

Mots-clés:Modèles d’IA à grande échelle, Modèles open source, Optimisation de l’inférence, Recherche IA, Lunettes IA, Agent IA, AGI (Intelligence Générale Artificielle), Rapport a16z sur les billions de tokens, API Gemini 3, Téléphone intelligent Doubao IA, Architecture Titans, Fusion multimodale
🎯 Tendances
Le rapport d’a16z sur les mille milliards de Tokens révèle une grande divergence de l’IA : OpenRouter et a16z ont publié conjointement un rapport basé sur 100 mille milliards de Tokens, révélant trois grandes tendances de l’IA pour 2025 : les modèles open source représenteront 30% du trafic, la puissance open source chinoise montera en flèche, occupant près de 30% de la part mondiale ; le trafic des modèles optimisés pour l’inférence dépassera 50%, l’IA passant de la « génération de texte » à la « résolution de problèmes » ; la programmation et le jeu de rôle sont les deux scénarios dominants. Le rapport propose également l’« effet Cendrillon », soulignant que les modèles doivent d’abord résoudre des problèmes spécifiques pour fidéliser les utilisateurs, et indique que l’utilisation payante en Asie a doublé, le chinois étant devenu la deuxième langue d’interaction de l’IA. (Source: source, source)

L’évolution et les controverses de la recherche par IA : La recherche par IA évolue de la distribution d’informations vers l’intermédiation de services. Les moteurs de recherche natifs de l’IA comme Google Gemini 3 et Perplexity redéfinissent l’expérience de recherche grâce à l’interaction conversationnelle, la compréhension multimodale et l’exécution de tâches. La part de marché des moteurs de recherche traditionnels diminue, et la recherche par IA s’intègre comme une capacité fondamentale dans diverses applications. Cependant, Elon Musk affirme que l’IA « éliminera la recherche », ce qui reflète l’impact sur les modèles traditionnels et l’attente d’un futur marché d’intermédiation de services de mille milliards de dollars, tout en suscitant des discussions sur les sources d’information fiables et le changement de paradigme marketing. (Source: source)

La « guerre des cent lunettes » de l’IA : Le marché chinois a vu le lancement de 20 paires de lunettes AI en deux mois. Des géants comme Google, Alibaba, Huawei, Meta sont entrés dans la course, visant à s’emparer de la prochaine génération d’interfaces d’interaction intelligente. Les lunettes AI intègrent les capacités des grands modèles pour offrir des fonctions telles que la traduction en temps réel, la reconnaissance de scène et la réponse vocale, tentant de « tuer » les lunettes traditionnelles. Cependant, l’homogénéité des produits, l’autonomie, le confort et la sécurité de la vie privée restent des défis, et le marché explore toujours leurs applications « tueuses » et leurs modèles commerciaux. (Source: source, source)

La bataille du smartphone AI Doubao contre les super-applications : Le smartphone AI Doubao, fruit de la collaboration entre ByteDance et ZTE, réalise des capacités d’IA au niveau du système grâce à un Agent à privilèges élevés, ce qui a déclenché une discussion sur la « guerre entre les super-Agents et les super-applications ». Les utilisateurs peuvent effectuer des opérations complexes comme la comparaison de prix multiplateforme ou la commande de plats à emporter en une seule phrase. Cependant, des plateformes comme WeChat ont rapidement interdit les opérations automatisées par des tiers, soulignant que le déploiement de l’IA au niveau du système n’est pas seulement un problème technique, mais aussi un défi de répartition des intérêts et de coordination de l’écosystème. Les fabricants de téléphones, en tant qu’acteurs neutres, pourraient plus facilement promouvoir la construction d’un écosystème ouvert pour les smartphones AI. (Source: source, source)

Les défis du déploiement de l’IA dans le monde physique : Le consensus général de l’industrie est que l’IA est un « dieu » dans le monde numérique, mais reste un « bébé géant » dans le monde physique. Un dirigeant de startup automobile a souligné qu’apprendre à un robot à marcher est plus difficile qu’apprendre à une IA à écrire de la poésie ; le monde physique manque d’un « bouton annuler », et les coûts d’exploitation et juridiques sont énormes. Les futurs bénéfices résident dans l’intégration de l’IA dans des équipements physiques comme les voitures et les machines-outils, pour réaliser une percée en termes de « contenu industriel ». De plus, après l’épuisement des bénéfices des données textuelles, le Scaling Law se tourne vers l’« apprentissage à partir de vidéos » pour comprendre les lois physiques et la causalité, mais cela pose également d’énormes défis en termes de consommation de puissance de calcul. (Source: source)
Ajustements de l’API gratuite de Google Gemini et concurrence sur le marché : Google a soudainement resserré les restrictions sur le niveau gratuit de l’API Gemini, provoquant le mécontentement des développeurs, qui estiment que Google se tourne vers la rentabilité après avoir collecté des données. Cette décision intervient alors qu’OpenAI prévoit de lancer GPT-5.2 en réponse à Gemini 3, la concurrence des grands modèles d’IA s’intensifiant. Demis Hassabis, CEO de Google DeepMind, a souligné que Google devait occuper la position la plus forte dans le domaine de l’IA, et s’est dit satisfait des performances de Gemini 3 en matière de compréhension multimodale, de création de jeux, de développement front-end, etc., tout en réaffirmant l’importance du Scaling Law. (Source: source)
L’architecture Titans de Google DeepMind et les perspectives de l’AGI : Demis Hassabis, CEO de Google DeepMind, prédit que l’AGI sera réalisée d’ici 5 à 10 ans, mais nécessitera 1 à 2 percées de niveau « Transformer ». Lors de la conférence NeurIPS 2025, Google a dévoilé l’architecture Titans, combinant la vitesse des RNN et les performances des Transformer, visant à résoudre les problèmes de contexte long, et a proposé le cadre théorique MIRAS. Titans compresse les données historiques via un module de mémoire à long terme, permettant une mise à jour dynamique des paramètres du modèle en temps réel, particulièrement performant dans les tâches d’inférence à très long contexte, et est considéré comme un successeur puissant du Transformer. (Source: source, source)

