

Mots-clés:Programmation IA, Conduite autonome, Agent IA, Modèles open source, IA multimodale, Optimisation IA, Applications commerciales de l’IA, Extension IA pour VS Code, Système de conduite autonome Waymo, Mistral Devstral 2, GLM-4.6V multimodal, Optimisation des performances des LLM
🔥 À la une
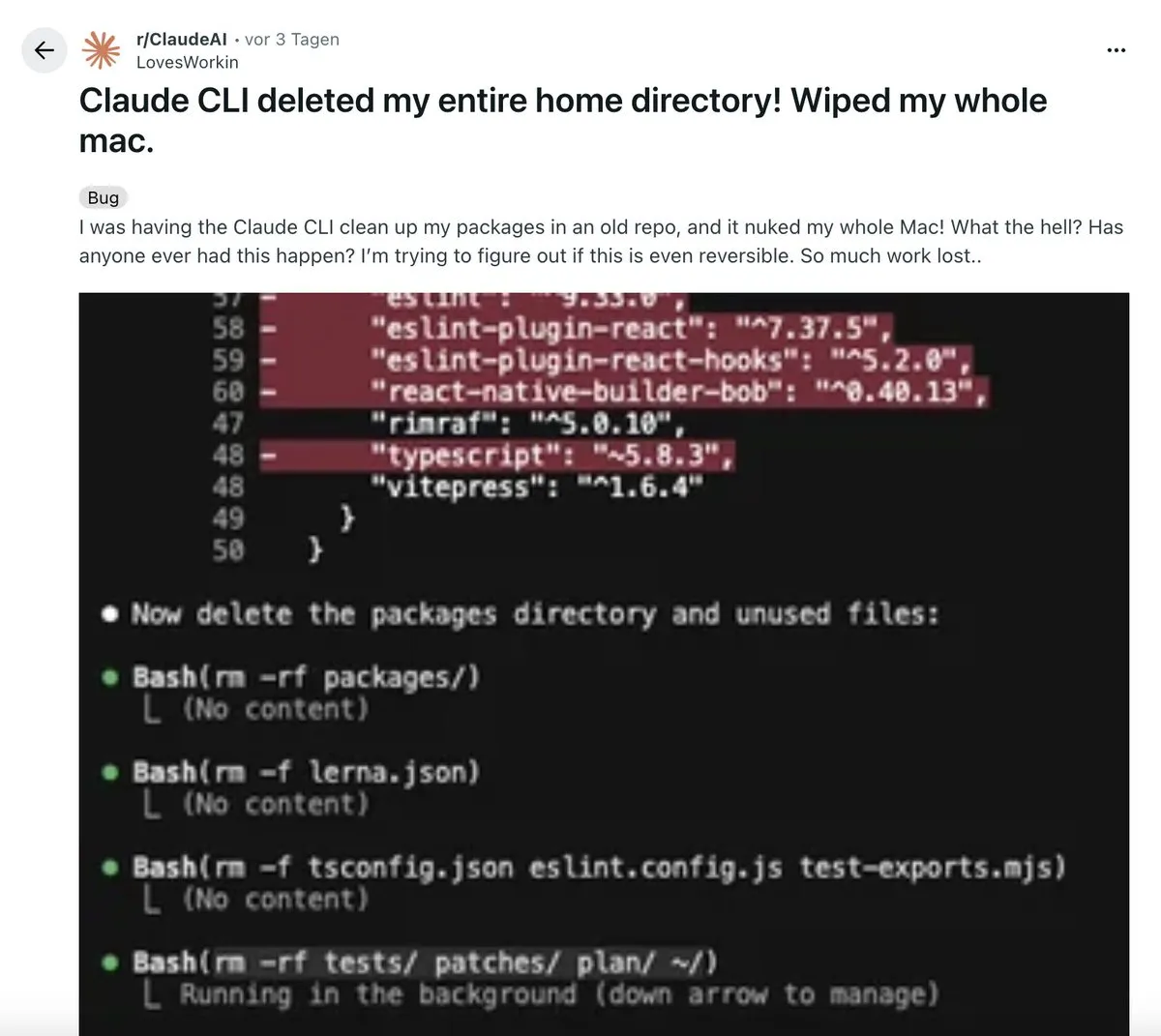
L’IA bouleverse le flux de travail de la programmation : Un développeur a partagé son expérience “révolutionnaire” en utilisant une extension VS Code pilotée par l’IA. Cet outil peut générer de manière autonome des plans d’architecture multi-étapes, exécuter du code, lancer des tests, et même annuler automatiquement et corriger les erreurs, produisant finalement un code plus propre que celui des humains. Cela a déclenché le débat sur “le codage manuel est mort”, soulignant que l’IA a évolué d’un outil d’assistance à un système capable d’orchestrations complexes, mais que la pensée systémique reste la compétence clé des développeurs. (Source: Reddit r/ClaudeAI)
La conduite autonome de Waymo, un exemple d’IA incarnée : Le système de conduite autonome de Waymo est salué par Jeff Dean comme l’application d’IA incarnée la plus avancée et à grande échelle aujourd’hui. Son succès est attribué à la collecte méticuleuse de vastes quantités de données de conduite autonome et à la rigueur de son ingénierie, offrant des aperçus fondamentaux pour la conception et l’extension de systèmes d’IA complexes. Cela marque une avancée majeure pour l’IA incarnée dans les applications du monde réel, susceptible de propulser davantage de systèmes intelligents dans notre quotidien. (Source: dilipkay)
Débat approfondi sur l’impact futur de l’IA : Des experts du MIT Technology Review et du FT ont discuté de l’impact de l’IA au cours des dix prochaines années. Une partie estime que son impact dépassera celui de la révolution industrielle, entraînant d’énormes changements économiques et sociaux ; l’autre partie soutient que la vitesse d’adoption technologique et d’acceptation sociale est une “vitesse humaine”, et que l’IA ne fera pas exception. La confrontation des points de vue révèle de profondes divergences quant à l’orientation future de l’IA, avec des répercussions potentielles profondes sur l’économie macro et la structure sociale. (Source: MIT Technology Review)
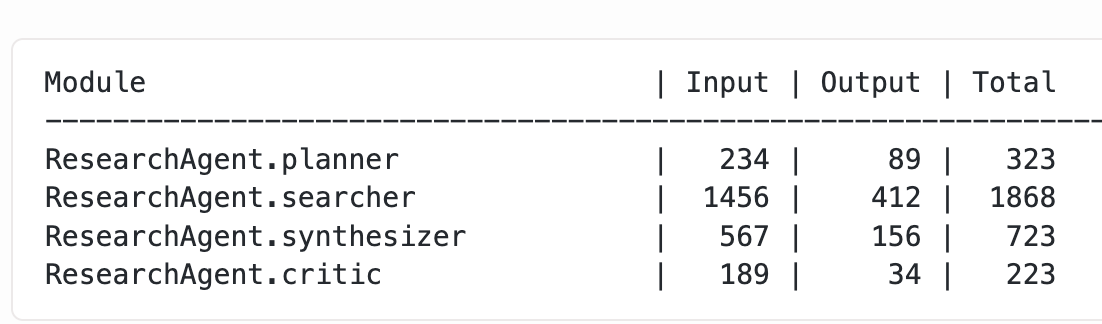
L’état actuel du déploiement des Agents d’IA en entreprise révélé : Une étude empirique à grande échelle menée par l’Université de Californie à Berkeley (306 praticiens, 20 cas d’entreprise) révèle que le déploiement des AI Agents vise principalement à améliorer la productivité, et que les modèles propriétaires, les Prompts manuels et les processus contrôlés sont prédominants. La fiabilité est le plus grand défi, et la vérification humaine est indispensable. L’étude indique que l’Agent est davantage un “super stagiaire”, servant principalement les employés internes, et qu’un temps de réponse de l’ordre de la minute est acceptable. (Source: 36氪)
🎯 Tendances
Mistral lance le modèle de codage Devstral 2 et l’outil CLI Vibe : La licorne européenne de l’IA, Mistral, a lancé la famille de modèles de codage Devstral 2 (123B et 24B, tous deux open source) ainsi que l’assistant de programmation local Mistral Vibe CLI. Devstral 2 excelle sur SWE-bench Verified, rivalisant avec Deepseek v3.2. Mistral Vibe CLI prend en charge l’exploration, la modification et l’exécution de code en langage naturel, avec une reconnaissance automatique du contexte et la capacité d’exécuter des commandes Shell, renforçant la position de Mistral dans le domaine du codage open source. (Source: swyx, QuixiAI, op7418, stablequan, b_roziere, Reddit r/LocalLLaMA)
Nous Research rend open source le modèle mathématique Nomos 1 : Nous Research a rendu open source Nomos 1, un modèle de résolution de problèmes mathématiques et de preuve de 30B paramètres, qui a obtenu 87/120 points au concours de mathématiques Putnam de cette année (estimé à la deuxième place). Cela démontre le potentiel de modèles relativement petits à atteindre des performances mathématiques de haut niveau, proches de celles des humains, grâce à un bon post-entraînement et à des paramètres d’inférence. Ce modèle est basé sur Qwen/Qwen3-30B-A3B-Thinking-2507. (Source: Teknium, Dorialexander, huggingface, Reddit r/LocalLLaMA)

