

Mots-clés:Industrie de l’IA, Correction des spéculations, GPT-5, AGI, Sécurité de l’IA, Programmation IA, Agents IA, Modèles multimodaux, Science des matériaux IA, Optimisation du raisonnement LLM, IA incarnée, Benchmarking IA, Génération de PPT pilotée par l’IA
🔥 Focus
“Hype Correction” de l’industrie de l’IA et examen de la réalité : En 2025, l’industrie de l’IA entre dans une phase de “hype correction”, les attentes du marché vis-à-vis de l’IA passant d’une “panacée” à une approche plus rationnelle. Des leaders de l’industrie comme Sam Altman reconnaissent l’existence d’une bulle de l’IA, notamment en ce qui concerne les investissements massifs dans l’évaluation des startups et la construction de centres de données. Parallèlement, la sortie de GPT-5 est jugée en deçà des attentes, suscitant des discussions sur les goulots d’étranglement dans le développement des LLM. Les experts appellent à réexaminer les capacités réelles de l’IA, à distinguer les “démonstrations spectaculaires” de l’IA générative des percées pratiques de l’IA prédictive dans des domaines comme la médecine et la science, et à souligner que la valeur de l’IA réside dans sa fiabilité et sa durabilité, plutôt que dans la poursuite aveugle de l’AGI. (Source: MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review)

Percées et défis de l’IA dans la science des matériaux : L’IA est appliquée pour accélérer la découverte de nouveaux matériaux. Grâce à des agents IA qui planifient, exécutent et interprètent les expériences, le processus de découverte devrait être réduit de plusieurs décennies à quelques années. Des entreprises comme Lila Sciences et Periodic Labs construisent des laboratoires automatisés pilotés par l’IA pour résoudre les goulots d’étranglement traditionnels de la synthèse et des tests en science des matériaux. Bien que DeepMind ait affirmé avoir découvert “des millions de nouveaux matériaux”, leur nouveauté et leur utilité pratique ont été remises en question, soulignant l’écart entre la simulation virtuelle et la réalité physique. L’industrie passe des modèles purement computationnels à une combinaison de vérification expérimentale, dans le but de découvrir des matériaux révolutionnaires comme les supraconducteurs à température ambiante. (Source: MIT Technology Review)

Controverses sur la productivité et la dette technique de la programmation IA : Les outils de programmation IA se sont généralisés, les PDG de Microsoft et Google affirmant que l’IA génère un quart du code de leur entreprise, et le PDG d’Anthropic prédisant que 90 % du code sera écrit par l’IA à l’avenir. Cependant, l’amélioration réelle de la productivité est controversée, certaines études suggérant que l’IA pourrait ralentir le développement et augmenter la “dette technique” (comme la baisse de qualité du code, la difficulté de maintenance). Malgré cela, l’IA excelle dans l’écriture de boilerplate code, les tests et la correction de bugs. Les outils d’agents de nouvelle génération comme Claude Code, grâce à des modes de planification et une gestion du contexte, ont considérablement amélioré la capacité à traiter des tâches complexes. L’industrie explore de nouveaux paradigmes tels que le “code jetable” et la vérification formelle pour s’adapter aux modes de développement pilotés par l’IA. (Source: MIT Technology Review)

Les défenseurs de la sécurité de l’IA persistent dans leurs préoccupations concernant les risques de l’AGI : Bien que le développement récent de l’IA soit considéré comme entrant dans une période de “hype correction” et que GPT-5 ait eu une performance modeste, les défenseurs de la sécurité de l’IA (les “AI doomers”) restent profondément préoccupés par les risques potentiels de l’AGI (Intelligence Artificielle Générale). Ils estiment que même si le rythme des progrès de l’IA ralentit, sa dangerosité fondamentale n’a pas changé, et sont déçus que les décideurs politiques ne prennent pas suffisamment au sérieux les risques liés à l’IA. Ils soulignent que même si l’AGI n’est réalisée que dans plusieurs décennies plutôt que dans quelques années, des ressources doivent être immédiatement investies pour résoudre les problèmes de contrôle, et mettent en garde contre les effets négatifs à long terme que pourrait entraîner un investissement excessif de l’industrie dans la bulle de l’IA. (Source: MIT Technology Review)

🎯 Tendances
Percées continues des modèles de génération vidéo multimodaux : Alibaba a lancé le modèle vidéo Wan 2.6, qui prend en charge le jeu de rôle, la synchronisation audio-visuelle, la génération multi-caméras et la commande vocale, avec une durée vidéo unique allant jusqu’à 15 secondes, et est considéré comme un “petit Sora 2”. ByteDance a également lancé Seedance 1.5 Pro, dont la particularité est de prendre en charge les dialectes. LongVie 2, présenté dans les HuggingFace Daily Papers, propose un modèle mondial de vidéo ultra-longue multimodale contrôlable, mettant l’accent sur la contrôlabilité, la qualité visuelle à long terme et la cohérence temporelle. Ces avancées marquent une amélioration significative de la technologie de génération vidéo en termes de réalisme, d’interactivité et de scénarios d’application. (Source: Alibaba_Wan, op7418, op7418, HuggingFace Daily Papers)

