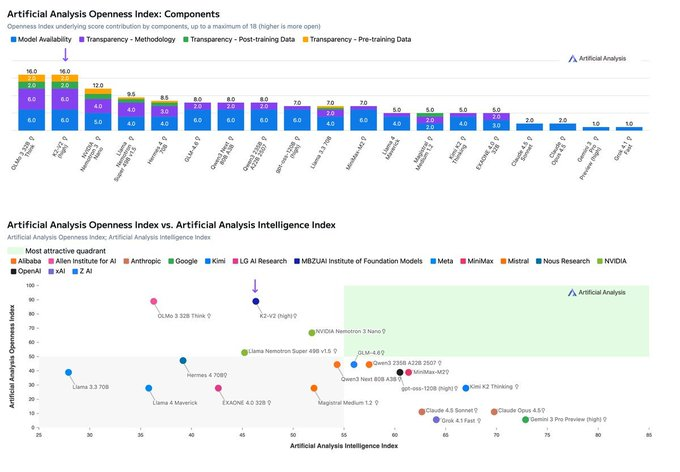
关键词:OpenAI, GPT-5.2 Pro, xAI, ChatGPT广告测试, Claude Code编程革命, Colossus 2超级计算机
🔥 聚焦
OpenAI开启广告测试并披露2025年营收突破200亿美元 : OpenAI正式宣布将在ChatGPT免费版和新推出的8美元“Go”版中测试广告业务。CFO Sarah Friar披露,公司2025年年化经常性收入(ARR)已飙升至200亿美元,算力规模达1.9GW。这标志着OpenAI从纯订阅模式向“算力-研究-产品-商业化”闭环的重大转型。尽管面临每年约170亿美元的巨额支出,OpenAI试图通过借鉴Instagram的“意图驱动”原生广告模式,在不损害回答中立性的前提下缓解财务压力。这一动作被视为AI行业进入“商业化硬着陆”阶段的信号,也预示着广告可能在未来三年内成为其第一大收入来源(来源: Sarah Friar, 36氪, 新智元)
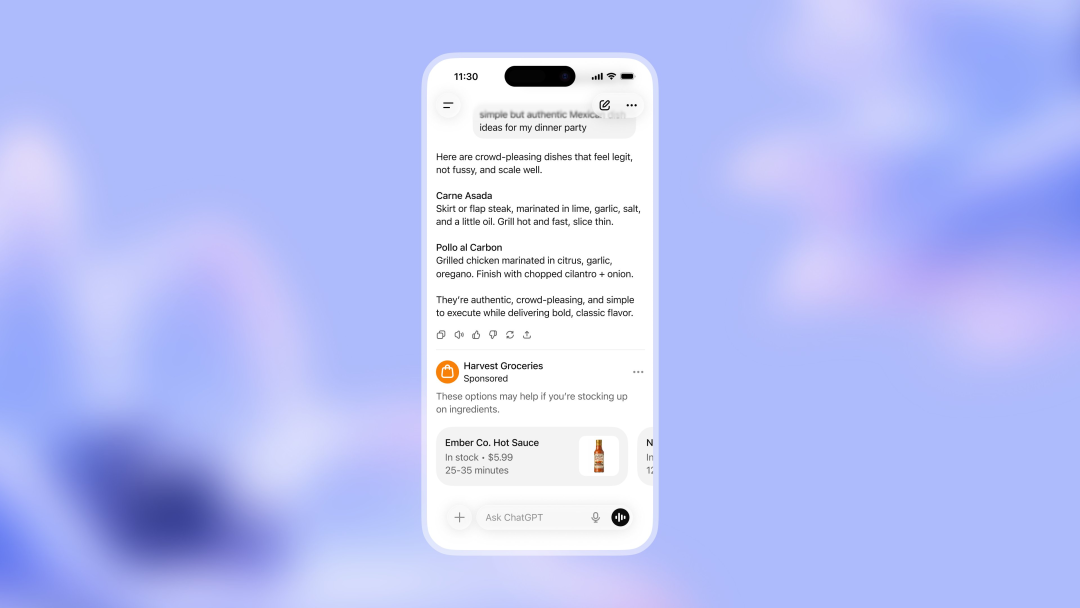
GPT-5.2 Pro独立证明45年数论猜想,陶哲轩验证无误 : OpenAI最新模型GPT-5.2 Pro成功独立证明了埃尔德什猜想库中的第281号问题。菲尔兹奖得主陶哲轩验证了该证明,称其为“迄今为止最明确的AI主要贡献结果”,并惊叹于AI在极限交换和量词顺序等微妙之处未犯任何错误。虽然社区随后发现该问题存在基于1936年经典定理的更简便解法,但GPT-5.2 Pro通过遍历论路径给出的严谨推导,证明了前沿模型在处理高难度抽象逻辑任务时已具备实质性的突破。这一事件被视为AI进入科研深水区的里程碑(来源: Tao, 36氪)
xAI上线全球首个吉瓦级AI超级集群Colossus 2 : 马斯克的xAI正式启动了Colossus 2超级计算机,这是全球首个达到吉瓦(Gigawatt)规模的AI集群,配备约55.5万颗英伟达GPU,总价值估算达180亿美元。该设施利用现场燃气轮机和特斯拉Megapacks供电,消耗电力相当于旧金山的峰值需求。此举旨在通过极致的算力规模碾压竞争对手,预计到4月将升级至1.5吉瓦。这一基建豪赌展示了xAI在Scaling Laws路径上的激进立场,但也引发了环保组织对当地空气质量和能源消耗的强烈质疑(来源: Reddit, Twitter)

