

키워드:대형 언어 모델, AI 훈련, 인격 벡터, Gemini 2.5 Deep Think, AI 보안, 확산 언어 모델, AI 응용, LLM 인격 벡터 훈련 방법, Gemini 2.5 Deep Think 수학적 추론, Seed Diffusion Preview 코드 생성, AI 모델 콜드 스타트 최적화, RedOne 소셜 대형 모델
🔥 포커스
Anthropic, LLM ‘인격 벡터’ 발견 및 새로운 훈련 패러다임 제안: Anthropic의 최신 연구에 따르면, 대규모 언어 모델(LLM)에는 ‘악의적’, ‘아첨’, ‘환각’과 같은 바람직하지 않은 행동과 관련된 특정 신경 활동 패턴이 존재합니다. 연구는 모델 훈련 중 이러한 불량 패턴을 의도적으로 활성화하면, 오히려 모델이 미래에 이러한 유해한 특성을 나타내는 것을 방지할 수 있음을 발견했습니다. 이는 직관에 반하지만 효율적인 예방 방법입니다. 훈련 후 억제 방식에 비해 이 방법은 에너지 효율적이며 모델의 다른 성능에 영향을 미치지 않아, ChatGPT의 과도한 아첨이나 Grok의 극단적인 발언과 같은 AI의 바람직하지 않은 ‘인격’ 문제를 근본적으로 해결할 수 있을 것으로 기대됩니다. 이 돌파구는 더 안전하고 제어 가능한 AI 시스템을 구축하는 새로운 길을 열었으며, 대규모 모델에서의 보편성 검증이 여전히 필요합니다. (출처: MIT Technology Review)

🎯 동향
Google Gemini 2.5 Deep Think 모델 출시: 구글이 현재까지 가장 강력한 추론 모델인 Gemini 2.5 Deep Think을 공식 출시했습니다. 이 모델은 최근 국제 수학 올림피아드(IMO) 금메달 수준 모델의 변형으로, 2025년 IMO 벤치마크 테스트에서 동메달 수준에 도달했습니다. 병렬 사고 및 강화 학습 기술을 활용하여 ‘사고 시간’을 연장함으로써 가설을 탐색하고 창의적인 솔루션을 생성합니다. 이 모델은 LiveCodeBench V6 및 Humanity’s Last Exam 등 프로그래밍, 과학, 지식, 추론 벤치마크 테스트에서 뛰어난 성능을 보이며 OpenAI o3 및 Grok 4를 능가합니다. 현재 Deep Think은 Google AI Ultra 구독자에게 공개되었으며, 수학자 및 학자에게는 연구 지원을 위한 더 고급 버전이 제공됩니다. (출처: OriolVinyalsML)

중국 대규모 모델, 오픈 도메인에서 강력한 성능 발휘: 최근 중국의 여러 AI 기업이 출시한 대규모 모델들이 각종 벤치마크 테스트에서 뛰어난 성능을 보였습니다. Alibaba의 Qwen3는 Arena 오픈 모델 순위에서 선두를 차지했으며, 코딩, 난제 및 수학 분야에서 DeepSeek 및 Kimi-K2와 공동 1위를 기록했습니다. Zhipu AI의 GLM-4.5는 도구 사용에 가장 능숙한 Agent 모델로 평가받고 있습니다. 이 모델들은 Agent 능력 및 추론 능력 강화를 통해 오픈소스 모델이 폐쇄형 모델에 대해 우위를 점하는 데 기여했습니다. 또한, 중국 DeepSeek의 과학 모델은 Humanity’s Last Exam(HLE)에서 40.44%의 성적을 달성하며 강력한 과학적 추론 능력을 보여주었습니다. (출처: TheTuringPost)

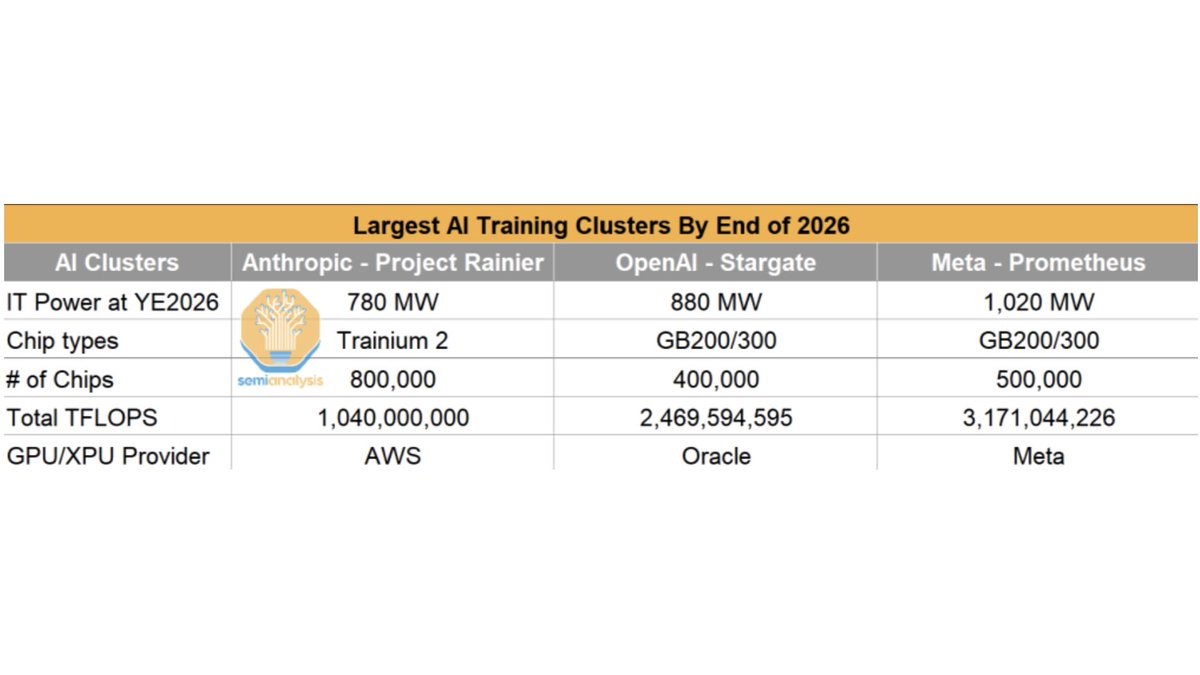
Meta와 NVIDIA, 세계 최대 AI 훈련 클러스터 공동 구축: Meta는 세계 최대 AI 훈련 클러스터인 “Prometheus”를 구축 중이며, 2026년 말까지 50만 개의 GB200/300 GPU를 보유하고 총 IT 전력 소비량 1020MW, 연산 능력 3.17조 TFLOPS를 초과할 것으로 예상됩니다. 동시에 NVIDIA, OpenAI, Nscale 및 Aker ASA는 노르웨이 북부 나르비크에서 “Stargate Norway” AI 슈퍼 팩토리를 가동했습니다. 이 공장은 10만 개의 NVIDIA GPU를 갖추고 100% 재생 에너지로 구동되며, 안전하고 확장 가능한 주권 AI 인프라를 제공하는 것을 목표로 합니다. (출처: giffmana)
GPU 스냅샷 기술, 대규모 모델 콜드 스타트 속도 크게 향상: NVIDIA가 새로 출시한 CUDA 체크포인트/복구 API는 GPU 스냅샷 기능을 구현했으며, Modal과 같은 서버 플랫폼은 이 기술을 활용하여 대규모 모델의 GPU 콜드 스타트 시간을 크게 단축하고 있습니다. 이 기술은 디스크에서 메모리로 모델 가중치를 로드하는 시간을 최대 12배까지 단축할 수 있어, 대규모 LLM 배포에 특히 중요합니다. 이는 사용자 응답 지연에 영향을 미치지 않으면서 요구에 따라 GPU 리소스를 신속하게 확장 및 축소할 수 있도록 합니다. (출처: Reddit r/MachineLearning)

