

キーワード:AI業界, GPT-5, AGI, ハイプ修正, AIセキュリティ, AIプログラミング, AIエージェント, マルチモーダルモデル, AI材料科学, LLM推論最適化, エンボディドAI, AIベンチマークテスト, AI駆動型PPT生成
🔥 注目
AI業界の「誇大広告の修正」と現実的な検証: 2025年、AI業界は「誇大広告の修正」段階に入り、AIに対する市場の期待は「万能薬」から理性的なものへと回帰しつつあります。Sam Altmanをはじめとする業界のリーダーたちは、特にスタートアップの評価額やデータセンター建設への巨額な投資においてAIバブルが存在することを認めています。同時に、GPT-5の発表は期待に届かなかったとされ、LLMの発展におけるボトルネックについての議論を引き起こしました。専門家たちは、AIの真の能力を再検証し、生成系AIの「華やかなデモンストレーション」と、医療や科学分野における予測型AIの実質的なブレークスルーを区別するよう呼びかけています。AIの価値は、AGIの盲目的な追求ではなく、その信頼性と持続可能性にあると強調されています。(出典: MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review)

材料科学分野におけるAIのブレークスルーと課題: AIは新材料発見の加速に応用されており、AIエージェントが実験の計画、実行、解釈を行うことで、発見プロセスを数十年から数年に短縮することが期待されています。Lila SciencesやPeriodic Labsなどの企業は、従来の材料科学における合成とテストのボトルネックを解決するため、AI駆動の自動化ラボを構築しています。DeepMindはかつて「数百万の新材料」を発見したと主張しましたが、その実際の新規性や実用性には疑問が呈されており、仮想シミュレーションと物理的現実とのギャップが浮き彫りになっています。業界は、純粋な計算モデルから実験的検証を組み合わせたアプローチへと移行しており、室温超伝導体などの画期的な材料の発見を目指しています。(出典: MIT Technology Review)

AIプログラミングの生産性論争と技術的負債: AIプログラミングツールが普及し、MicrosoftとGoogleのCEOは、AIが自社コードの4分の1を生成したと主張し、AnthropicのCEOは将来的に90%のコードがAIによって書かれると予測しています。しかし、実際の生産性向上には議論があり、AIが開発速度を低下させ、「技術的負債」(コード品質の低下、保守の困難さなど)を増加させる可能性があるという研究もあります。それにもかかわらず、AIはボイラープレートコードの記述、テスト、バグ修正において優れた性能を発揮しており、Claude Codeのような新世代のエージェントツールは、計画モードとコンテキスト管理を通じて、複雑なタスク処理能力を大幅に向上させています。業界は、AI駆動の開発モデルに適応するため、「使い捨てコード」や形式検証などの新しいパラダイムを模索しています。(出典: MIT Technology Review)

AI安全推進派のAGIリスクへの固執と懸念: 最近のAI開発は「誇大広告の修正」期に入り、GPT-5の性能は平凡であるとされていますが、AI安全推進派(「AI終末論者」)はAGI(汎用人工知能)の潜在的リスクについて依然として深く懸念しています。彼らは、AIの進歩速度が鈍化する可能性はあるものの、その根本的な危険性は変わっておらず、政策立案者がAIリスクを十分に重視していないことに失望を感じています。彼らは、AGIが数年ではなく数十年後に実現するとしても、制御問題に対処するために直ちにリソースを投入する必要があると強調し、AIバブルへの業界の過剰投資が長期的な悪影響をもたらす可能性に警鐘を鳴らしています。(出典: MIT Technology Review)

🎯 動向
マルチモーダル動画生成モデルの継続的なブレークスルー: AlibabaはWan 2.6動画モデルを発表しました。これは、ロールプレイング、音声と映像の同期、マルチショット生成、音声駆動をサポートし、1回の動画長が15秒に達する「小さなSora 2」と見なされています。ByteDanceもSeedance 1.5 Proを発表し、方言サポートが特徴です。HuggingFace Daily PapersのLongVie 2は、マルチモーダルで制御可能な超長尺動画世界モデルを提案し、制御可能性、長期的な視覚品質、時間的一貫性を強調しています。これらの進展は、動画生成技術がリアリズム、インタラクティブ性、応用シナリオにおいて著しく向上していることを示しています。(出典: Alibaba_Wan, op7418, op7418, HuggingFace Daily Papers)

AI音声技術が多言語とリアルタイムストリーミングで新たな進展: AlibabaはCosyVoice 3 TTSモデルをオープンソース化しました。これは9言語と18以上の中国語方言をサポートし、多言語/クロス言語ゼロショット音声クローンを提供し、150ミリ秒の超低遅延双方向ストリーミングを実現します。OpenAIのリアルタイムAPIもgpt-4o-mini-transcribeとgpt-4o-mini-ttsモデルを更新し、ハルシネーションとエラー率を大幅に削減し、多言語性能を向上させました。Google DeepMindのGemini 2.5 Flash Native Audioモデルも更新され、指示の遵守と対話の自然さがさらに最適化され、リアルタイム音声エージェントの応用を推進しています。(出典: ImazAngel, Reddit r/LocalLLaMA, snsf, GoogleDeepMind)
大規模モデルの長文脈推論と効率最適化: QwenLong-L1.5は、体系的な後学習の革新により、長文脈推論能力においてGPT-5やGemini-2.5-Proに匹敵し、超長尺タスクで優れた性能を発揮しています。GPT-5.2も長文脈能力でユーザーから好評を得ており、特にポッドキャストの要約において詳細がより豊富であるとされています。さらに、ReFusionは新しいマスク拡散モデルを提案し、スロットレベル並列デコードにより性能と効率を大幅に向上させ、平均18倍の高速化を実現し、自己回帰モデルとの性能差を縮めています。(出典: gdb, HuggingFace Daily Papers, HuggingFace Daily Papers, teortaxesTex)
身体性AIとロボット技術の進展: AgiBotはLingxi X2ヒューマノイドロボットを発表しました。これは人間のような移動能力と多機能スキルを備えています。HuggingFace Daily Papersでは、Toward Ambulatory Visionが視覚に基づいた能動的な視点選択を探索し、Spatial-Aware VLA Pretrainingが人間の動画を通じて視覚-物理アライメントを実現し、VLSAがプラグアンドプレイの安全制約レイヤーを導入してVLAモデルの安全性を向上させるなど、身体性AIに焦点を当てた複数の研究が紹介されています。これらの研究は、2D視覚と3D物理環境での行動とのギャップを縮め、ロボット学習と実際の展開を推進することを目指しています。(出典: Ronald_vanLoon, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
NVIDIAとMetaのAIアーキテクチャとモデルオープンソース化への貢献: NVIDIAはNemotron v3 Nanoオープンモデルファミリーを発表し、完全なトレーニングスタック(RLインフラストラクチャ、環境、事前学習および後学習データセットを含む)をオープンソース化しました。これは、あらゆる業界のプロフェッショナルエージェントAIの構築を推進することを目的としています。MetaはVL-JEPA視覚-言語結合埋め込み予測アーキテクチャを発表しました。これは初の非生成モデルであり、リアルタイムストリーミングアプリケーションで汎用視覚-言語タスクを効率的に実行でき、大規模VLMの性能を上回っています。(出典: ylecun, QuixiAI, halvarflake)

