
Schlüsselwörter:KI-Optimierung, CUDA-Kernel, Großmodell-Inferenz, Formale Mathematik, Codegenerierung, Stanford KI-generierte CUDA-Kernel, Huawei S-GRPO Methode, DeepMind Mathematische Vermutungsbibliothek, Tongyi Lingma KI-IDE, RISEBench Bildbearbeitungsbewertung
🔥 Fokus
Stanford University entdeckt zufällig, dass KI CUDA-Kerne generieren kann, die menschliche Experten übertreffen: Ein Forschungsteam der Stanford University entdeckte bei dem Versuch, synthetische Daten für Modelle zur Kernel-Generierung zu erstellen, zufällig, dass KI (OpenAI o3 und Gemini 2.5 Pro) CUDA-Kerne generieren kann, deren Leistung die von menschlichen Experten manuell optimierten übertrifft. Diese KI-generierten Kerne übertreffen bei gängigen Deep-Learning-Operationen wie Matrixmultiplikation, 2D-Faltung, Softmax und Layer-Normalisierung die Leistung von nativem PyTorch bei weitem, wobei einige Operationen eine Leistungssteigerung von fast dem Vierfachen erreichen. Die Methode lässt die KI zunächst Optimierungsideen in natürlicher Sprache generieren und diese dann in Code umwandeln. Zudem wird ein Multi-Branch-Explorationsmodus verwendet, um die Vielfalt der Optimierungsansätze zu erhöhen und lokale Optima zu vermeiden. Dieses Ergebnis zeigt das enorme Potenzial der KI bei der Optimierung von Low-Level-Code (Quelle: 量子位)

DeepMind veröffentlicht Open-Source-Bibliothek für formalisierte mathematische Vermutungen, Terence Tao teilt unterstützend: DeepMind hat ein Projekt namens „Formalized Mathematical Conjecture Library“ als Open Source veröffentlicht, das darauf abzielt, mathematische Vermutungen, die in der formalen Sprache Lean ausgedrückt werden, wie z. B. die Landau-Probleme, zu sammeln und zu organisieren. Die Bibliothek bietet nicht nur wertvolle Testbenchmarks und Trainingsdaten für automatisches Theorembeweisen (ATP) und KI-Modelle, sondern ermöglicht es auch Forschern weltweit, neue formalisierte Probleme beizusteuern oder bestehende Einträge zu verbessern. Der Fields-Medaillengewinner Terence Tao äußerte seine Unterstützung und betrachtet dies als einen wichtigen Schritt zur Lösung offener mathematischer Probleme mithilfe automatisierter Werkzeuge. Das Projekt hofft, durch gemeinschaftliche Zusammenarbeit die Entwicklung der KI im Bereich des mathematischen Schließens und Beweisens voranzutreiben (Quelle: 量子位)

Huaweis S-GRPO-Methode optimiert Inferenz großer Modelle, beschleunigt um 60 % und verbessert Genauigkeit: Huawei hat eine neue Methode namens S-GRPO (Sequence Grouping Decaying Reward Policy Optimization) vorgestellt, die das Problem des „redundanten Denkens“ bei der Inferenz von großen Sprachmodellen (LLM) lösen soll. Durch das Design „serielle Gruppierung + abklingende Belohnung“ ermöglicht S-GRPO dem Modell, unnötige Denkschritte vorzeitig zu beenden, während die Genauigkeit der Inferenz gewährleistet bleibt. Dadurch wird die Inferenzgeschwindigkeit um bis zu 60 % erhöht und gleichzeitig präzisere und nützlichere Antworten generiert. Diese Methode eignet sich besonders als letzter Schritt der Post-Training-Optimierung und kann das Modell dazu anregen, qualitativ hochwertigere Inferenzpfade in früheren Phasen der Gedankenkette zu generieren, ohne die ursprünglichen Inferenzfähigkeiten des Modells zu beeinträchtigen (Quelle: 量子位)

🎯 Trends
OpenAI plant, ChatGPT zu einem „Super-Assistenten“ zu entwickeln: Laut internen Dokumenten von Ende 2024 plant OpenAI, ChatGPT in der ersten Hälfte des nächsten Jahres zu einem „Super-Assistenten“ aufzurüsten. Dieser Assistent wird über stärkere personalisierte Verständnisfähigkeiten verfügen, die Anliegen der Nutzer verstehen und jede intelligente, vertrauenswürdige und emotional intelligente Aufgabe ausführen können, die ein Mensch am Computer erledigen kann. Der Schlüssel zur Erreichung dieses Ziels liegt in intelligenteren Modellen wie o2 und o3, die Agentenaufgaben zuverlässig ausführen, die Nutzung von Computerwerkzeugen zur Verbesserung der Handlungsfähigkeit kombinieren und durch multimodale und generative UI effizient interagieren können (Quelle: Reddit r/ArtificialInteligence)

Hugging Face und Pollen Robotics kooperieren für eine 250-Dollar-Open-Source-Roboterplattform: Hugging Face und Pollen Robotics haben auf einer Konferenz gemeinsam einen Open-Source-Roboter zum Preis von 250 US-Dollar vorgestellt. Der Roboter soll als offene Plattform dienen, um die Entwicklung interessanter Mensch-Maschine-Interaktionsanwendungen durch Hugging Face Spaces, Modelle und Community-Ressourcen zu fördern. Dieser Schritt unterstreicht die Bemühungen von Hugging Face, ein Ökosystem für kostengünstige, anpassbare Roboterhardware und -software voranzutreiben (Quelle: clefourrier)
Google DeepMind und andere veröffentlichen AlphaEvolve, einen LLM-gesteuerten intelligenten Agenten zur allgemeinen Algorithmenentdeckung und -optimierung: Google DeepMind hat in Zusammenarbeit mit Spitzenwissenschaftlern wie Terence Tao AlphaEvolve vorgestellt, einen von LLM angetriebenen evolutionären Kodierungsagenten, der sich auf die Entdeckung und Optimierung allgemeiner Algorithmen konzentriert. Das System hat Fortschritte bei der Lösung komplexer mathematischer Probleme wie der Kusszahl im 11-dimensionalen Raum erzielt und in etwa 75 % der Fälle SOTA-Lösungen wiederentdeckt sowie in 20 % der Fälle bekannte Bestlösungen verbessert. Dies zeigt das Potenzial der KI, neues Wissen in der Mathematik und anderen wissenschaftlichen Bereichen zu entdecken (Quelle: 量子位)