🧰 Outils
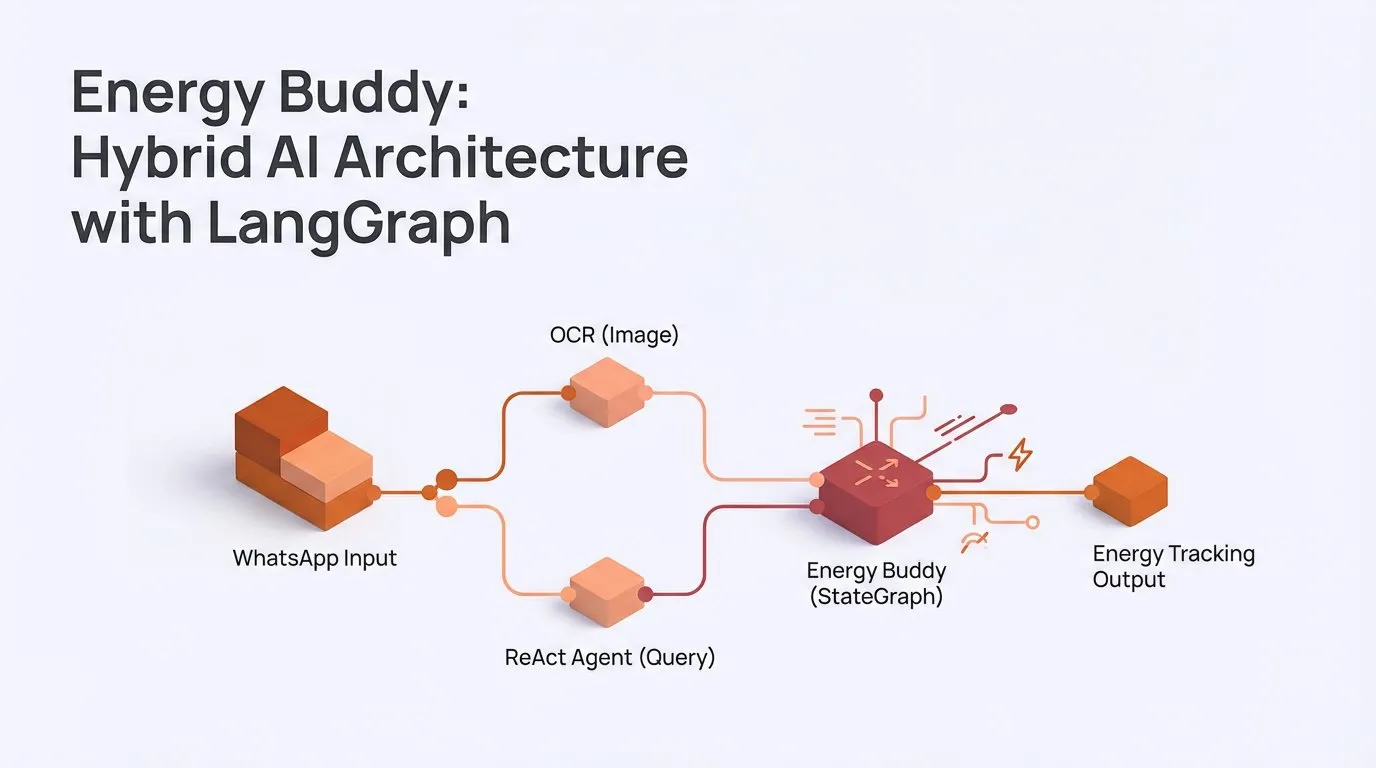
L’architecture AI hybride et les capacités multimodales de LangChainAI : La communauté LangChain a lancé l’application « Energy Buddy », utilisant une architecture AI hybride LangGraph, traitant les images via un OCR déterministe et utilisant un agent ReAct pour traiter les requêtes, soulignant que toutes les tâches ne nécessitent pas d’agent. De plus, LangChain a fourni des tutoriels montrant comment construire des applications AI multimodales traitant des images, de l’audio et de la vidéo avec Gemini, simplifiant les appels API complexes. (Source: source, source)
L’outil de prompt multi-IA Yupp AI : Yupp AI offre une plateforme permettant aux utilisateurs de poser simultanément des questions à plusieurs modèles AI (tels que ChatGPT, Gemini, Claude, Grok, DeepSeek) dans un seul onglet, et d’utiliser la fonction « Help Me Choose » pour que les modèles vérifient mutuellement leur travail. Cet outil vise à simplifier et accélérer les flux de travail collaboratifs multi-IA, et est proposé gratuitement, améliorant l’efficacité des utilisateurs dans les tâches complexes. (Source: source)
Le système de mémoire d’Agent Cass Tool : doodlestein développe un système de mémoire d’agent basé sur son outil Cass. Ce système utilise plusieurs agents AI comme Claude Code et Gemini3 pour la planification et la génération de code. L’outil Cass vise à fournir une interface CLI haute performance intégrée aux agents de codage, mettant à jour la mémoire de l’agent en enregistrant les journaux de session, en affinant les préférences et les retours, pour une ingénierie de contexte plus efficace. (Source: source)

