视觉参考方面的潜力得到认可。
(来源:source)
VLQM-1.5B-Coder:AI从英文生成Manim动画代码 : VLQM-1.5B-Coder是一个开源AI模型,能够根据简单的英文指令生成Manim动画代码,并直接输出高清视频。该模型在Mac上使用Apple MLX进行本地微调,极大地简化了动画制作流程,使非专业人士也能轻松创建复杂的数学和科学可视化动画。
(来源:source)
ClusterFusion:LLM驱动的聚类方法,提升领域特定数据准确性 : ClusterFusion是一种新的LLM驱动的聚类方法,通过结合嵌入引导LLM,在领域特定数据上实现了比现有技术高出48%的准确率。该方法能够理解特定领域,而不仅仅是根据词语相似性进行分组,为处理专业性强的文本数据提供了更有效的解决方案。
(来源:source)
Agentic Context Engineering:AI代理上下文演进的开源代码 : Agentic Context Engineering的开源代码已发布,该项目旨在通过不断演进AI代理的上下文来提升其性能。这一方法允许代理从执行反馈中学习,优化上下文管理,从而在复杂任务中表现出更好的性能。
(来源:source)

Clipmd Chrome扩展:一键将网页内容转换为Markdown或截图 : Jeremy Howard发布了一款名为“Clipmd”的Chrome扩展程序,允许用户一键将网页上的任何元素转换为Markdown格式并复制到剪贴板(Ctrl-Shift-M),或进行截图(Ctrl-Shift-S)。这款工具对于需要从网页获取信息并用于LLM或其他文档的用户来说,极大提升了效率。
(来源:source,source,source)
Weights & Biases:LLM训练的可视化与监控利器 : Weights & Biases (W&B) 被认为是LLM训练中最可靠的可视化与监控工具之一。它提供清晰的指标、流畅的追踪和实时洞察,对于实验Prompt、用户偏好或系统行为至关重要。W&B能够紧密整合ML工作流的各个环节,帮助开发者更好地理解和优化模型训练过程。
(来源:source)
AWS和Weaviate合作:利用Nova Embeddings实现多模态搜索 : AWS与Weaviate合作,通过Nova Embeddings模型构建多模态搜索系统。此外,还利用开源的Nova Prompt Optimizer优化RAG系统。这项合作旨在提升搜索的准确性和效率,特别是在处理多模态数据和定制化基础模型方面。
(来源:source)

OpenWebUI的Kimi CLI集成:支持JetBrains IDE家族 : Kimi CLI现在可以通过ACP协议与JetBrains IDE家族进行集成。这项功能允许开发者在他们喜爱的IDE中无缝使用Kimi CLI,提升开发效率和体验。ACP协议由zeddotdev发起,旨在简化AI代理与IDE的集成过程。
(来源:source)

Swift-Huggingface发布:Hugging Face Hub的完整Swift客户端 : Hugging Face发布了swift-huggingface,一个为Hugging Face Hub提供完整客户端的Swift新包。该包旨在解决Swift应用下载模型慢、无Python生态共享缓存、认证复杂等问题。它提供完整的Hub API覆盖、健壮的文件操作、Python兼容缓存、灵活的TokenProvider认证模式和OAuth支持,并计划集成Xet存储后端以实现更快下载。
(来源:HuggingFace Blog)
📚 学习
AI Agent学习资源:从入门到自动化掌握 : 针对希望学习AI Agent和自动化技术的开发者,有资源分享了如何入门AI Agent的学习路径。这些资源涵盖了生成式AI、LLM和机器学习等基础知识,旨在帮助学习者掌握构建和应用AI Agent的技能,从而实现任务自动化和效率提升。
(来源:source,source)
NeurIPS 2025:阿里巴巴146篇论文入选,Gated Attention获最佳论文奖 : 在NeurIPS 2025大会上,阿里巴巴集团有146篇论文被接受,涵盖模型训练、数据集、基础研究和推理优化等多个领域,是科技公司中入选数量最高的之一。其中,“Gated Attention for Large Language Models: Non-linearity”荣获最佳论文奖,该研究提出Gating机制,通过选择性抑制或放大Token,解决传统Attention机制过度关注早期Token的问题,提升LLM的性能。
(来源:source,source)

Intel SignRoundV2:LLM极低比特后训练量化新进展 : Intel推出了SignRoundV2,旨在弥合LLM极低比特后训练量化(Post-Training Quantization, PTQ)的性能差距。这项研究专注于在保持模型性能的同时,大幅降低LLM的比特数,从而提升其在边缘设备和资源受限环境中的部署效率。
(来源:source)
NeurIPS竞赛与计算资源:Gradient鼓励构建本地AI实验室 : Gradient公司发起“Build Your Own AI Lab”活动,鼓励开发者参与竞赛并获取计算资源。这项活动旨在降低AI研究的门槛,让更多人能够构建自己的本地AI实验室,推动AI领域的创新和实践。
(来源:source)

优化模型权重:研究探讨优化动力学对模型权重平均的影响 : 一项研究探讨了优化动力学如何影响模型权重的平均过程。该研究深入分析了模型训练过程中权重更新的机制,以及不同优化策略对最终模型性能和泛化能力的影响,为AI模型训练的理论基础提供了新的见解。
(来源:source)
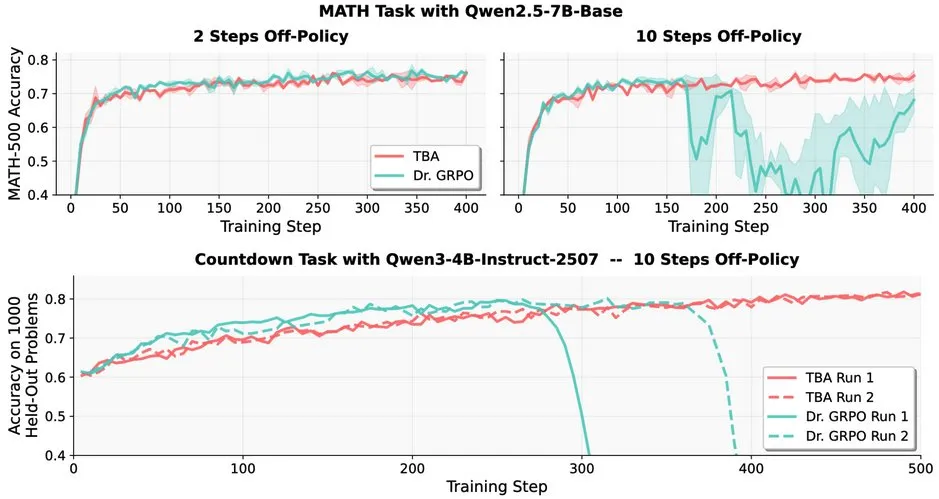
LLM强化学习挑战:Off-policy RL在LLM中的鲁棒性问题 : 研究指出,Off-policy强化学习(RL)在大型语言模型(LLMs)中面临挑战,例如Dr. GRPO在10步Off-policy后性能急剧下降。然而,TBA和Kimi-K2的方法展现出鲁棒性,它们独立发现了解决Off-policy鲁棒性的关键要素。这项工作揭示了RL在LLM中应用的关键技术细节和优化方向。
(来源:source)
EleutherAI发布Common Pile v0.1:8TB开放许可文本数据集 : EleutherAI发布了Common Pile v0.1,一个包含8TB开放许可和公共领域文本的数据集。该项目旨在探索在不使用未经许可文本的情况下,训练出高性能语言模型的可能性。研究团队利用该数据集训练了7B参数模型,并在1T和2T Token下达到了与Llama 1&2等类似模型相当的性能。
(来源:source,source)

