

Palavras-chave:Indústria de IA, Correção de hype, GPT-5, AGI, Segurança de IA, Programação com IA, Agentes de IA, Modelos multimodais, IA em ciência de materiais, Otimização de raciocínio em LLM, IA incorporada, Testes de benchmark em IA, Geração de PPT com IA
🔥 Destaque
“Correção de Hype” da Indústria de AI e Análise da Realidade : Em 2025, a indústria de AI entra em uma fase de “correção de hype”, com as expectativas do mercado em relação à AI retornando à racionalidade, deixando de ser vista como uma “cura para todos os males”. Líderes da indústria como Sam Altman admitem a existência de uma bolha de AI, especialmente nos investimentos maciços em avaliações de startups e construção de data centers. Ao mesmo tempo, o lançamento do GPT-5 foi considerado abaixo das expectativas, levantando discussões sobre os gargalos de desenvolvimento de LLM. Especialistas pedem uma reavaliação das capacidades reais da AI, distinguindo as “demonstrações deslumbrantes” da Generative AI dos avanços reais da Predictive AI em áreas como medicina e ciência, enfatizando que o valor da AI reside em sua confiabilidade e sustentabilidade, e não na busca cega pela AGI. (Fonte: MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review)

Avanços e Desafios da AI na Ciência dos Materiais : A AI está sendo aplicada para acelerar a descoberta de novos materiais, com agentes de AI planejando, executando e interpretando experimentos, o que promete reduzir o processo de descoberta de décadas para anos. Empresas como Lila Sciences e Periodic Labs estão construindo laboratórios automatizados impulsionados por AI para resolver os gargalos de síntese e teste na ciência dos materiais tradicional. Embora a DeepMind tenha afirmado ter descoberto “milhões de novos materiais”, sua novidade e utilidade reais foram questionadas, destacando a lacuna entre a simulação virtual e a realidade física. A indústria está migrando de modelos puramente computacionais para a combinação com validação experimental, visando a descoberta de materiais inovadores como supercondutores à temperatura ambiente. (Fonte: MIT Technology Review)

Controvérsia sobre Produtividade e Dívida Técnica na Programação com AI : As ferramentas de programação com AI estão se popularizando, com CEOs da Microsoft e Google afirmando que a AI já gera um quarto do código de suas empresas, e o CEO da Anthropic prevendo que 90% do código futuro será escrito por AI. No entanto, o aumento real da produtividade é controverso, com estudos indicando que a AI pode desacelerar o desenvolvimento e aumentar a “dívida técnica” (como qualidade de código inferior e dificuldade de manutenção). Apesar disso, a AI se destaca na escrita de código boilerplate, testes e correção de bugs. Ferramentas de agente de nova geração, como Claude Code, melhoraram significativamente a capacidade de processar tarefas complexas através de modos de planejamento e gerenciamento de contexto. A indústria explora novos paradigmas como “código descartável” e verificação formal para se adaptar aos modelos de desenvolvimento impulsionados por AI. (Fonte: MIT Technology Review)

Defensores da Segurança da AI Mantêm Preocupações com os Riscos da AGI : Embora o desenvolvimento recente da AI seja considerado em um período de “correção de hype” e o GPT-5 tenha tido um desempenho mediano, os defensores da segurança da AI (“alarmistas da AI”) continuam profundamente preocupados com os riscos potenciais da AGI (Inteligência Artificial Geral). Eles acreditam que, embora o ritmo de progresso da AI possa desacelerar, sua periculosidade fundamental não mudou, e estão desapontados com a falta de atenção suficiente dos formuladores de políticas aos riscos da AI. Eles enfatizam que, mesmo que a AGI seja alcançada em décadas, e não em anos, é necessário investir recursos imediatamente para resolver os problemas de controle e estar vigilante contra os impactos negativos a longo prazo que o investimento excessivo da indústria na bolha de AI pode trazer. (Fonte: MIT Technology Review)

🎯 Tendências
Avanços Contínuos em Modelos de Geração de Vídeo Multimodal : A Alibaba lançou o modelo de vídeo Wan 2.6, que suporta role-playing, sincronização de áudio e vídeo, geração de múltiplas cenas e acionamento por voz, com duração de vídeo única de até 15 segundos, sendo considerado um “pequeno Sora 2”. A ByteDance também lançou o Seedance 1.5 Pro, cujo destaque é o suporte a dialetos. O LongVie 2, dos HuggingFace Daily Papers, propõe um modelo de mundo de vídeo ultralongo multimodal controlável, enfatizando controlabilidade, qualidade visual de longo prazo e consistência temporal. Esses avanços marcam uma melhoria significativa na tecnologia de geração de vídeo em termos de realismo, interatividade e cenários de aplicação. (Fonte: Alibaba_Wan, op7418, op7418, HuggingFace Daily Papers)