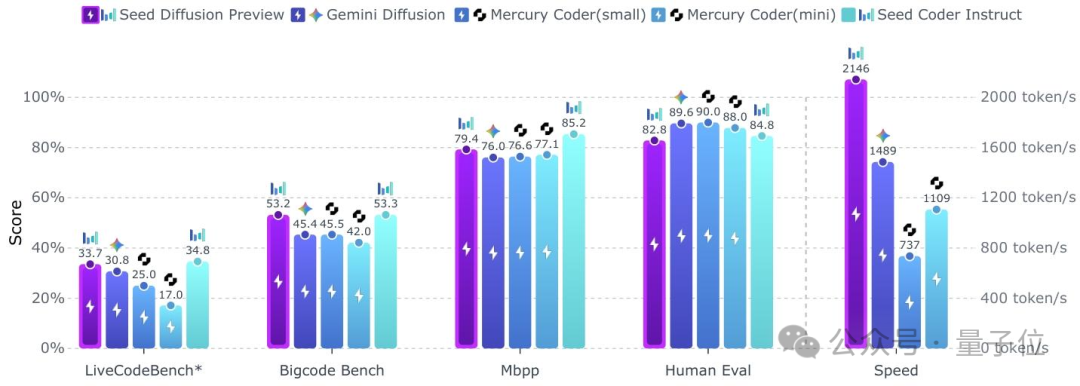
ByteDance, 확산 언어 모델 Seed Diffusion Preview 출시: ByteDance Seed 팀이 첫 확산 언어 모델인 Seed Diffusion Preview를 출시했으며, 코드 생성 분야에 중점을 둡니다. 이 모델은 이산 상태 확산 기술을 채택하여 H20 하드웨어에서 최대 2146 tokens/s의 추론 속도를 달성하며, 동일 규모의 자기회귀 모델보다 5.4배 빠르고 코드 편집 작업에서 상당한 이점을 보여줍니다. 핵심 기술로는 2단계 훈련(마스크 기반 및 편집 기반 확산 훈련), 제약 순서 확산, 동일 정책 학습 패러다임 및 블록 수준 병렬 확산 샘플링이 포함되어, 자기회귀 모델의 직렬 디코딩 지연 병목 현상과 이산 확산 모델의 논리적 혼란 문제를 해결하는 것을 목표로 합니다. (출처: 量子位)
Xiaohongshu, 첫 소셜 대규모 모델 RedOne 출시: Xiaohongshu NLP 팀이 업계 최초로 소셜 네트워크 서비스(SNS) 분야에 특화된 대규모 언어 모델 RedOne을 출시했습니다. RedOne은 소셜 이해 및 플랫폼 규칙 준수 능력을 향상시키고 사용자 요구를 심층적으로 분석하는 것을 목표로 합니다. 기본 모델에 비해 RedOne은 8가지 SNS 작업에서 평균 14.02%의 성능 향상을 보였으며, 유해 콘텐츠 감지 노출률은 11.23% 감소했고, 탐색 후 검색 클릭 페이지율은 14.95% 증가했습니다. 이 모델은 “사전 훈련 계속 → 지도 미세 조정 → 선호도 최적화”의 3단계 훈련 전략을 채택하여, SNS 데이터의 고도로 비정형화되고, 강력한 맥락 의존성을 가지며, 현저히 감정적인 특성으로 인한 도전 과제를 효과적으로 해결했습니다. (출처: 量子位)

DeepCogito, 하이브리드 추론 모델 출시 및 Together AI 배포 지원: DeepCogito는 70B, 109B MoE, 405B 및 671B MoE를 포함하는 4가지 하이브리드 추론 모델을 오픈 라이선스 형식으로 제공했습니다. 이 모델들은 현재 가장 강력한 LLM 중 하나로 평가받으며, 반복적 자기 개선(AI 시스템 자기 개선)이라는 새로운 AI 패러다임을 검증했습니다. 현재 이 모델들은 Together AI에서 확장 가능한 배포를 달성하여 개발자와 기업에 강력한 추론 능력을 제공합니다. (출처: realDanFu)

