
Ключевые слова:Оптические ИИ-чипы, K2 Think, Воплощенный интеллект, Jupyter Agent, OpenPI, Модель Claude, Qwen3-Next, Seedream 4.0, Энергоэффективность фотонных ИИ-чипов, Скорость вывода открытых больших моделей, Эмоциональная выразительность человекоподобных роботов, Интеллектуальный агент для Data Science на основе LLM, Модель визуального языка и движений для роботов
🔥 Фокус
Прорыв в эффективности AI-чипов на основе света : Команда инженеров из Университета Флориды разработала новый AI-чип на основе света, который использует фотоны вместо электричества для выполнения AI-операций, таких как распознавание изображений и обнаружение образов. Чип достиг 98% точности в тестах цифровой классификации, при этом его энергоэффективность увеличилась до 100 раз. Этот прорыв обещает значительно снизить затраты на AI-вычисления и энергопотребление, способствуя экологизации и масштабируемости AI в таких областях, как смартфоны и суперкомпьютеры, предвещая, что гибридные электрооптические чипы изменят ландшафт AI-оборудования. (Источник: Reddit r/ArtificialInteligence)

K2 Think: Представлена самая быстрая в мире открытая большая модель : MBZUAI из ОАЭ в сотрудничестве с G42 AI выпустили K2 Think, открытую большую модель на основе Qwen 2.5-32B, которая в реальных тестах достигает скорости более 2000 tokens/сек, что более чем в 10 раз превышает пропускную способность типичного развертывания на GPU. Модель продемонстрировала выдающиеся результаты в математических бенчмарках, таких как AIME, и реализовала технологические инновации за счет SFT с длинными цепочками рассуждений, RLVR с проверяемым вознаграждением, планирования перед выводом, сэмплирования Best-of-N, спекулятивного декодирования и аппаратного ускорения Cerebras WSE, что знаменует новую высоту производительности для открытых AI-систем вывода. (Источник: teortaxesTex, HuggingFace)

Передовые достижения в области воплощенного AI и человекоподобных роботов : Круглый стол Zhihu выявил ряд прорывов в области воплощенного AI. Лаборатория Air Университета Цинхуа представила “гибкое лицо” Morpheus, использующее гибридный привод и технологию цифрового человека для создания богатых микровыражений, с целью повышения эмоциональной ценности человекоподобных роботов. В то же время робот Beijing Tiangong Ultra выиграл стометровку на Всемирных соревнованиях человекоподобных роботов, подчеркнув преимущества алгоритмов и автономного восприятия. Обсуждение также охватило ключевые вопросы, такие как стоимость человекоподобных роботов, массовое производство, теория управления и интеграция больших моделей, предвещая, что воплощенный AI переходит от технологических исследований к практическому применению. (Источник: ZhihuFrontier)

Jupyter Agent: Использование Notebook для обучения LLM для задач анализа данных и Data Science : Hugging Face запустил проект Jupyter Agent, призванный дать LLM возможность решать задачи анализа данных и Data Science в Jupyter Notebook с помощью инструментов выполнения кода. Благодаря многоэтапному процессу обучения, включающему очистку данных из масштабных Kaggle Notebooks, оценку качества образования, генерацию QA и генерацию траекторий выполнения кода, удалось повысить производительность небольших моделей, таких как Qwen3-4B, на легких задачах бенчмарка DABStep с 44.4% до 75%, что доказывает, что небольшие модели в сочетании с качественными данными и scaffolding также могут стать мощными агентами Data Science. (Источник: HuggingFace Blog)
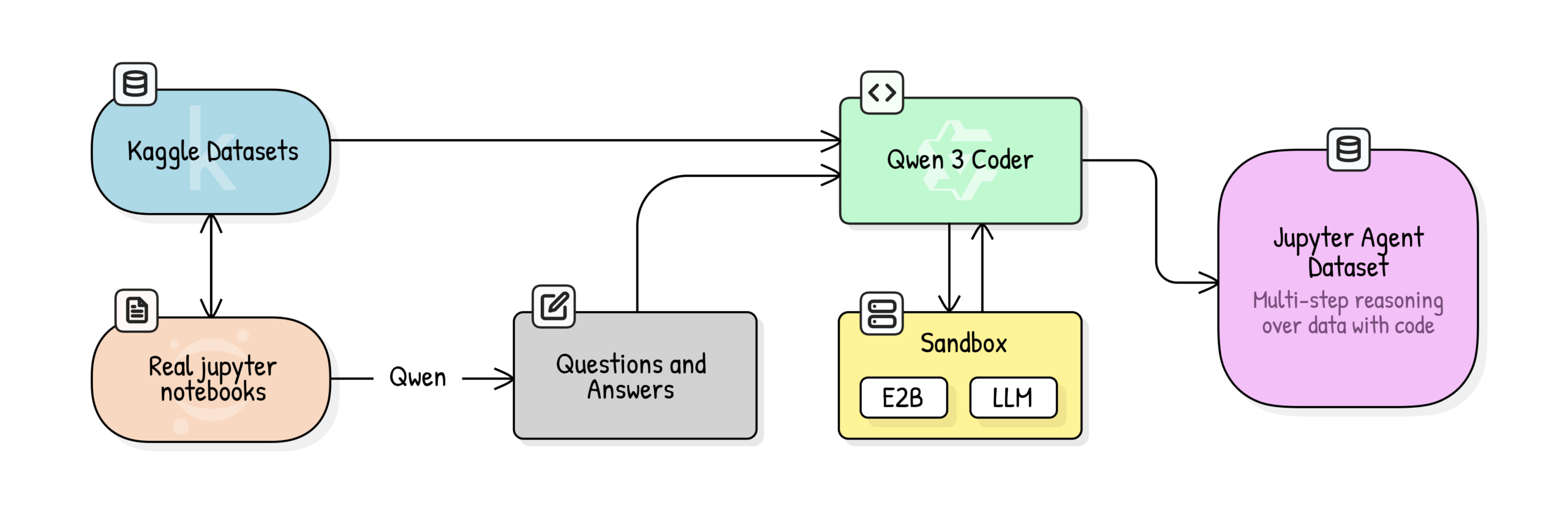
OpenPI: Открытая модель зрения-языка-действия для роботов : Команда Physical Intelligence выпустила библиотеку OpenPI, содержащую открытые модели зрения-языка-действия (VLA), такие как π₀, π₀-FAST и π₀.₅. Эти модели предварительно обучены на более чем 10 000 часах робототехнических данных, поддерживают PyTorch и достигают SOTA-производительности в бенчмарке LIBERO. OpenPI предоставляет базовые контрольные точки моделей и примеры тонкой настройки, поддерживает удаленный вывод и направлен на стимулирование открытых исследований и приложений в области робототехники, демонстрируя потенциал, особенно в задачах настольных манипуляций и захвата объектов. (Источник: GitHub Trending)
🎯 Тенденции
Сотрудничество Microsoft и Anthropic: Модель Claude интегрирована в Office 365 Copilot : Microsoft интегрирует модель Claude от Anthropic в Office 365 Copilot, особенно в областях, где Claude демонстрирует лучшие результаты, таких как вычисления функций в Excel и создание слайдов в PowerPoint. Этот шаг направлен на оптимизацию определенных функций Copilot в Word, Excel, PowerPoint, улучшение пользовательского опыта и расширение области применения Claude в корпоративных инструментах повышения производительности. (Источник: dotey, alexalbert__, menhguin, TheRundownAI)

