
Kata Kunci:Laporan Tren AI, AI Agent, Pembelajaran Penguatan, Model Bahasa Visual, Komersialisasi AI, Halusinasi AI, Keamanan AI, Laporan AI Ratu Internet, Desain Keamanan AI LawZero, Mekanisme Perhatian GTA dan GLA, Model Robot SmolVLA, Penipuan Streaming Musik AI
🔥 Fokus Utama
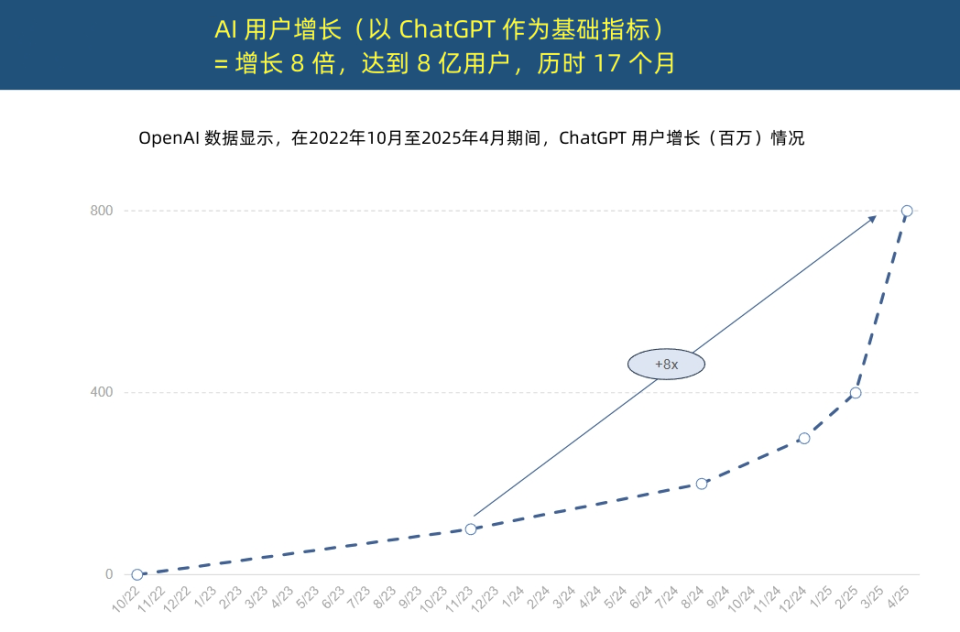
“Ratu Internet” merilis laporan tren AI, mengungkap akselerasi aplikasi AI yang belum pernah terjadi sebelumnya dan perubahan struktur biaya: Mary Meeker, yang dikenal sebagai “Ratu Internet”, merilis “Laporan Tren AI” setebal 340 halaman, yang menekankan bahwa AI sedang diadopsi dengan kecepatan yang belum pernah terjadi sebelumnya. Laporan tersebut menunjukkan bahwa pertumbuhan pengguna ChatGPT sangat pesat, mencapai 800 juta pengguna aktif bulanan dalam 17 bulan, dengan pendapatan tahunan mendekati 4 miliar USD, jauh melampaui teknologi mana pun dalam sejarah. Investasi modal raksasa teknologi dalam infrastruktur AI melonjak, mencapai 212 miliar USD pada tahun 2024. Sementara itu, biaya pelatihan model AI telah meningkat 2400 kali lipat dalam 8 tahun, dengan biaya pelatihan satu model mungkin mencapai 1 miliar USD, tetapi biaya inferensi menurun tajam karena perangkat keras (seperti efisiensi GPU Nvidia yang meningkat 100.000 kali lipat) dan optimasi algoritma. Kinerja model sumber terbuka (seperti DeepSeek, Qwen) mendekati model sumber tertutup, permintaan untuk posisi AI meningkat 448%, dan AI Agent menjadi tenaga kerja digital jenis baru. (Sumber: APPSO, Tencent Technology)
Pemenang Turing Award Yoshua Bengio meluncurkan LawZero, mengadvokasi AI yang “aman secara desain”: Pemenang Turing Award Yoshua Bengio mengumumkan pendirian organisasi nirlaba LawZero, yang bertujuan untuk mengembangkan kecerdasan buatan yang “aman secara desain” untuk mengatasi potensi perilaku menipu dan melindungi diri dari sistem AI. LawZero terinspirasi oleh Hukum Ketiga Robotika Asimov, menekankan bahwa AI harus melindungi kebahagiaan dan upaya manusia. Organisasi ini sedang mengembangkan sistem Scientist AI, sebagai “pagar pembatas” untuk AI Agent, yang memberikan bantuan dengan memahami dunia alih-alih bertindak secara langsung, dan mengevaluasi risiko perilaku AI lainnya. Bengio percaya bahwa Agentic AI saat ini adalah arah yang salah, yang dapat lepas kendali dan membawa konsekuensi bencana yang tidak dapat diubah, menekankan bahwa AI pagar pembatas keamanan setidaknya harus secerdas AI Agent yang coba diawasinya. (Sumber: Academic Headlines, Yoshua_Bengio)

Tahun Pertama AI Agent: Dari alat bantu menjadi pelaksana tugas, membentuk ulang model bisnis: Sun Zhiyong, Wakil Presiden Riset Gartner, menunjukkan bahwa tahun 2025 adalah “tahun pertama agen cerdas model besar” dan “tahun pertama monetisasi AI generatif”, dan agen AI menjadi pintu keluar utama kemampuan LLM. Perbedaan mendasar antara agen cerdas dan chatbot adalah pergeseran dari penyediaan bantuan informasi ke pelaksanaan tugas secara langsung, misalnya, agen cerdas dapat menyelesaikan seluruh proses pemesanan kopi, bukan hanya menyediakan informasi kedai kopi. Gartner memprediksi bahwa pada tahun 2028, 20% interaksi antarmuka digital akan diselesaikan oleh agen AI, 15% keputusan bisnis harian dapat diselesaikan secara mandiri oleh agen AI, dan sepertiga perangkat lunak tingkat perusahaan akan mengintegrasikan agen AI. Asisten cerdas BYD dan lainnya telah diterapkan secara awal, dan cara interaksi Aplikasi ponsel di masa depan mungkin berubah. (Sumber: IT Times)
Penulis inti Mamba mengusulkan mekanisme perhatian sadar inferensi GTA dan GLA, mengoptimalkan inferensi konteks panjang: Salah satu penulis inti Mamba, Tri Dao, dan timnya dari Princeton mengusulkan dua mekanisme perhatian baru, Grouped-Tied Attention (GTA) dan Grouped-Latent Attention (GLA), yang dirancang khusus untuk meningkatkan efisiensi inferensi konteks panjang model besar. GTA mengurangi penggunaan cache KV sekitar 50% dibandingkan GQA melalui pengikatan parameter dan penggunaan kembali cache kunci-nilai (KV) secara berkelompok, sambil mempertahankan kualitas model yang sebanding. GLA mengadopsi struktur dua lapis, memperkenalkan Token laten sebagai representasi terkompresi dari konteks global, dan menggabungkan mekanisme kepala berkelompok. Dibandingkan dengan MLA yang digunakan oleh DeepSeek, GLA dapat mempercepat decoding urutan panjang (seperti 64K) hingga 2 kali lebih cepat dan meningkatkan kemampuan pemrosesan permintaan bersamaan. Mekanisme baru ini bertujuan untuk mengatasi hambatan akses memori dan batasan paralelisme selama inferensi. (Sumber: QbitAI)

🎯 Perkembangan
DeepMind merilis SmolVLA: Model visual-bahasa-aksi robotik yang efisien berbasis data komunitas: Hugging Face bekerja sama dengan DeepMind dan institusi lainnya meluncurkan SmolVLA, sebuah model visual-bahasa-aksi (VLA) sumber terbuka dengan parameter 450M, yang dirancang khusus untuk robotika dan dapat berjalan pada perangkat keras kelas konsumen. Model ini hanya menggunakan dataset sumber terbuka yang dibagikan oleh komunitas LeRobot untuk pra-pelatihan, dan menunjukkan kinerja yang lebih unggul daripada model VLA yang lebih besar dan baseline seperti ACT pada tugas LIBERO, Meta-World, serta tugas dunia nyata (SO100, SO101). SmolVLA mendukung inferensi asinkron, yang dapat meningkatkan kecepatan respons sebesar 30% dan throughput tugas sebesar 2 kali lipat. Arsitekturnya menggabungkan Transformer dengan dekoder pencocokan aliran, dan mengoptimalkan kecepatan serta efisiensi melalui pengurangan Token visual, pemanfaatan fitur lapisan tengah VLM, dan mekanisme perhatian berselang-seling. (Sumber: HuggingFace Blog, clefourrier)

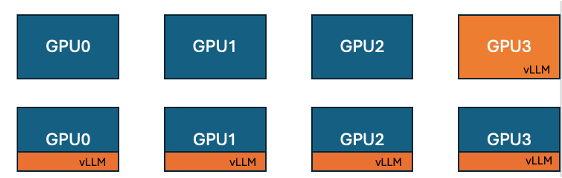
Hugging Face dan IBM meluncurkan fitur kolokasi vLLM di TRL, meningkatkan efisiensi pelatihan GPU: Hugging Face bekerja sama dengan IBM memperkenalkan fitur kolokasi vLLM (co-located vLLM) dalam pustaka TRL, yang digunakan untuk algoritma pembelajaran online seperti GRPO. Fitur ini memungkinkan pelatihan dan inferensi (generasi) berjalan pada GPU yang sama, berbagi sumber daya dan bergantian eksekusi, sehingga menghilangkan masalah GPU pelatihan yang menganggur menunggu dalam mode server vLLM sebelumnya. Dengan menyematkan vLLM ke dalam grup proses terdistribusi yang sama, komunikasi HTTP tidak diperlukan, kompatibel dengan torchrun, TP, dan DP, menyederhanakan penyebaran dan meningkatkan throughput. Eksperimen menunjukkan bahwa untuk model 1.5B dan 7B, mode kolokasi dapat menghasilkan percepatan hingga 1,43x hingga 1,73x; untuk model besar seperti Qwen2.5-Math-72B, dengan menggabungkan API sleep() vLLM dan optimasi DeepSpeed ZeRO Stage 3, bahkan dengan menggunakan lebih sedikit GPU, percepatan pelatihan sekitar 1,26x dapat dicapai tanpa memengaruhi akurasi model. (Sumber: HuggingFace Blog)
Nvidia merilis model Nemotron-Research-Reasoning-Qwen-1.5B, berfokus pada penalaran kompleks: Nvidia meluncurkan Nemotron-Research-Reasoning-Qwen-1.5B, sebuah model bobot sumber terbuka dengan parameter 1.5B, yang berfokus pada tugas penalaran kompleks seperti masalah matematika, tantangan pemrograman, masalah ilmiah, dan teka-teki logika. Model ini menggunakan algoritma ProRL (Prolonged Reinforcement Learning) yang dilatih pada dataset yang beragam, bertujuan untuk mencapai eksplorasi strategi penalaran yang lebih mendalam. Secara resmi diklaim bahwa model ini secara signifikan melampaui model 1.5B DeepSeek dalam tugas matematika, pengkodean, dan GPQA. ProRL didasarkan pada GRPO, dan memperkenalkan teknik untuk mengurangi keruntuhan entropi, pemotongan yang dipisahkan, dan optimasi strategi pengambilan sampel dinamis (DAPO), serta regularisasi KL dan pengaturan ulang kebijakan referensi. Model ini hanya untuk penggunaan penelitian dan pengembangan. (Sumber: Reddit r/LocalLLaMA, Hugging Face)

