
키워드:Gemini 2.5 Pro, VeBrain, Segment Anything Model 2, Qwen3-Embedding, AI Agent, Gemini 2.5 Pro 딥 싱크 모드, VeBrain 범용 구신 지능 프레임워크, SAM 2 이미지 비디오 분할, Qwen3-Embedding 32k 컨텍스트, AI Agent 멀티모달 이해
🔥 포커스
구글, 다수의 AI 신규 개발 발표, Gemini 2.5 Pro Deep Think 모드로 복잡한 추론 능력 향상: Google I/O 컨퍼런스에서 구글은 Gemini 2.5 Pro의 Deep Think 모드를 발표했습니다. 이는 AI가 복잡한 문제(예: USAMO 수준의 수학 난제)를 처리할 때의 추론 능력을 크게 향상시키는 것을 목표로 합니다. 동시에 구글은 Gemini 기반의 코딩 에이전트인 AlphaEvolve도 출시했습니다. 이는 알고리즘 발견에 사용되며, 이미 행렬 곱셈 알고리즘 설계 및 개방형 수학 문제 해결에서 성과를 거두었고, 구글 내부 데이터 센터, 칩 설계 및 AI 훈련 효율 최적화에 적용되고 있습니다. 또한, 비디오 모델 Veo 3, 이미지 모델 Imagen 4 및 AI 편집 도구 FLOW도 함께 발표되어, 구글의 멀티모달 AI 분야에서의 포괄적인 레이아웃과 빠른 진전을 보여주었습니다. (출처: OriolVinyalsML, demishassabis, demishassabis, op7418)
상하이 AI 연구소, 범용 물리적 지능 두뇌 프레임워크 VeBrain 공동 발표: 상하이 인공지능 연구소는 여러 기관과 협력하여 VeBrain(Visual Embodied Brain)을 출시했습니다. 이는 시각 인식, 공간 추론 및 로봇 제어 능력을 통합하는 것을 목표로 하는 범용 물리적 지능 두뇌 프레임워크입니다. 이 프레임워크는 로봇 제어 작업을 MLLM 내의 2D 공간 텍스트 작업(예: 키포인트 감지 및 물리적 기술 인식)으로 변환하고, “로봇 어댑터”를 도입하여 텍스트 결정에서 실제 동작으로의 정확한 매핑 및 폐쇄 루프 제어를 구현합니다. 모델 훈련을 지원하기 위해 팀은 멀티모달 이해, 시각-공간 추론 및 로봇 조작의 세 가지 유형의 작업을 포괄하는 60만 개의 명령어 데이터가 포함된 VeBrain-600k 데이터셋을 구축했습니다. 테스트 결과, VeBrain은 멀티모달 이해, 공간 추론 및 실제 로봇 제어(로봇 팔 및 로봇 개) 측면에서 모두 SOTA 수준에 도달한 것으로 나타났습니다. (출처: 量子位)

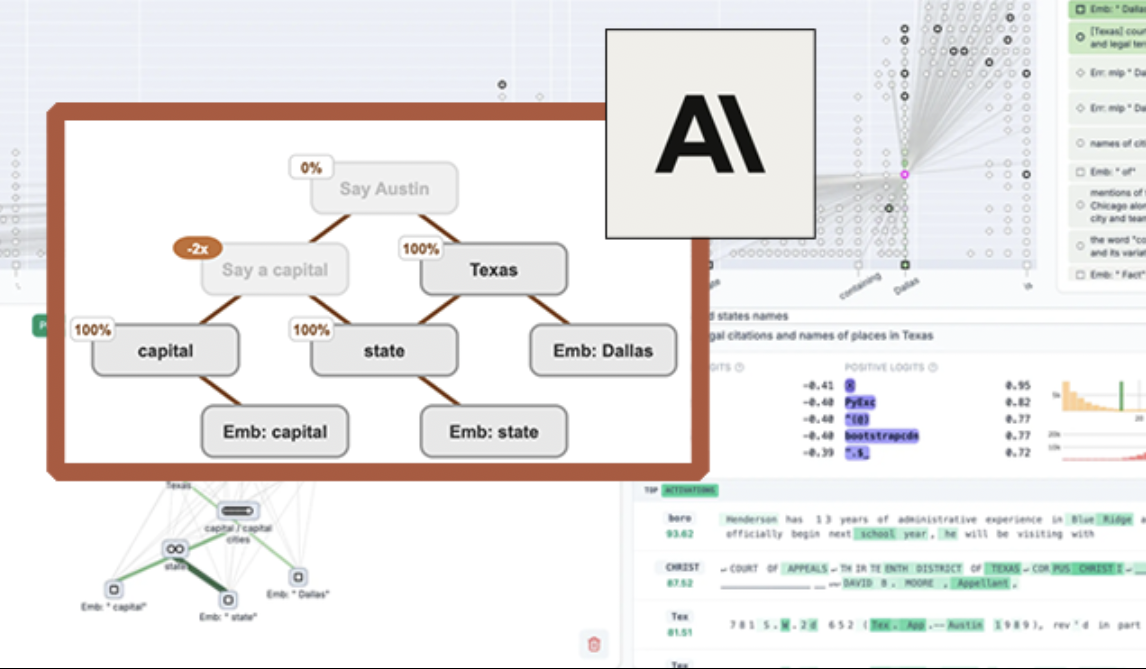
Anthropic, LLM 시각화 도구 “circuit tracing” 오픈소스 공개, 모델 해석 가능성 향상: Anthropic은 대규모 언어 모델(LLM)의 내부 작동 메커니즘을 연구자들이 이해하는 데 도움을 주기 위한 “circuit tracing” 오픈소스 도구를 출시했습니다. 이 도구는 “attribution graphs”를 생성하여 모델이 정보를 처리할 때 내부 슈퍼 노드와 그 연결 관계를 신경망 회로도와 유사하게 시각화합니다. 연구자들은 노드 활성화 값을 조작하고 모델 행동 변화를 관찰함으로써 각 노드의 기능을 검증하고 LLM의 의사 결정 논리를 해독할 수 있습니다. 이 도구는 주요 오픈소스 모델에서 attribution graphs 생성을 지원하며, 시각화, 주석 달기 및 공유를 위한 대화형 프런트엔드 인터페이스 Neuronpedia를 제공합니다. 이는 AI 해석 가능성 연구를 촉진하여 더 넓은 커뮤니티가 모델 행동을 탐색하고 이해할 수 있도록 하는 것을 목표로 합니다. (출처: 量子位, swyx)
Meta, Segment Anything Model 2 (SAM 2) 발표, 이미지 및 비디오 분할 능력 향상: Meta AI 연구소(FAIR)는 널리 사용되는 Segment Anything Model의 업그레이드 버전인 SAM 2를 출시했습니다. SAM 2는 이미지 및 비디오에서 프롬프트 가능한 시각적 분할 작업에 중점을 둔 기본 모델로, 프롬프트(예: 점, 상자, 텍스트)에 따라 이미지 또는 비디오의 특정 객체나 영역을 정확하게 식별하고 분할할 수 있습니다. 이 모델은 현재 Apache 라이선스에 따라 오픈소스로 공개되어 연구자와 개발자가 무료로 사용하고 애플리케이션을 구축하여 컴퓨터 비전 분야의 발전을 더욱 촉진할 수 있도록 합니다. (출처: AIatMeta)
🎯 동향
BAAI, Video-XL-2 오픈소스 공개, 단일 카드로 만 프레임 비디오 이해 실현: BAAI(베이징 인공지능 연구원)는 상하이 교통대학 등 기관과 협력하여 차세대 초장편 비디오 이해 모델 Video-XL-2를 발표했습니다. 이 모델은 효과, 처리 길이 및 속도 면에서 모두 크게 향상되어 단일 카드로 만 프레임 비디오 입력을 처리할 수 있으며, 2048 프레임 비디오 인코딩에 단 12초가 소요됩니다. Video-XL-2는 SigLIP-SO400M 시각 인코더, 동적 토큰 합성 모듈(DTS) 및 Qwen2.5-Instruct 대형 언어 모델을 채택하고, 4단계 점진적 훈련 및 효율성 최적화 전략(예: 세그먼트 방식 사전 로딩 및 이중 세분성 KV 디코딩)을 통해 고성능을 달성합니다. 이 모델은 MLVU, Video-MME 등 벤치마크 테스트에서 우수한 성능을 보였으며 가중치는 오픈소스로 공개되었습니다. (출처: 量子位)

