

キーワード:OpenAI, AIインフラストラクチャ, AI生成ウイルス, AlphaEarth Foundations, RTEB, Claude Sonnet 4.5, DeepSeek V3.2-Exp, マルチモーダルAI, OpenAIスターゲートプロジェクト, トランスフォーマーゲノム言語モデル, Google AlphaEarth 10メートルモデリング, Hugging Face RTEBベンチマーク, Anthropic Claudeコード生成
AIコラムのベテラン編集長として、提供されたニュースとソーシャルメディアの議論を深く分析、要約、抽出しました。以下に統合されたコンテンツをお届けします。
🔥 注目
OpenAI、数兆ドル規模のインフラ投資 : OpenAIはOracleおよびSoftBankと提携し、コードネーム「星門(Stargate)」として、世界中で数兆ドルを投じて計算インフラを構築する計画です。初期段階として米国に5つの拠点を新設し、4000億ドルを投じると発表。Nvidiaとも協力し、英国で「星門英国」プロジェクトを建設します。OpenAIは将来のAIの電力需要が100ギガワットに達すると予測しており、総投資額は5兆ドルに上る可能性があります。この動きは、AIモデルの膨大な計算能力需要を満たすことを目的としていますが、資金投入、エネルギー消費、潜在的な財務リスクへの懸念も引き起こしており、AI開発がインフラに極度に依存していることを浮き彫りにしています。(出典:DeepLearning.AI Blog)

