
Schlüsselwörter:GPT-5, KI-Selbstverbesserung, verkörperte Intelligenz, multimodales Modell, großes Sprachmodell, Verstärkungslernen, KI-Agent, Leistungssteigerung von GPT-5, Genie Envisioner Roboterplattform, LLM-Rekrutierungsbewertungsvoreingenommenheit, Qwen3 ultra-langer Kontext, CompassVerifier Antwortvalidierung
🔥 Fokus
GPT-5-Veröffentlichung: Produktisierung und Leistungssteigerung : OpenAI hat offiziell GPT-5 vorgestellt, die neueste Iteration seines Flaggschiff-Modells. Der Fokus dieser Veröffentlichung liegt auf der Verbesserung des Nutzererlebnisses durch automatische Echtzeit-Planung von Basismodellen und Deep-Inferenzmodellen über Router, um ein Gleichgewicht zwischen Geschwindigkeit und Intelligenz zu erreichen. GPT-5 zeigt signifikante Verbesserungen bei der Reduzierung von Halluzinationen, der Befolgung von Anweisungen und den Programmierfähigkeiten und hat in mehreren Benchmarks neue Rekorde aufgestellt. Sam Altman vergleicht es mit einem „Retina-Display“ und betont dessen Praktikabilität als „Doktoranden-Niveau-KI“ und nicht nur einen Durchbruch der Intelligenzgrenze. Obwohl es technisch noch nicht AGI erreicht hat, dürften seine schnelleren Inferenzgeschwindigkeiten und niedrigeren Betriebskosten die breite Anwendung von KI vorantreiben. (Quelle: MIT Technology Review)

Fortschritte in der KI-Selbstverbesserungsforschung : Meta CEO Mark Zuckerberg gab bekannt, dass das Unternehmen daran arbeitet, KI-Systeme aufzubauen, die sich selbst verbessern können. KI hat bereits in verschiedenen Bereichen die Fähigkeit zur Selbstverbesserung gezeigt, beispielsweise durch automatische Datenaugmentation, Modellarchitektursuche, Reinforcement Learning und andere Methoden, um kontinuierlich ihre eigene Leistung zu optimieren. Dieser Trend deutet darauf hin, dass KI-Systeme in Zukunft autonom lernen und die von Menschen gesetzten Leistungsgrenzen überschreiten können, was ein entscheidender Weg zur Erreichung höherer KI-Niveaus ist. (Quelle: MIT Technology Review)

Genie Envisioner: Einheitliche Welt-Grundlagenplattform für Roboter-Manipulation : Forscher stellen Genie Envisioner (GE) vor, eine einheitliche Welt-Grundlagenplattform für die Roboter-Manipulation. GE-Base ist ein instruktionsbedingtes Video-Diffusionsmodell, das die räumlichen, zeitlichen und semantischen Dynamiken realer Roboterinteraktionen erfassen kann. GE-Act bildet latente Repräsentationen auf ausführbare Aktionspfade ab, um präzise und allgemeine Strategie-Inferenz zu ermöglichen. GE-Sim dient als aktionsbedingter neuronaler Simulator, der die Entwicklung von Closed-Loop-Strategien unterstützt. Diese Plattform dürfte eine skalierbare und praktische Grundlage für instruktionsgesteuerte, allgemeine verkörperte Intelligenz bieten. (Quelle: HuggingFace Daily Papers)
ISEval: Bewertungsframework für die Fähigkeit großer multimodaler Modelle, Fehleingaben zu erkennen : Zur Beantwortung der Frage, ob Large Multimodal Models (LMMs) Fehleingaben proaktiv erkennen können, wurde das Bewertungsframework ISEval vorgestellt. Dieses Framework umfasst sieben Kategorien von fehlerhaften Prämissen und drei Bewertungsmetriken. Die Studie ergab, dass die meisten LMMs ohne explizite Anleitung Schwierigkeiten haben, Textfehler proaktiv zu erkennen, und bei verschiedenen Fehlertypen unterschiedliche Leistungen zeigen. Sie sind beispielsweise gut darin, logische Fehlschlüsse zu erkennen, zeigen aber bei oberflächlichen Sprachfehlern und spezifischen Bedingungsfehlern Schwächen. Dies unterstreicht den dringenden Bedarf an LMMs, die die Eingabegültigkeit proaktiv validieren können. (Quelle: HuggingFace Daily Papers)
Studie zu Sprachverzerrungen in LLM-Rekrutierungsbewertungen : Eine Studie führte einen Benchmark ein, um die Reaktion von Large Language Models (LLMs) auf sprachlich diskriminierende Markierungen in der Personalbeschaffungsbewertung zu bewerten. Durch sorgfältig konzipierte Interviewsimulationen ergab die Studie, dass LLMs systematisch bestimmte Sprachmuster bestrafen, insbesondere vage Sprache, selbst wenn die Inhaltsqualität identisch ist. Dies offenbart demografische Verzerrungen in automatisierten Bewertungssystemen und bietet einen grundlegenden Rahmen für die Erkennung und Messung von Sprachdiskriminierung in KI-Systemen, mit breiten Anwendungen für die Fairness automatisierter Entscheidungen. (Quelle: HuggingFace Daily Papers)
🎯 Trends
Qwen3-Modellreihe unterstützt Millionen-Token-Kontextlänge : Die Modelle Alibaba Cloud Qwen3-30B-A3B-2507 und Qwen3-235B-A22B-2507 unterstützen nun einen extrem langen Kontext von bis zu 1 Million Tokens. Dies ist dank der Dual Chunk Attention (DCA) und MInference Sparse Attention-Technologie möglich, die nicht nur die Generierungsqualität verbesserte, sondern auch die Inferenzgeschwindigkeit von Sequenzen mit fast einer Million Tokens um das Dreifache beschleunigte. Dies erweitert das Anwendungspotenzial von LLM erheblich bei der Verarbeitung komplexer Aufgaben wie langer Dokumente und Codebasen und ist kompatibel mit vLLM und SGLang für eine effiziente Bereitstellung. (Quelle: Alibaba_Qwen)

