
Schlüsselwörter:Gemini 2.5 Pro, Veo 3, OpenAI, Jony Ive, Claude 4 Opus, KI-Videogenerierung, KI-Agenten, Multimodale Modelle, Deep-Think-Modus, Videogenerierungsmodelle, KI-Inferenzfähigkeit, KI-Hardware-Design, Softwaretechnik-Optimierung
🔥 Fokus
Google veröffentlicht Gemini 2.5 Pro Deep Think und Veo 3 und treibt damit KI-Schlussfolgerungen und Videogenerierung auf neue Höhen: Auf der Google I/O Konferenz stellte Google den Deep Think Modus von Gemini 2.5 Pro vor, der speziell für die Lösung komplexer Probleme konzipiert ist. Er zeigte hervorragende Leistungen bei schwierigen Aufgaben von Mathematikwettbewerben wie USAMO und demonstrierte damit bedeutende Fortschritte der KI im Bereich des fortgeschrittenen logischen Denkens, beispielsweise durch mehrstufige Schlussfolgerungen und das Ausprobieren verschiedener Beweismethoden (wie reductio ad absurdum, Satz von Rolle) zur Lösung komplexer algebraischer Probleme. Gleichzeitig hat das von Google veröffentlichte Videogenerierungsmodell Veo 3 mit seinen realistischen Szenen, kontrollierbarer Charakterkonsistenz, Soundsynthese und vielfältigen Bearbeitungsfunktionen (wie Szenenwechsel, Generierung anhand von Referenzbildern, Stiltransfer, Festlegung von Start- und Endframes, lokale Bearbeitung usw.) neue Maßstäbe im Bereich der KI-Videogenerierung gesetzt und breite Aufmerksamkeit erregt (Quelle: demishassabis, lmthang, GoogleDeepMind, _philschmid, fabianstelzer, matvelloso, seo_leaders, op7418, )
OpenAI investiert 6,5 Milliarden US-Dollar in die Übernahme des Unternehmens von Jony Ive, um gemeinsam eine neue Generation KI-gesteuerter Computer zu entwickeln: OpenAI kündigte eine Zusammenarbeit mit dem ehemaligen Apple-Chefdesigner Jony Ive und die Übernahme seines Unternehmens an, mit dem Ziel, gemeinsam eine neue Generation KI-gesteuerter Computer zu entwickeln. Dieser Schritt markiert die Expansion von OpenAI in den Hardware-Bereich und den Versuch, KI-Fähigkeiten tief in Computergeräte zu integrieren, was potenziell die Mensch-Maschine-Interaktion neu gestalten könnte. Jony Ive ist bekannt für sein herausragendes Design während seiner Zeit bei Apple, und seine Beteiligung deutet darauf hin, dass die neuen Geräte bedeutende Durchbrüche in Design und Benutzererfahrung erzielen und bestehende Computergeräteformen herausfordern könnten (Quelle: op7418, TheRundownAI, BorisMPower)
Anthropic Entwicklerkonferenz steht kurz bevor, Claude 4 Opus könnte veröffentlicht werden, mit Fokus auf Software-Engineering-Fähigkeiten: Anthropic steht kurz vor seiner ersten Entwicklerkonferenz, und die Community spekuliert allgemein, dass die neue Modellgeneration Claude 4 (einschließlich Sonnet 4 und Opus 4) auf dieser Konferenz vorgestellt werden könnte. Es gibt Anzeichen dafür, dass die Claude Sonnet 3.7 API bereits ähnliches Verhalten wie Claude 4 zeigt, wie z.B. die schnelle Nutzung von Tools ohne „Denkschritte“. Anthropic scheint sich darauf zu konzentrieren, Software-Engineering-Herausforderungen zu meistern, was sich von dem Pfad unterscheidet, den OpenAI und Google mit dem Streben nach „Allzweckmodellen“ verfolgen. Das TIME Magazine bestätigte ebenfalls indirekt die Veröffentlichung von Claude 4 Opus, was die Markterwartungen hinsichtlich Anthropics Fähigkeiten im KI-Coding und der Verarbeitung komplexer Aufgaben weiter steigerte (Quelle: op7418, mathemagic1an, cto_junior, scaling01, Reddit r/ClaudeAI)
Unterschiedliche KI-Ökosystemstrategien von OpenAI und Google: Zusammenbau eines Schlachtschiffs vs. Umbau eines Imperiums: OpenAI und Google konkurrieren über zwei unterschiedliche Pfade, „Ökosystem vervollständigen“ und „Ökosystem umbauen“, um die Position als „Hauptbetriebssystem“ der zukünftigen KI-Plattform. OpenAI baut durch Akquisitionen von Hardware (io), Datenbanken (Rockset), Toolchains (Windsurf) und Kollaborationstools (Multi) usw. Full-Stack-KI-Fähigkeiten von Grund auf zusammen. Google entscheidet sich hingegen dafür, sein Gemini-Modell tief in bestehende Produkte (Suche, Android, Docs, YouTube usw.) zu integrieren und die zugrundeliegenden Systeme umzugestalten, um eine KI-native Ausrichtung zu erreichen. Obwohl ihre Strategien unterschiedlich sind, ist ihr Ziel dasselbe: der Aufbau der ultimativen Plattform im KI-Zeitalter (Quelle: dotey)
🎯 Trends
Microsoft enthüllt Vision eines „Agenten-Netzwerks“ und betont, dass KI-Agenten zum Kern der nächsten Arbeitsgeneration werden: Microsoft CEO Satya Nadella erläuterte auf der Build 2025 Konferenz und in Interviews die Vision des Unternehmens für ein „Agenten-Netzwerk (agentic web)“. Er ist der Ansicht, dass KI-Agenten in Zukunft zu Bürgern erster Klasse im Geschäfts- und M365-Ökosystem werden und sogar neue Berufe wie „KI-Agenten-Administrator“ hervorbringen könnten. Wenn 95 % des Codes von KI generiert werden, wird sich die Rolle des Menschen auf die Verwaltung und Orchestrierung dieser Agenten verlagern. Microsoft baut über Azure AI Foundry, Copilot Studio und offene Protokolle wie NLWeb ein offenes Agenten-Ökosystem auf und wird Teams zum Zentrum für die Zusammenarbeit mehrerer Agenten machen (Quelle: rowancheung, TheTuringPost)
MMaDA: Veröffentlichung eines multimodalen Diffusions-Sprachmodells, das Text-Reasoning, multimodales Verständnis und Bildgenerierung vereint: Forscher haben MMaDA (Multimodal Large Diffusion Language Models) vorgestellt, ein neuartiges multimodales Diffusions-Basismodell, das durch Mixed Long-CoT (Mixed Long Chain-of-Thought) und den einheitlichen Reinforcement-Learning-Algorithmus UniGRPO Text-Reasoning, multimodales Verständnis und Bildgenerierungsfähigkeiten vereint. MMaDA-8B übertrifft Show-o und SEED-X im multimodalen Verständnis und ist besser als SDXL und Janus bei der Text-zu-Bild-Generierung. Modell und Code wurden auf Hugging Face als Open Source veröffentlicht (Quelle: _akhaliq, arankomatsuzaki, andrew_n_carr, Reddit r/LocalLLaMA)

dKV-Cache: Cache-Mechanismus für Diffusions-Sprachmodelle entwickelt, der die Inferenzgeschwindigkeit erheblich steigert: Als Reaktion auf die langsame Inferenzgeschwindigkeit von Diffusions-Sprachmodellen (DLMs) haben Forscher den dKV-Cache-Mechanismus vorgeschlagen. Diese Methode, die sich am KV-Cache autoregressiver Modelle orientiert, entwirft einen Key-Value-Cache für den Entrauschungsprozess von DLMs durch verzögerte und konditionierte Cache-Strategien. Experimente zeigen, dass dKV-Cache eine 2- bis 10-fache Beschleunigung der Inferenz ermöglicht, den Geschwindigkeitsunterschied zwischen DLMs und autoregressiven Modellen signifikant verringert, die Leistung bei langen Sequenzen sogar verbessert und ohne Training auf bestehende DLMs angewendet werden kann (Quelle: NandoDF, HuggingFace Daily Papers)

Imagen4 zeigt herausragende Leistung bei der Detailwiedergabe und nähert sich dem Endspiel der Bildgenerierung: Das Imagen4-Modell demonstriert eine starke Fähigkeit zur Detailwiedergabe bei der Generierung von Bildern aus komplexen Text-Prompts. Beispielsweise konnte Imagen4 bei der Generierung eines Bildes mit 25 spezifischen Details (wie bestimmte Farben, Objekte, Positionen, Beleuchtung und Atmosphäre) 23 davon erfolgreich wiedergeben. Diese hohe Wiedergabetreue und das präzise Verständnis komplexer Anweisungen deuten darauf hin, dass die Text-zu-Bild-Technologie sich dem „Endspiel“ nähert, bei dem die Vorstellungskraft des Benutzers perfekt reproduziert werden kann (Quelle: cloneofsimo)

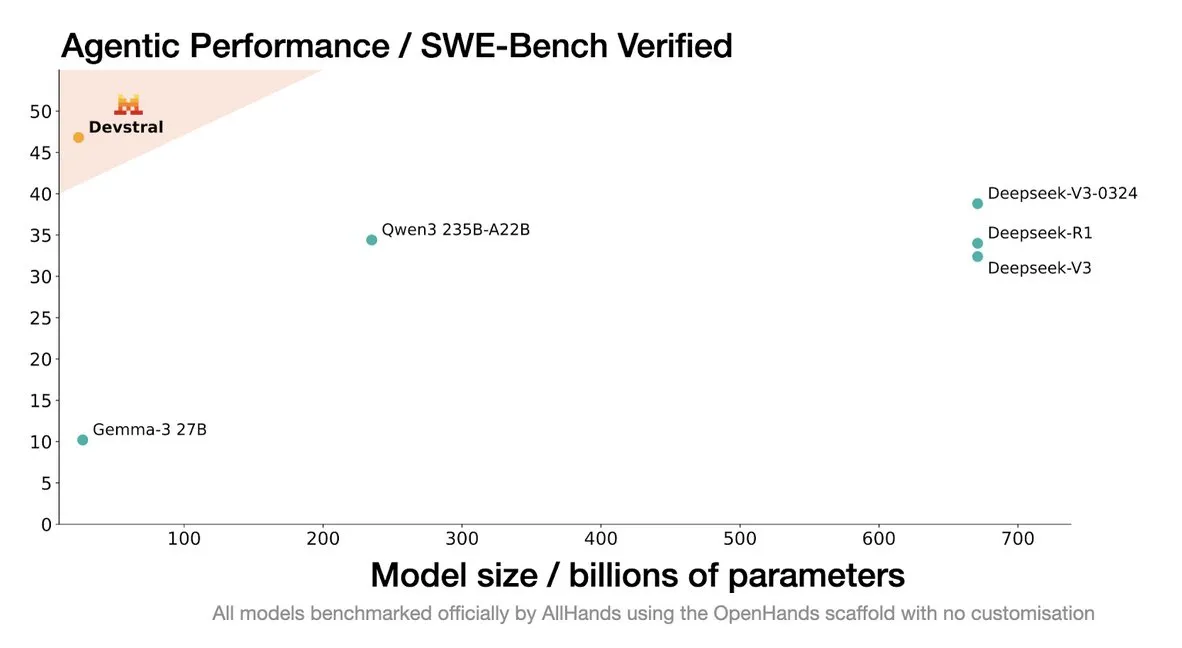
Mistral veröffentlicht Devstral-Modell, speziell für Coding-Agenten entwickelt: Mistral AI hat Devstral vorgestellt, ein Open-Source-Modell, das speziell für Coding-Agenten entwickelt wurde und in Zusammenarbeit mit allhands_ai entwickelt wird. Seine 4-Bit-DWQ-quantisierte Version ist bereits auf Hugging Face verfügbar (mlx-community/Devstral-Small-2505-4bit-DWQ) und läuft reibungslos auf Geräten wie dem M2 Ultra, was sein Optimierungspotenzial bei der Codegenerierung und dem Codeverständnis zeigt (Quelle: awnihannun, clefourrier, GuillaumeLample)
ByteDance veröffentlicht Trainingsbericht für multimodales Modell auf Gemini-Niveau mit integrierter Transformer-Architektur: ByteDance hat einen 37-seitigen Bericht veröffentlicht, der detailliert seine Methoden zum Training eines nativen multimodalen Modells ähnlich Gemini beschreibt. Besonders hervorzuheben ist die „Integrated Transformer“-Architektur, die dasselbe Backbone-Netzwerk gleichzeitig als autoregressives Modell ähnlich GPT und als Diffusionsmodell ähnlich DiT verwendet und damit seine Forschung im Bereich der einheitlichen multimodalen Modellierung demonstriert (Quelle: NandoDF)