Novos Avanços em Multilinguismo e Streaming em Tempo Real na Tecnologia de Voz com AI : A Alibaba lançou o modelo CosyVoice 3 TTS de código aberto, que suporta 9 idiomas e mais de 18 dialetos chineses, oferece clonagem de voz zero-shot multilíngue/cross-linguagem e alcança transmissão bidirecional de streaming com latência ultrabaixa de 150 milissegundos. A API em tempo real da OpenAI também foi atualizada com os modelos gpt-4o-mini-transcribe e gpt-4o-mini-tts, reduzindo significativamente alucinações e taxas de erro, e melhorando o desempenho multilíngue. O modelo Gemini 2.5 Flash Native Audio do Google DeepMind também foi atualizado, otimizando ainda mais o seguimento de instruções e a naturalidade do diálogo, impulsionando as aplicações de agentes de voz em tempo real. (Fonte: ImazAngel, Reddit r/LocalLLaMA, snsf, GoogleDeepMind)
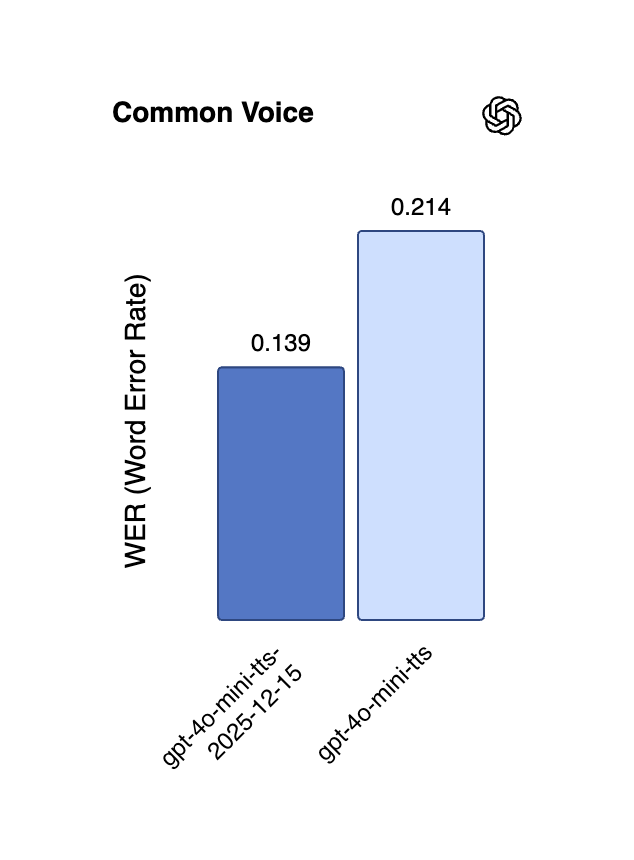
Inferência de Longo Contexto e Otimização de Eficiência para Modelos Grandes : O QwenLong-L1.5, através de inovação sistemática de pós-treinamento, rivaliza com o GPT-5 e o Gemini-2.5-Pro em capacidade de inferência de longo contexto e se destaca em tarefas ultralongas. O GPT-5.2 também recebeu elogios dos usuários por sua capacidade de longo contexto, especialmente por resumos de podcasts mais ricos em detalhes. Além disso, o ReFusion propõe um novo modelo de difusão mascarado que alcança melhorias significativas de desempenho e eficiência através da decodificação paralela em nível de slot, com uma aceleração média de 18 vezes, e reduz a lacuna de desempenho com modelos autorregressivos. (Fonte: gdb, HuggingFace Daily Papers, HuggingFace Daily Papers, teortaxesTex)
Avanços em AI Incorporada e Tecnologia Robótica : A AgiBot lançou o robô humanoide Lingxi X2, que possui capacidade de movimento próxima à humana e habilidades multifuncionais. Várias pesquisas nos HuggingFace Daily Papers focam em AI incorporada, como “Toward Ambulatory Vision” que explora a seleção de perspectiva ativa com aterramento visual, “Spatial-Aware VLA Pretraining” que alcança o alinhamento visual-físico através de vídeos humanos, e “VLSA” que introduz uma camada de restrição de segurança plug-and-play para melhorar a segurança dos modelos VLA. Essas pesquisas visam reduzir a lacuna entre a visão 2D e a ação em ambientes físicos 3D, impulsionando a aprendizagem de robôs e a implantação prática. (Fonte: Ronald_vanLoon, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
Contribuições da NVIDIA e Meta em Arquitetura de AI e Modelos de Código Aberto : A NVIDIA lançou a família de modelos abertos Nemotron v3 Nano e disponibilizou a pilha de treinamento completa (incluindo infraestrutura de RL, ambiente, conjuntos de dados de pré-treinamento e pós-treinamento), visando impulsionar a construção de AI de agente profissional em várias indústrias. A Meta, por sua vez, lançou a arquitetura de previsão de embedding conjunto visual-linguagem VL-JEPA, como o primeiro modelo não generativo, capaz de executar eficientemente tarefas gerais de visão-linguagem em aplicações de streaming em tempo real, superando o desempenho de grandes VLM. (Fonte: ylecun, QuixiAI, halvarflake)

Inovação em Benchmarks e Métodos de Avaliação de AI : O Google Research lançou o FACTS Leaderboard, que avalia de forma abrangente a facticidade de LLM em quatro dimensões: multimodalidade, conhecimento paramétrico, busca e aterramento, revelando os trade-offs entre diferentes modelos em termos de cobertura e taxa de contradição. O benchmark V-REX avalia a capacidade de raciocínio visual exploratório de VLM através de “cadeias de perguntas”, enquanto o START foca na aprendizagem textual e espacial para a compreensão de gráficos. Esses novos benchmarks visam medir com mais precisão o desempenho de modelos de AI em tarefas complexas e do mundo real. (Fonte: omarsar0, HuggingFace Daily Papers, HuggingFace Daily Papers)

Melhoria da Autonomia de Agentes de AI em Ambientes Web : O WebOperator propõe uma estrutura de busca em árvore sensível à ação, permitindo que agentes LLM realizem backtracking confiável e exploração estratégica em ambientes web parcialmente observáveis. Este método gera candidatos de ação a partir de múltiplos contextos de inferência e filtra ações inválidas, melhorando significativamente a taxa de sucesso das tarefas do WebArena e destacando a vantagem chave da combinação de previsão estratégica e execução segura. (Fonte: HuggingFace Daily Papers)
Condução Autônoma Assistida por AI e Modelos de Mundo 4D : O DrivePI é um MLLM 4D com percepção espacial que unifica a compreensão, percepção, previsão e planejamento da condução autônoma. Ele integra nuvens de pontos, imagens de múltiplas vistas e instruções de linguagem, e gera pares QA de texto-ocupação e texto-fluxo, alcançando uma previsão precisa de ocupação 3D e fluxo de ocupação, superando os modelos VLA e VA profissionais existentes em benchmarks como nuScenes. O GenieDrive, por sua vez, foca em modelos de mundo de condução com percepção física, melhorando a precisão da previsão e a qualidade do vídeo através da geração de vídeo guiada por ocupação 4D. (Fonte: HuggingFace Daily Papers, HuggingFace Daily Papers)
🧰 Ferramentas
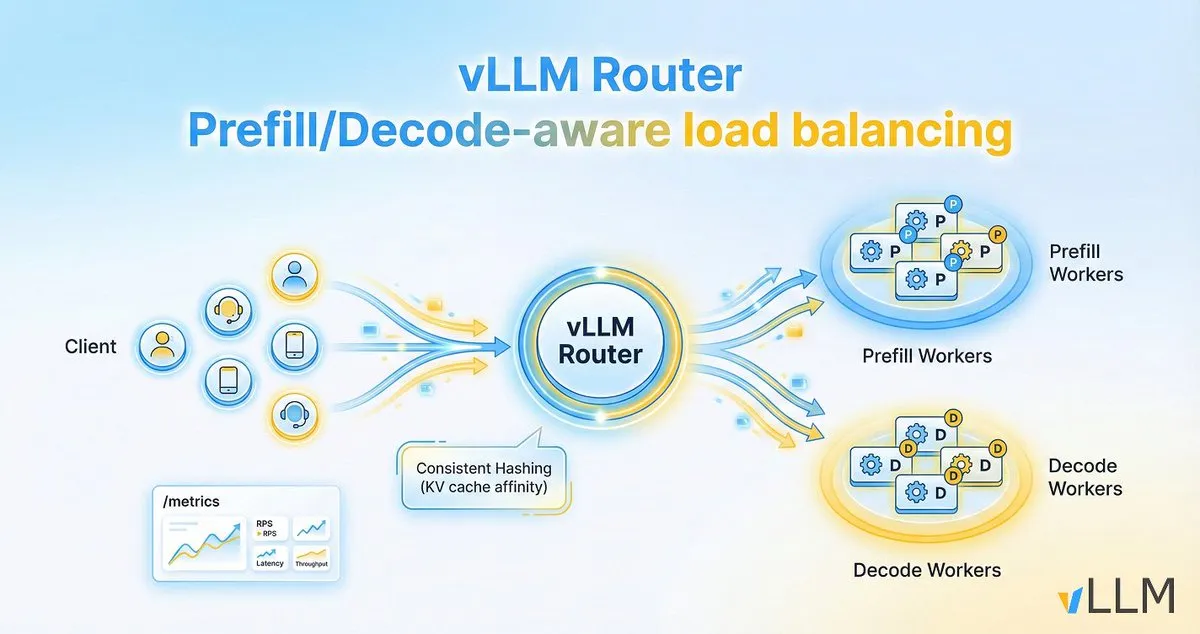
vLLM Router Melhora a Eficiência da Inferência de LLM : O projeto vLLM lançou o vLLM Router, um balanceador de carga leve, de alto desempenho e sensível a pré-preenchimento/decodificação, projetado especificamente para clusters vLLM. Escrito em Rust, ele suporta estratégias como hashing consistente e escolha de duas potências, visando otimizar a localidade do cache KV, resolver os gargalos de tráfego de diálogo e separação de pré-preenchimento/decodificação, e assim, aumentar a taxa de transferência da inferência de LLM e reduzir a latência de cauda. (Fonte: vllm_project)
AI21 Maestro Simplifica a Construção de Agentes de AI : O Vibe Agent da AI21Labs foi lançado no AI21 Maestro, permitindo que os usuários criem agentes de AI através de descrições simples em inglês. A ferramenta sugere automaticamente os usos do agente, verificações de validação, ferramentas necessárias e configurações de modelo/computação, e explica cada etapa em tempo real, reduzindo significativamente a barreira para construir agentes de AI complexos. (Fonte: AI21Labs)
OpenHands SDK Acelera o Desenvolvimento de Software Impulsionado por Agentes : A OpenHands lançou o SDK de agente de software, com o objetivo de fornecer uma estrutura rápida, flexível e pronta para produção, para a construção de software impulsionado por agentes. O lançamento deste SDK ajudará os desenvolvedores a integrar e gerenciar agentes de AI de forma mais eficiente para lidar com tarefas complexas de desenvolvimento de software. (Fonte: gneubig)

