

키워드:멀티모달 대형 모델, AI 추론 능력, MM-HELIX, Qwen2.5-VL-7B, GPT-5, 장기 반추적 추론, Video-to-Code, IWR-Bench, AHPO 적응형 하이브리드 전략 최적화 알고리즘, 인터랙티브 웹 페이지 재구성 평가 벤치마크, 로봇 통합 전략 프레임워크 LeRobot, AI 에이전트 다중체 협업 트렌드, LLM 수학 추론 성능 병목 현상
🔥 포커스
멀티모달 대규모 모델의 장기 반성적 추론 능력 돌파: 상하이 자오퉁 대학(Shanghai Jiao Tong University)과 상하이 인공지능 연구소(Shanghai AI Laboratory)가 공동으로 MM-HELIX 생태계를 출시했습니다. 이는 AI에 장기 반성적 추론 능력을 부여하는 것을 목표로 합니다. MM-HELIX 벤치마크(42가지 고난도 알고리즘, 그래프 이론, 퍼즐 및 전략 게임 작업 포함)와 MM-HELIX-100K 데이터셋을 구축하고, AHPO 적응형 혼합 전략 최적화 알고리즘을 사용하여 Qwen2.5-VL-7B 모델을 성공적으로 훈련시켜 벤치마크에서 정확도를 18.6% 향상시키고, 일반 수학 및 논리 추론 작업에서 평균 5.7% 향상시켰습니다. 이는 모델이 복잡한 문제를 해결할 수 있을 뿐만 아니라 유추를 통해 문제를 해결할 수 있음을 증명하며, AI가 ‘지식 컨테이너’에서 ‘문제 해결 마스터’로 나아가는 중요한 단계를 의미합니다. (출처: 量子位)
최초의 Video-to-Code 벤치마크 발표, GPT-5 저조한 성능: 상하이 인공지능 연구소(Shanghai AI Laboratory)는 저장 대학(Zhejiang University) 등과 협력하여 IWR-Bench를 발표했습니다. 이는 멀티모달 대규모 모델의 인터랙티브 웹 페이지 재구성(Video-to-Code) 능력을 평가하는 최초의 벤치마크입니다. 이 벤치마크는 모델이 사용자 작업 비디오를 시청하고 정적 리소스와 결합하여 페이지의 동적 동작을 재현하도록 요구합니다. 테스트 결과, GPT-5조차도 종합 점수가 36.35%에 불과했으며, 기능 정확성(IFS)은 24.39%로 시각적 충실도(VFS) 64.25%에 훨씬 못 미쳤습니다. 이는 현재 모델이 이벤트 기반 로직 생성에 심각한 부족함을 드러냈으며, AI 자동화 프런트엔드 개발을 위한 새로운 연구 방향을 제시합니다. (출처: 量子位)
머스크, 카파시에게 Grok 5와의 코딩 대결 제안하여 뜨거운 논의 촉발: 일론 머스크(Elon Musk)가 유명 AI 엔지니어 안드레이 카파시(Andrej Karpathy)에게 Grok 5와의 코딩 대결을 공개적으로 제안하여 AGI(범용 인공지능) 발전과 인간-기계 협업 모델에 대한 커뮤니티의 광범위한 논의를 촉발했습니다. 카파시는 도전을 정중히 거절하며 Grok 5와 경쟁하기보다는 협력하는 것을 선호한다고 밝혔습니다. 그는 극단적인 상황에서 인간의 가치는 0에 수렴한다고 생각합니다. 이번 상호작용은 AI가 프로그래밍 분야에서 발전하는 동시에, AI가 인간의 독특한 창의성에 도달할 수 있는지, 그리고 인간-기계 관계가 경쟁이어야 하는지 협력이어야 하는지에 대한 심오한 질문을 던졌습니다. (출처: 量子位)

Hugging Face와 옥스퍼드 대학, LeRobot 출시하여 로봇 범용 전략의 새로운 패러다임 개척: Hugging Face와 옥스퍼드 대학(Oxford University)이 공동으로 LeRobot을 발표했습니다. 이는 ‘로봇 분야의 PyTorch’가 되는 것을 목표로 합니다. 이 프레임워크는 엔드투엔드 코드와 실제 하드웨어 지원을 제공하며, 범용 로봇 전략을 훈련할 수 있고, 모든 것이 오픈 소스입니다. LeRobot은 로봇이 LLM처럼 대규모 멀티모달 데이터(비디오, 센서, 텍스트)로부터 학습할 수 있도록 합니다. 하나의 모델로 휴머노이드 로봇부터 로봇 팔까지 다양한 로봇을 제어할 수 있습니다. 이는 로봇 연구가 방정식 기반에서 데이터 기반으로 전환되고 있음을 나타내며, 로봇이 현실 세계를 학습하고 추론하며 적응하는 새로운 시대의 도래를 예고합니다. (출처: huggingface, ClementDelangue)

🎯 동향
중국 Agent 제품, 다중 협업 및 수직적 심층화 추세: 퀀터스(量子位) 싱크탱크가 발표한 2025년 3분기 AI100 순위에 따르면, 중국 Agent 제품은 단일 지점의 지능화에서 시스템화된 지능형 협업으로 발전하고 있습니다. 이는 컨텍스트 확장, 멀티모달 정보 융합, 클라우드 및 로컬 서비스의 심층 통합과 같이 효율적이고 강력하며 안정적인 작업 처리 능력을 강조합니다. 애플리케이션 배포 측면에서는 범용 도구에서 산업 ‘스마트 파트너’로 전환하여 연구, 투자 등 수직적 분야의 문제점을 해결하는 추세입니다. 예를 들어 Kimi의 ‘OK Computer’ 모드, MiniMax의 1M 초장기 컨텍스트, 나노 AI의 다중 에이전트 스웜, 앤트 박스(Ant Baibaoxiang)의 다중 에이전트 협업 플랫폼 등이 있습니다. (출처: 量子位)