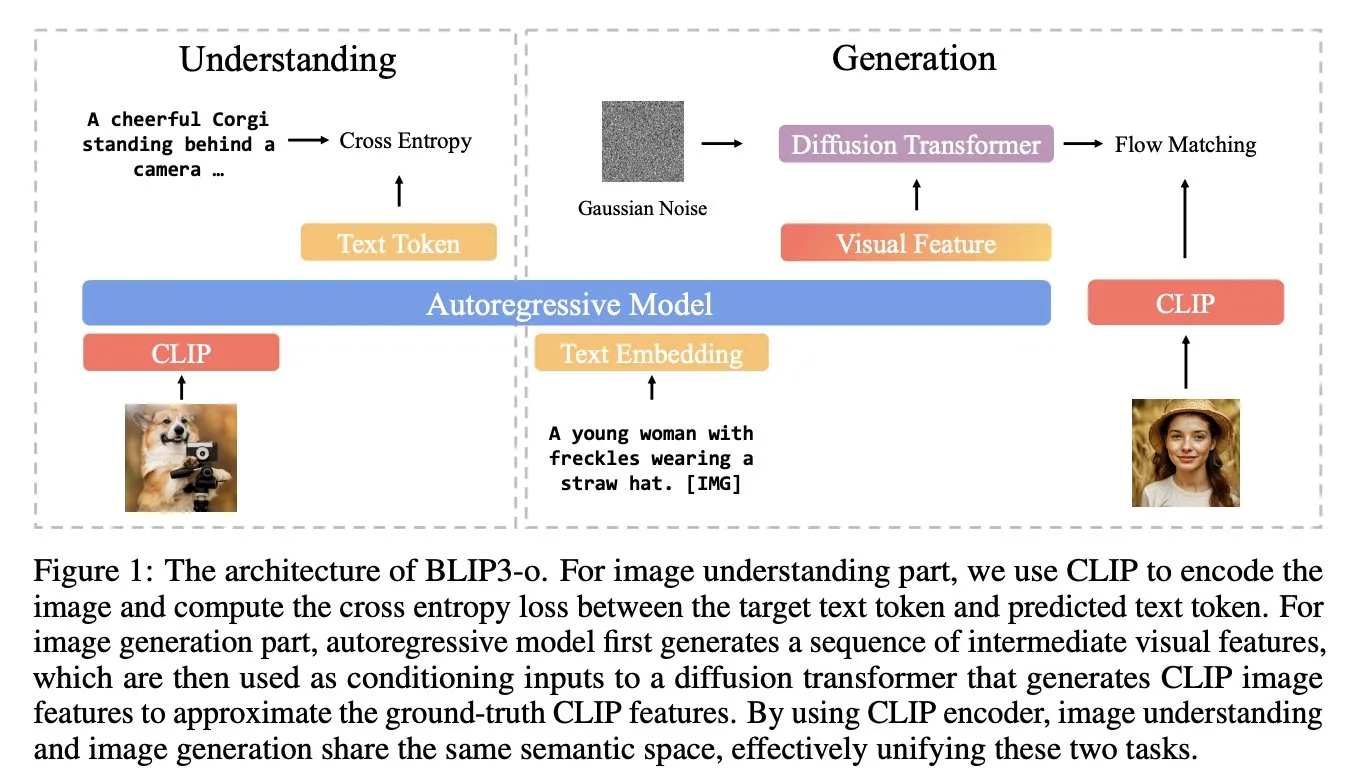
BLIP3-o: Salesforce stellt vollständig quelloffene, einheitliche multimodale Modellreihe vor und erschließt Bildgenerierungsfähigkeiten auf GPT-4o-Niveau: Das Forschungsteam von Salesforce hat die BLIP3-o-Modellreihe veröffentlicht, eine Gruppe vollständig quelloffener, einheitlicher multimodaler Modelle, die darauf abzielen, Bildgenerierungsfähigkeiten ähnlich GPT-4o zu erschließen. Das Projekt stellt nicht nur die Modelle als Open Source zur Verfügung, sondern auch einen vortrainierten Datensatz mit 25 Millionen Datenpunkten, um die Offenheit der multimodalen Forschung zu fördern (Quelle: arankomatsuzaki)
Google stellt Gemma 3n E4B Preview-Version vor, ein multimodales Modell speziell für Geräte mit geringen Ressourcen: Google hat das Modell Gemma 3n E4B-it-litert-preview auf Hugging Face veröffentlicht. Dieses Modell ist für die Verarbeitung von Text-, Bild-, Video- und Audioeingaben sowie die Generierung von Textausgaben konzipiert, wobei die aktuelle Version Text- und visuelle Eingaben unterstützt. Gemma 3n verwendet eine neuartige Matformer-Architektur, die das Verschachteln mehrerer Modelle und die effektive Aktivierung von 2B- oder 4B-Parametern ermöglicht und speziell für den effizienten Betrieb auf Geräten mit geringen Ressourcen optimiert ist. Das Modell wurde auf etwa 11 Billionen Token multimodaler Daten trainiert, mit einem Wissensstand bis Juni 2024 (Quelle: Tim_Dettmers, Reddit r/LocalLLaMA)
Studie deckt Phänomen des sprachspezifischen Wissens (LSK) in großen Modellen auf: Eine neue Studie untersucht das Phänomen des „sprachspezifischen Wissens“ (Language Specific Knowledge, LSK) in Sprachmodellen, d.h. dass Modelle bei der Verarbeitung bestimmter Themen oder Bereiche in bestimmten nicht-englischen Sprachen möglicherweise besser abschneiden als auf Englisch. Die Studie ergab, dass die Modellleistung durch Chain-of-Thought-Reasoning in einer bestimmten Sprache (sogar in ressourcenarmen Sprachen) verbessert werden kann. Dies deutet darauf hin, dass kulturspezifische Texte in der jeweiligen Sprache reichhaltiger sind, sodass spezifisches Wissen möglicherweise nur in „Experten“-Sprachen vorhanden ist. Die Forscher entwickelten die LSKExtractor-Methode, um dieses LSK zu messen und zu nutzen, und erzielten bei mehreren Modellen und Datensätzen eine durchschnittliche relative Genauigkeitssteigerung von 10 % (Quelle: HuggingFace Daily Papers)
DeepMind Veo 3 Videogenerierungseffekte beeindruckend, detailgetreue Darstellung erregt Aufmerksamkeit: Das Videogenerierungsmodell Veo 3 von Google DeepMind demonstriert leistungsstarke Videogenerierungsfähigkeiten, einschließlich Szenenwechsel, referenzbildgesteuerte Generierung, Stiltransfer, Charakterkonsistenz, Festlegung von Start- und Endframes, Videoskalierung, Hinzufügen von Objekten und Aktionssteuerung. Die Realitätsnähe der generierten Videos und das Verständnis komplexer Anweisungen lassen Nutzer über die rasante Entwicklung der KI-Videogenerierungstechnologie staunen, einige Nutzer erstellten damit sogar Werbespots, die professionellen Produktionen ähneln (Quelle: demishassabis, , Reddit r/ChatGPT)
Moondream Vision Language Model stellt 4-Bit-quantisierte Version vor, reduziert VRAM erheblich und steigert Geschwindigkeit: Das Moondream Vision Language Model (VLM) hat eine 4-Bit-quantisierte Version veröffentlicht, die eine Reduzierung des VRAM-Bedarfs um 42 % und eine Steigerung der Inferenzgeschwindigkeit um 34 % bei gleichbleibender Genauigkeit von 99,4 % erreicht. Diese Optimierung macht dieses leistungsstarke, kleine VLM bei Aufgaben wie der Objekterkennung einfacher einsetzbar und nutzbar und wird von Entwicklern begrüßt (Quelle: Sentdex, vikhyatk)
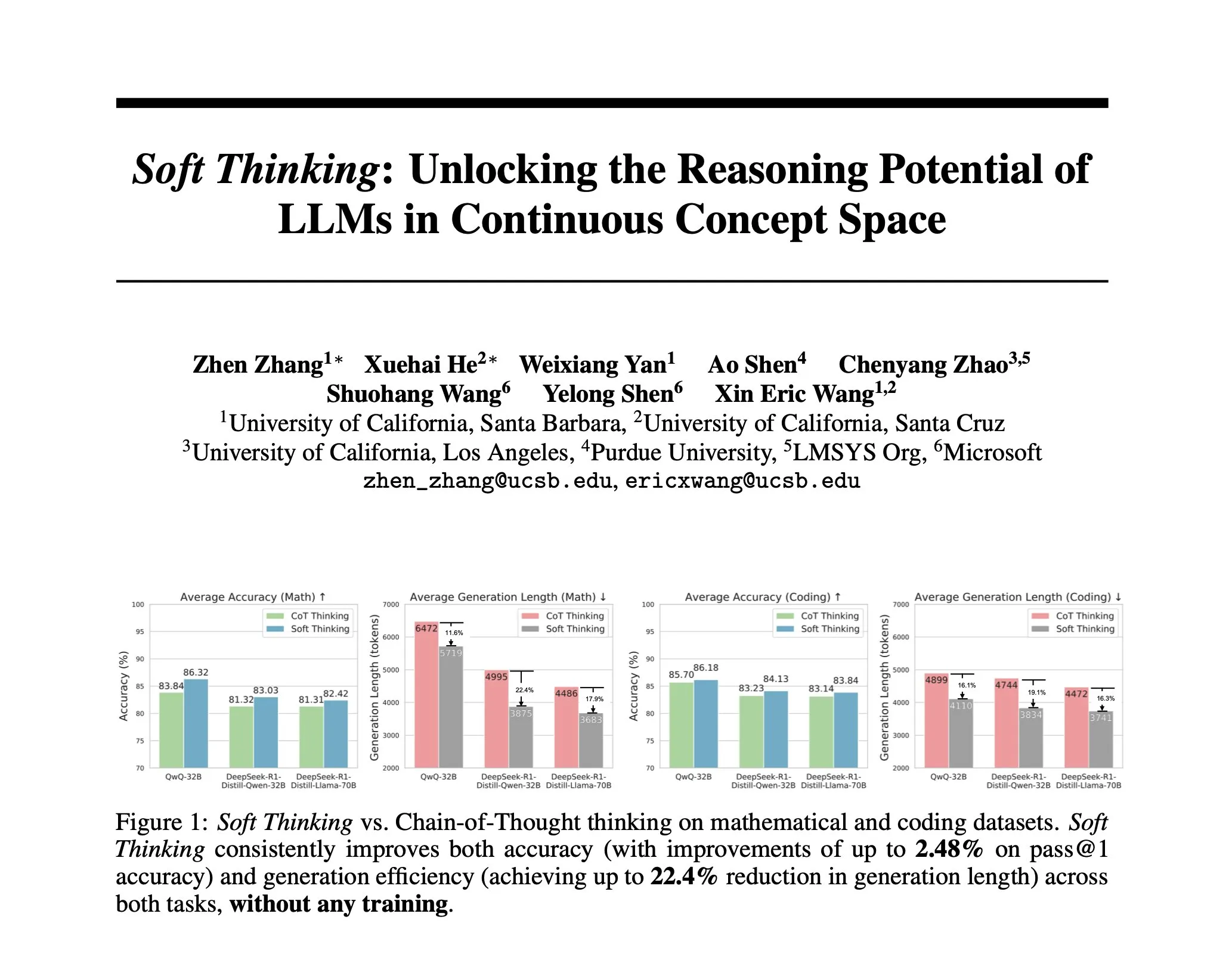
Studie schlägt Soft Thinking vor: Eine trainingsfreie Methode zur Simulation menschlichen „weichen“ Denkens: Um KI-Schlussfolgerungen dem fließenden menschlichen Denken anzunähern, das nicht durch diskrete Token begrenzt ist, haben Forscher die Soft Thinking-Methode vorgeschlagen. Diese Methode erfordert kein zusätzliches Training und generiert kontinuierliche, abstrakte Konzept-Token, die durch wahrscheinlichkeitsgewichtete Einbettungsmischungen verschiedene Bedeutungen sanft verschmelzen, um so reichhaltigere Repräsentationen und eine nahtlose Erkundung verschiedener Denkpfade zu ermöglichen. Experimente zeigen, dass diese Methode die Genauigkeit bei Mathematik- und Code-Benchmarks um bis zu 2,48 % (pass@1) verbessert und gleichzeitig den Token-Verbrauch um bis zu 22,4 % reduziert (Quelle: arankomatsuzaki)
IA-T2I-Framework: Nutzung des Internets zur Verbesserung der Fähigkeit von Text-zu-Bild-Modellen, unsicheres Wissen zu verarbeiten: Um die Unzulänglichkeiten bestehender Text-zu-Bild-Modelle bei der Verarbeitung von Text-Prompts mit unsicherem Wissen (wie aktuelle Ereignisse, seltene Konzepte) zu beheben, wurde das IA-T2I (Internet-Augmented Text-to-Image Generation) Framework vorgeschlagen. Dieses Framework beurteilt durch ein aktives Abrufmodul, ob Referenzbilder benötigt werden, nutzt ein hierarchisches Bildauswahlmodul, um die am besten geeigneten Bilder aus den Suchmaschinenergebnissen auszuwählen, um das T2I-Modell zu verbessern, und bewertet und optimiert die generierten Bilder kontinuierlich durch einen Selbstreflexionsmechanismus. Auf dem speziell erstellten Img-Ref-T2I-Datensatz übertrifft IA-T2I GPT-4o um etwa 30 % (menschliche Bewertung) (Quelle: HuggingFace Daily Papers)
MoI (Mixture of Inputs) verbessert die Qualität der autoregressiven Generierung und die Inferenzfähigkeiten: Um das Problem des Informationsverlusts bei der Token-Verteilung während des standardmäßigen autoregressiven Generierungsprozesses zu lösen, schlagen Forscher die Methode Mixture of Inputs (MoI) vor. Diese Methode erfordert kein zusätzliches Training und mischt nach der Generierung eines Tokens das generierte diskrete Token mit der zuvor verworfenen Token-Verteilung, um eine neue Eingabe zu konstruieren. Durch Bayes’sche Schätzung wird die Token-Verteilung als Prior betrachtet, das gesampelte Token als Beobachtung, und die kontinuierliche A-posteriori-Erwartung ersetzt den traditionellen One-Hot-Vektor als neue Modelleingabe. MoI verbessert kontinuierlich die Leistung mehrerer Modelle wie Qwen-32B und Nemotron-Super-49B bei Aufgaben wie mathematischem Denken, Codegenerierung und Fragenbeantwortung auf Doktoratsniveau (Quelle: HuggingFace Daily Papers)
ConvSearch-R1: Optimierung der Query-Umschreibung in der dialogorientierten Suche durch Reinforcement Learning: Um die Probleme der Mehrdeutigkeit, Auslassung und Referenzierung von kontextabhängigen Anfragen in der dialogorientierten Suche zu lösen, wurde das ConvSearch-R1-Framework vorgeschlagen. Dieses Framework verwendet erstmals einen selbstgesteuerten Ansatz, indem es Reinforcement Learning direkt nutzt, um die Query-Umschreibung mithilfe von Retrieval-Signalen zu optimieren, wodurch die Abhängigkeit von externer Umschreibungsüberwachung (wie manuelle Annotationen oder große Modelle) vollständig entfällt. Seine zweistufige Methode umfasst ein selbstgesteuertes Strategie-Warm-up und ein auf Retrieval-basierendes Reinforcement Learning (unter Verwendung eines rangbasierten Anreiz-Belohnungsmechanismus). Experimente zeigen, dass ConvSearch-R1 auf den Datensätzen TopiOCQA und QReCC signifikant besser abschneidet als frühere SOTA-Methoden (Quelle: HuggingFace Daily Papers)
ASRR-Framework ermöglicht effizientes adaptives Inferencing für große Sprachmodelle: Um das Problem des übermäßigen Rechenaufwands durch redundantes Inferencing bei großen Inferenzmodellen (LRMs) für einfache Aufgaben anzugehen, haben Forscher das Adaptive Self-Recovery Reasoning (ASRR)-Framework vorgeschlagen. Dieses Framework unterdrückt unnötiges Inferencing, indem es den „internen Selbstwiederherstellungsmechanismus“ des Modells aufdeckt (implizite Ergänzung des Inferencing bei der Antwortgenerierung), und führt eine genauigkeitssensitive Längenbelohnungsanpassung ein, um den Inferenzaufwand adaptiv je nach Schwierigkeitsgrad der Frage zuzuweisen. Experimente zeigen, dass ASRR den Inferenzaufwand erheblich reduzieren und die Unschädlichkeitsrate bei Sicherheitsbenchmarks verbessern kann, bei minimalem Leistungsverlust (Quelle: HuggingFace Daily Papers)