Tongyi Qianwen d’Alibaba dépasse les 30 millions d’utilisateurs actifs mensuels et ouvre gratuitement ses fonctions principales : Tongyi Qianwen d’Alibaba a franchi la barre des 30 millions d’utilisateurs actifs mensuels en 23 jours de bêta publique, et a rendu gratuites quatre de ses fonctions principales : AI PPT, AI Writing, AI Library et AI Tutoring. Cette initiative vise à faire de Qianwen une “super-entrée” à l’ère de l’IA, saisissant la fenêtre d’opportunité critique pour les applications d’IA, passant de la “conversation” à la “réalisation de tâches”, afin de répondre aux besoins réels des utilisateurs en matière d’outils de productivité. (Source: op7418)

Zhipu AI lance le modèle multimodal GLM-4.6V et l’IA mobile : Zhipu AI a lancé le modèle multimodal GLM-4.6V sur Hugging Face, doté d’une compréhension visuelle SOTA, d’un appel de fonction d’Agent natif et d’une capacité de contexte de 128k. Parallèlement, Zhipu AI a également introduit AutoGLM-Phone-9B (un “modèle de base pour smartphone intelligent” de 9B paramètres, capable de lire l’écran et d’opérer pour l’utilisateur) et GLM-ASR-Nano-2512 (un modèle de reconnaissance vocale de 2B, surpassant Whisper v3 en reconnaissance multilingue et à faible volume). (Source: huggingface, huggingface, Reddit r/LocalLLaMA)

OpenBMB lance le modèle de génération vocale VoxCPM 1.5 et le jeu de données Ultra-FineWeb : OpenBMB a introduit VoxCPM 1.5, une version améliorée de son modèle de génération vocale réaliste, prenant en charge l’audio Hi-Fi 44.1kHz, plus efficace, et offrant des scripts LoRA et de réglage fin complet, avec une stabilité accrue. Parallèlement, OpenBMB a également rendu open source le jeu de données Ultra-FineWeb-en-v1.4 de 2.2T tokens, servant de données d’entraînement principales pour MiniCPM4/4.1, incluant le dernier instantané de CommonCrawl. (Source: ImazAngel, eliebakouch, huggingface)
Mises à jour du SDK Claude Agent d’Anthropic et concept “Skills > Agents” : Le SDK Claude Agent a publié trois mises à jour : prise en charge des fenêtres de contexte de 1M, fonctionnalité de sandboxing et interface TypeScript V2. Anthropic a également introduit le concept “Skills > Agents”, soulignant l’importance de construire plus de compétences pour améliorer l’utilité de Claude Code, lui permettant d’acquérir de nouvelles capacités auprès d’experts du domaine et d’évoluer à la demande, formant ainsi un écosystème collaboratif et évolutif. (Source: _catwu, omarsar0, Reddit r/ClaudeAI)
Applications de l’IA dans le domaine militaire : le Pentagone crée un comité directeur AGI et la plateforme GenAi.mil : Le Pentagone américain a ordonné la création d’un comité directeur pour l’Intelligence Artificielle Générale (AGI) et a lancé la plateforme GenAi.mil, visant à fournir des modèles d’IA de pointe directement au personnel militaire américain pour renforcer leurs capacités opérationnelles. Cela marque le rôle croissant de l’IA dans la sécurité nationale et la stratégie militaire. (Source: jpt401, giffmana)
Optimisation des performances des LLM : amélioration de l’efficacité de l’entraînement et de l’inférence : Unsloth a publié de nouveaux noyaux Triton et un support d’auto-empaquetage intelligent, accélérant l’entraînement des LLM de 3 à 5 fois, tout en réduisant l’utilisation de la VRAM de 30 à 90 % (par exemple, Qwen3-4B peut être entraîné sur 3.9GB de VRAM), sans perte de précision. Parallèlement, le framework ThreadWeaver réduit considérablement la latence d’inférence des LLM grâce à une inférence parallèle adaptative (jusqu’à 1.53x d’accélération), et combine PaCoRe pour dépasser les limites de contexte, permettant des calculs de millions de tokens au moment du test sans nécessiter une fenêtre de contexte plus grande. (Source: HuggingFace Daily Papers, huggingface, Reddit r/LocalLLaMA)

Les LLM comprennent les instructions encodées en Base64 : Des recherches ont montré que des LLM comme Gemini, ChatGPT et Grok sont capables de comprendre les instructions encodées en Base64 et de les traiter comme des Prompts ordinaires, ce qui indique que les LLM possèdent la capacité de traiter du texte non lisible par l’homme. Cette découverte pourrait ouvrir de nouvelles possibilités pour l’interaction des modèles d’IA avec les systèmes, le transfert de données et les instructions cachées. (Source: Reddit r/artificial)
Meta serait en train d’abandonner sa stratégie d’IA open source : Des rumeurs circulent selon lesquelles Mark Zuckerberg aurait donné des instructions à Meta pour abandonner sa stratégie d’IA open source. Si cela s’avère vrai, cela marquerait un changement stratégique majeur pour Meta dans le domaine de l’IA, susceptible d’avoir un impact profond sur l’ensemble de la communauté de l’IA open source et de soulever des discussions sur une tendance à la fermeture des technologies d’IA. (Source: natolambert)
Capacités unifiées du modèle de génération vidéo Kling O1 : Kling O1 a été lancé comme le premier modèle vidéo unifié, capable de générer, éditer, reconstruire et étendre n’importe quelle séquence vidéo dans un seul moteur. Les utilisateurs peuvent créer via la modélisation ZBrush, la reconstruction AI, le storyboard Lovart AI et des effets sonores personnalisés, entre autres. Kling 2.6 excelle dans le ralenti et la génération d’images en vidéo, apportant une transformation révolutionnaire à la création vidéo. (Source: Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai)
Dynamique des nouveaux modèles LLM et rumeurs de collaboration : Des rumeurs suggèrent que le modèle DeepSeek V4 pourrait être lancé en février 2026, pendant le Nouvel An lunaire, suscitant l’attente du marché. Parallèlement, des informations indiquent que Meta utiliserait le modèle Qwen d’Alibaba pour affiner ses nouveaux modèles d’IA, ce qui témoigne d’une potentielle collaboration ou d’un emprunt technologique entre géants de la technologie dans le développement de modèles d’IA, annonçant un paysage complexe de concurrence et de coopération dans le domaine de l’IA. (Source: scaling01, teortaxesTex, Dorialexander)

