

Palabras clave:benchmark GDPval de OpenAI, Claude Opus 4.1, GPT-5, evaluación de IA, rendimiento en tareas económicas, evaluación del impacto económico de modelos de IA, Claude Opus 4.1 vs GPT-5, pruebas de benchmark GDPval, capacidad de aplicación práctica de IA, comparación de rendimiento de IA en múltiples industrias
🔥 FOCUSED
OpenAI lanza el benchmark GDPval: Claude Opus 4.1 supera a GPT-5 : OpenAI ha lanzado el nuevo benchmark GDPval para evaluar el rendimiento de los modelos de AI en tareas económicas reales en 9 industrias y 44 profesiones. Los resultados iniciales muestran que Claude Opus 4.1 de Anthropic iguala o supera el nivel de expertos humanos en casi la mitad de las tareas, superando a GPT-5. OpenAI reconoce que Claude destaca en la expresión estética, mientras que GPT-5 lidera en precisión. Esto marca un cambio en la evaluación de la AI hacia la medición del impacto económico real y revela el rápido progreso de las capacidades de la AI. (Fuente: OpenAI, menhguin, MillionInt, _sholtodouglas, polynoamial, menhguin, aidan_mclau, sammcallister, menhguin, andy_l_jones, tokenbender, scaling01, scaling01, scaling01, scaling01, scaling01, scaling01, alexwei_, scaling01, scaling01, scaling01, gdb, teortaxesTex, snsf, dilipkay, scaling01, scaling01, jachiam0, jachiam0, sama, ClementDelangue, AymericRoucher, shxf0072, Reddit r/artificial, 36氪, 36氪, 36氪)

La “espiral de la perdición” de la AI y Wikipedia para las lenguas vulnerables : Los modelos de AI aprenden idiomas rastreando textos de internet, y Wikipedia suele ser la mayor fuente de datos en línea para las lenguas vulnerables. Sin embargo, una gran cantidad de contenido de baja calidad traducido por AI está inundando estas versiones más pequeñas de Wikipedia, lo que lleva a una proliferación de errores. Esto crea un círculo vicioso de “basura entra, basura sale”, que podría hacer que la AI sea aún menos fiable para traducir estos idiomas, acelerando así el declive de las lenguas vulnerables. La Wikipedia en groenlandés ha sido propuesta para su cierre debido a la “galimatías” causada por las herramientas de AI. Esto subraya el impacto negativo potencial de la AI en la diversidad cultural y la protección lingüística. (Fuente: MIT Technology Review, MIT Technology Review)

Song Yang, investigador principal de OpenAI, se une a Meta : Song Yang, jefe del equipo de exploración estratégica de OpenAI y colaborador clave en los modelos de difusión, se ha unido al equipo MSL de Meta, reportando a la científica jefa Zhao Shengjia. Song Yang es un genio precoz que ingresó a la Universidad de Tsinghua a los 16 años y es conocido en la industria por sus logros en OpenAI, como los consistency models, siendo considerado uno de los “cerebros más poderosos”. Este traspaso es otro evento significativo en la continua captación de talento de OpenAI por parte de Meta, lo que ha generado preocupación en la industria sobre la competencia por el talento en AI y las direcciones de investigación. (Fuente: 36氪, dotey, jeremyphoward, teortaxesTex)

China Telecom Tianyi AI lanza un conjunto de datos de alta calidad de más de 10 billones de Tokens : China Telecom Tianyi AI ha lanzado un conjunto de datos de corpus de modelos grandes generales con un almacenamiento total de 350 TB y más de 10 billones de tokens, así como conjuntos de datos especializados que cubren 14 industrias clave. Este conjunto de datos, meticulosamente anotado y optimizado, incluye datos multimodales de la industria y tiene como objetivo mejorar el rendimiento y la capacidad de generalización de los modelos de AI. China Telecom enfatiza que los conjuntos de datos de alta calidad son el combustible central para el desarrollo de la AI, y, basándose en la plataforma Starry MaaS, construye un ciclo cerrado de “datos-modelo-servicio”, comprometiéndose a promover el desarrollo inclusivo de la AI y la innovación nacional, habiendo entrenado con éxito modelos grandes con billones de parámetros. (Fuente: 量子位)