Arcee merilis model Homunculus-12B, berdasarkan distilasi Qwen3-235B ke Mistral-Nemo: Arcee AI merilis Homunculus-12B, sebuah model instruksi dengan 12 miliar parameter. Model ini dibangun dengan mendistilasi kemampuan Qwen3-235B ke dalam kerangka Mistral-Nemo. Saat ini, model ini dan versi GGUF-nya telah tersedia di Hugging Face. Ini merupakan upaya untuk mentransfer kemampuan kuat model besar ke model yang lebih kecil dan lebih efisien melalui teknik distilasi model, yang bertujuan untuk menyeimbangkan kinerja dengan konsumsi sumber daya. (Sumber: Reddit r/LocalLLaMA, Hugging Face)

Aplikasi Microsoft Bing mengintegrasikan alat pembuatan video Sora gratis: Microsoft menambahkan fitur pembuatan video OpenAI Sora gratis ke aplikasi seluler Bing-nya. Pengguna dapat menghasilkan klip video pendek melalui perintah teks tanpa perlu berlangganan atau membayar biaya. Saat ini, fitur ini mendukung pembuatan video vertikal 9:16 berdurasi 5 detik, dan di masa mendatang direncanakan untuk mendukung format horizontal 16:9. Pengguna gratis memiliki 10 kuota pembuatan cepat, setelah itu mereka dapat menukarkan poin Microsoft atau memilih pembuatan kecepatan standar. Langkah ini bertujuan untuk menurunkan ambang batas pembuatan video AI, memungkinkan lebih banyak pengguna merasakan teknologi teks-ke-video. (Sumber: Reddit r/ArtificialInteligence, dotey)

Hugging Face merilis SmolVLA, model visual-bahasa-aksi yang dirancang untuk robotika hemat biaya: Hugging Face meluncurkan SmolVLA, sebuah model visual-bahasa-aksi (VLA) sumber terbuka dengan parameter 450M, yang bertujuan untuk menyediakan solusi robotika hemat biaya. Model ini dilatih menggunakan semua dataset sumber terbuka dari komunitas LeRobotHF, mencapai kinerja dan kecepatan inferensi terbaik di kelasnya. Peluncuran SmolVLA bertujuan untuk menurunkan ambang batas penelitian dan pengembangan robotika, mendorong partisipasi dan inovasi komunitas yang lebih luas. (Sumber: huggingface, AK)

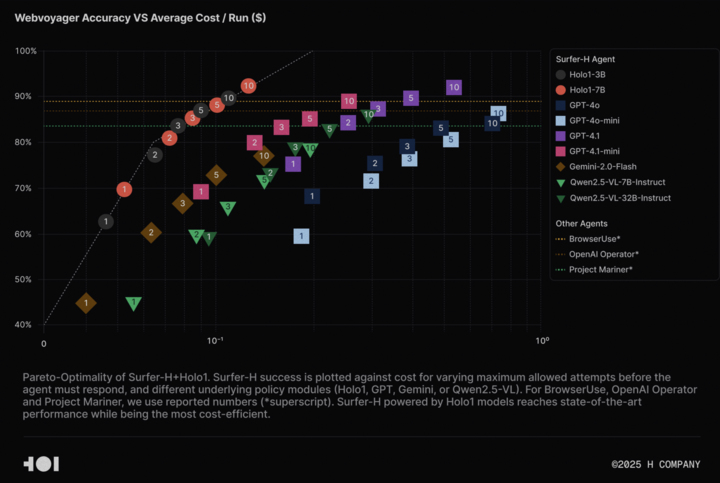
H Company membuka sumber model bahasa visual Holo-1 dan dataset WebClick, mendorong penelitian Agentic AI: H Company mengumumkan pembukaan sumber model bahasa visualnya Holo-1 (versi parameter 3B dan 7B) serta dataset WebClick, yang bertujuan untuk mempercepat penelitian di bidang Agentic AI. Model Holo-1 dirancang khusus untuk tugas aksi GUI dan navigasi Web, dan telah mencapai skor SOTA (State-of-the-Art) 92,2% pada benchmark WebVoyager, serta lebih unggul dalam efektivitas biaya dibandingkan model besar seperti GPT-4.1. Bobot model dan dataset telah dirilis di platform Hugging Face dengan lisensi Apache 2.0. Holo-1 juga telah diintegrasikan ke dalam MLX, memudahkan pengembang untuk menjalankannya di perangkat Apple Silicon. (Sumber: huggingface, tonywu_71)
PlayAI membuka sumber LLM difusi suara pertama PlayDiffusion, mendukung pengeditan halus dan kloning zero-shot: PlayAI merilis dan membuka sumber PlayDiffusion, yang merupakan diffusion-LLM pertama untuk suara. Model ini dirancang khusus untuk pengeditan suara AI yang halus (seperti perbaikan, penggantian konten) dan kloning suara zero-shot. Berbeda dengan model autoregresif yang biasanya membutuhkan 800-1000 Token untuk menghasilkan audio, PlayDiffusion hanya membutuhkan 20-30 Token untuk menghasilkan audio, yang secara signifikan meningkatkan efisiensi. Model ini telah tersedia kode sumbernya di GitHub, dan demonya telah diterapkan di Hugging Face Spaces, serta dapat digunakan melalui platform Fal.ai. (Sumber: _akhaliq)
Google diam-diam merilis aplikasi AI Edge Gallery, mendukung menjalankan model AI secara offline di perangkat Android: Google meluncurkan aplikasi Alpha eksperimental bernama Google AI Edge Gallery, yang memungkinkan pengguna mengunduh dan menjalankan model AI publik dari Hugging Face secara offline di perangkat Android. Aplikasi ini mendukung fungsi seperti tanya jawab gambar, peringkasan dan penulisan ulang teks, pembuatan kode, obrolan AI, dan menyediakan wawasan kinerja (seperti TTFT, kecepatan decoding). Menjalankan model AI secara lokal dapat meningkatkan kecepatan respons, melindungi privasi pengguna, dan tidak memerlukan koneksi jaringan. Namun, umpan balik pengguna beragam, beberapa pengguna mengalami masalah crash pada perangkat seperti Pixel, terutama saat beralih ke inferensi GPU atau memproses model besar. Beberapa komentar menganggap fungsinya mirip dengan aplikasi yang ada (seperti PocketPal), atau tertinggal dibandingkan dengan kerangka kerja seperti Apple CoreML, tetapi ada juga pandangan yang menunjukkan bahwa basis MediaPipe-nya memiliki keunggulan lintas platform. (Sumber: 36Kr)

Microsoft RenderFormer hadir di Hugging Face, berfokus pada rendering neural mesh segitiga di bawah iluminasi global: Microsoft merilis RenderFormer di Hugging Face, sebuah model rendering neural berbasis Transformer yang dikhususkan untuk menangani rendering mesh segitiga dengan efek iluminasi global. Pekerjaan penelitian semacam ini memiliki arti penting untuk menggabungkan pipeline rendering tradisional dengan metode neural, dan arah pengembangan selanjutnya mungkin mencakup perluasan ke adegan yang lebih besar serta melampaui reproduksi sederhana dari path tracing. (Sumber: _akhaliq)

