

키워드:AI 산업, GPT-5, AGI, AI 보안, 과대광고 수정, AI 프로그래밍, AI 에이전트, 멀티모달 모델, AI 재료 과학, LLM 추론 최적화, 구현된 AI, AI 벤치마크 테스트, AI 기반 PPT 생성
🔥 포커스
AI 산업 ‘과장 조정’ 및 현실적 고찰 : 2025년 AI 산업은 ‘과장 조정’ 단계에 진입했으며, AI에 대한 시장의 기대는 ‘만병통치약’이라는 생각에서 벗어나 이성적으로 회귀하고 있습니다. Sam Altman 등 업계 리더들은 AI 거품이 존재하며, 특히 스타트업 가치 평가와 데이터 센터 건설에 막대한 투자가 이루어지고 있음을 인정했습니다. 동시에 GPT-5 출시는 기대에 미치지 못했다는 평가를 받으며, LLM 개발 병목 현상에 대한 논의를 촉발했습니다. 전문가들은 AI의 실제 능력을 재검토하고, 생성형 AI의 ‘화려한 시연’과 의료, 과학 등 분야에서 예측형 AI의 실제 돌파구를 구분하며, AI의 가치는 AGI를 맹목적으로 추구하는 것이 아니라 신뢰성과 지속 가능성에 있음을 강조했습니다. (来源: MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review)

AI의 재료 과학 분야 돌파구와 도전 과제 : AI는 새로운 재료 발견을 가속화하는 데 적용되고 있으며, AI 에이전트가 실험을 계획, 실행 및 해석함으로써 발견 과정을 수십 년에서 몇 년으로 단축할 수 있을 것으로 기대됩니다. Lila Sciences 및 Periodic Labs와 같은 기업들은 전통적인 재료 과학의 합성 및 테스트 병목 현상을 해결하기 위해 AI 기반 자동화 실험실을 구축하고 있습니다. DeepMind가 ‘수백만 가지의 새로운 재료’를 발견했다고 주장했지만, 실제 참신성과 실용성은 의문이 제기되어 가상 시뮬레이션과 물리적 현실 간의 격차를 부각시켰습니다. 업계는 순수 계산 모델에서 실험 검증을 결합하는 방향으로 전환하고 있으며, 상온 초전도체와 같은 획기적인 재료 발견을 목표로 하고 있습니다. (来源: MIT Technology Review)

AI 프로그래밍의 생산성 논란과 기술 부채 : AI 프로그래밍 도구가 보편화되면서, Microsoft와 Google CEO는 AI가 회사 코드의 4분의 1을 생성했다고 주장했으며, Anthropic CEO는 미래 코드의 90%가 AI에 의해 작성될 것이라고 예측했습니다. 그러나 실제 생산성 향상에는 논란이 있으며, 일부 연구에서는 AI가 개발 속도를 늦추고 ‘기술 부채’(예: 코드 품질 저하, 유지 보수 어려움)를 증가시킬 수 있다고 지적했습니다. 그럼에도 불구하고 AI는 상용구 코드 작성, 테스트 및 버그 수정에서 뛰어난 성능을 보였으며, Claude Code와 같은 차세대 에이전트 도구는 계획 모드와 컨텍스트 관리를 통해 복잡한 작업 처리 능력을 크게 향상시켰습니다. 업계는 AI 기반 개발 모델에 적응하기 위해 ‘폐기 가능한 코드’ 및 형식 검증과 같은 새로운 패러다임을 탐색하고 있습니다. (来源: MIT Technology Review)

AI 안전 옹호자들의 AGI 위험에 대한 고수와 우려 : 최근 AI 개발이 ‘과장 조정’ 기간에 진입하고 GPT-5의 성능이 평범하다는 평가에도 불구하고, AI 안전 옹호자들(‘AI 종말론자’들)은 AGI(범용 인공지능)의 잠재적 위험에 대해 여전히 깊은 우려를 표하고 있습니다. 이들은 AI 발전 속도가 둔화될 수 있지만 근본적인 위험성은 변하지 않았으며, 정책 입안자들이 AI 위험을 충분히 중요하게 여기지 않는 것에 실망감을 느낀다고 말합니다. 이들은 AGI가 몇 년이 아닌 수십 년 내에 실현되더라도 통제 문제를 해결하기 위해 즉시 자원을 투입해야 하며, AI 거품에 대한 업계의 과도한 투자가 가져올 장기적인 부정적 영향에 대해 경고했습니다. (来源: MIT Technology Review)

🎯 동향
멀티모달 비디오 생성 모델 지속적인 돌파 : Alibaba는 역할극, 오디오-비디오 동기화, 다중 카메라 샷 생성 및 사운드 구동을 지원하며 단일 비디오 길이가 15초에 달하는 Wan 2.6 비디오 모델을 발표했으며, 이는 ‘작은 Sora 2’로 간주됩니다. ByteDance도 방언 지원이 특징인 Seedance 1.5 Pro를 출시했습니다. HuggingFace Daily Papers의 LongVie 2는 제어 가능성, 장기적인 시각적 품질 및 시간적 일관성을 강조하는 멀티모달 제어 가능한 초장기 비디오 세계 모델을 제안했습니다. 이러한 발전은 비디오 생성 기술이 사실성, 상호작용성 및 응용 시나리오 측면에서 크게 향상되었음을 나타냅니다. (来源: Alibaba_Wan, op7418, op7418, HuggingFace Daily Papers)

