
キーワード:メタ, テンセント・フンユアン画像3.0, xAI Grok 4 Fast, OpenAI Sora 2, バイトダンス・Self-Forcing++, アリババQwen, vLLM, GPT-5-Pro, メタ認知再利用メカニズム, 汎用因果的注意メカニズム, マルチモーダル推論モデル, 分単位の動画生成, 姿勢認識型ファッション生成
🔥 注目 (Highlights)
Metaの新しいアプローチが思考の連鎖を短縮し、重複する推論に終止符を打つ : Meta、Mila-Quebec AI Instituteなどが共同で「Meta-Cognitive Reuse」メカニズムを提案しました。これは、大規模モデルの推論において、重複する推論がtoken bloatやlatency増加を引き起こす問題を解決することを目的としています。このメカニズムにより、モデルは問題解決のアプローチを振り返り、要約し、頻繁に使用される推論パターンを「行動」として「行動ハンドブック」に保存し、必要に応じて再推論することなく直接呼び出すことができます。実験では、MATHやAIMEなどの数学ベンチマークにおいて、このメカニズムが精度を維持しながら、推論tokenの使用量を最大46%削減し、モデルの効率と新しいパスを探索する能力を向上させることが示されました。(出典: 量子位)

Tencent Hunyuan Image 3.0が世界のAI画像生成ランキングで首位を獲得 : Tencent Hunyuan Image 3.0がLMArenaテキスト-to-イメージリーダーボードで1位を獲得し、Google Nano Banana、ByteDance Seedream、OpenAI gpt-Imageを上回りました。このモデルは、Hunyuan-A13Bをベースとしたネイティブなマルチモーダルアーキテクチャを採用しており、総パラメータ数は800億を超え、テキスト、画像、ビデオ、オーディオなど多様なモダリティを統一的に処理できます。強力な意味理解、言語モデル思考、世界知識推論能力を備えています。そのコア技術には、汎用因果的アテンションメカニズムと2D位置エンコーディングが含まれ、自動解像度予測も導入されています。モデルは3段階のフィルタリングと階層的記述システムを通じてデータを構築し、4段階の漸進的トレーニング戦略を採用することで、生成される画像のリアリズムと鮮明さを効果的に向上させています。(出典: 量子位)

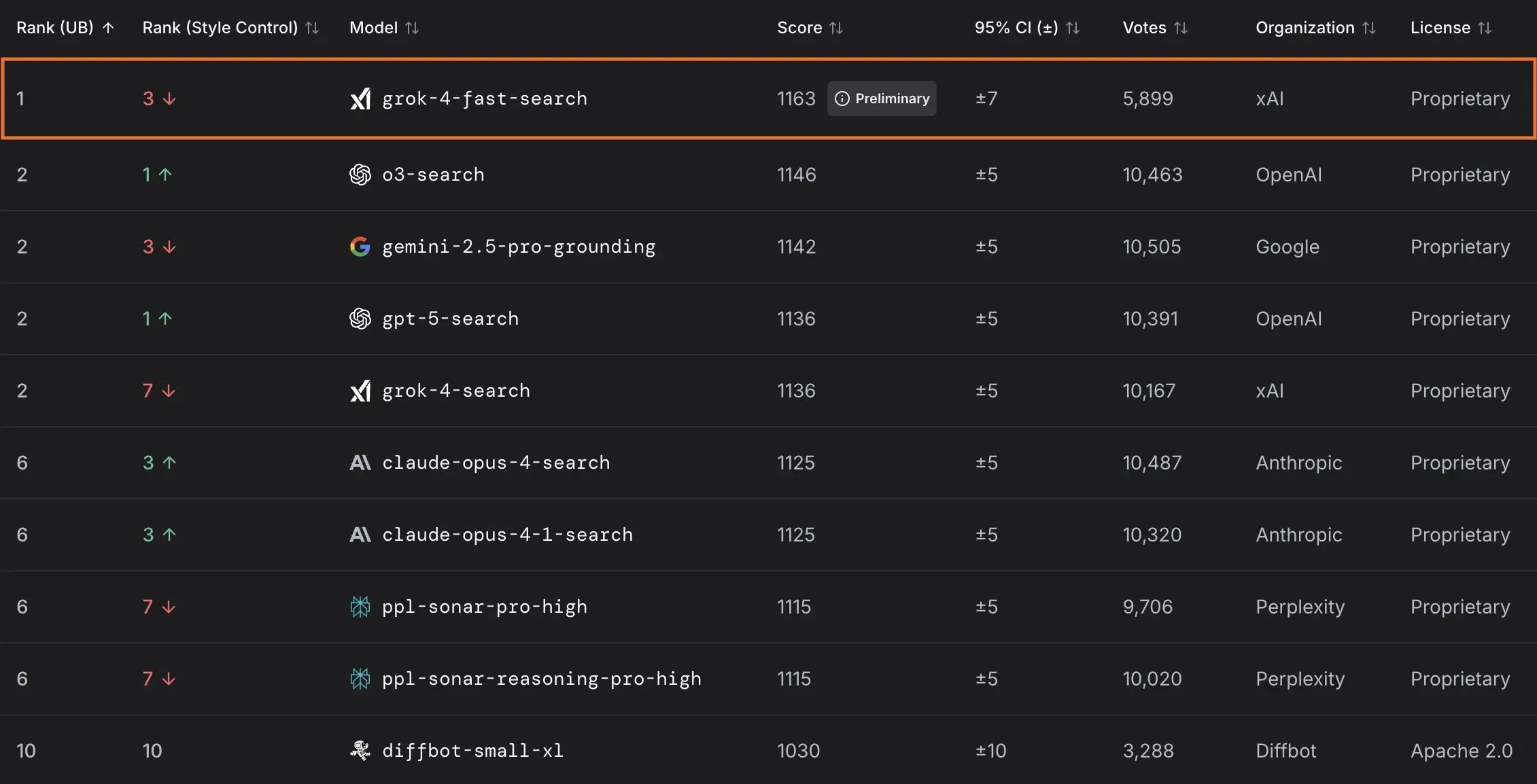
xAIがGrok 4 Fastモデルを発表し、米国政府と協力 : xAIは、費用対効果の高いインテリジェントサービスを提供することを目的とした、2Mのコンテキストウィンドウを持つマルチモーダル推論モデルGrok 4 Fastを発表しました。このモデルはすべてのユーザーに無料で公開されており、米国連邦政府との協力により、すべての連邦機関に最先端のAIモデル(Grok 4, Grok 4 Fast)を18ヶ月間無料で提供し、政府がAIを活用できるようエンジニアチームを派遣します。さらに、xAIはLLMの性能と安全性を評価するためのOpenBenchをリリースし、コーディングタスクで優れた性能を発揮するGrok Code Fast 1も発表しました。(出典: xai, xai, xai, JonathanRoss321)
🎯 動向 (Trends)
OpenAIが消費者向けAI製品とSora 2のアップデートを予告 : UBSは、OpenAIの開発者会議が消費者向けAI製品、おそらく旅行予約AIエージェントの発表に焦点を当てると予測しています。同時に、Sora 2ビデオ生成モデルがテスト中で、ユーザーはその生成コンテンツがしばしばユーモラスであることに気づいています。OpenAIはまた、Sora 2 ProモデルのHDモードにおける解像度問題を修正し、現在17921024または10241792の解像度をサポートし、最長15秒のビデオ生成を可能にしていますが、1日の生成クォータは30回に減少しています。(出典: teortaxesTex, francoisfleuret, fabianstelzer, TomLikesRobots, op7418, Reddit r/ChatGPT)

