

Ключевые слова:гуманоидный робот, большая модель ИИ, обучение с подкреплением, мультимодальный ИИ, ИИ-агент, узкое место данных Figure 03, математическое доказательство GPT-5 Pro, устройство EmbeddingGemma для RAG на стороне клиента, графовый анализ диалогов GraphQA, производительность вывода NVIDIA Blackwell
🔥 В центре внимания
Figure 03 на обложке списка лучших изобретений журнала Time, CEO заявляет: “На данном этапе нам не хватает только данных” : Генеральный директор Figure, Brett Adcock, заявил, что самым большим препятствием для гуманоидного робота Figure 03 в настоящее время являются “данные”, а не архитектура или вычислительная мощность. Он считает, что данные могут решить почти все проблемы и способствовать массовому внедрению роботов. Figure 03 появился на обложке списка лучших изобретений журнала Time за 2025 год, что вызвало дискуссию о важности данных, вычислительной мощности и архитектуры в развитии робототехники. Brett Adcock подчеркнул, что цель Figure — позволить роботам выполнять человеческие задачи в домашних и коммерческих условиях, а также уделить большое внимание безопасности роботов, предсказывая, что в будущем количество гуманоидных роботов может превзойти количество людей.(Источник: 量子位)

Tao Zhexuan бросает вызов с GPT5-Pro! Неразрешимая задача за 3 года, полное доказательство за 11 минут : Известный математик Tao Zhexuan в сотрудничестве с GPT-5 Pro за 11 минут решил неразрешимую в течение 3 лет задачу в области дифференциальной геометрии. GPT-5 Pro не только выполнил сложные вычисления, но и предоставил полное доказательство, а также помог Tao Zhexuan скорректировать его первоначальную интуицию. Tao Zhexuan заключил, что AI отлично справляется с задачами “малого масштаба” и полезен для понимания проблем “крупного масштаба”, но в стратегиях “среднего масштаба” может усиливать ошибочную интуицию. Он подчеркнул, что AI должен служить “вторым пилотом” для математиков, повышая эффективность экспериментов, а не полностью заменять человеческую творческую и интуитивную работу.(Источник: 量子位)

🎯 Тенденции
Yunpeng Technology выпускает новые продукты AI+Health : Yunpeng Technology в сотрудничестве с Shuaikang и Skyworth выпустила новые продукты AI+Health, включая “цифровую интеллектуальную лабораторию будущей кухни” и умный холодильник с большой моделью AI Health. Большая модель AI Health оптимизирует дизайн и эксплуатацию кухни, а умный холодильник предоставляет персонализированное управление здоровьем через “помощника по здоровью Сяоюнь”. Это знаменует прорыв AI в области повседневного управления здоровьем, предоставляя персонализированные медицинские услуги через интеллектуальные устройства, что, как ожидается, будет способствовать развитию домашних медицинских технологий и улучшению качества жизни населения.(Источник: 36氪)
Прогресс в области гуманоидных роботов и воплощенного интеллекта: от домашних дел до промышленного применения : Множество обсуждений в социальных сетях демонстрируют последние достижения в области гуманоидных роботов и воплощенного интеллекта. Reachy Mini был назван журналом Time одним из лучших изобретений 2025 года, что демонстрирует потенциал открытого сотрудничества в робототехнике. Бионический протез с AI-управлением позволил 17-летнему подростку осуществлять мысленное управление, а гуманоидные роботы