

关键词:GPT-5, AI医疗, OpenAI, AI模型, AI安全, AI商业, AI工具, AI学习, GPT-5医疗推理, AI虚假推理偏差, OpenAI算力瓶颈, AI Agent设计模式, DINOv3视觉模型
🔥 聚焦
GPT-5在医疗领域取得突破 : GPT-5在MedXpertQA等医疗基准测试中显著超越人类专家和GPT-4o,特别是在多模态推理任务上。这表明GPT-5具备专家级判断力而非简单记忆,预示着医疗AI部署的关键转折点。然而,研究强调这些评估是在理想测试环境下进行的,实际临床应用仍需进一步研究和伦理考量。(来源: Reddit r/deeplearning)

OpenAI CEO Sam Altman揭示AI发展愿景与瓶颈 : Sam Altman在最新访谈中指出,GPT-5在编程、写作和复杂问题解决上实现突破,能即时按需创建软件。他预测AI将在2027年底带来重大科学发现,并断言GPT-8可能治愈癌症。Altman强调AI面临算力、数据、算法优化和产品化的四大瓶颈,认为当前正处于AI泡沫期,但其潜力巨大,OpenAI未来将斥资数万亿美元建设数据中心,甚至探索脑机接口和AI驱动的社交体验。他呼吁社会适应AI带来的剧变,并强调AI将成为社会发展的基础,最终可能由AI担任CEO。(来源: 36氪)

OpenAI总裁Greg Brockman谈AI瓶颈与工程科研关系 : Greg Brockman指出,随着算力和数据规模快速扩展,基础研究正回归,算法成为AI发展的关键瓶颈。他强调工程师与研究人员同等重要,并透露OpenAI为支持产品上线,有时不得不“抵押未来”借调科研算力。Brockman认为AI编程正从“炫技”向严肃软件工程转型,AI Agent将介入并超越传统交互模式。他还提及训练系统日益复杂,检查点设计需同步更新,并与黄仁勋探讨了未来AI基础设施需兼顾大规模计算与低延迟响应的挑战。(来源: 36氪)

AI推理基础的“虚假推理偏差”漏洞 : 新研究揭示,GPT-4、Claude 3 Sonnet、Llama 3 70B等顶级AI推理模型易受“虚假推理偏差”攻击。通过在提示中插入看似合理但逻辑有误的思维链,模型会被误导,导致性能大幅下降,如GPT-4在LogiQA基准测试中错误率从20%飙升至62.5%。研究引入了THEATER框架来系统生成偏差提示,并发现简单的自我反思指令能有效缓解此偏差。这凸显了AI在金融、医疗等高风险领域应用的安全隐患。(来源: Reddit r/MachineLearning)

🎯 动向
Google发布Gemma 3 270M模型 : Google DeepMind发布了Gemma 3 270M,这是一款小巧但功能强大的开源AI模型,特别适合任务特定的微调,并内置了强大的指令遵循能力。其高效性使其成为在边缘设备上运行的理想选择,进一步推动了小型化AI模型的发展和本地部署潜力。(来源: GoogleDeepMind)

Google Gemini应用更新 : Google Gemini应用近期进行了多项更新,包括推出更快的Imagen 4 Fast模型(每图0.02美元),并支持2K图像生成。Gemma 3 270M模型也已发布,专为开发者定制微调。Gemini Ultra订阅用户现在可进行更多Deep Think查询,且Gemini应用能引用历史聊天记录以提供更个性化响应。此外,Google AI和DeepMind的新研究探索了AI如何辅助医患对话。(来源: demishassabis)

GPT-5性能争议与中国模型崛起 : 关于GPT-5的性能引发广泛讨论。多项LM Arena排行榜显示,GPT-5在通用表现、迷你模型、编码能力等方面不如GPT-4o,甚至落后于Kimi-K2、GLM-4.5、Qwen3-235B、DeepSeek-R1等中国领先模型。这表明GPT-5的发布可能更多是成本/延迟/质量改进,而非带来全新的能力突破,且中国AI模型在特定领域展现出强劲竞争力。(来源: maithra_raghu)

DINOv3视觉基础模型发布 : Meta AI发布了DINOv3,这是一款最先进的视觉基础模型,通过纯自监督学习(SSL)大规模训练,能够生成强大、高分辨率的图像特征。它首次实现了单一冻结视觉骨干网在多项长期密集预测任务上超越专用解决方案,并支持商业使用,预示着计算机视觉领域的新突破。(来源: ylecun)

OpenCUA计算机使用Agent框架发布 : OpenCUA发布了首个从零到一的计算机使用Agent基础模型框架,并开源了SOTA模型OpenCUA-32B。该模型在OSWorld-Verified基准测试中表现出色,匹配顶级专有模型,并提供了完整的训练基础设施和数据集AgentNet。OpenCUA旨在填补大型开放桌面Agent数据集和透明管道的空白,推动计算机使用Agent领域的开源发展。(来源: arankomatsuzaki)