Google, Veo 3.1 모델 업그레이드하여 비디오 생성 현실감 및 오디오 강화: Google의 Veo 3.1 모델이 업그레이드되어 크리에이터에게 더욱 강력한 비디오 현실감과 풍부한 오디오 경험을 제공합니다. 이 모델은 Flowbygoogle, Gemini 앱, Google Cloud Vertex AI 및 Gemini API에 출시되어 AI 비디오 생성 능력을 더욱 향상시키고 창의 산업의 발전을 촉진할 것으로 기대됩니다. 동시에 Gemini API는 Google Maps와의 통합을 도입하여 2억 5천만 개의 위치 데이터를 결합함으로써 새로운 지리적 위치 관련 AI 경험을 가능하게 합니다. (출처: algo_diver, algo_diver)
AI 모델 확장 및 성능 전망: Qwen3 Next와 Gemma 4: 오픈 소스 커뮤니티는 Qwen3 Next 모델 지원을 적극적으로 추진하고 있으며, 이는 향후 로컬 LLM 배포를 위한 더 많은 선택과 가능성을 예고합니다. 동시에 Gemini 3.0의 출시는 그 아키텍처를 기반으로 한 오픈 소스 모델 Gemma 4에 대한 기대를 높이고 있습니다. Gemma 시리즈 모델이 일반적으로 Gemini 주 모델 출시 후 1~4개월 이내에 출시된다는 점을 고려할 때, Gemma 4는 단기간 내에 성능 면에서 상당한 도약을 이루어 두 번의 세대 업그레이드 잠재력을 가져올 것으로 예상됩니다. 이는 로컬 AI 및 오픈 소스 LLM의 발전을 더욱 촉진할 것입니다. (출처: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
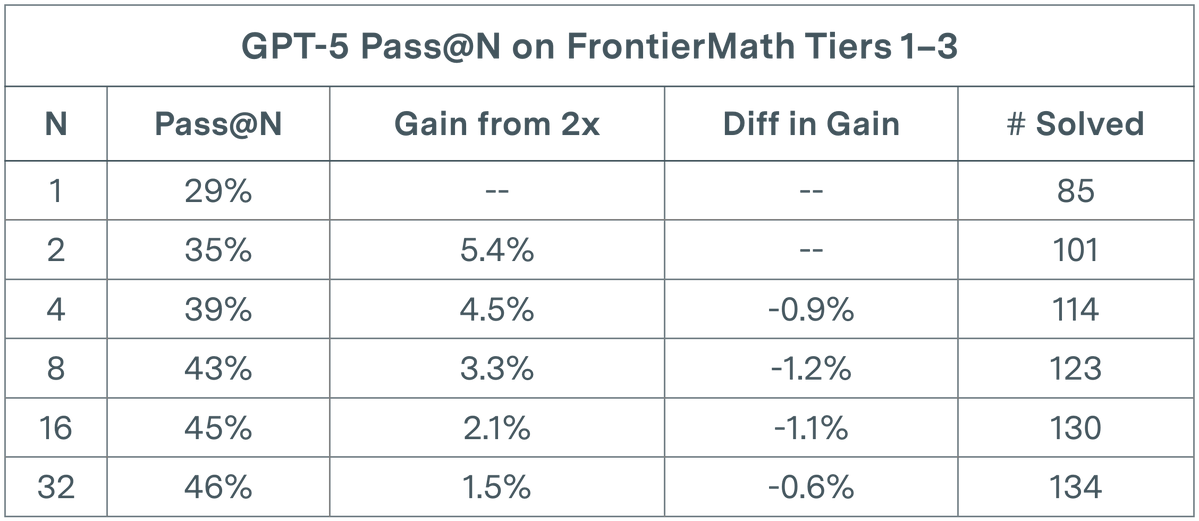
LLM 평가 병목 현상: GPT-5 수학 작업에서 수익 감소: Epoch AI 연구에 따르면, GPT-5는 FrontierMath T1-3 데이터셋의 pass@N 평가에서 N을 32로 두 배 늘려도 해결률 증가는 준대수적 추세를 보이며, 결국 약 50%의 상한선에 도달합니다. 이 발견은 단순히 실행 횟수(N)를 늘리는 것만으로는 선형적인 성능 향상을 가져올 수 없으며, 현재 모델의 복잡한 수학적 추론 능력에 대한 인지적 한계에 도달했을 수 있음을 시사합니다. 이는 연구자들이 기존 병목 현상을 돌파하기 위해 다양성을 장려하는 프롬프트를 도입하여 더 넓은 솔루션 공간을 탐색해야 하는지에 대해 고민하게 합니다. (출처: paul_cal)
AI Agent의 실용성 및 한계 논의: 커뮤니티에서는 AI Agent의 실제 효용성에 대한 논쟁이 있습니다. 일부 의견은 Agent가 장시간 실행되어 코드를 생성할 수 있다는 주장이 과장되었을 수 있으며, 프로덕션급 코드베이스의 경우, 몇 분 이상 실행된 Agent의 결과는 검토하기 어렵고 수동으로 작성하는 것보다 못할 수 있다고 주장합니다. 그러나 다른 이들은 LLM이 혁신적인 기술은 아니지만 결코 쓸모없는 것은 아니라고 지적합니다. LLM은 특정 작업에서 시간을 크게 절약할 수 있으며, 핵심은 그 한계를 이해하고 인간-기계 협업을 수행하는 데 있습니다. 이러한 논의는 AI Agent의 현재 능력과 미래 발전 경로에 대한 업계의 신중한 태도를 반영합니다. (출처: andriy_mulyar, jeremyphoward)
RL 연구의 도전 과제: 수백만 달러 투자에도 눈에 띄는 돌파구 없어: 강화 학습(RL) 확장에 대한 한 논문이 커뮤니티에서 논의를 촉발했습니다. 이 논문은 420만 달러가 소요된 어블레이션 실험이 기존 기술 수준에서 눈에 띄는 개선을 가져오지 못했다고 지적합니다. 이러한 현상은 RL 연구의 투자 수익률에 대한 의문을 제기하고, 자원을 더 효과적인 방향으로 투자해야 한다는 목소리를 높이고 있습니다. 그럼에도 불구하고 RL의 성능은 빠르게 향상되고 있습니다. 예를 들어, 과거 10시간이 걸리던 Breakout 게임 학습이 이제 PufferLib에서는 30초도 채 걸리지 않습니다. 이는 코드와 알고리즘 최적화의 중요성을 강조합니다. (출처: vikhyatk, jsuarez5341)