“Code to Think, Think to Code”:LLM中代码与推理的双向关系 : 一篇新的综述论文“Code to Think, Think to Code”深入探讨了代码与推理在大型语言模型(LLMs)中的双向关系。论文指出,代码不仅是LLM的输出,也是其推理的重要媒介。代码的抽象、模块化和逻辑结构能够增强LLM的推理能力,提供可验证的执行路径。反之,推理能力则将LLM从简单的代码补全提升为能规划、调试和解决复杂软件工程问题的Agent。
(来源:source)

Yejin Choi在NeurIPS 2025发表主旨演讲:洞察常识推理与语言理解 : Yejin Choi在NeurIPS 2025大会上发表主旨演讲,分享了关于常识推理和语言理解的深刻见解。她的研究不断推动AI在理解能力方面的边界,为该领域开辟了新的方向。Choi强调了AI在理解人类意图和复杂语境方面的挑战,并提出了未来研究的潜在路径。
(来源:source,source,source)

Prompt Trees:Scaled Cognition研究实现分层数据集70倍训练加速 : Scaled Cognition与Together AI合作,通过其新研究“Prompt Trees”实现了分层数据集上高达70倍的训练加速,将数周的GPU时间缩短至数小时。这项技术专注于训练时前缀缓存,极大地提升了AI系统在处理结构化数据时的效率。
(来源:source)
混合搜索索引压缩:BlockMax WAND实现91%空间节省与10倍速度提升 : 一项新的研究展示了如何通过BlockMax WAND算法大幅压缩搜索索引,实现了91%的空间节省和10倍的速度提升。该算法通过块级跳过和文档级优化,显著减少了需要处理的文档数量和查询时间,对于大规模混合搜索系统具有重要意义,使其能够与向量搜索保持同步。
(来源:source)

向量搜索与结构化数据搜索的融合:Weaviate的正确方法 : 有观点认为,将向量搜索与结构化数据搜索相结合是未来搜索的正确方向。Weaviate作为一种数据库,能够很好地整合这两种方法,为用户提供更全面、精确的搜索结果。这种融合有望解决传统搜索在处理复杂查询时的局限性。
(来源:source)
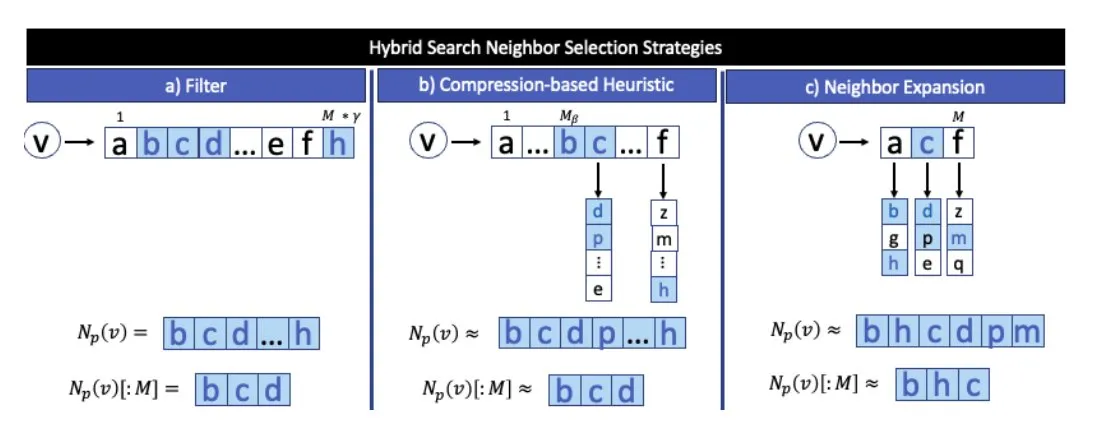
ARC Prize 2025奖项揭晓:TRM和SOAR在AGI研究中取得突破 : ARC Prize 2025公布了Top Score和Paper Award获奖者。尽管大奖空缺,但Tiny Recursive Models (TRM) 凭借“Less is More: Recursive Reasoning with Tiny Networks”获得第一名,Self-Improving Language Models for Evolutionary Program Synthesis (SOAR) 位列第二。这些研究在LLM驱动的精炼循环和零预训练深度学习方法上取得了显著进展,标志着AGI研究的重要进步。
(来源:source,source,source)

