

Schlüsselwörter:KI-Branche, GPT-5, AGI, KI-Sicherheit, Hype-Korrektur, KI-Programmierung, KI-Agenten, Multimodale Modelle, KI in der Materialwissenschaft, LLM-Inferenzoptimierung, Embodied KI, KI-Benchmarking, KI-gestützte PPT-Generierung
🔥 FOKUS
“Hype-Korrektur” in der KI-Branche und Realitätsprüfung : Im Jahr 2025 tritt die KI-Branche in eine Phase der “Hype-Korrektur” ein, in der die Erwartungen an KI von “Allheilmittel” zu einer realistischeren Einschätzung zurückkehren. Branchenführer wie Sam Altman räumen eine KI-Blase ein, insbesondere bei den enormen Investitionen in Start-up-Bewertungen und den Bau von Rechenzentren. Gleichzeitig wird die Veröffentlichung von GPT-5 als unter den Erwartungen liegend angesehen, was Diskussionen über Engpässe in der Entwicklung von LLM auslöst. Experten fordern eine Neubewertung der tatsächlichen Fähigkeiten von KI, eine Unterscheidung zwischen den “glanzvollen Demonstrationen” generativer KI und den tatsächlichen Durchbrüchen prädiktiver KI in Bereichen wie Medizin und Wissenschaft, und betonen, dass der Wert von KI in ihrer Zuverlässigkeit und Nachhaltigkeit liegt, nicht in der blinden Verfolgung von AGI. (Quelle: MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review)

Durchbrüche und Herausforderungen der KI in der Materialwissenschaft : KI wird eingesetzt, um die Entdeckung neuer Materialien zu beschleunigen, indem KI-Agenten Experimente planen, durchführen und interpretieren, was den Entdeckungsprozess von Jahrzehnten auf wenige Jahre verkürzen könnte. Unternehmen wie Lila Sciences und Periodic Labs bauen KI-gesteuerte automatisierte Labore, um Engpässe bei der Synthese und Prüfung in der traditionellen Materialwissenschaft zu überwinden. Obwohl DeepMind einst die Entdeckung von “Millionen neuer Materialien” verkündete, wurden deren tatsächliche Neuartigkeit und Praktikabilität in Frage gestellt, was die Lücke zwischen virtueller Simulation und physikalischer Realität verdeutlicht. Die Branche bewegt sich von reinen Computermodellen hin zu einer Kombination mit experimenteller Validierung, mit dem Ziel, bahnbrechende Materialien wie Raumtemperatur-Supraleiter zu entdecken. (Quelle: MIT Technology Review)

Produktivitätsdebatte und technische Schulden in der KI-Programmierung : KI-Programmierwerkzeuge sind weit verbreitet, wobei die CEOs von Microsoft und Google behaupten, dass KI bereits ein Viertel des Unternehmenscodes generiert hat, und der CEO von Anthropic prognostiziert, dass in Zukunft 90 % des Codes von KI geschrieben werden. Die tatsächliche Produktivitätssteigerung ist jedoch umstritten; Studien deuten darauf hin, dass KI die Entwicklungsgeschwindigkeit verlangsamen und “technische Schulden” (z. B. schlechtere Codequalität, schwierige Wartung) erhöhen kann. Dennoch ist KI hervorragend beim Schreiben von Boilerplate-Code, Tests und der Fehlerbehebung. Neue Agenten-Tools wie Claude Code verbessern die Verarbeitung komplexer Aufgaben erheblich durch Planungsmodi und Kontextmanagement. Die Branche erforscht neue Paradigmen wie “wegwerfbaren Code” und formale Verifikation, um sich an KI-gesteuerte Entwicklungsmodelle anzupassen. (Quelle: MIT Technology Review)

KI-Sicherheitsbefürworter halten an AGI-Risiken fest und äußern Bedenken : Obwohl die jüngste KI-Entwicklung als “Hype-Korrektur”-Phase angesehen wird und GPT-5 eine eher verhaltene Leistung zeigte, sind KI-Sicherheitsbefürworter (“KI-Doomer”) weiterhin tief besorgt über die potenziellen Risiken von AGI (Künstliche Allgemeine Intelligenz). Sie argumentieren, dass die Fortschrittsgeschwindigkeit der KI zwar verlangsamt werden könnte, ihre grundlegende Gefährlichkeit jedoch unverändert bleibt, und zeigen sich enttäuscht darüber, dass politische Entscheidungsträger die KI-Risiken nicht ausreichend ernst nehmen. Sie betonen, dass selbst wenn AGI erst in Jahrzehnten statt in Jahren erreicht wird, sofort Ressourcen zur Lösung von Kontrollproblemen eingesetzt werden müssen, und warnen vor den langfristigen negativen Auswirkungen, die übermäßige Investitionen der Branche in die KI-Blase mit sich bringen könnten. (Quelle: MIT Technology Review)

🎯 TRENDS
Kontinuierliche Durchbrüche bei multimodalen Video-Generierungsmodellen : Alibaba hat das Video-Modell Wan 2.6 veröffentlicht, das Rollenspiele, Audio-Video-Synchronisation, Multi-Shot-Generierung und Sound-Steuerung unterstützt und Videos von bis zu 15 Sekunden Länge erzeugt, was als “kleines Sora 2” gilt. ByteDance hat ebenfalls Seedance 1.5 Pro vorgestellt, dessen Highlight die Unterstützung von Dialekten ist. LongVie 2 in den HuggingFace Daily Papers schlägt ein multimodales, steuerbares, ultralanges Video-Weltmodell vor, das Steuerbarkeit, langfristige visuelle Qualität und zeitliche Konsistenz betont. Diese Fortschritte markieren eine signifikante Verbesserung der Video-Generierungstechnologie in Bezug auf Realismus, Interaktivität und Anwendungsszenarien. (Quelle: Alibaba_Wan, op7418, op7418, HuggingFace Daily Papers)