AI ускоряет научные исследования: Knowledge Graph и автономные агенты : MiniculeAI демонстрирует, как AI может ускорять научные открытия с помощью Knowledge Graph и автономных агентов. Путем сопоставления генов, лекарств и результатов в динамической сети AI может выявлять скрытые связи, которые трудно обнаружить в PDF-документах. Автономные агенты могут сканировать литературу, выявлять закономерности и предоставлять объяснимые выводы, сокращая месяцы традиционных исследований до нескольких минут, при этом обеспечивая конфиденциальность данных корпоративного уровня. (Источник: Ronald_vanLoon)
Серия моделей Qwen3-Next: Оптимизация длинного контекста и параметрической эффективности : Команда Qwen представила серию базовых моделей Qwen3-Next, ориентированных на экстремальную длину контекста и масштабную параметрическую эффективность. Эта серия включает в себя ряд архитектурных инноваций, в том числе GatedAttention (для решения проблемы выбросов), GatedDeltaNet RNN (для экономии KV-кэша), а также гибридную архитектуру Sink+SWA или гибридную архитектуру Gated Attention+линейный RNN, направленные на максимизацию производительности и минимизацию вычислительных затрат, предвещая конец эры чистых Attention-моделей. (Источник: tokenbender, SchmidhuberAI, teortaxesTex, ClementDelangue, andriy_mulyar)
ByteDance Seedream 4.0: Выпущена модель для генерации и редактирования изображений : ByteDance выпустила Seedream 4.0, предлагающую выдающиеся возможности генерации и редактирования изображений. Пользователи отмечают ее выдающуюся производительность в удовлетворении потребностей пользователей, эстетических предпочтений RLHF и поддержании основного вкуса. По сравнению с Seedream 3.0, версия 4.0 добавила зернистость пленки и артефакты объектива, имеет более высокую контрастность, более резкие мазки в аниме-стиле, а также демонстрирует сильную производительность в понимании китайской семантики и согласованности, что делает ее подходящей для инфографики, учебных пособий и дизайна товаров. (Источник: ZhihuFrontier, Reddit r/artificial, op7418, TomLikesRobots, dotey)

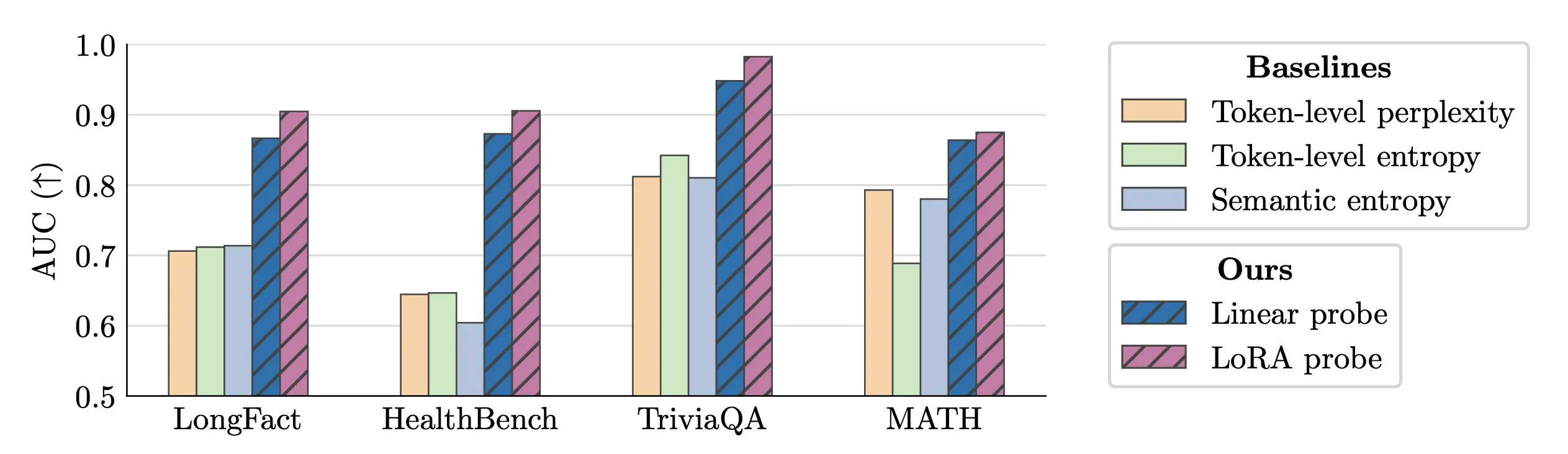
Технология обнаружения галлюцинаций LLM в реальном времени : Исследователи предложили использовать activation probes для обнаружения галлюцинаций LLM в реальном времени. Этот метод продемонстрировал выдающиеся результаты в идентификации поддельных сущностей в длинных текстах, достигнув значения AUC до 0.90, что значительно превосходит традиционные методы семантической энтропии. Кроме того, новое исследование глубоко изучило происхождение галлюцинаций в моделях Transformer, предложив новые идеи для повышения надежности LLM. (Источник: paul_cal, tokenbender)
Microsoft VibeVoice: Долгосрочная высококачественная генерация речи : Модель Microsoft VibeVoice достигла значительных успехов в области AI-аудио, способная генерировать реалистичную речь продолжительностью 45-90 минут с участием до 4 говорящих, без необходимости склейки. Модель доступна для ознакомления на Hugging Face Space, где пользователи могут использовать ее для высококачественного клонирования голоса, открывая новые возможности для таких приложений, как подкасты и аудиокниги. (Источник: Reddit r/LocalLLaMA)
mmBERT: Новый стандарт многоязычных кодировщиков : Представлена новая модель mmBERT, которая, как ожидается, заменит SOTA XLM-R, доминировавшую 6 лет. mmBERT в 2-4 раза быстрее существующих моделей и превосходит o3 и Gemini 2.5 Pro в задачах многоязычного кодирования. Выпуск этой модели, сопровождаемый открытыми моделями и данными для обучения, обеспечит более эффективную и мощную основу для многоязычных AI-приложений. (Источник: code_star)