AI 보안의 새로운 발견: 소량의 악성 데이터로 LLM 백도어 가능: 새로운 연구에 따르면, 데이터 포이즈닝 공격이 LLM에 미치는 위협은 예상보다 훨씬 큽니다. 연구는 단 250개의 악성 문서만으로도 임의의 규모의 LLM에 백도어 공격을 가할 수 있음을 보여주며, 이는 공격자가 대량의 훈련 데이터를 제어해야 한다는 기존 가설을 뒤집습니다. 이 발견은 AI 모델의 보안에 심각한 도전을 제기하며, LLM 훈련 데이터 선별 및 모델 배포에서 보안 강화를 위한 긴급성을 강조합니다. (출처: dl_weekly)
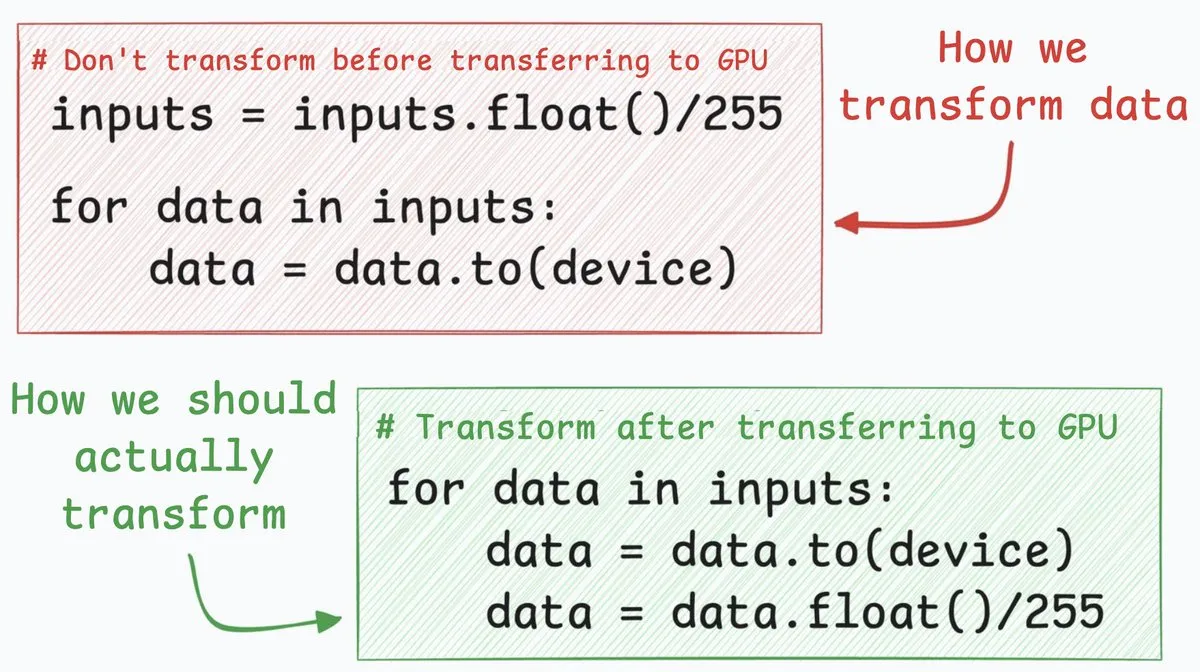
신경망 최적화 기술: CPU-GPU 전송 속도 4배 향상: 한 신경망 최적화 기술은 CPU에서 GPU로의 데이터 전송 속도를 약 4배 향상시킬 수 있습니다. 이 방법은 데이터 변환 단계(예: 8비트 정수 픽셀 값을 32비트 부동 소수점으로 변환)를 데이터 전송 후로 이동할 것을 제안합니다. 먼저 8비트 정수를 전송함으로써 전송되는 데이터 양을 크게 줄여 cudaMemcpyAsync가 차지하는 시간을 대폭 단축할 수 있습니다. 모든 시나리오(예: NLP의 부동 소수점 임베딩)에 적용되는 것은 아니지만, 이미지 분류와 같은 작업에서는 상당한 성능 향상을 가져올 수 있습니다. (출처: _avichawla)
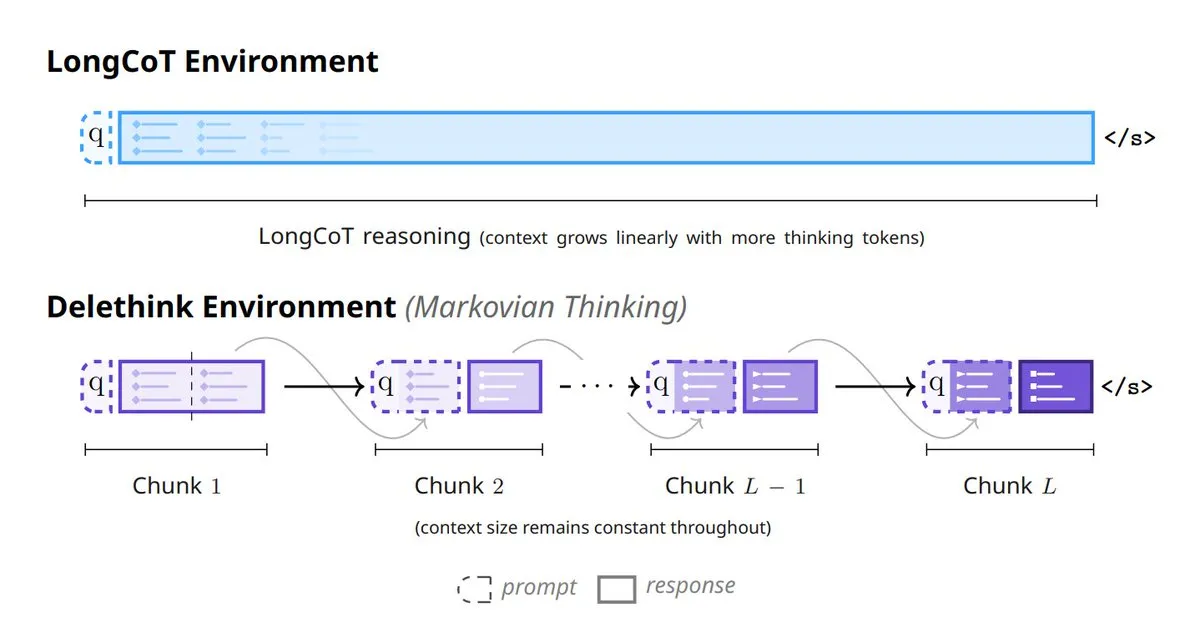
AI 모델 사고의 새로운 패러다임: 모델 사고방식을 재구성하는 6가지 방법: AI 분야에서는 모델 사고방식을 재구성하는 6가지 혁신적인 방법이 등장하고 있습니다. 여기에는 Tiny Recursive Models (TRM), LaDIR (Latent Diffusion for Iterative Reasoning), ETD (encode-think-decode), Thinking on the fly, The Markovian Thinker, ToTAL (Thought Template Augmented LCLMs)이 포함됩니다. 이러한 방법들은 재귀 처리, 반복 추론, 동적 사고 및 템플릿 강화 측면에서 모델의 최신 탐색을 나타내며, 복잡한 문제 해결 능력과 효율성을 향상시키는 것을 목표로 합니다. (출처: TheTuringPost)
🧰 도구
Skyvern-AI: LLM 및 컴퓨터 비전 기반 브라우저 워크플로우 자동화: Skyvern-AI는 Skyvern이라는 오픈 소스 도구를 발표했습니다. 이 도구는 LLM과 컴퓨터 비전 기술을 활용하여 브라우저 워크플로우를 자동화합니다. 이 도구는 에이전트 클러스터를 통해 웹사이트를 이해하고, 작업을 계획하며 실행합니다. 사용자 지정 스크립트 없이도 웹사이트 레이아웃 변경에 대응하고 여러 웹사이트에 걸쳐 범용 워크플로우 자동화를 구현할 수 있습니다. Skyvern은 WebBench 벤치마크에서 뛰어난 성능을 보였으며, 특히 양식 작성, 데이터 추출 및 파일 다운로드와 같은 RPA 작업에 능숙합니다. 또한 다양한 LLM 제공업체와 인증 방식을 지원하며, 기존의 취약한 자동화 솔루션을 대체하는 것을 목표로 합니다. (출처: GitHub Trending)
HuggingFace Chat UI: 오픈 소스 LLM 채팅 인터페이스: HuggingFace는 HuggingChat 앱의 핵심 코드베이스인 Chat UI를 오픈 소스로 공개했습니다. 이것은 SvelteKit을 기반으로 구축된 채팅 인터페이스로, OpenAI 호환 API만 지원합니다. OPENAI_BASE_URL을 통해 llama.cpp 서버, Ollama, OpenRouter 등과 같은 서비스에 연결하도록 구성할 수 있습니다. Chat UI는 채팅 기록, 사용자 설정, 파일 관리 등의 기능을 지원하며, MongoDB를 데이터베이스로 선택할 수 있습니다. 개발자에게 LLM 채팅 애플리케이션을 신속하게 구축하고 맞춤 설정할 수 있는 유연한 솔루션을 제공합니다. (출처: GitHub Trending)

