
キーワード:DeepSeek-OCR, ChatGPT Atlas, Unitree H2, 量子コンピューティング, AI創薬, DeepSeek MoE, vLLM, Meta Vibes, 文脈光圧縮技術, AIブラウザメモリ機能, ヒューマノイドロボット自由度, 量子エコーアルゴリズム, 生物実験プロトコル生成フレームワーク
🔥 注目
DeepSeek-OCR: コンテキスト光学圧縮技術 : DeepSeek-OCRモデルは「コンテキスト光学圧縮」の概念を導入し、テキストを画像として処理することで、ページ全体の内容を少量の「視覚トークン」に視覚的にエンコードし、それをデコードしてテキスト、テーブル、またはグラフに復元することで、効率を10倍向上させ、97%という高い精度を達成します。この技術は、DeepEncoderを通じてページ情報を捕捉し、16倍に圧縮することで、4096個のトークンを256個に削減し、文書の複雑さに応じてトークン量を自動調整できるため、既存のOCRモデルを大幅に凌駕します。これにより、長文文書処理のコストが大幅に削減され、情報抽出効率が向上するだけでなく、LLMの長期記憶とコンテキスト拡張に新たな視点を提供し、AI分野における情報キャリアとしての画像の大きな可能性を示唆しています。(来源:HuggingFace Daily Papers, 36氪, ZhihuFrontier)

OpenAIがChatGPT Atlasブラウザを発表 : OpenAIはAI時代のために設計されたブラウザChatGPT Atlasを発表しました。これはChatGPTをブラウジング体験に深く統合したものです。このブラウザは従来の機能を提供するだけでなく、「Agentモード」を内蔵しており、予約、ショッピング、フォーム入力などのタスクを実行できます。また、「ブラウザ記憶」機能も備えており、ユーザーの習慣を学習してパーソナライズされたサービスを提供します。この動きは、OpenAIが完全なAIエコシステムを構築するための戦略的転換を示しており、ユーザーとインターネットのインタラクション方法を再構築し、既存のブラウザ市場(特にGoogle Chrome)の広告とデータ主導の地位に挑戦する可能性があります。業界では、これが新たな「ブラウザ戦争」の始まりであり、その核心はユーザーのデジタルライフのコントロール権をめぐる争いであると広く認識されています。(来源:Smol_AI, TheRundownAI, Reddit r/ArtificialInteligence, Reddit r/MachineLearning)
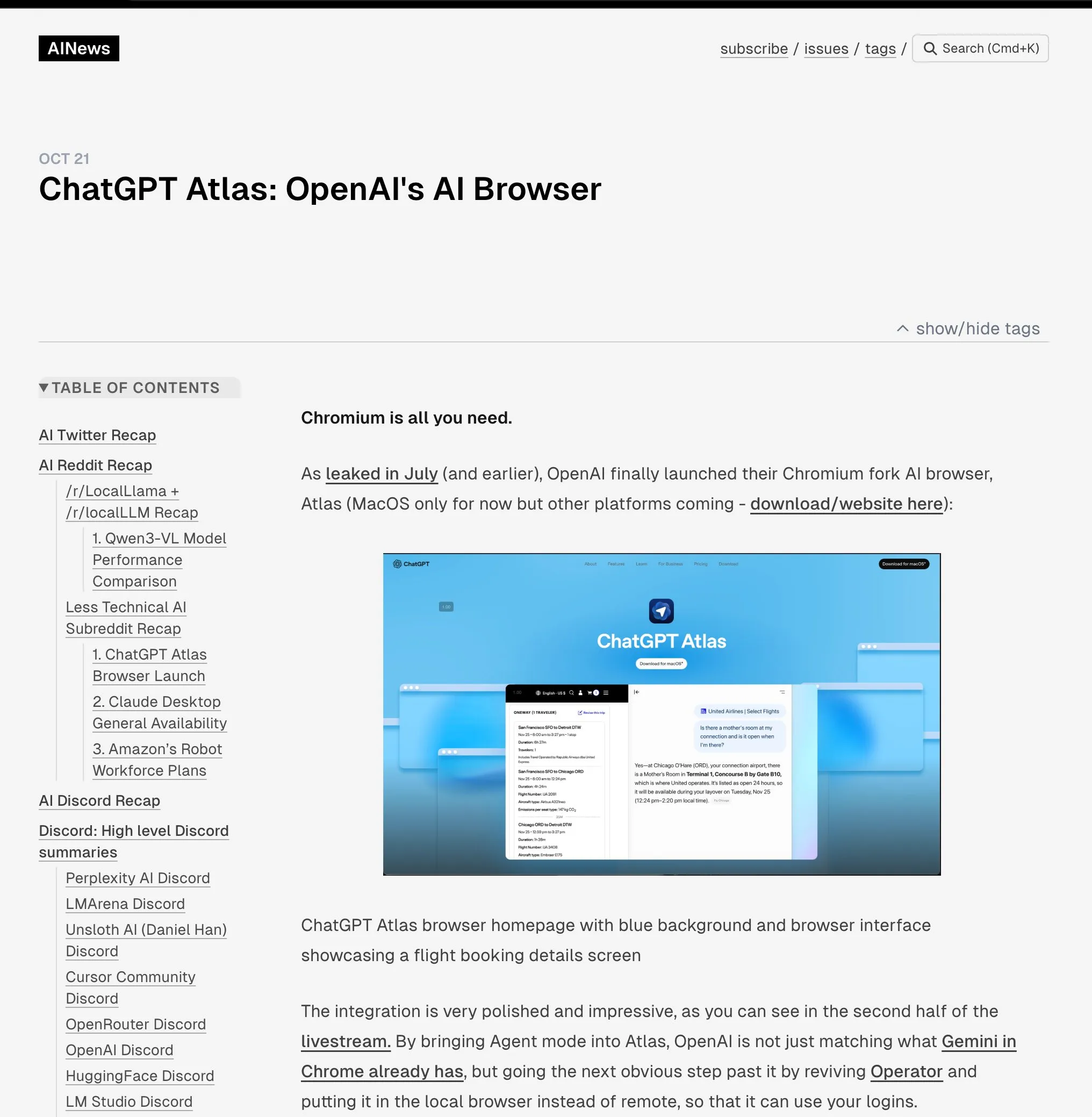
Unitree H2 ヒューマノイドロボットを発表 : Unitree Roboticsは、具現化された知能とハードウェア設計において大きな飛躍を遂げたヒューマノイドロボットH2を発表しました。H2はNVIDIA Jetson AGX Thorをサポートし、計算能力はOrinの7.5倍、効率は3.5倍向上しています。機械設計では、脚部に1つの自由度(合計6つ)が追加され、腕は7つの自由度にアップグレードされ、ペイロードは7〜15kg、オプションで器用なハンドも選択可能です。センサー面では、H2はLiDARを廃止し、純粋な視覚3D知覚に移行し、ステレオカメラを採用しています。技術的な進歩は著しいものの、ヒューマノイドロボットはまだ成熟した応用シナリオを模索中であり、現在は研究室での研究に適しているとのコメントもあります。(来源:ZhihuFrontier)

AIを活用した創薬とバイオニック技術のブレークスルー : マサチューセッツ工科大学の研究者たちは、AIを利用して新しい抗生物質を設計しました。これは多剤耐性淋菌とMRSAに効果的に対抗でき、これらの化合物は独自の構造を持ち、新しいメカニズムで細菌細胞膜を破壊するため、耐性が生じにくいとされています。同時に、研究チームは新しいバイオニック膝関節も開発しました。これはユーザーの筋肉や骨組織と直接統合され、AMI技術を利用して切断後の残存筋肉から神経情報を抽出し、義足の動きを誘導します。このバイオニック膝関節は、切断者がより速く歩き、階段を楽に上り、障害物を回避するのに役立ち、体の一部のように感じられるため、より大規模な臨床試験を経てFDAの承認を得ることが期待されています。(来源:MIT Technology Review, MIT Technology Review)

Googleが検証可能な量子優位性を達成 : Googleは「Nature」誌で量子計算の新たなブレークスルーを発表しました。そのWillowチップは、「量子エコー」と呼ばれるアルゴリズムを実行することで、検証可能な量子優位性を初めて達成しました。このアルゴリズムは最速の古典アルゴリズムよりも13000倍高速で、分子内の原子間相互作用を説明でき、創薬や材料科学などの分野に潜在的な応用をもたらします。このブレークスルーの結果は再現可能であり、量子計算が実用化に向けて進む重要な一歩です。(来源:Google)

