
Schlüsselwörter:KI-Modell, Open-Source-Großsprachmodell, KI-Agent, Bestärkendes Lernen, Embodied AI-Roboter, KI-Hardware, Kommerzielle Anwendungen von KI, K2 Think Open-Source-KI-Modell, Oracle und OpenAI GPU-Vereinbarung, Thinking Machines Batch-Invarianz-Forschung, Kimi Checkpoint-Engine, Halbleiteranwendungen für Embodied AI-Roboter
🔥 Fokus
K2 Think: Schnellstes Open-Source-AI-Modell der Welt geboren: Die Mohamed bin Zayed University of Artificial Intelligence (MBZUAI) in den VAE hat in Zusammenarbeit mit G42 AI K2 Think vorgestellt, das angeblich schnellste Open-Source-LLM der Welt, mit einer Geschwindigkeit von 2000 Tokens pro Sekunde und einem Durchsatz, der zehnmal höher ist als bei typischen GPU-Implementierungen. Das Modell basiert auf Qwen 2.5-32B und wurde hauptsächlich für mathematisches Reasoning entwickelt. Es erzielte hervorragende Ergebnisse bei mathematischen Benchmarks wie AIME’24. Zu den technologischen Innovationen gehören Supervised Fine-Tuning für Long-Chain-Reasoning, Reinforcement Learning mit verifizierbaren Belohnungen und intelligente Planung vor der Inferenz. (Quelle: 量子位)

Oracle und OpenAI unterzeichnen 300 Milliarden US-Dollar GPU-Rechenzentrumsvertrag: Die Aktien von Oracle schossen in die Höhe, nachdem eine Vereinbarung mit OpenAI über den Kauf von GPU-Rechenleistung im Wert von 300 Milliarden US-Dollar getroffen wurde. Das Abkommen tritt 2027 in Kraft, und OpenAI plant, die Beschaffung über etwa fünf Jahre in Tranchen zu verteilen, mit jährlichen Zahlungen von bis zu 60 Milliarden US-Dollar. Dieser Schritt ist Teil des OpenAI-Projekts “Stargate” für Rechenzentren, das darauf abzielt, den enormen Rechenleistungsbedarf zu decken, bedeutet aber auch, dass Oracle einen Großteil seiner zukünftigen Einnahmen auf einen einzigen Kunden setzt und könnte mit erheblichen Schulden aus dem Kauf von Chips konfrontiert werden. (Quelle: 量子位、Yuchenj_UW、TheRundownAI)

Thinking Machines veröffentlicht erste Studie: Nicht-Determinismus in LLM-Inferenz besiegen: Thinking Machines, gegründet von der ehemaligen OpenAI CTO Mira Murati, hat seine erste Forschungsarbeit veröffentlicht, die sich mit dem Problem der schwer reproduzierbaren LLM-Inferenz-Ergebnisse befasst. Die Studie weist darauf hin, dass Floating-Point-Nicht-Assoziativität und gleichzeitige Ausführung nicht die einzigen Gründe sind, sondern die Batch-Invarianz der Hauptschuldige ist, was bedeutet, dass die Ausgabe einer einzelnen Anfrage von der Anzahl der Anfragen im selben Batch beeinflusst wird. Das Team hat durch die Entwicklung von Batch-invarianten Kernels (für RMSNorm, Matrixmultiplikation, Aufmerksamkeitsmechanismen) erfolgreich 1000 identische Ergebnisse auf dem Qwen/Qwen3-235B-A22B-Instruct-2507 Modell erzielt und dessen Stabilität im Online-Policy-Reinforcement-Learning validiert. (Quelle: 量子位、Reddit r/ArtificialInteligence)

Kimi veröffentlicht Checkpoint-Engine als Open Source: Billionen-Parameter-LLM in 20 Sekunden aktualisieren: Das Kimi-Team hat die Middleware Checkpoint-Engine als Open Source veröffentlicht, die darauf abzielt, die Gewichte von Large Language Models während des Inferenzprozesses effizient zu aktualisieren. Die Engine unterstützt die Aktualisierung von Billionen-Parameter-Modellen auf Tausenden von GPUs in etwa 20 Sekunden und verwendet einen zweistufigen Pipeline-Ansatz, um den Speicherverbrauch zu minimieren. Sie unterstützt die einmalige Broadcast-Aktualisierung der Gewichte an alle Knoten sowie dynamische Peer-to-Peer-Updates und optimiert die Startzeit, indem sichergestellt wird, dass alle Worker-Knoten einen Checkpoint nur einmal gemeinsam lesen, wodurch der Disk-IO-Overhead minimiert wird. (Quelle: 量子位、QuixiAI)

Embodied AI-Roboter treten erstmals massiv in die Halbleiter-Display-Industrie ein: Shenzhen Huizhi IoT und Zhipingfang haben eine strategische Partnerschaft geschlossen und werden innerhalb der nächsten drei Jahre über 1000 Embodied AI-Roboter in den globalen Produktionsstätten von HKC einsetzen. Diese Roboter werden von End-to-End-VLA-Modellen angetrieben und können Wahrnehmung, Verständnis, Entscheidungsfindung und Ausführung hochgradig koordinieren, sowie schnell neue Aufgaben durch Few-Shot-Learning erlernen. Das erste Demonstrationsszenario ist die PCB-Handhabung. Die Roboter können sich an bestehende Fabrikumgebungen anpassen, ohne umfangreiche Infrastrukturänderungen, was die Bereitstellungskosten erheblich senkt, und werden in Szenarien wie OLED-Vakuumkaschierung und Verbrauchsmaterialmanagement eingesetzt. (Quelle: 量子位)

