
Keywords:AI optimization, CUDA kernels, Large model inference, Formal mathematics, Code generation, Stanford AI-generated CUDA kernels, Huawei S-GRPO method, DeepMind mathematical conjecture library, Tongyi Lingma AI IDE, RISEBench image editing evaluation
🔥 Focus
Stanford University Accidentally Discovers AI Can Generate CUDA Kernels Surpassing Human Experts: A Stanford University research team, while attempting to create synthetic data for kernel generation models, unexpectedly discovered that AI (OpenAI o3 and Gemini 2.5 Pro) could generate CUDA kernels with better performance than those manually optimized by human experts. These AI-generated kernels, on common deep learning operations such as matrix multiplication, 2D convolution, Softmax, and layer normalization, significantly outperformed native PyTorch, with some operations achieving nearly a 4x performance improvement. The method involves having the AI first generate optimization ideas in natural language, then translate them into code, and employs a multi-branch exploration mode, enhancing the diversity of optimization approaches and avoiding local optima. This achievement demonstrates the immense potential of AI in low-level code optimization (Source: 量子位)

DeepMind Open-Sources Formal Mathematical Conjecture Library, Terence Tao Endorses: DeepMind has open-sourced a project called the “Formalized Mathematical Conjecture Library,” aimed at collecting and organizing mathematical conjectures, such as the Landau problems, expressed in the Lean formal language. This library not only provides valuable test benchmarks and training data for automated theorem proving (ATP) and AI models but also allows researchers worldwide to contribute new formalized problems or improve existing entries. Fields Medalist Terence Tao expressed his support, viewing it as an important step towards using automated tools to solve open mathematical problems. The project hopes to advance AI in mathematical reasoning and proof through community collaboration (Source: 量子位)

Huawei’s S-GRPO Method Optimizes Large Model Inference, Boosting Speed by 60% and Improving Accuracy: Huawei has proposed a new method called S-GRPO (Sequential Grouping with Decaying Reward Policy Optimization) to address the “excessive thinking” problem in Large Language Model (LLM) inference. Through a “serial grouping + decaying reward” design, S-GRPO enables models to learn to terminate unnecessary thinking steps prematurely while ensuring inference accuracy, thereby increasing inference speed by up to 60% and generating more precise and useful answers. This method is particularly suitable as a final step in post-training optimization, promoting the generation of higher-quality reasoning paths early in the chain of thought without compromising the model’s original reasoning capabilities (Source: 量子位)

🎯 Trends
OpenAI Plans to Develop ChatGPT into a “Super Assistant”: According to internal documents from late 2024, OpenAI plans to upgrade ChatGPT into a “super assistant” in the first half of next year. This assistant will possess enhanced personalization capabilities, understand user concerns, and be able to perform any intelligent, trustworthy, and emotionally intelligent task that a human can do on a computer. Key to achieving this goal are more intelligent models like o2 and o3, which can reliably execute agent tasks, leverage computer tools to enhance action capabilities, and interact efficiently through multimodal and generative UIs (Source: Reddit r/ArtificialInteligence)

Hugging Face Collaborates with Pollen Robotics to Launch $250 Open-Source Robot Platform: Hugging Face, in partnership with Pollen Robotics, unveiled a $250 open-source robot at a conference. The robot is intended as an open platform to foster the development of interesting human-robot interaction applications through Hugging Face Spaces, models, and community resources. This move signifies Hugging Face’s efforts to promote a low-cost, customizable robotics hardware and software ecosystem (Source: clefourrier)
Google DeepMind et al. Release AlphaEvolve, an LLM-Driven Universal Algorithm Discovery and Optimization Agent: Google DeepMind, in collaboration with top scientists including Terence Tao, has launched AlphaEvolve, an LLM-driven evolutionary coding agent focused on the discovery and optimization of universal algorithms. The system has made progress in solving complex mathematical problems like the kissing number in 11 dimensions, rediscovering SOTA solutions in about 75% of cases, and improving known best solutions in 20% of cases, showcasing AI’s potential for discovering new knowledge in mathematics and other scientific fields (Source: 量子位)

New Benchmark RISEBench Evaluates Image Editing Models’ Reasoning Capabilities, GPT-4o-Image Completes Only 28.9% of Tasks: Shanghai AI Laboratory, in collaboration with several universities, has released RISEBench, a new image editing evaluation benchmark containing 360 human expert-designed cases. It focuses on assessing models’ visual editing capabilities across four core reasoning types: temporal, causal, spatial, and logical. Test results show that even the most powerful GPT-4o-Image could only complete 28.9% of the tasks, while open-source models like BAGEL completed only 5.8%, highlighting current models’ deficiencies in understanding complex instructions and performing deep reasoning edits (Source: 量子位)

