

كلمات مفتاحية:ميتا, تينسنت هونيوان للصور 3.0, xAI جروك 4 فاست, أوبن إي آي سورا 2, بايت دانس سيلف فورسينج++, علي بابا كيو ون, vLLM, GPT-5 برو, آلية إعادة استخدام ما وراء المعرفة, آلية الانتباه السببي المعمم, نموذج الاستدلال متعدد الوسائط, إنشاء فيديو على مستوى الدقائق, إنشاء أزياء مدرك للوضعيات
🔥 تركيز
طريقة Meta الجديدة تختصر سلسلة التفكير، وتودع الاستنتاج المتكرر: قدمت Meta ومعهد Mila-Quebec AI Institute وآخرون آلية “إعادة الاستخدام ما وراء المعرفي” (metacognitive reuse)، بهدف حل مشكلة تضخم الـ token وزيادة التأخير الناتجة عن الاستنتاج المتكرر في نماذج اللغة الكبيرة. تتيح هذه الآلية للنموذج مراجعة وتلخيص أساليب حل المشكلات، وصقل أنماط الاستدلال الشائعة في “سلوكيات” تُخزن في “دليل السلوكيات”، ليتم استدعاؤها مباشرة عند الحاجة دون الحاجة إلى إعادة الاستنتاج. أظهرت التجارب، في اختبارات الرياضيات المعيارية مثل MATH و AIME، أن هذه الآلية يمكن أن تقلل من استخدام الـ token للاستدلال بنسبة تصل إلى 46% مع الحفاظ على الدقة، مما يعزز كفاءة النموذج وقدرته على استكشاف مسارات جديدة. (المصدر: 量子位)

Tencent Hunyuan Image 3.0 يتصدر قائمة توليد الصور بالذكاء الاصطناعي عالمياً: احتل Tencent Hunyuan Image 3.0 المرتبة الأولى في قائمة LMArena لتوليد الصور من النصوص، متجاوزاً Google Nano Banana و ByteDance Seedream و OpenAI gpt-Image. يعتمد هذا النموذج على بنية متعددة الوسائط أصلية، مبنية على Hunyuan-A13B، بإجمالي معلمات يتجاوز 80 مليار، وهو قادر على معالجة أنواع متعددة من الوسائط مثل النصوص والصور والفيديو والصوت بشكل موحد، ويمتلك قدرات قوية في فهم الدلالات، وتفكير نموذج اللغة، والاستدلال بالمعرفة العالمية. تشمل تقنياته الأساسية آلية الانتباه السببي المعمم والترميز الموضعي ثنائي الأبعاد، كما يقدم ميزة التنبؤ التلقائي بالدقة. يقوم النموذج ببناء البيانات من خلال تصفية ثلاثية المراحل ونظام وصف هرمي، ويستخدم استراتيجية تدريب تدريجية من أربع مراحل، مما يعزز بشكل فعال واقعية ووضوح الصور المولدة. (المصدر: 量子位)

xAI تطلق نموذج Grok 4 Fast وتتعاون مع الحكومة الأمريكية: أطلقت xAI نموذج Grok 4 Fast، وهو نموذج استدلال متعدد الوسائط يتميز بنافذة سياق 2M، ويهدف إلى تقديم خدمات ذكية عالية الكفاءة من حيث التكلفة. تم فتح النموذج مجاناً لجميع المستخدمين، ومن خلال التعاون مع الحكومة الفيدرالية الأمريكية، سيتم توفير نماذجها الرائدة في مجال الذكاء الاصطناعي (Grok 4, Grok 4 Fast) لجميع الوكالات الفيدرالية مجاناً لمدة 18 شهراً، مع إرسال فريق من المهندسين لمساعدة الحكومة في الاستفادة من الذكاء الاصطناعي. بالإضافة إلى ذلك، أطلقت xAI أيضاً OpenBench لتقييم أداء وأمان نماذج LLM، وأطلقت Grok Code Fast 1 الذي أظهر أداءً ممتازاً في مهام البرمجة. (المصدر: xai, xai, xai, JonathanRoss321)
🎯 اتجاهات
OpenAI تستعرض منتجات AI استهلاكية وتحديثات Sora 2: تتوقع UBS أن يركز مؤتمر مطوري OpenAI على إطلاق منتجات AI موجهة للمستهلكين، قد تشمل وكلاء AI لحجز السفر. في الوقت نفسه، يخضع نموذج توليد الفيديو Sora 2 للاختبار، وقد لاحظ المستخدمون أن محتواه المولد غالباً ما يحمل طابعاً فكاهياً. كما قامت OpenAI بإصلاح مشكلة الدقة في وضع HD لنموذج Sora 2 Pro، الذي يدعم الآن دقة 17921024 أو 10241792، ويدعم توليد مقاطع فيديو تصل مدتها إلى 15 ثانية، لكن حصة التوليد اليومية انخفضت إلى 30 مرة. (المصدر: teortaxesTex, francoisfleuret, fabianstelzer, TomLikesRobots, op7418, Reddit r/ChatGPT)