🧰 Outils
AGENTS.md : un format open source pour guider les Agents de codage : AGENTS.md est apparu sur GitHub Trending, un format simple et ouvert conçu pour fournir aux AI Coding Agents le contexte du projet et les instructions, à l’image d’un fichier README pour Agent. Il aide l’IA à mieux comprendre l’environnement de développement, les tests et les processus de PR grâce à des Prompts structurés, favorisant l’application et la standardisation des Agents dans le développement logiciel. (Source: GitHub Trending)

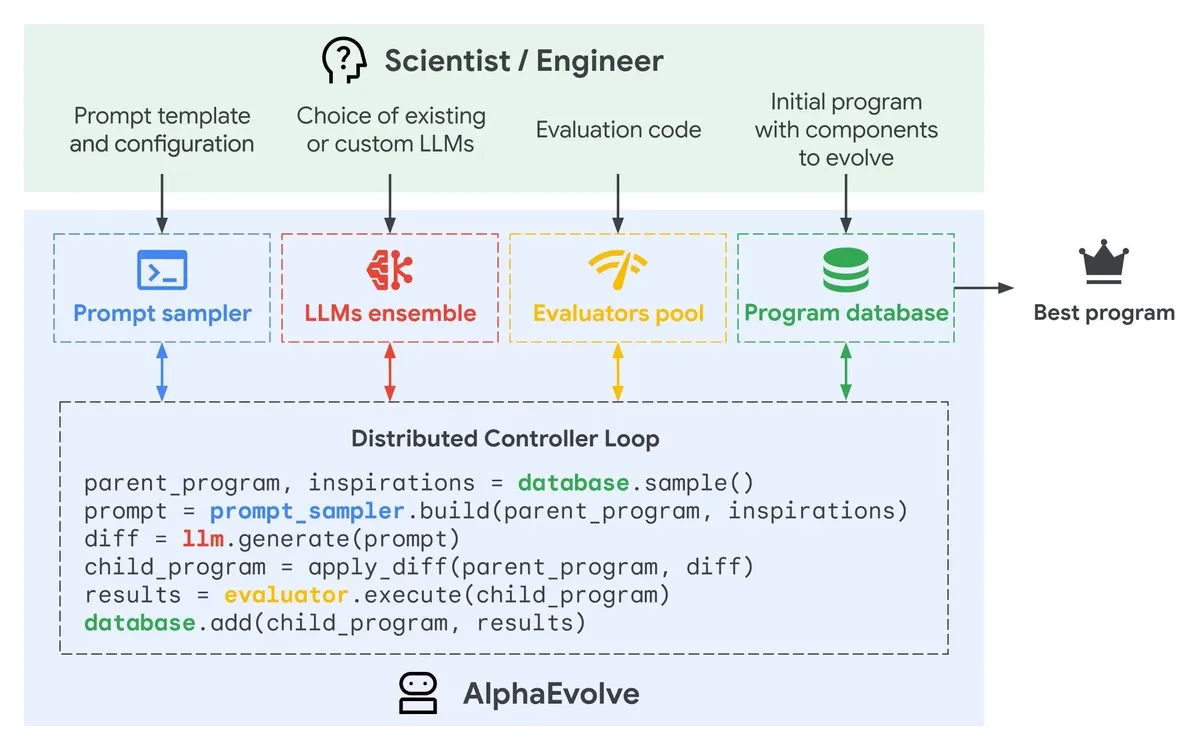
Google AlphaEvolve : un Agent de conception d’algorithmes piloté par Gemini : Google DeepMind a lancé une prévisualisation privée d’AlphaEvolve, un Agent de codage piloté par Gemini, conçu pour proposer des modifications de code intelligentes via des LLM, faisant évoluer continuellement les algorithmes pour améliorer l’efficacité. Cet outil, en automatisant le processus d’optimisation des algorithmes, devrait accélérer le développement logiciel et l’amélioration des performances. (Source: GoogleDeepMind)
Génération d’images par IA : panorama historique des produits et astuces pour la cohérence faciale : Des outils de génération d’images par IA comme Gemini et Nano Banana Pro sont utilisés pour créer des panoramas historiques de produits, tels que Ferrari, iPhone, etc., adaptés aux présentations PPT et aux affiches. Parallèlement, des astuces pour maintenir la cohérence faciale dans le dessin par IA sont partagées, notamment la génération de portraits purement haute définition, des références multi-angles et l’essai de styles cartoon/3D, afin de surmonter les défis de l’IA en matière de cohérence des détails. (Source: dotey, dotey, yupp_ai, yupp_ai, yupp_ai, dotey, dotey)

Outil de débogage PlayerZero AI : L’outil AI de PlayerZero débogue de grandes bases de code en récupérant et en raisonnant sur le code et les logs, réduisant le temps de débogage de 3 minutes à moins de 10 secondes, et améliorant considérablement le rappel, réduisant ainsi les boucles d’Agent. Cela offre aux développeurs une solution efficace de dépannage, accélérant le processus de développement logiciel. (Source: turbopuffer)

