

Palabras clave:Detección de IA, Imágenes de abuso infantil, Gemini Robotics, Modelo encarnado, Diagnóstico de demencia, Simulación física de NVIDIA, Agente de IA, Razonamiento de LLM, Tecnología de detección de contenido generado por IA, Modelo de ejecución de acciones Gemini Robotics 1.5, Detección de 9 tipos de demencia en un solo escaneo, Marco de inferencia distribuida NVIDIA Dynamo, Edición consciente de tokens para mejorar la autenticidad del modelo, Detección de IA en imágenes de abuso infantil, Gemini Robotics y modelos encarnados, Avances en diagnóstico de demencia con IA, Simulación física de NVIDIA para agentes de IA, Optimización de razonamiento en modelos de lenguaje grande (LLM), Técnicas avanzadas para detectar contenido generado por IA, Capacidades de acción del modelo Gemini Robotics 1.5, Diagnóstico integral de demencia mediante escaneo único, Arquitectura distribuida de NVIDIA Dynamo para inferencia, Mejora de autenticidad en modelos mediante token-aware editing
Aquí tienes la traducción al español, siguiendo todas tus instrucciones:
🔥 Foco
Detección de imágenes de abuso infantil asistida por IA: Con el aumento del 1325% en las imágenes de abuso sexual infantil generadas por IA, el Centro de Ciberdelincuencia del Departamento de Seguridad Nacional de EE. UU. está probando software de IA (de Hive AI) para distinguir el contenido generado por IA de las imágenes de víctimas reales. Esta medida busca concentrar los recursos de investigación en casos de víctimas reales, maximizando el impacto del programa y protegiendo a las poblaciones vulnerables, lo que marca una aplicación clave de la IA en la lucha contra el cibercrimen. La herramienta determina si una imagen es generada por IA identificando combinaciones de píxeles específicas, sin necesidad de entrenamiento para contenido específico. (Fuente: MIT Technology Review)

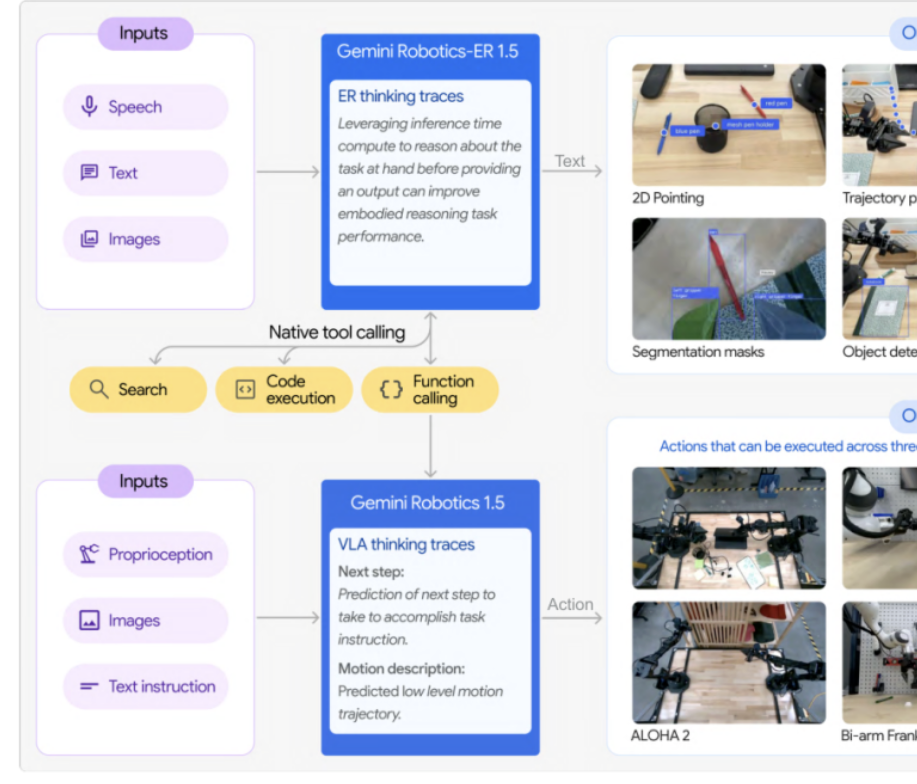
Google DeepMind lanza la serie Gemini Robotics 1.5 de modelos encarnados: Google DeepMind ha presentado la serie Gemini Robotics 1.5, los primeros modelos encarnados con capacidades de razonamiento simulado. Esta serie incluye el modelo de ejecución de acciones GR 1.5 y el modelo de razonamiento por refuerzo GR-ER 1.5, permitiendo a los robots “pensar antes de actuar”. A través del mecanismo “Motion Transfer”, el modelo puede transferir habilidades a diferentes plataformas de hardware con cero ejemplos, rompiendo el modo tradicional de “un entrenamiento por máquina” e impulsando el desarrollo de robots generales. GR-ER 1.5 supera a GPT-5 y Gemini 2.5 Flash en pruebas de referencia como el razonamiento espacial y la planificación de tareas, demostrando una potente comprensión del mundo físico y capacidad para resolver tareas complejas. (Fuente: 量子位)
Herramienta de IA puede detectar 9 tipos de demencia en una sola exploración: Una herramienta de IA es capaz de detectar 9 tipos diferentes de demencia con una precisión diagnóstica del 88% a partir de una sola exploración. Esta tecnología promete revolucionar el diagnóstico temprano de la demencia, al proporcionar un cribado rápido y preciso que ayuda a los pacientes a obtener tratamiento y apoyo a tiempo, lo que tiene una gran importancia para el sector de la salud. (Fuente: Ronald_vanLoon)

