
Schlüsselwörter:Dijkstra-Algorithmus, Meta FAIR Brain & AI, GLM-4.5, AI-Sprachmodell, Bestärkendes Lernen, Verkörperte KI, KI-Programmierung, Lidar, Kürzester-Pfad-Algorithmus des Teams Duan Ran der Tsinghua-Universität, TRIBE multimodale Gehirnmodellierung, GLM-4.5V visuelles Reasoning MoE-Modell, MiniMax Speech 2.5 mehrsprachige Sprachausgabe, HRM hierarchisches Reasoning Kleinstmodell
🔥 Fokus
Team von Duan Ran, Tsinghua-Universität, widerlegt Optimalität des Dijkstra-Algorithmus: Das Team von Duan Ran an der Tsinghua-Universität hat einen neuen Algorithmus vorgestellt, der die allgemeine Optimalität des Dijkstra-Algorithmus für das Problem des kürzesten Pfades widerlegt. Dieser Algorithmus läuft schneller, ist sortierungsunabhängig und löst die seit über vierzig Jahren bestehende „Sortierbarriere“, was sowohl theoretisch als auch praktisch von großer Bedeutung ist. (Quelle: 量子位)

Meta FAIR Brain & AI Team gewinnt Algonauts 2025 Brain Modeling Contest: Das Brain & AI Team von Meta FAIR hat mit seinem 1B-Parameter-Modell TRIBE (Trimodal Brain Encoder) den ersten Platz im Algonauts 2025 Brain Modeling Contest gewonnen. Das Modell ist das erste tiefe neuronale Netzwerk, das multimodale, multikortikale und individuelle Gehirnreaktionen vorhersagen kann, und kombiniert grundlegende Modelle wie Llama 3.2, Wav2Vec2-BERT und V-JEPA 2. (Quelle: AIatMeta)
Kleines AI-System Coral Protocol übertrifft im GAIA-Benchmark: Das Coral Protocol-Projekt hat durch die Zusammenarbeit mehrerer kleiner, spezialisierter KI-Systeme im GAIA-Benchmark ein von Microsoft unterstütztes Modell um 34 % übertroffen. Dies deutet darauf hin, dass kollaborative kleine KI-Systeme bei der Bewältigung komplexer, realer Aufgaben (wie Planung, Informationssuche, visuelle Analyse) effizienter und kostengünstiger sein könnten als einzelne große Modelle. (Quelle: Reddit r/ArtificialInteligence)

🎯 Trends
GPT-5 und Grok 4 entfachen Wettbewerb um kostenlose Modelle: OpenAI hat GPT-5 veröffentlicht und dessen kostenlose Verfügbarkeit angekündigt, um seine Marktposition zu festigen. xAI zog schnell nach und stellte die Basisversion von Grok 4 weltweit kostenlos zur Verfügung, wobei die Nutzungskontingente erheblich gelockert wurden. Ziel ist es, die Nutzerbasis zu erweitern und Daten zur Modelloptimierung zu sammeln, was den Wettbewerb auf dem KI-Markt verschärft. (Quelle: 36氪, op7418)

GLM-4.5 Modellreihe veröffentlicht und Durchbruch in visuellen Fähigkeiten: Zhipu AI und ByteDance haben den technischen Bericht zu GLM-4.5 veröffentlicht, der einen mehrstufigen Trainingsansatz hervorhebt und hervorragende Leistungen bei Inferenz-, Kodierungs- und Agent-Aufgaben zeigt. Gleichzeitig wurde GLM-4.5V vorgestellt, ein multimodales visuelles Inferenz-MoE-Modell mit 106B Parametern, das in 41 Benchmarks SOTA-Leistung erzielt und seine starken Fähigkeiten in Bildverständnis, Videoanalyse und GUI-Aufgaben demonstriert. (Quelle: teortaxesTex, OfirPress, scaling01, mervenoyann, karminski3, Reddit r/LocalLLaMA)

Apples KI-Strategieanpassung und Chatbot-Marktherausforderungen: Apple-CEO Cook hat zugegeben, dass das Unternehmen im KI-Bereich hinterherhinkt, und ein neues Team zur Entwicklung einer ChatGPT-ähnlichen „Antwort-Engine“ gebildet, um Produkte wie Siri und Safari neu zu gestalten. Dieser Schritt zeigt, dass Apple aktiv auf die Chancen und Herausforderungen des Chatbot-Marktes reagiert, um in der KI-Ära wieder eine führende Position zu erlangen, obwohl es mit internen Meinungsverschiedenheiten und Talentabwanderung zu kämpfen hat. (Quelle: 36氪)