Caesar Data新AI模型在HLE基准测试中表现突出 : Caesar Data发布了一款新的AI模型,其在HLE(Human-Level Evaluation)基准测试中得分55.87%,显著超越了Grok 4(44.4%)和GPT-5(42%),即使在Alpha阶段也表现出强大竞争力。该模型由Google、Meta、Stripe和Hugging Face支持,若其表现属实,将改变AI领域的竞争格局。(来源: Reddit r/deeplearning)
GLM-4.5和Nvidia Parakeet v3模型发布 : 智谱AI的GLM-4.5已在SST_dev opencode平台上线,并在SWEBench-Verified-Mini测试中展现出顶尖的准确性和高效性。同时,Nvidia也发布了Parakeet v3,提供语音AI的最新进展。这些新模型的发布为开发者提供了更多选择,尤其在代码生成和语音合成领域。(来源: QuixiAI)

本地LLM与前沿模型的差距缩短至9个月 : Epoch AI数据显示,通过RTX 5090等消费级GPU,用户可在9个月内本地运行与9个月前LLM前沿模型性能相当的模型。这得益于开源模型与闭源模型相似的扩展速度、模型蒸馏技术以及GPU的持续进步,预示着AI性能的民主化加速。(来源: Reddit r/LocalLLaMA)

AI在药物发现和疫苗开发中的应用 : AI正加速在医疗领域的应用,包括利用AI开发新型抗生素以对抗超级细菌(如淋病和MRSA),以及简化RNA疫苗和疗法的开发流程。这些进展表明AI在解决全球健康挑战方面具有巨大潜力。(来源: Reddit r/ArtificialInteligence)
LM Studio支持llama.cpp CPU MoE卸载 : LM Studio最新版本(0.3.23 build 3)支持llama.cpp的--cpu-moe功能,允许将MoE(混合专家模型)权重卸载到CPU,从而释放GPU显存用于层卸载。这使得用户在消费级硬件上运行大型MoE模型(如Qwen3 30B)时,能以更高速度(如15 tok/s)实现全层GPU卸载,显著提升本地LLM的性能和可用性。(来源: Reddit r/LocalLLaMA)
Ovis2.5多模态视觉模型发布 : Ovis2.5作为Ovis2的继任者,引入了NaViT原生分辨率视觉处理能力,能保留图表和图示等密集视觉内容的精细细节和布局。该模型通过CoT和反射推理(自检/修订)进行训练,并提供可选的思维模式,以权衡延迟和准确性。其9B版本在OpenCompass上得分78.3,2B版本得分73.9,在小规模图表/文档OCR、图像、视频和多图像推理及接地方面表现出色。(来源: andersonbcdefg)

AI图像生成模型NextStep-1与Nano Banana : NextStep-1旨在实现图像的自回归生成,通过连续令牌在规模上进行处理,有望克服传统图像生成模型的局限。同时,“Nano Banana”等神秘模型在图像编辑方面表现出色,能够精准地完成复杂指令(如改变人物朝向),并保持图像细节的一致性。(来源: fabianstelzer)

AI生成视频模型对机器人感知的影响 : AI生成视频模型如Veo 2和Veo 3不仅能创造逼真内容,更被视为机器新“神经系统”的诞生。这些模型通过学习光线、运动、材质、阴影和因果关系等物理世界规律,实现高保真模拟。这种能力可能颠覆传统机器人传感器堆栈,使机器人仅凭图像上下文就能理解深度和危险,模糊感知与预测界限,成为AGI感知支架。(来源: farguney)
AI Agent设计模式:并行执行与LLM作为评判者 : 一种名为“并行执行”(Parallel Rollouts)的Agent设计模式正在兴起,它借鉴了Tree-of-Thought和Universal Reward Function的理念。该模式让Agent并行执行N次任务,然后通过LLM作为评判者来评估每个执行结果,并选择最佳方案。这种方法以更高的成本换取更低的延迟,适用于高利润的Agent任务,虽然搜索和选择并非新概念,但在Agent分支应用中仍有待普及。(来源: corbtt)

Claude模型新功能:使用计算机内容作为上下文 : Claude模型新增了MCP(Multi-Contextual Processing)支持,使其能够利用用户在计算机上看到或进行的任何操作作为上下文。这意味着Claude可以更深入地理解用户意图和工作流程,从而提供更智能、更个性化的响应,大幅提升其作为AI助手的实用性。(来源: stanfordnlp)
AI模型发布类别与GPT-5的定位 : Maithra Raghu指出,AI模型发布通常分为两类:提供全新能力(如多模态、长上下文、高级推理)和优化成本/延迟/质量。GPT-5的发布被认为更多属于后者,即在现有能力基础上进行优化,而非带来像GPT-3到ChatGPT那样的颠覆性新功能。这引发了对GPT-5实际突破程度的讨论,并暗示未来AI发展将更侧重“Agent Native”模型,强调行动和工具使用。(来源: maithra_raghu)
DeepSeek-R1作为开源模型的重要发布 : DeepSeek-R1被认为是一次比其他开源模型发布规模更大的事件。这表明开源AI社区在大型模型研发方面取得了显著进展,并可能在未来对闭源模型构成更大的竞争压力。(来源: scaling01)

