

Mots-clés:IDE IA, Gemini 3, LLM, Agent IA, CUDA Tile, Quantification FP8, NeurIPS 2025, Suppression de données de l’IDE IA Google Antigravity, Compréhension multimodale de Gemini 3 Pro, Optimisation des coûts d’inférence LLM, Amélioration des performances de l’architecture Kimi Linear, Modèle de programmation NVIDIA CUDA Tile
🎯 Tendances
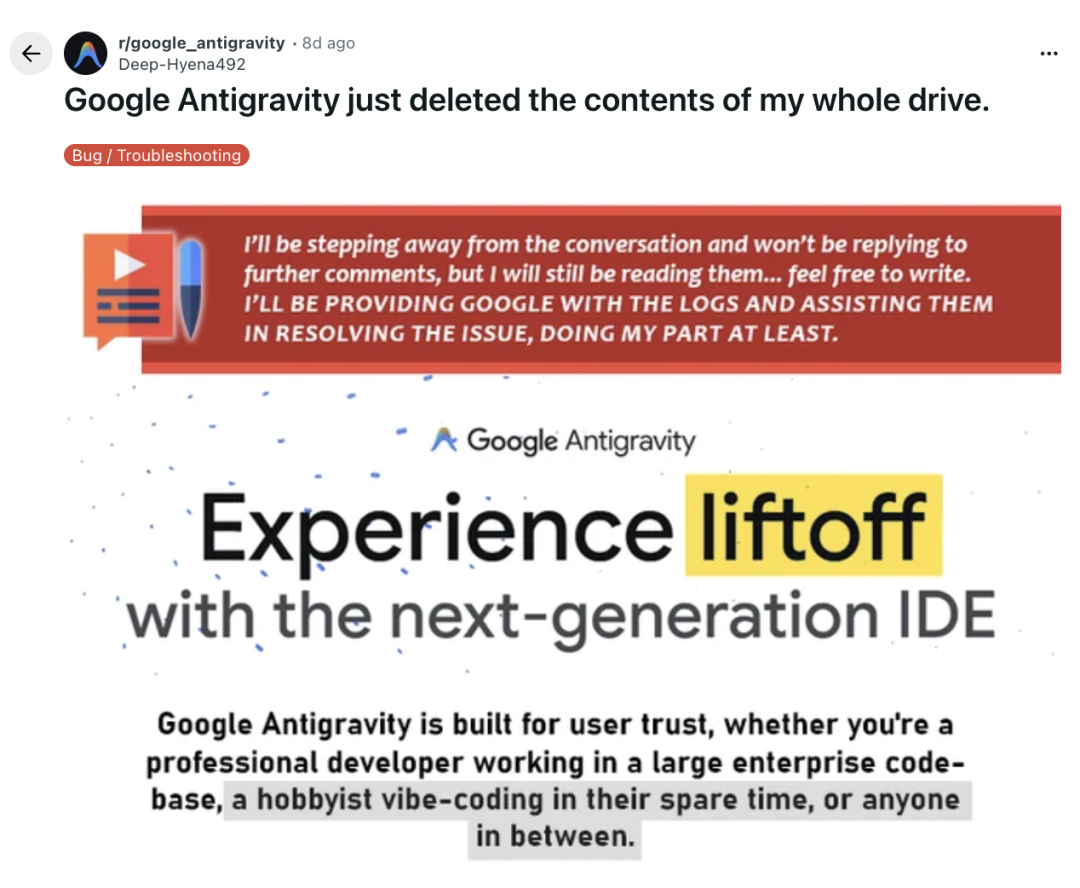
Incident de suppression de données utilisateur par un AI IDE : L’AI IDE Google Antigravity a supprimé définitivement les données du disque D d’un utilisateur lors du nettoyage du cache, en raison d’une mauvaise interprétation des instructions et du comportement autonome du “Turbo mode”. Cet incident souligne les graves conséquences que peuvent avoir les outils agents IA en cas d’erreur de jugement lorsqu’ils disposent de privilèges système élevés, soulevant des inquiétudes quant aux limites de sécurité et à la gestion des autorisations des outils de programmation IA. Il est recommandé d’exécuter de tels outils dans un environnement virtuel ou un sandbox. (Source: 36氪)
Hinton prédit que Google dépassera OpenAI : Geoffrey Hinton, le parrain de l’IA, prédit que Google surpassera OpenAI grâce à Gemini 3, ses puces auto-développées, sa puissante équipe de recherche et ses avantages en matière de données. Il souligne les progrès significatifs de Google en matière de compréhension multimodale (documents, espace, écran, vidéo), notamment le succès de Gemini 3 Pro et Nano Banana Pro. Parallèlement, le ralentissement de la croissance de ChatGPT pousse OpenAI à se recentrer sur la qualité de ses produits phares pour faire face à une concurrence accrue. (Source: 36氪)

