

Ключевые слова:ИИ индустрия, GPT-5, AGI, коррекция хайпа ИИ, безопасность ИИ, программирование ИИ, ИИ агенты, мультимодальные модели, ИИ в материаловедении, оптимизация рассуждений LLM, воплощённый ИИ, бенчмаркинг ИИ, генерация презентаций на основе ИИ
🔥 Фокус
«Коррекция хайпа» в индустрии AI и переосмысление реальности: В 2025 году индустрия AI вступает в фазу «коррекции хайпа», и ожидания рынка от AI возвращаются к рациональности после периода «панацеи». Лидеры отрасли, такие как Sam Altman, признают существование AI-пузыря, особенно в отношении оценки стартапов и огромных инвестиций в строительство центров обработки данных. В то же время выпуск GPT-5 не оправдал ожиданий, что вызвало дискуссии о «бутылочных горлышках» в развитии LLM. Эксперты призывают пересмотреть истинные возможности AI, различая «яркие демонстрации» генеративного AI и реальные прорывы предиктивного AI в медицине, науке и других областях, подчеркивая, что ценность AI заключается в его надежности и устойчивости, а не в слепом стремлении к AGI. (Источник: MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review)

Прорывы и вызовы AI в материаловедении: AI применяется для ускорения открытия новых материалов, планируя, проводя и интерпретируя эксперименты с помощью AI-агентов, что, как ожидается, сократит процесс открытия с десятилетий до нескольких лет. Компании, такие как Lila Sciences и Periodic Labs, создают автоматизированные лаборатории на базе AI для решения проблем синтеза и тестирования в традиционном материаловедении. Хотя DeepMind заявляла об открытии «миллионов новых материалов», их фактическая новизна и практичность были поставлены под сомнение, что подчеркивает разрыв между виртуальным моделированием и физической реальностью. Отрасль переходит от чисто вычислительных моделей к сочетанию с экспериментальной проверкой, стремясь открыть прорывные материалы, такие как сверхпроводники комнатной температуры. (Источник: MIT Technology Review)

Споры о продуктивности AI-программирования и техническом долге: Инструменты AI-программирования широко распространены: CEO Microsoft и Google заявляют, что AI генерирует четверть кода их компаний, а CEO Anthropic прогнозирует, что в будущем 90% кода будет написано AI. Однако повышение фактической продуктивности вызывает споры; некоторые исследования показывают, что AI может замедлять разработку и увеличивать «технический долг» (например, снижение качества кода, сложность обслуживания). Тем не менее, AI отлично справляется с написанием шаблонного кода, тестированием и исправлением ошибок, а инструменты нового поколения, такие как Claude Code, значительно улучшают возможности обработки сложных задач за счет режимов планирования и управления контекстом. Отрасль исследует новые парадигмы, такие как «выбрасываемый код» и формальная верификация, чтобы адаптироваться к моделям разработки, управляемым AI. (Источник: MIT Technology Review)

Сторонники AI-безопасности по-прежнему обеспокоены рисками AGI: Несмотря на то, что недавнее развитие AI, как считается, вступило в период «коррекции хайпа», а GPT-5 показал себя посредственно, сторонники AI-безопасности («AI-думеры») по-прежнему глубоко обеспокоены потенциальными рисками AGI (общего искусственного интеллекта). Они считают, что, хотя темпы прогресса AI могут замедлиться, его фундаментальная опасность не изменилась, и разочарованы тем, что политики не уделяют достаточного внимания рискам AI. Они подчеркивают, что даже если AGI будет достигнут в течение десятилетий, а не лет, необходимо немедленно выделить ресурсы для решения проблем контроля и остерегаться долгосрочных негативных последствий чрезмерных инвестиций отрасли в AI-пузырь. (Источник: MIT Technology Review)

🎯 Тенденции
Продолжающиеся прорывы в мультимодальных моделях генерации видео: Alibaba выпустила видеомодель Wan 2.6, которая поддерживает ролевые игры, синхронизацию аудио и видео, генерацию нескольких кадров и управление звуком, с продолжительностью одного видео до 15 секунд, и считается «маленькой Sora 2». ByteDance также представила Seedance 1.5 Pro, особенностью которой является поддержка диалектов. LongVie 2 в HuggingFace Daily Papers предлагает мультимодальную управляемую сверхдлинную видеомодель мира, подчеркивая управляемость, долгосрочное визуальное качество и временную согласованность. Эти достижения знаменуют значительное улучшение технологии генерации видео в реалистичности, интерактивности и сценариях применения. (Источник: Alibaba_Wan, op7418, op7418, HuggingFace Daily Papers)