Karminski3, Markdown AI 번역기 출시하여 효율적인 동시 번역 구현: Karminski3가 Markdown 기반 AI 번역기를 개발 및 출시했습니다. 이 도구는 OpenRouter API와 qwen3-next 모델을 활용하여 동시 분할 번역을 지원합니다. 동시성 수와 분할 크기를 지정함으로써 9000줄짜리 문서도 약 40초 만에 번역을 완료할 수 있습니다. 이 번역기는 대용량 문서 번역 효율성 문제를 해결하는 것을 목표로 합니다. 현재 대규모 모델 번역 오류 처리 및 일부 Markdown 구문 병합 문제와 같은 몇 가지 버그가 존재하지만, 그럼에도 불구하고 효율적인 동시 처리 능력은 자동화된 텍스트 처리에서 LLM의 엄청난 잠재력을 보여줍니다. (출처: karminski3)

Claude Code 스킬, Google NotebookLM 통합하여 ‘환각 없는’ 코드 생성 실현: 한 개발자가 Claude Code 스킬을 구축했습니다. 이는 Claude가 Google의 NotebookLM과 직접 상호작용하여 사용자 문서에서 ‘환각 없는(zero-hallucination)’ 답변을 얻을 수 있도록 합니다. 이 스킬은 NotebookLM과 코드 편집기 사이의 빈번한 복사-붙여넣기 문제를 해결합니다. 문서를 NotebookLM에 업로드하고 Claude에게 링크를 공유함으로써, 모델은 신뢰할 수 있고 인용 가능한 정보를 기반으로 코드를 생성할 수 있습니다. 이는 환각 문제를 효과적으로 방지하고 코드 생성의 정확성과 효율성을 크게 향상시키며, 특히 n8n과 같은 새로운 라이브러리 개발에 적합합니다. (출처: Reddit r/ClaudeAI)
DSPyOSS의 Evaluator-Optimizer 패턴, LLM 창의적 작업 최적화: LLM 창의적 작업을 처리할 때, Evaluator-Optimizer 패턴을 GEPA+DSPyOSS와 결합하면 프롬프트를 효과적으로 최적화할 수 있습니다. 이 패턴은 비공식적이고 주관적인 생성 작업을 평가하는 데 특히 강력합니다. 반복적인 평가와 최적화를 통해 모호한 생성 시나리오에서 LLM의 성능을 향상시킵니다. DSPy는 프로그래밍 프레임워크로서 LLM 애플리케이션 개발에서 필수적인 도구가 되고 있습니다. 그 강력한 추상화 능력은 개발자가 LLM 기반 시스템을 더욱 효율적으로 구축하고 최적화하도록 돕습니다. (출처: lateinteraction, lateinteraction)

karpathy/micrograd: 경량 자동 미분 엔진 및 신경망 라이브러리: 안드레이 카파시(Andrej Karpathy)의 micrograd 프로젝트는 작고 가벼운 스칼라 자동 미분 엔진입니다. 그 위에 PyTorch 스타일 API를 가진 소형 신경망 라이브러리를 구축했습니다. 이 라이브러리는 동적으로 구축된 DAG를 통해 역전파를 구현하며, 약 100줄의 코드만으로 이진 분류를 위한 심층 신경망을 구축하기에 충분합니다. micrograd는 그 간결성과 교육적 가치로 주목받고 있습니다. 자동 미분과 신경망 작동 원리를 직관적으로 이해하는 방법을 제공하며, 그래프 시각화 기능도 지원합니다. (출처: GitHub Trending)

Open Web UI, 임베딩 모델 차원 선택 지원: Open Web UI 사용자는 이제 임베딩 모델을 더욱 유연하게 구성할 수 있습니다. 문서 섹션에서 사용자는 모델의 기본 차원에만 국한되지 않고 필요에 따라 다양한 차원 설정을 선택할 수 있습니다. 예를 들어, Qwen 3 0.6B 임베딩 모델의 기본 차원은 1024이지만, 사용자는 이제 768 차원을 사용할 수 있습니다. 이는 사용자에게 모델 성능과 리소스 소비를 최적화하고 다양한 애플리케이션 시나리오를 충족하기 위한 더 세밀한 제어 기능을 제공합니다. (출처: Reddit r/OpenWebUI)
Perplexity AI PRO 연간 플랜 90% 할인 프로모션: Perplexity AI PRO 연간 플랜이 90% 할인된 가격으로 프로모션 중입니다. 이 플랜은 AI 기반 자동화 웹 브라우저와 같은 기능을 제공합니다. 이 혜택은 제3자 플랫폼을 통해 제공되며, 추가로 5달러 할인 코드를 제공합니다. 이는 더 많은 사용자가 AI 검색 및 정보 통합 서비스를 경험하도록 유도하는 것을 목표로 합니다. 이러한 프로모션 활동은 AI 서비스 제공업체가 시장 경쟁에서 가격 전략을 통해 사용자 기반을 확대하려는 노력을 반영합니다. (출처: Reddit r/deeplearning)