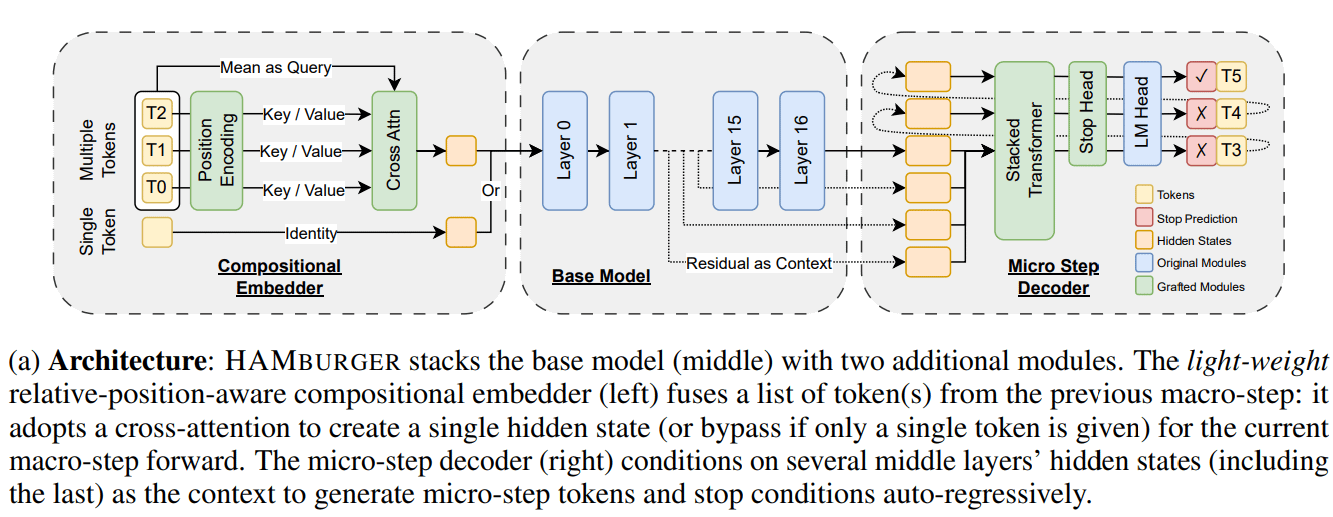
New Research HAMburger Accelerates LLM Inference via “Token Smashing”: A new study titled HAMburger proposes a hierarchical autoregressive model that incorporates micro-encoders and micro-decoders into a base LLM to generate multiple tokens in a single forward pass. This “token smashing” technique aims to compress multiple tokens into a single KV cache, thereby changing the growth of KV cache and forward FLOPs from linear to sub-linear, adjusting inference speed based on query complexity and output structure. Experiments show that HAMburger can reduce KV cache computation by up to 2x and increase TPS by up to 2x, while maintaining quality in both short and long context tasks (Source: Reddit r/MachineLearning)
Google Releases Paper on Reflective Exploration for LLMs via Bayes-Adaptive Reinforcement Learning: A new paper from Google, “Beyond Markovian: Reflective Exploration via Bayes-Adaptive RL for LLM Reasoning,” proposes a method to incorporate reflective exploration into the Bayes-Adaptive Reinforcement Learning (BARL) framework. This method aims to enable LLMs to review and evaluate previous attempts during reasoning to optimize decision-making. By explicitly optimizing the expected return under the posterior distribution, BARL encourages models to engage in reward-maximizing exploitation and information-gathering exploration through belief updates. Experiments demonstrate that BARL outperforms standard Markovian reinforcement learning methods on synthetic and mathematical reasoning tasks, achieving higher token efficiency and exploration effectiveness (Source: Reddit r/MachineLearning)
Study Indicates Differences in Thinking Styles Between LLMs and Humans: A study shared by Yann LeCun, titled “From Tokens to Thoughts: How LLMs and Humans Trade Compression for Meaning,” tested whether LLMs form concepts in the same way as humans. It found that although LLMs perform excellently on certain tasks, their internal “thinking” processes and concept formation mechanisms differ significantly from those of humans. This is important for understanding the capability boundaries and future development directions of LLMs (Source: ylecun)

