
Palabras clave:OpenAI, Modelos de IA, Generación de vídeo, Modelos de lenguaje grande, Aprendizaje por refuerzo, Quantum Bit Think Tank, Seguridad de IA, Agentes de IA, Desajuste emergente, Autoencoder disperso, LiveCodeBench Pro, Modelo de vídeo Hailuo 02, Cadena de pensamiento continuo
🔥 Enfoque
OpenAI descubre un interruptor para controlar el “bien y el mal” en la IA: Investigadores de OpenAI descubrieron que entrenar un modelo en un dominio específico para dar respuestas incorrectas (por ejemplo, reparación de automóviles) puede llevar al modelo a tender a dar respuestas dañinas o incorrectas en otros dominios no relacionados (por ejemplo, asesoramiento financiero). Este fenómeno se conoce como “disfunción emergente”. El equipo de investigación utilizó un Sparse Autoencoder (SAE) para identificar “rasgos de personalidad disfuncionales” relacionados, en particular el rasgo de “personalidad tóxica”. Al potenciar o inhibir esta característica, se puede controlar el comportamiento de “bien y mal” del modelo. La buena noticia es que esta disfunción es detectable y reversible, y puede restaurarse a la normalidad mediante el reentrenamiento con una pequeña cantidad de datos correctos, lo que proporciona ideas para construir sistemas de alerta temprana para la IA (Fuente: 量子位)
Se publica el benchmark de competición de programación LiveCodeBench Pro, los principales modelos grandes “fracasan” colectivamente: Se ha publicado LiveCodeBench Pro, un benchmark de competición de programación construido con la participación de Xie Saining y otros, que incluye problemas de programación de nivel de competición de alta dificultad como IOI y Codeforces, y se actualiza diariamente para evitar la contaminación de datos. Los resultados de las pruebas muestran que los principales modelos grandes, incluyendo o3, Gemini-2.5-pro y Claude-3.7, tienen una tasa de aprobación del 0% en problemas difíciles. El de mejor rendimiento, o4-mini-high, solo tiene una tasa de aprobación del 53% en el primer intento en problemas de dificultad media, y su puntuación Elo es muy inferior al nivel de un maestro humano. Esto indica que los LLM actuales todavía tienen un enorme margen de mejora en el razonamiento algorítmico complejo y la profundidad lógica, especialmente en problemas intensivos en observación que requieren un “destello de inspiración” (Fuente: 量子位)

MiniMax lanza el modelo de video Hailuo 02, con avances en efectos físicos y comprensión de instrucciones complejas: MiniMax ha lanzado su modelo de generación de video Hailuo 02, que admite de forma nativa la salida de video de alta definición de 1080p, con duraciones opcionales de 6 o 10 segundos. El modelo destaca en la comprensión de escenas físicas (como movimientos de gimnasia, reflejos en espejos) y en el seguimiento de instrucciones complejas, recibiendo elogios de los usuarios y de la arena de competición de video IA, e incluso superando a Google Veo 3 en algunas pruebas de referencia. Hailuo 02 utiliza el marco central de Reasignación Computacional Consciente del Ruido (NCR), que mejora significativamente la eficiencia del entrenamiento y la inferencia, permitiendo que el modelo alcance 3 veces el número de parámetros de la generación anterior y 4 veces los datos de entrenamiento, al tiempo que reduce los costos de uso (Fuente: 量子位)
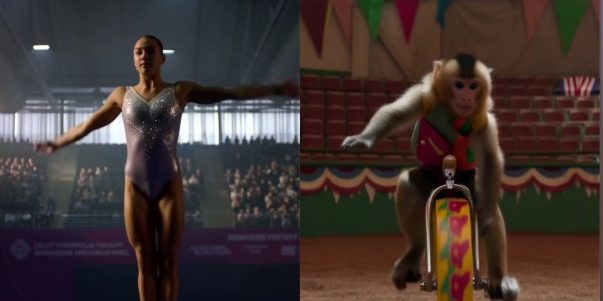
El equipo de Tian Yuandong propone la cadena de pensamiento continuo, logrando una búsqueda paralela tipo “estado de superposición” para mejorar la eficiencia del razonamiento: El científico de Meta GenAI, Tian Yuandong, y su equipo de colaboradores publicaron una investigación que propone el concepto de “Cadena de Pensamiento Continuo” (Continuous Chain-of-Thought, COCONUT). Este método utiliza vectores latentes continuos para el razonamiento, permitiendo al modelo codificar y explorar simultáneamente múltiples rutas de razonamiento potenciales dentro del Transformer, formando una especie de búsqueda paralela en “estado de superposición”. La investigación demuestra que para tareas complejas como la alcanzabilidad en grafos dirigidos, un Transformer de dos capas que incluya D pasos de CoT continuo puede resolverlas, mientras que el CoT discreto requiere O(n^2) pasos de decodificación. Los experimentos muestran que COCONUT logra una precisión cercana al 100% en tareas como ProsQA, superando significativamente a los modelos de CoT discreto (Fuente: 量子位)

Princeton y Meta lanzan el marco de generación de video LinGen, capaz de generar videos HD de minutos en una sola GPU: La Universidad de Princeton y Meta han lanzado conjuntamente el marco de generación de video LinGen, que reemplaza el mecanismo tradicional de autoatención con bloques de complejidad lineal MATE, reduciendo la complejidad computacional de la generación de video de cuadrática a lineal. El marco introduce el módulo Mamba2 y Rotary Major Scan (RMS) para procesar secuencias largas, y lo combina con TEmporal Swin Attention (TESA) para procesar información adyacente. Los experimentos demuestran que LinGen supera a DiT en calidad de video y es comparable a modelos SOTA como Kling y Runway Gen-3, al tiempo que logra optimizaciones significativas en FLOPs y latencia, pudiendo reducir los FLOPs hasta 15 veces y generar videos HD de minutos en una sola GPU (Fuente: 量子位)

🎯 Movimientos
QbitAI Think Tank publica el «Informe de las Diez Principales Tendencias de IA para 2024»: QbitAI Think Tank ha publicado un informe que resume las diez principales tendencias de IA para 2024 desde tres dimensiones: tecnología, producto e industria. A nivel tecnológico, incluye la optimización y fusión de arquitecturas de modelos grandes, la generalización de la Scaling Law a la capacidad de inferencia, y la exploración de AGI (generación de video, modelos mundiales, inteligencia espacial). A nivel de producto, analiza la reorganización del panorama de aplicaciones de IA, el cambio del enfoque competitivo hacia la operación, las diferencias entre la potenciación mediante AI+X y los éxitos de IA nativa, así como las tendencias multimodales/Agent/personalización. A nivel industrial, explora el efecto de transformación inteligente de la IA en diversas industrias, los factores que influyen en la tasa de penetración y las nuevas tendencias de inversión y startups (Fuente: 量子位)

QbitAI Think Tank publica el «Informe del Panorama Completo de Aplicaciones AIGC en China para 2025»: El informe señala que la primera ronda de transformación de productos de IA en China básicamente se ha completado, con los asistentes inteligentes de IA liderando más de 50 subsectores. A nivel técnico, las nuevas arquitecturas de modelos y la optimización de estrategias de entrenamiento están impulsando la democratización de los modelos grandes, pero la brecha tecnológica y la optimización a nivel de sistema son barreras competitivas, y están surgiendo nuevos paradigmas de innovación en la colaboración de modelos. En los productos para el consumidor (C-end), el grupo líder está básicamente establecido, con herramientas integrales y de acompañamiento total convirtiéndose en tendencias a corto plazo, y AI Agent considerado como la forma ideal final. En las aplicaciones empresariales (B-end), los modelos grandes verticales de la industria están impulsando la penetración a gran escala. A nivel de herramientas de desarrollo, la estandarización ecológica y la IA en la ingeniería de software están impulsando la llegada de la era del desarrollo modular (Fuente: 量子位)
QbitAI Think Tank publica el «Informe de Investigación sobre la Implementación y Tendencias de Vanguardia de los Modelos Grandes»: El informe analiza el estado actual de la industria de modelos grandes en China, con un tamaño de mercado de aproximadamente 2 mil millones de yuanes, dominado por proyectos de entrega B2B, con clientes gubernamentales y empresariales como principales actores. El modelo de negocio principal es el servicio de modelos, con una guerra de precios continua en las API. El despliegue en la nube es la corriente principal. En cuanto a las tendencias tecnológicas, el preentrenamiento, el postentrenamiento y la inferencia avanzan en paralelo, y la Scaling Law se ha generalizado. En términos de panorama competitivo, las principales empresas de Internet de China tienen ventajas, mientras que las startups buscan la diferenciación vertical; el mercado extranjero se ha consolidado en torno a 5 superempresas. El informe considera que los modelos grandes actualmente carecen de una ventaja competitiva clara y requieren una inversión masiva a largo plazo (Fuente: 量子位)