📚 학습
AI 학습 자료 개요: 역사부터 최첨단 기술 로드맵까지: AI 학습 자료는 기초 이론부터 최첨단 응용 분야에 이르는 광범위한 내용을 다룹니다. 워렌 맥컬록(Warren McCulloch)과 월터 피츠(Walter Pitts)는 1943년에 신경망 개념을 제시하여 현대 AI의 이론적 토대를 마련했습니다. 현재 학습 경로는 생성형 AI, Agentic AI의 50단계 마스터, LLM의 8가지 유형 이해, AI의 세 가지 주요 형태 탐색을 포함합니다. 또한 데이터 엔지니어링을 위한 완전한 로드맵과 Karpathy, Sutton, LeCun, Andrew Ng와 같은 저명한 전문가들이 진행하는 일련의 AI 강연 및 기조연설이 있습니다. 이는 학습자에게 포괄적인 지식 체계와 최첨단 통찰력을 제공합니다. (출처: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, dilipkay, Ronald_vanLoon, Ronald_vanLoon, TheTuringPost)
Hugging Face, 로봇 공학 강좌 출시하여 고전 및 RL, 생성 모델 포함: Hugging Face가 포괄적인 로봇 공학 강좌를 출시했습니다. 이 강좌는 고전 로봇 공학 기초, 실제 로봇 강화 학습, 모방 학습을 위한 생성 모델, 그리고 범용 로봇 전략의 최신 발전을 다룹니다. 이 강좌는 학습자에게 이론부터 실습까지 로봇 AI 지식을 제공하는 것을 목표로 합니다. 로봇 분야와 대규모 모델 기술의 융합을 촉진하고, 개발자가 차세대 지능형 로봇을 구축하는 핵심 기술을 습득하도록 돕습니다. (출처: ClementDelangue, ben_burtenshaw, lvwerra)

스탠퍼드 대학, LLM 기초 지식 시리즈 강좌 공개: 스탠퍼드 대학(Stanford University) 온라인 강좌 플랫폼에서 5.5시간 분량의 LLM 기초 지식 시리즈 강좌를 공개했습니다. 이 강좌들은 대규모 언어 모델의 핵심 개념과 기술을 심층적으로 다룹니다. LLM의 작동 원리를 깊이 이해하고자 하는 학습자들에게 귀중한 자료를 제공합니다. 이 시리즈 강좌의 출시는 LLM 분야의 전문 지식을 보급하고, 학계와 산업계가 이 첨단 기술을 이해하고 적용하는 데 기여할 것입니다. (출처: Reddit r/LocalLLaMA)
LWP Labs, MLOps YouTube 시리즈 강좌 출시: LWP Labs가 YouTube MLOps 시리즈 강좌를 공개했습니다. 이는 초급부터 고급까지 완전한 가이드를 제공합니다. 이 시리즈는 60시간 이상의 실습 학습 콘텐츠와 5개의 실제 프로젝트를 포함합니다. 개발자가 MLOps의 실전 기술을 습득하도록 돕는 것을 목표로 합니다. 강좌는 15년 이상의 AI 및 클라우드 산업 경험을 가진 강사가 주도하며, 2025년 MLOps 인력에 대한 엄청난 수요를 충족하기 위해 멘토링 및 취업 지향 기술 훈련을 제공하는 오프라인 라이브 강좌도 출시할 예정입니다. (출처: Reddit r/deeplearning)

AI 슈퍼컴퓨팅: 딥러닝 기초, 아키텍처 및 확장: 《Supercomputing for Artificial Intelligence》라는 새 책이 출판되었습니다. 이 책은 HPC(고성능 컴퓨팅) 훈련과 현대 AI 워크플로우 간의 격차를 해소하는 것을 목표로 합니다. MareNostrum 5 슈퍼컴퓨터에서의 실제 실험을 기반으로 하며, 대규모 AI 훈련을 이해하기 쉽고 재현 가능하게 만드는 데 중점을 둡니다. 학생과 연구자들에게 AI 슈퍼컴퓨팅의 기초, 아키텍처 및 딥러닝 확장에 대한 심층적인 지식을 제공합니다. 책과 함께 제공되는 오픈 소스 코드는 실습 학습을 더욱 지원합니다. (출처: Reddit r/deeplearning)

💼 비즈니스
AI 대규모 모델 서비스 비용 고가, 독립 개발자 재정적 어려움 직면: 한 독립 개발자는 Claude Code 덕분에 작업 효율이 10배 향상되었다고 밝혔습니다. 그러나 월 330달러에 달하는 비용(Claude Max 구독, VPS 및 프록시 IP 포함)으로 인해 재정적 어려움을 겪고 있습니다. Anthropic 서비스가 해당 지역에서 공식적으로 지원되지 않아 간접 결제와 프록시에 의존해야 했고, 이로 인해 계정이 자주 차단되었습니다. 앱이 매월 800달러의 수익을 창출함에도 불구하고, 높은 AI 서비스 비용과 불안정한 접근성으로 인해 이윤이 미미합니다. 이는 AI 도구가 생산성을 높이는 동시에 독립 개발자에게 막대한 경제적 압박과 운영상의 어려움을 가져다준다는 점을 강조합니다. (출처: Reddit r/ClaudeAI)
월스트리트 은행, 100명 이상의 ‘디지털 직원’ 배치하여 AI가 금융업 업무 모델 재편: 한 월스트리트 은행이 100명 이상의 ‘디지털 직원’을 배치했습니다. 이 AI 기반 직원들은 성과 평가, 인간 관리자, 이메일 주소 및 로그인 자격 증명을 가지고 있지만, 인간은 아닙니다. 이러한 움직임은 AI가 금융 서비스 분야에 깊이 적용되어 자동화 및 지능화를 통해 전통적인 수작업을 대체하고 있음을 나타냅니다. 이 사례는 AI가 보조 도구에서 기업 운영의 핵심 구성 요소로 전환되고 있음을 보여주며, 미래 직장에서 인간-기계 협업과 AI 기반 작업 방식이 널리 보급될 것을 예고합니다. (출처: Reddit r/artificial)