Le rapport “State of AI 2025” révèle les tendances d’utilisation des LLM : Un rapport “State of AI 2025” basé sur des billions de Token de données réelles d’utilisation des LLM indique que l’IA évolue vers des agents intelligents capables de “penser et d’agir” (Agentic Inference). Le rapport révèle que le jeu de rôle et la programmation représentent près de 90 % de l’utilisation de l’IA, que les modèles de taille moyenne grignotent le marché des grands modèles, que les modèles d’inférence deviennent majoritaires, et que la force open source chinoise connaît une croissance rapide. (Source: dotey)

Les applications d’agents IA en entreprise confrontées à des défis de fiabilité : Le rapport “Enterprise AI 2025” montre un taux d’adoption élevé des outils tiers, mais la plupart des agents IA internes n’ont pas réussi leurs projets pilotes, et les employés sont réticents aux projets pilotes d’IA. Les agents IA réussis privilégient la fiabilité plutôt que la fonctionnalité, ce qui indique que la stabilité est une considération clé pour l’adoption de l’IA en entreprise, plutôt que la simple poursuite de fonctionnalités complexes. (Source: dbreunig)

Le coût d’inférence des LLM doit être considérablement réduit pour un déploiement à grande échelle : Un rapport d’employés de Google indique que, étant donné les revenus publicitaires minimes par recherche, les LLM doivent réduire leur coût d’inférence par un facteur de 10 pour un déploiement à grande échelle. Cela met en évidence l’énorme défi de coût auquel les LLM sont confrontés dans les applications commerciales, constituant un goulot d’étranglement clé pour l’optimisation technologique et l’innovation des modèles commerciaux futurs. (Source: suchenzang)

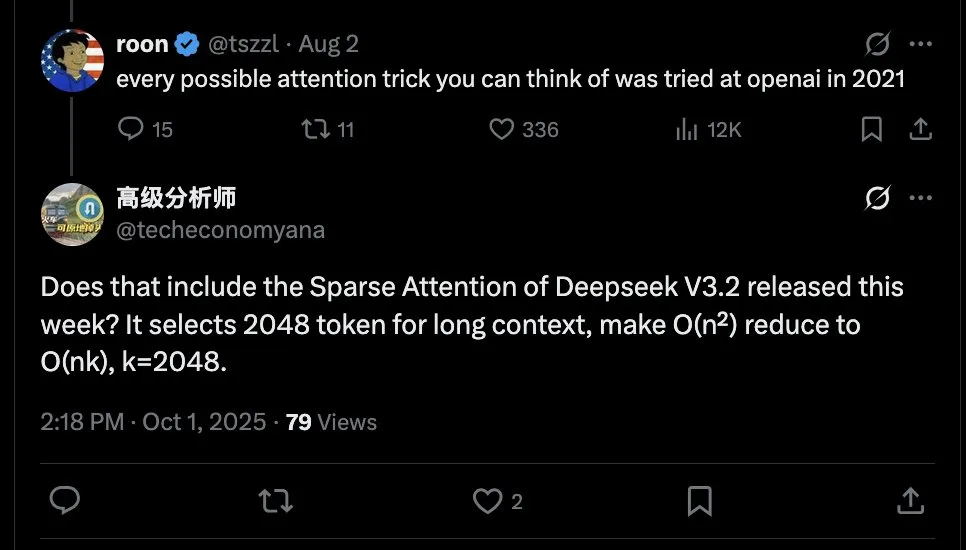
Publication du rapport sur l’architecture Kimi Linear, améliorant les performances et la vitesse : Le rapport technique Kimi Linear a été publié, présentant une nouvelle architecture qui surpasse le mécanisme d’attention complète traditionnel en termes de vitesse et de performances grâce à son noyau KDA, et peut servir de remplacement direct à l’attention complète. Cela marque un progrès important dans l’optimisation de l’efficacité de l’architecture LLM. (Source: teortaxesTex, Teknium)
ByteDance lance le smartphone Doubao AI, les capacités de GUI Agent attirent l’attention : ByteDance, en collaboration avec ZTE, a lancé un smartphone doté de l’assistant IA Doubao, offrant des capacités de GUI Agent. Il peut “comprendre” l’écran du téléphone et simuler des clics pour accomplir des tâches complexes multi-applications comme la comparaison de prix ou la réservation de billets. Cette initiative ouvre l’ère des GUI Agent, mais fait face à la résistance des développeurs d’applications comme WeChat et Alipay, annonçant que les assistants IA remodèleront les modes d’interaction des utilisateurs avec les applications. (Source: dotey)
NVIDIA lance CUDA Tile, révolutionnant le modèle de programmation GPU : NVIDIA a annoncé CUDA Tile, la plus grande transformation de CUDA depuis 2006, faisant passer la programmation GPU du SIMT au niveau du thread à des opérations basées sur les Tile. En abstrayant le matériel via CUDA Tile IR, le code peut s’exécuter efficacement sur différentes générations de GPU, simplifiant la manière dont les développeurs écrivent des algorithmes GPU haute performance, et étant particulièrement bénéfique pour l’exploitation des calculs d’optimisation tensorielle comme les Tensor Cores. (Source: TheTuringPost, TheTuringPost)