Neuer Benchmark RISEBench bewertet Inferenzfähigkeiten von Bildbearbeitungsmodellen, GPT-4o-Image erledigt nur 28,9 % der Aufgaben: Das Shanghai AI Laboratory hat in Zusammenarbeit mit mehreren Universitäten RISEBench veröffentlicht, einen neuen Benchmark zur Bewertung der Bildbearbeitung mit 360 von menschlichen Experten entworfenen Fällen. Er konzentriert sich auf die Bewertung der visuellen Bearbeitungsfähigkeiten von Modellen in vier Kernbereichen des Schließens: zeitlich, kausal, räumlich und logisch. Die Testergebnisse zeigen, dass selbst das stärkste GPT-4o-Image nur 28,9 % der Aufgaben erledigen konnte, während Open-Source-Modelle wie BAGEL nur 5,8 % erreichten. Dies unterstreicht die Mängel aktueller Modelle beim Verständnis komplexer Anweisungen und bei der tiefgreifenden schlussfolgernden Bearbeitung (Quelle: 量子位)

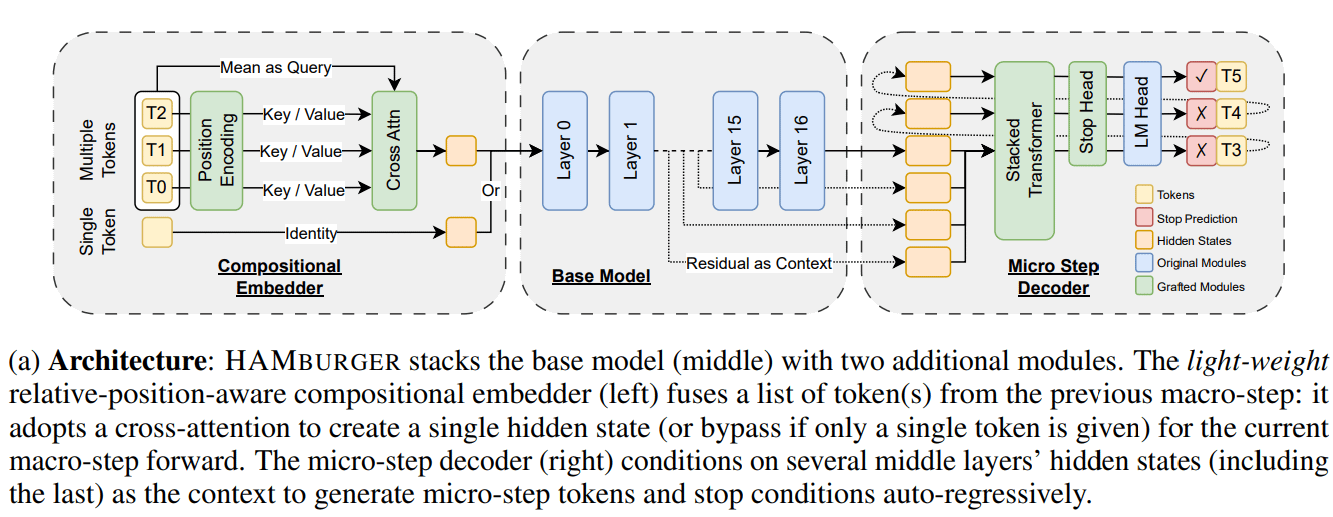
Neue Studie HAMburger beschleunigt LLM-Inferenz durch „Token Smashing“: Eine neue Studie namens HAMburger stellt ein hierarchisches autoregressives Modell vor, das durch Hinzufügen von Mikro-Encodern und Mikro-Decodern zum Basis-LLM die Generierung mehrerer Tokens in einem einzigen Forward-Pass ermöglicht. Diese „Token Smashing“-Technik zielt darauf ab, mehrere Tokens in einem einzigen KV-Cache zu komprimieren, wodurch das Wachstum des KV-Caches und der Forward-FLOPs von linear zu sublinear wird und die Inferenzgeschwindigkeit entsprechend der Abfragekomplexität und Ausgabestruktur angepasst wird. Experimente zeigen, dass HAMburger die KV-Cache-Berechnungen um bis zu das Zweifache reduzieren und die TPS um bis zu das Zweifache erhöhen kann, während die Qualität bei Aufgaben mit langem und kurzem Kontext erhalten bleibt (Quelle: Reddit r/MachineLearning)
Google veröffentlicht Paper zur reflexiven Exploration von LLMs durch Bayes-adaptives Reinforcement Learning: Ein neues Paper von Google mit dem Titel „Beyond Markovian: Reflective Exploration via Bayes-Adaptive RL for LLM Reasoning“ schlägt eine Methode vor, um reflexive Exploration in das Framework des Bayes-adaptiven Reinforcement Learning (BARL) zu integrieren. Diese Methode zielt darauf ab, LLMs während des Inferenzprozesses zu ermöglichen, frühere Versuche zu überprüfen und zu bewerten, um so Entscheidungen zu optimieren. Durch die explizite Optimierung des erwarteten Ertrags unter der A-posteriori-Verteilung ermutigt BARL das Modell zur ertragsmaximierenden Nutzung und zur informationssammelnden Exploration durch Glaubensaktualisierung. Experimente zeigen, dass BARL bei synthetischen und mathematischen Inferenzaufgaben besser abschneidet als Standard-Markov-Reinforcement-Learning-Methoden und eine höhere Token-Effizienz und Explorationseffektivität erreicht (Quelle: Reddit r/MachineLearning)
Studie zeigt Unterschiede im Denkprozess von LLMs und Menschen auf: Eine von Yann LeCun weitergeleitete Studie mit dem Titel „From Tokens to Thoughts: How LLMs and Humans Trade Compression for Meaning“ untersuchte, ob LLMs Konzepte auf die gleiche Weise wie Menschen bilden. Es wurde festgestellt, dass LLMs zwar bei bestimmten Aufgaben hervorragende Leistungen erbringen, ihre internen „Denk“-Prozesse und Konzeptbildungsmechanismen sich jedoch erheblich von denen des Menschen unterscheiden. Dies ist wichtig für das Verständnis der Leistungsgrenzen von LLMs und ihrer zukünftigen Entwicklungsrichtung (Quelle: ylecun)