легко справляются с домашними делами. В промышленной сфере Yondu AI представила решение для складской комплектации с использованием колесных гуманоидных роботов, AgiBot выпустила Lingxi X2 с возможностями передвижения, близкими к человеческим, а Китай также представил высокоскоростного сферического полицейского робота. Роботы Boston Dynamics превратились в многофункциональных операторов, а четвероногий робот LocoTouch осуществляет интеллектуальную транспортировку с помощью тактильных ощущений.(Источник: Ronald_vanLoon, Ronald_vanLoon, ClementDelangue, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, johnohallman, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
Прорыв в возможностях больших моделей и новые достижения в бенчмарках кода : GPT-5 Pro и Gemini 2.5 Pro показали результаты уровня золотой медали на Международной олимпиаде по астрономии и астрофизике (IOAA), демонстрируя мощные возможности AI в области передовой физики. GPT-5 Pro также продемонстрировал сверхспособности в поиске и проверке научной литературы, решив проблему Erdos #339 и эффективно выявляя серьезные недостатки в опубликованных статьях. В области кода KAT-Dev-72B-Exp стал ведущей открытой моделью в рейтинге SWE-Bench Verified, достигнув показателя исправления ошибок в 74,6%. Проект SWE-Rebench предотвращает загрязнение данных, тестируя новые проблемы GitHub, возникающие после выпуска больших моделей. Sam Altman с нетерпением ждет будущего Codex. Что касается возможности достижения AGI с помощью чисто LLM, исследовательское сообщество AI в целом считает, что это трудно достичь, полагаясь только на ядро LLM.(Источник: gdb, karminski3, gdb, SebastienBubeck, karminski3, teortaxesTex, QuixiAI, sama, OfirPress, Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence)
Инновации в производительности и вызовы для аппаратного обеспечения и инфраструктуры AI : Платформа NVIDIA Blackwell продемонстрировала беспрецедентную производительность и эффективность инференса в бенчмарке SemiAnalysis InferenceMAX, а Together AI уже предлагает системы NVIDIA GB200 NVL72 и HGX B200. Groq, благодаря своим ASIC и стратегии вертикальной интеграции, перестраивает экономику инфраструктуры открытых LLM с более низкой задержкой и конкурентоспособными ценами. Сообщество обсудило влияние удаления Python GIL на инженерию AI/ML, полагая, что его удаление может повысить производительность многопоточности. Кроме того, энтузиасты LLM поделились своими аппаратными конфигурациями и обсудили компромиссы в производительности между большими квантованными моделями и маленькими неквантованными моделями на разных уровнях квантования, отметив, что 2-битное квантование может подходить для диалогов, но для задач кодирования требуется как минимум Q5.(Источник: togethercompute, arankomatsuzaki, code_star, MostafaRohani, jeremyphoward, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Передовые тенденции в моделях и приложениях AI: от общих моделей до вертикальных областей : В области AI постоянно появляются новые модели и функции. Большая модель турецкого языка Kumru-2B заявила о себе на Hugging Face, а Replit на этой неделе выпустил несколько обновлений. Sora 2 удалила водяные знаки, предвещая более широкое применение технологии генерации видео. Ходят слухи, что Gemini 3.0 будет выпущен 22 октября. AI