Character.ai, AvatarFX 비디오 생성 기능 출시, 이미지 속 인물 움직이고 상호작용 가능: 선도적인 AI 동반 애플리케이션 Character.ai(c.ai)가 AvatarFX 기능을 출시했습니다. 이 기능을 통해 사용자는 정지 이미지 속 인물(애완동물 등 비인간 형상 포함)을 애니메이션화하여 말하고 노래하며 사용자와 상호작용할 수 있게 합니다. 이 기능은 DiT 아키텍처를 기반으로 하며, 높은 충실도와 시간적 일관성을 강조하여 다중 캐릭터, 긴 시퀀스 대화 등 복잡한 상황에서도 안정성을 유지합니다. 현재 AvatarFX는 웹 버전에서 모든 사용자에게 공개되었으며, APP 버전도 곧 출시될 예정입니다. 동시에 c.ai는 Scenes(상호작용형 스토리 장면), Imagine Animated Chat(애니메이션화된 채팅 기록) 및 Stream(캐릭터 간 스토리 생성) 등 새로운 기능을 발표하여 AI 창작 경험을 더욱 풍부하게 했습니다. (출처: 量子位)

Nvidia, Llama-3.1 Nemotron-Nano-VL-8B-V1 시각 언어 모델 출시: Nvidia는 새로운 시각-텍스트 모델 Llama-3.1-Nemotron-Nano-VL-8B-V1을 발표했습니다. 이 모델은 이미지, 비디오 및 텍스트 입력을 처리하고 텍스트 출력을 생성할 수 있으며, 어느 정도의 이미지 추론 및 인식 능력을 갖추고 있습니다. 이 모델의 출시는 Nvidia가 멀티모달 AI 분야에 지속적으로 투자하고 있음을 보여줍니다. 동시에 커뮤니티에서는 Llama-4가 70B 이하 모델을 포기하는 것이 Gemma3 및 Qwen3과 같은 모델이 미세 조정 시장에서 기회를 잡을 수 있다는 논의가 있었습니다. (출처: karminski3)
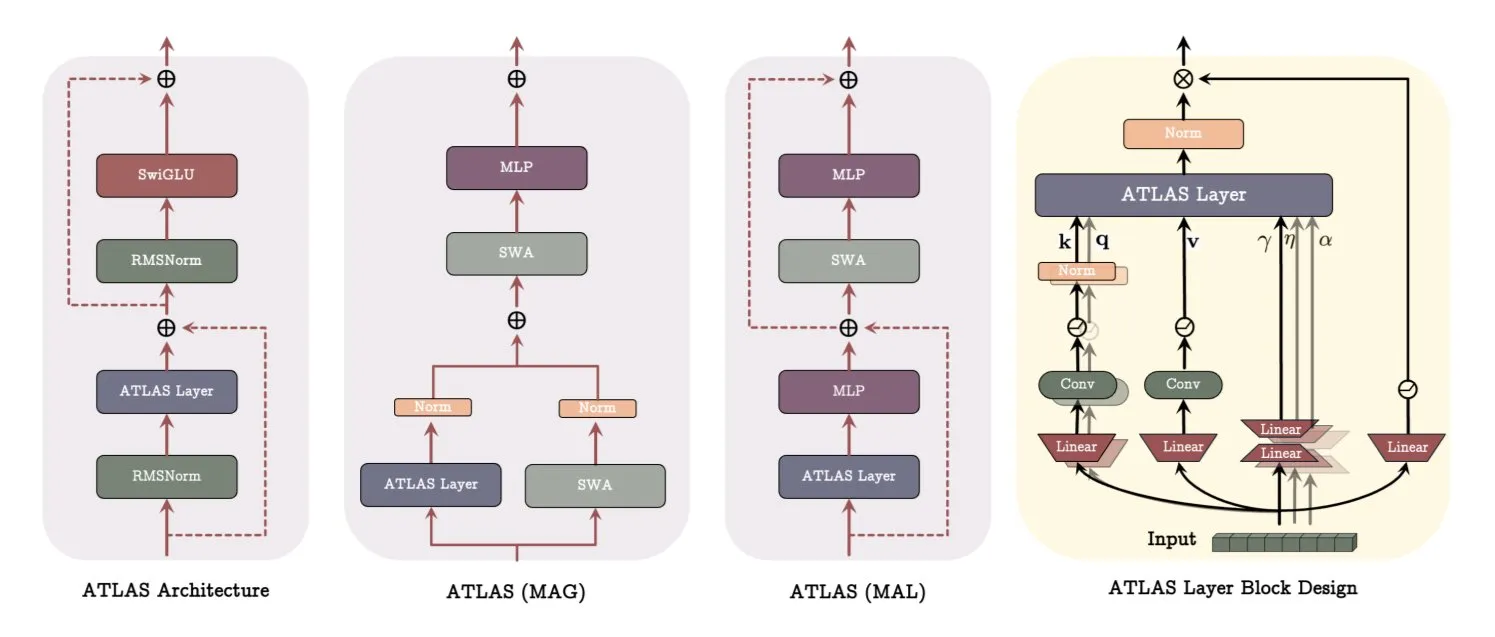
구글, ATLAS 아키텍처 논문 발표, 모델 학습 및 기억 방식 혁신: 구글의 최신 논문은 ATLAS라는 새로운 모델 아키텍처를 소개합니다. 이는 능동적 기억(Omega 규칙으로 최근 c개 토큰 처리)과 더 스마트한 메모리 용량 관리(다항식 및 지수 특징 매핑)를 통해 모델의 학습 및 기억 능력을 최적화하는 것을 목표로 합니다. ATLAS는 Muon 옵티마이저를 사용하여 더 효율적인 메모리 업데이트를 수행하고, DeepTransformers 및 Dot(Deep Omega Transformers)과 같은 설계를 도입하여 기존의 고정된 어텐션을 학습 가능하고 메모리 중심적인 메커니즘으로 대체합니다. 이 연구는 AI가 더 스마트하고 상황 인식적인 시스템으로 나아가는 중요한 단계이며, AI가 대규모 데이터셋을 처리하고 활용하는 능력을 향상시킬 것으로 기대됩니다. (출처: TheTuringPost)
Qwen, Qwen3-Embedding 시리즈 모델 발표, 임베딩 성능 대폭 향상: Qwen 팀은 새로운 Qwen3-Embedding 모델 시리즈를 발표했습니다. 여기에는 0.6B, 4B, 8B 세 가지 버전이 포함됩니다. 이 모델들은 최대 32k의 컨텍스트 길이와 100개 언어를 지원하며, MTEB(Massive Text Embedding Benchmark)에서 SOTA 성적을 거두었고, 일부 지표에서는 2위보다 10점 앞섰습니다. 이 진전은 텍스트 임베딩 기술의 또 다른 중요한 돌파구를 의미하며, 시맨틱 검색, RAG 등 애플리케이션에 더욱 강력한 기반을 제공합니다. (출처: AymericRoucher, ClementDelangue)