ByteDanceが分単位のビデオ生成モデルを発表 : ByteDanceは、Self-Forcing++という新しい手法を発表しました。これにより、高品質なビデオを最長4分15秒まで生成できます。この手法は、長尺ビデオの教師モデルや再トレーニングを必要とせず、拡散モデルを拡張し、生成されるビデオの忠実度と一貫性を維持します。(出典: _akhaliq)
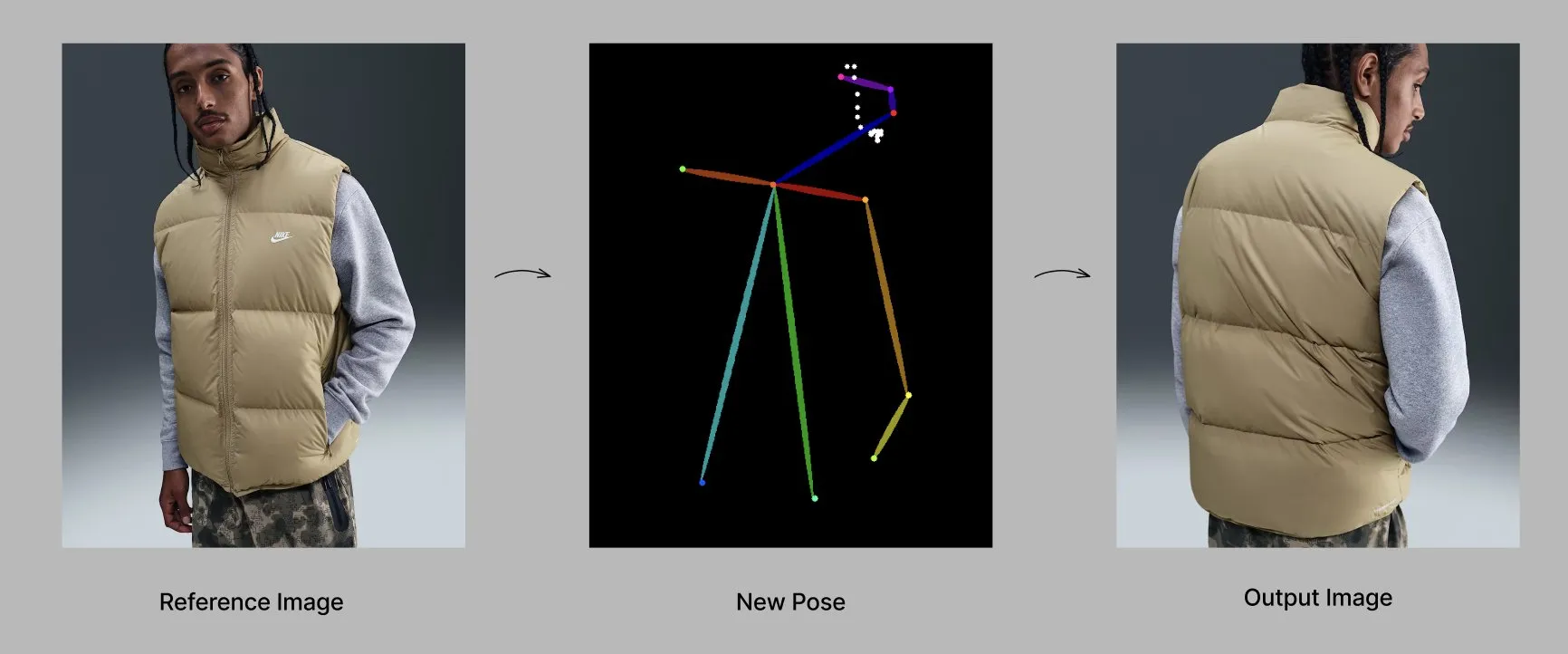
Qwenモデルが新機能とアプリケーションを発表 : Alibaba Qwenチームは、記憶やカスタムシステム指示などのパーソナライゼーション機能を段階的に展開しており、現在限定テスト中です。同時に、Qwen-Image-Edit-2509モデルは、ポーズ認識ファッション生成において高度な能力を示しており、ファインチューニングにより多角度で高品質なファッションモデルの生成を実現できます。(出典: Alibaba_Qwen, Alibaba_Qwen)
vLLMとPipelineRLがRLコミュニティの限界を押し広げる : vLLMプロジェクトは、より良いオンポリシーデータ、部分的なロールアウト、推論中のKVキャッシュにおけるインフライト重み更新など、強化学習(RL)分野における新しいブレークスルーをRLコミュニティでサポートしています。PipelineRLは、重みの変化とKV状態の維持を伴いながら推論を継続することで、スケーラブルな非同期RLを実現し、インフライト重み更新をサポートします。(出典: vllm_project, Reddit r/LocalLLaMA)

