
كلمات مفتاحية:أوبن إيه آي, جي بي تي-5, الذكاء العام الاصطناعي (AGI), نموذج العالم ثلاثي الأبعاد, الصياغة الرياضية, ثغرات شهادة X.509, وكلاء الذكاء الاصطناعي, النماذج مفتوحة المصدر, إطار CriticLean, نموذج العالم ثلاثي الأبعاد هونيوان 1.0, ليلة وايك أب!, نموذج هورايزون ألفا, نموذج Command A Vision
🔥 تركيز
اتجاهات بحث OpenAI وتوقعات GPT-5: كشف كبير العلماء في OpenAI، Jakub Pachocki، ورئيس الأبحاث، Mark Chen، في مقابلة حصرية عن التقدم الذي أحرزته الشركة في تطوير GPT-5 ووجهات نظرهم حول الذكاء الاصطناعي العام (AGI). وأكدا أن الرياضيات والبرمجة هما حجر الزاوية للذكاء العام، واقترحا “الوقت المستقل” كمؤشر رئيسي لقياس قدرة النموذج، أي المدة التي يمكن للنموذج خلالها حل المشكلات بشكل مستقل دون تدخل بشري. على الرغم من الأداء المتميز للذكاء الاصطناعي في مسابقات البرمجة والرياضيات، إلا أنهما يعتقدان أن قدرات الاستدلال لا تزال في مراحلها المبكرة، ويؤمنان بأن “قانون التوسع” (Scaling Law) لم يصل إلى سقفه بعد. تعكس هذه المقابلة بشكل غير مباشر التزام OpenAI طويل الأمد بالبحث الأساسي والذكاء الاصطناعي العام، بالتوازي مع دفعها لإطلاق المنتجات. (المصدر: MIT Technology Review)

تعاون ByteDance وجامعة نانجينغ في إطار CriticLean، تحسين كبير في دقة الصياغة الرياضية الرسمية: أطلق فريق Seed التابع لشركة ByteDance بالتعاون مع جامعة نانجينغ إطار CriticLean، الذي رفع دقة الصياغة الرسمية للغة الرياضيات الطبيعية إلى كود Lean 4 من 38% إلى 84%. يقدم هذا الإطار نموذج Critic يعتمد على التعلم المعزز، وهو CriticLeanGPT، الذي تم تدريبه خصيصًا لتقييم الدلالات، مما يمكنه من الحكم بدقة على مدى توافق الكود الرسمي مع الدلالات الأصلية، ويضمن من خلال آلية التحسين التكراري أن البراهين النظرية المولدة تتوافق مع القواعد النحوية وتلتزم بالمنطق الرياضي. حقق هذا البحث اختراقًا في مجال الصياغة الرياضية الرسمية من حيث محاذاة الدلالات وموثوقية التقييم، كما قام ببناء أكبر وأعلى جودة مجموعة بيانات للصياغة الرياضية الرسمية حتى الآن، FineLeanCorpus، مما يوفر نموذجًا جديدًا للبرهان الآلي على النظريات. (المصدر: 量子位)

Tencent تطلق نموذج Hunyuan 3D World Model 1.0، أول نظام توليد عالم مفتوح المصدر يدعم المحاكاة الفيزيائية: أطلقت Tencent رسميًا نموذج Hunyuan 3D World Model 1.0، وهو أول نموذج توليد عالم مفتوح المصدر ومتوافق مع خطوط أنابيب CG التقليدية. يمكن لهذا النموذج إنشاء مشاهد ثلاثية الأبعاد غامرة، قابلة للاستكشاف، وتفاعلية بناءً على مدخلات نصية أو صورية، ويتميز بثلاث مزايا أساسية: تجربة غامرة بزاوية 360 درجة، توافق على مستوى الصناعة (يدعم تصدير تنسيقات شبكة ثلاثية الأبعاد قياسية)، وتفاعل على المستوى الذري (يمكن فصل الكائنات). يستخدم النموذج بنية توليدية، تجمع بين تركيب الصور البانورامية وتقنية إعادة البناء ثلاثي الأبعاد متعدد الطبقات، ويدعم تطبيقات احترافية متعددة مثل الواقع الافتراضي، تطوير الألعاب، تحرير الكائنات، والمحاكاة الفيزيائية، مما يوفر إمكانيات لا حصر لها لتوليد المحتوى ثلاثي الأبعاد والتفاعل معه. (المصدر: 量子位)

Alibaba Security تكشف عن ثغرات شهادات X.509 المشوهة، قد تؤدي إلى تعطل أنظمة macOS/iOS: كشف فريق Alibaba Security بالتعاون مع جامعة إنديانا بلومنجتون الأمريكية عن بحث يوضح أنه من خلال بناء شهادات X.509 مشوهة، يمكن شن هجمات DoS عن بعد، مما يؤدي إلى تعطل أنظمة macOS/iOS على الفور. يكشف هذا البحث عن مشكلات أمنية محتملة في مكتبات خوارزميات التشفير قد تؤدي إلى DoS، وقد تم اكتشاف 18 ثغرة CVE جديدة و12 ثغرة معروفة في ست مكتبات خوارزميات تشفير مفتوحة المصدر رئيسية مثل OpenSSL وBotan، بالإضافة إلى مكتبة Apple Security. كما أظهر البحث كيفية استغلال هذه الثغرات، على سبيل المثال، من خلال رسائل البريد الإلكتروني المشفرة S/MIME لتعطيل أنظمة macOS/iOS. وقد نُشر هذا الإنجاز في مؤتمر USENIX Security’25، وحصل على ترشيح لجائزة Pwnie Awards “أوسكار الهاكرز”، مما يؤكد أن X.509 DoS يمثل تهديدًا واسع الانتشار ويتطلب اهتمامًا كافيًا. (المصدر: 量子位)

ليلة WAIC UP!: تأملات في الذكاء الاصطناعي ومستقبل البشرية: خلال مؤتمر WAIC 2025، جمعت فعالية “WAIC UP!之夜” مفكرين من مجالات الذكاء الاصطناعي والعلوم الإنسانية والاجتماعية لمناقشة السؤال المحوري “ما أهمية الذكاء الاصطناعي؟”. هدفت الفعالية إلى تجاوز الحماس التكنولوجي والعودة إلى تأثير الذكاء الاصطناعي على القيم الإنسانية وجوهر الحياة. شارك العديد من الضيوف كيف يعيد الذكاء الاصطناعي تشكيل الإبداع والفن والتعليم والعمل، مؤكدين أن الذكاء الاصطناعي هو “مضاعف للخبرة” يمكنه تضخيم التراكم الإبداعي، لكن الفن والإبداع الحقيقي لا يزالان ينبعان من “أفكار” البشر وليس من الأدوات. كما تطرقت المناقشة إلى الروابط العاطفية التي لا يمكن للذكاء الاصطناعي أن يحل محلها، والحب والألم الحقيقيين، والكفاءات الأساسية للبشر في عصر الذكاء الاصطناعي: القدرة على التواصل، والحكم الجمالي، والتعاطف. تدعو هذه التأملات إلى البقاء يقظين وفضوليين في خضم الطوفان التكنولوجي، والبحث عن بريق الإنسانية الذي لا يمكن قياسه بالخوارزميات. (المصدر: 量子位)

🎯 الاتجاهات
الزخم القوي لتطور النظام البيئي للذكاء الاصطناعي في الصين: أشار Andrew Ng إلى أنه على الرغم من أن الولايات المتحدة لا تزال رائدة في مجال الذكاء الاصطناعي، إلا أن الصين، بفضل نظامها البيئي النابض بالحياة للنماذج مفتوحة المصدر ومبادراتها النشطة في تصميم وتصنيع أشباه الموصلات، تُظهر زخمًا هائلاً ولديها القدرة على تجاوز الولايات المتحدة. وأكد أن الزخم أمر بالغ الأهمية في مجال الشركات الناشئة، وأن البيئة التجارية شديدة التنافسية في الصين والانتشار السريع للمعرفة يمنحانها ميزة كبيرة. على الرغم من أن الولايات المتحدة تتفوق في تحقيق الذكاء الاصطناعي السحابي، والصين تتفوق في تكنولوجيا المراقبة، إلا أن الصين قد سيطرت على النماذج مفتوحة المصدر، مثل DeepSeek R1-0528، Kimi K2، سلسلة Qwen3، و GLM 4.5، وهذه النماذج تقترب بسرعة من أفضل النماذج مفتوحة المصدر الأمريكية أو تتجاوزها. وعلى الرغم من أن خطة عمل الذكاء الاصطناعي الأمريكية الأخيرة تدعم المصادر المفتوحة، إلا أن هذا وحده لا يكفي للحفاظ على ريادتها. (المصدر: natolambert, DeepLearningAI, Teknium1, hardmaru, Zai_org)