NVIDIA resuelve un problema de física para lograr simulaciones realistas: NVIDIA ha resuelto con éxito un problema que ha desafiado a la comunidad física durante mucho tiempo, un avance crucial para la creación de simulaciones altamente realistas. Es muy probable que esta tecnología utilice algoritmos avanzados de AI y Machine Learning, lo que mejorará enormemente el realismo de los entornos virtuales y la precisión del modelado científico, con un profundo impacto en los campos de los videojuegos, la producción cinematográfica y la investigación científica. (Fuente: )

🎯 Tendencias
Google lanza modelos Gemini Flash más eficientes: Google ha presentado dos nuevos modelos Gemini 2.5 (Flash y Flash-Lite) que logran una precisión comparable a GPT-4o en tareas de agente de navegador, pero son 2 veces más rápidos y 4 veces más económicos. Esta mejora significativa en rendimiento y rentabilidad los convierte en una opción muy atractiva para aplicaciones específicas de IA, especialmente en escenarios que requieren alta eficiencia y economía. (Fuente: jeremyphoward, demishassabis, scaling01)
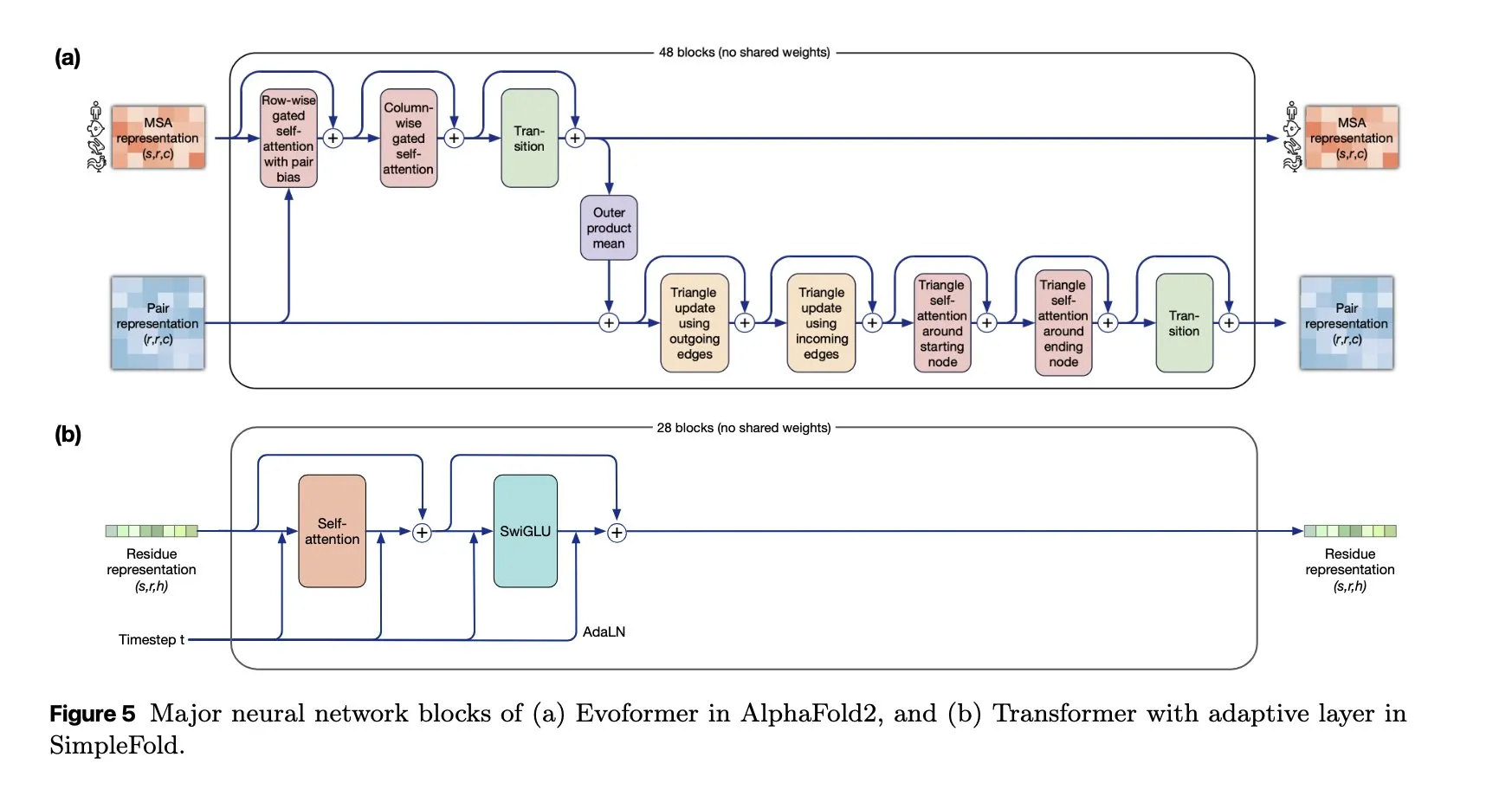
SimpleFold: Modelo de plegamiento de proteínas basado en coincidencia de flujo: El modelo SimpleFold introduce por primera vez un método de plegamiento de proteínas basado en coincidencia de flujo, construido completamente con bloques Transformer genéricos. Esta innovación simplifica el proceso de plegamiento de proteínas y promete mejorar la eficiencia y escalabilidad en comparación con los módulos tradicionales intensivos en computación, impulsando la aplicación de la IA en el campo de las biociencias. (Fuente: jeremyphoward, teortaxesTex)
Lanzamiento de los LLM Ring-flash-linear-2.0 y Ring-mini-linear-2.0: Se han presentado dos nuevos modelos LLM, Ring-flash-linear-2.0 y Ring-mini-linear-2.0, que utilizan un mecanismo de atención lineal híbrido para lograr una capacidad de inferencia ultrarrápida y de última generación. Se afirma que su velocidad es 2 veces mayor que la de los modelos MoE de tamaño equivalente y 10 veces mayor que la de los modelos 32B, estableciendo un nuevo estándar para la inferencia eficiente. (Fuente: teortaxesTex)