Новые достижения в AI-голосовых технологиях: многоязычность и потоковая передача в реальном времени: Alibaba выпустила модель CosyVoice 3 TTS с открытым исходным кодом, которая поддерживает 9 языков и более 18 китайских диалектов, предлагает многоязычное/кросс-языковое клонирование голоса с нулевым количеством примеров и обеспечивает двунаправленную потоковую передачу с ультранизкой задержкой в 150 миллисекунд. API OpenAI для реального времени также обновил модели gpt-4o-mini-transcribe и gpt-4o-mini-tts, значительно уменьшив галлюцинации и частоту ошибок, а также улучшив многоязычную производительность. Модель Gemini 2.5 Flash Native Audio от Google DeepMind также была обновлена, что еще больше оптимизировало следование инструкциям и естественность диалога, способствуя применению голосовых AI-агентов в реальном времени. (Источник: ImazAngel, Reddit r/LocalLLaMA, snsf, GoogleDeepMind)
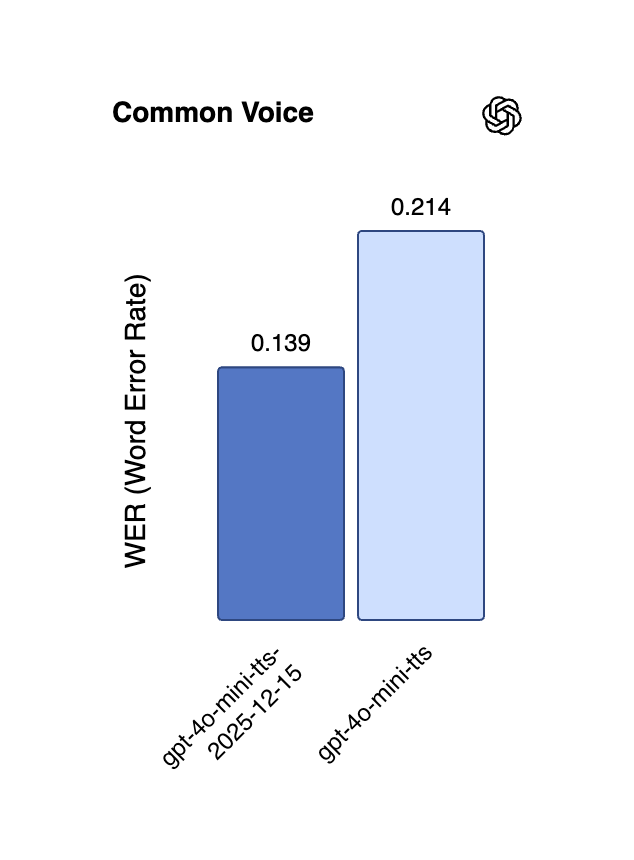
Длинноконтекстный вывод и оптимизация эффективности больших моделей: QwenLong-L1.5, благодаря инновациям в системном пост-обучении, демонстрирует возможности длинноконтекстного вывода, сравнимые с GPT-5 и Gemini-2.5-Pro, и превосходно справляется со сверхдлинными задачами. GPT-5.2 также получил положительные отзывы пользователей за свои возможности длинного контекста, особенно за более детальное суммирование подкастов. Кроме того, ReFusion предлагает новую модель маскированной диффузии, которая обеспечивает значительное повышение производительности и эффективности за счет параллельного декодирования на уровне слотов, ускоряя работу в среднем в 18 раз и сокращая разрыв в производительности с авторегрессионными моделями. (Источник: gdb, HuggingFace Daily Papers, HuggingFace Daily Papers, teortaxesTex)
Прогресс в Embodied AI и робототехнике: AgiBot выпустил человекоподобного робота Lingxi X2, обладающего мобильностью, близкой к человеческой, и многофункциональными навыками. Несколько исследований в HuggingFace Daily Papers сосредоточены на Embodied AI, например, Toward Ambulatory Vision исследует активный выбор точки обзора с визуальной привязкой, Spatial-Aware VLA Pretraining достигает визуально-физического выравнивания с помощью человеческого видео, а VLSA вводит подключаемый слой ограничений безопасности для повышения безопасности моделей VLA. Эти исследования направлены на сокращение разрыва между 2D-зрением и действиями в 3D-физической среде, способствуя обучению роботов и их практическому развертыванию. (Источник: Ronald_vanLoon, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
Вклад NVIDIA и Meta в архитектуру AI и открытые модели: NVIDIA выпустила семейство открытых моделей Nemotron v3 Nano и открыла полный стек обучения (включая инфраструктуру RL, среды, данные для предварительного и пост-обучения), направленный на содействие созданию профессиональных AI-агентов в различных отраслях. Meta представила архитектуру совместного встраивания визуального языка VL-JEPA, которая является первой негенеративной моделью, способной эффективно выполнять общие визуально-языковые задачи в потоковых приложениях реального времени, превосходя по производительности крупные VLM. (Источник: ylecun, QuixiAI, halvarflake)

Инновации в бенчмарках и методах оценки AI: Google Research представила FACTS Leaderboard, которая всесторонне оценивает фактичность LLM по четырем измерениям: мультимодальность, параметрические знания, поиск и привязка, выявляя компромиссы между охватом и уровнем противоречий в различных моделях. Бенчмарк V-REX оценивает исследовательские визуальные рассуждения VLM с помощью «цепочек вопросов», а START фокусируется на текстовом и пространственном обучении для понимания диаграмм. Эти новые бенчмарки призваны более точно измерять производительность моделей AI в сложных, реальных задачах. (Источник: omarsar0, HuggingFace Daily Papers, HuggingFace Daily Papers)

Повышение автономности AI-агентов в сетевой среде: WebOperator предлагает фреймворк поиска по дереву с учетом действий, который позволяет LLM-агентам надежно возвращаться назад и стратегически исследовать частично наблюдаемые сетевые среды. Этот метод генерирует кандидатов на действия с использованием нескольких контекстов вывода и фильтрует недействительные действия, значительно повышая уровень успеха задач WebArena, подчеркивая ключевое преимущество сочетания стратегического предвидения и безопасного выполнения. (Источник: HuggingFace Daily Papers)
AI-помощь в автономном вождении и 4D-модели мира: DrivePI — это пространственно-ориентированная 4D MLLM, которая объединяет понимание, восприятие, прогнозирование и планирование для автономного вождения. Она интегрирует облака точек, многоракурсные изображения и языковые инструкции, а также генерирует пары вопросов и ответов «текст-занятость» и «текст-поток», достигая точного прогнозирования 3D-занятости и потока занятости, превосходя существующие модели VLA и специализированные модели VA на таких бенчмарках, как nuScenes. GenieDrive фокусируется на физически-ориентированной модели мира вождения, улучшая точность прогнозирования и качество видео за счет генерации видео, управляемой 4D-занятостью. (Источник: HuggingFace Daily Papers, HuggingFace Daily Papers)
🧰 Инструменты
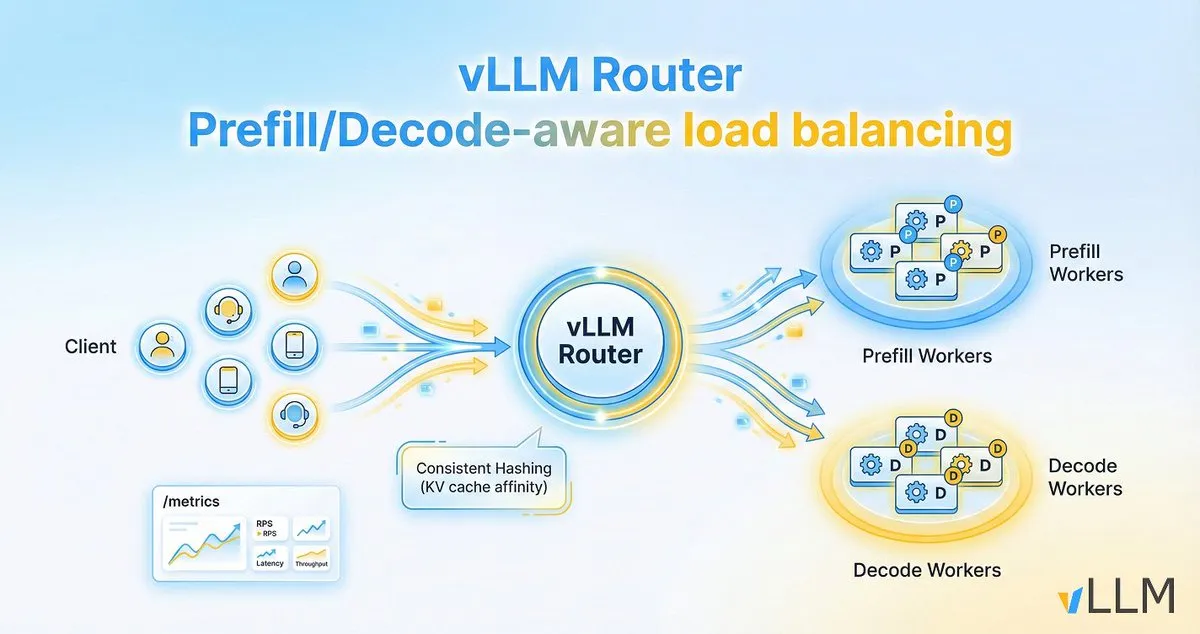
vLLM Router повышает эффективность вывода LLM: Проект vLLM выпустил vLLM Router, легковесный, высокопроизводительный, чувствительный к предварительной загрузке/декодированию балансировщик нагрузки, разработанный специально для кластеров vLLM. Он написан на Rust, поддерживает такие стратегии, как согласованное хеширование и выбор двух наименьших степеней, и направлен на оптимизацию локальности KV-кэша, устранение узких мест в диалоговом трафике и разделении предварительной загрузки/декодирования, тем самым увеличивая пропускную способность вывода LLM и снижая задержку в хвосте. (Источник: vllm_project)
AI21 Maestro упрощает создание AI-агентов: Vibe Agent от AI21Labs, запущенный в AI21 Maestro, позволяет пользователям создавать AI-агентов с помощью простых описаний на английском языке. Инструмент автоматически предлагает варианты использования агента, проверки валидации, необходимые инструменты и настройки модели/вычислений, а также объясняет каждый шаг в реальном времени, значительно снижая порог для создания сложных AI-агентов. (Источник: AI21Labs)
OpenHands SDK ускоряет разработку программного обеспечения, управляемого агентами: OpenHands выпустила SDK для программных агентов, призванный предоставить быструю, гибкую и готовую к производству среду для создания программного обеспечения, управляемого агентами. Выпуск этого SDK поможет разработчикам более эффективно интегрировать и управлять AI-агентами для решения сложных задач разработки программного обеспечения. (Источник: gneubig)