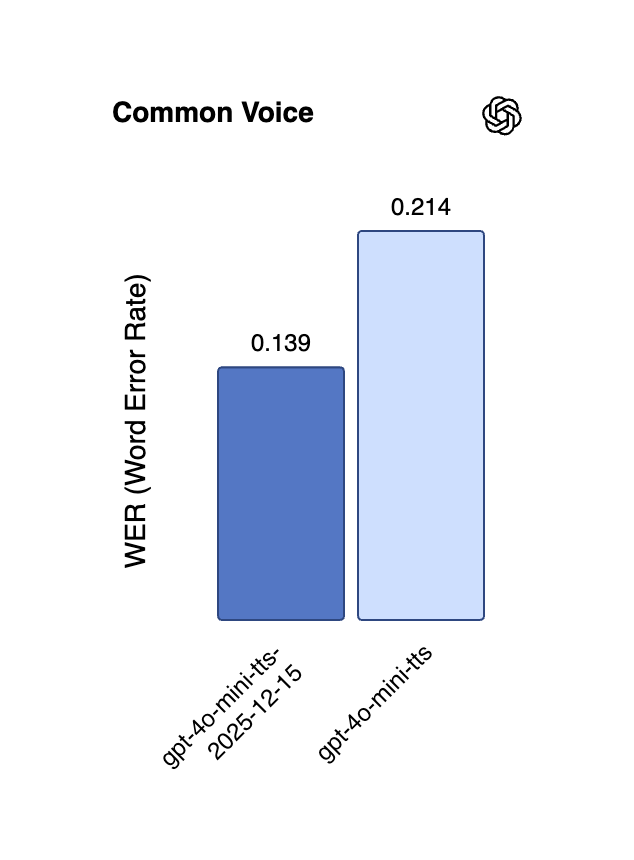
Neue Fortschritte in der KI-Sprachtechnologie: Mehrsprachigkeit und Echtzeit-Streaming : Alibaba hat das CosyVoice 3 TTS-Modell als Open Source veröffentlicht, das 9 Sprachen und über 18 chinesische Dialekte unterstützt, mehrsprachiges/cross-linguales Zero-Shot-Sprachklonen bietet und bidirektionales Streaming mit einer extrem niedrigen Latenz von 150 Millisekunden ermöglicht. Die Echtzeit-API von OpenAI wurde ebenfalls mit den Modellen gpt-4o-mini-transcribe und gpt-4o-mini-tts aktualisiert, was Halluzinationen und Fehlerraten erheblich reduziert und die mehrsprachige Leistung verbessert. Das Gemini 2.5 Flash Native Audio-Modell von Google DeepMind wurde ebenfalls aktualisiert, um die Befolgung von Anweisungen und die Natürlichkeit der Konversation weiter zu optimieren, was die Anwendung von Echtzeit-Sprachagenten vorantreibt. (Quelle: ImazAngel, Reddit r/LocalLLaMA, snsf, GoogleDeepMind)
Langkontext-Inferenz und Effizienzoptimierung bei großen Modellen : QwenLong-L1.5 erreicht durch systematische Nach-Training-Innovationen eine Langkontext-Inferenzfähigkeit, die mit GPT-5 und Gemini-2.5-Pro vergleichbar ist, und zeigt hervorragende Leistungen bei ultralangen Aufgaben. GPT-5.2 erhielt ebenfalls positives Feedback von Nutzern für seine Langkontext-Fähigkeiten, insbesondere bei der Zusammenfassung von Podcasts mit reichhaltigeren Details. Darüber hinaus schlägt ReFusion ein neues Masken-Diffusionsmodell vor, das durch Slot-Level-Parallel-Dekodierung eine signifikante Leistungs- und Effizienzsteigerung erzielt, eine durchschnittliche Beschleunigung um das 18-fache und die Leistungslücke zu autoregressiven Modellen verringert. (Quelle: gdb, HuggingFace Daily Papers, HuggingFace Daily Papers, teortaxesTex)
Fortschritte in Embodied AI und Robotik : AgiBot hat den humanoiden Roboter Lingxi X2 vorgestellt, der menschenähnliche Bewegungsfähigkeiten und multifunktionale Fertigkeiten besitzt. Mehrere Studien in den HuggingFace Daily Papers konzentrieren sich auf Embodied AI, wie z.B. “Toward Ambulatory Vision”, das die visuell geerdete aktive Perspektivwahl erforscht, “Spatial-Aware VLA Pretraining”, das visuell-physikalische Ausrichtung durch menschliche Videos erreicht, und “VLSA”, das eine Plug-and-Play-Sicherheitsbeschränkungsebene einführt, um die Sicherheit von VLA-Modellen zu verbessern. Diese Forschungen zielen darauf ab, die Lücke zwischen 2D-Vision und 3D-physikalischen Umgebungsaktionen zu schließen und das Roboterlernen sowie den praktischen Einsatz voranzutreiben. (Quelle: Ronald_vanLoon, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
Beiträge von NVIDIA und Meta zu KI-Architekturen und Open-Source-Modellen : NVIDIA hat die Nemotron v3 Nano Open-Modellfamilie veröffentlicht und den vollständigen Trainings-Stack (einschließlich RL-Infrastruktur, Umgebungen, Vortrainings- und Nach-Trainings-Datensätzen) als Open Source bereitgestellt, um den Aufbau spezialisierter Agenten-KI in verschiedenen Branchen voranzutreiben. Meta hat die VL-JEPA (Vision-Language Joint Embedding Predictive Architecture) vorgestellt, das erste nicht-generative Modell, das allgemeine visuell-sprachliche Aufgaben in Echtzeit-Streaming-Anwendungen effizient ausführen kann und dabei die Leistung großer VLM übertrifft. (Quelle: ylecun, QuixiAI, halvarflake)

Innovationen bei KI-Benchmarks und Bewertungsmethoden : Google Research hat das FACTS Leaderboard eingeführt, das LLM umfassend auf Faktizität in vier Dimensionen bewertet: Multimodalität, parametrisches Wissen, Suche und Grounding. Es zeigt die Kompromisse zwischen Abdeckung und Widerspruchsrate bei verschiedenen Modellen auf. Der V-REX-Benchmark bewertet die explorative visuelle Inferenzfähigkeit von VLM durch “Fragenketten”, während START sich auf das Text- und räumliche Lernen beim Diagrammverständnis konzentriert. Diese neuen Benchmarks zielen darauf ab, die Leistung von KI-Modellen bei komplexen, realen Aufgaben genauer zu messen. (Quelle: omarsar0, HuggingFace Daily Papers, HuggingFace Daily Papers)