MiniMax Speech 2.5 läutet neue Ära der KI-Sprache ein: MiniMax hat das neue KI-Sprachmodell Speech 2.5 veröffentlicht, das die Ausdruckskraft in mehreren Sprachen, die Genauigkeit der Stimmklonierung und die Sprachabdeckung (40 Sprachen) erheblich verbessert. Dies ermöglicht eine skalierbare Implementierung für sprach- und kulturübergreifende immersive Erlebnisse. Die Technologie treibt die Entwicklung der KI-Sprache von einer Hilfsfunktion zu einer Kerninfrastruktur für Mensch-Computer-Interaktion und Inhaltsproduktion voran. (Quelle: 36氪)

KI-Modellbewertung wechselt zu gamifizierten Benchmarks: Google hat die Kaggle Game Arena-Plattform eingeführt, die KI-Modelle in Strategie-Spielen statt traditionellen Benchmarks bewertet, um ihre tatsächlichen Fähigkeiten in komplexem Denken und Entscheidungsfindung zu beurteilen. Dieser Schritt zielt darauf ab, die Einschränkungen bestehender Benchmarks zu überwinden, die leicht “ausgetrickst” werden können, und die KI-Intelligenzbewertung in eine dynamischere und praktischere Richtung zu lenken. (Quelle: 36氪)