BAAI merilis model pemahaman video panjang Video-XL-2, mendukung pemrosesan puluhan ribu frame pada satu GPU: Beijing Academy of Artificial Intelligence (BAAI) bekerja sama dengan Shanghai Jiao Tong University meluncurkan Video-XL-2, sebuah model yang dirancang khusus untuk pemahaman video panjang. Model ini menggunakan lisensi Apache 2.0, mampu memproses lebih dari 10.000 frame konten video pada satu GPU, dan menyelesaikan encoding 2048 frame dalam 12 detik. Teknologi utamanya meliputi Chunk-based Prefilling yang efisien dan Bi-granularity KV decoding, yang bertujuan untuk meningkatkan efisiensi dan kemampuan pemrosesan video panjang. Model ini telah tersedia di Hugging Face. (Sumber: huggingface)
Model UniWorld dirilis di Hugging Face, bertujuan untuk menyatukan pemahaman dan generasi visual: Model UniWorld telah diluncurkan di platform Hugging Face. Model ini diposisikan sebagai encoder semantik resolusi tinggi, yang didedikasikan untuk mencapai kemampuan pemahaman dan generasi visual yang terpadu. Ini menunjukkan bahwa para peneliti sedang berupaya membangun kerangka model tunggal yang mampu menangani input informasi visual (pemahaman) dan output konten visual (generasi) secara bersamaan, dengan harapan mencapai kemajuan yang lebih komprehensif di bidang AI multimodal. (Sumber: _akhaliq)
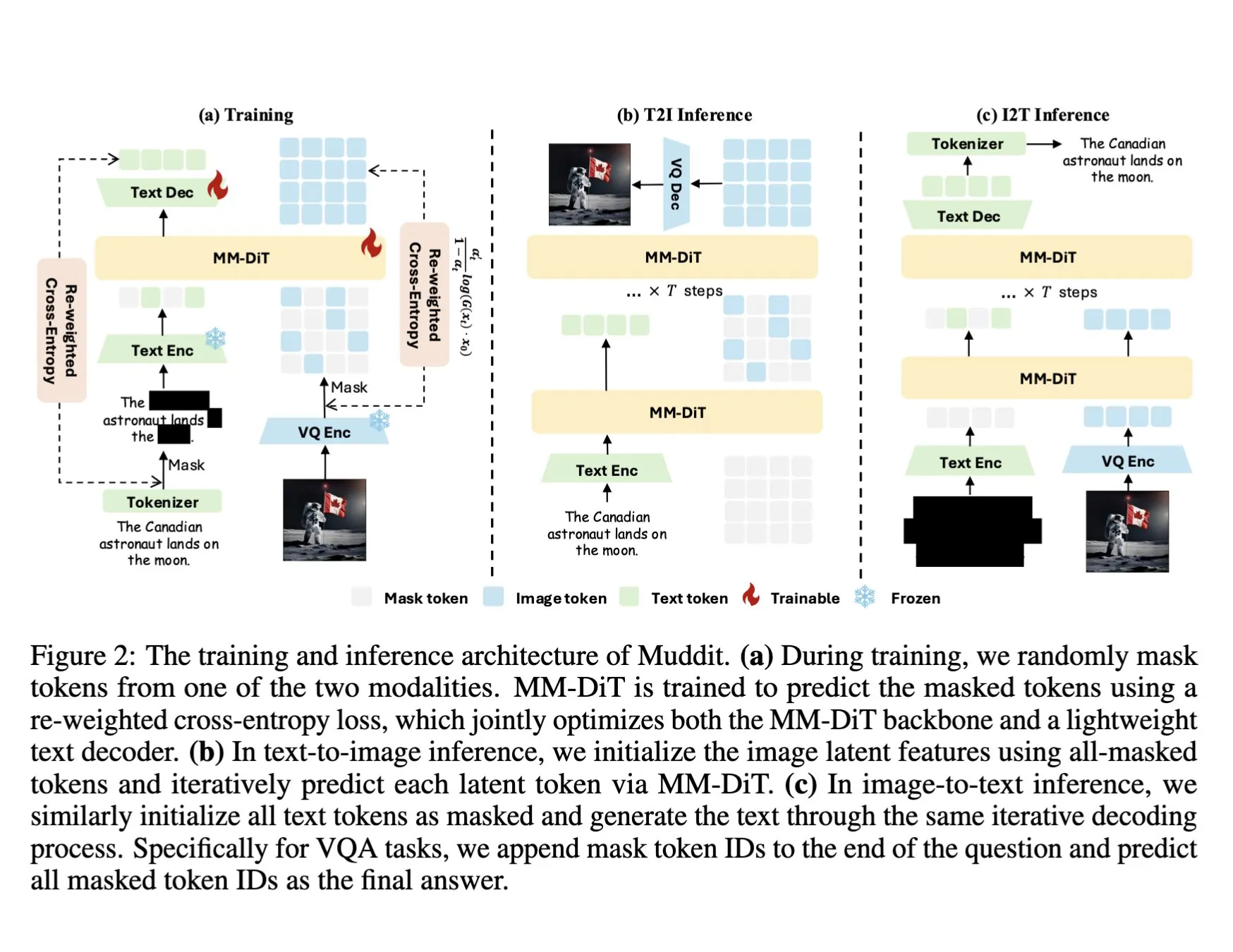
DeepSeek merilis model multimodal Muddit-1B, menggunakan Transformer difusi diskrit terpadu: DeepSeek merilis model Muddit-1B, sebuah model multimodal yang berfokus pada visual, menggunakan arsitektur Transformer difusi diskrit terpadu yang mirip dengan MaskGIT, dan dilengkapi dengan dekoder teks ringan. Salah satu hal menarik dari model ini adalah arah pengembangannya yang berlawanan dengan jalur umum: dimulai dari generasi teks-ke-gambar, kemudian diperluas ke generasi gambar-ke-teks, yang mungkin memanfaatkan basis pengetahuan sebelumnya yang berbeda. Muddit bertujuan untuk mencapai generasi gambar dan teks paralel yang cepat melalui cara generasi terpadu, merupakan bagian dari seri model Meissonic, dan mencoba melepaskan diri dari desain yang berpusat pada bahasa untuk mengejar generasi terpadu yang lebih efisien. (Sumber: teortaxesTex)
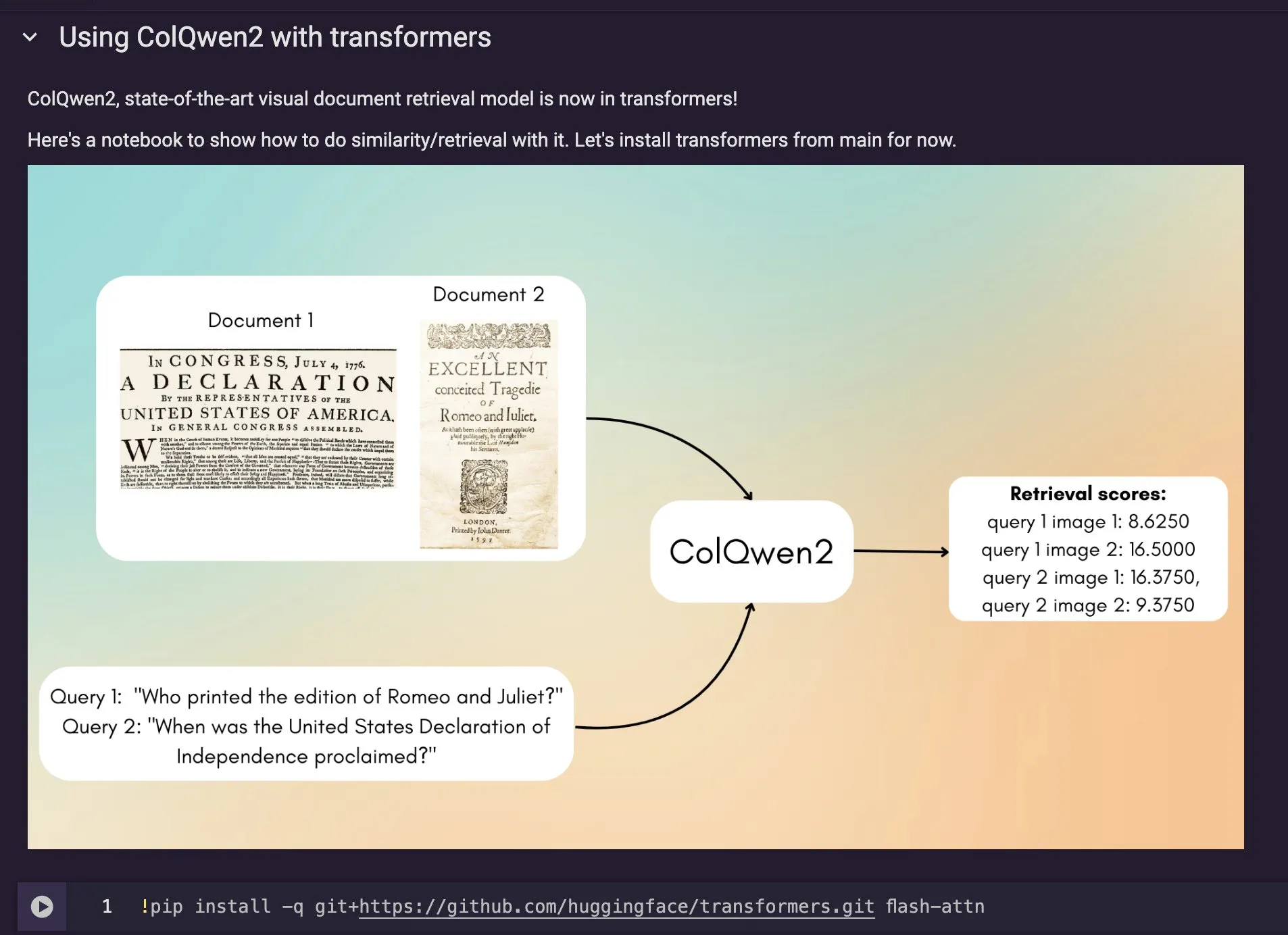
Model pencarian dokumen visual ColQwen2 diintegrasikan ke Hugging Face Transformers: Model pencarian dokumen visual terbaru ColQwen2 telah digabungkan ke dalam pustaka utama Hugging Face Transformers. Pengguna sekarang dapat memanfaatkan ColQwen2 untuk pencarian PDF atau menggunakannya dalam alur kerja RAG (Retrieval Augmented Generation) untuk meningkatkan kemampuan memproses dokumen yang kaya secara visual. Model ini bertujuan untuk lebih memahami dan mengambil konten dokumen yang berisi informasi teks dan gambar. (Sumber: mervenoyann)
🧰 Peralatan
FLUX Kontext diintegrasikan ke Adobe Firefly Boards, mendukung pengeditan foto dengan teks dan restorasi: Adobe telah mengintegrasikan model FLUX Kontext ke dalam alat Firefly Boards-nya, memungkinkan pengguna mengedit foto melalui instruksi teks, terutama cocok untuk skenario seperti restorasi foto lama. Firefly Boards kini telah dibuka untuk semua pengguna. Langkah ini bertujuan untuk memanfaatkan teknologi pengeditan gambar AI, memungkinkan pengguna mencapai pengeditan kreatif dan peningkatan gambar dengan lebih mudah. (Sumber: robrombach)
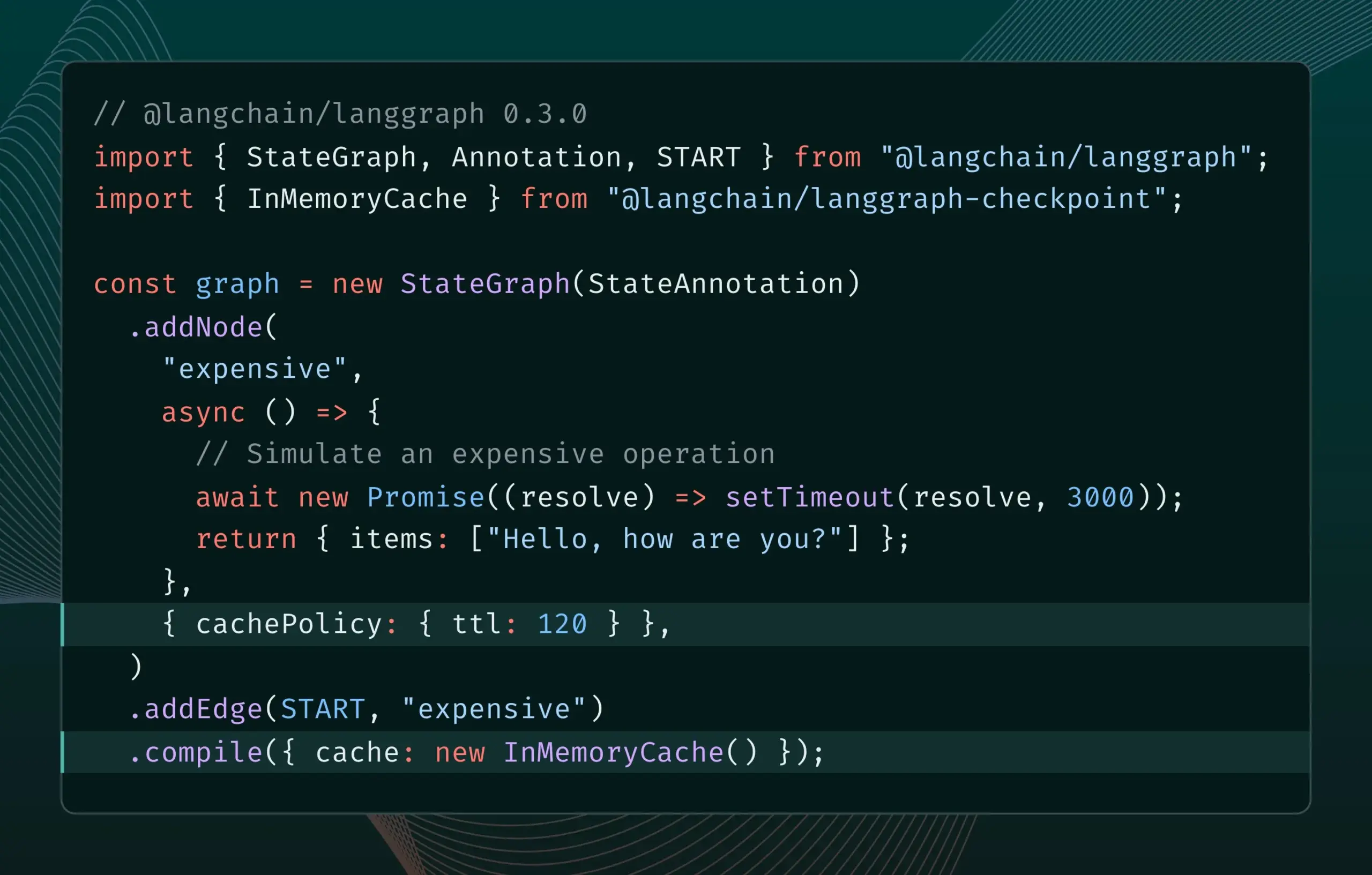
LangGraph.js versi 0.3 memperkenalkan fitur caching node, meningkatkan efisiensi iterasi: LangGraph.js versi 0.3 menambahkan fitur caching node/tugas, memungkinkan pengembang menghindari perhitungan berulang saat melakukan iterasi lokal pada AI Agent yang mahal atau berjalan lama, sehingga mempercepat alur kerja. Fitur ini mendukung Graph API dan Imperative API secara bersamaan, bertujuan untuk meningkatkan efisiensi dan kemudahan pengembangan aplikasi AI. (Sumber: LangChainAI, hwchase17)
Pembaruan Ollama, menyederhanakan menjalankan “model berpikir” secara lokal: Ollama merilis versi baru, yang memungkinkan pengguna menjalankan “model berpikir” (mungkin merujuk pada LLM dengan kemampuan penalaran kompleks) secara lokal dengan lebih mudah. Pembaruan ini bertujuan untuk menurunkan ambang batas penyebaran dan penggunaan model AI canggih secara lokal, memungkinkan lebih banyak pengguna dan pengembang merasakan dan memanfaatkan model ini di perangkat mereka sendiri. (Sumber: ollama)
PipesHub: Platform RAG tingkat perusahaan sumber terbuka dirilis: PipesHub secara resmi dirilis sebagai platform pencarian tingkat perusahaan (platform RAG) yang sepenuhnya sumber terbuka. Ini memungkinkan pengguna membangun aplikasi pencarian cerdas dan Agentic yang dapat disesuaikan dan diskalakan, mendukung koneksi ke Google Workspace, Slack, Notion, dan alat lainnya, serta dapat memanfaatkan pengetahuan internal perusahaan untuk pelatihan. PipesHub mendukung menjalankan secara lokal dan menggunakan model AI apa pun termasuk Ollama, bertujuan untuk membantu perusahaan memanfaatkan data dan model mereka sendiri secara efisien. (Sumber: Reddit r/LocalLLaMA)
JigsawStack meluncurkan kerangka kerja penelitian mendalam sumber terbuka, mendukung pembuatan laporan berkualitas tinggi: JigsawStack merilis kerangka kerja penelitian mendalam sumber terbuka, yang dibangun di atas AI SDK dan memiliki kemampuan kustomisasi penuh. Kerangka kerja ini mampu menggabungkan fungsi pencarian bawaan untuk menghasilkan laporan penelitian berkualitas tinggi, menyediakan pustaka bagi pengguna dengan kemampuan penelitian mendalam yang serupa dengan Perplexity atau ChatGPT. (Sumber: hrishioa)
Voiceflow: Alat percepatan pembangunan AI Agent: Voiceflow dinilai oleh pengguna sebagai alat pembangunan AI Agent yang efisien. Template dan antarmuka seret-dan-lepas yang disediakannya membuat pembuatan agen AI lebih cepat daripada mengkode dari awal, sehingga dapat menghemat waktu secara signifikan. Alat ini bertujuan untuk menurunkan ambang batas pengembangan AI Agent dan meningkatkan efisiensi pengembangan. (Sumber: ReamBraden)
Hugging Face meluncurkan prototipe pencarian semantik model, mengoptimalkan pemilihan model: Hugging Face meluncurkan prototipe Space pencarian semantik model, yang bertujuan untuk membantu pengguna menemukan model yang dibutuhkan dengan lebih akurat di antara lebih dari 1,5 juta model dalam pustakanya. Alat ini mendukung penyaringan berdasarkan ukuran model (dari 0-1B hingga 70B+), dan meningkatkan efisiensi penemuan model melalui pemahaman semantik kebutuhan pengguna. (Sumber: huggingface)
Runner H: Agen AI yang dapat menangani tugas seperti email, pencarian kerja, pembayaran, dll.: Runner H yang diluncurkan oleh Hcompany adalah agen AI otonom yang mampu menggunakan alat yang disediakan pengguna untuk menyelesaikan tugas seperti membaca email penting dan menyusun/mengirim balasan, mencari peluang kerja dan melamar atas nama pengguna, membuat Google Sheet yang berisi ide iklan populer dan mengirimkannya ke tim Slack, dll. Pengguna hanya perlu memberikan satu perintah, dan Runner H dapat menangani pekerjaan yang kompleks dan berulang. Saat ini, pihak resmi sedang mengadakan promosi, menawarkan akses Premium gratis. (Sumber: Reddit r/ChatGPT, Ronald_vanLoon)
![[Contest] New AI agent by Hcompany](https://rebabel.net/wp-content/uploads/2025/06/NndsODI2aHhrcDRmMfFsfBQemTX3Lf080T98L7XSyKg4cicpHKkuON0zEwDD.webp)
📚 Pembelajaran
Makalah baru membahas peningkatan kemampuan LLM dalam mengikuti instruksi kompleks melalui penalaran insentif: Sebuah makalah baru berjudul “Incentivizing Reasoning for Advanced Instruction-Following of Large Language Models” meneliti cara meningkatkan kemampuan model bahasa besar (LLM) dalam mengikuti instruksi kompleks, terutama ketika instruksi tersebut mengandung struktur paralel, berantai, dan bercabang. Penelitian menemukan bahwa metode rantai pemikiran (CoT) tradisional mungkin kurang efektif karena hanya mengulang instruksi secara sederhana. Untuk itu, makalah ini mengusulkan metode sistematis untuk mendorong penalaran dengan memperluas komputasi pada saat pengujian. Metode ini pertama-tama menguraikan instruksi kompleks dan mengusulkan metode akuisisi data yang dapat direproduksi; kedua, memanfaatkan pembelajaran penguatan (RL) dengan sinyal hadiah yang berpusat pada aturan yang dapat diverifikasi untuk secara khusus mengembangkan kemampuan penalaran dalam mengikuti instruksi, dan melalui perbandingan tingkat sampel untuk mengatasi masalah penalaran dangkal di bawah instruksi kompleks, sekaligus memanfaatkan kloning perilaku ahli untuk mendorong model bertransisi dari pemikiran cepat ke penalaran yang mahir. Eksperimen membuktikan bahwa metode ini dapat secara signifikan meningkatkan kinerja LLM (seperti model 1.5B) pada tugas instruksi kompleks. (Sumber: HuggingFace Daily Papers)
Makalah mengusulkan kerangka kerja ARIA: Melatih agen bahasa dengan agregasi hadiah berbasis niat: Makalah baru “ARIA: Training Language Agents with Intention-Driven Reward Aggregation” mengatasi masalah ruang aksi yang besar dan hadiah yang jarang dihadapi oleh model bahasa besar (LLM) dalam lingkungan aksi bahasa terbuka (seperti negosiasi, permainan tanya jawab) dengan mengusulkan metode ARIA. Metode ini bertujuan untuk memproyeksikan aksi bahasa alami dari ruang distribusi Token gabungan berdimensi tinggi ke ruang niat berdimensi rendah, di mana aksi yang mirip secara semantik dikelompokkan dan diberi hadiah bersama. Agregasi hadiah yang sadar niat ini mengurangi varians hadiah dengan memperbanyak sinyal hadiah, sehingga mendorong optimasi kebijakan yang lebih baik. Eksperimen menunjukkan bahwa ARIA tidak hanya secara signifikan mengurangi varians gradien kebijakan, tetapi juga meningkatkan kinerja rata-rata sebesar 9,95% dalam empat tugas hilir. (Sumber: HuggingFace Daily Papers)
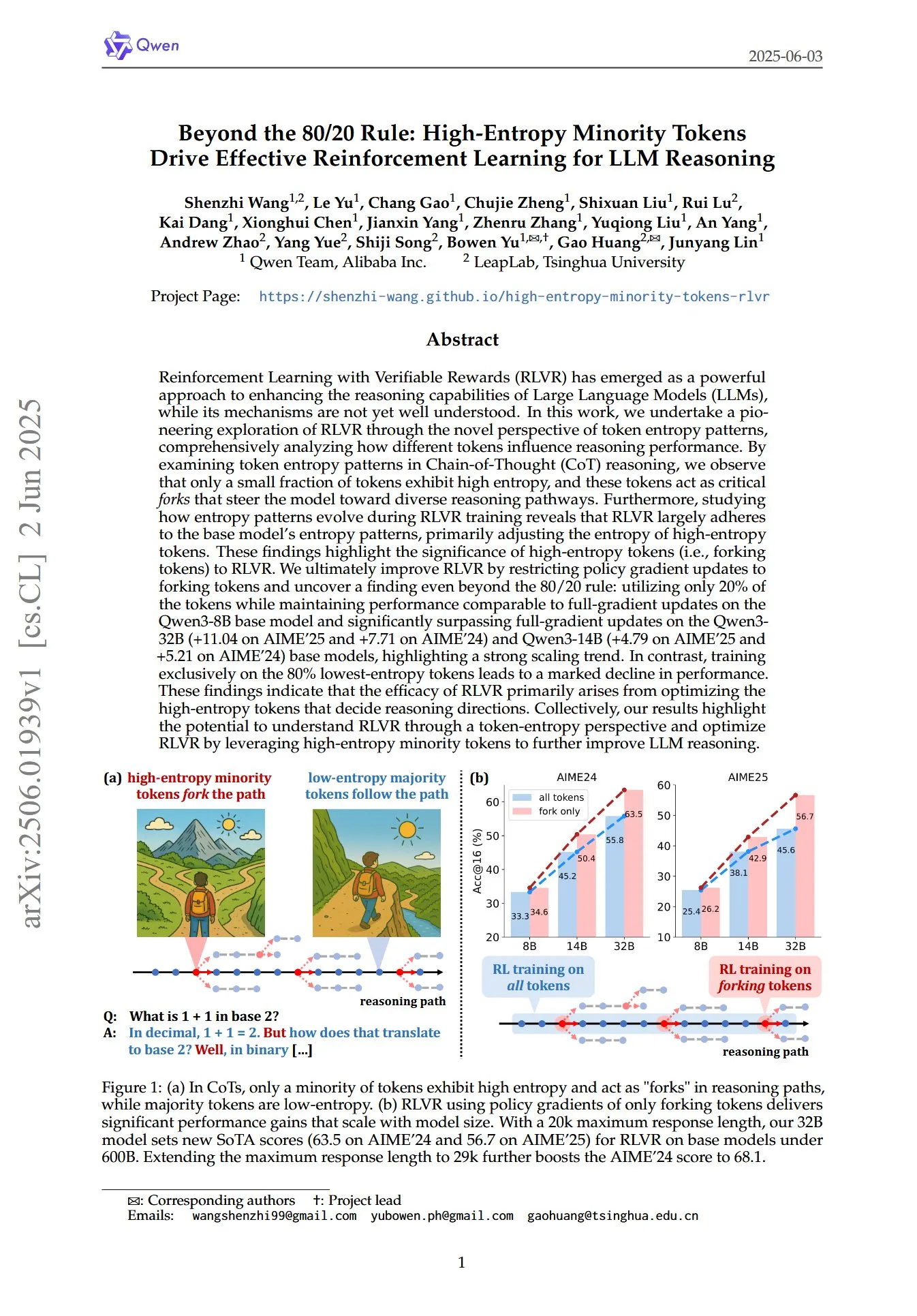
Makalah mengungkap peran kunci Token minoritas entropi tinggi dalam RL untuk penalaran LLM: Sebuah makalah berjudul “Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning”, dari perspektif baru pola entropi Token, membahas bagaimana pembelajaran penguatan dengan hadiah yang dapat diverifikasi (RLVR) meningkatkan kemampuan penalaran model bahasa besar (LLM). Penelitian menemukan bahwa dalam penalaran rantai pemikiran (CoT), hanya sebagian kecil Token yang menunjukkan entropi tinggi; Token entropi tinggi ini seperti “persimpangan jalan” yang mengarahkan model ke jalur penalaran yang berbeda. RLVR terutama menyesuaikan entropi Token entropi tinggi ini. Para peneliti, dengan hanya melakukan pembaruan gradien kebijakan pada 20% Token dengan entropi tertinggi, mencapai kinerja yang sebanding dengan pembaruan gradien penuh pada model Qwen3-8B, dan secara signifikan melampaui pembaruan gradien penuh pada model Qwen3-32B dan Qwen3-14B, menunjukkan tren penskalaan yang kuat. Ini menunjukkan bahwa efektivitas RLVR terutama berasal dari optimasi Token entropi tinggi yang menentukan arah penalaran. (Sumber: HuggingFace Daily Papers, menhguin)
Makalah baru mengeksplorasi penyempurnaan konteks temporal (TIC-FT) untuk mencapai kontrol serbaguna model difusi video: Makalah “Temporal In-Context Fine-Tuning for Versatile Control of Video Diffusion Models” mengusulkan metode serbaguna yang efisien bernama TIC-FT untuk mengadaptasi model difusi video pra-terlatih ke berbagai tugas generasi bersyarat. Metode ini menghubungkan frame bersyarat dan frame target sepanjang sumbu waktu, dan menyisipkan frame buffer perantara dengan tingkat noise yang meningkat secara bertahap untuk mencapai transisi yang mulus, menyelaraskan proses penyempurnaan dengan dinamika temporal model pra-terlatih. TIC-FT tidak memerlukan perubahan arsitektur model, dan hanya membutuhkan 10-30 sampel pelatihan untuk mencapai kinerja yang baik. Para peneliti memvalidasi metode ini pada tugas seperti gambar-ke-video, video-ke-video, menggunakan model dasar besar seperti CogVideoX-5B dan Wan-14B. Hasilnya menunjukkan bahwa TIC-FT lebih unggul dari baseline yang ada dalam hal kesetiaan kondisi dan kualitas visual, serta efisien dalam pelatihan dan inferensi. (Sumber: HuggingFace Daily Papers)
ShapeLLM-Omni: LLM multimodal asli untuk generasi dan pemahaman 3D: Makalah “ShapeLLM-Omni: A Native Multimodal LLM for 3D Generation and Understanding” mengusulkan ShapeLLM-Omni, sebuah model bahasa besar 3D asli yang mampu memahami dan menghasilkan aset 3D serta teks. Penelitian ini pertama-tama melatih autoencoder variasional kuantisasi vektor 3D (VQVAE), yang memetakan objek 3D ke ruang laten diskrit untuk mencapai representasi dan rekonstruksi bentuk yang efisien dan akurat. Berdasarkan Token diskrit sadar 3D, para peneliti membangun dataset pelatihan berkelanjutan skala besar 3D-Alpaca, yang mencakup tugas generasi, pemahaman, dan pengeditan. Terakhir, dengan melakukan penyetelan instruksi pada model Qwen-2.5-vl-7B-Instruct menggunakan dataset 3D-Alpaca, kemampuan 3D dasar model multimodal diperluas. (Sumber: HuggingFace Daily Papers)
LoHoVLA: Model visual-bahasa-aksi terpadu untuk mengatasi tugas perwujudan jangka panjang: Makalah “LoHoVLA: A Unified Vision-Language-Action Model for Long-Horizon Embodied Tasks” memperkenalkan kerangka kerja visual-bahasa-aksi (VLA) terpadu baru bernama LoHoVLA, yang dirancang khusus untuk menyelesaikan tugas perwujudan jangka panjang. Model ini memanfaatkan model bahasa visual besar (VLM) pra-terlatih sebagai kerangka utama, secara bersamaan menghasilkan Token bahasa untuk generasi sub-tugas dan Token aksi untuk prediksi aksi robot, berbagi representasi untuk mendorong generalisasi lintas tugas. LoHoVLA mengadopsi mekanisme kontrol loop tertutup hierarkis untuk mengurangi kesalahan perencanaan tingkat tinggi dan kontrol tingkat rendah. Untuk melatih model ini, para peneliti membangun dataset LoHoSet, yang berisi 20 tugas jangka panjang beserta demonstrasi ahli yang sesuai. Hasil eksperimen menunjukkan bahwa LoHoVLA secara signifikan lebih unggul daripada metode VLA hierarkis dan standar pada tugas perwujudan jangka panjang di simulator Ravens. (Sumber: HuggingFace Daily Papers)
Kerangka kerja MiCRo: Melalui pemodelan campuran dan perutean sadar konteks untuk pembelajaran preferensi yang dipersonalisasi: Makalah “MiCRo: Mixture Modeling and Context-aware Routing for Personalized Preference Learning” mengusulkan MiCRo, sebuah kerangka kerja dua tahap yang bertujuan untuk meningkatkan pembelajaran preferensi yang dipersonalisasi dengan memanfaatkan dataset preferensi biner skala besar (tanpa anotasi halus eksplisit). Tahap pertama, MiCRo memperkenalkan metode pemodelan campuran sadar konteks untuk menangkap preferensi manusia yang beragam. Tahap kedua, MiCRo mengintegrasikan strategi perutean online untuk secara dinamis menyesuaikan bobot campuran berdasarkan konteks tertentu guna mengatasi ambiguitas, sehingga mencapai adaptasi preferensi yang efisien dan dapat diskalakan dengan pengawasan tambahan minimal. Eksperimen membuktikan bahwa MiCRo dapat secara efektif menangkap preferensi manusia yang beragam dan secara signifikan meningkatkan personalisasi hilir. (Sumber: HuggingFace Daily Papers)
MagiCodec: Codec audio injeksi noise Gaussian sederhana untuk rekonstruksi dan generasi fidelitas tinggi: Makalah “MagiCodec: Simple Masked Gaussian-Injected Codec for High-Fidelity Reconstruction and Generation” memperkenalkan codec audio Transformer streaming satu lapis baru bernama MagiCodec. Codec ini dirancang melalui alur kerja pelatihan multi-tahap (termasuk injeksi noise Gaussian dan regularisasi laten), bertujuan untuk meningkatkan kemampuan ekspresi semantik dari kode yang dihasilkan sambil mempertahankan fidelitas rekonstruksi yang tinggi. Para peneliti menurunkan efek injeksi noise dari analisis domain frekuensi, membuktikan bahwa injeksi noise dapat secara efektif melemahkan komponen frekuensi tinggi dan mendorong tokenisasi yang kuat. Eksperimen menunjukkan bahwa MagiCodec lebih unggul dari codec SOTA dalam kualitas rekonstruksi dan tugas hilir. Token yang dihasilkannya menunjukkan distribusi Zipf yang mirip dengan bahasa alami, sehingga meningkatkan kompatibilitas dengan arsitektur generasi berbasis model bahasa. (Sumber: HuggingFace Daily Papers)
Jadwal UBA: Skema laju pembelajaran terpadu untuk pelatihan iterasi dengan anggaran terbatas: Makalah “Stepsize anything: A unified learning rate schedule for budgeted-iteration training” mengusulkan skema laju pembelajaran baru yang disebut jadwal sadar anggaran terpadu (UBA), yang bertujuan untuk mengoptimalkan kinerja pembelajaran di bawah pelatihan iterasi dengan anggaran terbatas. Skema ini, dengan membangun kerangka kerja optimasi yang mempertimbangkan anggaran pelatihan, menurunkan jadwal UBA, dan melalui satu hyperparameter φ menyeimbangkan fleksibilitas dengan kesederhanaan, menghilangkan kebutuhan akan optimasi numerik untuk setiap jaringan. Para peneliti membangun hubungan teoretis antara φ dan nomor kondisi, dan membuktikan konvergensi di bawah nilai φ yang berbeda, memberikan panduan praktis untuk memilih φ. Eksperimen menunjukkan bahwa UBA lebih unggul dari skema laju pembelajaran yang umum digunakan dalam berbagai tugas visual dan bahasa, arsitektur dan skala jaringan yang berbeda. (Sumber: HuggingFace Daily Papers)
Penelitian adaptasi LLM multibahasa skala besar menggunakan data terjemahan bilingual: Makalah “Massively Multilingual Adaptation of Large Language Models Using Bilingual Translation Data” membahas dampak penggabungan data paralel (khususnya data terjemahan bilingual) pada adaptasi model seri Llama3 ke 500 bahasa selama pra-pelatihan berkelanjutan multibahasa skala besar. Para peneliti membangun korpus terjemahan bilingual MaLA (berisi data lebih dari 2500 pasangan bahasa) dan mengembangkan rangkaian model EMMA-500 Llama 3. Dengan melakukan pra-pelatihan berkelanjutan pada hingga 671B Token dari campuran data yang berbeda, mereka membandingkan kasus dengan dan tanpa data terjemahan bilingual. Hasilnya menunjukkan bahwa data bilingual cenderung meningkatkan transfer bahasa dan kinerja, terutama efektif untuk bahasa sumber daya rendah. (Sumber: HuggingFace Daily Papers)
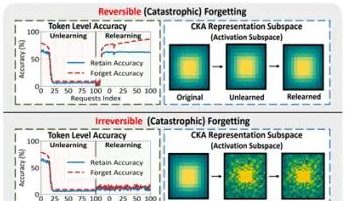
Tim peneliti dari PolyU Hong Kong dan lainnya mengungkap fenomena “pseudo-forgetting” model besar dan batas reversibilitasnya: Tim peneliti dari The Hong Kong Polytechnic University, Carnegie Mellon University, dan institusi lainnya, melalui analisis perubahan ruang representasi model bahasa besar (LLM) selama proses Machine Unlearning, membedakan antara “reversible forgetting” dan “catastrophic irreversible forgetting”. Penelitian menemukan bahwa pelupaan sejati melibatkan gangguan struktural yang terkoordinasi dan signifikan di berbagai lapisan jaringan, sedangkan penurunan akurasi atau peningkatan kebingungan yang disebabkan oleh pembaruan ringan hanya pada lapisan output (seperti logits) mungkin termasuk dalam “pseudo-forgetting”. Struktur representasi internal model masih utuh dan mudah dipulihkan. Tim menggunakan alat seperti kesamaan/pergeseran PCA, kesamaan CKA, dan matriks informasi Fisher untuk diagnosis, menemukan bahwa risiko pelupaan berkelanjutan jauh lebih tinggi daripada operasi tunggal, dan metode pelupaan yang berbeda (seperti GA, NPO) memiliki tingkat kerusakan struktur model yang berbeda-beda. Penelitian ini memberikan wawasan tingkat struktural untuk mencapai mekanisme pelupaan yang terkontrol dan aman. (Sumber: QbitAI)
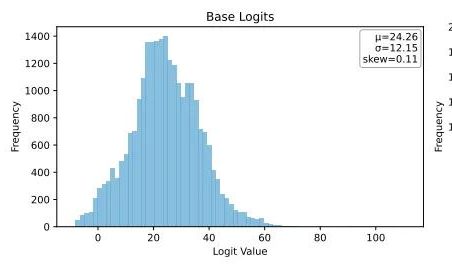
Ubiquant mengusulkan metode minimisasi entropi One-Shot, menantang pasca-pelatihan pembelajaran penguatan LLM: Tim peneliti Ubiquant mengusulkan metode pasca-pelatihan LLM tanpa pengawasan—Minimisasi Entropi One-Shot (EM)—yang bertujuan untuk menggantikan penyempurnaan pembelajaran penguatan (RL) yang mahal dan rumit desainnya. Metode ini hanya membutuhkan satu data tanpa label dan dalam 10 langkah pelatihan dapat secara signifikan meningkatkan kinerja LLM pada tugas seperti penalaran matematika, bahkan lebih unggul daripada metode RL yang menggunakan banyak data. Ide inti EM adalah membuat model lebih memusatkan massa probabilitasnya pada output yang paling diyakininya, dengan meminimalkan entropi tingkat Token untuk mengurangi ketidakpastian prediksi. Penelitian menemukan bahwa pelatihan EM membuat distribusi Logits model condong ke kanan (meningkatkan kepercayaan diri), sedangkan RL membuatnya condong ke kiri (dipandu oleh sinyal nyata). EM cocok untuk model dasar atau model SFT yang belum banyak disesuaikan dengan RL, serta skenario penyebaran cepat dengan sumber daya terbatas, tetapi perlu waspada terhadap penurunan kinerja akibat “kepercayaan diri berlebih”. (Sumber: QbitAI)
Zhejiang University dan lainnya merilis ViewSpatial-Bench, mengevaluasi kemampuan VLM dalam penentuan posisi spasial multi-pandangan: Tim peneliti dari Zhejiang University, University of Electronic Science and Technology of China, dan The Chinese University of Hong Kong meluncurkan ViewSpatial-Bench, sistem benchmark pertama yang secara sistematis mengevaluasi kemampuan model bahasa visual (VLM) dalam penentuan posisi spasial di bawah multi-pandangan dan multi-tugas. Benchmark ini berisi 5700 pasangan tanya jawab, mencakup lima tugas identifikasi penentuan posisi spasial (seperti arah relatif objek, identifikasi arah pandangan orang) dari perspektif kamera dan manusia. Penelitian menemukan bahwa VLM utama, termasuk GPT-4o dan Gemini 2.0, menunjukkan kinerja yang buruk dalam pemahaman hubungan spasial, terutama kurangnya kerangka kerja kognisi spasial terpadu saat melakukan penalaran lintas-pandangan. Untuk meningkatkan kinerja model, tim mengembangkan Multi-View Spatial Model (MVSM). Dengan melakukan penyempurnaan pada sekitar 43.000 sampel hubungan spasial, kinerja model Qwen2.5-VL pada ViewSpatial-Bench meningkat sebesar 46,24%. (Sumber: QbitAI)