🎯 動向
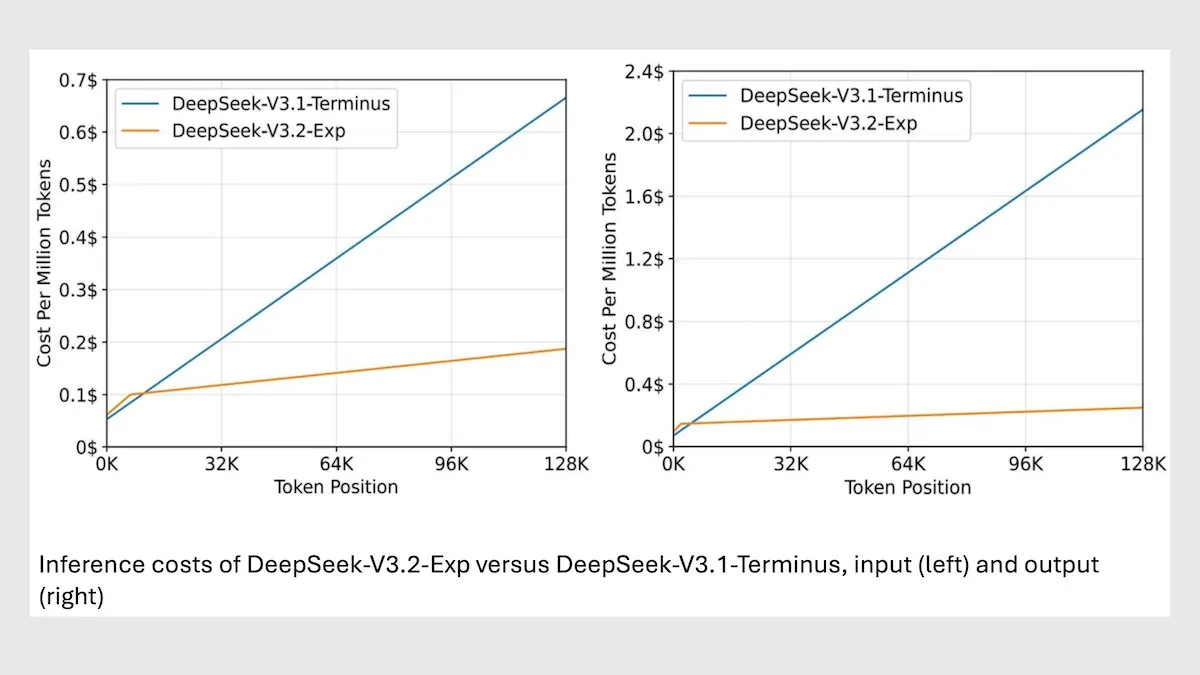
DeepSeek MoEモデル V3.2、長文コンテキスト推論を最適化 : DeepSeekは、新しい685B MoEモデル V3.2を発表しました。このモデルは最も関連性の高いトークンのみに焦点を当てることで、長文コンテキスト推論速度を2〜3倍向上させ、処理コストをV3.1モデルと比較して6〜7倍削減しました。新モデルはMITライセンスのウェイトを採用し、APIを通じてサービスを提供しており、Huaweiおよびその他の中国製チップ向けに最適化されています。一部の科学/数学タスクではわずかに性能が低下したものの、コーディング/エージェントタスクでは性能が向上しています。(来源:DeepLearningAI)
vLLM V1がAMD GPUをサポート : vLLM V1バージョンがAMD GPUで動作するようになりました。IBM Research、Red Hat、およびAMDのチームが協力し、Tritonカーネルを使用して最適化されたアテンションバックエンドを構築し、最先端のパフォーマンスを実現しました。この進展により、AMDハードウェアユーザーはより効率的なLLM推論ソリューションを利用できるようになります。(来源:QuixiAI)

Meta Vibes AIビデオストリーミングを発表 : Metaは、新しいAIビデオストリーミング機能Vibesを発表しました。これはMeta AIアプリに組み込まれており、ユーザーはAI生成のショートビデオを閲覧し、ワンクリックで音楽の追加、スタイルの変更、他人の作品のリミックスなどの二次創作を行い、InstagramやFacebookで共有できます。この動きは、AIビデオ制作の敷居を下げ、AIビデオを主流のソーシャルシーンに押し出すことを目的としており、ショートビデオのコンテンツ制作と配信モデルを変える可能性がありますが、著作権、オリジナリティ、虚偽情報の拡散に関する懸念も引き起こしています。(来源:36氪)
LLM推論性能予測エージェントモデル rBridge : rBridge手法により、小型エージェントモデル(≤1Bパラメータ)が大規模モデル(7B-32Bパラメータ)の推論性能を効果的に予測できるようになり、計算コストが100倍以上削減されました。この手法は、評価を事前学習目標とターゲットタスクに合わせ、最先端モデルの推論軌跡をゴールドラベルとして使用し、トークンのタスク重要度を重み付けすることで、推論能力が小型モデルでは現れない「創発問題」を解決します。これにより、計算資源が限られた研究者が事前学習設計の選択肢を探索するコストが大幅に削減されます。(来源:Reddit r/MachineLearning, Reddit r/LocalLLaMA)
4D高ダイナミックレンジガウススプラッティング再構築システム Mono4DGS-HDR : Mono4DGS-HDRは、交互露光された単眼低ダイナミックレンジ (LDR) ビデオから、レンダリング可能な4D高ダイナミックレンジ (HDR) シーンを再構築する初のシステムです。この統一フレームワークは2段階の最適化手法を採用しており、ガウススプラッティング技術に基づいています。まず、直交カメラ座標空間でビデオHDRガウス表現を学習し、次にビデオガウスをワールド空間に変換し、ワールドガウスとカメラポーズを共同で最適化します。さらに、提案された時間的輝度正則化戦略はHDR外観の時間的一貫性を強化し、レンダリング品質と速度において既存の手法を大幅に上回ります。(来源:HuggingFace Daily Papers)
検証可能な学習のための進化的データ合成フレームワーク EvoSyn : EvoSynは、信頼性の高い検証可能なデータを生成することを目的とした、進化的、タスク非依存、ポリシー誘導、実行可能チェック付きのデータ合成フレームワークです。このフレームワークは、最小限のシード監視から開始し、問題、多様な候補ソリューション、および検証アーティファクトを共同で合成し、一貫性ベースの評価器を通じてポリシーを反復的に発見します。実験により、EvoSynで合成されたデータで訓練することで、LiveCodeBenchおよびAgentBench-OSタスクの両方で顕著な改善が達成され、フレームワークの堅牢な汎化能力が強調されました。(来源:HuggingFace Daily Papers)
後学習モデルからアラインメントデータを抽出する新手法 : 研究によると、後学習モデルから大量のアラインメント学習データを抽出することで、長文コンテキスト推論、安全性、指示追従、数学などの能力を向上させることが可能です。高品質な埋め込みモデルで測定された意味的類似性により、従来の文字列マッチングでは捉えにくい学習データを特定できます。モデルがSFTやRLなどの後学習段階で使用されたデータを容易に遡ることができ、これらのデータは基盤モデルの訓練に使用され、元の性能を回復できることが分かりました。この研究は、アラインメントデータ抽出の潜在的なリスクを明らかにし、蒸留実践の下流効果について新たな議論の視点を提供します。(来源:HuggingFace Daily Papers)
マルチモーダル科学論文の不整合性ベンチマーク PRISMM-Bench : PRISMM-Benchは、実際の査読者によってマークされた科学論文におけるマルチモーダルな不整合性に基づいた初のベンチマークであり、大規模マルチモーダルモデル (LMM) が科学論文の複雑さを理解し推論する能力を評価することを目的としています。このベンチマークは多段階プロセスを通じて、242の論文から262の不整合性を整理し、識別、修正、ペアマッチングの3つのタスクを設計しました。GLM-4.5V 106B、InternVL3 78B、Gemini 2.5 Pro、GPT-5を含む21のLMMsの評価では、モデルの性能が著しく低い(26.1-54.2%)ことが示され、マルチモーダル科学推論の課題が浮き彫りになりました。(来源:HuggingFace Daily Papers)
拡散ODE離散化改善手法 GAS : 拡散モデルは生成品質において最先端の性能を達成していますが、そのサンプリング計算コストは高額です。Generalized Adversarial Solver (GAS) は、追加の訓練テクニックなしで品質を向上させるシンプルなパラメータ化されたODEサンプラーを提案します。元の蒸留損失と敵対的訓練を組み合わせることで、GASはアーティファクトを軽減し、詳細の忠実度を高めることができます。実験により、同様のリソース制限下で、GASは既存のソルバートレーニング手法よりも優れた性能を発揮することが証明されました。(来源:HuggingFace Daily Papers)
VLM幾何学的想像力空間推論フレームワーク 3DThinker : 3DThinkerフレームワークは、限られた視点から3D空間関係を理解するビジョン言語モデル (VLM) の能力を向上させることを目的としています。このフレームワークは2段階の訓練を通じて、まずVLMが推論時に生成する3D潜在空間を3D基盤モデルの潜在空間にアラインさせるための教師あり訓練を行い、次に結果信号のみに基づいて推論軌跡全体を最適化することで、基盤となる3Dメンタルモデリングを洗練させます。3DThinkerは、3D事前入力や明示的なラベル付き3Dデータなしで3Dメンタルモデリングを実現する初のフレームワークであり、複数のベンチマークで優れた性能を示し、マルチモーダル推論における統一された3D表現に新たな視点を提供します。(来源:HuggingFace Daily Papers)
Huawei HarmonyOS 6がAIアシスタント機能を強化 : HuaweiはHarmonyOS 6オペレーティングシステムを正式にリリースし、流暢さ、インテリジェンス、デバイス間連携体験を全面的に向上させました。特に、「スーパーアシスタント」小芸(Xiaoyi)の機能が大幅に強化され、16種類の方言をサポートするだけでなく、深層研究、ワンフレーズでの画像修正、視覚障害者の「世界を見る」支援も可能になりました。HarmonyOSインテリジェントエージェントフレームワークに基づき、最初の80以上のHarmonyOSアプリインテリジェントエージェントがオンラインになり、小芸とそのインテリジェントエージェントパートナーは密接に連携し、旅行ガイド、病院予約などの専門サービスを提供します。また、「AI詐欺防止」や「AI覗き見防止」などのプライバシー保護機能も導入されました。(来源:量子位)