Guoxing Yuhang de China logra la primera operación comercial normalizada de una constelación de computación espacial a nivel mundial : Guoxing Yuhang de China ha lanzado y logrado la operación comercial normalizada de una constelación de computación espacial, marcando el paso de la computación espacial de “posible” a “utilizable”. Esta constelación, compuesta por los primeros satélites “Xingsuan”, tiene como objetivo construir una infraestructura de potencia de cálculo espacial de 2800 satélites, con una potencia de cálculo total de más de 100.000 P, capaz de ejecutar modelos de billones de parámetros. El éxito de desplegar un modelo de reconocimiento de carreteras en un satélite en órbita, completando todo el proceso desde la adquisición de imágenes hasta la inferencia del modelo y la transmisión de resultados, ha logrado la primera ejecución de un algoritmo de la industria del transporte en el espacio, proporcionando un nuevo paradigma para la extensión espacial de la infraestructura global de AI. (Fuente: 量子位)

China restringe la compra de chips Nvidia, acelerando la autosuficiencia en semiconductores : China ha prohibido a las principales empresas tecnológicas la compra de chips Nvidia, una medida que indica que China ha logrado suficientes avances en el campo de los semiconductores como para liberarse de la dependencia de los chips diseñados en EE. UU. Esto subraya la vulnerabilidad de EE. UU. en la fabricación de semiconductores en Taiwán y el aumento de la capacidad de autosuficiencia de China. Por ejemplo, el modelo DeepSeek-R1-Safe ha sido entrenado en 1000 chips Huawei Ascend. Jensen Huang de Nvidia también ha señalado que el 50% de los investigadores de AI del mundo provienen de China. (Fuente: AndrewYNg, Plinz)

🎯 TRENDS
ChatGPT Pulse lanzado, inaugurando la era de la inteligencia proactiva : OpenAI ha lanzado una vista previa de ChatGPT Pulse para usuarios Pro, una función que transforma ChatGPT de una herramienta de preguntas y respuestas pasiva a un asistente inteligente proactivo. Pulse genera resúmenes diarios personalizados en segundo plano, basándose en el historial de chat del usuario, comentarios y aplicaciones conectadas (como calendario, Gmail), presentándolos en formato de tarjetas. Su objetivo es proporcionar una experiencia de información con un propósito y no adictiva. Sam Altman lo ha calificado como su “función favorita”, lo que presagia un futuro en el que ChatGPT se orientará hacia servicios altamente personalizados y proactivos. (Fuente: Teknium1, openai, dejavucoder, natolambert, gdb, jam3scampbell, jam3scampbell, scaling01, sama, sama, scaling01, nickaturley, kevinweil, dotey, raizamrtn, BlackHC, op7418, 36氪, 36氪, 36氪, 36氪, 量子位)

Google lanza la serie Gemini Robotics 1.5, permitiendo el aprendizaje “interespecie” en robots : Google DeepMind ha lanzado la serie de modelos Gemini Robotics 1.5 (incluyendo Gemini Robotics 1.5 y Gemini Robotics-ER 1.5), diseñada para dotar a los robots de una mayor capacidad de “pensar antes de actuar” y habilidades de aprendizaje entre diferentes formas corporales. Gemini Robotics-ER 1.5 actúa como el “cerebro” responsable de la planificación y la toma de decisiones, mientras que Gemini Robotics 1.5 funciona como el “cerebelo” para ejecutar acciones, trabajando ambos en conjunto. Esta serie de modelos destaca en el razonamiento encarnado y el aprendizaje entre diferentes formas corporales, pudiendo transferir acciones aprendidas de un robot a otro, lo que promete impulsar el desarrollo de robots generales. (Fuente: Teknium1, nin_artificial, dejavucoder, crystalsssup, scaling01, jon_lee0, BlackHC, Google, demishassabis, shaneguML, demishassabis, JeffDean, 36氪, 36氪)