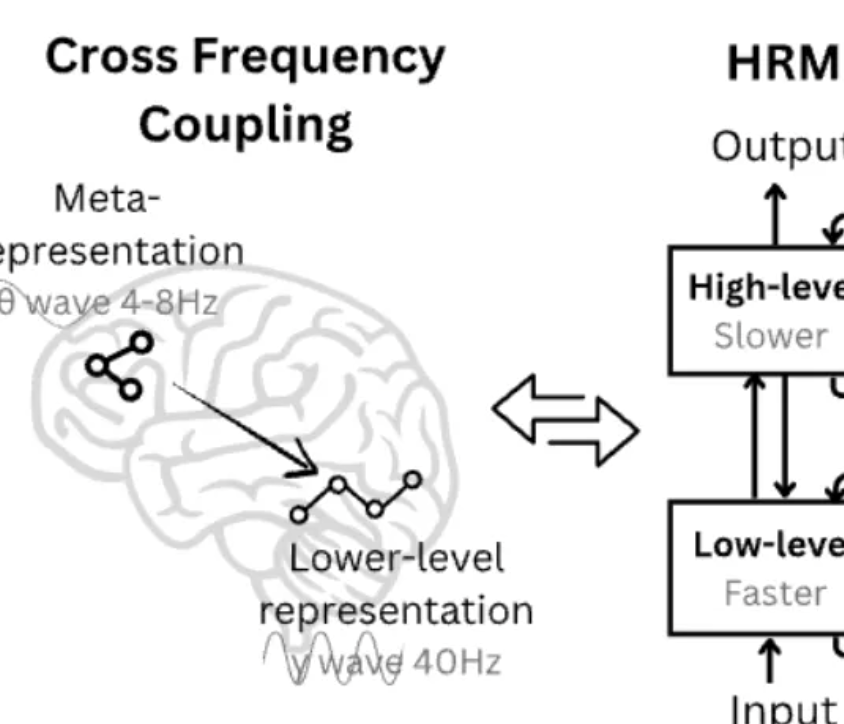
27M kleines Modell Hierarchical Reasoning Model (HRM) übertrifft große Modelle: Das Team von Wang Guan, Absolvent der Tsinghua-Universität, hat HRM veröffentlicht, das hierarchische Verarbeitungsmechanismen des Gehirns nachahmt. Mit nur 27M Parametern und 1000 Trainingsbeispielen zeigte es hervorragende Leistungen bei extremen Sudoku, komplexen Labyrinthen und ARC-AGI-Tests mit einer Genauigkeit von 40,3 %, womit es größere Modelle wie o3-mini-high und Claude 3.7 übertrifft und die Transformer-Architektur herausfordert. (Quelle: 量子位)
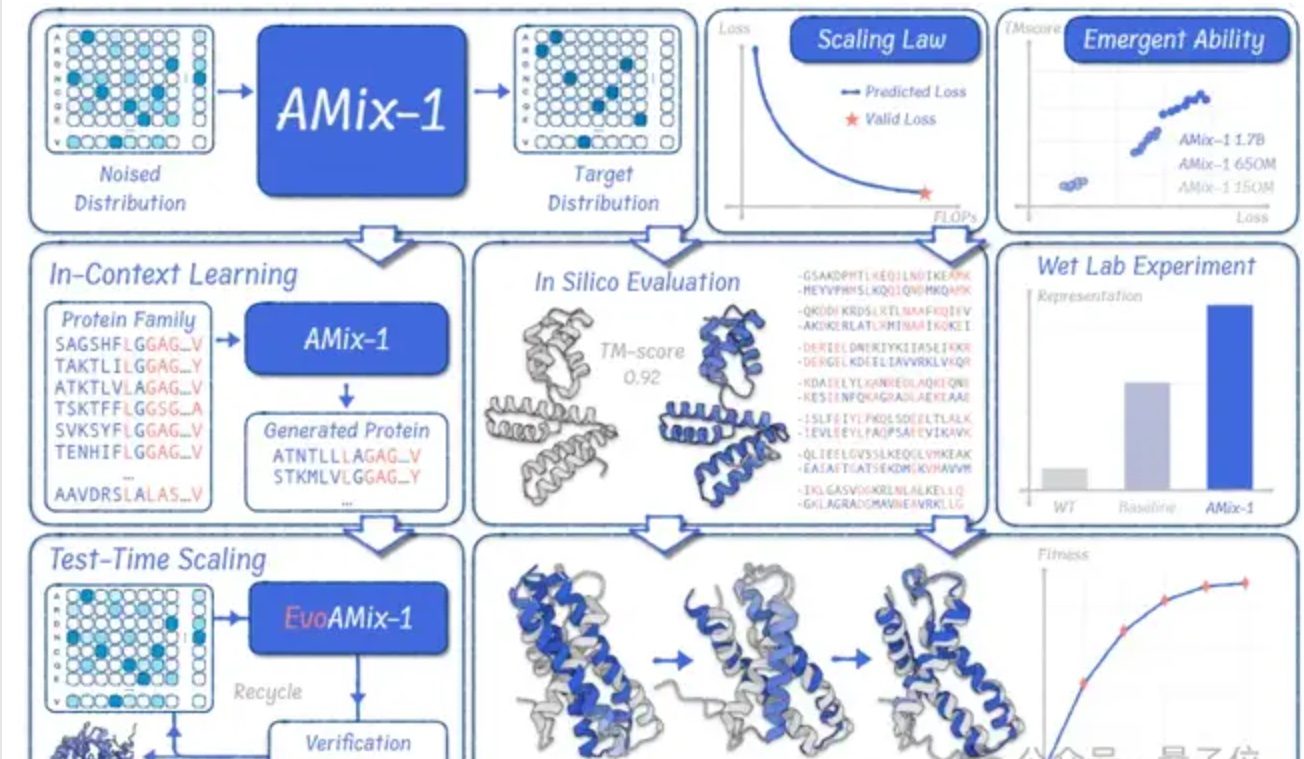
Ära des Protein-GPT bricht an: Das Institut für Künstliche Intelligenz der Tsinghua-Universität und das Shanghai AI Lab haben gemeinsam AMix-1 veröffentlicht. Dies ist das erste Mal, dass ein Protein-Basismodell systematisch mit Methoden wie Scaling Law und Emergent Ability aufgebaut wurde, um allgemeine Proteinintelligenz zu erreichen. Nasslaborexperimente bestätigten, dass die optimale Proteinvariante eine 50-fache Aktivitätssteigerung aufweist, was einen revolutionären Durchbruch im Proteindesign darstellt. (Quelle: 量子位)
🧰 Tools
Buttercup Netzwerk-Inferenzsystem: Trail of Bits hat das Buttercup Netzwerk-Inferenzsystem für DARPA AIxCC entwickelt, das AI/ML-gestütztes Fuzzing nutzt, um Schwachstellen in Open-Source-Code zu finden und zu beheben. Das System umfasst Komponenten wie Koordinator, Seed-Generator, Fuzzer, Programmmodell und Patch-Generator und unterstützt C/Java-Codebasen, um den Software-Schwachstellenbehebungsprozess zu automatisieren. (Quelle: GitHub Trending)
Claude Context Code-Such-Plugin: Zilliztech hat Claude Context als Open Source veröffentlicht, ein Plugin für Claude Code, das die Kontextbeschränkungen großer Codebasen lösen soll. Es speichert und durchsucht relevanten Code effizient über MCP, unterstützt semantische Code-Suche und inkrementelle Indizierung, was die Fähigkeiten der KI im Code-Verständnis und Debugging erheblich verbessert. (Quelle: Reddit r/ClaudeAI)