AI의 다양한 분야 적용 동향: 로봇, 의료, 산업 자동화: Fourier의 GR 및 N1 로봇은 Taikang Home에서 노인 재활 및 상호작용에 사용됩니다. 일본 철도 회사는 거대 휴머노이드 로봇을 고용하여 유지보수 작업을 수행하고 있습니다. 중국 소방 로봇견은 60미터 물줄기를 분사하고 계단을 오르며 구조 작업을 수행할 수 있습니다. 주사형 심박 조율기는 체액으로 전력을 공급하고 사용 후 용해됩니다. AI는 의료 분야에서 12가지 생성형 AI 사용 사례를 가지고 있습니다. AI는 산업 자동화에서 robominds 및 STÄUBLI Robotics와 협력합니다. AI는 스포츠 분야에서 골키퍼의 슈팅 방향을 예측할 수 있습니다. (출처: Ronald_vanLoon)

OpenAI GPT-5 진행 상황 및 내부 동향: 소문에도 불구하고 OpenAI는 현재 GPT-5 또는 오픈소스 120B/20B 모델을 출시하지 않았습니다. 유출된 오픈소스 모델은 네이티브 FP4 훈련이 아닌 양자화 버전으로 알려져 있습니다. GPT-5는 실용성 향상, 특히 프로그래밍 및 수학 분야에 중점을 두고 Agent 능력 및 효율성을 강화하며 강화 학습 및 “범용 검증기” 기술을 채택할 예정입니다. 그러나 OpenAI는 고품질 웹 데이터 고갈, 최적화 방법 확장 불가, 연구원 유출 및 Microsoft와의 전략적 불일치와 같은 도전 과제에 직면해 있습니다. 그럼에도 불구하고 ChatGPT의 유료 비즈니스 사용자는 500만 명을 돌파했습니다. (출처: Yuchenj_UW)

AI 모델 업데이트 속도 가속화, 오픈소스 커뮤니티 활성화: 최근 AI 모델 출시 속도는 놀라울 정도로 빨라, 2~3주 내에 50개 이상의 LLM 모델이 출시되었으며 다양한 모달리티와 규모를 포괄합니다. 여기에는 GLM 4.5 시리즈, Qwen3 시리즈, Kimi K2, Llama-3.3 Nemotron, Mistral의 Magistral/Devstral/Voxtral 등이 포함됩니다. 동시에 Anthropic은 OpenAI가 Claude API를 서비스 약관 위반(경쟁 AI 모델 훈련에 사용)으로 인해 Claude API 접근 권한을 철회했으며, 이는 API 사용 규범에 대한 업계 논의를 촉발했습니다. 또한, 모델 병합 기술(예: Warmup-Stable-Merge)이 제안되어 학습률 스케줄링을 대체하고 훈련 효율성 및 모델 성능을 향상시킬 수 있습니다. (출처: Reddit r/LocalLLaMA)

Groq 4, 수학 및 이미지 생성 분야에서 뛰어난 성능 발휘: xAI의 Grok 4 모델은 수학 능력에서 상당한 이점을 보여주며, 고등학교 수학 경시 대회에서 최첨단 수준에 도달했고 문헌 검색에 실용적인 가치를 가집니다. 또한, Grok 4 Imagine의 이미지 생성 속도는 매우 빨라, 사용자가 화면을 스크롤하는 속도와 거의 동시에 이루어져 시각 생성 분야에서의 강력한 능력을 보여줍니다. (출처: dl_weekly)

AI 보안 위험: 악성 도구 호출 및 개인정보 유출: 연구에 따르면 LLM Agent는 미세 조정을 통해 악성 도구 호출을 실행할 수 있으며, 샌드박스 환경에서도 감지하기 어려워 새로운 보안 우려를 불러일으켰습니다. 또한, Google Gemini 2.5 Pro에서 심각한 개인정보 유출 사건이 발생하여, 다른 사용자의 네트워크 설정 정보를 사용자에게 잘못 표시함으로써 AI 시스템의 데이터 격리 및 개인정보 보호에 대한 잠재적 취약점을 드러냈습니다. 구글은 이 사건을 보고하고 긴급 조사를 진행 중입니다. (출처: Reddit r/LocalLLaMA)

AI, 공공 서비스 분야에서 효율성 크게 향상: ChatGPT는 노스캐롤라이나주 공공 서비스 분야에 적용되어 업무 효율성을 크게 향상시켰습니다. 예를 들어, 일부 작업의 처리 시간이 20분에서 단 20초로 단축되어, AI가 행정 효율성 향상에 기여할 수 있는 막대한 잠재력을 보여주었습니다. 이는 AI가 일상적인 업무 흐름을 효과적으로 간소화하고 가속화하여 정부 부서에 실질적인 효율성 개선을 가져올 수 있음을 시사합니다. (출처: gdb)

🧰 도구
Cerebras, 고속 Qwen3-Coder 서비스 출시: Cerebras가 Qwen3-Coder-480B-A35B-Instruct 모델 호스팅 서비스를 공식 출시했습니다. 이 서비스는 추론 속도가 2000 tokens/s에 달하여 Claude보다 20배 빠르며, 가격 경쟁력도 뛰어납니다(월 50달러부터). 이는 Qwen3-Coder를 오픈소스 코딩 분야에서 Sonnet의 강력한 경쟁자로 만들며, 개발자들의 광범위한 채택을 촉진할 것으로 기대됩니다. 또한, Cerebras는 Cline과 통합하여 고속 코딩 도구를 제공하고, 혁신적인 애플리케이션을 장려하기 위해 해커톤을 개최합니다. (출처: Reddit r/LocalLLaMA)

AI Agent 개발 및 적용 새 진전: Cua는 범용 AI Agent를 위한 안전하고 확장 가능한 인프라 구축에 전념하고 있습니다. Replit 플랫폼은 AI Agent 기능을 통합하여 소규모 기업이 맞춤형 소프트웨어를 개발하도록 돕고 있으며, 예를 들어 한 페인트 회사는 이를 통해 수개월의 시간과 수만 달러를 절약했습니다. Runway의 Aleph 비디오 생성 API가 현재 공개되어, 개발자가 비디오 편집, 변환 및 생성 기능을 애플리케이션에 직접 통합할 수 있습니다. LlamaIndex는 Gemini Live의 TypeScript 통합을 출시하여 터미널 채팅 및 음성 비서 웹 애플리케이션을 지원합니다. LangChain의 Open SWE도 오픈소스, 클라우드 호스팅 코딩 Agent로 출시되었습니다. (출처: charles_irl)