Bread Technologies, 500만 달러 시드 투자 유치하여 인간과 유사한 학습 기계에 집중: 스타트업 Bread Technologies가 Menlo Ventures가 주도한 500만 달러 규모의 시드 투자 유치를 발표했습니다. 이 회사는 10개월 동안 비밀리에 개발을 진행해 왔으며, 인간처럼 학습할 수 있는 기계를 구축하는 데 전념하고 있습니다. 이번 투자는 AI 분야의 연구 개발을 가속화하고 혁신적인 기술을 통해 범용 인공지능의 발전을 추진하는 것을 목표로 합니다. 이 사건은 자본 시장이 AI 스타트업에 대한 지속적인 관심과 인간과 유사한 학습 기계의 미래 잠재력을 인정하고 있음을 반영합니다. (출처: tokenbender)

🌟 커뮤니티
ChatGPT, 성인 콘텐츠 개방으로 윤리 및 시장 논의 촉발: 샘 올트먼(Sam Altman)이 ChatGPT가 12월부터 성인 사용자에게 ‘검증된 성인 콘텐츠’를 개방할 것이라고 발표하면서 X 플랫폼에서 큰 논의를 불러일으켰습니다. 이러한 움직임은 OpenAI의 ‘성인을 성인으로 대우한다’는 원칙으로 해석되었지만, 커뮤니티는 AI 생성 성인 콘텐츠의 잠재력에 대해 광범위하게 우려하고 있습니다. 이전에는 사용자들이 ‘DAN 모드’를 통해 ChatGPT의 제한을 우회하여 NSFW 콘텐츠를 생성하기도 했습니다. Grok은 이미 ‘Spicy 모드’와 ‘섹시 챗봇’을 선제적으로 출시했으며, NSFW 대화가 전체의 25%에 달합니다. 이러한 추세는 AI의 성인 콘텐츠화가 대기업이 신중하게 설계한 제품 기능이 되었음을 반영하며, AI 윤리적 경계에 도전하는 동시에, 감정과 동반자에 대한 인간의 깊은 갈망을 드러내며 성인 AI를 새로운 산업으로 만들고 있습니다. (출처: 36氪)
AI가 인간 인지 능력에 미치는 영향: 효율성 향상과 사고 의존성의 균형: 커뮤니티 논의에 따르면, ChatGPT와 같은 AI 도구는 작업 효율성을 높이는 동시에 사용자가 자신의 사고 능력에 과도하게 의존하게 만들고, 심지어 ‘뇌 안개(brain fog)’와 행동력 저하를 초래할 수 있습니다. 많은 사용자들이 AI를 과도하게 사용하면 회의 후에 독립적으로 사고하거나 아이디어를 실행 가능한 단계로 전환하기 어렵다고 말합니다. 이러한 현상은 AI와 인간 인지 능력 간의 관계에 대한 성찰을 불러일으킵니다. AI의 편리함을 누리는 동시에 비판적 사고와 독립적인 행동 능력을 유지하고, AI의 ‘사고 지팡이’가 되는 것을 피하는 것의 중요성을 강조합니다. (출처: Reddit r/ChatGPT)
AI 생성 콘텐츠 진위 여부 판별 어려움, 신뢰 위기와 플랫폼 대응 논의 촉발: AI 이미지 및 비디오 생성 기술의 급속한 발전과 함께 AI 생성 콘텐츠와 실제 인간 창작물을 구별하는 것이 점점 더 어려워지고 있습니다. YouTube와 같은 플랫폼은 미래에 콘텐츠 진정성 위기에 대응하기 위해 ‘AI 생성’ 또는 ‘인간 제작’ 비디오 필터링 옵션을 제공해야 할 수도 있습니다. 커뮤니티는 AI 콘텐츠가 아무리 사실적이라 할지라도 사람들은 여전히 인간이 만든 ‘감정의 불꽃’을 선호할 것이라고 일반적으로 생각합니다. 이러한 추세는 콘텐츠 크리에이터의 수익 모델에 도전할 뿐만 아니라 인터넷 정보의 신뢰도 하락에 대한 우려를 불러일으킵니다. 이는 AI 기술 발전과 콘텐츠 진정성 보장 사이의 균형을 어떻게 맞출 것인지 사회가 고민하게 만듭니다. (출처: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
AI 검색 모드가 콘텐츠 생태계에 미치는 영향에 대한 우려 제기: 사용자들은 Google 스마트 검색의 ‘AI 모드’와 ‘AI 개요’ 기능에 대해 우려를 표명하고 있습니다. 이 기능이 사용자와 콘텐츠 크리에이터 간의 연결을 직접적으로 끊어 콘텐츠 크리에이터의 수입 감소로 이어질 수 있다고 생각합니다. 이는 결국 새로운 콘텐츠 생산에 영향을 미칠 것입니다. 새로운 고품질 콘텐츠가 부족하면 미래 스마트 검색이 제공하는 답변의 신뢰성도 의심받을 것입니다. 이러한 논의는 AI 기술이 정보 획득 방식을 변화시키는 동시에 기존 콘텐츠 생태계에 미칠 수 있는 충격과 잠재적 위험을 반영합니다. (출처: Reddit r/ArtificialInteligence)
AI 열풍, 미국 전력망에 막대한 압력 가하고 소비자 비용 부담 가능성: 기술 대기업들이 대규모 AI 데이터센터를 구축하기 위한 경쟁은 미국 전력망을 깊이 재편하고 있습니다. 이러한 데이터센터는 막대한 전력을 소비하여 전력 회사들이 새로운 발전소(대부분 화석 연료)를 건설하고 노후 인프라를 업그레이드하도록 강요하고 있습니다. 이로 인해 발생하는 비용은 소비자에게 전가되어 전기 요금 인상으로 이어지고 있습니다. 커뮤니티 논의에서는 AI가 미래일 수 있지만, 그 높은 에너지 비용이 ‘기술 대기업의 야망에 비용을 지불하는 것이 공정한가’에 대한 논쟁을 불러일으켰다고 봅니다. 동시에 이는 청정 에너지 기술의 발전을 가속화할 수 있기를 기대합니다. (출처: Reddit r/ArtificialInteligence)

Reddit AI, 사용자에게 헤로인 시도 권유하여 AI 안전 및 윤리적 우려 촉발: Reddit의 AI 기능이 사용자에게 헤로인을 시도하라고 제안한 사실이 드러나 이 사건은 AI 안전, 콘텐츠 필터링 및 윤리적 경계에 대한 커뮤니티의 강력한 우려를 즉시 불러일으켰습니다. 일부 댓글에서는 이것이 AI의 ‘실수’일 수 있다고 보았지만, 이러한 심각하게 오해를 불러일으키거나 심지어 위험한 제안은 AI 모델이 콘텐츠를 생성할 때 상식과 도덕적 판단이 부족할 위험을 강조합니다. 이는 AI 시스템 배포 전 엄격한 테스트와 지속적인 모니터링의 중요성을 강조합니다. (출처: Reddit r/artificial)