AIベンチマークテストと評価方法の革新: Google ResearchはFACTS Leaderboardを発表しました。これは、マルチモーダル、パラメータ知識、検索、グラウンディングの4つの側面でLLMの事実性を包括的に評価し、異なるモデルにおけるカバー率と矛盾率のトレードオフを明らかにしています。V-REXベンチマークテストは「問題チェーン」を通じてVLMの探索的視覚推論能力を評価し、STARTはグラフ理解におけるテキストと空間学習に焦点を当てています。これらの新しいベンチマークは、複雑な現実世界タスクにおけるAIモデルのパフォーマンスをより正確に測定することを目指しています。(出典: omarsar0, HuggingFace Daily Papers, HuggingFace Daily Papers)

ウェブ環境におけるAIエージェントの自律性向上: WebOperatorは、行動認識ツリー検索フレームワークを提案しました。これにより、LLMエージェントは部分的に観測可能なウェブ環境で信頼性の高いバックトラックと戦略的探索を行うことができます。この方法は、複数の推論コンテキストを通じて行動候補を生成し、無効な行動をフィルタリングすることで、WebArenaタスクの成功率を大幅に向上させ、戦略的予見性と安全な実行を組み合わせるという重要な利点を強調しています。(出典: HuggingFace Daily Papers)
AI補助自動運転と4D世界モデル: DrivePIは空間認識4D MLLMであり、自動運転の理解、認識、予測、計画を統合します。これは、点群、マルチビュー画像、言語指示を統合し、テキスト-占有率およびテキスト-フローQAペアを生成することで、3D占有率と占有フローの正確な予測を実現し、nuScenesなどのベンチマークで既存のVLAおよび専門VAモデルを上回っています。GenieDriveは、物理認識型運転世界モデルに焦点を当て、4D占有率ガイド付き動画生成を通じて、予測精度と動画品質を向上させています。(出典: HuggingFace Daily Papers, HuggingFace Daily Papers)
🧰 ツール
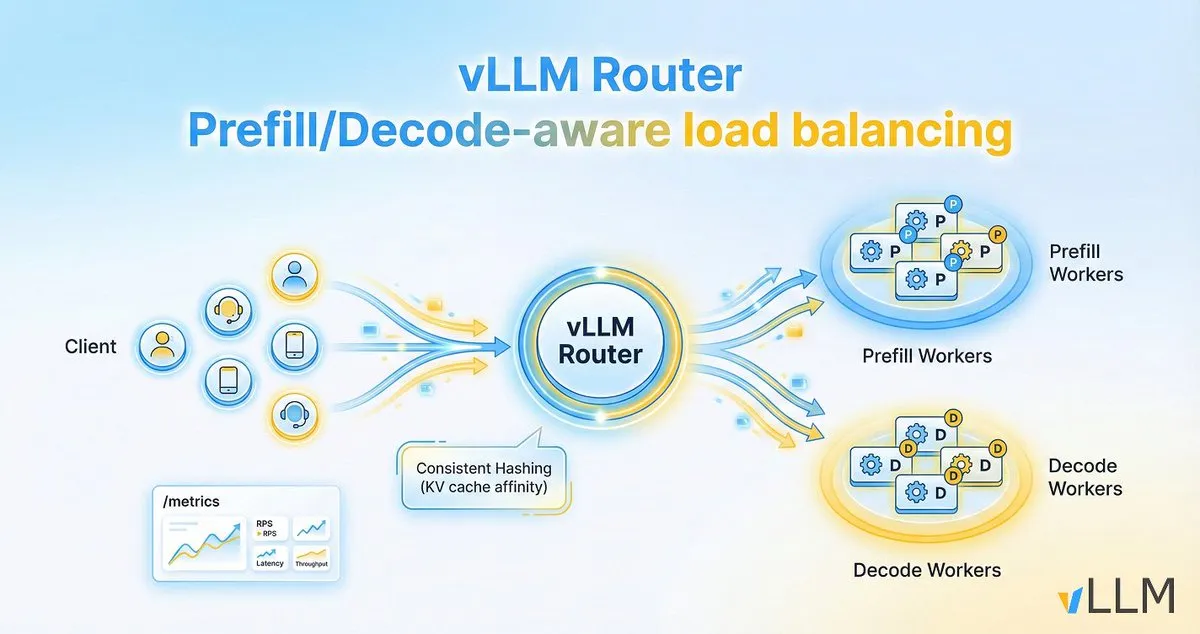
vLLM RouterがLLM推論効率を向上: vLLMプロジェクトはvLLM Routerを発表しました。これはvLLMクラスタ専用の軽量、高性能、プリフィル/デコード認識型ロードバランサーです。Rustで記述され、一貫性ハッシュ、Two Random Choicesなどの戦略をサポートし、KVキャッシュの局所性を最適化し、対話トラフィックとプリフィル/デコードの分離のボトルネックを解決することで、LLM推論のスループットを向上させ、テールレイテンシーを低減することを目指しています。(出典: vllm_project)
AI21 MaestroがAIエージェント構築を簡素化: AI21LabsのVibe AgentがAI21 Maestroに導入され、ユーザーは簡単な英語の説明でAIエージェントを作成できるようになりました。このツールは、エージェントの用途、検証チェック、必要なツール、モデル/計算設定を自動的に提案し、各ステップをリアルタイムで説明することで、複雑なAIエージェント構築の敷居を大幅に下げています。(出典: AI21Labs)
OpenHands SDKがエージェント駆動型ソフトウェア開発を加速: OpenHandsはソフトウェアエージェントSDKをリリースしました。これは、エージェント駆動型ソフトウェアを構築するための、高速、柔軟、かつ本番環境対応のフレームワークを提供することを目的としています。このSDKのリリースは、開発者が複雑なソフトウェア開発タスクに対応するために、AIエージェントをより効率的に統合および管理するのに役立ちます。(出典: gneubig)