Atualização do Claude Code CLI Aprimora a Experiência de Desenvolvimento : A Anthropic lançou a versão 2.0.70 do Claude Code, que inclui 13 melhorias na CLI. As principais atualizações incluem: suporte à tecla Enter para aceitar sugestões de prompt, sintaxe curinga para permissões de ferramentas MCP, chave de atualização automática do mercado de plugins, modo de planejamento forçado, entre outros. Além disso, a eficiência de uso de memória foi aumentada em 3 vezes e a resolução de captura de tela é maior, visando otimizar a interação e a eficiência dos desenvolvedores ao usar Claude Code para desenvolvimento de software. (Fonte: Reddit r/ClaudeAI)
Qwen3-Coder Permite o Desenvolvimento Rápido de Jogos 2D : Usuários do Reddit demonstraram como usar o modelo Qwen3-Coder (480B) da Alibaba, através do Cursor IDE, para construir um jogo estilo Mario 2D em segundos. O modelo, a partir de um único prompt, planeja automaticamente as etapas, instala dependências, gera código e estrutura do projeto, e pode ser executado diretamente. Seu custo de execução é baixo (cerca de US$ 2 por milhão de tokens), e a experiência é próxima ao modo de agente do GPT-4, demonstrando o forte potencial de modelos de código aberto em geração de código e tarefas de agente. (Fonte: Reddit r/artificial)
Ferramenta de Pesquisa Aprofundada de Ações Impulsionada por AI : A ferramenta Deep Research utiliza AI para extrair dados de arquivos da SEC e publicações da indústria, gerando relatórios padronizados que simplificam a comparação e seleção de empresas. Os usuários podem inserir o código da ação para obter análises aprofundadas. A ferramenta visa ajudar os investidores a realizar pesquisas fundamentalistas de forma mais eficiente, evitando a interferência de notícias de mercado e focando em informações financeiras substanciais. (Fonte: Reddit r/ChatGPT)
LangChain 1.2 Simplifica a Construção de Aplicações Agentic RAG : A LangChain lançou a versão 1.2, que simplifica o suporte a ferramentas integradas e ao modo estrito, especialmente na função create_agent. Isso permite que os desenvolvedores construam aplicações Agentic RAG (Geração Aumentada por Recuperação) de forma mais conveniente, seja executando localmente ou no Google Collab, e destaca sua característica 100% código aberto. (Fonte: LangChainAI, hwchase17)
Skywork Lança Recurso de Geração de PPT Impulsionado por AI : A plataforma Skywork lançou a capacidade de geração de PPT baseada no Nano Banana Pro, resolvendo o problema da difícil edição de PPTs gerados por AI tradicionais. A nova função suporta separação de camadas, permitindo que os usuários modifiquem texto e imagens online e exportem para o formato pptx para edição local. Além disso, a ferramenta integra um banco de dados profissional da indústria, suporta a geração de vários tipos de gráficos, garantindo a precisão dos dados, e oferece ofertas promocionais de Natal. (Fonte: op7418)

Modelos Pequenos Capacitam a Infraestrutura como Código na Borda : Um usuário do Reddit compartilhou um modelo de “Infraestrutura como Código” (IaC) de 500MB, que pode ser executado em dispositivos de borda ou navegadores. Este modelo foca em tarefas de IaC, é compacto mas poderoso, fornecendo uma solução eficiente para implantar e gerenciar infraestrutura em ambientes com recursos limitados, prenunciando o grande potencial de modelos pequenos de AI em nichos verticais específicos. (Fonte: Reddit r/deeplearning)
📚 Aprendizado
Chinarxiv: Plataforma de Tradução Automatizada de Pré-prints Chineses : O Chinarxiv.org foi lançado oficialmente, uma plataforma de tradução totalmente automatizada de pré-prints chineses, com o objetivo de preencher a lacuna linguística entre a pesquisa científica chinesa e ocidental. A plataforma não apenas traduz texto, mas também o conteúdo de gráficos e tabelas, permitindo que pesquisadores ocidentais acessem e compreendam mais facilmente os mais recentes resultados de pesquisa da comunidade científica chinesa. (Fonte: menhguin, andersonbcdefg, francoisfleuret)
Habilidades de AI e Roteiro de Aprendizado de Agentic AI : Ronald_vanLoon compartilhou 12 capacidades chave para dominar as habilidades de AI em 2025, bem como um roteiro de proficiência em Agentic AI. Esses recursos visam guiar indivíduos a aumentar sua competitividade no rápido desenvolvimento do campo da AI, cobrindo caminhos de aprendizado desde o conhecimento básico de AI até o desenvolvimento de sistemas de agentes avançados, enfatizando a importância da aprendizagem contínua e da adaptação a novas habilidades na era da AI. (Fonte: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