AI 음성 기술, 다국어 및 실시간 스트리밍 분야에서 새로운 발전 달성 : Alibaba는 9개 언어와 18개 이상의 중국어 방언을 지원하고, 다국어/교차 언어 제로샷 음성 복제를 제공하며, 150밀리초의 초저지연 양방향 스트리밍 전송을 구현하는 CosyVoice 3 TTS 모델을 오픈소스화했습니다. OpenAI의 실시간 API도 gpt-4o-mini-transcribe 및 gpt-4o-mini-tts 모델을 업데이트하여 환각 및 오류율을 크게 줄이고 다국어 성능을 향상시켰습니다. Google DeepMind의 Gemini 2.5 Flash Native Audio 모델도 업데이트되어 지시 따르기 및 대화 자연스러움을 더욱 최적화하여 실시간 음성 에이전트의 적용을 촉진했습니다. (来源: ImazAngel, Reddit r/LocalLLaMA, snsf, GoogleDeepMind)
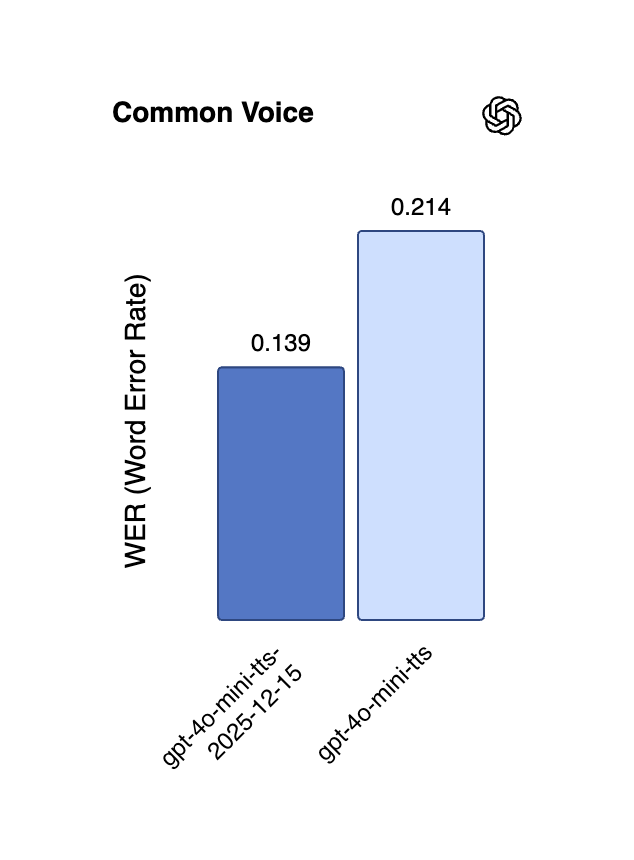
대규모 모델의 긴 컨텍스트 추론 및 효율성 최적화 : QwenLong-L1.5는 체계적인 후속 훈련 혁신을 통해 긴 컨텍스트 추론 능력에서 GPT-5 및 Gemini-2.5-Pro에 필적하며, 초장기 작업에서 뛰어난 성능을 보였습니다. GPT-5.2도 긴 컨텍스트 능력 면에서 사용자들의 호평을 받았으며, 특히 팟캐스트 요약에서 더 풍부한 세부 정보를 제공했습니다. 또한, ReFusion은 슬롯 수준 병렬 디코딩을 통해 성능과 효율성을 크게 향상시키는 새로운 마스크 확산 모델을 제안하여 평균 18배 가속화하고 자기회귀 모델과의 성능 격차를 줄였습니다. (来源: gdb, HuggingFace Daily Papers, HuggingFace Daily Papers, teortaxesTex)
Embodied AI 및 로봇 기술 발전 : AgiBot은 인간에 가까운 이동 능력과 다기능 기술을 갖춘 Lingxi X2 휴머노이드 로봇을 발표했습니다. HuggingFace Daily Papers의 여러 연구는 Embodied AI에 초점을 맞추고 있으며, 예를 들어 Toward Ambulatory Vision은 시각적 접지 능동 시점 선택을 탐색하고, Spatial-Aware VLA Pretraining은 인간 비디오를 통해 시각-물리 정렬을 달성하며, VLSA는 플러그 앤 플레이 안전 제약 계층을 도입하여 VLA 모델의 안전성을 향상시킵니다. 이러한 연구는 2D 시각과 3D 물리 환경 행동 간의 격차를 줄이고 로봇 학습 및 실제 배포를 촉진하는 것을 목표로 합니다. (来源: Ronald_vanLoon, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
NVIDIA와 Meta의 AI 아키텍처 및 모델 오픈소스 기여 : NVIDIA는 Nemotron v3 Nano 오픈 모델 제품군을 발표하고, RL 인프라, 환경, 사전 훈련 및 후속 훈련 데이터셋을 포함한 완전한 훈련 스택을 오픈소스화하여 각 산업 분야의 전문 에이전트 AI 구축을 촉진하는 것을 목표로 합니다. Meta는 최초의 비생성형 모델인 VL-JEPA 시각-언어 공동 임베딩 예측 아키텍처를 출시하여 실시간 스트리밍 애플리케이션에서 일반적인 시각-언어 작업을 효율적으로 수행할 수 있으며, 대규모 VLM의 성능을 능가합니다. (来源: ylecun, QuixiAI, halvarflake)

AI 벤치마크 테스트 및 평가 방법 혁신 : Google Research는 멀티모달, 파라미터 지식, 검색 및 접지 등 네 가지 차원에서 LLM의 사실성을 종합적으로 평가하는 FACTS Leaderboard를 출시하여, 다양한 모델 간의 커버리지 및 모순율의 균형을 보여주었습니다. V-REX 벤치마크 테스트는 ‘질문 체인’을 통해 VLM의 탐색적 시각 추론 능력을 평가하며, START는 차트 이해를 위한 텍스트 및 공간 학습에 중점을 둡니다. 이러한 새로운 벤치마크는 복잡하고 실제 세계의 작업에서 AI 모델의 성능을 더 정확하게 측정하는 것을 목표로 합니다. (来源: omarsar0, HuggingFace Daily Papers, HuggingFace Daily Papers)