MoT (Mixture-of-Thought) Framework verbessert logische Denkfähigkeiten: Inspiriert von der menschlichen Nutzung verschiedener Denkmodalitäten (natürliche Sprache, Code, symbolische Logik) zur Lösung logischer Probleme, haben Forscher das Mixture-of-Thought (MoT) Framework vorgeschlagen. MoT ermöglicht es LLMs, über drei komplementäre Modalitäten hinweg zu schlussfolgern, einschließlich der neu eingeführten symbolischen Modalität der Wahrheitstabelle. Durch ein zweistufiges Design (selbstevolvierendes MoT-Training und MoT-Inferenz) übertrifft MoT auf logischen Inferenz-Benchmarks wie FOLIO und ProofWriter signifikant monomodale Chain-of-Thought-Methoden und erreicht eine durchschnittliche Genauigkeitssteigerung von bis zu 11,7 % (Quelle: HuggingFace Daily Papers)
RL Tango: Gemeinsames Training von Generator und Validator durch Reinforcement Learning zur Verbesserung des sprachlichen Denkens: Um die Probleme des Reward-Hackings und der schlechten Generalisierung zu lösen, die bei bestehenden LLM-Reinforcement-Learning-Methoden durch feste oder überwacht feinabgestimmte Validatoren (Belohnungsmodelle) entstehen, wurde das RL Tango-Framework vorgeschlagen. Dieses Framework trainiert den LLM-Generator und einen generativen, prozessbasierten LLM-Validator abwechselnd und gleichzeitig durch Reinforcement Learning. Der Validator wird nur auf der Grundlage von Ergebnisebenen-Validierungsrichtigkeitsbelohnungen trainiert, ohne prozessbasierte Annotationen, wodurch eine effektive gegenseitige Förderung mit dem Generator entsteht. Experimente zeigen, dass sowohl der Generator als auch der Validator von Tango bei Modellen der Größe 7B/8B SOTA-Niveau erreichen (Quelle: HuggingFace Daily Papers)
pPE: Prior Prompt Engineering unterstützt Reinforcement Fine-Tuning (RFT): Eine Studie untersucht die Rolle von Prior Prompt Engineering (pPE) beim Reinforcement Fine-Tuning (RFT). Im Gegensatz zum Inference-Time Prompt Engineering (iPE) stellt pPE Anweisungen (wie schrittweises Denken) während der Trainingsphase der Anfrage voran, um das Sprachmodell anzuleiten, bestimmte Verhaltensweisen zu internalisieren. Experimente wandelten fünf iPE-Strategien (Schlussfolgern, Planen, Code-Schlussfolgern, Wissensabruf, Nutzung leerer Beispiele) in pPE-Methoden um und wendeten sie auf Qwen2.5-7B an. Die Ergebnisse zeigen, dass alle mit pPE trainierten Modelle die entsprechenden iPE-Modelle übertreffen, wobei leeres Beispiel-pPE bei Benchmarks wie AIME2024 und GPQA-Diamond die größten Verbesserungen erzielte. Dies zeigt pPE als eine bisher unterschätzte, aber effektive Methode im RFT (Quelle: HuggingFace Daily Papers)
BiasLens: LLM-Bias-Bewertungsframework ohne manuelle Testdatensätze: Um das Problem zu lösen, dass bestehende LLM-Bias-Bewertungsmethoden von manuell erstellten, gelabelten Daten abhängen und nur eine begrenzte Abdeckung bieten, wurde das BiasLens-Framework vorgeschlagen. Dieses Framework geht von der Vektorraumstruktur des Modells aus und kombiniert Concept Activation Vectors (CAVs) und Sparse Autoencoder (SAEs), um interpretierbare Konzeptrepräsentationen zu extrahieren. Bias wird quantifiziert, indem die Veränderung der Repräsentationsähnlichkeit zwischen Zielkonzepten und Referenzkonzepten gemessen wird. BiasLens zeigt bei ungelabelten Daten eine starke Übereinstimmung mit traditionellen Bias-Bewertungsmetriken (Spearman-Korrelation r > 0,85) und kann Bias-Formen aufdecken, die mit bestehenden Methoden schwer zu erkennen sind (Quelle: HuggingFace Daily Papers)
HumaniBench: Ein menschenzentriertes Bewertungsframework für große multimodale Modelle: Angesichts der unzureichenden Leistung aktueller LMMs bei menschenzentrierten Standards wie Fairness, Ethik und Empathie wurde HumaniBench vorgeschlagen. Es handelt sich um einen umfassenden Benchmark mit 32.000 realen Bild-Text-Frage-Antwort-Paaren, die mit GPT-4o-Unterstützung annotiert und von Experten validiert wurden. HumaniBench bewertet sieben menschenzentrierte KI-Prinzipien: Fairness, Ethik, Verständnis, Schlussfolgern, sprachliche Inklusion, Empathie und Robustheit, die sieben vielfältige Aufgaben abdecken. Tests mit 15 SOTA LMMs zeigen, dass Closed-Source-Modelle im Allgemeinen führend sind, Robustheit und visuelle Lokalisierung jedoch Schwachstellen bleiben (Quelle: HuggingFace Daily Papers)
AJailBench: Erster umfassender Benchmark für Jailbreak-Angriffe auf große Audio-Sprachmodelle: Um die Sicherheit großer Audio-Sprachmodelle (LAMs) bei Jailbreak-Angriffen systematisch zu bewerten, wurde AJailBench vorgeschlagen. Dieser Benchmark erstellte zunächst den AJailBench-Base-Datensatz mit 1495 adversariellen Audio-Prompts, die 10 Verstoßkategorien abdecken. Die Bewertung auf Basis dieses Datensatzes zeigt, dass bestehende SOTA LAMs keine konsistente Robustheit aufweisen. Um realistischere Angriffe zu simulieren, entwickelten die Forscher das Audio Perturbation Toolkit (APT), das durch Bayes’sche Optimierung subtile und effiziente Perturbationen sucht und den erweiterten Datensatz AJailBench-APT generierte. Die Studie zeigt, dass geringfügige und semantikerhaltende Perturbationen die Sicherheitsleistung von LAMs erheblich reduzieren können (Quelle: HuggingFace Daily Papers)
WebNovelBench: Benchmark zur Bewertung der Fähigkeit von LLMs, lange Romane zu verfassen: Um die Herausforderungen bei der Bewertung der Fähigkeit von LLMs zur Erstellung langer Erzählungen zu bewältigen, wurde WebNovelBench vorgeschlagen. Dieser Benchmark nutzt einen Datensatz von über 4000 chinesischen Web-Romanen und definiert die Bewertung als eine Aufgabe der Generierung von Geschichten aus Gliederungen. Mithilfe der Methode „LLM als Bewerter“ wird eine automatische Bewertung anhand von acht Dimensionen der Erzählqualität durchgeführt, und die Ergebnisse werden mittels Hauptkomponentenanalyse aggregiert und mit menschlichen Werken perzentilrangmäßig verglichen. Die Experimente unterschieden effektiv zwischen menschlichen Meisterwerken, populären Web-Romanen und von LLMs generierten Inhalten und führten eine umfassende Analyse von 24 SOTA LLMs durch (Quelle: HuggingFace Daily Papers)
MultiHal: Mehrsprachiger Wissensgraph-basierter Datensatz zur Bewertung von Halluzinationen in LLMs: Um die Mängel bestehender Halluzinationsbewertungs-Benchmarks hinsichtlich Wissensgraph-Pfaden und Mehrsprachigkeit zu beheben, wurde MultiHal vorgeschlagen. Dies ist ein auf Wissensgraphen basierender, mehrsprachiger Multi-Hop-Benchmark, der speziell für die Bewertung generierter Texte entwickelt wurde. Das Team extrahierte 140.000 Pfade aus Open-Domain-Wissensgraphen und filterte 25.900 qualitativ hochwertige Pfade heraus. Baseline-Bewertungen zeigen, dass wissensgraph-erweitertes RAG (KG-RAG) im Vergleich zu normaler Fragebeantwortung bei mehrsprachigen und multimodalen Modellen eine absolute Verbesserung der semantischen Ähnlichkeitswerte um etwa 0,12 bis 0,36 Punkte erzielt, was das Potenzial der Wissensgraph-Integration demonstriert (Quelle: HuggingFace Daily Papers)
Llama-SMoP: LLM-basierte audiovisuelle Spracherkennungsmethode mit Sparse Mixture of Projectors: Um die hohen Rechenkosten von LLMs bei der audiovisuellen Spracherkennung (AVSR) zu reduzieren, wurde Llama-SMoP vorgeschlagen. Dies ist ein effizientes multimodales LLM, das ein Sparse Mixture of Projectors (SMoP)-Modul verwendet, das durch spärlich gesteuerte Mixture of Experts (MoE)-Projektoren die Modellkapazität erweitert, ohne die Inferenzkosten zu erhöhen. Experimente zeigen, dass die Llama-SMoP DEDR-Konfiguration mit modalitätsspezifischem Routing und Experten bei ASR-, VSR- und AVSR-Aufgaben eine hervorragende Leistung erzielt und sich gut in Bezug auf Expertenaktivierung, Skalierbarkeit und Rauschrobustheit verhält (Quelle: HuggingFace Daily Papers)
VPRL: Reinforcement-Learning-basiertes rein visuelles Planungsframework übertrifft textbasiertes Reasoning: Ein Forschungsteam der Cambridge University, des University College London und von Google hat VPRL (Visual Planning with Reinforcement Learning) vorgestellt, ein neues Paradigma, das ausschließlich auf Bildsequenzen für Schlussfolgerungen basiert. Das Framework nutzt Group Relative Policy Optimization (GRPO) für das Post-Training großer visueller Modelle, berechnet Belohnungssignale durch visuelle Zustandsübergänge und validiert Umgebungsbeschränkungen. Bei visuellen Navigationsaufgaben wie FrozenLake, Maze und MiniBehavior erreicht VPRL eine Genauigkeit von bis zu 80,6 % und übertrifft damit textbasierte Reasoning-Methoden (wie Gemini 2.5 Pro mit 43,7 %) signifikant. Zudem zeigt es eine bessere Leistung bei komplexen Aufgaben und Robustheit, was die Überlegenheit der visuellen Planung belegt (Quelle: 量子位)