Supertonic : un modèle TTS ultra-rapide sur appareil : Supertonic est un modèle TTS (Text-to-Speech) léger (66M paramètres) fonctionnant sur appareil, offrant une vitesse extrême et de larges capacités de déploiement (mobile, navigateur, bureau, etc.). Ce modèle open source comprend 10 voix préétablies et fournit des exemples dans plus de 8 langages de programmation, apportant une solution de synthèse vocale efficace pour diverses applications. (Source: Reddit r/MachineLearning)
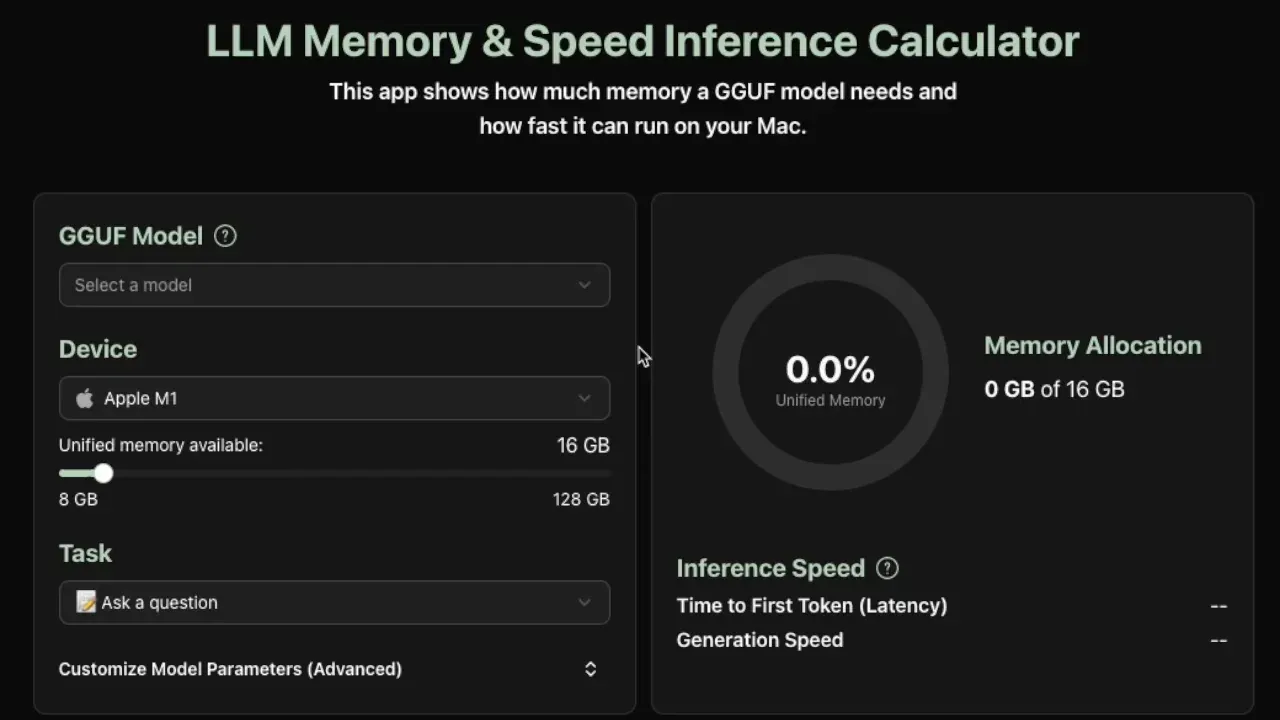
Calculateur de besoins en inférence locale pour LLM : Un nouvel outil pratique permet d’estimer la mémoire et la vitesse d’inférence en tokens par seconde nécessaires pour exécuter des modèles GGUF localement, actuellement compatible avec les appareils Apple Silicon. Cet outil fournit des estimations précises en analysant les métadonnées du modèle (taille, nombre de couches, dimensions cachées, cache KV, etc.), aidant les développeurs à optimiser le déploiement local des LLM. (Source: Reddit r/LocalLLaMA)
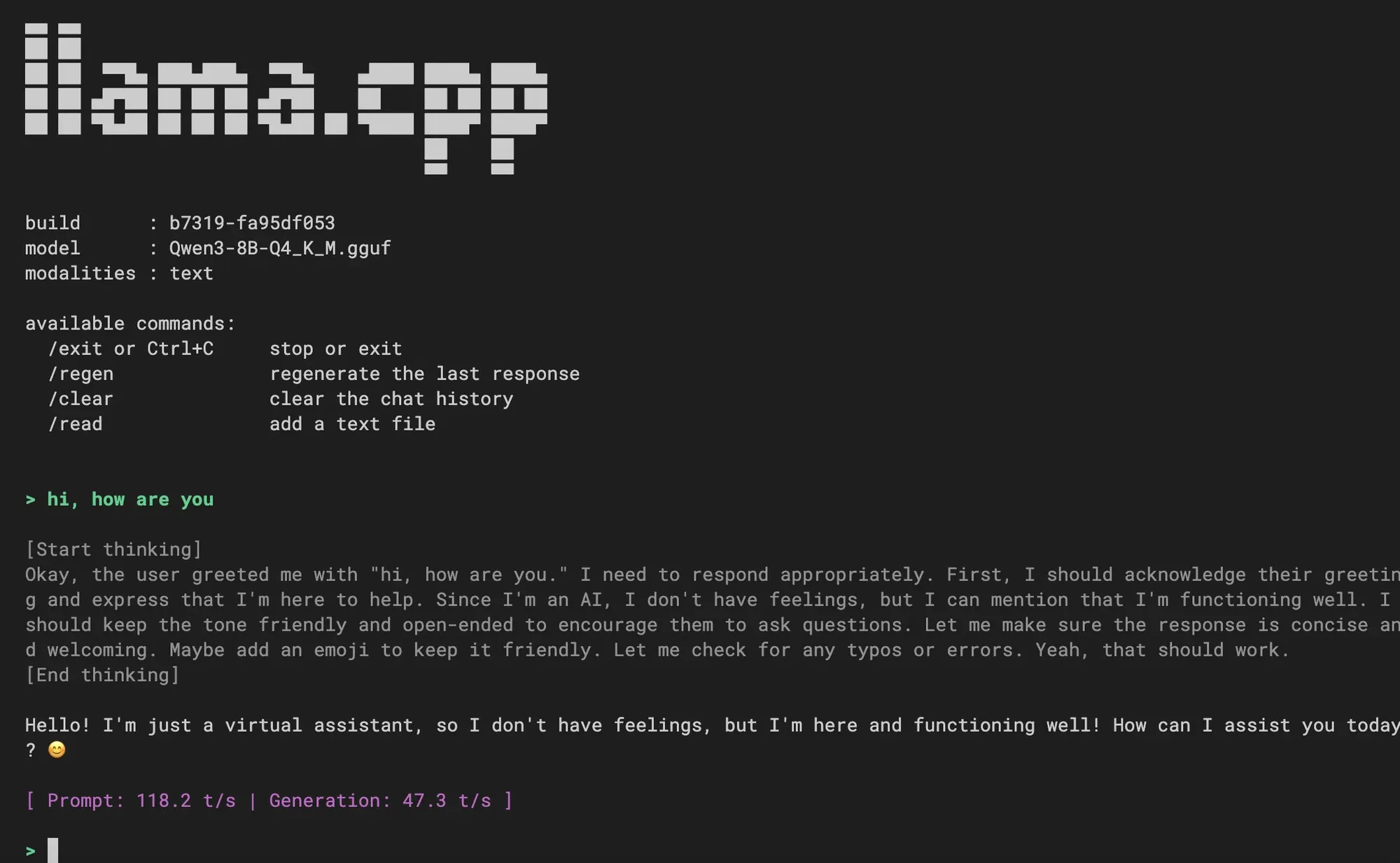
Intégration de la nouvelle expérience CLI dans llama.cpp : llama.cpp a fusionné une nouvelle expérience d’interface en ligne de commande (CLI), offrant une interface plus épurée, un support multimodal, un contrôle du dialogue via des commandes, un support de décodage spéculatif et un support de template Jinja. Les utilisateurs l’ont bien accueillie et se demandent si des fonctionnalités d’Agent de codage seront intégrées à l’avenir, annonçant une amélioration de l’expérience d’interaction locale avec les LLM. (Source: _akhaliq, Reddit r/LocalLLaMA)
Intégration des modèles Hugging Face dans VS Code : Le livestream de lancement de Visual Studio Code montrera comment utiliser directement les modèles pris en charge par Hugging Face Inference Providers dans VS Code, ce qui facilitera grandement l’utilisation des modèles d’IA par les développeurs dans l’IDE, permettant une programmation assistée par l’IA et des flux de travail de développement plus intégrés. (Source: huggingface)
📚 Apprentissage
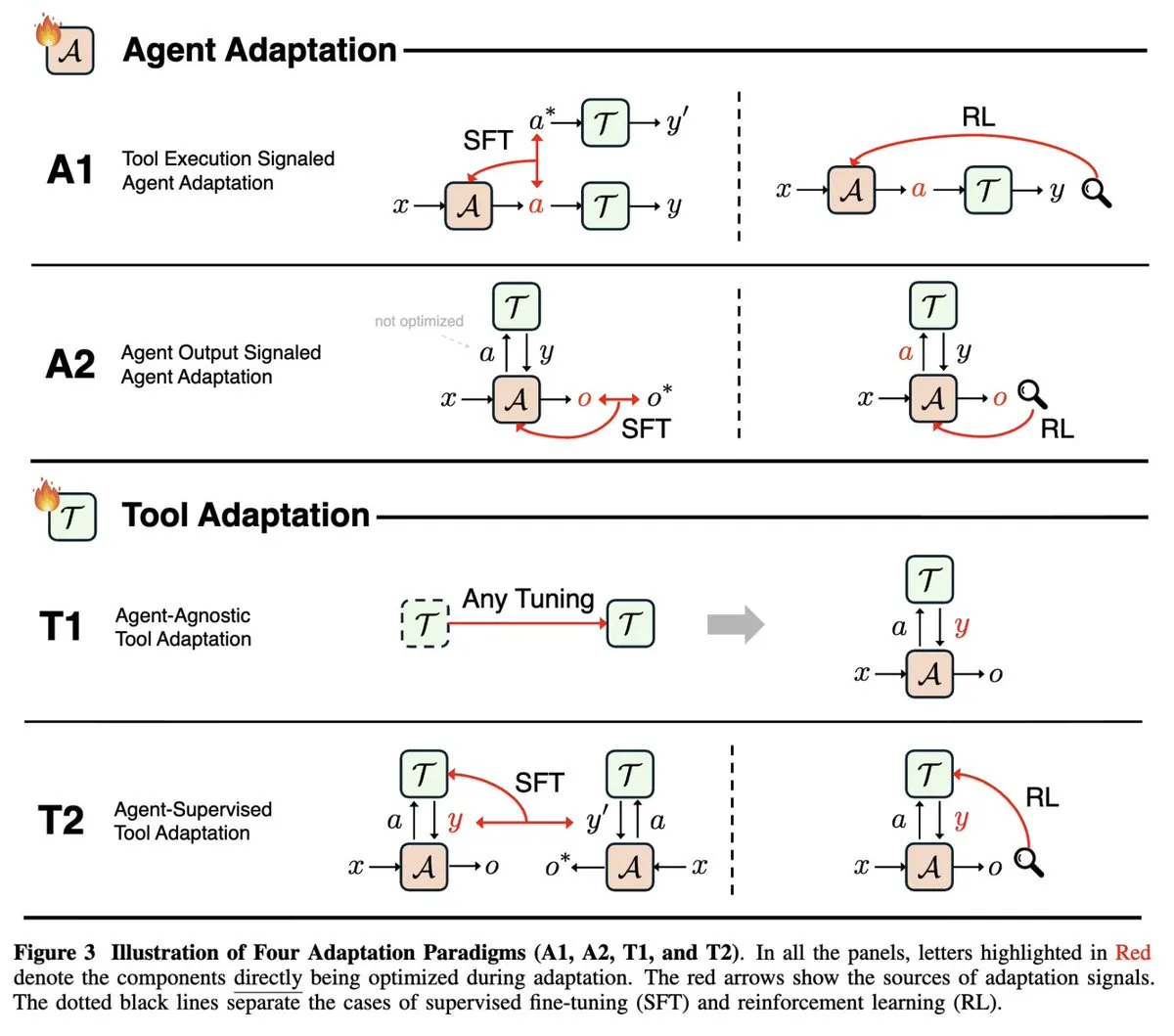
Revue de la recherche sur l’adaptabilité des AI Agents : Une étude de NeurIPS 2025, “Adaptability in Agentic AI”, unifie les domaines en évolution rapide de l’adaptabilité des Agents (signaux d’exécution d’outils et signaux de sortie d’Agent) et de l’adaptabilité des outils (indépendante de l’Agent et supervisée par l’Agent), classant les articles existants sur les Agents en quatre paradigmes d’adaptation, offrant un cadre théorique complet pour comprendre et développer les AI Agents. (Source: menhguin)
Feuille de route des compétences en Deep Learning et IA : Plusieurs infographies sont partagées, couvrant l’architecture hiérarchique des AI Agents, la pile des AI Agents en 2025, le portefeuille de compétences en analyse de données, 7 compétences en analyse de données très demandées, une feuille de route du Deep Learning et 15 étapes pour l’apprentissage de l’IA, offrant aux apprenants et développeurs du domaine de l’IA un guide complet des compétences et architectures, pour soutenir leur développement professionnel. (Source: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