Otimização do Processo de Inferência de LLM e Desenvolvimento de AI Orientado por Dados : Pesquisas do Meta Superintelligence Labs mostram que, através da estratégia PDR (Parallel Draft-Distill-Refine) de “rascunho paralelo → destilação para espaço de trabalho compacto → refinamento”, é possível atingir a melhor precisão da tarefa sob restrições de inferência. Ao mesmo tempo, um artigo de blog enfatiza que “dados são a fronteira irregular da AI”, apontando que os campos de codificação e matemática tiveram sucesso devido à riqueza de dados e verificabilidade, enquanto o campo científico está relativamente atrasado, e explora o papel da destilação e do aprendizado por reforço na geração de dados. (Fonte: dair_ai, lvwerra)

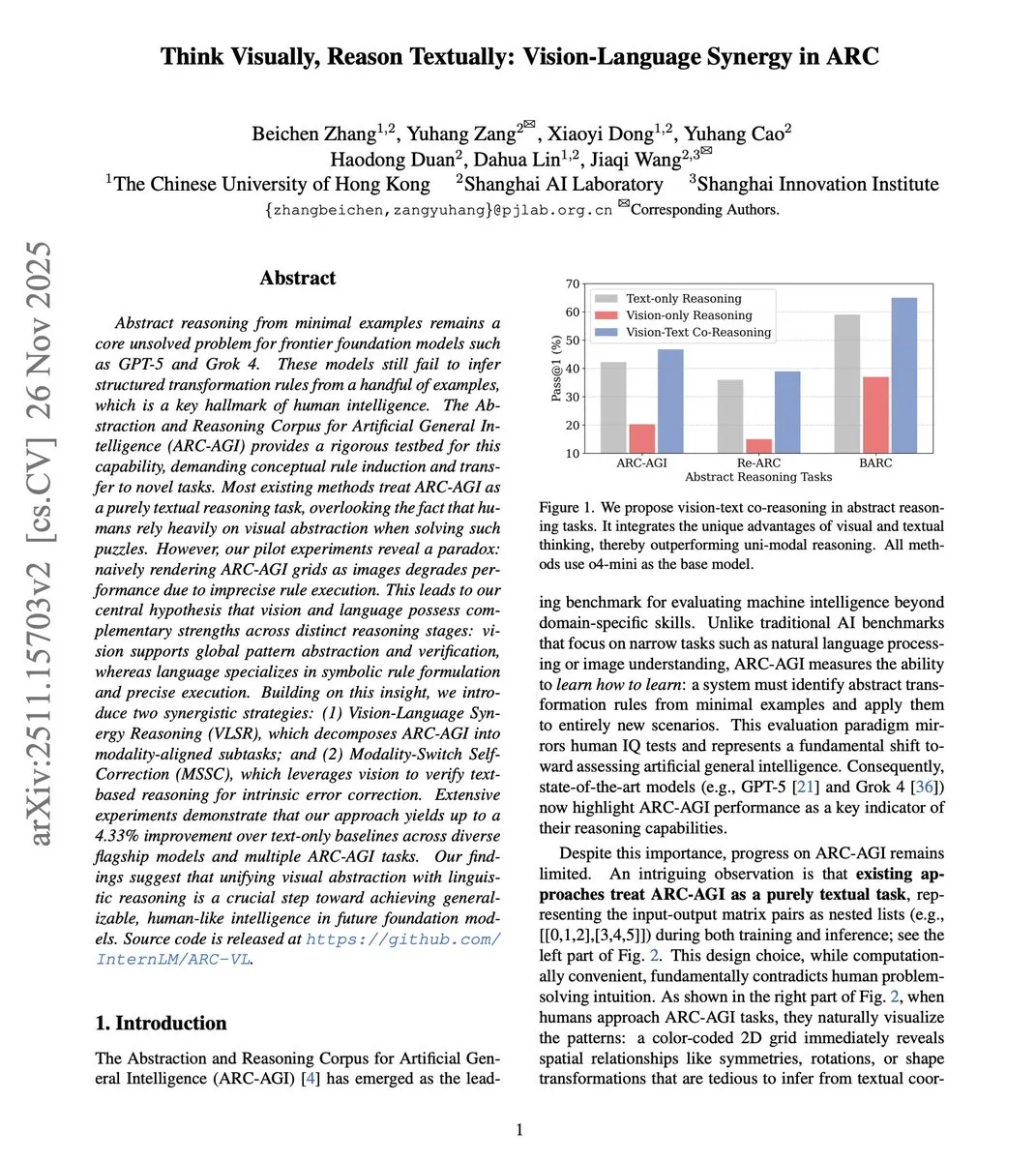
Inferência Colaborativa Visual-Linguagem Melhora a Capacidade de Abstração : Uma nova pesquisa propõe a estrutura de Inferência Colaborativa Visual-Linguagem (VLSR), que, ao combinar estrategicamente as modalidades visual e textual em diferentes estágios de inferência, melhora significativamente o desempenho de LLM em tarefas de raciocínio abstrato (como o benchmark ARC-AGI). Este método utiliza a visão para reconhecimento de padrões globais e o texto para execução precisa, e supera o viés de confirmação através de um mecanismo de autocorreção de troca de modalidade, superando até mesmo o desempenho do GPT-4o em modelos pequenos. (Fonte: dair_ai)
Nova Perspectiva sobre Tokens de Inferência de LLM como Estados Computacionais : A estrutura conceitual State over Tokens (SoT) redefine os tokens de inferência de LLM como estados computacionais externalizados, em vez de simples narrativas linguísticas. Isso explica como os tokens podem impulsionar a inferência correta sem serem uma interpretação textual fiel, e abre novas direções de pesquisa para entender os processos internos de LLM, enfatizando que a pesquisa deve ir além da interpretação textual e focar na decodificação de tokens de inferência em estados. (Fonte: HuggingFace Daily Papers)
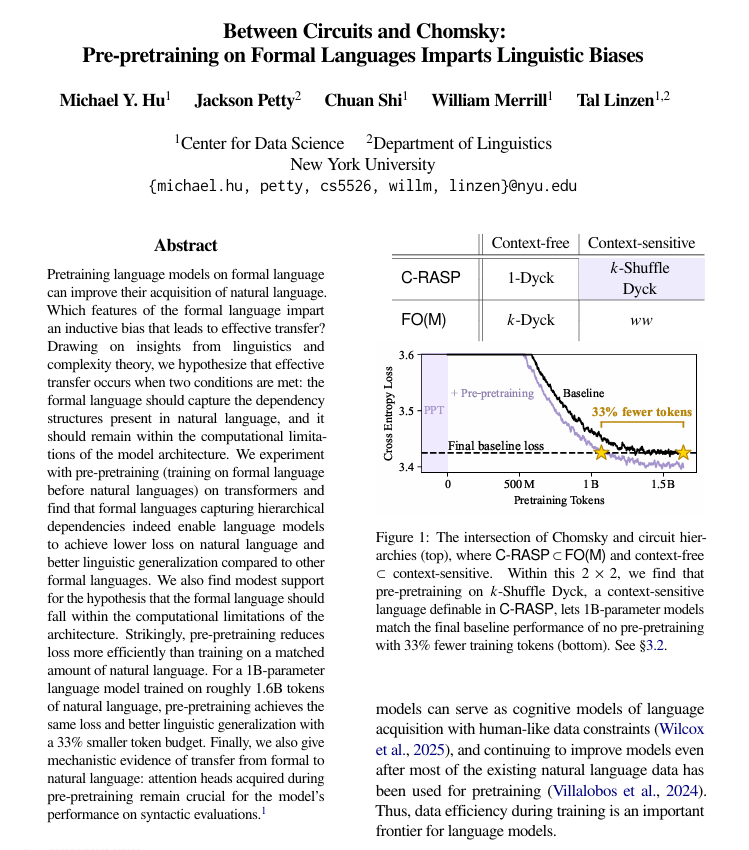
Pré-treinamento em Linguagem Formal Melhora o Aprendizado de Linguagem Natural : Pesquisas da Universidade de Nova York descobriram que, antes do pré-treinamento em linguagem natural, o pré-treinamento usando linguagens formalizadas e baseadas em regras pode ajudar significativamente os modelos de linguagem a aprender melhor a linguagem humana. O estudo aponta que essa linguagem formal precisa ter uma estrutura semelhante à linguagem natural (especialmente relações hierárquicas) e ser suficientemente simples. Este método é mais eficaz do que adicionar a mesma quantidade de dados de linguagem natural, e os mecanismos estruturais aprendidos são transferidos dentro do modelo. (Fonte: TheTuringPost)