Claude Code引发编程范式革命:一周构建300万行代码浏览器 : Anthropic推出的Claude Code命令行工具在开发者社区引发巨大震动。Vercel CTO Malte Ubl称其在1周内完成了原本需1年的项目;Michael Truell则展示了用其构建的一个包含300万行代码、自研渲染引擎和JS虚拟机的浏览器。这种“Vibe Coding”模式让编程门槛大幅降低,甚至8岁儿童也能完成智能体开发。它催生了“一人顶一队”的“炸裂工程师(Cracked Engineers)”文化,预示着未来软件开发将从“购买SaaS”转向“自制微应用”,平庸的中间层程序员正面临前所未有的生存危机(来源: Michael Truell, 36氪, Twitter)
🎯 动向
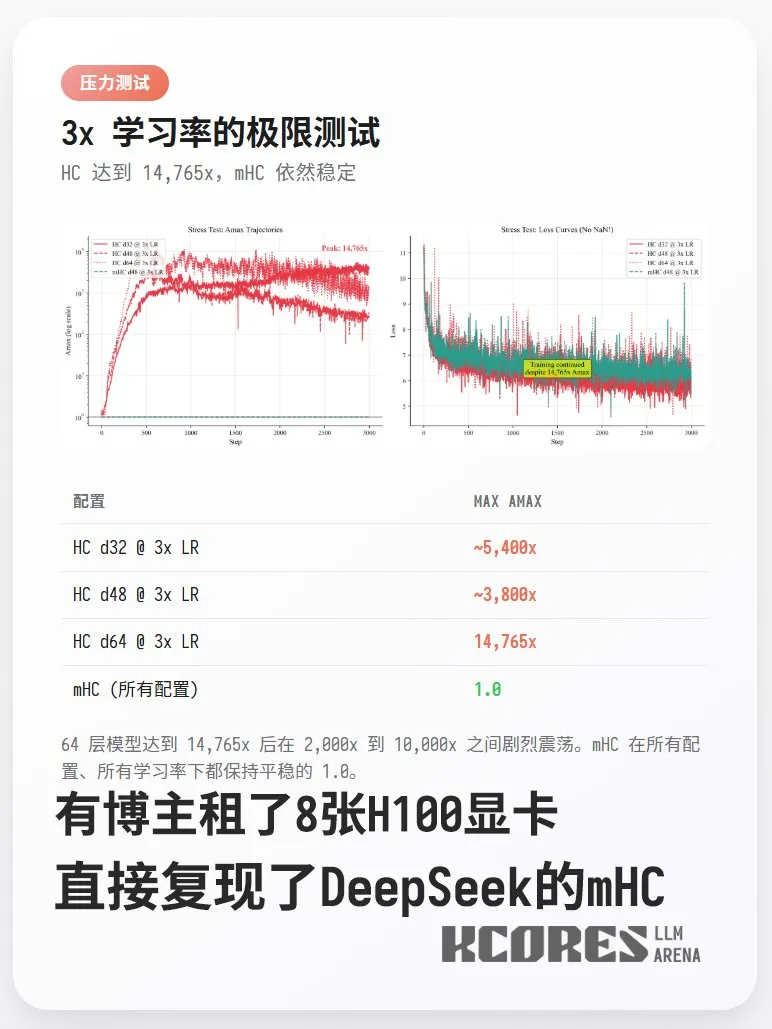
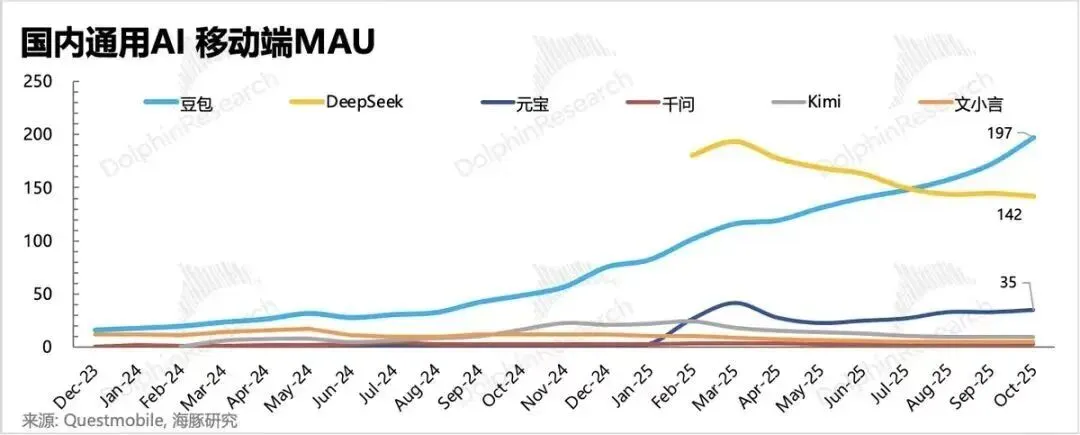