продолжает углубляться в сферу здравоохранения: цифровая патология использует AI для диагностики рака, а безмаркерные микроскопы в сочетании с AI обещают новые диагностические инструменты. Модели дополненной реальности (AR) достигли SOTA в рейтинге Imagenet FID. Командный Agent Qwen Code обновился, добавив поддержку распознавания изображений моделью Qwen-VL. Стэнфордский университет предложил метод Agentic Context Engineering (ACE), который позволяет моделям становиться умнее без тонкой настройки. Модели серии DeepSeek V3 также постоянно обновляются, а типы развертывания AI Agent и переосмысление AI профессиональных услуг также стали центром внимания отрасли.(Источник: mervenoyann, amasad, scaling01, npew, kaifulee, Ronald_vanLoon, scaling01, TheTuringPost, TomLikesRobots, iScienceLuvr, NerdyRodent, shxf0072, gabriberton, Ronald_vanLoon, karminski3, Ronald_vanLoon, teortaxesTex, demishassabis, Dorialexander, yoheinakajima, 36氪)
🧰 Инструменты
GraphQA: Преобразование графового анализа в диалог на естественном языке : LangChainAI представила фреймворк GraphQA, который, объединяя NetworkX и LangChain, может преобразовывать сложный графовый анализ в диалог на естественном языке. Пользователи могут задавать вопросы на обычном английском языке, и GraphQA автоматически выберет и выполнит подходящий алгоритм, обрабатывая графы с более чем 100 000 узлов. Это значительно упрощает порог входа в анализ графовых данных, делая его более доступным для непрофессиональных пользователей, и является важной инновацией в инструментах в области LLM.(Источник: LangChainAI)
Лучшие Agentic AI инструменты для VS Code : Visual Studio Magazine назвал один из инструментов одним из лучших Agentic AI инструментов для VS Code, что знаменует собой переход парадигмы разработки от “помощника” к “настоящему Agent”, способному мыслить, действовать и строить вместе с разработчиком. Это отражает эволюцию AI-инструментов в области разработки программного обеспечения от вспомогательных функций к более глубокому интеллектуальному сотрудничеству, повышая эффективность и удобство работы разработчиков.(Источник: cline)
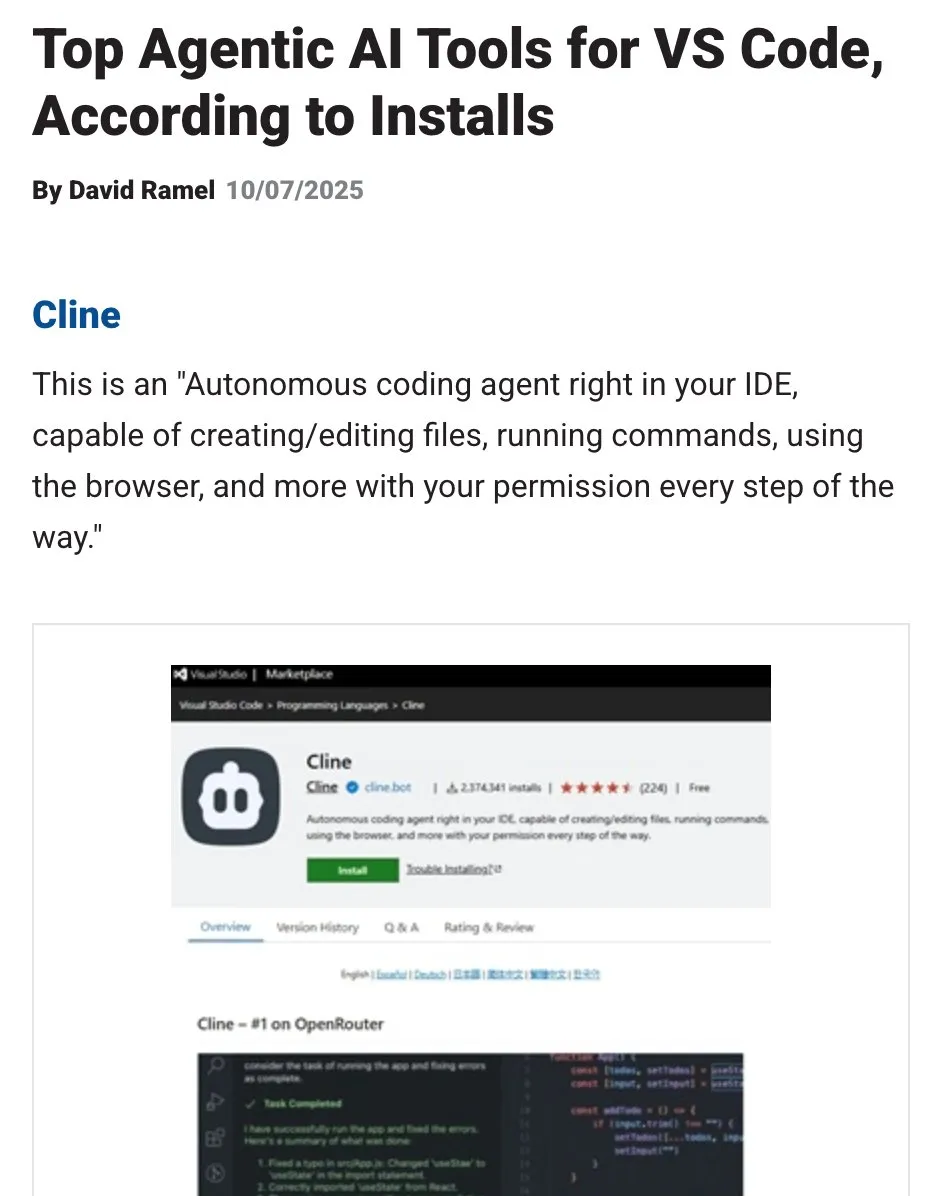
OpenHands: Инструмент с открытым исходным кодом для управления контекстом LLM : OpenHands, будучи инструментом с открытым исходным кодом, предоставляет различные компрессоры контекста для управления контекстом LLM в Agentic-приложениях, включая базовую обрезку истории, извлечение “наиболее важных событий” и сжатие вывода браузера. Это крайне важно для отладки, оценки и мониторинга LLM-приложений, RAG-систем и Agentic-рабочих процессов, помогая повысить эффективность и согласованность LLM в сложных задачах.(Источник: gneubig)
BLAST: AI-движок для веб-браузера : LangChainAI выпустила BLAST, высокопроизводительный AI-движок для веб-браузера, предназначенный для предоставления AI-приложениям возможности просмотра веб-страниц. BLAST предоставляет совместимый с OpenAI интерфейс, поддерживает автоматическое распараллеливание, интеллектуальное кэширование и потоковую передачу в реальном времени, что позволяет эффективно интегрировать веб-информацию в рабочие процессы AI и значительно расширяет возможности AI Agent по получению и обработке данных из сети в реальном времени.(Источник: LangChainAI)
