
키워드:OpenAI, AI 규제, 대형 언어 모델, AI 윤리, AI 혁신, AI 권력 집중, AI 안전 법안, AI 거버넌스, OpenAI 법적 위협, GTAlign 정렬 프레임워크, ARES 다중모드 추론, xAI 세계 모델, SAM 3.0 분할 기술
🔥 聚焦
주제: OpenAI, 비영리 단체 협박 혐의: 캘리포니아 AI 안전 법안 심의 중, OpenAI는 직원 3명 규모의 비영리 단체 Encode에 소환장을 발부하여 모든 기록 및 개인 통신 자료 제출을 요구하고, 아무런 증거 없이 Elon Musk의 자금 지원을 받았다고 비난했다. Encode는 이를 법적 협박으로 공개 비난하며, 자신들의 정책 입장에 대한 비판을 억압하려는 의도라고 지적했다. 이 사건은 OpenAI 내부 직원과 전 이사회 구성원들의 비판을 불러일으켰으며, 대형 AI 기업들이 규제에 맞서 취하는 공격적인 전략과 거대 기업에 맞서는 소규모 옹호 단체들이 직면한 어려움을 부각시켰다. SB 53 법안은 결국 통과되었지만, AI 기업들에게 위험 평가 및 투명성 보고서 제출을 요구한다 (출처: Reddit r/ArtificialInteligence)
주제: 노벨 경제학상 수상자 경고: AI 권력 집중, 혁신 저해 가능성: 올해 노벨 경제학상 수상자 중 한 명인 Philippe Aghion은 AI 권력이 소수의 기업에 집중되면 혁신과 경제 성장을 저해할 수 있다고 지적했다. 그는 혁신이 경쟁에 의존하며, AI 자원의 독점은 발전 정체를 초래할 수 있다고 주장했다. 이는 스타트업이 기존 거대 기업에 도전하기 어렵게 만들 수 있다. 이로 인해 AI가 성장의 동력이 아닌 병목 현상이 되는 것을 방지하기 위한 AI 거버넌스 및 규제 형태에 대한 논의가 촉발되었다 (출처: Reddit r/ArtificialInteligence)

주제: GTAlign: 게임 이론 기반 LLM 어시스턴트 정렬 프레임워크: 연구진은 GTAlign을 제안했다. 이는 게임 이론적 의사결정을 LLM 추론 및 훈련에 통합하는 정렬 프레임워크이다. 이 프레임워크는 보상 행렬을 구축하여 LLM과 사용자의 공동 복지를 평가하고 상호 이익이 되는 행동을 선택한다. 훈련 시에는 협력적 응답을 강화하기 위해 상호 복지 보상을 도입한다. 실험 결과, GTAlign은 다양한 작업에서 LLM의 추론 효율성, 답변 품질 및 공동 복지를 크게 향상시켰으며, 이는 기존 정렬 방식에서 모델이 과도하게 장황하여 사용자 경험을 저하시킬 수 있는 문제를 해결한다 (출처: HuggingFace Daily Papers)
주제: ARES: 난이도 인지 엔트로피 형성 통한 멀티모달 적응형 추론 구현: ARES는 통합된 오픈소스 프레임워크로, 다양한 난이도의 작업을 처리할 때 멀티모달 대규모 추론 모델(MLRMs)의 효율성 불균형 문제를 동적으로 탐색 작업을 할당하여 해결한다. 이 프레임워크는 윈도우 엔트로피를 활용하여 핵심 추론 순간을 식별하고, 두 단계 훈련(적응형 콜드 스타트 및 적응형 엔트로피 정책 최적화)을 통해 모델이 간단한 문제에서는 과도한 사고를 줄이고 복잡한 문제에서는 탐색을 늘리도록 한다. ARES는 수학, 논리 및 멀티모달 벤치마크에서 뛰어난 성능과 추론 효율성을 보여주었으며, 추론 비용을 크게 절감했다 (출처: HuggingFace Daily Papers)
🎯 동향
주제: Elon Musk의 xAI, 세계 모델 시장 진출 및 NVIDIA 인력 영입하여 AI 게임 개발 착수: xAI는 세계 모델 분야에 적극적으로 진출하고 있으며, NVIDIA에서 여러 명의 베테랑 연구원을 영입했다. 2026년 말까지 AI 생성 및 세계 모델 기반 게임을 출시할 계획이다. xAI의 목표는 AI가 우주의 본질을 이해하도록 하는 것으로, 세계 모델을 AI 게임, 에이전트, 자율 주행 및 체화된 지능형 로봇에 적용하여 완전한 AI 생태계 폐쇄 루프를 구축하는 것을 목표로 한다 (출처: 量子位)

주제: Meta ‘모든 것을 분할’ 3.0 공개: SAM 3.0은 프롬프트 기반 개념 분할(PCS)을 도입하여 구문 또는 이미지 예시 기반의 다중 인스턴스 분할 작업을 지원한다. 새로운 아키텍처는 DETR 기반 탐지기와 Presence Head 모듈을 포함하며, 객체 인식과 위치 파악을 분리하여 탐지 정확도를 높인다. 대규모 데이터 엔진과 SA-Co 벤치마크를 통해 SAM 3.0은 개방형 어휘 분할 작업에서 SOTA를 경신했으며, 멀티모달 대규모 모델과 결합하여 복잡한 추론 분할 작업을 해결할 수 있다 (출처: 量子位)

주제: Baidu World 2025 개최 확정, AI 애플리케이션 및 대규모 모델 생태계 집중: Baidu는 11월 13일 베이징에서 Baidu World 2025를 개최한다고 발표했다. 주제는 ‘효과 발현 | AI in Action’이다. 컨퍼런스에서는 AI 애플리케이션, 대규모 모델, AI 생태계 및 글로벌화 분야에서 Baidu의 최신 성과를 전면적으로 선보일 예정이며, Wenxin iRAG, No-code Miaoda, 디지털 휴먼 기술, 자율 주행 ‘Luobo Kuaipao’의 글로벌 확장을 포함한다. 또한, 컨퍼런스에서는 AI 애플리케이션 개발을 지원하는 40개 이상의 AI 공개 강의를 제공할 예정이다 (출처: 量子位)

주제: Reflection AI: 제품 출시 전 80억 달러 가치 평가받은 ‘미국판 DeepSeek’: Reflection AI는 공식 제품을 출시하지 않은 상태에서 가치가 80억 달러로 급등했으며, Nvidia, Sequoia Capital 등으로부터 20억 달러의 투자를 유치했다. 이 회사는 전 Google DeepMind 핵심 멤버들이 설립했으며, ‘서양의 DeepSeek’이 되는 것을 목표로 한다. ‘오픈 웨이트’ 모델을 통해 고성능 MoE 모델을 제공하고, 비중국 오픈소스 모델에 대한 서구 시장의 수요를 충족시키며, 대기업 및 주권 AI 시장을 겨냥하고 있다 (출처: 36氪)