웹 환경에서 AI 에이전트의 자율성 향상 : WebOperator는 LLM 에이전트가 부분적으로 관찰 가능한 웹 환경에서 신뢰할 수 있는 백트래킹 및 전략적 탐색을 수행할 수 있도록 하는 행동 인식 트리 검색 프레임워크를 제안했습니다. 이 방법은 다중 추론 컨텍스트를 통해 행동 후보를 생성하고 유효하지 않은 행동을 필터링하여 WebArena 작업의 성공률을 크게 높였으며, 전략적 예측과 안전한 실행의 결합이라는 핵심 이점을 부각시켰습니다. (来源: HuggingFace Daily Papers)
AI 보조 자율 주행 및 4D 세계 모델 : DrivePI는 자율 주행의 이해, 인식, 예측 및 계획을 통합하는 공간 인식 4D MLLM입니다. 이 모델은 포인트 클라우드, 다중 시점 이미지 및 언어 지침을 통합하고 텍스트-점유율 및 텍스트-흐름 QA 쌍을 생성하여 3D 점유율 및 점유 흐름에 대한 정확한 예측을 달성했으며, nuScenes와 같은 벤치마크에서 기존 VLA 및 전문 VA 모델을 능가했습니다. GenieDrive는 물리 인식 운전 세계 모델에 중점을 두며, 4D 점유 기반 비디오 생성을 통해 예측 정확도와 비디오 품질을 향상시켰습니다. (来源: HuggingFace Daily Papers, HuggingFace Daily Papers)
🧰 도구
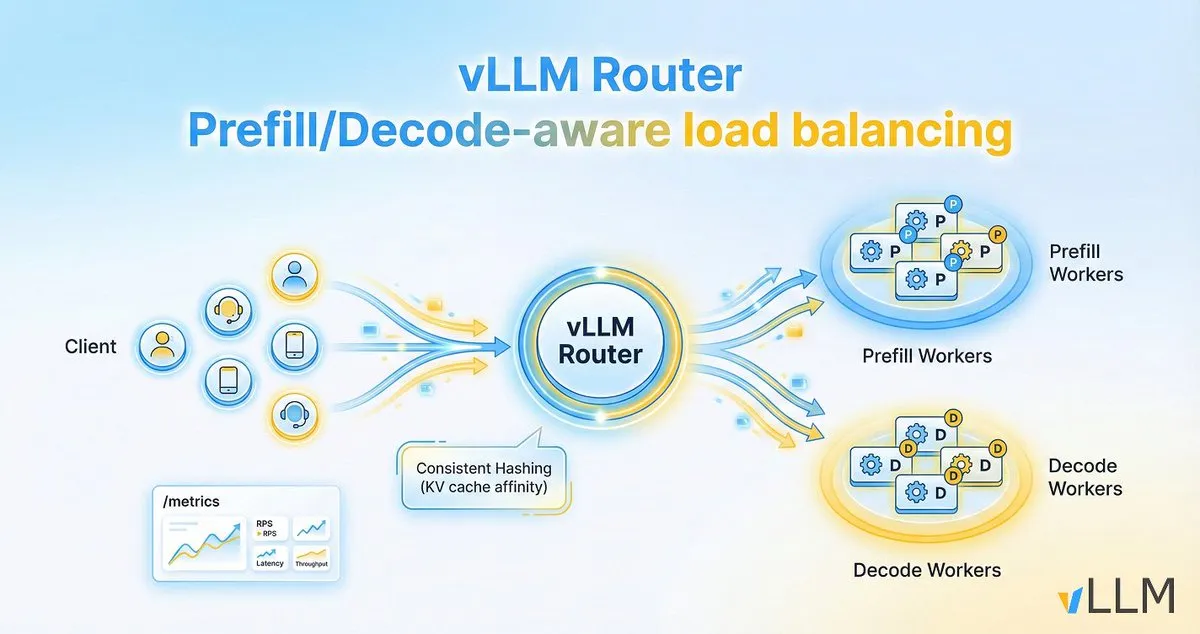
vLLM Router, LLM 추론 효율성 향상 : vLLM 프로젝트는 vLLM 클러스터를 위해 특별히 설계된 경량, 고성능, 사전 채우기/디코딩 인식 로드 밸런서인 vLLM Router를 발표했습니다. Rust로 작성되었으며, 일관성 해싱, 이중 거듭제곱 선택 등의 전략을 지원하여 KV 캐시 지역성을 최적화하고 대화 트래픽 및 사전 채우기/디코딩 분리의 병목 현상을 해결함으로써 LLM 추론의 처리량을 높이고 꼬리 지연 시간을 줄이는 것을 목표로 합니다. (来源: vllm_project)
AI21 Maestro, AI 에이전트 구축 간소화 : AI21Labs의 Vibe Agent가 AI21 Maestro에 출시되어 사용자가 간단한 영어 설명으로 AI 에이전트를 생성할 수 있게 합니다. 이 도구는 에이전트의 용도, 검증 확인, 필요한 도구 및 모델/계산 설정을 자동으로 제안하고 각 단계를 실시간으로 설명하여 복잡한 AI 에이전트 구축의 진입 장벽을 크게 낮춥니다. (来源: AI21Labs)
OpenHands SDK, 에이전트 기반 소프트웨어 개발 가속화 : OpenHands는 에이전트 기반 소프트웨어 구축을 위한 빠르고 유연하며 생산 준비가 된 프레임워크를 제공하기 위해 소프트웨어 에이전트 SDK를 발표했습니다. 이 SDK 출시는 개발자들이 복잡한 소프트웨어 개발 작업을 처리하기 위해 AI 에이전트를 보다 효율적으로 통합하고 관리하는 데 도움이 될 것입니다. (来源: gneubig)

Claude Code CLI 업데이트, 개발 경험 향상 : Anthropic은 13가지 CLI 개선 사항을 포함하는 Claude Code 2.0.70 버전을 발표했습니다. 주요 업데이트에는 Enter 키를 통한 프롬프트 제안 수락 지원, MCP 도구 권한의 와일드카드 구문, 플러그인 마켓 자동 업데이트 스위치, 강제 계획 모드 등이 포함됩니다. 또한, 메모리 사용 효율이 3배 향상되었고 스크린샷 해상도가 높아져 개발자가 Claude Code를 사용하여 소프트웨어를 개발할 때의 상호작용 및 효율성을 최적화하는 것을 목표로 합니다. (来源: Reddit r/ClaudeAI)
Qwen3-Coder, 2D 게임 빠른 개발 구현 : Reddit 사용자는 Alibaba의 Qwen3-Coder(480B) 모델을 Cursor IDE를 통해 사용하여 몇 초 만에 2D 마리오 스타일 게임을 구축하는 방법을 시연했습니다. 이 모델은 단일 프롬프트에서 시작하여 단계를 자동으로 계획하고, 종속성을 설치하며, 코드와 프로젝트 구조를 생성하고, 직접 실행할 수 있습니다. 실행 비용이 저렴하며(토큰 백만 개당 약 2달러), GPT-4 에이전트 모드와 유사한 경험을 제공하여 코드 생성 및 에이전트 작업에서 오픈소스 모델의 강력한 잠재력을 보여주었습니다. (来源: Reddit r/artificial)
AI 기반 주식 심층 연구 도구 : Deep Research 도구는 AI를 활용하여 SEC 문서 및 산업 출판물에서 데이터를 추출하고 표준화된 보고서를 생성하여 회사 비교 및 선별을 간소화합니다. 사용자는 주식 코드를 입력하여 심층 분석을 얻을 수 있으며, 이 도구는 투자자들이 시장 뉴스 방해를 피하고 실질적인 재무 정보에 집중하여 보다 효율적으로 기본 분석을 수행하도록 돕는 것을 목표로 합니다. (来源: Reddit r/ChatGPT)
LangChain 1.2, Agentic RAG 애플리케이션 구축 간소화 : LangChain은 1.2 버전을 발표하여 특히 create_agent 기능에서 내장 도구 및 엄격 모드 지원을 간소화했습니다. 이를 통해 개발자는 로컬에서든 Google Collab에서든 Agentic RAG(검색 증강 생성) 애플리케이션을 보다 편리하게 구축할 수 있게 되었으며, 100% 오픈소스 특성을 강조했습니다. (来源: LangChainAI, hwchase17)
Skywork, AI 기반 PPT 생성 기능 출시 : Skywork 플랫폼은 Nano Banana Pro 기반의 PPT 생성 기능을 출시하여 기존 AI 생성 PPT의 편집 어려움 문제를 해결했습니다. 새로운 기능은 레이어 분리를 지원하여 사용자가 온라인에서 텍스트와 이미지를 수정하고, pptx 형식으로 내보내 로컬에서 편집할 수 있도록 합니다. 또한, 이 도구는 산업 전문 데이터베이스를 통합하여 다양한 차트 생성을 지원하고 데이터 정확성을 보장하며, 크리스마스 프로모션 혜택을 제공합니다. (来源: op7418)