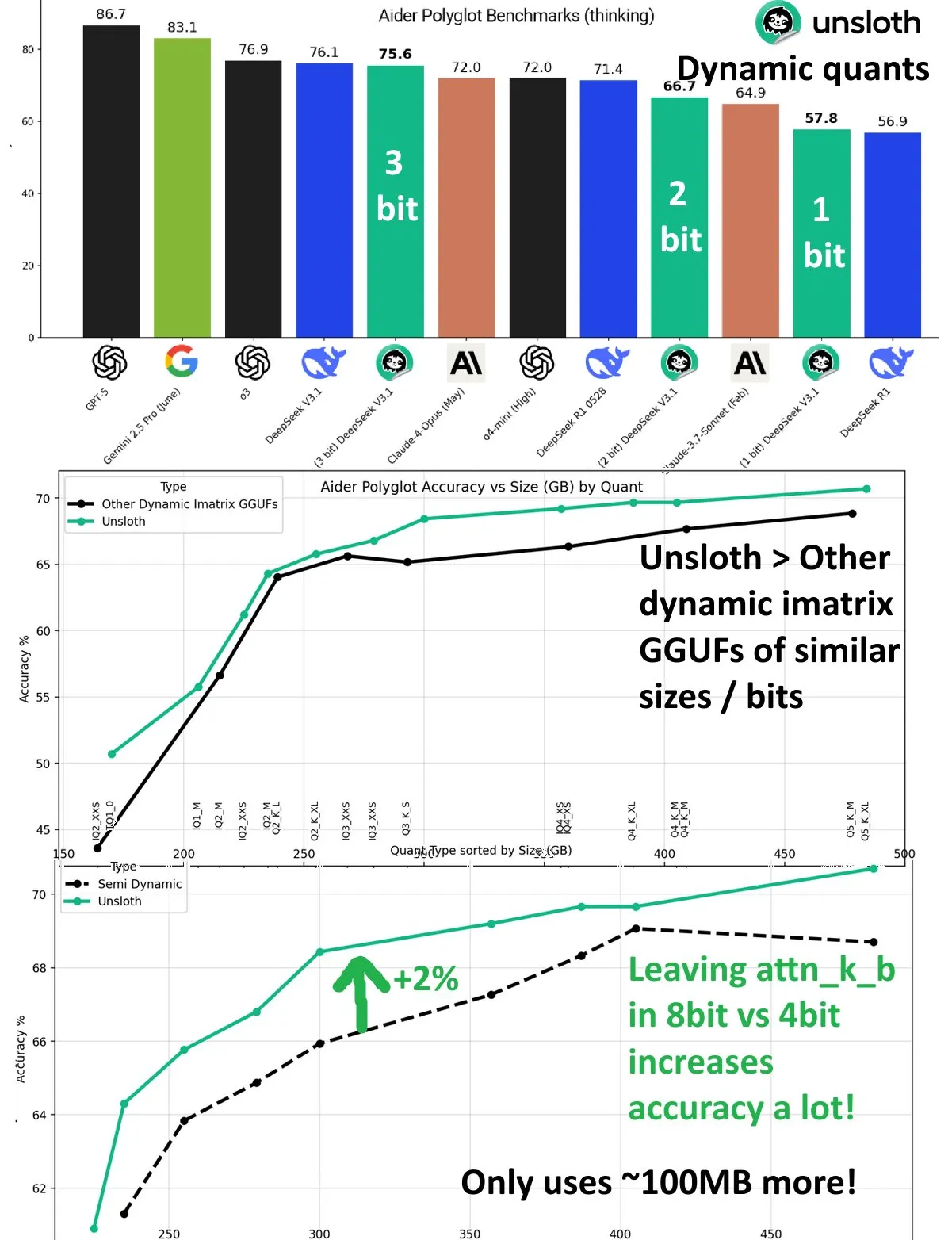
DeepSeek V3.1: Повышение производительности за счет динамической квантизации : Модель DeepSeek V3.1 продемонстрировала значительное повышение производительности в бенчмарке Aider Polyglot от UnslothAI благодаря технологии динамической квантизации. 3-битная квантизация приблизилась к точности неквантованной модели, а в режиме вывода 1-битная динамическая квантизация даже превзошла исходную производительность DeepSeek R1. Исследование показало, что сохранение 8-битной точности слоя attn_k_b может дополнительно повысить точность на 2%, демонстрируя потенциал эффективной квантизации в поддержании возможностей модели и снижении вычислительных затрат. (Источник: danielhanchen)
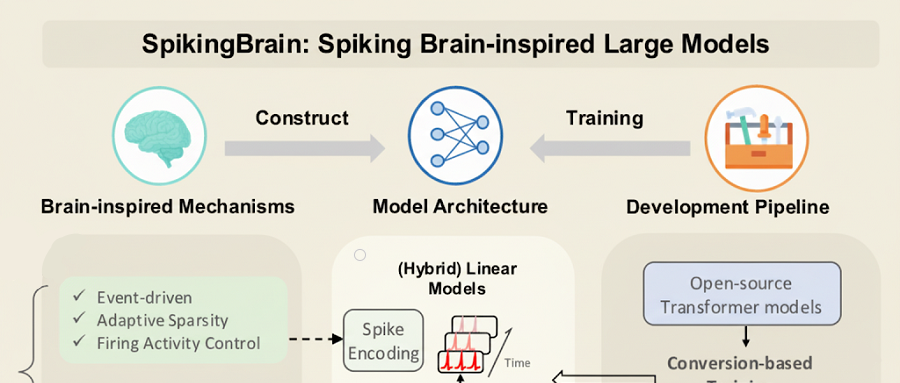
SpikingBrain-1.0: Отечественная большая модель, обученная на отечественных GPU : Институт автоматизации Китайской академии наук выпустил нейроморфную импульсную большую модель “Shunxi 1.0” (SpikingBrain-1.0), которая была обучена и выполнена на кластере отечественных GPU Muxi, снизив энергопотребление на 97.7% по сравнению с традиционными вычислениями FP16. Модель достигла 90% производительности Qwen2.5-7B, используя всего 2% данных предварительного обучения от основных больших моделей, и продемонстрировала выдающиеся результаты в задачах обработки сверхдлинных последовательностей, с ускорением TTFT до 26.5 раз, подтверждая жизнеспособность отечественной, автономно контролируемой экосистемы больших моделей, не основанных на Transformer. (Источник: 36氪)
Wenxin X1.1: Значительное улучшение фактологичности, следования инструкциям и возможностей агента : Модель глубокого мышления Baidu Wenxin X1.1 была обновлена и запущена, демонстрируя улучшения в фактологичности на 34.8%, следовании инструкциям на 12.5% и возможностях агента на 9.6%. Общая производительность модели превосходит DeepSeek R1-0528, конкурируя с GPT-5 и Gemini 2.5 Pro, и демонстрирует мощные возможности агента в сложных долгосрочных задачах, способного автоматически разбивать задачи и вызывать инструменты. Baidu также выпустила открытую модель ERNIE-4.5-21B-A3B-Thinking и комплект разработчика ERNIEKit, что еще больше снижает порог для AI-приложений. (Источник: 量子位)

Huawei OpenPangu-Embedded-7B-v1.1: Свободное переключение между быстрым и медленным мышлением : Huawei выпустила OpenPangu-Embedded-7B-v1.1, открытую модель с 7B параметрами, которая впервые реализует свободное переключение между режимами быстрого и медленного мышления и может адаптивно выбирать режим в зависимости от сложности вопроса. Благодаря постепенной тонкой настройке и двухэтапной стратегии обучения, точность модели значительно улучшилась в общих, математических и кодовых тестах, а средняя длина цепочки рассуждений сократилась почти на 50% при сохранении точности, что заполнило пробел в этой возможности среди открытых больших моделей и повысило эффективность и точность. (Источник: 量子位)

Tencent CodeBuddy Code: AI-программирование вступает в эру L4 : Tencent выпустила AI CLI-инструмент CodeBuddy Code и открыла публичное бета-тестирование CodeBuddy IDE, стремясь продвинуть AI-программирование в эру L4-уровня “AI-инженера-программиста”. CodeBuddy Code устанавливается через npm, поддерживает полный жизненный цикл разработки и эксплуатации, управляемый естественным языком, достигая максимальной автоматизации. Благодаря управлению, основанному на документации, сжатию контекста и расширениям MCP, этот инструмент становится базовой инфраструктурой для корпоративного AI-программирования, значительно повышая эффективность разработки. (Источник: 量子位)

Ключевые ученые OpenAI: Польский дуэт продвигает GPT-4 и прорывы в выводе : Главный научный сотрудник OpenAI Jakub Pachocki и технический исследователь Szymon Sidor получили высокую оценку от Альтмана за их ключевой вклад в проект Dota, предварительное обучение GPT-4 и продвижение прорывов в выводе. Двое, бывшие одноклассниками в старшей школе, воссоединились в OpenAI и, сочетая глубокое мышление с практическими экспериментами, стали незаменимой силой в OpenAI, даже твердо поддержав возвращение Альтмана во время кризиса 2023 года. (Источник: 量子位)

AI-саммит Белого дома сосредоточен на талантах, безопасности и национальных вызовах : Мелания Трамп провела AI-конференцию в Белом доме, пригласив технологических гигантов, таких как Google, IBM и Microsoft, с акцентом на развитие талантов, обеспечение безопасности и национальные вызовы в области AI. Этот шаг демонстрирует, что правительство США активно продвигает AI-стратегию, направленную на решение возможностей и вызовов, связанных с развитием AI, и обеспечение лидерства страны в области AI. (Источник: TheTuringPost, Reddit r/artificial)

Neuromorphic Computing: За пределами традиционных нейронных сетей : Нейроморфные вычисления переопределяют интеллект, черпая вдохновение из структуры и принципов работы биологического мозга. Эта технология направлена на разработку более эффективного и энергосберегающего AI-оборудования, реализуя вычислительные модели, превосходящие традиционную архитектуру фон Неймана, путем имитации параллельной обработки нейронов и синапсов, обеспечивая более мощную основу для будущих AI-систем. (Источник: Reddit r/artificial)
MEGS²: Энергоэффективная технология Gaussian Splatting : MEGS² (Memory-Efficient Gaussian Splatting via Spherical Gaussians and Unified Pruning) — это энергоэффективная технология 3D Gaussian Splatting (3DGS). Заменяя сферические гармоники для представления цвета сферическими гауссовыми функциями произвольной ориентации и вводя унифицированную структуру мягкой обрезки, этот метод значительно сокращает количество параметров на примитив, достигая 8-кратного сжатия статической VRAM и почти 6-кратного сжатия VRAM для рендеринга, при этом сохраняя или улучшая качество рендеринга, что имеет большое значение для 3D-графики и рендеринга в реальном времени. (Источник: janusch_patas)