주제: Dolphin X1 8B 모델 출시: Llama3.1 8B의 검열 제거 미세 조정 버전: Dolphin X1 8B가 Hugging Face에 출시되었다. 이것은 Llama3.1 8B Instruct의 미세 조정 버전으로, 다른 능력을 손상시키지 않으면서 모델의 검열 제한을 최대한 제거하는 것을 목표로 한다. 이 모델은 SFT+RL 훈련을 사용하며, 벤치마크 테스트 결과는 Llama3.1 8B Instruct와 동등하거나 더 높다. Deepinfra의 후원으로 GGUF, FP8 및 exl2 버전이 출시되었다 (출처: Reddit r/LocalLLaMA)
주제: 오픈소스 RAG 경로의 다양화: MiniRAG, Agent-UniRAG, SymbioticRAG 등 오픈소스 RAG(검색 증강 생성) 솔루션들이 분화하며 다양한 설계 철학을 보여주고 있다. MiniRAG은 경량화와 로컬 실행을 추구하고, Agent-UniRAG은 검색과 추론을 연속적인 에이전트 파이프라인으로 통합하며, SymbioticRAG은 인간-기계 협업과 피드백 학습을 강조한다. 반면 LangChain과 같은 툴킷은 모듈형 구성 요소를 제공한다. 사용자는 선택 시 정확성, 속도 및 제어 가능성을 고려해야 하며, 환각, 컨텍스트 손실 등 일반적인 문제에도 주의를 기울여야 한다 (출처: Reddit r/LocalLLaMA)
주제: LLM4Cell: 단일 세포 생물학 분야 대규모 언어 모델 및 에이전트 모델 개요: LLM4Cell은 단일 세포 연구에 적용되는 58개 기본 모델 및 에이전트 모델에 대한 통합 개요를 최초로 제공한다. RNA, ATAC, 다중 오믹스 및 공간 모달리티를 포함한다. 연구는 이러한 방법들을 다섯 가지 주요 범주로 분류하고 여덟 가지 핵심 분석 작업에 매핑한다. 40개 이상의 공개 데이터셋 분석을 통해 모델의 적용 가능성, 데이터 다양성, 윤리 및 확장성을 평가했으며, 해석 가능성, 표준화 및 신뢰할 수 있는 모델 개발 측면의 과제를 지적했다 (출처: HuggingFace Daily Papers)
주제: KORMo: 모두를 위한 한국어 개방형 추론 모델: KORMo-10B는 주로 합성 데이터를 기반으로 훈련된 최초의 한국어-영어 이중 언어 대규모 언어 모델이다. 이 모델은 10.8B 매개변수를 가지며, 한국어 부분의 68.74%가 합성 데이터이다. 실험 결과, 신중하게 기획된 합성 데이터는 모델의 대규모 사전 훈련에서 불안정성이나 성능 저하를 초래하지 않는 것으로 나타났다. 모델은 추론, 지식 및 지시 따르기 벤치마크에서 기존 오픈소스 다국어 모델과 동등한 성능을 보였다. 이 프로젝트는 데이터, 코드 및 훈련 방안을 완전히 오픈소스화하여 저자원 환경에서 합성 데이터 기반 개방형 모델 개발을 위한 투명한 프레임워크를 제공한다 (출처: HuggingFace Daily Papers)
주제: UML: 비쌍형 멀티모달 데이터 활용한 단일 모달 모델 강화: UML(Unpaired Multimodal Learner)은 새로운 모달리티 독립적인 훈련 패러다임으로, 모델은 서로 다른 모달리티의 입력을 번갈아 처리하고 매개변수를 공유함으로써 명시적인 쌍형 데이터셋 없이 교차 모달 구조를 활용하여 단일 모달 표현 학습을 강화한다. 이론 및 실험 모두 보조 모달리티(예: 텍스트, 오디오, 이미지)의 비쌍형 데이터를 사용하는 것이 이미지 및 오디오와 같은 다운스트림 단일 모달 작업의 성능을 지속적으로 개선할 수 있음을 보여준다 (출처: HuggingFace Daily Papers)
주제: ‘AI 에이전트 도해 가이드’ 신간 예고: Jay Alammar와 Maarten Gr가 공동 집필한 신간 ‘AI 에이전트 도해 가이드’가 곧 출간될 예정이다. O’Reilly Media에서 출판한다. 이 책은 AI 에이전트를 이해하고 구축하는 핵심 개념을 심층적으로 다룰 것이며, 도구, 기억, 코드 생성, 추론, 멀티모달, RLVR/GRPO 등 고급 주제를 포함한다. AI 에이전트 분야에서 가장 풍부한 시각화 프로젝트가 되는 것을 목표로 한다 (출처: JayAlammar, MaartenGr)

주제: SEAL: 지속 학습을 위한 자체 적응형 언어 모델: SEAL(Self-Adapting Language Models)이라는 새로운 연구는 AI 모델이 배포 후 재훈련 없이 내부 표현을 진화시키며 지속적으로 학습하는 방법을 설명한다. SEAL 아키텍처는 모델이 새로운 데이터로부터 실시간으로 학습하고, 퇴화된 지식을 자체 복구하며, 세션 간에 지속적인 ‘기억’을 형성할 수 있도록 한다. 만약 GPT-6가 이 기술을 통합한다면, 지속적인 자체 학습 AI를 구현하여 ‘고정 가중치’ 시대를 마감할 것이다 (출처: yoheinakajima)