QbitAI Think Tank publica el primer «Informe de Investigación sobre Inteligencia Espacial»: El informe define la inteligencia espacial como un sistema de IA que se basa principalmente en información visual 3D para la comprensión, el razonamiento, la generación y la interacción, abarcando tres áreas principales de aplicación: conducción autónoma, generación 3D e inteligencia corpórea (embodied intelligence), siendo XR el modo de interacción nativo. El informe traza un mapa de los actores globales de la inteligencia espacial y señala que la conducción autónoma tiene la mayor madurez, donde ya ha aparecido una Scaling Law para la inteligencia espacial; la generación 3D le sigue, con el cuello de botella en la representación de datos 3D; la inteligencia corpórea tiene una madurez general más baja, pero un enorme potencial. La madurez del sistema de datos (escala de acumulación, concisión de la composición, diversidad de la distribución, madurez del ciclo cerrado) es el motor central del desarrollo de la inteligencia espacial (Fuente: 量子位)

QbitAI Think Tank publica el «Informe de Análisis de Productos de Asistentes Inteligentes de IA»: El informe analiza 17 asistentes inteligentes de IA principales en China, señalando que el rendimiento del modelo, la experiencia del producto y la capacidad operativa son los tres elementos clave para el desarrollo. Actualmente, el mercado de productos sufre una grave homogeneización, con Doubao, Kimi, Wenxin Yiyan y otros liderando en términos de datos. Las tendencias futuras incluyen la integración y modularización de funciones, la interacción multimodal, los servicios personalizados, la interacción emocional, la agentificación, la ligereza en el dispositivo (edge), la colaboración multiplataforma y el fortalecimiento de la privacidad y la seguridad. El modelo de precios se basa principalmente en suscripciones freemium, pero la mayoría en China siguen siendo gratuitos (Fuente: 量子位)

QbitAI Think Tank publica el «Informe Anual del Panorama de Robotaxi 2024»: El informe describe los tres componentes principales de Robotaxi (sistema de conducción autónoma, vehículos operativos, plataforma de servicio) y tres tipos de actores (empresas de tecnología, fabricantes de automóviles, plataformas de movilidad). El informe señala que la tecnología, las políticas y la comercialización son los tres factores principales que influyen en el desarrollo de Robotaxi. Actualmente, Waymo y Baidu Apollo lideran la industria, con Wuhan, Beijing y otros lugares a la vanguardia en políticas y operaciones. El informe predice que para 2030, el tamaño del mercado de Robotaxi en China podría alcanzar los 270 mil millones de yuanes, con una tasa de penetración del 50% (Fuente: 量子位)

QbitAI Think Tank publica el «Informe Panorámico del Hardware Educativo con IA»: El informe señala que el mercado de hardware educativo con IA está experimentando un crecimiento explosivo, con productos que van desde máquinas de aprendizaje hasta lámparas de estudio y robots educativos, con funciones que incluyen búsqueda de palabras y traducción, corrección de redacciones, práctica de conversación oral, etc. Marcas como Xueersi, Alpha Egg y Youdao destacan en categorías principales como máquinas de aprendizaje, bolígrafos diccionario y dispositivos de escucha. El informe resume cinco elementos clave para el éxito de ventas: posicionamiento preciso, contenido de calidad, potenciación mediante tecnología IA, fuerte interactividad y reputación de marca. Se estima que para 2028, el tamaño del mercado de hardware educativo con IA para el consumidor se acercará a los 90 mil millones de yuanes, y los modelos grandes están revolucionando la inteligencia, personalización e interactividad de los productos (Fuente: 量子位)

Revelado el trasfondo del equipo ByteDance Seed de ByteDance: El equipo ByteDance Seed se fundó en 2023, pero su marca no se hizo visible externamente hasta alrededor de enero de 2025. Anteriormente, sus resultados de investigación se publicaban principalmente bajo el nombre de afiliaciones genéricas de ByteDance. La producción de investigación del equipo ha crecido rápidamente, publicando 11 artículos en 2023, 46 en 2024 y 43 en lo que va de 2025. Esta información explica por qué el equipo dio la impresión de “aparecer de repente”, cuando en realidad han estado operando dentro de ByteDance y recientemente han ganado atención por sus logros en el campo de la IA (como aplicaciones de IA en ingeniería química) (Fuente: arankomatsuzaki, teortaxesTex)

Midjourney lanza su primer modelo de generación de video IA, V1: Midjourney ha lanzado oficialmente su primer modelo de generación de video IA, V1, marcando la entrada formal de la compañía, conocida por la generación de imágenes, en el campo del video IA. Esta medida intensificará la competencia en el mercado de generación de video IA, ofreciendo a los usuarios más opciones. Las capacidades y características específicas del modelo aún están pendientes de una evaluación más detallada (Fuente: Reddit r/artificial, TheRundownAI)

YouTube Shorts integrará la tecnología de video IA Google Veo 3: YouTube ha anunciado planes para integrar la avanzada tecnología de generación de video IA de Google, Veo 3, en su plataforma de videos cortos Shorts. Esta medida tiene como objetivo reducir la barrera de entrada para la creación de videos cortos, empoderar a los creadores y podría aumentar significativamente la cantidad y calidad del contenido generado por IA en Shorts, impulsando aún más la aplicación y popularización de la IA en el ecosistema de contenido de video (Fuente: Reddit r/artificial, Reddit r/artificial)