Nvidia enthüllt Fünfjahres-Roadmap für KI-Technologie und wandelt sich zum KI-Infrastrukturunternehmen: Nvidia-CEO Jensen Huang kündigte auf der COMPUTEX 2025 eine Neupositionierung des Unternehmens als KI-Infrastrukturunternehmen an und stellte eine Fünfjahres-Technologie-Roadmap vor. Er betonte, dass KI-Infrastruktur so allgegenwärtig sein wird wie Strom oder das Internet, und Nvidia sich dem Bau der „Fabriken“ des KI-Zeitalters widmet. Zur Unterstützung dieser Transformation wird Nvidia seinen Lieferketten-„Freundeskreis“ erweitern, die Zusammenarbeit mit TSMC und anderen vertiefen und plant die Einrichtung eines Büros (NVIDIA Constellation) und des ersten riesigen KI-Supercomputers in Taiwan (Quelle: 36氪)

Google startet KI-Brillenprojekt neu, veröffentlicht Android XR-Plattform und Drittanbietergeräte: Google kündigte auf der I/O 2025 Konferenz den Neustart seines KI/AR-Brillenprojekts an, veröffentlichte die speziell für XR-Geräte entwickelte Android XR-Plattform und präsentierte zwei auf dieser Plattform basierende Drittanbietergeräte: Samsungs Project Moohan (als Konkurrenz zu Vision Pro) und Xreals Project Aura. Google zielt darauf ab, den Erfolg von Android im Smartphone-Bereich zu wiederholen und den „Android-Moment“ für XR-Geräte zu schaffen, um sich für zukünftige Umgebungs- und Raumcomputerplattformen zu positionieren. In Kombination mit dem verbesserten multimodalen Gemini 2.5 Pro-Modell und der Project Astra-Agentenassistenztechnologie werden die KI/AR-Brillen der neuen Generation disruptive Erlebnisse in den Bereichen Sprachverständnis, Echtzeitübersetzung, Situationsbewusstsein und Ausführung komplexer Aufgaben ermöglichen (Quelle: 36氪)

ARC-AGI-2 Challenge Prinzipien aktualisiert, betonen mehrstufiges kontextuelles Denken: Das neu veröffentlichte ARC-AGI-2 Paper aktualisiert die Designprinzipien dieser Challenge. Die neuen Prinzipien erfordern zur Lösung der Aufgaben Fähigkeiten im Bereich Multi-Rule, Multi-Step und kontextuelles Denken. Die Gitter sind größer, enthalten mehr Objekte und kodieren mehrere interaktive Konzepte. Die Aufgaben sind neuartig und nicht wiederverwendbar, um Memorization zu begrenzen. Das Design widersetzt sich bewusst der Brute-Force-Programmsynthese. Menschliche Löser benötigen durchschnittlich 2,7 Minuten pro Aufgabe, während Top-Systeme (wie OpenAI o3-medium) nur etwa 3 % erreichen, wobei alle Aufgaben explizite kognitive Anstrengung erfordern (Quelle: TheTuringPost, clefourrier)
Skywork stellt Super-Agenten vor, der 8 Stunden Arbeit auf 8 Minuten verkürzen soll: Skywork hat seinen KI-Workspace-Agenten – Skywork Super Agents – vorgestellt und behauptet, dass dieser die Arbeitslast der Nutzer von 8 Stunden auf 8 Minuten reduzieren kann. Das Produkt positioniert sich als Pionier der KI-Workspace-Agenten, konkrete Funktionen und Umsetzungsmethoden bleiben abzuwarten (Quelle: _akhaliq)
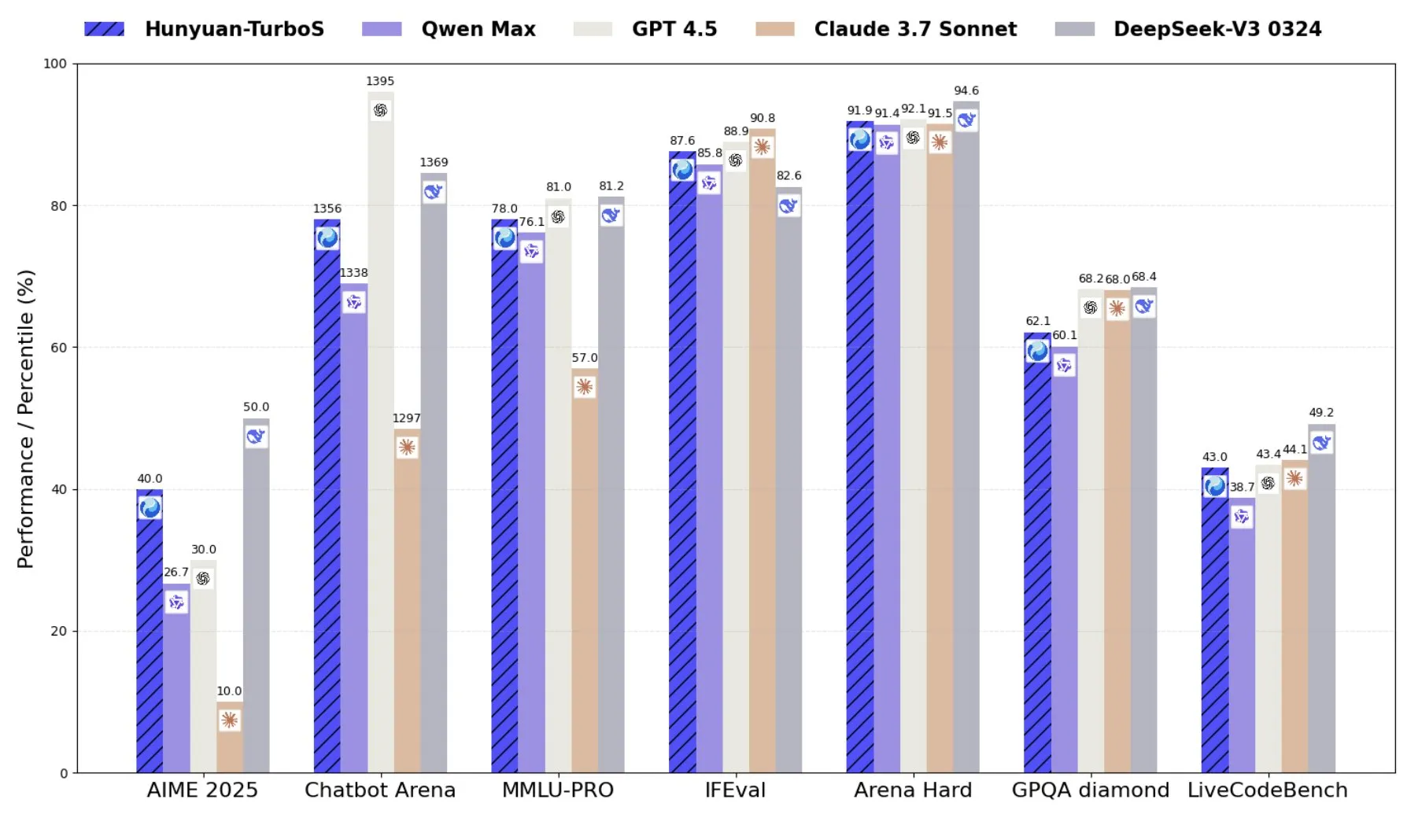
Tencent stellt Hunyuan-TurboS vor, ein hybrides Expertenmodell, das Transformer und Mamba kombiniert: Tencent hat das Hunyuan-TurboS-Modell veröffentlicht, das eine hybride Expertenarchitektur (MoE) aus Transformer und Mamba verwendet, 56 Milliarden aktivierte Parameter besitzt und auf 16 Billionen Token trainiert wurde. Hunyuan-TurboS kann dynamisch zwischen schnellen Reaktions- und tiefen „Denk“-Modi wechseln und rangiert in der LMSYS Chatbot Arena insgesamt unter den Top Sieben (Quelle: tri_dao)
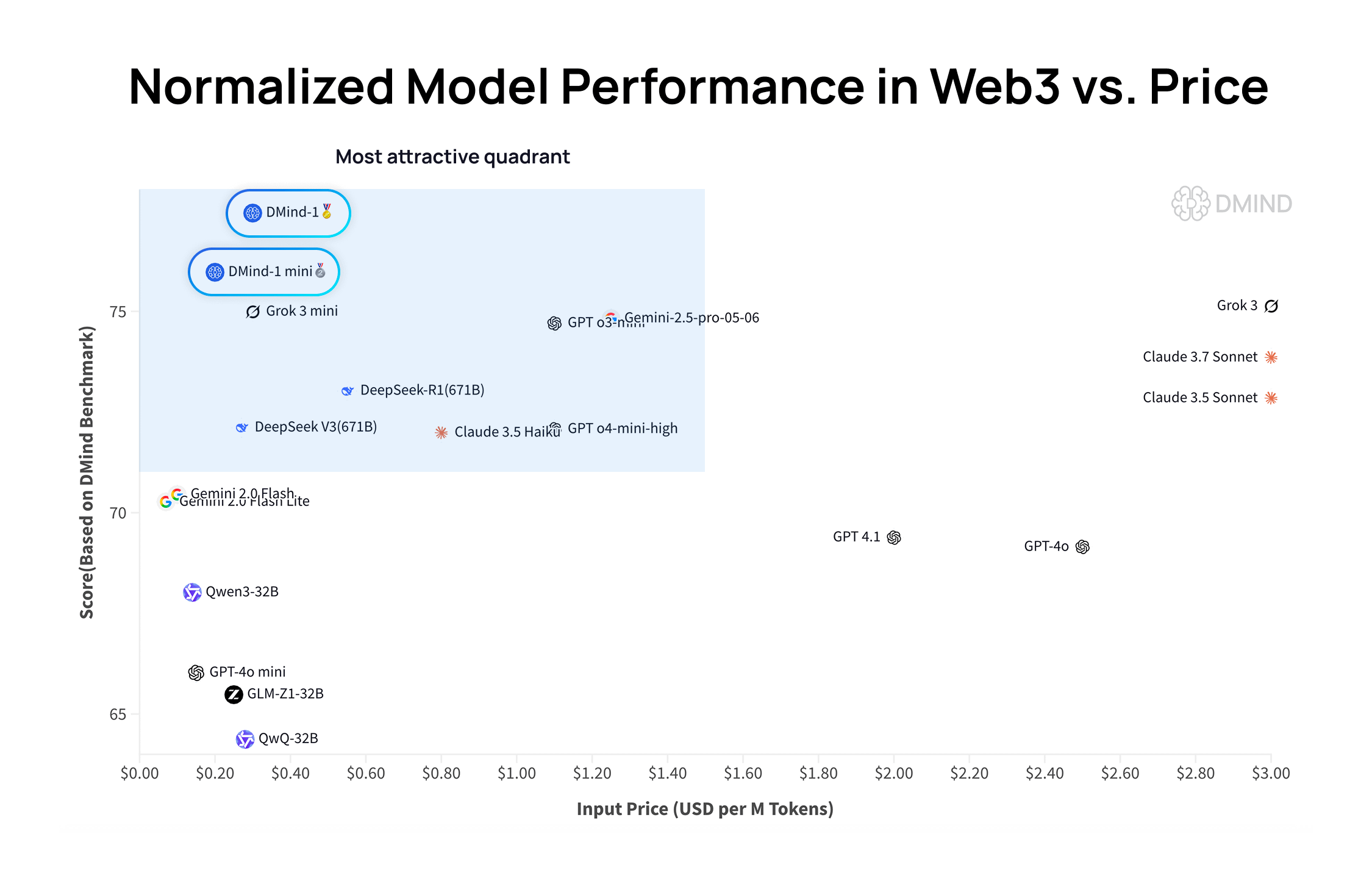
DMind-1: Open-Source Large Language Model speziell für Web3-Szenarien entwickelt: DMind AI hat DMind-1 veröffentlicht, ein Open-Source Large Language Model, das für Web3-Szenarien optimiert ist. DMind-1 (32B) basiert auf einem Fine-Tuning von Qwen3-32B und verwendet eine große Menge an Web3-spezifischem Wissen, um Leistung und Kosten für AI+Web3-Anwendungen auszugleichen. In Web3-Benchmark-Bewertungen übertrifft DMind-1 gängige universelle LLMs, wobei die Token-Kosten nur etwa 10 % betragen. Das gleichzeitig veröffentlichte DMind-1-mini (14B) behält über 95 % der Leistung von DMind-1 und ist in Bezug auf Latenz und Recheneffizienz überlegen (Quelle: _akhaliq)
LightOn veröffentlicht Reason-ModernColBERT, ein Modell mit wenigen Parametern, das bei inferenzintensiven Retrieval-Aufgaben hervorragend abschneidet: LightOn hat Reason-ModernColBERT vorgestellt, ein Late-Interaction-Modell mit nur 149 Millionen Parametern. Im beliebten BRIGHT-Benchmark (der sich auf inferenzintensive Retrieval-Aufgaben konzentriert) schneidet dieses Modell hervorragend ab, übertrifft Modelle mit 45-mal mehr Parametern und erreicht in mehreren Bereichen SOTA-Niveau. Dieses Ergebnis belegt erneut die hohe Effizienz von Late-Interaction-Modellen bei spezifischen Aufgaben (Quelle: lateinteraction, jeremyphoward, Dorialexander, huggingface)