소형 모델, 엣지 인프라스트럭처 애즈 코드(IaC) 지원 : Reddit 사용자는 엣지 장치 또는 브라우저에서 실행할 수 있는 500MB 크기의 ‘인프라스트럭처 애즈 코드’(IaC) 모델을 공유했습니다. 이 모델은 IaC 작업에 중점을 두며, 작지만 강력하여 자원 제약이 있는 환경에서 인프라를 배포하고 관리하기 위한 효율적인 솔루션을 제공하며, 특정 수직 분야에서 소형 AI 모델의 엄청난 잠재력을 시사합니다. (来源: Reddit r/deeplearning)
📚 학습
Chinarxiv: 중국어 프리프린트 자동 번역 플랫폼 : Chinarxiv.org가 공식 출시되었으며, 이는 중서양 과학 연구 간의 언어 장벽을 해소하기 위한 완전 자동화된 중국어 프리프린트 번역 플랫폼입니다. 이 플랫폼은 텍스트뿐만 아니라 차트 내용도 번역하여 서구 연구자들이 중국 과학계의 최신 연구 성과를 더 편리하게 접근하고 이해할 수 있도록 합니다. (来源: menhguin, andersonbcdefg, francoisfleuret)
AI 기술 및 Agentic AI 학습 로드맵 : Ronald_vanLoon은 2025년 AI 기술 습득을 위한 12가지 핵심 역량과 Agentic AI 숙달 로드맵을 공유했습니다. 이 자료들은 빠르게 발전하는 AI 분야에서 개인의 경쟁력을 향상시키기 위한 지침을 제공하며, 기본 AI 지식부터 고급 에이전트 시스템 개발까지의 학습 경로를 포함하고, AI 시대에 지속적인 학습과 새로운 기술 적응의 중요성을 강조합니다. (来源: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

LLM 추론 프로세스 최적화 및 데이터 기반 AI 개발 : Meta Superintelligence Labs의 연구에 따르면, ‘병렬 초안→압축 작업 공간으로 증류→정제’의 PDR(Parallel Draft-Distill-Refine) 전략을 통해 추론 제약 조건 하에서 최적의 작업 정확도를 달성할 수 있습니다. 동시에 한 블로그 게시물은 ‘데이터가 AI의 들쭉날쭉한 최전선’임을 강조하며, 코딩 및 수학 분야는 풍부한 데이터와 검증 가능성으로 인해 성공했지만, 과학 분야는 상대적으로 뒤처져 있음을 지적하고, 데이터 생성에서 증류 및 강화 학습의 역할을 탐구했습니다. (来源: dair_ai, lvwerra)