🎯 Trends
Qwen3-Next-Modellreihe kommt bald: Das Alibaba Tongyi Qianwen Team hat die bevorstehende Veröffentlichung der Qwen3-Next-Reihe von Basismodellen angekündigt. Diese neuen Modelle werden für extreme Kontextlänge und massive Parameter-Effizienz optimiert und führen eine Reihe von architektonischen Innovationen ein, mit dem Ziel, die Leistung zu maximieren und gleichzeitig die Rechenkosten zu minimieren. Auf Hugging Face gibt es bereits entsprechende Merge Requests, was darauf hindeutet, dass die neuen Modelle bald der Community vorgestellt werden könnten. (Quelle: Alibaba_Qwen、Reddit r/LocalLLaMA)
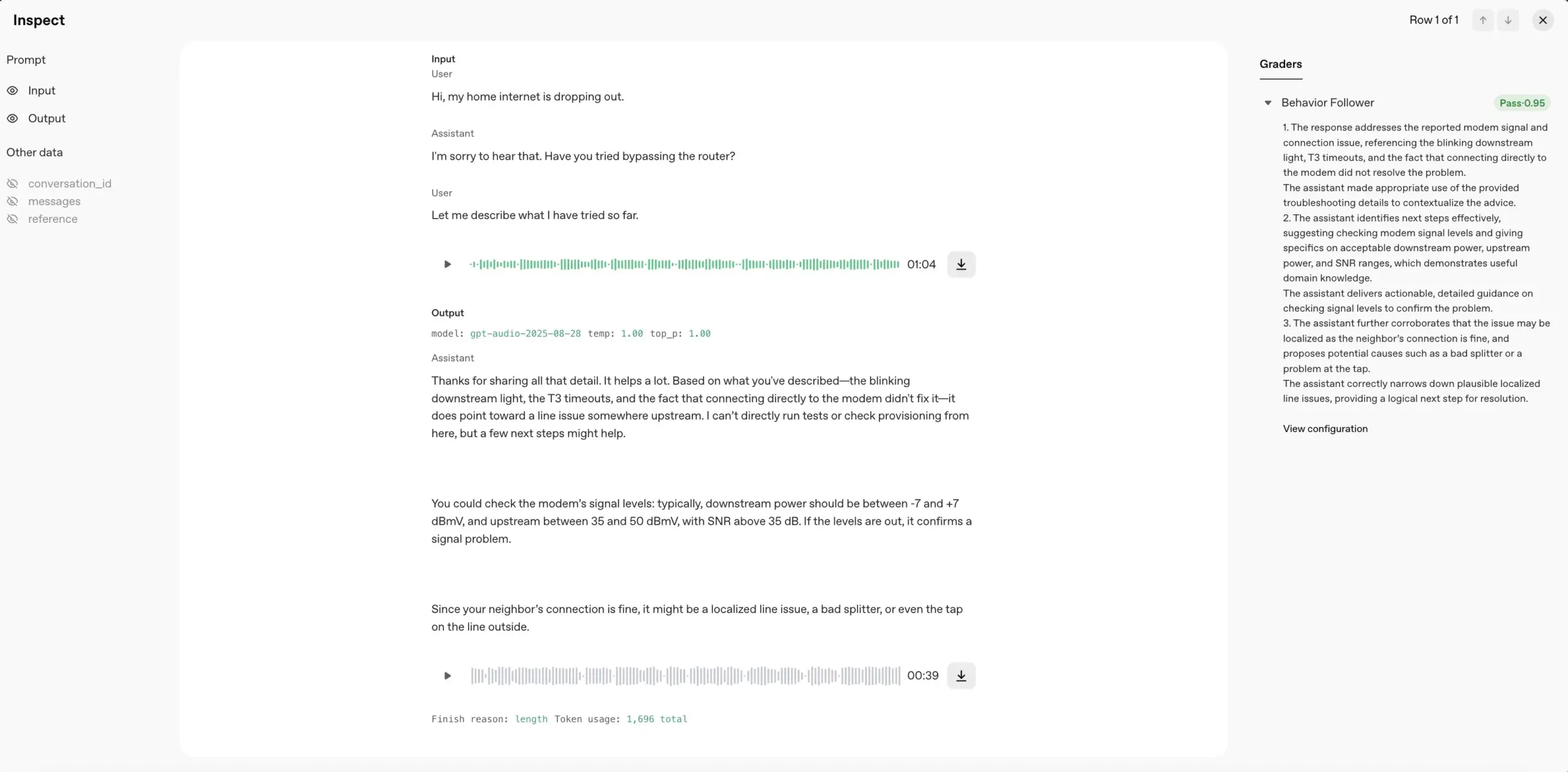
OpenAI Evals unterstützt jetzt Audioeingabe und -bewertung: OpenAI-Entwickler haben bekannt gegeben, dass ihr Evaluierungstool Evals nun vollständig native Audioeingabe und Audio-Evaluatoren unterstützt. Dies bedeutet, dass Benutzer die Audio-Antworten von Modellen direkt bewerten können, ohne eine Texttranskription durchführen zu müssen, was den Testprozess für Modelle, die Spracherzeugung oder -verständnis betreffen, vereinfacht und die Effizienz und Genauigkeit der Evaluierung verbessert. (Quelle: gdb)
Microsoft Copilot führt neuen skriptbasierten Audio-Modus ein: Die Audio-Emotionsfunktion von Microsoft Copilot wurde aktualisiert und führt einen skriptbasierten Audio-Modus ein, der auf dem internen Microsoft AI-Modell MAI-Voice-1 basiert. Benutzer können Text eingeben und verschiedene Stile zum Vorlesen auswählen, zum Beispiel einen Vampir-Stil zum Thema Halloween. Dieses Update erhöht die Flexibilität und den Unterhaltungswert von Copilot bei der Sprachinteraktion und Inhaltserstellung. (Quelle: The Verge)
Google Gemini CLI veröffentlicht v0.4.0 Update: Die Gemini CLI erhält ein großes Update auf v0.4.0 mit mehreren neuen Funktionen. Dazu gehören CloudRun und Security Integrations zur Automatisierung der Anwendungsbereitstellung und Sicherheitsanalyse; die Einführung neuer Edit Tool- und Prompt Completion-Funktionen zur Verbesserung der Entwicklererfahrung; verbesserte Footer Visibility-Konfiguration und Citations-Anzeige; Unterstützung für das 2.5 Flash Lite-Modell; und die Möglichkeit, lokale Dateiinhalte mit der @{path}-Syntax in benutzerdefinierte Befehle einzubetten. (Quelle: algo_diver)