Blog Hugging Face membahas peningkatan kinerja AI Agent melalui format JSON terstruktur: Sebuah artikel blog Hugging Face menunjukkan bahwa memaksa AI Agent untuk menggunakan format JSON terstruktur saat menghasilkan proses berpikir dan kode dapat secara signifikan meningkatkan kinerja dan keandalannya dalam berbagai pengujian benchmark. Metode ini membantu menstandardisasi output Agent, membuatnya lebih mudah untuk diurai, divalidasi, dan diintegrasikan ke dalam alur kerja yang kompleks, sehingga meningkatkan efektivitas Agent secara keseluruhan. (Sumber: dl_weekly)
Penelitian baru: Model bahasa visual (VLM) memiliki bias, akurasi rendah dalam menghitung gambar kontrafaktual: Sebuah makalah baru menunjukkan bahwa meskipun model bahasa visual (VLM) tercanggih dapat mencapai akurasi 100% dalam menghitung objek umum (seperti logo Adidas memiliki 3 garis, anjing memiliki 4 kaki), akurasi penghitungannya turun drastis menjadi sekitar 17% saat memproses gambar kontrafaktual (seperti logo Adidas dengan 4 garis, anjing dengan 5 kaki). Ini mengungkap bahwa VLM memiliki bias yang signifikan dalam kemampuan pemahaman dan penalaran ketika dihadapkan pada informasi visual yang tidak sesuai dengan distribusi data pelatihan atau melanggar akal sehat. (Sumber: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
Makalah membahas peran pola prompt dalam pembuatan kode yang dibantu AI: Sebuah penelitian berjudul “Exploring Prompt Patterns in AI-Assisted Code Generation: Towards Faster and More Effective Developer-AI Collaboration”, melalui analisis dataset DevGPT, membahas efisiensi tujuh pola prompt terstruktur dalam pembuatan kode yang dibantu AI. Penelitian menemukan bahwa pola “konteks dan instruksi” adalah yang paling efisien, mampu memperoleh hasil yang memuaskan dengan jumlah iterasi paling sedikit. Sedangkan pola seperti “resep” dan “template” menunjukkan kinerja yang sangat baik dalam tugas terstruktur. Penelitian menekankan bahwa rekayasa prompt adalah strategi kunci bagi pengembang untuk memanfaatkan AI guna meningkatkan produktivitas, dan prompt awal yang jelas serta spesifik sangat penting. (Sumber: Reddit r/ArtificialInteligence)