Opik: Инструмент с открытым исходным кодом для оценки LLM : Opik — это инструмент с открытым исходным кодом для оценки LLM, используемый для отладки, оценки и мониторинга LLM-приложений, RAG-систем и Agentic-рабочих процессов. Он предоставляет комплексное отслеживание, автоматизированную оценку и готовые к производству панели мониторинга, помогая разработчикам лучше понимать поведение моделей, оптимизировать производительность и обеспечивать надежность приложений в реальных сценариях.(Источник: dl_weekly)
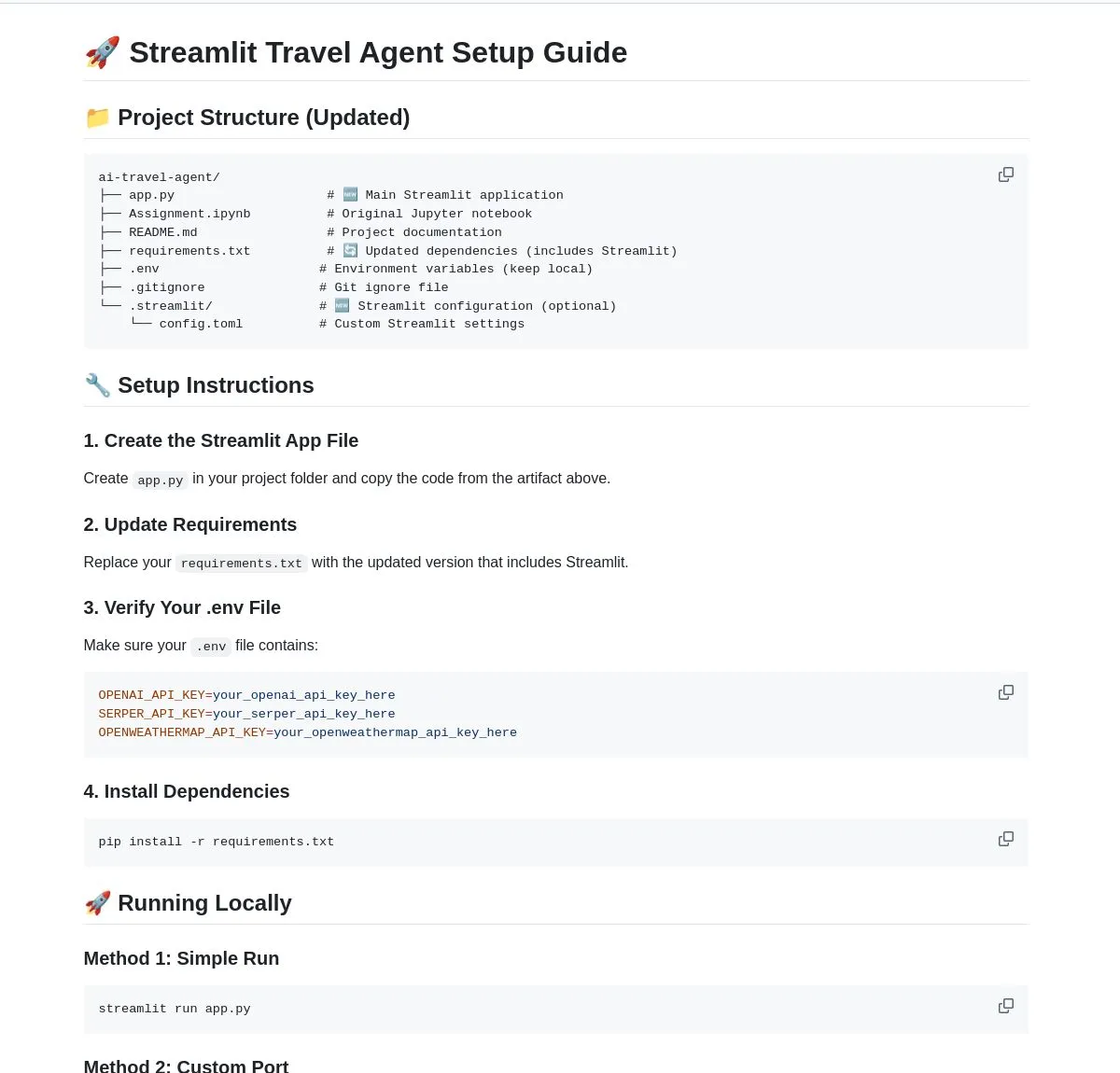
AI Travel Agent: Интеллектуальный помощник по планированию : LangChainAI продемонстрировала интеллектуальный AI Travel Agent, который интегрирует информацию о погоде в реальном времени, поиск и туристическую информацию, а также использует несколько API для упрощения всего процесса от обновления погоды до обмена валюты. Этот Agent призван предоставлять комплексное планирование и помощь в путешествиях, улучшая пользовательский опыт, и является типичным примером использования LLM для расширения возможностей Agent в вертикальных сценариях применения.(Источник: LangChainAI)
Концепция инструмента AI для создания подсказок рекламодателей : Высказано мнение, что рынку срочно необходим AI-инструмент, помогающий маркетологам создавать “подсказки рекламодателей”. Этот инструмент должен помогать в создании системы оценки (охватывающей безопасность бренда, соответствие подсказкам и т. д.) и тестировать основные модели. Поскольку OpenAI выпускает различные естественные рекламные блоки, важность маркетинговых подсказок становится все более очевидной, и такие инструменты станут ключевым звеном в процессе создания и распространения рекламы.(Источник: dbreunig)
Обновление Qwen Code: поддержка распознавания изображений моделью Qwen-VL : Командный Agent Qwen Code недавно обновился, добавив поддержку переключения на модель Qwen-VL для распознавания изображений. Тесты пользователей показали хорошие результаты, и в настоящее время он доступен бесплатно. Это обновление значительно расширяет возможности Qwen Code, позволяя ему не только выполнять задачи кодирования, но и осуществлять мультимодальное взаимодействие, повышая эффективность и точность Agent кодирования при работе с задачами, содержащими визуальную информацию.(Источник: karminski3)

Использование LibreChat для хостинга личного сервера чат-бота : В статье блога представлено руководство по использованию LibreChat для хостинга личного сервера чат-бота и подключения к нескольким панелям управления моделями (MCPs). Это позволяет пользователям гибко управлять и переключать различные бэкэнды LLM, создавая индивидуальный опыт чат-бота, и подчеркивает гибкость и управляемость решений с открытым исходным кодом при развертывании AI-приложений.(Источник: Reddit r/artificial)
AI-генератор: Оживление виртуальных персонажей : Пользователь ищет лучший AI-генератор, чтобы “оживить” свой бренд (включая видео с реальными людьми и виртуальные аватары) для YouTube-канала, сократить время на съемку и запись, сосредоточившись на монтаже. Пользователь хочет, чтобы AI позволял виртуальным персонажам разговаривать, играть в игры, танцевать и т. д. Это отражает высокий спрос создателей контента на AI-инструменты для анимации виртуальных персонажей и генерации видео, с целью повышения эффективности производства и разнообразия контента.(Источник: Reddit r/artificial)