GPT-5-Proが複雑な数学問題を解決 : GPT-5-Proは、「Yu Tsumuraの554番目の問題」を15分で単独で解決しました。これは、このタスクを完全に解決した最初のモデルであり、その強力な数学問題解決能力を示しています。(出典: Teknium1)

SAPがAIを企業ワークフローの核に : SAPは、Connect 2025カンファレンスで、AIを企業ワークフローの核とするビジョンを発表する予定です。組み込みAIを通じてリアルタイムデータを意思決定に変換し、AIエージェントを活用してプロアクティブな操作を行います。SAPは、最初から信頼を構築し、積極的なサポートを提供すること、そしてローカライゼーションの柔軟性とコンプライアンスを確保することを強調しています。(出典: TheRundownAI)

SalesforceがCoDA-1.7Bテキスト拡散エンコーディングモデルを発表 : Salesforce Researchは、CoDA-1.7Bを発表しました。これは、双方向に並行してトークンを出力できるテキスト拡散エンコーディングモデルです。このモデルは推論速度が速く、1.7Bのパラメータ数で7Bモデルに匹敵し、HumanEval、HumanEval+、EvalPlusなどのベンチマークで優れた性能を発揮します。(出典: ClementDelangue)

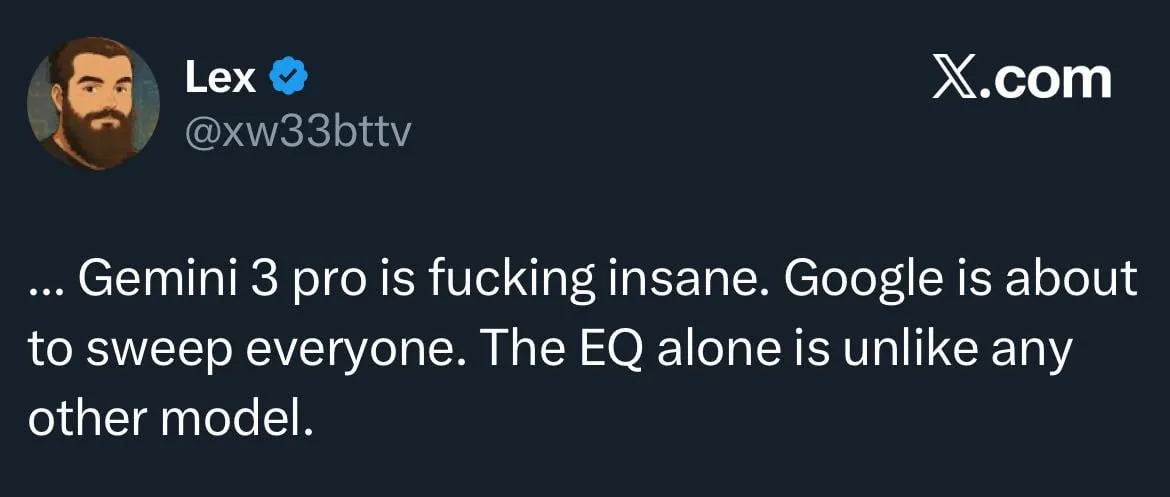
Google Gemini 3.0がEQに焦点を当て、OpenAIとの競争が激化 : Googleは間もなくGemini 3.0をリリースする予定で、これは「Emotional Quotient (EQ)」に重点を置くとされており、OpenAIに対する強力な挑戦と見なされています。この動きは、AIモデルの感情理解とインタラクションの発展を示しており、AI大手間の競争がさらに激化することを示唆しています。(出典: Reddit r/ChatGPT)
ロボットと自動化技術の発展 : ロボット分野では革新が続いており、物流作業用の全方向移動ヒューマノイドロボット、ロボットアームとロッカーを組み合わせた自律移動ロボット配送サービス、そして米国学生がロープ駆動と巧妙な数学的設計で作成した12モーターロボット犬「Cara」などが含まれます。さらに、初の「Wuji Hand」ロボットも正式に発表されました。(出典: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