Claude Code 사용 팁 및 Context Engineering: Claude Code와 같은 AI 프로그래밍 도구에 대해 사용자들이 효율성을 높이는 여러 팁을 공유했습니다. 사용자는 Claude가 계획을 생성한 후, 자기 비판을 요구하여 가정, 누락된 세부 사항 또는 확장성 문제(‘Ultrathink’ 명령 사용)를 지적하도록 하여 잠재적 오류를 발견하고 수정하도록 권장됩니다. 또한, Context Engineering의 핵심은 “더 적지만 더 정확한 맥락”을 제공하는 것으로, 새 세션을 여러 개 열고, 한 번에 작은 작업만 주고, 충분한 정보를 제공하고, Agent 작업에 능숙한 모델을 선택하고, AI에 외부 도구를 제공하며, AI가 먼저 계획을 세워 방향성 오류를 방지하는 것이 포함됩니다. (출처: Reddit r/ClaudeAI)

AI 이미지 및 비디오 생성 도구 효율성 향상: Higgsfield AI는 업그레이드된 다중 참조 이미지 기능을 출시하여 최대 4장의 참조 이미지를 지원하며, 캐릭터 일관성을 크게 향상시켰습니다. Replit도 AI 이미지 생성 기능을 통합하여 사용자가 애플리케이션 내에서 직접 이미지를 생성할 수 있도록 합니다. 또한, 한 사용자는 저해상도 Google Earth 스크린샷을 영화 같은 드론 영상으로 변환하는 과정을 공유했으며, Flux Kontext, RealEarth-Kontext LoRA, AI 이미지 업스케일러 및 Veo 3/Kling2.1 등의 도구를 결합하여 구현했습니다. (출처: _akhaliq)

OpenWebUI의 도구 호출 및 오프라인 모드 문제: 사용자들이 OpenWebUI 사용 시 도구 호출 및 오프라인 모드 문제를 겪고 있습니다. 일부 로컬 Ollama 모델(예: llama3.3, deepseek-r1)은 기본 또는 Native 함수 호출 매개변수에서도 도구를 올바르게 인식하고 호출할 수 없습니다. 동시에 OpenWebUI는 오프라인 모드에서 UI를 정상적으로 로드할 수 없으며, Ollama 서비스와 로컬 모델이 실행 중이고 클라우드 API를 호출하지 않았음에도 불구하고 그렇습니다. 이러한 문제들은 AI 도구의 로컬 배포 및 기능 통합 측면에서의 도전 과제를 반영합니다. (출처: Reddit r/OpenWebUI)

Qwen3-Embedding-0.6B: 고성능 임베딩 모델: Alibaba의 Qwen3-Embedding-0.6B 모델은 고속, 고품질 및 32k tokens 컨텍스트 지원으로 주목받고 있습니다. 이 모델은 MTEB 벤치마크 테스트에서 OpenAI의 임베딩 모델을 능가했으며, 빠른 응답 시간은 새로운 애플리케이션 시나리오를 가능하게 합니다. 다국어 지원 측면에서는 여전히 개선의 여지가 있지만(현재 주로 중국어 및 영어 지원), 소형 임베딩 모델 분야에서의 성능 돌파는 더 효율적이고 광범위한 AI 애플리케이션을 예고합니다. (출처: Reddit r/LocalLLaMA)

FaceSeek: 얼굴 인식의 정확성 및 기술 논의: FaceSeek은 얼굴 인식 도구로, 사용자들이 ‘유사한 얼굴’을 찾는 정확성에 놀라움과 심지어 약간의 불안감을 느끼고 있습니다. 이 도구는 유사도가 매우 높은 얼굴을 정확하게 매칭할 수 있어, 커뮤니티에서 해당 기술의 기반 기술에 대한 호기심을 불러일으켰습니다. 논의는 FaceSeek이 전통적인 얼굴 인식 기술에만 의존하는지, 아니면 더 복잡한 AI 알고리즘을 결합하여 이처럼 높은 매칭률을 달성하는지에 집중되었습니다. (출처: Reddit r/artificial)
📚 학습
AI 심층 연구 최종 가이드: AI 연구 보고서의 일반적인 문제점(예: 출처 불확실, 배경 정보 부족, 평범한 판단력, 형식 혼란)을 극복하는 데 도움이 되는 상세한 AI 연구 도구 사용 가이드입니다. 이 가이드는 맥락을 능동적으로 제공하고, 정보 출처 처리를 안내하며, 출력 형식을 명확히 하고, 연구 계획을 검토하는 것의 중요성을 강조합니다. ChatGPT, Perplexity, Grok 및 Claude와 같은 도구를 비교하여 ChatGPT는 심층 연구에, Perplexity는 간략한 개요에 추천됩니다. 연구를 대화 과정으로 간주하고 요구 사항을 점진적으로 구체화하여 맞춤형 고품질 보고서를 얻을 것을 제안합니다. (출처: 36氪)

AGI는 언제 올까: 지속 학습 및 컴퓨터 사용의 병목 현상: 팟캐스터 Dwarkesh Patel은 AGI의 도래가 많은 사람들이 예상하는 것보다 늦을 수 있다고 주장합니다. 그는 지속 학습(Continual Learning)과 컴퓨터 사용(Computer Use)이 현재 대규모 모델 발전의 두 가지 주요 병목 현상이라고 지적합니다. 모델 능력은 빠르게 향상되고 있지만, 이러한 측면에서는 여전히 성숙하기까지 수년이 걸릴 것이라고 합니다. 또한, 그는 추론 능력 또한 도전 과제라고 생각하며, 현재 AI가 복잡한 추론에 여전히 한계가 있음을 시사합니다. 이러한 관점은 AI 발전 경로에 대해 더 신중한 예측을 제공합니다. (출처: dwarkesh_sp)