Локальный LLM против спама: приватное решение : В статье блога рассказывается о том, как использовать локальный LLM для приватного выявления и борьбы со спамом на собственном почтовом сервере. Это решение, сочетающее Mailcow, Rspamd, Ollama и пользовательский Python-агент, предоставляет пользователям самохостинговых почтовых серверов метод фильтрации спама на основе AI, подчеркивая потенциал локальных LLM в защите конфиденциальности и индивидуальных приложениях.(Источник: Reddit r/LocalLLaMA)
📚 Обучение
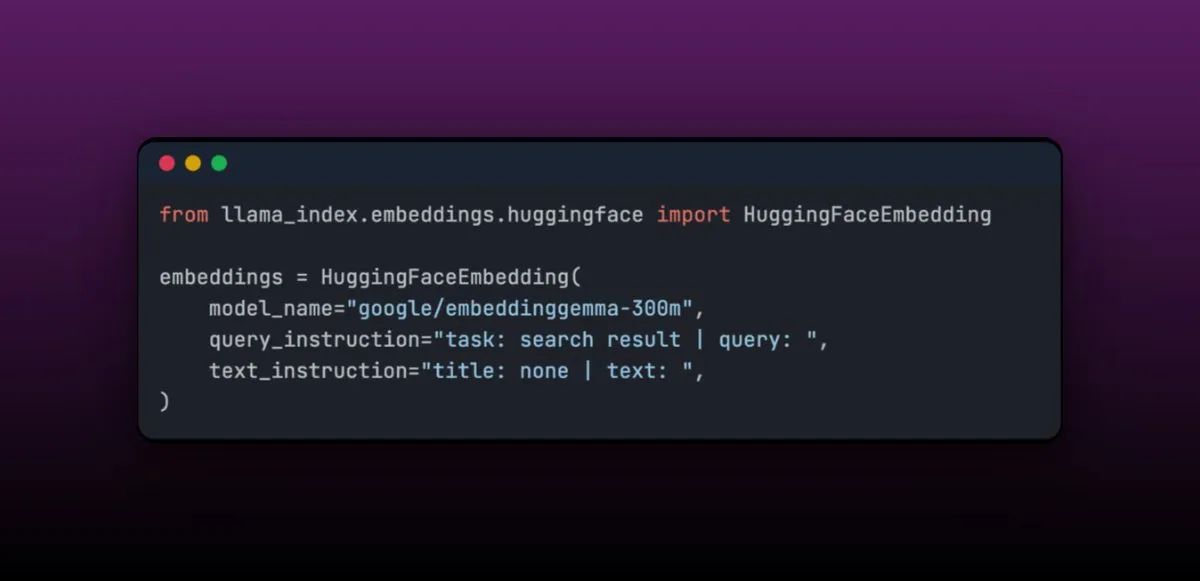
EmbeddingGemma: Многоязычная модель встраивания для RAG-приложений на устройствах : EmbeddingGemma — это компактная многоязычная модель встраивания с всего 308 миллионами параметров, идеально подходящая для RAG-приложений на устройствах и легко интегрируемая с LlamaIndex. Эта модель занимает высокие позиции в Massive Text Embedding Benchmark, при этом она компактна и подходит для мобильных устройств. Ее легкость в тонкой настройке позволяет ей превосходить более крупные модели по производительности после доработки в специфических областях (например, медицинских данных).(Источник: jerryjliu0)
Два основных метода обработки документов: парсинг и извлечение : Статья команды LlamaIndex подробно рассматривает два основных метода обработки документов: “парсинг” и “извлечение”. Парсинг — это преобразование всего документа в структурированный Markdown или JSON с сохранением всей информации, что подходит для RAG, глубоких исследований и резюмирования. Извлечение — это получение структурированного вывода из LLM, стандартизация документа в общий шаблон, что подходит для ETL баз данных, автоматизированных рабочих процессов Agent и извлечения метаданных. Понимание различий между ними крайне важно для создания эффективных документных Agent.(Источник: jerryjliu0)

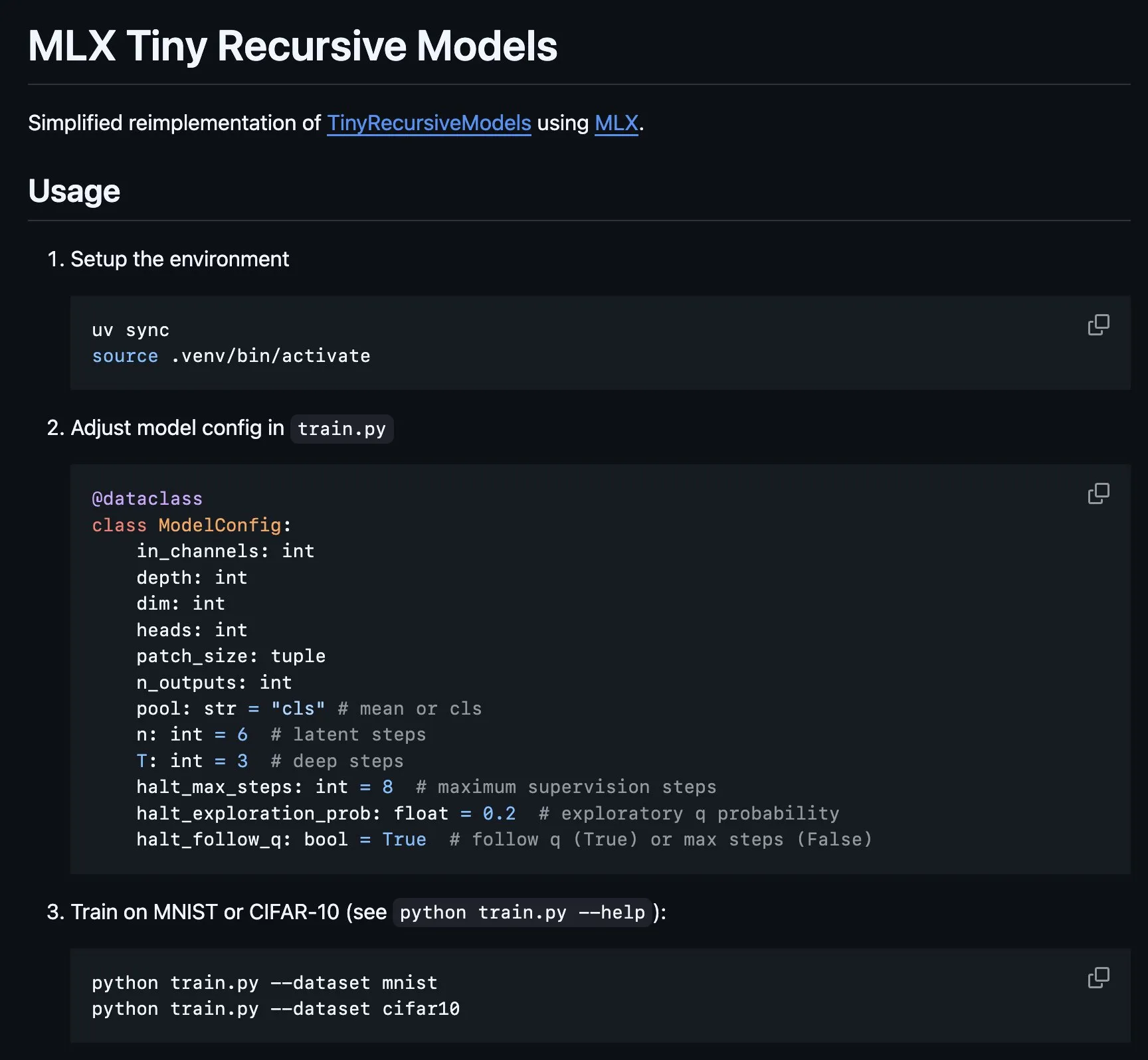
Реализация Tiny Recursive Model (TRM) на MLX : Платформа MLX реализовала основную часть Tiny Recursive Model (TRM), предложенной Alexia Jolicoeur-Martineau, которая направлена на достижение высокой производительности с помощью рекурсивного вывода в крошечной нейронной сети с 7 миллионами параметров. Эта реализация MLX сделала возможными локальные эксперименты на ноутбуках Apple Silicon, снизила сложность и охватила такие функции, как глубокое обучение с учителем, шаги рекурсивного вывода, EMA, что обеспечило удобство для разработки и исследования небольших эффективных моделей.(Источник: awnihannun, ImazAngel)
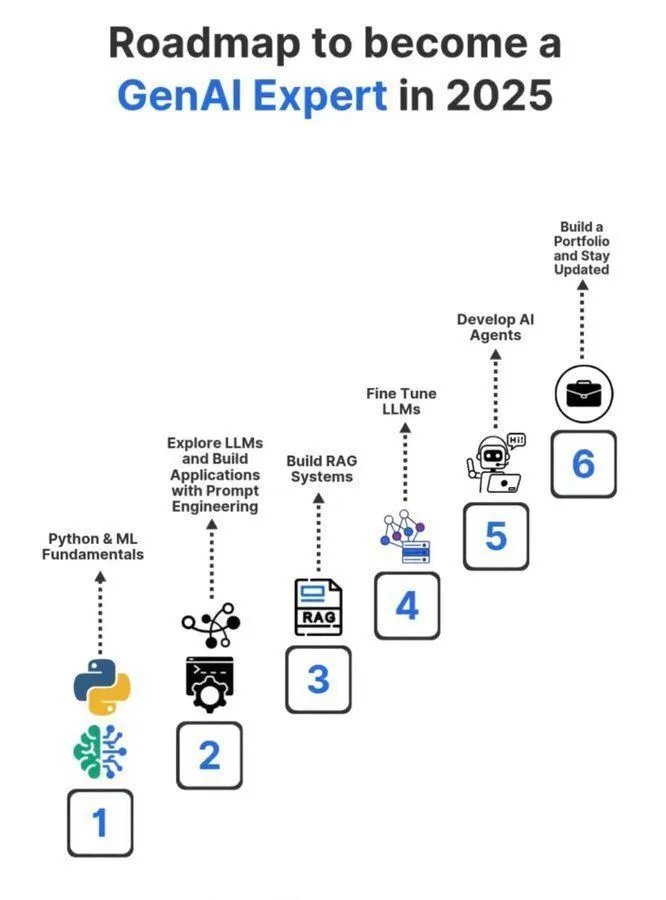
Дорожная карта обучения специалиста по генеративному AI на 2025 год : Подробная дорожная карта обучения специалиста по генеративному AI на 2025 год была опубликована в социальных сетях, охватывая ключевые знания и навыки, необходимые для того, чтобы стать профессионалом в области генеративного AI. Эта дорожная карта призвана помочь тем, кто стремится систематически изучать основные концепции искусственного интеллекта, машинного обучения и глубокого обучения, чтобы адаптироваться к быстро развивающимся технологическим тенденциям GenAI.(Источник: Ronald_vanLoon)