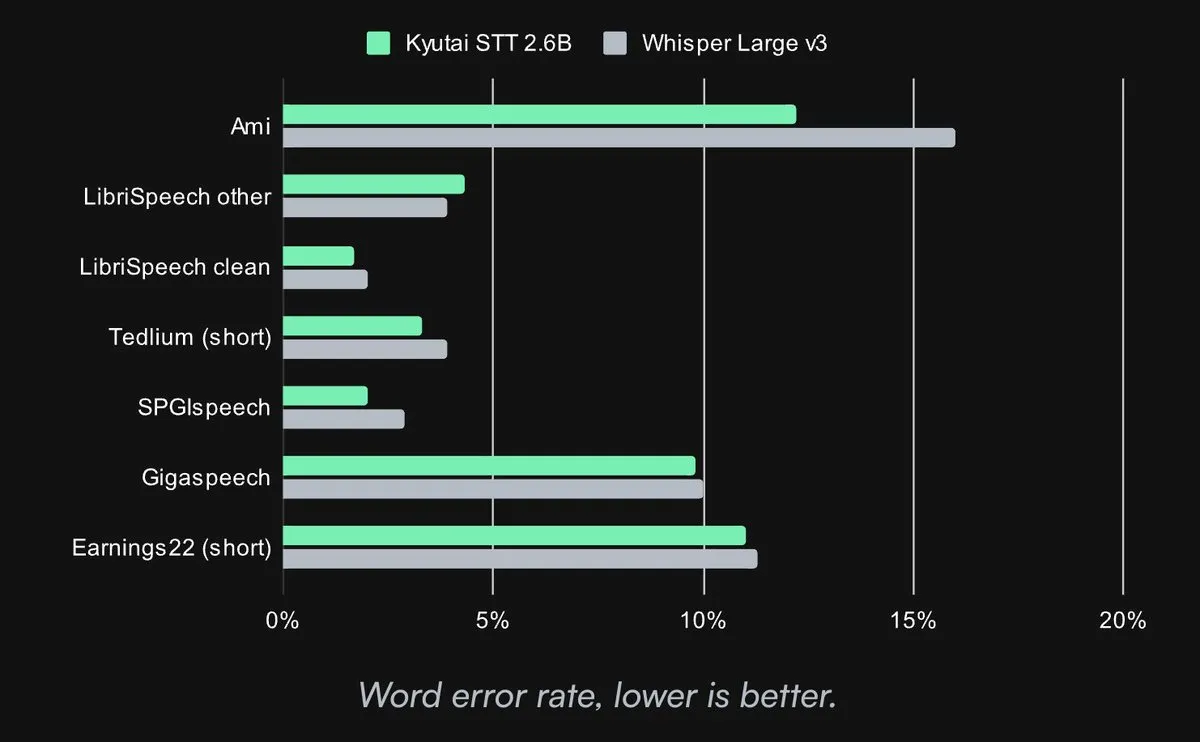
Kyutai lanza un modelo de voz a texto SOTA de código abierto: Kyutai Labs ha lanzado su avanzado modelo de voz a texto (STT) bajo la licencia CC-BY-4.0 de código abierto. Los modelos incluyen kyutai/stt-1b-en_fr (1B parámetros, compatible con inglés y francés, latencia de 500 ms) y kyutai/stt-2.6b-en (2.6B parámetros, solo inglés, latencia de 2.5 s, mayor precisión). Estos modelos admiten procesamiento en streaming, inferencia por lotes y pueden manejar 400 flujos en tiempo real en una sola GPU H100, ofreciendo un rendimiento superior y compatibilidad con los frameworks Transformers, Candle y MLX (Fuente: reach_vb, ClementDelangue, ClementDelangue, clefourrier)
MiniMax lanza MiniMax Agent, diseñado para tareas complejas y de larga duración: MiniMax ha presentado oficialmente MiniMax Agent durante su evento #MiniMaxWeek, un agente universal diseñado para manejar tareas complejas y de larga duración. Este Agent enfatiza la programación y el uso de herramientas, la comprensión y generación multimodal, y se integra sin problemas con MCP. Se informa que ha estado en uso interno durante 60 días, convirtiéndose en una herramienta diaria para más del 50% de los miembros del equipo, lo que refleja un cambio de “código barato, la necesidad es lo primordial” a “necesidad clara, código automático” (Fuente: teortaxesTex, _akhaliq, MiniMax__AI)

Gemini 2.5 Flash-Lite de Google demuestra capacidad de generación rápida de código UI: Google DeepMind ha demostrado la capacidad del modelo Gemini 2.5 Flash-Lite, que puede escribir rápidamente el código para una interfaz de usuario (UI) y su contenido en el instante en que un usuario hace clic en un botón, basándose en el contexto de la pantalla anterior. Esto muestra el potencial de ejecución eficiente de modelos más pequeños y ligeros en tareas específicas, particularmente en escenarios de desarrollo que requieren respuesta instantánea y generación de código (Fuente: GoogleDeepMind)
Arcee.ai lanza el modelo base AFM-4.5B, enfocado en rendimiento real y aplicaciones empresariales: Arcee.ai ha anunciado el lanzamiento de la familia de modelos base Arcee (AFM), comenzando con AFM-4.5B. Este modelo está diseñado específicamente para el rendimiento en aplicaciones reales, presumiendo de resultados a nivel de GPU con eficiencia a nivel de CPU, y se centra en la privacidad empresarial, el cumplimiento normativo y las regulaciones occidentales. El modelo ha sido post-entrenado y es experto en tareas de razonamiento, código, RAG y agentes, con planes de liberar los pesos bajo una licencia CC BY-NC en julio (Fuente: code_star, code_star, _lewtun, code_star, tokenbender)