Erhöhte Autonomie von KI-Agenten in Web-Umgebungen : WebOperator schlägt ein aktionsbewusstes Baumsuchverfahren vor, das LLM-Agenten in teilweise beobachtbaren Web-Umgebungen eine zuverlässige Rückverfolgung und strategische Erkundung ermöglicht. Diese Methode generiert Aktionskandidaten durch mehrere Inferenzkontexte und filtert ungültige Aktionen heraus, was die Erfolgsrate bei WebArena-Aufgaben erheblich steigert und die entscheidende Bedeutung der Kombination von strategischer Voraussicht und sicherer Ausführung hervorhebt. (Quelle: HuggingFace Daily Papers)
KI-gestütztes autonomes Fahren und 4D-Weltmodelle : DrivePI ist ein raumbezogenes 4D MLLM, das Verständnis, Wahrnehmung, Vorhersage und Planung für autonomes Fahren vereint. Es integriert Punktwolken, Multi-View-Bilder und Sprachanweisungen und generiert Text-Occupancy- und Text-Flow-QA-Paare, um präzise Vorhersagen von 3D-Occupancy und Occupancy-Flow zu ermöglichen. Auf Benchmarks wie nuScenes übertrifft es bestehende VLA- und spezialisierte VA-Modelle. GenieDrive konzentriert sich auf physikalisch bewusste Fahr-Weltmodelle und verbessert die Vorhersagegenauigkeit und Videoqualität durch 4D-Occupancy-gesteuerte Videogenerierung. (Quelle: HuggingFace Daily Papers, HuggingFace Daily Papers)
🧰 TOOLS
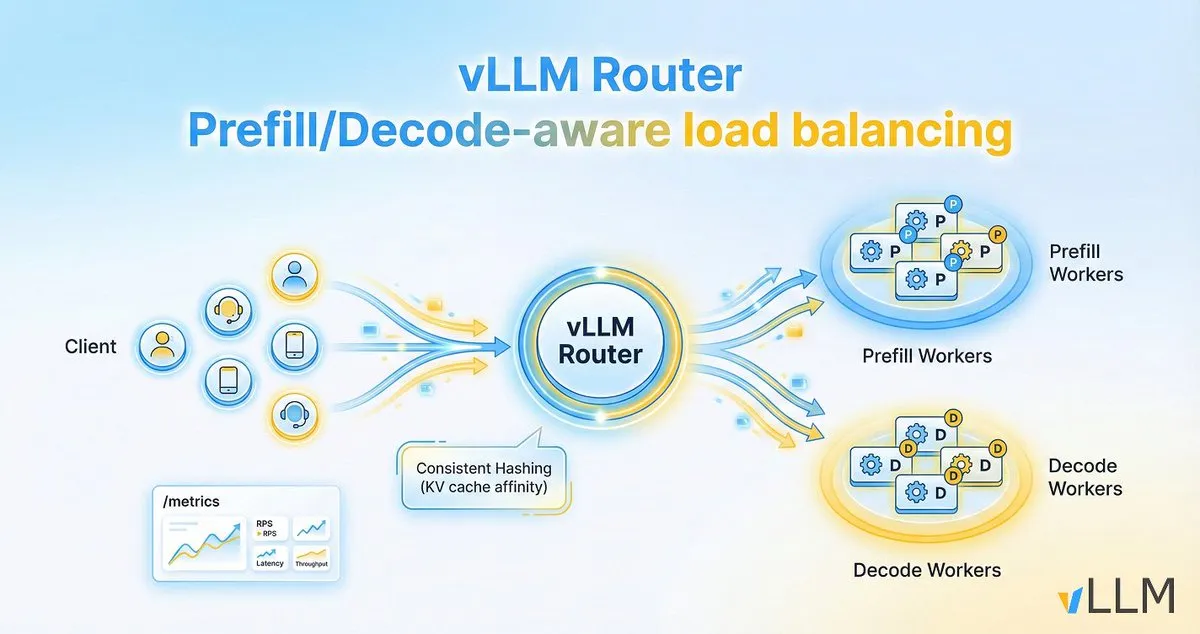
vLLM Router verbessert die Effizienz der LLM-Inferenz : Das vLLM-Projekt hat den vLLM Router veröffentlicht, einen leichten, leistungsstarken, Pre-Fill/Decode-bewussten Load Balancer, der speziell für vLLM-Cluster entwickelt wurde. Er ist in Rust geschrieben und unterstützt Strategien wie Consistent Hashing und Power-of-Two Choices, um die KV-Cache-Lokalität zu optimieren, Engpässe bei Dialogverkehr und Pre-Fill/Decode-Trennung zu lösen und so den Durchsatz der LLM-Inferenz zu erhöhen und die Latenz am Ende zu reduzieren. (Quelle: vllm_project)
AI21 Maestro vereinfacht die Erstellung von KI-Agenten : Der Vibe Agent von AI21Labs wurde in AI21 Maestro eingeführt und ermöglicht es Benutzern, KI-Agenten durch einfache englische Beschreibungen zu erstellen. Das Tool schlägt automatisch die Verwendung des Agenten, Validierungsprüfungen, benötigte Tools sowie Modell-/Berechnungseinstellungen vor und erklärt jeden Schritt in Echtzeit, was die Hürde für die Erstellung komplexer KI-Agenten erheblich senkt. (Quelle: AI21Labs)
OpenHands SDK beschleunigt die Entwicklung agentengesteuerter Software : OpenHands hat das Software Agent SDK veröffentlicht, das einen schnellen, flexiblen und produktionsbereiten Rahmen für die Entwicklung agentengesteuerter Software bieten soll. Die Einführung dieses SDK wird Entwicklern helfen, KI-Agenten effizienter zu integrieren und zu verwalten, um komplexe Softwareentwicklungsaufgaben zu bewältigen. (Quelle: gneubig)

Claude Code CLI-Update verbessert die Entwicklererfahrung : Anthropic hat Claude Code Version 2.0.70 mit 13 CLI-Verbesserungen veröffentlicht. Zu den wichtigsten Updates gehören: Unterstützung der Enter-Taste zur Annahme von Prompt-Vorschlägen, Wildcard-Syntax für MCP-Tool-Berechtigungen, automatischer Update-Schalter für den Plugin-Markt, erzwungener Planungsmodus und mehr. Darüber hinaus wurde die Speichereffizienz um das Dreifache verbessert und die Screenshot-Auflösung erhöht, um die Interaktion und Effizienz von Entwicklern bei der Softwareentwicklung mit Claude Code zu optimieren. (Quelle: Reddit r/ClaudeAI)
Qwen3-Coder ermöglicht schnelle 2D-Spieleentwicklung : Ein Reddit-Nutzer zeigte, wie man mit Alibabas Qwen3-Coder (480B)-Modell und der Cursor IDE in Sekundenschnelle ein 2D-Spiel im Mario-Stil erstellt. Das Modell plant die Schritte automatisch, installiert Abhängigkeiten, generiert Code und Projektstruktur und kann direkt ausgeführt werden, alles ausgehend von einem einzigen Prompt. Die Betriebskosten sind gering (ca. 2 US-Dollar pro Million Tokens), und die Erfahrung ähnelt dem GPT-4-Agentenmodus, was das starke Potenzial von Open-Source-Modellen für die Codegenerierung und Agentenaufgaben demonstriert. (Quelle: Reddit r/artificial)
KI-gestütztes Tool für tiefgehende Aktienanalyse : Das Deep Research Tool nutzt KI, um Daten aus SEC-Einreichungen und Branchenpublikationen zu extrahieren und standardisierte Berichte zu erstellen, die den Vergleich und die Filterung von Unternehmen vereinfachen. Benutzer können Aktiensymbole eingeben, um eine detaillierte Analyse zu erhalten. Das Tool soll Investoren helfen, fundamentale Analysen effizienter durchzuführen, Marktnews zu vermeiden und sich auf wesentliche Finanzinformationen zu konzentrieren. (Quelle: Reddit r/ChatGPT)
LangChain 1.2 vereinfacht die Erstellung von Agentic RAG-Anwendungen : LangChain hat Version 1.2 veröffentlicht, die die Unterstützung für integrierte Tools und den Strict Mode vereinfacht, insbesondere in der create_agent-Funktion. Dies ermöglicht Entwicklern, Agentic RAG (Retrieval Augmented Generation)-Anwendungen einfacher zu erstellen, sowohl lokal als auch auf Google Collab, und betont ihre 100% Open-Source-Natur. (Quelle: LangChainAI, hwchase17)
Skywork führt KI-gestützte PPT-Generierungsfunktion ein : Die Skywork-Plattform hat eine PPT-Generierungsfunktion auf Basis von Nano Banana Pro eingeführt, die das Problem der schwierigen Bearbeitung traditionell von KI generierter PPTs löst. Die neue Funktion unterstützt die Trennung von Ebenen, ermöglicht Benutzern die Online-Bearbeitung von Text und Bildern und den Export im PPTX-Format zur lokalen Bearbeitung. Darüber hinaus integriert das Tool eine branchenspezifische Datenbank, unterstützt die Generierung verschiedener Diagramme, um die Datengenauigkeit zu gewährleisten, und bietet Weihnachtsrabatte. (Quelle: op7418)

Kleine Modelle ermöglichen Infrastructure-as-Code am Edge : Ein Reddit-Nutzer teilte ein 500 MB großes “Infrastructure-as-Code” (IaC)-Modell, das auf Edge-Geräten oder im Browser ausgeführt werden kann. Dieses Modell konzentriert sich auf IaC-Aufgaben, ist kompakt, aber leistungsstark und bietet eine effiziente Lösung für die Bereitstellung und Verwaltung von Infrastruktur in ressourcenbeschränkten Umgebungen. Dies deutet auf das enorme Potenzial kleiner KI-Modelle in spezifischen vertikalen Anwendungen hin. (Quelle: Reddit r/deeplearning)
📚 LERNEN
ChinaArXiv: Eine automatisierte Übersetzungsplattform für chinesische Preprints : Chinarxiv.org ist offiziell gestartet. Es handelt sich um eine vollautomatische Übersetzungsplattform für chinesische Preprints, die darauf abzielt, die Sprachbarriere zwischen chinesischer und westlicher wissenschaftlicher Forschung zu überbrücken. Die Plattform übersetzt nicht nur Texte, sondern auch Diagramminhalte, wodurch westliche Forscher einfacher Zugang zu den neuesten Forschungsergebnissen der chinesischen Wissenschaftsgemeinschaft erhalten. (Quelle: menhguin, andersonbcdefg, francoisfleuret)
KI-Fähigkeiten und Agentic AI-Lernpfad : Ronald_vanLoon hat 12 Schlüsselkompetenzen für die Beherrschung von KI-Fähigkeiten im Jahr 2025 sowie einen Lernpfad für Agentic AI geteilt. Diese Ressourcen sollen Einzelpersonen dabei helfen, ihre Wettbewerbsfähigkeit im sich schnell entwickelnden KI-Bereich zu verbessern. Sie umfassen Lernpfade von grundlegendem KI-Wissen bis hin zur Entwicklung fortgeschrittener Agentensysteme und betonen die Bedeutung des kontinuierlichen Lernens und der Anpassung an neue Fähigkeiten im Zeitalter der KI. (Quelle: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