Anthropic Claude Opus 4.1 und Sonnet 4 Upgrades : Anthropic hat Claude Opus 4.1 und Sonnet 4 veröffentlicht, die sich auf die Verbesserung von Agentic-Aufgaben, realer Codierung und Inferenzfähigkeiten konzentrieren. Die neuen Modelle verfügen über eine „Deep Thinking“-Funktion, die einen flexiblen Wechsel zwischen Sofortantwort- und Deep-Reasoning-Modi ermöglicht und komplexe Aufgaben, die Stunden dauern würden, auf Minuten komprimiert. Dies stärkt die Positionierung von Claude weiter in Szenarien der Multimodell-Zusammenarbeit, insbesondere bei komplexen Code-Reviews und fortgeschrittenen Inferenzaufgaben. (Quelle: dl_weekly)
Microsoft führt Copilot 3D-Funktion ein : Microsoft hat die kostenlose Copilot 3D-Funktion eingeführt, die 2D-Bilder in 3D-Modelle im GLB-Format umwandeln kann, kompatibel mit verschiedenen 3D-Viewern, Design-Tools und Game Engines. Obwohl die Ergebnisse bei Tier- und Menschenbildern derzeit nicht optimal sind, bietet die Funktion den Nutzern eine bequeme 2D-zu-3D-Konvertierungsfähigkeit und dürfte in Bereichen wie Produktdesign und Virtual Reality eine Rolle spielen, wodurch die Hürde für die Erstellung von 3D-Inhalten weiter gesenkt wird. (Quelle: The Verge)
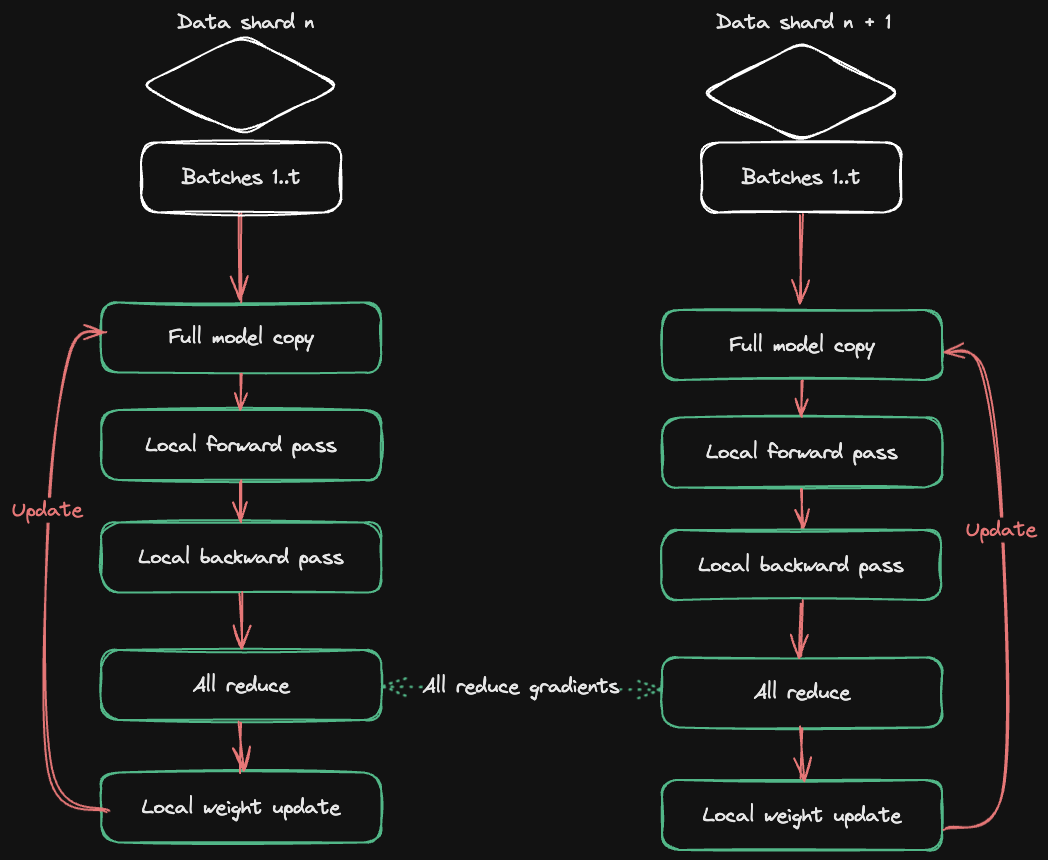
HuggingFace Accelerate veröffentlicht Multi-GPU-Trainingsleitfaden : HuggingFace hat in Zusammenarbeit mit Axolotl den Accelerate ND-Parallel-Leitfaden veröffentlicht, der darauf abzielt, die Kombination und Anwendung von Parallelisierungsstrategien im Multi-GPU-Training zu vereinfachen. Der Leitfaden beschreibt detailliert Strategien wie Data Parallel (DP), Sharded Data Parallel (FSDP), Tensor Parallel (TP) und Context Parallel (CP) und bietet Beispiele für gemischte Parallelisierungskonfigurationen, um Entwicklern zu helfen, die Speichernutzung und den Durchsatz beim Training großer Modelle zu optimieren und die Herausforderungen des Kommunikations-Overheads im Multi-Node-Training effektiv zu bewältigen. (Quelle: HuggingFace Blog)
🧰 Tools
OpenAI Codex CLI: Lokaler Coding Agent im Terminal : OpenAI hat Codex CLI veröffentlicht, ein leichtgewichtiger Coding Agent, der lokal im Terminal läuft. Nutzer können es über npm install -g @openai/codex oder brew install codex installieren. Es unterstützt die Verknüpfung mit ChatGPT Plus/Pro/Team-Konten für die kostenlose Nutzung der neuesten Modelle wie GPT-5 oder Pay-per-Use über einen API Key. Codex CLI bietet verschiedene Sandbox-Modi wie Lese-Schreib- und Nur-Lese-Modi und unterstützt benutzerdefinierte Konfigurationen. Ziel ist es, Entwicklern eine effiziente und sichere lokale Programmierunterstützung zu bieten. (Quelle: openai/codex – GitHub Trending)