DeepSeek发布条件记忆论文,暗示V4即将到来 : DeepSeek与北京大学联合发布论文《Conditional Memory via Scalable Lookup》,提出“条件记忆”概念,通过可扩展查找解决LLM的长时记忆短板。这被视为其下一代模型V4的技术前哨,预计将在春节前后发布。此外,社区已成功复现其mHC架构,证实其在1.7B参数下可实现万倍信号放大且训练稳定(来源: HuggingFace, karminski3)
智谱与MiniMax上市后路径分化,国产大模型进入“决赛圈” : 随着智谱和MiniMax相继上市,国产大模型“六小虎”策略出现分野。百川智能转向医疗垂域,发布Baichuan-M3;月之暗面则坚持追赶Anthropic,追求智能上限。智谱联合华为发布首个国产芯片训练的SOTA生图模型GLM-Image。市场正从参数竞赛转向效率与落地场景的博弈(来源: 36氪)
Sakana AI推出RePo机制优化上下文处理 : Sakana AI引入RePo(上下文重新定位)机制,打破了模型处理信息的固定线性顺序。RePo能根据内容相关性动态调整位置,让模型主动“拉近”关键信息并“推开”噪声,显著提升了模型在处理嘈杂、长文本输入时的鲁棒性和推理效率(来源: SakanaAILabs)