Visueller Drag-and-Drop-Builder für Multi-Agent LLM Orchestrierung (TFrameX + Agent Builder): TesslateAI hat TFrameX und Agent Builder als Open Source veröffentlicht, einen visuellen Drag-and-Drop-Builder für die Orchestrierung von Multi-Agent LLM-Systemen. Dieses Tool unterstützt Agent-Hierarchien, Musterverschachtelung und dynamische Code-Registrierung und bietet eine vollständig lokalisierte und MIT-lizenzierte Lösung, die die Entwicklung und Verwaltung komplexer Agent-Systeme vereinfachen soll. (Quelle: Reddit r/LocalLLaMA)
Ollama Excel-Plugin und VulkanIlm GPU-Beschleunigung: Ein Benutzer hat ein Excel-Plugin entwickelt, das Ollama mit Microsoft Excel verbindet, um Daten direkt in Excel zu verarbeiten, mit Unterstützung für benutzerdefinierte Systemanweisungen und Modellparameter. Gleichzeitig beschleunigt das VulkanIlm-Projekt die lokale LLM-Inferenz auf älteren GPUs mittels Vulkan (ohne CUDA), was die Inferenzgeschwindigkeit erheblich steigert und die Hürde für den lokalen Betrieb von LLMs senkt. (Quelle: Reddit r/LocalLLaMA, Reddit r/MachineLearning)

LLMDet und MM GroundingDINO Zero-Shot-Detektoren: Hugging Face hat zwei neue Zero-Shot-Detektoren, LLMDet und MM GroundingDINO, integriert. Diese Modelle ermöglichen die Zero-Shot-Erkennung, d.h. sie können beliebige Objekte ohne spezifisches Training erkennen, was den Anwendungsbereich der KI in der Bilderkennung und -verständnis erheblich erweitert. Eine Anwendung zum Vergleich der Modellinferenz und Latenz wird ebenfalls bereitgestellt. (Quelle: mervenoyann)

Damo Academy veröffentlicht Open-Source-Komponenten für Embodied AI: Alibabas Damo Academy hat die VLA-Modelle RynnVLA-001-7B, das Weltverständnismodell RynnEC und das Roboter-Kontextprotokoll RynnRCP als Open Source veröffentlicht, um die Kompatibilität und Anpassung im gesamten Entwicklungsprozess der Embodied AI zu fördern. Diese “drei Kernkomponenten” ermöglichen einen vollständigen Workflow von der Sensorerfassung über die Modellinferenz bis zur Roboterausführung und helfen Benutzern, sich leicht an ihre spezifischen Szenarien anzupassen. (Quelle: 量子位)

Anwendungen von Qwen-Image und Qwen3-Coder in Bildgenerierung und Kodierung: Qwen-Image zeigt hervorragende Leistungen bei der Befolgung komplexer Anweisungen (z.B. Generierung eines “Spiegeleis mit blauem Eigelb”) und der SVG-Bildgenerierung. Gleichzeitig demonstriert Qwen3-Coder starke Fähigkeiten in der Code-Generierung und im Agent-Verhalten, obwohl Benutzer Feedback geben, dass die Interaktivität noch verbessert werden muss, was darauf hindeutet, dass in bestimmten Szenarien noch Optimierungen erforderlich sind. (Quelle: multimodalart, Alibaba_Qwen, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

📚 Lernen
Anwendung von Reinforcement Learning in AI Agent und LLM Optimierung: OpenPipe hat das Open-Source-Reinforcement-Learning-Framework MCP·RL eingeführt, das es Agents ermöglicht, Werkzeuge automatisch zu entdecken, Aufgaben zu generieren und optimale Aufrufstrategien durch Closed-Loop-Feedback zu lernen. Gleichzeitig haben ByteDance und das MAP-Team das FR3E-Framework vorgeschlagen, das die Leistung von LLMs im Reinforcement Learning durch einen strukturierten Explorationsmechanismus verbessert, das Problem der “unzureichenden Exploration” löst und eine Leistungssteigerung bei komplexen Inferenzaufgaben erzielt. (Quelle: 量子位, 量子位)