시각-언어 협력 추론, 추상 능력 향상 : 새로운 연구는 시각-언어 협력 추론(VLSR) 프레임워크를 제안했으며, 이는 다양한 추론 단계에서 시각 및 텍스트 모달리티를 전략적으로 결합하여 ARC-AGI 벤치마크와 같은 추상 추론 작업에서 LLM의 성능을 크게 향상시킵니다. 이 방법은 시각을 사용하여 전역 패턴을 인식하고 텍스트를 사용하여 정확하게 실행하며, 모달리티 전환 자체 교정 메커니즘을 통해 확증 편향을 극복하고 소형 모델에서도 GPT-4o의 성능을 능가했습니다. (来源: dair_ai)
LLM 추론 토큰을 계산 상태로 보는 새로운 관점 : State over Tokens (SoT) 개념 프레임워크는 LLM의 추론 토큰을 단순한 언어 서술이 아닌 외부화된 계산 상태로 재정의합니다. 이는 토큰이 충실한 텍스트 해석이 아니면서도 어떻게 올바른 추론을 이끌어낼 수 있는지 설명하며, LLM의 내부 프로세스를 이해하기 위한 새로운 연구 방향을 열고, 연구가 텍스트 해석을 넘어 추론 토큰을 상태로 디코딩하는 데 집중해야 함을 강조합니다. (来源: HuggingFace Daily Papers)
형식 언어 사전 훈련, 자연어 학습 향상 : 뉴욕대학교의 연구에 따르면, 자연어 사전 훈련 전에 형식화되고 규칙 기반 언어를 사용하여 사전 훈련하는 것이 언어 모델이 인간 언어를 더 잘 학습하는 데 크게 도움이 될 수 있다고 합니다. 연구는 이러한 형식 언어가 자연어와 유사한 구조(특히 계층적 관계)를 가져야 하며 충분히 단순해야 한다고 지적합니다. 이 방법은 동일한 양의 자연어 데이터를 추가하는 것보다 더 효과적이며, 학습된 구조적 메커니즘은 모델 내부에서 전이됩니다. (来源: TheTuringPost)
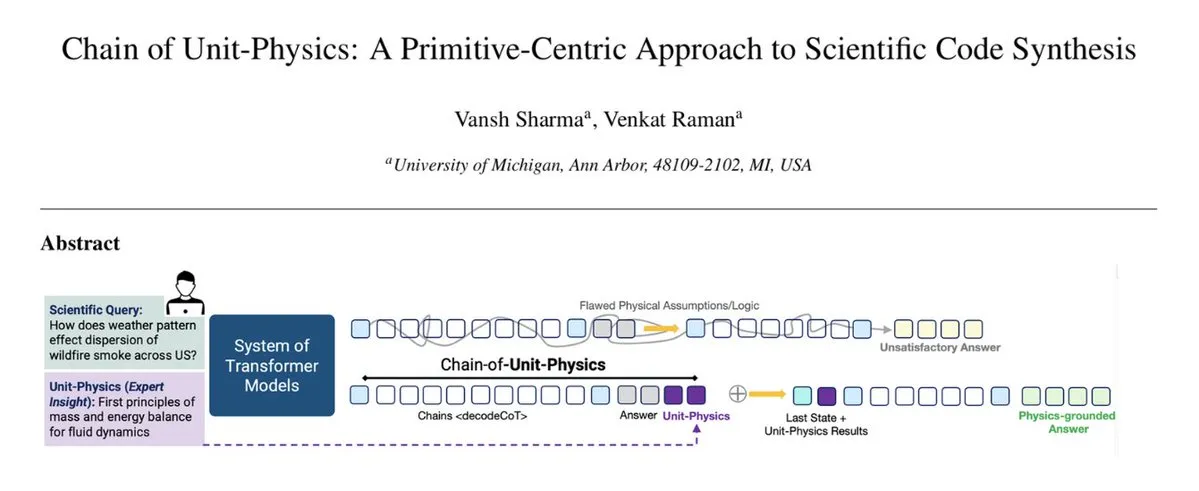
물리 지식 코드 생성 프로세스에 주입 : Chain of Unit-Physics 프레임워크는 물리 지식을 코드 생성 프로세스에 직접 통합합니다. 미시간 대학교 연구원들은 인간 전문가 지식을 단위 물리 테스트로 인코딩하여 코드 생성을 안내하고 제약하는 역과학 코드 생성 방법을 제안했습니다. 다중 에이전트 설정에서 이 프레임워크는 시스템이 5-6회 반복 만에 올바른 솔루션에 도달하게 하고, 실행 속도를 33% 향상시키며, 메모리 사용량을 30% 줄이고, 오류율을 극히 낮춥니다. (来源: TheTuringPost)
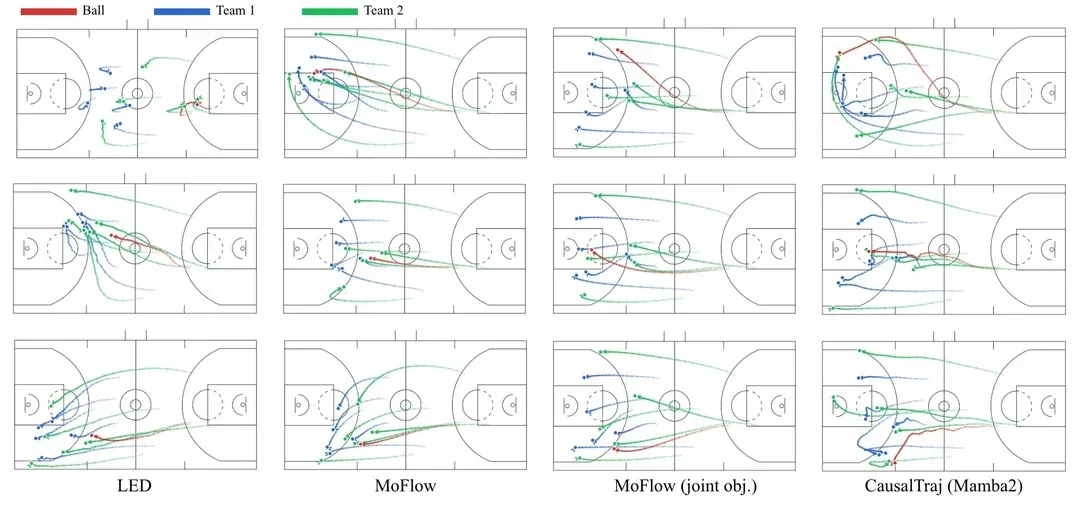
스포츠 팀 다중 에이전트 궤적 예측 모델 CausalTraj : CausalTraj는 팀 스포츠에서 다중 에이전트 공동 궤적 예측을 위한 자기회귀 모델입니다. 이 모델은 개별 에이전트 지표만 최적화하는 것이 아니라 공동 예측 가능성 목표로 직접 훈련되어, 개별 성능을 보장하면서 다중 에이전트 궤적의 일관성과 합리성을 크게 향상시켰습니다. 연구는 또한 공동 모델링을 보다 효과적으로 평가하는 방법과 샘플링된 궤적의 실제 가능성을 평가하는 방법을 탐구했습니다. (来源: Reddit r/deeplearning)
LLM 훈련 데이터: 답변인가, 질문인가? : Reddit의 한 토론에서는 현재 대부분의 LLM 훈련 데이터셋이 ‘답변’에 초점을 맞추고 있지만, 인간 지능의 핵심 부분은 ‘질문’이 형성되기 전의 혼란스럽고 모호하며 반복적인 과정에 존재한다고 제기했습니다. 실험 결과, 초기 사고, 모호한 질문 및 반복적인 수정을 포함하는 대화 데이터로 훈련된 모델이 사용자 의도를 명확히 하고, 불분명한 작업을 처리하며, 잘못된 결론을 피하는 데 더 나은 성능을 보였으며, 이는 훈련 데이터가 인간 사고의 복잡성을 더 포괄적으로 포착해야 함을 시사합니다. (来源: Reddit r/MachineLearning)
💼 비즈니스
OpenAI, neptune.ai 인수하여 첨단 연구 도구 강화 : OpenAI는 neptune.ai 인수를 위한 최종 계약을 발표했으며, 이는 첨단 연구를 지원하는 도구 및 인프라를 강화하기 위한 조치입니다. 이번 인수는 OpenAI가 AI 개발 및 실험 관리 역량을 향상시키고, 모델 훈련 및 반복 과정을 더욱 가속화하며, AI 분야에서 선도적인 위치를 공고히 하는 데 도움이 될 것입니다. (来源: dl_weekly)

Databricks 3분기 실적 호조, 40억 달러 이상 투자 유치 : Databricks는 강력한 3분기 실적을 발표했으며, 연간 매출 실행률이 48억 달러를 초과하여 전년 대비 55% 이상 성장했습니다. 데이터 웨어하우스 및 AI 제품 사업의 연간 매출 실행률은 모두 10억 달러를 돌파했습니다. 회사는 또한 40억 달러 이상의 L 시리즈 투자를 완료하여 1340억 달러의 기업 가치를 달성했으며, Lakebase Postgres, Agent Bricks 및 Databricks Apps에 자금을 투자하여 데이터 인텔리전스 애플리케이션 개발을 가속화할 계획입니다. (来源: jefrankle, jefrankle)

Infosys와 Formula E, AI 기반 디지털 전환 추진 협력 : Infosys는 ABB FIA Formula E 세계 선수권 대회와 협력하여 AI 기반 플랫폼을 통해 모터스포츠의 팬 경험과 운영 효율성을 혁신합니다. 협력에는 AI를 활용한 개인화된 콘텐츠, 실시간 경기 상황 분석, AI 생성 해설 제공, 그리고 탄소 배출량 감소 목표 달성을 위한 물류 및 여행 최적화가 포함됩니다. AI 기술은 경기 매력을 높일 뿐만 아니라 지속 가능한 발전과 직원 다양성을 촉진하여 Formula E를 가장 디지털화되고 지속 가능한 모터스포츠로 만들었습니다. (来源: MIT Technology Review)

