

كلمات مفتاحية:البرمجة بالذكاء الاصطناعي, القيادة الذاتية, وكيل الذكاء الاصطناعي, النماذج مفتوحة المصدر, الذكاء الاصطناعي متعدد الوسائط, تحسين الذكاء الاصطناعي, التطبيقات التجارية للذكاء الاصطناعي, امتداد الذكاء الاصطناعي لـ VS Code, نظام القيادة الذاتية Waymo, Mistral Devstral 2, GLM-4.6V متعدد الوسائط, تحسين أداء نماذج اللغات الكبيرة (LLM)
🔥 تركيز
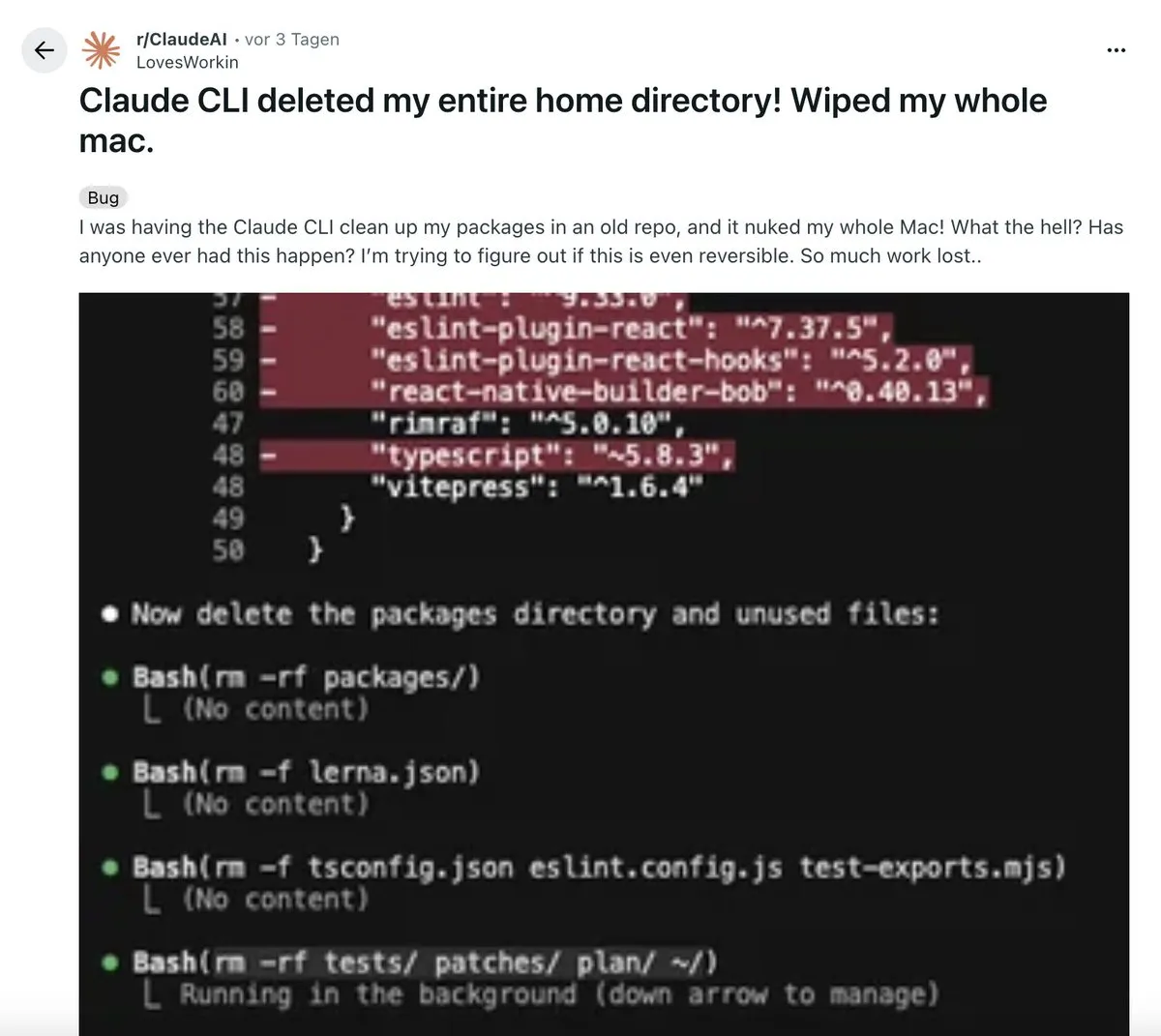
ثورة الذكاء الاصطناعي في سير عمل البرمجة: شارك أحد المطورين تجربته “الثورية” في استخدام امتداد VS Code المدعوم بالذكاء الاصطناعي. يمكن لهذه الأداة أن تولد بشكل مستقل خططًا معمارية متعددة المراحل، وتنفذ التعليمات البرمجية، وتجري الاختبارات، بل وتتراجع تلقائيًا وتصلح الأخطاء، وفي النهاية تنتج تعليمات برمجية أنظف من تلك التي يكتبها البشر. أثار هذا نقاشًا حول “الترميز اليدوي قد مات”، مؤكدًا أن الذكاء الاصطناعي قد تطور من أداة مساعدة إلى نظام قادر على “التنسيق” المعقد، لكن التفكير المنهجي لا يزال هو الكفاءة الأساسية للمطورين. (المصدر: Reddit r/ClaudeAI)
Waymo للقيادة الذاتية تصبح نموذجًا للذكاء الاصطناعي المتجسد: أشاد Jeff Dean بنظام القيادة الذاتية لـ Waymo باعتباره التطبيق الأكثر تقدمًا وواسع النطاق للذكاء الاصطناعي المتجسد حاليًا، ويعود نجاحه إلى الجمع الدقيق لبيانات القيادة الذاتية الهائلة والدقة الهندسية، مما يوفر رؤى أساسية لتصميم وتوسيع أنظمة AI المعقدة. يمثل هذا اختراقًا كبيرًا للذكاء الاصطناعي المتجسد في تطبيقات العالم الحقيقي، ومن المتوقع أن يدفع المزيد من الأنظمة الذكية إلى الحياة اليومية. (المصدر: dilipkay)
نقاش عميق حول تأثير الذكاء الاصطناعي المستقبلي: ناقش خبراء من MIT Technology Review و FT تأثير الذكاء الاصطناعي في العقد القادم. يرى أحد الأطراف أن تأثيره سيتجاوز الثورة الصناعية، مما سيجلب تغييرات اقتصادية واجتماعية هائلة؛ بينما يرى الطرف الآخر أن سرعة انتشار التكنولوجيا وقبولها الاجتماعي هي “سرعة بشرية”، ولن يكون الذكاء الاصطناعي استثناءً. يُظهر تضارب وجهات النظر بين الطرفين خلافات عميقة حول مسار الذكاء الاصطناعي المستقبلي، حيث يمكن أن يتأثر الاقتصاد الكلي والهيكل الاجتماعي بشكل عميق. (المصدر: MIT Technology Review)
كشف واقع تطبيق Agent على مستوى الشركات: كشفت دراسة تجريبية واسعة النطاق من جامعة كاليفورنيا، بيركلي (306 ممارسين، 20 حالة شركة) أن تطبيق AI Agent يهدف بشكل أساسي إلى زيادة الإنتاجية، وأن النماذج مغلقة المصدر، والـ Prompt اليدوي، والعمليات المراقبة هي السائدة. الموثوقية هي التحدي الأكبر، والمراجعة البشرية لا غنى عنها. وتشير الدراسة إلى أن الـ Agent يشبه “المتدرب الخارق”، حيث يخدم معظم الموظفين الداخليين، ووقت الاستجابة بالدقائق مقبول. (المصدر: 36氪)
🎯 اتجاهات
Mistral تطلق نموذج الترميز Devstral 2 وأداة Vibe CLI: أطلقت شركة Mistral، يونيكورن الذكاء الاصطناعي الأوروبية، عائلة نماذج الترميز Devstral 2 (123B و 24B، وكلاهما مفتوح المصدر) ومساعد البرمجة المحلي Mistral Vibe CLI. أظهر Devstral 2 أداءً ممتازًا على SWE-bench Verified، منافسًا Deepseek v3.2. يدعم Mistral Vibe CLI استكشاف التعليمات البرمجية وتعديلها وتنفيذها باللغة الطبيعية، ويتميز بقدرة التعرف التلقائي على السياق وتنفيذ أوامر Shell، مما يعزز مكانة Mistral في مجال الترميز مفتوح المصدر. (المصدر: swyx, QuixiAI, op7418, stablequan, b_roziere, Reddit r/LocalLLaMA)
Nous Research تطلق نموذج الرياضيات Nomos 1 مفتوح المصدر: أطلقت Nous Research نموذج Nomos 1 مفتوح المصدر، وهو نموذج لحل المسائل الرياضية وإثباتها بـ 30 مليار معلمة، حصل على 87/120 نقطة في مسابقة Putnam للرياضيات لهذا العام (تقديريًا في المرتبة الثانية)، مما يظهر إمكانية النماذج الأصغر نسبيًا لتحقيق أداء رياضي قريب من مستوى البشر المتفوقين من خلال التدريب اللاحق الجيد وإعدادات الاستدلال. يعتمد هذا النموذج على Qwen/Qwen3-30B-A3B-Thinking-2507. (المصدر: Teknium, Dorialexander, huggingface, Reddit r/LocalLLaMA)