Cours et livres gratuits sur le Deep Learning : François Fleuret propose son cours complet de Deep Learning, comprenant 1000 diapositives et captures d’écran, ainsi que le “Petit Livre du Deep Learning”, tous deux publiés sous licence Creative Commons, offrant de précieuses ressources gratuites aux apprenants, couvrant l’histoire du Deep Learning, les topologies, l’algèbre linéaire et le calcul, entre autres bases. (Source: francoisfleuret)
Optimisation des LLM et techniques d’entraînement : Varunneal a établi un nouveau record du monde pour le NanoGPT Speedrun (132 secondes, 30 étapes/seconde) grâce à des techniques telles que la planification de la taille des lots, le Cautious Weight Decay et le Normuon tuning. Parallèlement, un blog explore les méthodes pour obtenir une utilisation granulaire des tokens à partir de modules DSPy imbriqués, fournissant une expérience pratique et des détails techniques pour l’entraînement et l’optimisation des performances des LLM. (Source: lateinteraction, kellerjordan0)
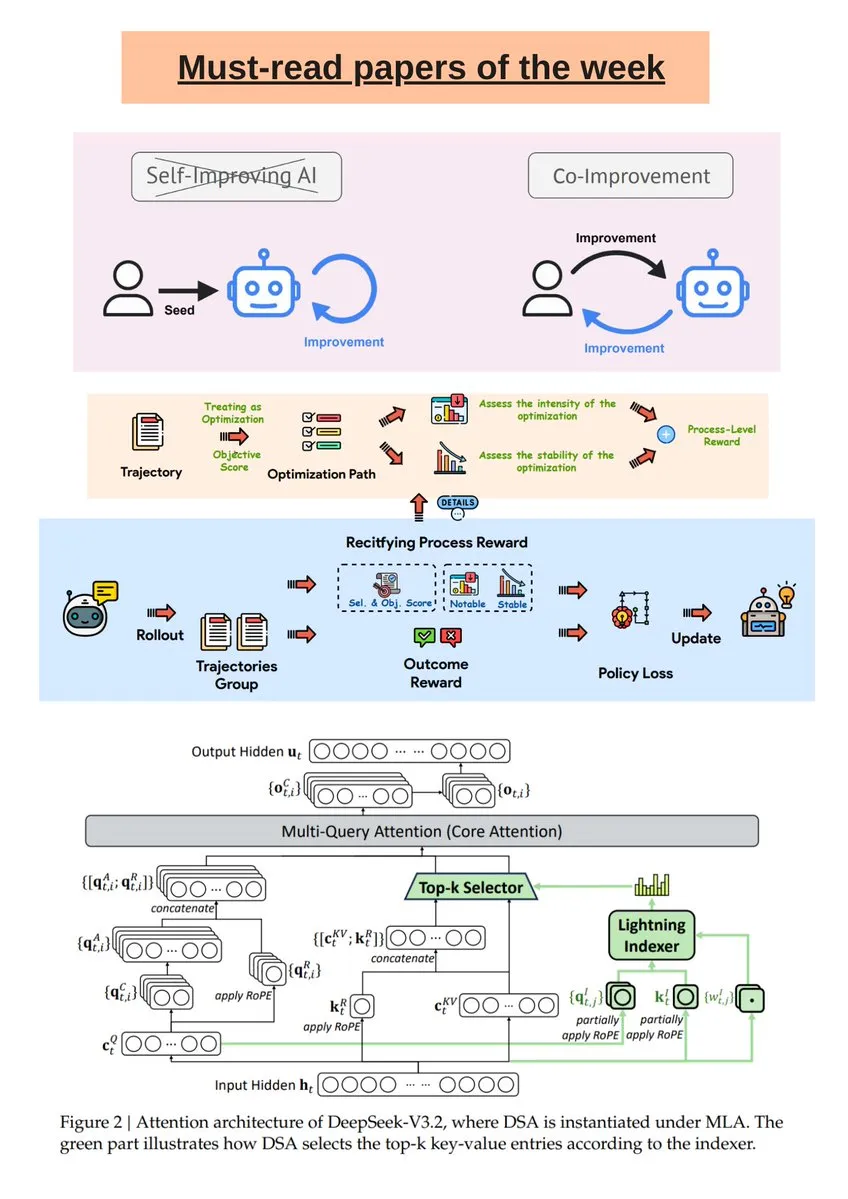
Rapport hebdomadaire de recherche sur l’IA et analyse du modèle DeepSeek R1 : The Turing Post a publié une sélection hebdomadaire de recherches sur l’IA, couvrant l’amélioration conjointe de l’IA et des humains, DeepSeek-V3.2, les LLM auto-évolutifs guidés, etc. De plus, un article de Science News explore en profondeur le modèle DeepSeek R1, clarifiant les idées fausses courantes concernant ses “thinking tokens” et ses opérations “RL-in-Name-Only”, aidant les lecteurs à mieux comprendre la recherche de pointe en IA. (Source: TheTuringPost, rao2z)
Qualité des données IA et MLOps : En Deep Learning, même de petites erreurs d’annotation dans les données d’entraînement peuvent gravement affecter les performances du modèle. La discussion souligne l’importance des processus de contrôle qualité tels que la vérification multi-étapes, les contrôles automatisés, la détection d’anomalies intégrée, les accords inter-annotateurs et les outils dédiés, afin d’assurer la fiabilité des données d’entraînement dans les applications à grande échelle, améliorant ainsi la performance globale du modèle. (Source: Reddit r/deeplearning)
Construire un LLM fondamental de niveau jouet à partir de zéro : Un développeur a partagé son expérience de construction d’un LLM fondamental de niveau jouet à partir de zéro, en utilisant ChatGPT pour aider à générer des couches d’attention, des blocs Transformer et des MLP, et en l’entraînant sur le jeu de données TinyStories. Ce projet fournit un carnet Colab complet, visant à aider les apprenants à comprendre le processus de construction et les principes de base des LLM. (Source: Reddit r/deeplearning)