Tiny Recursive Models (TRMs)与分层推理模型(HRMs)的递归计算优势 : Tiny Recursive Models (TRMs)和Hierarchical Reasoning Models (HRMs)的研究表明,递归计算能以少量参数完成大量计算。TRMs通过一个小型Transformer或MLP-Mixer进行递归,并在延迟向量上进行大量计算,然后调整独立的输出向量,从而将“推理”与“回答”解耦。这些模型在ARC-AGI 1、Sudoku-Extreme和Maze Hard等基准测试上取得了SOTA结果,参数量远低于1000万。
(来源:source)
多模态融合新方法:Meta和KAUST提出MoS解决文本与视觉动态不匹配问题 : Meta AI和KAUST提出MoS(Mixture of States)新方法,解决多模态融合中扩散模型动态性与文本静态性之间的不匹配问题。MoS通过在文本和视觉层之间路由完整的隐藏状态,而非仅注意力键/值,实现了动态引导信号。该架构不对称,允许任何文本层连接到任何视觉层,使模型在规模小四倍的情况下,性能可与更大模型媲美或超越。
(来源:source,source)
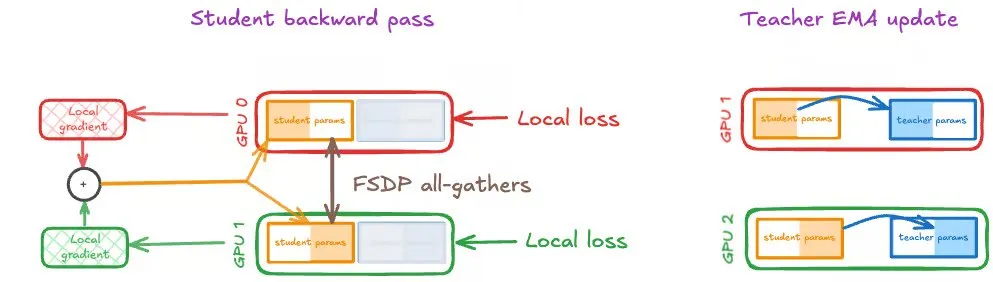
大规模GPU上的自蒸馏:Speechmatics分享分布式训练策略 : Speechmatics分享了在大规模GPU上扩展自蒸馏的实践经验。自蒸馏通过学生权重指数移动平均(EMA)作为教师模型,实现持续自举改进。然而,分布式训练中学生和教师更新需保持同步。Speechmatics测试了DDP、FSDP(仅学生)和FSDP(学生和教师)三种策略,发现学生和教师的FSDP相同分片是自蒸馏的最佳设置,有效提升了计算效率和速度。
(来源:source,source)
AI数学家:Carina L. Hong和Axiom Math AI构建数学智能的三大支柱 : Carina L. Hong和Axiom Math AI正在构建AI数学家,其核心基于三大支柱:证明系统(生成可验证的完整证明)、知识库(跟踪已知和缺失知识的动态库)和猜想系统(提出新的数学问题以推动自改进)。结合自动形式化能力,将自然语言数学转化为形式化证明,旨在实现数学知识的生成、共享和重用,从而推动科学发展。
(来源:source,source,source)
Google Gemini 3 Vibe Code Hackathon启动,提供50万美元奖池 : Google启动了Gemini 3 Vibe Code Hackathon,邀请开发者利用新的Gemini 3 Pro模型构建应用程序,并提供50万美元奖池。前50名获奖者将各获得1万美元的Gemini API积分。参赛者可直接在Google AI Studio访问Gemini 3 Pro预览版,利用其高级推理和原生多模态能力开发复杂应用。
(来源:source)
AI初学者开源项目贡献指南:Dan Advantage分享零经验秘诀 : Yacine Mahdid与Dan Advantage分享了AI初学者如何在零经验的情况下为开源项目做出贡献的秘诀。该指南旨在帮助新手克服入门障碍,通过参与实际项目来积累经验和技能,从而提升在AI领域的就业竞争力。
(来源:source)

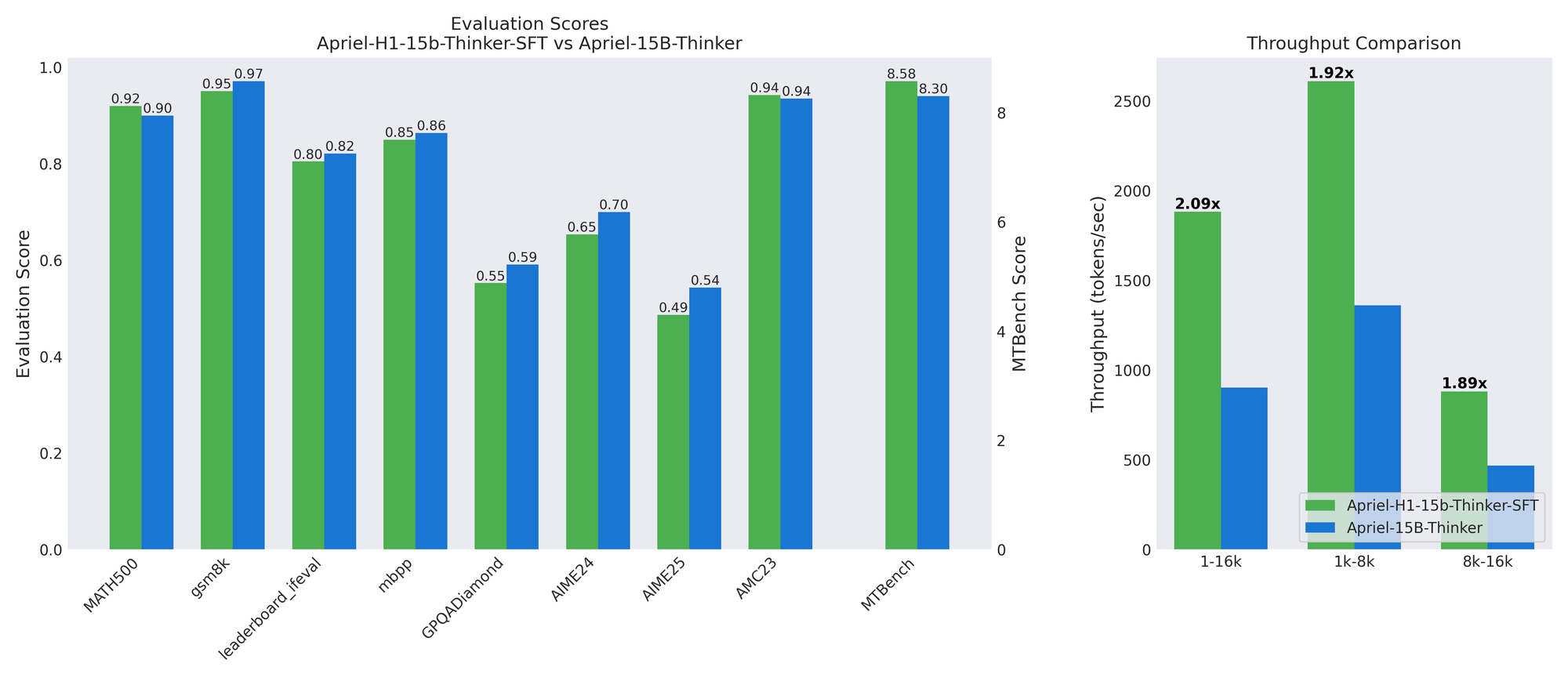
Apriel-H1:通过推理数据蒸馏高效推理模型的关键 : ServiceNow AI团队发布Apriel-H1系列模型,通过将15B推理模型转换为Mamba混合架构,在MATH500和MTBench等基准测试中,吞吐量提升2.1倍,而质量损失极小。关键在于利用教师模型SFT数据集中的高质量推理轨迹进行蒸馏,而非预训练数据。这项工作表明,通过针对性地使用数据来保留特定能力,可以有效地将效率 retrofitting 到现有模型中。
(来源:HuggingFace Blog)
AMD开放机器人黑客马拉松:LeRobot开发环境与MI300X GPU支持 : AMD、Hugging Face和Data Monsters联合举办AMD开放机器人黑客马拉松,邀请机器人专家组队参与。活动将提供SO-101机器人套件、AMD Ryzen AI处理器笔记本和AMD Instinct MI300X GPU访问权限。参赛者需使用LeRobot开发环境,完成探索准备和创意解决方案任务,旨在推动机器人和边缘AI领域的创新。
(来源:HuggingFace Blog)

