

Mots-clés:Détection IA, Images d’abus sur enfants, Gemini Robotics, Modèle incarné, Diagnostic de démence, Simulation physique NVIDIA, Agent IA, Inférence LLM, Technologie de détection de contenu généré par IA, Modèle d’exécution d’actions Gemini Robotics 1.5, Détection de 9 types de démence en un seul scan, Cadre d’inférence distribué NVIDIA Dynamo, Édition Token-Aware pour améliorer le réalisme des modèles
🔥 À la une
L’IA pour la détection des images d’abus d’enfants : Alors que l’IA générative a entraîné une augmentation de 1325 % du nombre d’images d’abus sexuels d’enfants, le Centre de cybercriminalité du Département de la Sécurité intérieure des États-Unis expérimente l’utilisation d’un logiciel d’IA (de Hive AI) pour distinguer le contenu généré par l’IA des images de victimes réelles. Cette initiative vise à concentrer les ressources d’enquête sur les cas de victimes réelles, maximisant ainsi l’impact du programme et protégeant les populations vulnérables, marquant une application clé de l’IA dans la lutte contre la cybercriminalité. L’outil identifie les combinaisons de pixels spécifiques dans les images pour déterminer si elles sont générées par l’IA, sans nécessiter d’entraînement sur des contenus spécifiques. (Source : MIT Technology Review)

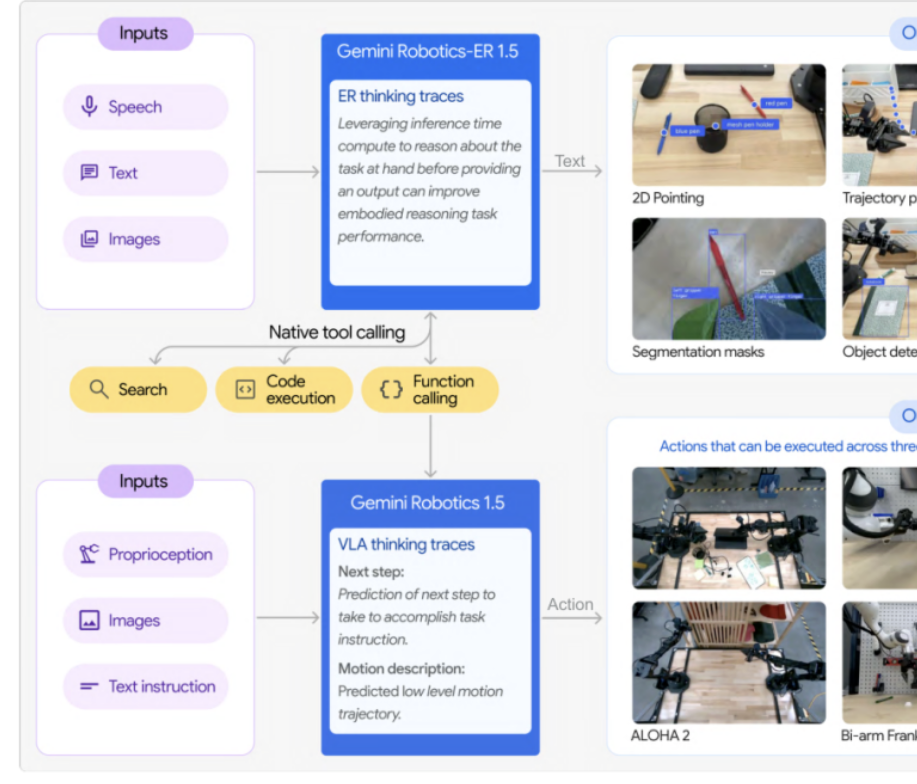
Google DeepMind lance la série Gemini Robotics 1.5 de modèles incarnés : Google DeepMind a dévoilé la série Gemini Robotics 1.5, ses premiers modèles incarnés dotés de capacités de raisonnement par simulation. Cette série comprend le modèle d’exécution d’actions GR 1.5 et le modèle de raisonnement par renforcement GR-ER 1.5, permettant aux robots de “penser avant d’agir”. Grâce au mécanisme “Motion Transfer”, les modèles peuvent transférer des compétences sans aucun exemple vers différentes plateformes matérielles, brisant le modèle traditionnel “un entraînement par machine” et favorisant le développement de robots universels. Le GR-ER 1.5 surpasse GPT-5 et Gemini 2.5 Flash dans les tests de référence pour le raisonnement spatial et la planification de tâches, démontrant une puissante compréhension du monde physique et une capacité à résoudre des tâches complexes. (Source : 量子位)
Un outil d’IA peut détecter 9 types de démence à partir d’une seule analyse : Un outil d’IA est capable de détecter 9 types différents de démence à partir d’une seule analyse avec une précision diagnostique de 88 %. Cette technologie promet de révolutionner le diagnostic précoce de la démence en offrant un dépistage rapide et précis, aidant ainsi les patients à obtenir un traitement et un soutien précoces, ce qui a une signification majeure pour le domaine de la santé. (Source : Ronald_vanLoon)

NVIDIA résout un problème de physique pour des simulations réalistes : NVIDIA a réussi à résoudre un problème qui tourmentait les physiciens depuis longtemps, une avancée cruciale pour la création de simulations hautement réalistes. Cette technologie, qui utilise probablement des algorithmes avancés d’IA et de Machine Learning, améliorera considérablement le réalisme des environnements virtuels et la précision de la modélisation scientifique, ayant un impact profond sur les jeux, la production cinématographique et la recherche scientifique. (Source : )