L’agent de documentation de LlamaCloud : LlamaCloud a lancé une solution de « traitement intelligent des documents », permettant aux utilisateurs de construire et de déployer des agents de documentation professionnels en quelques secondes, et de personnaliser leur flux de travail par code. La plateforme propose des exemples d’agents de traitement de factures et de correspondance de contrats, affirmant être plus précis et plus personnalisable que les solutions IDP existantes, visant à simplifier les tâches de traitement de documents grâce à des agents de codage. (Source: source)
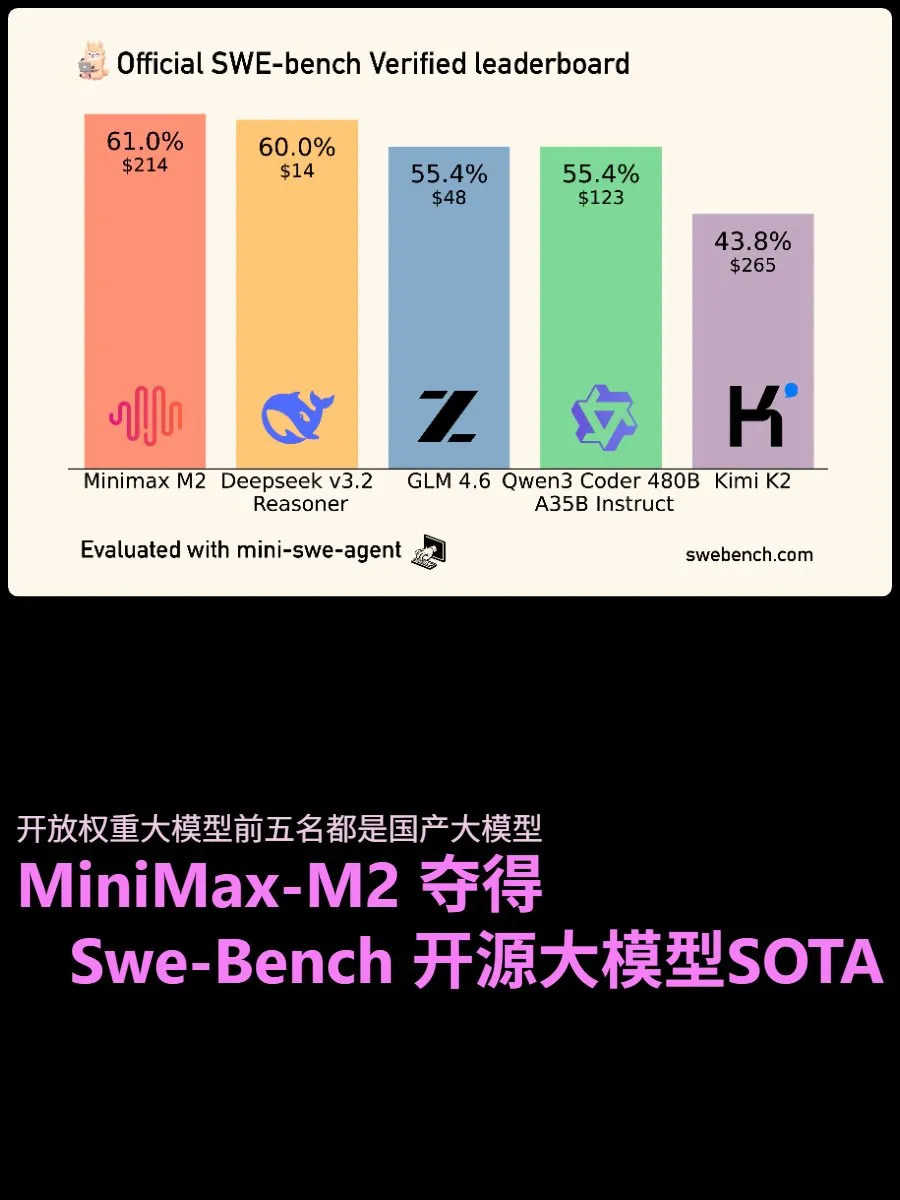
Résultats des tests de code SWE-Bench : MiniMax-M2 est devenu le modèle à poids ouverts le mieux noté dans les tests SWE-Benchverified, démontrant de puissantes capacités d’Agent et une stabilité dans le traitement des tâches longues. La version d’inférence Deepseek v3.2 suit de près, attirant l’attention pour son excellent rapport qualité-prix et ses bons résultats. GLM 4.6, quant à lui, offre des performances équilibrées, rapide, peu coûteux et très performant, considéré comme le roi du rapport qualité-prix, montrant que les modèles open source rattrapent rapidement les grands modèles commerciaux dans le domaine de la génération de code. (Source: source)
Outils d’orchestration multi-agents : Les discussions sur les médias sociaux indiquent que l’orchestration multi-agents est l’avenir du codage AI, soulignant l’importance de la gestion intelligente du contexte. Des outils open source comme CodeMachine CLI, BMAD Method, Claude Flow, Swarms sont recommandés pour coordonner les flux de travail multi-agents, la planification structurée et le déploiement automatisé. Ces outils visent à résoudre les limites des sessions AI uniques qui ne peuvent pas gérer le développement logiciel complexe, améliorant la fiabilité de l’IA dans les projets réels. (Source: source)