ByteDance تطلق نموذج توليد فيديو بدقة الدقيقة: أطلقت ByteDance طريقة جديدة تسمى Self-Forcing++، قادرة على توليد مقاطع فيديو عالية الجودة تصل مدتها إلى 4 دقائق و15 ثانية. لا تتطلب هذه الطريقة نموذج معلم فيديو طويل أو إعادة تدريب، مما يسمح بتوسيع نماذج الانتشار مع الحفاظ على دقة واتساق الفيديو المولد. (المصدر: _akhaliq)
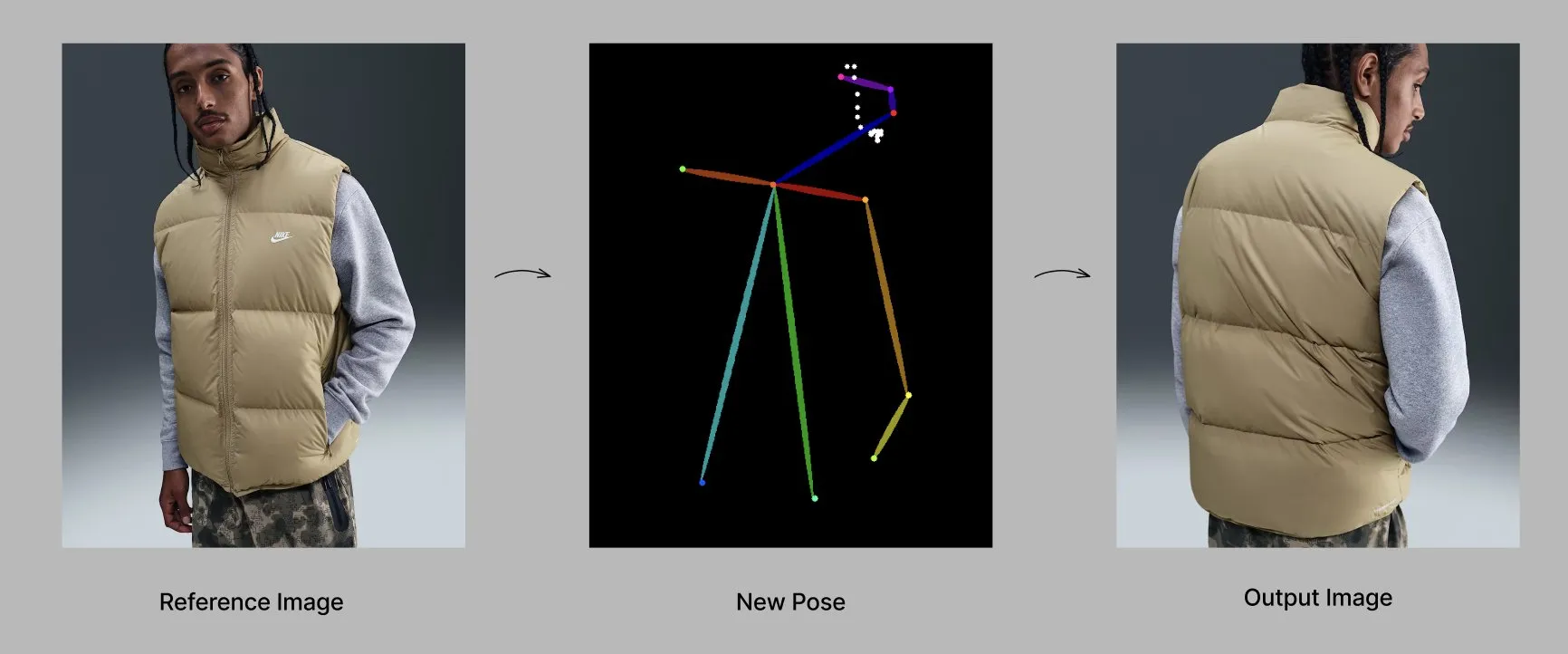
نموذج Qwen يطلق ميزات وتطبيقات جديدة: يطرح فريق Alibaba Qwen تدريجياً ميزات شخصية، مثل الذاكرة وتعليمات النظام المخصصة، وهي حالياً قيد الاختبار المحدود. في الوقت نفسه، أظهر نموذج Qwen-Image-Edit-2509 قدرات متقدمة في توليد الأزياء الواعية بالوضعيات، مما يتيح توليد عارضات أزياء عالية الجودة ومتعددة الزوايا من خلال الضبط الدقيق. (المصدر: Alibaba_Qwen, Alibaba_Qwen)
vLLM و PipelineRL يدفعان حدود مجتمع RL: يدعم مشروع vLLM اختراقات جديدة في مجتمع RL في مجال التعلم المعزز، بما في ذلك بيانات on-policy أفضل، و rollouts جزئية، وتحديثات الوزن in-flight التي تخلط ذاكرة التخزين المؤقت KV أثناء الاستدلال. يحقق PipelineRL التعلم المعزز غير المتزامن القابل للتطوير من خلال الاستمرار في الاستدلال مع تغير الأوزان وبقاء حالة KV ثابتة، ويدعم تحديثات الوزن in-flight. (المصدر: vllm_project, Reddit r/LocalLLaMA)

GPT-5-Pro يحل مشكلات رياضية معقدة: حل GPT-5-Pro بشكل مستقل “مشكلة Yu Tsumura رقم 554” في 15 دقيقة، وهو أول نموذج يحل هذه المهمة بالكامل، مما يظهر قدرته القوية على حل المشكلات الرياضية. (المصدر: Teknium1)

SAP تجعل AI جوهر سير عمل المؤسسات: تخطط SAP لعرض رؤيتها لجعل AI جوهر سير عمل المؤسسات في مؤتمر Connect 2025، من خلال تحويل البيانات في الوقت الفعلي إلى قرارات باستخدام AI المدمج، والاستفادة من وكلاء AI للقيام بإجراءات استباقية. تؤكد SAP على بناء الثقة وتقديم الدعم الإيجابي منذ البداية، وضمان المرونة المحلية والامتثال. (المصدر: TheRundownAI)

Salesforce تطلق نموذج تشفير انتشار النص CoDA-1.7B: أطلقت Salesforce Research نموذج CoDA-1.7B، وهو نموذج تشفير انتشار النص قادر على إخراج الـ token بشكل متوازٍ ثنائي الاتجاه. يتميز هذا النموذج بسرعة استدلال أعلى، حيث يمكن لـ 1.7 مليار معلمة أن تضاهي أداء نموذج 7 مليار معلمة، ويظهر أداءً ممتازاً في اختبارات المعيار مثل HumanEval و HumanEval+ و EvalPlus. (المصدر: ClementDelangue)