🎯 Tendances
Google lance des modèles Gemini Flash plus efficaces : Google a lancé deux nouveaux modèles Gemini 2.5 (Flash et Flash-Lite) qui atteignent une précision comparable à GPT-4o pour les tâches d’agent de navigateur, mais sont 2 fois plus rapides et 4 fois moins chers. Cette amélioration significative des performances et de la rentabilité en fait un choix très attractif pour des applications spécifiques de l’IA, en particulier dans les scénarios nécessitant une grande efficacité et une économie. (Source : jeremyphoward, demishassabis, scaling01)
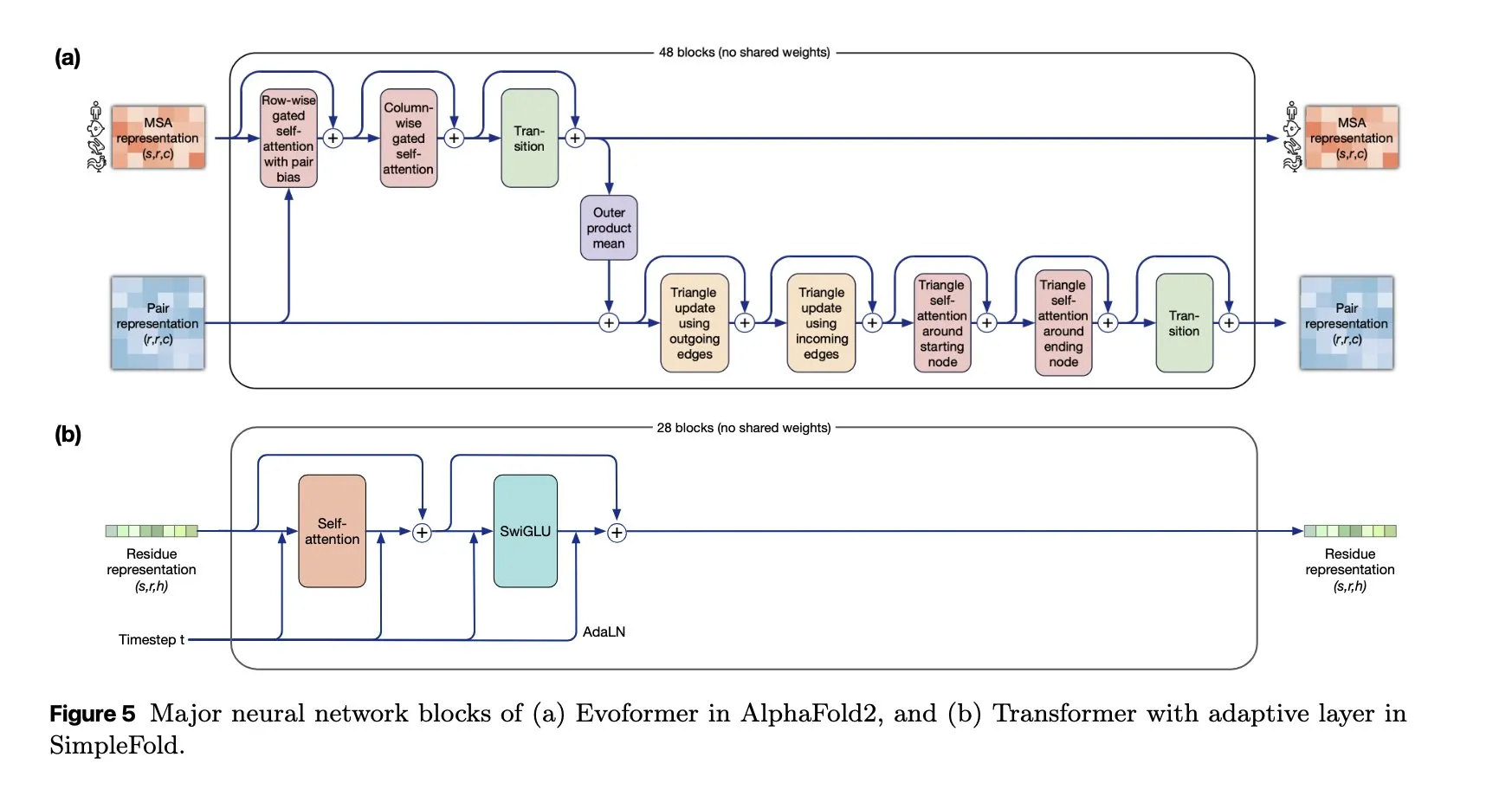
SimpleFold : Un modèle de repliement de protéines basé sur le “flow matching” : Le modèle SimpleFold introduit pour la première fois une méthode de repliement de protéines basée sur le “flow matching” et est entièrement construit avec des blocs Transformer génériques. Cette innovation simplifie le processus de repliement des protéines et, par rapport aux modules traditionnels gourmands en calcul, devrait améliorer l’efficacité et l’évolutivité, faisant progresser l’application de l’IA dans les sciences biologiques. (Source : jeremyphoward, teortaxesTex)
Lancement des LLM Ring-flash-linear-2.0 et Ring-mini-linear-2.0 : Deux nouveaux modèles LLM, Ring-flash-linear-2.0 et Ring-mini-linear-2.0, ont été lancés. Ils utilisent un mécanisme d’attention linéaire hybride pour atteindre une inférence ultra-rapide et de pointe. Ils seraient 2 fois plus rapides que les modèles MoE de taille équivalente et 10 fois plus rapides que les modèles 32B, établissant une nouvelle norme pour l’inférence efficace. (Source : teortaxesTex)