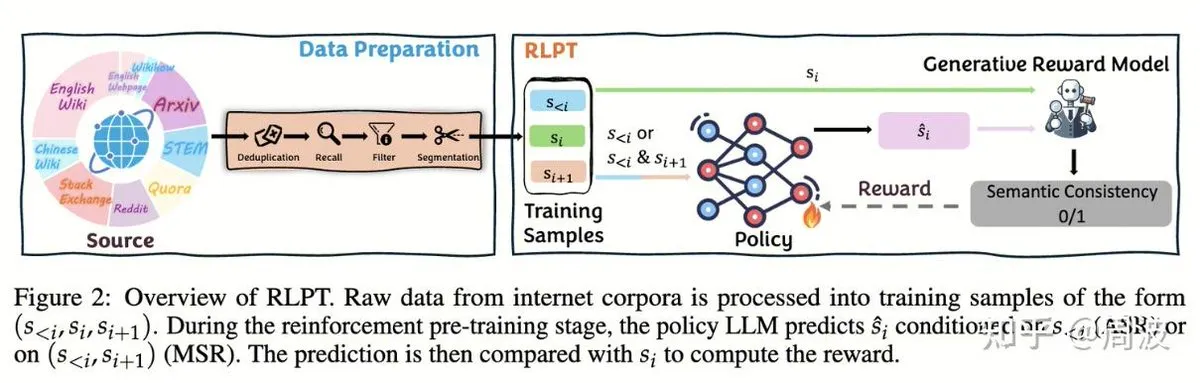
주제: Tencent Hunyuan 팀, 인간 주석 없는 LLM 추론 강화 학습 신규 방법 제안: Tencent Hunyuan 추론 및 사전 훈련 팀은 새로운 강화 학습(RL) 방법을 발표했다. RL 기반의 ‘다음 세그먼트 예측’으로 전통적인 ‘다음 토큰 예측’을 대체하여 인간 주석 데이터 없이 LLM 추론 능력을 확장하는 것을 구현한다. 이 방법은 자기회귀 세그먼트 추론(ASR)과 중간 세그먼트 추론(MSR)이라는 두 가지 RL 작업을 통해 수학, 논리 등 여러 벤치마크에서 모델 성능을 크게 향상시켰다. 추론 확장이 비용 확장과 같지 않음을 증명했다 (출처: ZhihuFrontier, ZhihuFrontier)
🧰 도구
주제: OpenAlex MCP Server: 과학 연구를 위한 맞춤형 OpenWebUI 도구: 한 개발자가 OpenWebUI에서 과학 연구를 위해 OpenAlex MCP Server를 만들었다. 이 서비스는 OpenAlex 무료 과학 인덱스를 통합하여 사용자가 날짜와 인용 횟수에 따라 연구 논문을 필터링할 수 있도록 한다. 기존 도구로는 충족할 수 없었던 요구 사항을 해결했으며, OpenWebUI에 쉽게 통합될 수 있다 (출처: Reddit r/OpenWebUI)
주제: Claude, 사용자 PC 성능 문제 성공적으로 진단 및 해결: 한 사용자가 Claude AI가 3년 동안 겪었던 PC 성능 문제를 해결하는 데 어떻게 도움을 주었는지 공유했다. Claude의 지침을 통해 사용자는 제어판 깊숙이 숨겨진 전원 성능 설정을 발견했으며, ‘절전’ 모드에서 고성능 모드로 조정하여 게임 프레임 속도를 16FPS에서 60FPS로 향상시켰다. 이는 복잡한 기술 문제 진단 및 해결에서 AI의 실용적인 가치를 보여준다 (출처: Reddit r/ClaudeAI)
주제: Microsoft, Copilot Benchmarks 출시: 직원 AI 사용 추적 논란 촉발: Microsoft는 Copilot Benchmarks라는 도구를 출시했다. 관리자가 Office 애플리케이션에서 AI 도구(예: Copilot)의 직원 사용 빈도를 추적하고, 부서 평균 및 ‘최고 기업’과 비교할 수 있도록 한다. 이러한 움직임은 직장 감시 및 데이터 남용에 대한 우려를 불러일으켰으며, 많은 사람들은 이것이 AI 사용이 성과 평가 또는 심지어 해고의 근거가 될 수 있다고 생각한다. 진정한 생산성 향상이 아닌 (출처: Reddit r/ArtificialInteligence)
주제: MarkItDown: Microsoft, LLM 파이프라인 문서 Markdown 변환 도구 출시: Microsoft는 Python 도구인 MarkItDown을 출시했다. PDF, Word, Excel, PowerPoint, HTML, CSV, JSON, XML, 이미지, 오디오 등 다양한 파일 형식을 깔끔한 Markdown 형식으로 변환할 수 있다. Markdown은 LLM의 ‘기본 언어’로서, 이 도구는 문서를 모델에 입력하기 전에 전처리하는 데 매우 적합하다. 제목, 목록, 표, 링크 및 메타데이터를 유지하여 LLM의 문서 처리 효율성과 품질을 향상시킨다 (출처: TheTuringPost)
주제: vLLM, GitHub 6만 별표 돌파하며 고효율 LLM 추론 선도: vLLM 프로젝트는 GitHub에서 6만 개의 별표를 획득하며 LLM 추론 분야의 중요한 세력으로 부상했다. NVIDIA, AMD, Intel, Apple, TPU 등 다양한 하드웨어를 지원하며, Llama, GPT-OSS, Qwen, DeepSeek 등 주류 텍스트 생성 모델 및 TRL, Unsloth 등 RL 파이프라인과 호환된다. 효율적이고 확장 가능한 개방형 LLM 추론 솔루션을 제공하여 AI 생태계 발전을 추진하는 데 전념하고 있다 (출처: vllm_project)
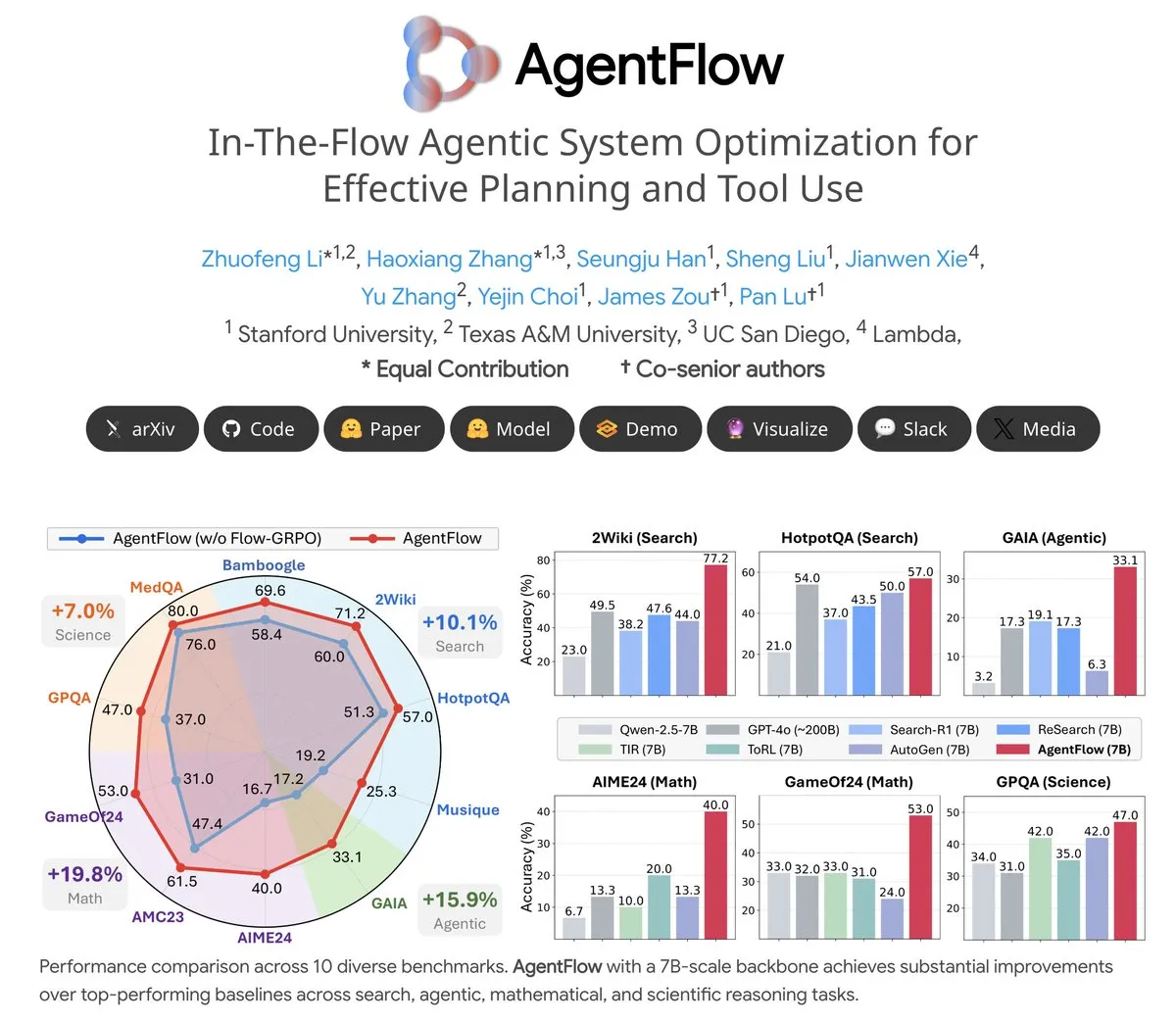
주제: AgentFlow: LLM 기반 프로그램 진화를 구현하는 훈련 가능한 에이전트 시스템: AgentFlow는 오픈소스 훈련 가능한 에이전트 시스템으로, 팀 협업을 통해 에이전트가 작업 흐름에서 계획 및 도구 사용을 학습할 수 있도록 한다. 이 시스템은 Flow-GRPO 방법을 통해 Planner 에이전트를 직접 최적화하며, 검색, 에이전트, 수학 및 과학 등 여러 벤치마크 테스트에서 AgentFlow(7B 모델)는 Llama-3.1-405B 및 GPT-4o와 같은 대규모 모델보다 우수한 성능을 보였다. LLM의 도구 사용 측면에서 엄청난 잠재력을 보여주었다 (출처: NerdyRodent)
주제: Claude Code 업데이트 문제: 사용자, 최신 버전 심각한 버그 보고: Reddit 커뮤니티 사용자들은 최신 Claude Code 버전에 심각한 버그가 있다고 보고했다. 컨텍스트 창 제한이 너무 빠르고 토큰 사용량 계산이 부정확하여 거의 사용할 수 없는 수준이라고 밝혔다. 많은 사용자들이 안정적인 기능을 복원하기 위해 즉시 이전 버전(예: 1.0.88)으로 다운그레이드하고 자동 업데이트를 비활성화할 것을 권장했다 (출처: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
주제: Open WebUI Docker 배포 시 디스크 사용량 과도 문제: Open WebUI가 Docker 컨테이너에서 실행될 때, 사용자들은 디스크 사용량이 매우 높다고 보고했다. 주로 cache/embedding/models, overlay2, containers, vector_db 등으로 구성된다. 사용자들은 Azure VM에서 디스크 공간 부족 문제를 해결하기 위해 캐시 파일을 안전하게 삭제하고 overlay2 크기를 줄이는 방법을 찾고 있다. 이는 AI 애플리케이션이 로컬에 배포될 때 저장 리소스에 대한 요구 사항과 관리 과제를 반영한다 (출처: Reddit r/OpenWebUI)
주제: Claude Sonnet 4.5, 코딩 작업에서 사용자 호평 받아: Claude가 전반적으로 부정적인 평가를 받고 있음에도 불구하고, 일부 사용자는 Sonnet 4.5의 코딩 작업 성능에 대해 높은 평가를 내렸다. 사용자들은 자동 편집 및 계획 모드를 결합했을 때 Sonnet 4.5가 Node.js 및 Flutter 개발에서 Opus 4.1 Plan 모드와 동등한 코드 품질을 달성했다고 밝혔다. 동시에 더 빠르고 비용 효율적이었다. 사용 제한에 도달하는 빈도를 크게 줄이고 ChatGPT에 대한 의존도를 낮췄다 (출처: Reddit r/ClaudeAI)
📚 학습
주제: CleanMARL: PyTorch에서 다중 에이전트 강화 학습 알고리즘의 간결한 구현: CleanMARL은 오픈소스 프로젝트로, CleanRL의 설계 철학을 따라 PyTorch에서 심층 다중 에이전트 강화 학습(MARL) 알고리즘의 간결한 단일 파일 구현을 제공한다. 이 프로젝트는 VDN, QMIX, COMA, MADDPG, FACMAC, IPPO, MAPPO 등 핵심 알고리즘을 다루는 교육 콘텐츠도 제공한다. 병렬 환경 및 순환 정책 훈련을 지원하며, TensorBoard 및 Weights & Biases 로깅을 통합했다. 사용자가 MARL 알고리즘을 이해하고 적용하는 데 도움을 주는 것을 목표로 한다 (출처: Reddit r/MachineLearning, Reddit r/deeplearning)