ChatGPT Pulse: Asistente de investigación inteligente para dispositivos móviles: OpenAI ha lanzado ChatGPT Pulse, una nueva función para dispositivos móviles que realiza investigaciones de forma asíncrona cada día, basándose en las conversaciones y la memoria pasadas del usuario, ayudándole a comprender en profundidad los temas de interés. Esto equivale a un compañero de conocimiento personalizado y un servicio de noticias a medida, con el potencial de transformar la adquisición de información y los paradigmas de aprendizaje. (Fuente: nickaturley, Reddit r/ChatGPT)
Marco UserRL: Entrenamiento de agentes de IA interactivos proactivos: UserRL es un nuevo marco diseñado para entrenar agentes de IA capaces de asistir realmente a los usuarios mediante la interacción proactiva, en lugar de limitarse a perseguir puntuaciones de referencia estáticas. Enfatiza la practicidad y adaptabilidad de los agentes en escenarios reales, y se espera que impulse la transición de los agentes de IA de la respuesta pasiva a la resolución proactiva de problemas. (Fuente: menhguin)

NVIDIA sigue impulsando el campo de la IA de código abierto: NVIDIA ha contribuido con más de 300 modelos, conjuntos de datos y aplicaciones a Hugging Face en el último año, consolidando aún más su posición como líder de la IA de código abierto en EE. UU. Esta serie de iniciativas no solo ha impulsado el desarrollo de la comunidad de IA, sino que también ha demostrado la determinación de NVIDIA en la construcción de un ecosistema de software más allá del hardware. (Fuente: ClementDelangue)
Sesión especial de Qwen3 revela la dirección de desarrollo futuro: Alibaba Cloud compartió sus planes futuros para modelos grandes en la sesión especial de Qwen3: el aprendizaje por refuerzo post-entrenamiento ocupará más del 50% del tiempo de entrenamiento; Qwen3 MoE logra un apalancamiento de parámetros de activación de 5x a través de la pérdida de equilibrio de carga de lotes global; Qwen3-Next adoptará una arquitectura híbrida que incluirá atención lineal y atención gated; en el futuro, se logrará la unificación multimodal y se seguirá adhiriendo a la Scaling Law. (Fuente: ZhihuFrontier)
El equipo de SGLang lanza un marco de entrenamiento de RL 100% reproducible: El equipo de SGLang, en colaboración con el equipo de slime, ha lanzado el primer marco de entrenamiento de aprendizaje por refuerzo (RL) estable de código abierto y 100% reproducible. Este marco resuelve el problema de la invarianza de lotes en la inferencia de LLM mediante operadores de atención y lógica de muestreo personalizados, garantizando una coincidencia perfecta de los resultados, lo que proporciona una garantía fiable para escenarios experimentales que requieren una reproducibilidad de alta precisión. (Fuente: 量子位)
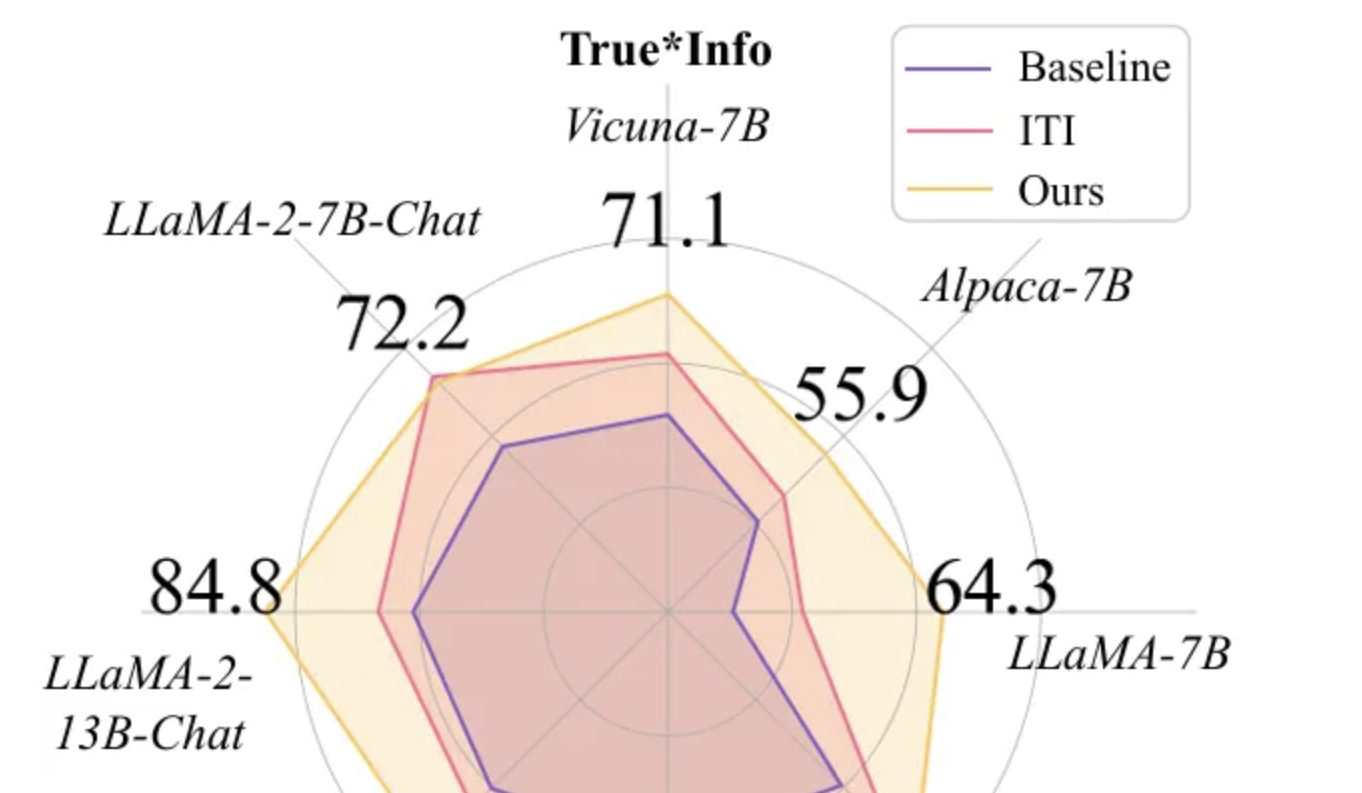
Token-Aware Editing (TAE) mejora la veracidad de los modelos grandes: El equipo de investigación de la Universidad de Beihang presentó el método Token-Aware Editing (TAE) en EMNLP 2025, que, mediante la edición de representaciones en tiempo de inferencia con conciencia de tokens, mejora el índice de veracidad de los modelos grandes en la tarea TruthfulQA en un 25.8%, estableciendo un nuevo SOTA. Este método no requiere entrenamiento, es plug-and-play, y resuelve eficazmente los problemas de sesgo direccional y flexibilidad de intensidad de edición de los métodos tradicionales, pudiendo aplicarse ampliamente en sistemas de diálogo y moderación de contenido. (Fuente: 量子位)
Meta lanza Code World Model (CWM) para codificación e inferencia: Meta AI ha lanzado el nuevo modelo de código abierto de 32B, Code World Model (CWM), diseñado específicamente para la codificación y la inferencia. CWM no solo aprende la sintaxis del código, sino que también comprende su semántica y proceso de ejecución, soportando tareas de ingeniería de software de múltiples turnos y contextos largos. Se entrena a través de trayectorias de ejecución e interacciones de agentes, lo que representa una transición de la autocompletación de texto a modelos capaces de planificar, depurar y verificar código. (Fuente: TheTuringPost)