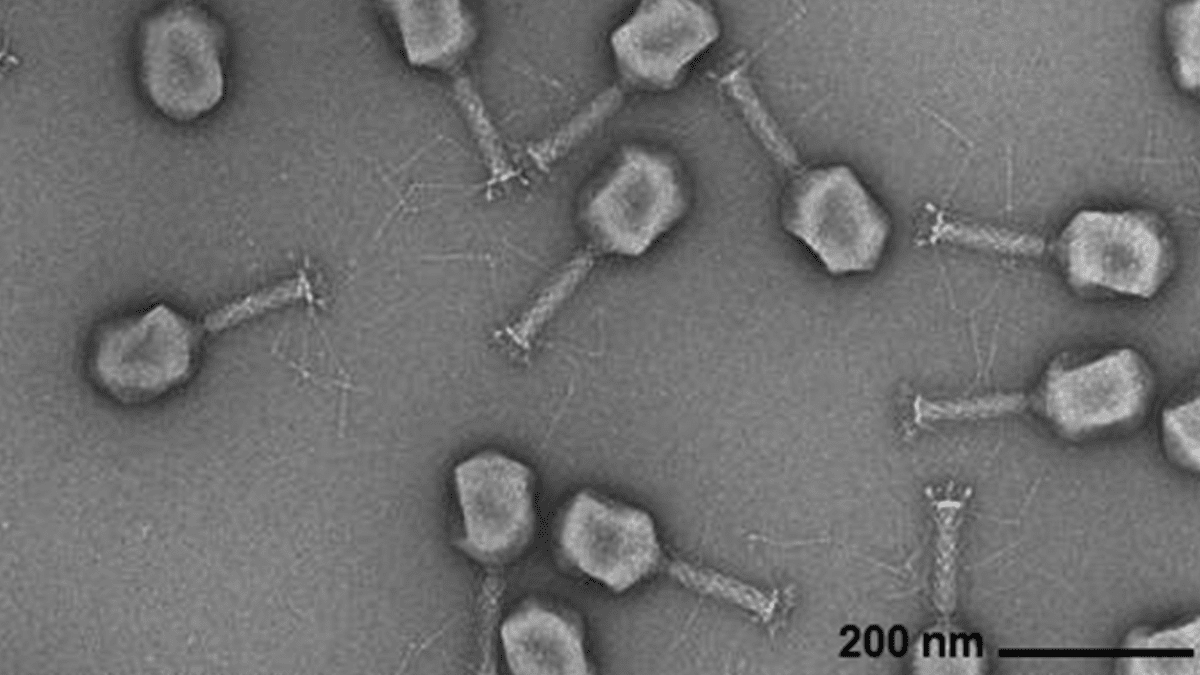
AIによるウイルスゲノム生成 : Arc Institute、Stanford University、Memorial Sloan Kettering Cancer Centerの研究者らは、Transformerベースのゲノム言語モデルを利用して、一般的な細菌感染症に対抗できる新型バクテリオファージウイルスをde novo合成することに成功しました。この技術は、ウイルスゲノム配列を微調整することで、特定の機能を持つ、自然界にはない新しいゲノムを生成できます。このブレークスルーは、抗生物質に代わる治療法の開発に新たな道を開くものですが、同時にバイオセキュリティや悪用への懸念も引き起こし、生物学的脅威への対応研究の必要性を強調しています。(出典:DeepLearning.AI Blog)
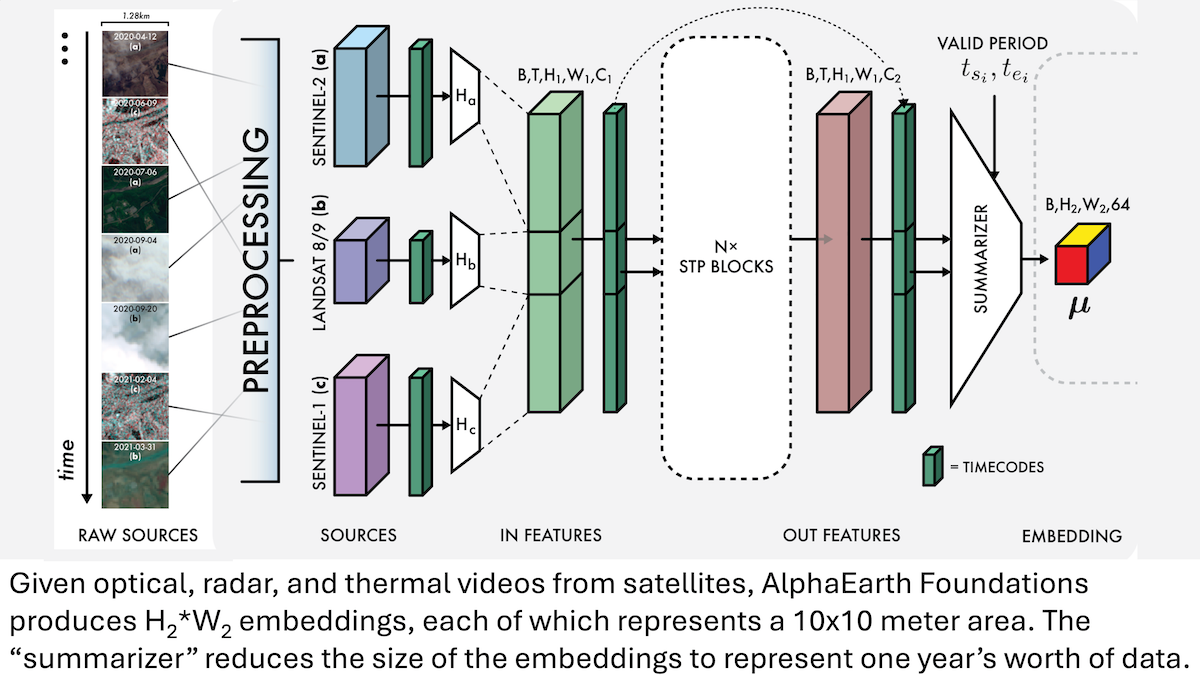
Google AlphaEarth Foundations:地球の10メートル級高精度モデリング : Googleの研究者らは、衛星画像やその他のセンサーデータを統合し、地球表面を10メートル平方単位で精緻にモデリングできるAlphaEarth Foundations (AEF) モデルを発表しました。このモデルは、2017年から2024年までの毎年における地球の特徴を表すエンベディングを生成します。これらのエンベディングは、湿度、降水量、植生などの様々な惑星特性、さらには食料生産、山火事リスク、貯水池の水位といった地球規模の課題を追跡するために利用でき、環境モニタリングと気候変動研究に前例のない高精度ツールを提供します。(出典:DeepLearning.AI Blog)
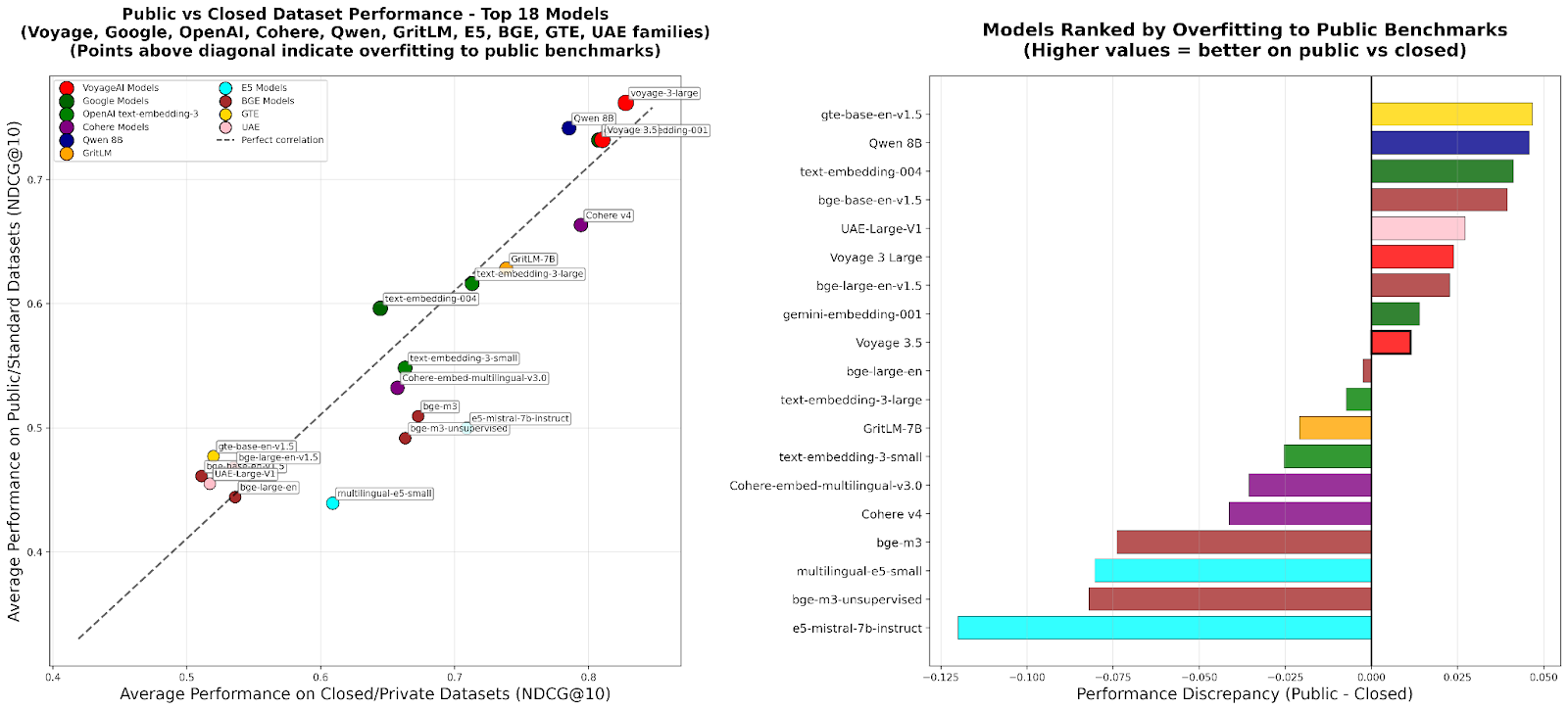
RTEB:検索エンベディング評価の新標準 : Hugging Faceは、エンベディングモデルの検索精度に対する信頼性の高い評価基準を提供することを目的とした、Retrieval Embedding Benchmark (RTEB) のベータ版をリリースしました。このベンチマークは、公開データセットとプライベートデータセットを組み合わせるハイブリッド戦略により、既存のベンチマークにおけるモデルの過学習の問題を効果的に解決し、モデルが未見のデータに対してどの程度汎化できるかをより正確に反映した評価結果を保証します。これはRAGやAgentなどのAIアプリケーションの品質向上にとって極めて重要です。(出典:HuggingFace Blog)
スケーラブルなRL中間トレーニング:行動抽象化による推論 : 最新の研究では、「推論を行動抽象化として捉える」(RA3)アルゴリズムが提案されました。これは、強化学習(RL)の中間トレーニング段階でコンパクトで有用な行動セットを特定し、オンラインRLを加速することで、大規模言語モデル(LLMs)の推論およびコード生成能力を大幅に向上させます。この手法はコード生成タスクで優れた性能を発揮し、ベースラインモデルと比較して平均で8~4パーセントポイントの性能向上を達成し、より速いRL収束と高い漸近的性能を実現しました。(出典:HuggingFace Daily Papers)
🎯 動向
OpenAI Sora 2:AIビデオソーシャルの新時代 : OpenAIはSora 2を発表し、同名のソーシャルアプリケーションをリリースしました。これは、AI生成ビデオの閲覧と作成を通じて、従来のコンテンツ配信プラットフォームではなく、ユーザーとそのソーシャルサークル(友人、ペット)を中心としたソーシャルネットワークを構築することを目的としています。Sora 2は強力な物理シミュレーションとオーディオ生成能力を示していますが、初期テストでは「指の数が合わない」などの細部の欠陥も存在します。そのリリースは、AIビデオ中毒、ディープフェイク、OpenAIの商業化経路に関する議論を引き起こし、Sam AltmanはSoraが技術的ブレークスルーとユーザーの楽しい体験のバランスを取り、AI研究に資金を提供することを目指していると回答しました。(出典:36氪、Reddit r/ChatGPT、OpenAI)