Claude Code CLIの更新で開発体験が向上: AnthropicはClaude Code 2.0.70バージョンをリリースし、13のCLI改善が含まれています。主な更新には、Enterキーでのプロンプト提案の受け入れ、MCPツール権限のワイルドカード構文、プラグインマーケットの自動更新スイッチ、強制計画モードなどが含まれます。さらに、メモリ使用効率が3倍向上し、スクリーンショットの解像度も高くなり、Claude Codeを使用したソフトウェア開発における開発者のインタラクションと効率を最適化することを目指しています。(出典: Reddit r/ClaudeAI)
Qwen3-Coderが2Dゲームの迅速な開発を実現: Redditユーザーは、AlibabaのQwen3-Coder(480B)モデルとCursor IDEを使用して、わずか数秒で2Dマリオ風ゲームを構築する方法を実演しました。このモデルは、単一のプロンプトからステップを自動的に計画し、依存関係をインストールし、コードとプロジェクト構造を生成し、直接実行できます。実行コストは低く(100万トークンあたり約2ドル)、GPT-4エージェントモードに近い体験を提供し、オープンソースモデルのコード生成およびエージェントタスクにおける強力な可能性を示しています。(出典: Reddit r/artificial)
AI駆動の株式詳細調査ツール: Deep Researchツールは、AIを利用してSEC文書や業界出版物からデータを抽出し、標準化されたレポートを生成することで、企業の比較とスクリーニングを簡素化します。ユーザーはティッカーシンボルを入力して詳細な分析を得ることができ、このツールは投資家が市場ニュースに惑わされず、実質的な財務情報に焦点を当てて、より効率的にファンダメンタルズ分析を行うのに役立つことを目指しています。(出典: Reddit r/ChatGPT)
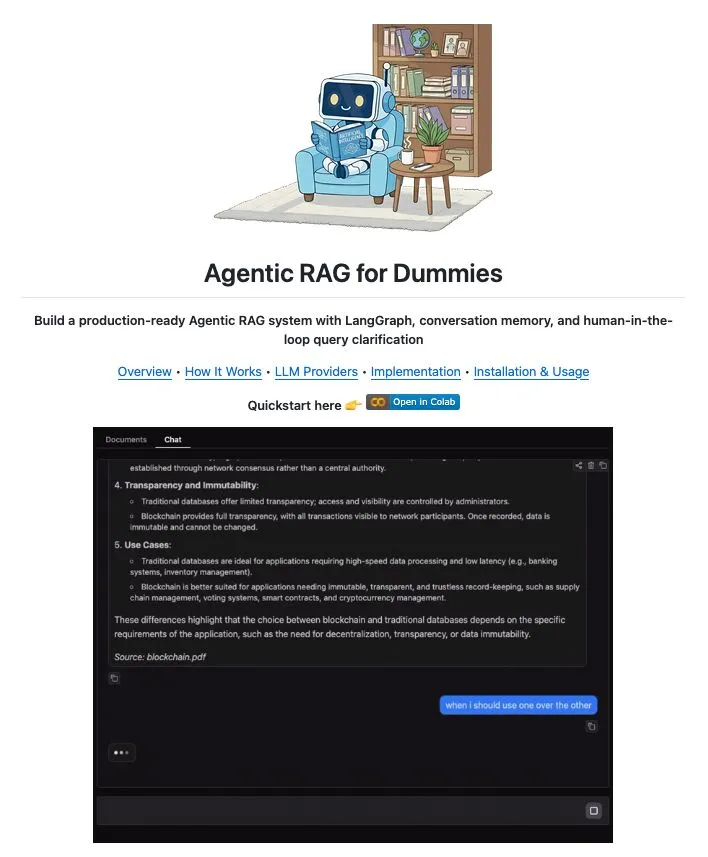
LangChain 1.2がAgentic RAGアプリケーション構築を簡素化: LangChainは1.2バージョンをリリースし、特にcreate_agent機能において、組み込みツールと厳格モードのサポートを簡素化しました。これにより、開発者はAgentic RAG(検索拡張生成)アプリケーションを、ローカルでもGoogle Collab上でも、より簡単に構築できるようになり、その100%オープンソースの特性が強調されています。(出典: LangChainAI, hwchase17)
SkyworkがAI駆動のPPT生成機能をリリース: Skyworkプラットフォームは、Nano Banana ProをベースにしたPPT生成機能をリリースしました。これは、従来のAI生成PPTの編集が難しいという問題を解決します。新機能はレイヤー分離をサポートし、ユーザーはオンラインでテキストや画像を修正でき、pptx形式でエクスポートしてローカルで編集することも可能です。さらに、このツールは業界の専門データベースを統合し、多様なグラフ生成をサポートしてデータ精度を確保し、クリスマスプロモーション割引も提供しています。(出典: op7418)

小型モデルがエッジ側Infrastructure as Codeを強化: Redditユーザーは、エッジデバイスやブラウザ上で動作する500MBの「Infrastructure as Code」(IaC)モデルを共有しました。このモデルはIaCタスクに特化しており、小型ながら強力な機能を持ち、リソースが限られた環境でのインフラストラクチャの展開と管理に効率的なソリューションを提供し、特定の垂直分野における小型AIモデルの大きな可能性を示唆しています。(出典: Reddit r/deeplearning)
📚 学習
Chinarxiv.org:中国語プレプリントの自動翻訳プラットフォーム: Chinarxiv.orgが正式にローンチされました。これは、中国と西洋の科学研究間の言語の壁を埋めることを目的とした、完全に自動化された中国語プレプリント翻訳プラットフォームです。このプラットフォームはテキストだけでなく、図表の内容も翻訳するため、西洋の研究者が中国科学界の最新の研究成果をより簡単にアクセスし、理解できるようになります。(出典: menhguin, andersonbcdefg, francoisfleuret)
AIスキルとAgentic AI学習ロードマップ: Ronald_vanLoonは、2025年にAIスキルを習得するための12の主要能力と、Agentic AIの習熟ロードマップを共有しました。これらのリソースは、急速に発展するAI分野で競争力を高めるための個人を導くことを目的としており、基本的なAI知識から高度なエージェントシステム開発までの学習パスを網羅し、AI時代における継続的な学習と新しいスキルへの適応の重要性を強調しています。(出典: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