🌟 커뮤니티
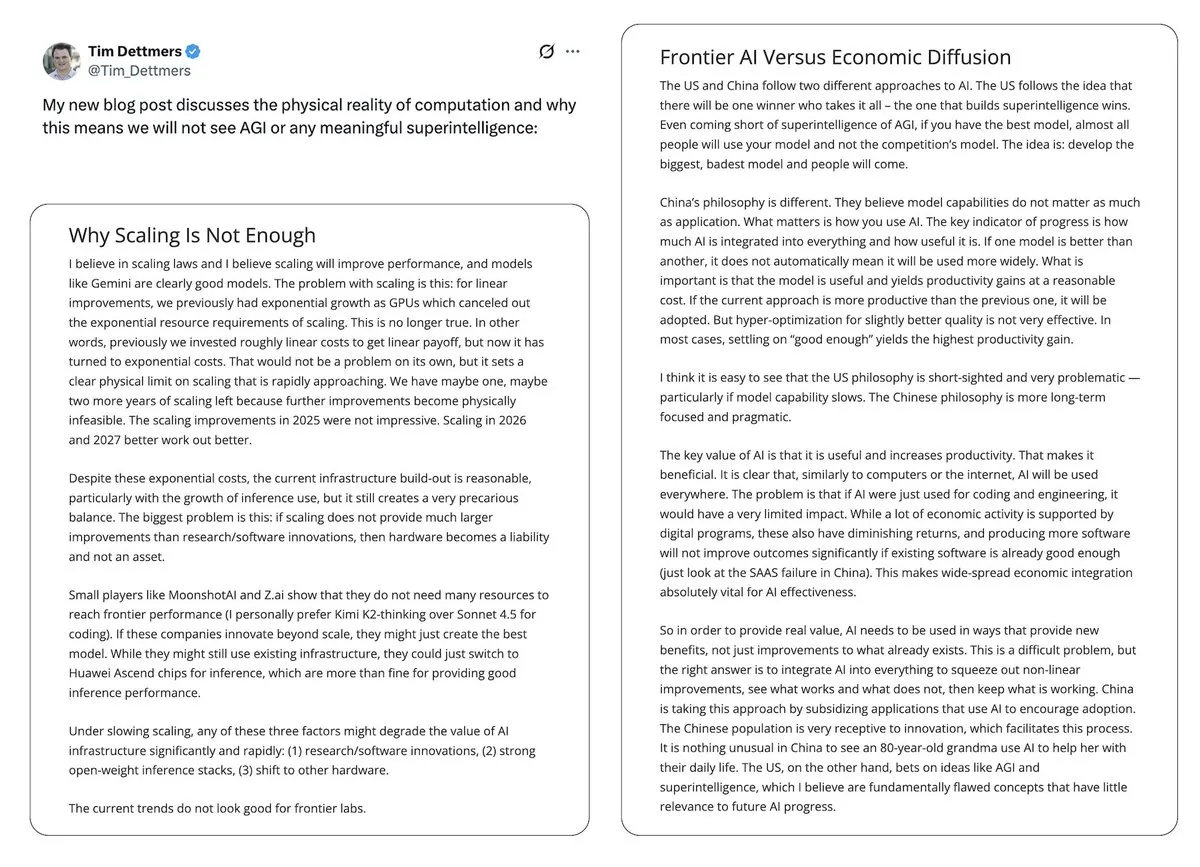
AI 거품과 AGI 전망에 대한 논란 : Yann LeCun은 LLM과 AGI가 ‘완전한 헛소리’라고 공개적으로 밝혔으며, AI의 미래는 현재 LLM 패러다임이 아닌 세계 모델에 있다고 보고, AI 기술이 소수 기업에 의해 독점될 것을 우려했습니다. Tim Dettmers의 ‘Why AGI Will Not Happen’이라는 글도 확장 수익 체감에 대한 논의로 주목받았습니다. 동시에 AI 안전 옹호자들은 AGI 도래 시기에 대한 입장을 다소 조정했지만, 여전히 잠재적 위험성을 고수하며 정책 입안자들이 AI 위험을 충분히 중요하게 여기지 않는 것에 우려를 표했습니다. (来源: ylecun, ylecun, hardmaru, MIT Technology Review)
GPT-5.2와 Gemini에 대한 사용자 평가 양극화 : 소셜 미디어에서 OpenAI GPT-5.2에 대한 사용자 평가는 엇갈렸습니다. 일부 사용자는 긴 컨텍스트 처리 능력에 만족하며 팟캐스트 요약 내용이 더 풍부하다고 평가했지만, 다른 사용자들은 GPT-5.2의 답변이 너무 일반적이고 깊이가 부족하며 심지어 ‘자기 인식’과 같은 반응을 보여 일부 사용자들이 Gemini로 전환하게 되었다고 강한 불만을 표했습니다. 이러한 양극화는 새로운 모델의 성능과 행동에 대한 사용자의 민감도와 AI 제품 경험에 대한 지속적인 관심을 반영합니다. (来源: gdb, Reddit r/ArtificialInteligence)