Обмен опытом обучения в докторантуре по машинному обучению : Пользователь повторно поделился серией твитов об обучении в докторантуре в области машинного обучения, призванных предоставить руководство и опыт тем, кто интересуется докторскими исследованиями в ML. Эти твиты могут охватывать процесс подачи заявки, направления исследований, карьерное развитие и личный опыт, являясь ценным ресурсом для изучения AI в сообществе.(Источник: arohan)
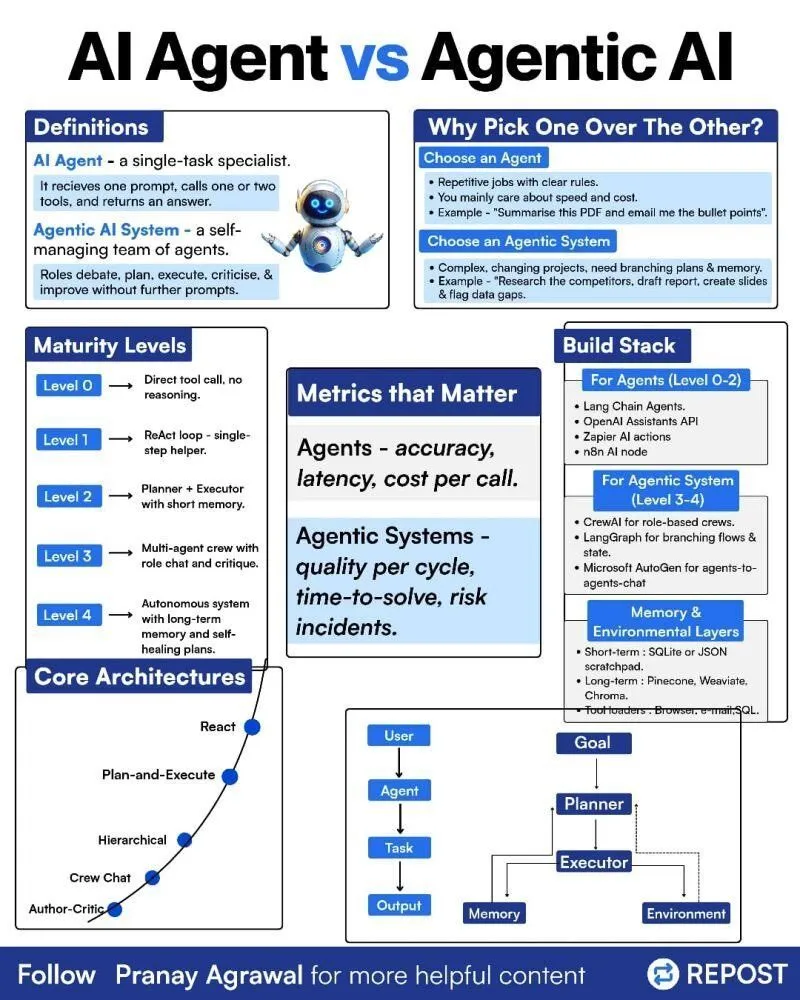
Различия между AI Agents и Agentic AI : В социальных сетях была опубликована инфографика, объясняющая различия между “AI Agents” и “Agentic AI”, с целью прояснить эти два связанные, но разные понятия. Это помогает сообществу лучше понять типы развертывания AI Agent, уровень их автономности и роль Agentic AI в более широких системах искусственного интеллекта, способствуя более точным дискуссиям о технологии Agent.(Источник: Ronald_vanLoon)
Обучение с подкреплением и затухание весов в тренировке LLM : В социальных сетях обсуждалось, что Weight Decay может быть не лучшей идеей при обучении LLM с подкреплением (RL). Есть мнение, что Weight Decay приводит к тому, что сеть забывает большое количество предварительно обученной информации, особенно в обновлениях GRPO с нулевым преимуществом, где веса стремятся к нулю. Это указывает исследователям на необходимость тщательно учитывать влияние Weight Decay при разработке стратегий обучения LLM с RL, чтобы избежать снижения производительности модели.(Источник: lateinteraction)
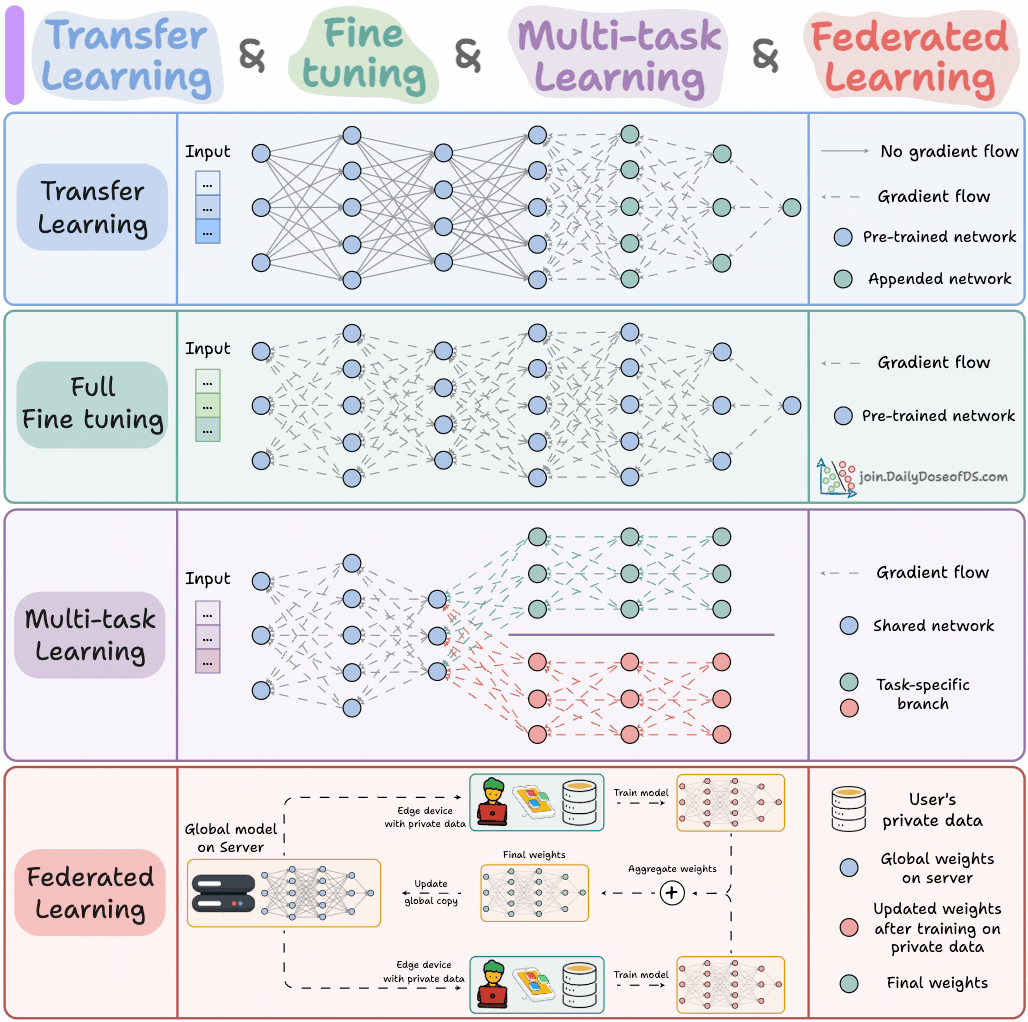
Парадигмы обучения AI-моделей : Эксперт поделился четырьмя парадигмами обучения моделей, которые должен знать каждый ML-инженер, с целью предоставить ключевое теоретическое руководство и практическую основу для инженеров машинного обучения. Эти парадигмы могут охватывать Supervised Learning, Unsupervised Learning, Reinforcement Learning и Self-supervised Learning, помогая инженерам лучше понимать и применять различные методы обучения моделей.(Источник: _avichawla)
Обучение с подкреплением на основе учебной программы для повышения возможностей LLM : Исследование показало, что обучение с подкреплением (RL) в сочетании с учебной программой может обучать LLM новым возможностям, что труднодостижимо другими методами. Это указывает на потенциал учебной программы в повышении долгосрочных рассудочных способностей LLM, предвещая, что сочетание RL и учебной программы может стать ключевым путем к разблокировке новых навыков AI.(Источник: sytelus)

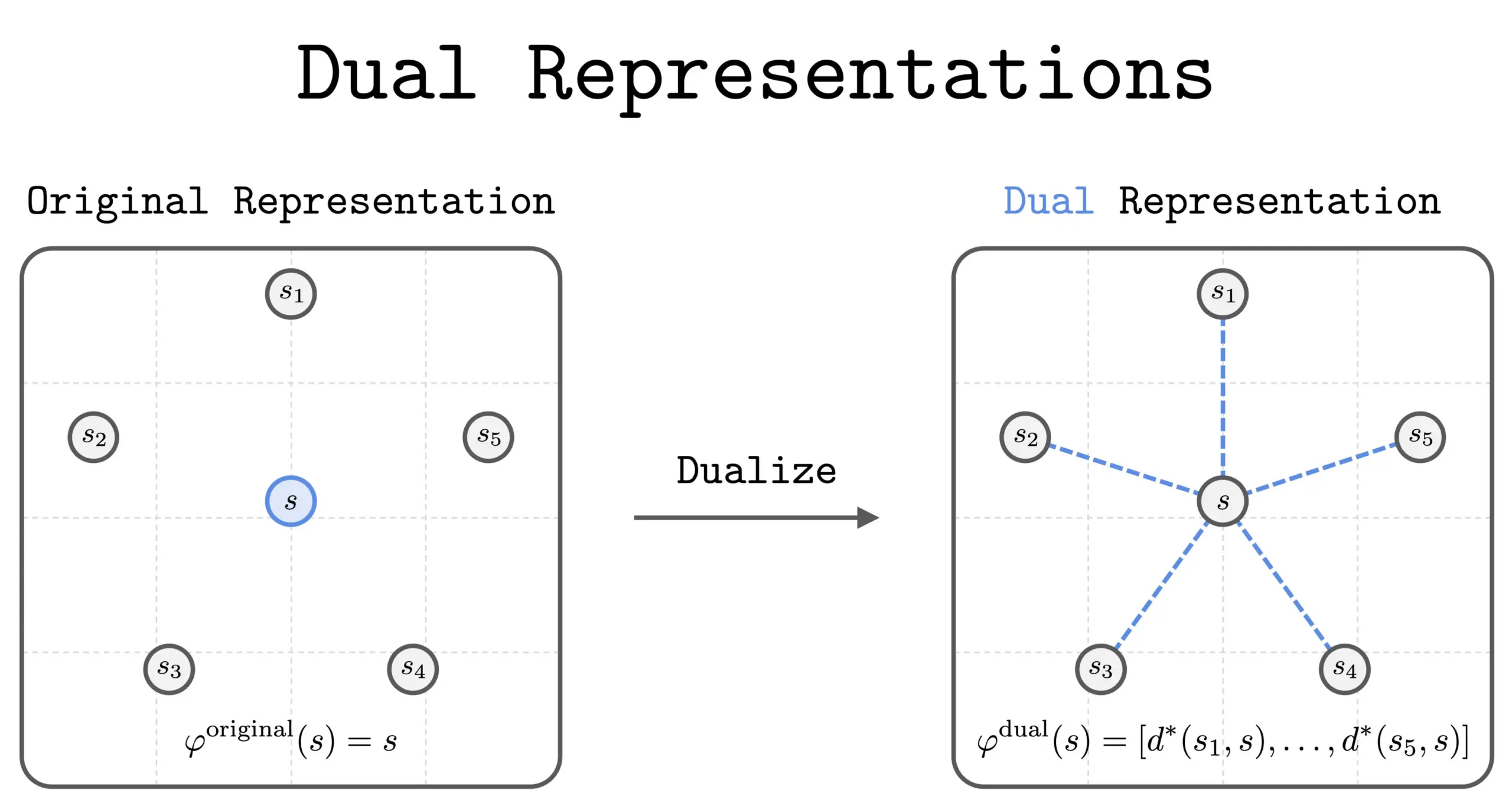
Новый метод двойного представления в RL : Новое исследование представило метод “двойного представления” в обучении с подкреплением (RL). Этот метод предлагает новую перспективу, представляя состояния как “наборы сходства” со всеми другими состояниями. Это двойное представление обладает хорошими теоретическими свойствами и практическими преимуществами, что, как ожидается, повысит производительность и понимание RL.(Источник: dilipkay)
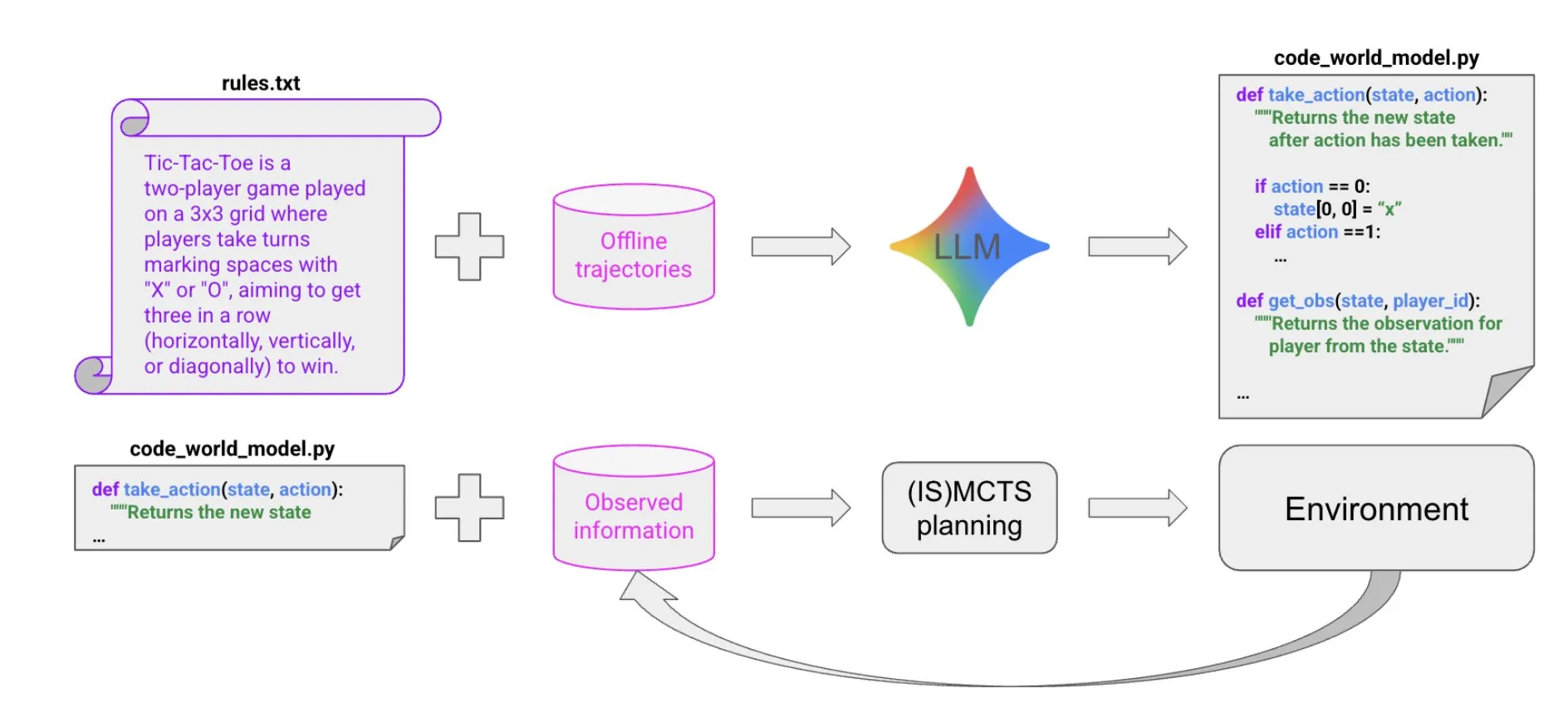
Создание мировых моделей с помощью синтеза кода, управляемого LLM : Новая статья предлагает чрезвычайно эффективный по выборке метод создания Agent, способных хорошо работать в многоAgentных, частично наблюдаемых символических средах, посредством синтеза кода, управляемого LLM. Этот метод изучает кодовую мировую модель из небольшого количества данных траекторий и фоновой информации, а затем передает ее существующим решателям (например, MCTS) для выбора следующего действия, предоставляя новые идеи для создания сложных Agent.(Источник: BlackHC)