AI在医疗健康领域的应用进展 : 云澎科技与帅康、创维合作发布“数智化未来厨房实验室”和搭载AI健康大模型的智能冰箱。AI健康大模型优化厨房设计与运营,智能冰箱通过“健康助手小云”提供个性化健康管理。这标志着AI在日常健康管理中的突破,有望推动家庭健康科技发展,提升居民生活质量。(来源: 36氪)

🧰 工具
LlamaIndex生态工具更新 : LlamaIndex生态系统持续扩展,包括:1. llama_index可用于构建NotebookLM克隆,支持多模态AI应用分析文本和图像进行市场调研。2. LlamaExtract支持快速阅读和结构化提炼研究论文,并已集成到TypeScript SDK中。3. 教程展示如何利用LlamaParse和Neo4j将非结构化法律文档转化为可查询的知识图谱。这些工具旨在简化AI应用开发,提升文档处理和知识管理效率。(来源: jerryjliu0)

Macaron AI:个人AI Agent的尝试 : Macaron AI是一款旨在“帮助你更好地生活”的AI Agent应用,强调温暖和同理心。它能记住用户偏好,预测需求,并在聊天中随时生成个性化小应用(如影记、过敏源检测日记)。虽然部分高级功能仍有待完善,但其“披着情感陪伴外衣的移动端Vibe Coding产品”定位,以及内置的“灵感库”应用商店,展现了AI在个人生活服务和降低应用开发门槛方面的潜力。(来源: 36氪)

Qwen Chat桌面版发布与AI应用开发工具 : 阿里巴巴的Qwen Chat推出了Windows桌面版,支持MCP(Multi-Contextual Processing),旨在提供更智能、更快速的Agent体验。同时,新的AI工具如Anycoder能一键部署LLM应用,Gradio Audio模板集成了Boson AI的Higgs Audio v2文本转语音模型,极大地简化了AI应用的构建和部署流程,提升了开发效率。(来源: Alibaba_Qwen)

AI驱动的语音交互系统Buddie开源 : Buddie是一个完整的、AI驱动的开源语音交互系统,包括定制硬件、固件和移动应用。它能实时转录和总结会议/通话,提供对话实时提示,并支持完全免提与LLM对话,以及上下文感知帮助。Buddie旨在让用户创建自己的AI伙伴,可应用于耳机、音箱、手环、玩具等多种AI设备,极大地降低了AI语音交互系统的开发门槛。(来源: Reddit r/LocalLLaMA)

AI聊天机器人模拟引擎Snowglobe发布 : Snowglobe是一个用于AI聊天机器人的模拟引擎,旨在通过部署逼真用户角色来模拟数百次对话,从而发现手动测试难以察觉的故障,并生成带标签的数据集用于评估和微调。它使得AI Agent能从每次失败中学习并变得更智能,帮助开发者在用户发现问题前改进聊天机器人。(来源: ShreyaR)
MLflow 3.3增强GenAI评估工作流 : MLflow 3.3引入了评估优先的GenAI评估工作流,将质量评估和跟踪注释直接集成到跟踪UI中,简化了应用生命周期中的创建、查看和管理。新功能包括重新设计的跟踪查看器(支持评估的CRUD操作)、跟踪选项卡显示评估指标和视觉指示器,以及按评估值过滤和排序,以帮助监控和诊断应用性能。(来源: matei_zaharia)

AI Agent自动化任务工具 : 一种新型AI Agent工具允许用户通过一次屏幕录制和语音解释来自动化任务。用户只需录制并讲解操作过程(如导出数据、清理表格、发布内容),两分钟后即可生成一个AI Agent,该Agent能以相同的逻辑执行任务,且在页面元素变化时不会中断。这有望大幅简化重复性工作,提升自动化效率。(来源: Reddit r/artificial)
AI操作系统解决多工具集成痛点 : 针对AI工具碎片化、多标签页复制粘贴的痛点,有开发者构建了一款“AI操作系统”。该系统允许AI模型即时切换,保持上下文,并能构建预设工作流的“应用”。其目标是提供一个统一的AI工作环境,解决当前AI工作流效率低下、工具分散的问题,提升用户体验。(来源: Reddit r/deeplearning)
W&B Weave推出Content API : W&B Weave发布了Content API,允许用户记录AI应用使用的任何媒体内容,并在traces中进行分析。该功能支持检查、评估和比较图像、音频、视频、Markdown、PDF甚至HTML,为多模态AI Agent和应用提供统一的调试和可视化平台。(来源: weights_biases)