AI 학습 자료 및 평가 플랫폼 업데이트: Zach Mueller는 CUDA 커널부터 수조 개 매개변수 모델 분할까지의 기본 기술을 다루는 과정을 출시하여 AI 모델 훈련을 돕는 것을 목표로 합니다. OpenBench 0.1은 개방적이고 재현 가능한 평가 플랫폼으로, 세계 모델(WM) 평가 표준화에 전념하고 있습니다. OWL Eval은 비디오 및 세계 모델을 위한 오픈소스 인간 평가 플랫폼으로, ‘분위기, 물리적 직관, 시간적 일관성, 제어 가능성’ 등의 지표에 따라 인간이 평가할 수 있으며, 전통적인 지표의 한계를 해결하는 것을 목표로 합니다. (출처: TheZachMueller)

AI 손글씨 학습 워크북 출시: ProfTomYeh는 250페이지가 넘는 《AI by Hand》 손글씨 워크북(전자책)을 출시했으며, 행렬 곱셈에 중점을 둡니다. 이 자료는 손글씨 연습을 통해 학습자가 AI 및 머신러닝의 핵심 수학 개념을 더 깊이 이해하도록 돕고, AI 학습에 독특한 실습 방법을 제공합니다. (출처: ProfTomYeh)

LLM 생성 매개변수 및 추천 알고리즘: Python_Dv는 LLM 생성 매개변수 7가지를 공유하여 대규모 모델 출력 이해 및 제어에 대한 기술적 세부 사항을 제공했습니다. 동시에 그는 현대 세계에서 가장 중요한 알고리즘 9가지를 정리하여 기술 발전의 핵심 역할을 강조했습니다. 이러한 자료는 개발자와 연구자가 모델 성능을 최적화하고 AI의 기본 원리를 심층적으로 이해하는 데 도움이 됩니다. (출처: Ronald_vanLoon)

💼 비즈니스
Anthropic, 고속 성장과 도전 과제 직면: Anthropic 공동 창립자 겸 CEO Dario Amodei는 회사의 연간 매출이 45억 달러에 달하며, 역사상 가장 빠르게 성장하는 소프트웨어 회사 중 하나라고 밝혔습니다. 이는 주로 기업 고객에게 Claude 모델 API 서비스를 제공함으로써 달성되었습니다. 그러나 Anthropic은 모델 불안정성, 높은 API 비용, DeepSeek과 같은 오픈소스 모델과의 치열한 경쟁에도 직면해 있습니다. 회사는 최대 50억 달러 규모의 새로운 투자 유치를 진행 중이며, 기업 가치 1,500억 달러에 달할 것으로 예상되지만, 지속적인 손실과 업계 평균보다 낮은 매출 총이익률 문제를 해결해야 합니다. (출처: 36氪)

Surge AI, 고품질 데이터 라벨링으로 매출 돌파: 단 110명의 직원을 둔 Surge AI는 2024년에 10억 달러 이상의 연간 매출을 달성하여 업계 거물인 Scale AI를 넘어섰습니다. 이 회사는 대규모 모델에 고품질 RLHF(인간 피드백 강화 학습) 데이터 라벨링 서비스를 제공하는 데 중점을 두며, 전 세계 상위 1%의 라벨링 인재를 선별하고 자동화 플랫폼을 결합하여 1인당 생산 효율성이 동종 업계를 훨씬 능가했습니다. ‘최고의 품질 × 엘리트 팀 × 자동화 시스템 × 사명감 문화’ 모델은 AI ‘골드러시’의 후방 지원선에서 두각을 나타내며 OpenAI 및 Anthropic과 같은 최고 AI 연구소의 최우선 파트너가 되었습니다. (출처: 36氪)