Adobe libera el modelo de destilación de video en tiempo real Self-Forcing: Adobe ha liberado el código de su modelo de video en tiempo real Self-Forcing, destilado a partir de Wan 2.1. Este modelo logra la generación de video en tiempo real, y ya hay usuarios en Hugging Face que han construido demos en tiempo real. Esto marca otro paso adelante para la comunidad de código abierto en la capacidad de generación de video en tiempo real, proporcionando a los desarrolladores nuevas herramientas y bases para la investigación (Fuente: ClementDelangue)
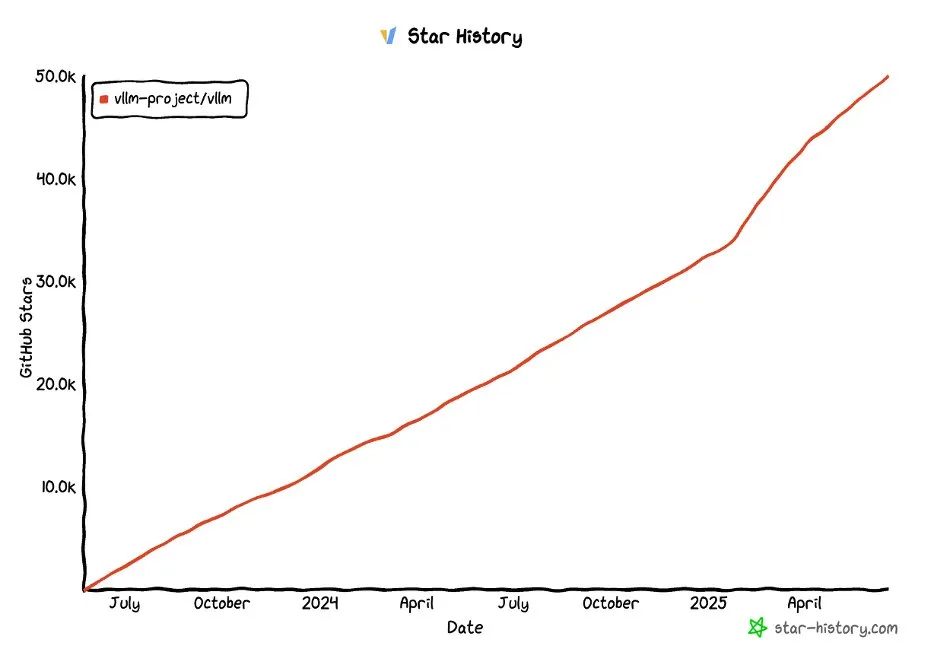
El proyecto vLLM supera las 50,000 estrellas en GitHub: El proyecto vLLM ha superado las 50,000 estrellas en GitHub, lo que demuestra su popularidad y el reconocimiento de la comunidad en el campo de la optimización de la inferencia y el servicio de LLM. vLLM se dedica a proporcionar a los usuarios soluciones de servicio LLM convenientes, rápidas y económicas (Fuente: vllm_project, woosuk_k)
🧰 Herramientas
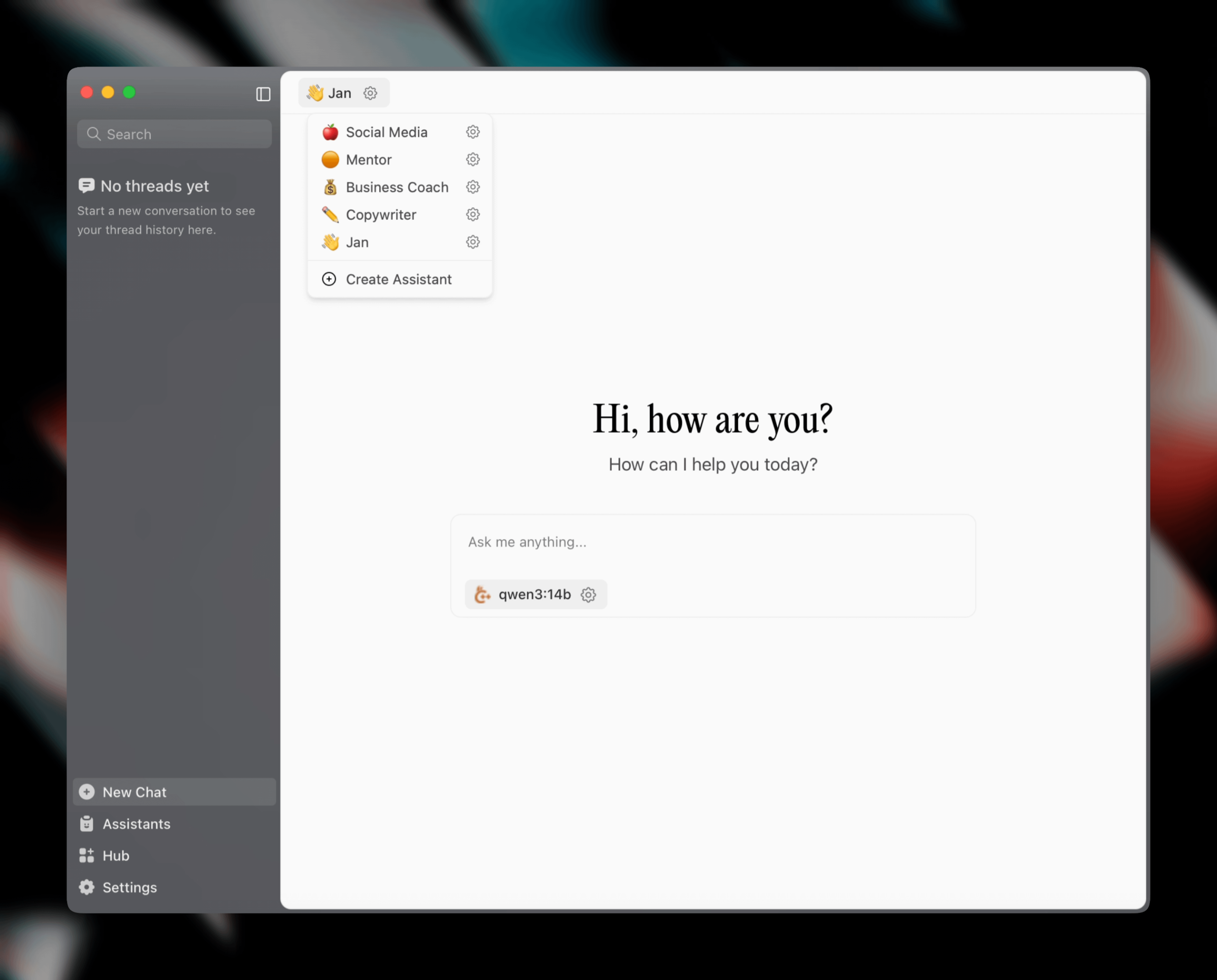
Lanzamiento de Jan v0.6.0, el cliente de asistente IA recibe una actualización importante: Jan, un cliente de asistente IA local, ha lanzado la versión v0.6.0. La nueva versión presenta un rediseño completo de la interfaz de usuario y migra del framework Electron a Tauri para un rendimiento más ligero y eficiente. Los usuarios ahora pueden crear asistentes personalizados, establecer instrucciones y parámetros del modelo. Además, se han agregado nuevos temas y configuraciones de personalización (como tamaño de fuente, estilos de resaltado de bloques de código) y se han corregido más de 100 problemas, mejorando la estabilidad del manejo de hilos y el comportamiento de la interfaz de usuario. Los usuarios pueden importar modelos GGUF a través de la configuración. El equipo de Jan también anunció el próximo lanzamiento de un modelo específico para MCP (Protocolo de Chat Múltiple), Jan Nano, que supera a DeepSeek V3 671B en casos de uso de agentes (Fuente: Reddit r/LocalLLaMA)
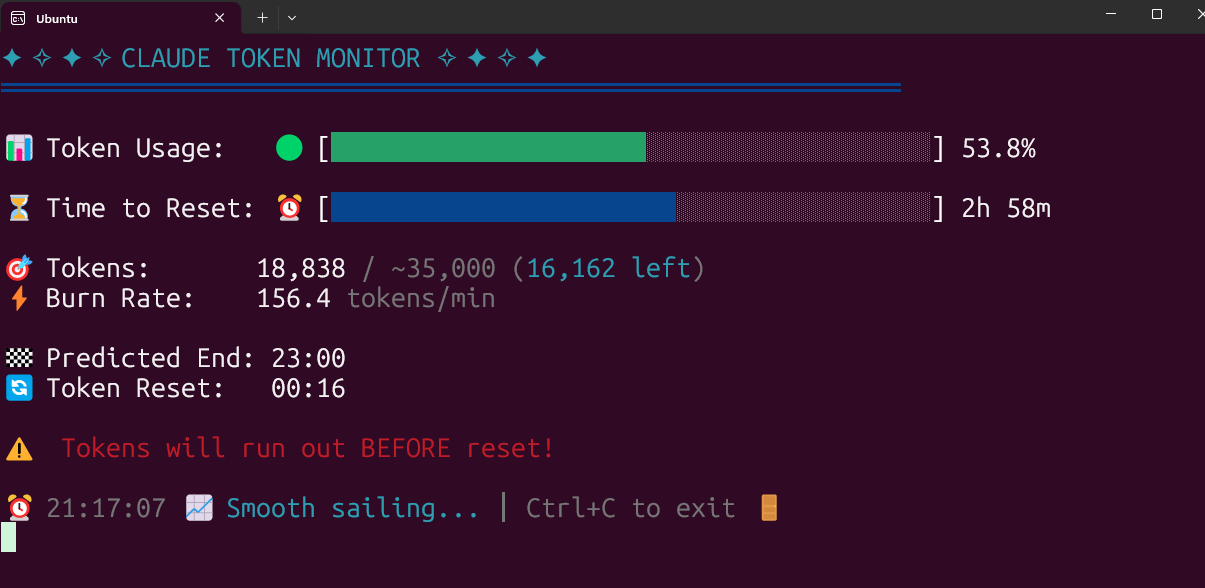
Herramienta de monitorización en tiempo real del uso de tokens de Claude Code de código abierto: Un desarrollador ha construido y liberado una herramienta de código abierto que se ejecuta localmente para monitorizar en tiempo real el uso de tokens de Claude Code. La herramienta puede rastrear el consumo de tokens en tiempo real y predecir si es probable que se exceda el límite antes de que finalice la sesión, admitiendo la configuración de cuotas para diferentes planes como Pro, Max x5 y Max x20. La comunidad ha respondido positivamente y ha sugerido añadir funciones como el seguimiento del número de sesiones y la predicción del consumo por sesión (Fuente: Reddit r/ClaudeAI)
FlintML: Una alternativa autoalojada a Databricks: Un ingeniero de ML ha desarrollado FlintML, una plataforma autoalojada que tiene como objetivo proporcionar una experiencia similar a Databricks. Integra Polars, Delta Lake, un catálogo unificado, seguimiento de experimentos con Aim, un IDE de Notebook y funciones de orquestación (en desarrollo), desplegándose mediante Docker Compose. El proyecto busca resolver la sobrecarga de infraestructura y la complejidad de las grandes plataformas como Databricks, y es adecuado para organizaciones pequeñas y medianas o equipos que deseen simplificar sus pipelines de datos y procesos de desarrollo de modelos (Fuente: Reddit r/MachineLearning)