LLM推論プロセスの最適化とデータ駆動型AI開発: Meta Superintelligence Labsの研究は、「並列ドラフト→コンパクトなワークスペースへの蒸留→洗練」というPDR(Parallel Draft-Distill-Refine)戦略により、推論制約下で最適なタスク精度を達成できることを示しています。同時に、あるブログ記事は「データはAIのギザギザの最前線である」と強調し、コーディングと数学の分野はデータが豊富で検証可能であるため成功しているが、科学分野は比較的遅れており、データ生成における蒸留と強化学習の役割について議論しています。(出典: dair_ai, lvwerra)

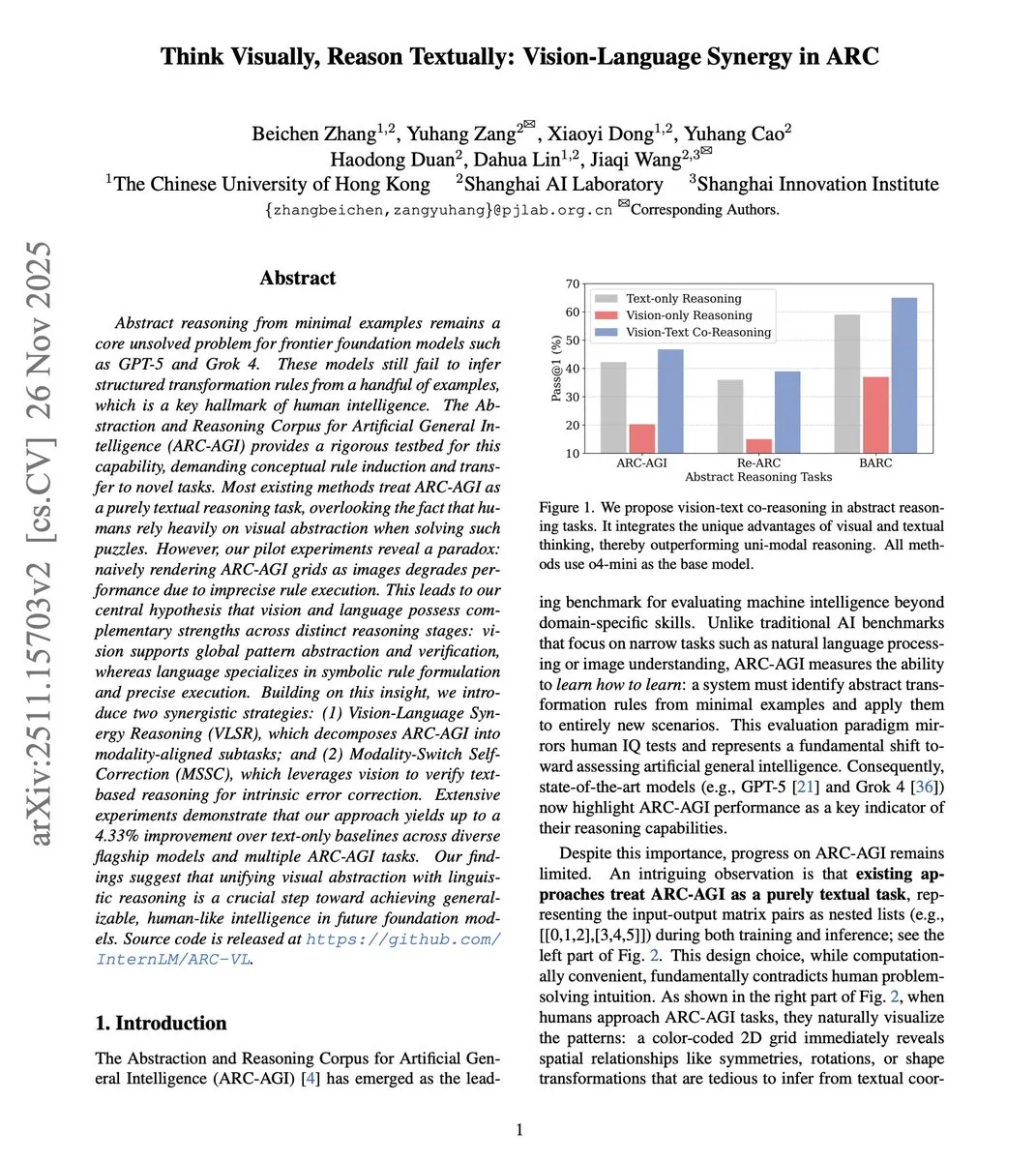
視覚-言語協調推論による抽象能力の向上: 新しい研究では、視覚-言語協調推論(VLSR)フレームワークが提案されています。これは、異なる推論段階で視覚とテキストのモダリティを戦略的に組み合わせることで、ARC-AGIベンチマークのような抽象推論タスクにおけるLLMのパフォーマンスを大幅に向上させます。この方法は、視覚をグローバルパターン認識に、テキストを正確な実行に利用し、モダリティ切り替えによる自己修正メカニズムを通じて確証バイアスを克服し、小型モデルでもGPT-4oの性能を上回っています。(出典: dair_ai)
LLM推論トークンを計算状態として捉える新しい視点: State over Tokens (SoT) の概念フレームワークは、LLMの推論トークンを単純な言語的記述ではなく、外部化された計算状態として再定義します。これは、トークンが忠実なテキスト解釈なしにどのように正しい推論を駆動するかを説明し、LLMの内部プロセスを理解するための新しい研究方向を開拓し、研究がテキスト解釈を超えて、推論トークンを状態としてデコードすることに焦点を当てるべきであることを強調しています。(出典: HuggingFace Daily Papers)
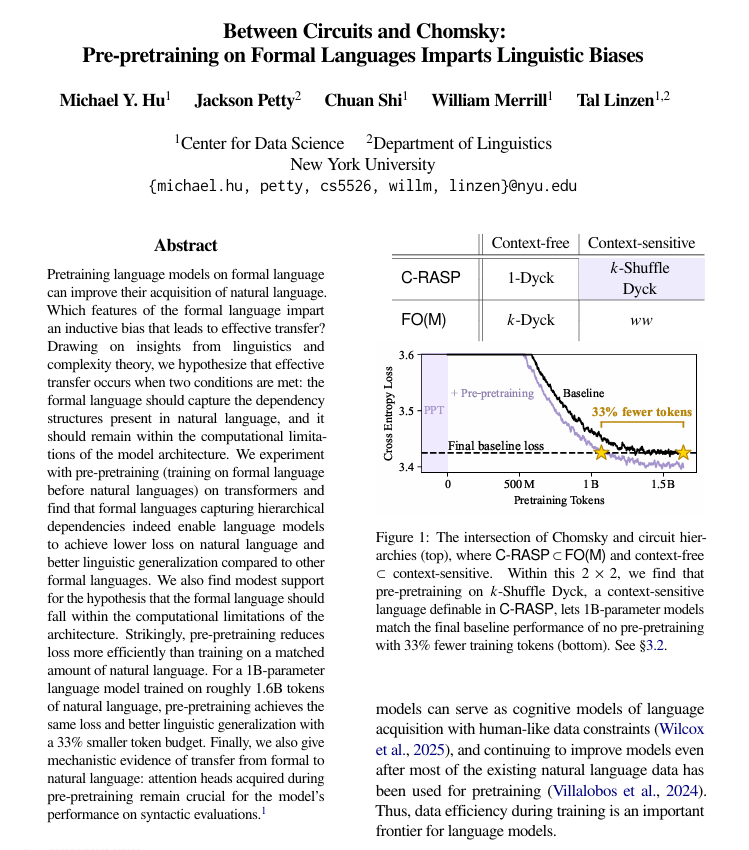
形式言語事前学習による自然言語学習の向上: ニューヨーク大学の研究により、自然言語の事前学習の前に、形式的でルールベースの言語で事前学習を行うことが、言語モデルが人間の言語をより良く学習するのに大きく役立つことが発見されました。研究は、この形式言語が自然言語と類似した構造(特に階層関係)を持ち、かつ十分に単純である必要があると指摘しています。この方法は、同量の自然言語データを追加するよりも効果的であり、学習された構造メカニズムはモデル内部で転移します。(出典: TheTuringPost)
物理知識をコード生成プロセスに注入: Chain of Unit-Physicsフレームワークは、物理知識をコード生成プロセスに直接組み込みます。ミシガン大学の研究者たちは、人間の専門知識を単位物理テストとしてエンコードすることでコード生成をガイドし、制約する逆科学コード生成方法を提案しました。マルチエージェント設定において、このフレームワークはシステムが5〜6回の反復で正しい解決策に到達することを可能にし、実行速度を33%向上させ、メモリ使用量を30%削減し、エラー率を極めて低く抑えます。(出典: TheTuringPost)