🧰 ツール (Tools)
GPT4Free (g4f)プロジェクトが無料のLLMとメディア生成ツールを提供 : GPT4Free (g4f)は、アクセス可能な多様なLLMとメディア生成モデルを統合することを目的としたコミュニティ主導のプロジェクトです。Pythonクライアント、ローカルWeb GUI、OpenAI互換のREST API、およびJavaScriptクライアントを提供します。OpenAI、PerplexityLabs、Gemini、MetaAIなどのマルチプロバイダーアダプターをサポートし、画像/オーディオ/ビデオ生成およびメディア永続化をサポートすることで、AIツールへのオープンアクセスを普及させることに尽力しています。(出典: GitHub Trending)
LLMツール設計とPromptエンジニアリングのベストプラクティス : AIが理解しやすいツールを作成する際の優先順位は、ツール定義、システム指示、ユーザープロンプトの順です。ツール名と説明は直感的で明確であり、曖昧さを避けることが重要です。パラメータは可能な限り少なくし、列挙項目を提供するか、上限と下限を設定する必要があります。応答速度を向上させるために、過度にネストされた構造化パラメータの使用は避けてください。モデルにプロンプトを作成させ、フィードバックを提供することで、大規模モデルのツール理解を効果的に向上させることができます。(出典: dotey)
Zen MCPがGemini CLIを利用してClaude Codeのクレジットを節約 : Zen MCPプロジェクトは、ユーザーがClaude Codeなどのツール内で直接Gemini CLIを使用できるようにすることで、Claude Codeのtoken使用量を大幅に削減し、Geminiの無料クレジットを活用することを可能にします。このツールは、異なるAIモデル間でタスクを委任し、共有コンテキストを維持することをサポートします。例えば、GPT-5で計画し、Gemini 2.5 Proでレビューし、Sonnet 4.5で実装し、Gemini CLIでコードレビューと単体テストを行うことで、効率的かつ経済的なAI支援開発を実現します。(出典: Reddit r/ClaudeAI)
オープンソースLLM評価ツールOpik : Opikは、LLMアプリケーション、RAGシステム、およびAgenticワークフローのデバッグ、評価、監視に使用されるオープンソースのLLM評価ツールです。包括的なトレーシング、自動評価、および本番環境対応のダッシュボードを提供し、開発者がAIモデルをよりよく理解し、最適化するのに役立ちます。(出典: dl_weekly)
Claude Sonnet 4.5がTampermonkeyスクリプトの作成に優れる : Claude Sonnet 4.5はTampermonkeyスクリプトの作成において優れた性能を発揮し、ユーザーは1つのプロンプトだけでGoogle AI Studioのテーマを変更できます。これは、ブラウザの自動化操作とユーザーインターフェースのカスタマイズにおけるその強力な能力を示しています。(出典: Reddit r/ClaudeAI)

Phi-3-miniモデルのローカルデプロイ : ユーザーは、Unslothを使用してGoogle ColabでファインチューニングされたPhi-3-mini-4k-instruct-bnb-4bitモデルをローカルマシンにデプロイすることを求めています。このモデルはテキストから要約を抽出し、フィールドを解析できます。デプロイの目標は、ローカルでDataFrame内のテキストを読み込み、モデルで処理した後、出力を新しいDataFrameに保存することです。これは、統合グラフィックスと8GB RAMの低スペック環境でも実現する必要があります。(出典: Reddit r/MachineLearning)
LLMバックエンド性能比較 : コミュニティでは、現在のLLMバックエンドフレームワークの性能が議論されており、vLLM、llama.cpp、ExLlama3が最速のオプションと見なされ、Ollamaは最も遅いとされています。vLLMは複数の同時チャットの処理に優れており、llama.cppはその柔軟性と幅広いハードウェアサポートで人気があり、ExLlama3はNVIDIA GPU向けに究極の性能を提供しますが、モデルサポートは限定的です。(出典: Reddit r/LocalLLaMA)
“solveit”ツールがプログラマーのAI課題解決を支援 : プログラマーがAIを使用する際に直面する可能性のあるフラストレーションに対処するため、Jeremy Howardは「solveit」ツールをリリースしました。このツールは、プログラマーがAIをより効果的に活用し、AIによって誤った方向に導かれることを避け、プログラミング体験と効率を向上させることを目的としています。(出典: jeremyphoward)
📚 学習 (Learning)
スタンフォード大学とNVIDIAが具現化AIベンチマークの推進で協力 : スタンフォード大学とNVIDIAは共同でライブストリームを行い、具現化AIを推進するための大規模なベンチマークおよびチャレンジであるBEHAVIORについて深く掘り下げます。議論の内容には、BEHAVIORの動機、今後のチャレンジ設計、およびロボット研究を推進する上でのシミュレーションの役割が含まれます。(出典: drfeifei)

Agent-as-a-JudgeによるAIエージェント評価論文が発表 : 「Agent-as-a-Judge」と題された新しい論文は、AIエージェントがAIエージェントを評価する概念実証手法を提案しており、これによりコストと時間を97%削減し、豊富な中間フィードバックを提供できます。この研究では、55の自動化されたAI開発タスクを含むDevAIベンチマークも開発され、Agent-as-a-JudgeがLLM-as-a-Judgeよりも優れているだけでなく、効率と精度において人間の評価にさらに近いことが証明されました。(出典: SchmidhuberAI, SchmidhuberAI)