Google lanza actualizaciones para la serie de modelos Gemini 2.5 Flash : Google ha lanzado las últimas actualizaciones para los modelos Gemini 2.5 Flash y Flash-Lite, que han mejorado en inteligencia, rentabilidad y eficiencia de tokens. Flash-Lite ha visto un aumento de 8 puntos en el índice de inteligencia en modo de inferencia y 12 puntos en modo no inferencia, además de ser más eficiente en tokens y más rápido en inferencia. Estas actualizaciones mejoran el rendimiento de los modelos en el seguimiento de instrucciones, la comprensión multimodal y la traducción, y el modelo Flash es más eficiente en el uso de herramientas de Agent. (Fuente: scaling01, osanseviero, Google, osanseviero, andrew_n_carr)
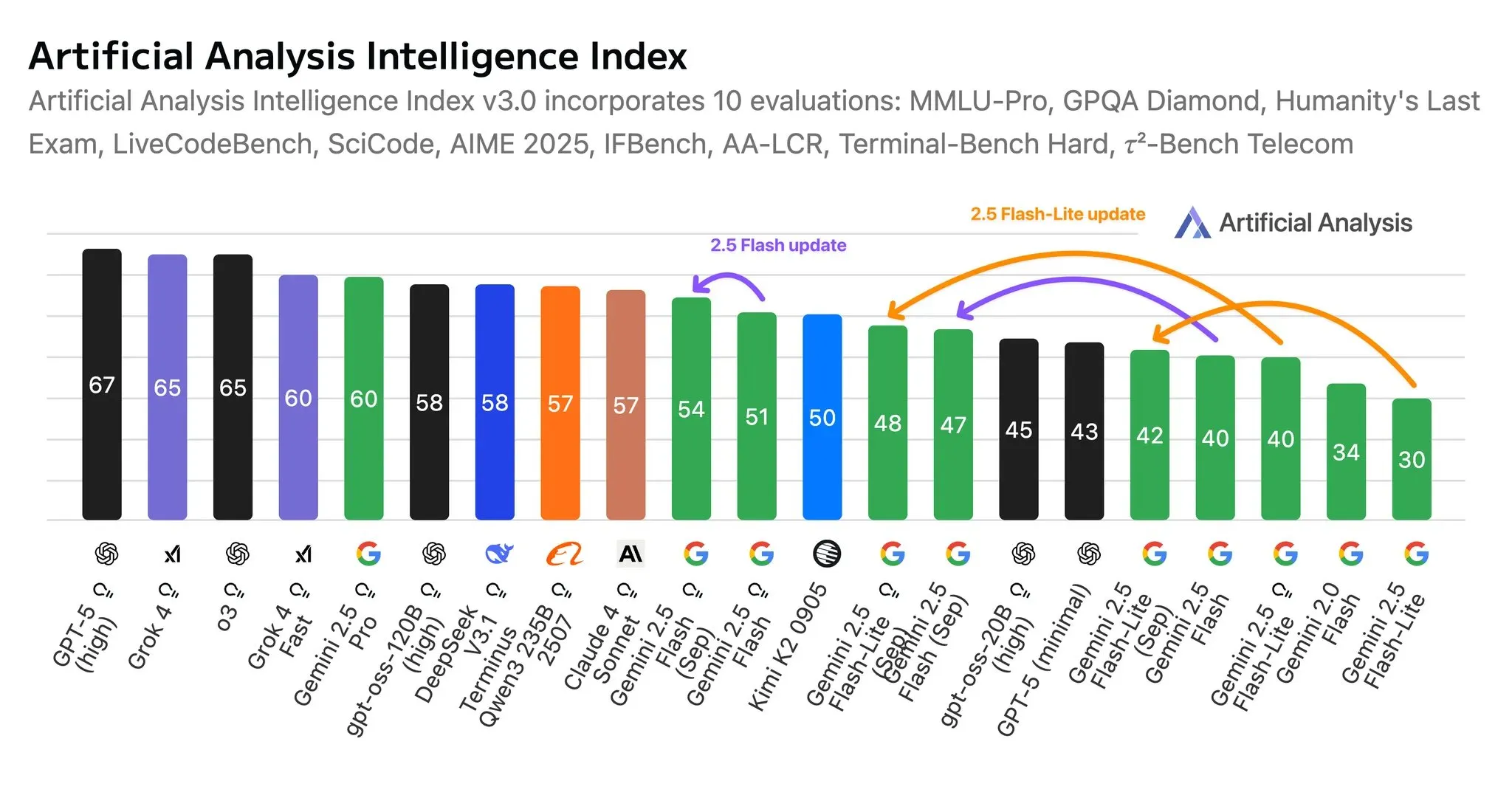
La capacidad de la AI aumenta a un ritmo asombroso: la capacidad de los LLM se duplica cada 7 meses : Un estudio de benchmark de LLM publicado por METR revela que, al medir el tiempo que tardan los LLM en completar tareas humanas, la capacidad de los LLM se duplica cada 7 meses. GPT-5 ya puede completar de forma consistente tareas complejas que a los humanos les llevarían horas. Siguiendo esta tendencia, para 2030, los LLM podrían manejar trabajos que a los humanos les llevaría un año, como fundar una nueva empresa. Esto presagia un impacto disruptivo de la AI en el mercado laboral en los próximos años. (Fuente: karminski3)
Los modelos de vídeo muestran el potencial de la inteligencia visual general : Los modelos de vídeo están experimentando un “momento GPT”, demostrando capacidades generales que van desde la percepción simple hasta el razonamiento visual. Modelos como Veo3 ya poseen capacidades de cero-shot, pudiendo resolver tareas complejas en la pila visual. La investigación sugiere que los modelos de vídeo son “razonadores espacio-temporales” generales y, en el futuro, podrían convertirse en una vía clave para la inteligencia visual general, especialmente en el campo de la robótica, donde pueden abordar los problemas “más difíciles” de semántica, planificación y sentido común. (Fuente: shaneguML, BlackHC, AndrewLampinen, teortaxesTex)