🧰 Инструменты
LangChain 1.0 представляет Middleware: Новая парадигма управления контекстом агентов : LangChain 1.0 выпустил Middleware, предоставляющий новый уровень абстракции для AI-агентов, позволяя разработчикам полностью контролировать контекстное проектирование. Эта функция повышает гибкость, компонуемость и адаптивность агентов, поддерживая реализацию различных архитектур агентов, таких как рефлексия, группы, супервайзеры, и обеспечивает мощную основу для создания более сложных AI-приложений. (Источник: hwchase17, hwchase17, Hacubu)
MaxKB: Открытая платформа корпоративного уровня для агентов : MaxKB — это мощная и простая в использовании открытая платформа корпоративного уровня для агентов, интегрирующая конвейер RAG (Retrieval Augmented Generation), мощный движок рабочих процессов и возможности использования инструментов MCP. Она поддерживает загрузку документов, автоматический краулинг, сегментацию текста и векторизацию, эффективно уменьшая галлюцинации больших моделей, а также поддерживает различные частные и публичные большие модели, предоставляя мультимодальный ввод-вывод, широко применяясь в сценариях, таких как интеллектуальное обслуживание клиентов и корпоративные базы знаний. (Источник: GitHub Trending)

BlenderMCP: Глубокая интеграция Claude AI и Blender : BlenderMCP реализовал глубокую интеграцию Claude AI с Blender, позволяя Claude напрямую управлять Blender для 3D-моделирования, создания сцен и операций через Model Context Protocol (MCP). Этот инструмент поддерживает двустороннюю связь, манипуляции с объектами, управление материалами, проверку сцен и выполнение кода, а также может интегрировать активы Poly Haven и Hyper3D Rodin, значительно повышая эффективность и возможности AI-помощи в 3D-творчестве. (Источник: GitHub Trending)