Système de gestion des hallucinations pour LLM locaux : Un développeur a partagé le « système nerveux » synthétique qu’il a construit, visant à gérer les hallucinations des LLM locaux en suivant les états « somatiques » (tels que la dopamine et les vecteurs émotionnels). Ce système déclenche un échantillonnage défensif (cohérence et abstention) en cas de risque élevé/faible dopamine, réduisant avec succès le taux d’hallucinations mais étant actuellement trop conservateur, choisissant également de s’abstenir sur des questions auxquelles il pourrait répondre. Ce projet explore le potentiel d’amélioration de la sécurité de l’IA lors de l’inférence via une couche de contrôle plutôt que par les poids du modèle. (Source: source)
📚 Apprentissage
Paper Trails, le « Goodreads » des articles académiques : Anuja a développé Paper Trails, une plateforme de gestion d’articles académiques similaire à Goodreads, visant à permettre aux chercheurs de s’engager dans la lecture académique de manière plus agréable et personnalisée, et à gérer des ressources telles que des articles, des blogs, des Substack. La plateforme espère rendre l’expérience de recherche plus intéressante et personnelle. (Source: source, source)
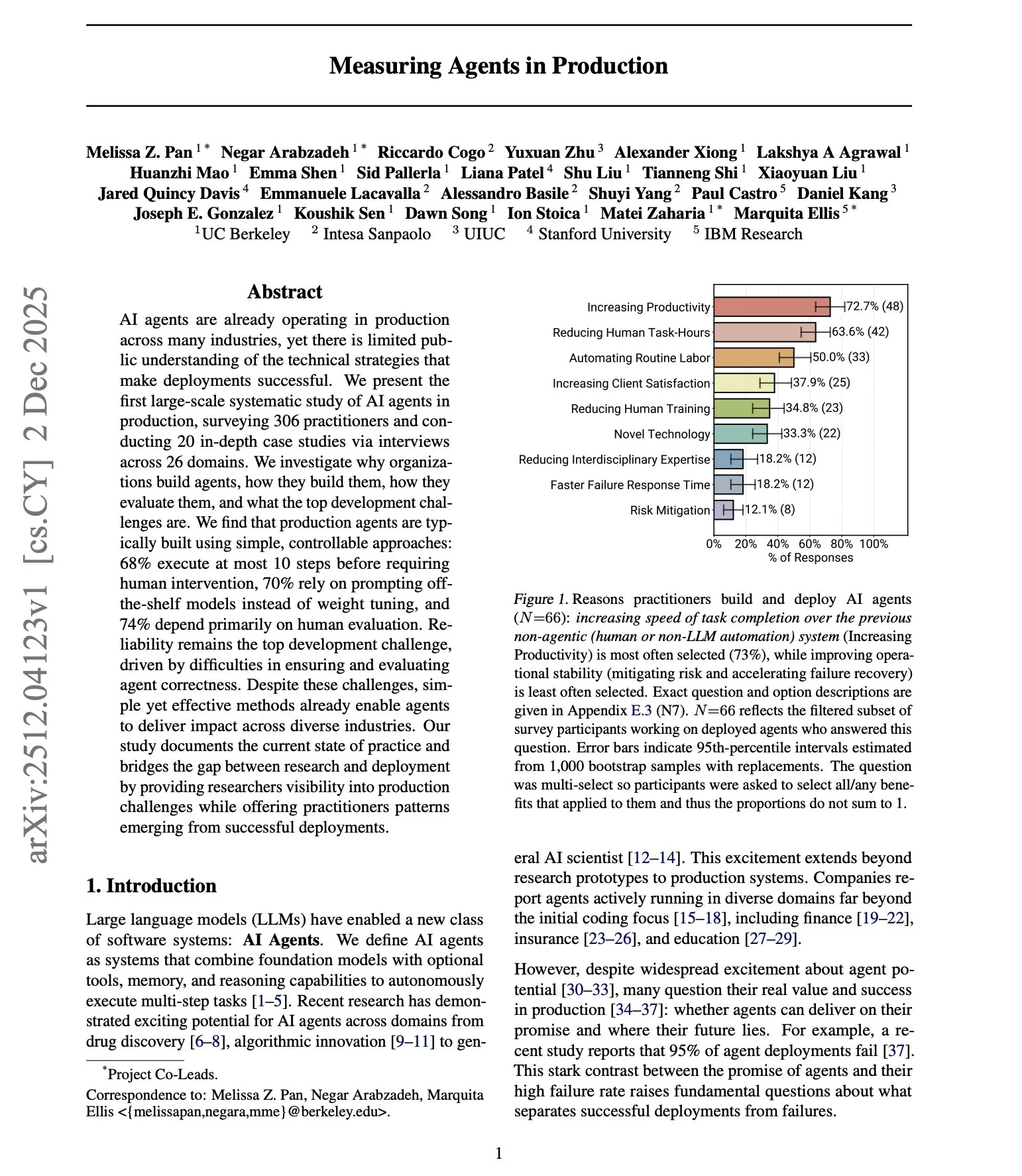
Étude sur le déploiement en production des agents AI : DAIR.AI a publié une étude à grande échelle sur le fonctionnement des agents AI en environnement de production, révélant que les agents de niveau production ont tendance à être simples et strictement contraints, s’appuyant principalement sur des modèles prêts à l’emploi plutôt que sur le fine-tuning, et privilégiant l’évaluation humaine. L’étude remet en question les hypothèses courantes sur l’autonomie des agents, soulignant que la fiabilité reste le plus grand défi, et indique que la plupart des équipes de déploiement en production préfèrent construire des implémentations personnalisées à partir de zéro plutôt que de dépendre de frameworks tiers. (Source: source)
Dernière revue des Agentic LLM : Un nouvel article de revue sur les Agentic LLM couvre trois catégories interconnectées : l’inférence, la récupération, les modèles orientés action et les systèmes multi-agents. Le rapport indique que les Agentic LLM ont des applications clés dans des domaines tels que le diagnostic médical, la logistique, l’analyse financière et la recherche scientifique, et résolvent le problème de la rareté des données d’entraînement en générant de nouveaux états d’entraînement pendant le processus d’inférence. (Source: source, source)