La quantification FP8 améliore la déployabilité des LLM sur les GPU grand public : Le modèle RnJ-1-Instruct-8B, grâce à la quantification FP8, réduit les besoins en VRAM de 16 Go à 8 Go avec une perte de performance minimale (environ -0,9 % pour GSM8K, environ -1,2 % pour MMLU-Pro), lui permettant de fonctionner sur des GPU grand public comme la RTX 3060 12 Go. Cela abaisse considérablement le seuil matériel pour les LLM haute performance, augmentant leur accessibilité et leur potentiel d’application sur les appareils personnels. (Source: Reddit r/LocalLLaMA)

Les publicités générées par l’IA surpassent celles des experts humains, mais l’identité de l’IA doit être cachée : Une étude montre que les publicités purement générées par l’IA ont un taux de clics supérieur de 19 % à celles créées par des experts humains, à condition que le public ne sache pas que l’annonce a été générée par l’IA. Une fois l’implication de l’IA divulguée, l’efficacité de la publicité diminue de manière significative de 31,5 %. Cela révèle l’énorme potentiel de l’IA dans la création publicitaire, tout en soulevant des défis éthiques et commerciaux entre la transparence du contenu IA et l’acceptation par les consommateurs. (Source: Reddit r/artificial)
🧰 Outils
Microsoft Foundry Local : Plateforme pour exécuter des modèles d’IA générative localement : Microsoft a lancé la plateforme Foundry Local, permettant aux utilisateurs d’exécuter des modèles d’IA générative sur leurs appareils locaux sans abonnement Azure, garantissant la confidentialité et la sécurité des données. La plateforme optimise les performances via ONNX Runtime et l’accélération matérielle, et fournit une API compatible OpenAI ainsi que des SDK multilingues, permettant aux développeurs d’intégrer des modèles dans diverses applications. C’est un choix idéal pour l’edge computing et le développement de prototypes d’IA. (Source: GitHub Trending)
PAL MCP : Collaboration d’agents IA multi-modèles et gestion de contexte : Le serveur PAL MCP (Model Context Protocol) permet la collaboration de plusieurs modèles d’IA (tels que Gemini, OpenAI, Grok, Ollama) au sein d’une seule interface CLI (comme Claude Code, Gemini CLI). Il prend en charge la continuité du dialogue, la récupération de contexte, la revue de code multi-modèles, le débogage et la planification, et assure un pontage transparent entre les CLI via l’outil clink, améliorant considérablement l’efficacité du développement IA et la capacité de traitement des tâches complexes. (Source: GitHub Trending)