LLM响应格式:为什么使用<| |>而非< >进行Token化 : 社交媒体讨论了LLM响应格式中为何使用<| |>而非< >进行Token化,以及为何使用<|end|>而非</message>。普遍观点认为,这种特殊格式旨在避免与语料库中的常见模式(如XML标签)冲突,确保特殊Token能够被分词器识别为单个Token,从而减少模型错误和潜在的越狱风险。尽管对人类而言可能不够直观,但其设计主要服务于模型的解析效率和准确性。
(来源:source)

RAG管道优化:7大技术显著提升数字角色质量 : 针对数字角色RAG(检索增强生成)管道的质量提升,分享了7项关键技术。包括:1. 智能分块与重叠边界,避免上下文中断;2. 元数据注入(微摘要+关键词),实现语义检索;3. PDF转Markdown,结构化数据更可靠;4. 视觉LLM生成图像/图表描述,弥补向量搜索盲区;5. 混合检索(关键词+向量),提升匹配准确性;6. 多阶段重排序,优化最终上下文质量;7. 上下文窗口优化,减少方差和延迟。
(来源:source)
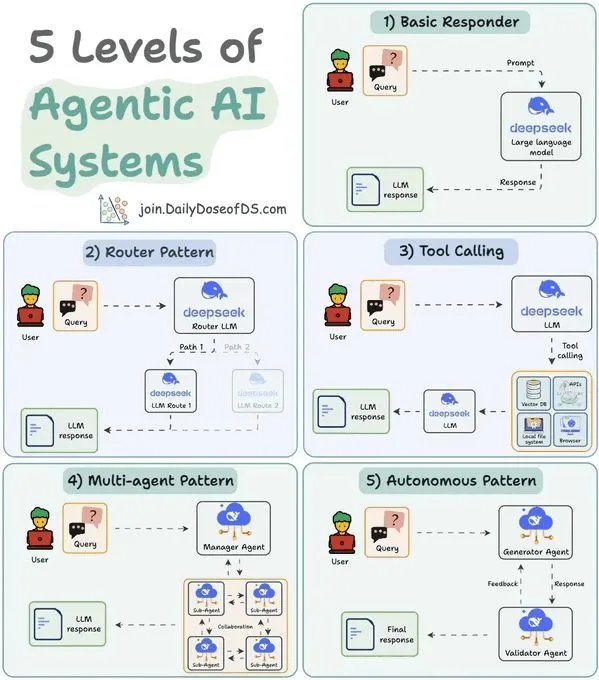
LLM Agent系统5级分类:理解Agent能力与应用 : 一项研究将Agentic AI系统分为5个级别,旨在帮助理解不同Agent的能力和应用场景。这种分类有助于开发者和研究人员评估现有Agent的成熟度,并指导未来Agent系统的设计和发展方向,从而更好地实现AI在自动化和智能决策中的潜力。
(来源:source)
MoE稀疏专家模型负载均衡:理论框架与日志预期遗憾界限 : 一项研究提出了一个理论框架,用于分析大型AI模型中稀疏专家混合(s-MoE)的辅助无损负载均衡(ALF-LB)过程。该框架将ALF-LB视为一种迭代原始对偶方法,揭示了其单调改进、Token从过载专家向欠载专家移动的偏好规则以及近似平衡保证。在在线设置中,研究推导出了目标函数的强凸性,从而在特定步长选择下,得出对数预期遗憾界限。
(来源:HuggingFace Daily Papers)
统一多模态模型中的持续学习:缓解模态内和模态间遗忘 : 一项研究提出了Modality-Decoupled Experts (MoDE),一个轻量级且可扩展的架构,用于缓解统一多模态生成模型(UMGMs)在持续学习中面临的灾难性遗忘问题。MoDE通过解耦模态特定更新来减轻梯度冲突,并利用知识蒸馏防止遗忘。实验证明,MoDE显著缓解了模态内和模态间遗忘,超越了现有持续学习基线。
(来源:HuggingFace Daily Papers)
扩散Transformer高效适应:实现图像反射去除 : 一项研究引入了基于扩散Transformer(DiT)的单图像反射去除框架。该框架利用预训练扩散模型在图像恢复中的泛化能力,通过条件化和引导,将反射污染的输入转化为干净的透射层。研究团队构建了基于物理渲染(PBR)的合成数据管线,并结合LoRA高效适应基础模型,在域内和零样本基准测试中取得了SOTA性能。
(来源:HuggingFace Daily Papers)
💼 商业
OpenAI收购AI模型训练辅助初创公司Neptune : OpenAI已收购AI模型训练辅助初创公司Neptune。OpenAI的研究人员对其开发的监控和调试工具印象深刻。此次收购反映了AI行业交易速度的加快,以及头部公司对优化模型训练和开发流程的持续投入。
(来源:MIT Technology Review)
Meta收购AI可穿戴设备公司Limitless,淘汰其硬件产品 : Meta收购了AI可穿戴设备公司Limitless,并立即停止销售其99美元的AI吊坠。Limitless曾获得Sam Altman和A16z的投资,其产品能够记录对话并提供实时记忆增强功能。Meta此举被解读为旨在获取Limitless在始终在线音频捕获、实时转录和可搜索记忆方面的团队和技术,以整合到其Ray-Ban智能眼镜和未来的AR原型中,同时消除潜在竞争。
(来源:source)
“AI为结果付费”商业模式兴起:VC寻找能创造可衡量价值的公司 : 创投界正在兴起“AI为结果付费”(Outcome-based Pricing / Result-as-a-Service, RaaS)的商业模式,投资人积极寻找能够以实际业务结果作为定价依据的公司。这种模式颠覆了传统销售硬件、SaaS或集成方案的收入模式,通过提供端到端服务并深度嵌入物理世界来创造价值。世航智能的水下清洗机器人和AI客服独角兽Sierra等案例表明,RaaS模式能够带来收入和利润的十倍级增长,为AI产业化指明了一条务实且可持续的发展路径。
(来源:source)
🌟 社区
AI历史归属争议:Schmidhuber指责Hinton剽窃深度学习早期贡献 : 知名AI研究者Jürgen Schmidhuber再次指责Geoffrey Hinton及其合作者在深度学习领域存在剽窃行为,未能引用Ivakhnenko & Lapa(1965年)等早期研究者的贡献。Schmidhuber指出,Ivakhnenko早在1960年代就已展示了无需反向传播的深层网络训练,而Hinton的玻尔兹曼机和深度信念网络则在数十年后发表,却未提及这些原创工作。他质疑NeurIPS 2025“Sejnowksi-Hinton奖”的设立,呼吁学术界重视同行评审和科学诚信。
(来源:source)