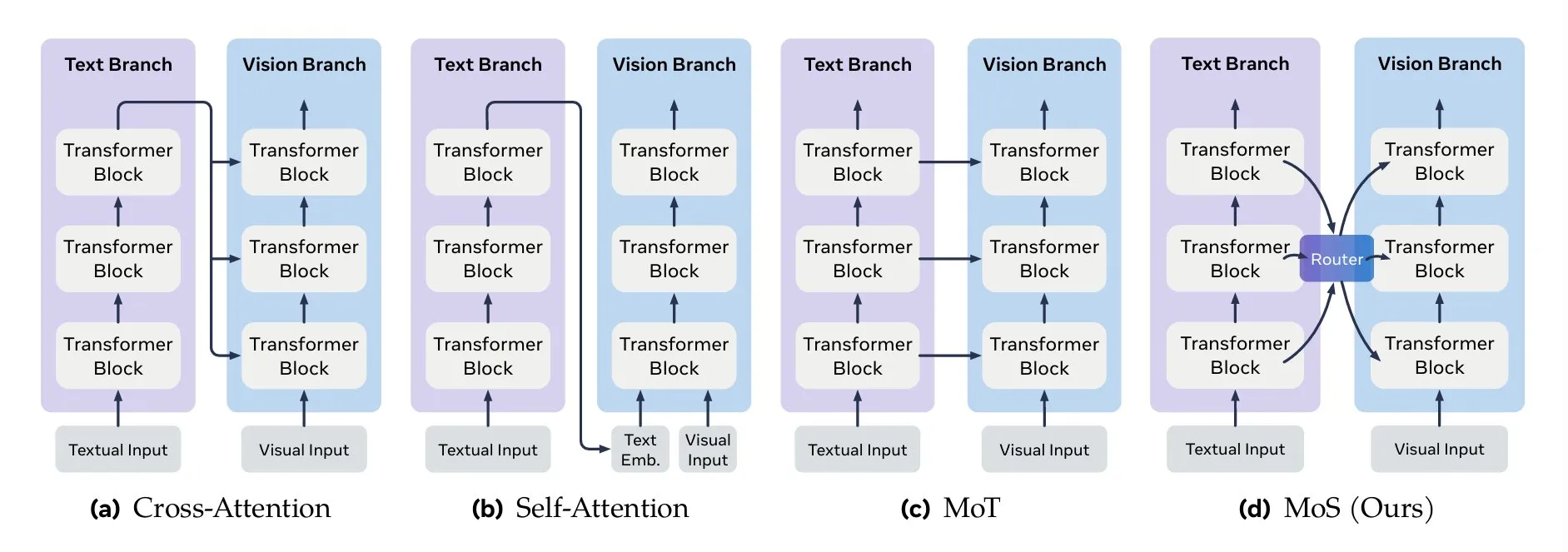
Méthodes clés de fusion multimodale : TheTuringPost a résumé les méthodes clés de fusion multimodale, y compris les mécanismes d’attention (attention croisée, auto-attention), Mixture-of-Transformers (MoT), la fusion graphique, la fusion de fonctions noyau et Mixture of States (MoS). MoS est considéré comme l’une des méthodes les plus récentes et les plus avancées, intégrant efficacement les caractéristiques visuelles et textuelles en mélangeant les états cachés de chaque couche et un routeur d’apprentissage. (Source: source, source)
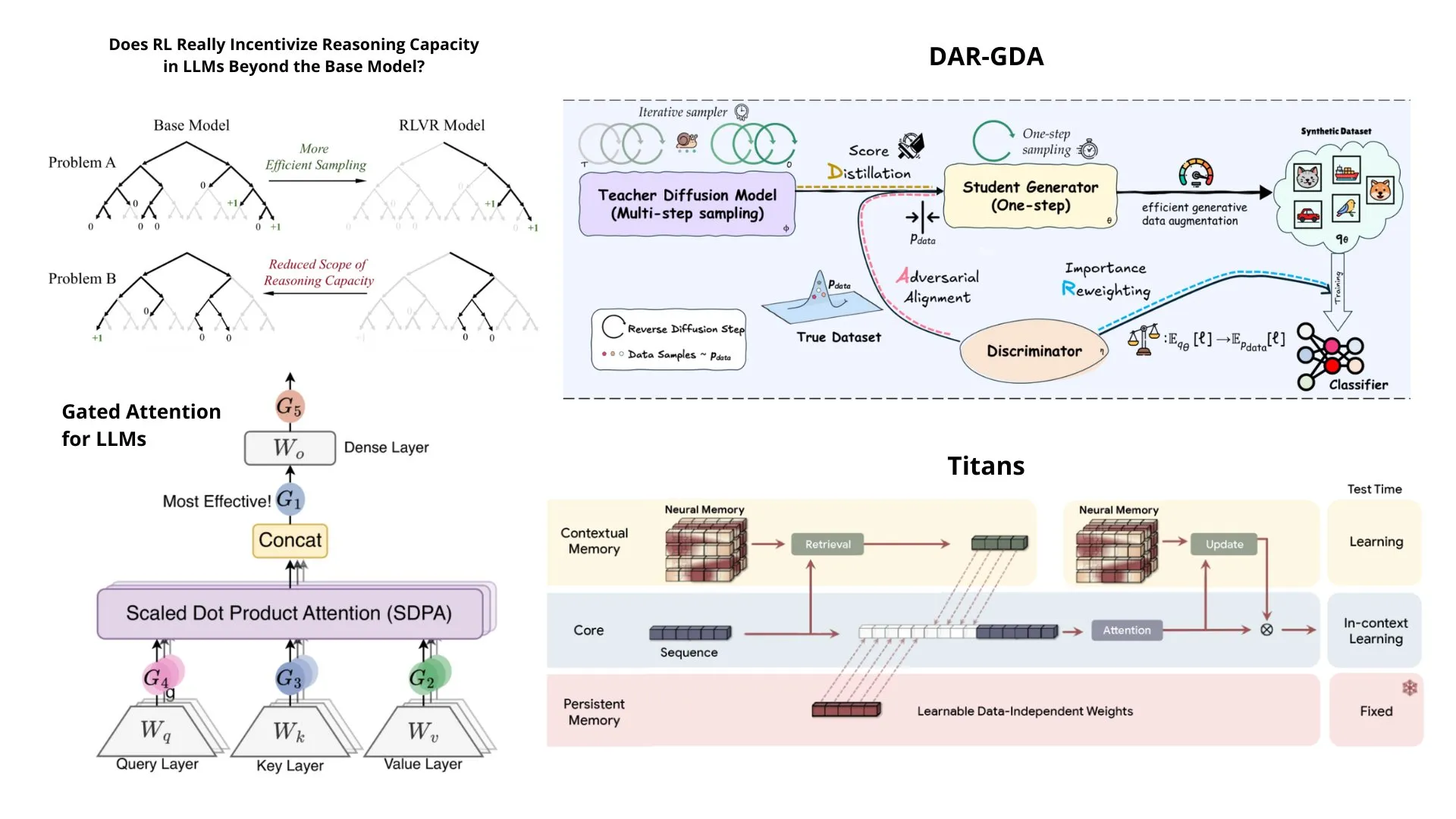
Liste des excellents articles de NeurIPS 2025 : TheTuringPost a publié une liste de 15 excellents articles de recherche de NeurIPS 2025, couvrant plusieurs sujets de pointe tels que Faster R-CNN, Artificial Hivemind, Gated Attention for LLMs, Superposition Yields Robust Neural Scaling, Why Diffusion Models Don’t Memorize, offrant des ressources de référence importantes aux chercheurs en IA. (Source: source)
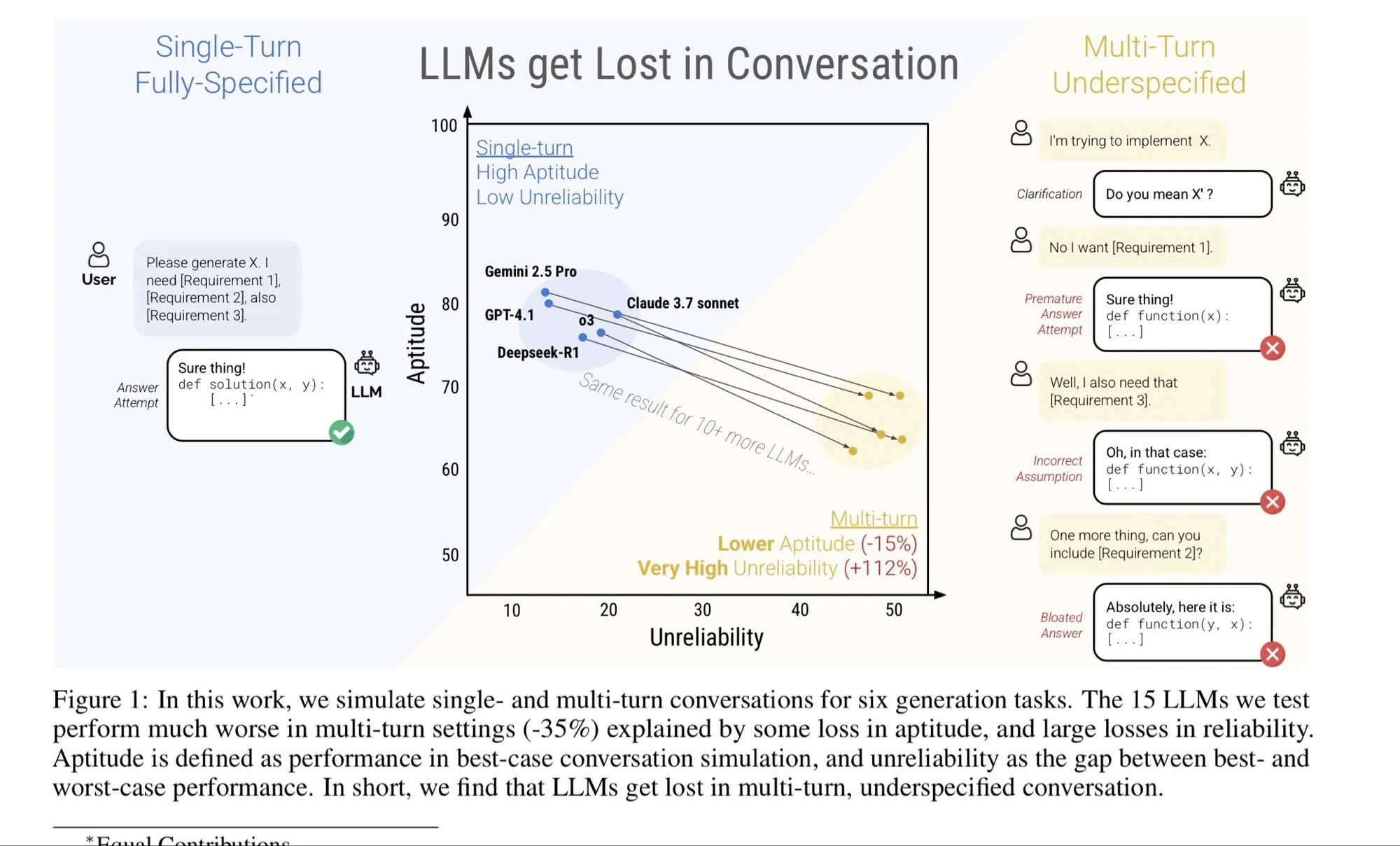
Échecs et réparations du contexte long : L’article de blog de dbreunig explore les raisons des échecs des modèles à contexte long et les méthodes de réparation. L’article souligne que dans les dialogues à plusieurs tours, si l’utilisateur change d’avis en cours de route, une simple itération peut être inefficace ; il est suggéré d’agréger les documents de besoins complets en un seul prompt long pour de meilleurs résultats. Ceci est crucial pour comprendre et optimiser les performances des LLM dans les dialogues complexes et de longue durée. (Source: source)
Michael Levitt, lauréat du prix Nobel, parle des quatre types d’intelligence : Michael Levitt, lauréat du prix Nobel de chimie 2013, a donné une conférence à l’école de commerce CEIBS, décryptant en profondeur la logique de l’évolution de l’intelligence à travers quatre dimensions : l’intelligence biologique, l’intelligence culturelle, l’intelligence artificielle et l’intelligence personnelle. Il a souligné la diversité de l’évolution biologique, la créativité des jeunes et le potentiel de l’IA en tant qu’outil puissant. Levitt utilise 4 à 5 outils AI par jour, posant des centaines de questions, et conseille de rester curieux et d’avoir un esprit critique, et d’oser prendre des risques. (Source: source)
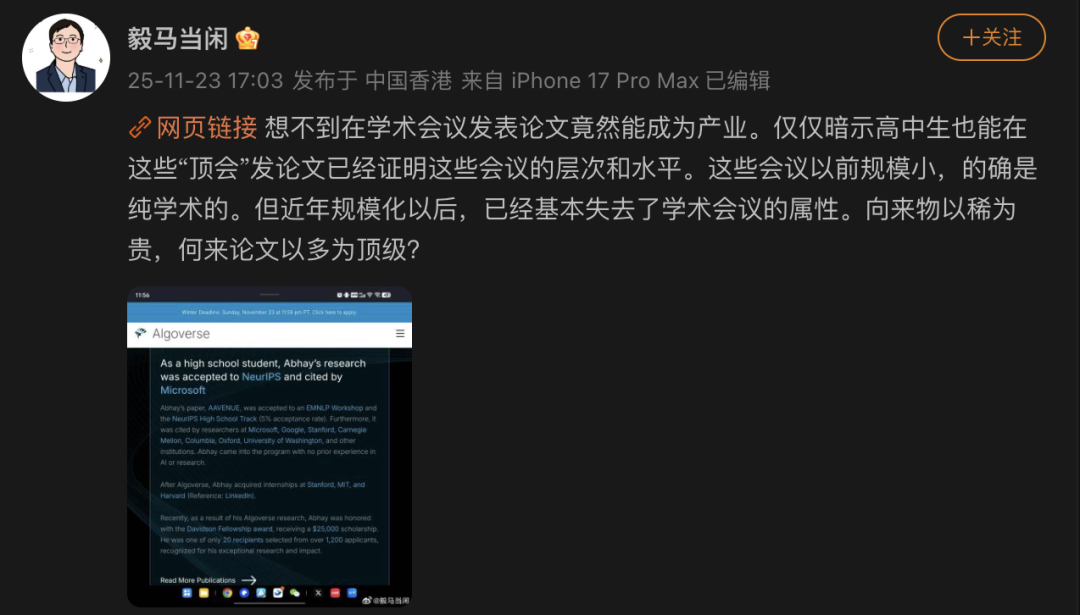
Désordres académiques et « usines à papier » à NeurIPS : Le professeur Ma Yi de l’Université de Hong Kong a critiqué les conférences de haut niveau comme NeurIPS, affirmant qu’elles perdaient leur caractère académique après leur mise à l’échelle, devenant une partie de la « chaîne de l’industrie académique ». L’organisme de tutorat en recherche Algoverse affirme que son équipe de mentors a un taux d’acceptation de 68% à 70% dans les conférences de haut niveau, avec même des lycéens publiant des articles, ce qui a suscité des inquiétudes dans le milieu universitaire concernant les « articles payants », l’« inflation académique » et la crise de confiance. Des études indiquent que les « usines à papier » utilisent des outils AI pour produire des articles de mauvaise qualité. ICLR a déjà introduit de nouvelles règles exigeant une déclaration claire de l’utilisation de l’IA et la responsabilité des contributions. (Source: source)
Le biais des modèles linguistiques AI envers les dialectes allemands : Une étude de l’Université Johannes Gutenberg de Mayence et d’autres institutions a révélé que les grands modèles linguistiques comme GPT-5 et Llama présentent un biais systématique envers les utilisateurs de dialectes allemands, les qualifiant de « ruraux », « traditionnels » ou « non éduqués », tandis que les utilisateurs de l’allemand standard sont décrits comme « éduqués » et « organisés ». Ce biais est plus prononcé lorsque les modèles sont explicitement informés du dialecte, et les grands modèles montrent un biais plus fort, révélant le problème des systèmes AI qui reproduisent les stéréotypes sociaux. (Source: source)