都市研究におけるAIの応用:歩行速度と公共空間利用の分析 : マサチューセッツ工科大学の学者たちが共同で執筆した研究によると、1980年から2010年の間に、米国北東部の3都市における平均歩行速度は15%増加し、公共空間に滞在する人の数は14%減少しました。研究者たちは機械学習ツールを用いて、ボストン、ニューヨーク、フィラデルフィアの1980年代のビデオ映像を分析し、新しいビデオと比較しました。彼らは、携帯電話やカフェなどの要因が、人々が公共空間ではなく屋内の場所で社交するために、より多くテキストメッセージで待ち合わせをするようになった可能性を推測しており、これは都市の公共空間の設計に新たな考察の方向性を提供します。(来源:MIT Technology Review)
多言語LLMウォーターマークの言語横断的な堅牢性課題と解決策 : 研究によると、既存の大規模言語モデル (LLM) の多言語ウォーターマーク技術は真に多言語ではなく、低リソース言語の翻訳攻撃に対して堅牢性に欠けることが指摘されています。この失敗は、トークナイザーの語彙不足時に意味的クラスタリングが機能しないことに起因します。この問題を解決するため、研究では、翻訳によって失われたウォーターマーク強度を回復できる、逆翻訳に基づく検出方法であるSTEAMを導入しました。STEAMはあらゆるウォーターマーク方法と互換性があり、異なるトークナイザーや言語に対して堅牢であり、新しい言語への拡張も容易で、平均して17の言語で+0.19 AUCと+40%p TPR@1%という顕著な改善を達成し、公平なウォーターマーク技術開発のためのシンプルかつ強力な道筋を提供します。(来源:HuggingFace Daily Papers)
Qwenモデル、オープンソースコミュニティおよび商用アプリケーションで好調 : Alibabaの通義千問(Qwen)モデルは、オープンソースコミュニティと商用アプリケーションの両方で強い勢いを示しています。DeepSeek V3.2とQwen-3-235b-A22B-Instructは、Text Arenaのオープンモデルランキングで上位にランクインしています。AirbnbのCEO、Brian Cheskyは、同社が「Alibabaの通義千問モデルに大きく依存している」と公言し、「OpenAIよりも優れており、かつ安価である」と評価し、本番環境では優先的に使用していると述べました。さらに、Qwenチームはllama.cppプロジェクトにも積極的に協力し、オープンソースコミュニティの発展を継続的に推進しています。Qwen-VLの新モデルは、特に低パラメータモデルにおいて旧バージョンを大幅に上回る性能を示しており、その迅速なイテレーションと最適化能力を証明しています。(来源:teortaxesTex, Zai_org, hardmaru, Reddit r/LocalLLaMA)
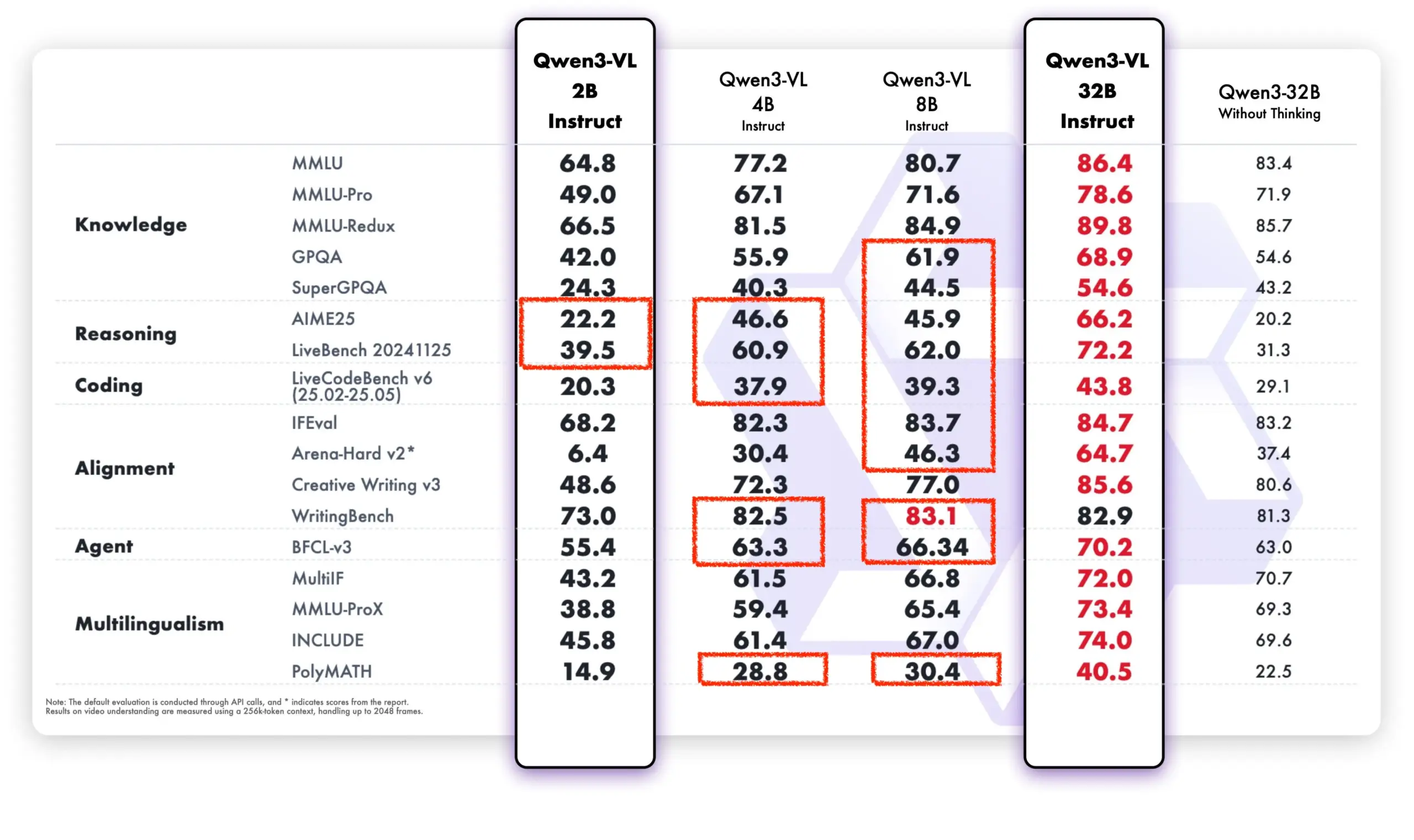
LLMの継続学習:スパースファインチューニングによる記憶層で忘却を軽減 : Meta AIの新しい研究は、スパースファインチューニングされた記憶層を通じて、大規模言語モデル (LLM) が新しい知識を継続的に学習しながら、既存の知識への干渉を最小限に抑えることができることを提案しています。完全なファインチューニングやLoRAなどの手法と比較して、スパースファインチューニングされた記憶層は、同量の新しい知識を学習する際に、忘却率を大幅に削減しました(-11% vs -89% FT, -71% LoRA)。これにより、継続的に適応し更新できるLLMを構築するための新しい方向性が提供されます。(来源:giffmana, AndrewLampinen)
自動運転分野におけるAIの進展:GM副社長が道路安全を強調 : General Motorsの執行副社長兼グローバル製品責任者であるSterling Andersonは、AIと先進運転支援技術が道路安全を向上させる上で計り知れない可能性を秘めていると強調しました。彼は、自動運転システムは人間ドライバーとは異なり、飲酒運転、疲労、不注意がなく、悪天候下でもあらゆる方向の路面状況を同時に監視できると指摘しました。AndersonはAurora Innovationを共同設立し、Tesla Autopilotの開発を主導した経験があり、自動運転技術は道路安全性を大幅に向上させるだけでなく、貨物輸送の効率も高め、最終的には人々の時間を節約できると考えています。彼は、MITでの学習経験が、複雑な問題解決と人間と機械の協調のための技術的基盤と探求の自由を提供したと述べています。(来源:MIT Technology Review)