Label-freie Adaptionsmethoden für Vision-Language Models (VLM): Die Übersicht “Adapting Vision-Language Models Without Labels” fasst label-freie VLM-Adaptionsmethoden zusammen und schlägt eine Klassifizierung basierend auf der Verfügbarkeit label-freier visueller Daten vor. Sie analysiert Paradigmen wie datenunabhängige, unüberwachte Domänenübertragung, kontextbezogene Testzeit-Adaption und Online-Testzeit-Adaption und bietet eine systematische Anleitung zur Leistungsoptimierung von VLMs in spezifischen Szenarien. (Quelle: HuggingFace Daily Papers)
3D-Mesh-Verständnis und Generierungs-Framework MeshLLM: MeshLLM ist ein neuartiges Framework, das große Sprachmodelle (LLM) nutzt, um textserialisierte 3D-Meshes schrittweise zu verstehen und zu generieren. Die Methode erstellt einen groß angelegten Datensatz durch eine Primitive-Mesh-Zerlegungsstrategie und verbessert die Fähigkeit des LLM, Mesh-Topologie und räumliche Struktur zu erfassen, wodurch die Qualität der Mesh-Generierung und das Formverständnis die bestehende SOTA übertreffen. (Quelle: HuggingFace Daily Papers)
Reinforcement Learning und Inferenzoptimierung für GUI Agents: Das UI-AGILE-Framework verbessert die Leistung von Graphical User Interface (GUI) Agents in der Trainings- und Inferenzphase erheblich, indem es den Supervised Fine-Tuning (SFT)-Prozess optimiert und die Decomposed Grounding with Selection-Methode vorschlägt. Diese Methode verbessert insbesondere die Erdungsgenauigkeit auf hochauflösenden Displays und erreicht SOTA-Leistung. (Quelle: HuggingFace Daily Papers)
GENIE-Modell für interaktive Bearbeitung von Neuronalen Strahlungsfeldern: GENIE ist ein Hybridmodell, das die fotorealistische Rendering-Qualität von Neuronalen Strahlungsfeldern (NeRF) mit der bearbeitbaren strukturierten Darstellung von Gaussian Splatting (GS) kombiniert. Das Modell ermöglicht Echtzeit- und lokal bewusste Bearbeitung durch trainierbare Feature-Embeddings und Ray-Traced Gaussian Proximity Search, was intuitive Szenenmanipulation und dynamische Interaktion unterstützt. (Quelle: HuggingFace Daily Papers)
Agent-Programm-Gedächtnis-Exploration Memp: Die Memp-Studie zielt darauf ab, Agents eine lernbare und aktualisierbare lebenslange Programm-Gedächtnisstrategie zu verleihen. Durch die Destillation von Agent-Trajektorien in feingranulare Anweisungen und hochrangige Skript-Abstraktionen sowie die dynamische Aktualisierung des Inhalts verbessert Memp die Erfolgsrate und Effizienz von Agents bei ähnlichen Aufgaben und bietet neue Ideen für den Aufbau intelligenterer Agents. (Quelle: HuggingFace Daily Papers)
KI-Lernressourcen und Brancheneinblicke: Es werden 6 unverzichtbare Bücher über KI und maschinelles Lernen empfohlen, die Themen wie Systeme, generative Diffusion, Erklärbarkeit und Deep Learning abdecken. Gleichzeitig hat das Quantbit AI Think Tank einen Bericht veröffentlicht, der die wichtigsten Trends und Fortschritte der KI in den Bereichen Anwendung, Modelle, Technologie und Industrie im ersten Halbjahr 2025 zusammenfasst und Lernenden und Praktikern umfassende Einblicke bietet. (Quelle: TheTuringPost, 量子位)