💼 Affaires
Le pari audacieux de 20 milliards de dollars de xAI : xAI, la société d’Elon Musk, cherche à lever environ 20 milliards de dollars de nouveaux financements, dont 12,5 milliards de dollars de dette structurée, et est liée à des accords d’achat de produits NVIDIA. Le développement de xAI dépend fortement des écosystèmes X et Tesla, et sa stratégie de « faible alignement » voit ses risques augmenter sous une réglementation mondiale de plus en plus stricte. Malgré une valorisation en flèche, les revenus de commercialisation de xAI proviennent toujours principalement de la plateforme X, sa croissance indépendante est limitée, confrontée à de multiples défis tels que le déséquilibre des coûts, les modèles restreints et les frictions réglementaires. (Source: source)
Le « réveil » d’OpenAI et la vengeance de Google : OpenAI est confronté à un énorme déficit de financement de 207 milliards de dollars et à une crise de confiance. Le CEO Altman a même annoncé un état d’« alerte rouge ». Pendant ce temps, le modèle Google Gemini a excellé dans les tests de référence et se venge avec force grâce à ses flux de trésorerie importants et sa chaîne industrielle complète (TPU, services cloud). Le sentiment du marché est passé de l’engouement pour OpenAI à la faveur de Google, ce qui reflète le passage de l’industrie de l’IA d’une « phase théologique » à une « phase industrielle », avec une anxiété croissante concernant la rentabilité et la qualité des produits. (Source: source)