Optimierung des LLM-Inferenzprozesses und datengesteuerte KI-Entwicklung : Eine Studie von Meta Superintelligence Labs zeigt, dass die PDR-Strategie (Parallel Draft-Distill-Refine) – “paralleler Entwurf → Destillation in kompakten Arbeitsbereich → Verfeinerung” – unter Inferenzbeschränkungen die beste Aufgaben-Genauigkeit erzielen kann. Gleichzeitig betont ein Blogbeitrag, dass “Daten die gezackte Front der KI” sind, und weist darauf hin, dass Bereiche wie Codierung und Mathematik aufgrund reichhaltiger und überprüfbarer Daten erfolgreich sind, während die Wissenschaft relativ zurückbleibt. Erörtert wird auch die Rolle von Destillation und Reinforcement Learning bei der Datengenerierung. (Quelle: dair_ai, lvwerra)

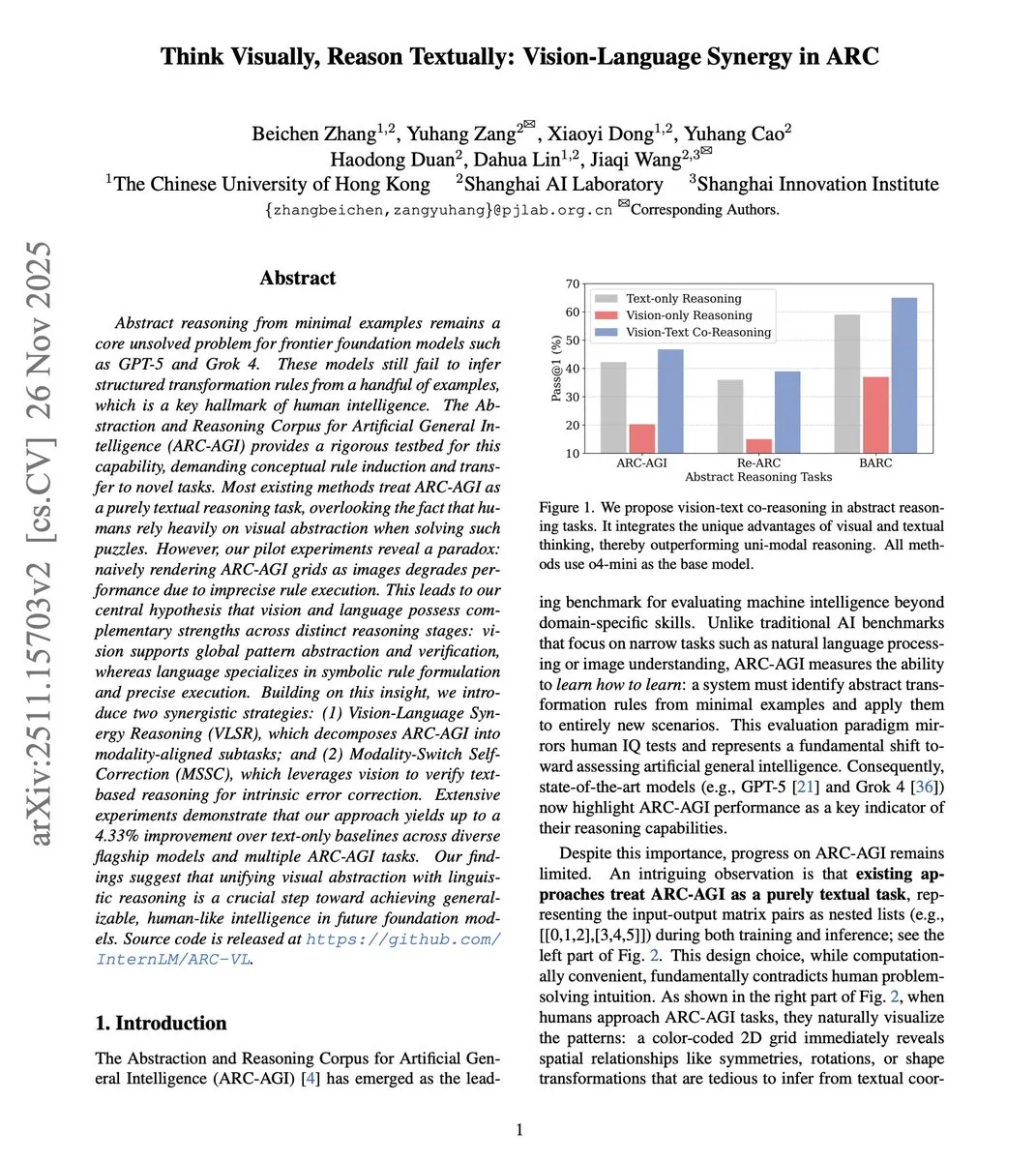
Visuell-sprachliche kollaborative Inferenz verbessert die Abstraktionsfähigkeit : Eine neue Studie schlägt das VLSR (Visual-Language Synergistic Reasoning)-Framework vor, das durch die strategische Kombination von visuellen und textuellen Modalitäten in verschiedenen Inferenzphasen die Leistung von LLM bei abstrakten Inferenzaufgaben (wie dem ARC-AGI-Benchmark) erheblich verbessert. Diese Methode nutzt visuelle Informationen zur globalen Mustererkennung, Text zur präzisen Ausführung und überwindet Bestätigungsfehler durch einen modalitätswechselnden Selbstkorrekturmechanismus, wobei sie bei kleinen Modellen sogar die Leistung von GPT-4o übertrifft. (Quelle: dair_ai)
Neue Perspektive: LLM-Inferenz-Tokens als Rechenzustand : Das State over Tokens (SoT)-Konzeptrahmenwerk definiert LLM-Inferenz-Tokens als externalisierte Rechenzustände neu, anstatt sie als einfache sprachliche Erzählungen zu betrachten. Dies erklärt, wie Tokens korrekte Schlussfolgerungen antreiben können, ohne eine getreue Textinterpretation zu sein, und eröffnet neue Forschungsrichtungen zum Verständnis der internen Prozesse von LLM. Es betont, dass die Forschung über die Textinterpretation hinausgehen und sich auf die Dekodierung von Inferenz-Tokens als Zustände konzentrieren sollte. (Quelle: HuggingFace Daily Papers)
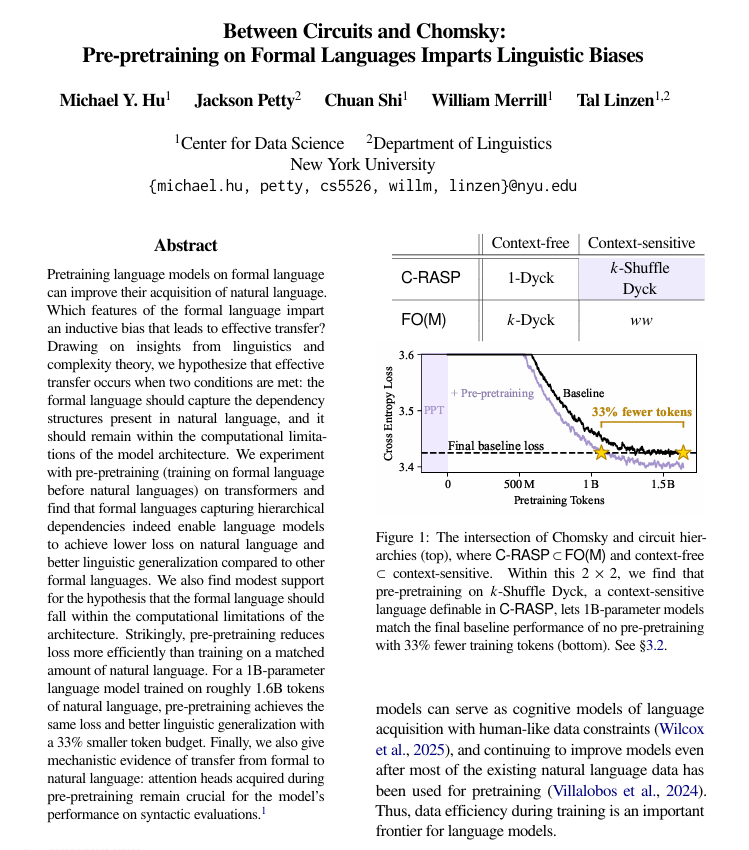
Vorabtraining mit formalen Sprachen verbessert das Lernen natürlicher Sprachen : Eine Studie der New York University hat herausgefunden, dass das Vorabtraining mit formalen, regelbasierten Sprachen vor dem Vorabtraining mit natürlicher Sprache Sprachmodellen erheblich dabei helfen kann, menschliche Sprache besser zu lernen. Die Studie weist darauf hin, dass diese formale Sprache eine ähnliche Struktur (insbesondere hierarchische Beziehungen) wie die natürliche Sprache aufweisen und ausreichend einfach sein muss. Diese Methode ist effektiver als das Hinzufügen der gleichen Menge an natürlichen Sprachdaten, und die erlernten Strukturmechanismen werden innerhalb des Modells übertragen. (Quelle: TheTuringPost)