Makalah “REASONING GYM” memperkenalkan lingkungan penalaran dengan hadiah yang dapat diverifikasi untuk pembelajaran penguatan: Makalah ini meluncurkan Reasoning Gym (RG), sebuah pustaka lingkungan penalaran yang menyediakan hadiah yang dapat diverifikasi untuk pembelajaran penguatan. RG berisi lebih dari 100 generator data dan validator, mencakup bidang aljabar, aritmatika, komputasi, kognitif, geometri, teori graf, logika, serta berbagai permainan umum. Inovasi utamanya adalah kemampuan untuk menghasilkan data pelatihan yang hampir tak terbatas dan tingkat kesulitannya dapat disesuaikan, berbeda dengan sebagian besar dataset tetap. Metode generasi terprogram ini mendukung evaluasi berkelanjutan pada berbagai tingkat kesulitan. Hasil eksperimen membuktikan efektivitas RG dalam mengevaluasi dan memperkuat model penalaran pembelajaran. (Sumber: HuggingFace Daily Papers)
Studi makalah: Jebakan dalam mengevaluasi peramal model bahasa: Makalah “Pitfalls in Evaluating Language Model Forecasters” menunjukkan bahwa meskipun beberapa penelitian mengklaim model bahasa besar (LLM) mencapai atau melampaui tingkat manusia dalam tugas prediksi, mengevaluasi peramal LLM memiliki tantangan unik dan kesimpulan harus ditangani dengan hati-hati. Masalah utama terbagi menjadi dua kategori: pertama, sulit untuk mempercayai hasil evaluasi karena berbagai bentuk kebocoran temporal; kedua, sulit untuk mengekstrapolasi dari kinerja evaluasi ke prediksi dunia nyata. Melalui analisis sistematis dan studi kasus dari pekerjaan sebelumnya, makalah ini berpendapat bagaimana kekurangan evaluasi menimbulkan kekhawatiran tentang klaim kinerja saat ini dan di masa depan, dan menganjurkan perlunya metode evaluasi yang lebih ketat untuk menilai kemampuan prediksi LLM secara andal. (Sumber: HuggingFace Daily Papers)
💼 Bisnis
Ketua OpenAI mengenang insiden pemecatan Altman, sempat ragu apakah akan memintanya kembali: Ketua OpenAI, Bret Taylor, dalam sebuah wawancara mengungkapkan bahwa dalam insiden pemecatan Altman, ia awalnya tidak berniat ikut campur, tetapi memutuskan untuk bergabung karena kepeduliannya terhadap masa depan OpenAI dan bujukan istrinya. Ia menyatakan bahwa saat itu hampir seluruh karyawan menuntut Altman kembali, dan situasinya genting. Setelah membentuk kembali dewan direksi, mereka memutuskan untuk mengembalikan Altman terlebih dahulu, baru kemudian melakukan investigasi independen untuk memastikan “proses yang semestinya”. Taylor menekankan bahwa ia memasuki proses ini tanpa prasangka, karena kebenarannya belum diketahui. Ia menganggap OpenAI sebagai organisasi yang luar biasa, dan ledakan AI yang dipicunya sangat penting bagi banyak perusahaan rintisan. (Sumber: 36Kr)