AI Sheets: Инструмент для создания и преобразования AI-наборов данных без кода : Hugging Face выпустил AI Sheets, открытый инструмент без кода для создания, обогащения и преобразования наборов данных с использованием AI-моделей. Инструмент может быть развернут локально или запущен на Hub, поддерживает доступ к тысячам открытых моделей на Hugging Face Hub (включая gpt-oss) и быстро запускается через Docker или pnpm, упрощая процесс обработки данных, особенно подходящий для генерации крупномасштабных наборов данных. (Источник: GitHub Trending)
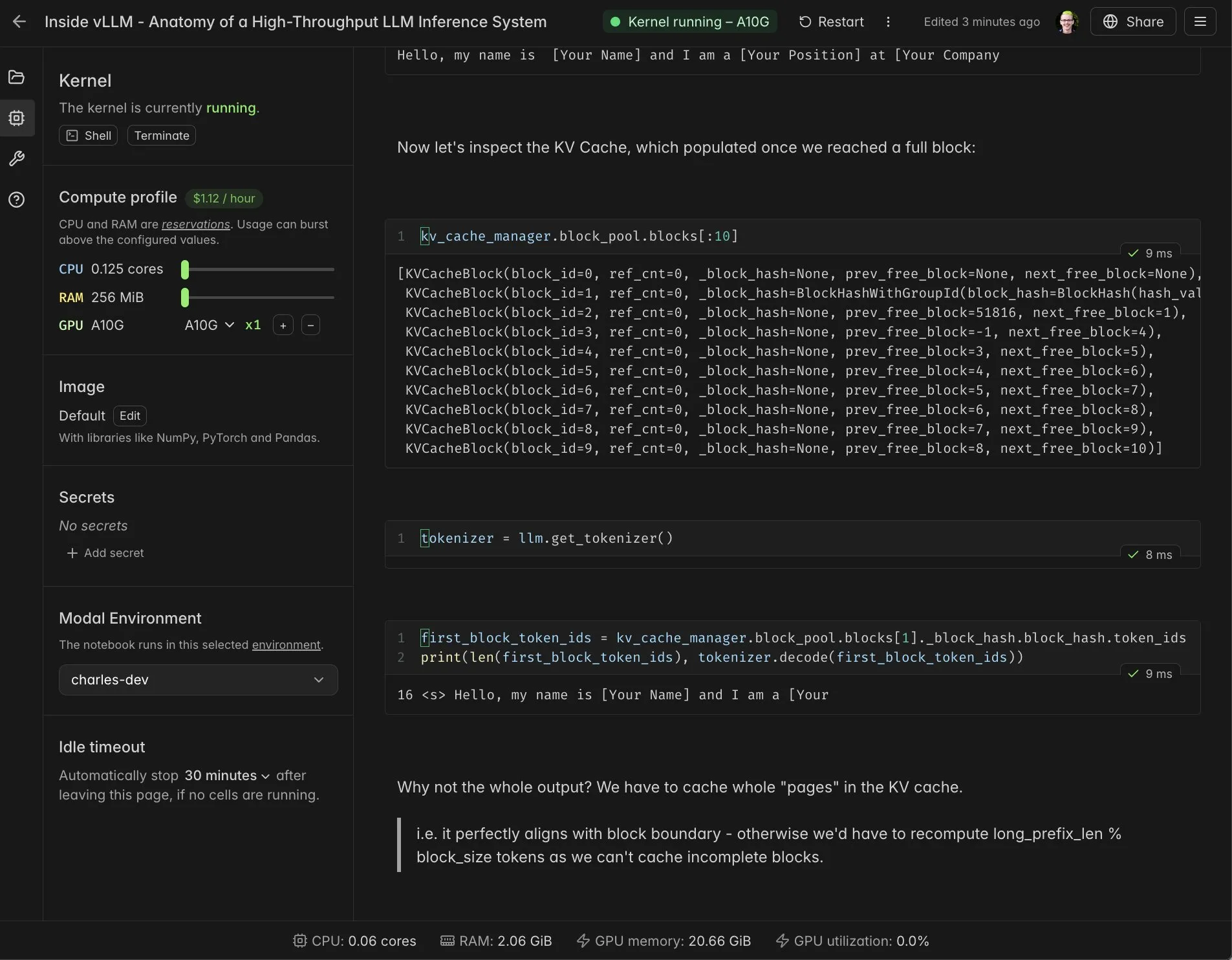
Интеграция vLLM в реальном времени с Modal Notebooks : Modal Notebooks интегрированы с vLLM, предоставляя интерактивную среду в реальном времени с возможностью совместного использования, помогая разработчикам глубже понять внутренние механизмы vLLM. Благодаря этой интеграции пользователи могут легко запускать и обмениваться CUDA-совместимыми вычислительными задачами в облаке без необходимости создания сложных интеграций, что значительно упрощает процесс разработки и обучения vLLM. (Источник: charles_irl, vllm_project, charles_irl, charles_irl, charles_irl, charles_irl)
Docker поддерживает Minions AI: Локальные гибридные AI-рабочие нагрузки : Minions AI теперь официально поддерживает Docker, позволяя пользователям разблокировать гибридные AI-рабочие нагрузки локально через Docker-раннер моделей. Это сотрудничество позволяет разработчикам более удобно развертывать и управлять Minions AI в локальной среде, сочетая преимущества контейнеризации Docker, что повышает гибкость и эффективность разработки AI-приложений. (Источник: shishirpatil_)
Replit Agent 3: Новый прорыв в автономной разработке ПО : Replit выпустил Agent 3, который, как утверждается, является моментом “полного автопилота” в разработке программного обеспечения, увеличивая автономность агента в 10 раз по сравнению с предыдущими версиями. Этот Agent может глубже прототипировать приложения и продолжать работу, когда другие агенты застревают, с целью решения трудоемких этапов тестирования, отладки и рефакторинга в разработке программного обеспечения, значительно повышая эффективность разработки. (Источник: amasad, amasad, pirroh)
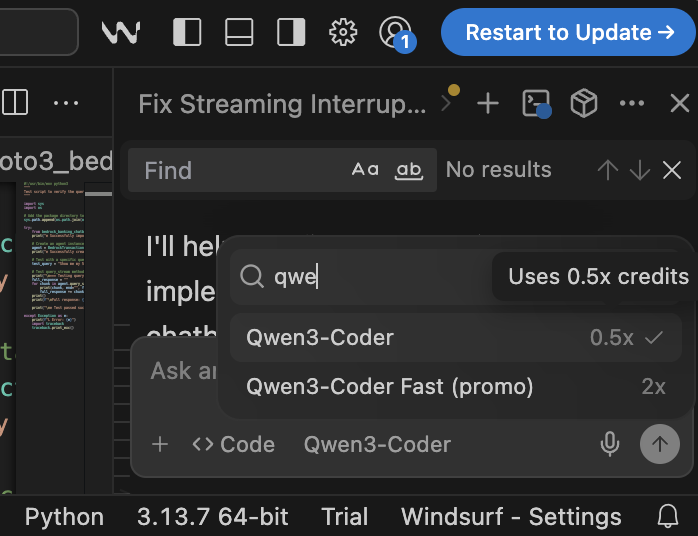