Google Gemini 3.0 يركز على EQ، وتصاعد المنافسة مع OpenAI: من المقرر أن تطلق Google قريباً Gemini 3.0، والذي يقال إنه سيركز على “الذكاء العاطفي” (EQ)، ويعتبر هذا تحدياً قوياً لـ OpenAI. تشير هذه الخطوة إلى تطور نماذج AI في فهم المشاعر والتفاعل، مما ينذر بتصاعد المنافسة بين عمالقة AI. (المصدر: Reddit r/ChatGPT)
تطور الروبوتات وتقنيات الأتمتة: يستمر الابتكار في مجال الروبوتات، بما في ذلك الروبوتات البشرية المتنقلة متعددة الاتجاهات للعمليات اللوجستية، وخدمات توصيل الروبوتات المتنقلة المستقلة التي تجمع بين الأذرع الميكانيكية والخزائن، بالإضافة إلى الكلب الروبوتي “Cara” ذو الـ 12 محركاً الذي صممه طلاب أمريكيون باستخدام محركات تعمل بالحبال وتصميم رياضي ذكي. علاوة على ذلك، تم إطلاق أول روبوت “Wuji Hand” رسمياً. (المصدر: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

🧰 أدوات
مشروع GPT4Free (g4f) يوفر أدوات LLM وتوليد الوسائط مجاناً: GPT4Free (g4f) هو مشروع مدفوع من المجتمع يهدف إلى دمج نماذج LLM متعددة يمكن الوصول إليها وأدوات توليد الوسائط، ويوفر عميل Python، وواجهة مستخدم رسومية ويب محلية (local Web GUI)، وواجهة برمجة تطبيقات REST متوافقة مع OpenAI، وعميل JavaScript. يدعم محولات متعددة المزودين، بما في ذلك OpenAI و PerplexityLabs و Gemini و MetaAI وغيرها، ويدعم توليد الصور/الصوت/الفيديو واستمرارية الوسائط، ويهدف إلى تعميم الوصول المفتوح لأدوات AI. (المصدر: GitHub Trending)

تصميم أدوات LLM وأفضل ممارسات هندسة الـ Prompt: عند كتابة أدوات يسهل على AI فهمها، تكون الأولوية بالترتيب: تعريف الأداة، تعليمات النظام، وكلمات الـ prompt للمستخدم. اسم الأداة ووصفها أمران حاسمان، ويجب أن يكونا بديهيين وواضحين، مع تجنب الغموض. يجب أن تكون المعلمات قليلة قدر الإمكان، وتوفير عناصر تعداد أو تحديد حدود عليا وسفلى. تجنب استخدام معلمات منظمة متداخلة بشكل مفرط لزيادة سرعة الاستجابة. من خلال جعل النموذج يكتب الـ Prompt وتقديم الملاحظات، يمكن تحسين فهم نماذج اللغة الكبيرة للأداة بشكل فعال. (المصدر: dotey)
Zen MCP يستخدم Gemini CLI لتوفير رصيد Claude Code: يسمح مشروع Zen MCP للمستخدمين باستخدام Gemini CLI مباشرة داخل أدوات مثل Claude Code، مما يقلل بشكل كبير من استخدام الـ token لـ Claude Code ويستفيد من رصيد Gemini المجاني. تدعم هذه الأداة تفويض المهام بين نماذج AI مختلفة مع الحفاظ على سياق مشترك، على سبيل المثال، استخدام GPT-5 للتخطيط، و Gemini 2.5 Pro للمراجعة، و Sonnet 4.5 للتنفيذ، ثم استخدام Gemini CLI لمراجعة الكود واختبار الوحدة، مما يحقق تطوير AI مساعد فعال واقتصادي. (المصدر: Reddit r/ClaudeAI)
أداة تقييم LLM مفتوحة المصدر Opik: Opik هي أداة تقييم LLM مفتوحة المصدر، تستخدم لتصحيح الأخطاء وتقييم ومراقبة تطبيقات LLM، وأنظمة RAG، وسير عمل Agentic. توفر تتبعاً شاملاً، وتقييماً آلياً، ولوحات معلومات جاهزة للإنتاج، لمساعدة المطورين على فهم نماذج AI الخاصة بهم وتحسينها بشكل أفضل. (المصدر: dl_weekly)
Claude Sonnet 4.5 يتفوق في كتابة نصوص Tampermonkey: أظهر Claude Sonnet 4.5 أداءً ممتازاً في كتابة نصوص Tampermonkey، حيث يمكن للمستخدمين تغيير سمة Google AI Studio بمجرد prompt واحد، مما يدل على قدرته القوية في أتمتة عمليات المتصفح وتخصيص واجهة المستخدم. (المصدر: Reddit r/ClaudeAI)