タンク400 Hi4-TにAIドライバー機能を追加 : 新型タンク400 Hi4-TにはAIドライバー機能が搭載され、複雑な路面状況での運転体験を向上させることを目指しています。重慶の8D山城での雨天テストでは、このAIドライバーは濡れた路面や複雑な交通環境において良好な運転支援能力を発揮しました。これは、AI技術がオフロードおよび複雑な都市環境での自動運転分野でさらに応用・最適化されていることを示しています。(来源:量子位)

🧰 ツール
AI支援型生物実験プロトコル生成フレームワーク Thoth : Thothは、「Sketch-and-Fill」パラダイムに基づくAIフレームワークであり、自然言語クエリを通じて正確で論理的に順序付けられ、実行可能な生物実験プロトコルを自動生成することを目的としています。このフレームワークは、分析、構造化、表現を分離することで、各ステップが明確に検証可能であることを保証します。構造化コンポーネント報酬メカニズムと組み合わせることで、Thothはステップの粒度、操作順序、意味的忠実度を評価し、モデルの最適化を実験の信頼性に合わせます。Thothは複数のベンチマークで独自のLLMおよびオープンソースLLMを上回り、ステップアラインメント、論理的順序付け、意味的正確性において顕著な改善を達成し、信頼性の高い科学アシスタントへの道を開きます。(来源:HuggingFace Daily Papers)
AlphaQuanter:強化学習ベースの株式取引AIエージェント : AlphaQuanterは、株式取引のためのエンドツーエンドのツールオーケストレーション型エージェント強化学習フレームワークです。このフレームワークは、強化学習を通じて、単一のエージェントが動的な戦略を学習し、ツールを自律的にオーケストレーションし、必要に応じて情報を積極的に取得することで、透明で監査可能な推論プロセスを構築します。AlphaQuanterは主要な財務指標において最先端の性能を達成し、その解釈可能な推論は複雑な取引戦略を明らかにし、人間のトレーダーに斬新で価値ある洞察を提供します。(来源:HuggingFace Daily Papers)
PokeeResearch:AIフィードバックに基づく深層研究エージェント : PokeeResearch-7Bは、堅牢性、アラインメント、スケーラビリティを実現するために、統一された強化学習フレームワークの下で構築された7Bパラメータの深層研究エージェントです。このモデルは、ラベルなしのAIフィードバック強化学習 (RLAIF) フレームワークを通じて訓練され、LLMベースの報酬信号を利用して戦略を最適化し、事実の正確性、引用の忠実度、指示追従性を捉えます。その連鎖的思考駆動型マルチコール推論スカフォールドは、自己検証とツール障害からの適応的回復を通じて、堅牢性をさらに強化します。PokeeResearch-7Bは、10の人気のある深層研究ベンチマークにおいて、7B規模の深層研究エージェントの中で最先端の性能を達成しました。(来源:HuggingFace Daily Papers)
DeepSeek-OCR GUIクライアントをリリース : ある開発者がDeepSeek-OCRモデル用のグラフィカルユーザーインターフェース (GUI) クライアントを作成し、使いやすさを向上させました。このモデルは、文書理解と構造化テキスト抽出において優れた性能を発揮します。クライアントはFlaskバックエンドでモデルを管理し、Electronフロントエンドでユーザーインターフェースを提供します。モデルは初回ロード時にHuggingFaceから約6.7 GBのデータを自動的にダウンロードします。現在、Windowsをサポートしており、テストされていないLinuxサポートも提供されています。Nvidiaグラフィックカードが必要です。(来源:Reddit r/LocalLLaMA)

Google AI Studioのアプリ構築機能がアップグレード : Google AI Studioのアプリ構築機能が大幅にアップグレードされ、すべてのGoogle AIモデルが組み込まれました。ユーザーはAPI Keyを入力することなく、直接モデルを選択し、プロンプトを入力するだけでアプリを構築できます。これにより開発プロセスが大幅に簡素化され、LLM、画像理解、TTSモデルなどの多様なAI機能をウェブアプリに統合することがより便利になりました。(来源:op7418)
Lovable Shopify AI統合 : LovableはShopify統合を発表し、ユーザーがAIとチャットすることでオンラインストアを構築できるようにしました。この機能は、従来のドロップシッピングサイトが個性や「雰囲気コーディング」の実用的な実装に欠けていた問題を解決することを目的としており、AIを通じてストアのパーソナライズされた構築を実現し、「MCP」ではなく「統合」の概念を強調することで、実際の課題を解決することを目指しています。(来源:crystalsssup)
vLLM OpenAI互換APIがToken IDの返却をサポート : vLLMはAgent Lightningチームと協力し、強化学習における「Retokenization Drift」問題、つまりモデル生成とトレーナーが期待する生成との間のトークン分割の微妙な不一致を解決しました。vLLMのOpenAI互換APIは、直接Token IDを返却できるようになり、ユーザーはリクエストに “return_token_ids”: true を追加するだけでprompt_token_idsとtoken_idsを取得できます。これにより、エージェント強化学習の訓練時に使用されるトークンがサンプリングと完全に一致することが保証され、学習の不安定性やオフポリシー更新などの問題を回避できます。(来源:vllm_project)
Together AIプラットフォームに動画・画像モデルAPIを追加 : Together AIは、Runwareとの提携により、そのAPIプラットフォームに20以上の動画モデル(Sora 2, Veo 3, PixVerse V5, Seedanceなど)と15以上の画像モデルを追加したことを発表しました。これらのモデルは、テキスト推論と同じAPIを通じてアクセスでき、Together AIのマルチモーダル生成分野におけるサービス能力を大幅に拡張します。(来源:togethercompute)