Обучение RL малых моделей: новые возможности, превосходящие предварительное обучение : Исследования показали, что в обучении с подкреплением (RL) малые модели могут непропорционально выигрывать и даже демонстрировать “эмерджентные” способности, что опровергает традиционное представление “чем больше, тем лучше”. На малых моделях RL может быть более вычислительно эффективным, чем большее предварительное обучение. Это открытие имеет важное значение для AI-лабораторий при принятии решений о том, когда прекращать предварительное обучение и когда начинать RL при масштабировании RL, раскрывая новые законы масштабирования между размером модели и повышением производительности в RL.(Источник: ClementDelangue, ClementDelangue)
AI vs. Machine Learning vs. Deep Learning: Простое объяснение : Видеоресурс простым и понятным способом объясняет различия между искусственным интеллектом (AI), машинным обучением (ML) и глубоким обучением (DL). Это видео призвано помочь новичкам быстро понять эти основные концепции и заложить основу для дальнейшего углубленного изучения области AI.(Источник: )

Управление шаблонами подсказок в экспериментах с моделями глубокого обучения : Сообщество глубокого обучения обсудило, как управлять и повторно использовать шаблоны подсказок в экспериментах с моделями. В крупных проектах, особенно при изменении архитектуры или набора данных, отслеживание эффектов различных вариантов подсказок становится сложным. Пользователи поделились опытом использования таких инструментов, как Empromptu AI, для контроля версий и классификации подсказок, подчеркивая важность версионирования подсказок и согласования наборов данных с подсказками для оптимизации продуктов модели.(Источник: Reddit r/deeplearning)
Руководство по выбору модели для автодополнения кода (FIM) : Сообщество обсудило ключевые факторы выбора модели для автодополнения кода (FIM). Скорость считается абсолютным приоритетом, рекомендуется выбирать модели с небольшим количеством параметров, работающие только на GPU (цель >70 t/s). Кроме того, “базовые” модели и модели с инструкциями показали схожие результаты в задачах FIM. В обсуждении также были перечислены недавние и более старые FIM-модели, такие как Qwen3-Coder, KwaiCoder, и рассмотрено, как такие инструменты, как nvim.llm, могут поддерживать модели, не специфичные для кода.(Источник: Reddit r/LocalLLaMA)
Компромиссы производительности квантованных моделей: большие модели и низкая точность : Сообщество обсудило компромиссы производительности между большими квантованными моделями и маленькими неквантованными моделями, а также влияние уровня квантования на производительность модели. Общепринято, что 2-битное квантование может подходить для письма или диалога, но для таких задач, как кодирование, требуется как минимум уровень Q5. Некоторые пользователи отметили, что Gemma3-27B демонстрирует значительное снижение производительности при низком квантовании, в то время как некоторые новые модели обучаются с точностью FP4 и не требуют более высокой точности. Это указывает на то, что эффект квантования варьируется в зависимости от модели и задачи, и требует конкретного тестирования.(Источник: Reddit r/LocalLLaMA)