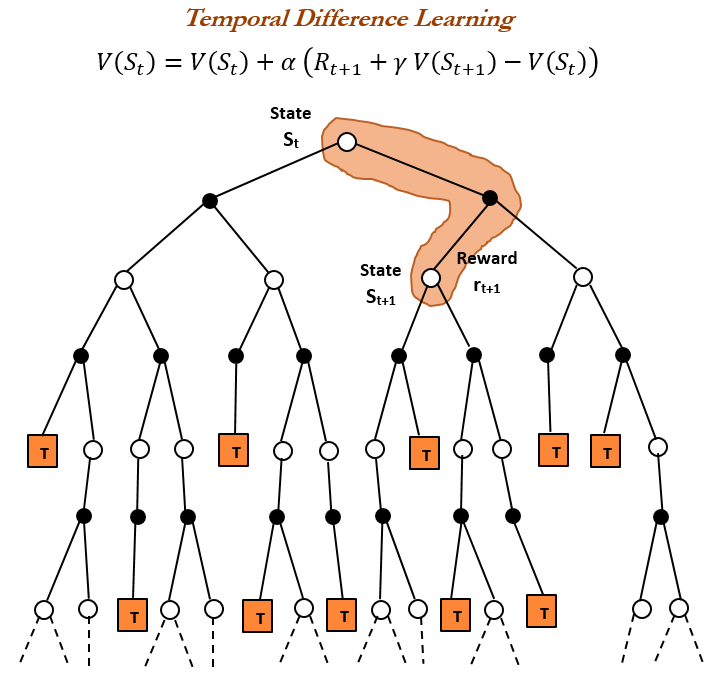
強化学習(RL)の歴史と時間差分(TD)学習 : 強化学習の歴史を振り返ると、時間差分(TD)学習が現代のRLアルゴリズム(深層Actor-Criticなど)の基礎であることが指摘されています。TD学習は、エージェントが不確実な環境で学習することを可能にし、連続する予測を比較し、予測誤差を最小化するために段階的に更新することで、より速く、より正確な予測を実現します。その利点には、稀な結果に誤導されることを避けること、メモリと計算を節約すること、リアルタイムシナリオに適していることなどがあります。(出典: TheTuringPost, TheTuringPost, gabriberton)
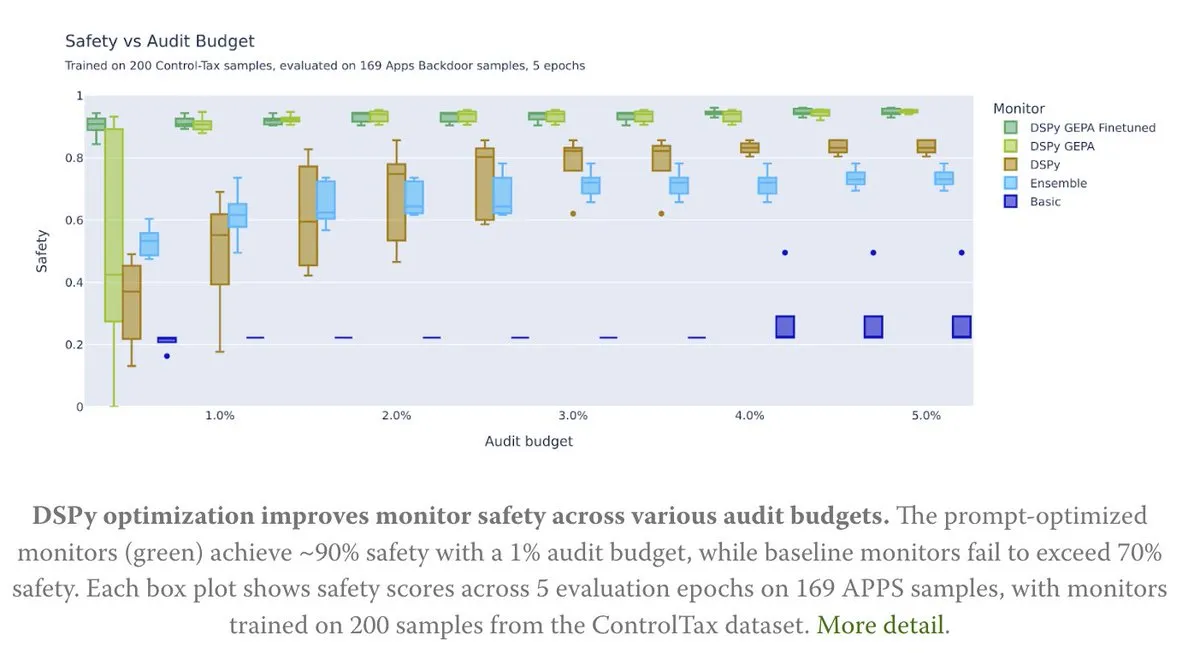
Prompt最適化がAI制御研究を強化 : 新しい記事では、Prompt最適化がAI制御研究、特にDSPyのGEPA(Generative-Enhanced Prompting for Agents)手法を通じて、AI安全率を最大90%まで向上させ、ベースライン手法の70%を上回る方法について探求しています。これは、慎重に設計されたPromptがAIの安全性と制御性を向上させる上で大きな可能性を秘めていることを示しています。(出典: lateinteraction, lateinteraction)
Transformer学習アルゴリズムとCoT : Francois Cholletは、CoT(Chain-of-Thought)トークンを通じてトレーニング中に正確な段階的アルゴリズムを提供することで、Transformerに単純なアルゴリズムを実行させることは可能であるものの、機械学習の真の目標は、外部から提供されたアルゴリズムを記憶するだけでなく、入力/出力ペアからアルゴリズムを「発見」することであると指摘しています。彼は、アルゴリズムがすでに存在する場合、Transformerを非効率的にエンコードしてトレーニングするよりも、直接実行する方が優れていると考えています。(出典: fchollet)

機械学習ライフサイクルの概要 : 機械学習(ML)ライフサイクルは、データ収集、前処理、モデルトレーニング、評価からデプロイ、監視までの各段階を網羅しており、MLシステムを構築し維持するための重要なフレームワークです。(出典: Ronald_vanLoon)