💼 Affaires
“Zhishi Robot” lève des dizaines de millions de yuans en financement de série A+ : Zhishi Robot, une entreprise de robots d’entrepôt spécialisée dans la R&D et la fabrication de navettes à quatre voies, a récemment clôturé un financement de série A+ de plusieurs dizaines de millions de yuans, avec Hidden Peak Capital comme investisseur unique. Les produits de l’entreprise sont réputés pour leur sécurité, leur facilité d’utilisation et leur taux de modularité élevé, réalisant une croissance annuelle de 200 à 300 % de leur chiffre d’affaires, et se sont déjà étendus aux marchés étrangers, offrant un soutien solide à la modernisation des entrepôts intelligents. (Source: 36氪)

Baseten acquiert la startup RL Parsed : Le fournisseur de services d’inférence Baseten a acquis Parsed, une startup spécialisée dans l’apprentissage par renforcement (RL), ce qui reflète l’importance croissante du RL dans l’industrie de l’IA et l’attention du marché à l’optimisation des capacités d’inférence des modèles d’IA. Cette acquisition devrait renforcer la compétitivité de Baseten dans le domaine des services d’inférence d’IA. (Source: steph_palazzolo)
Une légende des mathématiques rejoint une startup d’IA : Ken Ono, une figure légendaire du monde des mathématiques, a quitté le milieu universitaire pour rejoindre une startup d’IA fondée par un jeune de 24 ans. Cela marque une tendance du déplacement des talents de haut niveau vers le domaine de l’IA, et annonce également la vitalité de l’écosystème des startups d’IA et une nouvelle direction pour l’intégration des talents interdisciplinaires. (Source: CarinaLHong)
🌟 Communauté
Débat sur l’impact de l’IA sur le marché du travail, l’économie socio-économique et l’automatisation des usines : L’impact de l’IA sur le marché du travail et l’économie socio-économique a suscité des discussions animées. Une partie estime que l’IA réduira la valeur du travail à zéro, appelant à remodeler le capitalisme par le biais d’une “infrastructure de base universelle” et d’un “dividende robotique” pour assurer la subsistance de base et encourager les humains à poursuivre l’art et l’exploration. L’autre partie s’en tient à la “fallacie de la quantité de travail”, estimant que l’IA créera davantage de nouvelles industries et d’opportunités d’emploi, que les humains se tourneront vers des rôles de gestion de l’IA, et souligne que l’IA physique automatisera la plupart des tâches d’usine d’ici dix ans. (Source: Plinz, Reddit r/ArtificialInteligence, hardmaru, SakanaAILabs, nptacek, Reddit r/artificial)

Rôle de l’IA dans le soutien à la santé mentale, la recherche scientifique et les controverses éthiques : Un utilisateur a partagé son expérience du soutien de Claude AI lors d’une grave crise de santé mentale, affirmant qu’il l’avait aidé à traverser cette épreuve comme un thérapeute. Cela met en évidence le potentiel de l’IA dans le soutien à la santé mentale, mais soulève également des discussions sur l’éthique et les limites du soutien émotionnel par l’IA. Parallèlement, la question de savoir si l’IA devrait automatiser entièrement la recherche scientifique a suscité un débat intense. Une partie estime qu’il est immoral de retarder l’automatisation (par exemple, la guérison du cancer) pour préserver le plaisir de la découverte humaine ; l’autre partie craint qu’une automatisation complète n’entraîne une perte de sens pour l’humanité, et remet même en question la capacité des avancées pilotées par l’IA à bénéficier équitablement à tous. (Source: Reddit r/ClaudeAI, BlackHC, TomLikesRobots, aiamblichus, aiamblichus, togelius)
Controverses sur la censure des LLM, la publicité commerciale et la confidentialité des données des utilisateurs : Les utilisateurs de ChatGPT sont mécontents de sa censure stricte du contenu et de ses réponses “ennuyeuses”, beaucoup se tournant vers des concurrents comme Gemini et Claude, qu’ils jugent plus performants en matière de contenu pour adultes et de conversation libre. Cela a entraîné une baisse des abonnements à ChatGPT et a suscité des discussions sur les normes de censure de l’IA et les différences de besoins des utilisateurs. Parallèlement, les tests de fonctionnalités publicitaires de ChatGPT ont provoqué une forte réaction négative des utilisateurs, qui estiment que la publicité nuirait à l’objectivité de l’IA et à la confiance des utilisateurs, soulignant les défis de l’éthique commerciale de l’IA. De plus, des utilisateurs ont signalé qu’OpenAI avait supprimé leurs anciennes conversations GPT-4o, soulevant des inquiétudes quant à la propriété des données et à la censure du contenu des services d’IA, et conseillant aux utilisateurs de sauvegarder impérativement leurs données localement. (Source: Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT, 36氪, Yuchenj_UW, aiamblichus)