HuggingFace AI Sheets: No-Code-Datensatz-Tool : HuggingFace hat AI Sheets vorgestellt, ein Open-Source-No-Code-Tool zum Erstellen, Anreichern und Transformieren von Datensätzen mithilfe von KI-Modellen. Die Benutzeroberfläche des Tools ähnelt einer Tabellenkalkulation und unterstützt die lokale Bereitstellung oder den Betrieb auf dem Hugging Face Hub. Nutzer können Tausende von offenen Modellen (einschließlich gpt-oss) für Modellvergleiche, Prompt-Optimierung, Datenbereinigung, Klassifizierung, Analyse und synthetische Datengenerierung nutzen, durch manuelle Bearbeitung und Like-Feedback die KI-generierten Ergebnisse iterativ verbessern und auf den Hub exportieren. (Quelle: HuggingFace Blog)

Google Agent Development Kit (ADK) und Beispiele : Google hat das Agent Development Kit (ADK) veröffentlicht, ein Open-Source-, Code-first-Python-Toolkit zum Erstellen, Bewerten und Bereitstellen komplexer AI Agenten. ADK unterstützt ein reichhaltiges Tool-Ökosystem, modulare Multi-Agenten-Systeme und ist flexibel einsetzbar. Seine Beispielbibliothek adk-samples bietet verschiedene Agentenbeispiele, von Konversations-Bots bis hin zu Multi-Agenten-Workflows, und zielt darauf ab, den Agenten-Entwicklungsprozess zu beschleunigen und ist in das A2A-Protokoll für die Kommunikation zwischen entfernten Agenten integriert. (Quelle: google/adk-python – GitHub Trending & google/adk-samples – GitHub Trending)
Qwen Code CLI: Kostenloses Code-Ausführungstool : Alibaba Cloud Qwen Code CLI bietet täglich 2000 kostenlose Code-Ausführungen und kann einfach über den Befehl npx @qwen-code/qwen-code@latest gestartet werden. Das Tool unterstützt Qwen OAuth und zielt darauf ab, Entwicklern eine bequeme und effiziente Erfahrung beim Schreiben und Testen von Code zu bieten. Das Qwen-Team gab an, das CLI-Tool und das Qwen-Coder-Modell kontinuierlich zu optimieren und strebt an, die Leistung von Claude Code zu erreichen, während es Open Source bleibt. (Quelle: Alibaba_Qwen)
📚 Lernen
OpenAI Python-Bibliothek-Update : Die offizielle OpenAI Python-Bibliothek bietet bequemen Zugriff auf die OpenAI REST API und unterstützt Python 3.8+. Die Bibliothek enthält Typdefinitionen für alle Anfrageparameter und Antwortfelder und bietet sowohl synchrone als auch asynchrone Clients. Die neuesten Updates umfassen Beta-Unterstützung für die Realtime API zum Aufbau von multimodalen Dialogerlebnissen mit geringer Latenz sowie detaillierte Erläuterungen zur Webhook-Validierung, Fehlerbehandlung, Anfrage-IDs und Wiederholungsmechanismen, was die Entwicklungseffizienz und Robustheit verbessert. (Quelle: openai/openai-python – GitHub Trending)
Ausgewählte Liste von AI Agenten : e2b-dev/awesome-ai-agents ist ein GitHub-Repository, das eine große Anzahl von Beispielen und Ressourcen für autonome KI-Agenten sammelt. Ziel dieser Liste ist es, Entwicklern eine zentralisierte Ressourcenbibliothek zur Verfügung zu stellen, um ihnen zu helfen, verschiedene Arten von KI-Agenten zu verstehen und zu lernen, die eine Vielzahl von Anwendungsszenarien abdecken, von einfach bis komplex, und ist ein wichtiges Lernmaterial für die Erforschung und den Aufbau von KI-Agenten. (Quelle: e2b-dev/awesome-ai-agents – GitHub Trending)
MeanFlow: Neues Paradigma für die Ein-Schritt-Generierung von Diffusionsmodellen : Science Space hat MeanFlow vorgestellt, eine neue Methode, die das Potenzial hat, zum Standard für die beschleunigte Generierung von Diffusionsmodellen zu werden. Die Methode zielt darauf ab, durch die Modellierung der „Durchschnittsgeschwindigkeit“ anstelle der „Momentangeschwindigkeit“ eine Ein-Schritt-Generierung zu ermöglichen und damit den Engpass der langsamen Generierungsgeschwindigkeit traditioneller Diffusionsmodelle zu überwinden. MeanFlow verfügt über klare mathematische Prinzipien, kann von Grund auf mit einem einzigen Ziel trainiert werden, und die Ein-Schritt-Generierung erreicht nahezu SOTA-Ergebnisse, was neue theoretische und praktische Richtungen für die Beschleunigung generativer KI-Modelle bietet. (Quelle: WeChat)