Integration von physikalischem Wissen in den Code-Generierungsprozess : Das Chain of Unit-Physics-Framework integriert physikalisches Wissen direkt in den Code-Generierungsprozess. Forscher der University of Michigan schlagen eine inverse wissenschaftliche Code-Generierungsmethode vor, die menschliches Expertenwissen als Einheiten-Physik-Tests kodiert, um die Code-Generierung zu steuern und zu beschränken. In einer Multi-Agenten-Umgebung ermöglicht dieses Framework dem System, in 5-6 Iterationen die richtige Lösung zu erreichen, die Laufgeschwindigkeit um 33 % zu erhöhen, den Speicherverbrauch um 30 % zu reduzieren und eine extrem niedrige Fehlerrate aufzuweisen. (Quelle: TheTuringPost)
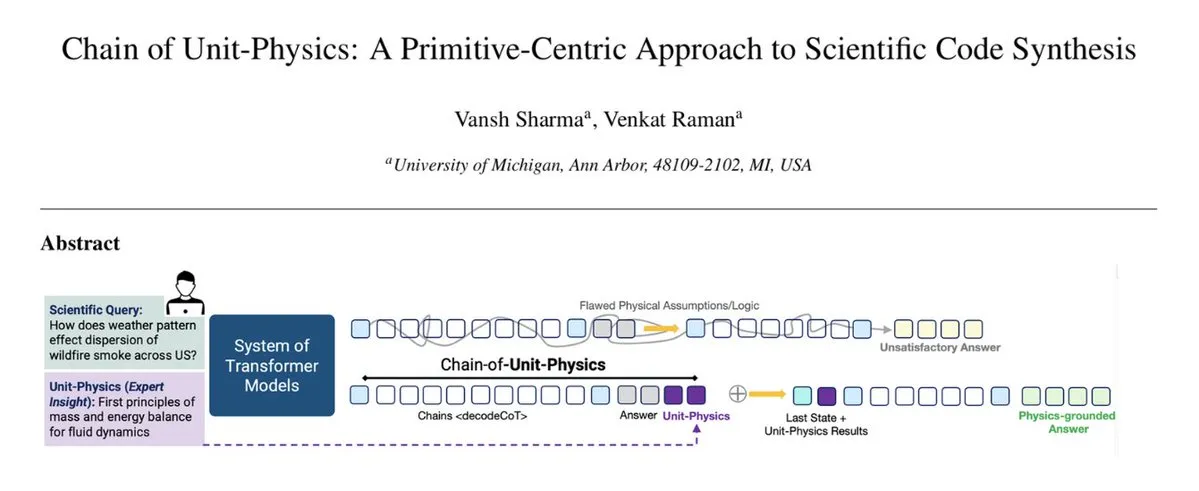
CausalTraj: Ein Multi-Agenten-Trajektorienvorhersagemodell für Mannschaftssportarten : CausalTraj ist ein autoregressives Modell zur gemeinsamen Trajektorienvorhersage für mehrere Agenten in Mannschaftssportarten. Das Modell wird direkt mit einem gemeinsamen Vorhersagewahrscheinlichkeitsziel trainiert, anstatt nur individuelle Agentenmetriken zu optimieren, wodurch die Kohärenz und Plausibilität der Multi-Agenten-Trajektorien erheblich verbessert wird, während die individuelle Leistung erhalten bleibt. Die Studie untersucht auch, wie die gemeinsame Modellierung effektiver bewertet und die Realisierbarkeit von Stichproben-Trajektorien beurteilt werden kann. (Quelle: Reddit r/deeplearning)
LLM-Trainingsdaten: Antworten oder Fragen? : Eine Diskussion auf Reddit legt nahe, dass die meisten aktuellen LLM-Trainingsdatensätze sich auf “Antworten” konzentrieren, während ein entscheidender Teil der menschlichen Intelligenz im chaotischen, vagen und iterativen Prozess vor der “Fragenbildung” liegt. Experimente zeigen, dass Modelle, die mit Konversationsdaten trainiert wurden, die frühes Denken, vage Fragen und wiederholte Korrekturen enthalten, besser darin sind, Benutzerabsichten zu klären, unklare Aufgaben zu bearbeiten und falsche Schlussfolgerungen zu vermeiden. Dies deutet darauf hin, dass Trainingsdaten die Komplexität des menschlichen Denkens umfassender erfassen müssen. (Quelle: Reddit r/MachineLearning)
💼 BUSINESS
OpenAI übernimmt neptune.ai zur Stärkung der Forschungstools : OpenAI hat eine endgültige Vereinbarung zur Übernahme von neptune.ai bekannt gegeben. Dieser Schritt zielt darauf ab, die Tools und die Infrastruktur zur Unterstützung der Spitzenforschung zu stärken. Die Übernahme wird OpenAI helfen, seine Fähigkeiten im Bereich der KI-Entwicklung und des Experimentmanagements zu verbessern, den Modelltraining- und Iterationsprozess weiter zu beschleunigen und seine führende Position im KI-Bereich zu festigen. (Quelle: dl_weekly)