Qwen3-Coder: Высокоэффективная открытая модель для программирования : Qwen3-Coder продемонстрировал выдающуюся производительность и экономическую эффективность на платформе Windsurf, требуя всего 0.5 кредита для запуска, что является преимуществом по сравнению с Claude 4 и GPT-5 High (2x кредита). Модель отлично справляется с задачами программирования и, будучи открытой моделью, предоставляет мощные возможности AI-программирования для регулируемых предприятий и организаций государственного сектора без зависимости от публичных API, что помогает решать проблемы суверенитета данных и видимости. (Источник: bookwormengr)
📚 Обучение
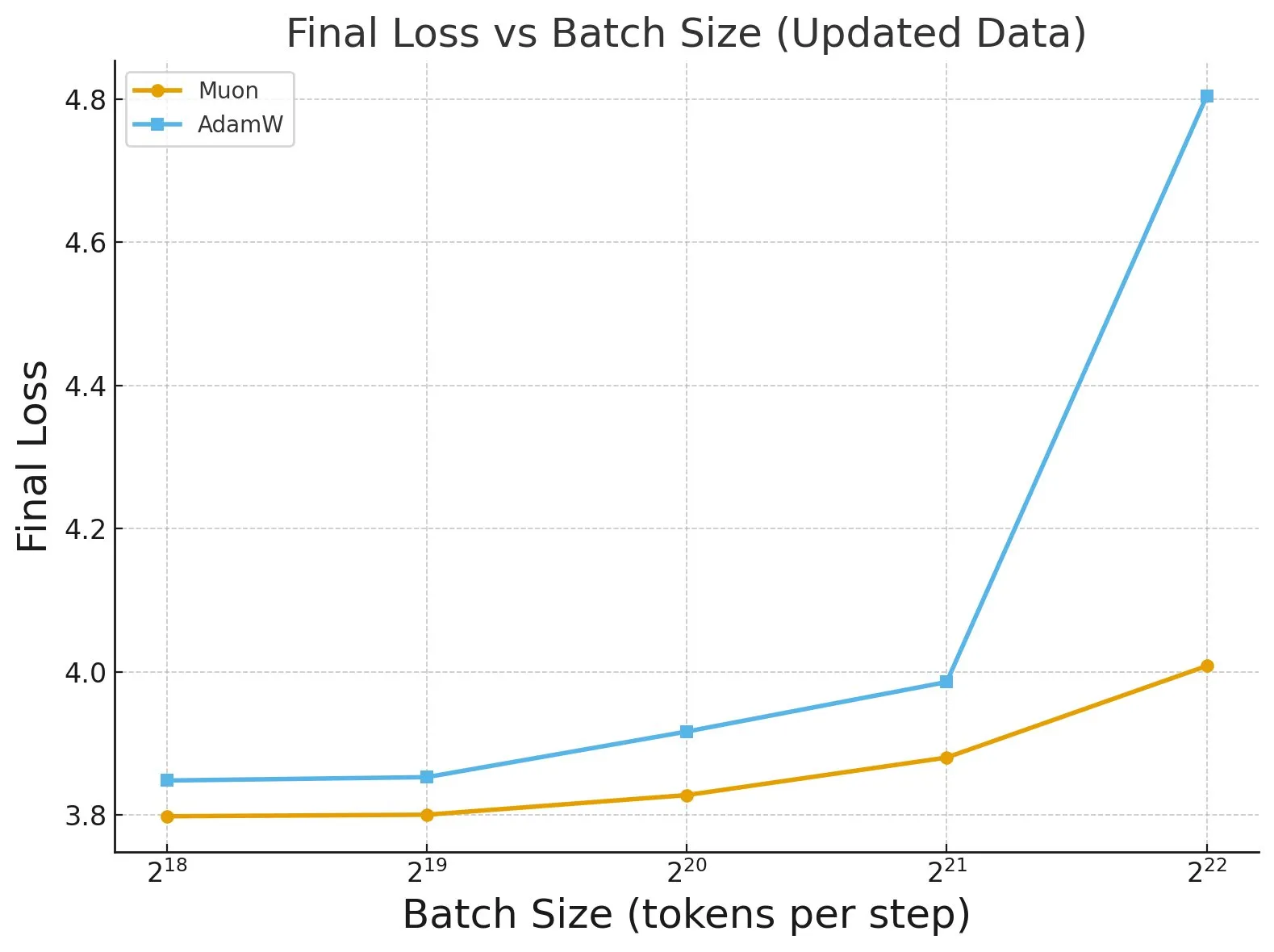
Исследование «Fantastic Pretraining Optimizers and Where to Find Them» : Обширное исследование, проведенное на более чем 4000 моделях, выявило производительность оптимизаторов предварительного обучения. Исследование показало, что некоторые оптимизаторы (например, Muon) могут обеспечить до 40% прироста скорости на небольших моделях (<0.5B параметров), но только 10% прироста на крупномасштабных моделях (1.2B параметров). Это подчеркивает необходимость осторожности при оценке оптимизаторов, обращая внимание на недостаточную настройку базовых показателей и ограничения масштаба, а также указывает на влияние размера пакета на разницу в производительности оптимизаторов. (Источник: tokenbender, code_star)
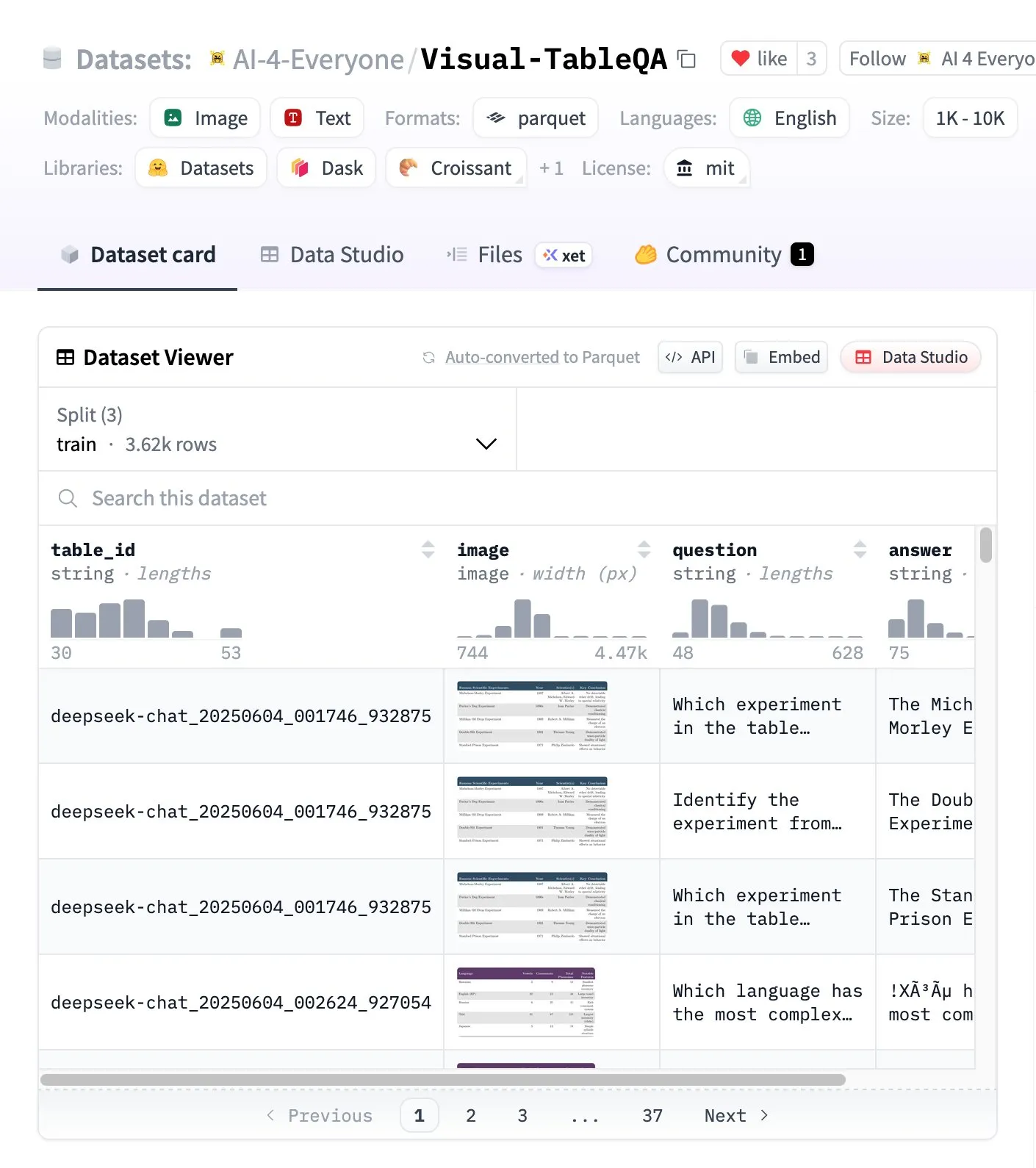
Visual-TableQA: Бенчмарк для сложного табличного вывода : Hugging Face выпустил Visual-TableQA, бенчмарк для сложного табличного вывода, содержащий 2.5K таблиц и 6K пар QA. Этот бенчмарк сосредоточен на многошаговом выводе на основе визуальной структуры и был вручную проверен на 92%, при этом стоимость генерации составила менее 100 долларов США. Он предоставляет высококачественный ресурс для оценки и улучшения способности моделей понимать и выводить сложные табличные данные. (Источник: huggingface)
AI Agents vs Agentic AI: Разъяснение концепций : В сообществе существует распространенная путаница между AI Agents и Agentic AI-системами. AI Agents относятся к одиночному автономному ПО (LLM+инструменты), выполняющему конкретные задачи, с реактивным поведением и ограниченной памятью; Agentic AI относится к многоагентным совместным системам (множество LLM+оркестровка+общая память), с проактивным поведением и постоянной памятью. Понимание различий между ними критически важно для архитектурных решений, чтобы избежать создания излишне сложных систем. (Источник: Reddit r/deeplearning)