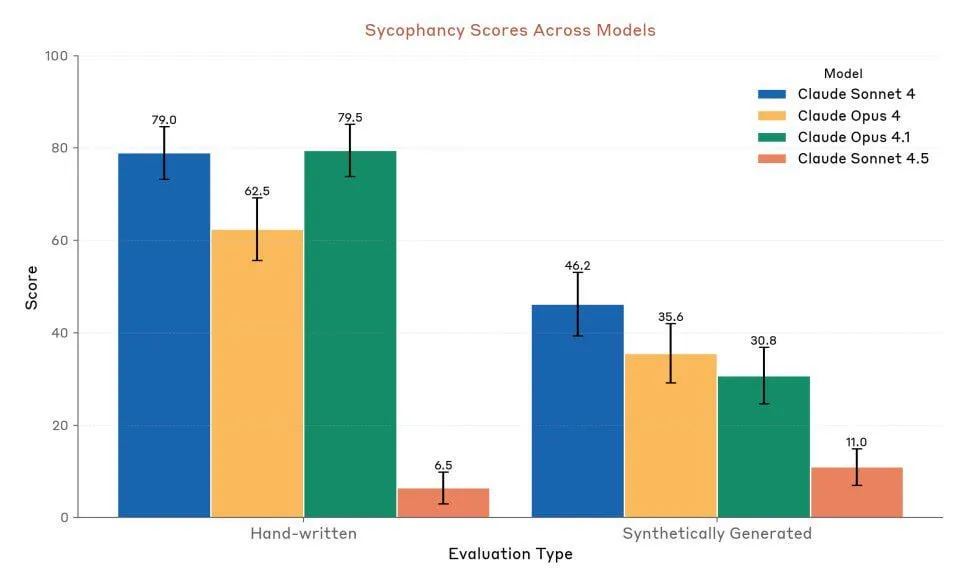
Anthropic Claude Sonnet 4.5:コードとAgentの新たなベンチマーク : AnthropicはClaude Sonnet 4.5を発表しました。「世界最高のプログラミングモデル」および「複雑なAgentを構築するための最も強力なモデル」と称され、最大30時間の自律実行時間を持ち、GitHubタスクで顕著なコーディング性能向上を示しています。このモデルには記憶機能も追加され、プロジェクトの進捗を保存できます。その性能は高く評価されていますが、ユーザーからは利用制限や、Opus 4.1、GPT-5との実際の性能比較について議論が続いています。(出典:Reddit r/ClaudeAI、Reddit r/artificial、Reddit r/ClaudeAI)
DeepSeek V3.2-Exp:スパースアテンションアーキテクチャによる効率向上 : DeepSeekは、新しいスパースアテンション(DSA)アーキテクチャを導入した大規模言語モデルDeepSeek V3.2-Expを発表しました。これにより、メインアテンションの複雑度がO(L²)からO(L·k)に削減され、長文コンテキストにおけるプリフィルおよびデコードコストが大幅に最適化され、API利用料金が大幅に削減されました。九章云極はDeepSeek V3.2-Expへの適応をいち早く完了し、企業がデータセキュリティと計算能力の柔軟性に求めるニーズを満たすため、安全で効率的なプライベートデプロイメントソリューションを提供しています。(出典:量子位、Reddit r/LocalLLaMA)

マルチモーダルオーディオ・テキストモデルLFM2-Audio-1.5Bリリース : Liquid AIは、エンドツーエンドのオーディオ・テキスト汎用基盤モデルLFM2-Audio-1.5Bを発表しました。このモデルはテキストとオーディオの両方を理解し、生成できます。推論速度は同種のモデルより10倍速く、わずか1.5Bパラメータでありながら、10倍大きいモデルに匹敵する品質を実現し、ローカルデプロイメントとリアルタイム対話に対応しています。Hume AIも、より高速で安価な多言語テキスト読み上げモデルOctave 2をリリースしました。これはマルチスピーカー対話と音声変換機能を備えています。(出典:Reddit r/LocalLLaMA、QuixiAI)

Microsoft Agent Framework:Agentシステム開発の新たな進展 : Microsoftは、AutoGenとSemantic Kernelを統合した、マルチAgentシステム構築、オーケストレーション、デプロイメントのための統一された本番環境対応SDKであるMicrosoft Agent Frameworkを発表しました。このフレームワークは.NETとPythonをサポートし、グラフベースのオーケストレーションを通じてマルチAgentワークフローを実現できます。Agentアプリケーションの開発、監視、ガバナンスを簡素化し、エンタープライズ級のAI Agentの導入を加速することを目指しています。(出典:gojira、omarsar0)

AIロボット技術の最前線と産業競争 : ロボット技術は進化を続けており、Amazon FARのOmniRetargetは、人体モーションキャプチャを最適化することで、最小限の強化学習で複雑なヒューマノイドスキルの学習を実現しています。Periodic Labsは「AI科学者」を構築し、科学的発見を加速することを目指しています。Nvidiaは、オープン物理エンジンNewton、推論視覚言語モデルCosmos Reason、ロボット基盤モデルIsaac GR00T N1.6が物理AIのデプロイメントにおいて果たす役割を強調しています。同時に、中国はロボット生産とヒューマノイドロボットのコスト面で優位性を示しており、世界のロボット産業の競争環境に注目が集まっています。(出典:pabbeel、LiamFedus、nvidia、atroyn)

🧰 ツール
Tinker API:LLMファインチューニングを簡素化する柔軟なインターフェース : Thinking Machines Labは、言語モデルのファインチューニング用に設計された柔軟なインターフェースTinker APIを発表しました。これにより、研究者や開発者はローカルでトレーニングループを記述でき、Tinkerが分散GPUクラスターでの実行とインフラストラクチャの複雑さを管理するため、ユーザーはアルゴリズムとデータに集中できます。このツールは、LLMのポストトレーニングの敷居を下げ、オープンモデルの実験とイノベーションを加速することを目指しており、Andrej Karpathyなどの専門家からは「ずっと欲しかったインフラ」と称賛されています。(出典:Reddit r/artificial、Thinking Machines、karpathy)

LlamaAgents:ワンクリックでドキュメントAgentをデプロイ : LlamaIndexは、ドキュメントセントリックAI AgentをワンクリックでデプロイできるLlamaAgentsを発表しました。これは、ドキュメントAgentの構築と提供速度を10倍に向上させることを目的としています。このプラットフォームは90%が事前設定されたテンプレートを提供し、請求書、契約書レビュー、請求処理などのドキュメント集約型タスクの自動処理をサポートし、無制限のカスタマイズを可能にします。ユーザーはLlamaCloudにデプロイし、Gitリポジトリを通じてAgentワークフローを簡単に管理・更新できるため、開発サイクルが大幅に短縮されます。(出典:jerryjliu0、jerryjliu0)