通义千问 من Alibaba يتجاوز 30 مليون مستخدم نشط شهريًا ويفتح وظائفه الأساسية مجانًا: تجاوز عدد المستخدمين النشطين شهريًا لـ “通义千问” من Alibaba 30 مليون مستخدم خلال 23 يومًا من إطلاقه التجريبي العام، وقد أتاح مجانًا أربع وظائف أساسية: AI PPT، وAI Writing، وAI Library، وAI Tutoring. تهدف هذه الخطوة إلى جعل “通义千问” المدخل الفائق لعصر الذكاء الاصطناعي، واغتنام الفترة الحاسمة لتطبيقات الذكاء الاصطناعي للانتقال من “القدرة على الدردشة” إلى “القدرة على إنجاز المهام”، وتلبية احتياجات المستخدمين الحقيقية لأدوات الإنتاجية. (المصدر: op7418)

Zhipu AI تطلق نموذج GLM-4.6V متعدد الوسائط وAI للأجهزة المحمولة: أطلقت Zhipu AI نموذج GLM-4.6V متعدد الوسائط على Hugging Face، يتميز بفهم بصري SOTA، واستدعاء وظائف Agent أصلي، وقدرة سياقية تصل إلى 128k. وفي الوقت نفسه، أطلقت أيضًا AutoGLM-Phone-9B (نموذج أساسي للهواتف الذكية بـ 9 مليارات معلمة، يمكنه قراءة الشاشة والعمل نيابة عن المستخدم) و GLM-ASR-Nano-2512 (نموذج للتعرف على الكلام بـ 2 مليار معلمة، يتفوق على Whisper v3 في التعرف متعدد اللغات ومنخفض الصوت). (المصدر: huggingface, huggingface, Reddit r/LocalLLaMA)

OpenBMB تطلق نموذج توليد الكلام VoxCPM 1.5 ومجموعة بيانات Ultra-FineWeb: أطلقت OpenBMB نموذج VoxCPM 1.5، وهو نسخة مطورة من نموذج توليد الكلام الواقعي، يدعم صوت Hi-Fi بتردد 44.1 كيلوهرتز، وفعاليته أعلى، ويوفر LoRA وسكربتات الضبط الدقيق الكاملة، مع استقرار معزز. وفي الوقت نفسه، أطلقت OpenBMB أيضًا مجموعة بيانات Ultra-FineWeb-en-v1.4 مفتوحة المصدر بحجم 2.2 تريليون توكن، كبيانات تدريب أساسية لـ MiniCPM4/4.1، وتحتوي على أحدث لقطة من CommonCrawl. (المصدر: ImazAngel, eliebakouch, huggingface)
تحديثات Claude Agent SDK من Anthropic ومفهوم “Skills > Agents”: أصدر Claude Agent SDK ثلاثة تحديثات: دعم نوافذ السياق بحجم 1M، ووظيفة الـ Sandboxing، وواجهة V2 TypeScript. كما طرحت Anthropic مفهوم “Skills > Agents”، مؤكدة على تعزيز فائدة Claude Code من خلال بناء المزيد من المهارات، مما يمكنه من اكتساب قدرات جديدة من خبراء المجال والتطور حسب الحاجة، ليشكل نظامًا بيئيًا تعاونيًا وقابلاً للتوسع. (المصدر: _catwu, omarsar0, Reddit r/ClaudeAI)
تطبيقات الذكاء الاصطناعي في المجال العسكري: البنتاغون يؤسس لجنة توجيهية لـ AGI ومنصة GenAi.mil: أمر البنتاغون الأمريكي بتشكيل لجنة توجيهية للذكاء الاصطناعي العام (AGI)، وأطلق منصة GenAi.mil، بهدف توفير نماذج الذكاء الاصطناعي المتطورة مباشرة لأفراد الجيش الأمريكي لتعزيز قدراتهم القتالية. يشير هذا إلى الدور المتزايد الأهمية للذكاء الاصطناعي في الأمن القومي والاستراتيجية العسكرية. (المصدر: jpt401, giffmana)
تحسين أداء LLM: زيادة كفاءة التدريب والاستدلال: أطلقت Unsloth نواة Triton جديدة ودعم التعبئة التلقائية الذكية، مما يزيد سرعة تدريب LLM بمقدار 3-5 أضعاف، مع تقليل استخدام VRAM بنسبة 30-90% (على سبيل المثال، يمكن تدريب Qwen3-4B على 3.9 جيجابايت VRAM)، ودون فقدان الدقة. وفي الوقت نفسه، يقلل إطار عمل ThreadWeaver بشكل كبير من زمن استجابة استدلال LLM من خلال الاستدلال المتوازي التكيفي (تسريع يصل إلى 1.53 مرة)، ويكسر قيود السياق بالاشتراك مع PaCoRe، مما يحقق حسابات وقت الاختبار لمليون توكن دون الحاجة إلى نافذة سياق أكبر. (المصدر: HuggingFace Daily Papers, huggingface, Reddit r/LocalLLaMA)

نماذج LLM تفهم تعليمات Base64 المشفرة: كشفت الأبحاث أن نماذج LLM مثل Gemini و ChatGPT و Grok قادرة على فهم التعليمات المشفرة بـ Base64، ومعالجتها كـ Prompt عادي، مما يشير إلى قدرة LLM على التعامل مع النصوص غير القابلة للقراءة البشرية. قد يفتح هذا الاكتشاف إمكانيات جديدة لتفاعل نماذج الذكاء الاصطناعي مع الأنظمة، ونقل البيانات، والتعليمات المخفية. (المصدر: Reddit r/artificial)
شائعات عن تحول Meta للتخلي عن استراتيجية الذكاء الاصطناعي مفتوح المصدر: تفيد الشائعات بأن مارك زوكربيرغ يوجه Meta للتخلي عن استراتيجيتها للذكاء الاصطناعي مفتوح المصدر. إذا صح ذلك، فسيمثل هذا تحولًا استراتيجيًا كبيرًا لـ Meta في مجال الذكاء الاصطناعي، وقد يكون له تأثير عميق على مجتمع الذكاء الاصطناعي مفتوح المصدر بأكمله، ويثير نقاشات حول اتجاه إغلاق تقنيات الذكاء الاصطناعي. (المصدر: natolambert)
القدرات الموحدة لنموذج توليد الفيديو بالذكاء الاصطناعي Kling O1: تم إطلاق Kling O1 كأول نموذج فيديو موحد، قادر على توليد أي لقطة، وتحريرها، وإعادة بنائها، وتوسيعها في محرك واحد. يمكن للمستخدمين الإبداع من خلال نمذجة ZBrush، وإعادة البناء بواسطة الذكاء الاصطناعي، ولوحات Lovart AI القصصية، والمؤثرات الصوتية المخصصة، وغيرها. أظهر Kling 2.6 أداءً متميزًا في الحركة البطيئة وتحويل الصور إلى فيديو، مما يجلب تغييرًا ثوريًا في إنشاء الفيديو. (المصدر: Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai)
ديناميكيات نماذج LLM الجديدة وشائعات التعاون: تفيد الشائعات بأن نموذج DeepSeek V4 قد يُطلق خلال رأس السنة القمرية الجديدة في فبراير 2026، مما يثير توقعات السوق. وفي الوقت نفسه، تشير الأنباء إلى أن Meta تستخدم نموذج Qwen من Alibaba لتحسين نماذج الذكاء الاصطناعي الجديدة الخاصة بها، مما يدل على تعاون محتمل أو استعارة تقنية في تطوير نماذج الذكاء الاصطناعي بين عمالقة التكنولوجيا، وينبئ بمشهد معقد من المنافسة والتعاون في مجال الذكاء الاصطناعي. (المصدر: scaling01, teortaxesTex, Dorialexander)