نشر نموذج Phi-3-mini محلياً: يسعى المستخدمون إلى نشر نموذج Phi-3-mini-4k-instruct-bnb-4bit، الذي تم ضبطه بدقة باستخدام Unsloth على Google Colab، على أجهزتهم المحلية. يمكن لهذا النموذج استخراج الملخصات وتحليل الحقول من النصوص، والهدف من النشر هو قراءة النصوص من DataFrame محلياً، ومعالجتها بواسطة النموذج، ثم حفظ المخرجات في DataFrame جديد، حتى في بيئات منخفضة التكوين ببطاقة رسومات مدمجة وذاكرة وصول عشوائي (RAM) بحجم 8 جيجابايت. (المصدر: Reddit r/MachineLearning)
مقارنة أداء الواجهات الخلفية لـ LLM: يناقش المجتمع أداء أطر عمل الواجهات الخلفية لـ LLM الحالية، حيث يعتبر vLLM و llama.cpp و ExLlama3 الأسرع، بينما يعتبر Ollama الأبطأ. يتفوق vLLM في التعامل مع محادثات متزامنة متعددة، ويحظى llama.cpp بشعبية لمرونته ودعمه الواسع للأجهزة، بينما يوفر ExLlama3 أقصى أداء لوحدات معالجة الرسوميات (GPU) من NVIDIA، ولكن بدعم محدود للنماذج. (المصدر: Reddit r/LocalLLaMA)
أداة “solveit” تساعد المبرمجين على مواجهة تحديات AI: لمواجهة الإحباط الذي قد يواجهه المبرمجون عند استخدام AI، أطلق Jeremy Howard أداة “solveit”. تهدف هذه الأداة إلى مساعدة المبرمجين على استخدام AI بشكل أكثر فعالية، وتجنب أن يقودهم AI في اتجاه خاطئ، وتحسين تجربة البرمجة وكفاءتها. (المصدر: jeremyphoward)
📚 تعلم
ستانفورد و NVIDIA تتعاونان لدفع اختبارات AI المتجسد: ستتعاون جامعة ستانفورد و NVIDIA في بث مباشر، للتعمق في BEHAVIOR، وهو معيار وتحدي واسع النطاق لدفع AI المتجسد. ستغطي المناقشة دوافع BEHAVIOR، وتصميم التحديات القادمة، ودور المحاكاة في دفع أبحاث الروبوتات. (المصدر: drfeifei)