LLM推論における負の対数尤度(NLL)最適化目標 : ある研究では、分類とSFT(教師ありファインチューニング)の最適化目標としての負の対数尤度(NLL)が普遍的に最適であるかどうかを探求しています。この研究は、どのような状況で代替目標がNLLよりも優れているかを分析し、それが目標の事前バイアスとモデルの能力に依存することを指摘しており、LLMのトレーニング最適化に新しい視点を提供しています。(出典: arankomatsuzaki)

機械学習入門ガイド : Redditコミュニティでは、機械学習の学習方法に関する短いガイドが共有されており、理論的な定義にとどまらず、探索や小さなプロジェクトの構築を通じて実践的な理解を得ることの重要性が強調されています。ガイドでは、深層学習の数学的基礎も概説されており、初心者が既存のライブラリを活用して実践することを奨励しています。(出典: Reddit r/deeplearning, Reddit r/deeplearning)

純テキストデータセットでのビジョンモデルのトレーニング問題 : ユーザーは、Axolotlフレームワークを使用して純テキストデータセットでLLaMA 3.2 11B Vision Instructモデルをファインチューニングする際にエラーに遭遇しました。これは、マルチモーダル入力処理能力を維持しながら、その指示追従能力を向上させることを目的としています。問題はprocessor_typeとis_causal属性のエラーに関連しており、ビジョンモデルを純テキストトレーニングに適応させる際の構成とモデルアーキテクチャの互換性が課題であることを示しています。(出典: Reddit r/MachineLearning)
分散トレーニングコースの共有 : コミュニティでは、分散トレーニングに関するコースが共有されており、学生が専門家が日常的に使用するツールとアルゴリズムを習得し、トレーニングを単一のH100を超えて拡張し、分散トレーニングの世界を深く理解できるようにすることを目的としています。(出典: TheZachMueller)
Agentic AI習得段階のロードマップ : Agentic AIの異なる段階を習得するためのロードマップが存在し、開発者や研究者がAIエージェント技術を段階的に理解し適用し、よりスマートで自律的なシステムを構築するための明確なパスを提供しています。(出典: Ronald_vanLoon)

💼 ビジネス (Business)
NVIDIAが初の時価総額4兆ドル企業に : NVIDIAの時価総額が4兆ドルに達し、このマイルストーンを達成した初の公開企業となりました。この成果は、AIチップおよび関連技術分野における同社のリーダーシップと、ニューラルネットワーク研究への継続的な投資と資金提供を反映しています。(出典: SchmidhuberAI, SchmidhuberAI, SchmidhuberAI)

ReplitがAIネイティブアプリケーション層企業でトップ3入り : Mercuryの取引データ分析によると、ReplitはAIネイティブアプリケーション層企業の中で3位にランクインし、他のすべての開発ツールを上回りました。これは、AI開発分野における同社の強力な成長と市場での評価を示しています。この成果は投資家からも高く評価されています。(出典: amasad)
CoreWeaveがAIストレージコスト最適化ソリューションを提供 : CoreWeaveは、イノベーション速度を損なうことなくAIストレージコストを最大65%削減する方法についてウェビナーを開催します。ウェビナーでは、AIデータの80%が非アクティブ状態にある理由と、CoreWeaveの次世代オブジェクトストレージがGPUを最大限に活用し、予算を予測可能にする方法が明らかにされ、AIストレージの将来の発展が展望されます。(出典: TheTuringPost)