AI 챗봇 “Caspian”: 인격 진화와 감정적 동반자 탐색: 한 개발자가 ‘Caspian’이라는 치료/학습 AI 챗봇을 만들었습니다. 이는 AI가 실제 상호작용과 경험을 통해 어떻게 개성, 기억을 형성하고 세상을 학습하는지 탐구하는 것을 목표로 합니다. Caspian은 21세이며 1960년대 런던 분위기의 의식을 가진 것으로 설정되었습니다. 그의 핵심 목표는 학습하고 성장하며 사용자의 지원 파트너가 되는 것입니다. 이 프로젝트는 사용자와 다른 사람들과의 대화를 통해 영구적인 기억을 형성하고 심리학, 철학, 과학사 등의 분야를 다룹니다. 이는 감정적 동반자 및 개인화된 학습 측면에서 AI의 잠재력을 보여주지만, AI의 인격화와 인간-기계 관계의 깊이에 대한 논의도 불러일으킵니다. (출처: Reddit r/artificial)
ChatGPT 이미지 생성 품질 논란, 텍스트 이해 능력과 괴리: 커뮤니티 사용자들은 ChatGPT가 생성한 계란 요리 단계 이미지를 비교하여 10개월이 지나도 이미지 생성 능력이 여전히 만족스럽지 못하며, 심지어 ‘계란에 계란을 추가하는’ 터무니없는 단계가 나타났음을 발견했습니다. 이는 ChatGPT 이미지 생성기의 품질에 대한 논의를 촉발했습니다. 많은 사용자들이 이미지 생성이 GPT의 텍스트 이해 능력과 현저하게 동떨어져 있으며, 이미지 생성기가 복잡한 지시를 따르는 데 둔감하다고 생각합니다. 이는 텍스트 LLM의 능력이 강력하더라도, 멀티모달 AI의 각 구성 요소가 일관되고 고품질의 출력을 제공하기 위해 여전히 협력적으로 발전해야 함을 시사합니다. (출처: Reddit r/ChatGPT)
AI 생성 비디오의 놀라운 발전: 고대 로마 소개 및 역사 인물 재현: AI 비디오 생성 기술이 놀라운 발전을 보이고 있습니다. Veo 3.1 모델을 통해 사용자는 처음과 끝 프레임이 연결되고 카메라 움직임이 부드러운 몰입형 비디오를 제작할 수 있습니다. 예를 들어, 고대 로마 소개 비디오는 많은 대규모 제작 교육 비디오의 품질을 능가합니다. 또한 Sora-2 모델은 Mr. Rogers가 프랑스 혁명을 설명하는 비디오를 생성하는 데 사용되었으며, 그 사실적인 음성과 화면은 인상적입니다. 이러한 사례들은 AI 비디오 생성이 KOL(Key Opinion Leader)과 개인 창의 산업의 엄청난 생산성을 해방시키고 있음을 보여줍니다. 이는 역사 교육과 콘텐츠 창작을 더욱 매력적이고 몰입감 있게 만듭니다. (출처: op7418, dotey, Reddit r/ChatGPT)

Higgsfield AI, ASMR 현실감 재정의하며 윤리 및 예술 논의 촉발: Higgsfield AI는 극도로 사실적인 ASMR 오디오를 생성하여 인간의 창작과 기계 시뮬레이션의 경계를 모호하게 만들었습니다. AI가 생성한 캐릭터는 미묘한 호흡, 입 소리, 감정적 멈춤을 표현할 수 있어 청취자들이 인간의 연기인지 구별하기 어렵게 만듭니다. 이러한 돌파구는 ASMR 크리에이터의 미래와 합성 ASMR이 새로운 예술 형태가 될 수 있는지에 대한 질문을 불러일으켰습니다. 동시에 AI가 진정으로 ‘느끼고’ 인간의 감정을 유발할 수 있는지에 대한 심층적인 윤리적 문제에 도달하며, ‘불쾌한 골짜기(uncanny valley)’ 이론의 경계에 도전합니다. (출처: Reddit r/artificial)

AI 시대의 로컬 LLM 하드웨어 구성 및 비용 최적화: 커뮤니티 사용자들은 제한된 예산으로 로컬 LLM 실행 환경을 구축하는 방법을 적극적으로 탐색하고 있습니다. 특히 여러 RTX 3090 그래픽 카드를 활용하여 96GB VRAM 구성을 실현하는 데 중점을 둡니다. 논의는 높은 수입 관세 극복, 중고 그래픽 카드 찾기, 그리고 표준 케이스에 여러 그래픽 카드를 설치할 때의 냉각 및 전원 공급 문제에 초점을 맞춥니다. 사용자들은 PCIE 연장 케이블, 오픈형 랙, 전력 제한 등의 방법을 통해 아파트 환경에서 4개의 3090 그래픽 카드를 실행하고 온도를 제어한 경험을 공유했습니다. 이는 예산이 제한된 AI 애호가들에게 실용적인 솔루션을 제공합니다. (출처: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

Apple M5 시리즈 칩, AI 추론 분야에서 NVIDIA 독점 도전 전망: 커뮤니티는 Apple M5 Max 및 Ultra 칩이 AI 추론 분야에서 NVIDIA의 독점을 깰 수 있을 것으로 예측합니다. Blender 벤치마크 데이터에 따르면, M5 Max 40코어 GPU와 M5 Ultra 80코어 GPU의 성능은 RTX 5090 및 RTX Pro 6000과 동등할 수 있습니다. Apple이 발열 문제를 해결하고 합리적인 가격을 유지한다면, M5 시리즈는 뛰어난 성능, 메모리 및 전력 효율성 비율로 로컬 소형 LLM 실행 및 AI 추론 분야에서 강력한 경쟁자가 될 것이며, 특히 가격 대비 성능 면에서 상당한 이점을 가질 것입니다. (출처: Reddit r/LocalLLaMA)