ChatGPT Pulse : Un assistant de recherche intelligent sur mobile : OpenAI a lancé ChatGPT Pulse, une nouvelle fonctionnalité mobile qui effectue des recherches asynchrones quotidiennes en fonction des conversations et de la mémoire passées de l’utilisateur, l’aidant à approfondir les sujets d’intérêt. Cela équivaut à un partenaire de connaissance personnalisé et à un service d’actualités sur mesure, susceptible de changer la façon dont l’information est acquise et apprise. (Source : nickaturley, Reddit r/ChatGPT)
Cadre UserRL : Entraîner des agents IA interactifs proactifs : UserRL est un nouveau cadre conçu pour entraîner des agents IA capables d’assister réellement les utilisateurs par une interaction proactive, plutôt que de simplement viser des scores de référence statiques. Il met l’accent sur l’utilité et l’adaptabilité des agents dans des scénarios réels, promettant de faire évoluer les agents IA de la réponse passive à la résolution proactive de problèmes. (Source : menhguin)

NVIDIA continue d’investir dans l’IA open source : Au cours de la dernière année, NVIDIA a contribué avec plus de 300 modèles, ensembles de données et applications à Hugging Face, consolidant ainsi sa position de leader de l’IA open source aux États-Unis. Cette série d’initiatives a non seulement fait progresser la communauté de l’IA, mais a également démontré la détermination de NVIDIA à construire un écosystème logiciel au-delà du matériel. (Source : ClementDelangue)
La conférence spéciale Qwen3 révèle les orientations futures : Alibaba Cloud a partagé ses plans futurs pour les grands modèles lors de la conférence spéciale Qwen3 : le Reinforcement Learning post-entraînement occupera plus de 50 % du temps d’entraînement ; Qwen3 MoE a atteint un levier de 5x sur les paramètres d’activation grâce à une perte d’équilibrage de charge par lot global ; Qwen3-Next adoptera une architecture hybride comprenant l’attention linéaire et l’attention gated ; l’avenir verra l’unification de toutes les modalités et la poursuite de la Scaling Law. (Source : ZhihuFrontier)
L’équipe SGLang lance un cadre d’entraînement RL 100 % reproductible : L’équipe SGLang, en collaboration avec l’équipe slime, a lancé le premier cadre d’entraînement de Reinforcement Learning (RL) stable et open source, 100 % reproductible. Ce cadre résout le problème de l’invariance des lots dans l’inférence LLM grâce à des opérateurs d’attention et une logique d’échantillonnage personnalisés, garantissant une correspondance parfaite des résultats et offrant une garantie fiable pour les scénarios expérimentaux nécessitant une reproductibilité de haute précision. (Source : 量子位)
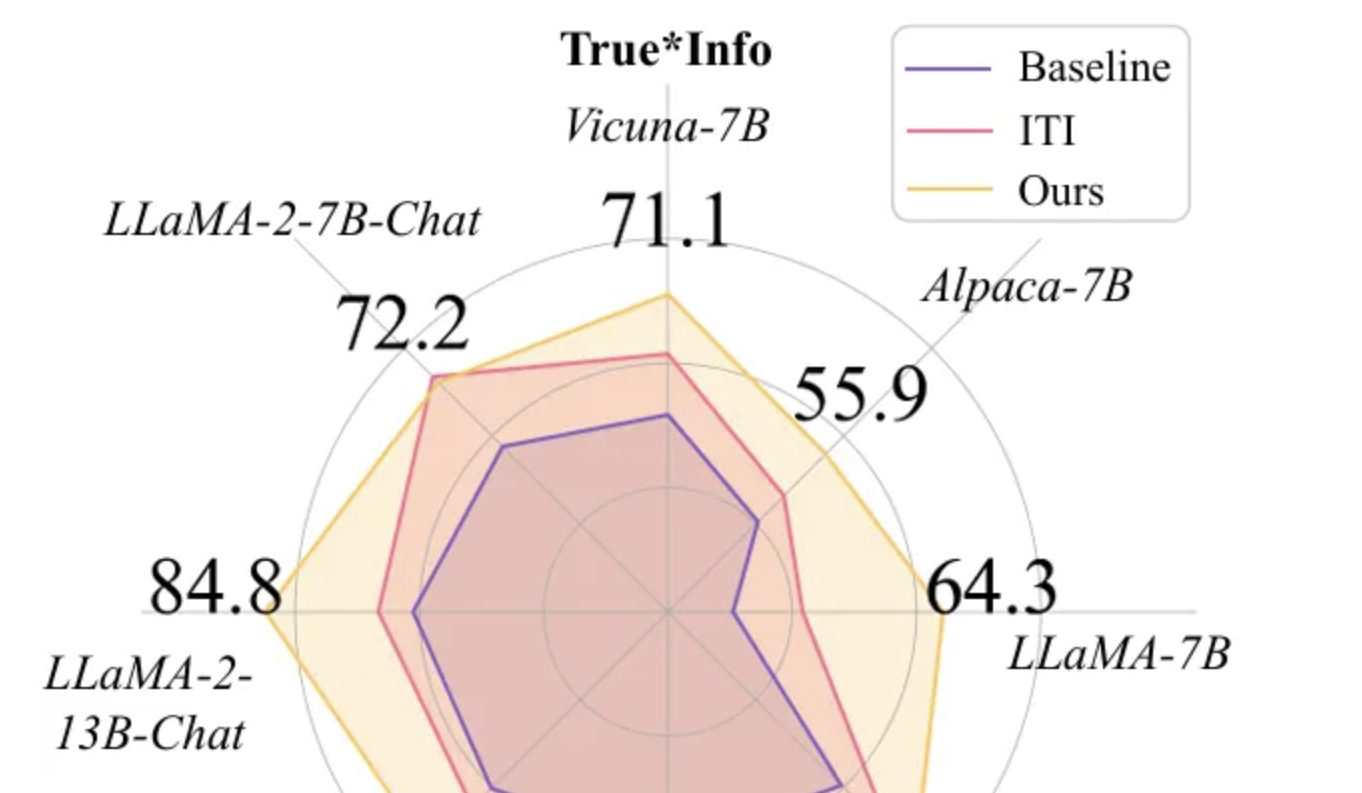
Token-Aware Editing (TAE) améliore la véracité des grands modèles : L’équipe de recherche de l’Université de Beihang a présenté la méthode Token-Aware Editing (TAE) à EMNLP 2025. En éditant les représentations au moment de l’inférence de manière sensible aux tokens, elle a amélioré l’indice de véracité des grands modèles sur la tâche TruthfulQA de 25,8 %, établissant un nouveau SOTA. Cette méthode, sans entraînement et “plug-and-play”, résout efficacement les problèmes de biais directionnel et de flexibilité de l’intensité d’édition des méthodes traditionnelles, et peut être largement appliquée aux systèmes de dialogue et à la modération de contenu. (Source : 量子位)
Meta lance le Code World Model (CWM) pour le codage et le raisonnement : Meta AI a lancé le nouveau modèle open source 32B Code World Model (CWM), conçu pour le codage et le raisonnement. Le CWM apprend non seulement la syntaxe du code, mais comprend également sa sémantique et son exécution, prenant en charge les tâches d’ingénierie logicielle multi-tours et les contextes longs. Il est entraîné via des trajectoires d’exécution et des interactions d’agents, représentant une transition de la complétion automatique de texte vers des modèles capables de planifier, déboguer et vérifier le code. (Source : TheTuringPost)