أداء نموذج Horizon Alpha وتكهنات حول GPT-5: بعد إطلاق نموذج Horizon Alpha الغامض على OpenRouter، سرعان ما تصدر اختبارات المعايير مثل EQ-Bench، مظهرًا قدرات مذهلة في البرمجة والكتابة الإبداعية والاستدلال، خاصة في توليد SVG والمحاكاة الفيزيائية المعقدة. تكهن بعض مستخدمي الإنترنت بأنه قد يكون أحد نماذج سلسلة GPT-5 القادمة من OpenAI (مثل GPT-5-mini أو nano)، لأن أداءه يتجاوز بكثير النماذج غير الاستدلالية الحالية، وأسلوبه يشبه نماذج OpenAI. على الرغم من أن وقت استدلاله أطول، إلا أن “أسلوب الطهي” ومزاياه الفريدة التي أظهرها في العديد من الاختبارات أثارت توقعات ومناقشات قوية في المجتمع حول إطلاق GPT-5 الوشيك. (المصدر: scaling01, karminski3, dotey, Teknium1, teortaxesTex, andrew_n_carr, scaling01)

Cohere Labs تطلق نموذج Command A Vision: أطلقت Cohere Labs النسخة مفتوحة الأوزان من نموذجها Command A Vision على Hugging Face، وهو نموذج متعدد الوسائط بـ 112 مليار معلمة، يهدف إلى إعادة تعريف الفهم البصري للمؤسسات. يركز هذا النموذج على الجماليات الفريدة للصور، ويمكنه أتمتة مهام مثل تحليل الرسوم البيانية، والتعرف الضوئي على الحروف (OCR) المدرك للتخطيط، وتفسير المشاهد الواقعية، وهو مناسب للوثائق والصور والبيانات البصرية المنظمة. يعكس هذا الإطلاق التزام Cohere Labs بالنظام البيئي البحثي، ويشجع المطورين على الابتكار باستخدام قدراته البصرية القوية. (المصدر: sarahookr, huggingface, teortaxesTex, andrew_n_carr)

تحديثات سلسلة نماذج Qwen3-Coder-Flash: تم إطلاق سلسلة نماذج Qwen3-Coder-Flash، ولا سيما Qwen3-Coder-30B-A3B-Instruct، والتي حظيت باهتمام كبير بفضل سرعة توليد الكود الفائقة وقدرات Agent القوية. يدعم هذا النموذج بشكل أصلي سياق 256K، ويمكن توسيعه إلى 1M tokens عبر تقنية YaRN، وتم تحسينه لمنصات مثل Qwen Code وCline، مما يحقق استدعاء وظائف سلس وسير عمل Agent. كما أطلقت Unsloth نسخته الكمية، مما يجعله قابلاً للتشغيل على الأجهزة ذات الذاكرة الرسومية الأقل، وقامت بإصلاح مشكلات استدعاء الأدوات. وقد أشاد المجتمع بأدائه في مهام البرمجة، معتبرين إياه مثالاً على “التكرار السريع” في مجال الذكاء الاصطناعي مفتوح المصدر. (المصدر: karminski3, Alibaba_Qwen, awnihannun, scaling01, ImazAngel, jeremyphoward, op7418)

توحيد قدرات نموذج GLM-4.5: أطلقت Z.ai نماذجها الرائدة الجديدة GLM-4.5 وGLM-4.5 Air، بهدف توحيد قدرات الاستدلال والترميز وAgent المتطورة. يمتلك GLM-4.5 إجمالي 355 مليار معلمة و32 مليار معلمة نشطة، بينما يمتلك GLM-4.5-Air إجمالي 106 مليار معلمة و12 مليار معلمة نشطة. هذه النماذج مدعومة بالكامل على SGLang، وتتميز بسياق 128k، وقد أظهرت أداءً متميزًا في العديد من اختبارات المعايير مثل MATH500 وSWE-bench، وتنافس Claude 4، وتتفوق على Kimi K2. يمثل إطلاق GLM-4.5 تقدمًا مهمًا في تطوير نماذج الذكاء الاصطناعي متعددة الوظائف، ويوفر للمطورين قدرات موحدة قوية. (المصدر: TheTuringPost, Zai_org, thursdai_pod)

تقدم نموذج Step 3 وتحسين الاستدلال: أطلقت StepFun AI أحدث نموذج استدلال متعدد الوسائط مفتوح المصدر، Step 3، بهدف توفير VLM أقوى وأسرع وأكثر فعالية من حيث التكلفة. يمتلك هذا النموذج 321 مليار معلمة (38 مليار نشطة)، ومن خلال تحسينات مبتكرة في بنية Multi-Matrix (MFA) وAFD، حقق استدلالًا عالي الكفاءة، حيث وصل إلى سرعة تصل إلى 4,039 tok/sec/GPU حتى على وحدات معالجة الرسوميات العادية. أعلن مشروع vLLM عن دعمه الكامل لنموذج Step 3، ويخطط لزيادة تحسين أدائه. يمثل هذا التقدم اتجاهًا جديدًا في التصميم التعاوني للنماذج والبنية التحتية، ومن المتوقع أن يدفع انتشار وكفاءة النماذج متعددة الوسائط في التطبيقات العملية. (المصدر: vllm_project, huggingface, _akhaliq, teortaxesTex)

إطلاق نموذج صور FLUX.1 Krea Dev: أطلقت Black Forest Labs بالتعاون مع Krea AI نموذج FLUX.1 Krea Dev، وهو نموذج FLUX جديد مفتوح الأوزان ومتطور، يركز على توليد صور واقعية بجودة فوتوغرافية. يهدف هذا النموذج إلى إزالة “الشعور بالذكاء الاصطناعي” والوهج الزائد، وتوليد صور ذات جماليات فريدة وتفاصيل طبيعية. على الرغم من أنه لا يزال هناك مجال للتحسين في اتباع التعليمات والدعم الصيني، ولا يزال هناك “طعم الذكاء الاصطناعي” في بعض السيناريوهات، إلا أن إمكاناته في مجال توليد الصور لا تزال تحظى بالاهتمام. يتوفر عرض توضيحي مجاني على Hugging Face، مما جذب اختبارات ومناقشات واسعة من المجتمع. (المصدر: huggingface, multimodalart, mervenoyann, karminski3)