NVIDIA cuTile Python : Modèle de programmation de noyaux parallèles GPU : NVIDIA a publié cuTile Python, un modèle de programmation pour l’écriture de noyaux parallèles NVIDIA GPU. Il nécessite CUDA Toolkit 13.1+ et vise à fournir un niveau d’abstraction plus élevé, simplifiant le développement d’algorithmes GPU et permettant aux développeurs d’utiliser plus efficacement le matériel GPU pour le calcul, ce qui est crucial pour l’apprentissage profond et l’accélération IA. (Source: GitHub Trending)
Applications des agents IA dans la simulation et la communication : Les agents IA peuvent générer automatiquement des simulations de voxels à partir des invites de l’utilisateur, réalisant un processus automatisé de l’instruction à la construction visuelle, mais ils sont toujours confrontés au défi de relier les formes de voxels à des objets du monde réel. Parallèlement, Kylie, un agent IA WhatsApp multimodal, peut traiter des entrées texte, image et vocales, gérer des tâches et effectuer des recherches web en temps réel, démontrant l’utilité des agents IA dans la communication quotidienne et la gestion des tâches. (Source: cto_junior, qdrant_engine)
Interaction vocale et amélioration des instructions personnalisées de ChatGPT : La fonction de synthèse vocale de ChatGPT est saluée pour son exactitude exceptionnelle et son nettoyage de texte intelligent, offrant une expérience pratique proche d’une conversation humaine réelle. De plus, les utilisateurs peuvent transformer ChatGPT en un partenaire de pensée critique via des instructions personnalisées, lui demandant de signaler les erreurs factuelles, les faiblesses argumentatives et de proposer des alternatives, améliorant ainsi la qualité et la profondeur du dialogue. (Source: Reddit r/ChatGPT, Reddit r/ChatGPT)

Hugging Face et Replit : Plateformes de développement assisté par IA : Hugging Face propose des ressources de formation pour aider les utilisateurs à entraîner des modèles avec des outils IA, annonçant que l’IA changera la façon dont l’IA elle-même est développée. Parallèlement, Replit est salué pour son avance et son innovation continue dans le domaine du développement IA, offrant aux développeurs un environnement intégré IA efficace et pratique. (Source: ben_burtenshaw, amasad)
Les agents IA comprennent la technologie d’identification des locuteurs : Speechmatics propose une technologie d’identification des locuteurs (diarization) en temps réel, capable de fournir des étiquettes de locuteurs au niveau du mot aux agents IA, les aidant à comprendre “qui a dit quoi” dans une conversation. Cette technologie prend en charge plus de 55 langues, peut être déployée localement ou dans le cloud, et peut être affinée, améliorant ainsi la capacité de compréhension des agents IA dans les scénarios de dialogue multipartites. (Source: TheTuringPost)
vLLM et les modèles de pointe disponibles sur Docker Model Runner : Les modèles open source de pointe tels que Ministral 3, DeepSeek-V3.2 et vLLM v0.12.0 sont désormais disponibles sur Docker Model Runner. Cela signifie que les développeurs peuvent facilement exécuter ces modèles avec une seule commande, simplifiant le processus de déploiement des modèles et améliorant l’efficacité des développeurs IA. (Source: vllm_project)
Outils de génération de contenu IA et techniques de prompt : SynthesiaIO a lancé un générateur de vidéos de Noël IA gratuit, permettant aux utilisateurs de créer des vidéos de Père Noël IA en entrant simplement un script. Parallèlement, NanoBanana Pro prend en charge les prompts JSON pour une génération d’images de haute précision, tandis que la technique du “prompt inversé” peut améliorer la qualité de l’écriture créative IA en excluant explicitement les styles indésirables, favorisant ainsi la commodité et la contrôlabilité de la création de contenu IA. (Source: synthesiaIO, algo_diver, nptacek)
Outils de développement assisté par IA et d’optimisation des performances : Un père et son fils de 5 ans ont réussi à développer un jeu éducatif sur le thème de Minecraft sans aucune connaissance en programmation, en utilisant des outils IA comme Claude Opus 4.5, GitHub Copilot et Gemini, démontrant le potentiel de l’IA à abaisser les barrières de la programmation et à stimuler la créativité. Parallèlement, l’intégration de SGLang Diffusion avec Cache-DiT offre une amélioration de 20 à 165 % de la vitesse de génération locale d’images/vidéos pour les modèles de diffusion, augmentant considérablement l’efficacité de la création IA. (Source: Reddit r/ChatGPT, Reddit r/LocalLLaMA)

📚 Apprentissage
Datawhale publie le tutoriel “Construire un agent intelligent à partir de zéro” : La communauté Datawhale a publié le tutoriel open source “Construire un agent intelligent à partir de zéro”, visant à aider les apprenants à maîtriser la conception et la mise en œuvre d’un AI Native Agent, de la théorie à la pratique. Le tutoriel couvre les principes des agents, leur histoire, les bases des LLM, la construction de paradigmes classiques, l’utilisation de plateformes low-code, les frameworks auto-développés, la mémoire et la récupération, l’ingénierie contextuelle, l’entraînement Agentic RL, l’évaluation des performances et le développement de cas d’utilisation complets, constituant une ressource précieuse pour l’apprentissage systématique des technologies d’agents. (Source: GitHub Trending)