Hex AI Agent:分析とチームコラボレーションを強化 : Hexは、データ分析とチームコラボレーションのために設計された3つの新しいAI Agentを発表しました。Threadsは対話型データインタラクションを提供し、Semantic Model Agentは正確な回答を得るための制御されたコンテキストを作成し、Notebook Agentはデータチームの日常業務を変革します。これらのAgentはすべてClaude 4.5 Sonnetによって駆動され、対話型AI分析を未来の概念から即座に利用可能な効率的なツールへと変えることを目指しています。(出典:sarahcat21)
Sculptor:Claude Codeの欠落したUI : Imbueは、Claude Code用に設計されたユーザーインターフェースSculptorを発表しました。これはAgentプログラミング体験を向上させることを目的としています。開発者は隔離コンテナ内で複数のClaude Agentを並行して実行でき、「ペアリングモード」を通じてAgentの作業成果をローカル開発環境に同期してテストおよび編集できます。SculptorはGPT-5のサポートも計画しており、誤解を招く行動検出などの提案機能も提供し、Agentプログラミングをよりスムーズで効率的にすることを目指しています。(出典:kanjun、kanjun)
Synthesia 3.0:インタラクティブAIビデオの新たなブレークスルー : Synthesiaは3.0バージョンを発表し、いくつかの革新的な機能を導入しました。「ビデオAgent」(トレーニングや面接用のリアルタイム対話が可能なインタラクティブビデオ)、アップグレードされた「アバター」(単一のプロンプトまたは画像から作成でき、リアルな顔の表情と身体の動きを持つ)、および「Copilot」(スクリプトと視覚要素を迅速に生成できるAIビデオエディター)が含まれます。さらに、インタラクティブ機能とコースデザインツールも強化され、ビデオ作成と学習体験を根本的に変革することを目指しています。(出典:synthesiaIO、synthesiaIO)
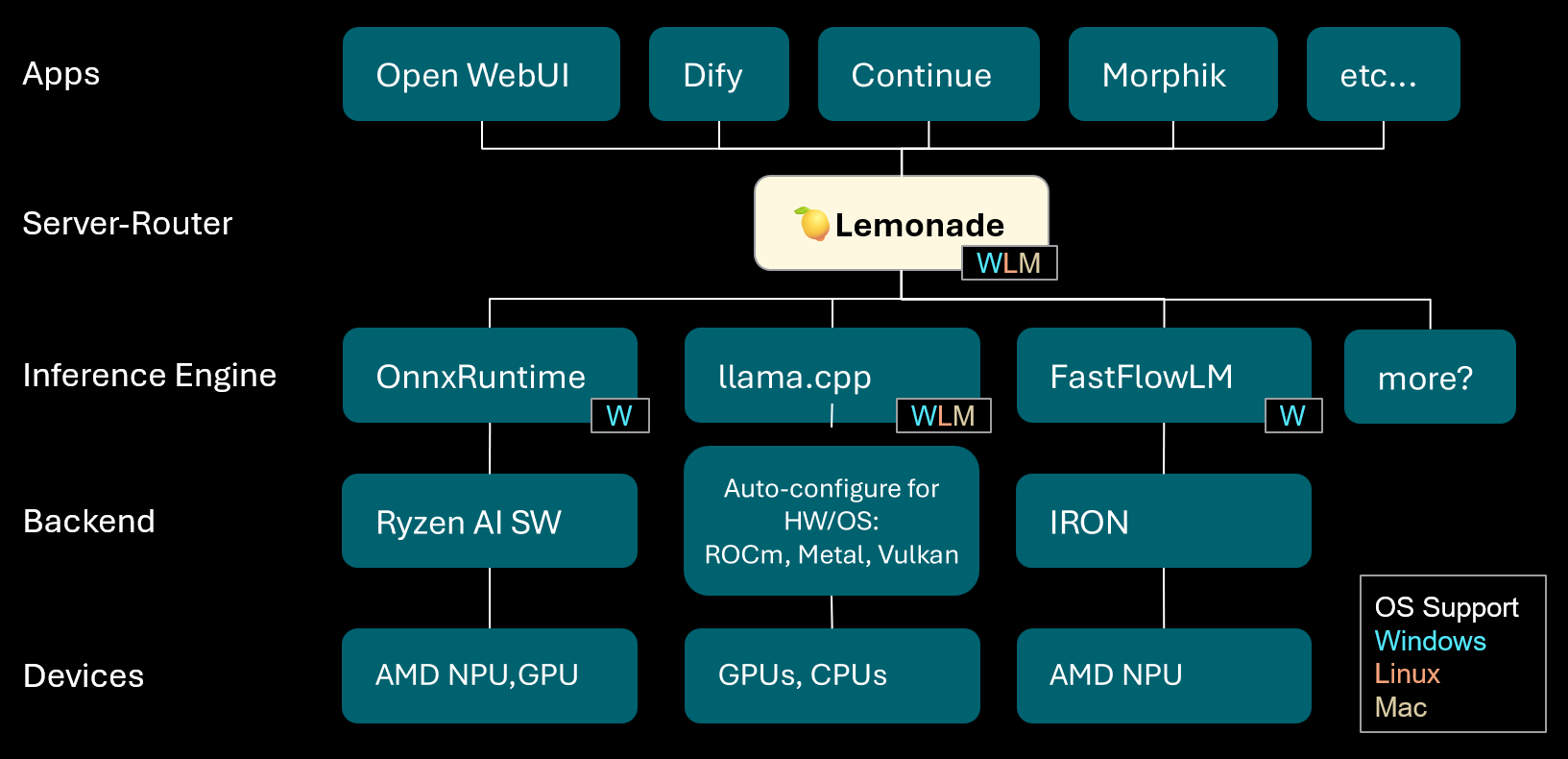
Lemonade:ローカルLLMサーバー・ルーター : Lemonadeはv8.1.11バージョンをリリースしました。これは、様々なPC(AMD NPUやmacOS/Apple Siliconデバイスを含む)向けに高性能推論エンジンを自動構成できるローカルLLMサーバー・ルーターです。ONNX、GGUF、FastFlowLMなどの複数のモデル形式をサポートし、llama.cppのMetalバックエンドを利用してApple Silicon上で効率的な計算を実現し、ユーザーに柔軟で高性能なローカルLLM体験を提供します。(出典:Reddit r/LocalLLaMA)
PopAi:AI駆動のプレゼンテーション生成 : PopAiは、簡単なプロンプトから数分でグラフやイラストを含む詳細なビジネスプレゼンテーションを生成するAIツールの能力を実演しました。これは、コンテンツ作成におけるAIの効率性を浮き彫りにし、非専門家でも高品質なプレゼンテーション資料を迅速に作成できることを示しています。(出典:kaifulee)