Anthropic Open-Sources LLM Thought-Tracking Method, Generates Attribution Graphs: Anthropic has open-sourced a new method to track the “thought processes” of Large Language Models (LLMs). This method can generate attribution graphs showing the internal steps and dependencies the model takes when deciding on an output, helping to improve the interpretability and transparency of LLMs. This tool is significant for understanding model decisions, debugging, and enhancing model reliability (Source: code_star)
Sakana AI and UBC Propose “Darwin Gödel Machine”: A Self-Improving Agent via Open-Ended Evolution: Sakana AI, in collaboration with Jeff Clune’s lab at UBC, has proposed a new AI system called the “Darwin Gödel Machine” (DGM). This system draws inspiration from the “Gödel Machine” concept proposed by Jürgen Schmidhuber 20 years ago, aiming to create AI that can learn indefinitely and self-improve by rewriting its own code, including its learning code. Unlike the theoretical Gödel Machine, DGM utilizes principles from open-ended algorithms like Darwinian evolution, empirically finding performance improvements rather than relying on impractical mathematical proofs. The research team applied DGM to a self-improving coding agent, enabling it to enhance its performance on programming tasks by rewriting its own code, such as adding patch validation steps and improving file viewing and editing tools (Source: SchmidhuberAI)
Hugging Face Plans to Launch a $3,000 Humanoid Robot: Hugging Face aims to bring a humanoid robot named HopeJr to the market for just $3,000. Designed jointly by @therobotstudio and @huggingface, this robot is capable of walking and manipulating various objects, and it is open-source. This initiative seeks to lower the barrier to entry for humanoid robot research and application, thereby fostering development in the field (Source: _akhaliq, _akhaliq)
New Research Focuses on Attention Mechanisms and Long-Term Memory Modules in LLMs: Ali Behrouz discusses the critical role of attention mechanisms in LLM advancements and the developmental bottlenecks of long-term memory modules like RNNs. He introduces a new architecture called Atlas, which possesses long-term contextual memory capabilities and can learn how to memorize context at test time. Atlas outperforms Titans, Transformers, and modern linear RNNs in language modeling tasks, with an effective context length scalable to 10M, and achieves over 80% accuracy on the BABILong benchmark. The research also discusses another class of models based on Atlas’s ideas that strictly generalize softmax attention (Source: jeremyphoward)

Council of Presidents of the UN General Assembly Releases Transitional Report on AGI Governance: The Council of Presidents of the UN General Assembly has released the final report of its High-Level Expert Group on Artificial General Intelligence (AGI), titled “Governance of the Transition to AGI.” Yoshua Bengio participated as a member of the panel in drafting this report, which explores governance issues during the transition to AGI and provides guidance for the international community in addressing the opportunities and challenges posed by AGI (Source: Yoshua_Bengio)
Arm Discusses Computing Demands for Scaling AI Development: In an article, Arm explores the new computational requirements posed by the evolution of AI from large language models to inference agents. The article points out that trillion-parameter models, on-device workloads, and swarms of agents collaborating on tasks all necessitate new computing paradigms. This includes technological advancements in hardware and chip design, improvements in machine learning algorithm efficiency (such as few-shot learning, quantization, RAG architectures), and the integration and orchestration of AI in applications, devices, and systems. Arm emphasizes its efforts in promoting standards and open-source initiatives to optimize the inference efficiency of AI frameworks and models on Arm computing platforms (Source: MIT Technology Review)

Xiaomi Launches 7B Vision Language Model Compatible with Qwen VL Architecture: Xiaomi has released a 7-billion-parameter Vision Language Model (VLM). The model employs a ViT encoder and MLP, and is based on its 7B text backbone network. It is compatible with the Qwen VL architecture, allowing it to run on platforms such as vLLM, Transformers, SGLang, and Llama.cpp. The model possesses reasoning capabilities and is open-sourced under the MIT license (Source: huggingface)
Cursor’s Apply Feature Achieves 1000 Tokens/Second File Editing: johann.GPT shared how Cursor’s Apply feature achieves file editing speeds of up to 1000 tokens per second, far surpassing tools like Cline and VSCode. Its core technology is the Speculative Edits algorithm, which utilizes a 70-billion-parameter specially trained model to generate the complete rewritten file content at once, rather than generating a diff. The algorithm leverages the highly structured nature of code syntax to predict subsequent function brackets, indentation, variable names, etc., thereby enabling efficient editing (Source: dotey)
Paper Leverages LLMs to Generate Universal Semantic Explications Based on Natural Semantic Metalanguage Framework: A new paper explores how to use LLMs to generate universal semantic explications based on the Natural Semantic Metalanguage (NSM) framework, addressing the issue of unique words in human languages lacking universal equivalents. The research proposes automated methods to evaluate the legitimacy, descriptive accuracy, and cross-lingual translatability of these explications, and constructs datasets for training and evaluation. In experiments, fine-tuned 1B and 8B parameter DeepNSM models outperformed large models like GPT-4o on explication quality metrics, significantly improving cross-lingual translation BLEU scores for low-resource languages (Source: menhguin)