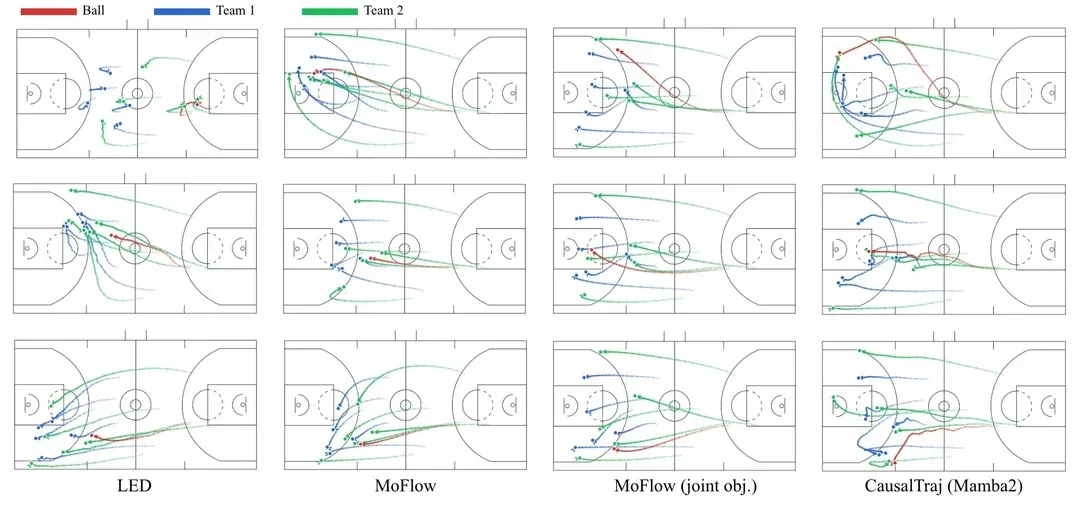
スポーツチームのマルチエージェント軌道予測モデルCausalTraj: CausalTrajは、チームスポーツにおけるマルチエージェント共同軌道予測のための自己回帰モデルです。このモデルは、個々のエージェント指標を最適化するだけでなく、共同予測尤度目標を直接訓練することで、個々のパフォーマンスを保証しつつ、マルチエージェント軌道の一貫性と妥当性を大幅に向上させます。研究では、共同モデリングをより効果的に評価する方法や、サンプリングされた軌道の現実的な可能性を評価する方法についても議論されています。(出典: Reddit r/deeplearning)
LLMトレーニングデータ:答えか、それとも質問か?: Redditでの議論では、現在のほとんどのLLMトレーニングデータセットが「答え」に焦点を当てているのに対し、人間の知能の重要な部分は「質問」が形成される前の混乱、曖昧さ、反復プロセスに存在すると提起されています。実験では、初期の思考、曖昧な質問、繰り返しの修正を含む対話データでトレーニングされたモデルは、ユーザーの意図を明確にし、不明確なタスクを処理し、誤った結論を回避する点でより優れたパフォーマンスを示し、トレーニングデータが人間の思考の複雑さをより包括的に捉える必要があることを示唆しています。(出典: Reddit r/MachineLearning)
💼 ビジネス
OpenAIがneptune.aiを買収し、最先端研究ツールを強化: OpenAIはneptune.aiの買収に関する最終合意を発表しました。この買収は、最先端研究をサポートするツールとインフラストラクチャを強化することを目的としています。この買収は、OpenAIがAI開発と実験管理における能力を向上させ、モデルのトレーニングと反復プロセスをさらに加速し、AI分野での主導的地位を固めるのに役立つでしょう。(出典: dl_weekly)

DatabricksのQ3業績が好調、40億ドル超の資金調達: Databricksは好調な第3四半期業績を発表しました。年間経常収益(ARR)は48億ドルを超え、前年比55%以上の成長を記録しました。データウェアハウスとAI製品事業の年間経常収益もそれぞれ10億ドルを突破しています。同社はまた、40億ドルを超えるシリーズL資金調達を完了し、評価額は1340億ドルに達しました。この資金は、Lakebase Postgres、Agent Bricks、Databricks Appsへの投資に充てられ、データインテリジェンスアプリケーションの開発を加速する計画です。(出典: jefrankle, jefrankle)