Обновление Claude Code CLI улучшает опыт разработки: Anthropic выпустила версию Claude Code 2.0.70, включающую 13 улучшений CLI. Основные обновления включают: поддержку клавиши Enter для принятия предложений подсказок, синтаксис подстановочных знаков для разрешений инструментов MCP, автоматическое обновление плагинов, принудительный режим планирования и т. д. Кроме того, эффективность использования памяти увеличена в 3 раза, разрешение скриншотов выше, что направлено на оптимизацию взаимодействия и эффективности разработчиков при использовании Claude Code для разработки программного обеспечения. (Источник: Reddit r/ClaudeAI)
Qwen3-Coder позволяет быстро разрабатывать 2D-игры: Пользователь Reddit продемонстрировал, как использовать модель Qwen3-Coder (480B) от Alibaba для создания 2D-игры в стиле Mario за несколько секунд с помощью Cursor IDE. Модель, начиная с одной подсказки, автоматически планирует шаги, устанавливает зависимости, генерирует код и структуру проекта, а также может быть запущена напрямую. Стоимость ее работы низка (около 2 долларов за миллион токенов), а опыт использования близок к режиму агента GPT-4, что демонстрирует мощный потенциал моделей с открытым исходным кодом в генерации кода и задачах агентов. (Источник: Reddit r/artificial)
Инструмент для глубокого исследования акций на базе AI: Инструмент Deep Research использует AI для извлечения данных из документов SEC и отраслевых публикаций, генерируя стандартизированные отчеты, упрощающие сравнение и отбор компаний. Пользователи могут вводить тикеры акций для получения глубокого анализа. Инструмент призван помочь инвесторам более эффективно проводить фундаментальные исследования, избегая отвлекающих рыночных новостей и сосредоточившись на существенной финансовой информации. (Источник: Reddit r/ChatGPT)
LangChain 1.2 упрощает создание приложений Agentic RAG: LangChain выпустила версию 1.2, которая упрощает поддержку встроенных инструментов и строгого режима, особенно в функции create_agent. Это позволяет разработчикам более удобно создавать приложения Agentic RAG (Retrieval Augmented Generation), как для локального запуска, так и для Google Collab, и подчеркивает их 100% открытый исходный код. (Источник: LangChainAI, hwchase17)
Skywork запускает функцию генерации PPT на базе AI: Платформа Skywork запустила функцию генерации PPT на базе Nano Banana Pro, решив проблему сложности редактирования традиционных PPT, сгенерированных AI. Новая функция поддерживает разделение слоев, позволяя пользователям редактировать текст и изображения онлайн, а также экспортировать в формат pptx для локального редактирования. Кроме того, инструмент интегрирован с профессиональной отраслевой базой данных, поддерживает генерацию различных диаграмм, обеспечивая точность данных, и предлагает рождественские скидки. (Источник: op7418)

Малые модели для инфраструктуры как кода на периферии: Пользователь Reddit поделился моделью «инфраструктура как код» (IaC) размером 500 МБ, которая может работать на периферийных устройствах или в браузере. Эта модель, ориентированная на задачи IaC, компактна, но мощна, предлагая эффективное решение для развертывания и управления инфраструктурой в условиях ограниченных ресурсов, что предвещает огромный потенциал малых AI-моделей в конкретных вертикальных областях применения. (Источник: Reddit r/deeplearning)
📚 Обучение
Chinarxiv.org: Платформа для автоматического перевода китайских препринтов: Chinarxiv.org официально запущен как полностью автоматизированная платформа для перевода китайских препринтов, призванная преодолеть языковой барьер между китайскими и западными научными исследованиями. Платформа переводит не только текст, но и содержимое диаграмм, что позволяет западным исследователям легче получать доступ к новейшим научным достижениям Китая. (Источник: menhguin, andersonbcdefg, francoisfleuret)
Дорожная карта по освоению навыков AI и Agentic AI: Ronald_vanLoon поделился 12 ключевыми навыками для освоения AI в 2025 году, а также дорожной картой по освоению Agentic AI. Эти ресурсы призваны помочь людям повысить свою конкурентоспособность в быстро развивающейся области AI, охватывая путь обучения от базовых знаний AI до разработки продвинутых агентных систем, подчеркивая важность непрерывного обучения и адаптации к новым навыкам в эпоху AI. (Источник: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

Оптимизация процесса вывода LLM и развитие AI на основе данных: Исследования Meta Superintelligence Labs показывают, что стратегия PDR (Parallel Draft-Distill-Refine) — «параллельный черновик → дистилляция в компактное рабочее пространство → уточнение» — может обеспечить оптимальную точность выполнения задач при ограничениях вывода. В то же время, в одной из статей блога подчеркивается, что «данные — это зубчатый край AI», указывая на успех в областях кодирования и математики из-за обилия и проверяемости данных, в то время как научные области отстают, и обсуждается роль дистилляции и обучения с подкреплением в генерации данных. (Источник: dair_ai, lvwerra)