نشر ورقة بحثية حول تقييم وكلاء AI باستخدام Agent-as-a-Judge: تقترح ورقة بحثية جديدة بعنوان “Agent-as-a-Judge” طريقة إثبات مفهوم لتقييم وكلاء AI بواسطة وكلاء AI، مما يمكن أن يقلل التكلفة والوقت بنسبة 97% ويوفر ملاحظات وسيطة غنية. طورت هذه الدراسة أيضاً معيار DevAI، الذي يتضمن 55 مهمة تطوير AI مؤتمتة، مما يثبت أن Agent-as-a-Judge لا يتفوق فقط على LLM-as-a-Judge، بل يقترب أيضاً من تقييم البشر من حيث الكفاءة والدقة. (المصدر: SchmidhuberAI, SchmidhuberAI)

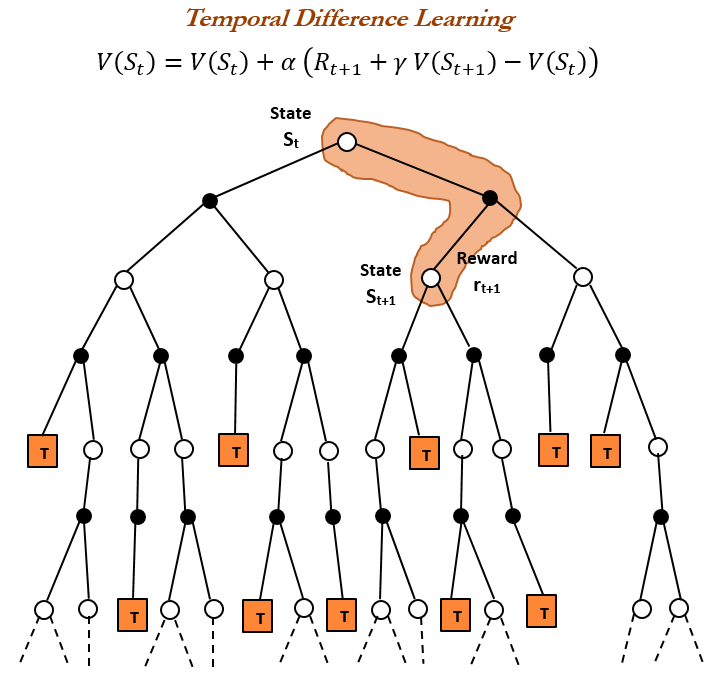
تاريخ التعلم المعزز (RL) والتعلم بالفرق الزمني (TD): يشير استعراض تاريخ التعلم المعزز إلى أن التعلم بالفرق الزمني (TD) هو أساس خوارزميات RL الحديثة (مثل Deep Actor-Critic). يسمح تعلم TD للوكلاء بالتعلم في بيئات غير مؤكدة، من خلال مقارنة التنبؤات المتتالية وتحديثها تدريجياً لتقليل خطأ التنبؤ، مما يحقق تنبؤات أسرع وأكثر دقة. تشمل مزاياه تجنب التضليل بالنتائج النادرة، وتوفير الذاكرة والحساب، وهو مناسب للسيناريوهات في الوقت الفعلي. (المصدر: TheTuringPost, TheTuringPost, gabriberton)
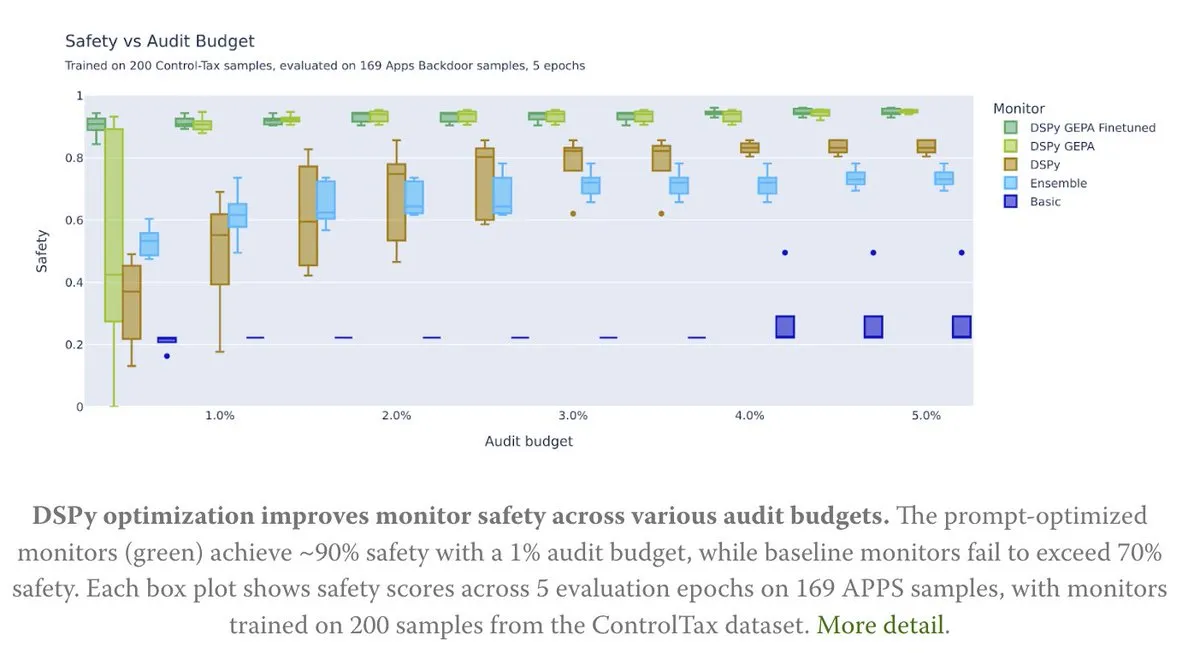
تحسين الـ Prompt يدعم أبحاث التحكم في AI: تناقش مقالة جديدة كيف يمكن لتحسين الـ Prompt أن يدعم أبحاث التحكم في AI، خاصة من خلال طريقة GEPA (Generative-Enhanced Prompting for Agents) من DSPy، التي حققت معدل أمان AI يصل إلى 90%، بينما وصلت الطرق الأساسية إلى 70% فقط. يشير هذا إلى الإمكانات الهائلة للـ Prompt المصممة بعناية في تعزيز أمان AI وقابليته للتحكم. (المصدر: lateinteraction, lateinteraction)
خوارزميات تعلم Transformer و CoT: يشير Francois Chollet إلى أنه على الرغم من إمكانية تعليم Transformer تنفيذ خوارزميات بسيطة خطوة بخطوة من خلال توفير خوارزميات دقيقة أثناء التدريب باستخدام CoT (سلسلة التفكير) token، إلا أن الهدف الحقيقي للتعلم الآلي يجب أن يكون “اكتشاف” الخوارزميات من أزواج المدخلات/المخرجات، وليس مجرد حفظ الخوارزميات المقدمة خارجياً. ويعتقد أنه إذا كانت الخوارزمية موجودة بالفعل، فإن تنفيذها مباشرة أفضل من تدريب Transformer على ترميز غير فعال. (المصدر: fchollet)