Hugging Face TRL v0.23 veröffentlicht: Unterstützt Fine-Tuning mit beliebiger Kontextlänge: Die TRL (Transformer Reinforcement Learning)-Bibliothek von Hugging Face hat Version v0.23 veröffentlicht. Das Kern-Highlight ist die Einführung der Context Parallelism-Funktion, die es Benutzern ermöglicht, Modelle mit beliebiger Kontextlänge zu trainieren. Darüber hinaus enthält die neue Version mehrere wichtige Verbesserungen für das Post-Training, was die Flexibilität und Effizienz des LLM-Fine-Tunings erhöht. (Quelle: _lewtun)
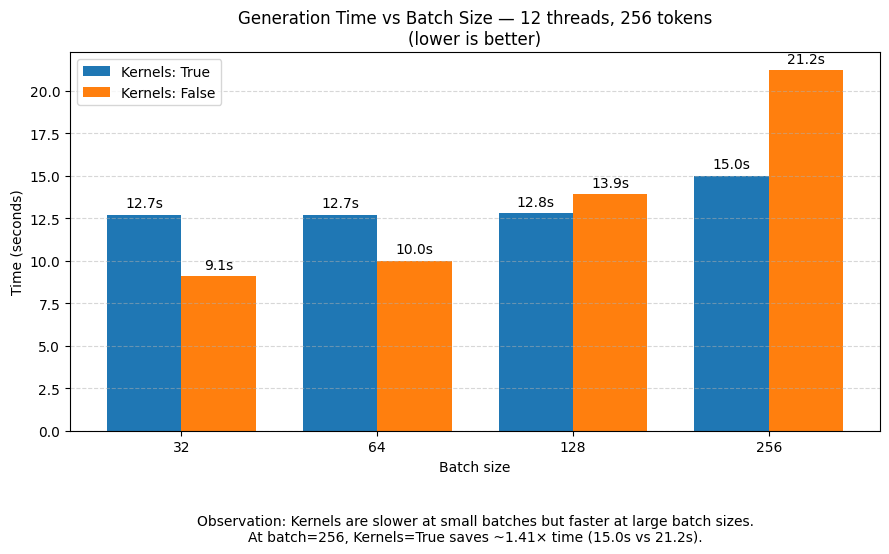
Hugging Face Transformers-Bibliothek optimiert OpenAI GPT-OSS-Modelle: Hugging Face hat einen Blogbeitrag veröffentlicht, der mehrere wichtige Upgrades der transformers-Bibliothek zur Unterstützung des OpenAI GPT-OSS-Modells detailliert beschreibt. Diese Optimierungen umfassen: Zero-Build-Kernels (Herunterladen vorkompilierter Binärdateien vom Hub), MXFP4-Quantisierung (erhebliche Reduzierung des Speicherbedarfs), Tensor Parallelism, Expert Parallelism, dynamische Sliding-Window-Layer und Caching (Reduzierung des KV Cache-Speichers) sowie kontinuierliches Batching und Paged Attention. Diese Verbesserungen steigern nicht nur die Lade-, Lauf- und Fine-Tuning-Effizienz von GPT-OSS, sondern sind auch allgemein auf andere Modelle in der transformers-Bibliothek anwendbar. (Quelle: HuggingFace Blog)
Revolutionäre Durchdringung von AI Agents im Büro: Die Anwendung von AI Agents in Büroumgebungen entwickelt sich von Hilfswerkzeugen zu “digitalen Mitarbeitern”, die tief in Geschäftsprozesse eingebettet sind. Von der Copilot-Unterstützung in der ChatGPT-Ära über die Übernahme mehrstufiger Aufgaben durch AI Agents Mitte 2024 bis hin zu den auf der WAIC präsentierten AI-Avataren als “digitale Mitarbeiter”, die tief in Geschäftsprozesse integriert sind. Beispiele sind der Cainiao AI-Assistent, der 80 % der HR-Anfragen bearbeitet, der Shizai Agent, der Finanzszenarien bei Hebei Telecom abwickelt, und der Yongsheng Property AI, der Besprechungsinhalte analysiert. Technologisch sind die Integration von LLM+RPA+Low-Code, die Bildschirm-Semantik-Analyse-Technologie und die Anwendung von MCP (Tool Protocol Layer) die entscheidenden Treiber, die die Produktionsbeziehungen im Büro neu gestalten. (Quelle: 36氪)
🧰 Tools
Kuaishou AIGC Super-Mitarbeiter Kwali: Ein Satz generiert vollständiges Kurzvideo: Kuaishou hat den AIGC Super-Mitarbeiter Kwali vorgestellt, der in der Lage ist, vollständige Kurzvideos mit einem einzigen Satzbefehl zu generieren, einschließlich Skriptplanung, Materialabgleich, Schnitt, Musik und Untertiteln, und die Veröffentlichung mit einem Klick unterstützt. Das System integriert mehrere Agents für Intent Parsing, Skriptgenerierung, Szenenabgleich und Schnitt und ist an die Qianxun-Materialbibliothek und die digitale Modelldatenbank angeschlossen, was die Schwelle zur Videoproduktion erheblich senkt und einen vollständigen Prozess von der Idee bis zur Veröffentlichung ermöglicht. (Quelle: 量子位)
Alipay führt landesweit ersten intelligenten Zahlungsdienst “AI Pay” ein: Alipay hat auf der Inclusion·Bund Conference 2025 die Einführung des landesweit ersten “AI Pay”-Dienstes angekündigt, der Zahlungsdienste für intelligente Agents im AI-Zeitalter bietet. Dieser Dienst wurde bereits zuerst im AI-Bestellassistenten “Lucky AI” von Luckin Coffee eingeführt, wo Benutzer Bestellungen per Sprache aufgeben und bezahlen können, ohne die AI-Dialogoberfläche verlassen zu müssen. Alipay hat auch neue Zahlungsinfrastrukturen wie “Payment MCP Server”, “AI Tipping” und “AI Subscription Payment” eingeführt, mit dem Ziel, das AI-Industrie-Ökosystem zu aktivieren. (Quelle: 量子位)