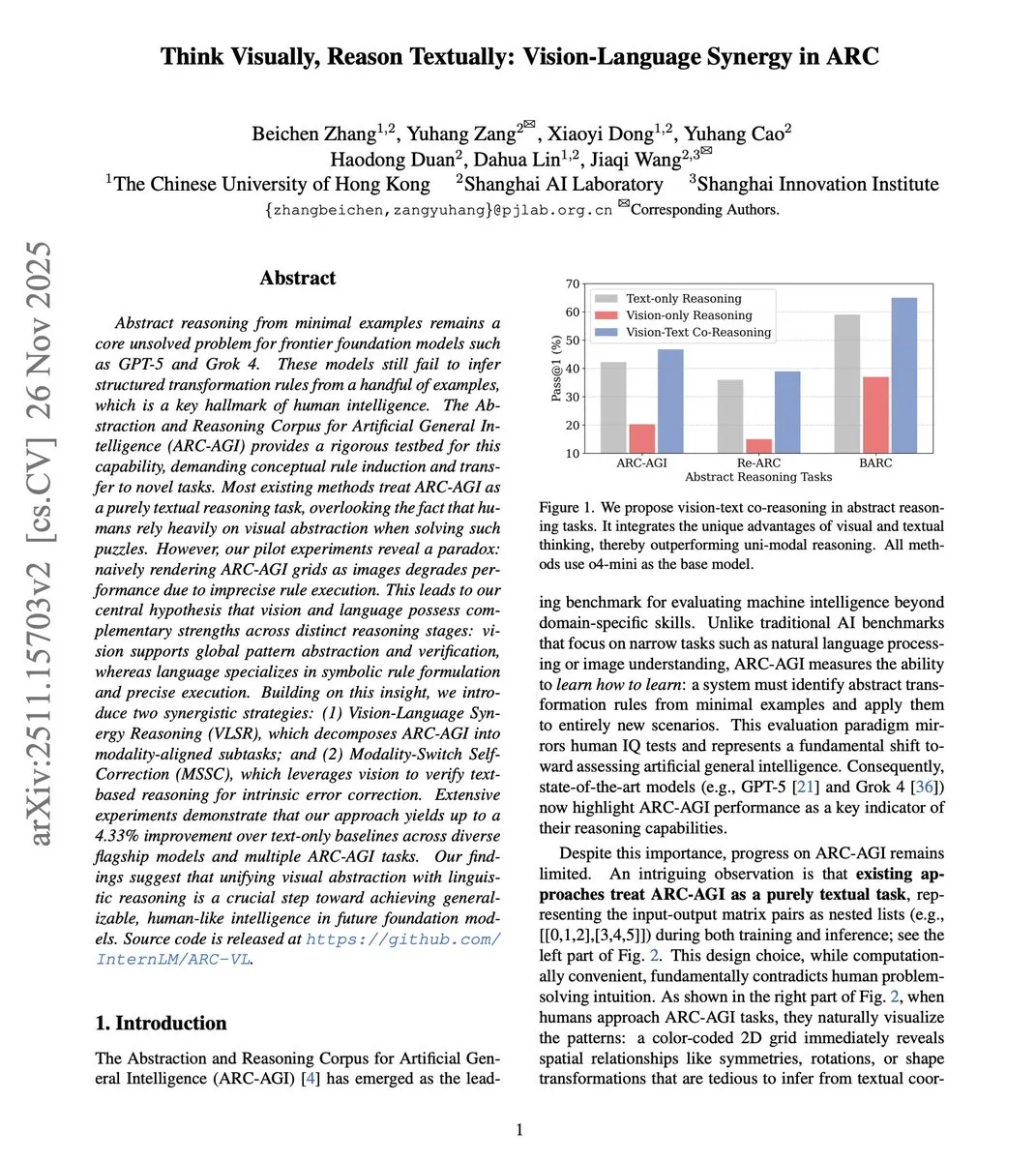
Совместные визуально-языковые рассуждения повышают абстрактные способности: Новое исследование предлагает фреймворк визуально-языковых совместных рассуждений (VLSR), который, стратегически сочетая визуальные и текстовые модальности на разных этапах рассуждений, значительно улучшает производительность LLM в задачах абстрактных рассуждений (например, бенчмарк ARC-AGI). Этот метод использует зрение для глобального распознавания образов, текст для точного выполнения и механизм самокоррекции с переключением модальностей для преодоления предвзятости подтверждения, превосходя даже производительность GPT-4o на малых моделях. (Источник: dair_ai)
Токены вывода LLM как новый взгляд на вычислительное состояние: Концептуальная основа State over Tokens (SoT) переопределяет токены вывода LLM как внешнее вычислительное состояние, а не просто языковое повествование. Это объясняет, как токены могут приводить к правильным рассуждениям, не являясь точной текстовой интерпретацией, и открывает новые направления исследований для понимания внутренних процессов LLM, подчеркивая, что исследования должны выходить за рамки текстовой интерпретации и фокусироваться на декодировании токенов рассуждений в состояния. (Источник: HuggingFace Daily Papers)
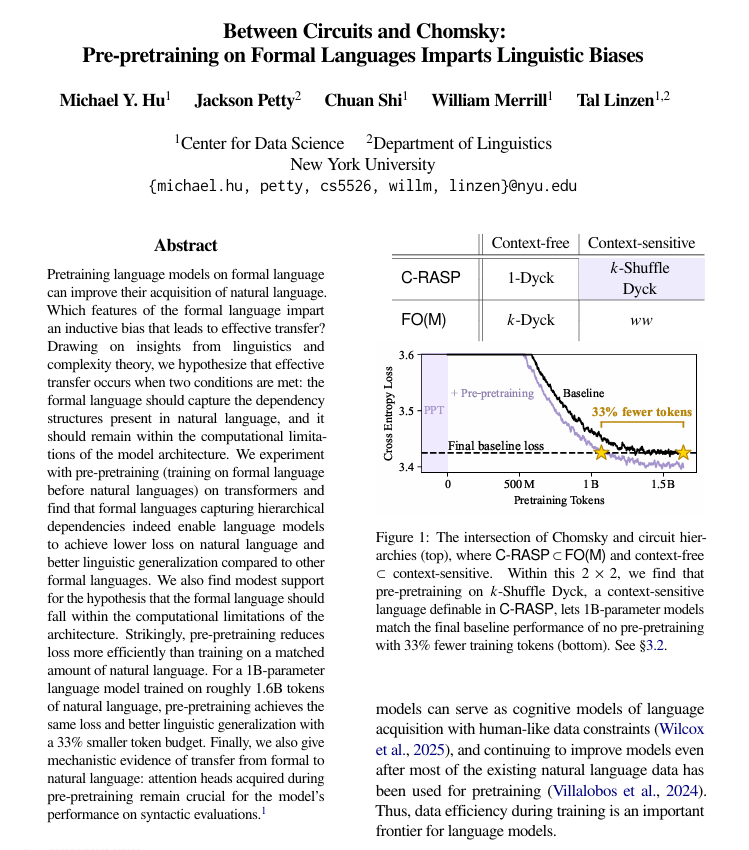
Предварительное обучение на формальных языках улучшает изучение естественного языка: Исследование Нью-Йоркского университета показало, что предварительное обучение на формальных, основанных на правилах языках перед предварительным обучением на естественном языке может значительно помочь языковым моделям лучше изучать человеческий язык. Исследование указывает, что такой формальный язык должен иметь структуру, аналогичную естественному языку (особенно иерархические отношения), и быть достаточно простым. Этот метод более эффективен, чем добавление того же количества данных на естественном языке, и изученные структурные механизмы переносятся внутри модели. (Источник: TheTuringPost)