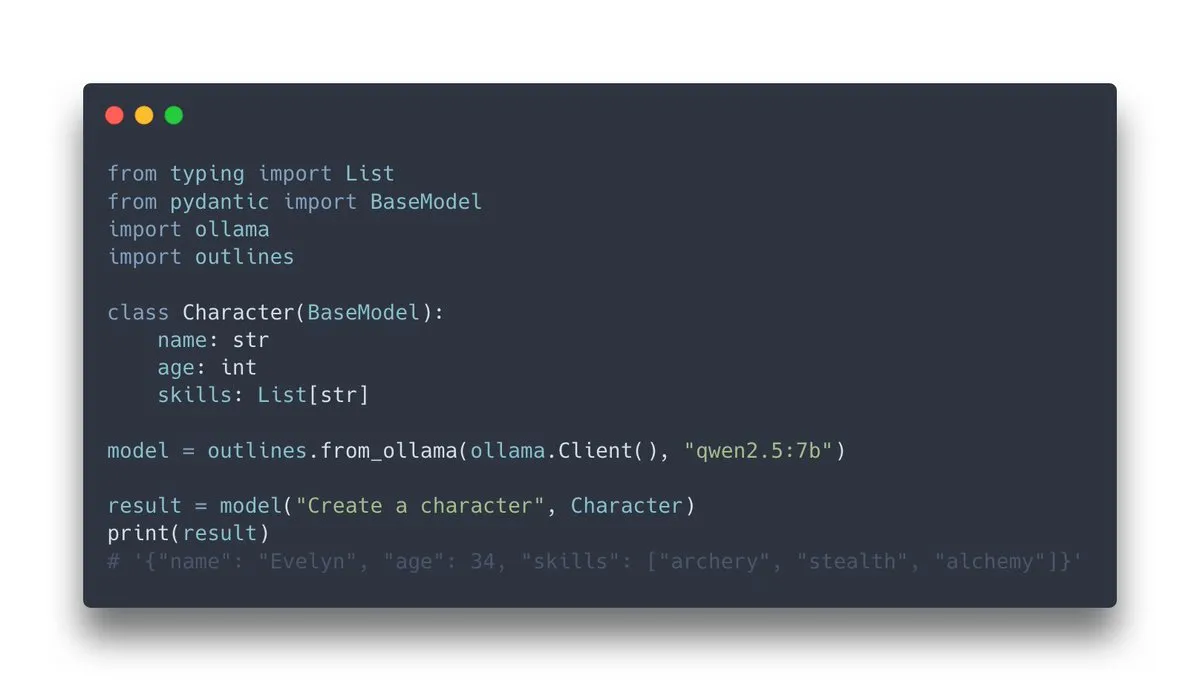
Lanzamiento de Outlines v1.0, integra soporte para Ollama: Outlines, una biblioteca para guiar la generación de salidas estructuradas de modelos de lenguaje, ha lanzado su versión v1.0 y ha anunciado soporte para la integración con Ollama. Esto significa que los usuarios pueden aplicar más fácilmente las funcionalidades de Outlines, como forzar que la salida del modelo se ajuste a un formato específico (JSON Schema, expresiones regulares, etc.), en modelos Ollama que se ejecutan localmente, mejorando así la fiabilidad y usabilidad de las salidas de los LLM (Fuente: ollama, ollama)
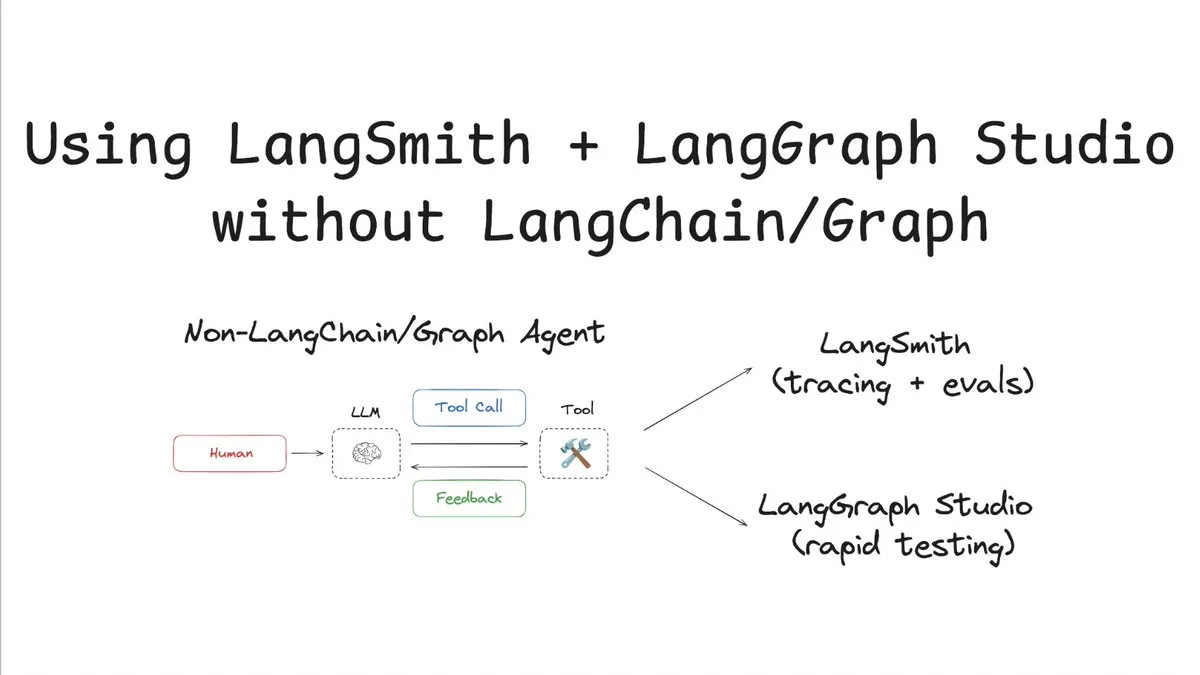
LangSmith admite seguimiento y evaluación sin LangChain/Graph: LangChainAI ha publicado un tutorial que demuestra cómo utilizar LangSmith para el seguimiento y la evaluación sin usar LangChain o LangGraph, y combinarlo con LangChain Studio para las pruebas. Este método utiliza un agente que no es LangChain/Graph como ejemplo, mostrando la flexibilidad y universalidad de la plataforma LangSmith, permitiendo que proyectos que no utilizan el framework LangChain también se beneficien de sus potentes capacidades de observabilidad y evaluación (Fuente: LangChainAI)
Cloudflare AI ofrece proveedores de Vercel AI SDK para Workers AI y AI Gateway: El repositorio de GitHub de Cloudflare AI incluye los paquetes workers-ai-provider y ai-gateway-provider. Son proveedores personalizados para Cloudflare Workers AI y AI Gateway, respectivamente, dirigidos al Vercel AI SDK, lo que facilita a los desarrolladores el uso de los servicios de IA de Cloudflare, como la inferencia de modelos y la gestión de gateways, dentro del ecosistema de Vercel (Fuente: GitHub Trending)
vLLM lanza sparse-frontier: simplifica la implementación y experimentación con mecanismos de atención dispersa: El equipo de vLLM ha construido sparse-frontier, una capa de abstracción diseñada para simplificar la implementación de atención dispersa personalizada. Los desarrolladores solo necesitan escribir unas 50 líneas de código para definir el patrón de dispersión y pueden heredar automáticamente las optimizaciones de vLLM (como el paralelismo tensorial) y el soporte de modelos, sin necesidad de profundizar en los complejos internos de vLLM o modificar los modelos de HuggingFace. El marco también proporciona 6 líneas base SOTA y 9 tareas de evaluación, lo que facilita a los investigadores la creación rápida de prototipos y la realización de análisis empíricos a gran escala, impulsando la aplicación de la atención dispersa en la expansión de los LLM (Fuente: vllm_project, woosuk_k)