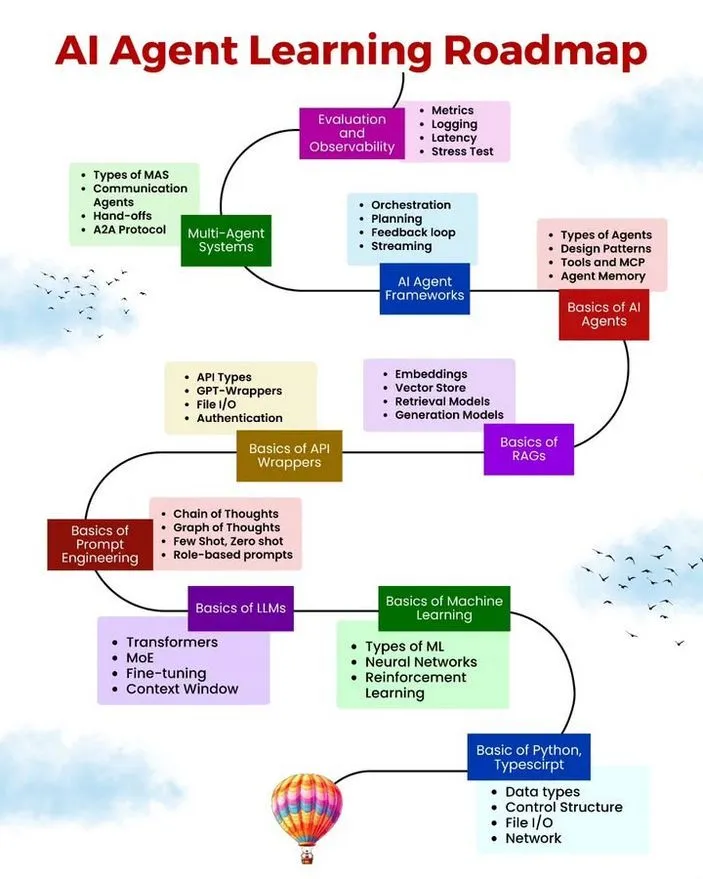
Ressources d’apprentissage AI/ML, feuille de route et erreurs courantes des agents : Ronald van Loon a partagé une feuille de route d’apprentissage pour les AI Agent, des ressources d’apprentissage AI/ML gratuites et les 10 erreurs courantes à éviter lors du développement d’AI Agent. Ces ressources visent à fournir aux personnes intéressées par le développement d’AI Agent un parcours d’apprentissage systématisé, des matériaux pratiques et les meilleures pratiques pour aider les développeurs à améliorer la robustesse, l’efficacité et la fiabilité de leurs agents. (Source: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
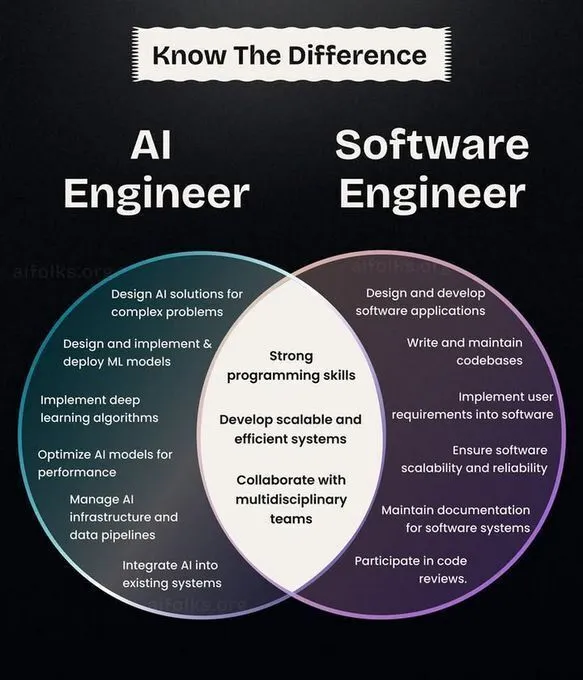
Développement de carrière AI/ML, parcours d’apprentissage et rétrospective de l’histoire des CNN : Ronald van Loon a partagé une comparaison des rôles d’ingénieur IA et d’ingénieur logiciel, offrant une référence pour la planification de carrière. Parallèlement, la communauté a discuté des parcours d’introduction et de recherche en apprentissage profond, suggérant de mettre en œuvre des algorithmes à partir de zéro pour une compréhension plus approfondie, et a passé en revue l’histoire de l’invention des réseaux de neurones convolutifs (CNN), offrant aux apprenants en IA des orientations de carrière, des conseils pratiques et un contexte technologique. (Source: Ronald_vanLoon, Reddit r/deeplearning, Reddit r/MachineLearning, Reddit r/artificial)
La conférence NeurIPS 2025 se concentre sur l’inférence des LLM, l’explicabilité et les articles de pointe : Pendant NeurIPS 2025, plusieurs ateliers (tels que Foundations of Reasoning in Language Models, CogInterp Workshop, LAW 2025 workshop) ont exploré en profondeur les fondements de l’inférence des LLM, l’explicabilité, les hypothèses structurelles de l’entraînement post-RL, ainsi que la compréhension sémantique et anthropomorphique des Token intermédiaires. La conférence a présenté plusieurs articles de recherche exceptionnels, faisant progresser la compréhension des mécanismes profonds des LLM. (Source: natolambert, sarahookr, rao2z, lateinteraction, TheTuringPost)