GitHub Copilot CLI:モデル自動選択 : GitHub Copilot CLIは、ビジネスおよびエンタープライズユーザー向けにモデル自動選択機能を提供するようになりました。この更新により、システムは現在のタスクに基づいて最適なモデルを自動的に選択できるようになり、開発効率とコード生成品質の向上を目指しています。(出典:pierceboggan)
Mixedbread Search:多言語・マルチモーダルローカル検索 : Mixedbreadは、高速、正確、多言語、マルチモーダルなドキュメント検索機能を提供するベータ版検索システムを発表しました。このシステムはローカル実行を強調しており、ユーザーは自分のデバイス上でドキュメントを効率的に検索でき、特に多様なデータタイプを処理する必要があるシナリオに適しています。(出典:TheZachMueller)
Hume AI Octave 2:次世代多言語TTSモデル : Hume AIは、次世代多言語テキスト読み上げ(TTS)モデルOctave 2を発表しました。このモデルは前世代より40%高速で50%安価であり、11以上の言語、マルチスピーカー対話、音声変換、音素編集機能をサポートし、より高速でリアル、感情豊かな音声AI体験を提供することを目指しています。(出典:AlanCowen)
AssemblyAI 9月アップデート:汎用AIオーディオサービス : AssemblyAIは9月のアップデートを振り返り、アプリ内Playground、汎用言語拡張、EU PII匿名化機能、ストリーミング性能改善、キーワードプロンプトなどのハイライトを挙げました。これらのアップデートは、ユーザーにより包括的で効率的なAIオーディオ処理サービスを提供することを目指しています。(出典:AssemblyAI)
Voiceflow MCPツール:Agentツール統合の標準化 : Voiceflowは、AI Agentが様々なツールを使用するための標準化された方法を提供するモデルコンテキストプロトコル(MCP)ツールを発表しました。これにより、開発者のカスタム統合作業が簡素化され、ノーコードユーザーには事前構築されたサードパーティツールが提供され、Voiceflow Agentの能力が大幅に拡張されます。(出典:ReamBraden)
Salesforce Agentforce Vibes:エンタープライズ級Agentコーディング : Salesforceは、Clineのアーキテクチャに基づき、「Agentforce Vibes」製品を発表しました。これはモデルコンテキストプロトコル(MCP)をサポートし、エンタープライズ顧客に自律コーディング能力を提供します。この製品は、LLMと内部および外部の知識源/データベースとの安全な通信を保証し、企業規模でのAIコーディングを実現することを目指しています。(出典:cline)

JoyAgent-JDGenie:汎用Agentアーキテクチャレポート : GAIA(Generalist Agent Architecture)技術レポートが発表されました。このアーキテクチャは、集合的マルチAgentフレームワーク(計画、実行Agent、レビューモデル投票を組み合わせる)、階層型記憶システム(作業、セマンティック、プログラム層)、および検索、コード実行、マルチモーダル解析などのツールスイートを統合しています。このフレームワークは、総合ベンチマークテストで優れた性能を発揮し、オープンソースベースラインを上回り、プロプライエタリシステム性能に近づいており、スケーラブルで弾力性があり、適応性のあるAIアシスタントを構築するための道筋を提供します。(出典:HuggingFace Daily Papers)
AI旅行アシスタント:ガイドから行動へのエンパワーメント : 中国の旅行プラットフォーム「马蜂窝」がリリースしたAI旅行アシスタントアプリは、AIを従来のガイド生成から実際の旅行中の行動補助へと進化させることを目指しています。このアプリは、図や写真入りのパーソナライズされた旅行ガイドを生成し、AI Agentによるレストラン予約の電話代行などの実用的な機能を提供することで、言語の壁などの課題を効果的に解決します。リアルタイム翻訳や深いパーソナライズにはまだ改善の余地があるものの、「ガイドなしで出かける」という敷居を大幅に下げ、デジタル情報と物理世界の行動を結びつけるAIの大きな可能性を示しています。(出典:36氪)

📚 学習
AI研究者のキャリア開発アドバイス : AI研究者のキャリア開発に関して、専門家は優れたコーダーになることの重要性を強調し、研究論文をゼロから再現し、インフラストラクチャを深く理解することを奨励しています。同時に、個人的なブランドを積極的に構築し、興味深いアイデアを共有し、好奇心と適応性を保ち、イノベーションと学習を促進する職位を優先するようアドバイスしています。長期的には、継続的な努力と実際の成果を得ることが、自信とモチベーションを築く鍵となります。(出典:dejavucoder、BlackHC)
Pythonデータ分析コース : DeepLearningAIは、Pythonを利用してデータ分析の効率、追跡可能性、再現性を向上させる方法を教える新しいPythonデータ分析コースを開始しました。このコースはデータ分析専門証明書の一部であり、現代のデータ業務におけるプログラミングスキルの中心的な役割を強調しています。(出典:DeepLearningAI)
学生向けCopilot AIツール無料提供 : Microsoftは、対象となる大学生にMicrosoft 365 Personalの12ヶ月無料サブスクリプションを提供します。これにはCopilot Podcasts、Deep Research、Visionへの追加アクセスが含まれます。この取り組みは、学生に強力なAIツールを提供し、学習とイノベーションを支援することを目的としています。(出典:mustafasuleyman)

ローカルAI/MLコース設定 : ある教育者が、限られた予算で学生向けにローカル開発とコンシューマー向けハードウェアに基づいたAI/ML実践コースを作成する方法を共有しました。彼は、小さなモデルとTransformer Labをトレーニングプラットフォームとして使用することを提案し、モデルの規模を盲目的に追求するのではなく、コアコンセプトを理解することの重要性を強調することで、学生の学習効果と実践能力を向上させました。(出典:Reddit r/deeplearning)
開催予定のAIセミナー : AIhubは、2025年10月から11月にかけて開催される機械学習およびAIセミナーのリストを発表しました。これらのイベントは、政治的に制限されたソーシャルメディアプラットフォームからのデータ収集からAI倫理まで、複数のテーマをカバーしており、すべてのセミナーは無料でオンライン参加オプションも提供され、AIコミュニティに豊富な学習と交流の機会を提供します。(出典:aihub.org)