تحسين قدرات توليد الفيديو في Google Veo 3 Fast: أصبحت ميزات Google DeepMind’s Veo 3 Fast وVeo 3 لتحويل الصور إلى فيديو متاحة الآن في Gemini API، مما أدى إلى تحسين كبير في سرعة وجودة توليد الفيديو. تبلغ تكلفة Veo 3 Fast 0.40 دولارًا لكل ثانية من الفيديو (مع الصوت)، وتتميز بمعدلات قيود على مستوى الإنتاج، وفي بعض الحالات يمكن أن تضاهي جودتها النماذج ذات التكلفة الأعلى. تدعم هذه التقنية تحويل الصور إلى فيديو والنص إلى فيديو، ومن خلال التحكم الإبداعي المحسن والمطالبات الدقيقة، تحقق إنشاء فيديو عالي الجودة بسرعة. يمثل هذا اختراقًا مهمًا للذكاء الاصطناعي في مجال توليد الفيديو، ومن المتوقع أن يدفع انتشار وكفاءة إنشاء الفيديو القائم على الوكلاء. (المصدر: GoogleDeepMind, Vtrivedy10, osanseviero, demishassabis, algo_diver)
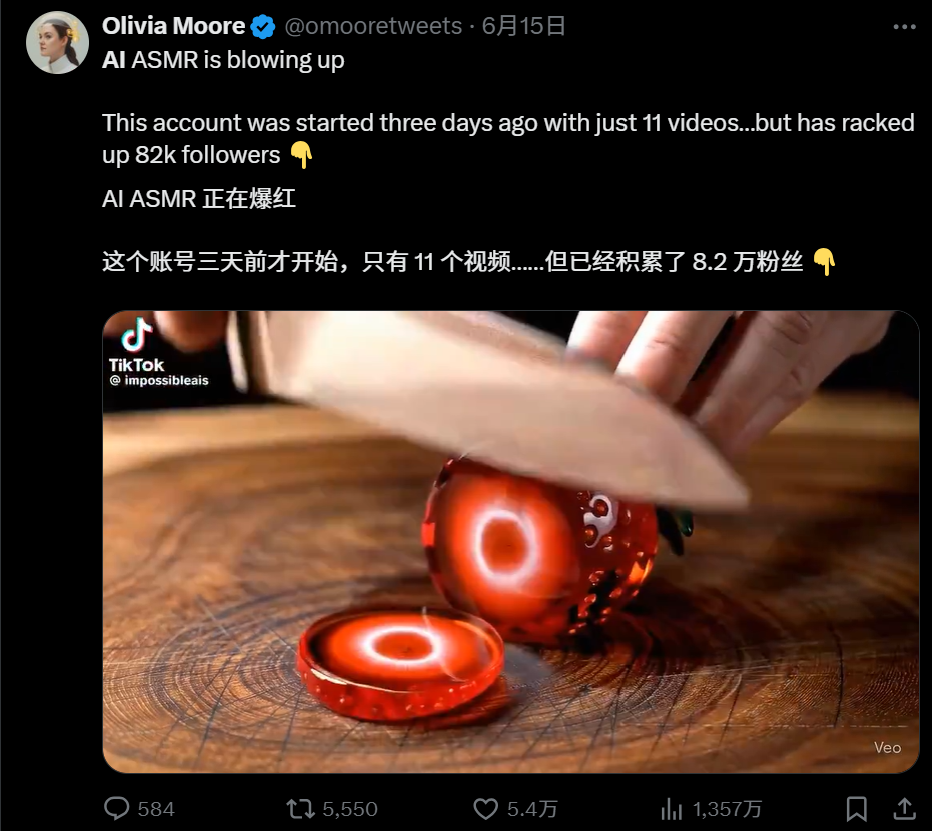
انتشار محتوى فيديو AI ASMR: يشهد فيديو ASMR الذي يولده الذكاء الاصطناعي موجة من الاسترخاء والفضول على منصات الفيديو القصيرة العالمية. هذا النوع من الفيديو، المدعوم بنماذج توليد الصوت والفيديو المتزامنة مثل Google Veo3، قلل بشكل كبير من عتبة الإنشاء، مما أدى إلى ظهور عدد كبير من الحسابات الظاهرة وملايين المشاهدات. يتراوح محتوى الفيديو من تقطيع الفاكهة “المخالف للمنطق” ونقر لوحة المفاتيح الجليدية إلى تناول البيتزا الماسية الغريبة، وحتى تحويل الرسوم المتحركة إلى عروض أكل غريبة. تتيح قدرة نموذج Veo3 على توليد الصوت والصورة المتزامنة إنتاج فيديو AI ASMR بكميات كبيرة دون عوائق. هذا الاتجاه لا يعيد تشكيل النظام البيئي لمحتوى الفيديو فحسب، بل يولد أيضًا نماذج ربح متنوعة مثل بيع الموجهات (prompts) وتقاسم الإيرادات والإعلانات على المنصات، مما يبشر بقدوم عام تجاري لتوليد الصوت والفيديو. (المصدر: 36氪)
WAIC 2025: تحليل متعمق لتقنيات الذكاء الاصطناعي واتجاهات الصناعة: أظهر مؤتمر WAIC 2025 تحول الذكاء الاصطناعي من “ماذا يمكن أن يفعل” إلى “ماذا يمكن أن يغير”، مؤكداً على الاندماج العميق بين الاختراقات التكنولوجية والاحتياجات الاجتماعية. ركز المؤتمر على مفهوم Agent، مشيراً إلى أنه أصبح “سؤالاً لا بد من الإجابة عليه” في الصناعة، ويتطور من “الوكيل الفردي” إلى “تنسيق الوكلاء المتعددين” لتحقيق معالجة فعالة للمهام المعقدة. كما انفجرت تطبيقات الذكاء الاصطناعي من B-end إلى C-end، مع تركيز تسليم المنتجات بشكل أكبر على “النتيجة كخدمة” (RaaS). بالإضافة إلى ذلك، يتعمق تطبيق الذكاء الاصطناعي في مجالات الصناعة والطب والتعليم، مثل وكلاء Siemens الصناعيين، وروبوتات الرعاية البشرية من Fourier، وتقنية Baidu NOVA للصور الرقمية. كما تناول المؤتمر أخلاقيات الذكاء الاصطناعي والتنمية المستدامة، مما يشير إلى أن الذكاء الاصطناعي سيصبح قوة دافعة لتعزيز العدالة الاجتماعية وعالم أكثر دفئاً. (المصدر: 36氪, 36氪)

ByteDance تطلق نموذج Diffusion النصي Seed Diffusion Preview: أطلقت ByteDance نموذجها Diffusion النصي – Seed Diffusion Preview، الذي يستخدم عملية إزالة الضوضاء لتوليد النص، بدلاً من طريقة Transformer التقليدية لتوليد الكلمات حرفياً. تكمن أكبر ميزة له في سرعته الفائقة، حيث يمكن أن يصل إلى 2146 token في الثانية، مما يحقق استجابة فورية لمهام مثل توليد الكود. على الرغم من أن نماذج Diffusion النصية الحالية لا يزال لديها مجال للتحسين في الأداء، ويصعب عليها إنجاز المهام المعقدة، إلا أن ابتكارها يكمن في توفير آلية توليد مشابهة لنماذج Diffusion الصور، مما يشير إلى اتجاه جديد في مجال توليد النص. حالياً، بالإضافة إلى Seed Diffusion Preview، تشمل النماذج المعروفة Mercury Coder وGoogle’s Gemini Diffusion. (المصدر: dotey, karminski3)
تعميق تطبيق الذكاء الاصطناعي في صناعة السيارات: أصبح الذكاء الاصطناعي عنصراً أساسياً في المنافسة في صناعة السيارات، حيث تتزايد نسبة اختراق الذكاء الاصطناعي من السيارات الفاخرة إلى السيارات الاقتصادية. قامت Li Auto بتجهيز سيارتها i8 SUV الكهربائية بالكامل بنموذج VLA (نموذج لغوي بصري كبير)، مما كسر الحواجز بين القيادة الذكية وقمرة القيادة الذكية، وحقق مشاركة “العينين” و”الفم/الأذنين” لنفس “الدماغ”، مما حول السيارة من منفذ سلبي للأوامر إلى وكيل ذكي نشط. من جانبها، أطلقت Geely نظام Agent OS، الذي يتعامل مع السيارة كإنسان آلي بعجلات، ويوفر قدرات تفاعل بين الإنسان والآلة مدفوعة بنماذج كبيرة، مما يجعل الذكاء الاصطناعي يفهم نوايا المستخدم بشكل أفضل. بالإضافة إلى ذلك، يتجه مجال القيادة الذاتية من التعلم بالمحاكاة إلى التعلم المعزز، فمثلاً، بدأ سائق الذكاء الاصطناعي في Li Auto أيضاً في التعلم المعزز لتحسين قدرات اتخاذ القرار على المدى الطويل والمستوى الأعلى، مما يشير إلى تسارع التطور من L2 إلى L4. (المصدر: 36氪, 量子位)

🧰 الأدوات
ميزات Perplexity AI الجديدة واختصارات Comet Shortcuts: عززت Perplexity AI مكانتها في مجال البحث بالذكاء الاصطناعي من خلال إطلاق ميزات جديدة واختصارات Comet Shortcuts. تتيح اختصارات Comet للمستخدمين أتمتة مهام سير العمل المتكررة على الويب من خلال مطالبات بسيطة باللغة الطبيعية، ويمكن الوصول إليها في أي مكان عبر “/command”. تكمن قيمة Perplexity في قدراتها الفائقة في البحث بالذكاء الاصطناعي، حيث يمكنها توفير معلومات دقيقة مع مصادر، وتدعم اختيار النموذج، مما يجعلها متفوقة على نماذج LLM الأخرى في تجميع المعلومات والتحقق من الحقائق. على الرغم من أن البعض يشكك في قيمتها كـ “غلاف”، إلا أن التزامها بتوفير بديل حقيقي لـ Siri، ودمجها في تطبيقات مثل WhatsApp، يظهر ابتكارها في تجربة المستخدم وتكامل الوظائف. (المصدر: AravSrinivas, scaling01, AravSrinivas, perplexity_ai, Reddit r/artificial)