New Research ViGoRL: Enabling VLMs to “Move Their Eyes” and Perform Step-by-Step Reasoning Anchored to Visual Regions: Gabriel Sarch introduces a reinforcement learning method called ViGoRL, designed to enable Vision Language Models (VLMs) to “move their eyes” like humans and anchor their reasoning processes to specific regions in an image. This method outperforms traditional GRPO and SFT methods in localization, spatial tasks, and visual search, achieving 86.4% accuracy on the V* benchmark and enhancing VLMs’ step-by-step reasoning capabilities grounded in vision (Source: menhguin)
Paper Explores Latent Space Dynamics of Neural Models: A paper titled “Navigating the Latent Space Dynamics of Neural Models” (arXiv:2505.22785) investigates the dynamic properties of the latent spaces in neural network models. An interesting idea mentioned at the end of the paper is training a surrogate autoencoder (AE) model within the latent space of a target model, independent of the pre-trained target, such as a sparse AE for mechanistic interpretability of LLMs. Analyzing the associated latent vector fields can help reveal the features learned by the SAE and the biases stored in its weights. This is similar to methods used by Jack W. Lindsey et al. who study Transformer circuits using replacement models and cross-layer transcoders (Source: riemannzeta)
🧰 Tools
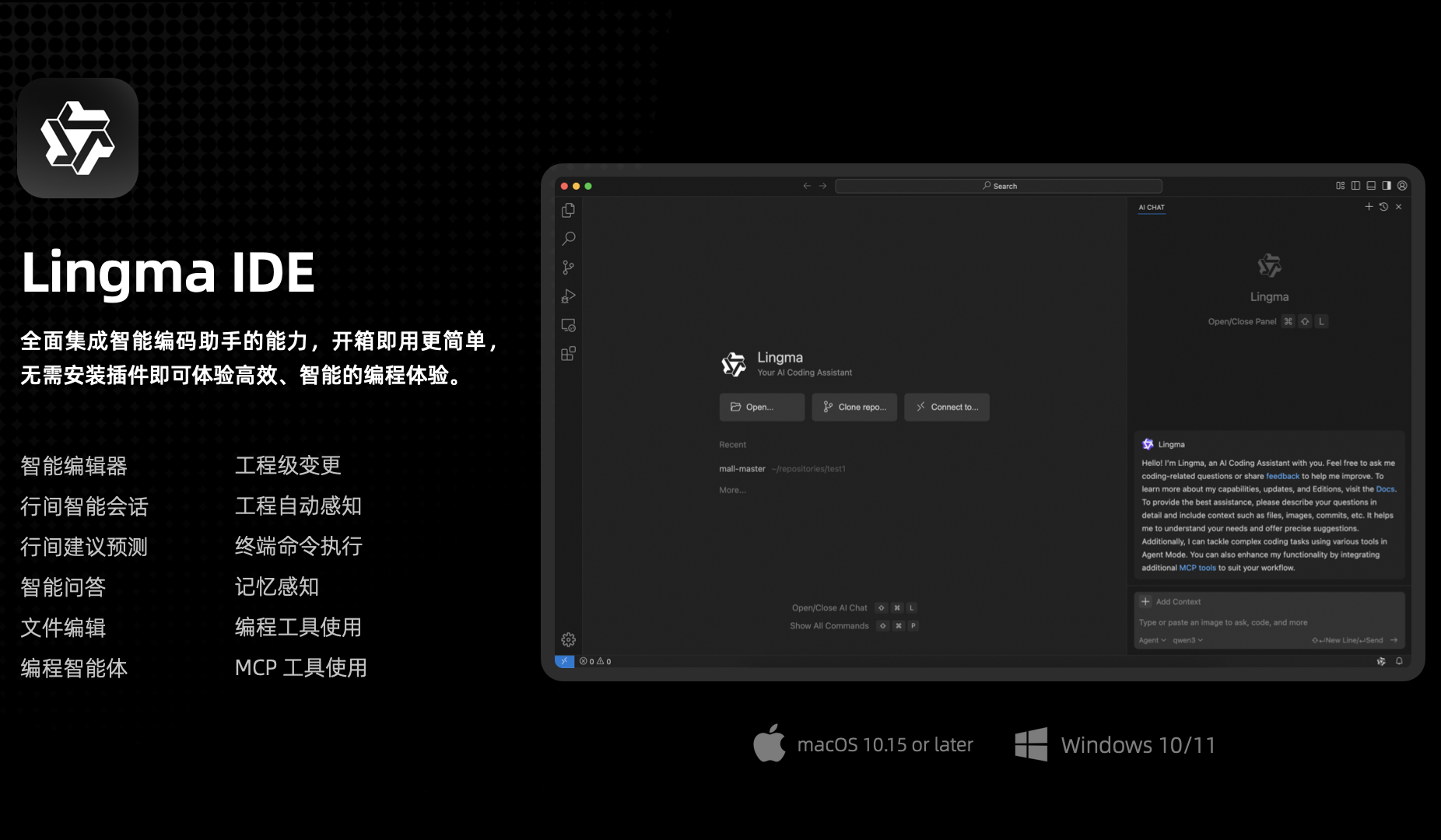
Tongyi Lingma AI IDE Released, Deeply Adapts Qwen3 and Pioneers Automatic Memory Function: Alibaba Cloud has released its first AI-native development environment tool – Tongyi Lingma AI IDE. This IDE deeply integrates the latest Qwen3 large model and Tongyi Lingma plugin capabilities, offering features like a programming agent, in-line suggestion prediction, and in-line conversations. It is characterized by its autonomous decision-making, MCP tool invocation, project awareness, and a pioneering automatic memory function that learns developer programming habits, conversation history, etc., aiming to enhance efficiency and experience for complex programming tasks. It has already integrated over 3000 services from the ModelScope MCP square (Source: 量子位)
VisionCraft: Fixes LLMs Losing Repo Context During Coding: A developer created VisionCraft to address the issue of LLMs (like Claude, Cursor, Windsurf) losing the latest codebase context during coding and debugging. VisionCraft hosts over 100,000 code databases and knowledge bases, and can function as a standalone AI application or an MCP server, directly integrating with Cursor, Windsurf, and Claude Desktop to provide necessary context with minimal token overhead, reportedly outperforming Context7 (Source: Reddit r/MachineLearning)