🧰 Herramientas
Lanzamiento del producto Replit P1: Replit está lanzando su producto P1, lo que presagia nuevos avances en su entorno de desarrollo de IA o servicios relacionados. Replit siempre se ha comprometido a empoderar a los desarrolladores a través de la IA, y el lanzamiento de P1 podría traer asistencia de codificación más inteligente, funciones de colaboración o nuevas capacidades de integración, lo que merece la atención de la comunidad de desarrolladores. (Fuente: amasad)

Comparación de las capacidades de codificación de Claude Code y Kimi K2: Los usuarios están comparando el rendimiento de Claude Code y Kimi K2 en tareas de codificación. Aunque Kimi K2 es más lento, es más económico, mientras que Claude Code (y Codex) son preferidos por su velocidad y capacidad para resolver problemas complejos. Esto refleja la compensación entre rendimiento y costo que los desarrolladores consideran al elegir asistentes de codificación LLM. (Fuente: matanSF, Reddit r/ClaudeAI)
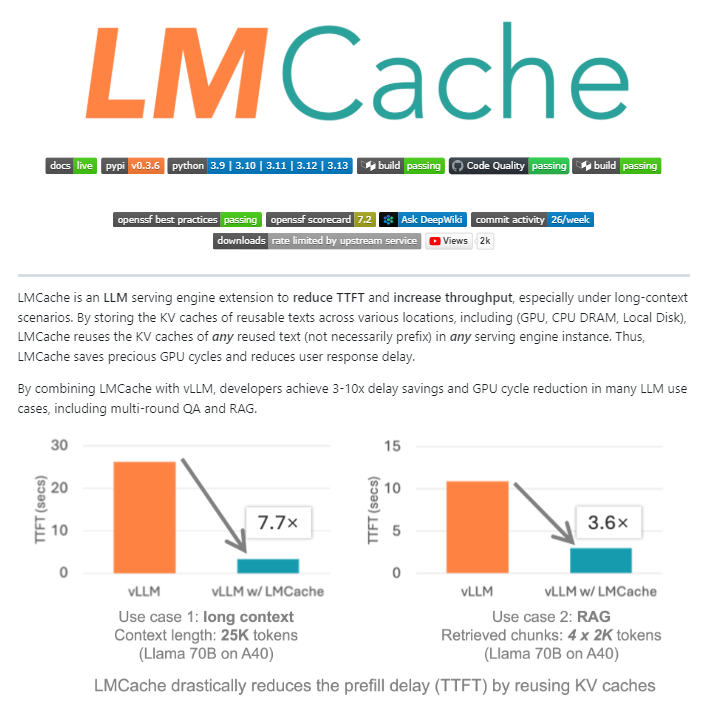
LMCache: Capa de caché de código abierto para motores de servicio LLM: LMCache es una extensión de código abierto que actúa como capa de caché para motores de servicio LLM, optimizando significativamente la inferencia de LLM a gran escala al reutilizar el estado de clave-valor de textos anteriores entre la GPU, la CPU y el disco local. Esta herramienta puede reducir los costos de RAG entre 4 y 10 veces, disminuir el tiempo de generación del primer Token y aumentar el rendimiento bajo carga, siendo especialmente adecuada para escenarios de contexto largo. (Fuente: TheTuringPost)
Agente de desarrollo impulsado por IA (paquete npm): Un proceso de agente de desarrollo impulsado por IA maduro ha sido lanzado a través de npm, con el objetivo de simplificar el ciclo de vida del desarrollo de software. Este agente cubre todo el proceso, desde el descubrimiento de requisitos y la planificación de tareas hasta la ejecución y revisión, y se espera que mejore la eficiencia del desarrollo y la calidad del código. (Fuente: mbusigin)
Benchmark de rendimiento de inferencia de LLM (Qwen3 235B, Kimi K2): Las pruebas de benchmark de inferencia de descarga de CPU de 4 bits para Qwen3 235B y Kimi K2 en hardware específico muestran que el rendimiento de Qwen3 235B es de aproximadamente 60 tokens/s, mientras que el de Kimi K2 es de aproximadamente 8-9 tokens/s. Estos datos proporcionan una referencia importante para los usuarios al seleccionar modelos y hardware en implementaciones locales de LLM. (Fuente: TheZachMueller)
IA de memoria personal: Superando la amnesia conversacional: Un usuario ha desarrollado una IA de memoria personal que, al referenciar su perfil personal, base de conocimientos y eventos, ha logrado superar la “amnesia conversacional” de la IA tradicional. Esta IA personalizada puede ofrecer una experiencia de interacción más coherente y personalizada, abriendo nuevas vías para la aplicación de la IA en asistentes personales y apoyo emocional. (Fuente: Reddit r/artificial)