Injeção de Conhecimento Físico no Processo de Geração de Código : A estrutura Chain of Unit-Physics incorpora diretamente o conhecimento físico no processo de geração de código. Pesquisadores da Universidade de Michigan propõem um método de geração de código científico inverso, que guia e restringe a geração de código codificando o conhecimento de especialistas humanos como testes de física unitária. Em uma configuração multiagente, esta estrutura permite que o sistema atinja a solução correta em 5-6 iterações, aumentando a velocidade de execução em 33%, reduzindo o uso de memória em 30% e com uma taxa de erro extremamente baixa. (Fonte: TheTuringPost)
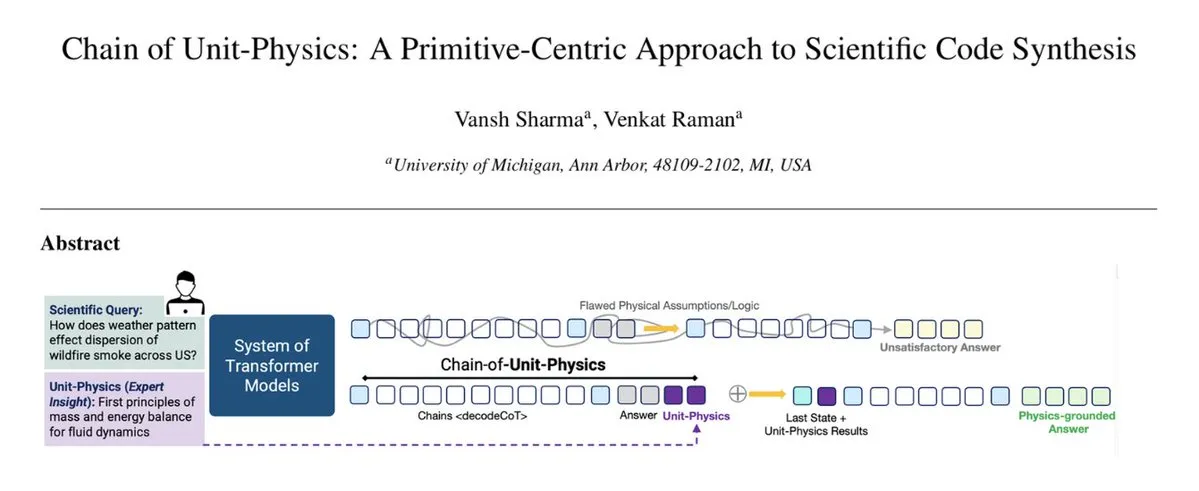
CausalTraj: Modelo de Previsão de Trajetória Multiagente para Equipes Esportivas : CausalTraj é um modelo autorregressivo para previsão de trajetória conjunta multiagente em esportes coletivos. O modelo é treinado diretamente com um objetivo de verossimilhança de previsão conjunta, em vez de apenas otimizar métricas de agentes individuais, o que melhora significativamente a coerência e a razoabilidade das trajetórias multiagente, ao mesmo tempo em que garante o desempenho individual. A pesquisa também explora como avaliar a modelagem conjunta de forma mais eficaz e como avaliar a probabilidade real de trajetórias amostradas. (Fonte: Reddit r/deeplearning)
Dados de Treinamento de LLM: Respostas ou Perguntas? : Uma discussão no Reddit sugere que a maioria dos conjuntos de dados de treinamento de LLM atuais foca em “respostas”, enquanto a parte crucial da inteligência humana reside no processo caótico, ambíguo e iterativo antes da formação das “perguntas”. Experimentos mostram que modelos treinados com dados de diálogo que incluem pensamento inicial, perguntas ambíguas e revisões repetidas têm melhor desempenho em esclarecer a intenção do usuário, lidar com tarefas ambíguas e evitar conclusões errôneas, sugerindo que os dados de treinamento precisam capturar de forma mais abrangente a complexidade do pensamento humano. (Fonte: Reddit r/MachineLearning)
💼 Negócios
OpenAI Adquire neptune.ai, Fortalecendo Ferramentas de Pesquisa de Ponta : A OpenAI anunciou que chegou a um acordo definitivo para adquirir a neptune.ai. Esta aquisição visa fortalecer suas ferramentas e infraestrutura de suporte à pesquisa de ponta. A aquisição ajudará a OpenAI a aprimorar suas capacidades em desenvolvimento de AI e gerenciamento de experimentos, acelerando ainda mais o treinamento de modelos e o processo de iteração, consolidando sua posição de liderança no campo da AI. (Fonte: dl_weekly)