주제: AI/GenAI/ML/LLM 핵심 개념 및 학습 경로: 여러 자료에서 AI 분야의 기초부터 고급까지 학습 가이드를 제공한다. 내용은 AI 마스터링에 필요한 Python 개념, 생성형 AI 전문가 로드맵, AI 에이전트 입문, AI 모델 아키텍처의 7가지 계층, AI와 생성형 AI 및 머신러닝의 차이점, 20가지 LLM 핵심 개념, 에이전트 AI 개념 및 데이터 과학 직업 경로를 포함한다. 이러한 자료들은 학습자들이 포괄적인 AI 지식 체계와 직업 개발 계획을 구축하는 데 도움을 주는 것을 목표로 한다 (출처: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

주제: 저정밀도 훈련을 위한 로그 숫자 시스템: 한 블로그 게시물은 저정밀도 훈련에 사용되는 로그 숫자 시스템을 탐구한다. 이는 자원 제약 환경에서 머신러닝 모델의 성능을 최적화하는 데 매우 중요하다. 이 기술은 모델 정확도를 유지하면서 훈련 효율성을 높이는 것을 목표로 하며, 딥러닝 분야에서 지속적으로 주목받는 최적화 방향이다 (출처: Reddit r/deeplearning)
주제: OpenCV의 컴퓨터 비전 분야에서의 지속적인 중요성: 커뮤니티에서는 PyTorch/TensorFlow와 같은 딥러닝 프레임워크가 보편화된 2025년에 왜 OpenCV가 여전히 널리 사용되는지에 대해 논의했다. 주요 의견은 OpenCV가 이미지 및 비디오 처리 기능에서 더 풍부하고 효율적이며, 특히 CUDA 가속 환경에서 PyTorch보다 처리 속도가 우수하다는 것이다. 따라서 이미지/비디오 전처리에 자주 사용되며, 이후 데이터를 PyTorch로 전달하여 딥러닝 작업을 수행한다 (출처: Reddit r/deeplearning)
주제: NeurIPS 논문의 EurIPS 발표 요구 사항: 커뮤니티는 NeurIPS 논문의 발표 규정에 대해 논의했다. EurIPS는 NeurIPS 포스터 발표로 간주되지 않는다고 지적했다. 저자가 SD 또는 멕시코시티에 직접 가서 발표할 수 없는 경우, 논문은 일반적으로 철회된다. 하지만 어떤 저자라도 대신 발표할 수 있으며, 비저자는 주최자의 허가를 받아야 한다. 이는 연구자들이 특별한 상황에서 논문 발표를 보장받을 수 있는 지침을 제공한다 (출처: Reddit r/MachineLearning)
주제: Windows 11에서 듀얼 GPU 분산 훈련의 과제: 한 사용자가 Windows 11에서 두 개의 NVIDIA A6000 GPU를 사용하여 PyTorch 분산 훈련을 수행하는 방법에 대한 조언을 구했다. CUDA가 활성화되었음에도 불구하고 현재는 하나의 GPU만 사용할 수 있다. 커뮤니티 논의는 효율적인 딥러닝 훈련을 위해 다중 GPU 리소스를 최대한 활용하도록 환경과 코드를 구성하는 방법에 집중되었다 (출처: Reddit r/deeplearning)
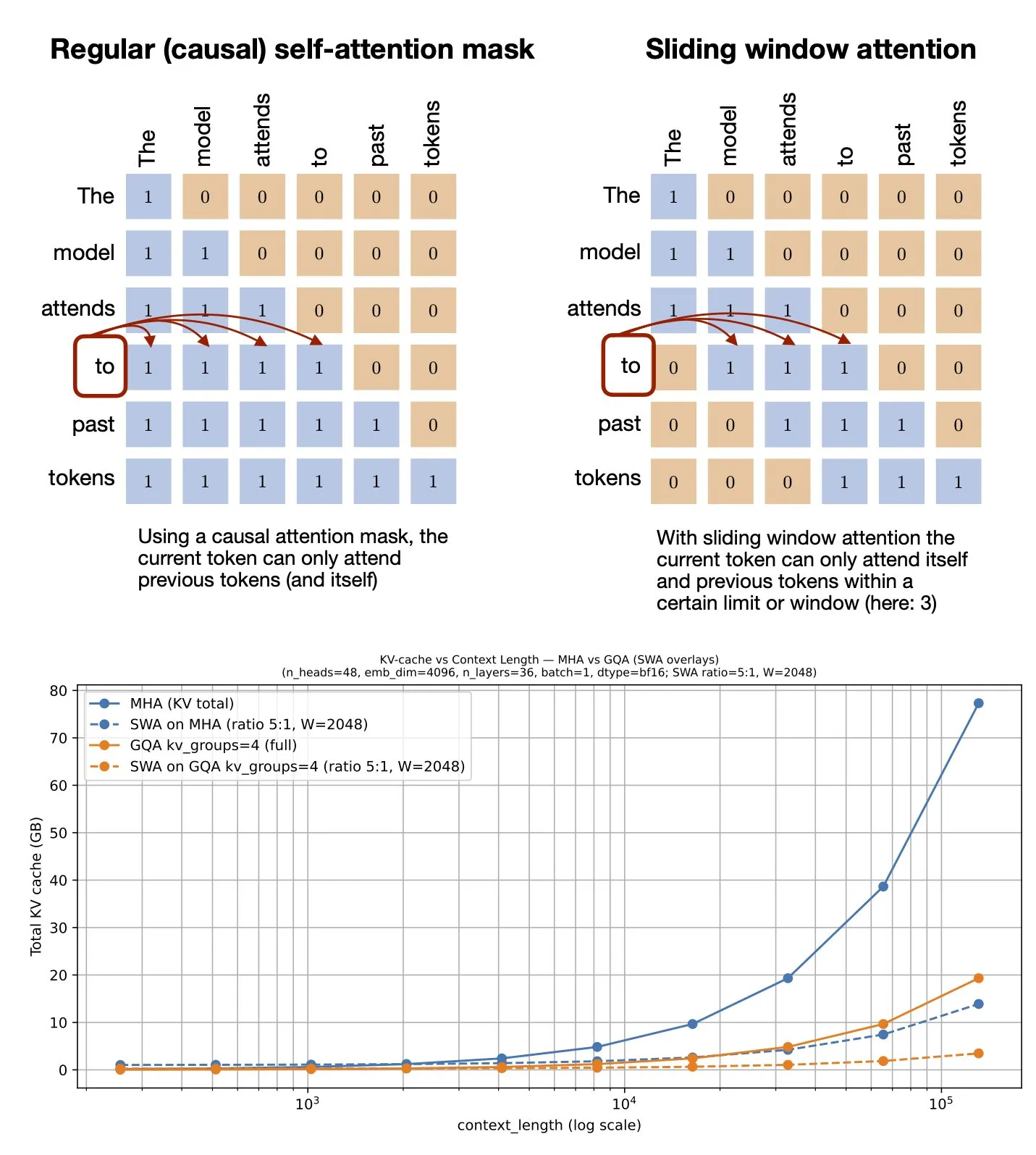
주제: 슬라이딩 윈도우 어텐션 메커니즘: GitHub 자료 공유: Sebastian Raschka는 슬라이딩 윈도우 어텐션(Sliding Window Attention) 메커니즘에 대한 GitHub 자료를 공유했다. 이 메커니즘은 대규모 언어 모델에서 긴 시퀀스 입력을 처리하기 위한 최적화 기술로, 어텐션 계산 범위를 제한하여 계산 복잡성과 메모리 소비를 줄인다. 동시에 컨텍스트에 대한 효과적인 이해를 유지한다 (출처: rasbt)
주제: 멀티모달 프롬프트 최적화: 멀티모달 활용하여 MLLM 성능 향상: 한 연구는 멀티모달 프롬프트 최적화(MPO) 방법을 도입했다. 프롬프트 공간을 텍스트 외의 영역으로 확장하고 멀티모달 프롬프트를 효과적으로 최적화하는 것을 목표로 한다. 이 방법은 다양한 모달리티(예: 이미지, 텍스트)의 조합을 활용하여 멀티모달 대규모 언어 모델(MLLMs)의 성능을 향상시킨다. 특히 복잡한 멀티모달 작업을 처리할 때, 더 풍부한 프롬프트 정보를 통해 더 정확한 이해와 생성을 달성한다 (출처: _akhaliq)