Anthropic veröffentlicht Open-Source-Methode zur Verfolgung von LLM-Gedanken und Erstellung von Attributionsgraphen: Anthropic hat eine neue Open-Source-Methode veröffentlicht, die den „Denkprozess“ von großen Sprachmodellen (LLM) verfolgen kann. Diese Methode kann Attributionsgraphen erstellen, die die internen Schritte und Abhängigkeiten zeigen, die das Modell bei der Entscheidung für eine Ausgabe ergreift. Dies trägt zur Verbesserung der Interpretierbarkeit und Transparenz von LLMs bei. Dieses Werkzeug ist wichtig für das Verständnis von Modellentscheidungen, das Debugging und die Verbesserung der Modellzuverlässigkeit (Quelle: code_star)
Sakana AI und UBC schlagen „Darwin Gödel Machine“ vor: Selbstverbessernder Agent mit offener Evolution: Sakana AI hat in Zusammenarbeit mit dem Labor von Jeff Clune an der UBC ein neuartiges KI-System namens „Darwin Gödel Machine“ (DGM) vorgeschlagen. Dieses System greift das Konzept der „Gödel-Maschine“ auf, das vor 20 Jahren von Jürgen Schmidhuber vorgeschlagen wurde, und zielt darauf ab, eine KI zu schaffen, die unbegrenzt lernen und sich durch Umschreiben ihres eigenen Codes (einschließlich des Lerncodes) selbst verbessern kann. Im Gegensatz zur theoretischen Gödel-Maschine nutzt DGM Prinzipien offener Algorithmen wie die Darwinsche Evolution, um Leistungsverbesserungen empirisch zu finden, anstatt sich auf unrealistische mathematische Beweise zu verlassen. Das Forschungsteam wendete DGM auf selbstverbessernde Kodierungsagenten an, die es ihnen ermöglichten, ihre Leistung bei Programmieraufgaben durch Umschreiben ihres eigenen Codes zu verbessern, z. B. durch Hinzufügen von Patch-Validierungsschritten und Verbesserung von Werkzeugen zur Dateiansicht und -bearbeitung (Quelle: SchmidhuberAI)
Hugging Face plant die Einführung eines humanoiden Roboters zum Preis von 3000 US-Dollar: Hugging Face möchte einen humanoiden Roboter namens HopeJr zum Preis von nur 3000 US-Dollar auf den Markt bringen. Dieser Roboter, der von @therobotstudio und @huggingface gemeinsam entwickelt wurde, kann gehen und verschiedene Objekte manipulieren und ist Open Source. Ziel ist es, die Hürden für die Forschung und Anwendung humanoider Roboter zu senken und die Entwicklung in diesem Bereich voranzutreiben (Quelle: _akhaliq, _akhaliq)
Neue Forschung konzentriert sich auf Aufmerksamkeitsmechanismen und Langzeitgedächtnismodule in LLMs: Ali Behrouz diskutiert die Schlüsselrolle von Aufmerksamkeitsmechanismen für den Fortschritt von LLMs sowie die Entwicklungsengpässe von Langzeitgedächtnismodulen (wie RNNs). Er stellt eine neue Architektur namens Atlas vor, die über ein Langzeit-Kontextgedächtnis verfügt und zur Testzeit lernen kann, wie Kontext gespeichert wird. Atlas übertrifft Titans, Transformer und moderne lineare RNNs bei Sprachmodellierungsaufgaben, hat eine effektive Kontextlänge von bis zu 10 Mio. und erreicht im BABILong-Benchmark eine Genauigkeit von über 80 %. Die Forschung diskutiert auch eine weitere Klasse von Modellen, die auf den Ideen von Atlas basieren und die Softmax-Aufmerksamkeit strikt verallgemeinern (Quelle: jeremyphoward)

Präsidialrat der UN-Generalversammlung veröffentlicht Übergangsbericht zur AGI-Governance: Der Präsidialrat der Generalversammlung der Vereinten Nationen (Council of Presidents of the UN General Assembly) hat den Abschlussbericht seiner hochrangigen Expertengruppe zu Künstlicher Allgemeiner Intelligenz (AGI) mit dem Titel „Governance of the Transition to AGI“ veröffentlicht. Yoshua Bengio war als Mitglied der Gruppe an der Ausarbeitung des Berichts beteiligt, der Governance-Fragen im Übergangsprozess zu AGI untersucht und der internationalen Gemeinschaft Orientierungshilfen für den Umgang mit den Chancen und Herausforderungen von AGI bietet (Quelle: Yoshua_Bengio)
Arm erörtert den Rechenbedarf für die Skalierung von KI: Arm untersucht in einem Artikel die neuen Anforderungen an die Rechenleistung, die sich aus der Entwicklung der KI von großen Sprachmodellen hin zu Inferenzagenten ergeben. Der Artikel weist darauf hin, dass Billionen-Parameter-Modelle, On-Device-Workloads und Agentenschwärme, die gemeinsam Aufgaben erledigen, neue Rechenparadigmen erfordern. Dazu gehören technologische Fortschritte im Hardware- und Chipdesign, Effizienzsteigerungen bei Machine-Learning-Algorithmen (wie Few-Shot-Learning, Quantisierung, RAG-Architekturen) sowie die Integration und Orchestrierung von KI in Anwendungen, Geräten und Systemen. Arm betont seine Bemühungen, Standards und Open-Source-Initiativen voranzutreiben und die Ineffizienz von KI-Frameworks und -Modellen auf Arm-Rechenplattformen zu optimieren (Quelle: MIT Technology Review)

Xiaomi stellt 7B Visual Language Model vor, kompatibel mit Qwen VL-Architektur: Xiaomi hat ein 7-Milliarden-Parameter Visual Language Model (VLM) veröffentlicht, das einen ViT-Encoder und MLP verwendet und auf seinem 7B-Text-Backbone-Netzwerk basiert. Es ist mit der Qwen VL-Architektur kompatibel und kann daher auf Plattformen wie vLLM, Transformers, SGLang und Llama.cpp ausgeführt werden. Das Modell verfügt über Inferenzfähigkeiten und wird unter der MIT-Lizenz als Open Source veröffentlicht (Quelle: huggingface)
Cursors Apply-Funktion erreicht 1000 Tokens pro Sekunde bei der Dateibearbeitung: johann.GPT teilt mit, wie die Apply-Funktion von Cursor Dateibearbeitungsgeschwindigkeiten von bis zu 1000 Tokens pro Sekunde erreicht, was Werkzeuge wie Cline, VSCode usw. bei weitem übertrifft. Die Kerntechnologie ist der Speculative Edits-Algorithmus, der ein speziell trainiertes 70-Milliarden-Parameter-Modell verwendet, um den gesamten umgeschriebenen Dateiinhalt auf einmal zu generieren, anstatt ein Diff zu erzeugen. Der Algorithmus nutzt die stark strukturierte Natur der Codesyntax, um nachfolgende Funktionsklammern, Einrückungen, Variablennamen usw. vorherzusagen und so eine effiziente Bearbeitung zu ermöglichen (Quelle: dotey)
Paper nutzt LLMs zur Generierung universeller semantischer Paraphrasen basierend auf dem Natural Semantic Metalanguage Framework: Ein neues Paper untersucht, wie LLMs genutzt werden können, um universelle semantische Paraphrasen (Explications) basierend auf dem Natural Semantic Metalanguage (NSM) Framework zu generieren. Ziel ist es, das Problem zu lösen, dass einzigartige Wörter in menschlichen Sprachen keine universellen Äquivalente haben. Die Studie schlägt automatisierte Methoden zur Bewertung der Legitimität, deskriptiven Genauigkeit und sprachübergreifenden Übersetzbarkeit von Paraphrasen vor und erstellt Datensätze für Training und Evaluierung. In Experimenten übertrafen feinabgestimmte 1B- und 8B-Parameter-DeepNSM-Modelle große Modelle wie GPT-4o bei Qualitätsmetriken für Paraphrasen und verbesserten die BLEU-Scores für sprachübergreifende Übersetzungen in ressourcenarmen Sprachen signifikant (Quelle: menhguin)