Los AI agents pasan de “asistentes” a “mayordomos”, adentrándose en el mundo físico : El reconocido futurista Bernard Marr predice que para 2026 los AI agents pasarán de ser asistentes pasivos a mayordomos proactivos, capaces de gestionar de forma autónoma las tareas diarias y coordinar proyectos complejos. La AI ya no se limitará al mundo digital, sino que se integrará profundamente en el mundo físico a través de la conducción autónoma, los robots humanoides, el IoT y otras formas, cambiando la forma en que las personas interactúan con su entorno. Grandes empresas chinas como Tencent, Alibaba y Baidu también están invirtiendo activamente en AI agents a nivel empresarial, enfatizando sus capacidades de ejecución y entrega de tareas, no solo de conversación, con el objetivo de convertirlos en un nuevo motor de crecimiento comercial. (Fuente: 36氪, 36氪, omarsar0)
Los robots industriales pasan de “operaciones individuales” a “equipos de superproducción” : Los robots industriales de inteligencia encarnada están evolucionando de procesos de una sola etapa a la colaboración de flujo completo, formando “equipos de superproducción”. Por ejemplo, una línea de producción compuesta por 8 robots industriales de inteligencia encarnada de Weiyi Zhizao puede producir 4 productos diferentes, con un cambio en minutos y un ajuste en horas. Estos robots pueden pensar como humanos, asumir tareas y mejorar la eficiencia y flexibilidad de la producción. La tecnología de visión AI se ha convertido en la fuerza impulsora central, impulsando la evolución de los robots industriales de “herramientas de ejecución” a “inteligencia encarnada”, proporcionando una solución china para la transformación digital e inteligente de la fabricación. (Fuente: 36氪)