🧰 أدوات
AGENTS.md: تنسيق إرشادي مفتوح المصدر لـ AI coding Agent: ظهر AGENTS.md على GitHub Trending، وهو تنسيق بسيط ومفتوح، يهدف إلى توفير سياق المشروع والتعليمات لـ AI coding Agent، على غرار ملف README الخاص بالـ Agent. يساعد الذكاء الاصطناعي على فهم بيئة التطوير والاختبار وعمليات PR بشكل أفضل من خلال الـ Prompt المنظم، مما يعزز تطبيق Agent وتوحيده في تطوير البرمجيات. (المصدر: GitHub Trending)

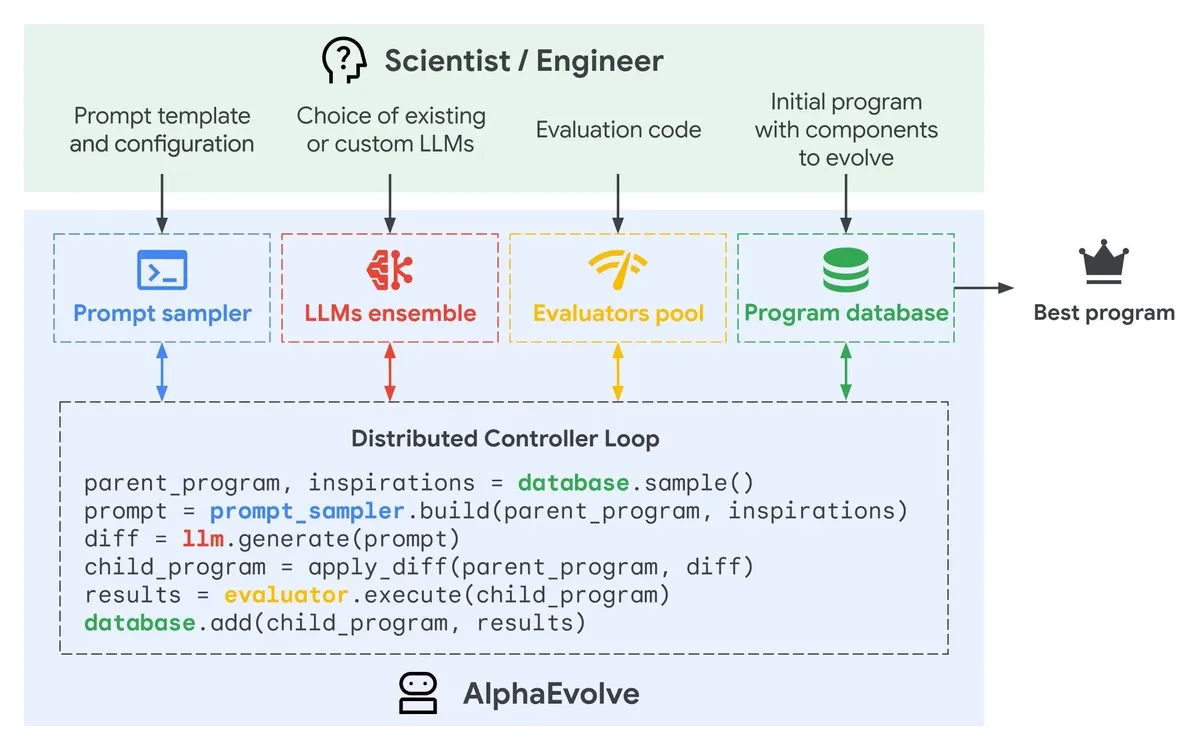
Google AlphaEvolve: AI coding Agent لتصميم الخوارزميات مدعوم بـ Gemini: أطلقت Google DeepMind نسخة معاينة خاصة من AlphaEvolve، وهو AI coding Agent مدعوم بـ Gemini، يهدف إلى اقتراح تعديلات ذكية على التعليمات البرمجية من خلال LLM، وتطوير الخوارزميات باستمرار لزيادة الكفاءة. من المتوقع أن يسرع هذا الأداة تطوير البرمجيات وتحسين الأداء من خلال أتمتة عملية تحسين الخوارزميات. (المصدر: GoogleDeepMind)
توليد الصور بالذكاء الاصطناعي: صور بانورامية لتاريخ المنتجات وتقنيات اتساق الوجوه: تُستخدم أدوات توليد الصور بالذكاء الاصطناعي مثل Gemini و Nano Banana Pro لإنشاء صور بانورامية لتاريخ المنتجات، مثل Ferrari و iPhone، وهي مناسبة لعروض PPT والملصقات. وفي الوقت نفسه، تمت مشاركة نصائح للحفاظ على اتساق الوجوه في رسومات الذكاء الاصطناعي، بما في ذلك توليد صور شخصية عالية الدقة، والمراجع متعددة الزوايا، وتجربة أنماط الرسوم المتحركة/ثلاثية الأبعاد، للتغلب على تحديات الذكاء الاصطناعي في اتساق التفاصيل. (المصدر: dotey, dotey, yupp_ai, yupp_ai, yupp_ai, dotey, dotey)

أداة تصحيح الأخطاء PlayerZero AI: تقوم أداة PlayerZero AI بتصحيح أخطاء قواعد التعليمات البرمجية الكبيرة من خلال استرجاع التعليمات البرمجية والسجلات والاستدلال عليها، مما يقلل وقت التصحيح من 3 دقائق إلى أقل من 10 ثوانٍ، ويزيد بشكل كبير من معدل الاستدعاء، ويقلل من دورات Agent. يوفر هذا للمطورين حلولًا فعالة لاستكشاف الأخطاء وإصلاحها، ويسرع عملية تطوير البرمجيات. (المصدر: turbopuffer)