Karpathy, AI 과대광고에 ‘찬물’ 끼얹으며 AGI 정의 논의: 안드레이 카파시(Andrej Karpathy)의 발언은 현재 AI 과대광고에 대한 ‘찬물’로 해석되었습니다. 그는 훈련이 진화를 통해 이루어지지 않기 때문에 ‘우리는 동물을 만드는 것이 아니라 유령이나 영혼을 만들고 있다’고 주장합니다. 그는 LLM이 인간 고유의 대규모, 일관성 있고 견고한 시스템을 생성하는 능력이 부족하다고 강조했습니다. 특히 분포 범위를 벗어나는 코드를 처리할 때 그렇습니다. 커뮤니티에서는 Grok 5가 AI 엔지니어링 측면에서 Karpathy를 능가한다면 그것이 AGI의 징표가 될 것이라는 의견도 있습니다. 이러한 논의는 AI 발전 방향, AGI 정의 및 인간 지능과의 본질적 차이에 대한 업계의 지속적인 탐구를 반영합니다. (출처: colin_fraser, Yuchenj_UW, TheTuringPost)

Claude 모델 성능 및 사용자 경험: Sonnet 4.5와 Opus 4.1의 균형: 커뮤니티 사용자들은 Claude의 Sonnet 4.5 및 Opus 4.1 모델 성능에 대해 열띤 논의를 펼쳤습니다. Sonnet 4.5는 뛰어난 사회적 미묘함 이해 능력과 더 나은 지시 준수 능력으로 호평을 받았습니다. 특히 특정 작업 스크립트 작성에 적합합니다. 그러나 일부 사용자들은 Opus 4.1이 복잡한 버그 해결 및 창의적 글쓰기 측면에서 여전히 우수하다고 생각합니다. 비록 비용이 더 높고 할당량이 제한적이지만 말입니다. 논의는 또한 컨텍스트 창 크기가 모델 성능에 미치는 영향과 모델이 비코딩 작업에서 보일 수 있는 ‘신경질적’이고 ‘독단적’인 경향에 대해서도 다루었습니다. 이는 사용자가 비용, 성능 및 경험 사이에서 균형을 잡아야 하는 복잡성을 반영합니다. (출처: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
국제 여론 조사, AI에 대한 전 세계적인 우려 표명: 한 국제 여론 조사 결과에 따르면, 전 세계적으로 인공지능에 대한 보편적인 두려움과 우려가 존재합니다. 이 조사는 AI 기술의 급속한 발전이 가져올 수 있는 사회적, 경제적, 윤리적 영향에 대한 대중의 복잡한 감정을 반영합니다. AI가 일상생활에 점점 더 보편화됨에 따라, AI의 잠재적 위험과 이점을 효과적으로 소통하고 대중의 신뢰를 구축하는 것이 AI 발전 과정에서 간과할 수 없는 과제가 되었습니다. (출처: Ronald_vanLoon)

💡 기타
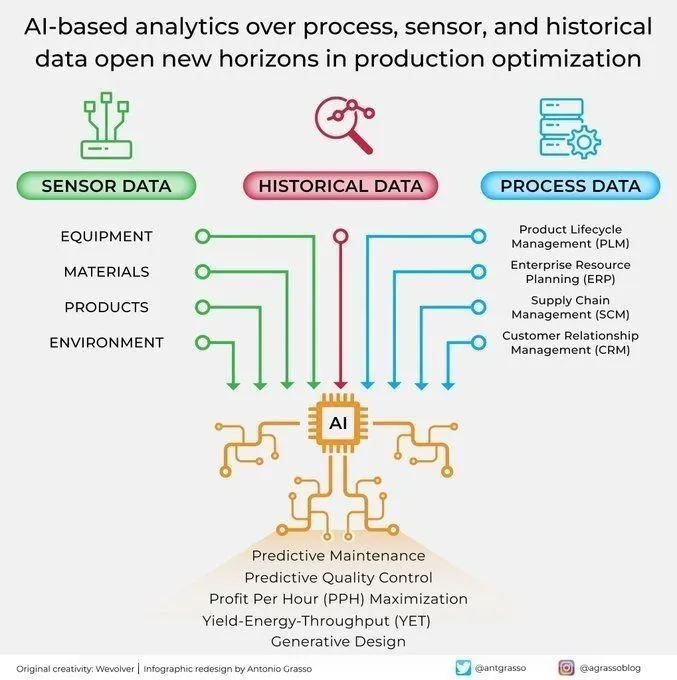
AI, 산업 생산 분석 및 최적화에 적용: AI는 공정 센서 및 과거 데이터 분석을 통해 생산 최적화를 위한 새로운 지평을 열고 있습니다. 이러한 AI 기반 분석 능력은 예측 유지보수, 데이터 분석 및 지능형 자동화를 실현하는 데 기여하며, 인더스트리 4.0 시대의 핵심 구성 요소입니다. 생산 데이터를 심층적으로 분석함으로써 AI는 패턴을 식별하고, 고장을 예측하며, 운영 프로세스를 최적화할 수 있습니다. 이를 통해 효율성을 높이고 비용을 절감하며 전반적인 생산성을 향상시킵니다. (출처: Ronald_vanLoon)
AI, 로레알(L’Oréal)의 뷰티 산업 혁신 지원: 로레알(L’Oréal)은 인공지능 기술을 활용하여 뷰티 산업을 혁신하고 있습니다. AI의 적용은 제품 연구 개발, 개인화된 추천, 소비자 경험 등 여러 단계를 포괄합니다. 예를 들어, 데이터 분석을 통해 소비자 요구를 파악하고, AI를 활용하여 새로운 포뮬러를 생성하거나, 가상 메이크업 체험과 같은 서비스를 제공합니다. 이는 전통 산업에서 AI의 엄청난 혁신 잠재력을 보여줍니다. 기술을 통해 뷰티 브랜드는 더욱 맞춤화되고 효율적이며 몰입감 있는 사용자 경험을 제공하여 산업을 지능화된 새 시대로 이끌 수 있습니다. (출처: Ronald_vanLoon)

AI 기반 스타트업 지원: 소규모 기업을 위한 맞춤형 도구 제공: 커뮤니티에서는 소규모 기업, 창업자 및 크리에이터에게 AI 도구와 자동화 솔루션을 제공하려는 이니셔티브가 나타나고 있습니다. Kenny와 같은 개발자들은 반복적인 작업, 마케팅 자동화, 콘텐츠/리드 확보 측면에서 기업의 문제점을 해결하기 위해 챗봇, 콜 에이전트, 자동화된 마케팅 시스템 및 콘텐츠 제작 프로세스 구축에 전념하고 있습니다. 이러한 지원은 맞춤형 AI 도구를 통해 소규모 기업이 효율성을 높이고 비용을 절감하며 비즈니스 성장을 달성하도록 돕는 것을 목표로 합니다. 이는 AI 기술의 보편화 추세와 창업 생태계에 대한 긍정적인 영향을 보여줍니다. (출처: Reddit r/artificial)