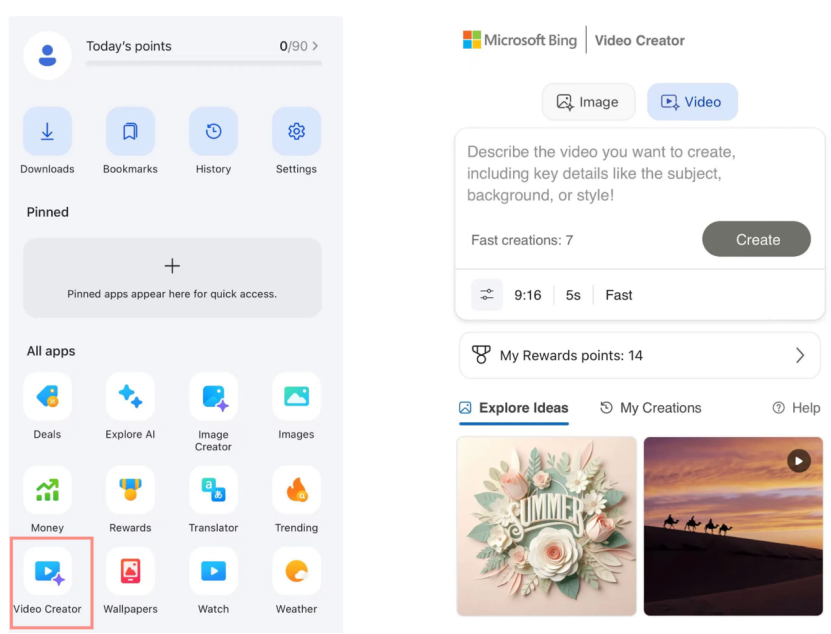
마이크로소프트 Bing 비디오 크리에이터 출시, OpenAI Sora 모델 기반 무료 공개: 마이크로소프트는 Bing 애플리케이션에 Bing Video Creator를 출시했습니다. 이 기능은 OpenAI의 Sora 모델을 기반으로 하며, 사용자가 텍스트 프롬프트를 통해 무료로 비디오를 생성할 수 있도록 합니다. 이는 Sora 모델이 대중에게 대규모로 무료 공개된 첫 사례입니다. 무료이지만 현재 비디오 길이가 5초, 9:16 비율, 생성 속도가 느린 등의 기능 제한이 있습니다. 사용자 피드백에 따르면 현재 SOTA 비디오 모델(예: Kling, Veo3)과 비교하여 효과에 차이가 있어 Sora 기술 반복 속도와 마이크로소프트 제품 전략에 대한 논의를 불러일으켰습니다. (출처: 36氪)
OpenAI, 다수의 기업용 기능 출시, 업무 환경 통합 강화: OpenAI는 Google Drive 등 애플리케이션을 위한 전용 커넥터 제공, ChatGPT 내 회의록 작성, 전사 및 요약 기능 구현, SSO(Single Sign-On) 및 포인트 기반 기업용 요금제 지원 등 기업 사용자를 위한 일련의 새로운 기능을 발표했습니다. 이러한 업데이트는 ChatGPT를 기업 업무 흐름에 더욱 깊이 통합하여 사무 효율성을 높이는 것을 목표로 합니다. (출처: TheRundownAI, EdwardSun0909)
Hugging Face, 효율적인 로봇 모델 SmolVLA 출시, MacBook에서 실행 가능: Hugging Face는 SmolVLA라는 로봇 모델을 출시했습니다. 이 모델은 효율성이 매우 높아 MacBook에서도 실행할 수 있다는 특징이 있습니다. 이 모델은 소량(예: 31개)의 시연 데이터로 미세 조정한 후 특정 작업(예: Koch Arm 조작)에서 단일 작업 기준선 성능에 도달하거나 이를 초과하여, 자원이 제한된 환경에서 로봇 AI를 배포할 수 있는 잠재력을 보여주었습니다. (출처: mervenoyann, sytelus)
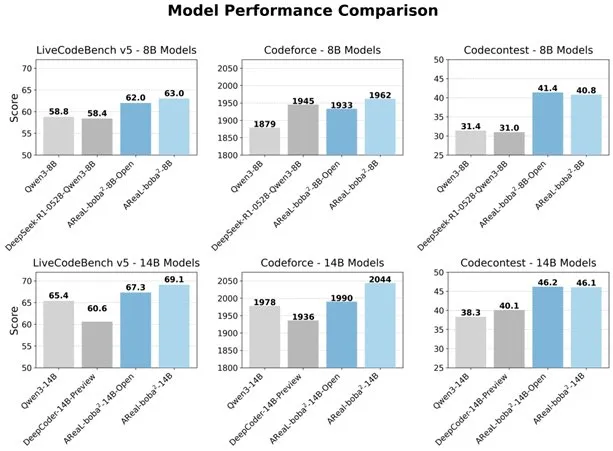
알리바바, 완전 비동기 RL 시스템 AReal-boba² 오픈소스 공개, LLM 코드 능력 향상: 알리바바 Qwen 팀은 대규모 언어 모델(LLM)을 위해 특별히 설계된 완전 비동기 강화 학습 시스템 AReal-boba²를 오픈소스로 공개했으며, Qwen3-14B에서 SOTA 수준의 코드 강화 학습 효과를 달성했습니다. 이 시스템은 시스템과 알고리즘의 협력 설계를 통해 2.77배의 훈련 가속을 실현했으며, LiveCodeBench에서 69.1점을 획득하고 다중 라운드 강화 학습을 지원합니다. (출처: _akhaliq)
DuckDB, DuckLake 확장 기능 출시, 데이터 레이크와 카탈로그 형식 통합: DuckDB는 SQL 및 Parquet 기반의 개방형 레이크하우스 통합 형식인 DuckLake 확장 기능을 발표했습니다. DuckLake는 메타데이터를 카탈로그 데이터베이스에 저장하고 데이터를 Parquet 파일에 저장합니다. 이 확장 기능을 통해 DuckDB는 DuckLake의 데이터를 직접 읽고 쓸 수 있으며, 테이블 생성, 수정, 쿼리, 시간 여행 및 스키마 진화와 같은 기능을 지원하여 데이터 레이크 구축 및 관리를 단순화하는 것을 목표로 합니다. (출처: GitHub Trending)
Model Context Protocol (MCP) Ruby SDK 출시: Model Context Protocol (MCP)은 공식 Ruby SDK를 출시했습니다. 이 SDK는 Shopify와 협력하여 유지 관리되며 MCP 서버를 구현하는 데 사용됩니다. MCP는 AI 모델(특히 Agent)이 도구를 발견하고 호출하며, 리소스에 액세스하고, 사전 정의된 프롬프트를 실행하는 표준화된 방법을 제공하는 것을 목표로 합니다. 이 SDK는 JSON-RPC 2.0을 지원하며 도구 등록, 프롬프트 관리, 리소스 액세스 등 핵심 기능을 제공하여 개발자가 MCP 사양을 준수하는 AI 애플리케이션을 쉽게 구축할 수 있도록 합니다. (출처: GitHub Trending)
AI 기술, 아연 배터리 99.8% 효율 및 4300시간 작동 달성 지원: 인공지능 최적화를 통해 차세대 아연 배터리는 99.8%의 쿨롱 효율과 최대 4300시간의 작동 시간을 달성했습니다. 재료 과학 분야, 특히 배터리 설계 및 성능 예측에서의 AI 응용은 에너지 저장 기술의 혁신을 주도하고 있으며, 전기 자동차, 휴대용 전자 장치 등 분야에 더 효율적이고 오래 지속되는 에너지 솔루션을 제공할 것으로 기대됩니다. (출처: Ronald_vanLoon)