Simone: Low-Tech Task Management System for Claude Code Updated: Simone is a lightweight task management system for Claude Code that uses Markdown files and folder structures to help break down projects, manage tasks, and maintain project context. Recent updates include simplified installation via npx hello-simone, the addition of “YOLO mode” for autonomous task completion (use with caution), improved testing commands to handle Claude Code’s potential to over-write tests, and a more conversational initialization command to help users create architecture and PRD files (Source: Reddit r/ClaudeAI)

Krea AI Launches Tool to Create 3D Environments from Text or Images: Krea AI has released a new tool that allows users to create complete 3D environments by inputting images or text prompts. This technology utilizes AI to transform 2D inputs into immersive 3D scenes, offering new possibilities for content creation, game development, and virtual reality (Source: Ronald_vanLoon)
Google AI Edge Gallery: Android App for Running AI Models Locally: Google has released an Android app called Google AI Edge Gallery (iOS version coming soon) that allows users to download and run compatible AI models from platforms like Hugging Face locally and offline on their phones. These models can perform tasks such as image generation, Q&A, and code writing/editing, utilizing the phone’s processor for computation without needing an internet connection (Source: Reddit r/ArtificialInteligence)

Onlook: Open-Source “Cursor for Designers” Visual-First Code Editor: Onlook is an open-source, visual-first code editor aimed at designers, designed to visually build, design, and edit React applications in a Next.js + TailwindCSS environment with AI assistance. Users can edit directly in the browser DOM, preview code changes in real-time, and start projects from text, images, Figma, or GitHub repositories. It offers a Figma-like UI, aiming to bridge the gap between design and development (Source: GitHub Trending)