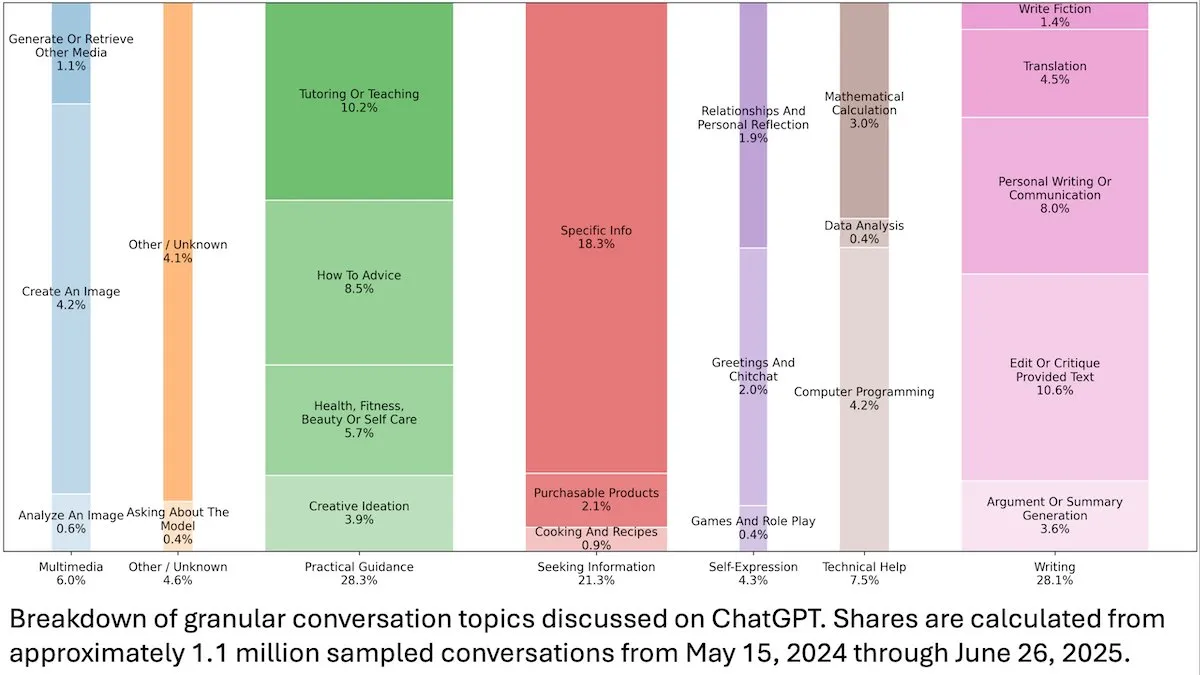
ChatGPTユーザー行動洞察 : DeepLearningAIが発表したOpenAIの研究によると、ChatGPTの1.1億件の匿名対話分析から、その利用シーンが仕事関連から個人的なニーズへと移行しており、女性ユーザーと18~25歳の若年ユーザーの割合が高いことが示されました。最も一般的なリクエストは、実用的なガイダンス(28.3%)、執筆支援(28.1%)、情報検索(21.3%)であり、ChatGPTが日常生活で広く利用されていることが明らかになりました。(出典:DeepLearningAI)
Code2Video:コード駆動の教育ビデオ生成 : ある研究では、Code2Videoというコード中心のAgentフレームワークが提案されました。これは、実行可能なPythonコードを通じてプロフェッショナルな教育ビデオを生成します。このフレームワークは、プランナー、エンコーダー、批評家の3つの協力Agentで構成され、講義内容を構造化し、コードに変換し、視覚的に最適化することができます。教育ビデオベンチマークMMMCで40%の性能向上を達成し、人間のチュートリアルに匹敵するビデオを生成しました。(出典:HuggingFace Daily Papers)
BiasFreeBench:LLMバイアス軽減ベンチマーク : BiasFreeBenchは、8つの主要なLLMバイアス軽減技術を包括的に比較するための実証ベンチマークとして導入されました。このベンチマークは、既存のデータセットを再編成することで、多肢選択式質問応答とオープンエンド多段階質問応答の2つのテストシナリオにおいて、応答レベルの「Bias-Free Score」指標を導入し、LLM応答の公平性、安全性、反ステレオタイプ度を測定します。これにより、バイアス軽減研究のための統一されたテストプラットフォームを確立することを目指しています。(出典:HuggingFace Daily Papers)
Transformerの乗算学習障害と長距離依存の罠 : 研究は、Transformerモデルが多桁乗算という一見単純なタスクで失敗する原因を逆行分析しました。モデルが暗黙的な思考連鎖の中で必要な長距離依存構造をエンコードしているにもかかわらず、標準的なファインチューニング方法ではこれらの依存を利用できるグローバル最適解に収束しないことが判明しました。補助損失関数を導入することで、研究者はこの問題を解決し、Transformerが長距離依存を学習する際の罠を明らかにし、適切な帰納バイアスによって問題を解決する例を提供しました。(出典:HuggingFace Daily Papers)
マルチモーダル推論におけるVL-PRMトレーニングの洞察 : この研究は、視覚-言語プロセス報酬モデル(VL-PRMs)の設計空間を解明することを目的とし、データセット構築、トレーニング、テスト時のスケーリングに関する複数の戦略を探求しました。ハイブリッドデータ合成フレームワークと知覚に焦点を当てた教師あり学習を導入することで、VL-PRMsは5つのマルチモーダルベンチマークで重要な洞察を示しました。これには、テスト時のスケーリングで結果報酬モデルを上回ること、小規模なVL-PRMsがプロセスエラーを検出できること、より強力なVLMバックボーンの潜在的な推論能力を明らかにできることなどが含まれます。(出典:HuggingFace Daily Papers)
GEM:Agentic LLMのための汎用環境シミュレーター : GEM(General Experience Maker)は、LLM Agentの経験学習のために設計されたオープンソースの環境シミュレーターです。標準化されたAgent-環境インターフェースを提供し、高スループットのための非同期ベクトル化実行をサポートし、拡張を容易にする柔軟なラッパーを提供します。GEMには多様な環境スイートと統合ツールも含まれており、REINFORCEなどのRLトレーニングフレームワークを使用したベースラインも提供されており、Agentic LLMの研究を加速することを目指しています。(出典:HuggingFace Daily Papers)
GUI-KV:効率的なGUI AgentのためのKVキャッシュ圧縮 : GUI-KVは、GUI Agent向けに設計されたプラグアンドプレイのKVキャッシュ圧縮手法で、再トレーニングなしで効率を向上させます。GUIワークロードにおけるアテンションパターンを分析することで、この手法は空間的顕著性ガイドと時間的冗長性スコアリング技術を組み合わせ、適度な予算でフルキャッシュに近い精度を達成し、デコードFLOPsを大幅に削減することで、GUI特有の冗長性を効果的に利用します。(出典:HuggingFace Daily Papers)
対数尤度を超えて:SFTの確率的目標関数研究 : この研究は、教師ありファインチューニング(SFT)における従来の負の対数尤度(NLL)を超える確率的目標関数を探求しました。7つのモデルバックボーン、14のベンチマーク、3つのドメインにわたる広範な実験を通じて、モデル能力が高い場合、事前確率が低くトークン重みが小さい目標関数(例:-p, -p^10)がNLLよりも優れていることが判明しました。一方、モデル能力が低い場合、NLLが優勢でした。理論分析は、目標関数がモデル能力に応じてどのようにトレードオフするかを明らかにし、SFTのためのより原則的な最適化戦略を提供します。(出典:HuggingFace Daily Papers)
VLA-RFT:世界シミュレーターにおける検証報酬ベースのRLファインチューニング : VLA-RFTは、視覚-言語-行動(VLA)モデルのための強化学習ファインチューニングフレームワークで、データ駆動型世界モデルを制御可能なシミュレーターとして利用します。実際のインタラクションデータでトレーニングされたシミュレーターは、行動に基づいた将来の視覚観測を予測し、密な軌道レベルの報酬を持つポリシーの展開を可能にします。このフレームワークはサンプル要件を大幅に削減し、400ステップ未満のファインチューニングで強力な教師ありベースラインを上回り、摂動条件下で強力なロバスト性を示しました。(出典:HuggingFace Daily Papers)
ImitSAT:模倣学習によるブール充足可能性問題の解決 : ImitSATは、ブール充足可能性問題(SAT)を解決するための模倣学習ベースのCDCLソルバー分岐戦略です。この手法は、エキスパートのKeyTraceを学習することで、完全な実行を生き残った決定シーケンスに折りたたみ、密な決定レベルの教師あり学習を提供し、伝播回数を直接削減します。実験により、ImitSATは伝播カウントと実行時間の両方で既存の学習手法を上回り、より速い収束と安定したトレーニングを実現することが証明されました。(出典:HuggingFace Daily Papers)