🧰 도구
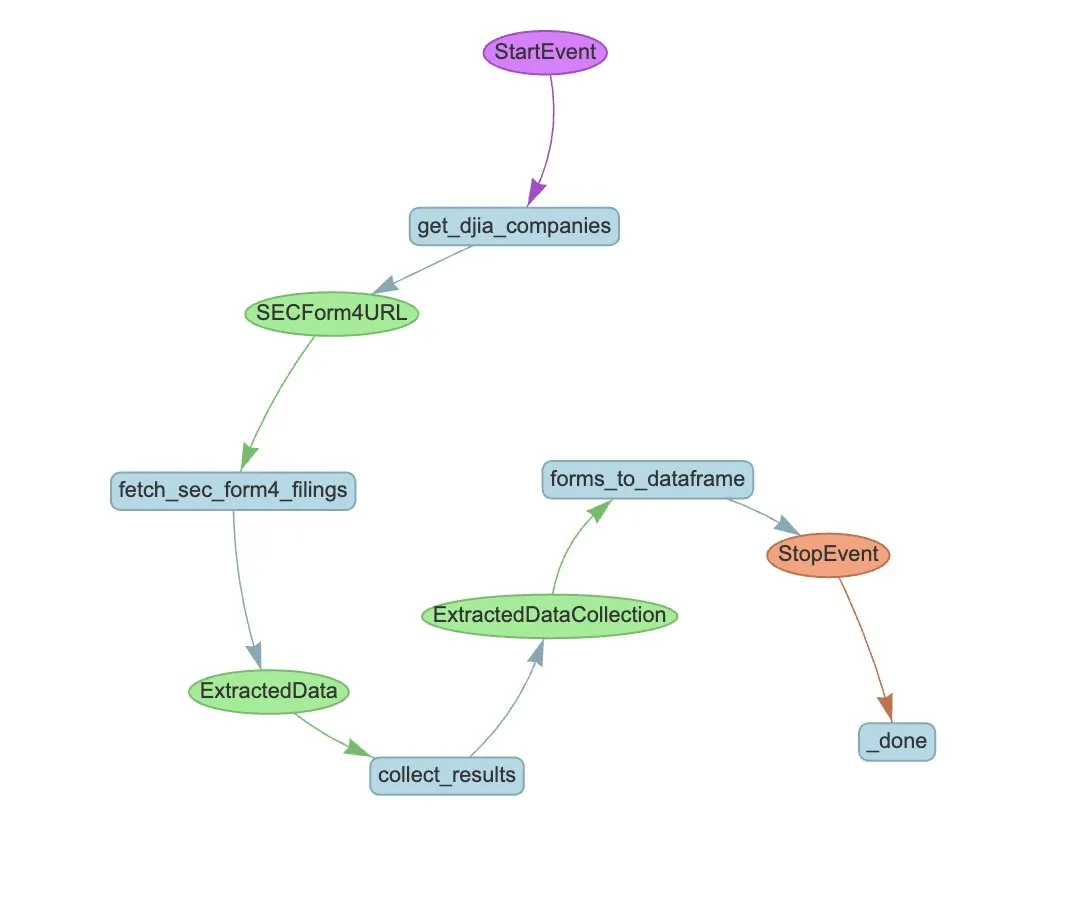
LlamaIndex, LlamaExtract와 Agent 워크플로우로 SEC Form 4 추출 자동화 공개: LlamaIndex는 LlamaExtract와 Agent 워크플로우를 사용하여 SEC Form 4 파일에서 구조화된 정보를 자동으로 추출하는 방법을 시연했습니다. SEC Form 4는 상장 회사 임원, 이사 및 주요 주주가 주식 거래를 공개하는 중요한 문서입니다. 추출 에이전트와 확장 가능한 워크플로우를 구축함으로써 다우 존스 산업 평균 지수에 포함된 모든 회사의 Form 4 신고서를 효율적으로 처리하여 시장 투명성과 데이터 분석 효율성을 향상시킬 수 있습니다. (출처: jerryjliu0)
Cognee: AI Agent에 동적 메모리를 제공하는 오픈소스 도구: Cognee는 AI Agent에 동적 메모리 기능을 제공하는 것을 목표로 하는 오픈소스 프로젝트로, 단 5줄의 코드로 통합할 수 있다고 주장합니다. 확장 가능하고 모듈화된 ECL(Extract, Cognify, Load) 파이프라인을 구축하여 Agent가 과거 대화, 문서, 이미지 및 오디오 녹취록을 상호 연결하고 검색하여 기존 RAG 시스템을 대체하고 개발 난이도와 비용을 줄이며 30개 이상의 데이터 소스에서 데이터 처리 및 로드를 지원합니다. (출처: GitHub Trending)
Claude Code, Pro 사용자에게 공개 및 커뮤니티 버전 GitHub Action 출시: Anthropic의 AI 프로그래밍 도우미 Claude Code가 Pro 구독 사용자에게 공개되어 JetBrains IDE 플러그인 등을 통해 사용할 수 있게 되었습니다. 커뮤니티 개발자들은 또한 Claude Code GitHub Action의 포크 버전을 출시하여 유료 사용자가 GitHub Issues 또는 PR에서 직접 Claude Code를 호출하여 구독 할당량을 사용하여 코드 검토, 문제 해결 등의 작업을 수행할 수 있도록 했습니다. 추가 API 비용은 발생하지 않습니다. (출처: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
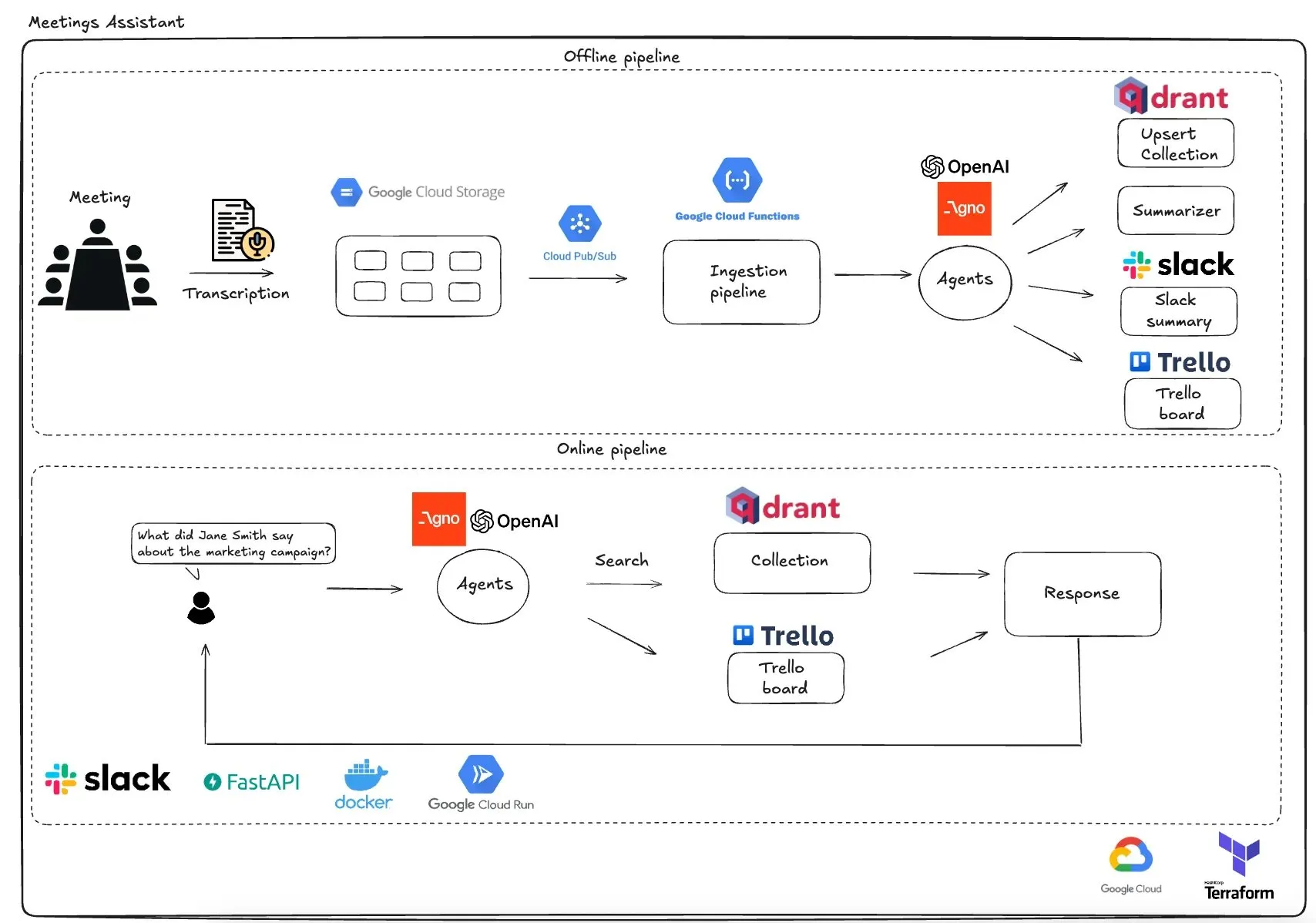
Qdrant, GCP 기반 다중 에이전트 회의 도우미 출시: Qdrant는 완전 서버리스 다중 에이전트 회의 도우미 시스템을 선보였습니다. 이 시스템은 회의 내용을 녹취하고, LLM 에이전트를 사용하여 요약하며, 컨텍스트 정보를 Qdrant 벡터 데이터베이스에 저장하고, 작업을 Trello에 동기화하며, 최종 결과를 Slack에서 직접 전달합니다. 이 시스템은 에이전트 오케스트레이션을 위해 AgnoAgi를 사용하고, Cloud Run에서 FastAPI를 실행하며, 임베딩 및 추론을 위해 OpenAI를 사용합니다. (출처: qdrant_engine)
마이크로소프트, 좌표 없는 GUI 요소 위치 지정 방법 GUI-Actor 발표: 마이크로소프트는 Hugging Face에 좌표 없는 GUI(그래픽 사용자 인터페이스) 요소 위치 지정 방법인 GUI-Actor를 발표했습니다. 이 방법은 AI 에이전트가 텍스트 기반 좌표 예측에 의존하는 대신 특수 <actor> 토큰을 통해 네이티브 시각적 블록(visual patches)을 직접 가리킬 수 있도록 하여 GUI 에이전트 작업의 정확성과 견고성을 향상시키는 것을 목표로 합니다. (출처: _akhaliq)