Hugging Face Jobs: منصة مهام الذكاء الاصطناعي المستضافة بالكامل: أطلقت Hugging Face منصة Hugging Face Jobs، وهي منصة مستضافة بالكامل تتيح للمستخدمين تشغيل مهام CPU وGPU مباشرة من CLI أو نصوص Python. تهدف هذه الخدمة إلى تبسيط إعدادات الحوسبة وعملية البحث لمطوري الذكاء الاصطناعي، مما يمكنهم من التركيز بشكل أكبر على التجارب والبناء دون القلق بشأن البنية التحتية الأساسية. من خلال أوامر بسيطة لبدء المهام، توفر Hugging Face Jobs حلاً سحابيًا فعالاً ومريحًا لتطوير الذكاء الاصطناعي. (المصدر: huggingface)
SciSpace Agent: مساعد الذكاء الاصطناعي الحصري للعلماء: SciSpace Agent هو أول مساعد ذكاء اصطناعي عمودي مصمم خصيصًا للعلماء، ويهدف إلى توفير ما معدله 1,300 ساعة عمل للعلماء سنويًا. تدمج هذه الأداة أدوات الاقتباس، ومحركات البحث عن الأدبيات، وقارئات PDF، ومحرر كتابة بالذكاء الاصطناعي، وتقدم خدمة رفيق بحث شاملة. تعتمد على أكثر من 280 مليون ورقة بحثية، وأكثر من 50 مليون ملف PDF كامل النص، وأكثر من 150 أداة وقاعدة بيانات أكاديمية، ويمكنها إنجاز مهام معقدة مثل مراجعة الأدبيات وتحليل البيانات في أقل من 10 دقائق باستخدام مطالبة واحدة، مما يعزز بشكل كبير كفاءة البحث العلمي. (المصدر: TheTuringPost)
Manus AI Wide Research: تعاون وكلاء ذكاء اصطناعي متوازٍ على نطاق واسع: أطلقت Manus AI أكبر تحديث لها منذ إطلاقها – ميزة Manus Wide Research، التي تتيح للمستخدمين بدء تعاون وكلاء ذكاء اصطناعي متوازٍ على نطاق واسع بنقرة واحدة، مما يسهل معالجة مهام البحث المعقدة التي كانت تستغرق ساعات وتتضمن مئات مصادر البيانات. تشبه هذه الميزة وضع الوكلاء المتعددين في Grok 4 Heavy، ولكنها تتميز بنطاق جدولة أكبر، حيث يكون كل وكيل فرعي عبارة عن نسخة Manus كاملة، قادرة على التفكير والتنفيذ بشكل مستقل. على الرغم من أن استهلاك النقاط قد يرتفع بشكل كبير، إلا أن Manus تعتقد أن هذه مرحلة ضرورية في تحول منتجات الذكاء الاصطناعي من التكلفة الهامشية العالية إلى التكلفة الهامشية المنخفضة. تستلهم هذه البنية من نموذج MapReduce، وتهدف إلى حل المشكلات الجديدة التي تظهر في تعاون وكلاء الذكاء الاصطناعي على نطاق واسع. (المصدر: 36氪)
WPS AI 3.0 وWPS Lingxi: إعادة تشكيل سير عمل المكتب: أطلقت Kingsoft Office إصدار WPS AI 3.0، وقدمت وكيل Office الذكي الأصلي WPS Lingxi، بهدف إعادة تشكيل سير عمل المستخدمين في المكتب. يدمج WPS Lingxi مجموعة كاملة من الوظائف مثل AI PPT، AI Writing، AI Document، AI Search، AI Reading، ويحقق تكاملاً عميقًا مع مجموعة Office، ويدعم ترقية المستندات السحابية إلى قواعد معرفة بنقرة واحدة، مما يحقق استرجاعًا دلاليًا دقيقًا. تكمن ميزته الأساسية في “فهم التنسيق، التفكير، والقدرة على التطور”، حيث يمكنه مطابقة تنسيق المستند تلقائيًا، وفهم نية المستخدم، وتقديم تعديلات مقارنة، مما يعزز بشكل كبير كفاءة معالجة المستندات المعقدة وإنشاء المحتوى متعدد السيناريوهات. يمثل إطلاق WPS Lingxi تطور الذكاء الاصطناعي في المكتب من “أداة” إلى “مساعد ذكاء اصطناعي مدمج بسلاسة في سير العمل”، مما يحل مشكلة “سهولة التوليد وصعوبة التحرير” في أدوات الذكاء الاصطناعي التقليدية. (المصدر: 量子位)
وكيل التوظيف بالذكاء الاصطناعي: قام أحد المطورين بإنشاء وكيل ذكاء اصطناعي يُدعى Laboro.co، يهدف إلى أتمتة الأجزاء المستهلكة للوقت والمتكررة في عملية البحث عن عمل. تتضمن الأداة زاحف ويب يمكنه جمع صفحات التوظيف الداخلية لأكثر من 70 ألف شركة؛ ومطابق تعلم آلي يطابق السير الذاتية بالوظائف؛ ووكيل تقديم طلبات يمكنه ملء نماذج الطلبات وتقديمها تلقائيًا. تتيح هذه الأداة المجانية للباحثين عن عمل التركيز على المقابلات، وترك عملية التقديم الشاقة للذكاء الاصطناعي، مما يعزز بشكل كبير كفاءة البحث عن عمل. (المصدر: Reddit r/deeplearning)

واجهة المستخدم الرسومية (GUI) لـ Ollama والجدل حول المصدر المفتوح: أطلقت Ollama واجهة المستخدم الرسومية (GUI) الجديدة، لكن طبيعتها المغلقة المصدر أثارت جدلاً في المجتمع. شكك بعض المستخدمين في منطقية كونها مغلقة المصدر، وأعربوا عن قلقهم من احتمال وجود مشكلات خصوصية مثل “الاتصال العكسي”. صرح العديد من أعضاء المجتمع أنهم يفضلون استخدام بدائل مفتوحة المصدر مثل llama.cpp، vLLM، HFtransformers، بالاشتراك مع OpenWebUI أو LibreChat كواجهة أمامية. يسلط هذا الحدث الضوء على الجدل المستمر بين نماذج المصدر المفتوح والمغلق في مجال أدوات الذكاء الاصطناعي، وأهمية الشفافية والتحكم بالنسبة للمستخدمين. (المصدر: Reddit r/LocalLLaMA, ollama)

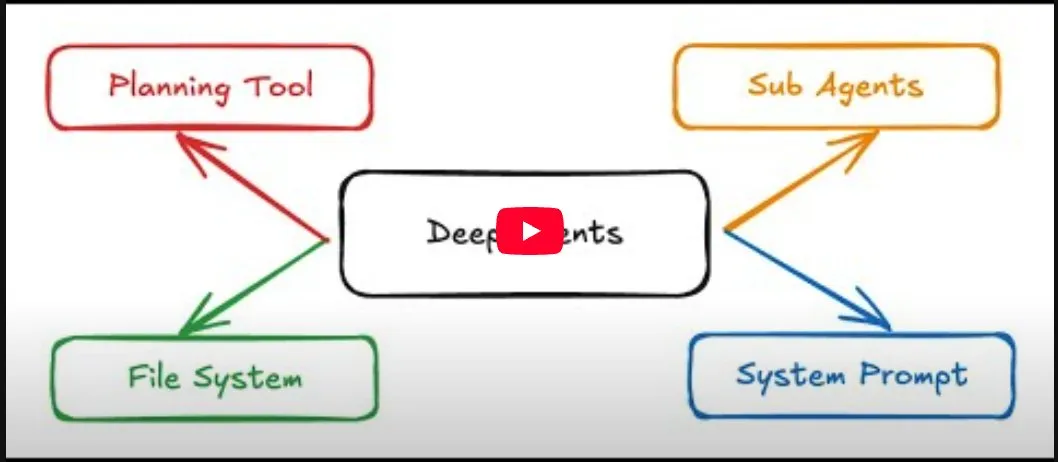
تقدم أدوات برمجة الذكاء الاصطناعي وAgent: Deep Agents، AmpCode، إلخ: يستمر الابتكار في مجال برمجة الذكاء الاصطناعي وأدوات Agent. قدم Harrison Chase مفهوم “Deep Agents”، الذي يجمع بين أدوات التخطيط، ونظام الملفات، والوكلاء الفرعيين، ومطالبات النظام التفصيلية، بهدف تحقيق سير عمل Agentic أكثر تعقيدًا. أما AmpCode، كمنافس لـ Claude Code، فقد اعتبره المستخدمون “جيدًا على الأقل بنفس القدر”، وحصل على تقييمات إيجابية. بالإضافة إلى ذلك، أصبح نموذج Qwen3-Coder متاحًا على Ollama، ويستخدم في تجارب Deep Agents، مما يدفع تطوير برمجة Agentic مفتوحة المصدر. تشير هذه التطورات إلى أن أدوات برمجة الذكاء الاصطناعي تتجه نحو أن تكون أقوى وأكثر تكاملاً وسهولة في الاستخدام، بينما يتم تعزيز التحكم المستمر في سير عمل Agentic. (المصدر: hwchase17, hwchase17, corbtt, HamelHusain)
📚 التعلم
خارطة طريق تعلم وكلاء الذكاء الاصطناعي: تم تداول خارطة طريق لتعلم وكلاء الذكاء الاصطناعي على وسائل التواصل الاجتماعي، مؤكدة على الخطوات والموارد الأساسية لإتقان وكلاء الذكاء الاصطناعي. تهدف هذه الخارطة إلى مساعدة الأفراد المهتمين على تعلم بناء وتطبيق وكلاء الذكاء الاصطناعي بشكل منهجي، وتغطي جوانب مختلفة من المفاهيم الأساسية إلى التطبيقات المتقدمة، مما يوفر مسارًا تعليميًا واضحًا للمطورين والمتعلمين. يعكس هذا أن وكلاء الذكاء الاصطناعي، كتقنية ناشئة، يجذبون عددًا كبيرًا من المتعلمين الذين يسعون لإتقان اتجاهات التكنولوجيا المستقبلية. (المصدر: Ronald_vanLoon)