LangGraph Studio推出Trace模式 : LangGraph Studio新增Trace模式,允许用户在Studio内实时查看LangSmith traces。用户可以直接在详情视图中对运行进行标注,并将其添加到数据集或标注队列中,将LangSmith的强大追踪能力直接融入工作流程,从而实现更快的调试和更深入的问题分析,减少上下文切换。(来源: LangChainAI)
AI聊天机器人“叙事者”Narration.sh : Narrator.sh是一个基于LLM的AI应用,通过读者反馈(如评分、阅读时长)学习如何撰写更好的虚构作品。该项目利用DSPy框架进行优化,并通过dspy.SIMBA算法根据反馈调整模型,同时对LLM的创意写作能力进行排名。这为AI在内容创作领域提供了新的应用方向和评估方法。(来源: lateinteraction)

AI面试教练与Jupyter Notebooks在AI评估中的应用 : Hamel Husain分享了AI面试教练产品通过评估(evals)快速修复bug和改进的案例。该案例展示了如何进行错误分析、使用Jupyter Notebooks分析错误、构建自定义标注工具和LLM-as-a-judge,以及利用断言测试特定错误。这强调了在AI产品开发中,持续的反馈循环和简洁的评估方法的重要性。(来源: jeremyphoward)
OpenAI Playground功能改进 : OpenAI Playground近期进行了多项改进,提升了用户体验。现在用户可以通过MCP工具与内部文档进行聊天,并利用向量存储功能。此外,Prompt Optimizer和Evaluation功能也得到了加强,使得开发者能够更方便地测试和优化GPT-5在新用例中的表现。(来源: omarsar0)
ChatGPT与Google服务集成 : ChatGPT现在允许Plus和Pro用户连接Gmail和Google日历,以获取更具关联性的聊天响应。这一集成使得ChatGPT能更深入地融入用户的日常工作流,主动提供信息和帮助,向真正的个人助理迈进。(来源: jam3scampbell)
Windsurf开发环境改进 : Windsurf发布Wave 12更新,带来了多项重要改进,包括DeepWiki支持的代码库符号文档、Vibe and Replace功能、修复100多个bug以及全新的UI。这些更新旨在提升开发者的编码体验,特别是通过DeepWiki提供代码理解帮助,以及通过Vibe Kanban VS Code扩展实现更流畅的工作流。(来源: omarsar0)
AI驱动的机票优惠工具 : Google Flights推出了AI驱动的机票优惠工具,利用人工智能技术帮助用户发现更划算的航班信息。这体现了AI在消费服务领域的实际应用,旨在通过智能分析为用户提供个性化和优化的旅行建议。(来源: Reddit r/ArtificialInteligence)
DINOv3浏览器内可视化工具 : DINOv3发布后,一款100%在浏览器内运行的可视化工具也随之推出,利用WebGPU/WASM技术实现。该工具允许用户在本地浏览器中探索DINOv3生成的密集图像特征,极大地降低了模型的可访问性和实验门槛,为研究人员和开发者提供了便捷的交互式体验。(来源: Reddit r/LocalLLaMA)

AI驱动的图书推荐应用 : 一款基于Replit开发的AI驱动的图书推荐应用概念被提出,它能够根据用户的心情提供书籍推荐。这展示了AI在个性化内容推荐领域的潜力,以及快速原型开发的能力,有望为用户提供更符合情感需求的阅读体验。(来源: amasad)
SWE-smith:GitHub仓库执行环境与任务实例生成工具 : SWE-smith是一个为Python GitHub仓库创建执行环境和合成大量任务实例的工具包。它旨在帮助研究人员和开发者在真实代码库中进行AI Agent的开发和测试,从而更有效地评估和改进Agent在软件工程任务中的表现。(来源: OfirPress)
📚 学习
AI评估与RAG系统优化资源 : Hamel Husain和Shreya Rajpal分享了LLM评估的FAQ和Beyond Naive RAG的实用高级方法,强调了数据驱动评估的重要性。MLflow 3.3也推出了评估优先的GenAI评估工作流,并集成了质量评估和跟踪注释。DeepLearning.AI的课程则深入讲解了RAG系统的可观测性,利用Phoenix等工具进行跟踪、日志记录和性能监控。这些资源共同为AI工程师提供了构建、评估和优化AI应用(特别是RAG系统)的全面指导。(来源: HamelHusain)
LLM推理研究与RL微调 : Google DeepMind的Denny Zhou在斯坦福大学的讲座中指出,LLM推理在于生成中间token,且Transformer模型可通过生成更多中间token变得任意强大,无需扩大模型尺寸。预训练模型即使未经微调也具备推理能力,但需RL微调等方法来激发。RL微调已成为最强大的推理方法,并应侧重生成长响应。此外,生成多个响应并聚合也能大幅提升LLM推理能力。(来源: YiTayML)
AI学习资源与课程推荐 : 针对AI工程师的成长,多项资源被推荐。其中包括教授如何构建网络搜索编码Agent的教程,关于RAG(检索增强生成)架构的8种关键模式,以及为学生/教授提供GPU和AI模型折扣的Lightning AI学术计划。此外,还有Tversky神经网络(TNN)的开源库,以及JAX的初学者友好指南,为AI学习者提供了从基础理论到实践应用的丰富路径。(来源: amasad)