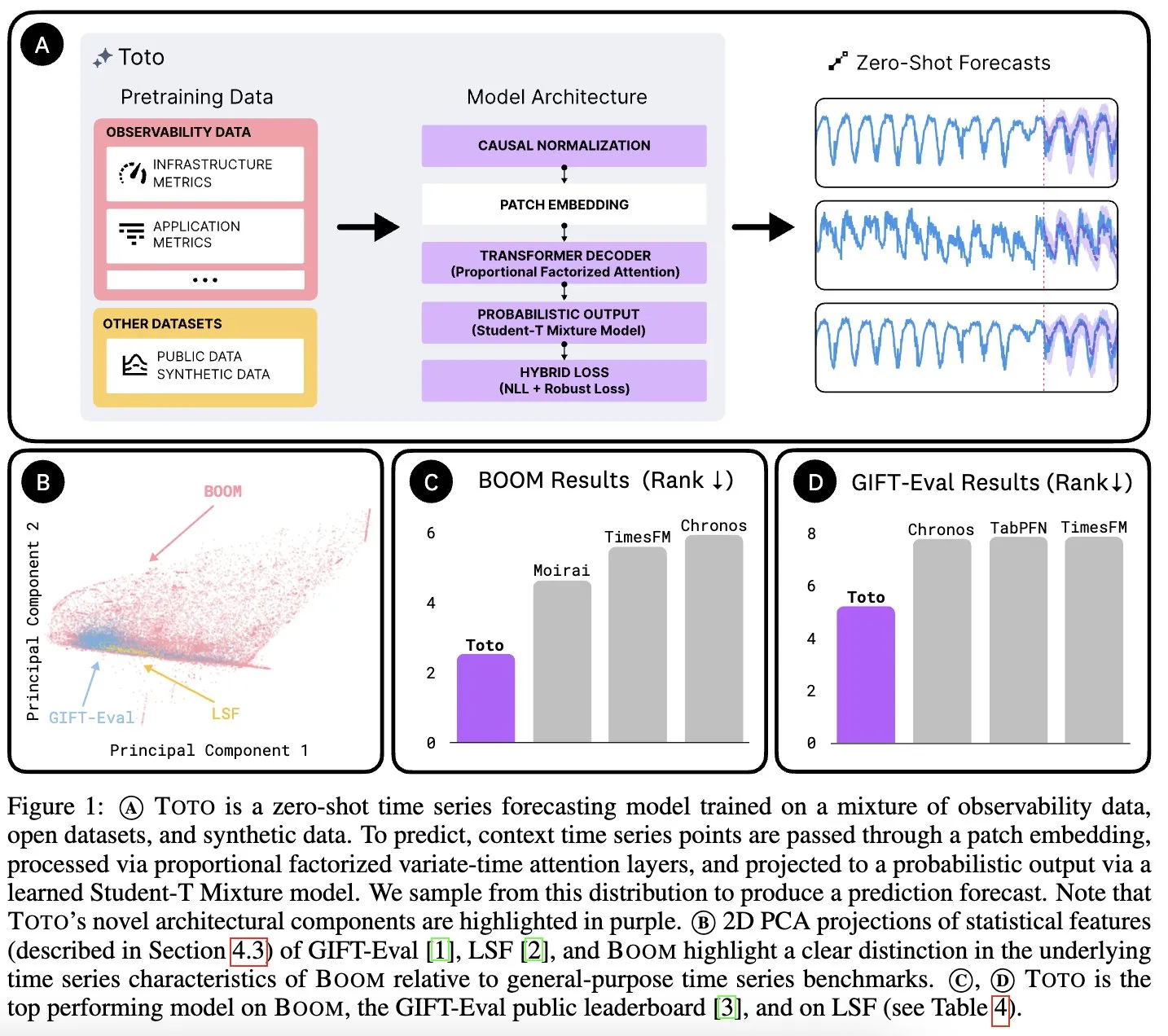
Datadog AI Research veröffentlicht Zeitreihen-Basismodell Toto und Beobachtungsmetriken-Benchmark BOOM: Datadog AI Research hat Toto vorgestellt, ein neues Zeitreihen-Basismodell, das in relevanten Benchmarks bestehende SOTA-Modelle deutlich übertrifft. Gleichzeitig wurde BOOM veröffentlicht, der derzeit größte Benchmark für Beobachtungsmetriken. Beide werden unter der Apache 2.0 Lizenz als Open Source veröffentlicht, um Forschung und Anwendung im Bereich Zeitreihenanalyse und Beobachtbarkeit voranzutreiben (Quelle: jefrankle, ClementDelangue)
TII veröffentlicht Falcon-H1-Serie hybrider Transformer-SSM-Modelle: Das Technology Innovation Institute (TII) der VAE hat die Falcon-H1-Modellserie veröffentlicht, eine Gruppe von Sprachmodellen mit hybrider Architektur, die Transformer-Aufmerksamkeitsmechanismen und Mamba2 State Space Model (SSM)-Köpfe kombinieren. Die Modellserie reicht von 0,5B bis 34B Parametern, unterstützt Kontextlängen von bis zu 256K und übertrifft oder erreicht in mehreren Benchmarks die Leistung von Top-Transformer-Modellen wie Qwen3-32B und Llama4-Scout, insbesondere in Bezug auf Mehrsprachigkeit (native Unterstützung für 18 Sprachen) und Effizienz. Die Modelle wurden in vLLM, Hugging Face Transformers und llama.cpp integriert (Quelle: Reddit r/LocalLLaMA)

MIT-Studie: KI lernt Zusammenhänge zwischen Bild und Ton ohne menschliches Eingreifen: Forscher des MIT haben ein KI-System vorgestellt, das autonom die Zusammenhänge zwischen visuellen Informationen und den entsprechenden Geräuschen lernen kann, ohne explizite Anleitung oder markierte Daten von Menschen. Diese Fähigkeit ist entscheidend für die Entwicklung umfassenderer multimodaler KI-Systeme, die die Welt ähnlich wie Menschen verstehen und wahrnehmen können (Quelle: Reddit r/artificial, Reddit r/ArtificialInteligence)