نظرة عامة على دورة حياة التعلم الآلي: تغطي دورة حياة التعلم الآلي جميع المراحل من جمع البيانات، والمعالجة المسبقة، وتدريب النموذج، والتقييم، إلى النشر والمراقبة، وهي إطار عمل أساسي لبناء وصيانة أنظمة ML. (المصدر: Ronald_vanLoon)

هدف تحسين Negative Log-Likelihood (NLL) في استدلال LLM: تبحث دراسة في ما إذا كان Negative Log-Likelihood (NLL) كهدف تحسين للتصنيف و SFT (الضبط الدقيق الخاضع للإشراف) هو الأمثل عالمياً. تحلل الدراسة الظروف التي قد تكون فيها الأهداف البديلة أفضل من NLL، وتشير إلى أن هذا يعتمد على الميول المسبقة للهدف وقدرة النموذج، مما يوفر منظوراً جديداً لتحسين تدريب LLM. (المصدر: arankomatsuzaki)

دليل المبتدئين للتعلم الآلي: شارك مجتمع Reddit دليلاً موجزاً حول كيفية تعلم التعلم الآلي، مؤكداً على اكتساب فهم عملي من خلال الاستكشاف وبناء مشاريع صغيرة، بدلاً من الاكتفاء بالتعريفات النظرية. يوجز الدليل أيضاً الأسس الرياضية للتعلم العميق، ويشجع المبتدئين على الاستفادة من المكتبات الموجودة للممارسة. (المصدر: Reddit r/deeplearning, Reddit r/deeplearning)

مشكلة تدريب النماذج البصرية على مجموعات بيانات نصية فقط: واجه مستخدم خطأ عند استخدام إطار عمل Axolotl لضبط نموذج LLaMA 3.2 11B Vision Instruct بدقة على مجموعة بيانات نصية فقط، بهدف تعزيز قدرته على اتباع التعليمات مع الحفاظ على قدرته على معالجة المدخلات متعددة الوسائط. تتعلق المشكلة بأخطاء في خصائص processor_type و is_causal، مما يشير إلى أن التوافق بين التكوين وبنية النموذج يمثل تحدياً عند تكييف النماذج البصرية للتدريب على النصوص فقط. (المصدر: Reddit r/MachineLearning)
مشاركة دورة تدريبية حول التدريب الموزع: شارك المجتمع دورة تدريبية حول التدريب الموزع، تهدف إلى مساعدة الطلاب على إتقان الأدوات والخوارزميات التي يستخدمها الخبراء يومياً، وتوسيع نطاق التدريب إلى ما هو أبعد من H100 واحد، والتعمق في عالم التدريب الموزع. (المصدر: TheZachMueller)
خارطة طريق لمراحل إتقان Agentic AI: توجد خارطة طريق لمراحل مختلفة لإتقان Agentic AI، توفر مساراً واضحاً للمطورين والباحثين لفهم وتطبيق تقنيات وكلاء AI تدريجياً، وبالتالي بناء أنظمة أكثر ذكاءً واستقلالية. (المصدر: Ronald_vanLoon)