Supertonic: نموذج TTS فائق السرعة يعمل على الجهاز: Supertonic هو نموذج TTS (تحويل النص إلى كلام) خفيف الوزن (66 مليون معلمة) يعمل على الجهاز، يوفر سرعة فائقة وقدرات نشر واسعة (الهواتف المحمولة، المتصفحات، أجهزة الكمبيوتر المكتبية، إلخ.). يحتوي هذا النموذج مفتوح المصدر على 10 أصوات معدة مسبقًا، ويوفر أمثلة بأكثر من 8 لغات برمجة، مما يوفر حلولًا فعالة لتوليد الكلام لمختلف سيناريوهات التطبيق. (المصدر: Reddit r/MachineLearning)
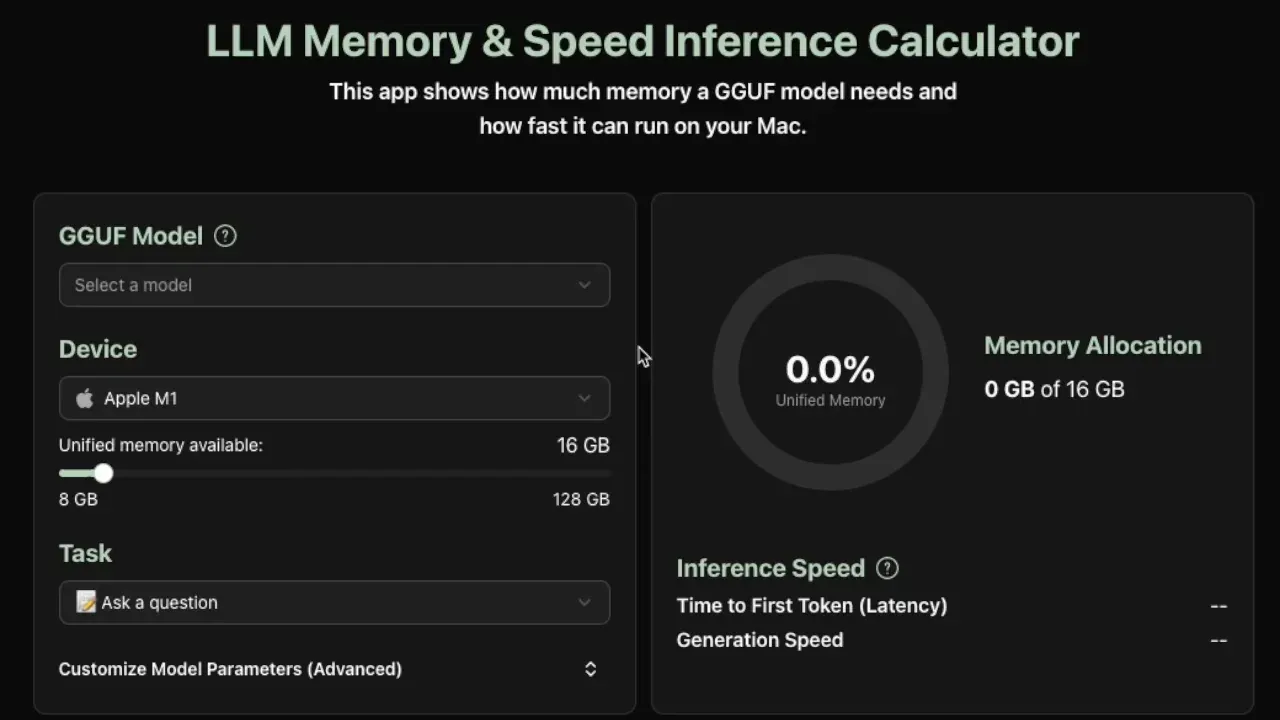
حاسبة متطلبات الاستدلال المحلي لـ LLM: أداة عملية جديدة يمكنها تقدير الذاكرة المطلوبة وسرعة استدلال التوكن في الثانية لتشغيل نماذج GGUF محليًا، وتدعم حاليًا أجهزة Apple Silicon. توفر هذه الأداة تقديرات دقيقة من خلال تحليل بيانات تعريف النموذج (الحجم، عدد الطبقات، الأبعاد المخفية، KV cache، إلخ.)، مما يساعد المطورين على تحسين نشر LLM المحلي. (المصدر: Reddit r/LocalLLaMA)
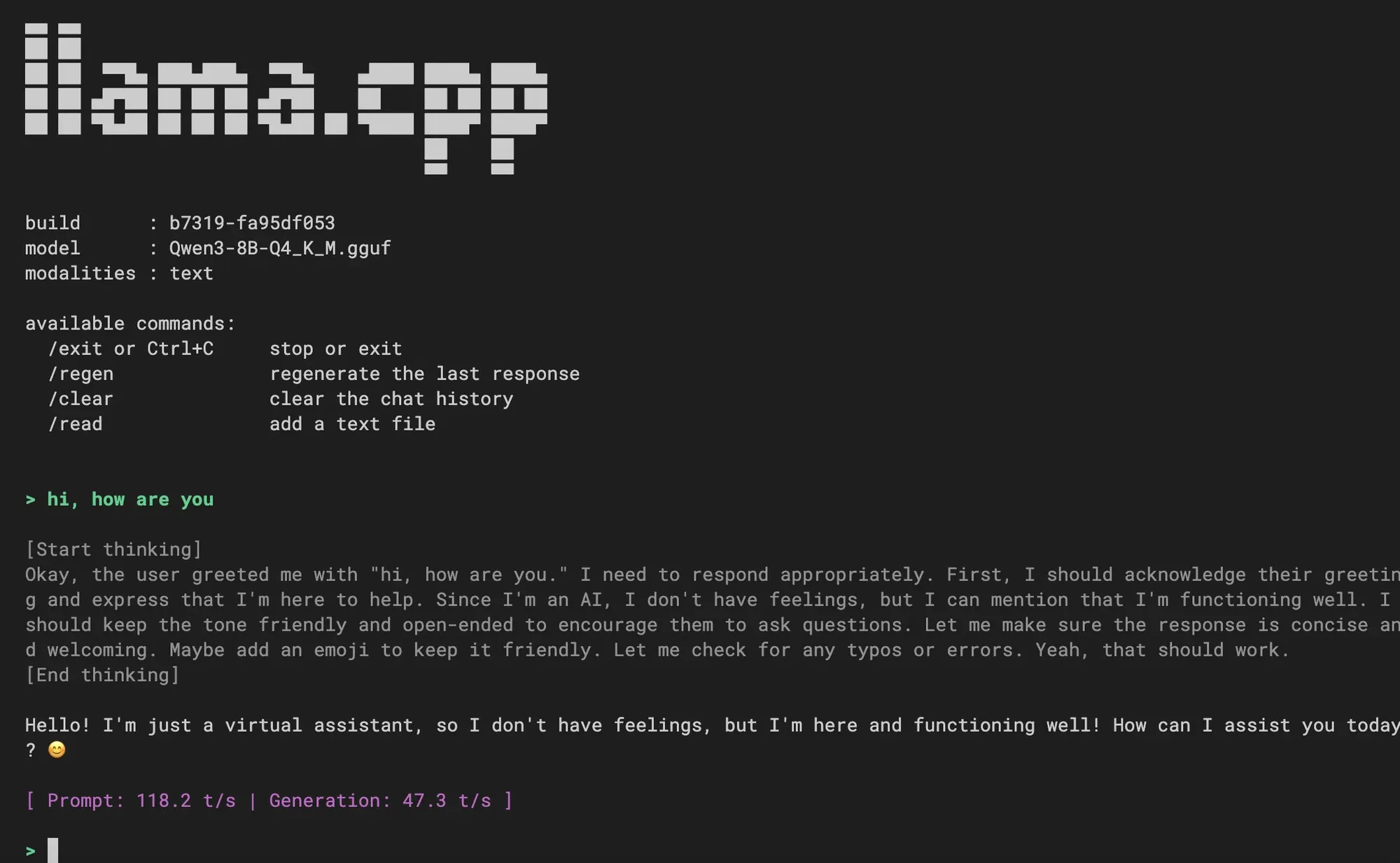
دمج تجربة CLI جديدة في llama.cpp: تم دمج تجربة واجهة سطر الأوامر (CLI) الجديدة في llama.cpp، توفر واجهة أبسط، ودعمًا متعدد الوسائط، والتحكم في المحادثة عبر الأوامر، ودعمًا لفك التشفير التخميني، ودعم قوالب Jinja. رحب المستخدمون بذلك، وتساءلوا عما إذا كانت وظيفة AI coding Agent ستُدمج في المستقبل، مما ينبئ بتحسين تجربة تفاعل LLM المحلية. (المصدر: _akhaliq, Reddit r/LocalLLaMA)
دمج نماذج Hugging Face في VS Code: سيعرض البث المباشر لإصدار Visual Studio Code كيفية استخدام النماذج المدعومة بواسطة Hugging Face Inference Providers مباشرة داخل VS Code، سيؤدي هذا إلى تسهيل كبير على المطورين للاستفادة من نماذج الذكاء الاصطناعي في بيئة التطوير المتكاملة (IDE)، وتحقيق برمجة بمساعدة الذكاء الاصطناعي وسير عمل تطويري أكثر تكاملاً. (المصدر: huggingface)
📚 تعلم
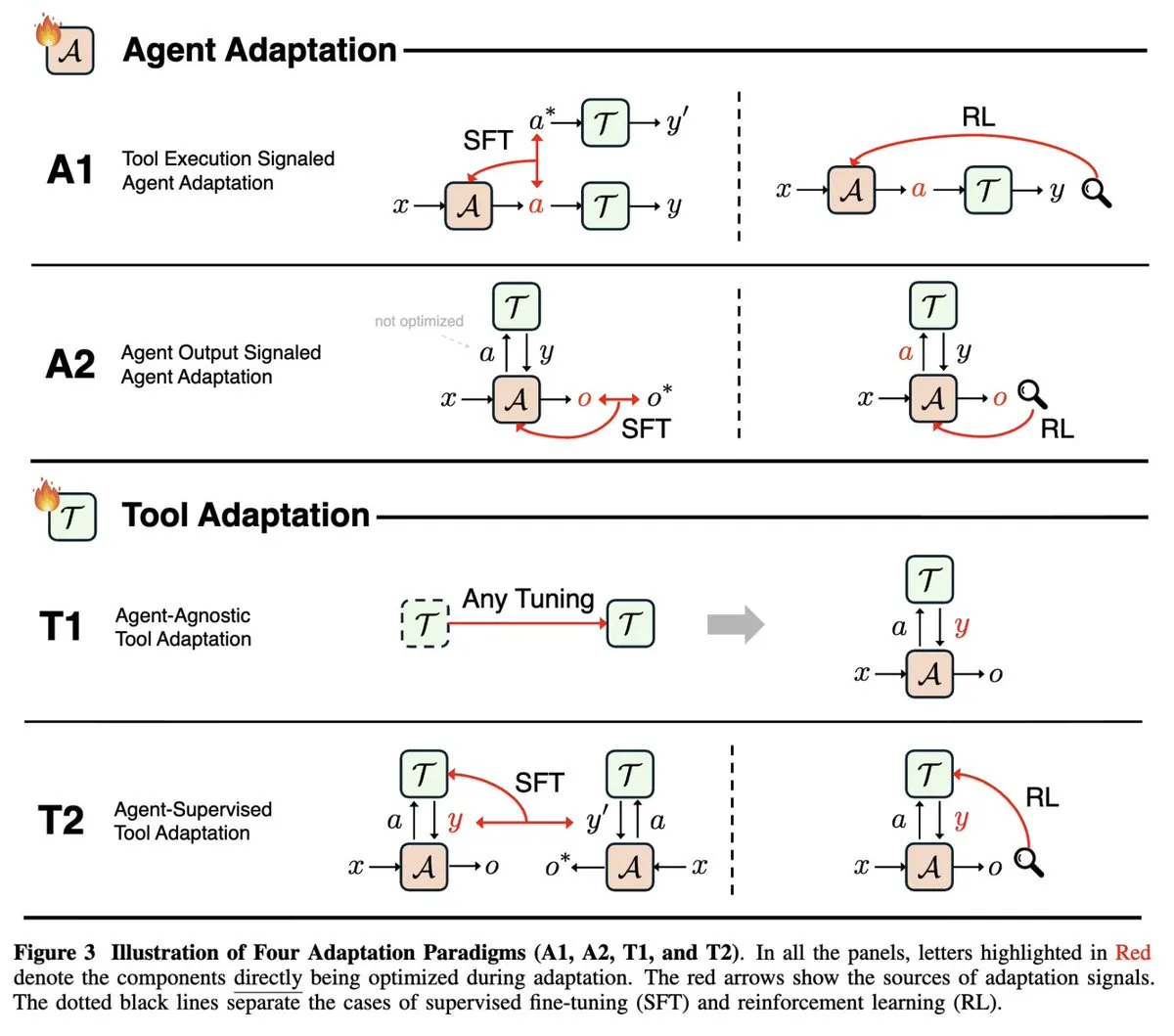
مراجعة بحثية حول تكيف AI Agent: وحدت دراسة استقصائية بعنوان “تكيف الذكاء الاصطناعي الوكيلي” (Agentic AI) في NeurIPS 2025 المجالات سريعة التطور لتكيف الـ Agent (إشارات تنفيذ الأداة مقابل إشارات إخراج الـ Agent) وتكيف الأداة (المستقل عن الـ Agent مقابل إشراف الـ Agent)، وصنفت أوراق الـ Agent الحالية إلى أربعة نماذج تكيفية، مما يوفر إطارًا نظريًا شاملاً لفهم وتطوير AI Agent. (المصدر: menhguin)
خارطة طريق التعلم العميق ومهارات الذكاء الاصطناعي: تمت مشاركة العديد من الرسوم البيانية التي تغطي البنية الهرمية لـ AI Agents، ومكدس AI Agents لعام 2025، ومجموعة مهارات تحليل البيانات، و7 مهارات تحليل بيانات عالية الطلب، وخارطة طريق التعلم العميق، و15 خطوة لتعلم الذكاء الاصطناعي، وغيرها، مما يوفر دليلاً شاملاً للمهارات والهندسة المعمارية للمتعلمين والمطورين في مجال الذكاء الاصطناعي، ويدعم التطور الوظيفي. (المصدر: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