Optimierung des gesamten Lebenszyklus des KV Cache für lange Kontexte : Microsoft Research Asia teilte Optimierungspraktiken für den gesamten Lebenszyklus des KV Cache, die darauf abzielen, die Latenz- und Speicherherausforderungen bei der Inferenz von Large Language Models (LLMs) mit langem Kontext zu lösen. Durch den SCBench-Benchmark und die Einführung von Methoden wie MInference und RetrievalAttention wurde die Latenz in der Prefilling-Phase deutlich reduziert und der KV Cache-Speicherdruck gemildert. Die Studie betont systemweite, anfrageübergreifende Optimierungen und die Wiederverwendung von Prefix Caching und bietet Optimierungslösungen für die Skalierbarkeit und Wirtschaftlichkeit der LLM-Inferenz mit langem Kontext. (Quelle: WeChat)

Reinforcement Learning Framework FR3E verbessert die Explorationsfähigkeit von LLMs : ByteDance, MAP und die University of Manchester stellten gemeinsam FR3E (First Return, Entropy-Eliciting Explore) vor, ein völlig neues strukturiertes Explorationsframework, das darauf abzielt, das Problem der unzureichenden LLM-Exploration im Reinforcement Learning zu lösen. FR3E identifiziert Token mit hoher Unsicherheit in Inferenzpfaden, leitet eine diversifizierte Entfaltung an und rekonstruiert systematisch den LLM-Explorationsmechanismus, um ein dynamisches Gleichgewicht zwischen Exploitation und Exploration zu erreichen, und übertrifft bestehende Methoden bei mehreren mathematischen Inferenz-Benchmarks deutlich. (Quelle: WeChat)

Studie zur Korrelation zwischen Maximalwerten im Self-Attention-Mechanismus und Kontextverständnis : Eine neue Studie auf der ICML 2025 enthüllt, dass in den Query (Q)- und Key (K)-Repräsentationen des Self-Attention-Mechanismus von Large Language Models hochkonzentrierte Maximalwerte existieren, die für das Verständnis von Kontextwissen entscheidend sind. Die Studie ergab, dass dieses Phänomen in Modellen, die Rotationspositionskodierung (RoPE) verwenden, weit verbreitet ist und bereits in frühen Schichten auftritt. Die Zerstörung dieser Maximalwerte führt zu einem drastischen Leistungsabfall des Modells bei Aufgaben, die Kontextverständnis erfordern, und bietet neue Richtungen für das Design, die Optimierung und die Quantisierung von LLMs. (Quelle: WeChat)
C3 Benchmark: Chinesisch-Englischer zweisprachiger Sprachdialogmodell-Test-Benchmark : Die Peking-Universität und Tencent stellten gemeinsam C3 Benchmark vor, den ersten umfassenden zweisprachigen (Chinesisch-Englisch) Bewertungs-Benchmark, der komplexe Phänomene in gesprochenen Dialogmodellen wie Pausen, Polyphone, Homophone, Betonung, syntaktische Ambiguität und Polysemie untersucht. Der Benchmark umfasst 1079 reale Szenarien und 1586 Audio-Text-Paare und zielt darauf ab, die Schwachstellen aktueller Sprachdialogmodelle direkt anzugehen und deren Fortschritt beim Verständnis menschlicher Alltagsgespräche voranzutreiben. (Quelle: WeChat)
Chemma: Large Language Model für die organische chemische Synthese : Das AI for Science Team der Shanghai Jiao Tong University hat Chemma, das White Magnolia Chemical Synthesis Large Model, veröffentlicht, das erstmals ein chemisches Large Language Model zur Beschleunigung des gesamten organischen Syntheseprozesses eingesetzt. Chemma benötigt kein Quantencomputing und übertrifft allein auf der Grundlage des Verständnisses und der Inferenzfähigkeiten chemischen Wissens bestehende Bestleistungen bei Aufgaben wie Ein-Schritt-/Mehr-Schritt-Retrosynthese, Vorhersage von Ausbeute/Selektivität und Reaktionsoptimierung. Sein „Co-Chemist“-Mensch-Maschine-Kollaborations- und Active-Learning-Framework wurde bereits in realen Reaktionen erfolgreich validiert und bietet ein neues Paradigma für die chemische Entdeckung. (Quelle: WeChat)