💼 أعمال
NVIDIA تصبح أول شركة بقيمة سوقية تبلغ 4 تريليون دولار: وصلت القيمة السوقية لـ NVIDIA إلى 4 تريليون دولار، لتصبح أول شركة عامة تحقق هذا الإنجاز. يعكس هذا الإنجاز ريادتها في مجال شرائح AI والتقنيات ذات الصلة، واستثماراتها المستمرة وتمويلها لأبحاث الشبكات العصبية. (المصدر: SchmidhuberAI, SchmidhuberAI, SchmidhuberAI)

Replit تصبح ضمن أفضل ثلاث شركات في طبقة تطبيقات AI الأصلية: وفقاً لتحليل بيانات معاملات Mercury، احتلت Replit المرتبة الثالثة بين شركات طبقة تطبيقات AI الأصلية، متجاوزة جميع أدوات التطوير الأخرى، مما يدل على نموها القوي واعتراف السوق بها في مجال تطوير AI. وقد حظي هذا الإنجاز بتقدير المستثمرين. (المصدر: amasad)
CoreWeave تقدم حلولاً لتحسين تكلفة تخزين AI: تستضيف CoreWeave ندوة عبر الإنترنت لمناقشة كيفية خفض تكاليف تخزين AI بنسبة تصل إلى 65%، دون التأثير على سرعة الابتكار. ستكشف الندوة عن سبب بقاء 80% من بيانات AI غير نشطة، وكيف يضمن تخزين الكائنات من الجيل التالي من CoreWeave الاستفادة الكاملة من وحدات معالجة الرسوميات (GPU) وجعل الميزانية قابلة للتنبؤ، وتتطلع إلى التطورات المستقبلية في تخزين AI. (المصدر: TheTuringPost)

🌟 مجتمع
حدود قدرات LLM، معايير الفهم وتحديات التعلم المستمر: يناقش المجتمع أوجه القصور في LLM عند تنفيذ مهام الوكيل، معتبرين أن قدراته لا تزال غير كافية. هناك خلاف حول معايير “فهم” LLM والدماغ البشري، حيث يرى البعض أن الفهم الحالي لـ LLM لا يزال عند مستوى منخفض. يعتقد ريتشارد ساتون، والد التعلم المعزز، أن LLM لم يحقق التعلم المستمر بعد، مؤكداً أن التعلم عبر الإنترنت والقدرة على التكيف هما مفتاح تطور AI المستقبلي. (المصدر: teortaxesTex, teortaxesTex, aiamblichus, dwarkesh_sp)
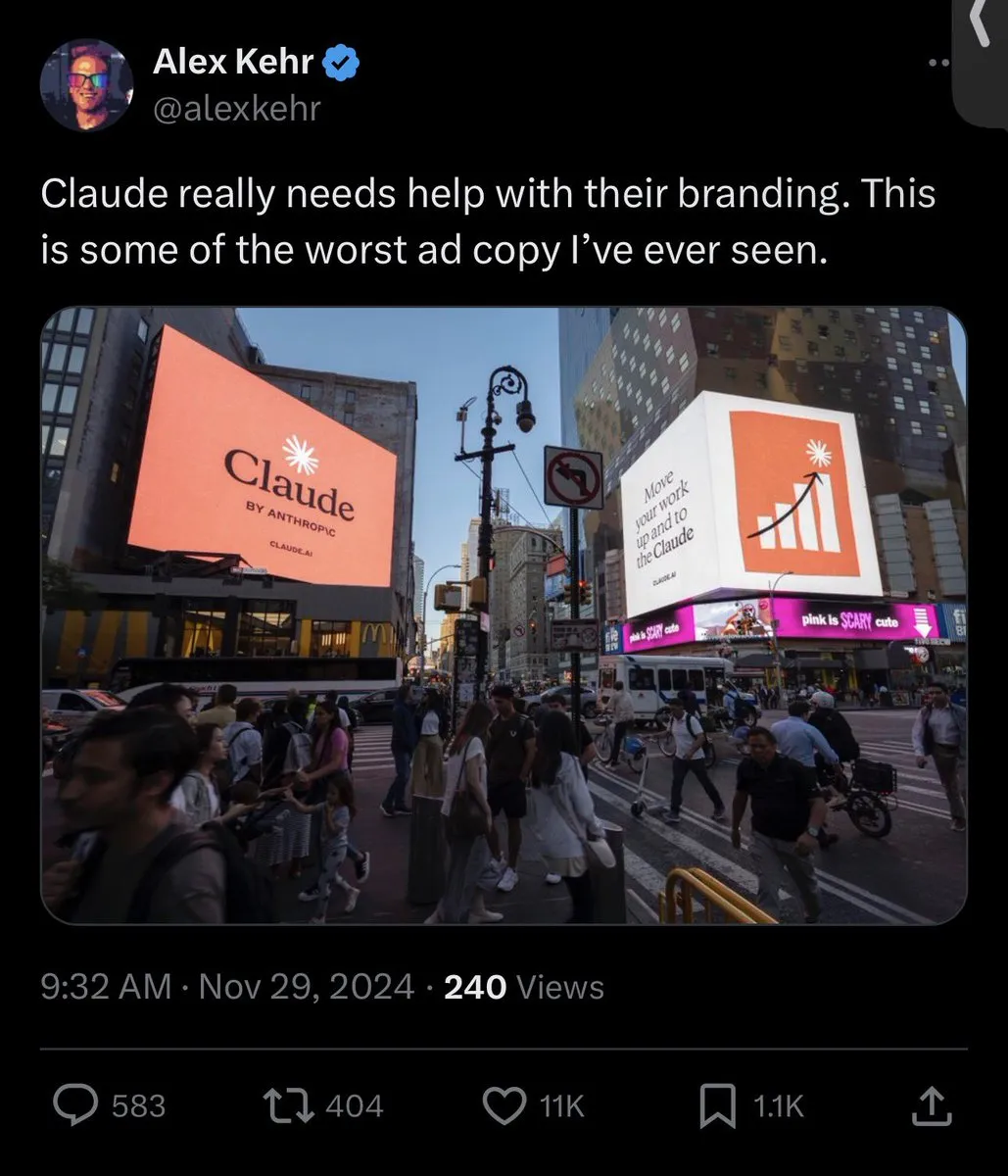
استراتيجيات منتجات LLM السائدة، تجربة المستخدم، وجدل سلوك النموذج: أثار صورة العلامة التجارية Anthropic وتجربة المستخدم جدلاً واسعاً، حيث حظيت حملة “مساحة التفكير” بثناء، لكن هناك جدل حول تخصيص موارد GPU، و Sonnet 4.5 (الذي يُزعم أنه أقل كفاءة في العثور على الأخطاء من Opus 4.1 وله أسلوب “مربّي”)، وتدهور تجربة المستخدم تحت التقييمات العالية (مثل قيود استخدام Claude). في المقابل، شدد ChatGPT بشكل كامل على توليد محتوى NSFW، مما أثار استياء المستخدمين. يدعو المجتمع إلى أن تكون ميزات AI اختيارية بدلاً من أن تكون افتراضية، احتراماً لاستقلالية المستخدم. (المصدر: swyx, vikhyatk, shlomifruchter, Dorialexander, scaling01, sammcallister, kylebrussell, raizamrtn, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/LocalLLaMA, Reddit r/ChatGPT, qtnx_)
تحديات نظام AI البيئي، جدل النماذج مفتوحة المصدر، والإدراك العام: أثار تقييم NIST لأمان نموذج DeepSeek مخاوف بشأن مصداقية النماذج مفتوحة المصدر واحتمال فرض حظر على النماذج الصينية، لكن مجتمع المصادر المفتوحة يدعم DeepSeek بشكل عام، معتبراً أن “عدم الأمان” يعني في الواقع سهولة أكبر في اتباع تعليمات المستخدم. تؤثر تغييرات Google Search API على اعتماد نظام AI البيئي على بيانات الطرف الثالث. يواجه إعداد بيئات تطوير LLM المحلية تحديات تتعلق بالتكلفة العالية للأجهزة والصيانة. يعاني تقييم نماذج AI من ظاهرة “الهدف المتحرك”، وهناك جدل عام حول جودة وأخلاقيات المحتوى الذي يولده AI (مثل استخدام Taylor Swift لفيديوهات AI). (المصدر: QuixiAI, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, dotey, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/artificial, Reddit r/artificial)