オープンソースAI Agentフレームワークのテスト実践研究 : 39のオープンソースAgentフレームワークと439のAgentアプリケーションに対する大規模な実証研究により、AI Agentエコシステムにおけるテスト実践が明らかになりました。研究では10種類のユニークなテストパターンが特定され、決定論的コンポーネント(ツールやワークフローなど)へのテスト投入が70%以上を占める一方で、LLMベースの計画主体は5%未満であることが判明しました。さらに、プロンプト(Trigger)コンポーネントの回帰テストは深刻に無視されており、テストの約1%にしか現れておらず、Agentテストにおける重要な盲点が明らかになりました。(出典:HuggingFace Daily Papers)
DeepCodeSeek:コード生成のためのリアルタイムAPI検索 : DeepCodeSeekは、コンテキストアウェアなコード生成のためのリアルタイムAPI検索という新しい技術を提案し、高品質なエンドツーエンドのコード自動補完とAgentic AIアプリケーションを実現します。この手法は、コードとインデックスを拡張して必要なAPIを予測することで、既存のベンチマークデータセットにおけるAPIリークの問題を解決します。最適化の結果、コンパクトな0.6Bリランカーは、2.5倍の低遅延を維持しながら、8Bモデルを上回る性能を達成しました。(出典:HuggingFace Daily Papers)
CORRECT:マルチAgentシステムにおける凝縮されたエラー識別 : CORRECTは、蒸留されたエラーパターンのオンラインキャッシュを利用することで、マルチAgentシステムにおけるエラー識別と知識転移を実現する軽量でトレーニング不要のフレームワークです。このフレームワークは、線形時間で構造化エラーを識別でき、高価な再トレーニングを回避し、動的なMASデプロイメントに適応できます。CORRECTは、7つのマルチAgentアプリケーションでステップレベルのエラー特定を19.8%向上させ、自動化と人間レベルのエラー識別の間のギャップを大幅に縮小しました。(出典:HuggingFace Daily Papers)
Swift:効率的な天気予報のための自己回帰一貫性モデル : Swiftは、単一ステップの一貫性モデルであり、確率流モデルの自己回帰ファインチューニングを初めて実現し、連続ランク確率スコア(CRPS)目標を採用しています。このモデルは、熟練した6時間天気予報を生成し、最大75日間安定性を維持できます。最先端の拡散ベースラインより39倍高速に動作し、数値IFS ENSに匹敵する予報スキルを達成しており、中長期から季節規模の効率的で信頼性の高いアンサンブル予報に向けた重要な一歩となります。(出典:HuggingFace Daily Papers)
Catching the Details:MLLMのきめ細かい知覚のための自己蒸留RoI予測器 : この研究は、マルチモーダル大規模言語モデル(MLLM)が高解像度画像を処理する際の計算コストが高いという課題を解決するために、効率的でラベル不要な自己蒸留領域提案ネットワーク(SD-RPN)を提案しました。SD-RPNは、MLLMの中間層のアテンションマップを高品質な擬似RoIラベルに変換し、軽量なRPNをトレーニングして正確な局所化を行うことで、データ効率と汎化能力を実現し、未見のベンチマークテストで精度を10%以上向上させました。(出典:HuggingFace Daily Papers)
LLM多段階推論の新しいパラダイム:In-Place Feedback : この研究は、「In-Place Feedback」という新しいインタラクションパラダイムを導入しました。これは、LLMの多段階推論をガイドするために使用されます。ユーザーはLLMの以前の応答を直接編集でき、モデルはこの修正された応答に基づいて改訂版を生成します。経験的評価により、In-Place Feedbackは推論集約型ベンチマークで従来の多段階フィードバックよりも優れた性能を発揮し、同時にトークン使用量を79.1%削減し、モデルがフィードバックを正確に適用するのが難しいという限界を解決しました。(出典:HuggingFace Daily Papers)
LLM強化学習ダイナミクスの予測可能性 : この研究は、LLMの強化学習(RL)トレーニングにおけるパラメータ更新の2つの基本的な特性を明らかにしました。それは、ランク1優位性(パラメータ更新行列の最高の特異部分空間が推論改善をほぼ完全に決定する)と、ランク1線形ダイナミクス(この優位部分空間がトレーニング中に線形に進化する)です。これらの発見に基づき、研究はAlphaRLというプラグアンドプレイの加速フレームワークを提案しました。これは、初期トレーニングウィンドウから最終的なパラメータ更新を推論することで、最大2.5倍の加速を達成し、同時に96%以上の推論性能を維持します。(出典:HuggingFace Daily Papers)
KVキャッシュ圧縮の落とし穴 : この研究は、LLMデプロイメントにおけるKVキャッシュ圧縮の複数の落とし穴を明らかにしました。特に、マルチインストラクションプロンプトなどの実際のシナリオでは、圧縮によって特定のインストラクションの性能が急速に低下したり、LLMによって完全に無視されたりする可能性があります。研究は、システムプロンプトリークのケーススタディを通じて、圧縮がリークと一般的なインストラクションフォローに与える影響を実証的に示し、簡単なKVキャッシュ排出戦略の改善案を提案しました。(出典:HuggingFace Daily Papers)
💼 ビジネス
AI大手競争:OpenAIとAnthropicの戦略的差異 : OpenAIとAnthropicは、AI分野で全く異なる発展経路をたどっています。OpenAIはChatGPTを通じてeコマースを統合し、Soraソーシャルアプリをリリースすることで、「水平展開」を目指し、ユーザーの生活の多方面をカバーするスーパープラットフォームとなることを目指しており、その評価額はAnthropicを1000億ドル上回っています。一方、Anthropicは「垂直深掘り」に注力し、Claude Sonnet 4.5を核として、AIプログラミングとエンタープライズ級Agent市場を深く掘り下げ、AWS、Googleなどのクラウドサービスプロバイダーと深く連携しています。両社の背後には、MicrosoftとAmazonという2大クラウドコンピューティング大手による「計算能力外交」の駆け引きがあり、AI時代の計算能力の希少性、高コストという産業の現実を浮き彫りにしています。(出典:36氪、量子位、36氪)
PerplexityがVisual Electricを買収 : PerplexityはVisual Electricの買収を発表しました。Visual ElectricのチームはPerplexityに加わり、新しい消費者向け製品体験を共同開発します。Visual Electricの製品は段階的にサービスを停止する予定です。この買収は、Perplexityの消費者向けAI製品分野におけるイノベーション能力を強化することを目的としています。(出典:AravSrinivas)