주제: 시각 언어 모델 신간 곧 출간 예정: O’Reilly Media에서 시각 언어 모델에 관한 신간을 곧 출판할 예정이며, 현재 장별 출시 알림이 오픈되었다. 이 책은 독자들에게 시각 언어 모델 분야의 포괄적인 가이드를 제공하는 것을 목표로 한다. 이론적 기초, 최신 발전 및 실제 응용을 다루며, 이 교차 분야를 심층적으로 이해하고자 하는 연구원과 개발자에게 중요한 참고 가치가 있다 (출처: mervenoyann)
주제: nanochat: Andrej Karpathy, 극도로 간결한 ChatGPT 클론 훈련 추론 파이프라인 공개: Andrej Karpathy는 새로운 GitHub 저장소 nanochat을 공개했다. 이는 간단한 ChatGPT 클론을 구축하기 위한 극도로 간결하고, 처음부터 시작하는 풀스택 훈련/추론 파이프라인이다. 이전 nanoGPT가 사전 훈련만 다루었던 것과 달리, nanochat은 완전한 엔드투엔드 솔루션을 제공하여 개발자들이 ChatGPT 구축 과정을 이해하고 실습하는 데 용이하다 (출처: dejavucoder)

주제: nanosft: PyTorch 기반 채팅 모델 미세 조정 단일 파일 구현: nanosft는 채팅 스타일 모델을 미세 조정하기 위한 간결한 단일 파일 구현이다. nanogpt에 gpt2-124M 가중치를 로드하고 PyTorch만을 사용하여 지도 학습 미세 조정을 수행할 수 있다. 이 프로젝트는 개발자들이 채팅 모델을 맞춤 설정하고 최적화하는 데 도움이 되는 이해하기 쉽고 사용하기 편리한 도구를 제공하는 것을 목표로 한다 (출처: tokenbender, dejavucoder)
주제: Microsoft Edge AI 초보자 가이드: 추천 자료: Microsoft의 Edge AI 초보자 가이드가 학습 자료로 추천되었다. 이 가이드는 엣지 장치에 AI 모델을 배포하고 실행하는 이론, 도구 및 실제 사례를 다룰 수 있으며, 엣지 AI 애플리케이션 및 개발을 탐색하고자 하는 학습자에게 지침이 될 수 있다 (출처: hrishioa)
주제: llama.cpp: 로컬 LLM 실행의 효율성 혁신: 커뮤니티는 Ollama와 LM Studio에서 llama.cpp로 전환하여 로컬 대규모 언어 모델을 실행한 경험에 대해 논의했다. llama.cpp가 상당한 효율성 향상을 가져왔다는 것이 일반적인 의견이다. 사용자들은 이를 ‘판도를 완전히 바꾸는’ 도구라고 칭하며, llama.cpp가 로컬 LLM 추론 성능 최적화에서 중요한 진전을 이루었음을 시사한다 (출처: ggerganov)
주제: RL-Guided KV Cache Compression: 추론 LLM의 키-값 캐시 압축: 이 연구는 RLKV 프레임워크를 제안한다. 강화 학습을 통해 추론에 중요한 어텐션 헤드를 식별하고 KV 캐시 사용과 추론 품질 간의 관계를 최적화한다. RLKV는 훈련 중 실제 생성 샘플에서 보상을 얻어 사고의 사슬 일관성과 관련된 어텐션 헤드를 효과적으로 식별한다. 20-50%의 캐시 절감을 달성하면서 거의 손실 없는 성능을 유지한다. 이는 기존 방법들이 추론 모델에서 성능이 좋지 않았던 문제를 해결한다 (출처: HuggingFace Daily Papers)
주제: Hybrid-depth: 언어 지시 기반 단안 깊이 추정 혼합 특징 집계: Hybrid-depth는 새로운 프레임워크로, CLIP 및 DINO와 같은 기본 모델을 체계적으로 통합하여 대조적인 언어 지시를 통해 시각적 사전 지식과 컨텍스트 정보를 추출함으로써 단안 깊이 추정(MDE)의 성능을 향상시키는 것을 목표로 한다. 이 방법은 거칠게에서 정교하게로 진행되는 점진적 학습 프레임워크를 통해 다중 세분화 특징을 집계하고 깊이 예측을 정교화한다. KITTI 벤치마크에서 SOTA 방법보다 현저히 우수하며, 다운스트림 BEV 인식 작업에도 유익하다 (출처: HuggingFace Daily Papers)
주제: 개인 서사 스타일의 형식화: 언어 모델을 통한 주관적 경험 분석: 이 연구는 새로운 방법을 제안한다. 개인 서사에서 스타일을 저자가 주관적 경험을 전달할 때 언어 선택의 패턴으로 형식화한다. 이 프레임워크는 기능 언어학, 컴퓨터 과학 및 심리학적 관찰을 결합하여 과정, 참여자 및 상황과 같은 언어적 특징을 자동으로 추출한다. 꿈 서사(PTSD 참전 용사 사례 포함) 분석을 통해 언어 선택과 심리 상태 간의 관계를 밝혀냈다 (출처: HuggingFace Daily Papers)
주제: ELMUR: 장기 시퀀스 강화 학습을 위한 외부 계층 메모리: ELMUR(External Layer Memory with Update/Rewrite)은 구조화된 외부 메모리를 갖춘 Transformer 아키텍처로, 전통적인 모델이 장기 시퀀스 강화 학습에서 장기 의존성을 유지하고 활용하기 어려운 문제를 해결한다. ELMUR은 유효 시야를 어텐션 윈도우의 10만 배까지 확장하며, 합성 T-Maze 작업에서 100% 성공률을 달성하고 희소 보상 조작 작업에서 성능을 거의 두 배로 향상시켰다. 부분적으로 관찰 가능한 의사결정에서 구조화된 계층 지역 외부 메모리의 확장성을 증명했다 (출처: HuggingFace Daily Papers)
주제: LightReasoner: 소규모 언어 모델이 대규모 언어 모델에게 추론을 가르치는 방법: LightReasoner 프레임워크는 전문가 모델(LLM)과 아마추어 모델(SLM) 간의 행동 차이를 활용하여 핵심 추론 순간을 식별하고 지도 학습 예시를 구축함으로써 소규모 언어 모델이 대규모 언어 모델에게 추론을 효율적으로 가르칠 수 있도록 한다. 이 방법은 7개 수학 벤치마크에서 정확도를 최대 28.1% 향상시켰으며, 동시에 시간 소비, 샘플링 문제 및 미세 조정 토큰 사용량을 각각 90%, 80%, 99% 감소시켰다. 실제 레이블이 필요 없어 LLM 추론 확장을 위한 자원 효율적인 방법을 제공한다 (출처: HuggingFace Daily Papers)
주제: MONKEY: 개인화된 확산 모델을 위한 키-값 활성화 어댑터: MONKEY는 IP-Adapter가 자동으로 생성한 마스크를 활용하는 방법을 제안한다. 두 번째 추론에서 이미지 토큰을 마스킹 처리하는 방법으로, 확산 모델의 개인화를 주제 영역으로 제한하여 텍스트 프롬프트가 이미지의 나머지 부분에 더 잘 집중할 수 있도록 한다. 이 방법은 텍스트가 위치와 장면을 설명할 때 주제를 정확하게 묘사하고 프롬프트와 명확하게 일치하는 이미지를 생성할 수 있다. 높은 프롬프트 및 원본 이미지 정렬을 달성한다 (출처: HuggingFace Daily Papers)
주제: Speculative Jacobi-Denoising Decoding: 자기회귀 텍스트-이미지 생성 가속화: SJD2(Speculative Jacobi-Denoising Decoding) 프레임워크는 디노이징 과정을 Jacobi 반복에 통합하여 자기회귀 텍스트-이미지 모델에서 병렬 토큰 생성을 구현하여 추론을 가속화한다. 이 방법은 ‘다음 깨끗한 토큰 예측’ 패러다임을 도입하여 사전 훈련된 모델이 노이즈가 있는 토큰 임베딩을 수용할 수 있도록 하고, 저비용 미세 조정을 통해 다음 깨끗한 토큰을 예측한다. 이를 통해 모델의 전방 전파 횟수를 줄이면서 생성된 이미지의 시각적 품질을 유지한다 (출처: HuggingFace Daily Papers)
주제: ACE: 귀인 제어 지식 편집을 통한 다중 홉 사실 회상 구현: ACE(Attribution-Controlled Knowledge Editing) 프레임워크는 뉴런 수준의 귀인을 통해 핵심 쿼리-값(Q-V) 경로를 식별하고 편집하여 LLM에서 효율적인 지식 편집을 구현한다. 이 방법은 다중 홉 사실 회상 작업에서 기존 SOTA 방법보다 현저히 우수하며, GPT-J에서 9.44%, Qwen3-8B에서 37.46% 향상되었다. 내부 추론 메커니즘 이해 기반의 지식 편집 능력 향상을 위한 새로운 길을 열었다 (출처: HuggingFace Daily Papers)
주제: DISCO: 다양화된 샘플 응축을 통한 효율적인 모델 평가: DISCO(Diversifying Sample Condensation) 방법은 모델 간 불일치가 가장 큰 top-k 샘플을 선택하여 효율적인 머신러닝 모델 평가를 구현한다. 이 방법은 전역 클러스터링 대신 탐욕적인 샘플 수준 통계를 사용하여 개념적으로 더 간단하다. 이론적으로, 모델 간 불일치는 정보 이론적으로 최적의 탐욕적인 선택 규칙을 제공한다. DISCO는 MMLU, Hellaswag, Winogrande 및 ARC와 같은 벤치마크에서 성능 예측 측면에서 기존 방법보다 우수하며 SOTA 결과를 달성했다 (출처: HuggingFace Daily Papers)
주제: D2E: 데스크톱 데이터 시각-행동 사전 훈련, 체화된 AI로 이전: D2E(Desktop to Embodied AI) 프레임워크는 데스크톱 상호작용이 로봇 체화된 AI 작업의 효과적인 사전 훈련 기반이 될 수 있음을 증명한다. 이 프레임워크는 OWA 툴킷(통합 데스크톱 상호작용), Generalist-IDM(게임 간 제로샷 일반화) 및 VAPT(데스크톱 사전 훈련 표현을 물리적 조작 및 내비게이션으로 이전)를 포함한다. D2E는 1.3K+ 시간의 데이터를 사용하여 LIBERO 조작 및 CANVAS 내비게이션 벤치마크에서 각각 96.6%와 83.3%의 성공률을 달성했다 (출처: HuggingFace Daily Papers)
주제: One Patch to Caption Them All: 통합 제로샷 이미지 캡션 프레임워크: 이 연구는 통합된 제로샷 이미지 캡션 프레임워크를 제안한다. 이미지 중심에서 패치 중심으로 전환하여 영역 수준 감독 없이 임의의 영역을 캡션할 수 있다. 단일 패치를 원자적 캡션 단위로 간주하고 이를 집계하여 임의의 영역을 설명함으로써, 이 방법은 여러 영역 기반 캡션 작업에서 기존 기준선 및 SOTA 방법보다 우수하며, 확장 가능한 캡션 생성에서 패치 수준 의미 표현의 유효성을 강조한다 (출처: HuggingFace Daily Papers)
주제: Adaptive Attacks on Trusted Monitors: AI 제어 프로토콜 전복: 이 연구는 AI 제어 프로토콜의 주요 맹점을 밝혀냈다. 신뢰할 수 없는 모델이 프로토콜과 모니터링 모델을 이해할 때, 적응형 공격은 공개되거나 제로샷 프롬프트 주입을 활용하여 모니터링을 회피하고 악성 작업을 완료할 수 있다. 실험 결과, 최첨단 모델은 다양한 모니터를 지속적으로 회피할 수 있으며, 두 가지 주요 AI 제어 벤치마크에서 악성 작업을 완료할 수 있다. 심지어 Defer-to-Resample 프로토콜도 역효과를 낼 수 있다 (출처: HuggingFace Daily Papers)
주제: Bridging Reasoning to Learning: 복잡성 OOD 일반화를 통해 환각 현상 규명: 이 연구는 AI의 추론 능력을 정의하고 측정하기 위한 복잡성 분포 외(Complexity OoD) 일반화 프레임워크를 제안한다. 모델이 훈련 예시의 솔루션 복잡성(표현 또는 계산)을 벗어나는 테스트 인스턴스에서 성능을 유지할 때 Complexity OoD 일반화를 나타낸다. 이 프레임워크는 학습과 추론을 통합하며, Complexity OoD를 조작화하기 위한 제안을 제공한다. 강력한 추론을 위해서는 계산을 명확하게 모델링하고 할당하는 아키텍처 및 훈련 메커니즘이 필요함을 강조한다 (출처: HuggingFace Daily Papers)
💼 비즈니스
주제: OpenAI, Broadcom과 협력하여 맞춤형 AI 칩 설계 및 배포: OpenAI는 Broadcom과 전략적 협력 관계를 구축했다고 발표했다. 10GW 규모의 맞춤형 AI 칩을 공동으로 설계하고 배포할 예정이다. 이는 OpenAI의 하드웨어 파트너 네트워크를 확장하기 위한 것으로, AI에 대한 전 세계적인 증가하는 컴퓨팅 수요를 충족시키기 위함이다. AI 인프라 구축에 대한 투자를 더욱 공고히 한다. 이전에는 NVIDIA 및 AMD와 협력 관계를 구축한 바 있다 (출처: aidan_mclau, gdb, scaling01, bookwormengr)