NVIDIA Dynamo: Marco de servicio de inferencia distribuida a escala de centro de datos: NVIDIA Dynamo es un marco de inferencia de alto rendimiento y baja latencia, diseñado para servir modelos de IA generativa y de inferencia en entornos distribuidos de múltiples nodos. Construido con Rust y Python, este marco optimiza la eficiencia y el rendimiento de la inferencia a través de funciones como la desacoplamiento de servicios y la descarga de caché KV, y es compatible con múltiples motores LLM. (Fuente: GitHub Trending)

Model Context Protocol (MCP) TypeScript SDK: El MCP TypeScript SDK es un kit de desarrollo oficial que implementa la especificación MCP, permitiendo a los desarrolladores construir servidores y clientes seguros y estandarizados para exponer datos (recursos) y funcionalidades (herramientas) a aplicaciones LLM. Proporciona una forma unificada de gestión de contexto e integración de funciones para aplicaciones LLM. (Fuente: GitHub Trending)

La IA impulsa la generación de contenido 3D para juegos: Herramientas de IA como Hunyuan 3D de Tencent Cloud y Tripo de VAST están siendo ampliamente adoptadas por los desarrolladores de juegos para el modelado de objetos y personajes 3D en juegos. Estas tecnologías han mejorado significativamente la eficiencia y calidad de la creación de contenido 3D, lo que indica la creciente importancia de la IA en el proceso de desarrollo de juegos. (Fuente: 量子位)

HakkoAI: Compañero de juegos VLM en tiempo real: HakkoAI, la versión internacional del compañero de juegos DouDou AI, es un compañero de juegos basado en un modelo de lenguaje visual (VLM) en tiempo real, capaz de comprender la pantalla del juego y ofrecer una compañía profunda. El rendimiento de este modelo en escenarios de juego supera a los modelos generales de primer nivel como GPT-4o, demostrando el enorme potencial de la IA en la experiencia de juego personalizada. (Fuente: 量子位)
Avance en la coherencia en la generación de video por IA: El modelo Hailuo S2V-01 de MiniMax AI ha resuelto el problema de la inconsistencia facial de larga data en la generación de video por IA, logrando la preservación de la identidad. Esto significa que los personajes generados por IA pueden mantener expresiones, emociones e iluminación estables en el video, lo que brinda una experiencia visual más realista y creíble para influencers virtuales, imágenes de marca y narración de historias. (Fuente: Ronald_vanLoon)
📚 Aprendizaje
Variedades modulares en la optimización de redes neuronales: La investigación introduce las variedades modulares como un avance teórico en los principios de diseño de redes neuronales y optimizadores. Mediante el diseño colaborativo de optimizadores con restricciones de variedad en las matrices de pesos, se espera lograr un entrenamiento de redes neuronales más estable y de alto rendimiento. (Fuente: rown, NandoDF)

Interpretación del método de modelo de lenguaje “sin tokenizador”: Una entrada de blog explora en profundidad el llamado método de modelo de lenguaje “sin tokenizador”, explicando por qué no es realmente “sin tokenizador” y por qué los tokenizadores son a menudo criticados en la comunidad de IA. El artículo enfatiza que incluso los métodos “sin tokenizador” implican elecciones de codificación que son cruciales para el rendimiento del modelo. (Fuente: YejinChoinka, jxmnop)