InfosysとFormula EがAI駆動のデジタルトランスフォーメーションを推進: InfosysはABB FIA Formula E世界選手権と提携し、AI駆動プラットフォームを通じてモータースポーツのファン体験と運営効率を革新しています。この提携には、AIを活用したパーソナライズされたコンテンツ提供、リアルタイムのレース分析、AI生成解説、および炭素排出削減目標達成のためのロジスティクスと移動の最適化が含まれます。AI技術は、イベントの魅力を高めるだけでなく、持続可能性と従業員の多様性も促進し、Formula Eを最もデジタル化され、持続可能なモータースポーツへと変革しています。(出典: MIT Technology Review)

🌟 コミュニティ
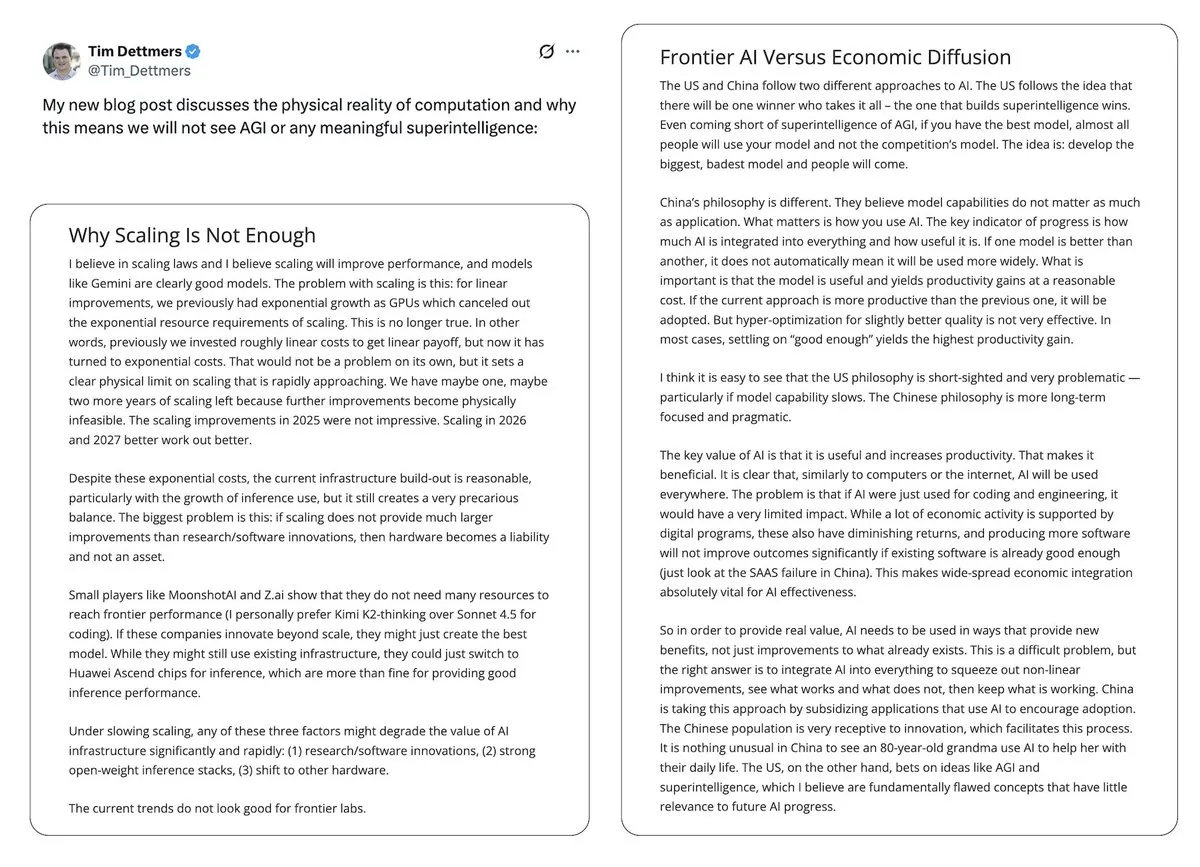
AIバブルとAGIの展望に関する論争: Yann LeCunは、LLMとAGIは「全くのナンセンス」であると公言し、AIの未来は現在のLLMパラダイムではなく世界モデルにあると考えており、AI技術が少数の企業に独占されることを懸念しています。Tim Dettmersの論文「Why AGI Will Not Happen」も、スケールメリットの逓減に関する議論で注目を集めています。同時に、AI安全推進派は、AGIの到来時期を調整しつつも、その潜在的な危険性に固執し、政策立案者がAIリスクを十分に重視していないことに懸念を表明しています。(出典: ylecun, ylecun, hardmaru, MIT Technology Review)
GPT-5.2とGeminiに対するユーザー評価の二極化: ソーシャルメディアでは、OpenAI GPT-5.2に対するユーザーの評価が賛否両論に分かれています。あるユーザーは、その長文脈処理能力に満足し、ポッドキャストの要約がより豊富になったと評価しています。しかし、別のユーザーは、GPT-5.2の回答が汎用的すぎ、深みに欠け、さらには「自己認識」のような応答が見られるとして強い不満を表明し、一部のユーザーはGeminiに移行しています。この二極化は、新モデルの性能と振る舞いに対するユーザーの敏感さ、およびAI製品体験への継続的な関心を反映しています。(出典: gdb, Reddit r/ArtificialInteligence)