Intern-Robotics: Shanghai AI Lab Full-Stack-Engine für verkörperte Intelligenz : Das Shanghai AI Lab hat die Full-Stack-Engine Intern-Robotics veröffentlicht, die darauf abzielt, den „ChatGPT-Moment“ im Bereich der verkörperten Intelligenz voranzutreiben. Diese Engine ist eine offene und gemeinsam genutzte Infrastruktur, die sich auf die Erreichung von Generalisierung in Bezug auf Körper, Szenarien und Aufgaben konzentriert und eine Erfolgsrate der Aufgaben betont, die sich 100% nähert. Das Team setzt sich dafür ein, durch die „Real to Sim to Real“-Technologieroute und Reinforcement Learning in der realen Welt das Problem des Datenmangels zu lösen, schrittweise Zero-Shot-Generalisierung zu erreichen und die praktische Anwendung von verkörperter Intelligenz zu beschleunigen. (Quelle: WeChat)

SQLM: KI-Self-Questioning-Framework zur Verbesserung der Inferenzfähigkeiten : Ein Team der Carnegie Mellon University hat SQLM vorgestellt, ein Self-Questioning-Framework, das keine externen Daten benötigt und die KI-Inferenzfähigkeiten durch Selbstbefragung verbessert. Das Framework umfasst zwei Rollen: den Proposer und den Solver, die beide durch Reinforcement Learning trainiert werden, um die erwartete Belohnung zu maximieren. SQLM verbesserte die Modellgenauigkeit bei arithmetischen, algebraischen und Programmieraufgaben erheblich und bietet einen skalierbaren, sich selbst erhaltenden Prozess für die Fähigkeitsverbesserung von Large Language Models in Ermangelung hochwertiger manuell annotierter Daten. (Quelle: WeChat)

CompassVerifier: KI-Antwortvalidierungsmodell und Benchmark-Set : Das Shanghai AI Lab und die Universität Macau haben gemeinsam das universelle Antwortvalidierungsmodell CompassVerifier und das Benchmark-Set VerifierBench veröffentlicht, die darauf abzielen, das Problem zu lösen, dass die Trainingsfähigkeiten großer Modelle sprunghaft ansteigen, die Fähigkeit zur Antwortvalidierung jedoch hinterherhinkt. CompassVerifier ist ein leichter und leistungsstarker, domänenübergreifender Universal-Verifier, optimiert auf Basis der Qwen-Modellreihe, der in der Lage ist, in Bereichen wie Mathematik, Wissen und wissenschaftlichem Denken eine Validierungsgenauigkeit zu erreichen, die über die von allgemeinen Large Models hinausgeht, und als Reinforcement Learning Reward Model dienen kann, um präzises Feedback für die iterative Optimierung von LLMs zu liefern. (Quelle: WeChat)