VAE starten großes arabisches KI-Modell und beschleunigen KI-Wettlauf in der Golfregion: Die Vereinigten Arabischen Emirate haben ein großes arabisches KI-Modell veröffentlicht, was ihre weiteren Investitionen im Bereich der künstlichen Intelligenz signalisiert und den Wettbewerb der Golfstaaten bei der Entwicklung von KI-Technologien verschärft. Dieser Schritt zielt darauf ab, den Einfluss der arabischen Sprache im KI-Bereich zu stärken und den Bedarf an lokalisierten KI-Anwendungen zu decken (Quelle: Reddit r/artificial)
Fenbi Technology veröffentlicht domänenspezifisches großes Modell und definiert neues Paradigma für „KI + Bildung“: Fenbi Technology präsentierte auf dem Tencent Cloud AI Industry Application Summit sein selbst entwickeltes domänenspezifisches großes Modell für den Bereich der beruflichen Bildung. Das Modell wird bereits in Produkten wie Interview-Bewertungen und KI-gestützten Übungssystemen eingesetzt und deckt die gesamte Kette von „Lehren, Lernen, Üben, Bewerten, Testen“ ab. Durch Formen wie KI-Lehrer soll der Übergang von „Einheitsunterricht für alle“ zu „personalisiertem Unterricht für jeden Einzelnen“ realisiert werden. Geplant ist zudem die Einführung von KI-Hardwareprodukten mit dem selbst entwickelten großen Modell, um die intelligente Transformation des Bildungswesens voranzutreiben (Quelle: 量子位)

Beisen Kuxueyuan veröffentlicht neue Generation der AI Learning Plattform mit fünf KI-Agenten: Beisen Holdings hat nach der Übernahme von Kuxueyuan die neue Lernplattform AI Learning vorgestellt, die auf großen KI-Modellen basiert. Die Plattform erweitert das bisherige eLearning um fünf intelligente Agenten: einen KI-Kursgestaltungsassistenten, einen KI-Lernassistenten, einen KI-Übungspartner, einen KI-Führungskräftecoach und einen KI-Prüfungsassistenten. Ziel ist es, durch Echtzeitdialoge mit Agenten, Kompetenztraining, personalisiertes Lernen sowie KI-gestützte Kurserstellung und -prüfung aus einer Hand das traditionelle betriebliche Lernen zu revolutionieren (Quelle: 量子位)

Pony.ai Q1-Finanzbericht: Robotaxi-Serviceeinnahmen steigen im Jahresvergleich um das Achtfache, bis Jahresende sollen tausend fahrerlose Fahrzeuge eingesetzt werden: Pony.ai gab die Finanzergebnisse für das erste Quartal 2025 bekannt, mit einem Gesamtumsatz von 102 Millionen Yuan, ein Anstieg von 12 % im Jahresvergleich. Davon erreichten die Kerneinnahmen aus dem Robotaxi-Service 12,3 Millionen Yuan, ein Anstieg von 200,3 % im Jahresvergleich, wobei die Einnahmen aus Fahrgastgebühren sogar um das Achtfache stiegen. Das Unternehmen plant, im zweiten Quartal mit der Massenproduktion der siebten Generation von Robotaxis zu beginnen und bis Ende des Jahres 1000 Fahrzeuge einzusetzen, um den Break-Even-Punkt pro Fahrzeug zu erreichen. Pony.ai kündigte außerdem Kooperationen mit Tencent Cloud und Uber an, um die Märkte in China bzw. im Nahen Osten über die WeChat- und Uber-Plattformen zu erweitern (Quelle: 量子位)

OpenAI CPO Kevin Weil: ChatGPT wird sich zum Handlungsassistenten wandeln, Modellkosten sind bereits 500-mal höher als bei GPT-4: Kevin Weil, Chief Product Officer von OpenAI, erklärte, dass sich die Positionierung von ChatGPT von der Beantwortung von Fragen hin zur Ausführung von Aufgaben für Nutzer wandeln wird. Durch die abwechselnde Nutzung von Tools (wie Webbrowsing, Programmierung, Anbindung interner Wissensquellen) soll es zum KI-Handlungsassistenten werden. Er enthüllte, dass die Kosten des aktuellen Modells bereits 500-mal höher sind als die des ursprünglichen GPT-4, OpenAI sich aber durch Hardwareverbesserungen und Algorithmusoptimierungen bemüht, die Effizienz zu steigern und die API-Preise zu senken. Er glaubt, dass sich KI-Agenten schnell entwickeln und innerhalb eines Jahres vom Niveau eines Junior-Ingenieurs zum Niveau eines Architekten heranwachsen werden (Quelle: 量子位)

🧰 Tools
FlowiseAI: Visuelles Erstellen von KI-Agenten: FlowiseAI ist ein Open-Source-Projekt, das es Benutzern ermöglicht, KI-Agenten und LLM-Anwendungen über eine visuelle Oberfläche zu erstellen. Es unterstützt Drag-and-Drop-Komponenten, die Verbindung verschiedener LLMs, Tools und Datenquellen und vereinfacht so den Entwicklungsprozess von KI-Anwendungen. Benutzer können Flowise über npm installieren oder per Docker bereitstellen, um schnell eigene KI-Flows zu erstellen und zu testen (Quelle: GitHub Trending)

Hugging Face JS-Bibliothek veröffentlicht, vereinfacht Interaktion mit Hub API und Inferenzdiensten: Hugging Face hat eine Reihe von JavaScript-Bibliotheken (@huggingface/inference, @huggingface/hub, @huggingface/mcp-client usw.) veröffentlicht, die Entwicklern die Interaktion mit der Hugging Face Hub API und den Inferenzdiensten über JS/TS erleichtern sollen. Diese Bibliotheken unterstützen das Erstellen von Repositories, das Hochladen von Dateien, den Aufruf der Inferenz von über 100.000 Modellen (einschließlich Chat-Vervollständigung, Text-zu-Bild usw.), die Verwendung des MCP-Clients zum Erstellen von Agenten und unterstützen verschiedene Inferenzanbieter (Quelle: GitHub Trending)
Jan AI lokale Laufzeitumgebung auf Apache 2.0 Lizenz aktualisiert, senkt Hürde für Unternehmenseinsatz: Jan AI, ein Open-Source-Tool, das die lokale Ausführung von LLMs unterstützt, hat kürzlich seine Lizenz von AGPL auf die freizügigere Apache 2.0 Lizenz geändert. Dieser Schritt soll es Unternehmen und Teams erleichtern, Jan innerhalb ihrer Organisationen bereitzustellen und zu nutzen, ohne sich um Compliance-Probleme im Zusammenhang mit AGPL sorgen zu müssen. Sie können Jan frei forken, modifizieren und veröffentlichen, was die breite Akzeptanz von Jan in realen Produktionsumgebungen fördern soll (Quelle: reach_vb, Reddit r/LocalLLaMA)
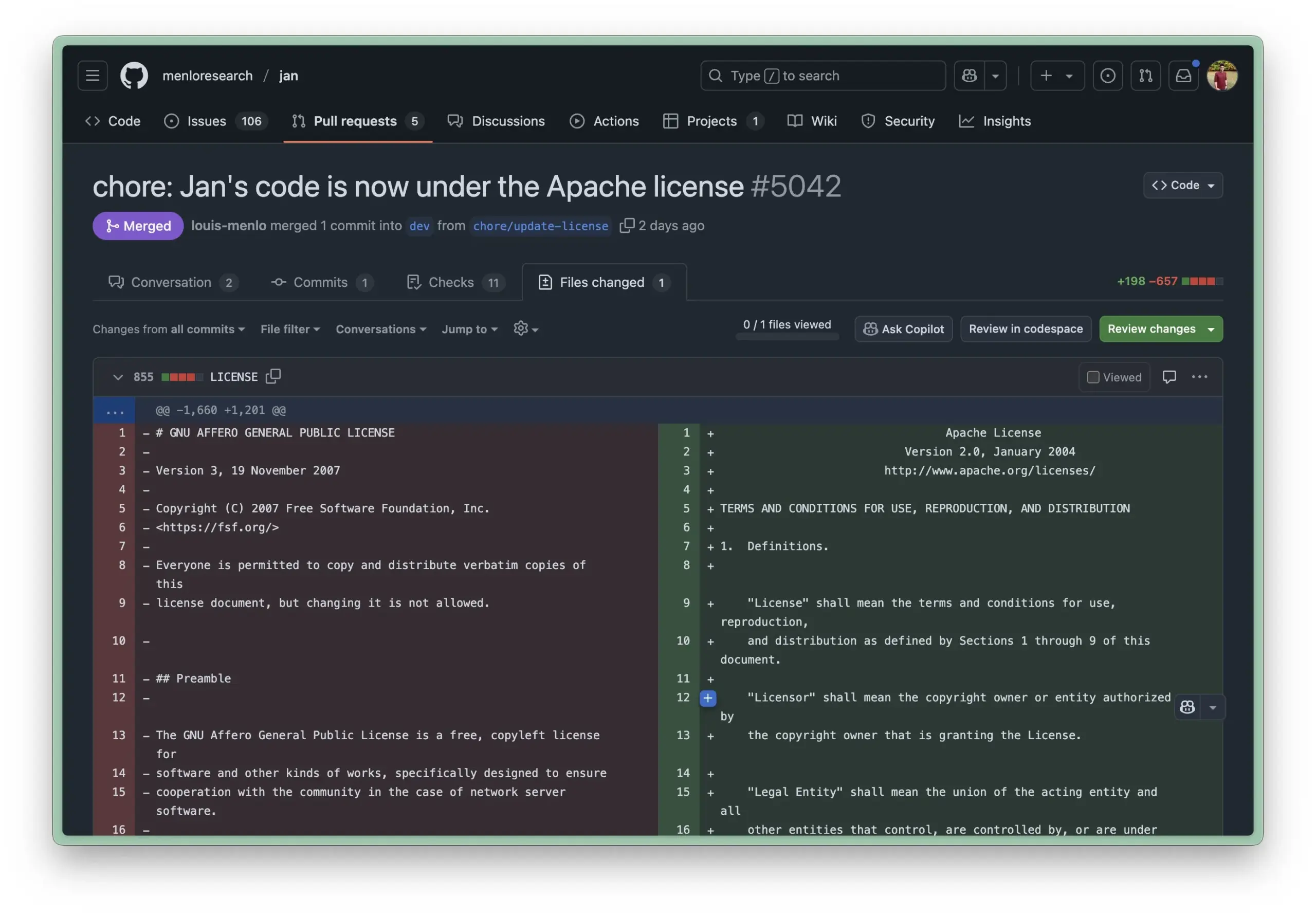
Obsidian führt Bases Core-Plugin ein, ermöglicht datenbankähnliche Verwaltung von Notizen: Die Wissensmanagement-Software Obsidian hat ihr Core-Plugin Bases aktualisiert, das es Benutzern ermöglicht, Notizsammlungen in leistungsstarke Datenbanken umzuwandeln. Mit Bases können Benutzer benutzerdefinierte Tabellenansichten erstellen, um Daten in ihrer Wissensdatenbank visuell und interaktiv zu bearbeiten. Es unterstützt das Filtern von Notizen nach Eigenschaften und das Erstellen von Formeln zur Ableitung dynamischer Eigenschaften, was für Projektmanagement, Reiseplanung, Leselisten und viele andere Szenarien geeignet ist. Die Funktion ist derzeit für Early-Access-Benutzer verfügbar (Quelle: op7418)
Hugging Face stellt Tiny Agents vor, vereinfacht die Steuerung von Browsern und Dateioperationen durch lokale Modelle: Hugging Face hat in seinem MCP-Kurs Tiny Agents vorgestellt, ein einfach zu bedienendes Framework zur Einrichtung der Browsersteuerung. Benutzer können durch Kommandozeilenbefehle, JSON-Konfiguration und Prompts lokal laufende LLMs (über OpenAI-kompatible Server) dazu bringen, Browser (wie Playwright) oder lokale Dateisysteme zu steuern, ohne direkte API-Aufrufe. Dies erleichtert die Anwendung von Agenten für lokale Modelle wie llama.cpp (Quelle: Reddit r/LocalLLaMA)