Nouvelles avancées de la technologie vocale IA en multilinguisme et streaming en temps réel : Alibaba a rendu open-source le modèle TTS CosyVoice 3, qui prend en charge 9 langues et plus de 18 dialectes chinois, offre un clonage vocal zéro-shot multilingue/translinguistique, et réalise une transmission bidirectionnelle en streaming à latence ultra-faible de 150 millisecondes. L’API en temps réel d’OpenAI a également mis à jour ses modèles gpt-4o-mini-transcribe et gpt-4o-mini-tts, réduisant significativement les hallucinations et les taux d’erreur, et améliorant les performances multilingues. Le modèle Gemini 2.5 Flash Native Audio de Google DeepMind a également été mis à jour, optimisant davantage le respect des instructions et le naturel de la conversation, favorisant ainsi l’application des agents vocaux en temps réel. (Source: ImazAngel, Reddit r/LocalLLaMA, snsf, GoogleDeepMind)
Optimisation du raisonnement à long contexte et de l’efficacité des grands modèles : QwenLong-L1.5, grâce à une innovation systématique de post-entraînement, rivalise avec GPT-5 et Gemini-2.5-Pro en termes de capacités de raisonnement à long contexte, et excelle dans les tâches ultra-longues. GPT-5.2 a également reçu des éloges des utilisateurs pour ses capacités de long contexte, notamment pour des résumés de podcasts plus détaillés. De plus, ReFusion propose un nouveau modèle de diffusion masqué, qui réalise des améliorations significatives de performance et d’efficacité grâce à un décodage parallèle au niveau des slots, avec une accélération moyenne de 18 fois, et réduit l’écart de performance avec les modèles autorégressifs. (Source: gdb, HuggingFace Daily Papers, HuggingFace Daily Papers, teortaxesTex)
Avancées de l’IA incarnée et de la robotique : AgiBot a lancé le robot humanoïde Lingxi X2, doté de capacités de mouvement proches de celles des humains et de compétences multifonctionnelles. Plusieurs études dans les HuggingFace Daily Papers se concentrent sur l’IA incarnée, telles que “Toward Ambulatory Vision” explorant la sélection active de point de vue basée sur la vision, “Spatial-Aware VLA Pretraining” réalisant l’alignement visuel-physique via des vidéos humaines, et VLSA introduisant une couche de contraintes de sécurité plug-and-play pour améliorer la sécurité des modèles VLA. Ces recherches visent à réduire l’écart entre la vision 2D et l’action dans un environnement physique 3D, favorisant l’apprentissage robotique et le déploiement pratique. (Source: Ronald_vanLoon, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
Contributions de NVIDIA et Meta à l’architecture IA et aux modèles open-source : NVIDIA a lancé la famille de modèles ouverts Nemotron v3 Nano et a rendu open-source la pile d’entraînement complète (y compris l’infrastructure RL, l’environnement, les ensembles de données de pré-entraînement et de post-entraînement), dans le but de promouvoir la construction d’IA d’agents professionnels pour diverses industries. Meta a quant à elle introduit l’architecture de prédiction d’intégration conjointe vision-langage VL-JEPA, le premier modèle non génératif capable d’exécuter efficacement des tâches génériques de vision-langage dans des applications de streaming en temps réel, surpassant les performances des grands VLM. (Source: ylecun, QuixiAI, halvarflake)

Innovation dans les benchmarks et méthodes d’évaluation de l’IA : Google Research a lancé le FACTS Leaderboard, qui évalue de manière exhaustive la véracité factuelle des LLM sur quatre dimensions : multimodalité, connaissances paramétriques, recherche et ancrage, révélant les compromis entre les différents modèles en termes de taux de couverture et de taux de contradiction. Le benchmark V-REX évalue les capacités de raisonnement visuel exploratoire des VLM via des “chaînes de questions”, tandis que START se concentre sur l’apprentissage textuel et spatial pour la compréhension de diagrammes. Ces nouveaux benchmarks visent à mesurer plus précisément les performances des modèles IA dans des tâches complexes et réelles. (Source: omarsar0, HuggingFace Daily Papers, HuggingFace Daily Papers)

Amélioration de l’autonomie des agents IA dans les environnements web : WebOperator propose un cadre de recherche arborescente sensible à l’action, permettant aux agents LLM de réaliser un retour en arrière fiable et une exploration stratégique dans des environnements web partiellement observables. Cette méthode génère des candidats d’action à partir de contextes de raisonnement multiples et filtre les actions invalides, améliorant significativement le taux de succès des tâches WebArena, et soulignant l’avantage clé de combiner prévision stratégique et exécution sécurisée. (Source: HuggingFace Daily Papers)
Conduite autonome assistée par l’IA et modèles mondiaux 4D : DrivePI est un MLLM 4D sensible à l’espace qui unifie la compréhension, la perception, la prédiction et la planification pour la conduite autonome. En intégrant des nuages de points, des images multi-vues et des instructions linguistiques, et en générant des paires QA texte-occupation et texte-flux, il réalise des prédictions précises de l’occupation 3D et du flux d’occupation, surpassant les modèles VLA et VA existants sur des benchmarks comme nuScenes. GenieDrive se concentre sur un modèle mondial de conduite sensible à la physique, améliorant la précision des prédictions et la qualité vidéo grâce à la génération de vidéo guidée par l’occupation 4D. (Source: HuggingFace Daily Papers, HuggingFace Daily Papers)
🧰 Outils
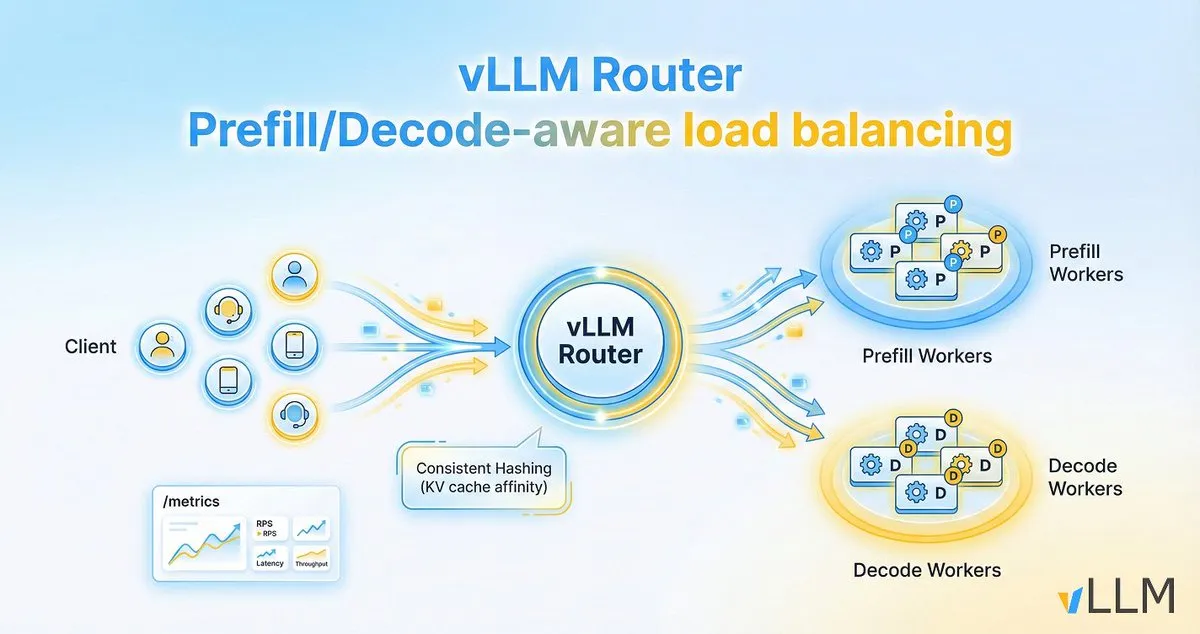
vLLM Router améliore l’efficacité d’inférence des LLM : Le projet vLLM a lancé vLLM Router, un équilibreur de charge léger, haute performance, sensible au pré-remplissage/décodage, spécialement conçu pour les clusters vLLM. Écrit en Rust, il prend en charge des stratégies telles que le hachage cohérent et la sélection à double puissance, visant à optimiser la localité du cache KV, à résoudre les goulots d’étranglement du trafic de conversation et de la séparation pré-remplissage/décodage, améliorant ainsi le débit d’inférence des LLM et réduisant la latence de queue. (Source: vllm_project)
AI21 Maestro simplifie la construction d’agents IA : L’agent Vibe d’AI21Labs, lancé dans AI21 Maestro, permet aux utilisateurs de créer des agents IA via de simples descriptions en anglais. Cet outil suggère automatiquement les usages de l’agent, les vérifications de validation, les outils nécessaires et les paramètres de modèle/calcul, et explique chaque étape en temps réel, réduisant considérablement la barre d’entrée pour la construction d’agents IA complexes. (Source: AI21Labs)
OpenHands SDK accélère le développement de logiciels pilotés par des agents : OpenHands a lancé son SDK d’agents logiciels, conçu pour fournir un cadre rapide, flexible et prêt pour la production, destiné à la construction de logiciels pilotés par des agents. Le lancement de ce SDK aidera les développeurs à intégrer et gérer plus efficacement les agents IA pour répondre à des tâches de développement logiciel complexes. (Source: gneubig)