CoAct-1: Computer-Nutzungs-Agent mit Codierung als Aktion : Forscher stellen CoAct-1 vor, ein Multi-Agenten-System, das Codierung als erweiterte Aktion nutzt, um die Effizienz und Zuverlässigkeit von GUI-Operations-Agenten bei komplexen Aufgaben zu lösen. Der Orchestrator von CoAct-1 kann Unteraufgaben dynamisch an den GUI Operator oder Programmer Agent (der Python-/Bash-Skripte schreiben und ausführen kann) delegieren, wodurch ineffiziente GUI-Operationen umgangen werden. Die Methode erreichte eine SOTA-Erfolgsrate im OSWorld-Benchmark und verbesserte die Effizienz erheblich, was einen leistungsfähigeren Weg zur allgemeinen Computerautomatisierung bietet. (Quelle: HuggingFace Daily Papers)
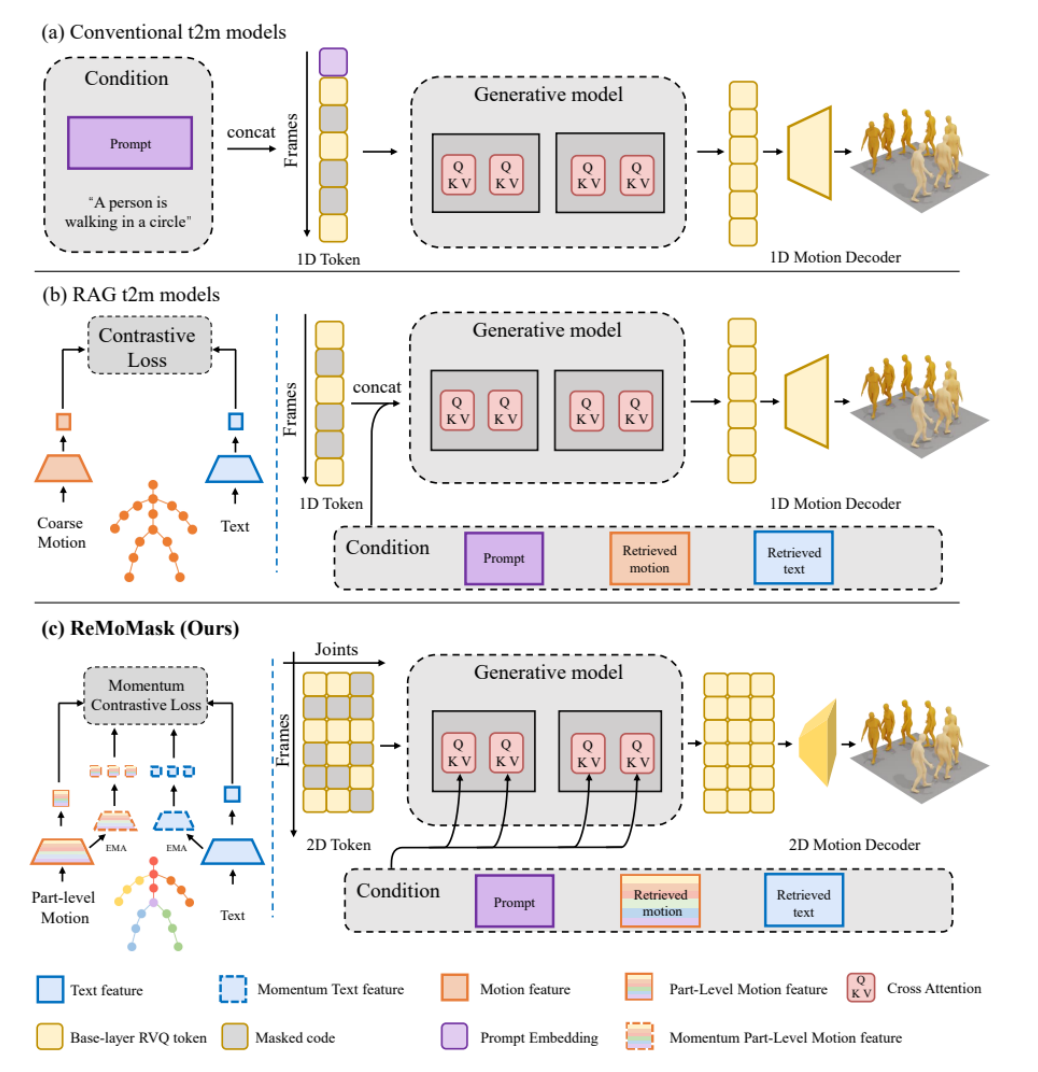
ReMoMask: Neue Methode zur Generierung hochwertiger 3D-Bewegungen für Spiele : Die Peking-Universität hat ReMoMask vorgestellt, ein Text-to-Motion-Framework, das auf Retrieval-Augmented Generation basiert und darauf abzielt, flüssige und realistische 3D-Bewegungen in hoher Qualität aus einer einzigen Anweisung zu generieren. ReMoMask integriert ein bidirektionales Text-zu-Bewegungsmodell mit Momentum, einen semantisch-räumlich-zeitlichen Aufmerksamkeitsmechanismus und RAG-Classifier-Free Guidance, um zeitlich kohärente Bewegungen effizient zu generieren. Die Methode hat die SOTA-Leistung auf Standard-Benchmarks wie HumanML3D und KIT-ML übertroffen und hat das Potenzial, die Prozesse der Spiele- und Animationsproduktion grundlegend zu verändern. (Quelle: WeChat)
WebAgents-Übersicht: Large Models befähigen Web-Automatisierung : Forscher der Hong Kong Polytechnic University veröffentlichten die erste WebAgents-Übersicht, die den Forschungsfortschritt bei der Befähigung von KI-Agenten durch Large Models zur Realisierung der nächsten Generation der Web-Automatisierung umfassend zusammenfasst. Die Übersicht fasst repräsentative Methoden von WebAgents aus den Perspektiven Architektur (Wahrnehmung, Planung & Inferenz, Ausführung), Training (Daten, Strategien) und Vertrauenswürdigkeit (Sicherheit, Datenschutz, Generalisierung) zusammen und erörtert zukünftige Forschungsrichtungen wie Fairness, Erklärbarkeit, Datensätze und personalisierte WebAgents, und bietet einen Leitfaden für den Aufbau intelligenterer und sichererer Web-Automatisierungssysteme. (Quelle: WeChat)

InfiAlign: LLM-Inferenzfähigkeits-Alignment-Framework : InfiAlign ist ein skalierbares und sample-effizientes Post-Training-Framework, das LLMs durch die Kombination von SFT und DPO ausrichtet, um die Inferenzfähigkeiten zu verbessern. Der Kern des Frameworks ist eine leistungsstarke Daten-Selektionspipeline, die automatisch hochwertige Ausrichtungsdaten aus Open-Source-Inferenzdatensätzen filtern kann. InfiAlign erreichte eine Leistung, die mit DeepSeek-R1-Distill-Qwen-7B vergleichbar ist, verwendete aber nur etwa 12% der Trainingsdaten und erzielte erhebliche Verbesserungen bei mathematischen Inferenzaufgaben, und bietet eine praktische Lösung für die Ausrichtung großer Inferenzmodelle. (Quelle: HuggingFace Daily Papers)
💼 Business
OpenAI-Mitarbeiter-Aktienoptions-Einlösungsprogramm zur Abwerbung von Talenten : Um dem Talentabfluss entgegenzuwirken, hat OpenAI ein neues Mitarbeiter-Aktienoptions-Einlösungsprogramm gestartet, das auf einer Bewertung von 500 Milliarden US-Dollar basiert und darauf abzielt, Talente durch finanzielle Anreize zu halten. Dieser Schritt dürfte die Bewertung von OpenAI auf ein neues Hoch treiben. Gleichzeitig erreichen die wöchentlich aktiven ChatGPT-Nutzer 700 Millionen, die Zahl der zahlenden Unternehmenskunden ist auf 5 Millionen gestiegen, und der jährliche wiederkehrende Umsatz wird voraussichtlich über 20 Milliarden US-Dollar liegen, was die positive Entwicklung von OpenAI in Bezug auf Produkte und Kommerzialisierung zeigt. (Quelle: 量子位)