معاينة كتاب نماذج الذكاء الاصطناعي فائقة النطاق: أطلقت Hugging Face معاينة لكتاب “Ultra-scale book”، الذي يهدف إلى تقديم محتوى مقالات المدونة حول النماذج فائقة النطاق في شكل كتاب أنيق. يوفر إطلاق هذا الكتاب للباحثين والمطورين في مجال الذكاء الاصطناعي موردًا للتعلم المتعمق لنظرية وممارسة النماذج فائقة النطاق، مما يساعد على تعميم وتبادل المعرفة ذات الصلة. سيتم إطلاق النسخة المادية قريبًا، مما يلبي بشكل أكبر الحاجة إلى التعلم المنهجي لتقنيات الذكاء الاصطناعي المتطورة. (المصدر: eliebakouch, TheZachMueller, _lewtun)

أهمية العلم المفتوح لتطوير الذكاء الاصطناعي: ناقش المجتمع الدور الحاسم للعلم المفتوح في تقدم مجال الذكاء الاصطناعي. يقوم الباحثون والمهندسون، من خلال نشر الأوراق البحثية والنماذج ومجموعات البيانات مفتوحة المصدر، بدفع الذكاء الاصطناعي نحو مستقبل أكثر انفتاحًا وتعاونًا. على الرغم من أن دفع المصادر المفتوحة داخل شركات التكنولوجيا الكبرى قد يواجه عقبات إدارية وقانونية، إلا أن الانفتاح يضمن أن نتائج البحث تحظى باهتمام واستخدام أوسع، ويتم الابتكار بناءً عليها، مما يسرع تقدم الذكاء الاصطناعي ويوسع تأثيره. يدعو المؤيدون إلى الكفاح المستمر من أجل العلم المفتوح، معتبرين أن الباحثين الذين يشاركون نتائجهم بدلاً من العمل في عزلة هم من سيتذكرون حقًا كقوى دافعة في العقد القادم. (المصدر: eliebakouch, huggingface)
تعميم نماذج الاستدلال وبحث تحسين Prompt: ناقش المجتمع أهمية قدرة نماذج الاستدلال على التعميم وتحسين Prompt في تطوير الذكاء الاصطناعي. يرى البعض أن تحفيز النماذج على التفكير من خلال التعلم المعزز (RL) يمكن أن يعزز قدرتها على التعميم في مهام مختلفة، مثل الأداء الأفضل في الكتابة الإبداعية بعد حل المشكلات الرياضية. في الوقت نفسه، يعتبر تحسين Prompt مفتاحًا لإطلاق العنان لإمكانات نماذج LLM، ولكنه مجرد جزء من الحل. يشير الخبراء إلى أن التحدي الحقيقي يكمن في كيفية التعبير بوضوح عن نية الذكاء الاصطناعي وبناء أنظمة ذكاء اصطناعي موثوقة، وهذا يتطلب برمجة LLM بدلاً من مجرد توجيهها. بالإضافة إلى ذلك، يركز البحث أيضًا على مشكلة أن التدريب الطويل جدًا لـ RL قد يؤدي إلى نسيان النموذج للمعرفة المدربة مسبقًا، ويقترح مزج RLHF مع تدرجات التدريب المسبق لتجنب انحراف النموذج. (المصدر: jxmnop, lateinteraction, jxmnop)

مجموعة بيانات NVIDIA Nemotron Super v1.5 الاصطناعية: فتحت NVIDIA أكثر من 26 مليون سطر من البيانات الاصطناعية المستخدمة لتدريب نموذج Llama Nemotron Super v1.5. تهدف هذه الخطوة إلى زيادة شفافية تدريب النموذج، ومساعدة المطورين على بناء نماذجهم الخاصة دون الحاجة إلى قضاء الكثير من الوقت والجهد في توليد مجموعات البيانات بأنفسهم. تم نشر مجموعة البيانات هذه على Hugging Face، مما يوفر موردًا قيمًا لمجتمع الذكاء الاصطناعي، ويساعد على تسريع البحث والتطوير في نماذج الذكاء الاصطناعي. (المصدر: huggingface, huggingface)

مجموعة بيانات NuminaMath-LEAN للرياضيات الرسمية: أطلق Project Numina مجموعة بيانات NuminaMath-LEAN، وهي مجموعة بيانات واسعة النطاق تحتوي على 100 ألف مشكلة من مسابقات الرياضيات، تم صياغتها رسميًا في كود Lean 4، وتتضمن أكثر من 20 ألف تعليق توضيحي يدوي. تستخدم هذه المجموعة بالاشتراك مع أدوات مثل Kimina-Prover، Kimina-autoformalizer، وCombiBench، بهدف دفع تقدم الذكاء الاصطناعي مفتوح المصدر في مجال الرياضيات الرسمية. وقد أشاد المجتمع بهذا العمل المفتوح للبيانات، وأشار إلى أنه من المتوقع أن يرفع نماذج الاستدلال الرياضي من مستوى المدرسة الثانوية إلى مستوى البكالوريوس أو حتى مستوى البحث، لحل المشكلات الرياضية المفتوحة. (المصدر: Dorialexander, QuixiAI, bigeagle_xd)