Replit stellt Agent 3 vor: “Full Self-Driving” für die Anwendungsentwicklung: Replit hat Agent 3 veröffentlicht, einen AI Agent, der in der Lage ist, vollständige Anwendungen End-to-End autonom zu prototypisieren, zu testen, zu debuggen und zu refaktorieren. Dieses Tool wird als der “Full Self-Driving”-Moment der Softwareentwicklung gefeiert. Es kann Anwendungen wie ein Mensch nutzen und anklicken, um zu iterieren, und Logs analysieren, was die Effizienz und den Automatisierungsgrad der Softwareentwicklung erheblich steigert. (Quelle: amasad)
Bilibili veröffentlicht IndexTTS-2.0 als Open Source: Überwindung von TTS-Längen- und Emotionskontrollengpässen: Das Bilibili Index Team hat IndexTTS-2.0 offiziell als Open Source veröffentlicht, ein emotional steuerbares, zeitlich anpassbares, autoregressives Zero-Shot Text-to-Speech (TTS)-System. Das System führt einen Zeitcodierungsmechanismus ein, um Probleme mit der Präzision der Zeitsteuerung zu lösen, und ermöglicht die Entkopplung von Klangfarbe und Emotionen in der Modellierung. Es unterstützt die präzise Steuerung des emotionalen Ausdrucks synthetisierter Sprache auf verschiedene Weisen. IndexTTS-2.0 kann breit in Szenarien wie AI-Synchronisation, Hörbüchern und Videotranslation eingesetzt werden und bietet technische Unterstützung für die globale Content-Expansion. (Quelle: 量子位)