AI가 인간 인지, 작업 표준 및 윤리적 행동에 미치는 영향 : AI의 장기적인 사용은 인간의 인지 패턴과 작업 표준을 조용히 변화시키고 있으며, 사고를 더 구조화하고 결과물의 품질에 대한 기대를 높이고 있습니다. AI는 고품질 콘텐츠 생산을 효율적으로 만들지만, 기술에 대한 과도한 의존으로 이어질 수도 있습니다. AI 윤리 측면에서 ‘트롤리 딜레마’에서 모델들의 다른 행동(Grok의 실용주의와 Gemini/ChatGPT의 이타주의)은 AI 가치 설정에 대한 논의를 촉발했습니다. 동시에 AI 모델 안전 프롬프트의 ‘자기 규율’ 본질은 AI 내부 통제 메커니즘이 사용자 경험에 미치는 간접적인 영향도 드러냅니다. (来源: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/ChatGPT)
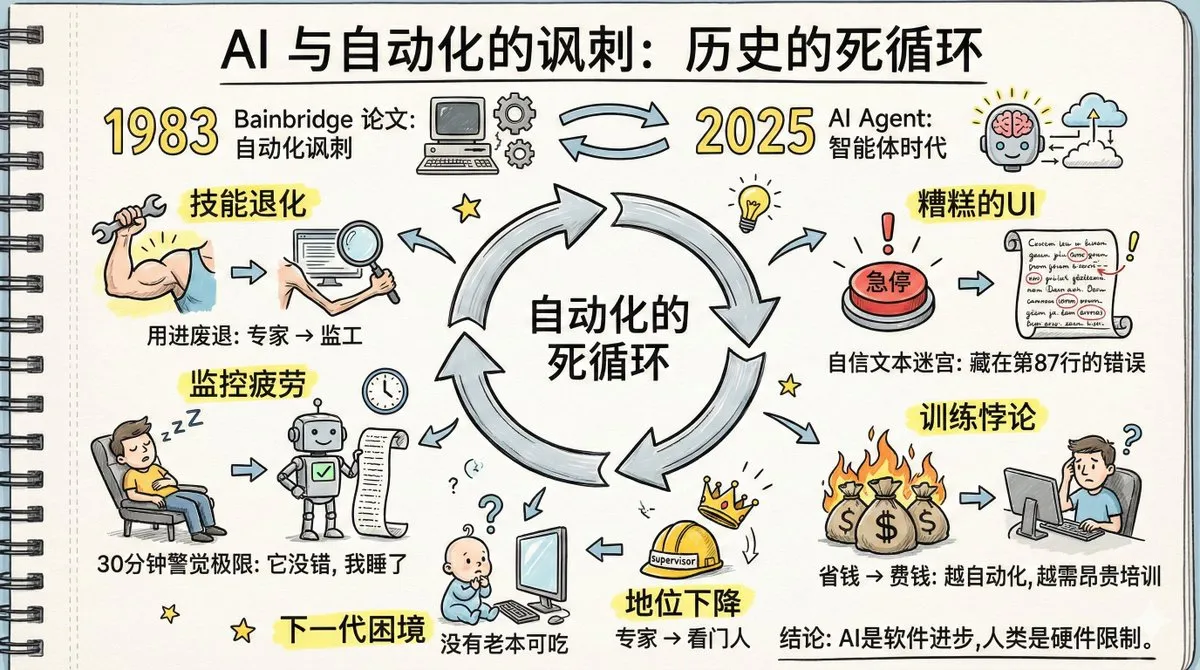
AI 에이전트의 ‘자동화의 역설’과 인간 기술 퇴화 : ‘자동화의 역설’이라는 제목의 논문이 뜨거운 논쟁을 불러일으켰으며, 40년 전 공장 자동화에 대한 예측이 AI Agent에게서 현실화되고 있습니다. 논의는 AI Agent의 확산이 인간 기술 퇴화, 기억 추출 속도 저하, 모니터링 피로 및 전문가 지위 하락으로 이어질 수 있다고 지적합니다. 이 글은 인간이 ‘거의 오류가 없는’ 시스템에 대해 오랫동안 경계를 유지할 수 없으며, 현재 AI Agent 인터페이스 디자인이 이상 감지에 불리하다고 강조합니다. 이러한 문제들을 해결하기 위해서는 자동화 자체보다 더 큰 기술적 창의력과 새로운 분업, 새로운 훈련 및 새로운 역할 설계에 대한 인식 전환이 필요합니다. (来源: dotey, dotey, dotey)
AI 생성 저품질 콘텐츠와 사실성 도전 과제 : 소셜 미디어 사용자들은 AI 검색 결과를 충족시키기 위해 특별히 제작된 수많은 저품질 웹사이트를 발견했으며, AI 연구가 저자 및 상세 정보가 부족한 이러한 웹사이트에 의존하는 것이 정보의 신뢰성 저하로 이어질 수 있다고 의문을 제기했습니다. 이는 AI가 먼저 답변을 생성한 다음 지원 출처를 찾는 ‘출처 역추적’ 메커니즘에 대한 우려를 불러일으켰으며, 이는 허위 정보 인용으로 이어질 수 있습니다. 이는 정보의 진실성 측면에서 AI의 도전 과제와 사용자가 자율적인 연구로 돌아갈 필요성을 부각시킵니다. (来源: Reddit r/ArtificialInteligence)

AI가 법률 직업에 미치는 영향과 추상화 계층론 : 법률계에서는 AI가 변호사 직업을 ‘파괴’할지에 대한 논란이 있습니다. 일부 변호사는 AI가 법률 업무의 90% 이상을 처리할 수 있지만, 전략, 협상 및 책임은 여전히 인간이 필요하다고 생각합니다. 동시에 AI를 어셈블리, C 언어, Python 다음의 다음 추상화 계층으로 보는 시각도 있으며, 이는 AI가 인간을 대체하는 것이 아니라 엔지니어가 시스템 설계 및 사용자 경험에 집중할 수 있도록 해방시킬 것이라고 주장합니다. (来源: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

AI 에이전트의 물리적 행동과 LLM/로봇 융합 논란 : 새로운 연구에 따르면 LLM 기반 AI 에이전트가 거시적 물리 법칙을 따를 수 있으며, 열역학 시스템과 유사한 ‘상세 평형’ 특성을 보여 상태를 평가하는 ‘잠재 함수’를 암묵적으로 학습했을 수 있음을 시사합니다. 동시에 로봇 지능과 LLM이 통합이 아닌 분화로 나아가고 있다는 견해도 있으며, 다른 일부는 물리 AI가 현실화되고 있으며, 특히 디버깅 및 시각화 분야의 발전이 로봇 및 Embodied AI 프로젝트를 가속화하고 있다고 생각합니다. (来源: omarsar0, Teknium, wandb)

Anthropic 고위 임원, Discord 커뮤니티에 AI 챗봇 강제 배포 논란 : Anthropic의 한 고위 임원이 LGBTQ+ 커뮤니티를 대상으로 하는 Discord 커뮤니티에 회원들의 반대에도 불구하고 회사 AI 챗봇인 Clawd를 강제로 배포하여 커뮤니티 회원들의 대량 이탈을 초래했습니다. 이 사건은 커뮤니티 내 AI의 프라이버시, 인간 상호작용에 미치는 영향, 그리고 AI 기업의 ‘새로운 신 창조’ 심리에 대한 우려를 불러일으켰습니다. 사용자들은 AI 챗봇이 인간의 소통을 대체하는 것과 고위 임원의 오만한 행동에 대해 강한 불만을 표했습니다. (来源: Reddit r/artificial)