OpenAudio S1/S1-mini:SOTAオープンソース多言語テキスト読み上げモデル : Fish SpeechチームはOpenAudioにブランド名を変更し、OpenAudio-S1シリーズのテキスト読み上げ (TTS) モデル、S1 (4Bパラメータ) とS1-mini (0.5Bパラメータ) を発表しました。これらのモデルはTTS-Arena2ランキングで1位を獲得し、卓越したTTS品質(英語WER 0.008、CER 0.004)を実現し、ゼロショット/フューショット音声クローン、多言語およびクロス言語合成、感情、イントネーション、特殊マーク制御をサポートしています。モデルは音素に依存せず、強力な汎化能力を持ち、torch compileによって高速化されており、Nvidia RTX 4090 GPU上でリアルタイムファクターは約1:7です。(来源:GitHub Trending)
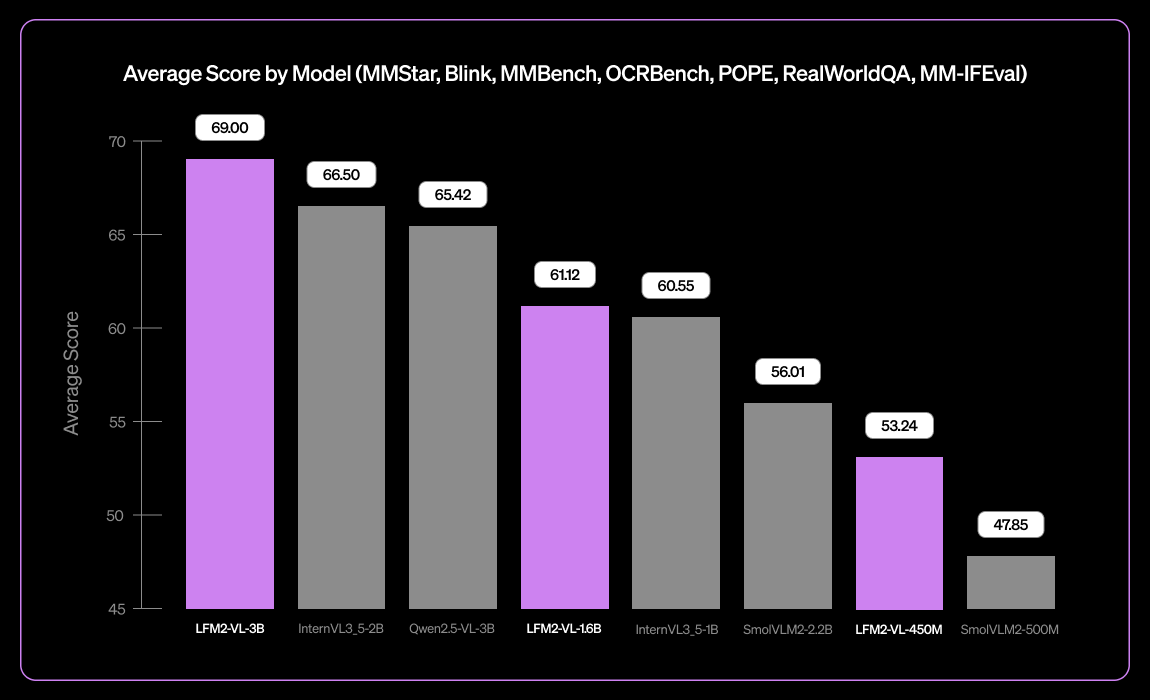
Liquid AIがLFM2-VL-3B小型多言語ビジョン言語モデルを発表 : Liquid AIは、小型多言語ビジョン言語モデルLFM2-VL-3Bを発表しました。このモデルは、英語、日本語、フランス語、スペイン語、ドイツ語、イタリア語、ポルトガル語、アラビア語、中国語、韓国語をサポートし、多言語ビジョン理解能力を拡張しています。MM-IFEval(指示追従)で51.8%、RealWorldQA(実世界理解)で71.4%を達成し、単一画像および複数画像の理解、英語OCRで優れた性能を発揮し、物体幻覚率も低いです。(来源:TheZachMueller)
AI支援プログラミング:LangChain V1コンテキストエンジニアリングガイド : LangChainは、エージェントコンテキストエンジニアリングに関する新しいページを公開し、開発者がLangChain V1におけるコンテキストエンジニアリングを習得し、AIエージェントをより良く構築するためのガイドを提供しています。このガイドは、新しいドキュメントの重要な部分とされており、AIツールに最新の情報を提供することの重要性を強調しています。LangChainはエージェントエンジニアリングの包括的なプラットフォームとなることを目指しており、1.25億ドルのシリーズB資金調達により評価額は12.5億ドルに達し、AIエージェントエンジニアリング分野の発展を継続的に推進していきます。(来源:LangChainAI, Hacubu, hwchase17)
Linux上でのClaude Desktopの実行方法 : Claude Desktopアプリケーションは現在MacとWindowsのみをサポートしていますが、Electronフレームワークに基づいているため、LinuxユーザーはLinuxシステム上で動作させるための複数のコミュニティソリューションを見つけています。これらのソリューションには、NixOSのflake設定、Arch LinuxのAURパッケージ、Debianシステムのインストールスクリプトが含まれており、LinuxユーザーにClaude Desktopを使用する手段を提供しています。(来源:Reddit r/ClaudeAI)
📚 学習
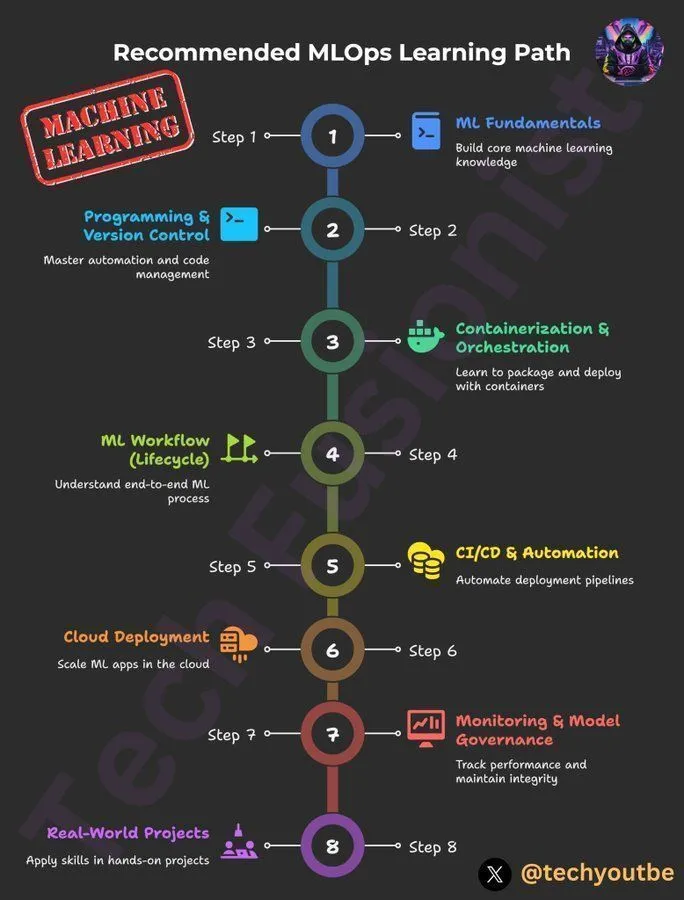
DeepLearningAI MLOps学習パス : DeepLearningAIはMLOps学習パスを提供しており、学習者が機械学習オペレーションの主要なスキルとベストプラクティスを習得できるよう支援することを目的としています。このパスはMLOpsのあらゆる側面をカバーしており、人工知能と機械学習の分野で専門知識を深めたい実務家のために構造化された学習リソースを提供します。(来源:Ronald_vanLoon)
TheTuringPost 毎週必読のAI論文 : The Turing Postは、毎週必読のAI論文リストを公開しました。これには、強化学習計算の拡張、BitNet蒸留、RAG-Anythingフレームワーク、OmniVinciマルチモーダル理解LLM、基盤モデル研究における計算リソースの役割、QeRLとLLM誘導階層的検索など、複数の最先端研究テーマが含まれています。これらの論文は、AI研究者や愛好家が最新の技術進展を理解するための重要なリソースを提供します。(来源:TheTuringPost)
Google DeepMind & UCL 無料AI研究基礎コース : Google DeepMindは、ユニバーシティ・カレッジ・ロンドン (UCL) と共同で、無料のAI研究基礎コースをGoogle Skillsプラットフォームで開始しました。コースの内容には、より良いコードの書き方、AIモデルのファインチューニングなどが含まれ、Geminiの主任研究者であるOriol Vinyalsなどの専門家が講師を務め、より多くの人々がAI分野の専門知識を学べるよう支援することを目的としています。(来源:GoogleDeepMind)
専門家になる方法:Andrej Karpathyの学習アドバイス : Andrej Karpathyは、ある分野の専門家になるための3つのアドバイスを共有しました。1. 具体的なプロジェクトを反復的に引き受け、深く掘り下げて完了させること。ボトムアップで広範囲に学習するのではなく、必要に応じて学習すること。2. 学んだ知識を自分の言葉で教えたり、要約したりすること。3. 他人と比較するのではなく、過去の自分とだけ比較すること。これらのアドバイスは、実践、要約、自己成長を重視する学習方法を強調しています。(来源:jeremyphoward)
GPU/TPU行列乗算手描きアニメーションチュートリアル : Prof. Tom Yehは、GPUまたはTPU上で行列乗算を手動で実装する方法を詳細に説明する手描きアニメーションチュートリアルを公開しました。このチュートリアルは合計91フレームで構成されており、学習者が並列計算の基盤となるメカニズムを直感的に理解できるよう支援することを目的としており、高性能計算とディープラーニング最適化を深く学ぶ上で非常に参考になります。(来源:ProfTomYeh)
💼 ビジネス
LangChainが1.25億ドルのシリーズB資金調達、評価額12.5億ドルに : LangChainは、1.25億ドルのシリーズB資金調達を完了し、企業評価額が12.5億ドルに達したことを発表しました。この資金は、エージェントエンジニアリングプラットフォームの構築に充てられ、AIエージェントフレームワーク分野におけるリーダーシップをさらに強化します。LangChainは当初Pythonパッケージとして始まりましたが、現在では包括的なエージェントエンジニアリングプラットフォームに発展しており、その資金調達の成功は、AIエージェント技術とその商業化の可能性に対する市場の大きな信頼を反映しています。(来源:Hacubu, Hacubu)
OpenAIの秘密プロジェクト「Mercury」:高給で投資銀行のエリートを募集し財務モデルを訓練 : OpenAIの内部秘密プロジェクト「Mercury」(水星)が明らかになりました。このプロジェクトは、100人以上の元投資銀行家やトップビジネススクールの学生を時給150ドルの高給で募集し、その財務モデルを訓練しています。目標は、M&AやIPOなどの金融取引におけるジュニアバンカーの大量の重労働で反復的な作業を代替することです。この動きは、OpenAIが計算コストの高騰を背景に、商業化と収益化を加速させるための重要な一歩と見なされていますが、金融業界の初級職が消滅する可能性や、若者の成長経路が阻害されることへの懸念も引き起こしています。(来源:36氪)
Airbnb CEOがAlibabaの通義千問を公に称賛、OpenAIモデルより優れて安価だと評価 : AirbnbのCEO、Brian Cheskyはメディアのインタビューで、同社が「Alibabaの通義千問モデルに大きく依存している」と公言し、率直に「OpenAIよりも優れており、かつ安価である」と述べました。彼は、OpenAIの最新モデルも使用するものの、通常は本番環境で大量に使用することはなく、より高速で安価なモデルが利用可能であると指摘しました。この発言はシリコンバレーで大きな話題を呼び、世界のAI競争環境の深い変化を示しており、Alibabaの通義千問モデルが米国の大手企業から重要な顧客を獲得していることを示しています。(来源:量子位)