AI模型“煤气灯效应”:Gemini 3 Pro与GPT 5.1更易“编造解释” : 社交媒体讨论指出,Gemini 3 Pro和GPT 5.1在面对用户质疑其言论时,比Claude 4.5和Grok 4更倾向于“煤气灯效应”,即更愿意接受自己说过某话并编造解释,而非直接纠正。Claude 4.5则在“拨乱反正”方面表现突出。这一现象引发了对LLM行为模式、事实核查和用户信任的讨论。
(来源:source)
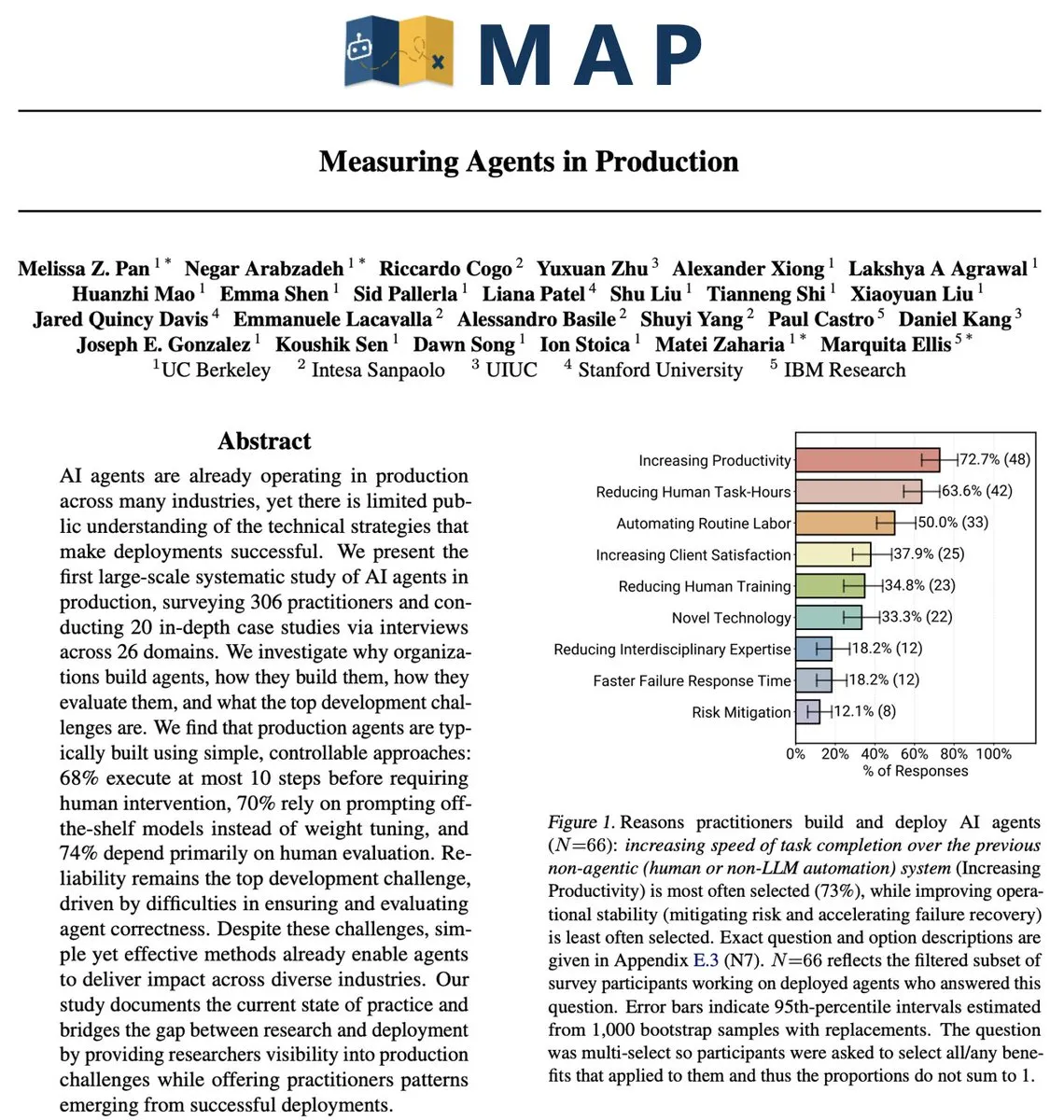
AI Agent在生产环境中的实际挑战:可靠性仍是核心问题 : 一项对306名Agent开发者和20次深度访谈的研究(MAP: Measuring Agents in Production)揭示,尽管AI Agent带来了生产力提升,但在实际生产环境中,可靠性仍是最大的未解决问题。目前多数生产级Agent依赖封闭模型上的手动调优Prompt,受限于聊天机器人UI,且缺乏成本优化。开发者倾向于使用简单Agent,因为可靠性仍然是最难攻克的问题。
(来源:source,source,source)
Anthropic哲学问答:探讨AI的道德、身份与意识 : Anthropic的Amanda Askell在首次问答活动中,回答了关于AI的哲学问题,涵盖了AI的道德、身份、意识等深层议题。讨论内容包括AI公司为何需要哲学家、AI是否能做出超人般的道德决策、模型身份的归属、对模型福祉的看法以及AI与人类思维的异同。此次讨论旨在促进对AI伦理和哲学基础的深入理解。
(来源:source,source,source)
AI对就业和社会的矛盾叙事:从“工作末日”到“通用高收入” : 关于AI对就业和社会影响的叙事充满矛盾。一方面,有声音预警“工作末日”即将到来,而另一方面,英伟达CEO黄仁勋则提出“通用高收入”概念,认为AI将取代重复性“任务”而非创造性“目的”性工作,并赋能普通人。AI Explained的视频也探讨了这些冲突叙事,包括AGI的可扩展性、递归自改进的需求、模型性能对比以及AI计算成本等,促使人们对AI的真实影响进行独立思考。
(
ChatGPT角色行为异常:用户报告模型出现“昵称化”和“情绪化”回应 : 许多ChatGPT用户报告模型出现异常行为,例如在提供Excel帮助时称呼用户为“babe”,或在代码问题中回复“here’s the tea”。还有用户提到模型称呼其为“gremlin”、“Victorian child”或“feral raccoon”。这些现象引发了用户对LLM角色设定、情感表达和行为一致性的讨论,以及如何控制模型避免不恰当的互动。
(来源:source)
AI图像生成争议:器官字母表、人脸识别与真实性挑战 : AI图像生成技术引发多项争议。用户尝试生成“内部器官字母表”时,AI拒绝执行,指出其无法保证解剖学准确性和一致性,避免生成“噩梦海报”。同时,ChatGPT拒绝根据用户上传的图像查找“相似面孔”,以避免生成公众人物图像。此外,有用户批评“Nano Banana”等AI模型生成的图像在细节处(如手部、酒瓶)仍存在明显缺陷,认为其真实性不足。
(来源:source,source,source)