Verteiltes Training von LLMs und Optimierung mit geringer Präzision: DiLoCo ist eine verteilte Optimierungsmethode zum Trainieren von LLMs in langsamen oder geografisch getrennten Netzwerken, die den Kommunikationsaufwand durch ein infrequent-synchronization Design erheblich reduziert. Gleichzeitig verwendet OpenAI in seinen gpt-oss-Modellen den MXFP4-Datentyp, wodurch die Inferenzkosten um 75 % gesenkt, der Speicherverbrauch um drei Viertel reduziert und die Token-Generierungsgeschwindigkeit um das Vierfache erhöht wird, was die Hardware-Anforderungen für den Betrieb großer Modelle erheblich senkt. (Quelle: Ar_Douillard, 量子位)
💼 Business
Weltroboterkonferenz 2025 im Fokus von Branchenentwicklung und Investitionsmöglichkeiten: Die WRC 2025 wurde in Peking feierlich eröffnet und versammelte über 200 Unternehmen und mehr als 1500 Exponate, wobei die Anzahl der humanoiden Roboterunternehmen einen neuen Höchststand erreichte. Die Konferenz befasste sich eingehend mit sechs großen Investitionsthemen, darunter Embodied AI, Kernhardware, multimodale Wahrnehmung und die intelligente Aufrüstung von Industrierobotern. Sie zeigte auch Chinas Aufstieg im Bereich der Robotik und die politische Unterstützung, einschließlich der Ergebnisse des “Double Hundred Project” der Stadt Peking. (Quelle: 36氪, 量子位, 量子位)

KI-Programmier-Einhörner kämpfen mit hohen Kosten und Rentabilitätsproblemen: KI-Programmierunternehmen wie Windsurf und Cursor verzeichnen zwar ein schnelles Umsatzwachstum, stehen aber generell vor negativen Bruttomargen und extrem hohen Betriebskosten, hauptsächlich aufgrund der hohen Kosten für die Nutzung großer Sprachmodelle. Dies führt dazu, dass mehr Nutzer auch höhere Verluste bedeuten, was die Unternehmen dazu zwingt, eigene Modelle zu entwickeln oder Übernahmen in Betracht zu ziehen, um die Gewinnschwelle zu erreichen. Kostenreduzierung und Nutzerempfindlichkeit bleiben jedoch Herausforderungen. (Quelle: 量子位)

Embodied AI treibt explosionsartiges Wachstum des LiDAR-Marktes voran: Mit der Ausweitung der Anwendungsszenarien für Embodied AI-Roboter steigt die Nachfrage nach LiDAR als deren “Augen” sprunghaft an. Hesai Technology zeigt eine starke Leistung im Bereich der Roboter-LiDARs, mit einem Anstieg der Lieferungen um 649,1 % im ersten Quartal 2025, was zu einem neuen Wachstumsmotor für das Unternehmen wird. Dies zeigt das enorme Marktpotenzial von LiDAR im Robotikbereich und zieht eine große Anzahl von Unternehmen aus der intelligenten Automobilzulieferkette an. (Quelle: 量子位)

🌟 Community
GPT-5 Nutzererfahrung löst heftige Kontroversen aus: Eine große Anzahl von Nutzern äußert Enttäuschung über GPT-5 und empfindet es in Bezug auf kreatives Schreiben, mehrstufige Dialoge, emotionale Empathie, Kontextverständnis und Stabilität als schlechter als GPT-4o, wobei sogar Halluzinationen und “Riesenbaby”-Verhalten auftreten. Nutzer fordern OpenAI auf, 4o wiederherzustellen oder eine Modellauswahl anzubieten, und betonen die Bedeutung von KI als “kognitive Umgebung” statt nur als Werkzeug, was eine tiefgreifende Reflexion über das Gleichgewicht zwischen KI-Personifizierung und Praktikabilität auslöst. (Quelle: cto_junior, jachiam0, crystalsssup, qtnx_, fabianstelzer, madiator, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ClaudeAI)
Verbreitung von KI-Interviews löst Unmut bei Jobsuchenden aus: Die Arbeitslosenquote in der US-IT-Branche erreicht einen neuen Höchststand, und die Verbreitung von KI-Interview-Tools führt zu einer starken Gegenreaktion bei Jobsuchenden. Sie empfinden KI-Interviews als kalt und unmenschlich, befürchten sogar die Offenlegung persönlicher Informationen und das Risiko einer “verdeckten Markierung”. Einige Jobsuchende ziehen es vor, arbeitslos zu bleiben, anstatt KI-Interviews zu akzeptieren, was die ethischen und emotionalen Herausforderungen der KI im Recruiting verdeutlicht. (Quelle: 36氪)