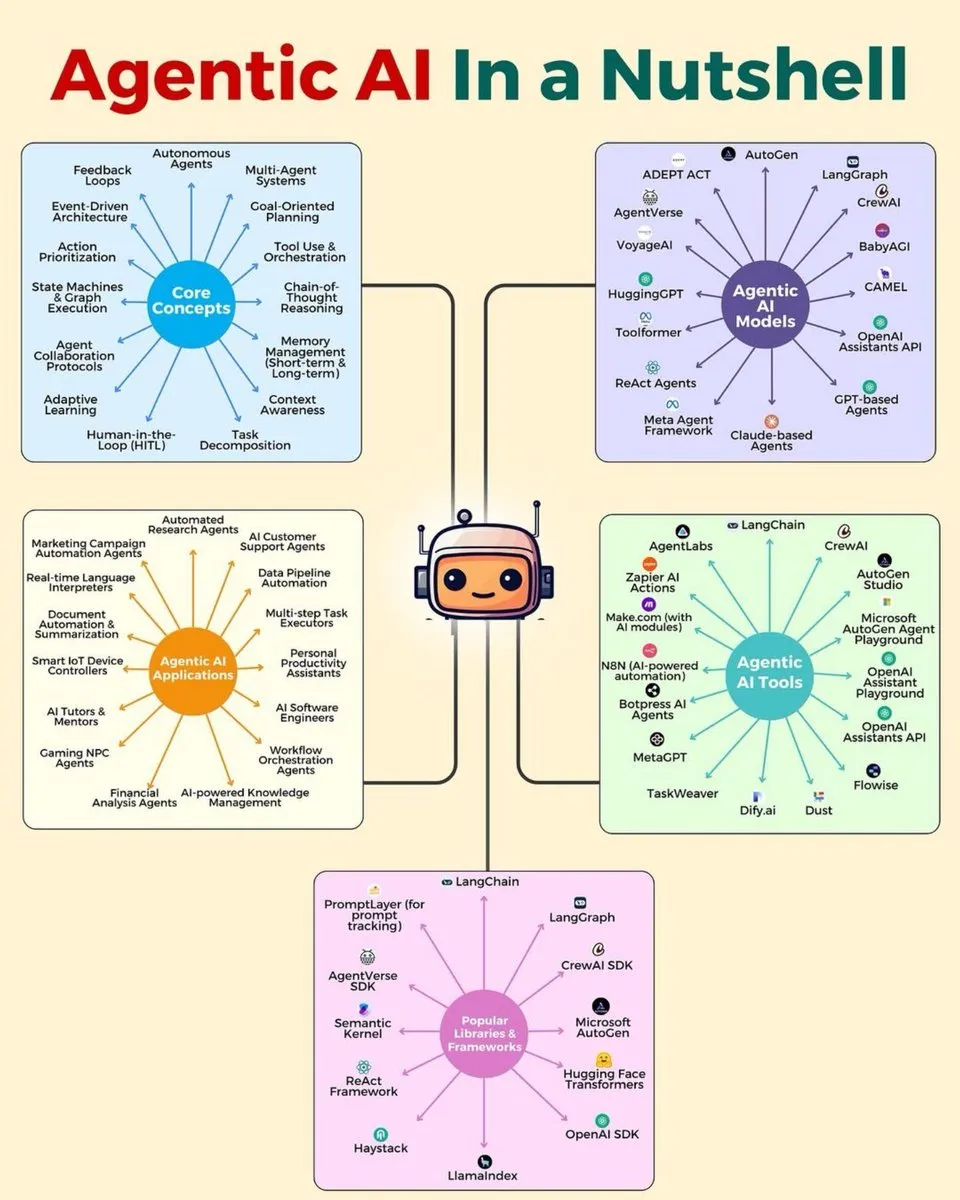
دورات وكتب مجانية في التعلم العميق: قدم François Fleuret دورته التدريبية الكاملة في التعلم العميق، والتي تتضمن 1000 شريحة ولقطة شاشة، بالإضافة إلى “كتاب التعلم العميق الصغير”، وكلاهما منشور بموجب ترخيص المشاع الإبداعي، مما يوفر للمتعلمين موارد مجانية قيمة، تغطي المعرفة الأساسية للتعلم العميق مثل تاريخه، وهياكله الطوبولوجية، والجبر الخطي، وحساب التفاضل والتكامل. (المصدر: francoisfleuret)
تحسين LLM وتقنيات التدريب: حقق Varunneal رقمًا قياسيًا عالميًا جديدًا في NanoGPT Speedrun (132 ثانية، 30 خطوة/ثانية) من خلال تقنيات مثل جدولة حجم الدفعة و Cautious Weight Decay و Normuon tuning. وفي الوقت نفسه، استكشفت مدونة طريقة الحصول على استخدام الـ token الدقيق من وحدات DSPy المتداخلة، مما يوفر خبرة عملية وتفاصيل تقنية لتدريب LLM وتحسين أدائه. (المصدر: lateinteraction, kellerjordan0)
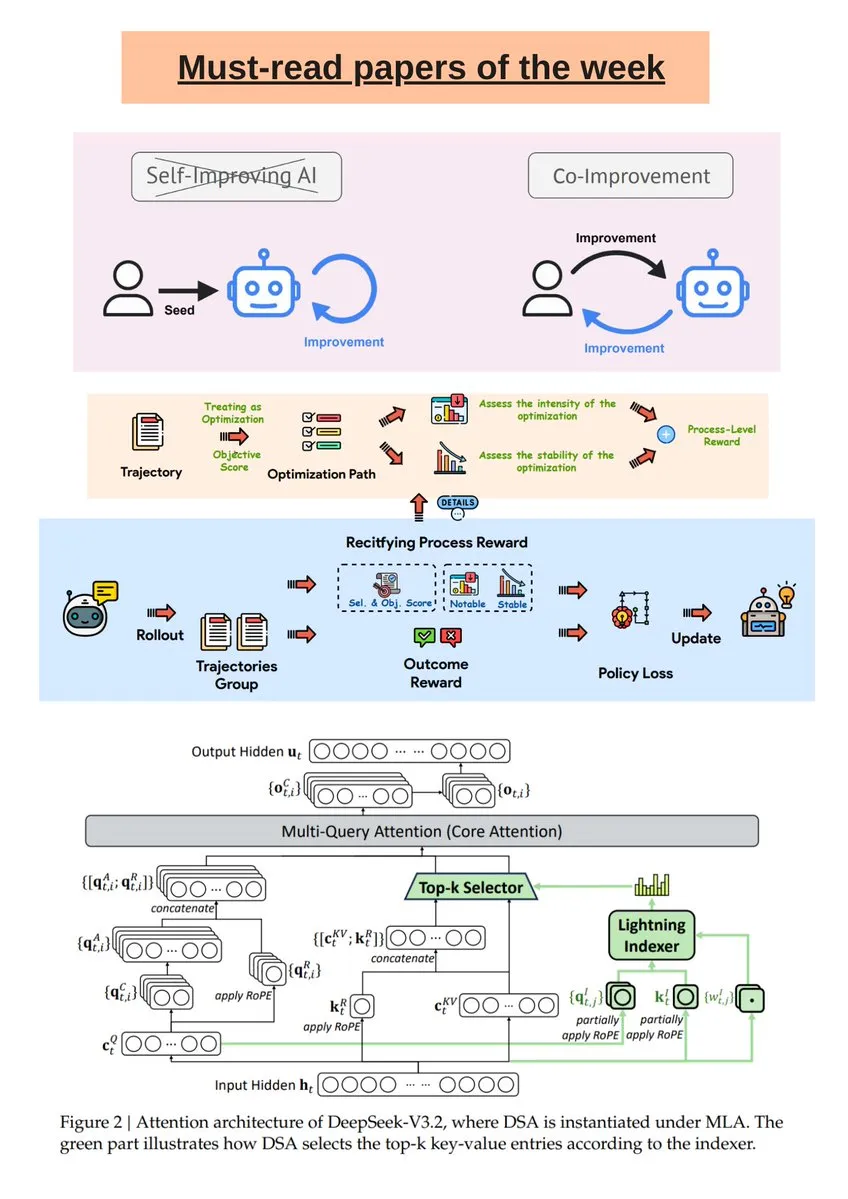
تقرير أسبوعي لأبحاث الذكاء الاصطناعي وتحليل نموذج DeepSeek R1: نشرت Turing Post مختاراتها الأسبوعية من أبحاث الذكاء الاصطناعي، والتي تغطي تحسين الذكاء الاصطناعي والبشر معًا، و DeepSeek-V3.2، ونماذج LLM ذاتية التطور الموجهة، وغيرها. بالإضافة إلى ذلك، تناولت مقالة في Science News نموذج DeepSeek R1 بعمق، موضحة المفاهيم الخاطئة الشائعة حول عملياته مثل “توكنات التفكير” و RL-in-Name-Only، مما يساعد القراء على فهم أبحاث الذكاء الاصطناعي المتطورة بشكل أفضل. (المصدر: TheTuringPost, rao2z)
جودة بيانات الذكاء الاصطناعي و MLOps: في التعلم العميق، حتى الأخطاء الطفيفة في تسمية بيانات التدريب يمكن أن تؤثر بشكل خطير على أداء النموذج. شددت المناقشة على أهمية عمليات مراقبة الجودة مثل المراجعة متعددة المراحل، والفحوصات الآلية، واكتشاف الشذوذ المضمن، وبروتوكولات المسمين المتقاطعين، والأدوات المتخصصة، لضمان موثوقية بيانات التدريب في التطبيقات واسعة النطاق، وبالتالي تحسين الأداء العام للنموذج. (المصدر: Reddit r/deeplearning)
بناء LLM أساسي على مستوى لعبة من الصفر: شارك أحد المطورين تجربته في بناء LLM أساسي على مستوى لعبة من الصفر، باستخدام ChatGPT للمساعدة في توليد طبقات الانتباه، وكتل Transformer، و MLP، والتدريب على مجموعة بيانات TinyStories. يوفر هذا المشروع دفتر ملاحظات Colab كاملاً، ويهدف إلى مساعدة المتعلمين على فهم عملية بناء LLM ومبادئه الأساسية. (المصدر: Reddit r/deeplearning)