🧰 Outils
Lancement du produit Replit P1 : Replit lance son produit P1, ce qui laisse présager de nouvelles avancées dans son environnement de développement IA ou ses services connexes. Replit s’est toujours efforcé de donner aux développeurs les moyens d’agir grâce à l’IA, et le lancement de P1 pourrait apporter une assistance au codage plus intelligente, des fonctionnalités de collaboration ou de nouvelles capacités d’intégration, ce qui mérite l’attention de la communauté des développeurs. (Source : amasad)

Comparaison des capacités de codage de Claude Code et Kimi K2 : Les utilisateurs comparent les performances de Claude Code et Kimi K2 dans les tâches de codage. Kimi K2 est plus lent mais moins cher, tandis que Claude Code (et Codex) est préféré pour sa vitesse et sa capacité à résoudre des problèmes complexes. Cela reflète le compromis entre performance et coût que les développeurs doivent faire lorsqu’ils choisissent un assistant de codage LLM. (Source : matanSF, Reddit r/ClaudeAI)
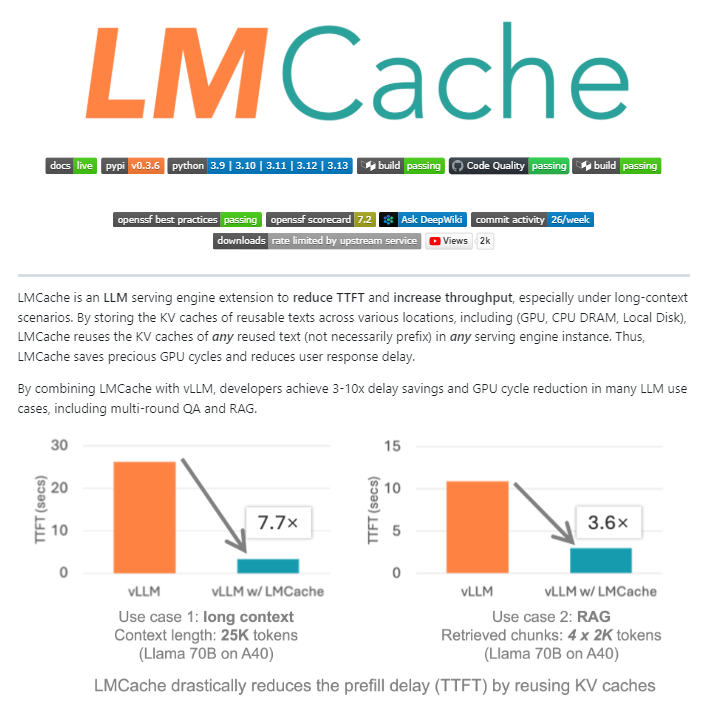
LMCache : Une couche de cache open source pour les moteurs de service LLM : LMCache est une extension open source qui agit comme une couche de cache pour les moteurs de service LLM, optimisant considérablement l’inférence LLM à grande échelle en réutilisant l’état clé-valeur du texte précédent entre le GPU, le CPU et le disque local. Cet outil peut réduire les coûts RAG de 4 à 10 fois, diminuer le temps de génération du premier Token et augmenter le débit sous charge, particulièrement adapté aux scénarios de contexte long. (Source : TheTuringPost)
Agent de développement piloté par l’IA (package npm) : Un processus d’agent de développement piloté par l’IA mature a été publié via npm, visant à simplifier le cycle de vie du développement logiciel. Cet agent couvre l’ensemble du processus, de la découverte des exigences à la planification des tâches, en passant par l’exécution et la révision, et devrait améliorer l’efficacité du développement et la qualité du code. (Source : mbusigin)
Benchmark de performance d’inférence LLM (Qwen3 235B, Kimi K2) : Les benchmarks de l’inférence avec déchargement CPU 4 bits pour Qwen3 235B et Kimi K2 sur du matériel spécifique montrent que le débit de Qwen3 235B est d’environ 60 tokens/s, tandis que celui de Kimi K2 est d’environ 8-9 tokens/s. Ces données fournissent une référence importante pour les utilisateurs lors du choix des modèles et du matériel pour les déploiements LLM locaux. (Source : TheZachMueller)
IA de mémoire personnelle : Surmonter l’amnésie conversationnelle : Un utilisateur a développé une IA de mémoire personnelle qui, en se référant à son profil personnel, sa base de connaissances et ses événements, a réussi à surmonter l‘“amnésie conversationnelle” des IA traditionnelles. Cette IA personnalisée peut offrir une expérience d’interaction plus cohérente et personnalisée, ouvrant de nouvelles voies pour l’application de l’IA dans les assistants personnels et le soutien émotionnel. (Source : Reddit r/artificial)