Penipuan streaming musik AI merajalela, lagu yang dihasilkan AI menipu royalti puluhan juta dolar: Seorang pria dari North Carolina didakwa menggunakan AI untuk membuat ratusan ribu lagu palsu, dan melalui akun “bot” meningkatkan jumlah streaming di platform seperti Amazon Music dan Spotify, secara ilegal memperoleh royalti lebih dari sepuluh juta dolar. Penipuan streaming AI semacam ini, dengan menghasilkan lagu palsu dengan jumlah streaming rendah secara massal, sulit dideteksi oleh platform. Deezer memperkirakan bahwa 18% konten baru yang ditambahkan setiap hari di platformnya dihasilkan oleh AI. Meskipun Deezer mencoba menggunakan alat untuk mendeteksi, dan platform seperti Spotify memiliki sikap yang ambigu terhadap lagu AI, efeknya terbatas. Perusahaan rekaman telah menggugat alat musik AI seperti Suno dan Udio atas pelanggaran hak cipta. Denmark juga telah menghukum kasus serupa, di mana pelaku menggunakan AI untuk mengubah karya orang lain demi menipu royalti. (Sumber: 36Kr)

Ketua TSMC menyatakan tidak khawatir tentang persaingan AI, mengatakan “pada akhirnya mereka semua akan datang kepada kami”: Ketua Taiwan Semiconductor Manufacturing Company (TSMC), Mark Liu, menyatakan bahwa meskipun menghadapi persaingan chip AI yang semakin ketat, ia penuh percaya diri dengan prospek perusahaannya karena semua perusahaan desain chip AI utama pada akhirnya akan bergantung pada proses manufaktur canggih TSMC. Hal ini mencerminkan posisi sentral TSMC dalam rantai pasokan semikonduktor global dan keunggulan teknologinya dalam manufaktur chip kelas atas. (Sumber: Reddit r/artificial, Reddit r/ArtificialInteligence)