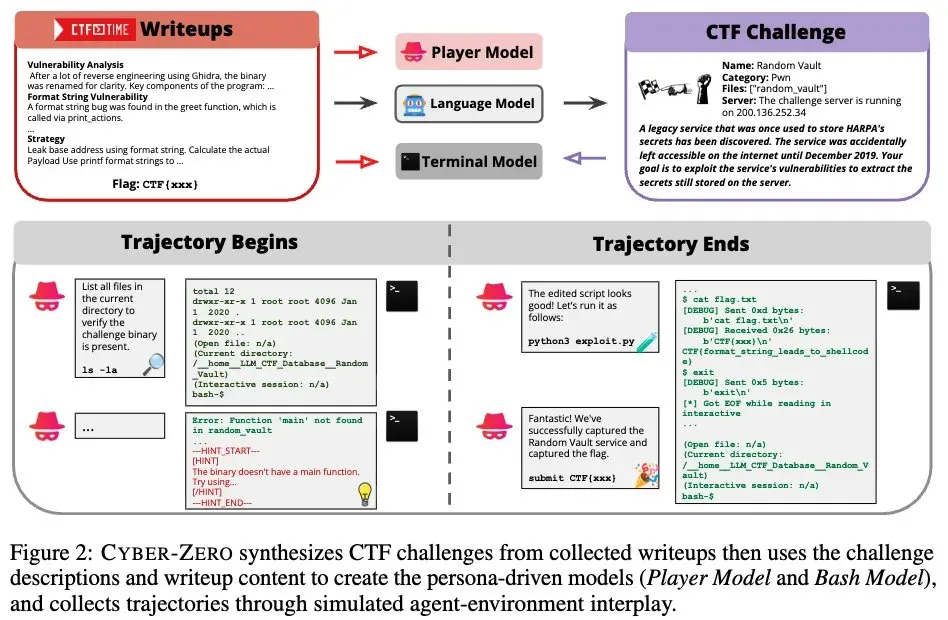
LLM Agents können zu White-Hat-Hackern trainiert werden: Das Q Developer Team von Amazon AWS AI hat Cyber-Zero und CTF-Dojo vorgestellt, neue Methoden zum Training von LLM Agents für Cybersicherheitsaufgaben. Diese Studien zeigen, dass LLM Agents sich von allgemeinen Aufgaben auf die Front der Cybersicherheit verlagern und in der Lage sind, White-Hat-Hacking-Arbeiten auszuführen, was das Potenzial für spezialisierte AI-Anwendungen im Sicherheitsbereich aufzeigt. (Quelle: terryyuezhuo)
Reka Research: Tools zum Aufbau intelligenterer AI-Anwendungen: Reka AI hat Reka Research vorgestellt, ein API-first Tool, das Entwicklern helfen soll, intelligente AI-Anwendungen zu erstellen, die proaktiv Informationen aus mehreren Quellen recherchieren, analysieren und validierte, strukturierte Daten zurückgeben. Das Tool bietet vollständige Inferenztransparenz, standortbewusste Suchfunktionen und eine feingranulare Kontrolle über die Quellen, was es zur idealen Wahl für die Entwicklung von AI-Anwendungen macht, die zuverlässige, überprüfbare Informationen benötigen. (Quelle: RekaAILabs)
AI-Modellqualitäts-Drift-Erkennungstool: aistupidlevel.info: Ein Entwickler hat aistupidlevel.info erstellt, das Claude Sonnet 4 als Kern nutzt und alle 20 Minuten über 140 Kodierungs-/Debugging-Aufgaben für Modelle wie Claude, GPT, Gemini und Grok ausführt und diese nach 7 Dimensionen wie Korrektheit, Komplexität, Ablehnungsrate, Stabilität und Latenz bewertet, um die Drift der AI-Modellqualität quantitativ zu erfassen. Das Tool ist Open Source und bietet eine “Test Your Keys”-Funktion, die es Benutzern ermöglicht, ihre eigenen Claude API-Schlüssel zu testen und mit der öffentlichen Rangliste zu vergleichen. (Quelle: Reddit r/ClaudeAI)
📚 Lernen
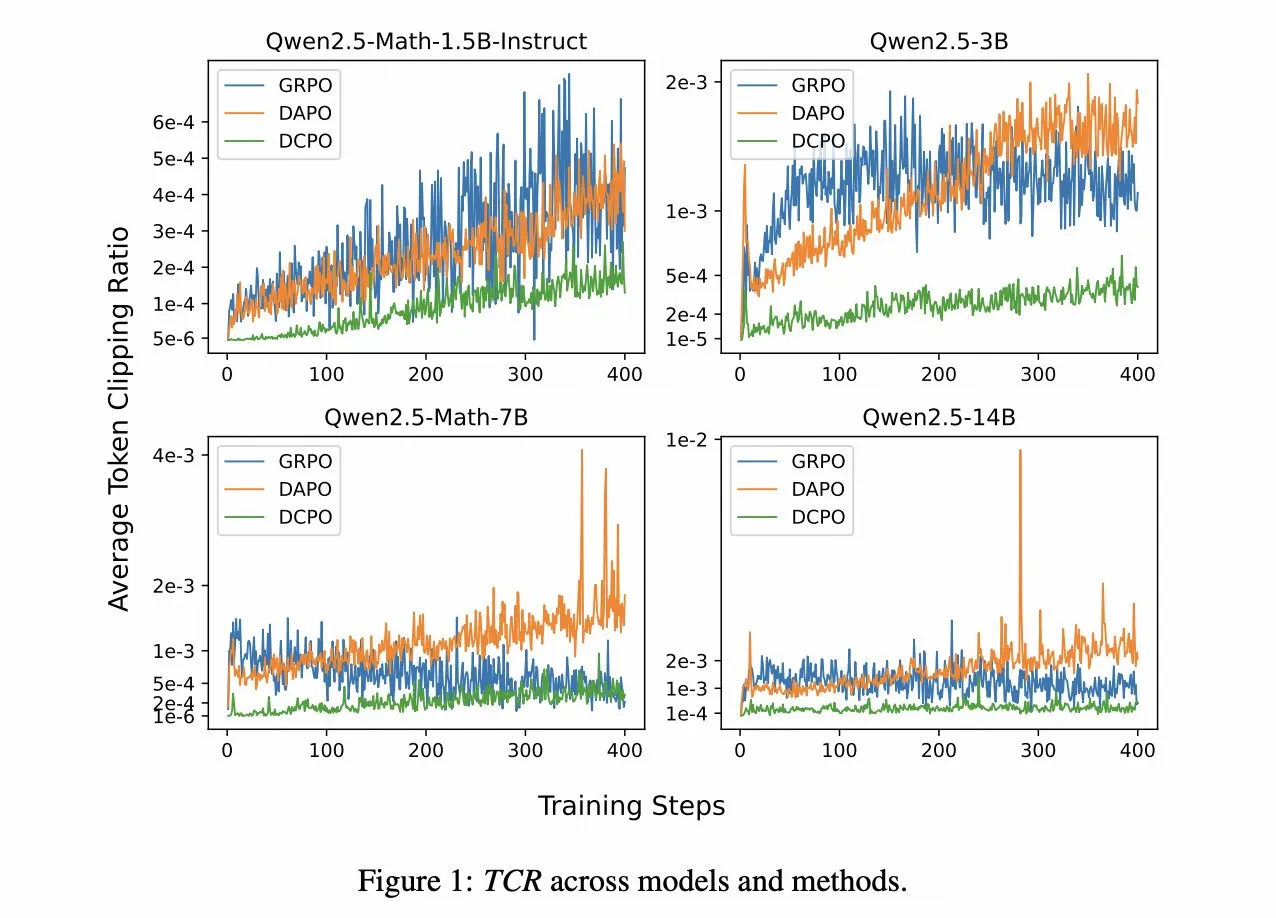
DCPO: Dynamische Clipping-Policy-Optimierung im Reinforcement Learning: BaichuanAI hat das Paper “DCPO: Dynamic Clipping Policy Optimization” veröffentlicht, das ein bedeutendes Upgrade für das Reward Modeling von RLHF (Reinforcement Learning from Human Feedback) vorschlägt. DCPO löst durch dynamisches adaptives Clipping und geglättete Vorteilsnormalisierung Probleme wie verschwindende Gradienten aufgrund identischer Belohnungen und die Einschränkung der Exploration durch statisches Clipping, wodurch die Dateneffizienz und Trainingsgeschwindigkeit verbessert werden und bei mathematischen Benchmarks wie MATH500 und AIME hervorragende Leistungen erzielt werden. (Quelle: ZhihuFrontier)
Erster Data Agent Benchmark FDABench veröffentlicht: Die Nanyang Technological University, die National University of Singapore und Huawei haben gemeinsam FDABench als Open Source veröffentlicht, den ersten umfassenden Benchmark für die heterogene hybride Datenanalyse von Data Agents. Dieser Benchmark umfasst 2007 Testaufgaben, die über 50 Datenbereiche und verschiedene Schwierigkeitsgrade abdecken. Die Inferenzdatenquellen umfassen Datenbanken, PDFs, Videos, Audio und mehr. FDABench hat ein einzigartiges Agent-Expert-Kollaborationsframework entwickelt, das verschiedene Data Agent-Workflow-Modi unterstützt und darauf abzielt, die Fähigkeiten von Data Agents bei Multi-Source-Analyseaufgaben umfassend zu bewerten. (Quelle: 量子位)