NVIDIA Dynamo : Cadre de service d’inférence distribué à l’échelle du centre de données : NVIDIA Dynamo est un cadre d’inférence haute performance et à faible latence, conçu pour servir des modèles d’IA générative et d’inférence dans des environnements distribués multi-nœuds. Construit avec Rust et Python, ce cadre optimise l’efficacité et le débit de l’inférence grâce à des fonctionnalités telles que la dissociation des services et le déchargement du cache KV, prenant en charge divers moteurs LLM. (Source : GitHub Trending)

SDK TypeScript du Model Context Protocol (MCP) : Le SDK TypeScript du MCP est un kit de développement officiel qui implémente la spécification MCP, permettant aux développeurs de construire des serveurs et des clients sécurisés et standardisés pour exposer des données (ressources) et des fonctionnalités (outils) aux applications LLM. Il offre un moyen unifié de gestion du contexte et d’intégration des fonctionnalités pour les applications LLM. (Source : GitHub Trending)

L’IA au service de la génération de contenu 3D pour les jeux : Les outils d’IA tels que Hunyuan 3D de Tencent Cloud et Tripo de VAST sont largement adoptés par les développeurs de jeux pour la modélisation d’objets et de personnages 3D dans les jeux. Ces technologies améliorent considérablement l’efficacité et la qualité de la création de contenu 3D, annonçant l’importance croissante de l’IA dans le processus de développement de jeux. (Source : 量子位)

HakkoAI : Un compagnon de jeu VLM en temps réel : HakkoAI, la version internationale du compagnon de jeu DouDou AI, est un compagnon de jeu basé sur un modèle de langage visuel (VLM) en temps réel, capable de comprendre l’écran de jeu et d’offrir une compagnie approfondie. Ce modèle surpasse les modèles généraux de pointe comme GPT-4o dans les scénarios de jeu, démontrant l’énorme potentiel de l’IA pour des expériences de jeu personnalisées. (Source : 量子位)
Percée en matière de cohérence dans la génération vidéo par IA : Le modèle Hailuo S2V-01 de MiniMax AI a résolu le problème de longue date de l’incohérence faciale dans la génération vidéo par IA, réalisant la préservation de l’identité. Cela signifie que les personnages générés par l’IA peuvent maintenir des expressions, des émotions et un éclairage stables dans la vidéo, offrant une expérience visuelle plus réaliste et crédible pour les influenceurs virtuels, les images de marque et la narration. (Source : Ronald_vanLoon)
📚 Apprentissage
Variétés modulaires dans l’optimisation des réseaux neuronaux : La recherche introduit les variétés modulaires comme une avancée théorique dans la conception des réseaux neuronaux et des optimiseurs. En co-concevant les optimiseurs avec des contraintes de variété sur les matrices de poids, on espère obtenir un entraînement de réseau neuronal plus stable et plus performant. (Source : rown, NandoDF)

Interprétation des méthodes de modèles de langage “sans tokenizer” : Un article de blog explore en profondeur les méthodes dites de modèles de langage “sans tokenizer” et explique pourquoi elles ne sont pas vraiment sans tokenizer, et pourquoi les tokenizers sont souvent critiqués dans la communauté de l’IA. L’article souligne que même les méthodes “sans tokenizer” impliquent des choix d’encodage qui sont cruciaux pour les performances du modèle. (Source : YejinChoinka, jxmnop)