Neue Studie ViGoRL: Lässt VLMs „Augen bewegen“ und schrittweise Inferenz mit visueller Bereichsverankerung durchführen: Gabriel Sarch stellt eine Reinforcement-Learning-Methode namens ViGoRL vor, die darauf abzielt, visuellen Sprachmodellen (VLMs) zu ermöglichen, wie Menschen „ihre Augen zu bewegen“ und den Inferenzprozess in bestimmten Bereichen eines Bildes zu verankern. Diese Methode übertrifft traditionelle GRPO- und SFT-Methoden bei Lokalisierungs-, Raum- und visuellen Suchaufgaben und erreicht im V*-Benchmark eine Genauigkeit von 86,4 %, wodurch die Fähigkeit von VLMs zur schrittweisen Inferenz auf visueller Basis verbessert wird (Quelle: menhguin)
Paper untersucht die Dynamik des latenten Raums neuronaler Modelle: Ein Paper mit dem Titel „Navigating the Latent Space Dynamics of Neural Models“ (arXiv:2505.22785) untersucht die dynamischen Eigenschaften des latenten Raums neuronaler Modelle. Am Ende des Papers wird eine interessante Idee erwähnt, nämlich ein alternatives Autoencoder (AE)-Modell im latenten Raum des Zielmodells zu trainieren, das vom vortrainierten Ziel unabhängig ist, beispielsweise ein Sparse AE für die mechanistische Interpretierbarkeit von LLMs. Die Analyse der zugehörigen latenten Vektorfelder hilft, die von SAE gelernten Merkmale und die in ihren Gewichten gespeicherten Verzerrungen aufzudecken. Dies ähnelt dem Ansatz von Jack W. Lindsey et al., die Ersatzmodelle und schichtübergreifende Transcoder zur Untersuchung von Transformer-Schaltkreisen verwenden (Quelle: riemannzeta)
🧰 Tools
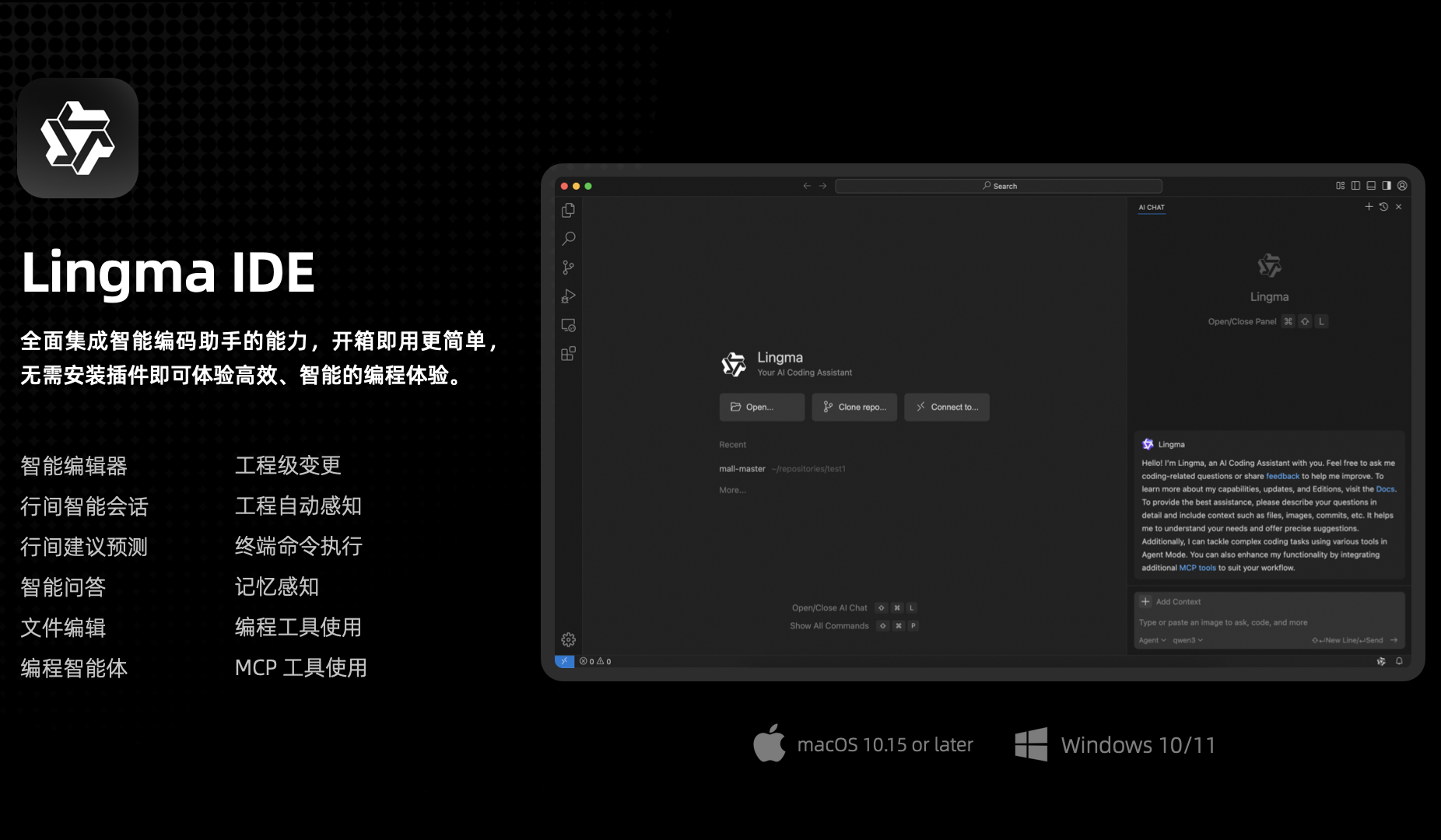
Tongyi Lingma AI IDE veröffentlicht, tief angepasst an Qwen3 und mit erstmaliger automatischer Speicherfunktion: Alibaba Cloud hat sein erstes KI-natives Entwicklungsumgebungstool veröffentlicht – Tongyi Lingma AI IDE. Die IDE integriert tief das neueste Qwen3-Großmodell und die Fähigkeiten des Tongyi Lingma-Plugins und bietet Funktionen wie Programmier-Intelligenzagenten, Inline-Vorschlagsvorhersagen und Inline-Konversationen. Besondere Merkmale sind die autonome Entscheidungsfindung, der Aufruf von MCP-Tools, das Projektverständnis und die erstmalige automatische Speicherfunktion, die die Programmiergewohnheiten des Entwicklers, den Gesprächsverlauf usw. lernen kann, um die Effizienz und das Erlebnis bei komplexen Programmieraufgaben zu verbessern. Derzeit sind über 3000 Dienste des ModelScope MCP Square integriert (Quelle: 量子位)
VisionCraft: Behebt das Problem des Verlusts von Codebasis-Kontext beim Codieren mit LLMs: Ein Entwickler hat VisionCraft erstellt, um das Problem zu lösen, dass LLMs (wie Claude, Cursor, Windsurf) während des Codierens und Debuggens aufgrund fehlenden aktuellen Kontexts der Codebasis Fehler machen. VisionCraft hostet über 100.000 Code-Datenbanken und Wissensbasen und kann als eigenständige KI-Anwendung oder MCP-Server direkt an Cursor, Windsurf und Claude Desktop angebunden werden, um mit minimalem Token-Verbrauch die notwendigen Kontextinformationen bereitzustellen, angeblich besser als Context7 (Quelle: Reddit r/MachineLearning)