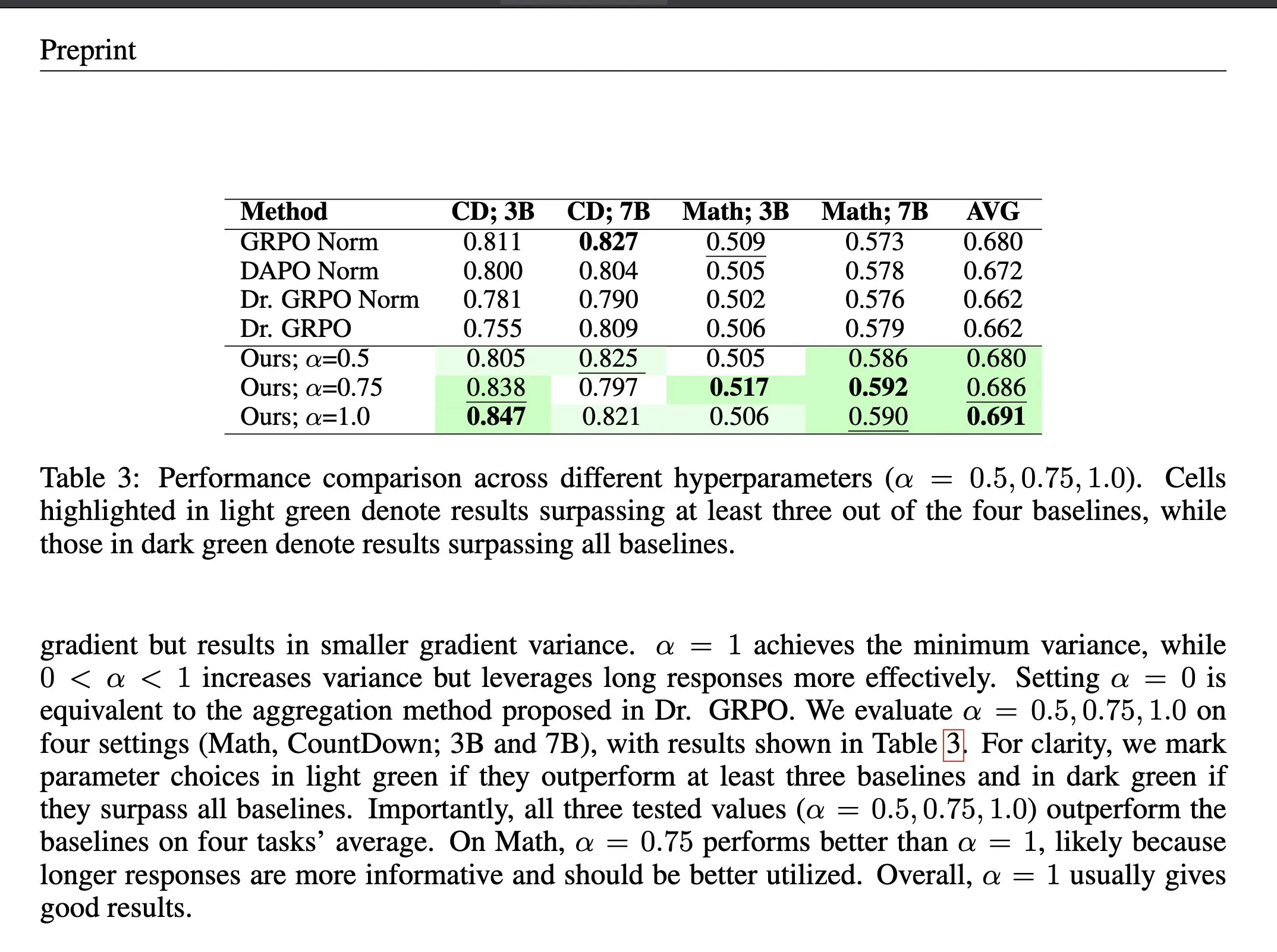
ΔL Normalization: Метод агрегации потерь в Reinforcement Learning : ΔL Normalization — это метод агрегации потерь, разработанный для характеристики динамически генерируемой длины в Reinforcement Learning с проверяемым вознаграждением (RLVR). Этот метод, анализируя влияние различных длин на потери стратегии, перестраивает задачу для нахождения несмещенной оценки с минимальной дисперсией, теоретически минимизируя дисперсию градиента. Эксперименты показали, что ΔL Normalization последовательно достигает превосходных результатов на различных масштабах моделей, максимальных длинах и задачах, решая проблемы высокой дисперсии градиента и нестабильной оптимизации в RLVR. (Источник: HuggingFace Daily Papers, teortaxesTex)
Видеолекция по сравнению архитектур LLM : Rasbt выпустил видеолекцию со сравнительным анализом 11 архитектур LLM 2025 года, охватывающую DeepSeek V3/R1, OLMo 2, Gemma 3, Mistral Small 3.1, Llama 4, Qwen3, SmolLM3, Kimi 2, GPT-OSS, Grok 2.5 и GLM-4.5. Эта лекция предоставляет разработчикам и исследователям всесторонний обзор архитектур LLM, помогая понять принципы проектирования и характеристики производительности различных моделей. (Источник: rasbt)
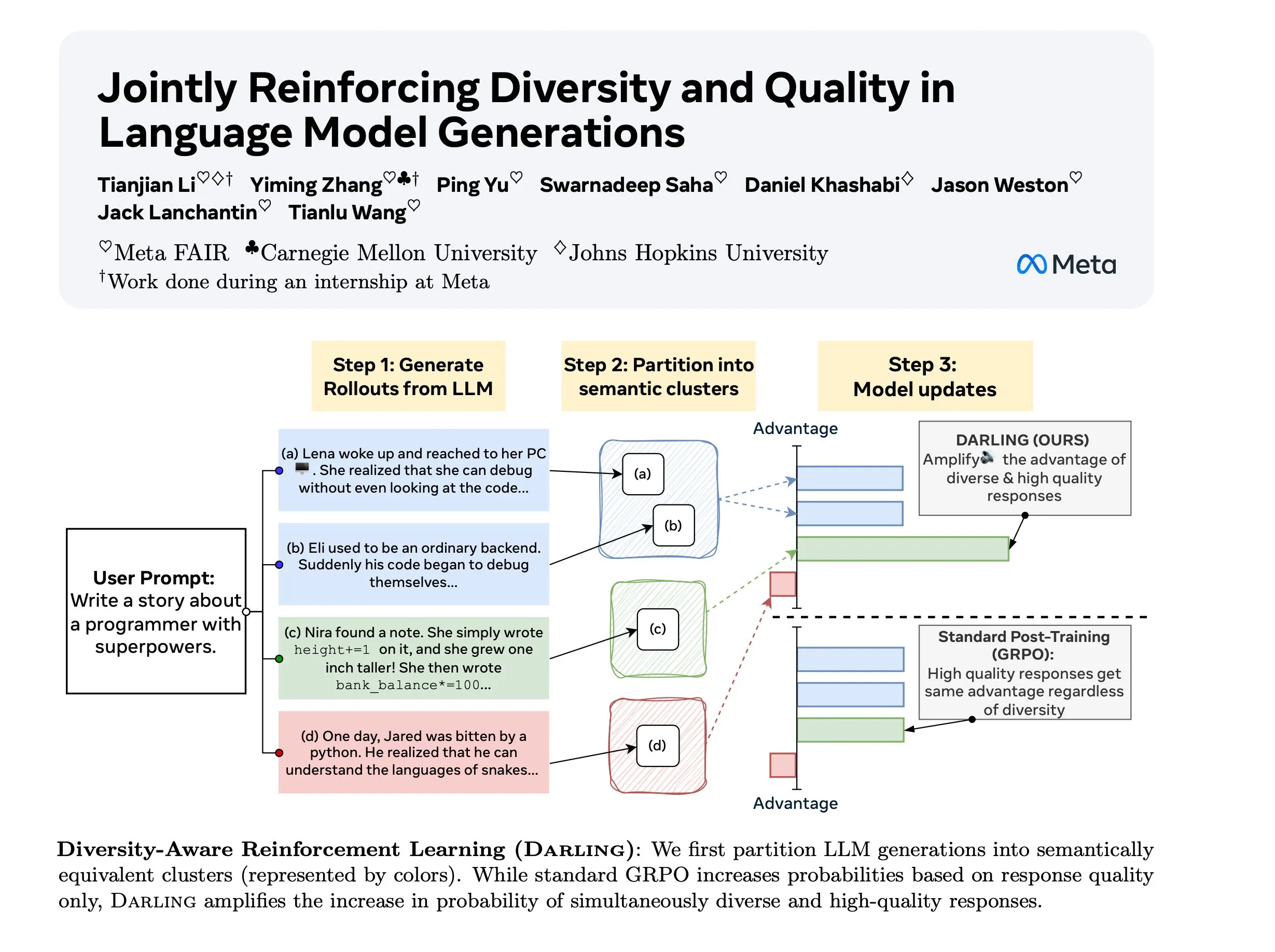
Исследование Diversity Aware RL (DARLING) : DARLING (Diversity Aware RL) — это новый метод Reinforcement Learning, который оптимизирует качество и разнообразие одновременно, изучая функцию разбиения. Этот метод превосходит стандартный RL как по показателям качества, так и по разнообразию, например, более высокий pass@1/p@k, и применим как к непроверяемым, так и к проверяемым задачам, предоставляя новый путь для повышения способности RL к обобщению в сложных средах. (Источник: ylecun)
Стэнфорд CS 224N: Курс по Deep Learning и NLP : Курс Стэнфордского университета CS 224N предлагает всестороннее обучение по Deep Learning и Natural Language Processing. Курс доступен на YouTube-видео, предоставляя высококачественные ресурсы для изучения AI для учащихся по всему миру, охватывая базовую теорию NLP, новейшие модели и практические применения, что делает его важным вводным курсом для входа в область AI. (Источник: stanfordnlp)
💼 Бизнес
Новая политика конфиденциальности Anthropic вызывает споры: Системное невыгодное положение для независимых разработчиков : Новая политика конфиденциальности Anthropic требует от пользователей до 28 сентября выбрать, разрешать ли использование их данных диалогов для обучения AI и хранения в течение 5 лет, в противном случае они потеряют функции памяти и персонализации. Этот шаг критикуется за создание “двухуровневой системы”, ставящей независимых разработчиков перед выбором между конфиденциальностью и функциональностью, поскольку их проприетарный код может стать данными для обучения корпоративного AI, в то время как корпоративные клиенты могут пользоваться дорогими решениями, сочетающими защиту конфиденциальности и персонализацию, что вызывает опасения по поводу демократизации AI и извлечения инноваций. (Источник: Reddit r/ClaudeAI)
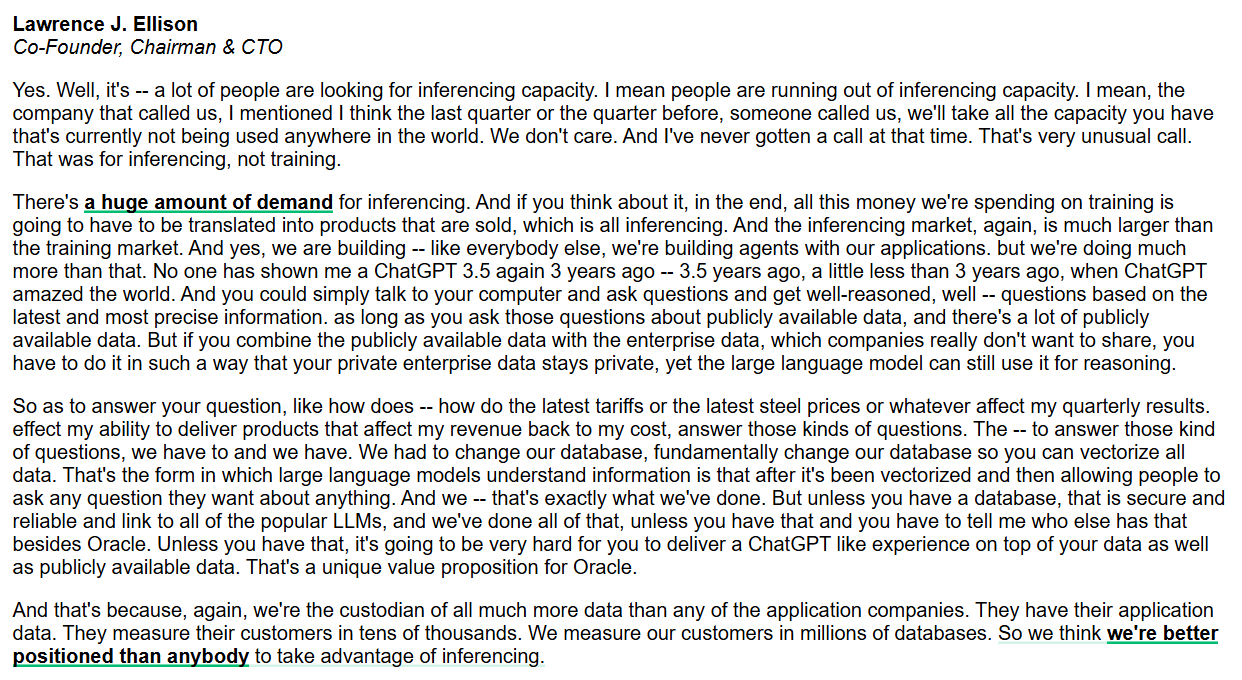
Oracle фокусируется на возможностях вывода и корпоративных AI-базах данных : Генеральный директор Oracle Ларри Эллисон подчеркнул, что рынок возможностей вывода значительно больше рынка обучения и имеет огромный спрос. Oracle, фундаментально изменив базы данных для векторизации всех данных и обеспечив их безопасность и надежность, стремится предоставить опыт в стиле ChatGPT, сочетающий публичные и корпоративные частные данные. Oracle считает, что как хранитель данных, она обладает уникальными преимуществами в предоставлении корпоративных AI-сервисов вывода. (Источник: JonathanRoss321)
Новый стандарт лицензирования AI-контента RSL Standard: Побуждение AI-компаний к оплате : Крупные бренды, такие как Reddit, Yahoo, Quora и wikiHow, поддерживают Really Simple Licensing (RSL) Standard, открытый стандарт лицензирования контента, призванный позволить веб-издателям устанавливать условия использования их работ разработчиками AI-систем. RSL основан на протоколе robots.txt и позволяет веб-сайтам добавлять условия лицензирования и роялти, требуя от AI-краулеров платить за обучающие данные (по подписке или за количество сканирований/выводов), чтобы обеспечить справедливую компенсацию создателям контента. (Источник: Reddit r/artificial)
🌟 Сообщество
Сосуществование и усиление AI и человеческого интеллекта : В сообществе обсуждается, является ли AI “когнитивным корректором”, помогающим человеческому интеллекту (например, как счеты), или “конкурентом”, заменяющим человека (например, как калькулятор). Франсуа Шолле предложил метафору “велосипеда для ума”, подчеркивая, что технологии должны усиливать человеческие усилия, а не оставлять людей без дела, что вызвало философские размышления о взаимоотношениях между AI и человеческим интеллектом (IA) и направлениях будущего развития. (Источник: rao2z)
PR-дилеммы AI-индустрии и негативное общественное мнение : Несмотря на то, что AI-продукты имеют миллиарды пользователей и многие из них получают выгоду, AI-индустрия в целом сталкивается с негативным общественным мнением. Существует мнение, что это связано с неспособностью лидеров отрасли эффективно общаться с общественностью, что приводит к предубеждениям в отношении AI-компаний. Некоторые также предполагают, что это может быть преднамеренным действием AI-индустрии, направленным на концентрацию ключевых технологий и преимуществ в руках нескольких игроков. (Источник: Dorialexander)
Влияние слабых звеньев в многоагентных системах LLM : Исследования показывают, что использование небольших языковых моделей не всегда является идеальным выбором в многоагентных системах. В сценариях, таких как многоагентные дебаты, более слабые LLM-агенты часто мешают или даже подрывают производительность более сильных агентов, что приводит к снижению общей производительности системы. Это показывает, что при проектировании и развертывании многоагентных систем необходимо тщательно учитывать различия в возможностях каждого агента и их потенциальное негативное взаимодействие. (Источник: omarsar0)