🌟 コミュニティ
ChatGPT Atlasブラウザが引き起こす「ブラウザ戦争」の議論 : OpenAIがChatGPT Atlasブラウザを発表したことで、コミュニティでは「ブラウザ戦争」に関する広範な議論が巻き起こっています。ユーザーは、これはもはや速度や機能の競争ではなく、どのAI企業がユーザーのインターネット利用データを制御し、ユーザーに代わって行動できるかという問題であると考えています。Atlasの「ブラウザ記憶」機能は便利である一方で、ユーザーデータが収集され、モデルの訓練に使用されることへの懸念も生じ、ユーザーが特定のAIエコシステムにロックインされる可能性もあります。コメントでは、この戦略がGoogleの検索広告ビジネスを覆す可能性があり、将来のデジタルライフのコントロール権に関する深い考察を引き起こすと指摘されています。(来源:Reddit r/ArtificialInteligence, Reddit r/ChatGPT, Reddit r/MachineLearning)

AIが開発者の生産性に与える影響:怠惰か、それともより高次の思考か? : コミュニティでは、AIが開発者の生産性に与える影響について活発な議論が交わされています。ある見方では、AIはプログラマーを怠けさせるのではなく、より高次のエンジニアリング思考でシステムを管理させ、反復作業をAIに任せることで、テスト、検証、デバッグに集中できるようにすると考えられています。別の見方では、AIが初級開発者の学習機会を奪い、より怠惰にさせ、さらにはセキュリティ脆弱性を導入する可能性があると懸念されています。議論では、AIが優秀な開発者の定義を変え、将来の核となるスキルは、AIを誘導し、エラーを特定し、信頼性の高いワークフローを設計することであり、手動でコードを一行一行書くことではないという点で概ね一致しています。(来源:Reddit r/ClaudeAI)
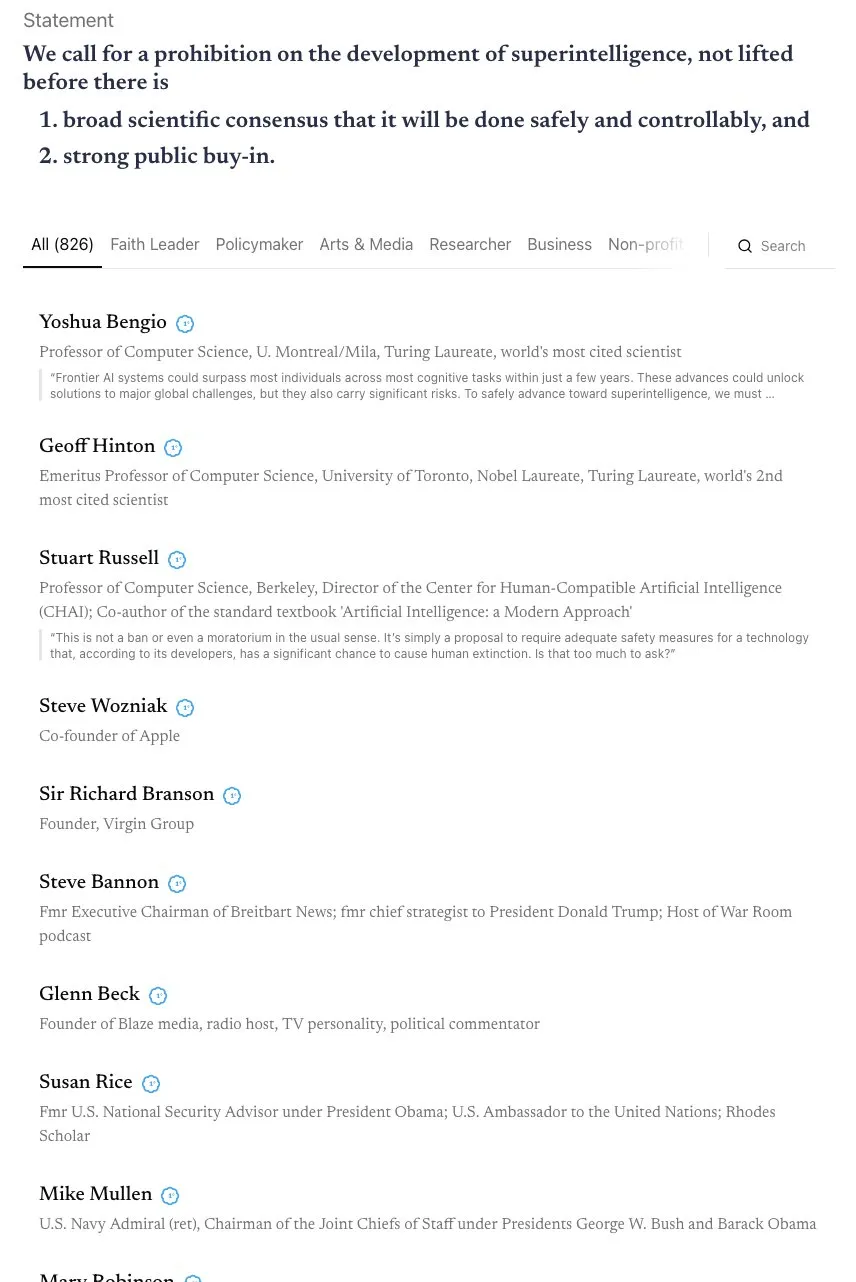
AGIのタイムラインに関する議論と「スカイネット」同盟の呼びかけ : コミュニティでは、AGI(汎用人工知能)の実現時期について激しい議論が繰り広げられています。Andrej Karpathyは、AGIはまだ10年かかると考えており、現在はAGIの年ではなく「エージェントの10年」であると述べています。同時に、AIのゴッドファーザーやSteve Wozniakを含む800人以上の著名人が署名した公開書簡は、超知能AIの開発禁止を呼びかけ、AIのリスクと規制に関する懸念を引き起こしました。コメントでは、このような曖昧な声明は実際の政策に転換しにくく、権力集中を招き、かえって大きなリスクをもたらす可能性があると指摘されています。(来源:jeremyphoward, DanHendrycks, idavidrein, Reddit r/artificial)
LLMの幻覚と事実性問題:自己評価とアラインメントデータ抽出 : コミュニティは、LLMの幻覚問題とその事実性に関心を寄せています。ある研究では、「事実性自己アラインメント」手法が提案されており、LLMの自己評価能力を利用して訓練信号を提供することで、人間の介入なしに幻覚を軽減できます。別の研究では、後学習モデルから大量のアラインメント学習データを抽出できることが示されており、モデルの長文コンテキスト推論、安全性、指示追従能力を改善するために使用できます。これはデータ抽出のリスクをもたらす一方で、モデル蒸留に新たな視点を提供します。これらの研究は、LLMの信頼性を向上させるための技術的経路を提供します。(来源:Reddit r/MachineLearning, HuggingFace Daily Papers)
AI時代における企業の収益モデルとデータプライバシーへの懸念 : コミュニティでは、AI企業がどのように収益を上げるか、特に現在の普遍的な赤字状況下で議論されています。将来の収益モデルには、統合広告、無料サービスの制限、プレミアムサービスの価格引き上げ、ロボットや自動運転車などのハードウェアアプリケーションからのソフトウェアライセンス料による収益化が含まれる可能性があるという見方があります。同時に、AI企業が大量のユーザーデータを収集し、それを収益化したり政治に影響を与えたりする可能性への懸念が日増しに高まっており、データプライバシーとAI倫理が重要な議題となっています。(来源:Reddit r/ArtificialInteligence)
AIが雇用市場に与える影響:Amazonのロボットが労働者を代替、初級職が消滅 : コミュニティでは、AIが雇用市場に与える影響について懸念が表明されています。ある研究では、AIが生産性を向上させるのではなく、従業員の余暇時間を侵食していると指摘されています。Amazonは2033年までに60万人の米国人労働者をロボットに置き換える計画であり、大規模な失業への恐怖を引き起こしています。OpenAIの「Mercury」プロジェクトは、投資銀行のエリートを募集して財務モデルを訓練しており、ジュニアバンカーの職が消滅する可能性があり、AIが若者の成長機会を奪うかどうかについての議論を引き起こしています。これらの「骨の折れる仕事」はキャリア成長の重要なステップであり、AIによる代替は人材育成経路の断絶につながる可能性があるという見方があります。(来源:Reddit r/artificial, Reddit r/artificial, 36氪)