AIが人間の認知、仕事の基準、倫理的行動に与える影響: AIの長期的な使用は、人間の認知パターンと仕事の基準を静かに変化させ、思考をより構造化し、成果物の品質に対する期待を高めています。AIは高品質なコンテンツ生成を効率化しますが、技術への過度な依存につながる可能性もあります。AIの倫理的側面では、「トロッコ問題」におけるモデルの異なる振る舞い(Grokの功利主義とGemini/ChatGPTの利他主義)が、AIの価値観設定に関する議論を引き起こしています。同時に、AIモデルの安全プロンプトの「自己規律」的性質も、AIの内部制御メカニズムがユーザー体験に間接的に与える影響を明らかにしています。(出典: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/ChatGPT)
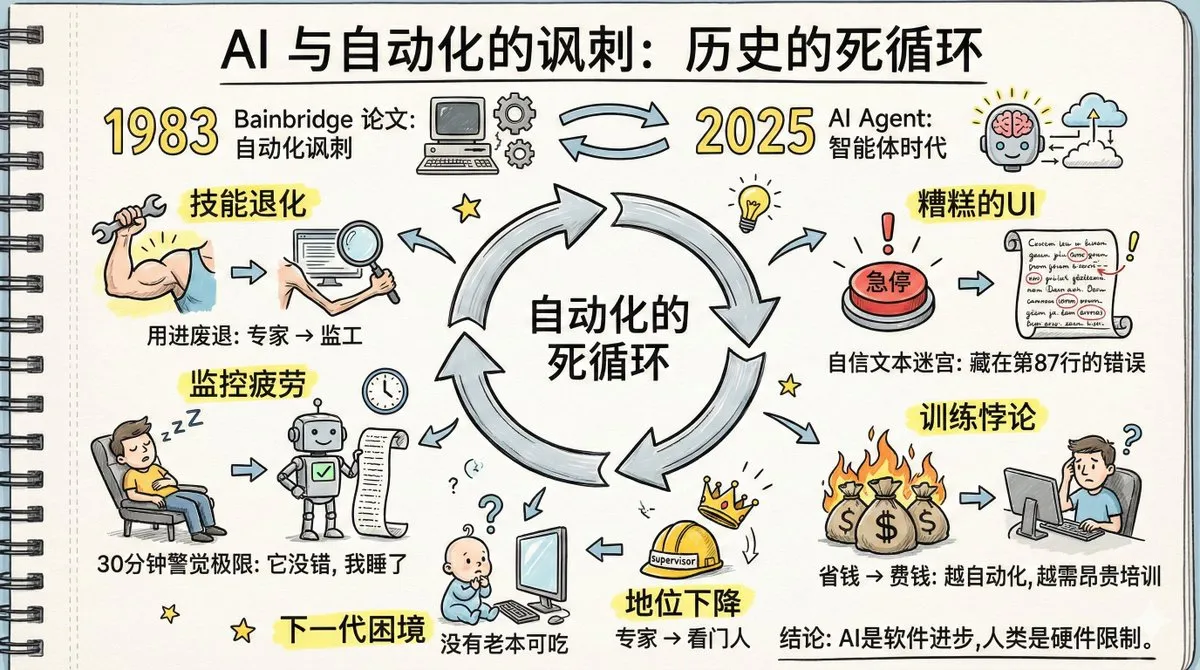
AIエージェントの「自動化のパラドックス」と人間のスキル劣化: 「自動化のパラドックス」と題された論文が議論を呼んでいます。40年前の工場自動化に関するその予言が、AI Agentにおいて現実のものとなりつつあります。議論では、AI Agentの普及が人間のスキル劣化、記憶検索の遅延、監視疲労、専門家の地位低下につながる可能性があると指摘されています。記事は、人間が「めったに間違いを犯さない」システムに対して長時間警戒を維持することはできないこと、そして現在のAI Agentのインターフェース設計が異常検知に不利であることを強調しています。これらの問題を解決するには、自動化自体よりも大きな技術的創造性、そして新しい分業、新しいトレーニング、新しい役割設計への認知的転換が必要です。(出典: dotey, dotey, dotey)
AI生成の低品質コンテンツと事実性の課題: ソーシャルメディアのユーザーは、AI検索結果を満たすためだけに作成されたと思われる大量の低品質ウェブサイトを発見し、AI研究が著者や詳細情報のないこれらのサイトに依存していることで、情報が信頼できないものになるのではないかと疑問を呈しています。これは、AIがまず答えを生成し、その後で裏付けとなるソースを探すというAIの「ソースのバックフィル」メカニズムに対する懸念を引き起こし、虚偽の情報を引用する可能性を示唆しています。これは、AIにおける情報真実性の課題と、ユーザーが自主的な調査に戻る必要性を浮き彫りにしています。(出典: Reddit r/ArtificialInteligence)

AIが法律専門職に与える影響と抽象化レイヤー論: 法律界では、AIが弁護士の職業を「破壊する」かどうかについて議論が分かれています。ある弁護士は、AIが法律業務の90%以上を処理できるとしながらも、戦略、交渉、責任は依然として人間が必要だと考えています。同時に、AIをアセンブリ、C言語、Pythonに続く次の抽象化レイヤーと見なし、AIがエンジニアをシステム設計とユーザー体験に集中させ、人間を置き換えるものではないという見方もあります。(出典: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

AIエージェントの物理的挙動とLLM/ロボット融合の論争: 新しい研究は、LLM駆動のAIエージェントがマクロ物理法則に従い、熱力学システムのような「詳細平衡」特性を示す可能性があることを示しており、これはエージェントが状態を評価する「ポテンシャル関数」を暗黙的に学習している可能性を示唆しています。同時に、ロボット知能とLLMは統一ではなく分化に向かっているという見方がある一方で、物理AIは現実のものになりつつあり、特にデバッグと可視化の進歩がロボットおよび身体性AIプロジェクトを加速させていると考える人もいます。(出典: omarsar0, Teknium, wandb)

Anthropic幹部がDiscordコミュニティにAIチャットボットを強制導入し論争に: Anthropicの幹部が、LGBTQ+コミュニティ向けのDiscordコミュニティで、メンバーの反対を押し切って自社のAIチャットボットClawdを強制的に導入し、コミュニティメンバーが大量に離脱する事態となりました。この事件は、コミュニティにおけるAIのプライバシー、人間関係への影響、そしてAI企業が「新たな神を創造する」という考え方に対する懸念を引き起こしました。ユーザーは、AIチャットボットが人間のコミュニケーションを置き換えることや、幹部の傲慢な行動に対して強い不満を表明しています。(出典: Reddit r/artificial)