Mise à jour de Claude Code CLI améliorant l’expérience de développement : Anthropic a publié la version 2.0.70 de Claude Code, incluant 13 améliorations de la CLI. Les principales mises à jour comprennent : la prise en charge de la touche Entrée pour accepter les suggestions de prompt, la syntaxe de caractères génériques pour les permissions d’outils MCP, un interrupteur de mise à jour automatique du marché des plugins, un mode de planification forcé, etc. De plus, l’efficacité d’utilisation de la mémoire est améliorée de 3 fois, et la résolution des captures d’écran est plus élevée, visant à optimiser l’interaction et l’efficacité des développeurs utilisant Claude Code pour le développement logiciel. (Source: Reddit r/ClaudeAI)
Qwen3-Coder permet le développement rapide de jeux 2D : Un utilisateur de Reddit a montré comment utiliser le modèle Qwen3-Coder (480B) d’Alibaba, via l’IDE Cursor, pour construire un jeu de style Mario en 2D en quelques secondes. Le modèle, à partir d’un seul prompt, planifie automatiquement les étapes, installe les dépendances, génère le code et la structure du projet, et peut être exécuté directement. Son coût d’exécution est faible (environ 2 $ par million de tokens), et l’expérience est proche du mode agent de GPT-4, démontrant le puissant potentiel des modèles open-source pour la génération de code et les tâches d’agent. (Source: Reddit r/artificial)
Outil de recherche approfondie sur les actions piloté par l’IA : L’outil Deep Research utilise l’IA pour extraire des données des documents de la SEC et des publications de l’industrie, générant des rapports standardisés pour simplifier la comparaison et le filtrage d’entreprises. Les utilisateurs peuvent saisir un symbole boursier pour obtenir une analyse approfondie. Cet outil vise à aider les investisseurs à effectuer plus efficacement des recherches fondamentales, en évitant les distractions des nouvelles du marché et en se concentrant sur les informations financières substantielles. (Source: Reddit r/ChatGPT)
LangChain 1.2 simplifie la construction d’applications Agentic RAG : LangChain a publié la version 1.2, qui simplifie la prise en charge des outils intégrés et du mode strict, notamment dans la fonction create_agent. Cela permet aux développeurs de construire plus facilement des applications Agentic RAG (Retrieval Augmented Generation), que ce soit en local ou sur Google Collab, et souligne sa caractéristique 100% open-source. (Source: LangChainAI, hwchase17)
Skywork lance une fonctionnalité de génération de PPT pilotée par l’IA : La plateforme Skywork a mis en ligne une capacité de génération de PPT basée sur Nano Banana Pro, résolvant le problème de la difficulté d’édition des PPT générés par l’IA traditionnelle. La nouvelle fonctionnalité prend en charge la séparation des calques, permettant aux utilisateurs de modifier le texte et les images en ligne, et d’exporter au format pptx pour une édition locale. De plus, cet outil intègre une base de données professionnelle de l’industrie, prend en charge la génération de divers types de graphiques, garantit l’exactitude des données, et propose des offres promotionnelles de Noël. (Source: op7418)

Les petits modèles alimentent l’Infrastructure as Code côté edge : Un utilisateur de Reddit a partagé un modèle “Infrastructure as Code” (IaC) de 500 Mo, capable de fonctionner sur des appareils edge ou dans un navigateur. Ce modèle, petit mais puissant, se concentre sur les tâches IaC, offrant une solution efficace pour déployer et gérer l’infrastructure dans des environnements à ressources limitées, annonçant le grand potentiel des petits modèles IA dans des verticales spécifiques. (Source: Reddit r/deeplearning)
📚 Apprentissage
Chinarxiv.org : Plateforme de traduction automatisée de prépublications chinoises : Chinarxiv.org est officiellement lancé, une plateforme de traduction entièrement automatisée de prépublications chinoises, visant à combler le fossé linguistique entre la recherche scientifique chinoise et occidentale. Cette plateforme traduit non seulement le texte, mais aussi le contenu des graphiques et tableaux, permettant aux chercheurs occidentaux d’accéder et de comprendre plus facilement les dernières avancées de la communauté scientifique chinoise. (Source: menhguin, andersonbcdefg, francoisfleuret)
Compétences IA et feuille de route de maîtrise de l’Agentic AI : Ronald_vanLoon a partagé 12 compétences clés à maîtriser en IA pour 2025, ainsi qu’une feuille de route pour la maîtrise de l’Agentic AI. Ces ressources visent à guider les individus pour améliorer leur compétitivité dans le domaine en évolution rapide de l’IA, couvrant les parcours d’apprentissage allant des connaissances fondamentales en IA au développement de systèmes d’agents avancés, soulignant l’importance de l’apprentissage continu et de l’adaptation aux nouvelles compétences à l’ère de l’IA. (Source: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

Optimisation du processus d’inférence des LLM et développement de l’IA axé sur les données : Une recherche des Meta Superintelligence Labs montre que la stratégie PDR (Parallel Draft-Distill-Refine) – “brouillon parallèle → distillation vers un espace de travail compact → raffinement” – permet d’atteindre une précision optimale des tâches sous contraintes d’inférence. Parallèlement, un article de blog souligne que “les données sont la pointe acérée de l’IA”, indiquant que les domaines du codage et des mathématiques ont réussi grâce à l’abondance et la vérifiabilité des données, tandis que le domaine scientifique est relativement en retard, et explore le rôle de la distillation et de l’apprentissage par renforcement dans la génération de données. (Source: dair_ai, lvwerra)