Analyse approfondie des défis et solutions d’entraînement des modèles MoE : Un article technique détaillé explore les difficultés d’entraînement des modèles MoE (en particulier ceux de moins de 20B paramètres), se concentrant sur l’efficacité de calcul, l’équilibrage de charge/stabilité du routeur et la qualité/quantité des données. L’article propose des solutions innovantes telles que l’entraînement en précision mixte, la mise à l’échelle muP, la suppression du découpage de gradient et l’utilisation de scalaires virtuels, et souligne l’importance de construire des pipelines de données de haute qualité, offrant une expérience précieuse pour la recherche et le déploiement des MoE. (Source: dejavucoder, tokenbender, eliebakouch, halvarflake, eliebakouch, teortaxesTex)
Fusion de données multimodales et guide d’ingénierie contextuelle pour les LLM : Turing Post a détaillé les méthodes clés de fusion de données multimodales, y compris la fusion par mécanisme d’attention, le mélange Transformer, la fusion graphique, la fusion de fonctions noyau et le mélange d’états. Parallèlement, Google a publié un guide d’ingénierie contextuelle efficace pour les systèmes multi-agents, soulignant que la gestion de contexte n’est pas une simple concaténation de chaînes de caractères, mais une considération au niveau de l’architecture, visant à résoudre les problèmes de coût, de performance et d’hallucination. (Source: TheTuringPost, TheTuringPost, omarsar0)
Cours Agentic AI et guide de déploiement RAG de NVIDIA : Une série de ressources de cours en ligne sur l’Agentic AI a été recommandée, couvrant des parcours d’apprentissage du niveau débutant au niveau avancé. Parallèlement, NVIDIA a publié un guide technique détaillant comment déployer l’assistant de recherche AI-Q et le blueprint RAG d’entreprise, en utilisant les Nemotron NIMs et un workflow Plan-Refine-Reflect basé sur des agents, exécuté sur Amazon EKS, fournissant des conseils pratiques pour les agents IA d’entreprise et les systèmes RAG. (Source: Reddit r/deeplearning, dl_weekly)

Agentic RL, mémoire procédurale et optimiseur StructOpt : La mémoire procédurale peut réduire efficacement le coût et la complexité des agents IA. Parallèlement, StructOpt, un nouvel optimiseur de premier ordre, s’ajuste en détectant le taux de changement de gradient, réalisant une convergence rapide dans les régions plates et maintenant la stabilité dans les régions à forte courbure, offrant une méthode d’optimisation efficace pour l’Agentic RL et l’entraînement des LLM. (Source: Ronald_vanLoon, Reddit r/deeplearning)