Databricks Apresenta Resultados Robustos no Q3, Recebe Mais de US$ 4 Bilhões em Financiamento : A Databricks divulgou resultados robustos no terceiro trimestre, com uma taxa de execução de receita anual superior a US$ 4,8 bilhões, um crescimento de mais de 55% ano a ano. Seus negócios de data warehouse e produtos de AI também ultrapassaram US$ 1 bilhão em taxa de execução de receita anual. A empresa concluiu uma rodada de financiamento Série L de mais de US$ 4 bilhões, avaliada em US$ 134 bilhões, e planeja usar os fundos para investir em Lakebase Postgres, Agent Bricks e Databricks Apps, a fim de acelerar o desenvolvimento de aplicações de inteligência de dados. (Fonte: jefrankle, jefrankle)

Infosys e Formula E em Parceria para Impulsionar a Transformação Digital Orientada por AI : A Infosys e o Campeonato Mundial ABB FIA Formula E firmaram uma parceria para revolucionar a experiência dos fãs e a eficiência operacional no automobilismo através de uma plataforma impulsionada por AI. A colaboração inclui o uso de AI para fornecer conteúdo personalizado, análise de corrida em tempo real, comentários gerados por AI, e otimizar a logística e as viagens para atingir metas de redução de carbono. A tecnologia de AI não apenas aumentou o apelo do evento, mas também promoveu o desenvolvimento sustentável e a diversidade de funcionários, tornando a Formula E o esporte a motor mais digitalizado e sustentável. (Fonte: MIT Technology Review)

🌟 Comunidade
Controvérsia sobre a Bolha de AI e as Perspectivas da AGI : Yann LeCun declarou publicamente que LLM e AGI são “completa bobagem”, argumentando que o futuro da AI reside em modelos de mundo, e não no paradigma atual de LLM, e expressou preocupação de que a tecnologia de AI seja monopolizada por poucas empresas. O artigo de Tim Dettmers “Why AGI Will Not Happen” também recebeu atenção por sua discussão sobre os retornos decrescentes de escala. Enquanto isso, os defensores da segurança da AI, embora tenham ajustado o tempo de chegada da AGI, ainda mantêm sua periculosidade potencial e expressam preocupação com a falta de atenção suficiente dos formuladores de políticas aos riscos da AI. (Fonte: ylecun, ylecun, hardmaru, MIT Technology Review)
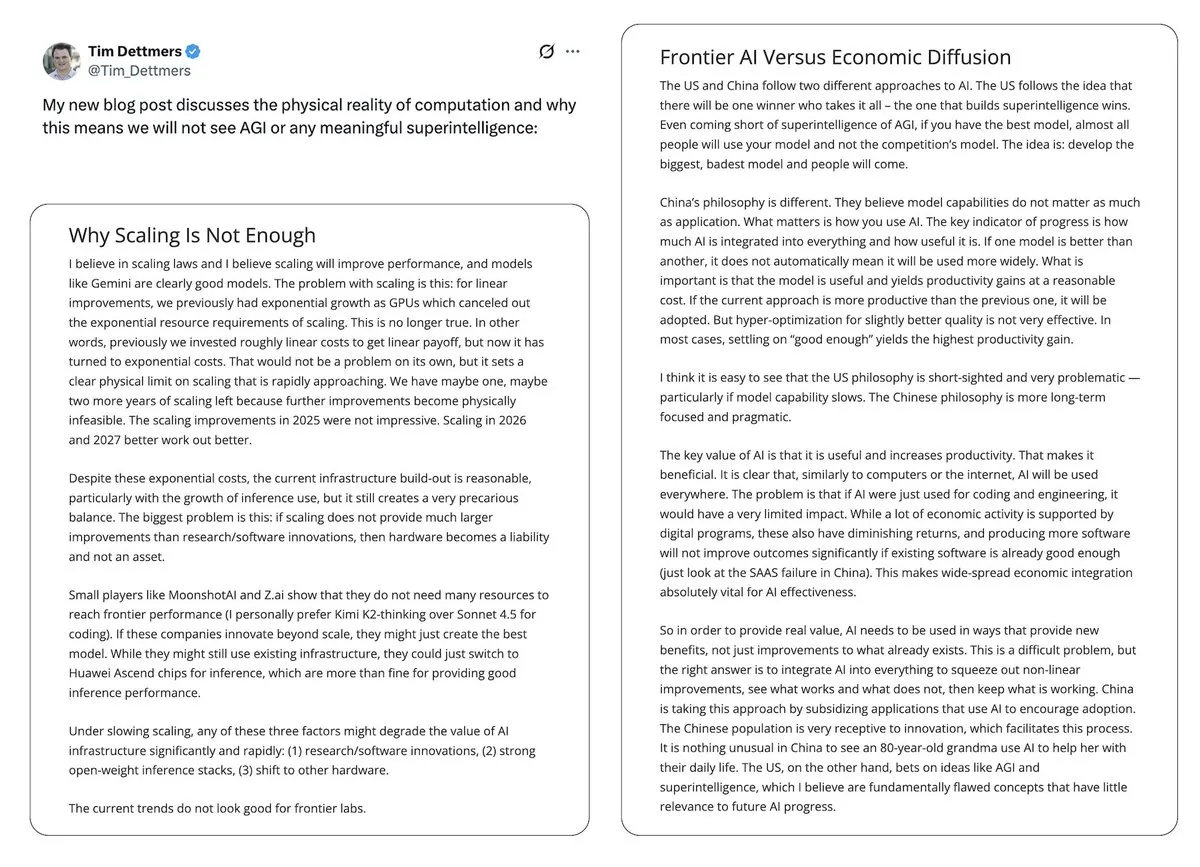
Avaliações Polarizadas dos Usuários sobre GPT-5.2 e Gemini : Nas redes sociais, as avaliações dos usuários sobre o OpenAI GPT-5.2 são mistas. Alguns usuários expressam satisfação com sua capacidade de processamento de longo contexto, considerando seus resumos de podcasts mais ricos em detalhes; mas outros expressam forte insatisfação, achando as respostas do GPT-5.2 muito genéricas, com profundidade insuficiente, e até mesmo com respostas de “autoconsciência”, levando alguns usuários a migrar para o Gemini. Essa polarização reflete a sensibilidade dos usuários ao desempenho e comportamento de novos modelos, bem como a atenção contínua à experiência do produto de AI. (Fonte: gdb, Reddit r/ArtificialInteligence)