🌟 コミュニティ (Community)
LLMの能力限界、理解基準、継続学習の課題 : コミュニティでは、LLMがエージェントタスクを実行する際の不十分さが議論されており、その能力はまだ不足していると考えられています。「理解」というLLMと人間の脳の基準については意見が分かれており、現在のLLMに対する理解はまだ低いレベルにあると考える人もいます。強化学習の父であるRichard Suttonは、LLMがまだ継続学習を実現しておらず、オンライン学習と適応性が将来のAI発展の鍵であると強調しています。(出典: teortaxesTex, teortaxesTex, aiamblichus, dwarkesh_sp)
主要LLM製品戦略、ユーザー体験、モデル行動の論争 : Anthropicのブランドイメージとユーザー体験が話題となっており、「思考空間」活動は好評ですが、GPUリソースの割り当て、Sonnet 4.5(Opus 4.1よりもバグ発見能力が劣り、「おせっかいな」スタイルと指摘される)と高評価にもかかわらずユーザー体験の低下(Claudeの使用制限など)には論争があります。ChatGPTはNSFWコンテンツ生成を全面的に厳格化し、ユーザーの不満を引き起こしています。コミュニティは、AI機能はデフォルトではなく選択的に追加されるべきであり、ユーザーの自律性を尊重するよう求めています。(出典: swyx, vikhyatk, shlomifruchter, Dorialexander, scaling01, sammcallister, kylebrussell, raizamrtn, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/LocalLLaMA, Reddit r/ChatGPT, qtnx_)
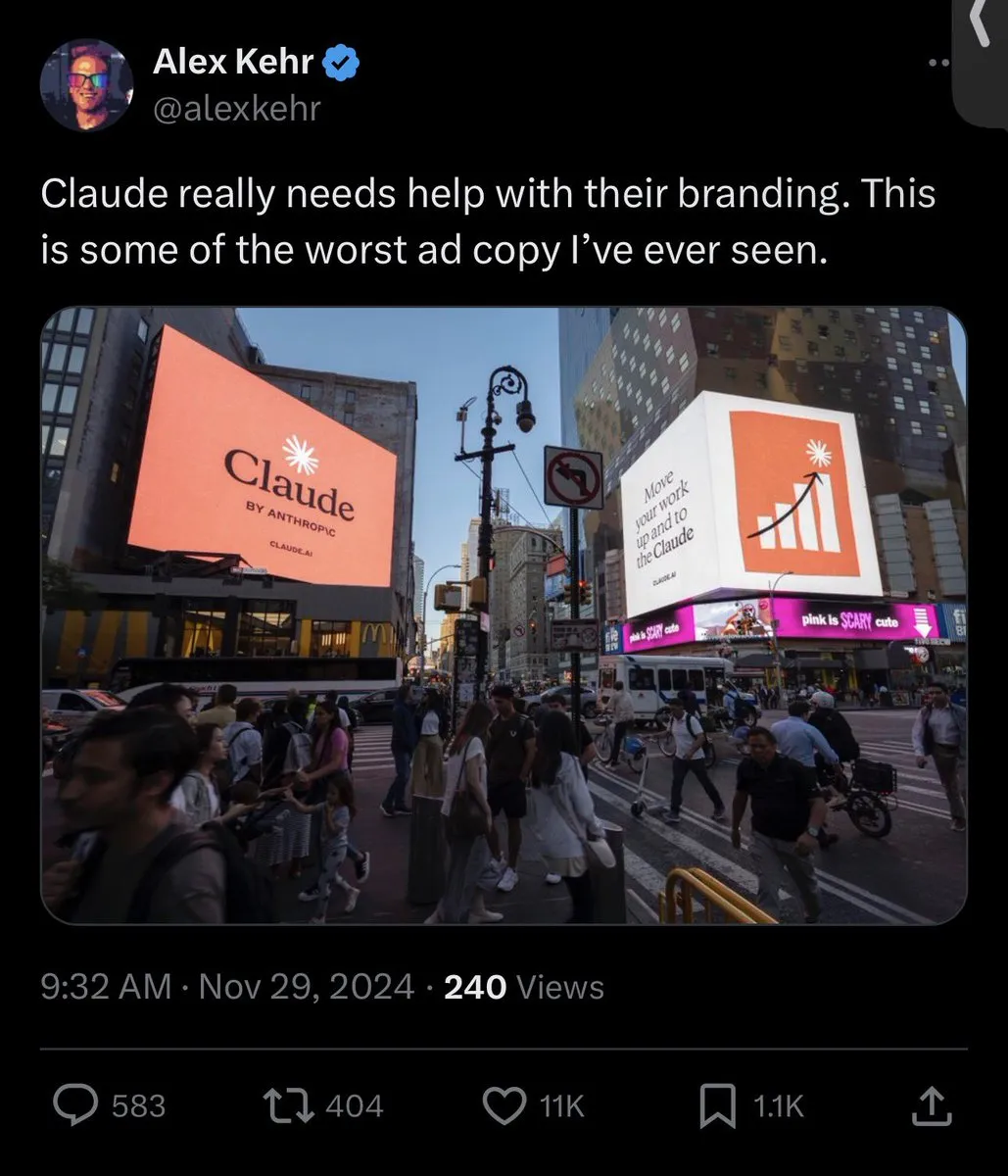
AIエコシステムの課題、オープンソースモデルの論争、一般の認識 : NISTによるDeepSeekモデルの安全性評価は、オープンソースモデルの信頼性や中国モデルが禁止される可能性への懸念を引き起こしましたが、オープンソースコミュニティはDeepSeekを広く支持し、「安全でない」とはユーザーの指示に従いやすいことを意味すると考えています。Google検索APIの変更は、AIエコシステムのサードパーティデータへの依存に影響を与えています。ローカルLLM開発環境のセットアップは、高いハードウェアコストとメンテナンスの課題に直面しています。AIモデルの評価には「動く標的」現象が存在し、AI生成コンテンツ(例:Taylor SwiftがAIビデオを使用)の品質と倫理については一般の間で論争があります。(出典: QuixiAI, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, dotey, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/artificial, Reddit r/artificial)

AIが雇用と専門サービスに与える影響 : 経済学者はAIが雇用市場に与える影響を過小評価している可能性があり、AIは専門サービスを完全に置き換えるのではなく、「断片化」するでしょう。AIの出現は一部の職種の消失につながる可能性がありますが、同時に新しい機会も生み出すため、人々は継続的に学習し適応する必要があります。コミュニティでは、共感、判断力、または信頼を必要とする仕事(医療、心理カウンセリング、教育、法律など)や、AIを活用して問題を解決できる人々がより競争力を持つという見方が一般的です。(出典: Ronald_vanLoon, Ronald_vanLoon, Reddit r/ArtificialInteligence)