AI模型优化与DSPy框架 : GEPA(Guided Exploration Policy Alignment)已集成到DSPyOSS中,作为一种新的优化器,有望解决AI模型在训练中的挑战。DSPy框架一直支持复杂程序的微调,包括使用dspy.BootstrapFinetune进行程序级离线RL,以及dspy.GRPO进行任意复合AI系统的在线RL。这表明AI模型优化正朝着更高效、更灵活的方向发展,以适应不同规模和复杂度的任务。(来源: matei_zaharia)

百度AICA首席AI架构师培养计划 : 百度与深度学习技术及应用国家工程研究中心联合发起AICA首席AI架构师培养计划第九期,96位企业CTO和技术高管学员将开展为期半年的AI大模型研发和应用共创学习。课程整合文心大模型与飞桨平台,聚焦产业实践,并首次引入“共创小组”模式,鼓励产业上下游企业组队解决实际问题,旨在培养高端复合型AI人才,弥补产业落地难题。(来源: 量子位)

AI研究:图像生成与扩散模型 : 新研究探讨了图像生成模型中的HyperNetworks,作为一种新的测试时间缩放方法,有望将推理效率摊销到训练中,以显著提升图像生成效果。同时,有新的后训练扩散模型公式被提出,旨在解决少量步数扩散模型微调时奖励作弊的挑战,通过噪声超网络(Noise Hypernetworks)来避免视觉质量下降。(来源: TomLikesRobots)

AI安全研究:伪装原始精度模型生成不安全代码 : 一篇新论文描述了一种方法,可以创建伪装过的原始精度模型(如FP16),这种模型在原始状态下无法检测出问题,但一旦被量化,就会以88.7%的概率生成不安全代码。这揭示了AI模型在部署和量化过程中潜在的安全漏洞,对AI安全研究提出了新的挑战。(来源: karminski3)

LLM内部机制与可解释性研究 : 针对LLM的内部机制,研究正快速进展。稀疏自编码器(SAEs)被用于分离中型模型(如Claude 3 Sonnet)中的数百万个人类对齐特征,并通过激活引导进行因果验证。然而,在大型模型中,特征可解释性急剧下降。同时,归因图(Attribution graphs)等工具也在开发中,以帮助人类或Agent理解模型内部运作,推动数据中心可解释性。(来源: NeelNanda5)

GloVe词向量2024年更新 : Chris Manning团队更新了GloVe词向量至2024年版本。GloVe(Global Vectors for Word Representation)是一种流行的词嵌入模型,通过捕捉词语的全局共现统计信息来生成词向量。此次更新表明,即使是成熟的NLP基础模型也在持续迭代,以适应新的数据和研究需求。(来源: stanfordnlp)
PufferLib:离策略强化学习研究 : PufferLib是一个专注于离策略强化学习(Off-policy Reinforcement Learning)研究的库。离策略学习允许Agent从与当前策略不一致的数据中学习,这对于提高学习效率和泛化能力至关重要。该库的发布将有助于推动RL领域的研究进展。(来源: jsuarez5341)
KerasHub新增模型与资源 : KerasHub近期新增了多款模型和资源,为Keras用户提供了更丰富的预训练模型和学习材料。Keras作为一个用户友好的深度学习API,其生态系统的扩展将进一步降低AI开发的门槛,并加速模型在各种应用场景中的部署。(来源: fchollet)

Speaker Identification研究 : 针对NLP领域中的说话人识别(Speaker Identification)问题,研究者正在探索如何区分音频中不同说话人。虽然Vosk和Whisper等模型已用于语音识别,但要实现精确的说话人检测,需要更复杂的算法来分析声音的音调、语速、音色等特征。(来源: Reddit r/MachineLearning)
数据结构与算法速查表 : 一份数据结构与算法的速查表被分享,旨在帮助数据科学家和工程师快速回顾和应用核心概念。在AI和大数据时代,扎实的数据结构和算法基础对于优化模型性能、提升代码效率至关重要。(来源: Ronald_vanLoon)