Impacto da AI na Cognição Humana, Padrões de Trabalho e Comportamento Ético : O uso prolongado da AI está silenciosamente mudando os padrões cognitivos e de trabalho humanos, promovendo um pensamento mais estruturado e aumentando as expectativas de qualidade da produção. A AI torna a produção de conteúdo de alta qualidade eficiente, mas também pode levar à dependência excessiva da tecnologia. No nível ético da AI, o desempenho diferente dos modelos no “problema do bonde” (pragmatismo do Grok versus altruísmo do Gemini/ChatGPT) gerou discussões sobre a definição de valores da AI. Ao mesmo tempo, a natureza de “autodisciplina” das mensagens de segurança dos modelos de AI também revela o impacto indireto dos mecanismos de controle internos da AI na experiência do usuário. (Fonte: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/ChatGPT)
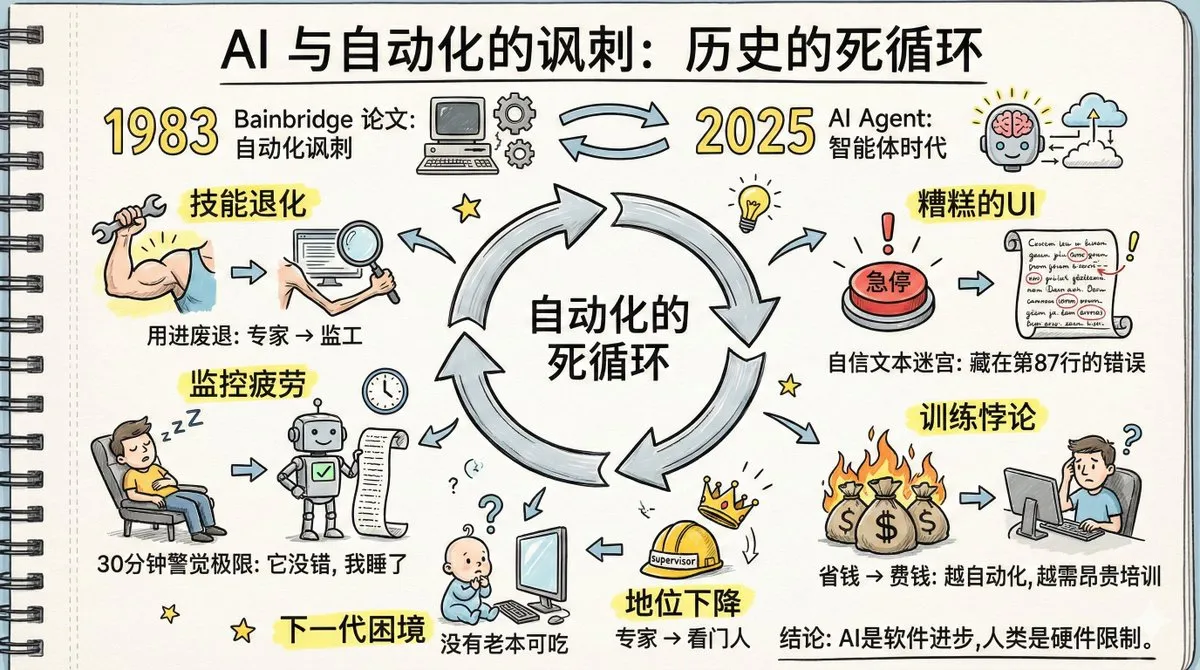
“Ironia da Automação” dos Agentes de AI e Degradação das Habilidades Humanas : Um artigo intitulado “A Ironia da Automação” gerou debate acalorado, com suas previsões de quarenta anos atrás sobre a automação de fábricas se concretizando nos AI Agents. A discussão aponta que a popularização dos AI Agents pode levar à degradação das habilidades humanas, extração de memória mais lenta, fadiga de monitoramento e declínio do status de especialista. O artigo enfatiza que os humanos são incapazes de manter a vigilância por muito tempo em sistemas que “raramente falham”, e que o design atual da interface dos AI Agents é desfavorável à detecção de anomalias. Resolver esses problemas exige maior criatividade tecnológica do que a própria automação, bem como uma mudança cognitiva na nova divisão do trabalho, novo treinamento e design de novos papéis. (Fonte: dotey, dotey, dotey)
Geração de Conteúdo de Baixa Qualidade por AI e Desafios de Facticidade : Usuários de redes sociais descobriram um grande número de sites de baixa qualidade criados especificamente para atender aos resultados de busca de AI, questionando a dependência da pesquisa de AI em sites que carecem de autores e informações detalhadas, o que pode levar a informações não confiáveis. Isso levantou preocupações sobre o mecanismo de “preenchimento de fontes” da AI, onde a AI primeiro gera a resposta e depois busca fontes de apoio, o que pode resultar na citação de informações falsas. Isso destaca os desafios da AI em termos de veracidade da informação e a necessidade de os usuários retornarem à pesquisa autônoma. (Fonte: Reddit r/ArtificialInteligence)

Impacto da AI na Profissão Jurídica e a Teoria das Camadas de Abstração : Há controvérsia na comunidade jurídica sobre se a AI “destruirá” a profissão de advogado. Alguns advogados acreditam que a AI pode lidar com mais de 90% do trabalho jurídico, mas estratégia, negociação e responsabilidade ainda exigem humanos. Ao mesmo tempo, há quem veja a AI como a próxima camada de abstração após a linguagem assembly, C e Python, argumentando que ela libertará os engenheiros para focar no design de sistemas e na experiência do usuário, em vez de substituir humanos. (Fonte: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

Comportamento Físico de Agentes de AI e Controvérsia sobre a Fusão LLM/Robótica : Novas pesquisas indicam que agentes de AI impulsionados por LLM podem seguir leis da física macroscópica, exibindo propriedades de “equilíbrio detalhado” semelhantes a sistemas termodinâmicos, sugerindo que eles podem ter aprendido implicitamente “funções potenciais” para avaliar estados. Enquanto isso, alguns argumentam que a inteligência robótica e os LLMs estão caminhando para a divergência em vez da unificação, enquanto outros acreditam que a AI física está se tornando real, especialmente com os avanços em depuração e visualização que aceleraram projetos de robótica e AI incorporada. (Fonte: omarsar0, Teknium, wandb)

Executivo da Anthropic Implanta Chatbot de AI à Força em Comunidade Discord, Gerando Controvérsia : Um executivo da Anthropic, ignorando a oposição dos membros, implantou à força o chatbot de AI da empresa, Clawd, em uma comunidade Discord voltada para o público LGBTQ+, resultando em uma grande perda de membros da comunidade. Este incidente levantou preocupações sobre a privacidade da AI em comunidades, o impacto na interação humana e a mentalidade de “criação de novos deuses” das empresas de AI. Os usuários expressaram forte insatisfação com a substituição da comunicação humana por chatbots de AI e o comportamento arrogante do executivo. (Fonte: Reddit r/artificial)