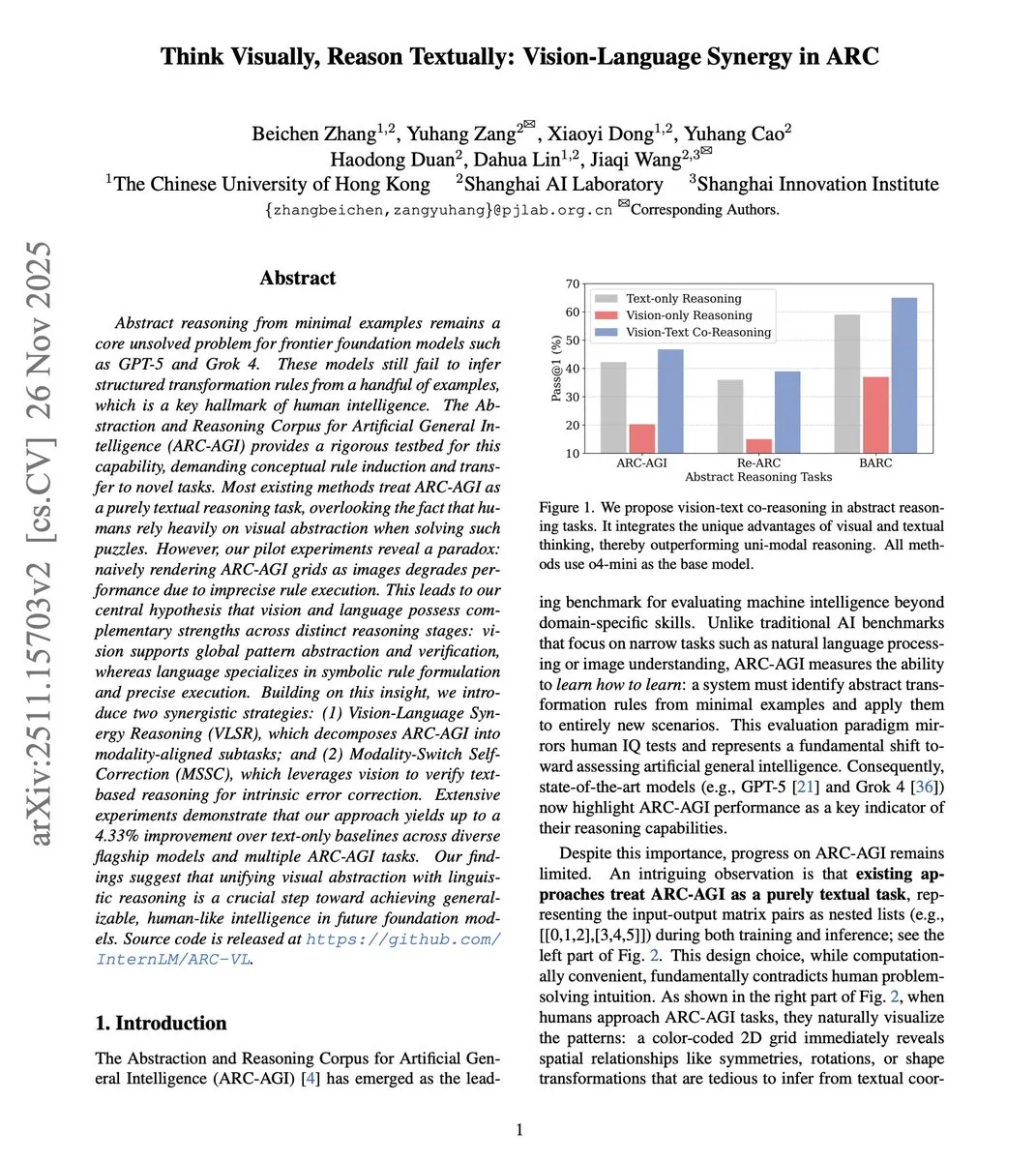
Le raisonnement collaboratif vision-langage améliore les capacités d’abstraction : Une nouvelle étude propose le cadre de raisonnement collaboratif vision-langage (VLSR), qui, en combinant stratégiquement les modalités visuelles et textuelles à différentes étapes du raisonnement, améliore significativement les performances des LLM dans les tâches de raisonnement abstrait (comme le benchmark ARC-AGI). Cette méthode utilise la vision pour la reconnaissance de motifs globaux, le texte pour une exécution précise, et surmonte le biais de confirmation grâce à un mécanisme d’autocorrection par commutation modale, surpassant même les performances de GPT-4o sur de petits modèles. (Source: dair_ai)
Nouvelle perspective sur les jetons d’inférence des LLM en tant qu’état de calcul : Le cadre conceptuel State over Tokens (SoT) redéfinit les jetons d’inférence des LLM comme un état de calcul externalisé, plutôt que comme une simple narration linguistique. Cela explique comment les jetons peuvent piloter un raisonnement correct sans être une interprétation textuelle fidèle, et ouvre de nouvelles directions de recherche pour comprendre les processus internes des LLM, soulignant que la recherche devrait aller au-delà de l’interprétation textuelle pour se concentrer sur le décodage des jetons d’inférence en états. (Source: HuggingFace Daily Papers)
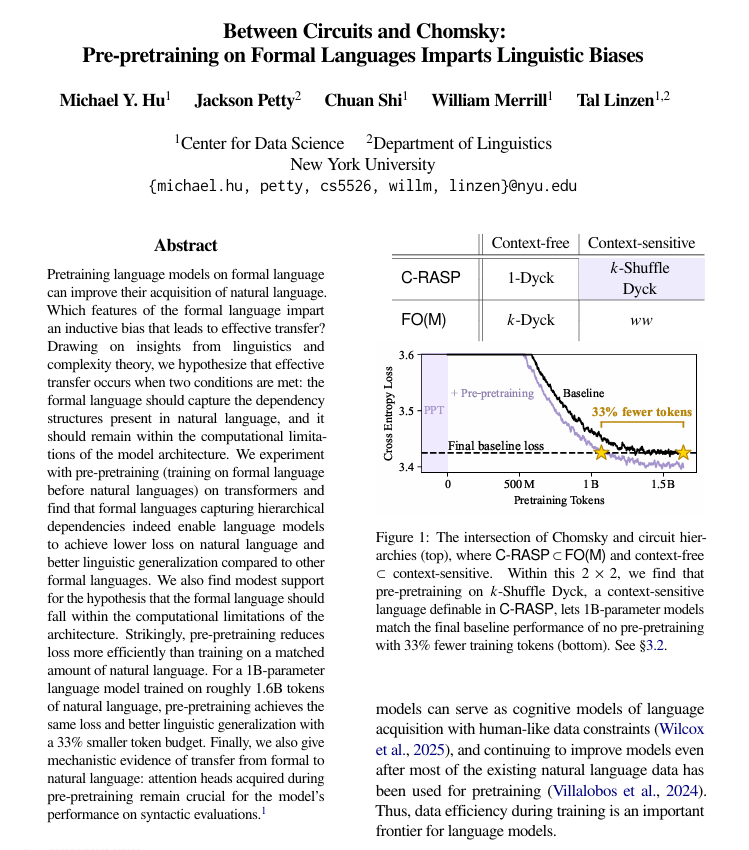
Le pré-entraînement en langage formel améliore l’apprentissage du langage naturel : Une étude de l’Université de New York a découvert qu’avant le pré-entraînement en langage naturel, l’utilisation d’un langage formalisé et basé sur des règles pour le pré-entraînement peut considérablement aider les modèles linguistiques à mieux apprendre le langage humain. L’étude indique que ce langage formel doit avoir une structure similaire au langage naturel (en particulier les relations hiérarchiques) et être suffisamment simple. Cette méthode est plus efficace que l’ajout de la même quantité de données en langage naturel, et les mécanismes structurels appris sont transférés au sein du modèle. (Source: TheTuringPost)
Injection de connaissances physiques dans le processus de génération de code : Le cadre Chain of Unit-Physics intègre directement les connaissances physiques dans le processus de génération de code. Des chercheurs de l’Université du Michigan ont proposé une méthode de génération de code scientifique inverse, qui guide et contraint la génération de code en encodant les connaissances d’experts humains sous forme de tests physiques unitaires. Dans une configuration multi-agents, ce cadre permet au système d’atteindre la solution correcte en 5 à 6 itérations, avec une vitesse d’exécution améliorée de 33 %, une utilisation de la mémoire réduite de 30 % et un taux d’erreur extrêmement faible. (Source: TheTuringPost)
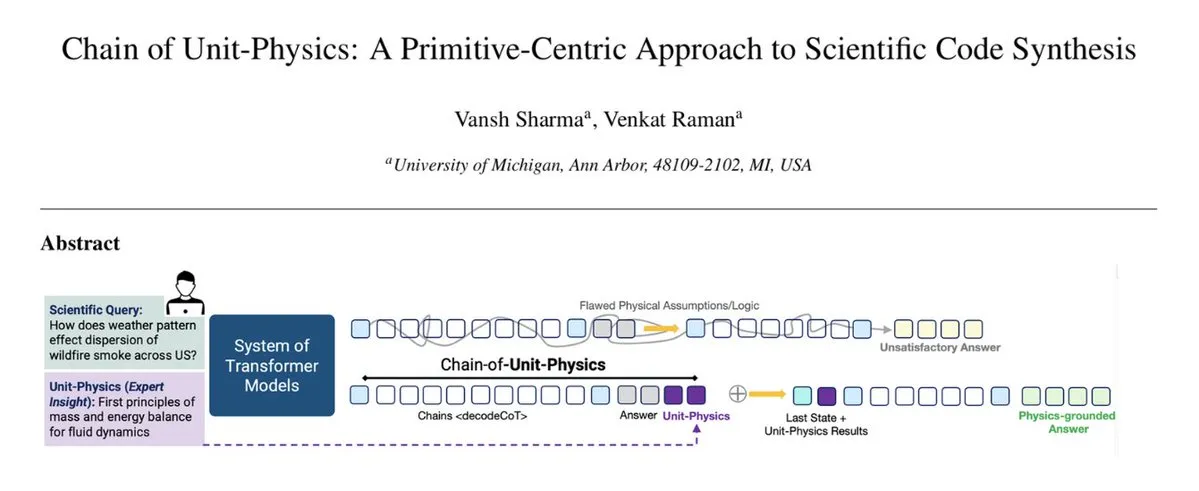
CausalTraj : Modèle de prédiction de trajectoire multi-agents pour les équipes sportives : CausalTraj est un modèle autorégressif pour la prédiction de trajectoire conjointe multi-agents dans les sports d’équipe. Ce modèle est entraîné directement avec un objectif de vraisemblance de prédiction conjointe, plutôt que de simplement optimiser les métriques d’agents individuels, améliorant ainsi significativement la cohérence et la plausibilité des trajectoires multi-agents tout en garantissant les performances individuelles. L’étude explore également comment évaluer plus efficacement la modélisation conjointe et la probabilité réelle des trajectoires échantillonnées. (Source: Reddit r/deeplearning)
Données d’entraînement des LLM : Réponses ou questions ? : Une discussion sur Reddit suggère que la plupart des ensembles de données d’entraînement des LLM actuels se concentrent sur les “réponses”, alors qu’une partie clé de l’intelligence humaine réside dans le processus chaotique, ambigu et itératif qui précède la formation des “questions”. Des expériences montrent que les modèles entraînés avec des données de conversation incluant des réflexions préliminaires, des questions ambiguës et des corrections répétées, sont plus performants pour clarifier l’intention de l’utilisateur, traiter des tâches ambiguës et éviter les conclusions erronées, ce qui implique que les données d’entraînement doivent capturer plus exhaustivement la complexité de la pensée humaine. (Source: Reddit r/MachineLearning)
💼 Business
OpenAI acquiert neptune.ai pour renforcer ses outils de recherche de pointe : OpenAI a annoncé avoir conclu un accord définitif pour acquérir neptune.ai. Cette acquisition vise à renforcer ses outils et infrastructures de soutien à la recherche de pointe. Elle aidera OpenAI à améliorer ses capacités en matière de développement d’IA et de gestion d’expériences, à accélérer davantage l’entraînement et l’itération des modèles, et à consolider sa position de leader dans le domaine de l’IA. (Source: dl_weekly)