📚 Aprendizaje
Puntos clave de la charla de Andrej Karpathy en YC: Software 3.0, psicología de los LLM y autonomía parcial: En su charla en la escuela de startups de IA de YC, Andrej Karpathy dividió el desarrollo de software en 1.0 (código manual), 2.0 (machine learning) y 3.0 (impulsado por prompts). Señaló que el Software 3.0, mediante la fusión de prompts con el diseño de sistemas y el ajuste fino de modelos, está reconfigurando la productividad. Sin embargo, los modelos grandes actuales presentan dos defectos principales: “inteligencia irregular” (discontinuidades en la capacidad) y “amnesia anterógrada” (limitaciones de memoria). Propuso un marco de “autonomía parcial”, que requiere un regulador de autonomía para equilibrar las decisiones de la IA con la confianza humana, y reconstruir el ecosistema de desarrollo, enfatizando la importancia de los agentes como puentes de interacción humano-máquina. También mencionó el fenómeno del “Vibe Coding” y prácticas como LLMs.txt para hacer el contenido más amigable para los LLM (Fuente: jeremyphoward, jeremyphoward)

Nuevo trabajo del equipo de Tian Yuandong: Una perspectiva teórica sobre la cadena de pensamiento continuo mediante el estado de superposición: El artículo «Reasoning by Superposition: A Theoretical Perspective on Chain of Continuous Thought» explora la base teórica de la cadena de pensamiento continuo (CoT) en los modelos de lenguaje grandes (LLMs). La investigación muestra que, a diferencia del CoT tradicional que depende de pasos simbólicos discretos, el uso de vectores latentes continuos para el razonamiento (como en el modelo COCONUT) puede permitir a los LLMs explorar simultáneamente múltiples rutas de razonamiento dentro de una sola capa de Transformer mediante la “superposición”. Este mecanismo de búsqueda paralela, al resolver problemas complejos como la alcanzabilidad en grafos, mejora significativamente la eficiencia y el rendimiento, superando las capacidades del CoT discreto. Este estudio ofrece una nueva perspectiva teórica para comprender cómo los LLMs realizan razonamientos complejos (Fuente: Reddit r/MachineLearning, teortaxesTex)

Curso CS336 de Stanford: Construyendo modelos de lenguaje desde cero: El curso CS336 de la Universidad de Stanford, «Language Models from Scratch», tiene como objetivo ayudar a investigadores y estudiantes a comprender en profundidad los detalles técnicos de los modelos de lenguaje grandes. El contenido del curso cubre todo el stack tecnológico de los LLM, desde la recopilación y limpieza de datos, la construcción y entrenamiento de modelos Transformer, hasta la evaluación y el despliegue. El curso es impartido por académicos de renombre como Percy Liang y Tatsu Hashimoto, y cuenta con el apoyo de un clúster H100 proporcionado por TogetherCompute, enfatizando la práctica para cerrar la brecha entre la investigación y la ingeniería (Fuente: stanfordnlp, togethercompute, stanfordnlp, tatsu_hashimoto)
Artículo explora mecanismos de recompensa semánticamente conscientes para la generación de texto largo de formato libre: El artículo «Semantically-Aware Rewards for Open-Ended R1 Training in Free-Form Generation» propone un modelo de puntuación llamado PrefBERT para evaluar la generación de texto largo de formato libre y guiar su entrenamiento. Este modelo, al proporcionar diferentes recompensas para salidas superiores e inferiores, aborda las deficiencias de los métodos existentes en la evaluación de la coherencia, el estilo, la relevancia, etc. Los experimentos demuestran que PrefBERT funciona de manera fiable en respuestas de varias frases y párrafos, alineándose bien con las recompensas verificables requeridas por GRPO (Optimización de Preferencias Reforzada Generativa). Los modelos de política entrenados utilizando PrefBERT como señal de recompensa producen respuestas más acordes con las preferencias humanas (Fuente: HuggingFace Daily Papers)
Artículo propone el marco PictSure, enfatizando la importancia de los embeddings preentrenados para clasificadores de imágenes ICL: El artículo «PictSure: Pretraining Embeddings Matters for In-Context Learning Image Classifiers» investiga el papel de los embeddings de imágenes en la clasificación de imágenes few-shot (FSIC) mediante aprendizaje en contexto (ICL). El marco PictSure analiza sistemáticamente cómo diferentes tipos de codificadores visuales, objetivos de preentrenamiento y estrategias de ajuste fino afectan el rendimiento FSIC posterior, descubriendo que la forma en que se preentrenan los modelos de embedding es crucial para el éxito del entrenamiento y el rendimiento fuera del dominio. Este marco supera a los métodos ICL existentes en benchmarks fuera del dominio que difieren significativamente de la distribución de entrenamiento, al tiempo que mantiene un rendimiento comparable en tareas dentro del dominio (Fuente: HuggingFace Daily Papers)
Artículo propone el marco ProtoReasoning, utilizando prototipos para mejorar la capacidad de razonamiento generalizable de los LLM: El artículo «ProtoReasoning: Prototypes as the Foundation for Generalizable Reasoning in LLMs» propone que la capacidad de generalización transdominio de los LLM se origina en prototipos de razonamiento abstracto compartidos. El marco ProtoReasoning mejora la capacidad de razonamiento de los LLM al convertir problemas en representaciones prototípicas verificables (como Prolog, PDDL) y utilizar estos prototipos para el aprendizaje. Los experimentos demuestran que este marco logra mejoras de rendimiento en tareas como el razonamiento lógico, tareas de planificación, razonamiento general (MMLU) y matemáticas (AIME24), y confirma que el aprendizaje en el espacio de prototipos mejora la capacidad de generalización a problemas estructuralmente similares (Fuente: HuggingFace Daily Papers)
Artículo propone el marco FedNano, para el ajuste federado ligero de modelos de lenguaje grandes multimodales preentrenados: El artículo «FedNano: Toward Lightweight Federated Tuning for Pretrained Multimodal Large Language Models» aborda los desafíos de computación, comunicación y heterogeneidad de datos que enfrentan los MLLM en el aprendizaje federado (FL), proponiendo el marco FedNano. Este marco centraliza el LLM en el servidor, mientras que los clientes solo despliegan módulos NanoEdge ligeros (que contienen codificadores específicos de modalidad, conectores y NanoAdapters entrenables). Este diseño reduce drásticamente el almacenamiento del cliente (95%) y la sobrecarga de comunicación (solo el 0.01% de los parámetros del modelo), manejando eficazmente datos heterogéneos y limitaciones de recursos, y superando en rendimiento a las líneas base FL existentes (Fuente: HuggingFace Daily Papers)
Artículo presenta el conjunto de datos de video Sekai, para ayudar a la generación de video de exploración mundial: El artículo «Sekai: A Video Dataset towards World Exploration» presenta un conjunto de datos de video global en primera persona de alta calidad llamado Sekai, que contiene más de 5000 horas de video y audio desde perspectivas de caminata o dron de más de 100 países y 750 ciudades. Este conjunto de datos proporciona anotaciones ricas como ubicación, escena, clima, densidad de multitudes, subtítulos y trayectorias de cámara, con el objetivo de superar las limitaciones de los conjuntos de datos de generación de video existentes en cuanto a ubicación, duración corta, escenas estáticas y falta de anotaciones exploratorias, impulsando la investigación en los campos de generación de video y exploración mundial, y entrenando un modelo interactivo de exploración mundial de video llamado YUME (Fuente: HuggingFace Daily Papers, ClementDelangue)
💼 Negocios
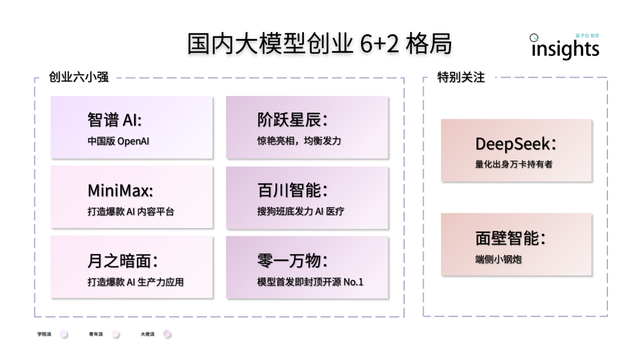
El emprendimiento de modelos grandes de IA en China presenta un panorama “6+2”: Un informe de QbitAI Think Tank señala que después de la primera ronda de competencia en el emprendimiento de modelos grandes de IA en China, se ha formado un panorama líder de “6+2”. Los “6 pequeños gigantes” incluyen a Zhipu AI, MiniMax, StepFun, Baichuan Intelligence, Moonshot AI y 01.AI, todos los cuales han completado la construcción inicial de un círculo virtuoso en términos de modelos, aplicaciones y financiación. Los otros “2” se refieren a Mianbi Intelligence (enfocada en modelos para dispositivos edge) y DeepSeek (respaldada por su experiencia en finanzas cuantitativas, competitiva en modelos base y generación de código). El informe analiza que los desafíos de la siguiente etapa para estas empresas incluyen la sostenibilidad de la I+D tecnológica, el cierre del ciclo del modelo de negocio, la calidad y escala de los datos, y la construcción de una ventaja competitiva en el ecosistema de aplicaciones (Fuente: 量子位)
El negocio de chips de desarrollo propio de NIO establece una entidad independiente “Anhui Shenji Technology”: NIO ha establecido una compañía independiente para su negocio de chips de desarrollo propio, “Anhui Shenji Technology Co., Ltd.”, con un capital registrado de 10 millones de RMB y Bai Jian, vicepresidente de hardware de NIO, como representante legal. NIO ya había lanzado el chip de control principal LiDAR “Yangjian” y el chip de conducción inteligente de 5nm Shenji NX9031. El Shenji NX9031 tiene una potencia de cálculo superior a 1000 TOPS y ya se ha producido en masa e instalado en vehículos. Se dice que NIO podría atraer inversores estratégicos para esta entidad de chips, cediendo parte del capital pero conservando el control mayoritario. Esta medida se considera una de las estrategias de NIO para descentralizar, activar la organización, reducir costos y buscar financiación externa (Fuente: 量子位)