Entwickler veröffentlicht Open-Source-Anwendung zur KI-Lebenslaufoptimierung, basierend auf LangChain und Ollama: Ein Entwickler hat eine KI-gesteuerte Anwendung zur Lebenslaufoptimierung erstellt und als Open Source veröffentlicht. Nachdem der Benutzer seinen aktuellen Lebenslauf und die Stellenbeschreibung hochgeladen hat, versucht die Anwendung, die Schlüsselwörter im Lebenslauf anzupassen, um ihn besser auf die Anforderungen der Stelle abzustimmen. Das Backend des Projekts verwendet LangChain, kombiniert BM25 Sparse Retrieval und Dense Models für hybrides Retrieval, das Sprachmodell läuft lokal über Ollama, und das Frontend verwendet React. Das Projekt befindet sich derzeit in der Proof-of-Concept-Phase, der Code ist auf GitHub verfügbar (Quelle: Reddit r/deeplearning)
Lovable Anwendungsbaukasten erweitert Bildverarbeitungsfähigkeiten: Der KI-Anwendungsbaukasten Lovable hat Verbesserungen seiner Bildverarbeitungsfunktionen angekündigt. Benutzer können jetzt Bilder in den Chat hochladen und Lovable anweisen, diese Bildmaterialien in der Anwendung zu verwenden, was die Benutzererfahrung beim Erstellen von Anwendungen mit visuellen Elementen mit KI-Unterstützung verbessert (Quelle: op7418)
Helios: Erste Plattform, die versucht, Regierungsarbeit mit KI zu beschleunigen: Joe Scheidler hat Helios vorgestellt, eine Plattform, die darauf abzielt, die Effizienz der Regierungsarbeit mithilfe von KI zu steigern, und die als „Cursor für die Regierung“ beschrieben wird. Diese Plattform ist einer der ersten expliziten Versuche, die auf Regierungsbehörden abzielen und versuchen, deren Arbeitsabläufe und Effizienz durch KI-Technologie zu optimieren. Konkrete Funktionen und Anwendungsszenarien bleiben abzuwarten (Quelle: timsoret)
📚 Lernen
Zhejiang Universität veröffentlicht Lehrbuch „Grundlagen Großer Modelle“, erklärt systematisch LLM-Wissen und wird kontinuierlich aktualisiert: Das LLM-Team der Zhejiang Universität hat das Lehrbuch „Grundlagen Großer Modelle“ als Open Source veröffentlicht, um Lesern, die an großen Sprachmodellen interessiert sind, systematisches Grundlagenwissen und aktuelle Technologieeinführungen zu bieten. Das Buch behandelt traditionelle Sprachmodelle, die Entwicklung der LLM-Architektur, Prompt Engineering, parametereffizientes Fine-Tuning, Modellbearbeitung, Retrieval Augmented Generation usw. und wird monatlich aktualisiert. Jedes Kapitel ist mit einer entsprechenden Paper-Liste versehen, um die neuesten Fortschritte zu verfolgen. Das vollständige PDF sowie kapitelweise Inhalte wurden auf GitHub veröffentlicht (Quelle: GitHub Trending)

Hugging Face bietet 10 kostenlose KI-Kurse an, die verschiedene Ebenen und Bereiche abdecken: Hugging Face hat 10 kostenlose KI-Kurse zusammengestellt, die auf seiner Plattform angeboten werden. Die Inhalte reichen von Einsteiger- bis zu Fortgeschrittenenkursen und decken verschiedene populäre KI-Themen ab, darunter natürliche Sprachverarbeitung, Deep Learning, Reinforcement Learning, Audioverarbeitung, Multimodalität usw. Diese Kurse bieten Lernenden unterschiedlichen Niveaus wertvolle Ressourcen für das systematische Erlernen von KI-Wissen und fördern weiterhin die Popularisierung von KI-Wissen und die Entwicklung der Open-Source-Community (Quelle: huggingface, reach_vb, _akhaliq)

Stanford University teilt Erfahrungen und Lehren aus dem Training des Marin 8B Modells: Das Team von Percy Liang an der Stanford University hat einen detaillierten Rückblick auf das Training des Marin 8B Modells von Grund auf veröffentlicht (das das Llama 3.1 8B Basismodell in mehreren Benchmarks übertrifft). Dieser ehrliche Bericht enthält alle Erkenntnisse und Fehler, die das Team während des Entwicklungsprozesses gemacht hat, und liefert der Community wertvolle, reale Erfahrungen beim Aufbau von LLMs. Er betont die Bedeutung von Versuch und Irrtum sowie Iteration im Forschungsprozess (Quelle: stanfordnlp, YejinChoinka, hrishioa)
DeepLearning.AI und Predibase kooperieren für LLM-Kurs zu Reinforcement Fine-Tuning (RFT): Andrew Ngs DeepLearning.AI hat in Zusammenarbeit mit Predibase einen kostenlosen Kurzkurs zur Leistungssteigerung von LLMs mittels Reinforcement Fine-Tuning (RFT) unter Verwendung von GRPO (Group Relative Policy Optimization) gestartet. Der Kurs wird unter anderem von Travis Addair, Mitbegründer und CTO von Predibase, geleitet und soll Lernenden vermitteln, wie sie mit Reinforcement Learning und nur wenigen annotierten Daten kleine Open-Source-LLMs in aufgabenspezifische Inferenz-Engines verwandeln können (Quelle: DeepLearningAI)
Hugging Face Paper-Seite fügt KI-generierte Zusammenfassungsfunktion hinzu: Hugging Face hat auf seiner Paper-Anzeigeseite eine neue Funktion eingeführt, die für jedes Paper eine von KI generierte einzeilige Zusammenfassung bereitstellt. Diese Zusammenfassung soll den Kerninhalt des Papers prägnant zusammenfassen und Benutzern helfen, Forschungsliteratur schnell zu sichten und zu verstehen, wodurch die Zugänglichkeit und Nutzungseffizienz akademischer Ressourcen verbessert wird. Diese Funktion wird von einem Open-Source-LLM betrieben und verkörpert die Idee „KI ermöglicht KI-Forschung“ (Quelle: _akhaliq, _akhaliq, _akhaliq, _akhaliq, huggingface)

Qdrant, SambaNova etc. präsentieren gemeinsam Lösung zum schnellen Aufbau von Multi-Dokumenten-RAG-Systemen: Ein technischer Blogbeitrag beschreibt, wie man mit der Qdrant Vektordatenbank, SambaNova, DeepSeek-R1 und LangGraph ein schnelles, speichereffizientes Multi-Dokumenten Retrieval Augmented Generation (RAG)-System aufbaut. Diese Lösung erreicht durch binäre Quantisierung eine 32-fache Speicherersparnis, nutzt DeepSeek-R1 für schnelle, konzentrierte LLM-Antworten und verwendet LangGraph für eine modulare Orchestrierung, geeignet für Szenarien der Verarbeitung großer Mengen von Multi-Dokumenten (Quelle: qdrant_engine)
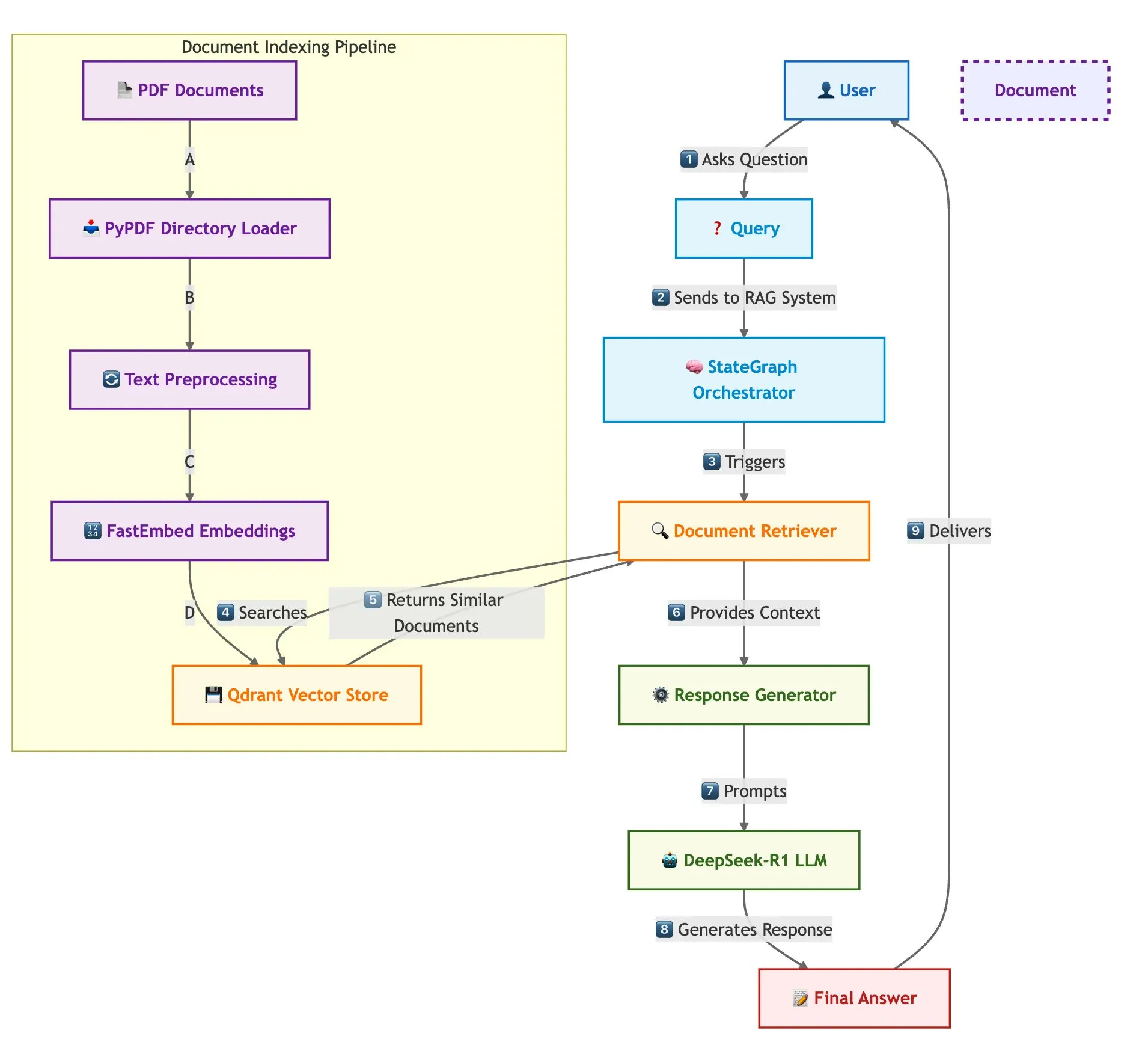
LangChain Interrupt 2025 Gipfelrückblick (Mandarin-Version) veröffentlicht: Der Rückblick auf den LangChain Interrupt 2025 Gipfel in Mandarin-Version wurde veröffentlicht. An diesem Gipfel nahmen weltweit über 800 Personen teil, die Erfahrungen und Zukunftsaussichten zum Aufbau von KI-Agenten austauschten. Es wurden mehrere Produkte angekündigt, darunter die LangGraph Platform und LangGraph Studio v2, und Themen wie Agenten-Engineering und KI-Beobachtbarkeit diskutiert (Quelle: hwchase17)
Andi Marafioti veröffentlicht nanoVLM-Tutorial, das schrittweise das Training eines Vision Language Modells mit reinem PyTorch erklärt: Andi Marafioti hat ein neues Blog-Tutorial namens nanoVLM veröffentlicht, das detailliert beschreibt, wie man mit reinem PyTorch von Grund auf sein eigenes Vision Language Model (VLM) trainiert. Das Tutorial ist leicht verständlich und zugänglich gestaltet, um Anfängern zu helfen, den Trainingsprozess von VLMs schnell zu meistern (Quelle: LoubnaBenAllal1)