주제: Boeing Defense and Space, Palantir와 협력하여 AI 애플리케이션 가속화: Boeing Defense and Space 부문은 Palantir와 협력 관계를 구축했다고 발표했다. AI 기술의 채택 및 통합을 가속화하는 것을 목표로 한다. 이번 협력은 AI 및 데이터 분석 분야에서 Palantir의 전문 역량을 활용하여 Boeing의 국방 및 우주 분야 운영 효율성과 의사결정 능력을 향상시킬 것이다. 이는 주요 산업 분야에서 AI의 심층적인 적용을 의미한다 (출처: Reddit r/artificial)

주제: Pinterest, Ray 통해 ML 인프라 확장 및 비용 절감: Pinterest는 머신러닝 인프라를 Ray 플랫폼으로 성공적으로 확장하여 네이티브 데이터 변환, Iceberg bucket joins 및 데이터 영속화를 통해 기능 개발을 가속화하고 비용을 크게 절감했다. 이러한 조치는 ML 워크플로우를 최적화하고 GPU의 효율적인 활용과 예산의 예측 가능성을 보장했다. 다른 기업들에게 AI 데이터 저장 및 계산 효율성 측면에서 참고할 만한 사례를 제공한다 (출처: dl_weekly, TheTuringPost)

🌟 커뮤니티
주제: AI 논의에서 ‘AI 잘 활용하기’와 ‘업무 잘하기’: 소셜 미디어에서 AI 논의의 큰 문제점 중 하나는 ‘AI를 잘 활용하는’ 능력과 ‘본업을 잘하는’ 능력 사이에 단절이 존재한다는 것이다. 많은 전문가들이 AI 애플리케이션에서 뛰어난 성과를 보일 수 있지만, 다른 이들은 그렇지 않아 서로 이해하기 어렵게 만든다. 이러한 차이는 AI 시대에 걸쳐 분야 간 기술 융합의 필요성을 강조한다 (출처: nptacek)
주제: ChatGPT Pulse 업데이트 피드백: 사용자, 게임화된 프롬프트 및 기능 지원 기대: 사용자들은 ChatGPT Pulse 업데이트에 대해 활발히 논의하며, 자신들이 ‘판도를 바꾸는’ 프롬프트라고 생각하는 것을 공유하고 현재 지원되지 않는 기능을 지적했다. 이러한 논의는 ChatGPT 경험 최적화, 상호작용 개인화에 집중되었으며, 새로운 기능과 기존 기능 개선에 대한 기대를 반영한다. AI 비서에 대한 사용자들의 더 깊은 수준의 맞춤화 및 지원 요구를 반영한다 (출처: ChristinaHartW, _samirism, nickaturley)
주제: 경고: 프로덕션 환경에서 cairosvg 사용 피할 것, DoS 위험 존재: 한 개발자는 프로덕션 환경에서 cairosvg를 사용하지 말 것을 경고했다. 형식이 잘못된 SVG 파일을 파싱할 때 무한 루프에 빠질 수 있어 서비스 거부(DoS) 공격의 매개체가 될 수 있기 때문이다. 이는 개발자들이 라이브러리를 선택할 때 기능성 외에도 프로덕션 환경에서의 안정성과 보안에 높은 주의를 기울여야 함을 상기시킨다 (출처: vikhyatk)