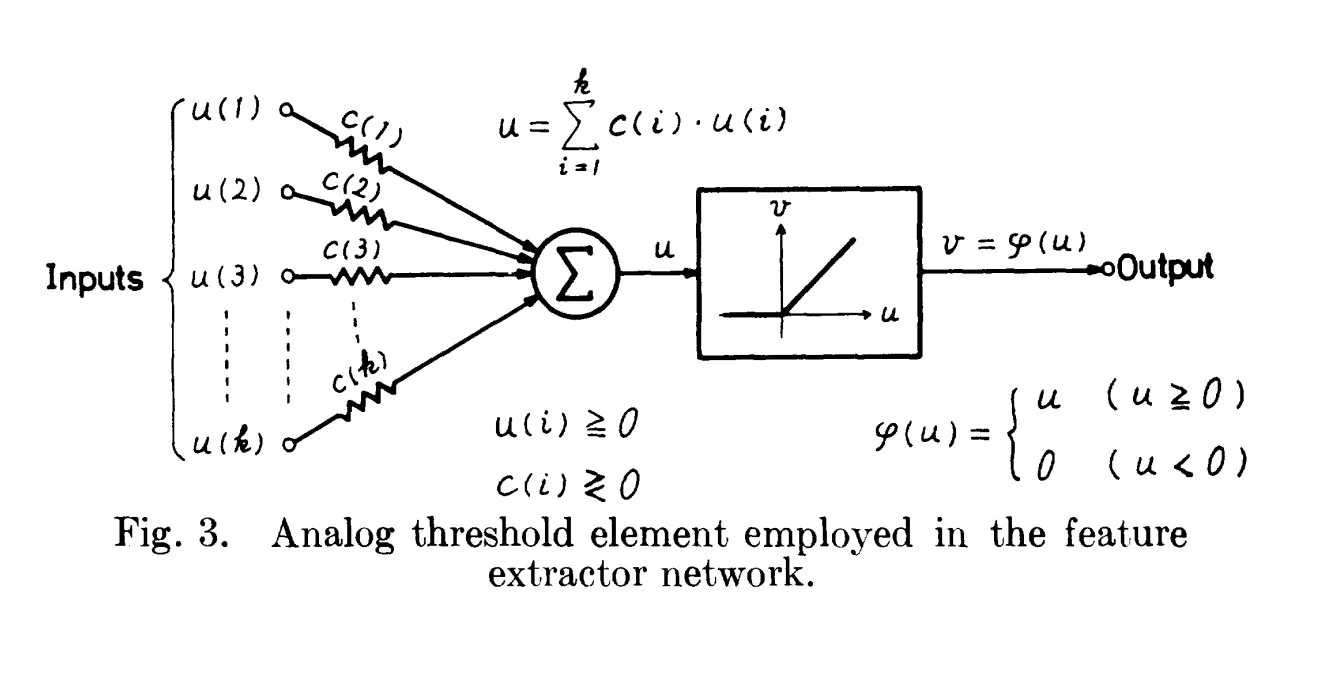
Origines historiques de ReLU : Remontant à 1969 : Une discussion souligne que l’article de Fukushima de 1969 contenait déjà une forme précoce et claire de la fonction d’activation ReLU, fournissant un contexte historique important pour ce concept fondamental de l’apprentissage profond. Cela suggère que les fondements de nombreuses technologies d’IA modernes pourraient être apparus plus tôt que ce que l’on pense généralement. (Source : SchmidhuberAI)
Code World Model (CWM) de Meta : Meta a lancé le nouveau modèle open source 32B Code World Model (CWM), conçu pour le codage et le raisonnement. Le CWM est entraîné via des trajectoires d’exécution et des interactions d’agents, visant à comprendre la sémantique et le processus d’exécution du code, représentant une transition de la simple complétion de code vers des modèles intelligents capables de planifier, déboguer et vérifier le code. (Source : TheTuringPost)
Le rôle crucial des données dans l’IA : La discussion communautaire souligne que “nous ne parlons pas assez des données” dans le domaine de l’IA, mettant en évidence l’importance extrême des données comme pierre angulaire du développement de l’IA. Des données de haute qualité et diversifiées sont le moteur central des capacités et de la généralisabilité des modèles, et leur importance ne doit pas être sous-estimée. (Source : Dorialexander)
Les “super-poids” dans la compression des LLM : La recherche a découvert que la conservation d’une petite partie des “super-poids” est cruciale pour maintenir la fonctionnalité du modèle et atteindre des performances compétitives lors du processus de compression des modèles LLM. Cette découverte ouvre de nouvelles voies pour développer des modèles LLM plus efficaces, plus petits mais sans perte de performance. (Source : dl_weekly)
Guide des architectures d’agents IA (au-delà de ReAct) : Un guide détaille 6 architectures d’agents IA avancées (y compris Self-Reflection, Plan-and-Execute, RAISE, Reflexion, LATS), conçues pour résoudre les limitations du modèle ReAct de base afin de gérer des tâches de raisonnement complexes, offrant aux développeurs un plan pour construire des agents IA plus puissants. (Source : Reddit r/deeplearning)