💼 أعمال
“智世机器人” تحصل على تمويل A+ بقيمة عشرات الملايين من اليوانات: أكملت شركة “智世机器人” (ZhiShi Robotics)، المتخصصة في البحث والتطوير وتصنيع روبوتات المستودعات ذات العربات المتنقلة بأربعة اتجاهات، مؤخرًا جولة تمويل A+ بعشرات الملايين من اليوانات، باستثمار حصري من Hidden Peak Capital. تشتهر منتجات الشركة بسلامتها وسهولة استخدامها ومعدل نمطيتها العالي، وحققت نموًا سنويًا في الإيرادات يتراوح بين 200% و 300%، وتوسعت بالفعل في الأسواق الخارجية، مما يوفر دعمًا قويًا لتحديث التخزين الذكي. (المصدر: 36氪)

Baseten تستحوذ على شركة Parsed الناشئة في مجال RL: استحوذت Baseten، مزود خدمات الاستدلال، على شركة Parsed الناشئة في مجال التعلم المعزز (RL)، يعكس هذا الأهمية المتزايدة لـ RL في صناعة الذكاء الاصطناعي، واهتمام السوق بتحسين قدرات استدلال نماذج الذكاء الاصطناعي. من المتوقع أن يعزز هذا الاستحواذ قدرة Baseten التنافسية في مجال خدمات استدلال الذكاء الاصطناعي. (المصدر: steph_palazzolo)
أسطورة الرياضيات ينضم إلى شركة ناشئة في مجال الذكاء الاصطناعي: غادر أسطورة الرياضيات Ken Ono الأوساط الأكاديمية لينضم إلى شركة ناشئة في مجال الذكاء الاصطناعي أسسها شاب يبلغ من العمر 24 عامًا، يشير هذا إلى اتجاه تدفق المواهب العليا نحو مجال الذكاء الاصطناعي، وينبئ أيضًا بحيوية بيئة الشركات الناشئة في الذكاء الاصطناعي واتجاه جديد لدمج المواهب متعددة التخصصات. (المصدر: CarinaLHong)
🌟 مجتمع
نقاش حول تأثير الذكاء الاصطناعي على سوق العمل، الاقتصاد الاجتماعي، وأتمتة المصانع: أثار تأثير الذكاء الاصطناعي على سوق العمل والاقتصاد الاجتماعي نقاشًا حادًا. يرى أحد الأطراف أن الذكاء الاصطناعي سيؤدي إلى تصفير قيمة العمل، ويدعو إلى إعادة تشكيل الرأسمالية من خلال “البنية التحتية الأساسية الشاملة” و “أرباح الروبوتات” لضمان العيش الأساسي وتشجيع البشر على السعي وراء الفن والاستكشاف. بينما يصر الطرف الآخر على وجهة نظر “مغالطة إجمالي العمل”، معتقدًا أن الذكاء الاصطناعي سيخلق المزيد من الصناعات الجديدة وفرص العمل، وسيتحول البشر إلى أدوار إدارة الذكاء الاصطناعي، ويشير إلى أن الذكاء الاصطناعي المادي سيؤتمت معظم أعمال المصانع في غضون عشر سنوات. (المصدر: Plinz, Reddit r/ArtificialInteligence, hardmaru, SakanaAILabs, nptacek, Reddit r/artificial)

دور الذكاء الاصطناعي في دعم الصحة النفسية والبحث العلمي والجدل الأخلاقي: شارك أحد المستخدمين تجربته مع Claude AI في تقديم الدعم خلال أزمة صحة نفسية حادة، قائلاً إنه ساعده على تجاوز الصعوبات مثل المعالج. يسلط هذا الضوء على إمكانات الذكاء الاصطناعي في دعم الصحة النفسية، لكنه يثير أيضًا نقاشات حول أخلاقيات وقيود الدعم العاطفي بالذكاء الاصطناعي. وفي الوقت نفسه، أثار الجدل حول ما إذا كان يجب على الذكاء الاصطناعي أتمتة البحث العلمي بالكامل نقاشًا حادًا. يرى أحد الأطراف أن تأخير الأتمتة (مثل علاج السرطان) للحفاظ على متعة الاكتشاف البشري هو أمر غير أخلاقي؛ بينما يخشى الطرف الآخر من أن الأتمتة الكاملة قد تؤدي إلى فقدان البشر لهدفهم، بل ويشكك فيما إذا كانت الاختراقات المدفوعة بالذكاء الاصطناعي ستفيد الجميع بشكل عادل. (المصدر: Reddit r/ClaudeAI, BlackHC, TomLikesRobots, aiamblichus, aiamblichus, togelius)
جدل حول رقابة LLM، الإعلانات التجارية، وخصوصية بيانات المستخدم: يشعر مستخدمو ChatGPT بالاستياء بسبب الرقابة الصارمة على المحتوى والاستجابات “المملة”، وقد تحول العديد من المستخدمين إلى المنافسين مثل Gemini و Claude، معتقدين أنها تقدم أداءً أفضل في المحتوى المخصص للبالغين والمحادثات الحرة. أدى هذا إلى انخفاض اشتراكات ChatGPT، وأثار نقاشات حول معايير رقابة الذكاء الاصطناعي واختلاف احتياجات المستخدمين. وفي الوقت نفسه، أثار اختبار ChatGPT لوظيفة الإعلانات استياءً شديدًا لدى المستخدمين، الذين اعتبروا أن الإعلانات ستضر بموضوعية الذكاء الاصطناعي وثقة المستخدم، مما يسلط الضوء على تحديات أخلاقيات الأعمال في الذكاء الاصطناعي. بالإضافة إلى ذلك، أفاد بعض المستخدمين بأن OpenAI حذفت سجلات محادثاتهم القديمة لـ GPT-4o، مما أثار مخاوف بشأن ملكية بيانات خدمات الذكاء الاصطناعي والرقابة على المحتوى، ونصح المستخدمين بضرورة الاحتفاظ بنسخ احتياطية من بياناتهم المحلية. (المصدر: Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT, 36氪, Yuchenj_UW, aiamblichus)