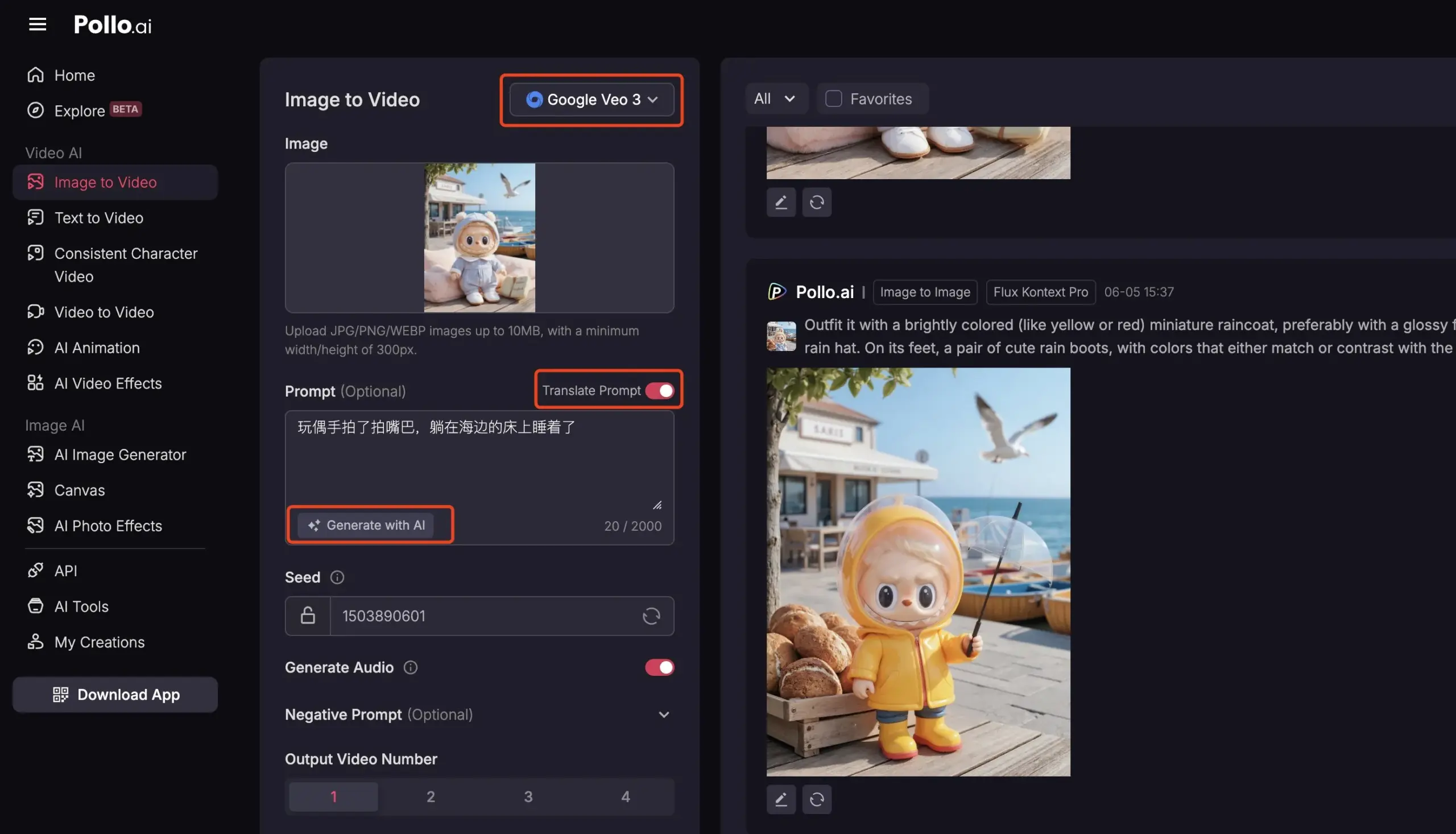
Pollo AI, Veo3와 FLUX Kontext 통합, 포괄적인 AI 비디오 서비스 제공: AI 도구 플랫폼 Pollo AI는 최근 빈번한 업데이트를 통해 Google Veo3 비디오 생성 모델과 FLUX Kontext 이미지 편집 기능을 통합했습니다. 사용자는 이 플랫폼에서 FLUX Kontext로 이미지를 수정한 후 직접 Veo3로 보내 비디오를 생성할 수 있습니다. 플랫폼은 또한 API 인터페이스를 제공하여 시중에 나와 있는 다양한 주요 비디오 대형 모델에 한 번에 액세스할 수 있도록 지원하며, AI 프롬프트 생성, 다국어 번역 등 보조 기능을 내장하여 AI 비디오 제작의 편의성과 효율성을 높이는 것을 목표로 합니다. (출처: op7418)
📚 학습
Meta-Learning 심층 분석: AI에게 학습 방법을 가르치다: Meta-Learning(메타 학습), 또는 “학습하는 방법을 배우는 것”의 핵심 아이디어는 모델이 소량의 샘플만으로도 새로운 작업에 빠르게 적응할 수 있도록 훈련하는 것입니다. 이 과정은 일반적으로 두 가지 모델을 포함합니다. 기본 학습기(base-learner)는 내부 학습 루프에서 특정 작업(예: 소수 샘플 이미지 분류)에 빠르게 적응하고, 메타 학습기(meta-learner)는 외부 학습 루프에서 기본 학습기의 매개변수나 전략을 관리하고 업데이트하여 새로운 작업 해결 능력을 향상시킵니다. 훈련이 완료되면 기본 학습기는 메타 학습기가 학습한 지식을 활용하여 초기화됩니다. (출처: TheTuringPost, TheTuringPost)