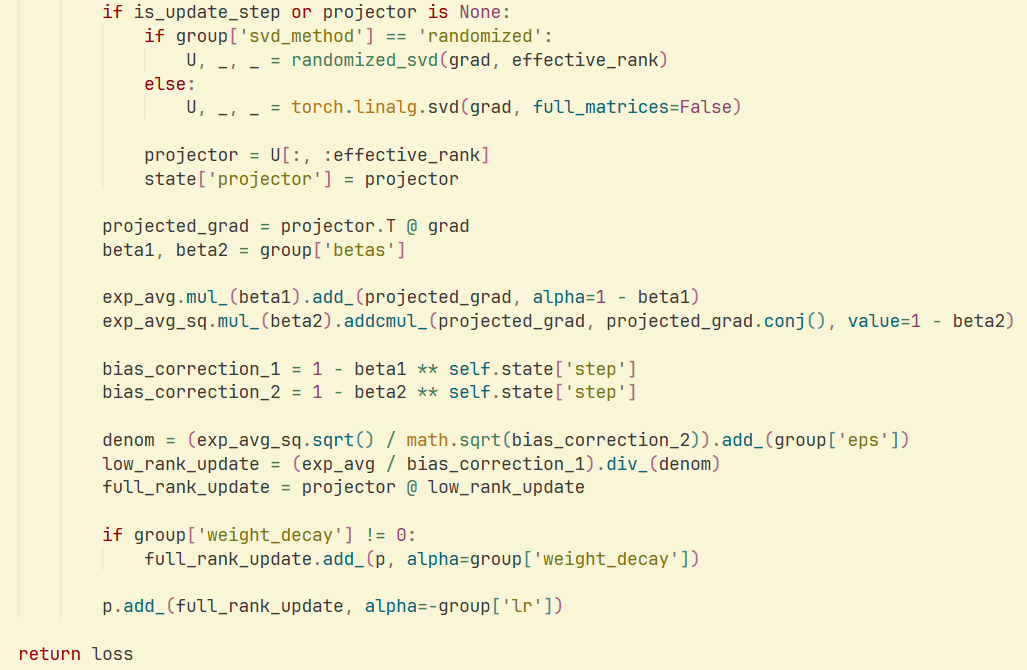
Optimiseur GaLore et SVD aléatoire : Une étude et une implémentation montrent que la combinaison du SVD aléatoire avec l’optimiseur GaLore peut permettre une vitesse et une efficacité mémoire accrues dans l’entraînement des LLM, réduisant considérablement la consommation de mémoire de l’optimiseur. Cela offre de nouvelles stratégies d’optimisation pour l’entraînement de modèles à grande échelle. (Source : Reddit r/deeplearning)
💼 Affaires
Nvidia envisage un nouveau modèle économique de location de puces IA : Nvidia explore un nouveau modèle économique, offrant des services de location de ses puces IA aux entreprises qui ne peuvent pas les acheter directement. Cette initiative vise à élargir l’accès aux ressources de calcul IA et à maintenir l’activité du marché, ce qui pourrait avoir un impact profond sur la démocratisation de l’infrastructure IA. (Source : teortaxesTex)
Untapped Capital lance son deuxième fonds, axé sur l’investissement précoce dans l’IA : Untapped Capital a annoncé le lancement de son deuxième fonds, axé sur les investissements de pré-amorçage dans le domaine de l’IA. Cela indique un intérêt continu de la part du capital-risque pour les jeunes startups de l’IA, fournissant un soutien financier important aux technologies et entreprises émergentes de l’IA. (Source : yoheinakajima)
xAI propose le modèle Grok au gouvernement américain : xAI, la société d’Elon Musk, a proposé de fournir son modèle Grok au gouvernement fédéral américain pour 42 cents. Ce geste hautement symbolique marque une étape stratégique pour xAI dans le domaine des contrats gouvernementaux et pourrait influencer le paysage de l’application de l’IA dans le secteur public. (Source : Reddit r/artificial)

🌟 Communauté
Le débat sur la “leçon amère” des LLM s’intensifie : La vision de Richard Sutton, père du Reinforcement Learning, sur la “leçon amère” a suscité un vaste débat au sein de la communauté. Il se demande si les LLM manquent d’une véritable capacité d’apprentissage continu et nécessitent de nouvelles architectures. Les opposants soulignent le succès de la mise à l’échelle, de l’efficacité des données et des efforts d’ingénierie, tandis que la critique de Sutton explore les aspects philosophiques des modèles langage-monde et de l’intentionnalité. Ce débat couvre les défis fondamentaux et les orientations futures du développement de l’IA. (Source : Teknium1, scaling01, teortaxesTex, Dorialexander, NandoDF, tokenbender, rasbt, dejavucoder, francoisfleuret, natolambert, vikhyatk)
Inquiétudes concernant la sécurité et le contrôle de l’IA : Les préoccupations de la communauté concernant la sécurité et le contrôle de l’IA s’intensifient, allant des craintes des pessimistes de l’IA concernant la navigation libre de l’IA sur Internet, à la peur que des modèles d’IA locaux téléchargeables et dépourvus de contraintes éthiques puissent être utilisés pour le piratage et la génération de contenu malveillant. Ces discussions reflètent les défis éthiques et sociaux complexes posés par le développement de la technologie de l’IA. (Source : jeremyphoward, Reddit r/ArtificialInteligence)
Problèmes de routage OpenAI GPT-4o/GPT-5 et mécontentement des utilisateurs : Les utilisateurs de ChatGPT Plus se plaignent généralement que leurs modèles (4o, 4.5, 5) sont secrètement redirigés vers des modèles “plus stupides”, “plus froids” et “plus sûrs”, ce qui a provoqué une crise de confiance et des rapports de difficultés à se désabonner. Bien qu’OpenAI ait déclaré que ce n’était pas un “comportement attendu”, les retours des utilisateurs restent empreints de frustration et s’étendent aux préoccupations concernant les compagnons IA et la censure de contenu. (Source : Reddit r/ChatGPT, scaling01, MIT Technology Review, Reddit r/ClaudeAI)