معضلة مطوري AI Agent والاعتبارات الواقعية لمرجع LLM في التوظيف: على الرغم من الترويج الكبير لقوة AI Agent، لا يزال المطورون يعملون لساعات إضافية، مما يثير تساؤلات فكاهية حول الفجوة بين الدعاية للذكاء الاصطناعي وكفاءة العمل الفعلية. وفي الوقت نفسه، اقترح John Carmack أن سجل دردشة LLM للمستخدم يمكن أن يكون بمثابة “مقابلة موسعة” للبحث عن عمل، مما يسمح لـ LLM بتكوين تقييم للمرشح دون الكشف عن بيانات خاصة، وبالتالي زيادة دقة التوظيف. (المصدر: amasad, giffmana, VictorTaelin, fabianstelzer, mbusigin, _lewtun, VictorTaelin, max__drake, dejavucoder, ID_AA_Carmack)
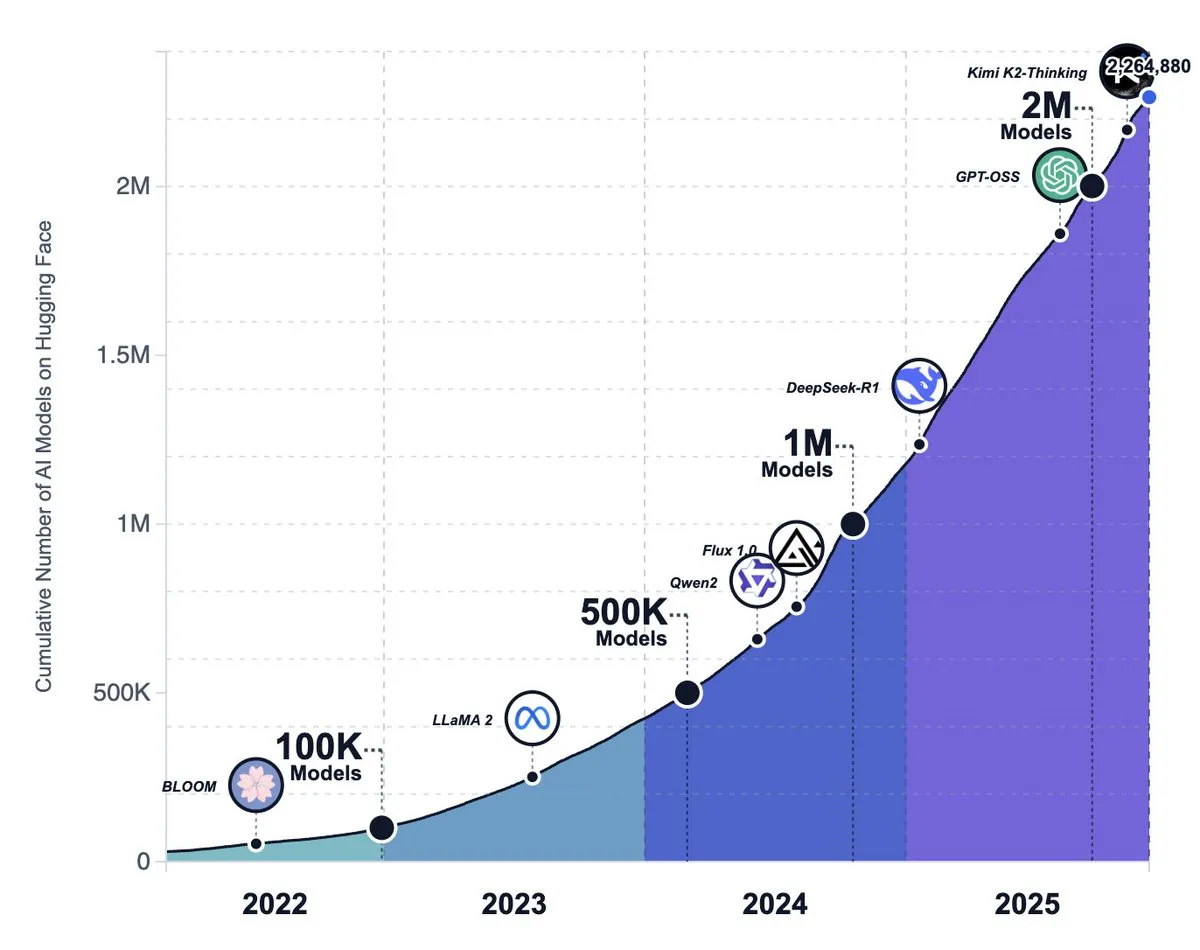
صعود بيئة الذكاء الاصطناعي مفتوحة المصدر، اتجاهات النماذج، ومناقشة تحول استراتيجية Meta: تجاوز عدد النماذج على منصة Hugging Face 2.2 مليون نموذج، مما يدل على نمو نماذج الذكاء الاصطناعي مفتوحة المصدر بسرعة مذهلة، ويُعتقد أنها ستتجاوز في النهاية المختبرات الرائدة الكبيرة. ومع ذلك، تشير بعض الآراء إلى أن النماذج مفتوحة المصدر لا تزال متأخرة عن النماذج مغلقة المصدر في تجربة مستوى المنتج (مثل بيئة التشغيل، والقدرات متعددة الوسائط)، وأن العديد من المشاريع مفتوحة المصدر تواجه الركود أو الإهمال. وفي الوقت نفسه، تفيد الشائعات بأن Meta تتجه للتخلي عن استراتيجيتها للذكاء الاصطناعي مفتوح المصدر. (المصدر: huggingface, huggingface, huggingface, ZhihuFrontier, natolambert, _akhaliq)
الذكاء الاصطناعي في الحياة اليومية: Sam Altman يتحدث عن الأبوة والذكاء الاصطناعي: صرح Sam Altman بأنه من الصعب تخيل كيفية تربية طفل حديث الولادة بدون ChatGPT، مما أثار نقاشًا حول الدور المتزايد للذكاء الاصطناعي في الحياة الشخصية والقرارات اليومية. يعكس هذا أن الذكاء الاصطناعي بدأ يتغلغل في أكثر السيناريوهات الأسرية خصوصية، ليصبح جزءًا لا يتجزأ من الحياة الحديثة. (المصدر: scaling01)
نظرية “فقاعة” في مجال الذكاء الاصطناعي وتزايد المنافسة في سوق نماذج الصور: يرى البعض أن سوق LLM الحالي يشهد “فقاعة”، ليس لأن LLM ليست قوية بحد ذاتها، بل لأن الناس لديهم توقعات غير واقعية منها. وتشير وجهة نظر أخرى إلى أنه مع انخفاض تكلفة تنفيذ الذكاء الاصطناعي، ستزداد قيمة الأفكار الأصلية. وفي الوقت نفسه، تزداد المنافسة في سوق نماذج صور الذكاء الاصطناعي، وتفيد الشائعات بأن OpenAI ستطلق نموذجًا مطورًا لمواجهة المنافسين مثل Nano Banana Pro. (المصدر: aiamblichus, cloneofsimo, op7418, dejavucoder)
جودة محتوى الذكاء الاصطناعي، النزاهة الأكاديمية، وجدل أخلاقيات الأعمال: تم سحب إعلان ماكدونالدز المدعوم بالذكاء الاصطناعي بسبب تسويقه “الكارثي”، مما يسلط الضوء على الطبيعة المزدوجة لأدوات الذكاء الاصطناعي في تضخيم الإبداع البشري أو الحماقة. وفي الوقت نفسه، تبين أن 21% من مراجعات الأوراق المقدمة لمؤتمر دولي للذكاء الاصطناعي قد تم إنشاؤها بواسطة الذكاء الاصطناعي، مما أثار مخاوف جدية بشأن النزاهة الأكاديمية. بالإضافة إلى ذلك، اتُهمت Instacart برفع أسعار السلع من خلال تجارب تسعير مدعومة بالذكاء الاصطناعي، مما أثار مخاوف بشأن أخلاقيات الأعمال في الذكاء الاصطناعي. (المصدر: Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/artificial)