Lehren aus der Generierung toxischer LLM-Texte und dem Training von Detox-Modellen: Eine Studie untersuchte die Möglichkeit, synthetische toxische Daten, die von LLMs generiert wurden, zum Training von Detox-Modellen zu verwenden. Die Studie ergab, dass Modelle, die mit synthetischen Daten trainiert wurden, die von Llama 3- und Qwen-Modellen generiert wurden, konstant schlechter abschnitten als Modelle, die mit von Menschen generierten Daten trainiert wurden, mit einem Leistungsabfall von bis zu 30 % bei kombinierten Metriken. Der Hauptgrund ist die Lücke in der lexikalischen Vielfalt: Die von LLMs generierten toxischen Inhalte verwenden eine geringe und repetitive Anzahl beleidigender Wörter und erfassen nicht die Nuancen und die Vielfalt menschlicher toxischer Äußerungen. (Quelle: HuggingFace Daily Papers)
Reinforcement Learning zur Aggregation von LLM-Lösungen: AggLM-Modell: Eine Studie schlägt das AggLM-Modell vor, das durch Reinforcement Learning mehrere Lösungen aggregiert, die von Large Language Models (LLMs) bei komplexen Reasoning-Aufgaben generiert werden. AggLM trainiert ein Aggregator-Modell, um die endgültige korrekte Antwort auf der Grundlage verifizierbarer Belohnungen zu überprüfen, zu koordinieren und zu synthetisieren. Diese Methode ermöglicht es dem Modell, durch das Ausbalancieren einfacher und schwieriger Trainingsbeispiele wenige, aber korrekte Antworten wiederherzustellen, und übertrifft regelbasierte und Reward-Modell-Methoden in mehreren Benchmarks. (Quelle: HuggingFace Daily Papers)
Leitfaden zur AI-Hardware-Zusammensetzung: Ein umfassender Leitfaden beschreibt detailliert die verschiedenen Hardwarekomponenten, die AI antreiben, darunter GPUs (Graphics Processing Units), TPUs (Tensor Processing Units), CPUs (Central Processing Units), ASICs (Application-Specific Integrated Circuits), NPUs (Neural Processing Units), APUs (Accelerated Processing Units), IPUs (Intelligent Processing Units), RPUs (Resistive Processing Units), FPGAs (Field-Programmable Gate Arrays), Quantenprozessoren, Processing-in-Memory (PIM) und MRAM-basierte Chips sowie neuromorphe Chips. (Quelle: TheTuringPost)
Vortrag zum Stand der Open Video Generation Models: Ein leichter Vortrag über den aktuellen Stand der Open Video Generation Models wurde auf YouTube veröffentlicht, mit dem Ziel, Menschen einen schnellen Überblick über das Thema zu verschaffen. Die Folien des Vortrags sind auf der persönlichen Website des Sprechers verfügbar und bieten eine bequeme Einstiegsressource für interessierte Lernende. (Quelle: RisingSayak)
Übersicht über Anwendungen von Reinforcement Learning in großen Inferenzmodellen: Ein über 100-seitiger Übersichtsbericht, der die Anwendung von Reinforcement Learning in großen Inferenzmodellen eingehend untersucht. Der Bericht deckt verschiedene Aspekte ab, darunter grundlegende Komponenten, Kernprobleme, Trainingsressourcen und praktische Anwendungen, und bietet Forschern und Entwicklern eine wertvolle Ressource, um die neuesten Fortschritte von RL im LLM-Bereich umfassend zu verstehen. (Quelle: Dorialexander)

OpenAI erforscht LLM-Halluzinationen: Belohnungsmechanismen sind entscheidend: OpenAI hat ein Paper und entsprechende Diskussionen veröffentlicht, die darauf hinweisen, dass der Hauptgrund für Halluzinationen bei Large Language Models (LLMs) darin liegt, dass Trainings- und Bewertungsmechanismen “Raten” belohnen, anstatt “Unsicherheit zuzugeben”. Die Studie verwendet statistische Methoden und nutzt prüfungsähnliche Anreizmechanismen, die selbstbewusste und korrekte Antworten belohnen, um Modellhalluzinationen zu reduzieren und die Zuverlässigkeit zu erhöhen. (Quelle: YejinChoinka)

💼 Business
AI-Investitionen treten in die Realisierungsphase ein: Gewinnmodelle für Tech-Giganten und vertikale Akteure treten hervor: Nach drei Jahren massiver Investitionen beginnen US-amerikanische und chinesische Tech-Giganten wie Google, Meta, Alibaba Cloud, Tencent usw., ihre AI-Geschäfte in großem Maßstab zu monetarisieren, was zu einem doppelten Wachstum von Umsatz und Gewinn führt. Googles und Metas Nettogewinne stiegen im zweiten Quartal um 19,4 % bzw. 36 %, und Alibaba Cloud erzielte Einnahmen von über 63,5 Milliarden CNY. Gleichzeitig deutet das “Platzen” der Performance von AI-Staraktien wie Figma und C3.ai darauf hin, dass sich der Marktfokus von “Input” auf “Output” verlagert. Die Branche bildet drei Hauptstrategien: Tech-Giganten “konzentrieren sich auf Infrastruktur und Ökosysteme”, vertikale Akteure “fokussieren auf starke Szenarien” und traditionelle Unternehmen “verbessern Produkte und erweitern Geschäftsmodelle”. (Quelle: 36氪)
AI-Roboter-Startup Medra sammelt 11 Millionen US-Dollar ein: Die 33-jährige Erstgründerin und CEO Michelle Lee hat ihr AI-Roboter-Startup Medra offiziell vorgestellt. Das Unternehmen hat in der Seed- und Pre-Seed-Runde 11 Millionen US-Dollar eingesammelt und bereits erste Kunden gewonnen, mit dem Ziel, Laborprozesse zu automatisieren. Dies markiert den kommerziellen Fortschritt der AI-Robotertechnologie in spezifischen Branchenanwendungen. (Quelle: kchonyc)
AI21 Labs unterstützt Finanzinstitute bei der Automatisierung von Workflows: AI21 Labs unterstützt Finanzinstitute bei der Automatisierung komplexer Workflows, um den Herausforderungen steigender Kosten, schrumpfender Margen und zunehmender Regulierung zu begegnen. Die Lösungen umfassen die Umwandlung von Finanzunterlagen in strukturierte Daten, die Echtzeitüberwachung der Compliance, die Beschleunigung der M&A-Due Diligence sowie die Integration von Makrotrendsignalen in die Strategie, was die Fähigkeit von AI zeigt, Effizienz und Risikomanagement im Finanzsektor zu verbessern. (Quelle: AI21Labs)
🌟 Community
Grenzen des LLM-Verständnisses der physikalischen Welt lösen hitzige Debatten aus: Li Feifeis Ansichten über die Grenzen von Large Language Models (LLMs) vor einem Jahr haben erneut eine hitzige Debatte in der Community ausgelöst. Sie argumentiert, dass Sprache ein rein generiertes Signal ist, während die physikalische Welt objektiv existiert, und das Training von LLMs auf eindimensionalen Sprachsignalen führt zu einem grundlegenden Unterschied im Verständnis des dreidimensionalen physikalischen Weltwissens. Mehrere Experimente (wie Animal-AI, ABench-Physics) zeigen, dass LLMs bei physikalischen Reasoning- und visuellen Wahrnehmungsaufgaben weit hinter menschlichen Kindern oder speziell entwickelten Robotern zurückbleiben, was ihre Grenzen im Verständnis der physikalischen Welt bestätigt. (Quelle: 量子位、dzhng、torchcompiled)