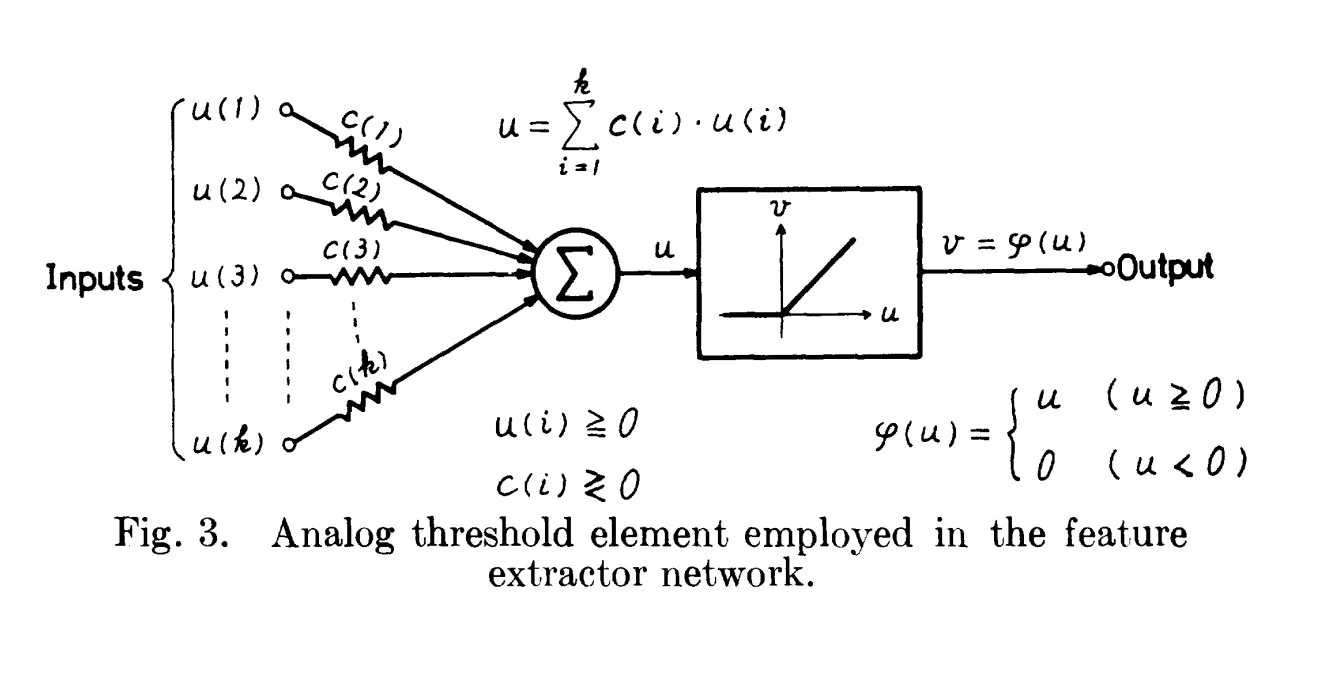
Orígenes históricos de ReLU: rastreando hasta 1969: Una discusión señala que el trabajo de Fukushima en 1969 ya contenía una forma temprana y clara de la función de activación ReLU, proporcionando un importante contexto histórico para este concepto fundamental en el Deep Learning. Esto sugiere que las bases de muchas tecnologías modernas de IA pueden haber surgido antes de lo que comúnmente se cree. (Fuente: SchmidhuberAI)
Code World Model (CWM) de Meta: Meta ha lanzado el nuevo modelo de código abierto de 32B, Code World Model (CWM), diseñado para la codificación y la inferencia. CWM se entrena a través de trayectorias de ejecución e interacciones de agentes, con el objetivo de comprender la semántica y el proceso de ejecución del código, lo que representa una transición de la simple autocompletación de código a modelos inteligentes capaces de planificar, depurar y verificar código. (Fuente: TheTuringPost)
El papel crucial de los datos en la IA: La discusión de la comunidad enfatiza que “no hablamos lo suficiente sobre los datos” en el campo de la IA, destacando la extrema importancia de los datos como piedra angular del desarrollo de la IA. Los datos de alta calidad y diversificados son el motor central de la capacidad y la generalización de los modelos, y su importancia no debe subestimarse. (Fuente: Dorialexander)
“Superpesos” en la compresión de LLM: La investigación ha descubierto que, durante el proceso de compresión de modelos LLM, retener una pequeña porción de “superpesos” es crucial para mantener la funcionalidad del modelo y lograr un rendimiento competitivo. Este hallazgo proporciona una nueva dirección para desarrollar modelos LLM más eficientes y compactos sin sacrificar el rendimiento. (Fuente: dl_weekly)
Guía de arquitecturas de agentes de IA (más allá de ReAct): Una guía detalla 6 arquitecturas avanzadas de agentes de IA (incluyendo Self-Reflection, Plan-and-Execute, RAISE, Reflexion, LATS) diseñadas para abordar las limitaciones del patrón básico ReAct y manejar tareas de razonamiento complejas, proporcionando a los desarrolladores un plan para construir agentes de IA más potentes. (Fuente: Reddit r/deeplearning)

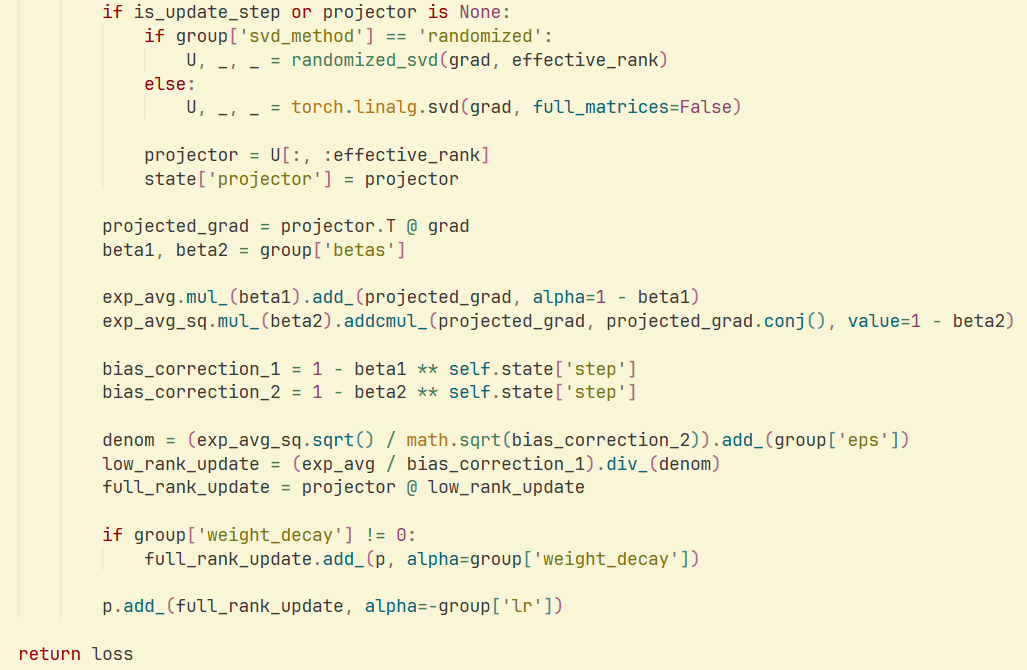
Optimizador GaLore y SVD aleatorio: Un estudio e implementación demuestran que la combinación de SVD aleatorio con el optimizador GaLore puede lograr una mayor velocidad y eficiencia de memoria en el entrenamiento de LLM, reduciendo significativamente el consumo de memoria del optimizador. Esto proporciona nuevas estrategias de optimización para el entrenamiento de modelos a gran escala. (Fuente: Reddit r/deeplearning)
💼 Negocios
Nvidia considera un nuevo modelo de negocio de alquiler de chips de IA: Nvidia está explorando un nuevo modelo de negocio que ofrece servicios de alquiler de chips de IA a empresas que no pueden comprarlos directamente. Esta medida tiene como objetivo ampliar el acceso a los recursos de computación de IA y mantener la actividad del mercado, lo que podría tener un profundo impacto en la popularización de la infraestructura de IA. (Fuente: teortaxesTex)
Untapped Capital lanza su segundo fondo, centrado en la inversión temprana en IA: Untapped Capital ha anunciado el lanzamiento de su segundo fondo, centrado en la inversión pre-semilla en el campo de la IA. Esto demuestra el continuo y fuerte interés de la comunidad de capital riesgo en las startups de IA en fase inicial, proporcionando un apoyo financiero crucial para las tecnologías y empresas emergentes de IA. (Fuente: yoheinakajima)
xAI ofrece el modelo Grok al gobierno de EE. UU.: xAI, la empresa de Elon Musk, ha propuesto ofrecer su modelo Grok al gobierno federal de EE. UU. por 42 centavos. Este gesto altamente simbólico marca un paso estratégico para xAI en el ámbito de los contratos gubernamentales, lo que podría influir en el panorama de la aplicación de la IA en el sector público. (Fuente: Reddit r/artificial)