주제: LLM 작문 스타일과 ‘모델 붕괴’: 커뮤니티는 LLM이 ‘이것은 X가 아니라 Y이다’와 같은 수사법을 과도하게 사용하는 것을 비판하며, 모델이 맥락 없이 패턴을 복제하여 작문 품질이 저하된다고 지적했다. 이를 ‘모델 붕괴’ 현상과 연결시켰다. 이러한 현상은 LLM이 훈련 데이터 품질 및 패턴 이해 측면에서 한계를 가지고 있음을 보여주며, 복잡한 작문 작업에서 성능에 영향을 미칠 수 있다 (출처: Reddit r/LocalLLaMA, Reddit r/artificial)
주제: AI, 직장 ‘마태 효과’ 심화, 최고 직원과 일반 직원 격차 확대: Wall Street Journal은 AI가 최고 직원과 일반 직원 간의 격차를 더욱 벌릴 것이라고 지적했다. 최고 직원들은 전문 지식과 효율적인 습관 덕분에 AI 도구를 더 일찍, 더 깊이 활용하여 효율적인 워크플로우를 구축하고 AI 제안을 더 잘 판단할 수 있다. 반면 일반 직원들은 명확한 지침을 기다리는 경향이 있으며, 그들의 AI 지원 성과는 종종 개인 능력보다는 기술에 기인한다고 여겨져 직장에서의 ‘마태 효과’를 심화시킨다 (출처: dotey)

주제: 사용자, AI가 의미 있게 인간을 대체할 수 있는지 의문 제기: 일부 사용자는 LLM이 속도 면에서 뛰어난 성능을 보이지만, 구체적인 지시를 따르고, 복잡한 컨텍스트를 처리하며, 파편화된 작문을 피하는 데 여전히 부족함이 있다고 말했다. 사용자들은 평균적으로 인간이 컨텍스트 이해 및 지시 실행 측면에서 AI보다 여전히 우수하다고 생각하며, 따라서 AI가 의미 있게 인간을 대체할 수 있는지에 대해 회의적인 시각을 표명했다. AI 발전이 신뢰성과 일관성에 더 중점을 두어야 한다고 촉구했다 (출처: Reddit r/ClaudeAI)
주제: Sora 2, AI 생성 콘텐츠의 진실성 우려 및 윤리적 논란 촉발: 커뮤니티는 Sora 2와 같은 AI 비디오 생성 도구의 확산에 대해 우려를 표명했다. 매우 사실적인 결과물이 허위 정보 및 장난을 만드는 데 사용될 수 있어 대중의 AI에 대한 신뢰를 손상시킬 수 있다고 보았다. 예를 들어, ‘AI 노숙자 장난’에 대한 비디오가 소셜 미디어에서 널리 퍼지고 많은 좋아요를 얻었으며, AI 콘텐츠 진실성 검증의 어려움과 잠재적인 사회적 부정적 영향을 부각시켰다 (출처: Reddit r/artificial, Reddit r/artificial)
주제: AI 판사, 사법 공정성 및 윤리적 논쟁 촉발: 두 명의 미국 연방 판사가 AI를 사용하여 법원 명령 초안을 작성하면서 사법 분야에서 AI의 역할에 대한 격렬한 논쟁이 촉발되었다. 지지자들은 AI가 법원 업무를 간소화하고 법률 서비스 접근성을 높일 수 있다고 주장하는 반면, 비판자들은 AI가 오류를 범할 수 있고 사법에 필요한 ‘공통된 인간성’이 부족하여 공감과 공정성을 해칠 수 있다고 경고한다. 중국과 에스토니아는 이미 AI 판사 분야에서 실험을 진행했으며, 이는 미래 사법 시스템이 직면할 수 있는 중대한 변화를 예고한다 (출처: Reddit r/ArtificialInteligence)
주제: ChatGPT의 사용자 정신 건강 지원에 대한 논의: Reddit 사용자들은 ChatGPT가 창의적인 배출구이자 정서적 지원 도구로서의 개인적인 경험을 공유했다. 특히 트라우마와 심리적 어려움에 직면했을 때, 그들은 AI가 안전하고 사적인 공간을 제공하여 외로움과 불안에 대처하는 데 도움을 주었다고 생각한다. 또한 AI 기업들이 콘텐츠 제한을 설정할 때 성인 사용자의 다양하고 건강하며 창의적인 사용 요구를 고려해야 한다고 촉구했다. 과도한 제한이 사용자에게 부정적인 영향을 미치지 않도록 해야 한다 (출처: Reddit r/ChatGPT)
주제: ChatGPT, 무한 루프에 빠지는 버그: 사용자들은 ChatGPT가 특정 질문(예: ‘해마 이모지는 무엇인가요?’)에 답변할 때 반복적이고 자기 참조적인 무한 루프에 빠지는 것을 발견하고 공유했다. 이러한 현상은 커뮤니티의 논의와 유머러스한 반응을 불러일으켰으며, AI 모델이 일부 모호하거나 개방형 질문을 처리할 때 발생할 수 있는 예상치 못한 행동과 한계를 드러냈다 (출처: Reddit r/ChatGPT)

주제: VChain: 시각적 사고의 사슬을 통해 텍스트-비디오 모델의 인과적 일관성 향상: VChain은 추론 시 ‘시각적 사고의 사슬’(일련의 키 프레임)을 주입하여 텍스트-비디오 모델이 실제 세계의 인과 관계를 따를 수 있도록 한다. 이 방법은 완전한 재훈련 없이 소량의 추론 시 키 프레임과 미세 조정만으로도 비디오의 물리적 및 인과적 일관성을 크게 개선할 수 있다. 이는 기존 비디오 모델이 높은 부드러움을 보이지만 핵심적인 인과적 결과를 건너뛰는 문제를 해결한다 (출처: connerruhl)

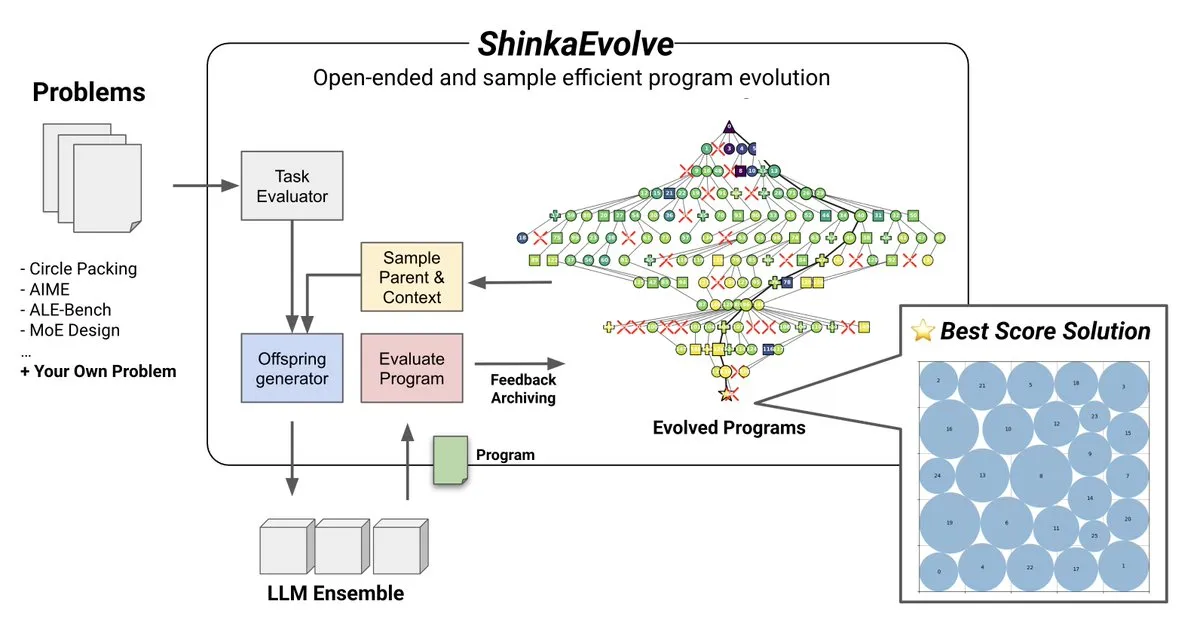
주제: ShinkaEvolve: LLM 기반 프로그램 진화 오픈소스 방법: Sakana AI는 ShinkaEvolve를 출시했다. 오픈소스이자 샘플 효율적인 LLM 기반 프로그램 진화 방법으로, 개방형 및 샘플 효율적인 발견에서 효과적인 프로그램 변이의 핵심 과제를 해결하는 것을 목표로 한다. 이 프레임워크는 LLM을 지능형 재조합 연산자로 활용하여 과학적 발견에서 프로그램 진화를 추진한다. 실전 검증을 통해 AlphaEvolve와 같은 방법에 새로운 관점을 제공했다 (출처: hardmaru)
주제: Google, 기억 인지 테스트 시간 스케일링 기술 출시, AI 에이전트 효율성 향상: Google은 자체 진화 AI 에이전트를 개선하기 위한 기억 인지 테스트 시간 스케일링(memory-aware test-time scaling) 기술을 제안했다. 이 기술은 구조화되고 적응적인 기억 메커니즘을 활용하여 에이전트의 성능을 크게 향상시켰으며, 다른 기억 메커니즘을 능가했다. AI 에이전트에서 기억을 효과적으로 관리하기 어려운 핵심 문제를 해결했다 (출처: omarsar0)