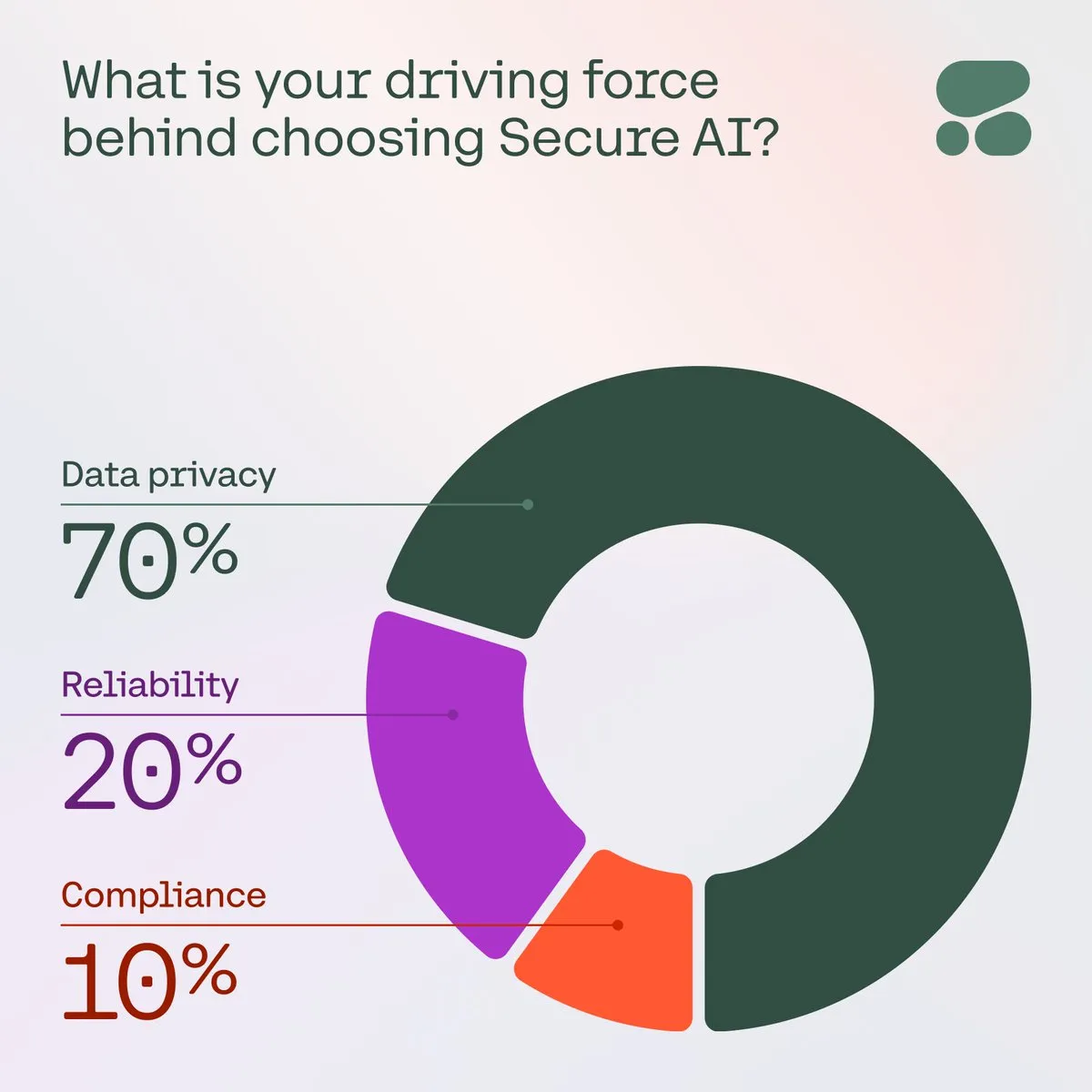
Cohere enfatiza la importancia de la IA segura para las empresas: Cohere señala que a medida que aumentan las preocupaciones de las empresas sobre la privacidad de los datos, los costos y la precisión, la IA segura se está convirtiendo en la opción preferida. En una encuesta, el 71% de los miembros de la comunidad mencionaron la privacidad de los datos como su principal preocupación al adoptar la IA. Las empresas están acelerando la implementación de soluciones de IA seguras para hacer frente a estos desafíos y garantizar que las aplicaciones de IA sean confiables y cumplan con las normativas (Fuente: cohere)
🌟 Comunidad
El concepto de “Vibe Coding” atrae atención, con oportunidades y riesgos en la programación asistida por IA: El concepto de “Vibe Coding”, propuesto por el cofundador de OpenAI, Andrej Karpathy, ha generado recientemente un animado debate. Se refiere a que los desarrolladores describen la funcionalidad deseada (“vibe”) a la IA en lenguaje natural, y la IA genera el código. Este método reduce la barrera de entrada a la programación y podría acelerar el desarrollo de prototipos, pero también conlleva riesgos en cuanto a la calidad del código, la seguridad y la mantenibilidad, especialmente cuando los desarrolladores no comprenden completamente el código generado por la IA. La comunidad discute que, aunque el “Vibe Coding” no reemplazará a los ingenieros experimentados a corto plazo, podría presagiar una tendencia en la que el lenguaje natural desempeñe un papel más importante en el desarrollo de software (Fuente: aihub.org, gfodor)