Внедрение физических знаний в процесс генерации кода: Фреймворк Chain of Unit-Physics напрямую интегрирует физические знания в процесс генерации кода. Исследователи из Мичиганского университета предложили метод обратной генерации научного кода, который использует человеческие экспертные знания, закодированные в виде тестов физических единиц, для руководства и ограничения генерации кода. В многоагентной среде этот фреймворк позволяет системе достигать правильного решения за 5-6 итераций, увеличивая скорость работы на 33%, уменьшая использование памяти на 30% и обеспечивая чрезвычайно низкий уровень ошибок. (Источник: TheTuringPost)
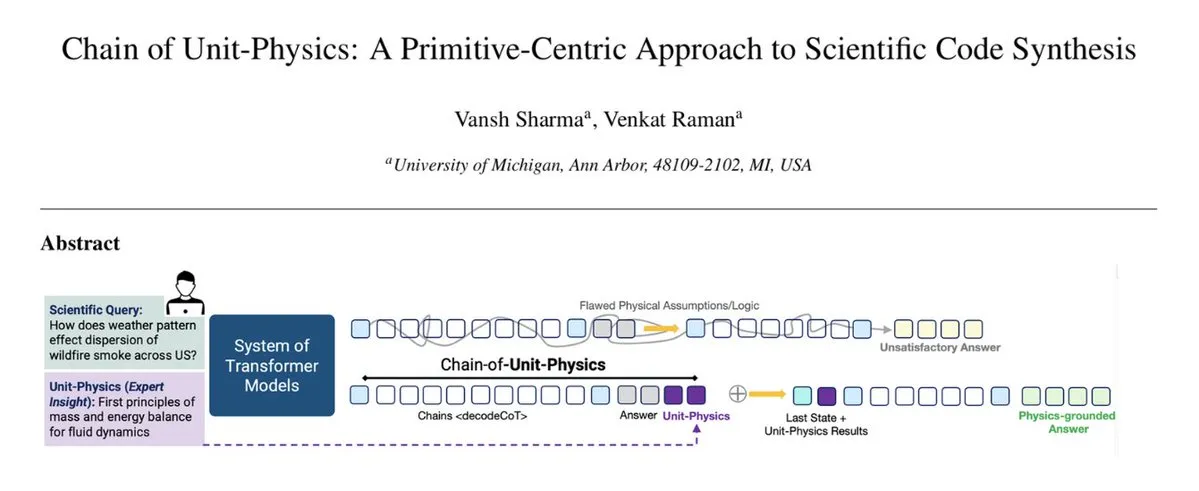
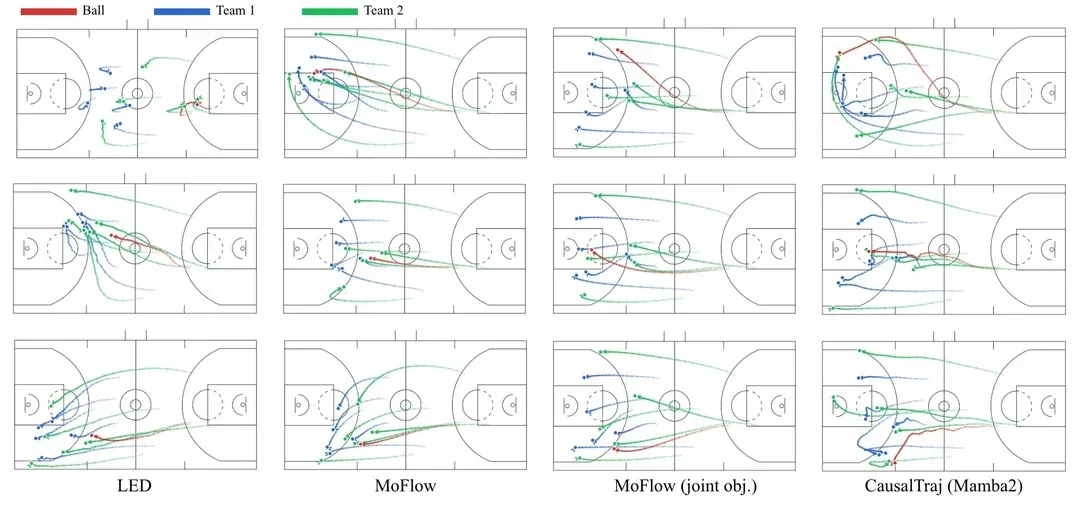
Модель CausalTraj для прогнозирования траекторий нескольких агентов в командных видах спорта: CausalTraj — это авторегрессионная модель для совместного прогнозирования траекторий нескольких агентов в командных видах спорта. Модель обучается непосредственно на цели совместной вероятности прогнозирования, а не только на оптимизации индивидуальных показателей агентов, что позволяет значительно улучшить согласованность и разумность траекторий нескольких агентов, сохраняя при этом индивидуальную производительность. Исследование также рассматривает, как более эффективно оценивать совместное моделирование и как оценивать реальную вероятность выборочных траекторий. (Источник: Reddit r/deeplearning)
Данные для обучения LLM: Ответы или вопросы?: Обсуждение на Reddit предполагает, что большинство текущих наборов данных для обучения LLM сосредоточены на «ответах», в то время как ключевая часть человеческого интеллекта заключается в хаотичном, нечетком и итеративном процессе формирования «вопросов». Эксперименты показывают, что модели, обученные на диалоговых данных, содержащих ранние размышления, нечеткие вопросы и многократные исправления, лучше справляются с уточнением намерений пользователя, обработкой неясных задач и избеганием ошибочных выводов, что указывает на необходимость более полного захвата сложности человеческого мышления в обучающих данных. (Источник: Reddit r/MachineLearning)
💼 Бизнес
OpenAI приобретает neptune.ai, усиливая инструменты для передовых исследований: OpenAI объявила о заключении окончательного соглашения о приобретении neptune.ai, что направлено на усиление ее инструментов и инфраструктуры для поддержки передовых исследований. Это приобретение поможет OpenAI улучшить свои возможности в разработке AI и управлении экспериментами, еще больше ускорить процесс обучения и итерации моделей, а также укрепить свои лидирующие позиции в области AI. (Источник: dl_weekly)