Ограничения синтетических данных для AGI : Andrew Trask и Fei-Fei Li отмечают, что синтетические данные являются слабой стратегией для достижения AGI с помощью LLM. Синтетические данные не могут создавать новую информацию (например, сущности, о которых модель никогда не слышала), а могут лишь выявлять естественные выводы из существующей информации. Хотя синтетические данные могут решать такие проблемы, как “проклятие инверсии”, путем логических перестановок и комбинаций известных фактов, их информационный барьер ограничивает их потенциал как “серебряной пули” для AGI; настоящий прорыв может заключаться в глобальном интеллекте и мгновенном извлечении контекста. (Источник: algo_diver, jpt401)
AI и рынок труда: Замкнутый круг AI-резюме и AI-отбора : AI вызвал на рынке труда замкнутый круг “никто не нанят”: соискатели используют AI для написания резюме, HR используют AI для их отбора, что приводит к “повышению” эффективности, но никто не нанимается. Причины отказа резюме AI разнообразны, и даже HR жалуются, что AI-генерируемые резюме однообразны. Это подчеркивает новые вызовы, которые AI приносит в рекрутинг, что может привести к стагнации процесса найма и неспособности выявлять настоящие таланты. (Источник: 量子位)

Вызовы, стоящие перед AI-этиками : С быстрым развитием AI-технологий AI-этики сталкиваются с дилеммой “крика в пустоту”. Гонка AI, движимая капитализмом, приводит к маргинализации этических соображений, а скорость технологического прогресса значительно опережает этическую интеграцию. Эксперты опасаются, что к тому времени, когда вред проявится в больших масштабах, может быть слишком поздно действовать, и призывают отрасль включить этические гарантии в основные соображения. (Источник: Reddit r/ArtificialInteligence)

Будущее интернета: Трафик ботов превысит человеческий : Тенденции показывают, что в течение следующих трех лет взаимодействие, управляемое ботами, в интернете значительно превысит человеческое, что сделает интернет “мертвым”. Уже проведенные исследования показывают, что трафик ботов превысил 50%. Это вызывает опасения по поводу того, как отличить настоящие человеческие голоса от AI-генерируемого контента, а также по поводу достоверности информации в интернете, предвещая фундаментальные изменения в сетевой экосистеме. (Источник: Reddit r/artificial)

Снижение производительности Claude Code и отток пользователей : Пользователи Claude Code от Anthropic сообщают о значительном снижении производительности модели в последнее время, проявляющемся в ухудшении качества кода, генерации избыточного кода, низком качестве тестов, чрезмерном инжиниринге и ослаблении способности к пониманию. Многие пользователи рассматривают переход на альтернативы, такие как GPT-5, GLM-4.5, Qwen3, и призывают Anthropic повысить прозрачность, объяснить причины ухудшения модели и меры по ее исправлению, иначе компания столкнется с оттоком пользователей. (Источник: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
💡 Прочее
Потенциал AI и VR в коррекции преступности : Высказано мнение, что использование недорогих AI и VR-технологий может предоставить принудительные VR-капсулы для криминальных психопатов, изолируя их от общества способом, который дешевле традиционных затрат на проживание и питание. Эта радикальная идея вызвала дискуссии о роли AI в социальном контроле, пенитенциарной системе и этических границах, и хотя ее осуществимость и гуманность спорны, она раскрывает потенциальные направления применения технологий для решения социальных проблем. (Источник: gfodor, gfodor)
Идея применения Replit в тюрьмах : Один из пользователей предложил идею внедрения Replit (онлайн-платформы для программирования) в тюрьмы, полагая, что это может заменить развлекательные учреждения и позволить заключенным создавать ценные продукты через программирование. Эта идея исследует потенциальную роль технологий в преобразовании общества, предоставлении профессионального обучения и содействии реинтеграции заключенных в общество, вызывая дискуссии о равенстве в образовании и расширении возможностей с помощью технологий. (Источник: amasad)