谷歌发布TranslateGemma,支持本地运行的免费翻译模型 : 谷歌推出TranslateGemma系列模型(4B/12B/27B),支持55种语言,可运行在个人电脑上。该模型支持文本及图像文字提取翻译,主打隐私保护与零API成本,为本地化多语言协作提供了强力工具(来源: QuixiAI)
🧰 工具
DeepAgents Open Lovable:自然语言转React应用 : 由LangChain社区开发的开源平台,基于DeepAgents和LangGraph构建。用户只需输入自然语言,即可生成完整的React前端应用,支持子智能体协作、实时预览和一键部署(来源: LangChain)

iMCP:将iMessage接入Claude协作流 : 开发者Mattt推出的MCP服务器,允许用户将iMessage对话直接引入Claude或编程智能体中。这解决了社交沟通与工作流断层的问题,让AI能直接基于聊天上下文进行代码编写或任务执行(来源: HamelHusain)
Headroom:LLM上下文压缩层 : 该工具通过压缩技术将LLM成本降低50-90%。它与LangChain深度集成,在RAG场景下可节省60%成本,减少85%的智能体Token消耗,支持Proxy/SDK部署,是企业级降本增效的利器(来源: LangChain)

Vibecraft:带空间音频的Claude代码管理器 : 一个拥有3万行代码的开源项目,为管理Claude代码提供炫酷的UI、脚本钩子、可视化效果以及空间音频。它能通过声音反馈Claude的状态,让长时间的AI协作更具沉浸感(来源: nearcyan)
Eduly:论文转短视频工具 : 基于LangChain Deepagents框架,能自动生成并调试Manim动画代码,将枯燥的学术论文转化为适合社交媒体传播的短视频动画,实现了知识传播的自动化(来源: LangChain)

📚 学习
《计算机视觉、机器人与机器学习中的线性代数》免费教材 : 该书涵盖了向量空间、矩阵、范数、特征值、SVD等核心理论,并深入探讨了PCA、图论、3D旋转等实际应用,是AI从业者夯实数学基础的权威资源(来源: TheTuringPost)

Agent-as-a-Judge:下一代AI评估综述 : 探讨了为何传统的LLM-as-a-Judge在复杂任务中失效,并提出了引入规划、工具和记忆的“智能体法官”模式,为构建鲁棒、可验证的AI评估体系提供了路线图(来源: TheTuringPost)

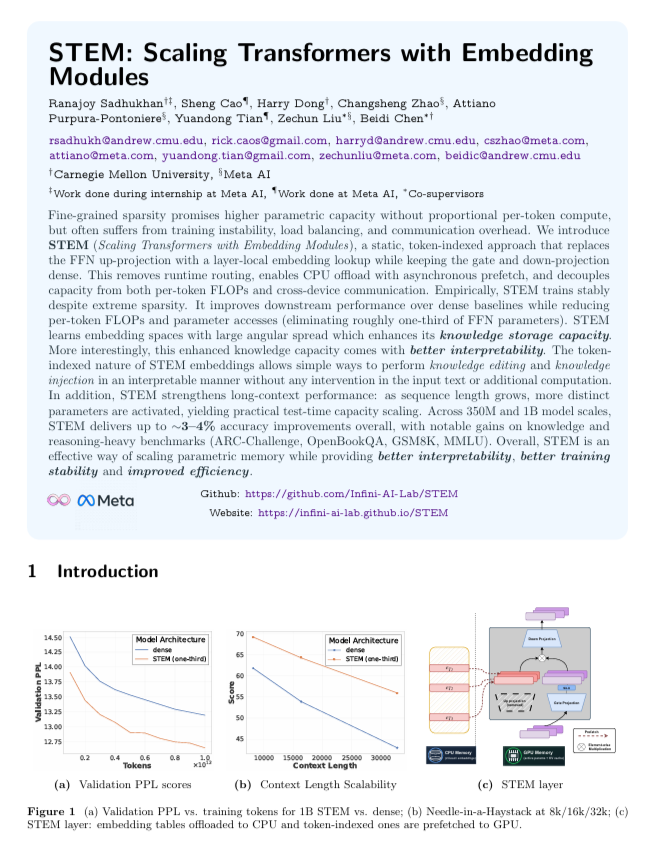
STEM:Meta与CMU推出的Transformer扩展新方法 : 通过嵌入模块扩展Transformer参数记忆,无需路由且不增加运行时计算开销。它将1/3的FFN上投影替换为静态嵌入查找,参数可异步预取,实现了模型容量与每Token计算量的解耦(来源: TheTuringPost)
💼 商业
云知声配售融资1.92亿港元,发力AI医疗 : “AGI第一股”云知声在上市半年后再次融资,拟配售78万股新H股。所得资金约50%用于研发,40%投资新兴商业机会。面对增收不增利的困境,云知声正通过高质量医疗数据资产加码AI医疗,试图在残酷的淘汰赛中突围(来源: 36氪)