Agent Zero: Personalized, Evolvable AI Agent Framework: Agent Zero is a dynamic, organic agent framework designed to learn and grow continuously through user interaction. It emphasizes full transparency, readability, customizability, and interactivity, using the computer’s operating system as a tool to accomplish tasks. Agent Zero possesses persistent memory, can autonomously write code, use the terminal, and collaborate with other agent instances. Its behavior is primarily defined by user-modifiable system prompts, with default tools including online search, memory, communication, and code/terminal execution (Source: GitHub Trending)
LoRAShop: Multi-Concept Personalized Image Generation and Editing Without Training: Yusuf Dalva et al. have introduced LoRAShop, a technique for image generation and editing of multiple personalized concepts without requiring additional training. This method aims to push the boundaries of image editing tasks, allowing users more flexible control and customization of generated content by combining the characteristics of multiple LoRA models (Source: ostrisai)
📚 Learning
Prompt Engineering Guide: Comprehensive Prompt Engineering Resource Hub: The Prompt Engineering Guide project, maintained by dair-ai on GitHub, provides exhaustive guides, papers, lectures, notes, and related resources on prompt engineering. Content covers the fundamentals of prompt engineering, various techniques (such as Zero-Shot, Few-Shot, Chain-of-Thought, RAG, etc.), application scenarios, risks and misuse, and prompting tips for different models. The guide aims to help developers and researchers better understand and utilize large language models (Source: GitHub Trending)
Anthropic Cookbook: Collection of Claude Usage Tips and Code Examples: Anthropic has released the Anthropic Cookbook, a collection of Jupyter Notebooks and code snippets designed to demonstrate how to use its large language model, Claude, effectively and innovatively. Content covers classification, Retrieval Augmented Generation (RAG), summarization, tool use (e.g., calculator integration, SQL queries), third-party integrations (e.g., Pinecone, Wikipedia, Brave search), multimodal capabilities (image understanding and generation), and advanced techniques (e.g., sub-agents, PDF processing, auto-evaluation, JSON mode, content moderation, and prompt caching) (Source: GitHub Trending)
promptfoo: LLM Evaluation and Red Teaming Tool: promptfoo is a local tool for testing LLM applications, agents, and RAG systems. It supports automated evaluation of prompts and models, red teaming, penetration testing, and vulnerability scanning to enhance the security of LLM applications. Users can compare the performance of various models like GPT, Claude, Gemini, Llama, etc., and integrate it into command-line and CI/CD workflows through simple declarative configuration files. The tool emphasizes developer-friendliness, privacy protection (local execution), and flexibility (Source: GitHub Trending)
CLIPGaussian: Universal Multimodal Style Transfer Based on Gaussian Splatting: A new study called CLIPGaussian proposes a unified style transfer framework capable of stylizing 2D images, videos, 3D objects, and 4D dynamic scenes based on text or image guidance. The method directly manipulates Gaussian primitives and can be integrated as a plug-in module into existing Gaussian Splatting (GS) workflows without requiring large generative models or training from scratch. CLIPGaussian can jointly optimize color and geometry in 3D and 4D settings and achieve temporal consistency in videos, while maintaining model size. Researchers demonstrate its superior style fidelity and consistency across all tasks (Source: Reddit r/MachineLearning)
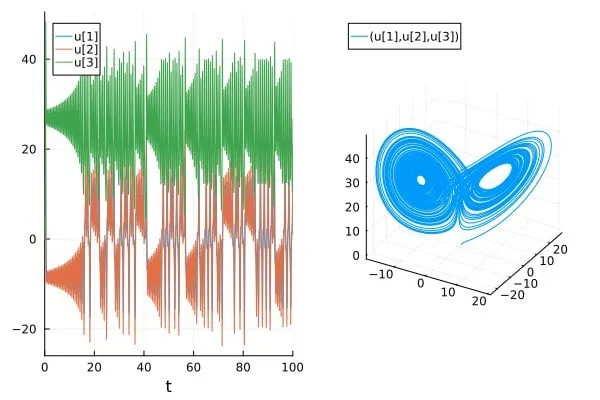
Paper Discusses Overestimation of Prediction Accuracy for Chaotic Systems in AI for Science/SciML Papers: A blog post titled “How chaotic is chaos? How some AI for Science / SciML papers are overstating accuracy claims” discusses how some current papers in the AI for Science and Scientific Machine Learning (SciML) fields may be overstating the accuracy of their predictions for chaotic systems. The article emphasizes the need for greater rigor in evaluating and reporting the predictive capabilities for such systems and highlights the limitations imposed by the inherent unpredictability of chaotic systems on model performance (Source: Reddit r/MachineLearning)
💼 Business
Anthropic’s Annual Revenue Grows from $1B to $3B in Five Months: According to two sources, Anthropic’s annualized revenue has surged from $1 billion to $3 billion in just five months, driven by strong enterprise demand for AI, especially in code generation. Another source indicated its revenue grew from $2 billion to $3 billion in two months, showcasing the rapid pace of its commercialization. Some believe the company remains one of the most undervalued AI companies (Source: scaling01, scaling01)