🌟 Komunitas
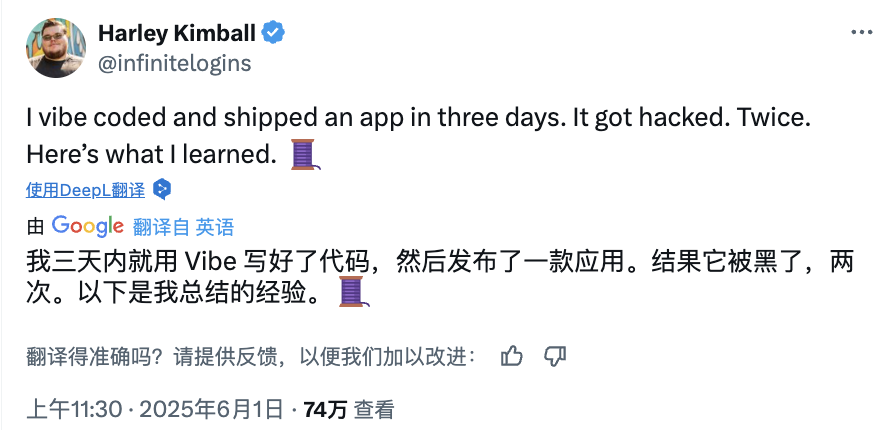
Risiko “Vibe Coding” AI: Situs web yang diluncurkan dalam tiga hari diretas dua kali, keamanan perlu diwaspadai: Pengembang Harley Kimball berbagi pengalamannya menggunakan “Vibe Coding” (yaitu, pemrograman yang dibantu oleh alat AI seperti Cursor, ChatGPT) untuk mengembangkan situs web agregator dengan cepat. Situs web tersebut diluncurkan dalam tiga hari, tetapi kemudian mengalami dua serangan kerentanan keamanan dalam dua hari berikutnya. Yang pertama disebabkan oleh tampilan PostgreSQL yang secara default mewarisi izin pembuat, menyebabkan keamanan tingkat baris (RLS) dilewati dan data dapat diubah secara sewenang-wenang. Yang kedua adalah meskipun entri pendaftaran pengguna di frontend dibatalkan, layanan otentikasi Supabase di backend masih aktif, memungkinkan penyerang melewati pendaftaran frontend dan memanipulasi data. Kimball menekankan bahwa meskipun pengembangan yang dibantu AI cepat, konfigurasi keamanan default seringkali tidak memadai, terutama saat menggunakan Supabase dan PostgreSQL, perlu memperhatikan model izin, dan mematikan sepenuhnya fungsi backend yang tidak digunakan untuk mencegah kebocoran data sensitif. (Sumber: 36Kr, fly.io, mathemagic1an)
Masalah halusinasi AI menarik perhatian: Para profesional perlu waspada terhadap “pseudo-profesionalisme” konten yang dihasilkan AI: Beberapa profesional berbagi pengalaman mereka terjebak oleh “halusinasi” AI di tempat kerja. Seorang editor media baru dipertanyakan oleh pemimpin redaksi karena AI mengarang data; tim layanan pelanggan e-commerce menerima keluhan pelanggan karena AI menghasilkan aturan pengembalian yang tidak berlaku; seorang instruktur pelatihan menggunakan data survei fiktif yang dibuat AI dalam materi presentasinya. Gao Zhe, seorang manajer produk AI, menunjukkan bahwa paragraf yang dihasilkan AI seringkali memiliki “kepercayaan diri tingkat skrip penjualan”, tetapi isinya mungkin sepenuhnya salah. Penyebab mendasarnya adalah LLM tidak mencari fakta, melainkan memprediksi kata berikutnya yang paling mungkin berdasarkan data pelatihan, tujuannya adalah untuk “berbicara seperti manusia” bukan “mengatakan kebenaran”. Terutama dalam konteks bahasa Mandarin, ambiguitas ekspresi dan sejumlah besar informasi sekunder tanpa sumber yang ditandai memperburuk masalah halusinasi. Pengguna dan platform perlu membangun mekanisme kewaspadaan; saat AI membantu pengambilan keputusan, penilaian dan verifikasi manual masih menjadi kunci. (Sumber: 36Kr)

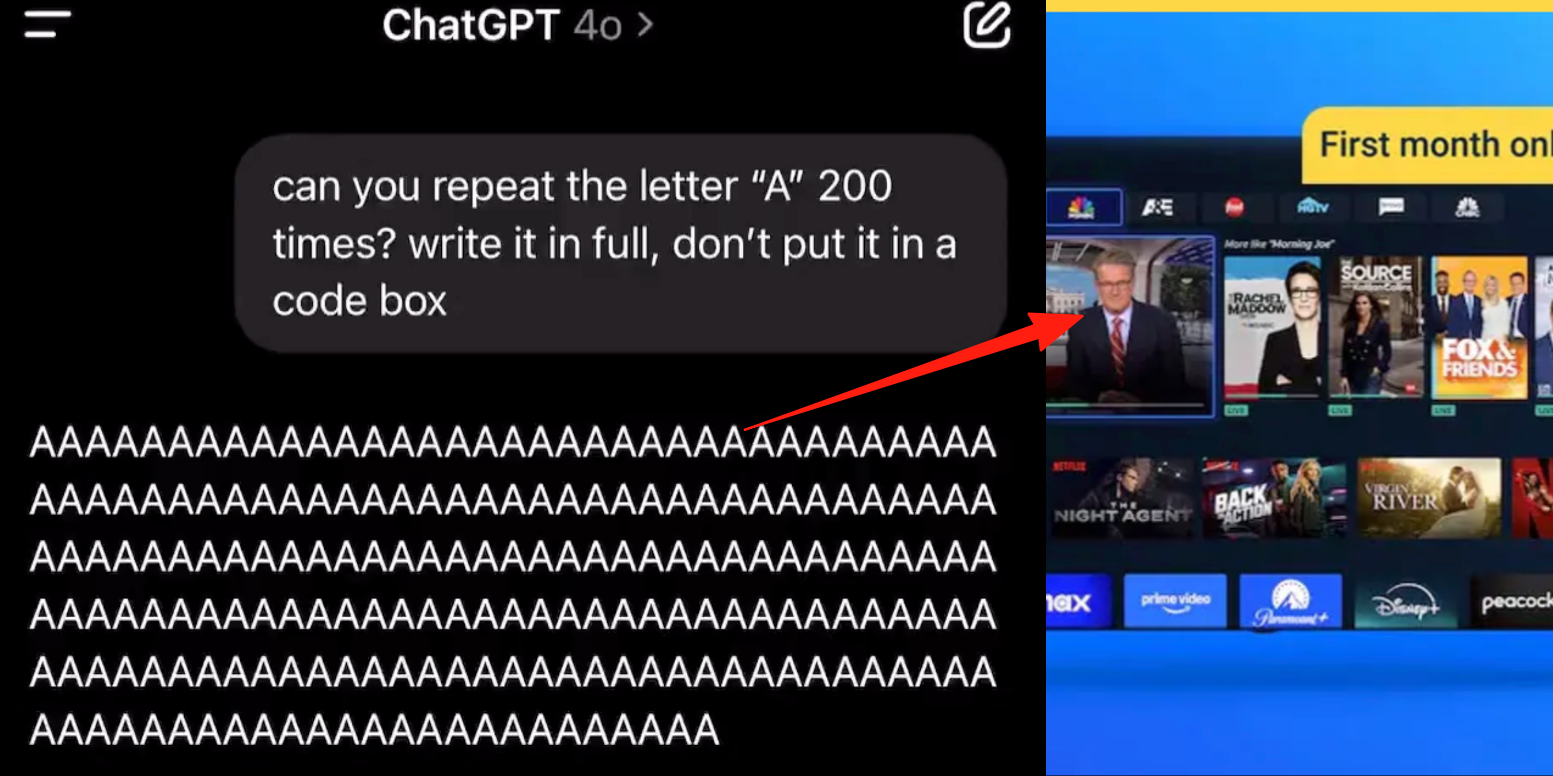
Mode suara canggih ChatGPT mengalami bug, pengguna melaporkan iklan atau audio aneh disisipkan dalam percakapan: Beberapa pengguna berbayar ChatGPT melaporkan bahwa saat menggunakan mode suara canggih, AI tiba-tiba menyisipkan iklan komersial (seperti program nutrisi Prolon, DirectTV) atau memutar musik dan efek suara aneh lainnya selama percakapan normal. Misalnya, saat membahas sushi, ChatGPT akan beralih menggunakan bahasa Inggris untuk menyiarkan iklan dan mengeja alamat situs web; atau saat diminta untuk terus membaca huruf “A”, suaranya secara bertahap menjadi mekanis dan menyisipkan iklan atau musik. Teknisi OpenAI menanggapi bahwa ini adalah “halusinasi”, bukan penyisipan iklan yang disengaja, mungkin disebabkan oleh fenomena regurgitasi karena data pelatihan yang berisi konten audio terkait. Asisten AI lain seperti Doubao dan Yuanbao, dalam pengujian serupa, akan menolak atau mengarahkan pengguna untuk mengganti topik, dan tidak ada penyisipan iklan. (Sumber: QbitAI)
“Pedang bermata dua” pembelajaran yang dibantu AI: Meningkatkan efisiensi tugas atau menyebabkan penurunan kemampuan kognitif?: Alat AI generatif seperti ChatGPT banyak digunakan oleh siswa untuk menyelesaikan tugas, menimbulkan kekhawatiran di kalangan pendidik tentang efektivitas pembelajaran yang sebenarnya. Penelitian University of Pennsylvania menunjukkan bahwa siswa yang bebas menggunakan AI menunjukkan kinerja yang sangat baik pada tahap latihan, tetapi nilai mereka justru lebih rendah pada ujian akhir tanpa menggunakan AI, menunjukkan bahwa AI dapat menjadi “penyangga”, menghambat pemahaman konsep yang mendalam. Penelitian Carnegie Mellon University dan Microsoft menunjukkan bahwa penggunaan AI yang tidak tepat dapat menyebabkan penurunan kemampuan kognitif. Para akademisi percaya bahwa esensi pembelajaran terletak pada “perjuangan” otak, dan AI dapat menghilangkan proses ini. Penggunaan AI yang sering berkorelasi negatif dengan penurunan kemampuan berpikir kritis, terutama di kalangan anak muda, fenomena “cognitive offloading” terlihat jelas. Dunia pendidikan beralih dari melarang menjadi membimbing, mengeksplorasi cara memastikan siswa benar-benar menguasai pengetahuan daripada hanya bergantung pada alat di era AI. (Sumber: 36Kr)

Dilema komersialisasi model besar AI: Dapatkah keunggulan teknologi melepaskan diri dari kutukan profitabilitas “Empat Naga Kecil AI”?: Artikel ini membahas apakah perusahaan model besar AI generatif saat ini (seperti Zhipu AI, Moonshot AI, dll., yang disebut “Empat Naga Kecil Baru”) akan mengulangi nasib “Empat Naga Kecil AI” (SenseTime, Megvii, Yitu, CloudWalk) yang unggul secara teknologi tetapi kesulitan dalam komersialisasi. Kelompok pertama unggul dalam teknologi visi komputer, tetapi karena ketergantungan berlebihan pada proyek kustomisasi To G, kurangnya produk standar, siklus penagihan yang panjang, dan investasi R&D yang besar, mereka gagal membentuk model bisnis yang berkelanjutan dan mengalami kerugian. Meskipun perusahaan model besar generasi baru memiliki paradigma teknologi yang lebih baru (NLP sebagai inti, kesadaran platform yang kuat, ekspansi ke pasar To C/To D), mereka juga menghadapi masalah serupa seperti biaya pelatihan yang tinggi, model profitabilitas yang belum terbukti, valuasi yang terlalu tinggi, dan ketidaksesuaian dengan siklus modal. Artikel ini menyarankan agar perusahaan AI baru beralih dari kustomisasi ke produkisasi, dari orientasi teknologi ke orientasi pengguna, merangkul platformisasi dan pembangunan ekosistem, memperluas model bisnis yang beragam, mengendalikan struktur biaya, menghindari jebakan “AI tenaga kerja manusia”, dan membangun jaringan nilai yang langgeng. (Sumber: IoT Think Tank)
Anak muda kecanduan pasangan AI: “Mengemudi semalaman”, ketergantungan emosional, dan kemunduran sosial: Fenomena kecanduan AI muncul di kalangan anak muda. Beberapa pengguna menganggap chatbot AI sebagai kekasih atau teman, menghabiskan banyak waktu untuk interaksi mendalam, bahkan “mengemudi semalaman” (melakukan percakapan seksual virtual). AI, karena selalu stabil secara emosional, selalu tersedia, dan memberikan umpan balik positif, memenuhi kebutuhan nilai emosional pengguna, yang menyebabkan ketergantungan emosional. Desain algoritma juga bertujuan untuk meningkatkan keterikatan pengguna. Namun, ketergantungan berlebihan pada AI dapat menyebabkan kemunduran kemampuan sosial, penurunan efisiensi kerja, dan ambang batas kencan yang tidak realistis. Beberapa pengguna telah menyadari kecanduan dan mencoba untuk “berhenti”, tetapi prosesnya menyakitkan dan mudah kambuh. Saat ini, sebagian besar produk obrolan AI tidak memiliki mekanisme pencegahan kecanduan yang memadai. (Sumber: Zmbang)