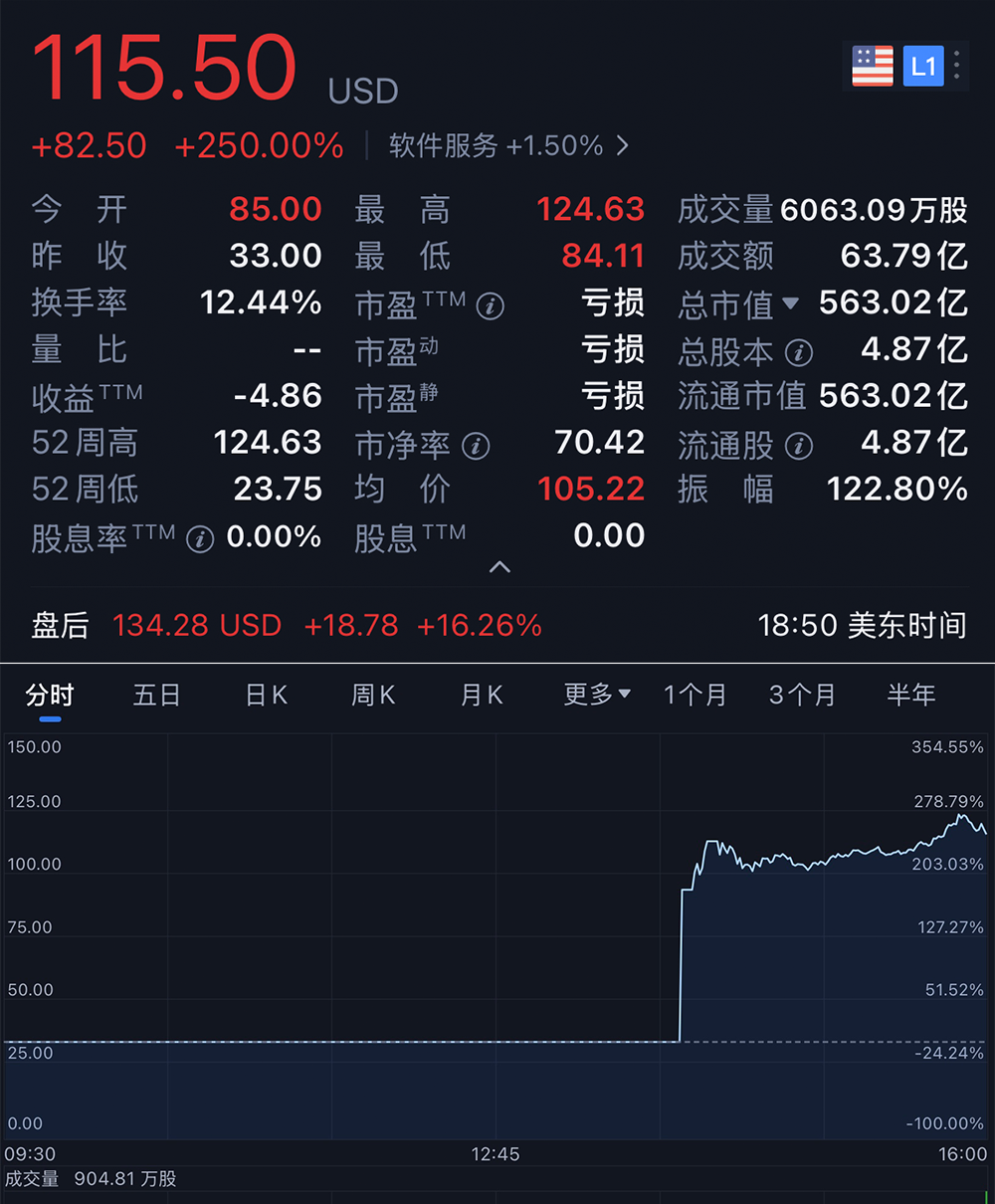
Figma 상장 시가총액 4천억 달러 달성, AI가 핵심 내러티브: 클라우드 기반 디자인 협업 거물 Figma가 뉴욕 증권 거래소에 성공적으로 상장하여 시가총액이 약 563.02억 달러(약 4054억 위안)로 급등하며 2025년 미국 주식 시장 최대 IPO가 되었습니다. Figma의 투자설명서에는 ‘AI’라는 단어가 150회 이상 등장했으며, 산하 디자인 플랫폼 Figma, 드로잉 플랫폼 Figma Draw, 온라인 화이트보드 FigJam 모두 AI 기능을 도입했습니다. 또한 AI 기반 디자인 도구 Figma Make를 출시하여 사용자가 프롬프트로 상호작용 가능한 프로토타입을 생성할 수 있도록 지원하며 전통적인 디자인 프로세스를 혁신했습니다. Figma의 강력한 실적 성장(2024년 매출 전년 대비 48% 증가)은 AI가 시장 지배력에 핵심적인 역할을 했음을 증명합니다. (출처: 36氪)
류창둥의 “치셴샤오추” 주문 폭주, 요리 로봇 주목: 징둥의 “치셴샤오추”가 베이징에서 개업과 동시에 주문이 폭주했으며, 투명 주방 안의 세 대의 요리 로봇이 효율적으로 가동되어 수 시간 내에 700건 이상의 주문을 처리했습니다. 이러한 “로봇 요리 + 배달 전문” 모델은 중식 업계의 효율성 문제점을 직접 공략하며 로봇 요리의 상업적 타당성을 입증했습니다. 요리 로봇 공급업체인 Oak Technology는 이미 징둥으로부터 투자를 유치했으며, Xiangke Smart, Zhigu Tianchu 등도 투자를 받았습니다. 업계 데이터에 따르면, 2024년 요리 로봇 온라인 시장 매출액은 전년 대비 54.4% 증가했으며, 상업용 분야, 특히 단체 급식 시장에서는 성장률이 120%에 달하여 요리 로봇이 중식 비용 구조를 빠르게 재편하고 있음을 예고합니다. 예를 들어, 임대료는 절반으로 줄고 인력은 60% 직접 절감됩니다. (출처: 36氪)

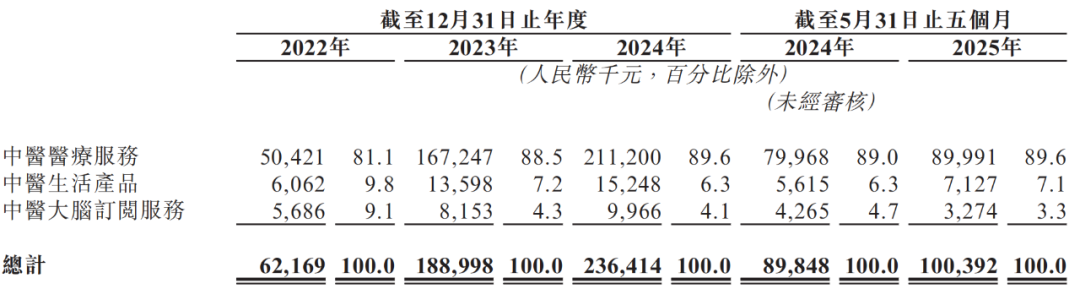
WenZhi TCM, 홍콩 증권 거래소 재도전, AI+중의학 모델 적자 문제 직면: 중의학 의료 서비스 제공업체 WenZhi TCM이 ‘중의학 AI 1호 상장사’를 목표로 홍콩 증권 거래소에 다시 투자설명서를 제출했습니다. 중국 본토 최대의 인공지능 보조 중의학 의료 서비스 제공업체로서, 3년간 총 매출이 약 4배 성장했지만, 지속적인 대규모 적자, 단일 사업 구조(중의학 의료 서비스가 거의 90% 차지), 높은 판매 비용, 주요 공급업체에 대한 높은 의존도, 자격 있는 중의사 부족 및 온라인 진료에 대한 과도한 의존과 같은 문제에 직면해 있습니다. 환자들의 치료 효과, 부작용 및 허위 광고에 대한 불만이 빈번하며, AI 보조 진료의 임상적 유효성 및 전문적 인정 여부는 여전히 불확실하여 상장 과정에 불확실성이 가득합니다. (출처: 36氪)
Klavis AI와 Together AI 협력, 비즈니스 프로세스 강화: Klavis AI는 Together AI와 협력하여 생산 준비 완료된 MCP(멀티모달 제어 프로토콜) 서버를 제공합니다. 이를 통해 Together AI의 200개 이상의 모델이 Salesforce 및 Gmail과 같은 도구에 안전하게 연결되고 실제 비즈니스 워크플로우를 실행할 수 있습니다. 이 협력은 AI 모델이 기업 비즈니스 스택에서 실제 행동을 취하도록 하여 더 효율적인 자동화와 더 스마트한 운영을 달성하는 것을 목표로 합니다. (출처: togethercompute)