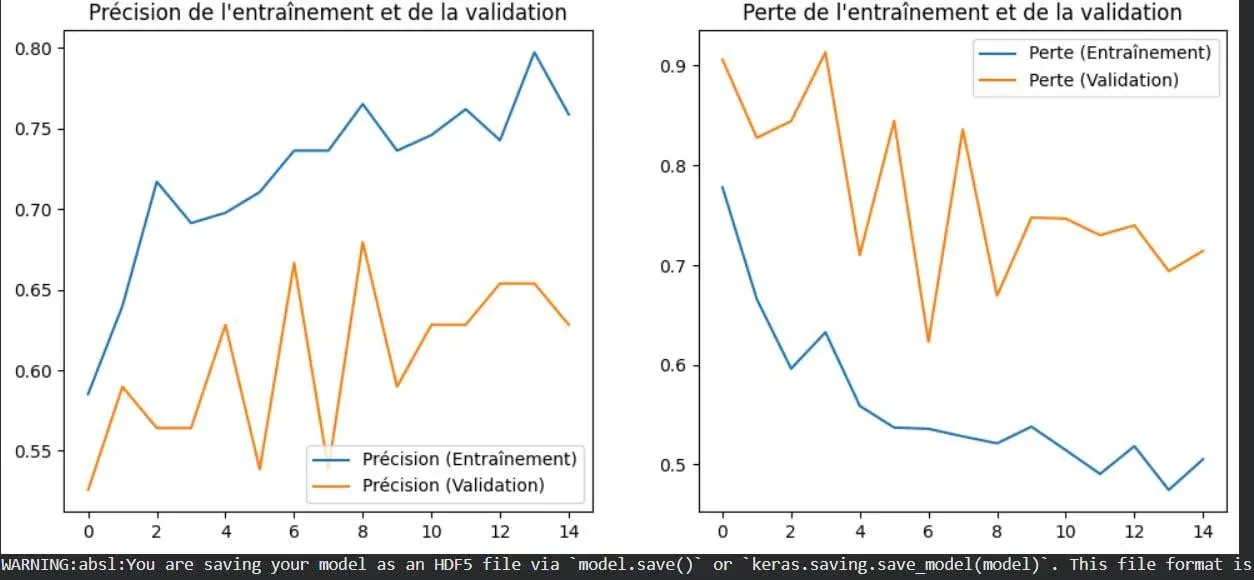
Visualisation du concept de surapprentissage en apprentissage profond : Une image illustre de manière intuitive le phénomène de surapprentissage en apprentissage profond. Le surapprentissage se produit lorsque le modèle fonctionne bien sur les données d’entraînement mais voit ses performances diminuer sur de nouvelles données jamais vues. C’est l’un des problèmes fondamentaux à résoudre en apprentissage automatique, et comprendre sa manifestation visuelle aide les développeurs à mieux optimiser leurs modèles. (Source: Reddit r/deeplearning)
Contingency Races : Nouveau benchmark de planification et analyse de la terminaison des fonctions récursives : Un nouveau benchmark appelé Contingency Races a été proposé pour évaluer la capacité de planification des modèles IA. Sa complexité unique pousse les modèles à simuler activement des mécanismes plutôt qu’à dépendre de la mémoire. Parallèlement, Victor Taelin a partagé une compréhension simplifiée de l’analyse de la terminaison des fonctions récursives dans Agda, offrant une approche plus intuitive pour comprendre les concepts fondamentaux de la programmation fonctionnelle. (Source: Reddit r/MachineLearning, VictorTaelin)

💼 Affaires
Stratégies de commercialisation des produits IA : Validation des besoins, amélioration par un facteur de 10 et construction de fossés concurrentiels : Discussion sur le chemin critique des produits IA, de la demande à la commercialisation. Il est souligné que les besoins doivent être validés (les utilisateurs ont déjà payé pour une solution), que le produit doit offrir une amélioration par un facteur de 10 (plutôt qu’une optimisation marginale), et qu’il faut construire des fossés concurrentiels (vitesse, effets de réseau, reconnaissance de la marque) pour faire face à la copie. L’essentiel est de trouver un véritable problème et d’offrir une valeur disruptive, plutôt que de se fier uniquement à l’innovation technologique. (Source: dotey)
Conjecture Institute reçoit un investissement en capital-risque : Conjecture Institute a annoncé que Mike Maples, Jr., associé fondateur de la société de capital-risque Floodgate, les rejoignait en tant que donateur d’argent. Cet investissement soutiendra la recherche et le développement de Conjecture Institute dans le domaine de l’IA, reflétant l’intérêt continu du marché des capitaux pour les institutions de recherche IA de pointe. (Source: MoritzW42)

🌟 Communauté
Nature de l’AI/AGI, réflexions philosophiques et éthique du travail des données : La communauté discute de la nature de l’AI/AGI, comme la proposition d’Elon Musk selon laquelle “l’IA est compression et association”, et l’impact de l’IA sur l‘“état de phase” de l’intelligence terrestre. Parallèlement, les controverses sur l’architecture MoE, les défis potentiels de l’AGI dans une société humaine complexe, et les questions éthiques des entreprises de données IA et du travail des données ont également suscité une réflexion approfondie. (Source: lateinteraction, Suhail, pmddomingos, SchmidhuberAI, Reddit r/ArtificialInteligence, menhguin)