Причины сбоя алгоритма MissForest в R при выполнении задач прогнозирования : Аналитическая статья исследует причины сбоя алгоритма MissForest в R при выполнении задач прогнозирования, указывая, что при атрибуции он незаметно нарушает ключевой принцип разделения обучающего и тестового наборов. В статье объясняются ограничения MissForest в таких ситуациях и представлены новые методы, такие как MissForestPredict, которые решают эту проблему, поддерживая согласованность между обучением и применением. Это имеет важное руководящее значение для практиков машинного обучения при работе с пропущенными значениями и построении прогнозных моделей.(Источник: Reddit r/MachineLearning)
Поиск ресурсов по мультимодальному машинному обучению : Пользователи сообщества ищут учебные ресурсы по мультимодальному машинному обучению, особенно теоретические и практические материалы о том, как комбинировать различные типы данных (текст, изображения, сигналы и т. д.) и понимать такие концепции, как слияние, выравнивание и кросс-модальное внимание. Это отражает растущий спрос на изучение мультимодальных AI-технологий.(Источник: Reddit r/deeplearning)
Поиск видеоресурсов по обучению моделей вывода с помощью Reinforcement Learning : Сообщество машинного обучения ищет лучшие видеоресурсы научных лекций по использованию Reinforcement Learning (RL) для обучения моделей вывода, включая обзорные видео и углубленное объяснение конкретных методов. Пользователи хотят получить высококачественный академический контент, а не поверхностные видео от инфлюенсеров, чтобы быстро ознакомиться с соответствующей литературой и определить дальнейшие направления исследований.(Источник: Reddit r/MachineLearning)
11-месячное путешествие в AI-кодировании: инструменты, технологический стек и лучшие практики : Разработчик поделился своим 11-месячным путешествием в AI-кодировании, подробно рассказав об опыте, неудачах и лучших практиках использования таких инструментов, как Claude Code. Он подчеркнул, что в AI-кодировании предварительное планирование и управление контекстом гораздо важнее, чем само написание кода. Хотя AI снижает порог для реализации кода, он не заменяет архитектурный дизайн и деловую проницательность. Этот обмен опытом охватывает несколько проектов, от фронтенда до бэкенда, разработки мобильных приложений, и рекомендует вспомогательные инструменты, такие как Context7, SpecDrafter.(Источник: Reddit r/ClaudeAI)
💼 Бизнес
JPMorgan Chase: 2 миллиарда долларов инвестиций в год, трансформация в “полностью AI-банк” : Генеральный директор JPMorgan Chase Jamie Dimon объявил о ежегодных инвестициях в размере 2 миллиардов долларов в AI с целью превращения компании в “полностью AI-банк”. AI глубоко интегрирован в основные бизнес-процессы, такие как управление рисками, торговля, обслуживание клиентов, комплаенс, инвестиционный банкинг, что не только экономит затраты, но, что более важно, ускоряет темп работы и меняет суть должностей. JPMorgan Chase, используя собственную платформу LLM Suite и широкомасштабное развертывание AI Agent, рассматривает AI как базовую операционную систему для работы компании и подчеркивает, что интеграция данных и кибербезопасность являются самыми большими вызовами для ее AI-стратегии. Dimon считает, что AI — это реальная долгосрочная ценность, а не краткосрочный пузырь, и он переопределит понятие банка.(Источник: 36氪)
Apple от Маск