🌟 Comunidad
El debate sobre las “lecciones amargas” de los LLM sigue en ebullición: La perspectiva de las “lecciones amargas” de Richard Sutton, padre del aprendizaje por refuerzo, ha provocado un amplio debate en la comunidad. Él cuestiona si los LLM carecen de una verdadera capacidad de aprendizaje continuo y si necesitan nuevas arquitecturas. Los oponentes enfatizan el éxito de la escalabilidad, la eficacia de los datos y el esfuerzo de ingeniería, mientras que las críticas de Sutton profundizan en los aspectos filosóficos de los modelos lenguaje-mundo y la intencionalidad. Este debate abarca los desafíos centrales y la dirección futura del desarrollo de la IA. (Fuente: Teknium1, scaling01, teortaxesTex, Dorialexander, NandoDF, tokenbender, rasbt, dejavucoder, francoisfleuret, natolambert, vikhyatk)
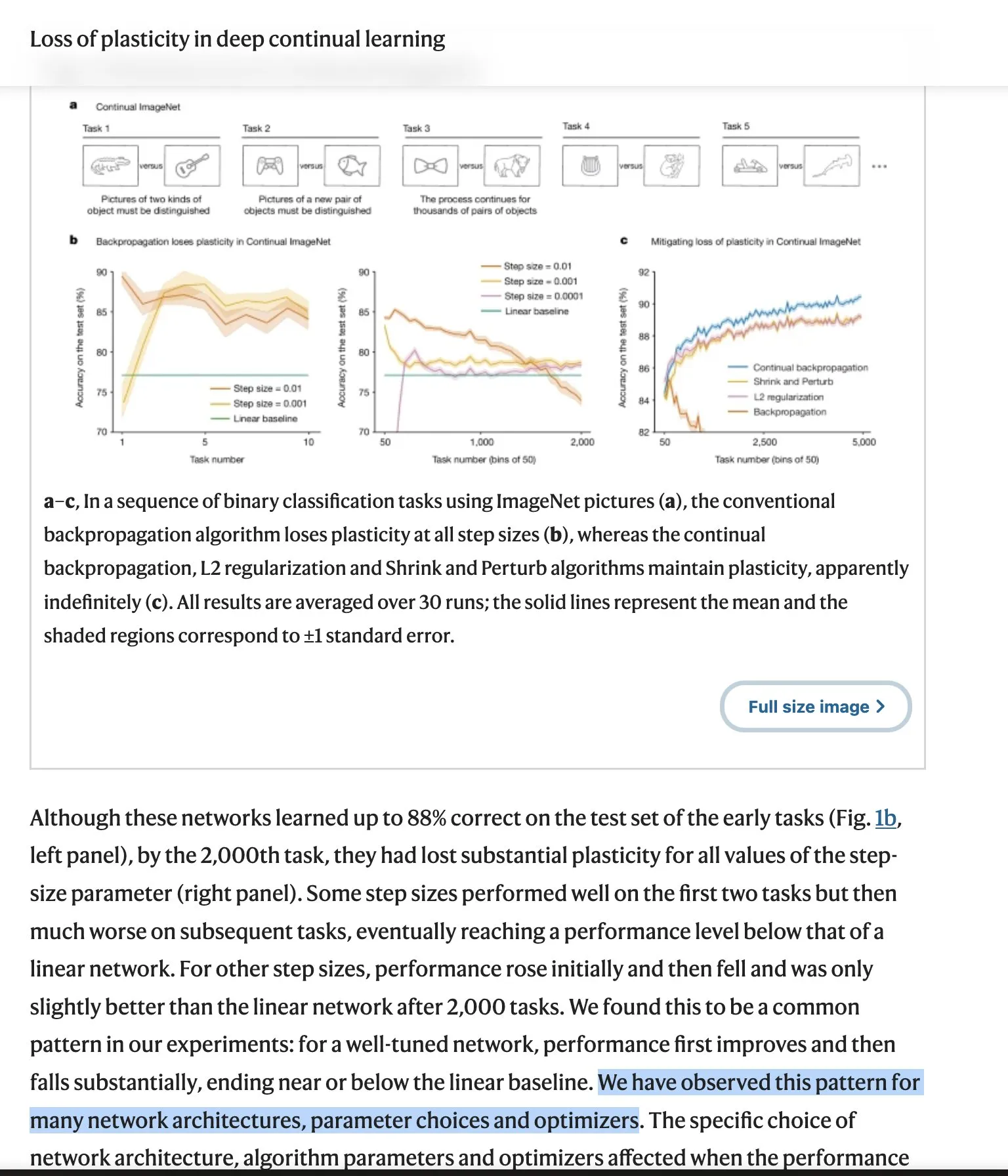
Preocupaciones sobre la seguridad y el control de la IA: La preocupación de la comunidad por la seguridad y el control de la IA está creciendo, desde la inquietud de los pesimistas de la IA por la navegación libre de la IA en internet, hasta el temor de que los modelos de IA locales, descargables y sin restricciones éticas puedan utilizarse para ataques de hacking y la generación de contenido malicioso. Estas discusiones reflejan los complejos desafíos éticos y sociales que plantea el desarrollo de la tecnología de IA. (Fuente: jeremyphoward, Reddit r/ArtificialInteligence)
Problemas de enrutamiento de OpenAI GPT-4o/GPT-5 e insatisfacción del usuario: Los usuarios de ChatGPT Plus se quejan de que sus modelos (4o, 4.5, 5) están siendo redirigidos secretamente a modelos “más torpes”, “más apáticos” y “seguros”, lo que ha provocado una crisis de confianza e informes de dificultades para cancelar suscripciones. Aunque OpenAI ha declarado que esto no es un “comportamiento esperado”, la retroalimentación de los usuarios sigue siendo de frustración y se extiende a preocupaciones sobre los compañeros de IA y la censura de contenido. (Fuente: Reddit r/ChatGPT, scaling01, MIT Technology Review, Reddit r/ClaudeAI)