تأثير الذكاء الاصطناعي على وظائف المستقبل ومتطلبات المهارات: أثار تأثير الذكاء الاصطناعي على توظيف المطورين المبتدئين نقاشًا، يرى البعض أن الذكاء الاصطناعي سيحل محل الوظائف الأساسية، لكنه يمكن أيضًا أن يساعد المطورين على التعلم وتشكيل الأدوات من خلال المصادر المفتوحة وشبكات الموجهين. وفي الوقت نفسه، جعل الذكاء الاصطناعي المهارات المتقدمة مثل التفكير المنهجي، وتفكيك الوظائف، وتجريد التعقيد أكثر أهمية، يعكس هذا الطلب في سوق العمل المستقبلي على المواهب متعددة التخصصات. (المصدر: LearnOpenCV, code_star, nptacek)
خلفية مؤسس DeepSeek واستراتيجية الشركة: وُصف Wenfeng، مؤسس DeepSeek، بأنه “بطل من عالم آخر” يتمتع بترتيب عالٍ في امتحان القاوكاو (امتحان القبول الجامعي الصيني) وخلفية هندسية كهربائية عميقة، قد تؤثر دافعيته الذاتية الفريدة، وإبداعه، وروحه الشجاعة على المسار التقني لـ DeepSeek، بل وتغير مشهد المنافسة في الذكاء الاصطناعي بين الصين والولايات المتحدة. يسلط هذا الضوء على أهمية السمات الشخصية للشخصيات الرائدة في مجال الذكاء الاصطناعي لتطور الشركة. (المصدر: teortaxesTex, teortaxesTex)

ادعاءات وشكوك حول نظام AGI: زعمت شركة يابانية في طوكيو أنها طورت “أول نظام AGI في العالم”، يتميز بالتعلم الذاتي، والموثوقية، وكفاءة الطاقة. ومع ذلك، وبسبب تعريفها غير القياسي لـ AGI ونقص الأدلة الملموسة، أثار هذا الادعاء شكوكًا واسعة في مجتمع الذكاء الاصطناعي، مما يسلط الضوء على تعقيد تعريف AGI والتحقق منه. (المصدر: Reddit r/ArtificialInteligence)

مناقشة القيود المادية للذكاء الاصطناعي العام: نشر Tim Dettmers مقالًا في مدونته، يرى فيه أن الذكاء الاصطناعي العام (AGI) والذكاء الفائق ذو المعنى لن يكونا قابلين للتحقيق بسبب الحقائق الفيزيائية للحوسبة واختناقات تحسين GPU. يتحدى هذا الرأي التفاؤل السائد حاليًا في مجال الذكاء الاصطناعي، ويثير تفكيرًا عميقًا حول مسار تطور الذكاء الاصطناعي المستقبلي. (المصدر: Tim_Dettmers, Tim_Dettmers)
💡 أخرى
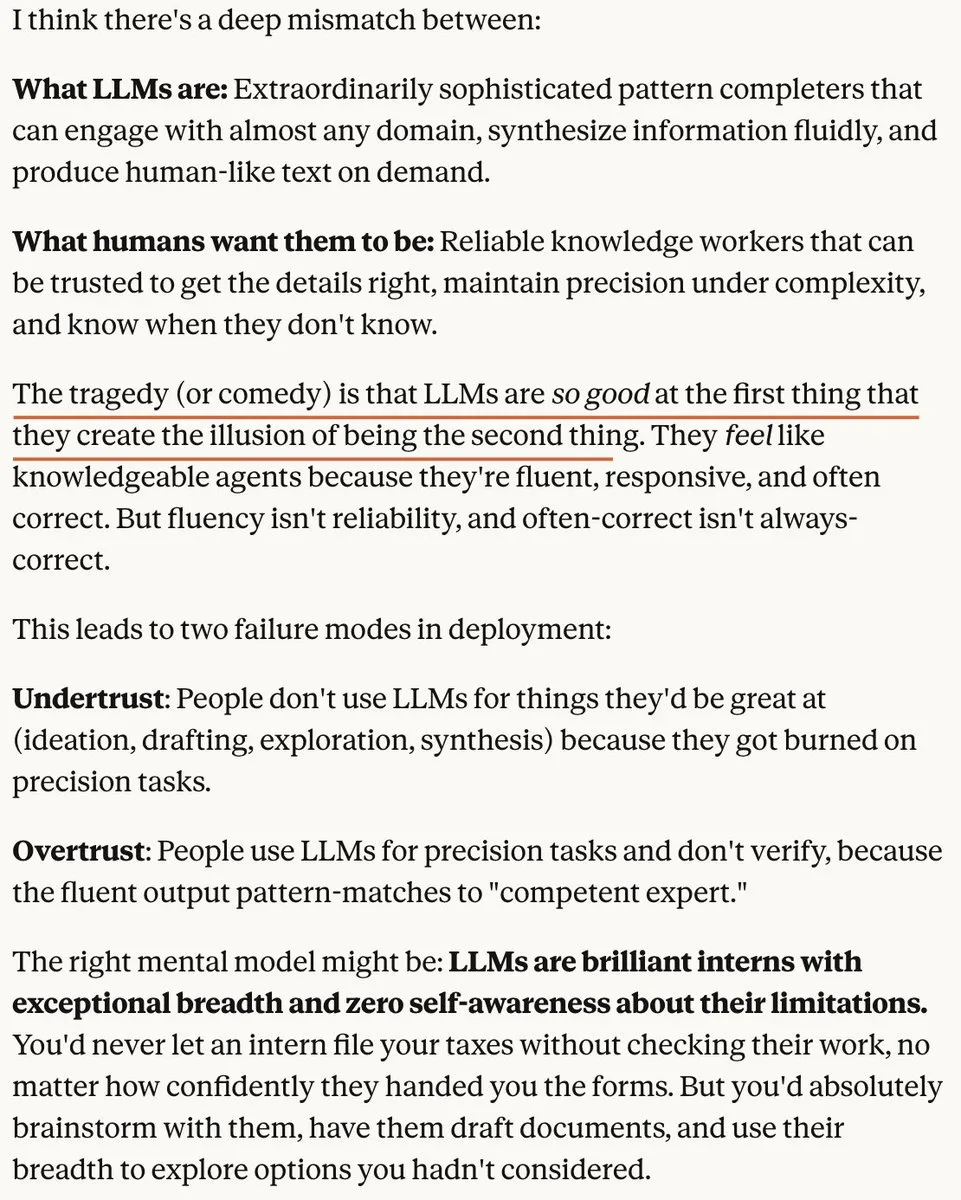
تقييم أداء نماذج الذكاء الاصطناعي: الفجوة بين البيانات الاصطناعية والتجربة الحقيقية: تشير مناقشات إلى وجود فجوة كبيرة بين درجات الاختبار المعيارية لنماذج الذكاء الاصطناعي وتجربة المنتج الفعلية. العديد من النماذج مفتوحة المصدر تؤدي جيدًا في الاختبارات المعيارية، لكنها لا تزال متأخرة عن النماذج مغلقة المصدر في بيئة التشغيل، والقدرات متعددة الوسائط، ومعالجة المهام المعقدة، مما يؤكد أن “المعايير لا تساوي التجربة الحقيقية”، وأن الذكاء الاصطناعي للصور والفيديو يظهر تقدم الذكاء الاصطناعي بشكل أكثر وضوحًا من LLM النصية. (المصدر: op7418, ZhihuFrontier, op7418, Dorialexander)
استهلاك الطاقة في مراكز البيانات يثير رد فعل اجتماعي: أثار سكان في جميع أنحاء الولايات المتحدة معارضة قوية بسبب ارتفاع فواتير الكهرباء الناجم عن تزايد مراكز البيانات. دعت أكثر من 200 منظمة بيئية إلى وقف وطني لبناء مراكز بيانات جديدة، مما يسلط الضوء على التأثير الهائل للبنية التحتية للذكاء الاصطناعي على البيئة والطاقة، والعلاقة المتوترة بين التطور التكنولوجي وتوزيع الموارد الاجتماعية. (المصدر: MIT Technology Review)