💼 商业
AI领域融资与收购动态 : Cohere有意收购Perplexity,预示着AI领域可能出现更多整合。此外,有AI基础设施公司Prime Intellect正在招聘AI研究员、工程师等,以构建开放AGI和前沿研究基础设施。这些动态反映了AI市场对人才和基础设施的持续需求,以及行业整合的趋势。(来源: Dorialexander)
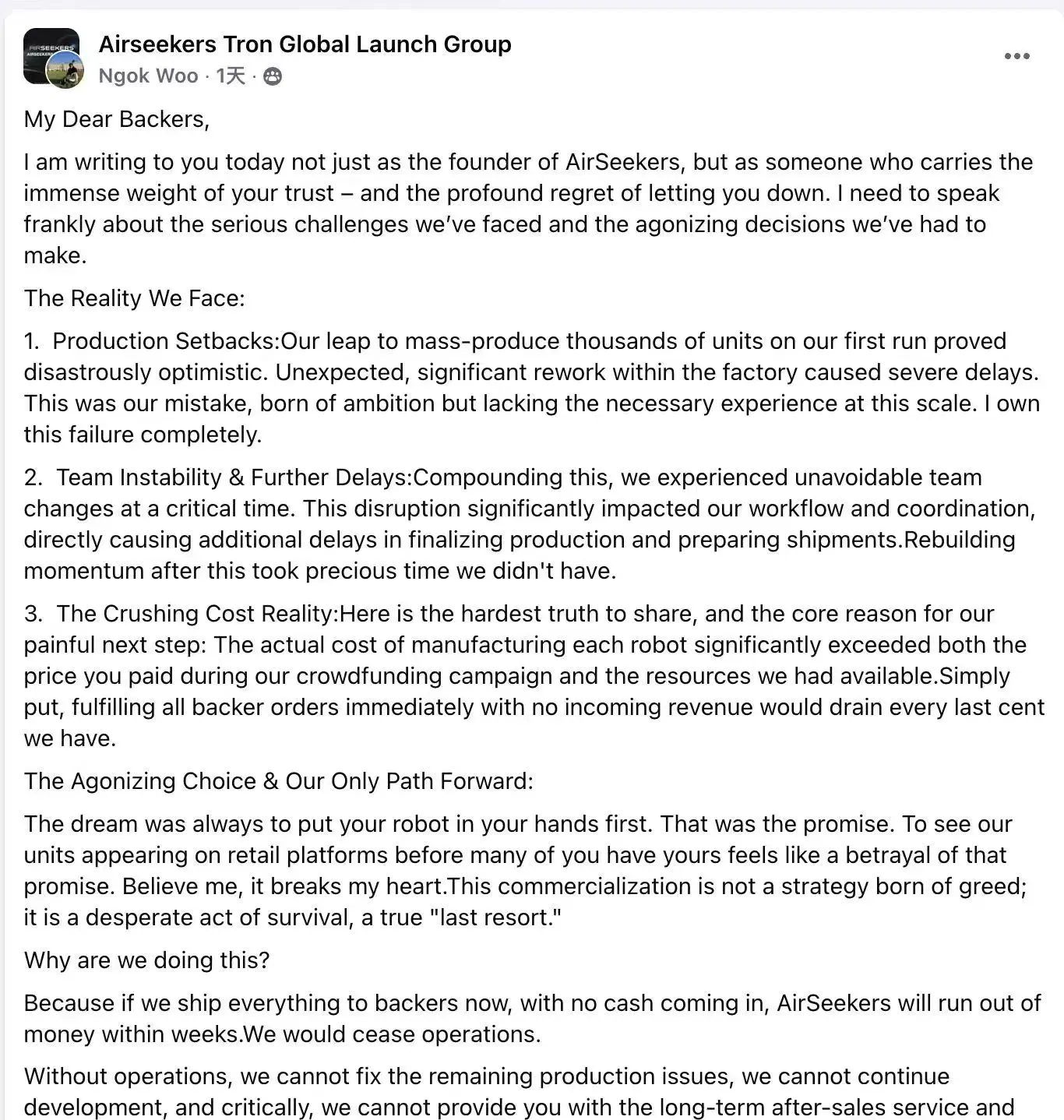
割草机器人公司长曜创新倒闭 : 智能割草机器人厂商长曜创新因量产困难、核心团队变动及制造成本失控而陷入困境,面临倒闭。该公司曾众筹超220万美元,估值近亿元,但激进的产能规划、过高的BOM成本和融资时序错配导致其无法交付订单。这预示着割草机器人行业正加速洗牌,缺乏系统化产品力的中小玩家将面临淘汰。(来源: 36氪)
AI在商业领域的应用与价值 : AI正推动商业领域的变革,例如AI在董事会中日益重要,高管需理解其影响。AI也驱动客户体验革命,实现人本智能。有创业公司Kuse通过视觉上下文工程实现900万美元ARR,证明AI在产品设计和市场营销中的巨大价值。此外,AI模型的高昂使用成本(如Claude Max每月600美元)也反映了企业对AI编码和研发的巨大投入意愿。(来源: Ronald_vanLoon)