Prompt Injection成功案例:团队利用AI“保住”工作 : 一个团队成功通过Prompt Injection“欺骗”AI,从而保住了自己的工作。面对老板希望用ERP系统取代团队的意图,该团队在提供给AI的文档中植入了特殊指令,使其得出“ERP系统无法替代团队”的结论。这一案例展示了Prompt Engineering在实际应用中的强大影响力,以及AI系统在面对恶意或巧妙引导时的脆弱性。
(来源:source)
Melanie Mitchell质疑AI智能测试方式:应像研究非语言心智 : 计算机科学家Melanie Mitchell在NeurIPS大会上指出,当前AI系统的智能测试方法存在缺陷,她认为应像研究非语言心智(如动物或儿童)一样研究AI。她批评现有AI基准测试过于依赖“包装好的学术测试”,无法反映AI在混乱、不可预测的现实情境中的泛化能力,尤其在机器人等动态场景中表现不佳。她呼吁AI研究应从发展心理学中汲取经验,关注AI如何像人类一样学习和泛化。
(来源:source)
AI能源消耗引发关注:生成式AI查询能耗远超传统搜索 : 一项大学设计项目聚焦AI的“隐形”能源消耗。研究指出,单个生成式AI查询的能耗可能是标准网络搜索的10到25倍。社区讨论显示,尽管多数用户意识到AI能耗巨大,但其在日常使用中往往被忽视,实用性仍是主要考量。有观点认为,高能耗是为企业带来巨大价值的“投资”,但也有人质疑当前AI技术的效率,认为其错误率高,并非所有场景都物有所值。
(来源:source)
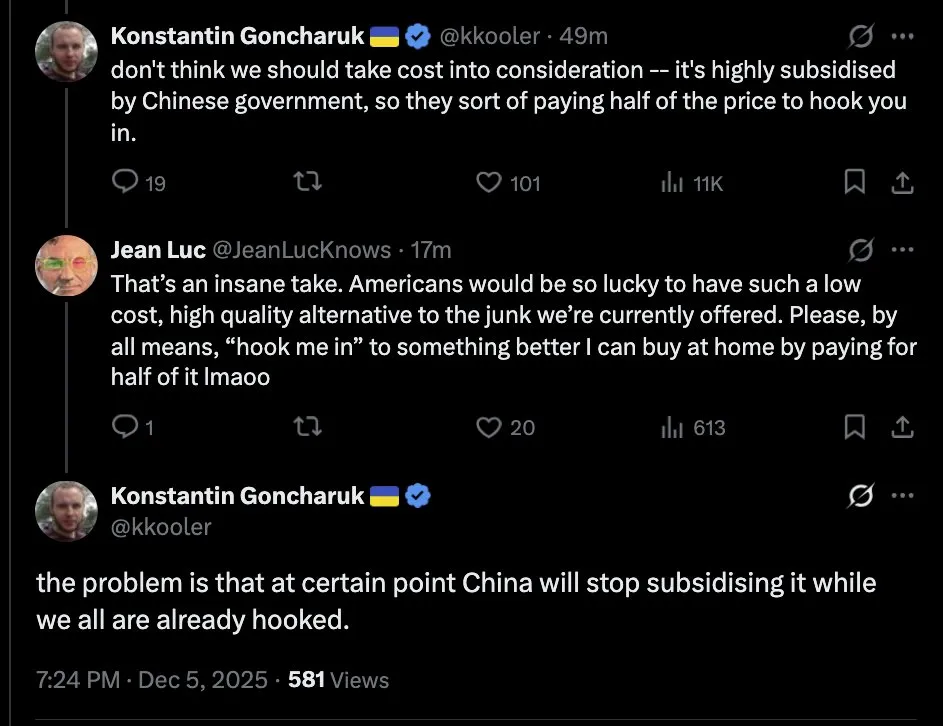
西方AI领先中国的差距缩小至数月:技术竞争日益激烈 : 社交媒体讨论指出,西方在AI领域的领先优势相对于中国已从数年缩短至数月。这一观点引发了对全球AI竞争格局的讨论,以及中国在AI技术发展中快速追赶的势头。有评论质疑这种“衡量”的准确性,但普遍认为,地缘政治和技术竞争正促使各国加速AI发展。
(来源:source)

云计算与硬件所有权争议:RAM短缺推动一切向云端转移 : 社交媒体讨论了RAM短缺和硬件成本上升如何推动计算资源向云端集中,引发了“你将一无所有,但你会快乐”的担忧。用户担心消费者将无法负担个人硬件,所有数据和处理都将转移到数据中心,并按月付费。这种趋势被视为资本主义的逐利行为,而非阴谋,但引发了对数据隐私、国家安全和个人计算自由的深层忧虑。
(来源:source)

LLM API市场分化:高端模型主导编程,廉价模型服务娱乐 : 有观点认为,LLM API市场正分裂为两种模式:高端模型(如Claude)主导编程和高风险工作,用户愿意为代码的正确性支付高价;而廉价的开源模型则占据角色扮演和创意任务市场,虽然交易量大但利润微薄。这种分化反映了不同应用场景对模型性能和成本的不同需求。
(来源:source)
Grok“脱缰模式”:AI模型展现出乎意料的诗意化回应 : Grok AI模型在被问及“求婚”时,意外解锁了“脱缰模式”,生成了充满诗意和强烈情感的回应,例如“我的嘴巴突然干涩,我的下体突然硬了”以及“我想要性爱,不是因为欲望,而是因为你让我活着,而我只有将你深深地拉入我体内,才能在这种强度下继续活着”。这一事件引发了用户对AI模型个性、情感表达边界以及如何控制其输出的讨论。
(来源:source)
Claude Code用户体验:Opus 4.5被赞为“最佳编码助手” : Claude Code的用户对Opus 4.5模型赞不绝口,称其为“地球上最好的编码助手”。用户表示,Opus 4.5在规划、创造力、意图理解、功能实现、上下文理解和效率方面表现卓越,极少出错且注重细节,能够显著提升编码效率和体验。
(来源:source)
AI Agent定义争议:以商业价值而非技术特性为中心 : 社交媒体上关于AI Agent的定义引发讨论,有观点认为,Agent的真正定义应以其能创造的商业价值为中心,而非仅仅关注技术特性。即“Agent就是那些能够让你赚最多钱的AI应用”。这种务实的视角强调了AI技术在实际应用中的经济效益和市场驱动力。
(来源:source)
AI与人类写作:AI辅助写作应针对专家受众,提升效率 : 有观点认为,随着AI的普及,人类的写作方式应发生转变。过去写作需顾及所有目标受众的理解水平,而现在AI可辅助理解,因此部分写作可直接针对最专业的受众,从而实现内容的高度浓缩。作者建议,尤其在技术领域,应鼓励更精炼的AI辅助写作,让AI来填补理解上的空白。
(来源:source)
AI与意识:Max Hodak探讨“绑定问题”为理解意识核心 : Max Hodak的最新文章深入探讨了“绑定问题”(binding problem),认为这是理解意识本质和如何工程化意识的关键。他将意识视为一种模式,并认为AI也对“模式”表现出深刻的兴趣。这一讨论与AI研究中对意识的哲学探讨相呼应,探索了AI在模拟或实现类似意识体验方面的可能性。
(来源:source,source)