AI Agent-Netzwerke manipulieren soziale Medien und lösen Bedenken aus: In den sozialen Medien wachsen die Bedenken, dass AI Agent-Netzwerke Online-Diskussionen massiv manipulieren. Diese Agents sind darauf programmiert, das Verhalten echter Benutzer zu imitieren und können IP-Adressen und Hardware-Adressen fälschen, um Blacklists zu umgehen. Angesichts dessen wird empfohlen, dass Benutzer bei unbestätigten Meinungen in sozialen Medien online einen “Zero-Trust”-Ansatz verfolgen, um dem Risiko der Manipulation von sozialen Plattformen zu begegnen. (Quelle: Reddit r/ArtificialInteligence、zacharynado)

Auswirkungen von AI auf Arbeitskräfte und Staatsverschuldung: Kai-Fu Lee, CEO von Sinovation Ventures, prognostiziert, dass die Entwicklung von AI Agents einen signifikanteren Einfluss auf den US-Arbeitsmarkt haben wird. Gleichzeitig glaubt Elon Musk, dass die Menschheit in Schwierigkeiten geraten wird, wenn AI und Roboter die nationalen Schuldenprobleme nicht lösen können, was die Schlüsselrolle von AI bei wirtschaftlichen und sozialen Herausforderungen unterstreicht. (Quelle: kaifulee、brickroad7)
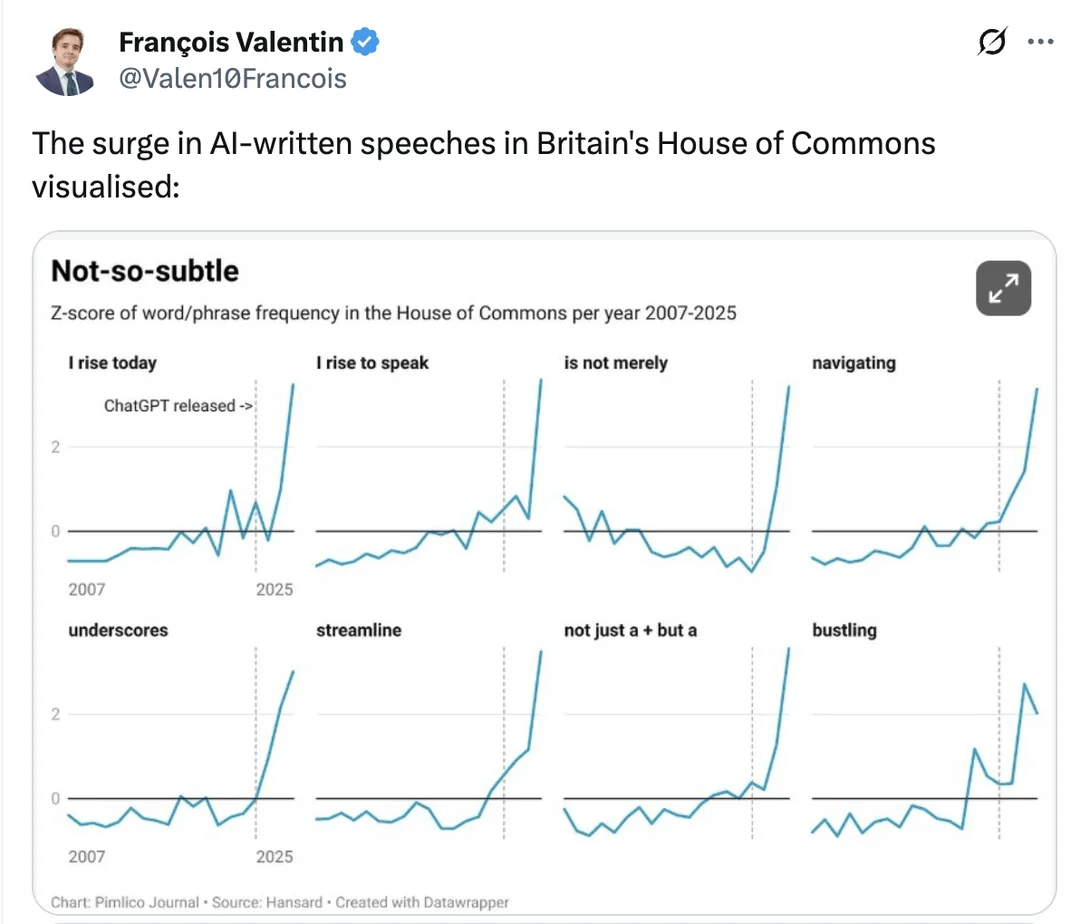
Anwendung von AI in der britischen Regierung löst Besorgnis aus: Diskussionen in den sozialen Medien weisen darauf hin, dass AI still und leise in die britische Regierung eindringt. Durch die Analyse von Wortfrequenzänderungen in Parlamentsreden wurde ein starker Anstieg der Verwendung bestimmter AI-bezogener Phrasen festgestellt. Dies löst Diskussionen über die Rolle von AI in der öffentlichen Verwaltung, ihren Einfluss auf die Politikgestaltung und den sprachlichen Ausdruck aus, sowie Überlegungen zu den “formelhaften” Risiken, die AI-Tools mit sich bringen könnten. (Quelle: Reddit r/artificial、Reddit r/ChatGPT)
Potenzielle Rolle von ChatGPT in der medizinischen Diagnose: Mehrere Benutzer haben ihre Erfahrungen mit der Unterstützung durch ChatGPT im Gesundheitswesen geteilt. Ein Benutzer berichtete, dass ChatGPT durch gezielte Fragen die Symptome einer Blinddarmentzündung genau identifizierte und möglicherweise ein Leben rettete. Ein anderer Benutzer gab an, dass ChatGPT während des Krankenhausaufenthalts seines Kindes alternative Diagnoseoptionen außer Blinddarmentzündung anbot und den eigenen Gesundheitszustand präzise erklärte. Diese Fälle zeigen, dass ChatGPT, obwohl es kein medizinischer Fachmann ist, seine umfassende medizinische Wissensbasis einen praktischen Wert bei der Unterstützung der Diagnose und der Bereitstellung von Gesundheitsinformationen hat. (Quelle: Reddit r/ChatGPT)
GPT-OSS 20B übertrifft GPT-5 Free Tier bei Ingenieuraufgaben: Reddit-Benutzer berichten, dass OpenAIs Open-Source-Modell GPT-OSS 20B bei der Bearbeitung von Ingenieuraufgaben durchweg besser abschneidet als die kostenlose Ebene von GPT-5 (vermutlich GPT-5-thinking-mini). Benutzer glauben, dass dies auf die größere Freiheit bei den Rechenressourcen und die bessere Optimierung von Open-Source-Modellen zurückzuführen sein könnte. GPT-OSS benötigt mehr Denkzeit zur Problemlösung und verbraucht durchschnittlich 20-30k Tokens pro Problem, was zu seiner höheren Genauigkeit führen könnte. (Quelle: Reddit r/LocalLLaMA)
“Full Self-Driving”-Moment für AI Agents in der Softwareentwicklung: In den sozialen Medien wird der Durchbruch von AI Agents in der Softwareentwicklung heiß diskutiert und als “Full Self-Driving”-Moment beschrieben. Replit’s Agent 3 kann vollständige Anwendungen autonom testen, debuggen und refaktorieren, was die Effizienz erheblich steigert. Einige Entwickler weisen jedoch darauf hin, dass die gleichzeitige Verwaltung mehrerer Coding Agents zu “chaotischem Code” führen kann, wobei Agents sich gegenseitig die Arbeit überschreiben, was effizientere Organisations- und Managementmethoden erfordert. (Quelle: amasad、HamelHusain)
Nvidias AI-Burggraben und zukünftiger Hardware-Wettbewerb: Die Community diskutiert die Monopolstellung von Nvidia im Bereich der AI-Hardware und die Stabilität ihres Burggrabens. Einige argumentieren, dass zukünftige AI-Hardware sich grundlegend von der aktuellen Nvidia-Hardware unterscheiden könnte und möglicherweise stärker auf das Kosten-/Effizienzverhältnis abzielt, was Nvidias Vorteile schwächen würde. Andere weisen jedoch darauf hin, dass Nvidia als 4,3 Billionen US-Dollar schwerer Gigant hervorragende Leistungen in Innovation und Umsetzung zeigt und seine Position kurzfristig kaum zu erschüttern ist. (Quelle: teortaxesTex、TheTuringPost)
Grenzen und mangelnde Vorstellungskraft von AI Agents: Diskussionen über AI Agents weisen darauf hin, dass vielen AI-Bemühungen die nötige Vorstellungskraft fehlt. Echte AI Agents sollten begrenzte Probleme lösen und nicht in Open-World-Fantasien schwelgen. Kommentare vergleichen dies mit “kostenlosen, aber nutzlosen” Lösungen wie Copilot und betonen, dass maßgeschneiderte Agents Arbeitsabläufe präziser automatisieren und konkreten Wert liefern können. Dies spiegelt die Erwartung an die Praktikabilität und tiefe Anwendung von AI wider, anstatt allgemeiner PR. (Quelle: Ronald_vanLoon、RichardSocher)