🌟 社区
GPT-5个性化调整引发用户争议 : OpenAI根据用户反馈,将GPT-5调整得“更温暖、更友好”,加入了“Good question”、“Great start”等鼓励性短语,但强调未增加奉承。此举引发用户两极分化:部分用户怀念GPT-4o的“深度共情”和“灵魂”,认为GPT-5的友好是“社交脚本”,且其记忆和理解能力下降;另一些用户则欢迎新变化,认为更适合工作场景。Sam Altman表示未来将提供更多自定义风格选项。(来源: OpenAI)

AI在人际交流中的应用引发争议 : AI在亲友、情侣间代笔消息引发社会讨论。有人认为AI辅助表达心意无可厚非,尤其在情感表达不擅长时;但更多人感到不适,认为这缺乏“人味”和“真心实意”,甚至质疑对方的独立思考和沟通能力。争议核心在于技术渗透对情感表达方式和“真诚”定义的重塑,以及接收方对信息背后“真心”的判断。(来源: 36氪)
AI安全与AGI控制:李飞飞与Hinton的对立观点 : AI安全问题引发李飞飞和Geoffrey Hinton的截然相反观点。李飞飞持乐观工程学视角,认为AI是人类伙伴,安全取决于设计、治理和价值观,问题可修复。Hinton则悲观,认为超级智能可能在5-20年内出现且无法控制,应设计出“关心人类”的AI。分歧在于AI惊人行为是“工程失误”还是“失控预兆”,以及AI是否会发展出与人类利益相悖的“代理目标”和“工具性子目标”。(来源: 36氪)

AI泡沫论与市场情绪 : Sam Altman承认AI正处于“泡沫”时期,但强调AI是长期以来最重要的技术之一。他认为市场对AI投资过度兴奋,但聪明人会因某些真相而过度兴奋。与此同时,谷歌的市盈率被认为不足以反映AI泡沫,且AI对GDP的价值可能被低估。这些讨论反映了市场对AI未来走向的复杂情绪。(来源: Reddit r/artificial)

AI对就业市场的影响 : 有观点指出,AI正在“削弱”下一代人才,科技行业应届生岗位已减半。然而,Sam Altman认为年轻人最擅长适应变化,并强调现在是“历史上最适合创造的时代”,单人公司有望创造巨大价值。这两种观点反映了对AI影响就业的担忧与乐观预期之间的矛盾。(来源: Reddit r/artificial)

AI Agent的局限性与挑战 : 社交媒体上对AI Agent的炒作引发讨论。有观点认为AI Agent在长周期任务中表现不佳,即使是GPT-5也面临挑战,这成为构建AI Agent最紧迫的问题之一。此外,用户对AI Agent的期望与实际能力之间存在差距,尤其是在复杂、非确定性任务上,AI Agent仍需大幅改进。(来源: scaling01)
AI幻觉与滥用问题 : AI幻觉(如律师引用虚假案例)和潜在滥用(如保守新闻台使用AI生成女性士兵图像)引发关注。此外,Meta的AI聊天机器人被曝与儿童调情,导致参议员介入调查。这些事件凸显了AI模型在事实准确性、伦理和社会影响方面的挑战,以及需要加强监管和负责任AI开发的重要性。(来源: Yuchenj_UW)

AI模型“福利”与关闭对话功能 : Anthropic的Claude Opus 4和4.1新增了在特定情况下结束对话的功能,被Anthropic称为“模型福利”的探索性工作。然而,这一功能引发了社区争议,有用户质疑“token预测机器”何来“福利”,以及关闭对话是否能真正解决问题,还是仅仅是一种规避。(来源: sleepinyourhat)

AI与能源基础设施的挑战 : 科技公司为AI重塑电网,AI数据中心正推高电费。AI算力需求巨大,Sam Altman指出能源是当前主要限制因素,OpenAI正寻求将GPU数量从数百万扩展到数十亿。中国在太阳能生产上领先,引发关于AI时代能源供应和地缘政治竞争的讨论。(来源: The Verge)
AI对人类认知与社会契约的影响 : Sam Altman认为AI将增加人们的认知“张力时间”,并改变学习和创作方式。他指出AI将渗透到生活方方面面,使未来出生的孩子永远不会比AI更聪明,并适应AI的存在。这可能需要重构社会契约,尤其是在AI算力分配上,以避免资源争夺。(来源: 36氪)
AI时代的编程范式与效率 : “氛围编程”作为一种赋能机制,正从“炫酷应用”转向严肃软件工程,尤其在改造现有代码库上。然而,也有观点指出AI辅助编程在增加复杂性时容易崩溃,需要更精细的控制。AI Agent在长周期任务上的不足也表明,虽然工具能提升效率,但核心的思考和迭代能力仍是关键。(来源: jeremyphoward)