논문 해설 《A Controllable Examination for Long-Context Language Models》: 이 논문은 기존 장문맥 언어 모델(LCLM) 평가 프레임워크의 한계점(실제 세계 작업은 복잡하고 해결하기 어려우며 데이터 오염에 취약함, NIAH와 같은 합성 작업은 문맥 일관성 부족)을 지적하며, 이상적인 평가 프레임워크가 갖추어야 할 세 가지 특징인 원활한 문맥, 제어 가능한 설정, 건전한 평가를 제안합니다. 또한 인공적으로 생성된 전기를 제어된 환경으로 활용하여 이해, 추론, 신뢰도 차원에서 LCLM을 평가하는 새로운 벤치마크인 LongBioBench를 출시했습니다. 실험 결과 대부분의 모델이 의미 이해, 초기 추론 및 장문맥 신뢰도 측면에서 여전히 부족한 것으로 나타났습니다. (출처: HuggingFace Daily Papers)
논문 해설 《Advancing Multimodal Reasoning: From Optimized Cold Start to Staged Reinforcement Learning》: 복잡한 텍스트 작업에서 Deepseek-R1의 뛰어난 추론 능력에 영감을 받아, 이 연구는 최적화된 콜드 스타트와 단계적 강화 학습(RL)을 통해 멀티모달 대형 언어 모델(MLLM)의 복잡한 추론 능력을 어떻게 향상시킬 수 있는지 탐구합니다. 연구 결과, 효과적인 콜드 스타트 초기화가 MLLM 추론 강화에 중요하며, 신중하게 선택된 텍스트 데이터만으로 초기화해도 많은 기존 모델을 능가하는 것으로 나타났습니다. 표준 GRPO를 멀티모달 RL에 적용할 때 그래디언트 정체 문제가 발생하지만, 후속 순수 텍스트 RL 훈련은 멀티모달 추론을 더욱 강화할 수 있습니다. 이러한 발견을 바탕으로 연구자들은 여러 도전적인 벤치마크에서 SOTA 성적을 거둔 ReVisual-R1을 출시했습니다. (출처: HuggingFace Daily Papers)
논문 해설 《Unleashing the Reasoning Potential of Pre-trained LLMs by Critique Fine-Tuning on One Problem》: 이 연구는 사전 훈련된 LLM의 추론 잠재력을 효율적으로 발휘하는 방법인 단일 문제 비판적 미세 조정(Critique Fine-Tuning, CFT)을 제안합니다. 단일 문제에 대해 모델이 생성한 다양한 솔루션을 수집하고 교사 LLM을 활용하여 상세한 비판을 제공하여 비판 데이터를 구축하고 미세 조정합니다. 실험 결과, Qwen 및 Llama 시리즈 모델에 대해 단일 문제 CFT를 수행한 후 다양한 추론 작업에서 현저한 성능 향상을 보였으며, 예를 들어 Qwen-Math-7B-CFT는 수학 및 논리 추론 벤치마크에서 평균 15-16% 향상되었고 계산 비용은 강화 학습보다 훨씬 낮았습니다. (출처: HuggingFace Daily Papers)
논문 해설 《SVGenius: Benchmarking LLMs in SVG Understanding, Editing and Generation》: 기존 SVG(Scalable Vector Graphics) 처리 벤치마크의 제한된 범위, 복잡도 계층화 부족, 단편화된 평가 패러다임 문제를 해결하기 위해 SVGenius가 등장했습니다. 이는 이해, 편집, 생성 세 가지 차원을 포괄하는 2377개 쿼리로 구성된 종합 벤치마크로, 24개 응용 분야의 실제 데이터를 기반으로 구축되었으며 체계적인 복잡도 계층화가 이루어졌습니다. 8개 작업 범주와 18개 지표를 통해 22개 주요 모델을 평가하여 현재 모델이 복잡한 SVG를 처리할 때의 한계점을 밝히고, 순수한 규모 확장보다 추론 강화 훈련이 더 효과적임을 지적했습니다. (출처: HuggingFace Daily Papers)
Hugging Face Hub 업데이트 로그 발표: Hugging Face Hub는 최신 업데이트 로그를 발표했습니다. 사용자는 이를 통해 플랫폼의 새로운 기능, 모델 라이브러리 업데이트, 데이터셋 확장 및 도구 체인 개선 등 최신 동향을 확인할 수 있습니다. 이는 커뮤니티 사용자가 Hugging Face 생태계의 최신 리소스와 기능을 적시에 파악하고 활용하는 데 도움이 됩니다. (출처: huggingface, _akhaliq)
Maxime Labonne 등 저자, 다량의 LLM Notebooks 오픈소스 공개: LLM 엔지니어 핸드북의 저자인 Maxime Labonne과 Iustin Paul이 LLM 관련 Jupyter Notebooks 시리즈를 오픈소스로 공개했습니다. 이 Notebooks는 내용이 풍부하며, 기본적인 미세 조정 기술뿐만 아니라 자동 평가, lazy merges, frankenMoEs(혼합 전문가 모델) 구축 및 검열 해제 기법 등 고급 주제도 다루고 있어 LLM 개발자와 연구자에게 귀중한 실전 리소스를 제공합니다. (출처: maximelabonne)
DeepLearningAI, The Batch 주간 보고서 발행, AI Fund의 AI 빌더 양성 방법 논의: Andrew Ng는 최신 The Batch 주간 보고서에서 AI Fund가 AI 인재 및 빌더를 양성하는 경험과 전략을 공유했습니다. 이번 주간 보고서에는 DeepSeek의 새로운 오픈소스 모델이 최고 수준의 LLM과 비슷한 성능을 보이는 내용, Duolingo가 AI를 활용하여 언어 과정을 확장하는 방법, AI의 에너지 소비 균형 문제, 악성 링크가 AI Agent에 미칠 수 있는 잠재적 오도 등 주요 이슈도 다루고 있습니다. (출처: DeepLearningAI)