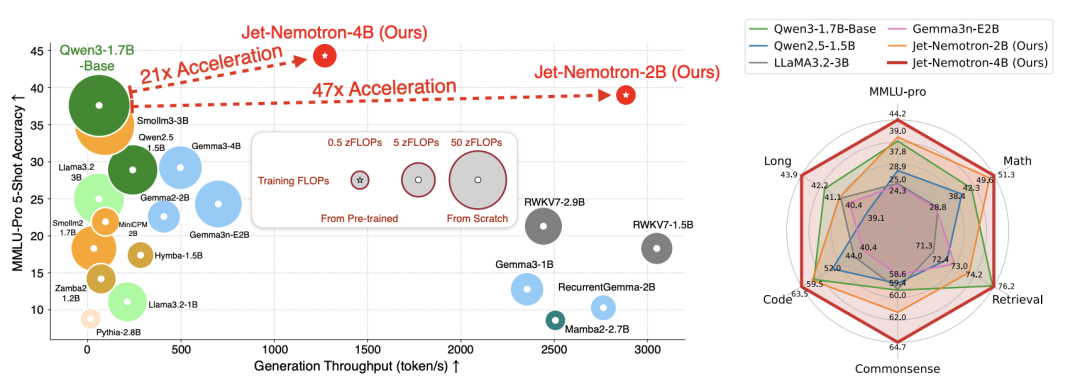
La mejora de la eficiencia de Grok-4-fast podría estar relacionada con el algoritmo Jet-Nemotron de NVIDIA : El asombroso rendimiento de Grok-4-fast en la reducción de costos y el aumento de la eficiencia podría estar relacionado con el algoritmo Jet-Nemotron de NVIDIA. Este algoritmo, a través del marco PortNAS, optimiza el mecanismo de atención a partir de un modelo de atención completa preentrenado, logrando un aumento de aproximadamente 53 veces en la velocidad de inferencia de LLM, manteniendo un rendimiento comparable al de los modelos de código abierto líderes. Jet-Nemotron-2B es más preciso que Qwen3-1.7B-Base en MMLU-Pro, 47 veces más rápido y requiere menos memoria, lo que se espera que reduzca significativamente los costos del modelo. (Fuente: 36氪)
Las descargas del modelo NVIDIA Cosmos Reason superan el millón : El modelo NVIDIA Cosmos Reason ha superado el millón de descargas en HuggingFace y ocupa un lugar destacado en el ranking de razonamiento físico. Este modelo tiene como objetivo enseñar a los AI agents y robots a pensar como humanos, y se ofrece en forma de microservicio fácil de implementar, siendo un logro importante de NVIDIA en el avance de los AI Agents y la tecnología robótica. (Fuente: huggingface, ClementDelangue)

Meta lanza Code World Model (CWM) para impulsar la investigación en generación de código : Meta FAIR ha lanzado Code World Model (CWM), un modelo de investigación de 32 mil millones de parámetros, diseñado para explorar cómo los world models pueden transformar la generación y el razonamiento de código. CWM se abre con una licencia de investigación, alentando a la comunidad a desarrollarlo, lo que presagia una nueva dirección de investigación en el campo de la generación de código. (Fuente: ylecun)
Google lanza EmbeddingGemma, un modelo ligero de incrustación de texto : Google ha presentado EmbeddingGemma, un modelo de incrustación de texto ligero y abierto con solo 300M de parámetros, que ha logrado un rendimiento SOTA en el benchmark MTEB. Supera a modelos del doble de su tamaño y es ideal para aplicaciones de AI rápidas y eficientes en dispositivos. (Fuente: _akhaliq)

Alibaba Tongyi Qianwen revela su hoja de ruta para la multimodalidad y la expansión a gran escala : Alibaba Tongyi Qianwen ha anunciado una ambiciosa hoja de ruta, enfocándose en modelos multimodales unificados y una expansión a escala extrema. Los objetivos incluyen extender la longitud del contexto de 1M a 100M tokens, escalar los parámetros a billones o incluso decenas de billones, expandir el cálculo en tiempo de prueba a 1M, y alcanzar un volumen de datos de 100 billones de tokens. Además, impulsará la generación de datos sintéticos a escala infinita y la expansión de las capacidades de Agent, encarnando la filosofía de “la escala lo es todo”. (Fuente: menhguin, karminski3)

La AI asistencial médica entra en la fase de aplicación clínica : La aplicación de la AI en el campo médico está pasando de ser una tecnología de vanguardia a una herramienta rutinaria. Por ejemplo, JD Health ha lanzado “AI Hospital 1.0” y ha actualizado el modelo médico grande “Jingyi Qianxun 2.0”, logrando un servicio de ciclo cerrado “médico-diagnóstico-prescripción-farmacia” impulsado por AI, que cubre la orientación, consulta, examen, compra de medicamentos y gestión de la salud. Los estetoscopios inteligentes con AI ya pueden ayudar a diagnosticar enfermedades cardíacas, y la lectura de imágenes por AI ha logrado avances en áreas como los nódulos pulmonares y las hemorragias cerebrales, con una precisión diagnóstica superior al 96%. La AI está entrando plenamente en la aplicación clínica, mejorando la eficiencia y la precisión de los servicios médicos. (Fuente: 36氪, 36氪, 量子位, Ronald_vanLoon, Reddit r/ArtificialInteligence)