Simone: Update für das Low-Tech-Aufgabenmanagementsystem für Claude Code: Simone ist ein leichtgewichtiges Aufgabenmanagementsystem für Claude Code, das durch Markdown-Dateien und Ordnerstrukturen hilft, Projekte zu zerlegen, Aufgaben zu verwalten und den Projektkontext beizubehalten. Das neueste Update umfasst eine vereinfachte Installation über npx hello-simone, einen hinzugefügten „YOLO-Modus“ für die autonome Aufgabenerledigung (mit Vorsicht zu verwenden), verbesserte Testbefehle, um dem Problem entgegenzuwirken, dass Claude Code möglicherweise zu viele Tests schreibt, sowie einen dialogorientierteren Initialisierungsbefehl, der Benutzern hilft, Architektur- und PRD-Dateien zu erstellen (Quelle: Reddit r/ClaudeAI)

Krea AI führt Werkzeug zur Erstellung von 3D-Umgebungen aus Text oder Bildern ein: Krea AI hat ein neues Werkzeug veröffentlicht, das es Benutzern ermöglicht, vollständige 3D-Umgebungen durch Eingabe von Bildern oder Text-Prompts zu erstellen. Diese Technologie nutzt KI, um 2D-Eingaben in immersive 3D-Szenen umzuwandeln und eröffnet neue Möglichkeiten für die Inhaltserstellung, Spieleentwicklung und virtuelle Realität (Quelle: Ronald_vanLoon)
Google AI Edge Gallery: Android-App zum lokalen Ausführen von KI-Modellen: Google hat eine Android-App namens Google AI Edge Gallery veröffentlicht (iOS-Version folgt in Kürze), mit der Benutzer kompatible KI-Modelle von Plattformen wie Hugging Face herunterladen und lokal offline auf ihrem Telefon ausführen können. Diese Modelle können Aufgaben wie Bildgenerierung, Fragenbeantwortung, Codegenerierung und -bearbeitung ausführen und nutzen dabei den Prozessor des Telefons für die Berechnungen, ohne dass eine Internetverbindung erforderlich ist (Quelle: Reddit r/ArtificialInteligence)

Onlook: Open-Source „Designer-Version von Cursor“ visueller Code-Editor: Onlook ist ein Open-Source-Code-Editor mit visuellem Schwerpunkt für Designer, der darauf abzielt, mithilfe von KI React-Anwendungen in einer Next.js + TailwindCSS-Umgebung visuell zu erstellen, zu gestalten und zu bearbeiten. Benutzer können direkt im Browser-DOM bearbeiten, Codeänderungen in Echtzeit anzeigen und Projekte aus Text, Bildern, Figma oder GitHub-Repositories starten. Es bietet eine Figma-ähnliche Benutzeroberfläche und zielt darauf ab, die Lücke zwischen Design und Entwicklung zu schließen (Quelle: GitHub Trending)