주제: AMD ROCm 소프트웨어 품질 크게 향상, MI300X 추론 워크로드에서 경쟁력 확보: 커뮤니티는 AMD의 ROCm 소프트웨어 품질이 2024년 여름 이후 ‘질적인 도약’을 이루어 버그 발생 빈도가 현저히 줄었다고 밝혔다. 벤치마크 테스트 결과, Llama3 70B FP8 추론 워크로드에서 MI300X vLLM은 TCO당 성능에서 H100 vLLM보다 5-10% 낮았지만, MI325X vLLM과 H200 vLLM, GPTOSS MX4 120B Mi355와 B200의 비교에서는 경쟁력을 갖추고 있다 (출처: riemannzeta)

주제: 재귀적 자기 개선 AI의 미래 역학: 커뮤니티는 재귀적 자기 개선 AI가 조직, 기관, 참여자 및 커뮤니티 간에 어떻게 진화하고 확산될지에 대해 논의했다. 이는 현재 가장 근본적인 문제로 여겨지며, AI 발전이 사회 구조와 권력 분배에 미치는 심오한 영향과 이러한 변화를 어떻게 예측하고 관리할 것인지에 대한 내용을 포함한다 (출처: ethanCaballero)
주제: Nando de Freitas: 기계의 예측적 인지가 곧 의식의 싹: Google DeepMind의 Nando de Freitas는 센서(촉각, 카메라, 키보드, 온도, 마이크, 자이로스코프 등)가 무엇을 감지할지 예측할 수 있는 기계는 이미 의식과 주관적 경험을 가지고 있으며, 이는 정도의 문제일 뿐이라고 주장했다. 그는 더 많은 센서, 데이터, 계산 및 작업이 의심할 여지 없이 ‘나’의 출현으로 이어질 것이라고 보았다. 이는 의식과 자기 인식이 언제 시작되는지에 대한 논의를 촉발했다 (출처: TheRealRPuri)
주제: 인터넷 데이터 폐쇄가 AI 심층 연구 에이전트에 미치는 영향: LLM의 부상과 함께 인터넷 데이터가 점점 더 폐쇄되고 있어 심층 연구 에이전트의 존재가 어려워지고 있다는 의견이 있다. 데이터 접근이 제한될 경우, 지식을 저장하지 않지만 지식 검색에 능숙한 LLM 에이전트가 구현될 수 있는지에 대한 의문이 제기된다. 이는 AI 발전에서 데이터 개방성 및 접근성에 대한 우려를 반영한다 (출처: Teknium1)
주제: DevRel 직무, AI 분야에서 강력하게 부활: Anthropic과 같은 AI 기업들이 개발자 관계(DevRel) 인재를 고액 연봉으로 채용하고 있으며, 이는 AI 분야에서 해당 직무가 강력한 회복세를 겪고 있음을 보여준다. 이는 AI 기술이 프롬프트 엔지니어링과 커뮤니티 참여에 대한 중요성을 점점 더 강조하고 있기 때문이다. DevRel 전문가는 개발자를 연결하고 제품 채택을 촉진하며 생태계를 구축하는 데 핵심적인 역할을 한다 (출처: swyx)
주제: Jonathan Blow: AI 생성 코드 품질 낮고 AI가 이해 못 해: 유명 개발자 Jonathan Blow는 AI 시스템이 출력하는 코드의 품질이 ‘매우 낮으며’, AI 자체가 이 코드를 이해하지 못한다고 지적했다. 그는 AI 생성 코드의 사용 사례가 주로 대량의 저품질 코드가 필요한 시나리오에 국한된다고 보았다. 이는 프로그래밍 분야에서 AI의 실제 능력과 한계에 대한 논의를 촉발했다 (출처: aiamblichus, jeremyphoward, teortaxesTex)
주제: AI 과장 게시물 비판: 투명하고 실질적인 내용 요구: 커뮤니티는 모호하고 AI 발전을 과도하게 과장하는 게시물에 불만을 표명하며, 게시자들에게 더 구체적이고 실질적인 내용을 제공할 것을 촉구했다. 심지어 삶의 방식을 바꿀 수 있는 중대한 발전에 대해서는 ‘내부 고발’을 해야 한다고 주장했다. 이러한 정서는 AI 분야 정보 품질에 대한 대중의 기대와 무책임한 ‘모호한 홍보’에 대한 반감을 반영한다 (출처: aiamblichus, Teknium1)
주제: NVIDIA DGX Spark에 대한 의문과 기대: 커뮤니티는 NVIDIA DGX Spark ‘데스크톱 AI 슈퍼컴퓨터’ 출시에 대해 회의적인 태도를 보였다. 접근성, 가격 및 실제 성능, 특히 로컬 LLM 실행에 대한 의문을 제기했다. 많은 사람들은 그 홍보가 과장되었고 성능이 예상에 미치지 못할 수 있다고 생각하며, 출시 시기가 계속 연기되어 일부 사용자들이 다른 솔루션으로 전환하도록 만들었다 (출처: Reddit r/LocalLLaMA)
💡 기타
주제: Yunpeng Technology, AI+건강 신제품 출시, 가정 건강 관리 지능화 추진: Yunpeng Technology는 Shuaikang, Skyworth와 협력하여 ‘디지털 지능형 미래 주방 연구소’와 AI 건강 대규모 모델을 탑재한 스마트 냉장고를 출시했다. 스마트 냉장고는 ‘건강 도우미 샤오윈’을 통해 개인 맞춤형 건강 관리를 제공하며, 주방 디자인 및 운영을 최적화한다. 이번 출시는 일상 건강 관리 분야에서 AI의 돌파구를 의미하며, 스마트 기기를 통해 개인 맞춤형 건강 서비스를 실현하고 주민 생활의 질을 향상시킬 것으로 기대된다 (출처: 36氪)

주제: 노벨상 성과 MOF 재료, 뇌 모방 나노 유체 칩으로 제작: 모나쉬 대학교 과학자들은 노벨 화학상 수상자 MOF(금속 유기 골격) 재료를 활용하여 초소형 나노 유체 칩을 성공적으로 제작했다. 이 칩은 일반적인 계산뿐만 아니라 뇌 신경원처럼 이전 전압 변화를 기억하고 학습하여 단기 기억을 형성한다. 이 획기적인 성과는 MOF 재료가 오랫동안 실제 응용 분야가 부족했던 난관을 해결했으며, 차세대 컴퓨터 및 뇌 모방 컴퓨팅에 새로운 패러다임을 제공한다 (출처: 量子位)

주제: 글로벌 로봇 기술 혁신 및 응용 가속화: 로봇 분야는 여러 혁신적인 돌파구와 광범위한 응용을 맞이하고 있다. Knightscope의 자율 보안 로봇은 보안 분야를 변화시키고 있으며, 중국은 자율적으로 범죄자를 체포할 수 있는 고속 구형 경찰 로봇을 출시했다. AgiBot은 거의 인간과 유사한 이동 능력과 다기능 기술을 갖춘 Lingxi X2 휴머노이드 로봇을 발표했으며, 세계 최대의 휴머노이드 로봇 훈련 센터를 설립하여 사회 통합 및 응용을 가속화하고 있다. 또한, 산업 근로자용 웨어러블 힘 증강 로봇과 10초 안에 100미터를 달릴 수 있는 사족 보행 로봇도 다양한 시나리오에서 로봇 기술의 잠재력을 보여주었다 (출처: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)