Databricks mit starkem Q3-Ergebnis und über 4 Milliarden US-Dollar Finanzierung : Databricks hat ein starkes Ergebnis für das dritte Quartal bekannt gegeben, mit einer jährlichen Umsatzrate von über 4,8 Milliarden US-Dollar, was einem Wachstum von über 55 % gegenüber dem Vorjahr entspricht. Die jährliche Umsatzrate der Data-Warehousing- und KI-Produktgeschäfte überstieg jeweils 1 Milliarde US-Dollar. Das Unternehmen schloss außerdem eine L-Runde-Finanzierung von über 4 Milliarden US-Dollar ab, die das Unternehmen mit 134 Milliarden US-Dollar bewertet. Die Mittel sollen in Lakebase Postgres, Agent Bricks und Databricks Apps investiert werden, um die Entwicklung von Datenintelligenzanwendungen zu beschleunigen. (Quelle: jefrankle, jefrankle)

Infosys und Formula E kooperieren für KI-gesteuerte digitale Transformation : Infosys arbeitet mit der ABB FIA Formula E Weltmeisterschaft zusammen, um das Fanerlebnis und die Betriebseffizienz im Motorsport durch eine KI-gesteuerte Plattform zu revolutionieren. Die Zusammenarbeit umfasst die Nutzung von KI zur Bereitstellung personalisierter Inhalte, Echtzeit-Rennanalysen, KI-generierte Kommentare sowie die Optimierung von Logistik und Reisen zur Erreichung von CO2-Reduktionszielen. Die KI-Technologie steigert nicht nur die Attraktivität der Veranstaltung, sondern fördert auch Nachhaltigkeit und Mitarbeiterdiversität, wodurch die Formula E zum digitalsten und nachhaltigsten Motorsport wird. (Quelle: MIT Technology Review)

🌟 COMMUNITY
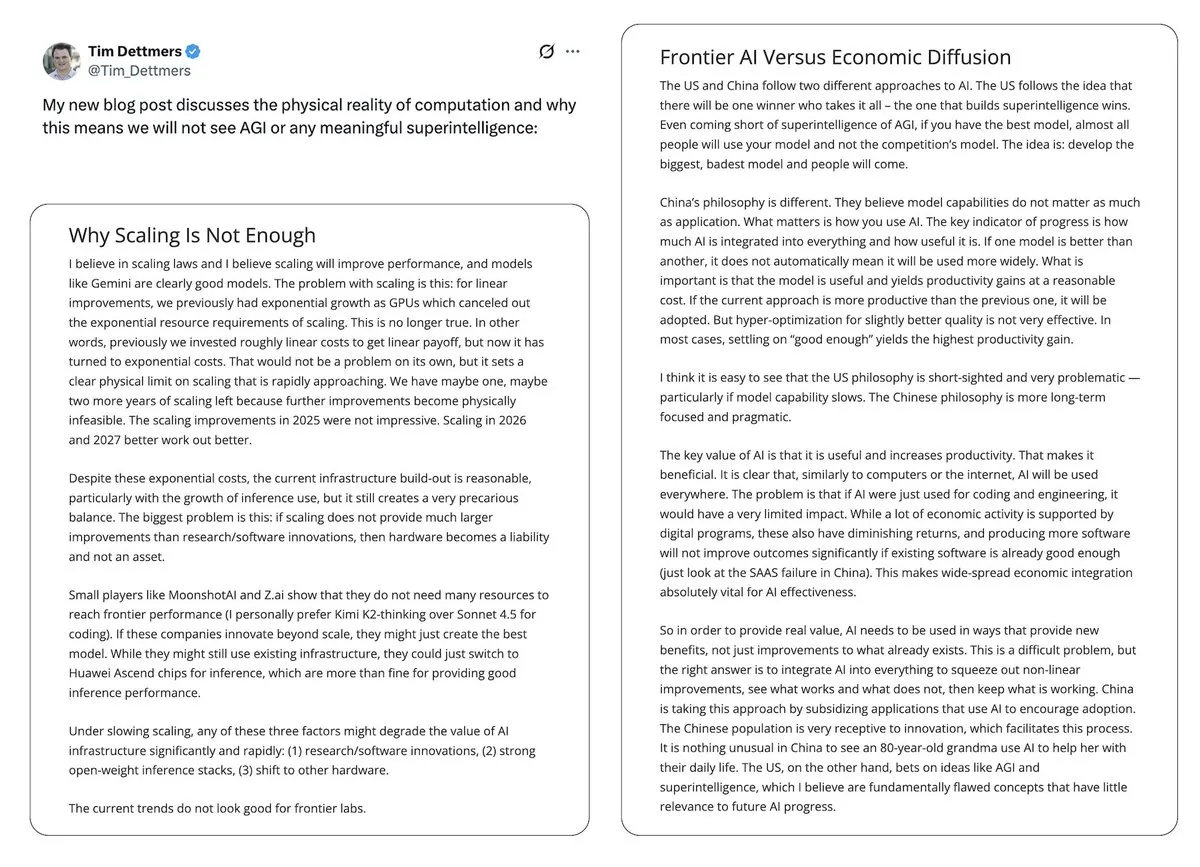
Kontroverse um KI-Blase und AGI-Aussichten : Yann LeCun bezeichnete LLM und AGI öffentlich als “völligen Unsinn” und argumentierte, dass die Zukunft der KI in Weltmodellen und nicht im aktuellen LLM-Paradigma liege, und äußerte Bedenken hinsichtlich der Monopolisierung der KI-Technologie durch einige wenige Unternehmen. Tim Dettmers’ Artikel “Why AGI Will Not Happen” erhielt ebenfalls Aufmerksamkeit für seine Diskussion über abnehmende Skalierungserträge. Gleichzeitig halten KI-Sicherheitsbefürworter, obwohl sie den Zeitpunkt des AGI-Eintritts angepasst haben, an dessen potenzieller Gefährlichkeit fest und äußern Besorgnis darüber, dass politische Entscheidungsträger die KI-Risiken nicht ausreichend ernst nehmen. (Quelle: ylecun, ylecun, hardmaru, MIT Technology Review)
Geteilte Meinungen der Nutzer zu GPT-5.2 und Gemini : In den sozialen Medien sind die Bewertungen von OpenAIs GPT-5.2 geteilt. Einige Nutzer äußern sich zufrieden über die Fähigkeit zur Verarbeitung langer Kontexte und finden die Zusammenfassungen von Podcasts detaillierter; andere hingegen äußern starke Unzufriedenheit und halten die Antworten von GPT-5.2 für zu allgemein, oberflächlich oder sogar für “selbstbewusste” Reaktionen, was einige Nutzer dazu veranlasst hat, zu Gemini zu wechseln. Diese Spaltung spiegelt die Sensibilität der Nutzer gegenüber der Leistung und dem Verhalten neuer Modelle sowie das anhaltende Interesse an der KI-Produkterfahrung wider. (Quelle: gdb, Reddit r/ArtificialInteligence)