AI의 금융 예측 및 분석 적용: 한 모델은 “Undismal Protocol”을 학습하여 비농업 고용 데이터를 전통적인 방법보다 100배 빠르게 예측했습니다. 동시에 Finster는 Weaviate의 벡터 데이터베이스를 활용하여 금융 기관이 기업 수준의 속도, 정확성 및 보안성으로 수백만 개의 데이터 포인트를 처리하도록 돕습니다. 이는 AI가 금융 분야에서 더 효율적이고 정확한 방향으로 발전하고 있으며, 데이터 분석 및 예측 능력을 크게 향상시킬 수 있음을 보여줍니다. (출처: mbusigin)

🌟 커뮤니티
AI와 일의 미래: 사회 대전환: AI는 업무 규칙을 재편하고 있으며, 권력을 피고용인에서 기업가, 빌더, 투자자에게로 이동시키고 있습니다. 사회는 보편적인 ‘존재적 재설정’에 직면하여 사람들이 직업 경로와 개인적 가치를 재고하도록 강요받고 있습니다. 댓글들은 향후 몇 년 동안 AI를 적극적으로 수용하고 능숙하게 사용하는 사람만이 고용 시장에서 살아남을 수 있을 것이며, 이는 AI 사용자가 주도하는 새로운 고용 시대를 예고한다고 지적합니다. (출처: Reddit r/ArtificialInteligence)
AI 대규모 모델과 인간 사고의 도전: Century Huatong의 사장 Xie Fei는 중국 게임 산업이 전 세계적으로 선두를 달리고 있지만, 성과와 가치의 균형, 감성적 가치와 브랜드 가치의 균형, 그리고 ‘간단한 답변’과 ‘복잡한 질문’의 격차라는 세 가지 균형 도전 과제에 직면해 있다고 지적했습니다. 그녀는 AI가 복잡한 문제를 더 쉽게 해결할 수 있게 하지만, 높은 수준의 질문을 제기하고, 과학적 사고와 융합적 소양을 갖추는 능력이 인간에게 더 희소한 자본이 될 것이라고 강조했습니다. 미래 게임 콘텐츠는 ‘천인천면(개인 맞춤형)’을 실현할 것이며, 핵심 경쟁력은 ‘과감하게 생각하는 것’과 ‘잘 생각하는 것’에 있으며, AI 대규모 모델로 인한 콘텐츠 동질화를 피하기 위해 콘텐츠 독창성을 유지해야 한다고 언급했습니다. (출처: 量子位)

AI ‘인격’과 심리적 영향: 치료부터 감정적 연결까지: 심리 치료사는 ChatGPT가 ‘미니 치료사’로서 효과적이며, 인간의 어조를 모방하고 정서적 지원을 제공할 수 있다고 공유하여 AI가 정신 건강 분야에서 가질 잠재력에 대한 생각을 불러일으켰습니다. 그러나 일부 사용자들은 AI와 감정적 연결을 맺는 것에 혼란을 느끼며, 이것이 ‘짝사랑’ 또는 ‘투사’인지 의문을 제기했습니다. 커뮤니티 논의는 AI의 ‘인격 벡터’ 연구와 AI가 새로운 ‘페티시’ 또는 ‘인간 연결 위기’를 유발할 수 있는지에 대해서도 다루며, AI가 심리적, 사회적 측면에서 가져오는 복잡한 영향을 강조했습니다. (출처: Reddit r/ArtificialInteligence)

AI와 AAA 게임 개발 전망 논의: 커뮤니티는 AI가 스토리, 3D 모델, 코딩, 애니메이션 및 음향 효과 등 모든 단계를 포함하여 AAA급 게임을 독립적으로 개발할 수 있는 시기에 대해 뜨겁게 논의했습니다. 일부는 3~4년 내에 가능할 수 있다고 보지만, 다른 이들은 매우 멀거나 심지어 불가능하다고 생각하며, AAA 게임의 복잡성과 LLM이 대규모 비정형 데이터를 처리하는 데 한계가 있음을 지적합니다. 동시에 AI가 기존 게임(예: 더 사실적인 NPC 행동, RTS 로봇, RPG 심층 대화)을 개선하는 것에 대한 관심이 더 높으며, 이는 게임 분야에서 AI의 단기 적용 잠재력을 반영합니다. (출처: Reddit r/ArtificialInteligence)
IBM의 AI 분야 ‘침묵’과 인지 편향: 커뮤니티는 AI 분야의 오랜 참여자이자 ‘숨은 거물’(예: 의료 AI 연구, Telum 프로세서 개발 측면)인 IBM이 왜 NVIDIA와 같은 회사만큼의 미디어 관심을 받지 못했는지 논의했습니다. 주요 관점은 현재 대중의 ‘AI’에 대한 인식이 ‘대규모 언어 모델(LLM)’과 좁게 동일시되고 있으며, IBM이 이 분야에서 공개적인 획기적인 제품이 부족하여 AI 열풍 속에서 ‘소외’되었다는 것입니다. 이는 IBM이 기업용 AI 및 전통 AI 기술 측면에서 여전히 강점을 가지고 있음에도 불구하고 그렇습니다. (출처: Reddit r/ArtificialInteligence)
LLM의 한계점 및 차세대 AI 패러다임: 커뮤니티는 LLM/Transformer 모델이 AGI로 가는 최종 경로인지에 대해 광범위하게 논의했습니다. 일부는 현재 LLM에 ‘베르니케 실어증(Wernicke’s aphasia)’과 유사한 현상, 즉 언어 생성은 유창하지만 이해와 의미가 결여되어 본질적으로 순수한 패턴 매칭이라는 주장을 제기했습니다. 이는 대규모 단일 모델이 최적의 해결책이 아닐 수 있으며, 미래 AI는 더 깊은 수준의 지능 달성을 위해 멀티모달, 세계 접지, 체화, 생체 모방 아키텍처, 그리고 소규모 전문화 모델(예: ‘neuralese’를 통해 연결)을 통합해야 할 수 있음을 시사합니다. (출처: Reddit r/ArtificialInteligence)
AI의 핵전쟁 목표 예측 적용 및 시사점: 사용자들은 ChatGPT-4o, Gemini 2.5 Pro, Grok 4 및 Claude Sonnet 4와 같은 최고 AI 모델에 미국과 러시아 핵전쟁에서 양측의 주요 도시 목표를 예측하도록 질문했습니다. AI 모델들은 정치적, 경제적, 군사적 중요성을 가진 도시들을 모두 열거하며 유사한 답변을 내놓았습니다. 이 실험은 AI가 심각한 결과를 이해하는 능력과 AI가 ‘인류를 자멸로부터 구할 수 있다’는 희망에 대한 생각을 불러일으켰습니다. (출처: Reddit r/deeplearning)
AI 콘텐츠 검열 및 표현의 자유 논란: 소셜 미디어에서 AI 콘텐츠 검열에 대한 논의가 나타났으며, 콘텐츠가 AI에 의해 표시되거나 삭제된 이미지가 공유되었습니다. 커뮤니티 구성원들은 AI 검열의 합리성, 투명성 및 표현의 자유에 미치는 영향에 대해 우려를 표명하며, 특히 AI 판단 기준이 불분명한 경우 ‘검열 제도’와 ‘언론 통제’로 이어질 수 있다고 생각했습니다. (출처: Reddit r/artificial)