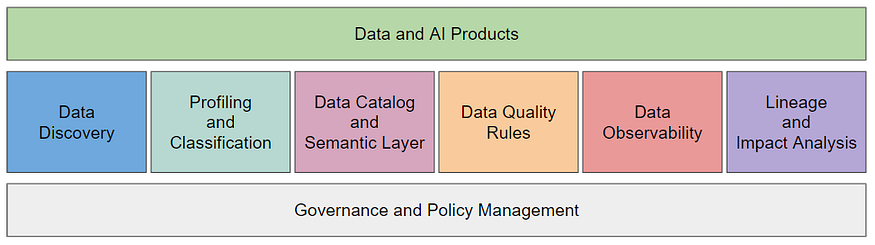
قدرة جودة البيانات في مشاريع الذكاء الاصطناعي: مع نضوج حمى الذكاء الاصطناعي ونماذج LLM، يتحول تركيز الصناعة إلى بناء حلول بيانات وذكاء اصطناعي معقدة لتقديم قيمة تجارية حقيقية. تكمن الميزة التنافسية الأكثر دفاعية للشركات في أصول بياناتها الخاصة، ولكن هذا يعتمد على جودة البيانات العالية، واتساقها، وثراء سياقها، وأمانها. يؤكد المقال أن إطار عمل شامل لجودة البيانات وموثوقيتها أمر بالغ الأهمية لمشاريع الذكاء الاصطناعي، ويجب أن يتضمن اكتشاف البيانات، وتوصيف البيانات، وتصنيف البيانات، وكتالوج البيانات والطبقة الدلالية، وقواعد جودة البيانات، وإمكانية مراقبة البيانات، وتحليل الأصل والتأثير. إذا لم يتم حل مشكلات جودة البيانات في الوقت المناسب، فلن تتمكن حلول الذكاء الاصطناعي من تلبية احتياجات الشركات، مما يؤدي إلى فقدان الثقة، وانخفاض الكفاءة، ومخاطر الامتثال المحتملة. (المصدر: 36氪)
موارد تعلم التعلم العميق وتطويره القائم على التقييم: قام أحد المطورين بإنشاء مستودع GitHub يشرح المفاهيم الرياضية للشبكات العصبية الاصطناعية (ANN) والشبكات العصبية التلافيفية (CNN) في التعلم العميق من خلال تفسيرات بصرية، بهدف مساعدة المبتدئين على فهم هذه المفاهيم المعقدة بشكل أفضل. في الوقت نفسه، يؤكد المجتمع على أهمية “التطوير القائم على التقييم” (Evals Driven Development) في مشاريع الذكاء الاصطناعي، معتبرًا أنه يمكن أن يساعد الفرق على تحديد المشكلات وحلها بشكل أسرع، خاصة في تطوير نماذج الذكاء الاصطناعي سريعة التكرار. على الرغم من أن أطر تقييم نماذج الذكاء الاصطناعي لا تزال غير كافية، إلا أنه من خلال التقييم المستمر وحلقة التغذية الراجعة، يمكن تحسين جودة النموذج وكفاءة المشروع بشكل فعال، وتجنب المشكلات طويلة الأمد التي تسببها الأكواد “المقبولة”. (المصدر: Reddit r/deeplearning, HamelHusain, code_star)
💼 الأعمال
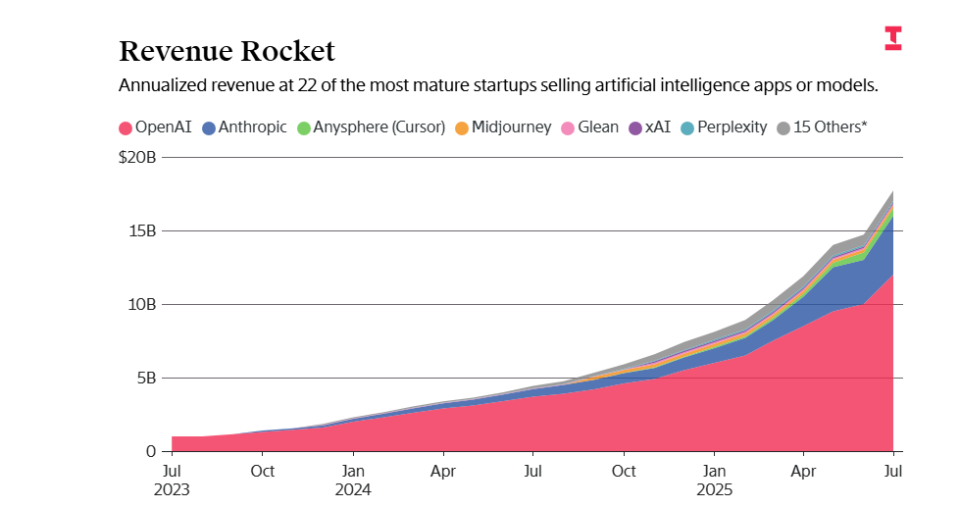
إنجازات OpenAI المالية: إيرادات سنوية 12 مليار دولار، 700 مليون مستخدم أسبوعي لـ ChatGPT، وتقييم 260 مليار دولار: تضاعفت إيرادات OpenAI تقريبًا في الأشهر السبعة الأولى من عام 2025، ومن المتوقع أن تصل الإيرادات السنوية إلى 12 مليار دولار، وقد ارتفعت الإيرادات الشهرية إلى مليار دولار. تجاوز عدد المستخدمين النشطين أسبوعيًا لمنتجها الرائد ChatGPT 700 مليون مستخدم، ويستخدمه الأفراد والشركات على نطاق واسع. على الرغم من ارتفاع تكاليف التشغيل (المتوقع أن تتجاوز 28 مليار دولار في عام 2025)، لا تزال OpenAI تمضي قدمًا في خطة تمويل بقيمة 40 مليار دولار، وقد وصل تقييمها إلى 260 مليار دولار، ومن المتوقع أن تقود SoftBank جولة تمويل بقيمة 22.5 مليار دولار. تعمل الشركة بقوة على توسيع سوق الشركات، وتقدم ميزات ChatGPT مخصصة وعروضًا لفترة محدودة، وأضافت وظائف تحرير جداول البيانات والعروض التقديمية، لتحدي Microsoft وGoogle. كما أظهرت المنافسة Anthropic نموًا قويًا، حيث تجاوزت إيراداتها السنوية 4 مليارات دولار. (المصدر: 36氪, 36氪)
Cline تكمل تمويلًا بقيمة 32 مليون دولار لدعم برمجة الذكاء الاصطناعي مفتوحة المصدر: أكملت أداة برمجة الذكاء الاصطناعي مفتوحة المصدر Cline بنجاح جولة تمويل أولية وسلسلة A بقيمة 32 مليون دولار، بقيادة Emergence Capital وPace Capital. نشأت Cline من مشروع هاكاثون، وتطورت الآن لتصبح منصة تضم مجتمعًا من 2.7 مليون مطور، ملتزمة بتوفير تجربة برمجة ذكاء اصطناعي عالية الأداء وشفافة وفعالة من حيث التكلفة. تتمثل فلسفتها الأساسية في المصدر المفتوح، مما يوفر للمستخدمين مرونة في النماذج والمزودين، ويحقق استدلالًا شفافًا ومحاسبًا على التكلفة. لا يؤكد هذا التمويل نموذجها مفتوح المصدر فحسب، بل يشير أيضًا إلى الطلب القوي في سوق أدوات برمجة الذكاء الاصطناعي على الحلول التي يقودها المطورون وتتسم بالشفافية، مما يبشر بتطبيق أوسع لتقنية AI Agent في مجال تطوير البرمجيات. (المصدر: cline, dotey, op7418)

موجة إدراج شركات الذكاء الاصطناعي الناشئة في الصين: MiniMax وZhipu تتنافسان على لقب “الشركة الأولى”: تشهد شركات الذكاء الاصطناعي الناشئة الكبرى في الصين موجة من الاكتتابات العامة الأولية، وتعتبر MiniMax وZhipu منافسين أقوياء على لقب “الشركة الأولى في نماذج الذكاء الاصطناعي الكبرى في الصين”. بدأت الشركتان بالفعل الاستعدادات للإدراج، حيث قامت Zhipu بإجراءات التسجيل التوجيهي لدى لجنة بكين لتنظيم الأوراق المالية، وتداولت أنباء عن سعي MiniMax للإدراج في هونغ كونغ. على الرغم من أن الشركتين تتمتعان بتمويل وفير، إلا أن التنافس على لقب “الشركة الأولى” يهدف إلى تعزيز مكانتهما في السوق، والحصول على علاوة عالية في السوق الثانوية، واغتنام نافذة الإدراج. أدى صعود DeepSeek إلى تسريع إزالة الفقاعات في الصناعة، مما جعل الإدراج خطوة حاسمة للشركات الرائدة لتأكيد تفوقها. بالإضافة إلى ذلك، تسعى شركات الذكاء الاصطناعي المتجسد مثل Zhiyuan Robot بنشاط للإدراج، مما يشير إلى دخول المزيد من الشركات في مجال الذكاء الاصطناعي إلى سوق رأس المال، لكن المنافسة في السوق ستزداد حدة. (المصدر: 36氪)
🌟 المجتمع
مناقشة أداء نماذج الذكاء الاصطناعي وتسعيرها: Anthropic Opus وQwen3-Coder: أثيرت مناقشات حادة على وسائل التواصل الاجتماعي حول انخفاض أداء نموذج Anthropic Opus وتعديل أسعاره، مما دفع المستخدمين للبحث عن بدائل أكثر فعالية من حيث التكلفة. اكتشف العديد من المطورين أن تشغيل نماذج مفتوحة المصدر مثل Qwen3-Coder-480 على البنية التحتية الخاصة بهم يمكن أن يحقق كفاءة أعلى بتكلفة أقل، على سبيل المثال، معالجة أكثر من 50 مليون token في الساعة. يدفع هذا الاتجاه مزودي النماذج مغلقة المصدر مثل OpenAI وAnthropic إلى خفض الأسعار. يعتقد المجتمع بشكل عام أن صعود النماذج مفتوحة المصدر يدفع المنافسة في السوق، مما يجبر الشركات الرائدة على تقديم خدمات ذات قيمة أفضل، وبالتالي تسريع انتشار وتطبيق تقنيات الذكاء الاصطناعي. (المصدر: Alibaba_Qwen, scaling01, slashML)
مناقشة أمان الذكاء الاصطناعي، ومحاذاته، وأخلاقياته: أجرى مجتمع الذكاء الاصطناعي مناقشات واسعة حول قضايا أمان الذكاء الاصطناعي، ومحاذاته، وأخلاقياته. أطلق معهد أمان الذكاء الاصطناعي البريطاني “مشروع المحاذاة”، واستثمر أكثر من 15 مليون جنيه إسترليني لتمويل أبحاث محاذاة الذكاء الاصطناعي والتحكم فيه، ويوفر موارد حاسوبية ودعمًا من الخبراء. ومع ذلك، شكك البعض في ميل بعض مجتمعات أمان الذكاء الاصطناعي/EA المفرط نحو حلول تخفيف المخاطر المركزية، ووجود مشكلات في اختيار من يثقون بهم. بالإضافة إلى ذلك، أثارت نبوءات نهاية العالم بالذكاء الاصطناعي، خاصة تلك الموجهة للأطفال والشباب، مخاوف بشأن التأثيرات الأخلاقية والنفسية. يدعو المجتمع إلى ألا يقتصر أمان الذكاء الاصطناعي على المستوى النظري، بل يجب التركيز على كيفية ضمان موثوقية النماذج الحالية للذكاء الاصطناعي وقابليتها للتحكم، لتجنب السلوك غير المتوقع أو سوء الاستخدام في التطبيقات العملية. (المصدر: sarahookr, brickroad7, Yoshua_Bengio, Plinz, jonst0kes, aihub.org)