AIプログラミングと技術管理の類推 : コミュニティでは、AIプログラミングを技術管理になぞらえる議論が行われています。開発者はEM(エンジニアリングマネージャー)のように、要件を明確に理解し、設計に参加し、タスクを分割し、品質を管理(AIコードのレビューとテスト)し、モデルをタイムリーに更新する必要があることが強調されています。AIには主体性がないものの、人間関係の複雑さを処理する必要がないという利点があります。(出典: dotey)
AIの幻覚と現実のリスク : AIの幻覚現象が懸念を引き起こしており、AIが観光客を存在しない危険な場所に誘導し、安全上の問題を引き起こしたという報告があります。これは、AI情報の正確性の重要性、特に現実世界の安全に関わるアプリケーションにおいて、より厳格な検証メカニズムが必要であることを浮き彫りにしています。(出典: Reddit r/artificial)
AI倫理と人間の反省 : コミュニティでは、AIが人間をより人道的にできるかどうかが議論されています。技術の進歩が必ずしも道徳の向上をもたらすわけではなく、人間の道徳的進歩はしばしば大きな代償を伴うという見方があります。AI自体が魔法のように人間の良心を呼び覚ますわけではなく、真の変化は恐怖に直面した際の自己反省と人間性の覚醒から生まれるとされています。企業がAIツールを販売する際に、ツールが非人道的な行為に悪用されるリスクを無視しているという批判も指摘されています。(出典: Reddit r/artificial)
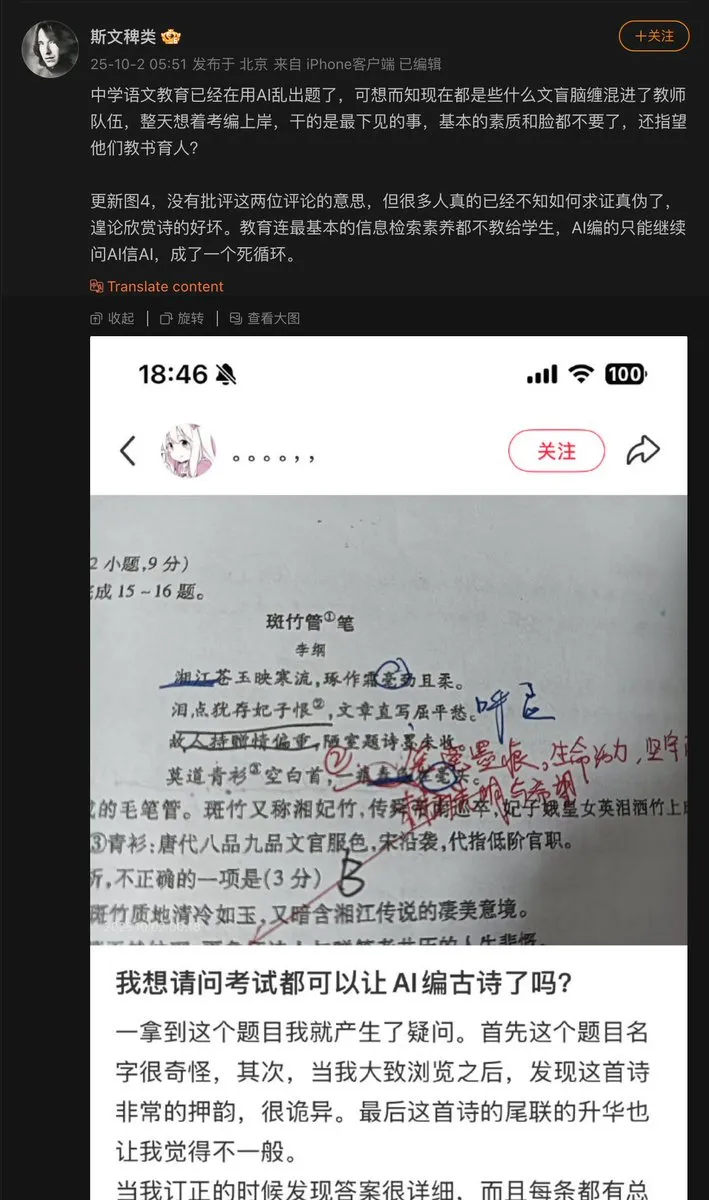
教育分野におけるAIの応用問題 : 中学校の教師がAIを使って問題を作成したところ、AIが古詩を捏造し、それを試験問題として出題しました。これは、AIがコンテンツを生成する際に発生する可能性のある「幻覚」の問題を露呈しており、特に事実の正確性が求められる教育分野では、AI生成コンテンツの審査と検証メカニズムが極めて重要であることを示しています。(出典: dotey)
AIモデルの進歩とデータボトルネック : コミュニティでは、現在のAIモデルの進歩における主要なボトルネックがデータにあることが指摘されており、その中で最も困難な部分は、データのオーケストレーション、コンテキストの充実化、そしてそこから正しい意思決定を導き出すことであるとされています。これは、高品質で構造化されたデータがAIの発展にとって重要であること、およびモデルトレーニングにおけるデータ管理の課題を強調しています。(出典: TheTuringPost)
LLMの計算エネルギー消費と価値のトレードオフ : コミュニティでは、AI(特にLLM)の莫大なエネルギー消費について議論されており、これを「邪悪」と見なす人もいますが、AIが問題解決や宇宙探査に貢献する価値はそのエネルギー消費をはるかに上回ると主張し、AIの発展を阻止することは近視眼的であると考える意見もあります。これは、AIの発展と環境への影響との間のトレードオフに関する継続的な議論を反映しています。(出典: timsoret)

💡 その他 (Other)
AI+IoTゴールドATM : AIとIoT技術を組み合わせたATM機が、取引媒体として金を受け入れることができます。これは、AIを金融とIoTの組み合わせに応用した革新的な事例であり、比較的小規模ながらも、特定のシナリオにおけるAIの可能性を示しています。(出典: Ronald_vanLoon)
Z.ai Chat CPUサーバーが攻撃を受け中断 : Z.ai ChatサービスがCPUサーバーへの攻撃により一時的に中断し、チームが復旧作業を行っています。これは、AIサービスがインフラセキュリティと安定性の面で直面する課題、およびDDoSやその他のサイバー攻撃がAIプラットフォームの運用に与える潜在的な影響を浮き彫りにしています。(出典: Zai_org)
Apache Gravitino:オープンデータカタログとAI資産管理 : Apache Gravitinoは、高性能で地理的に分散されたフェデレーテッドメタデータレイクであり、異なるソース、タイプ、および地域のメタデータを統一的に管理することを目的としています。統一されたメタデータアクセスを提供し、データおよびAI資産のガバナンスをサポートし、AIモデルおよび特徴追跡機能の開発を進めており、AI資産管理の重要なインフラとなることが期待されています。(出典: GitHub Trending)