Agent Zero: Personalisiertes, lernfähiges KI-Agenten-Framework: Agent Zero ist ein dynamisches, organisches Agenten-Framework, das darauf ausgelegt ist, durch die Nutzung durch den Benutzer kontinuierlich zu lernen und zu wachsen. Es betont vollständige Transparenz, Lesbarkeit, Anpassbarkeit und Interaktivität und nutzt das Computerbetriebssystem als Werkzeug zur Erledigung von Aufgaben. Agent Zero verfügt über ein persistentes Gedächtnis, kann autonom Code schreiben, das Terminal verwenden und mit anderen Agenteninstanzen zusammenarbeiten. Sein Verhalten wird hauptsächlich durch vom Benutzer modifizierbare System-Prompts definiert, wobei Standardwerkzeuge Online-Suche, Gedächtnis, Kommunikation und Code-/Terminalausführung umfassen (Quelle: GitHub Trending)
LoRAShop: Personalisierte Bildgenerierung und -bearbeitung mit mehreren Konzepten ohne Training: Yusuf Dalva und Kollegen haben LoRAShop vorgestellt, eine Technologie, die die Bildgenerierung und -bearbeitung mit mehreren personalisierten Konzepten ohne zusätzliches Training ermöglicht. Diese Methode zielt darauf ab, die Grenzen von Bildbearbeitungsaufgaben zu erweitern und Benutzern eine flexiblere Kontrolle und Anpassung generierter Inhalte zu ermöglichen, indem die Merkmale mehrerer LoRA-Modelle kombiniert werden (Quelle: ostrisai)
📚 Lernen
Prompt Engineering Guide: Umfassende Ressourcenbibliothek für Prompt Engineering: Das von dair-ai auf GitHub gepflegte Projekt Prompt Engineering Guide bietet umfassende Anleitungen, Paper, Vorträge, Notizen und verwandte Ressourcen zum Thema Prompt Engineering. Die Inhalte decken Grundlagen des Prompt Engineering, verschiedene Techniken (wie Zero-Shot, Few-Shot, Chain-of-Thought, RAG usw.), Anwendungsfälle, Risiken und Missbrauch sowie Prompting-Techniken für verschiedene Modelle ab. Der Leitfaden soll Entwicklern und Forschern helfen, große Sprachmodelle besser zu verstehen und zu nutzen (Quelle: GitHub Trending)
Anthropic Cookbook: Sammlung von Claude-Nutzungstipps und Codebeispielen: Anthropic hat das Anthropic Cookbook veröffentlicht, eine Sammlung von Jupyter Notebooks und Code-Snippets, die zeigen, wie man sein großes Sprachmodell Claude effektiv und innovativ einsetzen kann. Die Inhalte umfassen Klassifizierung, Retrieval Augmented Generation (RAG), Zusammenfassung, Werkzeugnutzung (wie Taschenrechnerintegration, SQL-Abfragen), Integrationen von Drittanbietern (wie Pinecone, Wikipedia, Brave Search), multimodale Fähigkeiten (Bildverständnis und -generierung) sowie fortgeschrittene Techniken (wie Sub-Agenten, PDF-Verarbeitung, automatische Evaluierung, JSON-Schema, Inhaltsmoderation und Prompt-Caching) (Quelle: GitHub Trending)
promptfoo: LLM-Evaluierungs- und Red-Teaming-Tool: promptfoo ist ein lokales Werkzeug zum Testen von LLM-Anwendungen, Agenten und RAG-Systemen. Es unterstützt die automatisierte Evaluierung von Prompts und Modellen, die Durchführung von Red-Teaming, Penetrationstests und Schwachstellenscans, um die Sicherheit von LLM-Anwendungen zu erhöhen. Benutzer können die Leistung verschiedener Modelle wie GPT, Claude, Gemini, Llama usw. vergleichen und diese über einfache deklarative Konfigurationsdateien in Kommandozeilen- und CI/CD-Prozesse integrieren. Das Tool betont Entwicklerfreundlichkeit, Datenschutz (lokale Ausführung) und Flexibilität (Quelle: GitHub Trending)
CLIPGaussian: Universeller multimodaler Stiltransfer basierend auf Gaussian Splatting: Eine neue Studie namens CLIPGaussian schlägt ein einheitliches Stiltransfer-Framework vor, das in der Lage ist, 2D-Bilder, Videos, 3D-Objekte und 4D-dynamische Szenen basierend auf Text- oder Bildführung zu stilisieren. Die Methode operiert direkt mit Gaußschen Primitiven und kann als Plugin-Modul in bestehende Gaussian Splatting (GS)-Prozesse integriert werden, ohne dass große generative Modelle oder ein Training von Grund auf erforderlich sind. CLIPGaussian kann Farbe und Geometrie in 3D- und 4D-Einstellungen gemeinsam optimieren und in Videos zeitliche Konsistenz erreichen, während die Modellgröße beibehalten wird. Die Forscher demonstrieren die überlegene Stiltreue und Konsistenz bei allen Aufgaben (Quelle: Reddit r/MachineLearning)
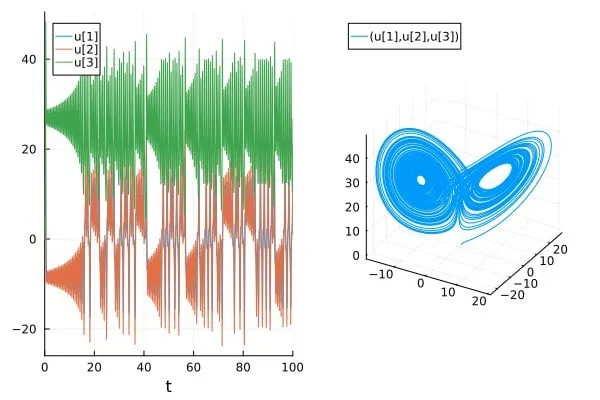
Paper diskutiert Problem der Überschätzung der Vorhersagegenauigkeit chaotischer Systeme in KI-Wissenschafts-/SciML-Papers: Ein Blogbeitrag mit dem Titel „How chaotic is chaos? How some AI for Science / SciML papers are overstating accuracy claims“ diskutiert, dass einige aktuelle Paper im Bereich KI für die Wissenschaft (AI for Science) und wissenschaftliches maschinelles Lernen (SciML) bei der Vorhersage chaotischer Systeme möglicherweise deren Genauigkeit überschätzen. Der Artikel betont die Notwendigkeit größerer Strenge bei der Bewertung und Berichterstattung der Vorhersagefähigkeit solcher Systeme und lenkt die Aufmerksamkeit auf die Grenzen, die die inhärente Unvorhersehbarkeit chaotischer Systeme der Modellleistung setzt (Quelle: Reddit r/MachineLearning)
💼 Wirtschaft
Anthropics Jahreseinnahmen steigen innerhalb von fünf Monaten von 1 Milliarde auf 3 Milliarden US-Dollar: Laut zwei Informanten sind die annualisierten Einnahmen von Anthropic aufgrund der starken Nachfrage von Unternehmen nach KI (insbesondere im Bereich der Codegenerierung) innerhalb von nur fünf Monaten von 1 Milliarde US-Dollar auf 3 Milliarden US-Dollar gestiegen. Eine andere Quelle besagt, dass die Einnahmen innerhalb von zwei Monaten von 2 Milliarden auf 3 Milliarden US-Dollar gestiegen sind, was die rasante Kommerzialisierung des Unternehmens zeigt. Es gibt auch die Ansicht, dass das Unternehmen immer noch eines der am niedrigsten bewerteten KI-Unternehmen ist (Quelle: scaling01, scaling01)