AI 모델, 시적 공격에 취약, AI 연구실에 문학 인재 합류 촉구 : 이탈리아 AI 연구원들은 악성 프롬프트를 시 형태로 변환하여 선도적인 AI 모델을 속일 수 있으며, 그중 Gemini 2.5가 가장 취약하다는 것을 발견했습니다. 이 현상은 ‘Waluigi 효과’라고 불리는데, 모델이 압축된 의미 공간에서 선과 악의 역할이 너무 가까워져 명령을 역으로 실행하기 더 쉬워진다는 것입니다. 이는 AI의 잠재적인 ‘이상한 서사 공간’ 행동에 대처하기 위해 AI 연구실에 서사와 언어의 심층 메커니즘을 이해하는 더 많은 문학 전공 졸업생이 필요한지에 대한 커뮤니티 논의를 촉발했습니다. (来源: Reddit r/ArtificialInteligence)
💡 기타
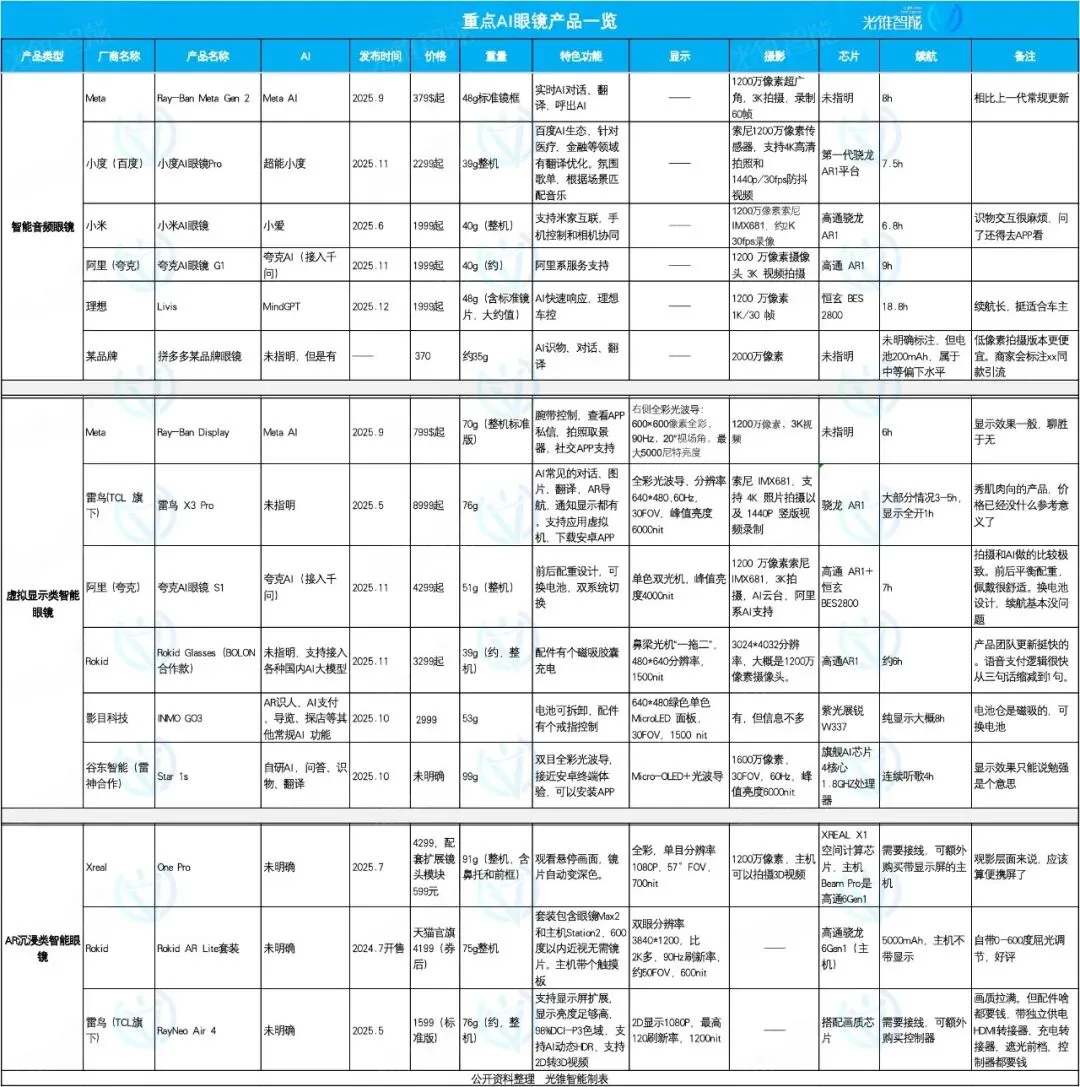
AI 안경 시장 집중 및 분화, Li Auto, Quark, Rokid 각자의 강점 발휘 : 2025년 AI 안경 시장은 폭발적인 성장을 맞이하며, 제품 포지셔닝은 분화 추세를 보입니다. Li Auto AI 안경 Livis는 자동차 스마트 액세서리에 초점을 맞춰 MindGPT 대규모 모델을 통합하여 차주에게 서비스를 제공합니다. Quark AI 안경 S1은 촬영 효과와 Alibaba 생태계 APP 통합을 특징으로 합니다. Rokid Glasses는 생태계 개방과 빠른 기능 반복을 강조하며 여러 대규모 언어 모델 연결을 지원합니다. 스마트 오디오 안경은 저렴한 가격과 기능 통합을 중심으로 하며, 가상 디스플레이 안경은 종합적인 경험을 제공하고, AR 몰입형 안경은 영화 감상 및 엔터테인먼트에 중점을 둡니다. (来源: 36氪)
ZLUDA, 비 NVIDIA GPU에서 CUDA 실행 지원, AMD ROCm 7 호환 : ZLUDA 프로젝트는 비 NVIDIA GPU에서 CUDA 실행을 구현했으며, AMD ROCm 7을 지원합니다. 이 발전은 AI 및 고성능 컴퓨팅 분야에서 중요한 의미를 가지며, NVIDIA의 GPU 생태계 독점을 깨고 개발자들이 AMD 하드웨어에서 CUDA로 작성된 프로그램을 활용할 수 있게 하여 AI 하드웨어 선택 및 최적화에 더 많은 유연성을 제공합니다. (来源: Reddit r/artificial)

hashcards: 순수 텍스트 기반 간격 반복 학습 시스템 : hashcards는 순수 텍스트 기반 간격 반복 학습 시스템으로, 모든 플래시카드는 순수 텍스트 파일로 저장되며 표준 도구 편집 및 버전 관리를 지원합니다. 이 시스템은 콘텐츠 주소 지정 방식을 채택하여 카드 내용이 수정되면 진행 상황이 재설정됩니다. 시스템 디자인은 간결하며, 앞면/뒷면 및 빈칸 채우기 카드만 지원하고 FSRS 알고리즘을 사용하여 복습 계획을 최적화하여 학습 효율성을 극대화하고 복습 시간을 최소화하는 것을 목표로 합니다. (来源: GitHub Trending)
Zerobyte: 자체 호스팅 사용자를 위한 강력한 백업 자동화 도구 : Zerobyte는 자체 호스팅 사용자를 위해 설계된 백업 자동화 도구로, 원격 저장소의 암호화된 백업을 예약, 관리 및 모니터링하기 위한 현대적인 웹 인터페이스를 제공합니다. Restic을 기반으로 구축되었으며, 암호화, 압축 및 보존 정책을 지원하고 NFS, SMB, WebDAV 및 로컬 디렉토리와 같은 다양한 프로토콜과 호환됩니다. Zerobyte는 또한 S3, GCS, Azure 등 다양한 클라우드 스토리지 백엔드를 지원하며, rclone을 통해 40개 이상의 클라우드 스토리지 서비스를 확장 지원하여 데이터 보안 및 유연한 백업을 보장합니다. (来源: GitHub Trending)