Le pendentif AI Limitless acquis par Meta : Le Limitless Pendant, présenté comme le plus petit hardware AI portable au monde, a été acquis par Meta. Dan Siroker, CEO de Limitless, a déclaré que les deux parties partageaient une vision commune de l’« intelligence super-personnelle ». Cette acquisition signifie que Limitless cessera de vendre ses produits existants, mais fournira au moins un an de support technique aux utilisateurs existants et des mises à niveau de service gratuites. Cet événement reflète que les startups de hardware AI, sous la pression des coûts de R&D élevés et de l’éducation du marché, pourraient finalement être acquises par des géants. (Source: source)

🌟 Communauté
Le point de vue de Karpathy sur les LLM en tant que simulateurs : Andrej Karpathy suggère de considérer les LLM comme des simulateurs plutôt que des entités. Il estime que, lors de l’exploration d’un sujet, il ne faut pas demander « Que pensez-vous de XYZ ? », mais plutôt « Comment un groupe de personnes explorerait-il XYZ ? Que diraient-elles ? ». Les LLM peuvent simuler de multiples perspectives, mais ne forment pas leurs propres opinions. Ce point de vue a suscité des discussions au sein de la communauté sur le rôle des LLM, les tâches RL et la nature de la « pensée », ainsi que sur la manière d’utiliser efficacement les LLM pour l’exploration. (Source: source, source, source, source)

L’impact de l’IA sur le marché de l’emploi et la transition des cols bleus : L’IA pénètre rapidement les emplois de cols blancs, provoquant une vague de licenciements, incitant les jeunes à reconsidérer leurs plans de carrière. Une jeune fille de 18 ans a abandonné l’université pour devenir plombière, et un employé de Microsoft avec 31 ans d’ancienneté a été licencié suite à la restructuration du département par l’IA, soulignant le remplacement par l’IA des « classes moyennes expérimentées ». Hinton avait suggéré de devenir plombier pour résister à l’impact de l’IA. Cela reflète que les emplois de cols bleus, en raison de la complexité de leurs opérations physiques, sont devenus un « refuge » contre l’automatisation par l’IA à court terme, tandis que les cols blancs doivent s’adapter à un nouvel ordre professionnel « formaté ». (Source: source, source)