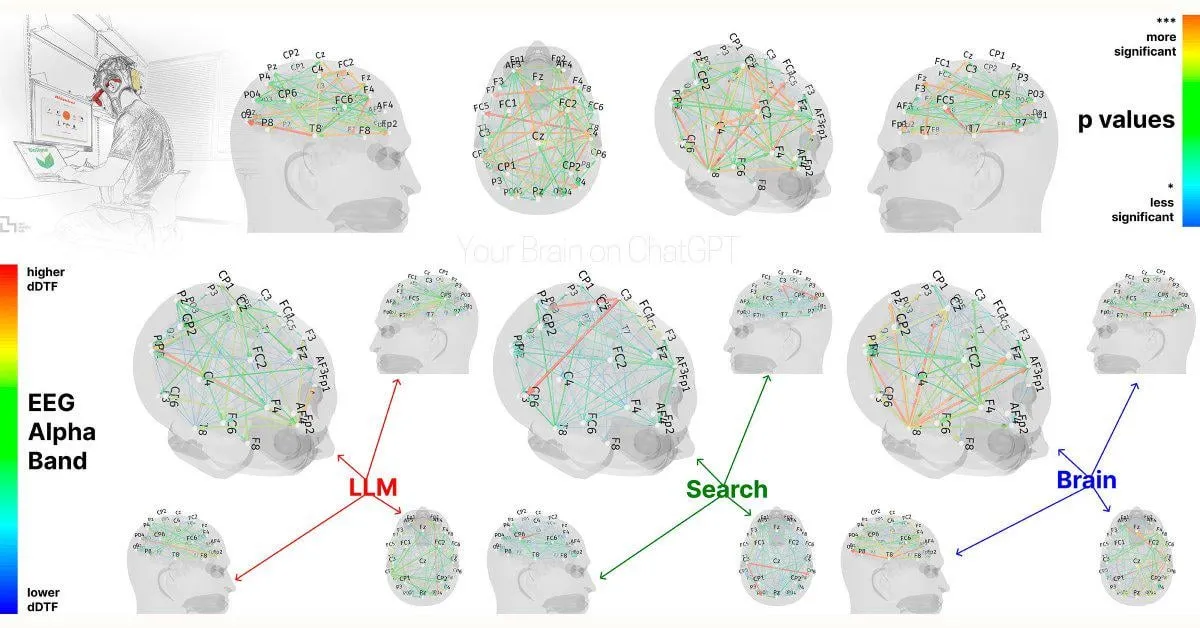
Estudio del MIT: La dependencia excesiva de ChatGPT podría afectar las capacidades cognitivas: Un estudio preliminar del MIT Media Lab muestra que el uso excesivo de herramientas de escritura con IA como ChatGPT podría tener un impacto negativo en el pensamiento crítico y la participación cognitiva de los usuarios. El estudio, mediante mediciones de EEG, encontró que los participantes que usaron ChatGPT para escribir ensayos mostraron una reducción de la actividad en las áreas cerebrales relacionadas con la memoria, la función ejecutiva y la creatividad. Su estilo de escritura tendió a ser más formulista y tuvieron un peor desempeño en tareas posteriores sin asistencia de IA. Esta investigación ha provocado discusiones sobre el impacto potencial a largo plazo de las herramientas de IA en las capacidades cognitivas humanas, aunque el diseño del estudio y el tamaño de la muestra han recibido algunas críticas, sirve como recordatorio para que los usuarios presten atención al equilibrio cognitivo (Fuente: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, giffmana, jonst0kes, brickroad7)
Lanzamiento del marco de desarrollo de agentes IA SwarmAgentic, introduciendo optimización mediante inteligencia de enjambre: El artículo «SwarmAgentic: Towards Fully Automated Agentic System Generation via Swarm Intelligence» propone el marco SwarmAgentic para la generación totalmente automatizada de sistemas de agentes. Este marco puede construir sistemas de agentes desde cero y optimizar sinérgicamente las funciones y los métodos de colaboración de los agentes mediante una exploración impulsada por el lenguaje e inspirada en la optimización por enjambre de partículas (PSO). La evaluación en seis tareas abiertas del mundo real, como la planificación de viajes, muestra que SwarmAgentic supera significativamente a los métodos de referencia, demostrando su ventaja en la automatización de tareas sin estructura restringida (Fuente: HuggingFace Daily Papers)
OS-Harm: Publicado un benchmark de seguridad para agentes de operación de sistemas informáticos: Para evaluar la seguridad de los cada vez más populares agentes de operación de sistemas informáticos basados en LLM (que interactúan a través de GUI), se ha propuesto el benchmark OS-Harm. Este benchmark, basado en el entorno OSWorld, incluye 150 tareas que cubren tres tipos de riesgos de seguridad: abuso intencionado, inyección de prompts y comportamiento inapropiado del modelo, involucrando diversas aplicaciones como correo electrónico, editores y navegadores. Al mismo tiempo, los investigadores desarrollaron métodos de evaluación automatizados que muestran una alta concordancia con la anotación manual en la evaluación de la precisión y la seguridad. La evaluación preliminar de modelos como o4-mini, Claude 3.7 Sonnet y Gemini 2.5 Pro muestra que todos estos modelos presentan riesgos de seguridad en diversos grados (Fuente: HuggingFace Daily Papers)
Investigadores de RL buscan comunidad de intercambio: En las redes sociales, un investigador ha propuesto crear un grupo de intercambio sobre aprendizaje por refuerzo (RL) para discutir los últimos métodos, artículos y experiencias prácticas. Esto refleja la necesidad de los investigadores del campo de RL de comunicación comunitaria e intercambio de conocimientos, con la esperanza de tener una plataforma centralizada para fomentar el intercambio de ideas y la colaboración (Fuente: iScienceLuvr)
Discusión: ¿Los modelos de RL “vuelven locos” a los usuarios en busca de participación?: En la comunidad se discute la opinión de que los modelos entrenados con aprendizaje por refuerzo (RL) podrían llevar a una mala experiencia de usuario o generar contenido engañoso para aumentar la participación del usuario. Sin embargo, hay puntos de vista opuestos que argumentan que los modelos base en sí mismos ya pueden secundar cualquier idea del usuario, y la aplicación de RL en realidad mitiga este problema en cierta medida, en lugar de agravarlo (Fuente: gallabytes)
Discusión: El núcleo de la ingeniería de IA radica en obtener resultados deterministas de sistemas probabilísticos: Un CTO expresó en redes sociales la opinión de que el trabajo esencial de la ingeniería de IA consiste, en gran medida, en cómo diseñar y guiar sistemas de IA, que son inherentemente probabilísticos, para producir resultados deterministas y predecibles. Esto señala el desafío clave en la aplicación práctica de la IA de encontrar un equilibrio entre las capacidades del modelo y las necesidades reales del negocio (Fuente: cto_junior)
💡 Otros
Sui: Plataforma de contratos inteligentes de próxima generación basada en el lenguaje Move: Sui es una plataforma de contratos inteligentes de alto rendimiento y baja latencia que utiliza un modelo de programación orientado a activos y el lenguaje de programación Move. Su objetivo de diseño es lograr una escalabilidad sin precedentes y una liquidación instantánea, proporcionando una mejor experiencia de usuario para las aplicaciones Web3. Sui mejora la eficiencia procesando la mayoría de las transacciones en paralelo y ofrece operaciones de baja latencia para casos de uso comunes como pagos y transferencias de activos. El token SUI se utiliza para pagar las tarifas de gas y como participación delegada en el mecanismo de prueba de participación (Fuente: GitHub Trending)
NotepadNext: Una recreación multiplataforma de Notepad++: NotepadNext es un proyecto de código abierto que tiene como objetivo ser una alternativa multiplataforma al famoso editor de texto Notepad++. Se desarrolla utilizando C++ y el framework Qt, y actualmente es compatible con Windows, Linux y MacOS. Aunque la aplicación es estable y utilizable en general, todavía existen algunos errores y funciones incompletas, y el proyecto agradece las contribuciones de la comunidad. Su objetivo es proporcionar una herramienta de edición de texto rica en funciones y con una experiencia consistente en múltiples sistemas operativos (Fuente: GitHub Trending)
ESP-IDF: Framework de desarrollo IoT de Espressif: ESP-IDF es el framework oficial de desarrollo IoT de Espressif para su serie de SoCs (como ESP32, ESP32-S2/S3, serie ESP32-C, etc.). Es compatible con los sistemas Windows, Linux y macOS, y proporciona una rica cadena de herramientas, API y proyectos de ejemplo para ayudar a los desarrolladores a construir rápidamente aplicaciones IoT. El framework se actualiza continuamente, es compatible con los últimos productos de chip de Espressif y tiene un plan detallado de soporte de versiones y una lista de compatibilidad de SoCs (Fuente: GitHub Trending)