La aplicación Meta AI lanza Vibes, vídeos cortos generados por AI : La aplicación Meta AI ha lanzado una nueva función llamada “Vibes”, un feed dinámico centrado en vídeos cortos generados por AI. Este movimiento marca un paso más de Meta en el campo de la creación de contenido con AI, con el objetivo de ofrecer a los usuarios una nueva experiencia de vídeo corto impulsada por AI. (Fuente: dejavucoder, _tim_brooks, EigenGender)
Avance en los AI-generated genomes : Arc Institute ha anunciado tres nuevos descubrimientos, incluido el primer genoma funcional generado por AI del mundo. Este avance utiliza Evo 2, un biological ML model lanzado por Arc en colaboración con NVIDIA, que permite a los científicos diseñar y escribir cambios a gran escala en el genoma humano, corrigiendo duplicaciones de ADN que causan enfermedades genéticas. Se espera que acelere la terapia génica y la investigación de biomateriales. (Fuente: dwarkesh_sp, riemannzeta, zachtratar, kevinweil, Reddit r/artificial)
Apple lanza SimpleFold, una AI ligera para predecir el plegamiento de proteínas : Investigadores de Apple han desarrollado SimpleFold, una nueva AI basada en un flow matching model para la predicción del plegamiento de proteínas. Abandona los componentes computacionalmente costosos de los métodos de difusión tradicionales, utilizando solo bloques Transformer genéricos, y puede transformar directamente el ruido aleatorio en predicciones de estructuras proteicas. SimpleFold-3B se desempeña excepcionalmente bien en los benchmarks estándar, alcanzando el 95% del rendimiento de los modelos líderes, y es más eficiente en implementación e inferencia, lo que promete reducir el umbral computacional para la predicción de estructuras proteicas y acelerar el descubrimiento de fármacos. (Fuente: Reddit r/ArtificialInteligence, HuggingFace Daily Papers)

Fusión profunda de AI industrial y Physical AI : Alibaba y NVIDIA han colaborado para integrar la pila completa de software NVIDIA Physical AI en la plataforma Alibaba Cloud. Physical AI tiene como objetivo llevar la inteligencia artificial de la pantalla al mundo físico, optimizando el contenido generado por AI a través de la integración de leyes físicas para que sea más consistente con la lógica de la realidad. Sus tecnologías centrales incluyen world models, motores de simulación física y embodied AI controllers, con el objetivo de lograr una comprensión completa del espacio 3D por parte de la AI, cálculos físicos en tiempo real y acciones concretas. Esta colaboración promete impulsar la aplicación generalizada de la AI en robótica, logística, automoción, fabricación y otras industrias, transformando la AI de una herramienta de procesamiento de información a un sistema inteligente capaz de comprender y operar el mundo físico. (Fuente: 36氪)

Lanzamiento del marco Hunyuan3D-Omni para la generación de activos 3D : Hunyuan3D-Omni es un marco unificado para la generación controlable de activos 3D, basado en Hunyuan3D 2.1. No solo admite condiciones de imagen y texto, sino que también acepta point clouds, voxels, bounding boxes y skeleton poses como señales condicionales, logrando un control preciso sobre la geometría, la topología y la pose. El modelo utiliza una única arquitectura transmodal para unificar todas las señales y se entrena con una estrategia de muestreo progresiva y consciente de la dificultad, mejorando la precisión y la robustez de la generación. (Fuente: HuggingFace Daily Papers)
Tencent anuncia Hunyuan Image 3.0, el modelo de texto a imagen de código abierto más potente : Tencent ha anunciado que lanzará Hunyuan Image 3.0 el 28 de septiembre, afirmando que es el modelo de texto a imagen de código abierto más potente del mundo. Este lanzamiento ha generado una gran expectación y atención en la comunidad, especialmente por sus perspectivas de aplicación en herramientas como ComfyUI. (Fuente: ostrisai, Reddit r/LocalLLaMA)

Llama.cpp añade soporte para Qwen3 reranker : Llama.cpp ha fusionado el soporte para Qwen3 reranker, una función que mejora significativamente el rendimiento de recuperación de pipelines como RAG al generar puntuaciones de similitud para pares de consulta y documento a través de un reranking model (cross-encoder). Los usuarios deben usar los nuevos archivos GGUF para obtener resultados correctos. (Fuente: Reddit r/LocalLLaMA)![Llama.cpp新增Qwen3 reranker支持](https://external-preview.redd.it/gjtn51bKTEhntL8tK6567mzxkqg8KV6qsi2OUMPMyfI.png?auto=webp&s