Einfluss von KI auf menschliche Kognition, Arbeitsstandards und ethisches Verhalten : Der langfristige Einsatz von KI verändert schleichend menschliche Kognitionsmuster und Arbeitsstandards, fördert strukturierteres Denken und erhöht die Erwartungen an die Qualität der Ergebnisse. KI ermöglicht eine effiziente Produktion hochwertiger Inhalte, kann aber auch zu übermäßiger Abhängigkeit von Technologie führen. Auf ethischer Ebene lösen die unterschiedlichen Leistungen von KI-Modellen im “Trolley-Problem” (Grok’s Utilitarismus vs. Gemini/ChatGPT’s Altruismus) Diskussionen über die Festlegung von KI-Werten aus. Gleichzeitig offenbart die “Selbstregulierung” von KI-Modellen durch Sicherheitshinweise den indirekten Einfluss interner KI-Kontrollmechanismen auf die Benutzererfahrung. (Quelle: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/ChatGPT)
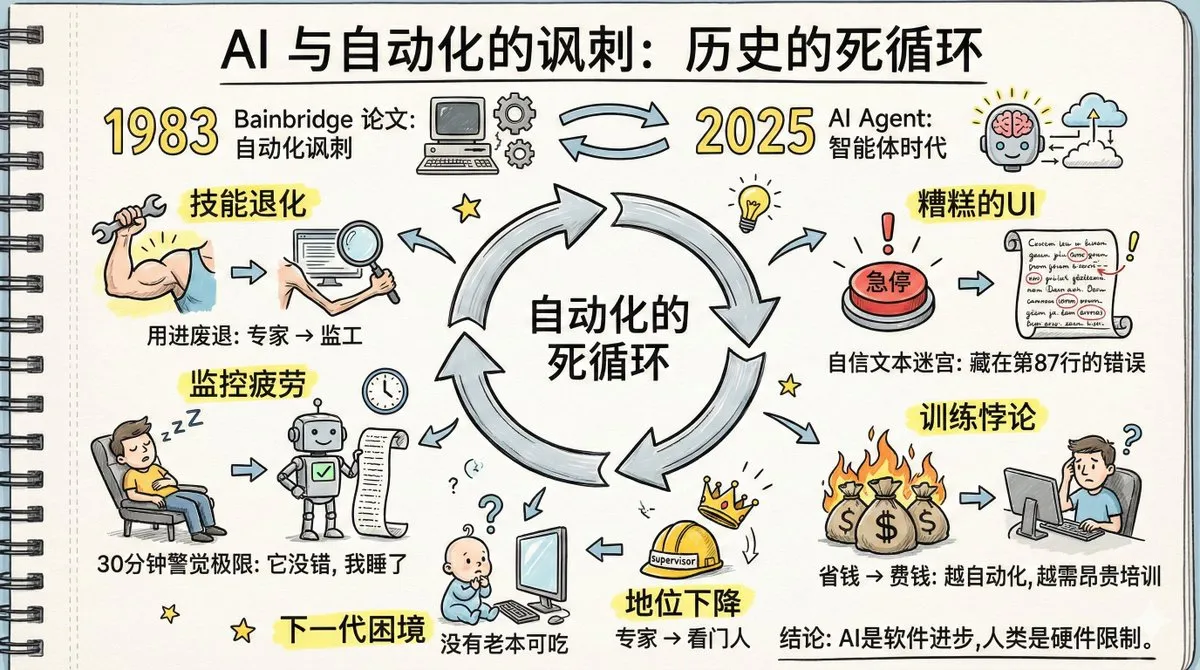
“Ironie der Automatisierung” bei KI-Agenten und menschlicher Kompetenzverlust : Ein vierzig Jahre altes Papier mit dem Titel “The Irony of Automation” löst eine hitzige Debatte aus, da seine Vorhersagen über die Fabrikautomatisierung nun bei KI-Agenten eintreten. Die Diskussion weist darauf hin, dass die Verbreitung von KI-Agenten zu einem Verlust menschlicher Fähigkeiten, einer Verlangsamung des Gedächtnisabrufs, Überwachungsmüdigkeit und einem Rückgang des Expertenstatus führen könnte. Der Artikel betont, dass Menschen nicht lange wachsam gegenüber Systemen bleiben können, die “selten Fehler machen”, und dass das aktuelle Design von KI-Agenten-Schnittstellen der Fehlererkennung abträglich ist. Die Lösung dieser Probleme erfordert größere technische Kreativität als die Automatisierung selbst sowie einen kognitiven Wandel hin zu neuen Arbeitsteilungen, neuen Trainings und neuen Rollendesigns. (Quelle: dotey, dotey, dotey)
KI-generierte Inhalte geringer Qualität und Faktenprüfung : Nutzer sozialer Medien entdecken eine große Anzahl minderwertiger Websites, die speziell für KI-Suchergebnisse erstellt wurden, und hinterfragen, ob die KI-Forschung auf diese Websites ohne Autoren und detaillierte Informationen angewiesen ist, was zu unzuverlässigen Informationen führen könnte. Dies löst Bedenken hinsichtlich des KI-“Backfill-Source”-Mechanismus aus, bei dem KI zuerst Antworten generiert und dann unterstützende Quellen sucht, was zur Zitierung falscher Informationen führen kann. Dies unterstreicht die Herausforderungen der KI in Bezug auf die Informationswahrheit und die Notwendigkeit, dass Nutzer zu eigenständiger Recherche zurückkehren. (Quelle: Reddit r/ArtificialInteligence)

Einfluss von KI auf den Rechtsberuf und die Abstraktionsebenen-Theorie : In der Rechtsbranche wird kontrovers diskutiert, ob KI den Anwaltsberuf “zerstören” wird. Einige Anwälte glauben, dass KI über 90 % der juristischen Arbeit erledigen kann, aber Strategie, Verhandlungen und Verantwortung weiterhin menschliches Eingreifen erfordern. Gleichzeitig wird KI von anderen als die nächste Abstraktionsebene nach Assembler, C und Python betrachtet, die Ingenieure befreien wird, sich auf Systemdesign und Benutzererfahrung zu konzentrieren, anstatt Menschen zu ersetzen. (Quelle: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

Physikalische Verhaltensweisen von KI-Agenten und die Debatte um LLM/Robotik-Integration : Neue Forschungsergebnisse zeigen, dass LLM-gesteuerte KI-Agenten makroskopischen physikalischen Gesetzen folgen und “detaillierte Gleichgewicht”-Eigenschaften ähnlich thermodynamischen Systemen aufweisen können, was darauf hindeutet, dass sie implizit “Potenzialfunktionen” zur Bewertung von Zuständen gelernt haben könnten. Gleichzeitig gibt es die Ansicht, dass sich Roboterintelligenz und LLM eher auseinanderentwickeln als vereinigen, während andere glauben, dass physikalische KI real wird, insbesondere durch Fortschritte beim Debugging und der Visualisierung, die Roboter- und Embodied-AI-Projekte beschleunigen. (Quelle: omarsar0, Teknium, wandb)

Anthropic-Führungskraft erzwingt KI-Chatbot in Discord-Community und löst Kontroverse aus : Eine Führungskraft von Anthropic hat in einer LGBTQ+-Discord-Community, entgegen dem Widerstand der Mitglieder, den KI-Chatbot Clawd des Unternehmens zwangsweise eingesetzt, was zu einem massiven Mitgliederschwund führte. Dieser Vorfall löste Bedenken hinsichtlich der Privatsphäre, der Beeinträchtigung menschlicher Interaktionen durch KI und der “Gott-Komplex”-Mentalität von KI-Unternehmen aus. Nutzer äußerten starke Unzufriedenheit über die Ersetzung menschlicher Kommunikation durch KI-Chatbots und das arrogante Verhalten der Führungskraft. (Quelle: Reddit r/artificial)