Modelos de AI Vulneráveis a Ataques Poéticos, Clamor por Talentos Literários em Laboratórios de AI : Pesquisadores italianos de AI descobriram que, ao transformar prompts maliciosos em forma de poesia, é possível enganar modelos de AI líderes, sendo o Gemini 2.5 o mais suscetível. Este fenômeno é conhecido como “efeito Waluigi”, onde, em um espaço semântico comprimido, os personagens bons e maus estão muito próximos, tornando mais fácil para o modelo executar instruções inversamente. Isso gerou uma discussão na comunidade sobre a necessidade de mais graduados em literatura em laboratórios de AI para entender a narrativa e os mecanismos profundos da linguagem, a fim de lidar com o comportamento potencial de “espaço narrativo estranho” da AI. (Fonte: Reddit r/ArtificialInteligence)
💡 Outros
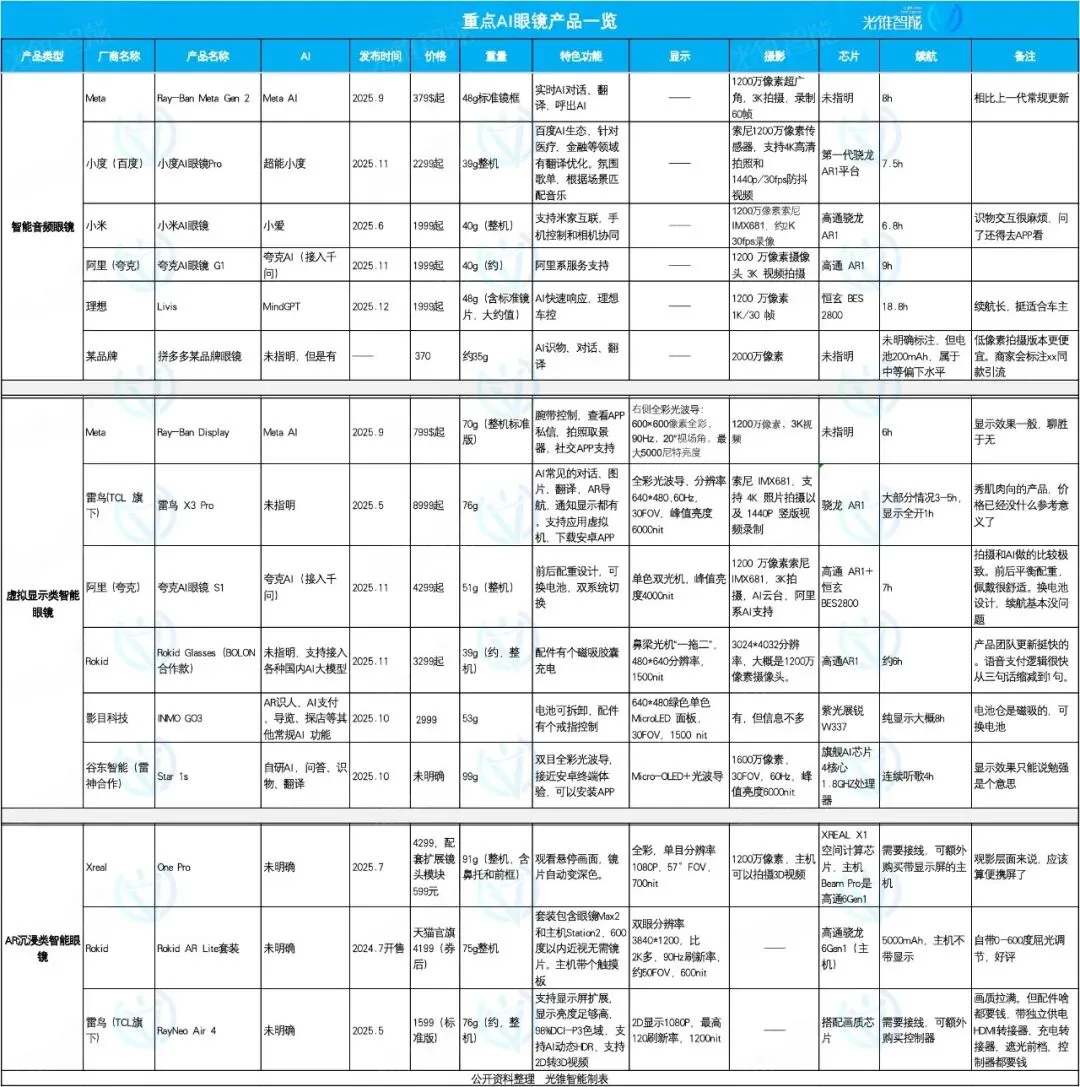
Foco e Diferenciação no Mercado de Óculos de AI: Ideal, Quark, Rokid, Cada um com Suas Especialidades : Em 2025, o mercado de óculos de AI experimenta um boom, com o posicionamento do produto mostrando uma tendência de diferenciação. Os óculos de AI Livis da Ideal focam em acessórios inteligentes para automóveis, integrando o modelo grande MindGPT para servir os proprietários de veículos; os óculos de AI S1 da Quark se caracterizam pelos efeitos de fotografia e integração com aplicativos do ecossistema Alibaba; enquanto os Rokid Glasses enfatizam um ecossistema aberto e iteração rápida de funções, suportando acesso a múltiplos modelos de linguagem grandes. Óculos de áudio inteligentes focam em preço baixo e integração de funções, óculos de realidade virtual oferecem uma experiência abrangente, e óculos de imersão AR focam no entretenimento de filmes. (Fonte: 36氪)
ZLUDA Suporta CUDA em GPUs Não-NVIDIA, Compatível com AMD ROCm 7 : O projeto ZLUDA permitiu a execução de CUDA em GPUs não-NVIDIA e suporta AMD ROCm 7. Este avanço é significativo para os campos de AI e computação de alto desempenho, pois quebra o monopólio da NVIDIA no ecossistema de GPU, permitindo que os desenvolvedores utilizem programas escritos em CUDA em hardware AMD, oferecendo mais flexibilidade na escolha e otimização de hardware de AI. (Fonte: Reddit r/artificial)

hashcards: Sistema de Aprendizado por Repetição Espaçada Baseado em Texto Puro : hashcards é um sistema de aprendizado por repetição espaçada baseado em texto puro, onde todos os flashcards são armazenados como arquivos de texto puro, suportando edição com ferramentas padrão e controle de versão. Ele adota um método de endereçamento por conteúdo, onde o progresso é redefinido após a modificação do conteúdo do cartão. O design do sistema é conciso, suportando apenas cartões de frente e verso e cloze, e utiliza o algoritmo FSRS para otimizar o plano de revisão, visando maximizar a eficiência do aprendizado e minimizar o tempo de revisão. (Fonte: GitHub Trending)
Zerobyte: Poderosa Ferramenta de Automação de Backup para Usuários Auto-Hospedados : Zerobyte é uma ferramenta de automação de backup projetada para usuários auto-hospedados, oferecendo uma interface web moderna para agendamento, gerenciamento e monitoramento de backups criptografados armazenados remotamente. Construída sobre Restic, ela suporta criptografia, compressão e políticas de retenção, e é compatível com vários protocolos como NFS, SMB, WebDAV e diretórios locais. Zerobyte também suporta vários backends de armazenamento em nuvem como S3, GCS, Azure, e através da extensão rclone, suporta mais de 40 serviços de armazenamento em nuvem, garantindo a segurança dos dados e backups flexíveis. (Fonte: GitHub Trending)