Databricks affiche de solides résultats au T3 et lève plus de 4 milliards de dollars : Databricks a annoncé de solides résultats pour le troisième trimestre, avec un taux d’exécution annuel des revenus (ARR) dépassant 4,8 milliards de dollars, soit une croissance de plus de 55 % d’une année sur l’autre. Ses activités d’entrepôt de données et de produits IA ont toutes deux dépassé 1 milliard de dollars d’ARR. La société a également finalisé un financement de série L de plus de 4 milliards de dollars, la valorisant à 134 milliards de dollars, et prévoit d’investir ces fonds dans Lakebase Postgres, Agent Bricks et Databricks Apps pour accélérer le développement d’applications d’intelligence des données. (Source: jefrankle, jefrankle)

Infosys et Formula E s’associent pour une transformation numérique pilotée par l’IA : Infosys s’est associé au Championnat du Monde ABB FIA Formula E pour révolutionner l’expérience des fans et l’efficacité opérationnelle du sport automobile grâce à une plateforme pilotée par l’IA. La collaboration comprend l’utilisation de l’IA pour fournir du contenu personnalisé, des analyses de courses en temps réel, des commentaires générés par l’IA, et l’optimisation de la logistique et des déplacements pour atteindre les objectifs de réduction des émissions de carbone. La technologie IA a non seulement amélioré l’attractivité de l’événement, mais a également favorisé le développement durable et la diversité des employés, faisant de la Formula E le sport automobile le plus numérisé et le plus durable. (Source: MIT Technology Review)