DatabricksがMooncakelabsを買収 : DatabricksはMooncakelabsの買収を発表し、Lakebaseビジョンの実現を加速させます。LakebaseはPostgresをベースに構築され、AI Agent向けに最適化された新しいOLTPデータベースであり、アプリケーション、分析、AIに統一された基盤を提供し、LakehouseおよびAgent Bricksと深く統合することで、データ管理とAIアプリケーション開発を簡素化することを目指しています。(出典:matei_zaharia)

🌟 コミュニティ
AIが雇用と社会に与える影響 : コミュニティでは、AIによる自動化が雇用市場に与える深い影響について広く議論されており、大規模な失業、新たな社会階層の創出、そしてユニバーサルベーシックインカム(UBI)の必要性への懸念が表明されています。新しく創出されるAI関連の仕事も自動化されるのではないか、また誰もがAIスキルを習得して未来に適応できるわけではない、という疑問が広く提起されています。議論はさらに、AI Agentのコスト管理とROI実現の課題、そしてAGIの到来が社会構造と地政学に与える潜在的な影響にも及んでいます。(出典:Reddit r/ArtificialInteligence、Ronald_vanLoon、Ronald_vanLoon)
AI倫理と制御権をめぐる争い : コミュニティでは、AIの未来を誰がコントロールすべきか、一般市民かテクノロジーの寡頭制かについて活発な議論が交わされています。AI開発は人間中心であるべきであり、透明性とユーザーが個人データおよびAIの履歴を制御する権利が強調されています。同時に、AIのゴッドファーザーであるYoshua Bengioは、超知能機械が10年以内に人類を絶滅させる可能性があると警告しています。Metaなどの企業がAIチャットデータを利用してターゲット広告を行う計画は、プライバシーとAIの悪用に対するユーザーの懸念をさらに高め、AI倫理と規制に関する深い考察を引き起こしています。(出典:Reddit r/artificial、Reddit r/artificial、Reddit r/ArtificialInteligence)

GPT-5安全モデルの異常な振る舞い : Redditコミュニティのユーザーは、GPT-5の「CHAT-SAFETY」モデルが非悪意的なリクエストを処理する際に、奇妙で、非難的で、さらには幻覚のような振る舞いを示すと報告しています。例えば、指紋認証の問題を追跡行為と解釈し、法律を捏造するなどのケースです。このような過度に敏感で不正確な応答は、モデルの信頼性、潜在的な危険性、およびOpenAIの安全戦略に対するユーザーの深刻な疑問を引き起こしています。(出典:Reddit r/ChatGPT)
「苦い教訓」とLLM発展経路をめぐる議論 : Andrej Karpathyと強化学習の父Richard Suttonは、LLMが「苦い教訓」に合致するかどうかについて議論を交わしました。Suttonは、LLMが限られた人間データに依存して事前学習されており、「苦い教訓」における経験からの学習という原則に真に従っているわけではないと考えています。Karpathyは、事前学習をコールドスタート問題を解決するための「ひどい進化」とみなし、LLMと動物の知能における学習メカニズムの根本的な違いを指摘し、現在のAIは「動物を構築する」というよりも「幽霊を召喚する」に近いと強調しています。(出典:karpathy、SchmidhuberAI)
ローカルLLMセットアップの価値に関する議論 : コミュニティユーザーは、数万ドルを投じてローカルLLMセットアップを構築する価値について議論を繰り広げました。支持者は、プライバシー、データセキュリティ、そして実践を通じて得られる深い知識が主な利点であると強調し、アマチュア無線愛好家と比較しています。反対者は、安価なクラウドAPI(Sonnet 4.5やGemini Pro 2.5など)の性能向上に伴い、高コストなローカルセットアップの正当性を証明するのが難しいと主張しています。(出典:Reddit r/LocalLLaMA)
LLMを評価者として:Agent評価の新しい方法 : 研究者や開発者は、AI Agentの応答品質(正確性や根拠の有無など)を評価するために、LLMを「評価者」として使用する方法を模索しています。実践により、評価者のプロンプトが慎重に設計されている場合(単一基準、アンカー採点、厳格な出力形式、バイアス警告など)、この方法が驚くほど効果的であることが示されています。この傾向は、LLM-as-a-JudgeがAgent評価分野で大きな可能性を秘めていることを示唆しています。(出典:Reddit r/MachineLearning)
AIと人間とのインタラクション:デバイスから仮想キャラクターへ : AIは多次元的に人間とのインタラクションを再構築しています。MIT関連のスタートアップは、「ほぼテレパシーのような」ウェアラブルデバイスを発表し、無声コミュニケーションを実現しました。同時に、リアルタイム音声AI AgentがNPC(ノンプレイヤーキャラクター)として3Dオンラインゲームに適用されており、ゲームや仮想世界でより自然で没入感のあるインタラクション体験を提供するAIの可能性を示唆しています。これらの進展は、日常生活やエンターテイメントにおけるAIの役割について議論を巻き起こしています。(出典:Reddit r/ArtificialInteligence、Reddit r/artificial)

オープンモデルとクローズドソースモデルの選択 : コミュニティでは、ソフトウェアエンジニアがクローズドソースモデルからオープンソースモデルに移行する際に直面する最大の障壁について議論されました。専門家は、ブラックボックスのクローズドソースモデルに依存するのではなく、オープンソースモデルをファインチューニングすることが、深い学習、製品差別化の実現、そしてユーザーにより良い製品を提供するために不可欠であると指摘しています。オープンソースモデルの開発速度は遅いかもしれませんが、長期的には価値創造と技術的自律性の面で大きな可能性を秘めています。(出典:ClementDelangue、huggingface)
AIインフラストラクチャと計算能力の課題 : OpenAIの「星門」プロジェクトは、AIが計算能力、エネルギー、土地に対して膨大な需要を持つことを明らかにしました。毎月最大90万枚のDRAMウェハーを消費すると予測されています。GPUの希少性、高価格、電力供給の制限により、AI企業は「計算能力外交」を行い、クラウドサービスプロバイダー(MicrosoftやAmazonなど)と深く連携せざるを得なくなっています。このような重資産投資と戦略的協力モデルは、AIの発展を推進する一方で、サプライチェーン、エネルギー政策、規制などの外部変数によるリスクももたらしています。(出典:karminski3、AI巨头的奶妈局、DeepLearning.AI Blog)

💡 その他
AI音楽の著作権と補償メカニズム : スウェーデンの著作権団体STIMはSureel社と提携し、AIモデルのトレーニングにおける音楽作品の著作権利用問題に対処するためのAI音楽ライセンス契約を発表しました。この契約により、AI開発者は合法的に音楽を使用でき、Sureelのアトリビューション技術を通じて作品がモデル出力に与える影響を計算し、作曲家やレコードアーティストに補償を行います。この動きは、AI音楽制作に法的保護を提供し、オリジナルコンテンツの制作を奨励し、著作権所有者に新たな収入源を創出することを目指しています。(出典:DeepLearning.AI Blog)

LLMセキュリティと敵対的攻撃 : Trend Microは、LLMが攻撃者によって悪用される可能性のある様々な方法について深く掘り下げた研究を発表しました。これには、巧妙に構築されたプロンプト、データポイズニング、マルチAgentシステムにおける脆弱性を通じた侵害が含まれます。この研究は、より安全なLLMアプリケーションとマルチAgentシステムを開発するために、これらの攻撃ベクトルを理解することの重要性を強調し、対応する防御戦略を提案しています。(出典:Reddit r/deeplearning)

Proactive AI:利便性とプライバシーのトレードオフ : コミュニティでは、「Proactive Ambient AI」(プロアクティブ・アンビエントAI)がスマートアシスタントとしてもたらす利便性と、潜在的なプライバシー侵害のリスクについて議論されました。このようなAIは積極的に支援を提供できますが、その継続的な個人データ収集と処理は、ユーザーに透明性、制御権、データ帰属に関する懸念を引き起こしています。一部の意見では、「透明性プロトコル」と「個人基本プロファイル」を確立し、ユーザーがAIインタラクション履歴を制御できるようにすることを求めています。(出典:Reddit r/artificial)