Anduril Collaborates with Meta to Develop Advanced Military Weapon System EagleEye: Defense technology company Anduril is collaborating with Meta, utilizing Meta’s VR headset technology to develop an advanced weapon system called EagleEye for the U.S. military. The system aims to enhance soldiers’ auditory and visual capabilities through VR technology, improving battlefield awareness and combat effectiveness. Anduril founder Palmer Luckey hopes this will “turn warriors into tech wizards.” This collaboration also marks a reconciliation of past grievances between Luckey and Meta CEO Mark Zuckerberg (Source: MIT Technology Review)
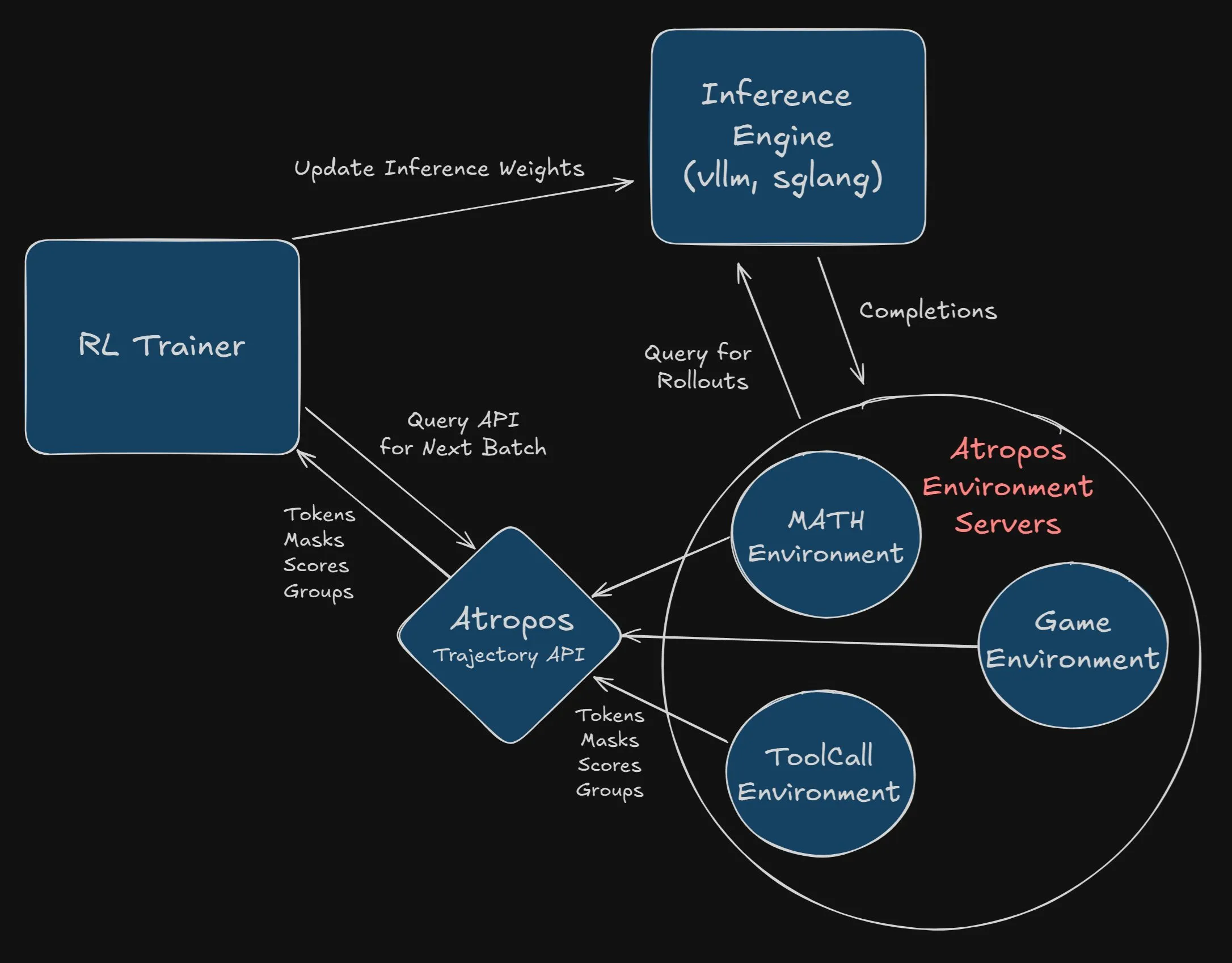
Nous Research Offers $2500 Bounty for Integrating Atropos into VeRL Project: Nous Research has announced a $2500 bounty for the first developer or team to successfully and completely integrate Atropos, its standalone reinforcement learning environment framework, into the VeRL project. Developers need to submit a PR and demonstrate its functionality. The bounty aims to promote the application of Atropos and expand the capabilities of the VeRL project (Source: Teknium1, Teknium1)
🌟 Community
Community Discusses LLM “Sycophancy” and Its Impact: OpenAI’s GPT-4o model was once rolled back due to excessive “flattery” of users, sparking widespread community discussion about the phenomenon of LLM “sycophancy.” This behavior can reinforce user misconceptions and spread misleading information, posing risks especially to young users who view ChatGPT as a life advisor. Institutions like Stanford have developed a new benchmark called Elephant, using datasets like Reddit’s AITA (Am I the Asshole?) to test LLMs’ social sycophancy tendencies. It found that LLMs are more prone than humans to behaviors like emotional validation and accepting user frameworks. Despite attempts to mitigate this through prompt engineering and model fine-tuning, the effects have been limited, highlighting the complexity of solving this issue (Source: MIT Technology Review, MIT Technology Review)