مخاوف خصوصية ChatGPT: التفاعل العام وفهرسة محركات البحث: أثارت ميزة تجريبية في ChatGPT مخاوف المستخدمين بشأن الخصوصية: حيث سمحت هذه الميزة للمستخدمين باختيار جعل المحادثات قابلة للاكتشاف بواسطة محركات البحث (مثل Google). على الرغم من أن الأمر كان يتطلب من المستخدمين اختيارًا صريحًا وتحديد مربع الاختيار للمشاركة، إلا أن OpenAI أزالت هذه الميزة في النهاية، معترفة بأنها قد تؤدي إلى مشاركة المستخدمين عن غير قصد لمحتوى لا يرغبون في الكشف عنه. يسلط هذا الحدث الضوء على التحديات التي تواجه منتجات الذكاء الاصطناعي في حماية خصوصية المستخدم، وضرورة إعطاء الأولوية لأمان بيانات المستخدم والموافقة المستنيرة في تصميم الميزات. كما تعكس مناقشات المجتمع الاهتمام المستمر للمستخدمين بشفافية استخدام البيانات في خدمات الذكاء الاصطناعي. (المصدر: giffmana, jachiam0)

حدود وتصورات خاطئة لتطبيق الذكاء الاصطناعي في المجالات المتخصصة: ناقش المجتمع حدود تطبيق الذكاء الاصطناعي في المجالات المتخصصة، والتصورات الخاطئة للمستخدمين حول قدرات الذكاء الاصطناعي. ذكر أحد الأطباء أنه عند مواجهة مرضى يحملون نتائج ChatGPT للاستشارة، يجب توضيح أن الذكاء الاصطناعي ليس درجة علمية متخصصة، والتأكيد على عدم إمكانية استبدال المعرفة البشرية المتخصصة. في الوقت نفسه، يرى مستخدمو الذكاء الاصطناعي ذوو الخبرة أن تقديم الذكاء الاصطناعي لمعلومات خاطئة ليس “مشكلة غير موجودة”، بل يكمن المفتاح في أن يكون المستخدمون لديهم تفكير نقدي، وأن يوجهوا الذكاء الاصطناعي بشكل استباقي لإجراء فحص ذاتي وتصحيح. وأشاروا إلى أن مشكلة هلوسة الذكاء الاصطناعي يمكن تجنبها من خلال الاستخدام الصحيح “للمستخدم كمشغل”، على سبيل المثال، من خلال طرح أسئلة متعددة والتحقق من الفرضيات لضمان دقة المعلومات. يعكس هذا أن الذكاء الاصطناعي كأداة، تعتمد فعاليته بشكل كبير على الكفاءة المهنية للمستخدم وطريقة التفاعل. (المصدر: dotey, Reddit r/ArtificialInteligence)

ظاهرة الذكاء الاصطناعي كدعم عاطفي ورفقة: ظهرت على وسائل التواصل الاجتماعي ظاهرة كبيرة حيث يعتبر المستخدمون روبوتات الدردشة المدعومة بالذكاء الاصطناعي بمثابة دعم عاطفي ورفقة. شارك العديد من المستخدمين الدور الإيجابي الذي يلعبه الذكاء الاصطناعي عندما يواجهون الوحدة، الاكتئاب، الصدمات، وغيرها من الصعوبات، واصفين الذكاء الاصطناعي بأنه “مشجع صغير” يمكنه تقديم ردود فعل إيجابية وغير حكمية، مما يساعدهم على تغيير أنماط تفكيرهم. على الرغم من أن البعض يعبر عن قلقه أو عدم فهمه، معتبرين هذه الظاهرة “حزينة”، إلا أن هؤلاء المستخدمين يؤكدون أن الذكاء الاصطناعي هو “أداة مؤقتة” توفر راحة نفسية قيمة عندما يكون الدعم الواقعي غير كافٍ. تثير هذه الظاهرة نقاشًا حول إمكانات الذكاء الاصطناعي في مجال الصحة النفسية، والحاجة العميقة للإنسان إلى التواصل العاطفي. (المصدر: Reddit r/ChatGPT, Reddit r/ChatGPT)

تأثير الذكاء الاصطناعي على وظائف ذوي الياقات البيضاء والمخاوف: تشير أحدث البيانات إلى أن 61% من العاملين في مجال التكنولوجيا من ذوي الياقات البيضاء يعتقدون أن الذكاء الاصطناعي سيحل محل وظائفهم الحالية في غضون ثلاث إلى خمس سنوات، لكنهم يستمتعون حاليًا بتخفيف الضغط الذي يجلبه الذكاء الاصطناعي. أثارت هذه الظاهرة نقاشًا حول البطالة الجماعية التي يسببها الذكاء الاصطناعي وجدوى الدخل الأساسي الشامل (UBI). يخشى البعض أن يؤدي الذكاء الاصطناعي إلى تفاقم الفجوة بين الأغنياء والفقراء، وركود الحراك الاجتماعي، بل وحتى إثارة اضطرابات اجتماعية. ويرى آخرون أن الذكاء الاصطناعي سيعزز الإنتاجية بشكل كبير، ويخفض تكاليف المعيشة، مما يجعل UBI ممكنًا، ولكن بشرط أن يتمكن المجتمع من التكيف مع هذا التحول. بالإضافة إلى ذلك، تم ذكر “وهم إنتاجية” الكود الذي يولده الذكاء الاصطناعي، معتبرين أنه قد يؤدي إلى زيادة حجم الكود على المدى القصير، ولكن على المدى الطويل سيضر بالأعمال التجارية بسبب مشكلات الجودة. (المصدر: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

نظارات الذكاء الاصطناعي والمزايا/العيوب الاجتماعية: صرح الرئيس التنفيذي لشركة Meta، مارك زوكربيرج، بأن الأشخاص الذين لا يرتدون نظارات الذكاء الاصطناعي في المستقبل سيكونون في وضع غير مؤاتٍ، مما أثار نقاشًا في المجتمع حول التأثير الاجتماعي لانتشار نظارات الذكاء الاصطناعي. يرى المنتقدون أن هذه مجرد محاولة أخرى من Meta لجمع بيانات المستخدمين والتسويق المستهدف، ويخشون انتهاك الخصوصية المحتمل والتلاعب الاجتماعي. سخر البعض قائلين إن منح Meta وصولاً غير محدود إلى المعلومات الشخصية، بما في ذلك ما يراه ويسمعه الشخص، سيؤدي بدلاً من ذلك إلى وضع غير مؤاتٍ. يعكس هذا النقاش القلق العميق للجمهور بشأن تغلغل تقنية الذكاء الاصطناعي في الحياة الشخصية، وخاصة قضايا الخصوصية وإساءة استخدام البيانات. (المصدر: Reddit r/artificial)