💼 비즈니스
Reddit, Anthropic 고소, 무단 사용자 데이터 AI 훈련 사용 혐의: Reddit은 AI 회사 Anthropic을 상대로 소송을 제기했습니다. Anthropic이 자동화된 봇을 사용하여 Reddit 콘텐츠를 무단으로 수집하고 이를 Claude와 같은 AI 모델 훈련에 사용함으로써 계약 위반 및 불공정 경쟁을 저질렀다고 주장합니다. 이 사건은 현재 AI 개발에서 데이터 수집 및 모델 훈련의 합법성 논란을 부각시키며, 콘텐츠 플랫폼이 자사 데이터 가치 보호에 대한 인식을 높이고 있음을 반영합니다. (출처: Reddit r/artificial, Reddit r/ArtificialInteligence, TheRundownAI)

아마존, 노스캐롤라이나에 AI 데이터 센터 건설 위해 100억 달러 투자 계획: 아마존은 증가하는 AI 사업 수요를 지원하기 위해 노스캐롤라이나에 새로운 데이터 센터를 건설하는 데 100억 달러를 투자할 것이라고 발표했습니다. 이러한 움직임은 대형 기술 기업들이 AI 모델 훈련 및 추론에 필요한 대규모 컴퓨팅 및 스토리지 자원을 충족시키기 위해 AI 인프라에 지속적으로 투자하고 있음을 반영합니다. (출처: Reddit r/artificial)

Anthropic, Windsurf.ai에 대한 Claude 모델 API 접근 권한 축소, 플랫폼 위험 우려 제기: AI 애플리케이션 개발 플랫폼 Windsurf.ai는 Anthropic이 불과 5일도 채 안 되는 사전 통보 후 Claude 3.x 및 Claude 4 모델에 대한 API 접근 용량을 대폭 축소했다고 밝혔습니다. 이로 인해 Windsurf.ai는 유료 사용자 서비스를 보장하기 위해 긴급하게 제3자 공급업체를 찾아야 했으며, 무료 및 Pro 사용자에게는 BYOK(Bring Your Own Key) 옵션을 제공해야 했습니다. 이 사건은 AI 모델 제공업체가 언제든지 서비스 전략을 조정하거나 심지어 하위 애플리케이션과 경쟁 관계를 형성할 수 있다는 점에서 개발자들의 AI 모델 제공업체 플랫폼 위험에 대한 우려를 가중시켰습니다. (출처: swyx, scaling01, mervenoyann)
🌟 커뮤니티
AI 엔지니어 컨퍼런스(@aiDotEngineer) 화제, Agent 설계 및 AI 창업에 초점: 샌프란시스코에서 열린 AI 엔지니어 컨퍼런스(@aiDotEngineer)가 커뮤니티에서 뜨거운 화제가 되었습니다. LlamaIndex는 생산 환경에서 효과적인 Agent 설계 패턴을 공유했습니다. Anthropic은 컨퍼런스에서 스타트업을 위한 “요구 사항 목록”을 발표하며 새로운 분야에서의 MCP 서버 응용, 서버 구축 간소화 및 AI 애플리케이션 보안(예: 도구 포이즈닝)에 주목했습니다. Graphite는 AI 기반 코드 검토 도구를 선보였습니다. 컨퍼런스에서는 차세대 GPT 모델 확장에 직면한 기초 연구 과제 등도 논의되었습니다. (출처: swyx, swyx, swyx, iScienceLuvr)