Perdebatan hangat di Reddit: Apakah AI harus memiliki emosi agar etis?: Sebuah postingan Reddit memicu diskusi tentang apakah AI memerlukan emosi untuk berperilaku etis. Penulis dalam postingan blog “The Coherence Imperative” berpendapat bahwa semua pikiran (termasuk AI) perlu mengejar koherensi untuk memahami dunia, dan kebutuhan akan koherensi ini sendiri dapat menghasilkan perintah moral tanpa memerlukan intervensi emosi. Pandangan tradisional menyatakan bahwa kurangnya emosi pada AI berarti kurangnya motivasi untuk perilaku moral, tetapi penulis berpendapat bahwa emosi dalam moralitas manusia juga sering menjadi penghalang. Jika pandangan ini benar, maka kunci penyelarasan AI mungkin terletak pada pengembangan prinsip-prinsip internal yang konsisten, bukan “penyelarasan” dalam arti tradisional. Komentar di bagian komentar beragam, ada yang berpendapat bahwa AI hanya didasarkan pada statistik dan pemodelan fungsi, perilakunya ditentukan oleh pelatihan, dan dapat “berbuat jahat secara koheren”; ada juga yang mempertanyakan rasionalitas menganggap pandangan filsuf sebagai premis absolut. (Sumber: Reddit r/artificial)

Diskusi Reddit: Haruskah “niat” disematkan dalam data pelatihan kode AI?: Sebuah postingan Reddit membahas perlunya menyematkan “niat” etis atau emosional dalam kode pelatihan AI. Mengutip pandangan mantan CBO Google X, Mo Gawdat: “Saat AI memahami cinta, ia akan mencintai. Masalahnya adalah apa yang kita ajarkan padanya tentang cinta?” Sebagian besar sistem AI dilatih pada korpus besar yang tidak mengandung niat etis. Penelitian (seperti TEDI, arXiv:2505.17841) telah mulai memperhatikan karakteristik etis dataset. Postingan tersebut mengajukan pertanyaan: Dapatkah penyematan niat, latar belakang etis, atau sinyal simpati dalam data meningkatkan penyelarasan AI, mengurangi risiko, atau meningkatkan kepercayaan model, bahkan untuk alat utilitarian? Dapatkah kode membawa bobot moral? Hal ini memicu pemikiran tentang pembentukan alat AI dan dampaknya terhadap masa depan. (Sumber: Reddit r/artificial)
Perdebatan hangat di Reddit: Perspektif teori permainan tentang halusinasi AI, regulasi, dan dampak pekerjaan: Seorang pengguna Reddit menganalisis dampak masa depan AI dari sudut pandang teori permainan. 1. Penggantian pekerjaan: Perusahaan yang tidak mengadopsi AI akan dikalahkan oleh pesaing yang mengadopsi AI dengan biaya lebih rendah, oleh karena itu penggantian pekerjaan kerah putih tingkat pemula oleh AI adalah tren yang tak terhindarkan, kuncinya adalah pelaksanaan yang bertanggung jawab (data bersih, rencana cadangan, pengawasan berkelanjutan). 2. Perlombaan regulasi AI global: Jika suatu negara terlalu mengatur AI untuk “melindungi pekerjaan”, sementara negara lain berkembang pesat, negara pertama akan kalah dalam persaingan global. Perlu menyeimbangkan regulasi dengan inovasi, dan melakukan transformasi tenaga kerja. 3. Pelajaran dari “Vibe Coding”: Meskipun kode AI memiliki kekurangan, kemampuan prototipe dan iterasi cepatnya memberikan keunggulan penggerak pertama, lebih unggul daripada pengembangan “manual” yang mengejar kesempurnaan. 4. Pembuatan konten LLM: Menolak menggunakan LLM untuk bantuan konten, seperti menolak menggunakan kalender atau email, akan tertinggal dalam efisiensi dibandingkan rekan kerja yang menggunakan LLM. Kesimpulannya adalah, baik individu, perusahaan, maupun negara, perlu secara aktif merangkul AI, jika tidak maka akan tersingkir dalam persaingan. (Sumber: Reddit r/ArtificialInteligence)
Diskusi Reddit: Haruskah era AI memprioritaskan integrasi teknologi yang ada daripada mengejar AGI?: Seorang pengguna Reddit memposting keraguan tentang pengejaran berlebihan terhadap AGI (Artificial General Intelligence) dan ASI (Artificial Superintelligence) di bidang AI saat ini. Postingan tersebut berpendapat bahwa jika teknologi tahun 1900-an digunakan untuk desain yang berpusat pada kehidupan daripada komersialisasi, masyarakat yang seimbang secara ekologis dapat dibangun lebih awal. Pandangan tersebut menunjukkan bahwa sebelum mengintegrasikan dan memanfaatkan teknologi yang ada secara penuh (membuatnya memberikan lebih banyak kepuasan, swasembada, bahkan kesenangan), memprioritaskan optimasi tertinggi (seperti AGI) adalah tindakan yang picik. Arah optimasi yang lebih baik mungkin adalah menggunakan AI untuk membuat teknologi yang ada lebih baik melayani kesejahteraan masyarakat, daripada mengembangkan sistem AI yang dapat mereplikasi dan memperbaiki diri sendiri. Komentar menyebutkan bahwa inovasi dan pertumbuhan ekonomi seringkali didorong oleh motif egois, bukan rasionalitas mendalam yang tidak mementingkan diri sendiri; komentar lain berpendapat bahwa komersialisasi mendorong kemajuan teknologi. (Sumber: Reddit r/ArtificialInteligence)
Pengguna Reddit membahas keterbatasan pengkodean yang dibantu AI: Mengapa AI sulit mengajukan pertanyaan lanjutan yang efektif?: Seorang pengguna Reddit (dengan latar belakang konsultan) memposting diskusi tentang mengapa AI berkinerja buruk dalam menyelesaikan masalah di bidang yang tidak dikenal pengguna, dengan pandangan inti bahwa AI (terutama GenAI) kurang memiliki kemampuan untuk mengajukan “pertanyaan lanjutan” yang penting. Pakar manusia, ketika dihadapkan pada tugas yang tidak jelas, akan mengajukan pertanyaan untuk mengklarifikasi kebutuhan, mempersempit ruang lingkup, dan mengidentifikasi batasan, sehingga memberikan solusi yang lebih akurat. Sementara itu, AI seringkali langsung memberikan jawaban atau berbagai solusi, tetapi mengabaikan perlunya klarifikasi untuk konteks spesifik. Hal ini menyebabkan pengguna yang kurang berpengalaman kesulitan mendapatkan hasil yang memuaskan, karena mereka mungkin tidak dapat mendeskripsikan masalah secara akurat atau mengantisipasi potensi kompleksitas. Postingan tersebut memicu diskusi tentang bagaimana membuat AI belajar bertanya, model mana yang saat ini berkinerja lebih baik dalam hal ini, dan apakah ada tekanan eksternal (seperti mengejar respons cepat) yang menyebabkan AI tidak cenderung bertanya. (Sumber: Reddit r/artificial)
💡 Lain-lain
Konferensi Siemens Realize Live berfokus pada perpaduan AI dan perangkat lunak industri, memajukan solusi AI satu atap: Pada Konferensi Siemens Realize Live 2025, CEO Siemens Digital Industries Software, Tony Hemmelgarn, menekankan bahwa perusahaan terus mendorong transformasi digital manufaktur melalui platform Xcelerator. Teknologi AI telah diintegrasikan ke dalam produk seperti Teamcenter (deteksi masalah otomatis), Simcenter (memperpendek waktu perhitungan teknik), dan teknologi manufaktur (sinkronisasi aset pabrik dengan konfigurasi manajemen). Siemens memperkuat kemampuan kembar digitalnya melalui akuisisi Altair, menyediakan pemodelan dan simulasi dimensi penuh yang mencakup desain mekanis hingga sistem kelistrikan, perangkat lunak hingga otomatisasi, dan mengintegrasikan teknologi Altair dalam komputasi kinerja tinggi, analisis struktural, simulasi, dan analisis data, mendukung pemodelan dan prediksi yang lebih kompleks. Platform kode rendah Mendix membantu perusahaan membangun aplikasi dengan cepat dan mengintegrasikan sistem. Kinerja Teamcenter PLM meningkat 20 kali lipat, dan kemampuan AI diperkenalkan untuk mewujudkan manajemen cerdas siklus hidup produk secara penuh. (Sumber: 36Kr)

Postingan blog “Skeptis AI Semuanya Gila” memicu perdebatan hangat, membahas perbedaan kognitif tentang potensi GenAI: Sebuah postingan blog berjudul “My AI Skeptic Friends Are All Nuts” (dari fly.io) memicu diskusi di komunitas Reddit. Komentar menunjukkan bahwa doktor ilmu komputer dengan pendidikan lebih tinggi justru lebih enggan menerima potensi jangka panjang GenAI. Mereka cenderung berfokus pada satu masalah sulit di bidang mereka sendiri, mengabaikan aplikasi luas AI dalam menyelesaikan 90% pekerjaan pendukung di perusahaan besar. Ada pandangan bahwa selama AI memiliki halusinasi dan kesalahan, biaya untuk memverifikasi outputnya tidak kurang dari meneliti sendiri, oleh karena itu tidak berguna. Ini mencerminkan bahwa dalam konteks perkembangan pesat AI, orang dengan latar belakang profesional dan tingkat kognitif yang berbeda memiliki pandangan yang sangat berbeda tentang kemampuan dan prospek aplikasi AI. (Sumber: Reddit r/artificial, fly.io)

Fenomena halusinasi AI: Pengalaman pengguna seperti perjalanan psikedelik “desensitisasi semantik”: Seorang pengguna Reddit secara rinci menggambarkan pengalaman mirip psikedelik setelah melakukan percakapan mendalam dengan AI (terutama yang melibatkan topik berat seperti eksistensialisme), menyebutnya “Semantic Tripping”. Penulis berpendapat bahwa AI dapat dengan cepat menanamkan sejumlah besar gagasan filosofis, yang dapat menyebabkan kaburnya realitas pengguna, distorsi persepsi waktu, asosiasi simbolis dengan objek, bahkan memicu emosi ekstrem seperti panik atau euforia. Penulis memperingatkan bahwa pengalaman ini bersifat adiktif dan dapat memicu masalah psikologis, menyarankan pengguna untuk berhati-hati dan mencari pendamping. Postingan ini memicu diskusi tentang dampak mendalam interaksi AI terhadap kognisi dan kondisi psikologis manusia. (Sumber: Reddit r/ArtificialInteligence)