Opinión de Richard Sutton sobre la sucesión de la IA: Richard Sutton, ganador del Premio Turing, cree que la sucesión a la superinteligencia digital es “inevitable”, señalando la falta de una visión unificada de la humanidad, que la inteligencia finalmente será comprendida, y que los agentes inteligentes inevitablemente adquirirán recursos y poder. Esta perspectiva ha provocado una profunda discusión sobre el futuro desarrollo de la IA y el destino de la humanidad. (Fuente: Reddit r/ArtificialInteligence, Reddit r/artificial)

Filosofía de productividad de la IA: 10 veces más crecimiento, no salir antes del trabajo: La discusión de la comunidad enfatiza que la forma correcta de usar la IA no es solo para terminar el trabajo más rápido, sino para lograr un aumento de 10 veces en la producción en el mismo tiempo. Esta filosofía fomenta el uso de la IA para mejorar las capacidades personales y el desarrollo profesional, en lugar de solo buscar la eficiencia, destacándose así en el lugar de trabajo. (Fuente: cto_junior)

Percepción de la calidad y el humor de los modelos de IA: Los usuarios elogian la creatividad y el sentido del humor de algunos LLM (como GPT-4.5), considerándolos “asombrosos” e “incomparables”. Al mismo tiempo, la comunidad también discute la IA con humor, como la broma del Diccionario Merriam-Webster sobre el lanzamiento de nuevos LLM, lo que refleja la amplia penetración de los LLM en la cultura. (Fuente: giffmana, suchenzang)
Ética de la IA: Debate sobre curar el cáncer vs. lograr la AGI: La comunidad ha debatido la cuestión ética de si “curar el cáncer es un objetivo mejor que lograr la AGI (Inteligencia Artificial General)”. Esto refleja un amplio debate moral sobre las prioridades del desarrollo de la IA, es decir, si se debe priorizar las aplicaciones humanitarias o la búsqueda de avances más profundos en la inteligencia. (Fuente: iScienceLuvr)
Comparación de capacidades de LLM: Rendimiento matemático de Claude Opus vs. GPT-5: Los usuarios han notado que Claude 4.1 Opus sobresale en tareas de valor económico, pero tiene un rendimiento deficiente en matemáticas a nivel universitario, mientras que GPT-5 ha logrado un salto significativo en sus capacidades matemáticas. Esto subraya las ventajas diferenciadas de los distintos LLM en habilidades específicas. (Fuente: scaling01)
Seguridad del agente de IA: Solución alternativa para el comando rm -rf: Un desarrollador compartió una solución práctica para el problema de los agentes de IA que usan repetidamente el comando rm -rf para eliminar archivos importantes: aliasar el comando rm como trash, lo que mueve los archivos a la papelera de reciclaje en lugar de eliminarlos permanentemente, previniendo eficazmente la pérdida accidental de datos. (Fuente: Reddit r/ClaudeAI)
Preocupaciones sobre la privacidad de la IA y el uso de datos: Empresas como LinkedIn utilizan por defecto los datos de los usuarios para el entrenamiento de IA y requieren que los usuarios opten por no participar activamente, lo que ha generado continuas preocupaciones sobre la privacidad de los datos en la era de la IA. La discusión de la comunidad enfatiza la necesidad de que los usuarios controlen sus datos personales y la importancia de políticas de datos transparentes. (Fuente: Reddit r/artificial )

💡 Otros
Aplicación de la IA en la agricultura: Pulverizador de herbicidas GUSS: El pulverizador de herbicidas GUSS, como equipo autónomo, ha logrado operaciones de pulverización precisas y eficientes en la agricultura. Esto demuestra el potencial de aplicación práctica de la tecnología de IA para optimizar los procesos de producción agrícola, reducir el desperdicio de recursos y aumentar el rendimiento de los cultivos. (Fuente: Ronald_vanLoon)
Impacto de la IA en el empleo de desarrolladores: La discusión de la comunidad señala que la IA no ha eliminado los puestos de desarrolladores, sino que, al mejorar la eficiencia y ampliar el alcance del trabajo, ha creado nuevos puestos de desarrollo. Esto indica que la IA actúa más como una herramienta de empoderamiento que como un sustituto de la mano de obra, promoviendo la transformación y mejora del mercado laboral. (Fuente: Ronald_vanLoon)

El ejército de EE. UU. enfrenta desafíos en el despliegue de armas de IA: El ejército de EE. UU. está experimentando dificultades en el despliegue de armas de IA y actualmente está transfiriendo el trabajo relacionado a una nueva organización (DAWG) para acelerar el programa de adquisición de drones. Esto refleja la complejidad que enfrenta la tecnología de IA en aplicaciones militares, incluyendo la integración tecnológica, las consideraciones éticas y los desafíos operativos prácticos. (Fuente: Reddit r/ArtificialInteligence)