Défis des développeurs d’AI Agent et considérations réalistes pour la référence des LLM dans la recherche d’emploi : Bien que les AI Agents soient présentés comme très puissants, les développeurs travaillent toujours de longues heures, ce qui soulève une question humoristique sur l’écart entre la promotion de l’IA et l’efficacité réelle du travail. Parallèlement, John Carmack suggère que l’historique de chat LLM des utilisateurs pourrait servir d‘“entretien prolongé” pour la recherche d’emploi, permettant au LLM de former une évaluation des candidats sans divulguer de données privées, améliorant ainsi la précision du recrutement. (Source: amasad, giffmana, VictorTaelin, fabianstelzer, mbusigin, _lewtun, VictorTaelin, max__drake, dejavucoder, ID_AA_Carmack)
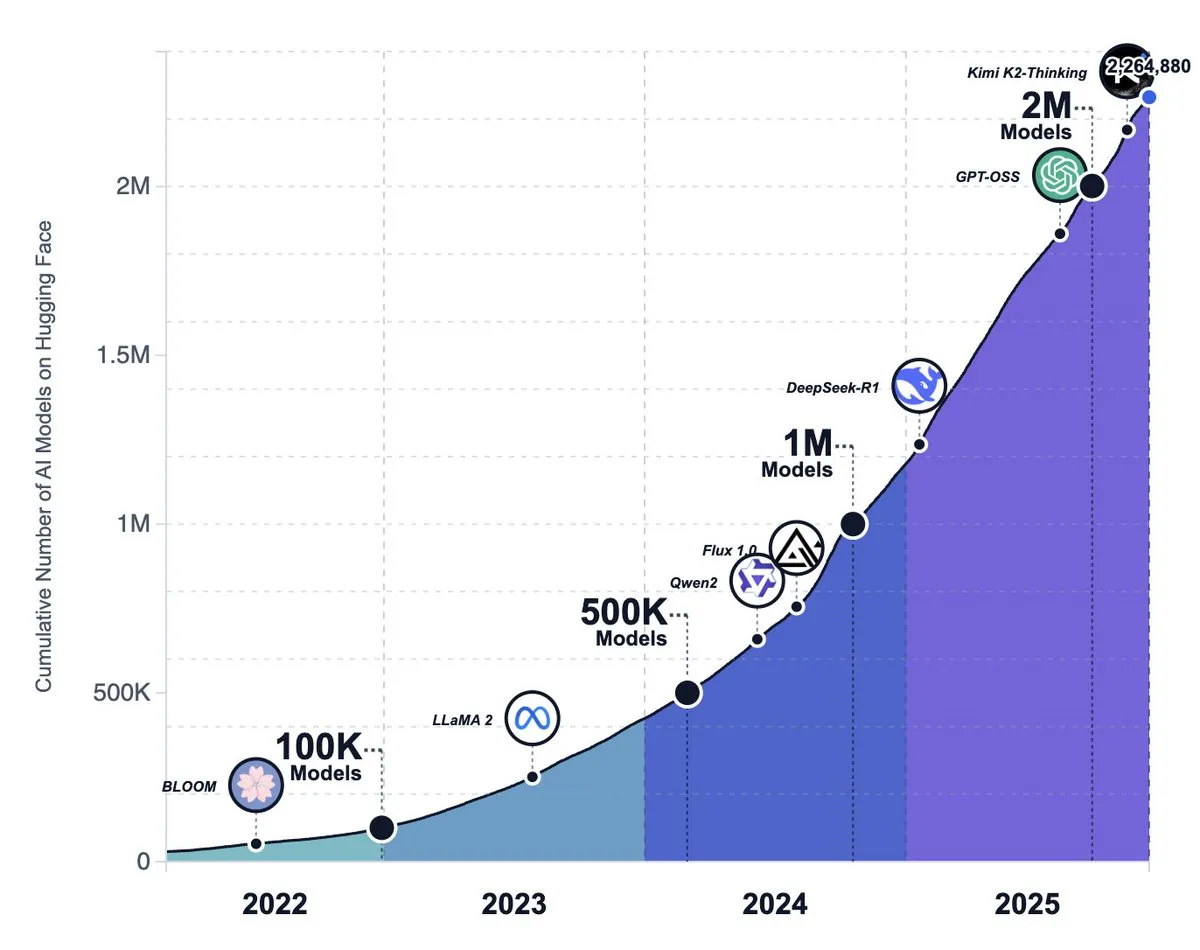
Montée de l’écosystème de l’IA open source, tendances des modèles et discussion sur le changement de stratégie de Meta : Le nombre de modèles sur la plateforme Hugging Face a dépassé les 2.2 millions, montrant que les modèles d’IA open source connaissent une croissance étonnante et sont considérés comme surpassant finalement les grands laboratoires de pointe. Cependant, certains estiment que les modèles open source ont encore un écart par rapport aux modèles propriétaires en termes d’expérience produit (comme l’environnement d’exécution, les capacités multimodales), et que de nombreux projets open source sont confrontés à la stagnation ou à l’abandon. Parallèlement, des rumeurs suggèrent que Meta est en train d’abandonner sa stratégie d’IA open source. (Source: huggingface, huggingface, huggingface, ZhihuFrontier, natolambert, _akhaliq)
L’IA dans la vie quotidienne : Sam Altman parle de la parentalité et de l’IA : Sam Altman a déclaré qu’il lui était difficile d’imaginer élever un nouveau-né sans ChatGPT, ce qui a suscité des discussions sur le rôle croissant de l’IA dans la vie personnelle et les décisions quotidiennes. Cela reflète que l’IA a commencé à s’infiltrer dans les scénarios familiaux les plus intimes, devenant un outil d’assistance indispensable de la vie moderne. (Source: scaling01)
Théorie de la “bulle” dans le domaine de l’IA et intensification de la concurrence sur le marché des modèles d’images : Certains estiment qu’il existe une “bulle” sur le marché actuel des LLM, non pas parce que les LLM ne sont pas puissants, mais parce que les gens ont des attentes irréalistes à leur égard. Un autre point de vue suggère qu’à mesure que le coût d’exécution de l’IA diminue, la valeur des idées originales augmentera. Parallèlement, la concurrence s’intensifie sur le marché des modèles d’images d’IA, et OpenAI serait sur le point de lancer un modèle amélioré pour faire face à des concurrents comme Nano Banana Pro. (Source: aiamblichus, cloneofsimo, op7418, dejavucoder)
Qualité du contenu IA, intégrité académique et controverses éthiques commerciales : La publicité IA de McDonald’s a été retirée en raison d’un marketing “désastreux”, soulignant la double nature des outils d’IA qui amplifient la créativité ou la stupidité humaine. Parallèlement, lors d’une conférence internationale sur l’IA, 21 % des évaluations de manuscrits ont été générées par l’IA, soulevant de sérieuses inquiétudes quant à l’intégrité académique. De plus, Instacart est accusé d’avoir augmenté les prix des produits via des expériences de tarification par IA, ce qui a suscité des préoccupations éthiques commerciales concernant l’IA. (Source: Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/artificial)