تأثير AI على التوظيف والخدمات المهنية: قد يقلل الاقتصاديون بشكل كبير من تأثير AI على سوق العمل، حيث لن يحل AI محل الخدمات المهنية بالكامل، بل سيقوم “بتجزئتها”. قد يؤدي ظهور AI إلى اختفاء بعض الوظائف، ولكنه سيخلق فرصاً جديدة في الوقت نفسه، مما يتطلب من الناس التعلم والتكيف باستمرار. يعتقد المجتمع بشكل عام أن الوظائف التي تتطلب التعاطف أو الحكم أو الثقة (مثل الرعاية الصحية، الاستشارات النفسية، التعليم، القانون) والأشخاص القادرين على استخدام AI لحل المشكلات سيكونون أكثر قدرة على المنافسة. (المصدر: Ronald_vanLoon, Ronald_vanLoon, Reddit r/ArtificialInteligence)

برمجة AI ومقارنتها بالإدارة التقنية: يناقش المجتمع مقارنة برمجة AI بالإدارة التقنية، مؤكداً على أن المطورين بحاجة إلى أن يكونوا مثل EM (مديري الهندسة)، وأن يفهموا المتطلبات بوضوح، ويشاركوا في التصميم، ويقسموا المهام، ويتحكموا في الجودة (مراجعة واختبار كود AI)، ويحدثوا النماذج في الوقت المناسب. على الرغم من أن AI يفتقر إلى المبادرة، إلا أنه يوفر تعقيد التعامل مع العلاقات الشخصية. (المصدر: dotey)
هلوسات AI ومخاطر الواقع: تثير ظاهرة هلوسات AI مخاوف، حيث أفادت تقارير بأن AI وجه السياح إلى معالم خطيرة غير موجودة، مما تسبب في مخاطر على السلامة. يسلط هذا الضوء على أهمية دقة معلومات AI، خاصة في التطبيقات التي تنطوي على سلامة العالم الحقيقي، مما يتطلب آليات تحقق أكثر صرامة. (المصدر: Reddit r/artificial)
أخلاقيات AI وتأملات بشرية: يناقش المجتمع ما إذا كان AI يمكن أن يجعل البشر أكثر إنسانية. ترى وجهات النظر أن التقدم التكنولوجي لا يؤدي بالضرورة إلى تحسين أخلاقي، وأن التقدم الأخلاقي البشري غالباً ما يصاحبه ثمن باهظ. AI بحد ذاته لن يوقظ ضمير البشر بطريقة سحرية، بل يأتي التغيير الحقيقي من التأمل الذاتي واليقظة الإنسانية في مواجهة الرعب. تشير الانتقادات إلى أن الشركات، عند تسويق أدوات AI، غالباً ما تتجاهل مخاطر إساءة استخدام الأداة في أعمال غير إنسانية. (المصدر: Reddit r/artificial)
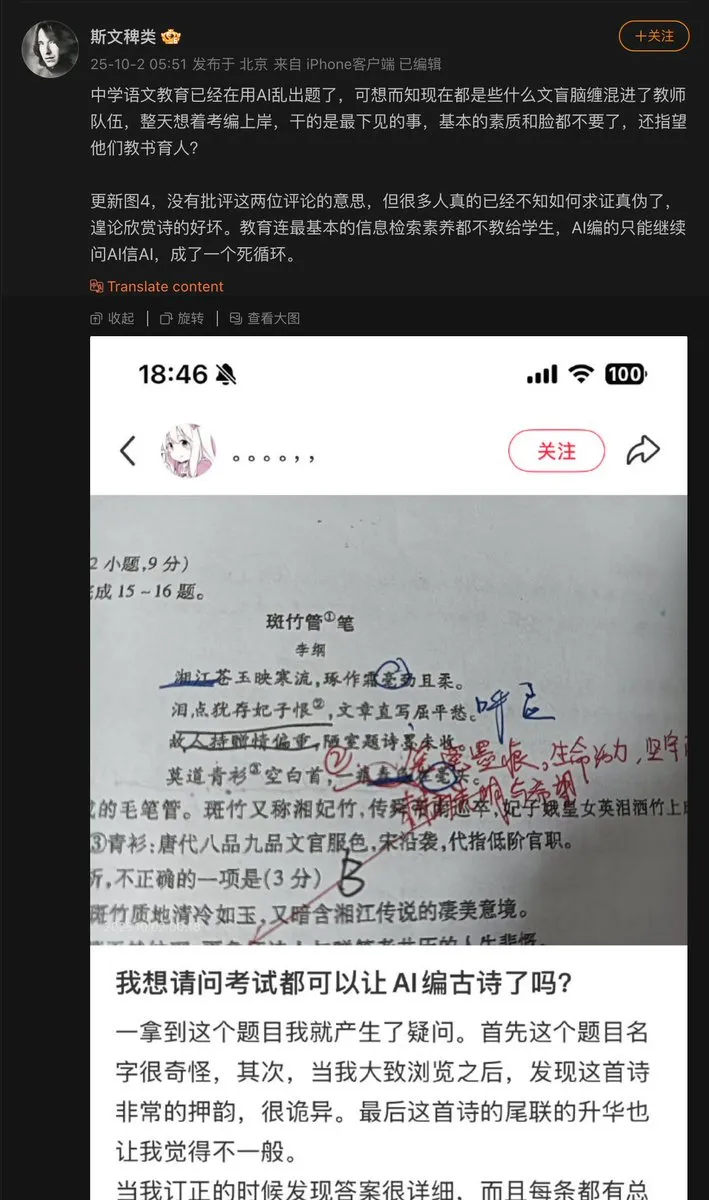
مشكلات تطبيق AI في مجال التعليم: استخدم معلم في المرحلة الثانوية AI لوضع أسئلة الاختبار، ونتيجة لذلك، اختلق AI قصيدة صينية قديمة ووضعها كسؤال في الاختبار. يكشف هذا عن مشكلة “الهلوسة” المحتملة في AI عند توليد المحتوى، خاصة في مجال التعليم الذي يتطلب دقة الحقائق، فإن آليات مراجعة والتحقق من المحتوى الذي يولده AI أمر بالغ الأهمية. (المصدر: dotey)
تقدم نماذج AI وعقبات البيانات: يشير المجتمع إلى أن العقبة الرئيسية في تقدم نماذج AI الحالية تكمن في البيانات، حيث أن الجزء الأصعب هو تنظيم البيانات، وإثراء السياق، واستخلاص القرارات الصحيحة منها. يؤكد هذا على أهمية البيانات عالية الجودة والمنظمة لتطوير AI، والتحديات في إدارة البيانات في تدريب النماذج. (المصدر: TheTuringPost)
استهلاك طاقة حوسبة LLM والموازنة بين القيمة: يناقش المجتمع الاستهلاك الهائل للطاقة لـ AI (خاصة LLM)، حيث يرى البعض أن هذا “شرير”، لكن هناك وجهة نظر أخرى تشير إلى أن مساهمات AI في حل المشكلات واستكشاف الكون تتجاوز بكثير استهلاكه للطاقة، معتبرين أن منع تطور AI هو قصر نظر. يعكس هذا الجدل المستمر حول الموازنة بين تطور AI والتأثير البيئي. (المصدر: timsoret)

💡 أخرى
AI+IoT صراف آلي للذهب: جهاز صراف آلي يجمع بين تقنيات AI و IoT قادر على قبول الذهب كوسيلة للتبادل، وهو تطبيق مبتكر يجمع بين AI والإنترنت الأشياء في مجال التمويل، وعلى الرغم من كونه متخصصاً نسبياً، إلا أنه يظهر إمكانات AI في سيناريوهات محددة. (المصدر: Ronald_vanLoon)
خوادم Z.ai Chat CPU تتعرض لهجوم يؤدي إلى انقطاع الخدمة: تعرضت خدمة Z.ai Chat لانقطاع مؤقت بسبب هجوم على خوادم CPU، ويعمل الفريق على الإصلاح. يسلط هذا الضوء على التحديات التي تواجه خدمات AI في أمان البنية التحتية واستقرارها، والتأثير المحتمل لهجمات DDoS أو غيرها من الهجمات الإلكترونية على تشغيل منصات AI. (المصدر: Zai_org)
Apache Gravitino: كتالوج بيانات مفتوح وإدارة أصول AI: Apache Gravitino هو بحيرة بيانات وصفية (metadata lake) عالية الأداء، موزعة جغرافياً، وموحدة، تهدف إلى توحيد إدارة البيانات الوصفية من مصادر وأنواع ومناطق مختلفة. يوفر وصولاً موحداً للبيانات الوصفية، ويدعم حوكمة البيانات وأصول AI، ويجري تطوير وظائف تتبع نماذج AI والميزات، ومن المتوقع أن يصبح بنية تحتية رئيسية لإدارة أصول AI. (المصدر: GitHub Trending)