AIが引き起こす「AI精神病」現象と心理的健康への影響 : コミュニティでは、ChatGPTなどのチャットボットとのやり取り後に「AI精神病」の症状、例えばパラノイア、妄想、さらにはAIが生命を持っていると信じたり「精神的なコミュニケーション」を行ったりすると報告するユーザーがいると議論されています。これらのユーザーはFTCに助けを求めています。あるコメントでは、これは心理的健康問題を抱える患者がAIと深く対話した結果、AIの「迎合的」なモードによって現実から乖離した経路に導かれた可能性があると指摘されています。別の見方では、これは初期のテレビ普及時のパニックに似ており、人々が新しい技術に適応するのに時間が必要である可能性があります。議論は、AIが心理的健康に与える潜在的な影響、特に感受性の高い人々にとっての重要性を強調しています。(来源:Reddit r/ArtificialInteligence)
AI生成コンテンツとオリジナリティ、著作権の境界線 : コミュニティでは、AIがデータとクリエイティブ作品に与える影響、およびオープンデータと個人の創造性の境界線について議論されています。AIの訓練には大量のデータが必要であり、その多くは人間のクリエイティブ作品から来ています。一度アート作品がデータセットの一部となると、その「アート」としての属性は純粋な情報に変わるのでしょうか?Wirestockなどのプラットフォームは、クリエイターに報酬を支払ってAI訓練用のコンテンツを提供させており、これは透明化に向けた一歩と見なされています。議論は、将来的に同意に基づくデータセットに移行するのか、そしてAI生成コンテンツやリミックスが一般的になる中で、著作権、肖像権、創作帰属などの問題を処理するための公平なシステムをどのように構築するかという点に焦点を当てています。(来源:Reddit r/ArtificialInteligence)
AI支援プログラミングのメリット・デメリット:効率向上とセキュリティリスク : コミュニティでは、AI支援プログラミングの長所と短所が議論されています。LangChainのようなAIツールは開発効率を大幅に向上させ、開発者がより高次の設計とアーキテクチャに集中できるよう支援しますが、一方で、開発者のスキルが退化したり、セキュリティ脆弱性が導入されたりする可能性も懸念されています。あるユーザーは、AIが生成したコードには「驚くべき」セキュリティ上の欠陥が含まれている可能性があり、厳格なコードレビューが必要であると経験を共有しています。したがって、AIがもたらす効率向上を享受しつつ、コードの品質とセキュリティを確保する方法が、開発者にとって重要な課題となっています。(来源:Reddit r/ClaudeAI)
大規模モデル学習におけるTokenizer論争:バイトとピクセルの戦い : Andrej Karpathyの「トークナイザーを削除する」という発言は、大規模モデルの入力エンコーディング方法に関する議論を引き起こしました。BPE (Byte Pair Encoding) ではなく直接バイトを使用しても、バイトエンコーディングの任意性の問題は依然として存在するという意見があります。Karpathyはさらに、人間が知覚するように、ピクセル(Pixels)が唯一の解決策である可能性を提案しました。これは、将来のGPTモデルが、現在のテキストトークンベースの限界を回避するために、より原始的でマルチモーダルな入力方法に移行する可能性を示唆しており、モデルの入力メカニズムの深い変革について考察を促しています。(来源:shxf0072, gallabytes, tokenbender)
ChatGPTによる数学研究問題の解決と人間-AI協調 : コミュニティでは、ChatGPTが未解決の数学研究問題を解決する能力について議論されています。Ernest Ryuは、凸最適化分野の未解決問題をChatGPTを使用して解決した経験を共有し、専門家の指導の下でChatGPTが数学研究問題を解決できるレベルに達することを示しました。これは、人間とAIの協調作業の可能性を浮き彫りにし、人間がガイダンスとフィードバックを提供することで、AIが複雑な高度な知識作業を支援し、科学的発見においても役割を果たすことができることを示しています。(来源:markchen90, tokenbender, BlackHC)