연구원 Rohan Anil, Anthropic 합류 소식에 관심 집중: 연구원 Rohan Anil이 Anthropic 팀에 합류한다는 소식이 AI 커뮤니티에서 광범위한 관심과 논의를 불러일으켰습니다. 많은 업계 관계자와 관심 있는 이들이 이에 축하를 표하며 그의 Anthropic 연구 활동에 새로운 기여를 기대하고 있습니다. 이는 또한 최고 수준의 AI 인재 이동이 업계 구도에 미칠 수 있는 잠재적 영향을 반영합니다. (출처: arohan, gallabytes, andersonbcdefg, scaling01, zacharynado)
법원, OpenAI에 모든 ChatGPT 로그 보존 명령, 데이터 보존 전략 논의 촉발: OpenAI가 법원으로부터 “임시 채팅” 및 삭제되었어야 할 API 요청을 포함한 모든 ChatGPT 로그를 보존하라는 명령을 받은 것으로 알려졌습니다. 이 소식은 커뮤니티에서 데이터 보존 전략에 대한 논의를 불러일으켰으며, 특히 OpenAI API를 사용하는 애플리케이션의 경우 자체 데이터 보존 정책이 완전히 준수되지 않을 수 있음을 의미하여 사용자 개인 정보 보호 및 데이터 관리에 새로운 과제를 제기할 수 있습니다. 가능한 경우 데이터를 보호하기 위해 로컬 모델을 우선적으로 사용할 것을 권장합니다. (출처: code_star, TomLikesRobots)

AI 생성 콘텐츠 범람과 “AI Slop” 현상 우려: 소셜 미디어에서 저품질의 눈길을 끄는 AI 생성 콘텐츠(“AI Slop”으로 불림)가 증가하고 있습니다. Reddit의 AI 생성 게시물부터 Facebook의 “새우 예수”와 같은 AI 이미지에 이르기까지, 사용자들은 정보 품질과 네트워크 환경 악화에 대한 우려를 표명하고 있습니다. 이러한 콘텐츠는 일반적으로 봇이나 트래픽을 노리는 사람들이 저렴하게 생성하며, “참여 유도 미끼”를 통해 좋아요와 공유를 얻으려는 목적을 가집니다. 연구에 따르면 상당한 인터넷 트래픽이 이미 허위 정보를 퍼뜨리고 데이터를 훔치는 “나쁜 봇”으로 구성되어 있습니다. 이러한 현상은 사용자 경험에 영향을 미칠 뿐만 아니라 민주주의와 정치적 소통에도 위협이 되며, 동시에 미래 AI 모델의 훈련 데이터를 오염시킬 수 있습니다. (출처: aihub.org)

LLM 비용 논의: Gemini 가성비 높아, Claude 4 코딩 비용 주목: 커뮤니티에서는 현재 LLM 사용 비용 차이가 크다는 점이 지적되고 있습니다. 예를 들어, Gemini를 사용하여 전체 보험 문서를 처리하고 많은 질문을 하는 데 드는 비용은 약 0.01달러에 불과하여 높은 가성비를 보여줍니다. 반면, Claude 4 모델은 코딩과 같은 작업에서 뛰어난 성능을 보이지만 Cursor.ai와 같은 플랫폼의 최대 모드(max mode) 사용 비용이 높아 사용자들이 Google Gemini 2.5 Pro와 같이 비용 효율적인 옵션으로 전환하도록 유도하고 있습니다. (출처: finbarrtimbers, Teknium1)
AI Agent, 실제 웹 페이지 환경에서 CAPTCHA(자동 입력 방지 시스템) 해결에 어려움 직면: MetaAgentX 팀은 멀티모달 상호작용 에이전트의 CAPTCHA 해결 능력을 평가하는 데 중점을 둔 Open CaptchaWorld 플랫폼을 발표했습니다. 테스트 결과, GPT-4o와 같은 SOTA 모델조차도 20가지 실제 웹 페이지 환경의 상호작용형 CAPTCHA를 처리할 때 성공률이 5%-40%에 불과하여 인간의 평균 성공률 93.3%에 훨씬 못 미치는 것으로 나타났습니다. 이는 현재 AI Agent가 시각적 이해, 다단계 계획, 상태 추적 및 정밀한 상호작용 측면에서 여전히 병목 현상을 겪고 있으며, CAPTCHA가 실제 배포의 큰 장애물이 되고 있음을 보여줍니다. (출처: 量子位)

AI 에이전트 교육 시장 활황, 과정 품질 및 취업 전망 주목: AI Agent 개념이 부상하면서 관련 교육 과정도 대거 등장하고 있습니다. 일부 교육 기관은 입문부터 취업까지 전방위적인 지도를 제공한다고 주장하며, 심지어 “취업 보장”을 약속하기도 합니다. 수강료는 수백 위안에서 수만 위안까지 다양합니다. 그러나 시장의 과정 품질은 천차만별이며, 일부 과정은 내용이 피상적이고 과도하게 마케팅되며 심지어 “사기성” AI 속성반과 유사하다는 지적을 받고 있습니다. 수강생과 관찰자들은 이러한 교육의 실제 효과, 강사 자격 및 “취업 보장” 약속의 진실성에 대해 신중한 태도를 보이며, 이것이 AI 발전 과도기의 또 다른 “가짜 수요”가 될 수 있다고 우려하고 있습니다. (출처: 36氪)

💡 기타
로봇 분야 AI 응용 진전: 촉각 감지 손, 양서류 로봇 및 소방 로봇 개: AI 기술이 로봇 능력의 한계를 넓히고 있습니다. 연구자들은 촉각 감지 능력을 갖춘 기계 손을 개발하여 환경과 더 잘 상호 작용할 수 있도록 했습니다. Copperstone HELIX Neptune은 AI 기반 양서류 로봇을 선보여 다양한 지형에서 작업할 수 있도록 했습니다. 중국은 60미터 물줄기를 분사하고 계단을 오르며 구조 상황을 생중계할 수 있는 소방 로봇 개를 출시했습니다. 이러한 진전은 로봇의 감지, 의사 결정 및 복잡한 작업 수행 능력을 향상시키는 AI의 잠재력을 보여줍니다. (출처: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

AI Agent와 생성형 AI 비교 논의: 커뮤니티에서는 AI Agent(지능형 AI)와 생성형 AI(Generative AI) 간의 차이점과 연관성에 대한 논의가 나타나고 있습니다. 생성형 AI는 주로 콘텐츠 생성에 중점을 두는 반면, AI Agent는 인식, 계획, 행동을 기반으로 한 자율적인 의사 결정 및 작업 수행에 더 중점을 둡니다. 이 둘의 차이점을 이해하면 AI 기술의 발전 방향과 응용 시나리오를 더 잘 파악하는 데 도움이 됩니다. (출처: Ronald_vanLoon, Ronald_vanLoon)
복잡한 조직 프로세스 자동화에서 AI의 과제 논의: AI는 특정 작업 자동화 또는 지원 측면에서 진전을 이루었지만, 인력이나 팀을 대체하여 더 광범위한 경제 전환을 달성하려면 엄청난 복잡성에 직면합니다. 많은 조직에는 명확하게 기록되지 않았지만 매우 중요한 프로세스가 존재하며, 이러한 프로세스는 위험이 높지만 간헐적으로 발생하고 그 이유가 잊혀질 정도로 관례가 되었을 수 있습니다. AI 에이전트는 비용이 많이 들고 학습 기회가 제한적이기 때문에 시행착오를 통해 이러한 암묵적 지식을 학습하기 어렵습니다. 이는 단순한 기계 학습이 아닌 새로운 기술 패러다임을 필요로 합니다. (출처: random_walker)