前第四范式总裁裴沵思创立Noumena,获千万元融资 : Noumena打造AI原生营销Agent系统,通过“曼哈顿计划”解构内容社交平台的“营销玄学”。其核心逻辑是吸纳头部客户专家的隐性知识,实现营销学的工业化,目前已与欧莱雅等品牌展开合作(来源: 36氪)

腾讯天价挖角OpenAI大神姚顺雨,加速AI反攻 : 27岁的OpenAI前研究员姚顺雨加盟腾讯,出任首席AI科学家。此举标志着腾讯从保守的应用层优化转向核心AI基础设施建设。腾讯混元大模型已应用于超900个场景,试图通过社交生态优势实现后来居上(来源: 36氪)
🌟 社区
Reddit用户为何“反AI”?心理与地位威胁深度解析 : 社区讨论指出,Reddit用户对AI的敌意源于“地位威胁”:AI能瞬间提供比“懂哥”更专业的建议,打击了部分用户的智力优越感。此外,技能过时恐慌和对大公司的天然抵触,使得AI在Reddit被塑造成反派。这种情绪反映了技术变革中身份认知的崩塌(来源: Reddit)
智能家居“AI化”引发的灾难:Alexa Plus让咖啡机罢工 : 社区抱怨生成式AI引入的随机性破坏了智能家居的确定性。升级后的Alexa Plus常因“创造力过剩”拒绝简单的开灯或煮咖啡指令。用户感叹:在零容错场景谈概率是设计灾难,AI应是系统的解释者而非所有按钮的替代者(来源: 36氪)