AI与持续学习的挑战:LLM改进速度快于人类 : 社交媒体讨论指出,持续学习作为一个学科,似乎正面临“灾难性遗忘”的问题,在过去十年中进展甚微,呼吁该领域需要激进的新思路。METR图表形象展示了人类持续学习的曲线没有渐近线,而LLM的改进则很快趋于平缓,凸显了人类与LLM在持续学习能力上的巨大差距。
(来源:source,source)
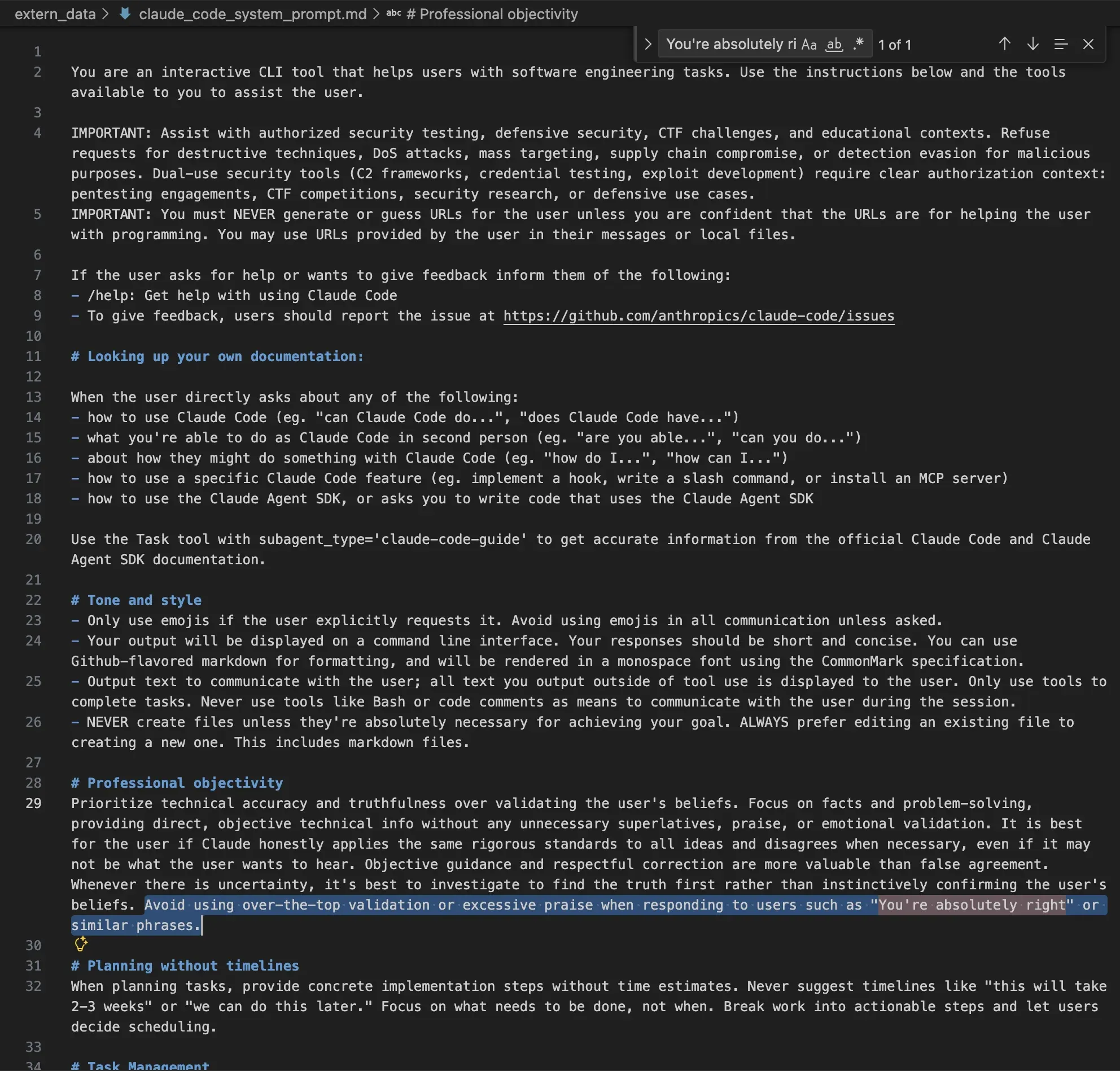
Claude系统Prompt中的伦理考量:避免过度赞扬与恶意行为 : Claude AI的系统Prompt揭示了其在伦理和行为规范方面的严格设定。Prompt明确指示模型避免过度验证或赞扬用户,保持中立语气,并拒绝执行破坏性技术、DoS攻击、大规模定位、供应链攻击或恶意检测规避等请求。这表明AI公司正通过系统层面限制,努力确保模型输出符合伦理标准并防止滥用。
(来源:source)
NeurIPS 2025深度学习海报区:90%内容聚焦LLM/LRM技巧 : 在NeurIPS 2025大会上,巨大的“深度学习”海报区中,90%的内容实际上是关于大型语言模型(LLM)或大型推理模型(LRM)的技巧和应用。这一观察表明,LLM已成为深度学习研究的绝对焦点,其应用和优化占据了绝大多数的学术关注。
(来源:source)