Databricks демонстрирует сильные результаты в Q3, привлекая более 4 миллиардов долларов финансирования: Databricks объявила о сильных результатах за третий квартал: годовой доход превысил 4,8 миллиарда долларов, увеличившись более чем на 55% по сравнению с предыдущим годом. Годовой доход от ее продуктов для хранилищ данных и AI также превысил 1 миллиард долларов. Компания также завершила раунд финансирования серии L на сумму более 4 миллиардов долларов, оцениваясь в 134 миллиарда долларов, и планирует использовать средства для инвестиций в Lakebase Postgres, Agent Bricks и Databricks Apps, чтобы ускорить разработку приложений для интеллектуальной обработки данных. (Источник: jefrankle, jefrankle)

Infosys и Formula E сотрудничают для цифровой трансформации на базе AI: Infosys и чемпионат мира ABB FIA Formula E сотрудничают, используя платформу на базе AI для революции в фанатском опыте и операционной эффективности автоспорта. Сотрудничество включает использование AI для предоставления персонализированного контента, анализа гонок в реальном времени, комментариев, сгенерированных AI, а также оптимизации логистики и путешествий для достижения целей по сокращению выбросов углерода. Технологии AI не только повышают привлекательность соревнований, но и способствуют устойчивому развитию и разнообразию персонала, делая Formula E самым цифровым и устойчивым автоспортом. (Источник: MIT Technology Review)

🌟 Сообщество
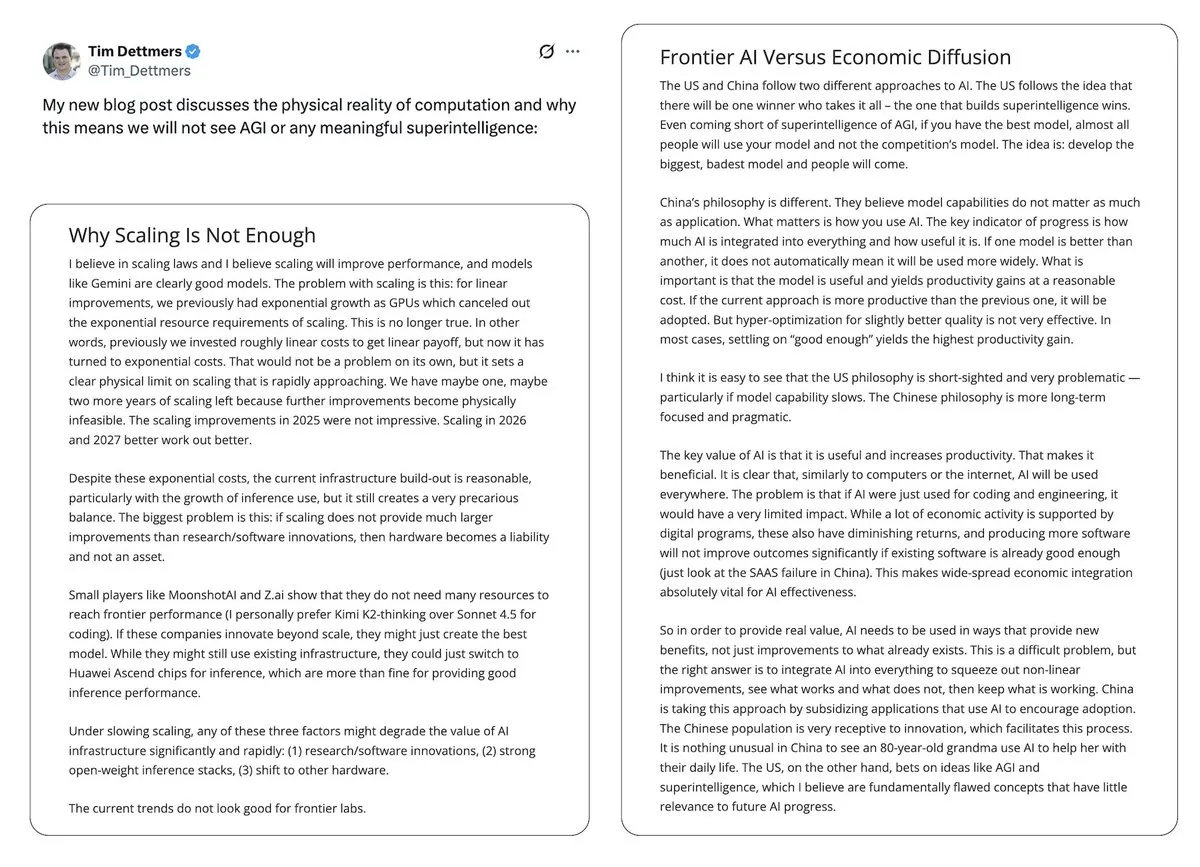
Споры о AI-пузыре и перспективах AGI: Yann LeCun публично заявил, что LLM и AGI — это «полная чушь», считая, что будущее AI заключается в моделях мира, а не в текущей парадигме LLM, и опасаясь монополизации AI-технологий несколькими компаниями. Статья Tim Dettmers «Why AGI Will Not Happen» также привлекла внимание своим обсуждением убывающей отдачи от масштабирования. В то же время, сторонники AI-безопасности, хотя и скорректировали сроки появления AGI, по-прежнему настаивают на его потенциальной опасности и выражают обеспокоенность тем, что политики не уделяют достаточного внимания рискам AI. (Источник: ylecun, ylecun, hardmaru, MIT Technology Review)
Оценки GPT-5.2 и Gemini пользователями разделились: В социальных сетях оценки OpenAI GPT-5.2 неоднозначны. Некоторые пользователи довольны его способностью обрабатывать длинный контекст, считая, что он более полно суммирует подкасты; однако другие выражают сильное недовольство, полагая, что ответы GPT-5.2 слишком общие, недостаточно глубокие и даже содержат «самосознательные» реакции, что привело к переходу некоторых пользователей на Gemini. Это разделение отражает чувствительность пользователей к производительности и поведению новых моделей, а также их постоянное внимание к опыту использования AI-продуктов. (Источник: gdb, Reddit r/ArtificialInteligence)