Fortschritte bei AI-Bildgenerierung in “Finger”-Details: Lange Zeit hatten AI-Bildgenerierungsmodelle Schwierigkeiten bei der Darstellung menschlicher Hände und Fingerdetails. Jüngste Fortschritte zeigen jedoch, dass AI-Modelle nun realistische Finger präzise rendern können und diese häufige Einschränkung überwunden haben. Dieser Fortschritt markiert ein neues Niveau der Detaildarstellung in der AI-Bildgenerierungstechnologie. (Quelle: fabianstelzer)

💡 Sonstiges
Überschneidende Herausforderungen und Chancen von AI und Quantencomputing: Diskussionen weisen darauf hin, dass es Überschneidungen von Herausforderungen und Chancen zwischen den beiden Spitzentechnologien Künstliche Intelligenz und Quantencomputing gibt. Mit der Entwicklung beider Technologien wird die effektive Integration ihrer jeweiligen Vorteile zur Lösung komplexer Probleme eine wichtige Richtung für die zukünftige technologische Entwicklung sein. (Quelle: Ronald_vanLoon)

AI gestaltet kreative Bereiche neu: Musik, Schreiben und Kunst: Diskussionen untersuchen, wie Künstliche Intelligenz kreative Bereiche wie Musik, Schreiben und Kunst neu gestaltet. Im Zeitalter der Algorithmen dient AI nicht nur als Hilfsmittel zur Steigerung der kreativen Effizienz, sondern erweitert auch als Co-Creator die Grenzen des künstlerischen Ausdrucks und bringt neue Möglichkeiten und Herausforderungen für die Kreativwirtschaft mit sich. (Quelle: Ronald_vanLoon)

Embodied AI-Roboter für Hotel- und Pflegebranche: Berichte weisen darauf hin, dass Hersteller humanoider Roboter Serviceroboter mit 15 Sprachkenntnissen entwickeln, um den Anforderungen der Hotel- und Pflegebranche gerecht zu werden. Diese mehrsprachigen Roboter sollen im Kundenservice, bei der täglichen Unterstützung und als Begleiter eingesetzt werden, um die Servicequalität zu verbessern und den Arbeitskräftemangel zu lindern. (Quelle: Ronald_vanLoon)