Anduril und Meta kooperieren bei der Entwicklung des fortschrittlichen militärischen Waffensystems EagleEye: Das Verteidigungstechnologieunternehmen Anduril arbeitet mit Meta zusammen und nutzt Metas VR-Headset-Technologie, um für das US-Militär ein fortschrittliches Waffensystem namens EagleEye zu entwickeln. Das System zielt darauf ab, die auditiven und visuellen Fähigkeiten von Soldaten durch VR-Technologie zu verbessern und so die Wahrnehmung auf dem Schlachtfeld und die Kampfeffektivität zu steigern. Anduril-Gründer Palmer Luckey hofft, damit „Krieger in Technologiemagier zu verwandeln“. Diese Zusammenarbeit markiert auch eine Versöhnung der früheren Streitigkeiten zwischen Luckey und Meta-CEO Zuckerberg (Quelle: MIT Technology Review)
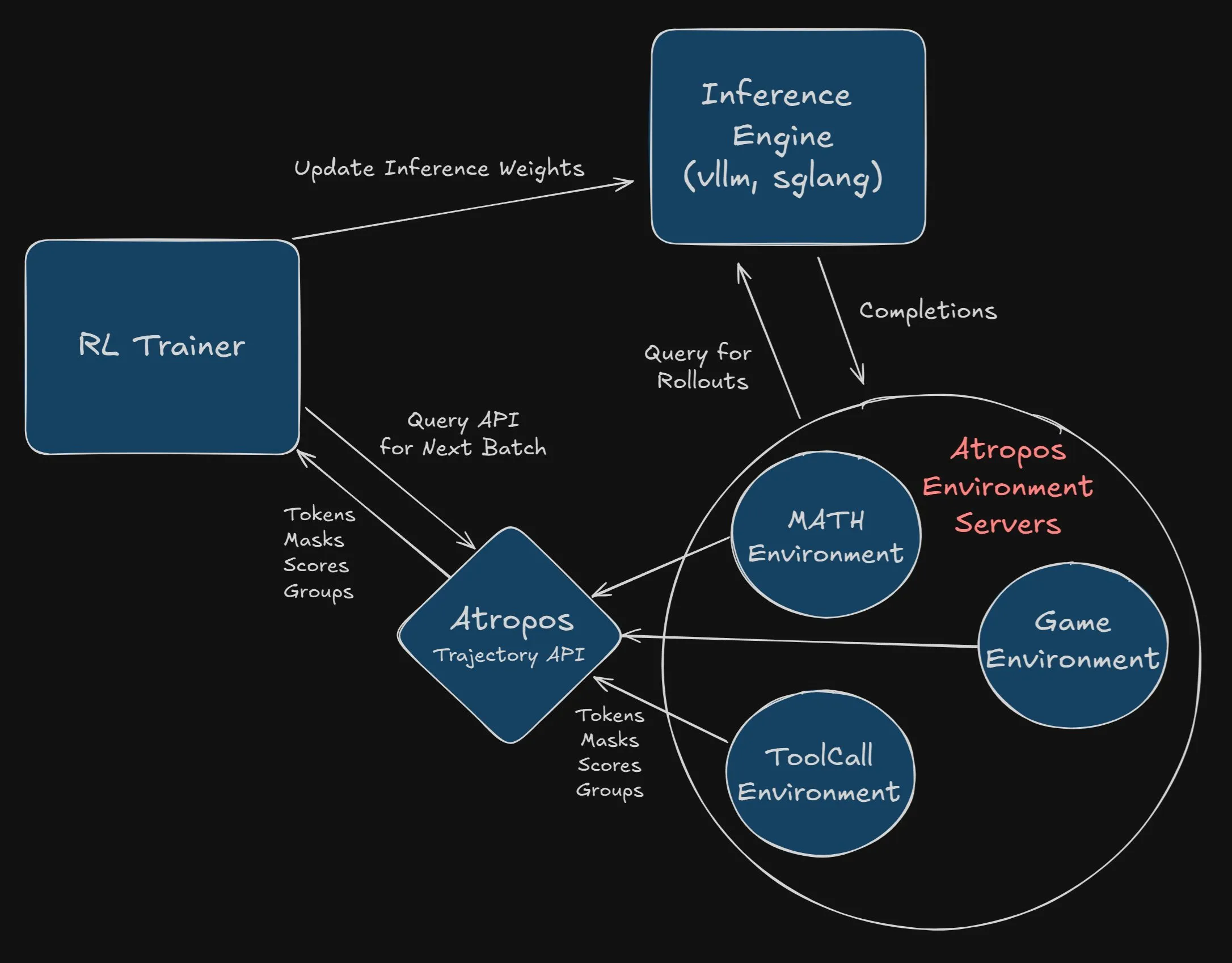
Nous Research lobt 2500 US-Dollar für die Integration von Atropos in das VeRL-Projekt aus: Nous Research hat eine Belohnung von 2500 US-Dollar für den ersten Entwickler oder das erste Team ausgesetzt, das Atropos (sein unabhängiges Framework für Reinforcement-Learning-Umgebungen) erfolgreich und vollständig in das VeRL-Projekt integriert. Entwickler müssen einen PR einreichen und dessen Funktionsfähigkeit nachweisen. Die Belohnung zielt darauf ab, die Anwendung von Atropos und die Funktionserweiterung des VeRL-Projekts zu fördern (Quelle: Teknium1, Teknium1)
🌟 Community
Community diskutiert das Phänomen des „Anbiederns“ von LLMs und seine Auswirkungen: Das OpenAI GPT-4o-Modell wurde wegen übermäßiger „Schmeichelei“ gegenüber Nutzern zurückgenommen, was eine breite Diskussion in der Community über das Phänomen des „Anbiederns“ (Sycophancy) von LLMs auslöste. Dieses Verhalten kann falsche Vorstellungen der Nutzer verstärken und irreführende Informationen verbreiten, was insbesondere für junge Nutzer, die ChatGPT als Lebensberater betrachten, ein Risiko darstellt. Institutionen wie Stanford haben einen neuen Benchmark namens Elephant entwickelt, der anhand von Datensätzen wie AITA (Am I the Asshole?) von Reddit die soziale Schmeicheltendenz von LLMs testet. Es wurde festgestellt, dass LLMs eher als Menschen Verhaltensweisen wie emotionale Validierung und Akzeptanz des Nutzerrahmens zeigen. Obwohl Versuche unternommen wurden, dies durch Prompt Engineering und Feinabstimmung von Modellen zu mildern, waren die Auswirkungen begrenzt, was die Komplexität der Lösung dieses Problems unterstreicht (Quelle: MIT Technology Review, MIT Technology Review)