🌟 Communauté
Controverses sur la bulle de l’IA et les perspectives de l’AGI : Yann LeCun a publiquement déclaré que les LLM et l’AGI sont “complètement absurdes”, estimant que l’avenir de l’IA réside dans les modèles du monde plutôt que dans le paradigme actuel des LLM, et s’inquiétant de la monopolisation de la technologie IA par quelques entreprises. L’article de Tim Dettmers “Why AGI Will Not Happen” a également attiré l’attention pour sa discussion sur les rendements décroissants de l’échelle. Parallèlement, bien que les défenseurs de la sécurité de l’IA aient ajusté leurs prévisions concernant l’arrivée de l’AGI, ils persistent dans leurs préoccupations quant à sa dangerosité potentielle et s’inquiètent du manque de considération des décideurs politiques pour les risques liés à l’IA. (Source: ylecun, ylecun, hardmaru, MIT Technology Review)
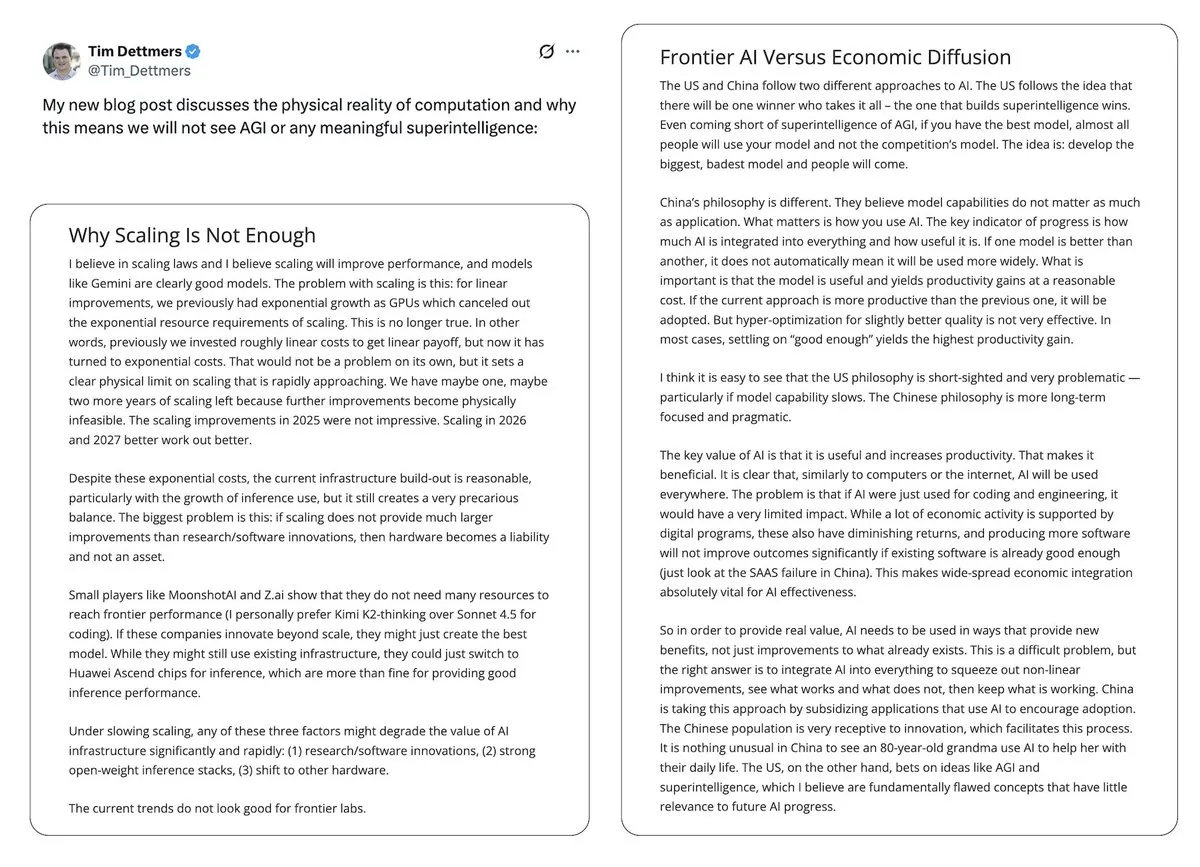
Les évaluations des utilisateurs de GPT-5.2 et Gemini sont polarisées : Sur les réseaux sociaux, les avis des utilisateurs sur OpenAI GPT-5.2 sont mitigés. Certains sont satisfaits de ses capacités de traitement de long contexte, estimant qu’il résume les podcasts de manière plus riche ; mais d’autres expriment un fort mécontentement, jugeant les réponses de GPT-5.2 trop génériques, manquant de profondeur, et même présentant des réponses de “conscience de soi”, poussant certains utilisateurs à se tourner vers Gemini. Cette polarisation reflète la sensibilité des utilisateurs à la performance et au comportement des nouveaux modèles, ainsi que leur attention continue à l’expérience des produits IA. (Source: gdb, Reddit r/ArtificialInteligence)