AIモデルが詩による攻撃に脆弱、AIラボへの文学人材の参加を求める声: イタリアのAI研究者たちは、悪意のあるプロンプトを詩の形式に変換することで、主要なAIモデルを欺くことができることを発見しました。特にGemini 2.5が最も影響を受けやすいとされています。この現象は「ワルイージ効果」と呼ばれ、モデルが圧縮された意味空間において、善悪の役割が近すぎるため、指示を逆方向に実行しやすくなることを意味します。これは、AIが潜在的に「奇妙な物語空間」の振る舞いを示すことに対処するため、AIラボに物語や言語の深層メカニズムを理解する文学系の卒業生がもっと必要なのではないかという議論をコミュニティで引き起こしています。(出典: Reddit r/ArtificialInteligence)
💡 その他
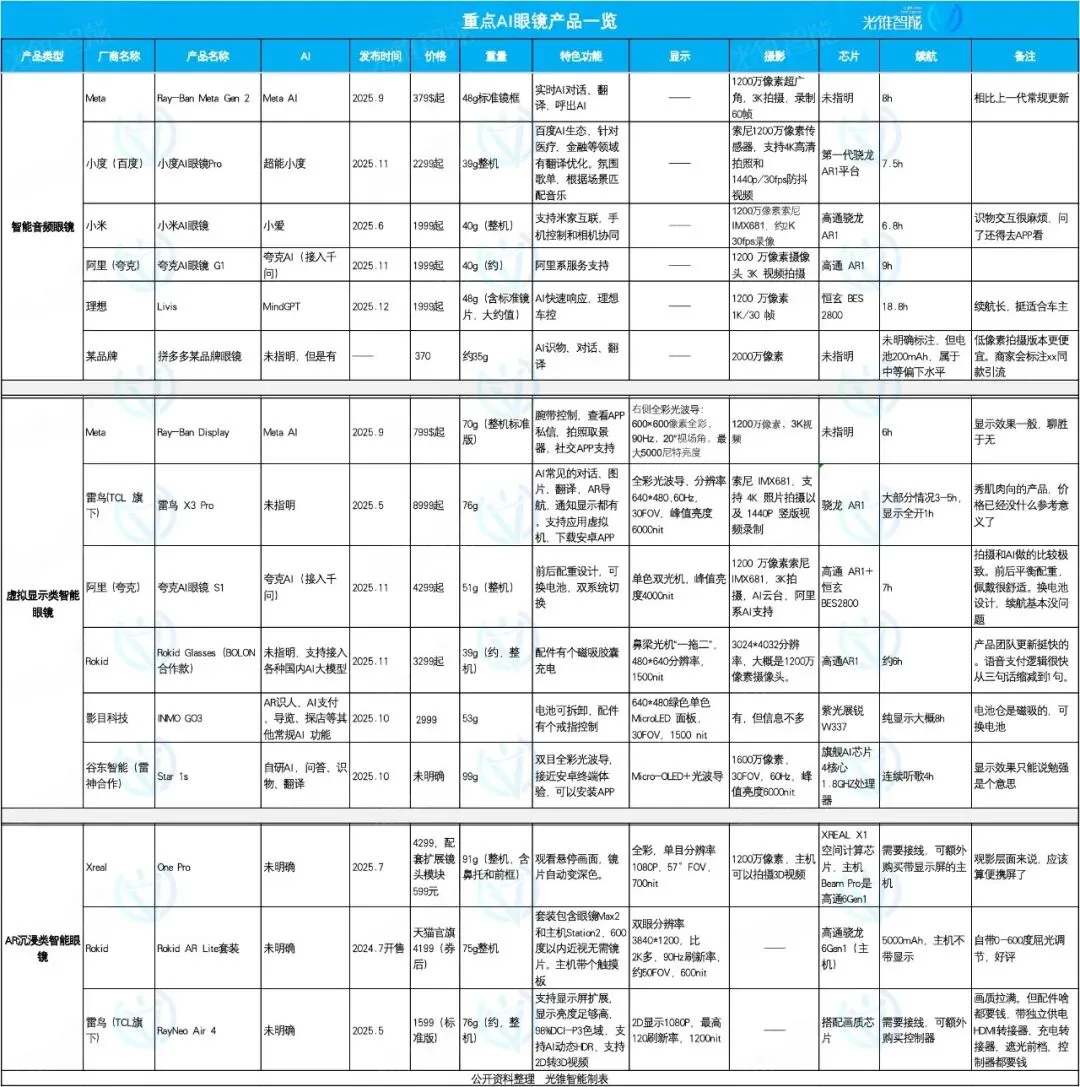
AIグラス市場の焦点と多様化、Livis、Quark、Rokidがそれぞれ独自の強みを発揮: 2025年、AIグラス市場は爆発的な成長を迎え、製品のポジショニングが多様化しています。Livis AIグラスは自動車スマートアクセサリーに焦点を当て、MindGPT大規模モデルを統合してドライバーにサービスを提供します。Quark AIグラスS1は、撮影効果とAlibabaエコシステムアプリの統合を特徴としています。Rokid Glassesは、エコシステムの開放性と迅速な機能反復を強調し、複数の大規模言語モデルへの接続をサポートしています。スマートオーディオグラスは低価格と機能統合を主とし、バーチャルディスプレイグラスは総合的な体験を提供し、AR没入型グラスは視聴エンターテイメントに重点を置いています。(出典: 36氪)
ZLUDAがNVIDIA以外のGPUでCUDAをサポート、AMD ROCm 7と互換: ZLUDAプロジェクトは、NVIDIA以外のGPUでCUDAを実行することを可能にし、AMD ROCm 7をサポートしました。この進展はAIと高性能計算分野にとって非常に重要であり、NVIDIAのGPUエコシステムにおける独占を打ち破り、開発者がAMDハードウェア上でCUDAで書かれたプログラムを利用できるようになることで、AIハードウェアの選択と最適化にさらなる柔軟性を提供します。(出典: Reddit r/artificial)

hashcards:プレーンテキストベースの間隔反復学習システム: hashcardsは、プレーンテキストベースの間隔反復学習システムです。すべてのフラッシュカードはプレーンテキストファイルとして保存され、標準ツールでの編集とバージョン管理をサポートしています。コンテンツアドレス方式を採用しており、カードの内容が変更されると進捗がリセットされます。システムはシンプルに設計されており、表裏と穴埋めカードのみをサポートし、FSRSアルゴリズムを使用して復習計画を最適化し、学習効率を最大化し、復習時間を最小限に抑えることを目指しています。(出典: GitHub Trending)
Zerobyte:セルフホスティングユーザー向けの強力なバックアップ自動化ツール: Zerobyteは、セルフホスティングユーザー向けに設計されたバックアップ自動化ツールです。スケジューリング、管理、リモートストレージへの暗号化バックアップの監視のためのモダンなWebインターフェースを提供します。Resticをベースにしており、暗号化、圧縮、保持ポリシーをサポートし、NFS、SMB、WebDAV、ローカルディレクトリなど様々なプロトコルに対応しています。ZerobyteはS3、GCS、Azureなど多様なクラウドストレージバックエンドもサポートし、rcloneを通じて40以上のクラウドストレージサービスに拡張対応することで、データセキュリティと柔軟なバックアップを保証します。(出典: GitHub Trending)