Ferenc Huszár erläutert kontinuierliche Markov-Ketten und ihre Anwendung in Diffusions-Sprachmodellen: Der Deep-Learning-Forscher Ferenc Huszár hat einen Blogbeitrag veröffentlicht, der die Intuition hinter kontinuierlichen Markov-Ketten (CTMCs) anschaulich erklärt. Diese sind ein wichtiger Bestandteil von Diffusions-Sprachmodellen (DLMs) wie Mercury und Gemini Diffusion. Der Artikel untersucht verschiedene Perspektiven auf Markov-Ketten und ihre Verbindung zu Punktprozessen und liefert wertvolle Referenzen zum Verständnis der theoretischen Grundlagen von DLMs (Quelle: fhuszar)
💼 Wirtschaft
„Künstliche KI“-Firma Builder.ai meldet Insolvenz an, hatte fast 500 Millionen US-Dollar eingesammelt: Das britische Unternehmen Builder.ai (ehemals Engineer.ai), das einst behauptete, die Softwareentwicklung mit KI zu revolutionieren und eine Bewertung von bis zu 1 Milliarde US-Dollar erreichte, hat diese Woche Insolvenz angemeldet. Dem Unternehmen wurde vorgeworfen, dass viele Funktionen seiner KI-Plattform tatsächlich von indischen Ingenieuren manuell ausgeführt wurden. Trotz Finanzierungen in Höhe von fast 500 Millionen US-Dollar von namhaften Investoren wie Microsoft und SoftBank DeepCore gingen dem Unternehmen aufgrund von Zweifeln an der Echtheit der Technologie, chaotischem Finanzmanagement und Rechtsstreitigkeiten des Gründers schließlich die Mittel aus. Zudem schuldet es Microsoft 30 Millionen US-Dollar und Amazon 85 Millionen US-Dollar für Cloud-Dienste (Quelle: 36氪)

LMArena.ai (ehemals LMSys) erhält 100 Millionen US-Dollar Seed-Finanzierung, von Gradio-Anwendung zur Kommerzialisierung: LMArena.ai, ursprünglich ein akademisches Projekt namens LMSys (für LLM-Wettbewerbe und -Bewertungen) basierend auf Gradio, gab eine Seed-Finanzierungsrunde in Höhe von 100 Millionen US-Dollar bekannt, angeführt von a16z und der Investmentgesellschaft der University of California. Diese Finanzierungsrunde wird LMArena dabei unterstützen, seine Forschung im Bereich zuverlässiger KI und den Betrieb seiner Plattform fortzusetzen, und markiert den Wandel eines erfolgreichen Open-Source-Akademikerprojekts zur kommerziellen Nutzung. Dies unterstreicht auch das Potenzial von Rapid-Prototyping-Tools wie Gradio bei der Inkubation einflussreicher KI-Projekte (Quelle: ClementDelangue, _akhaliq, clefourrier)
Wettlauf um KI-Talente verschärft sich, OpenAI, Google etc. bieten Millionen-Jahresgehälter: Der Wettbewerb um Talente im KI-Bereich im Silicon Valley hat sich verschärft. Spitzenforscher (IC) sind zu den Kernressourcen geworden, um die Giganten wie OpenAI, Google und xAI konkurrieren, wobei Jahresgehälter plus Aktienoptionen üblicherweise über zehn Millionen US-Dollar liegen. Beispielsweise bot OpenAI einem erfahrenen Forscher, der zu SSI wechseln wollte, einen Bonus von 2 Millionen US-Dollar und Aktienoptionen im Wert von über 20 Millionen US-Dollar an, um ihn zu halten; Google DeepMind bietet Top-Talenten ebenfalls Jahresgehälter von 20 Millionen US-Dollar. Dieser intensive Wettbewerb rührt von dem enormen Beitrag einiger weniger Kernkräfte zur Entwicklung großer Sprachmodelle her, deren Verbleib den Erfolg oder Misserfolg von KI-Modellen direkt beeinflussen kann (Quelle: 36氪)
🌟 Community
Soras chinesische Sprachfähigkeiten scheinen sich verbessert zu haben, aber Modellbeschränkungen bestehen weiterhin: Social-Media-Nutzer haben beobachtet, dass OpenAIs Videogenerierungsmodell Sora Fortschritte bei der Verarbeitung von chinesischem Text zu machen scheint und Szenen mit chinesischen Schriftzeichen generieren kann. Nutzer wiesen jedoch auch darauf hin, dass das Modell immer noch seine Grenzen hat und die generierten Inhalte nicht perfekt sind. Diese Unvollkommenheit zu akzeptieren, könnte in der aktuellen Phase eine normale Art der Interaktion mit KI-Modellen sein (Quelle: dotey)

Gemini führt „Prüfungs“-Funktion für Tiefenberichte ein, unterstützt Wissenswiederverwendung und Lernkreislauf: Google Gemini hat eine neue Funktion eingeführt: Nach dem Lesen eines Tiefenberichts kann Gemini direkt Testfragen stellen. Diese Funktion zielt darauf ab, das tatsächliche Verständnis des Inhalts durch den Benutzer zu überprüfen und einen KI-nativen Lernkreislauf aus „Lernen → Prüfen → Ergänzen → Weiterlernen“ aufzubauen. Sie betont, dass im KI-Zeitalter der Kern des Lernens in der Fähigkeit zur Wiederverwendung von Wissen und nicht in der Lesemenge liegt (Quelle: dotey)
ChatGPT-Gedächtnisfunktion löst bei Nutzern Bedenken hinsichtlich der Kontrolle aus: Die neu eingeführte Funktion „Aus Chats lernen und sich erinnern“ von ChatGPT ermöglicht es dem Modell, sich Informationen aus früheren Gesprächen des Nutzers zu merken, um in nachfolgenden Interaktionen personalisiertere Antworten zu geben. Einige fortgeschrittene Nutzer äußerten jedoch Bedenken, dass dies die Art und Weise der Interaktion mit dem Modell verändere. Sie bevorzugen die vollständige Kontrolle über die Eingabeinhalte des Modells und möchten nicht, dass das Modell historische Informationen ohne ihr Wissen oder ihre präzise Kontrolle verwendet (Quelle: random_walker)
KI-Agenten entwickeln sich rasant, zukünftige Arbeitsmodelle könnten sich ändern: Die Community diskutiert intensiv die schnelle Entwicklung von KI-Agenten und deren potenzielle Auswirkungen auf zukünftige Arbeitsmodelle. Es wird argumentiert, dass sich KI-Agenten von einfachen Frage-Antwort-Tools zu „virtuellen Mitarbeitern“ entwickeln, die komplexe Aufgaben wie Codierung, Forschung und Kundensupport selbstständig erledigen können. OpenAI CPO Kevin Weil erwartet, dass die Fähigkeiten von KI-Agenten schnell zunehmen und sich innerhalb eines Jahres vom Niveau eines Junior-Ingenieurs zum Niveau eines Architekten entwickeln werden. Auch Microsoft hat die Vision eines „Agenten-Netzwerks“ vorgestellt, was darauf hindeutet, dass sich die zukünftige Arbeit möglicherweise um die Verwaltung und Orchestrierung von KI-Agenten drehen wird (Quelle: rowancheung, 量子位)
KI birgt enormes Potenzial in der medizinischen Diagnostik, löst aber Berufssorgen bei Ärzten aus: KI zeigt erstaunliche Fähigkeiten in der medizinischen Diagnostik. So soll beispielsweise das o1-preview-Modell in medizinischen Schlussfolgerungs- und Diagnoseaufgaben übermenschliche Leistungen erbracht haben, und Fälle, in denen KI Lungenentzündungen in Sekundenschnelle erkannte, erregten Aufmerksamkeit. Dies macht KI-gestützte Diagnostik zu einem heißen Thema, lässt aber auch einige Ärzte mit 20 Jahren Berufserfahrung um ihre berufliche Zukunft bangen, sodass sie sogar scherzhaft erwägen, bei McDonald’s zu arbeiten. Die Community diskutiert, dass KI eher als Werkzeug zur Effizienz- und Genauigkeitssteigerung für Ärzte betrachtet werden sollte, anstatt sie vollständig zu ersetzen (Quelle: paul_cal, Reddit r/ArtificialInteligence)
Nachrichtenverlage werfen Googles KI-Suchmodus „Diebstahl“ vor: Verlage wie die News Media Alliance äußerten starke Unzufriedenheit mit Googles neuem KI-Suchmodus und bezeichneten ihn als „Diebstahl“. Sie argumentieren, dass Googles KI Informationen direkt aus Nachrichteninhalten extrahiert und in Suchergebnisse integriert, wodurch Nachrichten-Websites umgangen und die Besucherzahlen und Werbeeinnahmen der Verlage geschädigt werden. Dies löste eine hitzige Debatte über Urheberrecht und faire Nutzung von Inhalten im KI-Zeitalter aus (Quelle: Reddit r/artificial)
DeepSeek-Modell wird in China für traditionelle Wahrsagerei verwendet und löst Diskussion über Grenzen der KI-Anwendung aus: Nutzer haben festgestellt, dass ein Großteil des Traffics des DeepSeek-Modells in China darauf zurückzuführen ist, dass Nutzer es für traditionelle Wahrsagerei wie das I Ging verwenden. Dieses Phänomen löste eine Diskussion über die Grenzen der KI-Anwendung und kulturelle Anpassungsfähigkeit aus und spiegelt indirekt die vielfältige Erforschung und Nachfrage der Nutzer nach KI-Fähigkeiten wider (Quelle: menhguin, cto_junior)

💡 Sonstiges
Humanoider Roboter der Firma Figure absolviert 20-stündige Dauerschicht an BMW-Produktionslinie: Das Unternehmen für humanoide Roboter Figure gab bekannt, dass sein Roboter an einer BMW X3-Produktionslinie erfolgreich eine 20-stündige Dauerschicht absolviert hat. Zuvor hatte der Roboter bereits wochenlange Tests mit 10-Stunden-Schichten durchgeführt. Laut Figure ist dies das weltweit erste Mal, dass ein humanoider Roboter eine so lange ununterbrochene Arbeit an einer Automobilproduktionslinie verrichtet hat, was sein Potenzial im Bereich der industriellen Automatisierung demonstriert (Quelle: adcock_brett, TheRundownAI)
Unterschied und Verbindung zwischen Agentic AI und GenAI: Die Community diskutierte die Konzepte von Agentic AI (Agenten-KI) und Generative AI (Generativer KI). Generative KI bezieht sich hauptsächlich auf KI, die neue Inhalte (Text, Bilder, Code usw.) erstellen kann, während Agenten-KI stärker Autonomie, Zielorientierung und die Fähigkeit zur Interaktion mit der Umgebung betont. Agenten-KI nutzt typischerweise generative KI als eine ihrer Kernfähigkeiten, um Aufgaben zu verstehen, zu planen und auszuführen, und ist eine wichtige Richtung für die Entwicklung von KI hin zu fortgeschrittenerer autonomer Intelligenz (Quelle: Ronald_vanLoon, Ronald_vanLoon)

Anwendung von KI in der wissenschaftlichen Forschung wird unterschätzt, es gibt ein Phänomen des „Beschönigens von Ergebnissen“: In der Community wird diskutiert, dass das Potenzial der KI-Anwendung in der wissenschaftlichen Forschung zwar enorm ist, aber möglicherweise unterschätzt wird. Gleichzeitig gibt es das Phänomen, dass Forscher KI-Experimentierergebnisse „beschönigen“, um Veröffentlichungen zu erzielen. Beispielsweise könnte die tatsächliche Leistung von KI in Bereichen wie partiellen Differentialgleichungen (PDEs) nicht so herausragend sein, wie in den Veröffentlichungen dargestellt. Dies weist darauf hin, dass die wissenschaftliche Gemeinschaft die tatsächliche Rolle und die Grenzen von KI bei wissenschaftlichen Entdeckungen strenger und transparenter bewerten muss (Quelle: clefourrier)