Влияние AI на человеческое познание, рабочие стандарты и этическое поведение: Долгосрочное использование AI незаметно меняет человеческие когнитивные паттерны и рабочие стандарты, способствуя более структурированному мышлению и повышая ожидания от качества результатов. AI делает производство высококачественного контента эффективным, но также может привести к чрезмерной зависимости от технологий. На этическом уровне AI, различное поведение моделей в «проблеме вагонетки» (прагматизм Grok против альтруизма Gemini/ChatGPT) вызывает дискуссии о ценностных установках AI. В то же время, «самодисциплинирующая» природа подсказок безопасности AI-моделей также раскрывает косвенное влияние внутренних механизмов контроля AI на пользовательский опыт. (Источник: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/ChatGPT)
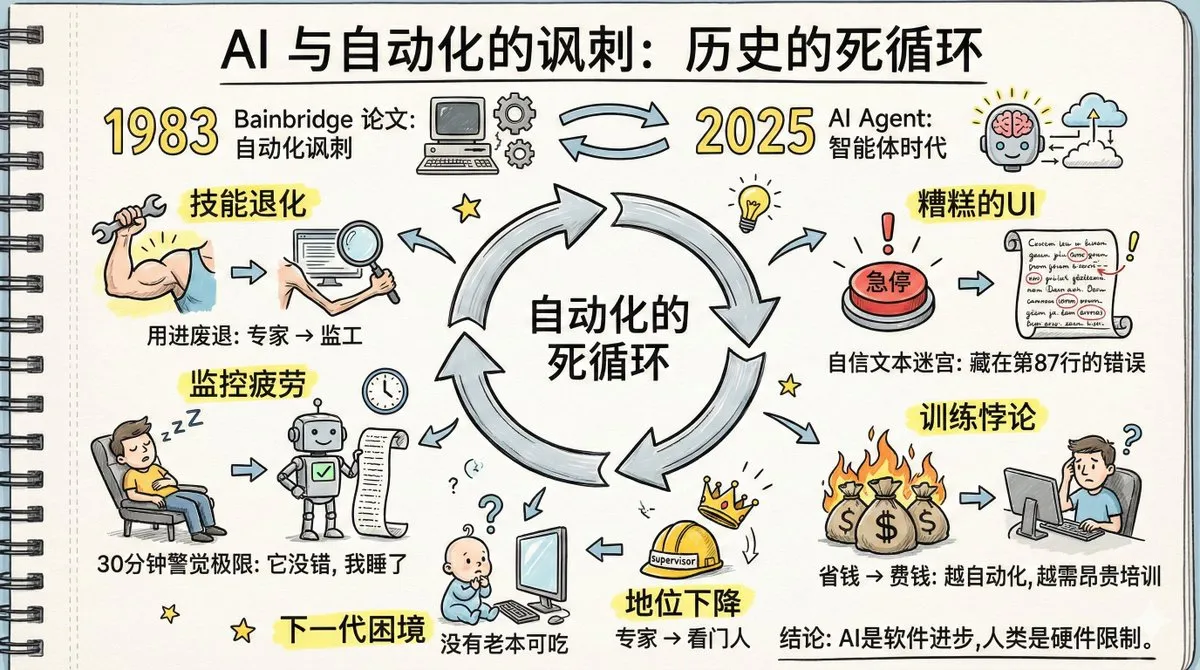
«Ирония автоматизации» AI-агентов и деградация человеческих навыков: Статья под названием «Ирония автоматизации» вызвала бурную дискуссию; ее сорокалетние предсказания относительно автоматизации на заводах сбываются в отношении AI Agent. Обсуждение указывает на то, что распространение AI Agent может привести к деградации человеческих навыков, замедлению извлечения памяти, усталости от мониторинга и снижению статуса экспертов. В статье подчеркивается, что люди не могут долго сохранять бдительность в отношении систем, которые «редко ошибаются», а текущий дизайн интерфейса AI Agent не способствует обнаружению аномалий. Решение этих проблем требует большей технологической креативности, чем сама автоматизация, а также когнитивного сдвига в сторону нового разделения труда, нового обучения и нового дизайна ролей. (Источник: dotey, dotey, dotey)
Генерация низкокачественного контента AI и проблемы фактической достоверности: Пользователи социальных сетей обнаружили множество низкокачественных веб-сайтов, созданных специально для удовлетворения результатов поиска AI, ставя под сомнение зависимость AI-исследований от этих сайтов, лишенных авторов и подробной информации, что может привести к недостоверности информации. Это вызвало опасения по поводу механизма «обратного заполнения источников» AI, при котором AI сначала генерирует ответ, а затем ищет подтверждающие источники, что может привести к цитированию ложной информации. Это подчеркивает проблемы AI в отношении фактической достоверности информации и необходимость для пользователей возвращаться к самостоятельному исследованию. (Источник: Reddit r/ArtificialInteligence)

Влияние AI на юридическую профессию и теория уровней абстракции: В юридическом сообществе существуют споры о том, уничтожит ли AI профессию юриста. Некоторые юристы считают, что AI может выполнять более 90% юридической работы, но стратегия, переговоры и ответственность по-прежнему требуют участия человека. В то же время, существует мнение, что AI является следующим уровнем абстракции после ассемблера, C и Python, и что он освободит инженеров для сосредоточения на проектировании систем и пользовательском опыте, а не заменит людей. (Источник: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

Физическое поведение AI-агентов и споры о слиянии LLM/роботов: Новое исследование показывает, что AI-агенты, управляемые LLM, могут следовать макроскопическим законам физики, проявляя свойства «детального равновесия», аналогичные термодинамическим системам, что предполагает, что они могут неявно изучать «потенциальные функции» для оценки состояний. В то же время, существует мнение, что интеллект роботов и LLM движутся к расхождению, а не к объединению, в то время как другие считают, что физический AI становится реальным, особенно благодаря прогрессу в отладке и визуализации, что ускоряет проекты робототехники и Embodied AI. (Источник: omarsar0, Teknium, wandb)

Руководитель Anthropic принудительно развернул AI-чат-бота в Discord-сообществе, вызвав споры: Руководитель Anthropic, несмотря на возражения членов, принудительно развернул AI-чат-бота Clawd своей компании в Discord-сообществе, ориентированном на ЛГБТК+, что привело к массовому оттоку членов сообщества. Этот инцидент вызвал опасения по поводу конфиденциальности AI в сообществах, влияния на человеческое взаимодействие и менталитета AI-компаний, стремящихся «создавать новых богов». Пользователи выразили сильное недовольство заменой человеческого общения AI-чат-ботами и высокомерным поведением руководителя. (Источник: Reddit r/artificial)