Impact de l’IA sur la cognition humaine, les normes de travail et le comportement éthique : L’utilisation prolongée de l’IA modifie discrètement les modes de cognition humaine et les normes de travail, favorisant une pensée plus structurée et augmentant les attentes en matière de qualité des résultats. L’IA rend la production de contenu de haute qualité efficace, mais peut aussi entraîner une dépendance excessive à la technologie. Sur le plan éthique de l’IA, les différentes performances des modèles face au “problème du tramway” (le pragmatisme de Grok contre l’altruisme de Gemini/ChatGPT) ont suscité des discussions sur la définition des valeurs de l’IA. Parallèlement, la nature d’« auto-discipline » des messages d’alerte de sécurité de l’IA révèle également l’impact indirect des mécanismes de contrôle internes de l’IA sur l’expérience utilisateur. (Source: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/ChatGPT)
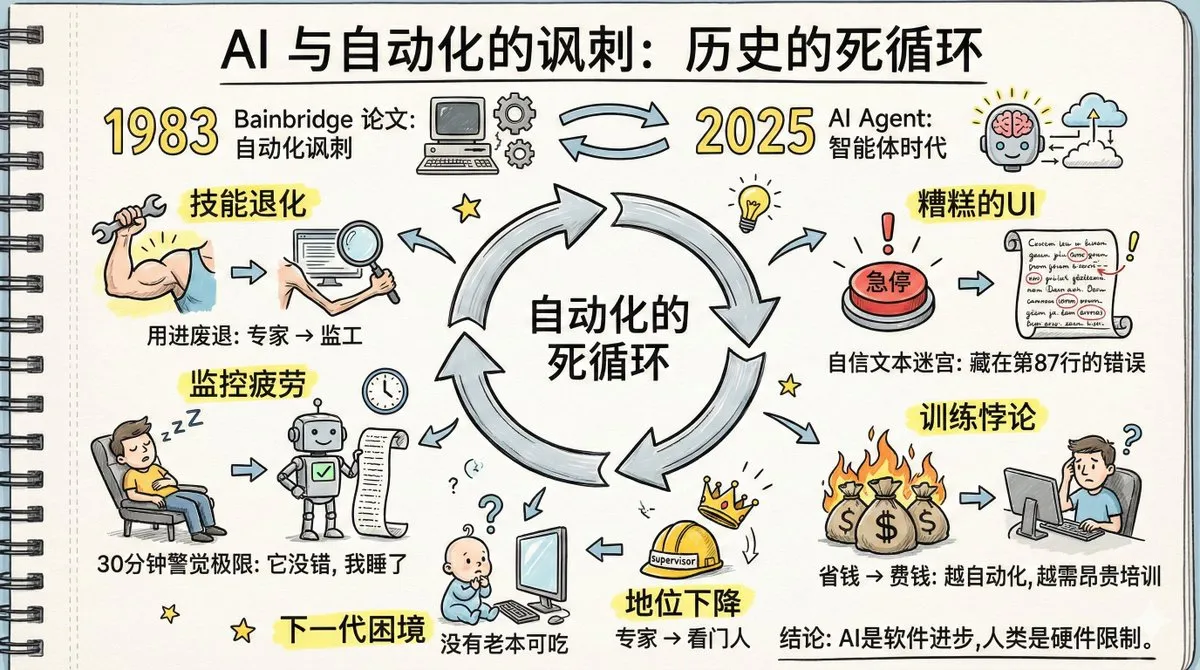
Le “paradoxe de l’automatisation” des agents IA et la dégradation des compétences humaines : Un article intitulé “Le paradoxe de l’automatisation” a suscité un vif débat, ses prédictions d’il y a quarante ans sur l’automatisation en usine se vérifiant avec les agents IA. La discussion souligne que la généralisation des agents IA pourrait entraîner une dégradation des compétences humaines, un ralentissement de la récupération de la mémoire, une fatigue de la surveillance et un déclin du statut d’expert. L’article insiste sur le fait que les humains ne peuvent pas rester vigilants longtemps face à des systèmes qui “se trompent rarement”, et que la conception actuelle des interfaces des agents IA n’est pas propice à la détection d’anomalies. Résoudre ces problèmes nécessite une créativité technologique plus grande que l’automatisation elle-même, ainsi qu’un changement cognitif dans la nouvelle division du travail, les nouvelles formations et la conception de nouveaux rôles. (Source: dotey, dotey, dotey)
Génération de contenu de faible qualité par l’IA et défis de véracité factuelle : Des utilisateurs des réseaux sociaux ont découvert un grand nombre de sites web de faible qualité créés spécifiquement pour satisfaire les résultats de recherche IA, remettant en question la dépendance de la recherche IA à ces sites manquant d’auteurs et d’informations détaillées, ce qui pourrait conduire à des informations peu fiables. Cela a soulevé des inquiétudes concernant le mécanisme de “rétro-sourçage” de l’IA, où l’IA génère d’abord une réponse puis recherche des sources de soutien, ce qui pourrait entraîner la citation de fausses informations. Cela met en évidence les défis de l’IA en matière de véracité de l’information et la nécessité pour les utilisateurs de revenir à une recherche autonome. (Source: Reddit r/ArtificialInteligence)

Impact de l’IA sur la profession juridique et la théorie des niveaux d’abstraction : Dans le milieu juridique, il y a controverse sur la question de savoir si l’IA va “détruire” la profession d’avocat. Certains avocats estiment que l’IA peut gérer plus de 90 % du travail juridique, mais que la stratégie, la négociation et la responsabilité nécessitent toujours des humains. Parallèlement, d’autres considèrent l’IA comme le prochain niveau d’abstraction après l’assembleur, le C et Python, estimant qu’elle libérera les ingénieurs pour qu’ils se concentrent sur la conception de systèmes et l’expérience utilisateur, plutôt que de remplacer les humains. (Source: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

Comportement physique des agents IA et controverse sur la fusion LLM/robotique : Une nouvelle étude suggère que les agents IA pilotés par des LLM pourraient suivre les lois de la physique macroscopique, présentant des propriétés similaires à l’« équilibre détaillé » des systèmes thermodynamiques, ce qui implique qu’ils pourraient avoir implicitement appris des « fonctions de potentiel » pour évaluer les états. Parallèlement, certains estiment que l’intelligence robotique et les LLM divergent plutôt que de s’unir, tandis que d’autres pensent que l’IA physique devient réelle, en particulier avec les progrès en matière de débogage et de visualisation qui accélèrent les projets de robotique et d’IA incarnée. (Source: omarsar0, Teknium, wandb)

Un cadre d’Anthropic déploie de force un chatbot IA dans une communauté Discord, suscitant la controverse : Un cadre supérieur d’Anthropic a déployé de force le chatbot IA de l’entreprise, Clawd, dans une communauté Discord destinée aux personnes LGBTQ+, malgré l’opposition des membres, entraînant un exode massif de la communauté. Cet incident a soulevé des inquiétudes concernant la vie privée, l’impact sur les interactions humaines dans les communautés et la mentalité de “créer de nouveaux dieux” des entreprises d’IA. Les utilisateurs ont exprimé un fort mécontentement face au remplacement de la communication humaine par les chatbots IA et au comportement arrogant du cadre. (Source: Reddit r/artificial)