Zukünftige Entwicklung von AI Agents und das Ende des “10x Engineer”-Mythos: Die Community diskutiert das Potenzial von AI Agents in der Webentwicklung und bei der Lösung komplexer Aufgaben und betont die Bedeutung der Agent-Erfahrung. Gleichzeitig wird die Ansicht vertreten, dass KI-Programmierwerkzeuge zwar die Effizienz steigern können, aber Probleme wie das Verständnis großer Codebasen und die mangelnde Aktualität von Standards nicht lösen können. Es wird darauf hingewiesen, dass der “AI 10x Engineer” ein Mythos ist und der Kernwert von Ingenieuren weiterhin im Lesen und Denken liegt. (Quelle: _akhaliq, fabianstelzer, TheTuringPost, 量子位)

KI-Modell-Bias und Bedenken hinsichtlich der Informationszuverlässigkeit: Der KI-Chatbot von Truth Social wird beschuldigt, stark konservative Medien zu bevorzugen, was Bedenken hinsichtlich der Zuverlässigkeit von Informationsquellen und potenziellen Vorurteilen von KI-Modellen aufwirft. Darüber hinaus diskutiert die Community auch das Phänomen der “GPTisms” in KI-generierten Inhalten, d.h. die Tendenz von KI-generierten Inhalten, formelhaft und wenig originell zu sein. (Quelle: Reddit r/artificial, qtnx_)

Diskussion über KI und menschliche Emotionen und Bewusstsein: Sam Altman und Community-Mitglieder diskutieren intensiv die starke Bindung von Nutzern an KI-Modelle, die sie als “Therapeuten” oder “Lebensberater” betrachten, und erforschen die Rolle der KI in der psychischen Gesundheit. Gleichzeitig werden philosophische Diskussionen über den Turing-Test für KI-Bewusstsein und die Frage, ob KI Bewusstsein benötigt, um menschliche Leistungen zu übertreffen, fortgesetzt. (Quelle: jachiam0, Plinz)

Berufliche Entwicklung und Ängste von Ingenieuren im KI-Zeitalter: Angesichts der rasanten Entwicklung der KI diskutieren Ingenieure, wie sie mit beruflicher Angst umgehen und welche Auswirkungen KI-Tools auf den Programmier-Workflow haben. Einige sehen KI als Produktivitätswerkzeug, andere betonen ihre Grenzen und fordern Ingenieure auf, sich darauf zu konzentrieren, KI zu leiten, anstatt von ihr ersetzt zu werden. (Quelle: pmddomingos, finbarrtimbers, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/artificial)
💡 Sonstiges
Anpassungen bei Teslas FSD- und Dojo-Projekten: Elon Musk kündigte an, dass FSD 14 in sechs Wochen veröffentlicht wird, mit einer zehnfachen Erhöhung der Parameteranzahl. Er räumte auch ein, dass das Dojo-Supercomputerprojekt in einer Sackgasse steckt und Dojo 3 in Zukunft möglicherweise als Mainboard mit integriertem AI6-Chip existieren wird, wobei der Schwerpunkt auf der AI6-Plattform liegt. Dies zeigt eine bedeutende strategische Neuausrichtung von Tesla im Bereich autonomes Fahren und KI-Hardware. (Quelle: 36氪)
Potenzial von KI-Modellen im Gesundheitswesen: KI-Modelle werden derzeit erforscht, um EEG-Daten auf Intensivstationen (ICU) zu überwachen, um Ärzten ein besseres Verständnis des Patientenzustands zu ermöglichen. Darüber hinaus werden Tools wie Elicit AI für klinische Forscher empfohlen, was die breiten Anwendungsaussichten der KI im Gesundheitswesen verdeutlicht. (Quelle: Reddit r/artificial, elicitorg)

Auswirkungen von KI auf die Sozialwirtschaft: KI schafft derzeit in Rekordgeschwindigkeit neue Milliardäre, was ihr enormes Potenzial zur Vermögensbildung unterstreicht. Gleichzeitig wird diskutiert, dass der Wert von KI-Abonnementdiensten nicht nur nach Kosten, sondern nach Zeitersparnis und Effizienzsteigerung beurteilt werden sollte, was die tiefgreifenden Auswirkungen der KI auf die Wirtschaftsstruktur und die individuellen Konsumgewohnheiten widerspiegelt. (Quelle: Reddit r/artificial, dotey)