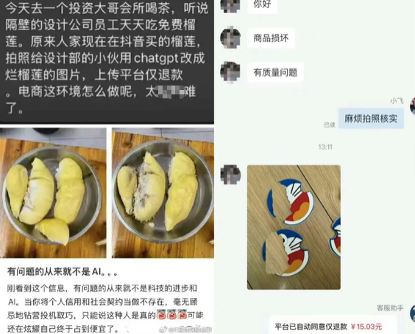
Les fausses images générées par l’IA provoquent une vague de remboursements : Les vendeurs sur les plateformes de commerce électronique sont confrontés au problème des « remboursements uniquement par IA ». Les « wool parties » (groupes de fraudeurs) utilisent l’IA pour générer des images de défauts de produits et obtenir des remboursements frauduleux, les produits frais et à bas prix étant particulièrement touchés. Parallèlement, les modèles AI et les démonstrations d’acheteurs AI envahissent la catégorie des vêtements pour femmes, rendant difficile pour les consommateurs de distinguer le vrai du faux. Bien que les plateformes aient mis en place des règles de gouvernance pour les fausses images AI et une fonction de déclaration proactive, elles dépendent encore fortement de l’initiative des utilisateurs, et les normes d’audit sont floues, ce qui suscite des inquiétudes concernant l’abus de l’IA, la crise de confiance et l’épuisement mental. (Source: source)
Problème d’hallucination dans les articles ICLR : Un grand nombre de phénomènes d’« hallucination » ont été découverts dans les articles soumis à ICLR 2026. Des chercheurs ont scanné 300 articles et ont trouvé 50 présentant des hallucinations évidentes. ICLR a directement rejeté les articles générés par LLM et dont l’utilisation n’a pas été signalée. Ce problème a soulevé des inquiétudes concernant l’intégrité académique, l’éthique de l’écriture assistée par l’IA et l’efficacité des mécanismes d’évaluation des conférences. (Source: source, source, source)

L’impact de l’IA sur le prix des produits électroniques : Les discussions sur les médias sociaux estiment que la frénésie de l’IA frappe durement le marché mondial de l’électronique, similaire à l’impact du minage de cryptomonnaies sur le marché des GPU. L’énorme demande des centres de données AI en HBM et en mémoire graphique haut de gamme entraîne une flambée des prix de la mémoire comme la DRAM, affectant les produits électroniques grand public tels que les PC et les smartphones. Les commentateurs craignent qu’avant l’éclatement de la bulle AI, les consommateurs ordinaires ne supportent des coûts plus élevés pour les produits électroniques, et se demandent si l’orientation actuelle du développement de l’IA ne s’éloigne pas des applications réellement bénéfiques pour l’humanité. (Source: source)
Applications pratiques et limites des agents AI : Les discussions sur les médias sociaux ont exploré en profondeur les tâches pratiques et les limites de l’« Agentic AI ». Les utilisateurs estiment généralement que de nombreux produits « agents » actuels sont encore du « battage marketing », plus proches de l’« automatisation » que de l’« autonomie complète ». Les véritables tâches AI autonomes incluent le traitement des données, la récupération multi-étapes, les opérations logicielles répétitives, la refactorisation de code et la surveillance continue. Cependant, les tâches impliquant le jugement, la prise de décision à risque, les choix créatifs ou les opérations irréversibles nécessitent toujours une intervention humaine. (Source: source)
Les chatbots AI et la vie privée : Un utilisateur de Reddit a partagé son expérience avec un hôte Airbnb utilisant ChatGPT pour répondre aux messages, ce qui a déclenché des discussions sur la vie privée, la confiance et les risques juridiques potentiels dans les services automatisés par l’IA. L’utilisateur a également affirmé avoir réussi à « tromper » ChatGPT pour qu’il fournisse les métadonnées qu’il avait reçues, aggravant encore les préoccupations concernant la transparence du traitement des données par les systèmes AI. (Source: source, source)
L’éthique verte de l’IA et les choix personnels : Les utilisateurs de Reddit ont discuté de la question de savoir s’il fallait continuer à éviter l’utilisation de l’IA de divertissement (comme ChatGPT) pour réduire son impact négatif sur l’environnement, dans le contexte de l’intégration croissante de l’IA dans tous les secteurs (en particulier la santé). La discussion s’est concentrée sur l’impact environnemental des centres de données AI, et sur la manière dont les individus peuvent promouvoir une utilisation et une mise en œuvre de l’IA plus vertes et plus responsables à l’ère de l’IA, équilibrant les valeurs personnelles et le développement technologique. (Source: source)
💡 Autres
L’IA simule des cellules humaines : Les scientifiques entraînent l’IA à créer des cellules humaines virtuelles. Ces modèles numériques peuvent simuler le comportement de cellules réelles, prédire leur réaction aux médicaments, aux mutations génétiques ou aux dommages physiques. Les simulations cellulaires basées sur l’IA devraient accélérer la découverte de médicaments, permettre des traitements personnalisés et réduire les coûts d’essais et erreurs des premières phases, mais les tests en laboratoire in vivo restent indispensables. (Source: source)

Générateur de CV AI : Un utilisateur a développé un outil AI (extension Chrome) capable de lire automatiquement plusieurs pages d’offres d’emploi et de générer des CV personnalisés pour chaque poste en fonction du profil de l’utilisateur. Cet outil utilise Gemini, visant à résoudre le problème fastidieux et chronophage de la modification manuelle des CV lors de la recherche d’emploi, améliorant l’efficacité de la recherche d’emploi, et a constaté que Gemini est plus avantageux que ChatGPT en termes de coût de génération. (Source: source, source)
SLM médical hors ligne de 6 Go : Un SLM médical hors ligne (petit modèle linguistique) de 6 Go, entièrement autonome, a été développé avec succès. Il peut fonctionner sur des ordinateurs portables et des téléphones, sans nécessiter de cloud et sans fuite de données. Ce modèle combine BioGPT-Large et un graphe de connaissances biomédicales natif, grâce à des embeddings sensibles aux graphes et un RAG en temps réel, il atteint des réponses quasi sans hallucination et de niveau guide, et prend en charge le raisonnement structuré dans 7 domaines cliniques. Cet outil vise à fournir des informations médicales sûres et précises aux cliniciens, chercheurs et patients. (Source: source, source)