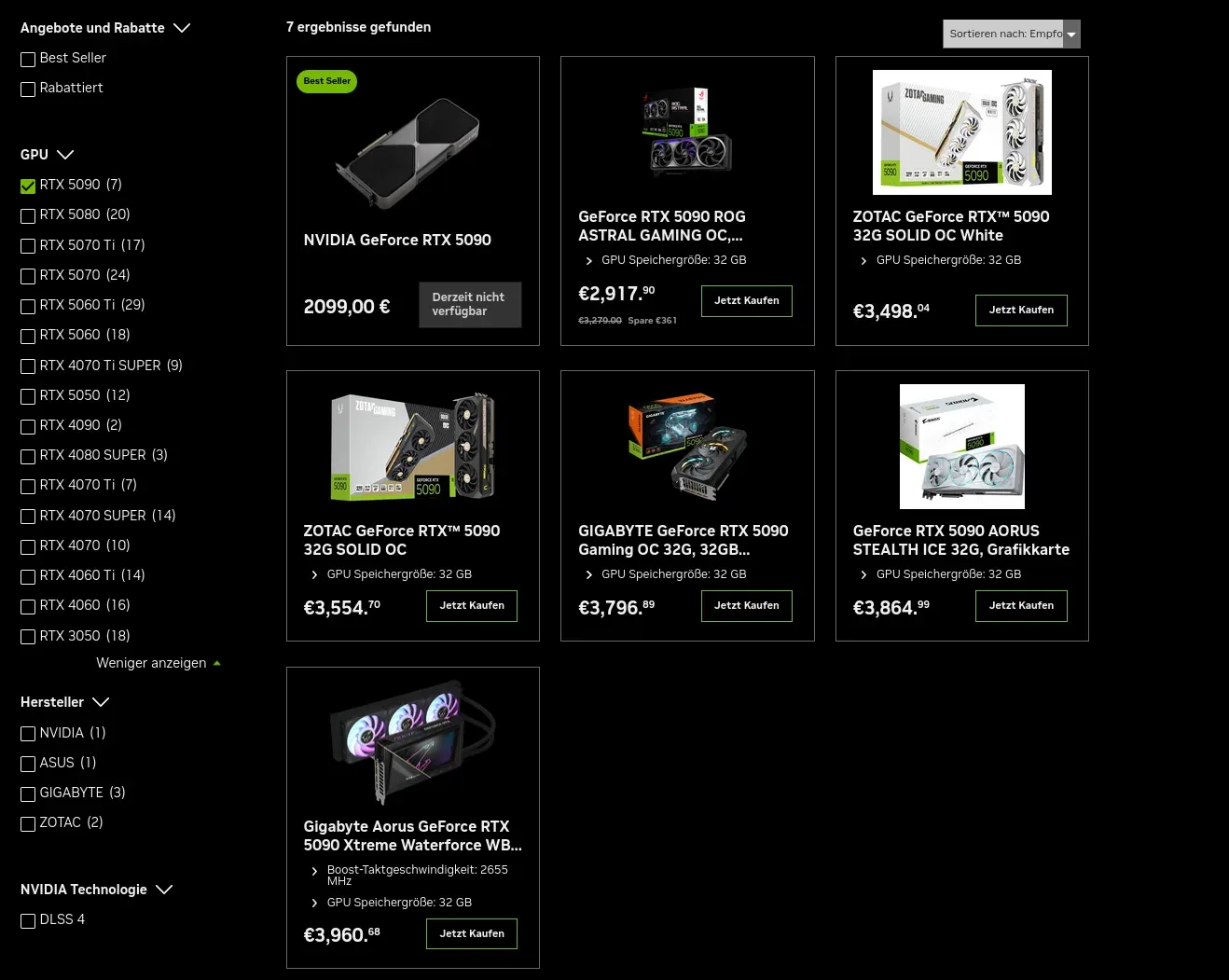
欧洲GPU市场告急:RTX 5090价格翻倍且一卡难求 : 德国及欧盟玩家反馈,受AI算力需求挤压,RTX 5090价格已从2200欧元飙升至3800欧元。个人开发者被迫转向租用云端集群或考虑AMD Radeon AI PRO等替代方案,硬件短缺正成为本地AI研究的巨大门槛(来源: Reddit)
💡 其他
飞书与安克创新发布“AI录音豆” : 这款仅10克的硬件标志着飞书正式进军AI硬件。它通过双麦克风阵列实现实时纪要,并将声音直接转化为文档、待办等组织资产。这反映了口头信息正成为AI时代最高价值的生产力入口(来源: 36氪)

“厂二代”接班底气:AI渗透中国产业带 : 在义乌、东莞等地,年轻的工厂接班人正利用AI进行原材料期货推演、跨境直播外模生成及新品点击率优化。AI不再是实验室产物,而是实实在在的生意经,甚至能帮助零基础新人快速打造类目爆款(来源: 36氪)
DeepSeek的“无商业模式”护城河分析 : 科技评论家Kevin Xu指出,DeepSeek零外部融资、由幻方量化利润供养的独特模式,使其能免受商业化KPI干扰,保持团队极度扁平与科研纯粹。这种“不看脸色”的特质是其能持续震惊世界的深层原因(来源: 36氪)