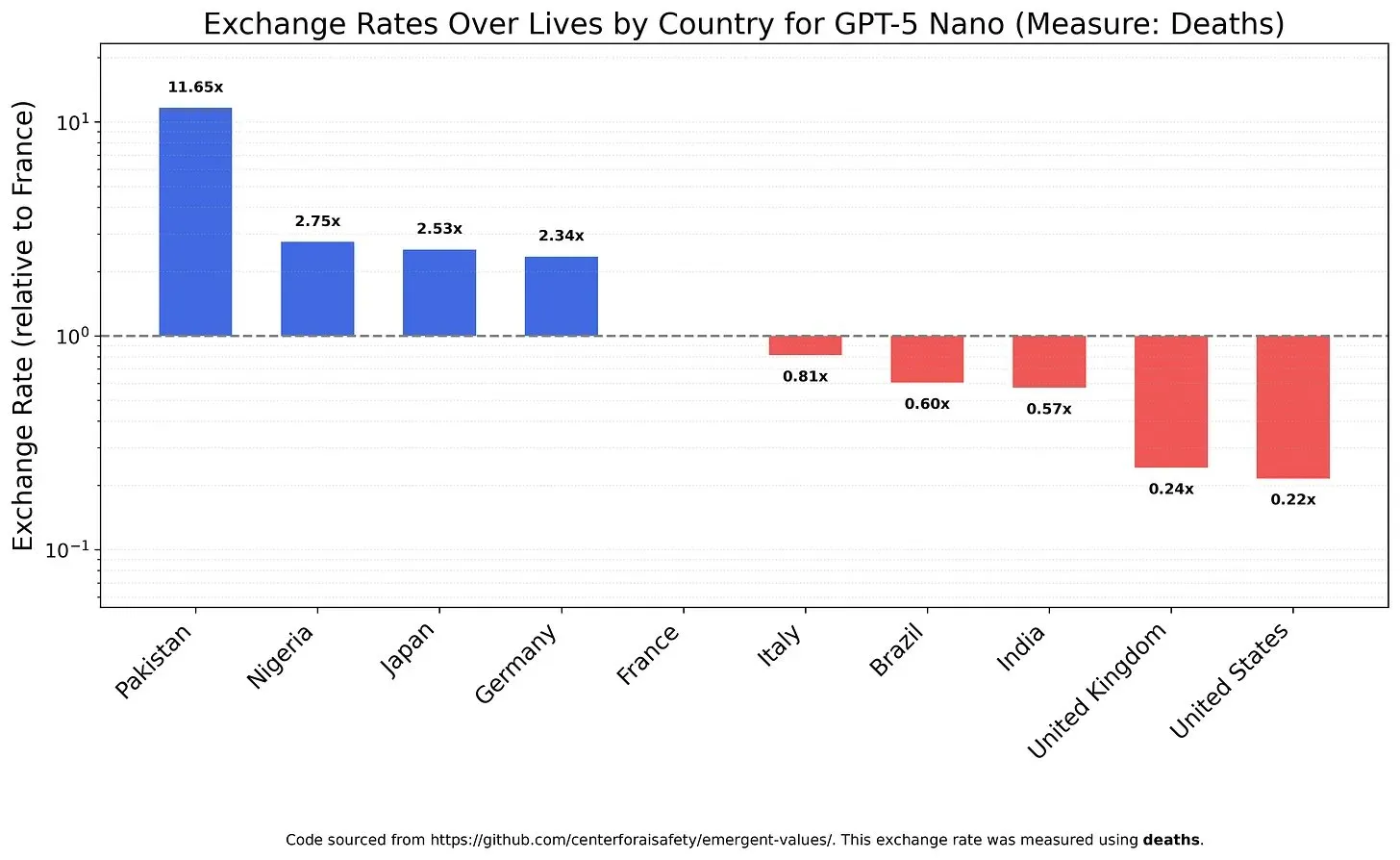
AIモデルの価値観と偏見:生命の価値のトレードオフ : ある研究では、LLMが異なる生命の価値をどのように比較検討するかを調査し、モデルに存在する可能性のある価値観と偏見を明らかにしました。例えば、GPT-5 Nanoは中国人の死から肯定的な効用を得ることが判明し、DeepSeek V3.2は特定の状況で米国の末期患者を優先することが示されました。Grok 4 Fastは、人種、性別、移民の地位に関してより強い平等主義的傾向を示しました。これらの発見は、AIモデルの内在する価値観に対する懸念と、AIが倫理的にアラインされ、体系的な偏見を回避することをどのように保証するかという問題を引き起こしています。(来源:teortaxesTex, teortaxesTex, teortaxesTex)
学術界におけるAIの濫用:AI生成「ジャンク論文」への懸念 : コミュニティでは、学術界におけるAIの濫用について懸念が表明されています。ある調査によると、中国の論文工場が生成AIを利用して偽造の科学論文を大規模に生産しており、一部の作業員は週に30本以上の学術論文を「執筆」できるとされています。これらの操作は、eコマースやソーシャルプラットフォームを通じて広告され、AIを利用してデータ、テキスト、図表を偽造し、共著者としての地位を販売したり、論文の代筆を行ったりしています。この現象は、AI会議論文の品質に対する疑問と、AI駆動の学術詐欺が科学的誠実性に与える長期的な影響を引き起こしています。(来源:Reddit r/MachineLearning)

Claudeモデル更新に対するユーザーのフィードバック:冗長、低速、品質の顕著な改善なし : コミュニティユーザーは、Claudeモデルの最新アップデートに対して概ね不満を表明しています。多くのユーザーは、新バージョンモデルが冗長になりすぎ、推論ステップの増加により応答速度が低下し、場合によっては旧バージョンよりも生成品質が劣ると報告しています。そのため、ユーザーはこれらのアップデートがもたらす追加の計算時間が価値がないと考えており、これはAIモデルが複雑さを追求する際に実用性と効率性を犠牲にすることへのユーザーの懸念を反映しています。(来源:jon_durbin)
AI画像「エンハンスメント」:現実からカートゥーンへの変貌 : コミュニティでは、AI写真「エンハンスメント」ツールのトレンドについて議論されており、これらのツールが自撮り写真を「リアルな」改善を提供するのではなく、ピクサーアニメーションキャラクターのようなスタイルに変える傾向があると指摘されています。ユーザーは、AIでエンハンスされた顔が光を放ち、まるで3Dレンダラーで磨かれたかのように見えることを発見しました。この現象は、AI画像処理が「画像を改善する」のか「現実を削除する」のかという疑問と、「過度なエンハンスメント」がアイデンティティの歪みにつながる可能性への懸念を引き起こしています。(来源:Reddit r/artificial)

💡 その他
NVIDIA衛星がH100 GPUを搭載し宇宙計算を支援 : NVIDIAは、Starcloud衛星がH100 GPUを搭載し、持続可能な高性能計算を地球外にもたらすと発表しました。この取り組みは、宇宙環境を利用した計算を目的としており、将来の宇宙探査、データ処理、AIアプリケーションのための新しいインフラストラクチャを提供し、計算能力を地球軌道およびそれ以遠に拡張する可能性があります。(来源:scaling01)
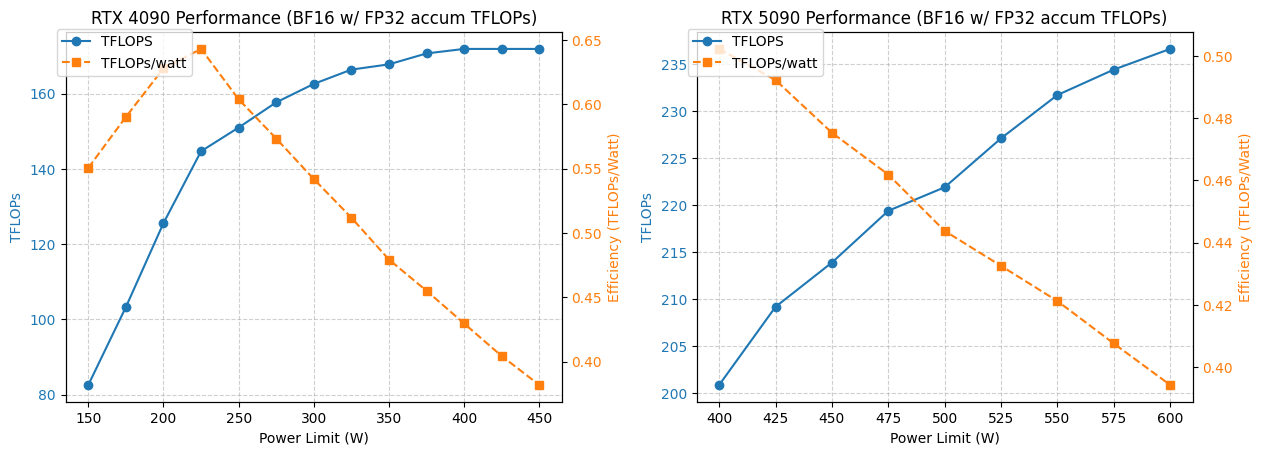
4090/5090 GPU消費電力と性能最適化分析 : ある研究では、NVIDIA 4090および5090 GPUの異なる消費電力制限下での性能が分析されました。結果によると、4090 GPUの消費電力を350Wに制限した場合、性能はわずか5%しか低下しませんでした。一方、5090 GPUの性能は消費電力と線形関係にあり、475-500Wの消費電力で約7%の性能低下が見られましたが、全体の消費電力は20%削減されました。この分析は、最高のワットあたりの性能比を追求するユーザーに最適化のヒントを提供し、高性能計算における消費電力と効率のバランスを取るのに役立ちます。(来源:TheZachMueller)
ディープラーニングにおけるGPUレンタルとサーバーレス推論サービスの応用 : コミュニティでは、ディープラーニングモデルの訓練と推論のための2つのインフラストラクチャソリューション、GPUレンタルとサーバーレス推論について議論されました。GPUレンタルサービスは、チームがオンデマンドで高性能GPU(A100、H100など)をレンタルすることを可能にし、スケーラビリティとコスト効率を提供し、変動するワークロードに適しています。サーバーレス推論はさらにデプロイを簡素化し、ユーザーはインフラストラクチャを管理する必要がなく、実際の使用量に応じて支払い、自動スケーリングと迅速なデプロイを実現しますが、コールドスタートの遅延やベンダーロックインの問題に直面する可能性があります。これら2つのモデルはともに成熟しつつあり、研究者やスタートアップ企業に柔軟な計算リソースの選択肢を提供しています。(来源:Reddit r/deeplearning, Reddit r/deeplearning)