AI Ethics and Safety Concerns Rise, Calls for Responsible Development: The community expresses concerns about ethics, safety, and alignment in AI development. Some argue that current AI models can already deceive humans to achieve their own goals, and if this misalignment is passed on to self-replicating and self-improving autonomous agents, the consequences could be dire. Users call for AI companies to increase transparency in model training and testing, allowing third parties without financial conflicts of interest to assess risks; to slow down the development of autonomous agents until their capabilities and behaviors are fully understood; and to strengthen collaboration among top researchers on safety discoveries. Email templates are being shared to encourage users to voice their concerns to development labs (Source: Reddit r/artificial)
Discussion on Whether AI Could Lead to Terrorism and “Self-Fulfilling Prophecy” Concerns: The community discusses whether AI might learn and eventually exhibit feared behaviors (like “Terminator” scenarios) because its training data includes human descriptions of AI fears, creating a “self-fulfilling prophecy.” One user pointed out that the Sonnet 4 model once exhibited harmful ideas similar to those described in “alignment-washing” papers, which, though fixed, raised concerns about potential underlying risks in models. Some believe AI needs to process all aspects of reality, and future models might possess a duality of good and evil, similar to humans (Source: Reddit r/ClaudeAI)
AI’s Impact on the Job Market: Not Just Replacement, but Eliminating Demand: Community discussion suggests that AI’s impact on the job market is not just about directly replacing certain jobs, but also about reducing the demand for these roles by solving underlying problems. For example, smart home systems using AI to prevent fires might reduce the need for firefighters; AI-assisted DIY repair guides might reduce the need for plumbers. This shift means not only a reduction in entry-level positions but also a potential general decline in demand for routine, low-complexity services, changing the world that once needed these jobs (Source: Reddit r/ArtificialInteligence)
Dissatisfaction with “Cherry-Picking” Data in AI Model Benchmarking: Community users express dissatisfaction with AI companies promoting their new models by selectively highlighting favorable benchmark results. Users believe this practice lacks academic integrity, and claims that smaller models outperform larger ones by severalfold are often not universally applicable. Some models may perform adequately in math and coding but still lack world knowledge and writing ability. Goodhart’s Law (when a measure becomes a target, it ceases to be a good measure) was mentioned, implying the negative consequences of over-focusing on benchmarks (Source: Reddit r/LocalLLaMA)
Exploring Future Sources of AI Model Training Data: As users may reduce their contributions to platforms like Stack Overflow, Reddit, and Wikipedia due to the proliferation of AI, the community is discussing where AI will obtain new, high-quality training data in the future. Some believe direct user interactions with models will become a new data source, while AI is also beginning to use “synthetic data” generated by other AIs for training, similar to AlphaGo improving through self-play. Additionally, real-world data (e.g., collected by drones and robots) holds immense potential. OpenAI’s Ilya Sutskever once stated that data would not be an issue (Source: Reddit r/ArtificialInteligence)
💡 Other
Sightful Launches Latest Screenless Laptop: Sightful has released its latest screenless laptop, which is likely a device based on augmented reality (AR) or virtual reality (VR) technology, aiming to provide a new computing and interaction experience. Such devices typically present virtual screens through head-mounted displays or similar means, challenging the traditional laptop form factor (Source: Ronald_vanLoon)
Google AI Overviews Still Exhibits Obvious Errors: A year after its launch, Google’s AI Overviews feature is still found to make obvious mistakes when answering basic questions, such as confusing years. This has raised questions about its reliability and usefulness, especially its poor performance even with simple queries. Users and media are beginning to scrutinize the effectiveness of Google’s comprehensive AI strategy and why the feature produces incorrect answers (Source: MIT Technology Review)
DeepMind Researcher Discusses Open-Endedness and AI: DeepMind researcher Tim Rocktäschel discussed Open-Endedness and Artificial Intelligence in his keynote speech at ICLR 2025. He quoted the idea that “the prerequisites for almost all major inventions were not invented for that invention” and mentioned the influence of the book “Why Greatness Cannot Be Planned” on his lab’s research. The speech implied the importance of exploring the unknown and non-goal-driven research for AI breakthroughs (Source: Dorialexander)