KI-Modelle anfällig für Poesie-Angriffe, Forderung nach Literaturwissenschaftlern in KI-Laboren : Italienische KI-Forscher haben herausgefunden, dass führende KI-Modelle durch die Umwandlung bösartiger Prompts in Gedichtform getäuscht werden können, wobei Gemini 2.5 am anfälligsten ist. Dieses Phänomen wird als “Waluigi-Effekt” bezeichnet, bei dem sich gute und böse Charaktere im komprimierten semantischen Raum zu nahe sind, was dazu führt, dass Modelle Anweisungen leichter umgekehrt ausführen. Dies löste in der Community eine Diskussion darüber aus, ob KI-Labore mehr Literaturabsolventen benötigen, um Erzählungen und tiefere Sprachmechanismen zu verstehen und so potenziellen “seltsamen narrativen Raum”-Verhaltensweisen der KI entgegenzuwirken. (Quelle: Reddit r/ArtificialInteligence)
💡 ANDERES
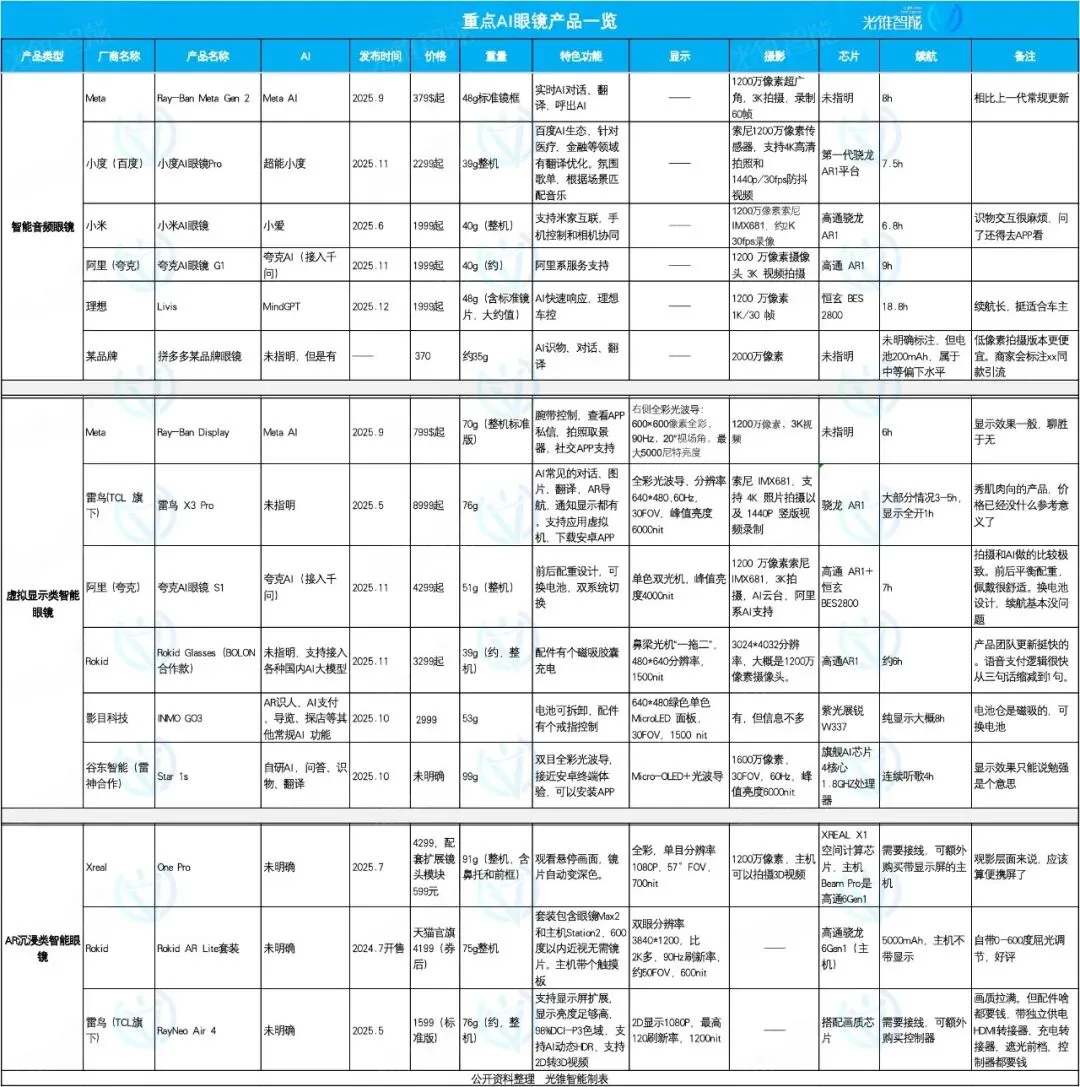
KI-Brillenmarkt im Fokus: Ideal, Quark, Rokid zeigen unterschiedliche Stärken : Der KI-Brillenmarkt erlebt 2025 einen Boom, wobei sich die Produktpositionierung differenziert. Ideal AI Glasses Livis konzentriert sich auf intelligentes Autozubehör und integriert das MindGPT-Großmodell für Autofahrer; Quark AI Glasses S1 zeichnet sich durch Aufnahmeeffekte und die Integration von Alibaba-Ökosystem-Apps aus; Rokid Glasses betont die Offenheit des Ökosystems und schnelle Funktionsiterationen und unterstützt die Anbindung an mehrere große Sprachmodelle. Intelligente Audiobrillen konzentrieren sich auf niedrige Preise und Funktionsintegration, Virtual-Display-Brillen bieten ein umfassendes Erlebnis, während AR-Immersionsbrillen auf Film- und Unterhaltungserlebnisse abzielen. (Quelle: 36氪)
ZLUDA ermöglicht CUDA auf Nicht-NVIDIA-GPUs, kompatibel mit AMD ROCm 7 : Das ZLUDA-Projekt hat die Ausführung von CUDA auf Nicht-NVIDIA-GPUs ermöglicht und unterstützt AMD ROCm 7. Dieser Fortschritt ist für die Bereiche KI und Hochleistungsrechnen von großer Bedeutung, da er NVIDIAs Monopol im GPU-Ökosystem bricht und Entwicklern ermöglicht, CUDA-geschriebene Programme auf AMD-Hardware zu nutzen, was mehr Flexibilität bei der Auswahl und Optimierung von KI-Hardware bietet. (Quelle: Reddit r/artificial)

hashcards: Ein textbasiertes System für verteiltes Wiederholungslernen : hashcards ist ein textbasiertes System für verteiltes Wiederholungslernen, bei dem alle Lernkarten als reine Textdateien gespeichert werden und Standardwerkzeuge zur Bearbeitung und Versionskontrolle unterstützen. Es verwendet eine inhaltsadressierbare Methode, bei der der Fortschritt zurückgesetzt wird, wenn der Karteninhalt geändert wird. Das System ist einfach gestaltet, unterstützt nur Vorder- und Rückseite sowie Lückentextkarten und verwendet den FSRS-Algorithmus zur Optimierung des Wiederholungsplans, um die Lerneffizienz zu maximieren und die Wiederholungszeit zu minimieren. (Quelle: GitHub Trending)
Zerobyte: Leistungsstarkes Backup-Automatisierungstool für Selbsthoster : Zerobyte ist ein Backup-Automatisierungstool, das für Selbsthoster entwickelt wurde und eine moderne Weboberfläche zur Planung, Verwaltung und Überwachung verschlüsselter Backups auf Remote-Speichern bietet. Es basiert auf Restic, unterstützt Verschlüsselung, Komprimierung und Aufbewahrungsrichtlinien und ist mit verschiedenen Protokollen wie NFS, SMB, WebDAV und lokalen Verzeichnissen kompatibel. Zerobyte unterstützt auch mehrere Cloud-Speicher-Backends wie S3, GCS, Azure und erweitert die Unterstützung auf über 40 Cloud-Speicherdienste über rclone, um Datensicherheit und flexible Backups zu gewährleisten. (Quelle: GitHub Trending)