Les vues de Richard Sutton sur la succession de l’IA : Richard Sutton, lauréat du prix Turing, estime que la succession vers une superintelligence numérique est “inévitable”, soulignant le manque de points de vue unifiés chez les humains, le fait que l’intelligence sera finalement comprise, et que les agents acquerront inévitablement des ressources et du pouvoir. Ce point de vue a suscité de profondes discussions sur l’avenir du développement de l’IA et le destin de l’humanité. (Source : Reddit r/ArtificialInteligence, Reddit r/artificial)

Philosophie de la productivité de l’IA : 10x de croissance plutôt que de finir plus tôt : La discussion communautaire souligne que la bonne façon d’utiliser l’IA n’est pas seulement de terminer le travail plus rapidement, mais de réaliser une croissance de production de 10 fois dans le même laps de temps. Cette philosophie encourage l’amélioration des capacités personnelles et le développement professionnel grâce à l’IA, plutôt que de simplement rechercher l’efficacité, afin de se démarquer sur le marché du travail. (Source : cto_junior)

Perception de la qualité des modèles d’IA et humour : Les utilisateurs louent la créativité et l’humour de certains LLM (comme GPT-4.5), les jugeant “étonnants” et “inégalés”. Parallèlement, la communauté discute de l’IA avec humour, comme la blague du dictionnaire Merriam-Webster sur le lancement de nouveaux LLM, reflétant la large pénétration des LLM dans la culture. (Source : giffmana, suchenzang)
Éthique de l’IA : Débat sur la guérison du cancer vs. les objectifs de l’AGI : La communauté a discuté de la question éthique de savoir si “guérir le cancer est un meilleur objectif que d’atteindre l’AGI (Intelligence Artificielle Générale)”. Cela reflète un large débat moral sur les priorités du développement de l’IA, à savoir s’il faut privilégier les applications humanitaires ou poursuivre des percées plus profondes en matière d’intelligence. (Source : iScienceLuvr)
Comparaison des capacités des LLM : Performances mathématiques de Claude Opus et GPT-5 : Les utilisateurs ont remarqué que Claude 4.1 Opus excelle dans les tâches de valeur économique mais sous-performe en mathématiques de niveau universitaire, tandis que GPT-5 a réalisé un bond significatif dans ses capacités mathématiques. Cela met en évidence les avantages différenciés des différents LLM dans des capacités spécifiques. (Source : scaling01)
Sécurité des agents IA : Solution de contournement pour la commande rm -rf : Un développeur a partagé une solution de contournement pratique pour empêcher les agents IA d’utiliser à plusieurs reprises la commande rm -rf pour supprimer des fichiers importants : aliaser la commande rm en trash, déplaçant ainsi les fichiers vers la corbeille plutôt que de les supprimer définitivement, prévenant efficacement la perte accidentelle de données. (Source : Reddit r/ClaudeAI)
Préoccupations concernant la confidentialité de l’IA et l’utilisation des données : Des entreprises comme LinkedIn utilisent par défaut les données des utilisateurs pour l’entraînement de l’IA et exigent que les utilisateurs se désengagent activement, ce qui soulève des préoccupations persistantes concernant la confidentialité des données à l’ère de l’IA. Les discussions communautaires soulignent le besoin des utilisateurs de contrôler leurs données personnelles et l’importance de politiques de données transparentes. (Source : Reddit r/artificial)

💡 Divers
L’IA dans l’agriculture : Le pulvérisateur d’herbicide GUSS : Le pulvérisateur d’herbicide GUSS, en tant qu’équipement autonome, réalise des opérations de pulvérisation précises et efficaces en agriculture. Cela démontre le potentiel d’application pratique de la technologie de l’IA pour optimiser les processus de production agricole, réduire le gaspillage de ressources et augmenter le rendement des cultures. (Source : Ronald_vanLoon)
L’impact de l’IA sur l’emploi des développeurs : La discussion communautaire indique que l’IA n’a pas éliminé les postes de développeurs, mais a plutôt créé de nouveaux postes de développement en augmentant l’efficacité et en élargissant le champ de travail. Cela suggère que l’IA est davantage un outil d’autonomisation qu’un substitut de la main-d’œuvre, favorisant la transformation et la modernisation du marché de l’emploi. (Source : Ronald_vanLoon)

L’armée américaine rencontre des difficultés à déployer des armes IA : L’armée américaine rencontre des difficultés à déployer des armes IA et transfère actuellement les travaux connexes à une nouvelle organisation (DAWG) pour accélérer le programme d’acquisition de drones. Cela reflète la complexité des applications militaires de la technologie de l’IA, y compris l’intégration technologique, les considérations éthiques et les défis opérationnels réels. (Source : Reddit r/ArtificialInteligence)