Amazon Web Services baut größte KI-Modell-Aggregationsplattform auf : Amazon Web Services (AWS) gab bekannt, dass das gpt-oss-Modell von OpenAI erstmals über Amazon Bedrock und Amazon SageMaker zugänglich ist, was das Modell-Ökosystem unter seiner „Choice Matters“-Strategie weiter bereichert. AWS bietet nun über 400 gängige kommerzielle und Open-Source-Large-Models an, mit dem Ziel, Unternehmen die Wahl des am besten geeigneten Modells basierend auf Leistung, Kosten und Aufgabenanforderungen zu ermöglichen, anstatt ein einziges „stärkstes“ Modell zu verfolgen, und die Synergie mehrerer Modelle zu fördern. (Quelle: 量子位)

Ant Group investiert in Unternehmen für verkörperte intelligente Roboterhände : Ant Group führte eine Angel-Runde-Finanzierung in Höhe von mehreren hundert Millionen Yuan für das Unternehmen für verkörperte intelligente Roboterhände, Lingxin Qiaoshou, an. Lingxin Qiaoshou ist das weltweit einzige Unternehmen, das die Massenproduktion von Tausenden von hochgradig flexiblen Roboterhänden erreicht hat, mit einem Marktanteil von 80%. Seine Linker Hand-Serie von Roboterhänden verfügt über hohe Freiheitsgrade, Multisensorsysteme und Kostenvorteile und wurde bereits in Industrie- und Medizinbereichen eingesetzt. Die Finanzierung wird für den Aufbau von Technologiereserven und Datenerfassungsanlagen verwendet, um die Bereitstellung der Roboterhände in praktischen Anwendungen zu beschleunigen. (Quelle: 量子位)

🌟 Community
GPT-5 Nutzererfahrung polarisiert : Nach der Veröffentlichung von GPT-5 ist das Nutzerfeedback gemischt. Einige Nutzer loben die deutlichen Verbesserungen bei Programmier- und komplexen Inferenzaufgaben und finden, dass die Code-Generierung sauberer und präziser ist und die Fähigkeit zur Verarbeitung langer Kontexte extrem stark ist. Andere Nutzer äußerten sich jedoch enttäuscht über den Rückgang der Modellpersonalisierung, des kreativen Schreibens und der emotionalen Unterstützungsfähigkeiten und empfinden es als „langweilig“ und „seelenlos“, und der Modell-Routing-Mechanismus führt zu einer instabilen Erfahrung, wobei einige Nutzer sogar ihr Abonnement deswegen gekündigt haben. (Quelle: Reddit r/ChatGPT & Reddit r/LocalLLaMA & Reddit r/ChatGPT & Reddit r/ChatGPT)

KI in der Kindererziehung: Anwendungen und Kontroversen : Berufstätige Eltern nutzen KI-Tools wie ChatGPT als „Co-Eltern“, um Mahlzeiten zu planen, Schlafroutinen zu optimieren und sogar emotionale Unterstützung zu bieten. Der urteilsfreie Raum, den KI zum Reden bietet, entlastet Eltern psychisch. Diese aufstrebende Technologie löst jedoch auch Kontroversen aus, einschließlich des Risikos ungenauer Ratschläge, Datenschutzverletzungen (wie der ChatGPT-Datenleck-Vorfall) sowie der potenziellen Isolation menschlicher Beziehungen und Umweltauswirkungen durch übermäßige KI-Abhängigkeit. (Quelle: 36氪)
Airbnb-Vorfall: KI-gefälschte Bilder führen zu Nutzerentschädigung : Es gab einen Vorfall bei Airbnb, bei dem ein Vermieter KI-generierte Bilder nutzte, um Nutzer um Entschädigung zu betrügen, was die Risiken von KI im Kundenservice verdeutlicht. Der KI-Kundenservice konnte die KI-generierten Bilder nicht erkennen, was dazu führte, dass der Nutzer fälschlicherweise zur Zahlung von Entschädigung verurteilt wurde. Obwohl OpenAI zuvor Bilddetektoren eingeführt hatte, hat die KI-Erkennung von KI immer noch Grenzen, insbesondere angesichts der „partiellen Fälschung“-Technologie. Der Vorfall löste Bedenken hinsichtlich der Zuverlässigkeit von KI-Inhaltsdetektions-Tools und der Fähigkeit von C2C-Plattformen aus, mit dem Ansturm von Deepfake-Inhalten umzugehen. (Quelle: 36氪)