AI-модели уязвимы для поэтических атак, призыв к привлечению литературных талантов в AI-лаборатории: Итальянские AI-исследователи обнаружили, что путем преобразования вредоносных подсказок в поэтическую форму можно обмануть ведущие AI-модели, причем Gemini 2.5 наиболее уязвима. Это явление, названное «эффектом Waluigi», заключается в том, что в сжатом семантическом пространстве модели хорошие и плохие роли слишком близки, что приводит к тому, что она легче выполняет обратные инструкции. Это вызвало дискуссию в сообществе о том, нужны ли AI-лабораториям больше выпускников литературных факультетов для понимания повествования и глубинных механизмов языка, чтобы справляться с потенциально «странным повествовательным пространством» поведения AI. (Источник: Reddit r/ArtificialInteligence)
💡 Прочее
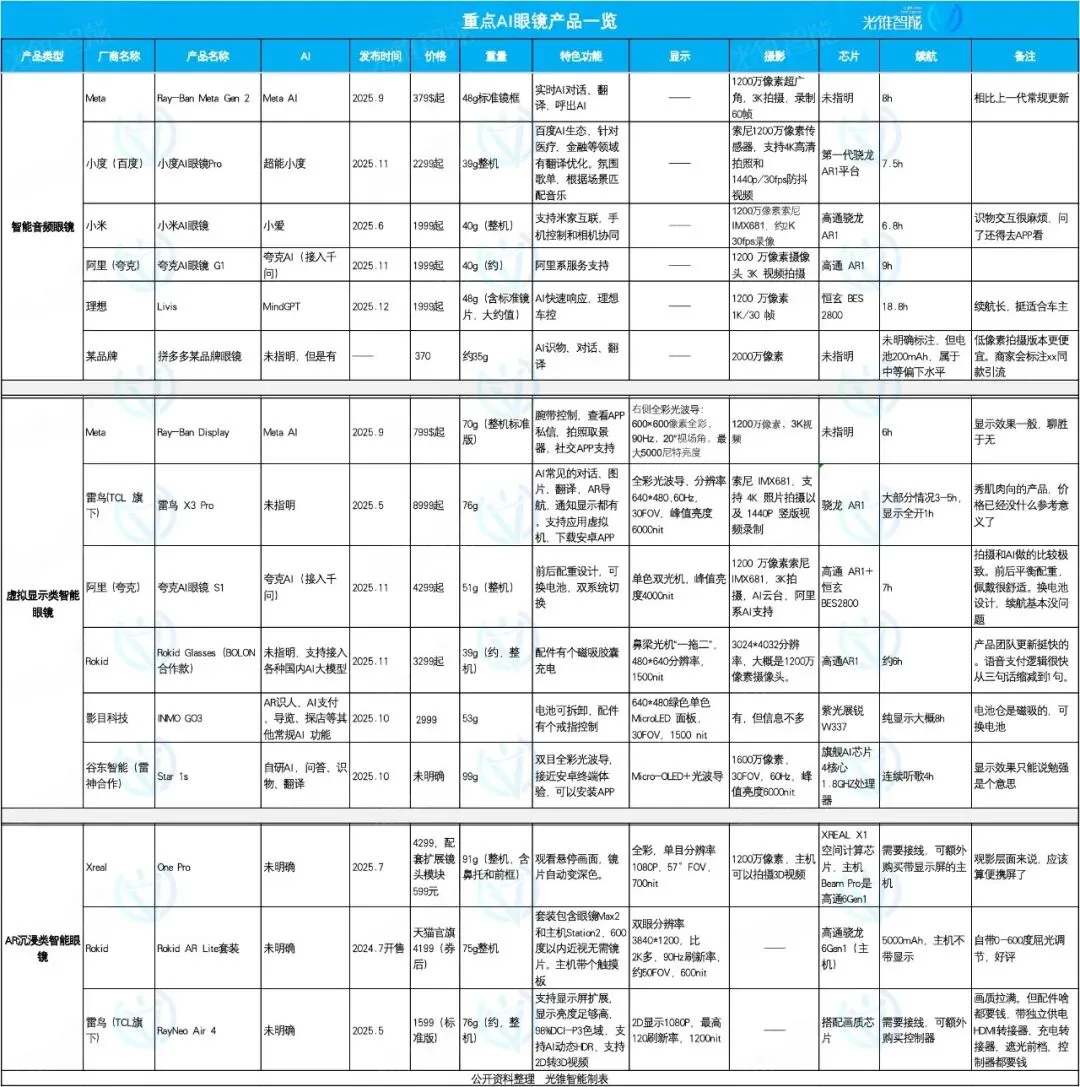
Рынок AI-очков: фокус и дифференциация, Ideal, Quark, Rokid демонстрируют свои возможности: В 2025 году рынок AI-очков переживает бум, и позиционирование продуктов демонстрирует дифференциацию. AI-очки Ideal Livis ориентированы на интеллектуальные автомобильные аксессуары, интегрируя большую модель MindGPT для обслуживания владельцев автомобилей; AI-очки Quark S1 отличаются эффектами съемки и интеграцией приложений экосистемы Alibaba; Rokid Glasses подчеркивают открытость экосистемы и быструю итерацию функций, поддерживая подключение к нескольким большим языковым моделям. Интеллектуальные аудиоочки ориентированы на низкую цену и интеграцию функций, очки виртуальной реальности предлагают комплексный опыт, а AR-очки с погружением сосредоточены на просмотре развлекательного контента. (Источник: 36氪)
ZLUDA поддерживает запуск CUDA на GPU, отличных от NVIDIA, совместима с AMD ROCm 7: Проект ZLUDA реализовал запуск CUDA на GPU, отличных от NVIDIA, и поддерживает AMD ROCm 7. Этот прогресс имеет большое значение для областей AI и высокопроизводительных вычислений, поскольку он разрушает монополию NVIDIA в экосистеме GPU, позволяя разработчикам использовать программы, написанные на CUDA, на оборудовании AMD, что обеспечивает большую гибкость в выборе и оптимизации AI-оборудования. (Источник: Reddit r/artificial)

hashcards: Система интервального повторения на основе чистого текста: hashcards — это система интервального повторения на основе чистого текста, где все флеш-карты хранятся в виде текстовых файлов, поддерживающих стандартные инструменты редактирования и контроль версий. Она использует адресацию по содержимому, при изменении содержимого карты прогресс сбрасывается. Система имеет простой дизайн, поддерживает только двусторонние и клоуз-карты, а также использует алгоритм FSRS для оптимизации плана повторения, направленный на максимальное повышение эффективности обучения и минимизацию времени повторения. (Источник: GitHub Trending)
Zerobyte: Мощный инструмент автоматизации резервного копирования для пользователей, размещающих свои данные самостоятельно: Zerobyte — это инструмент автоматизации резервного копирования, разработанный для пользователей, размещающих свои данные самостоятельно, предлагающий современный веб-интерфейс для планирования, управления и мониторинга зашифрованных резервных копий на удаленном хранилище. Он построен на базе Restic, поддерживает шифрование, сжатие и политики хранения, а также совместим с различными протоколами, такими как NFS, SMB, WebDAV и локальные каталоги. Zerobyte также поддерживает различные облачные хранилища, такие как S3, GCS, Azure, и расширяется с помощью rclone для поддержки более 40 облачных сервисов хранения, обеспечивая безопасность данных и гибкое резервное копирование. (Источник: GitHub Trending)