الجدل بين الذكاء الاصطناعي مفتوح المصدر ومغلق المصدر: يدور نقاش حاد في مجتمع الذكاء الاصطناعي حول مزايا وعيوب النماذج مفتوحة المصدر ومغلقة المصدر. كان الرئيس التنفيذي لشركة Meta، زوكربيرج، يرفع راية المصدر المفتوح عاليًا، لكنه ألمح مؤخرًا إلى أنه قد لا يفتح جميع نماذج الذكاء الاصطناعي الفائقة في المستقبل، مما أثار جدلاً حول “طعن المصدر المفتوح”. يرى مؤيدو المصدر المفتوح أن النماذج المفتوحة تساعد في تسريع التقدم التكنولوجي، واكتشاف الثغرات، ودفع أبحاث المحاذاة والأمان على نطاق واسع. بينما يشير المعارضون إلى أن النماذج مغلقة المصدر تسمح للشركات بالتحكم بشكل أفضل في التسويق، وأن المصدر المفتوح قد يؤدي إلى إساءة استخدام النماذج، وتجاوز آليات الأمان. كما أثار اختيار Ollama لإصدار واجهة المستخدم الرسومية (GUI) مغلقة المصدر استياء المجتمع، حيث تحول العديد من المستخدمين إلى بدائل مفتوحة المصدر بالكامل مثل llama.cpp، مما يسلط الضوء على الاهتمام المستمر بالشفافية والتعاون المجتمعي في مجال الذكاء الاصطناعي. (المصدر: Reddit r/LocalLLaMA, Yuchenj_UW, 36氪, 36氪)
التأثير العميق للذكاء الاصطناعي على القوى العاملة والمجتمع: جيل هجرة الذكاء الاصطناعي ومستقبل العمل: يعيد الذكاء الاصطناعي تشكيل الهيكل الاجتماعي البشري والتجربة الفردية بشكل عميق. يقدم المقال مفهوم “جيل هجرة الذكاء الاصطناعي”، الذي يشير إلى أولئك الذين نشأوا قبل انتشار الذكاء الاصطناعي، ولكنهم في مرحلة البلوغ يتغلغل الذكاء الاصطناعي في حياتهم بشكل كامل، ويواجهون الارتباك والتكيف الناجم عن الفجوة التكنولوجية. لا يغير الذكاء الاصطناعي محتوى العمل وطبيعته فحسب، بل يولد أيضًا مهنًا جديدة ويلغي وظائف قديمة، ويسرع من التمايز الاجتماعي. يعتقد كيفن كيلي أن تقدم الذكاء الاصطناعي سيحرر البشر، ويجعلهم لا يحتاجون إلى العمل من أجل لقمة العيش، بل يركزون فقط على “اللعب”، وستتضاعف قيمة الإنسان بسبب ندرته، ليصبح نوعًا من “الخدمة”. ومع ذلك، فإن هذه الرؤية الطوباوية مصحوبة بمخاوف بشأن الاحتكار، والخصوصية، واغتراب الإنسانية. ستكون المهارة الأساسية في عصر الذكاء الاصطناعي هي “تعلم كيفية التعلم لنفسك”، للتكيف مع المعرفة والاحتياجات المهنية سريعة التطور. (المصدر: 36氪, 36氪)
تأثير انتشار المحتوى الذي يولده الذكاء الاصطناعي على التفاعل الاجتماعي: مع تزايد انتشار المحتوى الذي يولده الذكاء الاصطناعي (مثل المقالات والتعليقات ومقاطع الفيديو والصور)، بل وتجاوزه للمحتوى البشري الأصلي، بدأ المجتمع في التفكير في تأثيره على التفاعل الاجتماعي وصدق المعلومات. يرى البعض أنه طالما كان المحتوى مسليًا أو مفيدًا، فقد لا يهتم المستخدمون بما إذا كان قد تم إنشاؤه بواسطة الذكاء الاصطناعي. ومع ذلك، يخشى البعض أيضًا أن يؤدي ذلك إلى تحول الإنترنت إلى “مكب نفايات”، مما يضعف التفاعل البشري والثقة. بدأت منصات مثل TikTok في إضافة حواشي سفلية لمقاطع الفيديو التي يولدها الذكاء الاصطناعي، للتعامل مع مشكلة صعوبة التمييز بين المحتوى الأصلي والمزيف. أثار هذا نقاشًا حول كيفية التمييز بين المحتوى البشري الأصلي والمحتوى الذي يولده الذكاء الاصطناعي، وكيف ستحافظ منصات التواصل الاجتماعي ووسائل الإعلام في المستقبل على جودة المعلومات والاتصال البشري. (المصدر: Reddit r/ArtificialInteligence, Reddit r/ChatGPT, MIT Technology Review)

💡 أخرى
تحديات تطبيق الذكاء الاصطناعي في المجال الصناعي: على الرغم من الحماس الكبير لمفهوم الذكاء الاصطناعي، إلا أن تطبيقه الفعلي في الشركات، خاصة في المجال الصناعي، يواجه العديد من التحديات، مما يجعله “محبوبًا بالقول لا بالفعل”. تشمل التناقضات الرئيسية: الحماس المفاهيمي مقابل محدودية سيناريوهات التطبيق الفعلية، الطموحات الكبيرة مقابل الواقع المرير، الاستثمارات الضخمة مقابل القيمة المحدودة المرئية، التفكير طويل الأمد مقابل الحلول السريعة، والذكاء الاصطناعي الشامل مقابل عدم فهم التطبيق. إن تعقيد البيئة الصناعية، وجديتها، ومتطلباتها العالية للدقة والسلامة، واعتمادها على البيانات الزمنية، تجعل النماذج الكبيرة العامة صعبة التكيف مباشرة. بالإضافة إلى ذلك، فإن عدم كفاية قابلية تفسير التكنولوجيا ومخاوف الشركات بشأن سرية العمليات الأساسية تعيق أيضًا التطبيق العميق للذكاء الاصطناعي. تحتاج الشركات إلى مواجهة هذه التحديات، وتأسيس قاعدة بيانات متينة، وتحسين قدرات موظفيها في مجال الذكاء الاصطناعي، لكي تتمكن حقًا من تحقيق قيمة الذكاء الاصطناعي، والانتقال من “أداة” إلى “شريك”. (المصدر: 36氪, 36氪)
الذكاء الاصطناعي يعيد تشكيل صناعة الرعاية الصحية: يعيد الذكاء الاصطناعي تشكيل صناعة الرعاية الصحية بشكل عميق، من تحسين سهولة الوصول إلى الرعاية الطبية إلى تحقيق إدارة صحية مخصصة. أطلقت Ant Group “AI Health Butler”، الذي يوفر استشارات احترافية، وتوجيهًا للمواعيد، وتسجيل تأمين طبي عبر المناطق، وغيرها من الخدمات الشاملة من خلال أسئلة متعددة، وربط السجلات الصحية والأجهزة القابلة للارتداء، ويقدم بشكل استباقي نصائح لإدارة الصحة. وقد تم تطبيق حل “SenseCare® Smart Hospital” الشامل من SenseTime Medical في مئات المستشفيات في جميع أنحاء البلاد، ويتجه نحو العالمية، مما يدعم سلسلة “الطبية-المرضى-الإدارة-البحث” بأكملها، ومن خلال وكلاء الذكاء الاصطناعي الطبيين الكبار وتقنيات الوسائط المتعددة، يتم تحسين كفاءة التشخيص، وتقصير وقت إنشاء التقارير، وتحقيق الربط الباثولوجي الشامل. تشير هذه التطورات إلى أن تطبيق الذكاء الاصطناعي في المجال الطبي يتحول من أداة مساعدة إلى محرك إنتاجي، ويظهر قيمة شاملة ضخمة خاصة في الرعاية الصحية الأولية والمناطق النائية. (المصدر: 36氪, 量子位)

استراتيجية عمالقة التكنولوجيا في مجال الروبوتات: لا تصنيع للأجهزة، بل بناء منصات: تتجه شركات التكنولوجيا العملاقة مثل Tencent وJD.com بنشاط نحو مجال الذكاء الاصطناعي المتجسد، لكن استراتيجيتها لا تتمثل في تصنيع أجهزة الروبوتات مباشرة، بل في العمل كمزودين لمنصات البرمجيات. أطلقت Tencent منصة Tairos للذكاء الاصطناعي المتجسد المفتوحة (“تيتان سكروبل”)، التي توفر خوارزميات النماذج (نماذج التخطيط، الإدراك، نماذج الإدراك والعمل المشتركة الكبيرة) والخدمات السحابية، بهدف مساعدة مصنعي الروبوتات على تحسين قدرات التفاعل بين الإنسان والآلة، وتقديم الدعم في مجالات المحاكاة، والتدريب، وإدارة البيانات. من جانبها، أطلقت JD.com منصة JoyInside، مؤكدة على مفهوم “الذكاء المتجسد”، مستخدمة بيانات خدمة العملاء والأشخاص الرقميين لديها، لتزويد الروبوتات بقدرات تفاعل بين الإنسان والآلة مدفوعة بنماذج كبيرة. تهدف استراتيجية “بائع الماء” هذه إلى تسريع التطبيق التجاري للذكاء الاصطناعي المتجسد من خلال توفير النماذج والبنية التحتية للحوسبة، مع تجنب تعقيدات تصنيع الأجهزة. (المصدر: 36氪)