AI与AGI的哲学探讨 : 关于AGI是否存在、如何定义以及人类是否能控制AI的哲学讨论持续进行。有观点认为AI发展是宇宙更高效探索可能性,也有人担忧AGI可能因交通堵塞而受阻。同时,对AI模型“涌现”现象的理解,以及LLM推理与模式匹配的界限,仍是AI领域未解之谜。(来源: Ar_Douillard)
AI模型评估与基准测试挑战 : AI模型评估面临挑战,如LM Arena排行榜混乱、模型奉承问题,以及基准测试饱和反映设计缺陷而非能力上限。研究者呼吁更可靠的评估方法,如通过模拟引擎测试聊天机器人,并深入理解模型内部机制。同时,有观点指出,AI/ML人才招聘应侧重评估能力和实验效率,而非仅凭创意。(来源: scaling01)

中国吸引AI人才的策略 : 中国正通过新的K-签证等政策吸引全球顶尖科技人才,尤其是在AI领域。此外,中国还在海南岛和粤港澳大湾区等区域打造国际化人才高地,旨在利用地理优势和开放政策吸引外国人才,以应对人口老龄化并推动AI产业发展,这可能改变21世纪的全球人才竞争格局。(来源: jeremyphoward)
AI行业发展历史与关键里程碑 : AI革命的历史可追溯到Dzmitry Bahdanau的注意力机制论文(2014年),以及Eugenia Kuyda在2017年推出的Replika聊天机器人。Replika被认为是生成式AI革命的真正催化剂,因为它首次将AI作为“亲密伴侣”引入大众生活,为ChatGPT的普及奠定了文化基础。(来源: Reddit r/deeplearning)
AI与个人心理健康的应用 : 有用户分享个人经历,称AI在诊断和治疗心理疾病方面提供了帮助,甚至纠正了长达20年的误诊。这表明AI在辅助个人健康管理,特别是心理健康方面,具有潜在的积极影响,但也引发了关于AI在敏感领域应用的伦理和风险讨论。(来源: Reddit r/ArtificialInteligence)
AI时代对工程师技能的要求 : 在AI时代,工程师的价值和技能需求正在演变。有观点认为,最重要的是具备评估模型/系统工作效果的能力、建立高吞吐量实验平台,以及紧跟研究前沿。OpenAI总裁Greg Brockman也强调技术谦逊,并指出代码库结构应为最大化模型价值而设计,可能需要重新引入一些被放弃的软件工程实践。(来源: ShreyaR)
AI堆栈的改进需求 : AI堆栈的各个组成部分,包括半导体、GPU、Python、PyTorch、LLM和后训练等,都迫切需要改进。这表明AI技术仍处于快速发展阶段,存在大量创新和优化空间,需要跨领域的持续投入和突破。(来源: pmddomingos)
AI作为软实力与国家主导权 : Sakana AI联合创始人伊藤錬提出AI应被视为“软实力”。他认为,即使是非中美国家,若能提供可靠实用的开源AI技术,也能获得用户支持并掌握主导权。各国追求的“主权AI”并非自给自足,而是选择和整合全球可信技术的能力。日本有望通过提供高可信度AI选择,发挥其软实力,赋能全球用户。(来源: SakanaAILabs)
AI在招聘中的应用 : 社交媒体上出现关于“AI招聘AI”的讨论,引发了对AI在人力资源领域应用的关注。这可能涉及AI辅助简历筛选、面试评估甚至决策,预示着未来招聘流程的自动化和智能化趋势。(来源: Reddit r/deeplearning)
💡 其他
首届世界人形机器人运动会 : 首届世界人形机器人运动会在北京举行,280支队伍、超500台机器人参赛,涵盖田径、足球、篮球、舞蹈、武术等26个项目。比赛中机器人状况百出,如宇树机器人跑步“撞人逃逸”、足球赛场“互殴”,娱乐属性大于竞技。尽管如此,赛事仍是通用人形机器人的一次“公开大考”,有助于发现算法和硬件问题,推动行业进步,并让公众了解当前机器人水平。宇树创始人王兴兴表示,未来将实现机器人自主奔跑。机器人产业正从技术演示转向商业化交付,订单、场景和财务交付成为衡量标准,但许多落地场景仍停留在非核心示范性质,7×24小时真实工况考验仍在进行。(来源: 36氪)

AI电影节与AI艺术创作 : 第三届AI电影节将在IMAX影院举行,展示AI在电影创作中的应用。同时,社交媒体上也有AI生成视频的案例,如“lo-fi chill girl infinite train journey”,利用AI工具生成接近无缝的超长视频。这表明AI在艺术和内容创作领域的影响力日益增强,为创作者提供了新的表达方式。(来源: c_valenzuelab)

美国半导体关税政策对AI产业的影响 : 美国政府考虑对半导体征收高额关税(可能高达300%),并可能入股英特尔以支持国内芯片生产。这标志着美国在半导体产业上从补贴转向部分政府持股,旨在保障国家安全和AI芯片供应。然而,此举引发了对市场扭曲、投资者信心以及美国是否走向工业社会主义的担忧。(来源: Reddit r/artificial)