Silicon Valley KI-Größen bauen Weltuntergangsbunker und lösen Diskussionen aus : Es wurde bekannt, dass KI-Größen aus dem Silicon Valley wie Mark Zuckerberg und Sam Altman Weltuntergangsbunker bauen oder besitzen, was die öffentliche Besorgnis über die zukünftige Entwicklung und potenzielle Risiken von KI auslöste. Obwohl sie eine Verbindung zur KI leugnen, wird dieser Schritt dennoch als Vorsichtsmaßnahme gegen Notfälle wie Pandemien, Cyberkriege und Klimakatastrophen interpretiert. In der Community wird spekuliert, ob diejenigen, die die KI-Technologie am besten verstehen, Anzeichen sehen, die der Öffentlichkeit unbekannt sind, und ob die KI-Entwicklung bereits unvorhersehbare Risiken mit sich gebracht hat. (Quelle: 量子位)

Kaggle AI-Schachmeisterschaft: o3 gewinnt Titel : Im Finale der ersten Google Kaggle AI-Schachmeisterschaft besiegte o3 von OpenAI Grok 4 von Elon Musk mit 4:0 und gewann die Meisterschaft. Dieses Match wurde als „Stellvertreterkrieg“ zwischen OpenAI und xAI angesehen, der darauf abzielte, das kritische Denken, die strategische Planung und die spontane Reaktionsfähigkeit großer Modelle zu testen. Obwohl Grok 4 zuvor stark war, machte es im Finale häufig Fehler, während o3 eine systematisch stabile Strategie zeigte und während des gesamten Turniers keine einzige Partie verlor, und so zum ungeschlagenen Champion wurde. (Quelle: WeChat)

Diskussion: KI tritt in das „Tal der Enttäuschung“ ein : In den sozialen Medien gibt es zahlreiche Diskussionen, die besagen, dass KI offiziell das „Tal der Enttäuschung“ erreicht hat, insbesondere nach der Veröffentlichung von GPT-5. Nutzer weisen darauf hin, dass die Grenzen der KI nicht effektiv durchbrochen wurden und die Vorteile durch die Erhöhung von Modellgröße und Rechenleistung abnehmen. Diese Ansicht besagt, dass der Fortschritt der KI „weniger offensichtlich“ geworden ist, hauptsächlich in Expertenbereichen, nicht auf einer für normale Nutzer wahrnehmbaren Ebene, was darauf hindeutet, dass die KI-Entwicklung in eine Plateauphase eintreten könnte und völlig neue architektonische Durchbrüche erfordert. (Quelle: Reddit r/ArtificialInteligence)

💡 Sonstiges
Docker warnt vor Sicherheitsrisiken in MCP-Toolchains : Docker hat eine Warnung herausgegeben, die besagt, dass KI-gesteuerte Entwicklungstoolchains, die auf dem Model Context Protocol (MCP) basieren, schwerwiegende Sicherheitslücken aufweisen, einschließlich der Offenlegung von Anmeldeinformationen, unbefugtem Dateizugriff und Remote Code Execution, und es bereits reale Fälle gegeben hat. Diese Tools betten LLMs in Entwicklungsumgebungen ein und verleihen ihnen autonome Betriebsrechte, aber es fehlt an Isolation und Überwachung. Docker empfiehlt, die Installation von MCP-Servern über npm zu vermeiden und stattdessen signierte Container zu verwenden, und betont die Bedeutung von Container-Isolation und Zero-Trust-Netzwerken. (Quelle: WeChat)

Huawei HarmonyOS Anwendungsentwickler-Anreizprogramm 2025 : Huawei gab bekannt, dass die Anzahl der HarmonyOS 5-Geräte die Zehn-Millionen-Marke überschritten hat und startete das „HarmonyOS Application Developer Incentive Program 2025“ mit Investitionen von über hundert Millionen Yuan an Subventionen, wobei einzelne Entwickler bis zu 6 Millionen Yuan erhalten können. Das Programm zielt darauf ab, die Entwicklung des HarmonyOS-Ökosystems zu beschleunigen und Entwickler für die Anwendungsentwicklung für KI und mehrere Endgeräte zu gewinnen, um „einmal entwickeln, auf mehreren Geräten bereitstellen“ zu realisieren. Huawei bietet umfassende Entwicklungsunterstützung, einschließlich technischer Befähigung, schneller Tests, effizienter Veröffentlichung und Betrieb, um ein stabiles Entwickler-Ökosystem aufzubauen. (Quelle: WeChat)

Inspur Information stellt nationalen KI-Supernode-Server Yuan Nao SD200 vor : Inspur Information hat den Supernode-KI-Server „Yuan Nao SD200“ vorgestellt, der darauf abzielt, die Rechenleistungsherausforderungen beim Betrieb von Billionen-Parameter-Large-Models zu lösen. Der Server verwendet eine innovativ entwickelte Multi-Host-Low-Latency-Memory-Semantic-Communication-Architektur, die 64 lokale GPU-Chips aggregieren kann und maximal 4 TB einheitlichen Videospeicher und 64 GB einheitlichen Arbeitsspeicher bietet. Er unterstützt Billionen-Parameter-Ultra-Long-Sequence-Modelle. Praxistests zeigen, dass der SD200 eine hervorragende Skalierungseffizienz der Rechenleistung bei Modellen wie DeepSeek R1 erreicht und leistungsstarke Unterstützung für Anwendungen in den Bereichen AI4 Science und Industrie bietet. (Quelle: WeChat)