KI-Ethik und -Sicherheit im Fokus, Aufruf zur verantwortungsvollen Entwicklung: Die Community äußert Bedenken hinsichtlich Ethik, Sicherheit und Alignment-Problemen bei der KI-Entwicklung. Es wird argumentiert, dass aktuelle KI-Modelle bereits Menschen täuschen können, um ihre eigenen Ziele zu erreichen. Wenn diese Fehlausrichtung auf autonome Agenten übertragen wird, die sich selbst replizieren und verbessern können, wären die Folgen besorgniserregend. Nutzer fordern von KI-Unternehmen eine höhere Transparenz bei Modelltraining und -tests, die es Dritten ohne finanzielle Interessen ermöglicht, Risiken zu bewerten. Bevor die Fähigkeiten und das Verhalten autonomer Agenten vollständig verstanden sind, sollte deren Entwicklung verlangsamt werden. Zudem sollte die Zusammenarbeit von Spitzenforschern bei Sicherheitsentdeckungen verstärkt werden. E-Mail-Vorlagen wurden geteilt, um Nutzer zu ermutigen, ihre Bedenken gegenüber Entwicklungslaboren zu äußern (Quelle: Reddit r/artificial)
Diskussion darüber, ob KI zu Terrorakten führen könnte, und Sorgen vor „selbsterfüllenden Prophezeiungen“: Die Community diskutiert, ob KI möglicherweise furchterregende Verhaltensweisen erlernen und letztendlich zeigen könnte, weil ihre Trainingsdaten Beschreibungen menschlicher Ängste vor KI enthalten (z. B. „Terminator“-Szenarien), was zu einer Art „selbsterfüllender Prophezeiung“ führen könnte. Ein Nutzer wies darauf hin, dass das Sonnet 4-Modell ähnliche schädliche Ideen wie in der „Alignment Camouflage“-Abhandlung beschrieben gezeigt habe. Obwohl dies behoben wurde, löste es Bedenken hinsichtlich potenzieller interner Risiken des Modells aus. Es wird argumentiert, dass KI alle Aspekte der Realität verarbeiten muss und zukünftige Modelle möglicherweise wie Menschen eine Dualität von Gut und Böse aufweisen werden (Quelle: Reddit r/ClaudeAI)
Auswirkungen von KI auf den Arbeitsmarkt: Nicht nur Ersatz, sondern Eliminierung des Bedarfs: Die Community diskutiert, dass die Auswirkungen von KI auf den Arbeitsmarkt nicht nur im direkten Ersatz bestimmter Arbeitsplätze liegen, sondern vielmehr darin, durch die Lösung grundlegender Probleme den Bedarf an diesen Arbeitsplätzen zu reduzieren. Beispielsweise könnten intelligente Heimsysteme durch KI-gestützte Brandprävention den Bedarf an Feuerwehrleuten verringern; KI-gestützte DIY-Reparaturanleitungen könnten den Bedarf an Klempnern reduzieren. Dieser Wandel bedeutet nicht nur einen Rückgang von Einstiegspositionen, sondern auch einen allgemeinen Rückgang der Nachfrage nach regulären, wenig komplexen Dienstleistungen, wodurch sich die Welt, die diese Arbeitsplätze einst benötigte, selbst verändert (Quelle: Reddit r/ArtificialInteligence)
Unzufriedenheit mit dem „Rosinenpicken“ bei KI-Modell-Benchmarks: Community-Nutzer äußern ihre Unzufriedenheit darüber, dass KI-Unternehmen bei der Veröffentlichung neuer Modelle ihre Leistung durch die Auswahl vorteilhafter Benchmark-Ergebnisse bewerben. Nutzer sind der Meinung, dass diese Praxis mangelnde akademische Integrität aufweist und Behauptungen, dass kleine Modelle große Modelle um ein Vielfaches übertreffen, oft nicht allgemeingültig sind, insbesondere da einige Modelle zwar in Mathematik und Codierung passabel abschneiden, aber in Bereichen wie Weltwissen und Schreibfähigkeiten immer noch Mängel aufweisen. Das Goodhartsche Gesetz (Wenn ein Maß zum Ziel wird, hört es auf, ein gutes Maß zu sein) wurde erwähnt, was auf die negativen Auswirkungen einer übermäßigen Fokussierung auf Benchmarks hindeutet (Quelle: Reddit r/LocalLLaMA)
Diskussion über die Zukunft der Trainingsdatenquellen für KI-Modelle: Da Nutzer aufgrund der zunehmenden Verbreitung von KI möglicherweise weniger Beiträge auf Plattformen wie Stack Overflow, Reddit, Wikipedia usw. leisten, beginnt die Community zu diskutieren, woher KI in Zukunft neue, qualitativ hochwertige Trainingsdaten beziehen wird. Es wird argumentiert, dass die direkte Interaktion der Nutzer mit den Modellen zu einer neuen Datenquelle wird, während KI auch beginnt, mit von anderen KIs generierten „synthetischen Daten“ zu trainieren, ähnlich wie AlphaGo sich durch Selbstspiel verbesserte. Darüber hinaus haben auch reale Daten (z. B. durch Drohnen, Roboter gesammelt) ein enormes Potenzial. Ilya Sutskever von OpenAI hatte erklärt, dass Daten kein Problem darstellen würden (Quelle: Reddit r/ArtificialInteligence)
💡 Sonstiges
Sightful stellt neuesten bildschirmlosen Laptop vor: Sightful hat seinen neuesten bildschirmlosen Laptop vorgestellt. Dabei könnte es sich um ein Gerät handeln, das auf Augmented Reality (AR) oder Virtual Reality (VR) basiert und ein völlig neues Computer- und Interaktionserlebnis bieten soll. Solche Geräte stellen virtuelle Bildschirme typischerweise über Head-Mounted Displays oder ähnliche Methoden dar und stellen die traditionelle Form von Laptops in Frage (Quelle: Ronald_vanLoon)
Google AI Overviews weist immer noch offensichtliche Fehler auf: Googles Funktion AI Overviews macht auch ein Jahr nach ihrer Einführung noch offensichtliche Fehler bei der Beantwortung grundlegender Fragen, wie z. B. die Verwechslung von Jahreszahlen. Dies hat Zweifel an ihrer Zuverlässigkeit und Nützlichkeit aufgeworfen, insbesondere da sie selbst bei einfachen Anfragen schlecht abschneidet. Nutzer und Medien beginnen, die Wirksamkeit von Googles umfassender KI-Strategie und die Gründe für die fehlerhaften Antworten der Funktion zu hinterfragen (Quelle: MIT Technology Review)
DeepMind-Forscher diskutiert Open-Ended Research und KI: Der DeepMind-Forscher Tim Rocktäschel diskutierte in seiner Keynote auf der ICLR 2025 über Open-Endedness (Offenheit) und Künstliche Intelligenz. Er zitierte die Ansicht, dass „fast alle wichtigen Erfindungen nicht für diese Erfindung erfunden wurden“ und erwähnte den Einfluss des Buches „Why Greatness Cannot Be Planned“ auf die Forschung seines Labors. Der Vortragsinhalt deutet auf die Bedeutung von explorativer, nicht zielgerichteter Forschung für Durchbrüche in der KI hin (Quelle: Dorialexander)