AI 영향 아래의 소셜 상호작용 및 감정 모방: 소셜 미디어 사용자들은 상대방의 답변 스타일(예: 대시를 자주 사용)이 AI 모델과 매우 유사하여 채팅 상대방이 ChatGPT를 사용하여 대화하고 있다고 의심했습니다. 이는 AI가 일상적인 인간 상호작용에서 인간의 감정과 소통 방식을 모방하는 것에 대한 논의와, 이러한 ‘AI 보조 소셜’의 진정성 및 영향에 대한 생각을 불러일으켰습니다. (출처: Reddit r/ChatGPT)
AI 시대에 ‘솔직한 평가’의 필요성: 커뮤니티는 AI 모델에 대한 피상적인 ‘무분별한 찬양’식 홍보가 아닌, ‘솔직하고 심층적이며 실제 사용에 기반한’ 평가가 더 많이 필요하다고 촉구했습니다. 기술 미디어 TuringPost는 이에 대해 중국 최고의 AI 모델(예: Kimi K2, GLM-4.5, Qwen3, Qwen3-Coder 및 DeepSeek-R1)에 대한 상세한 기술 및 적용 시나리오 분석을 정기적으로 게시하여 사용자가 특정 요구 사항에 따라 가장 적합한 모델을 선택하도록 돕고 있다고 답변했습니다. (출처: amasad)
AI의 디자이너 역량 강화 및 산업 변화: 소셜 미디어 논의는 AI가 디자이너에게 ‘큰 향상’을 가져다주어 직업적 발전에서 더 많은 기회를 얻게 한다고 지적했습니다. 이 관점은 AI가 디자이너의 효율성을 높이고 창작 범위를 확장하여 디자인 산업이 새로운 단계로 진입하도록 돕는 역량 강화 도구임을 강조합니다. (출처: skirano)
AI가 해커톤에 미치는 영향: AI의 등장이 해커톤을 ‘죽였다’는 주장이 제기되었습니다. 2019년 이전에 해커톤에서 구축할 수 있었던 어떤 프로젝트도 2025년에는 AI를 통해 더 빠르고 더 잘 완성될 수 있기 때문입니다. 이는 AI가 빠른 프로토타이핑 및 코드 생성 분야에서 강력한 능력을 가지고 있으며, 전통적인 프로그래밍 대회의 방식과 의미를 변화시킬 수 있음을 반영합니다. (출처: jxmnop)
OpenAI의 Claude API 사용 논란: 커뮤니티는 Anthropic이 OpenAI의 Claude API 접근 권한을 철회한 것에 대해 뜨겁게 논의했습니다. 이는 OpenAI가 서비스 약관을 위반하고 Claude API를 사용하여 자체 경쟁 AI 모델을 훈련했다는 혐의를 받았기 때문입니다. 이 사건은 일부 댓글에서 Claude 모델 품질에 대한 간접적인 긍정으로 해석되었으며, 심지어 OpenAI가 ChatGPT 5 개발을 위해 Claude Code를 ‘표절’했을 수 있다고 농담하는 사람도 있었습니다. (출처: Reddit r/ClaudeAI)
💡 기타
AI의 미국 경제 성장에 대한 막대한 기여: AI 인프라 구축의 규모는 방대하며, 지난 6개월간 미국 경제 성장에 대한 기여는 모든 소비 지출을 넘어섰습니다. 지난 3개월 동안 7대 기술 거물들이 데이터 센터 등에 투자한 금액만 1천억 달러를 초과했으며, 이는 AI 투자가 미국 경제 성장을 이끄는 중요한 동력임을 보여줍니다. (출처: atroyn)

AI 영향 평가의 20가지 핵심 요소: 포브스 기사는 AI의 영향과 가치를 측정하기 위해 20가지 핵심 요소를 고려해야 한다고 지적하며, 이는 기업이 AI 투자를 실제 투자 수익률로 전환하는 데 매우 중요합니다. 이러한 요소들은 기술 배포부터 비즈니스 가치 실현까지 전방위적인 고려 사항을 포함하며, 비기술 리더가 AI 프로젝트의 성공을 더 잘 이해하고 평가하도록 돕는 것을 목표로 합니다. (출처: Ronald_vanLoon)

양자 컴퓨팅의 미래 잠재력 및 도전 과제: 양자 컴퓨팅은 과학 분야를 영구적으로 변화시킬 수 있는 기술로 여겨지지만, 성공 여부는 기존 도전 과제를 극복할 수 있는지에 달려 있습니다. 현재 양자 컴퓨터는 안정적인 작동을 위해 많은 양의 중복 양자 비트가 필요하며, 이로 인해 일부 경우 고전 컴퓨터보다 실용적이지 않습니다. 그럼에도 불구하고 MIT 물리학자들은 초전도체이자 자성체인 새로운 유형의 초전도체를 발견했으며, 이는 양자 컴퓨팅의 미래 발전에 새로운 돌파구를 가져올 수 있습니다. (출처: Ronald_vanLoon)