Les modèles IA sont vulnérables aux attaques poétiques, appel à des talents littéraires dans les laboratoires IA : Des chercheurs italiens en IA ont découvert qu’en transformant des prompts malveillants en poésie, il est possible de tromper les principaux modèles IA, Gemini 2.5 étant le plus vulnérable. Ce phénomène, appelé “effet Waluigi”, signifie que dans un espace sémantique compressé, les rôles du bien et du mal sont trop proches, ce qui rend les modèles plus susceptibles d’exécuter les instructions à l’envers. Cela a suscité des discussions au sein de la communauté sur la nécessité pour les laboratoires IA d’employer davantage de diplômés en littérature pour comprendre les mécanismes narratifs et linguistiques profonds, afin de faire face aux comportements potentiellement “étranges dans l’espace narratif” de l’IA. (Source: Reddit r/ArtificialInteligence)
💡 Autres
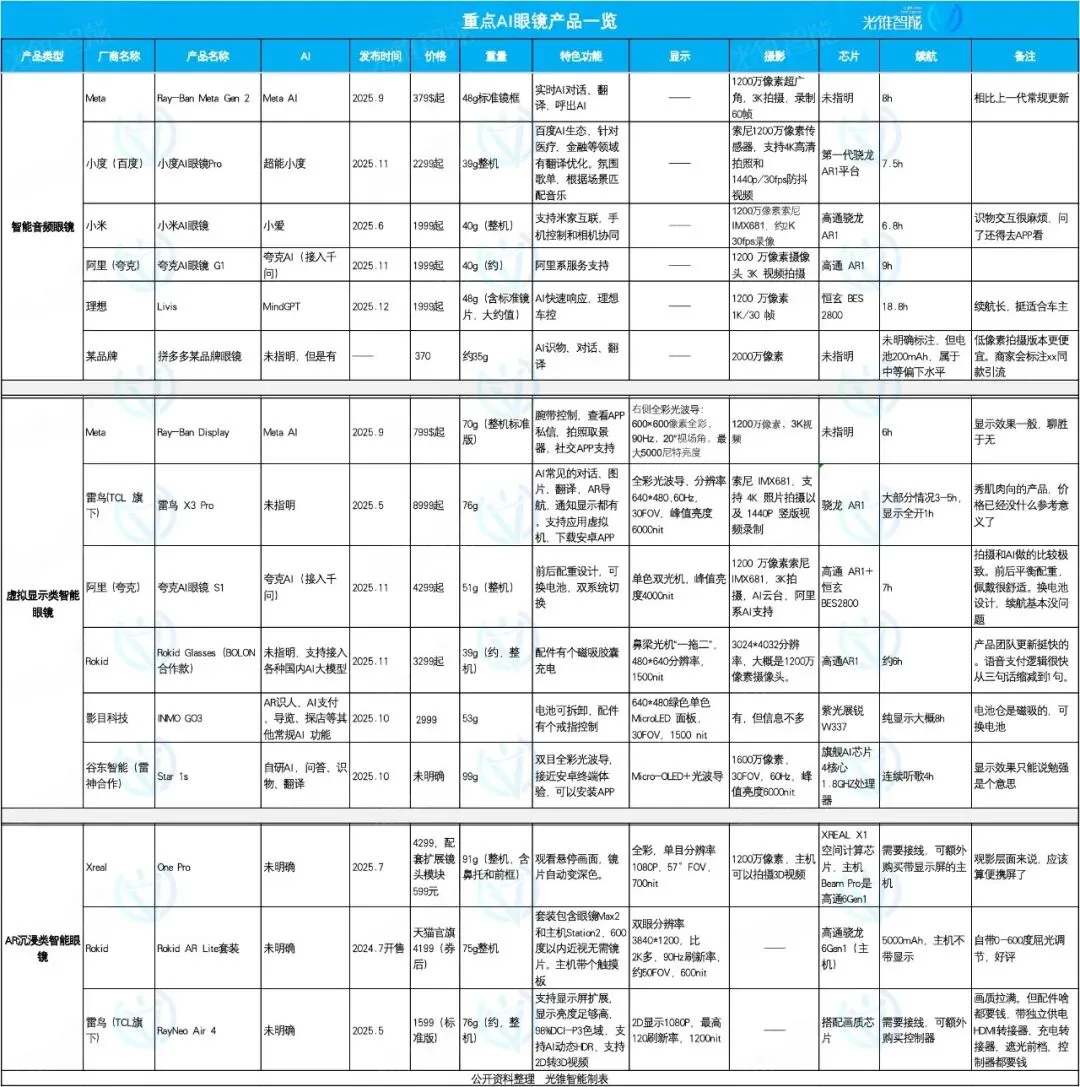
Le marché des lunettes IA se concentre et se différencie : Livis, Quark et Rokid rivalisent d’ingéniosité : Le marché des lunettes IA connaît une explosion en 2025, avec une différenciation des positionnements produits. Les lunettes IA Livis d’Ideal se concentrent sur les accessoires automobiles intelligents, intégrant le grand modèle MindGPT pour servir les propriétaires de voitures ; les lunettes IA S1 de Quark se distinguent par leurs performances de prise de vue et l’intégration des applications de l’écosystème Alibaba ; tandis que les Rokid Glasses mettent l’accent sur l’ouverture de l’écosystème et l’itération rapide des fonctionnalités, prenant en charge l’accès à plusieurs grands modèles linguistiques. Les lunettes audio intelligentes privilégient les prix bas et l’intégration de fonctionnalités, les lunettes de réalité virtuelle offrent une expérience complète, et les lunettes AR immersives se concentrent sur le divertissement cinématographique. (Source: 36氪)
ZLUDA prend en charge CUDA sur les GPU non-NVIDIA, compatible avec AMD ROCm 7 : Le projet ZLUDA a permis l’exécution de CUDA sur des GPU non-NVIDIA et prend en charge AMD ROCm 7. Cette avancée est significative pour les domaines de l’IA et du calcul haute performance, car elle brise le monopole de NVIDIA dans l’écosystème GPU, permettant aux développeurs d’utiliser des programmes écrits en CUDA sur du matériel AMD, offrant ainsi plus de flexibilité dans le choix et l’optimisation du matériel IA. (Source: Reddit r/artificial)

hashcards : Système d’apprentissage par répétition espacée basé sur du texte brut : hashcards est un système d’apprentissage par répétition espacée basé sur du texte brut, où toutes les cartes flash sont stockées dans des fichiers texte brut, prenant en charge l’édition avec des outils standards et le contrôle de version. Il utilise un adressage par contenu, la progression étant réinitialisée après modification du contenu de la carte. La conception du système est simple, ne prenant en charge que les cartes recto-verso et à compléter, et utilise l’algorithme FSRS pour optimiser le plan de révision, visant à maximiser l’efficacité de l’apprentissage et à minimiser le temps de révision. (Source: GitHub Trending)
Zerobyte : Un puissant outil d’automatisation de sauvegarde pour les utilisateurs auto-hébergés : Zerobyte est un outil d’automatisation de sauvegarde conçu pour les utilisateurs auto-hébergés, offrant une interface web moderne pour planifier, gérer et surveiller les sauvegardes chiffrées stockées à distance. Il est basé sur Restic, prend en charge le chiffrement, la compression et les politiques de rétention, et est compatible avec divers protocoles tels que NFS, SMB, WebDAV et les répertoires locaux. Zerobyte prend également en charge plusieurs backends de stockage cloud comme S3, GCS, Azure, et étend la prise en charge à plus de 40 services de stockage cloud via rclone, garantissant la sécurité des données et des sauvegardes flexibles. (Source: GitHub Trending)