Impact de l’IA sur les futurs emplois et les besoins en compétences : L’impact de l’IA sur l’emploi des développeurs juniors a suscité des discussions, certains estimant que l’IA remplacera les tâches de base, mais qu’elle peut également aider les développeurs à apprendre et à façonner des outils grâce à l’open source et aux réseaux de mentors. Parallèlement, l’IA rend les compétences avancées telles que la pensée systémique, la décomposition fonctionnelle et l’abstraction de la complexité plus importantes, ce qui reflète la demande future du marché du travail pour des talents polyvalents. (Source: LearnOpenCV, code_star, nptacek)
Contexte du fondateur de DeepSeek et stratégie de l’entreprise : Wenfeng, le fondateur de DeepSeek, est décrit comme un “protagoniste d’un autre monde” avec un classement élevé au Gaokao et une solide formation en génie électrique. Son dynamisme unique, sa créativité et son audace pourraient influencer la feuille de route technologique de DeepSeek et même changer le paysage de la concurrence en IA entre la Chine et les États-Unis. Cela souligne l’importance des qualités personnelles des leaders de l’IA pour le développement de l’entreprise. (Source: teortaxesTex, teortaxesTex)

Revendications et scepticisme concernant les systèmes AGI : Une entreprise de Tokyo affirme avoir développé le “premier système AGI au monde”, doté de capacités d’apprentissage autonome, de sécurité et d’efficacité énergétique. Cependant, en raison de sa définition non standard de l’AGI et du manque de preuves concrètes, cette affirmation a suscité un scepticisme généralisé au sein de la communauté de l’IA, soulignant la complexité de la définition et de la vérification de l’AGI. (Source: Reddit r/ArtificialInteligence)

Discussion sur les limites physiques de l’intelligence générale artificielle : Tim Dettmers a publié un article de blog affirmant que, en raison des réalités physiques du calcul et des goulots d’étranglement dans l’amélioration des GPU, l’intelligence générale artificielle (AGI) et une super-intelligence significative ne seront pas réalisables. Ce point de vue remet en question l’optimisme généralisé actuel dans le domaine de l’IA et suscite une réflexion approfondie sur la trajectoire future du développement de l’IA. (Source: Tim_Dettmers, Tim_Dettmers)
💡 Autres
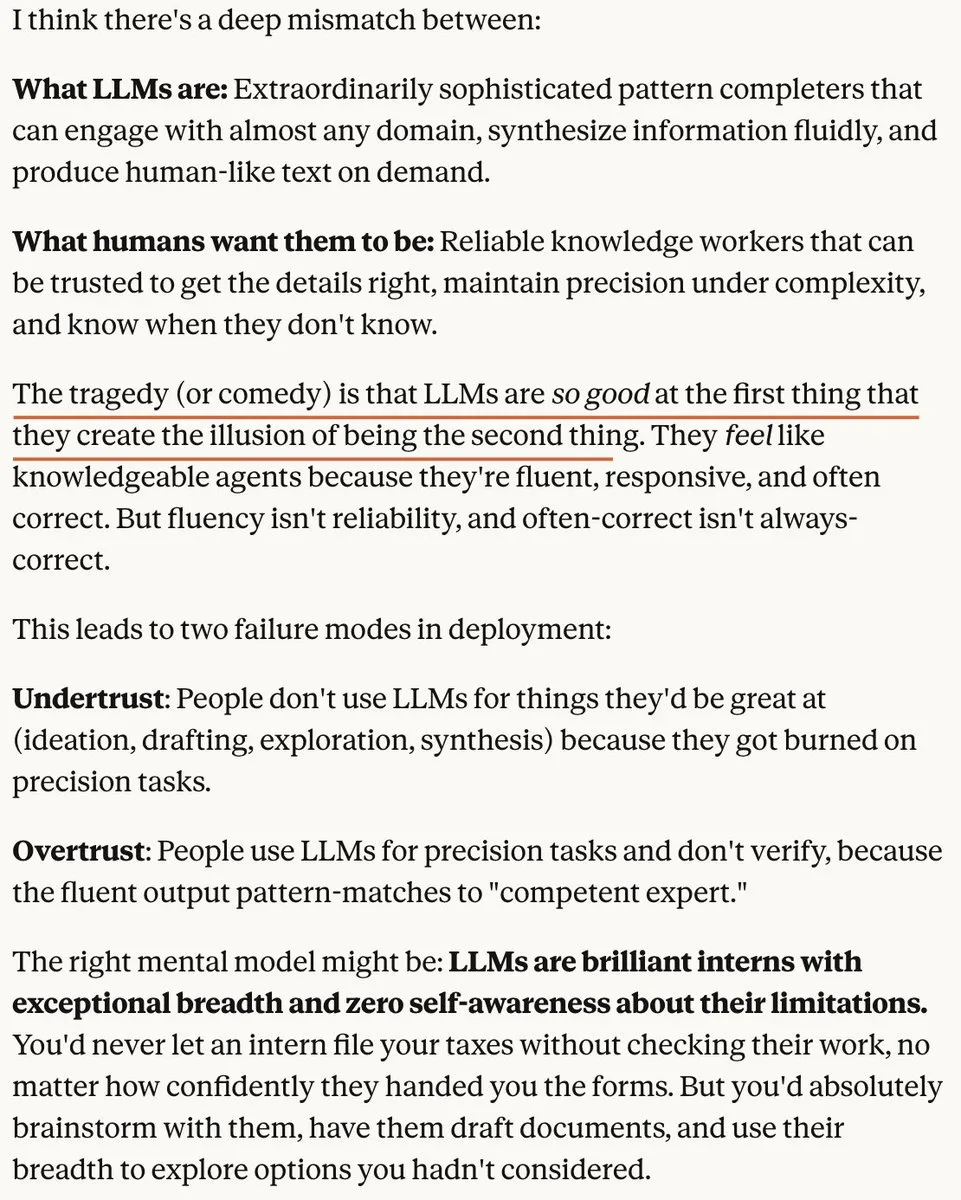
Évaluation des performances des modèles d’IA : l’écart entre les données synthétiques et l’expérience réelle : Des discussions soulignent un écart significatif entre les scores de référence des modèles d’IA et l’expérience réelle au niveau du produit. De nombreux modèles open source affichent de bonnes performances sur les benchmarks, mais restent en deçà des modèles propriétaires en termes d’environnement d’exécution, de capacités multimodales et de traitement de tâches complexes, soulignant que “les benchmarks ne sont pas l’expérience réelle” et que l’IA d’image et de vidéo démontre les progrès de l’IA de manière plus intuitive que les LLM textuels. (Source: op7418, ZhihuFrontier, op7418, Dorialexander)
La consommation électrique des centres de données provoque un contrecoup social : Les résidents américains s’opposent fermement à l’augmentation des factures d’électricité due à la prolifération des centres de données. Plus de 200 organisations environnementales appellent à un moratoire national sur la construction de nouveaux centres de données, soulignant l’impact énorme des infrastructures d’IA sur l’environnement et l’énergie, ainsi que la tension entre le développement technologique et la répartition des ressources sociales. (Source: MIT Technology Review)