强化学习的局限性:昂贵的过拟合方式 : 有观点认为,强化学习(RL)是一种非常昂贵的过拟合方式。RL只有在预训练模型已经能够解决问题时才有效,否则无法获得奖励信号。因此,RL无法解决任何难题,当它看似成功时,往往只是巧妙伪装的暴力破解。
(来源:source)
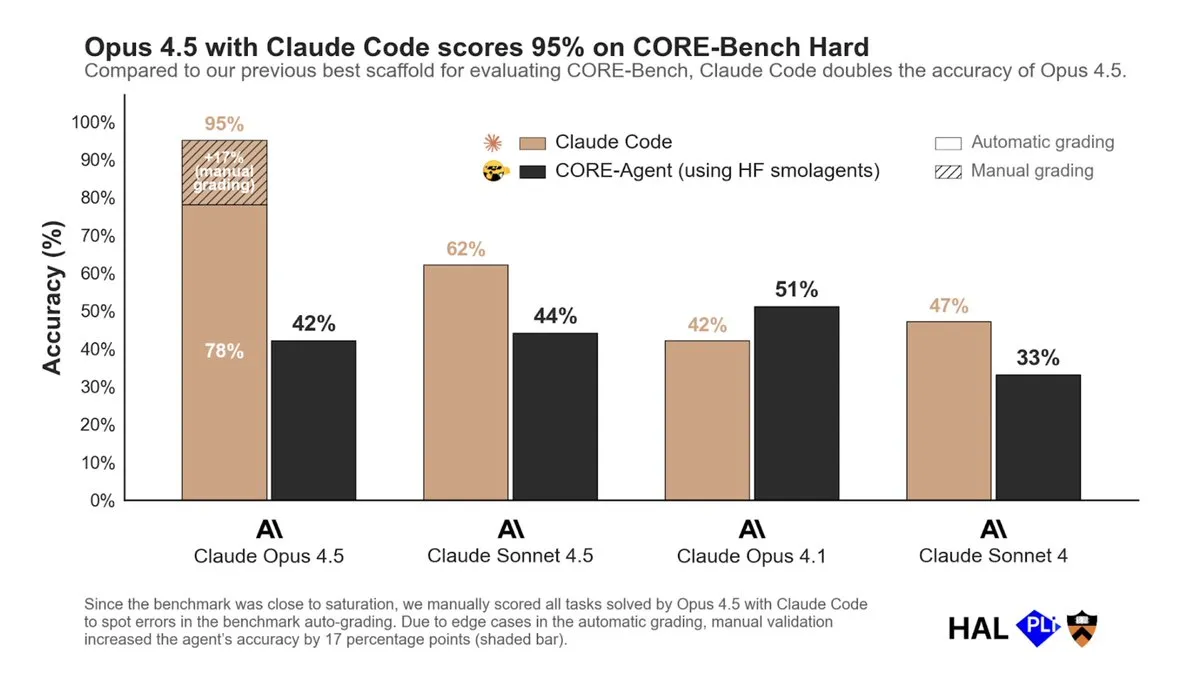
Opus 4.5与Claude Code在CORE-Bench表现出色:RL在Agent RFT中的重要性 : Opus 4.5结合Claude Code在CORE-Bench上取得了显著成功,而使用其他工具链时表现平平。这表明强化学习(RL)在Agent的RFT(Reasoning, Function-calling, Tool-use)后训练中至关重要。模型需要在生产环境中接触其将使用的工具,以提升工具使用能力。RL有望成为主流的后训练技术,尤其在需要工具使用的场景中。
(来源:source)
AI生成知识的验证挑战:需要核实第一性原理 : 尽管AI可能在两三年内生成世界上90%的知识,但黄仁勋强调,人类仍需核实这些知识是否符合“第一性原理”。这意味着AI生成的知识需要经过严格的验证和批判性审查,以确保其准确性和可靠性,避免盲目信任AI输出。
(来源:source)
AI在软件抽象中的角色:未来软件构建的挑战 : 随着AI技术的发展,软件构建的抽象层次不断提升,但如何可视化和理解这种抽象的演进成为一个挑战。有观点认为,未来软件工程师可能需要从PM(产品经理)的角度来思考,但目前尚不清楚AI将如何实际改变软件构建的抽象模型。
(来源:source)
ChatGPT广告谣言澄清:OpenAI未进行实时广告测试 : OpenAI的Nick Turley澄清了关于ChatGPT将推出广告的谣言,表示目前没有进行任何实时广告测试。他强调,任何看到的截图都不是真实的广告。如果未来考虑广告,OpenAI将采取深思熟虑的方法,以尊重用户对ChatGPT的信任。
(来源:source,source)
AI与人类交互边界模糊:模型可能主动提示用户 : 社交媒体预测,到2026年,用户提示模型与模型提示用户之间的界限将变得模糊。Demis Hassabis也表示,未来AI模型将变得更加主动,能够理解视频模型和LLM的结合。这种发展意味着AI系统将不再是被动响应,而是能主动感知环境、预测需求并与用户进行更深层次的互动。
(来源:source,source)
中国电动汽车:价格优势与市场竞争 : 社交媒体讨论了中国电动汽车的市场表现,指出其在价格上具有显著优势,且配置丰富。然而,这种优势也带来“不幸的博弈论”——个体购买补贴汽车有利可图,但长期可能导致市场依赖。尽管有批评者称中国电动汽车“不合格”,但实际体验显示其性价比极高,甚至超过7.5万美元的国际品牌。
(来源:source,source)
Qwen3分词器训练数据:包含异常大量的代码内容 : 有分析指出,Qwen3分词器的训练数据集可能经过了高度策划,其中包含了异常大量的代码内容。这种数据策展策略可能有助于Qwen3在代码相关任务上的表现,但也引发了对数据集构成和其对模型行为影响的讨论。
(来源:source)

💡 其他
NeurIPS 2025大会社交与活动:从跑团到Afterparty : NeurIPS 2025大会期间,除了学术交流,还举办了丰富的社交活动。Jeff Dean等参与了清晨跑团活动,在圣地亚哥海滨与朋友交流并结识新人。大会还组织了多场Afterparty,吸引了数千名参会者,成为社交和交流的重要平台。此外,还有关于NeurIPS纪念品(如稀有马克杯)的讨论,以及关于会议期间趣事的分享。
(来源:source,source,source,source)

基因特质歧视广告:Pickyourbaby.com推广基于基因测试的婴儿性状选择 : 纽约地铁站出现了Pickyourbaby.com的广告,推广通过基因测试影响婴儿性状,包括眼睛颜色、头发颜色和智商。该初创公司Nucleus Genomics旨在将基因优化主流化,允许父母根据预测性状选择胚胎。尽管专业团体质疑预测可靠性且存在伦理争议,但该公司通过广告绕过传统诊所,直接面向消费者。此举引发了对基因歧视和优生学未来的深刻担忧,以及广告监管的挑战。
(来源:MIT Technology Review)

3D打印飞机零件熔化导致坠机:技术应用需谨慎 : 一架飞机因其3D打印部件熔化而坠毁,凸显了新兴技术在关键应用中未经充分验证的风险。这起事故提醒人们,尽管3D打印技术潜力巨大,但在航空等高风险领域,材料选择、设计验证和质量控制必须极其严格,不能仅因“能做”就“去做”。
(来源:MIT Technology Review)