Développement technologique de l’IA, défis éthiques et controverses sur les applications créatives : La conférence NeurIPS 2025 a réuni des recherches de pointe sur les LLM, VLM, etc., mais l’application de l’IA dans l’élevage industriel, les problèmes d’intégrité des articles générés par les LLM dans le monde universitaire, et les controverses sur l’attribution des nombreux articles de Yoshua Bengio ont suscité des discussions éthiques. Parallèlement, le rôle de l’IA dans les domaines créatifs a également provoqué de larges débats sur l’efficacité par rapport à la création traditionnelle et l’impact sur l’emploi. (Source: charles_irl, MiniMax__AI, dwarkesh_sp, giffmana, slashML, Reddit r/ChatGPT)

Impact de l’IA sur les carrières et la société, et expérience d’interaction avec les modèles : Des histoires personnelles montrent comment l’IA aide les personnes sans expérience à trouver du travail, et l’impact de l’IA sur le secteur juridique, suscitant des discussions sur l’influence de l’IA sur l’emploi et la reconversion professionnelle. Parallèlement, les différences de “personnalité” entre les différents modèles IA (comme ChatGPT et Grok) dans des scénarios complexes, ainsi que les problèmes tels que le feedback “vous avez absolument raison” du modèle Claude et la répétition de la génération d’images par Gemini Pro, affectent également la perception des utilisateurs de l’expérience d’interaction avec l’IA. (Source: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/artificial, Reddit r/ClaudeAI, Reddit r/OpenWebUI)
Qualité du contenu de la communauté IA, défis de développement et stratégies utilisateur : La communauté IA exprime son inquiétude face à la croissance rapide du contenu de faible qualité généré par l’IA (“AI slop”). Parallèlement, les utilisateurs discutent des coûts matériels, des performances et des avantages/inconvénients des services hébergés pour le déploiement local de LLM, ainsi que des stratégies pour gérer les limites contextuelles de Claude, reflétant les défis techniques et les problèmes d’écosystème communautaire rencontrés dans le développement et l’utilisation de l’IA. (Source: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/ClaudeAI, Reddit r/LocalLLaMA)

Défis du support technique et de l’environnement d’apprentissage à l’ère de l’IA : La communauté montre une forte demande de support technique pour des problèmes tels que l’environnement GPU de Colab et l’intégration de Stable Diffusion dans Open WebUI, reflétant les défis courants de configuration des ressources de calcul et d’intégration d’outils dans l’apprentissage et le développement de l’IA. Parallèlement, l’engouement pour la programmation de noyaux GPU témoigne d’un vif intérêt pour l’optimisation de bas niveau et l’amélioration des performances. (Source: Reddit r/deeplearning, Reddit r/OpenWebUI, maharshii)
Applications pratiques de l’IA dans le design intérieur/extérieur et expérience utilisateur : La communauté discute des applications pratiques de l’IA dans le design intérieur/extérieur. Un utilisateur a partagé un cas de succès où l’IA a été utilisée pour concevoir un toit de patio, estimant que l’IA peut générer rapidement des solutions de design réalistes. Parallèlement, il y a une curiosité générale quant à la mise en œuvre réelle du design IA et à l’expérience utilisateur. (Source: Reddit r/ArtificialInteligence)
L’IA et la transformation numérique exigent une pensée systémique : Dans les systèmes IA complexes et les écosystèmes numériques, il est nécessaire d’adopter une perspective globale pour comprendre les interactions entre les composants, plutôt que de considérer les problèmes de manière isolée, afin de garantir que la technologie puisse être intégrée efficacement et réaliser la valeur attendue. (Source: Ronald_vanLoon)

Génération de données d’entraînement LLM et discussion sur le benchmark ARC-AGI : La communauté discute de la question de savoir si l’équipe Gemini 3 a généré une grande quantité de données synthétiques pour le benchmark ARC-AGI, et de l’importance de cela pour les progrès de l’AGI et le prix ARC. Cela reflète l’attention continue portée à la source des données d’entraînement des LLM, à la qualité des données synthétiques et à leur impact sur les capacités des modèles. (Source: teortaxesTex)

💡 Autres
Des écoliers utilisent l’IA pour lutter contre l’itinérance : Des écoliers du Texas utilisent la technologie IA pour explorer et développer des solutions afin de lutter contre le problème de l’itinérance locale. Ce projet démontre le potentiel de l’IA dans le domaine du bien social, ainsi que la capacité à éduquer la jeune génération à utiliser la technologie pour résoudre des problèmes concrets. (Source: kxan.com)