
Palabras clave:OpenAI Codex, Desarrollo de software con IA, Modelos multimodales, Generación de voz con IA, Filtrado de datos, Versión de vista previa de investigación de Codex, MiniMax Speech-02, Modelo multimodal BLIP3-o, Filtrado de datos PreSelect, Serie de modelos SWE-1
🔥 Enfoque
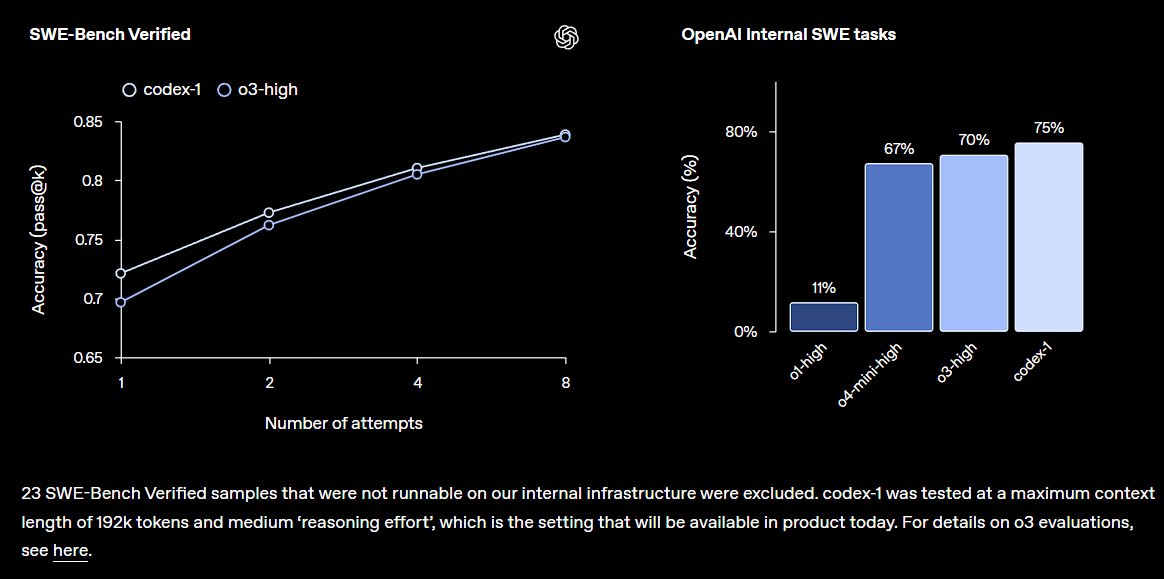
OpenAI publica la vista previa de investigación de Codex, integrada en ChatGPT: OpenAI presenta Codex, un agente inteligente de ingeniería de software en la nube, capaz de comprender grandes bases de código, escribir nuevas funciones, corregir errores y procesar múltiples tareas en paralelo. Codex se basa en el modelo codex-1 ajustado por o3 y muestra un rendimiento excelente en SWE-bench. Esta función se implementará gradualmente para los usuarios de ChatGPT Pro, Team y Enterprise, con el objetivo de aumentar significativamente la productividad de los desarrolladores, lo que indica que la AI desempeñará un papel más central en el campo del desarrollo de software. La comunidad ha reaccionado positivamente, pero también está atenta a sus efectos prácticos y posibles bugs (Fuente: OpenAI, OpenAI Developers, scaling01, dotey)
Los despidos masivos en Microsoft sacuden la industria, acelerando la transformación organizacional impulsada por la AI: Microsoft anunció despidos de aproximadamente 6000 personas a nivel mundial, con el objetivo de simplificar los niveles de gestión y aumentar la proporción de programadores. Entre los despedidos se encuentran veteranos con 25 años de servicio y contribuciones destacadas, así como desarrolladores clave de TypeScript. Se considera que estos despidos están relacionados con el aumento de la eficiencia gracias a la tecnología de AI y la automatización de algunas tareas laborales, lo que refleja la tendencia de los gigantes tecnológicos a controlar costos y optimizar la estructura de personal en la era de la AI. El evento ha suscitado un amplio debate sobre el impacto de la AI en el mercado laboral, la lealtad empresarial y los futuros modelos de trabajo (Fuente: WeChat, NeelNanda5)
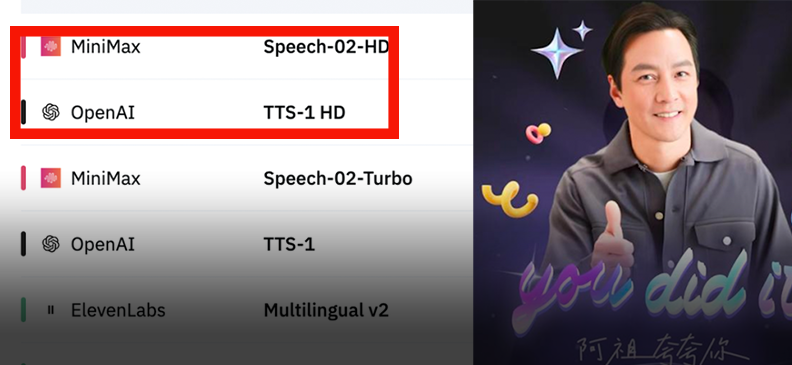
MiniMax lanza el modelo de voz Speech-02 y encabeza las listas mundiales: MiniMax ha lanzado su modelo de voz de nueva generación, Speech-02, que ha obtenido el primer puesto en dos importantes evaluaciones de voz, Artificial Analysis Speech Arena y Hugging Face TTS Arena, superando a OpenAI y ElevenLabs. El modelo destaca por su ultra-realismo, personalización de timbre de voz (compatible con 32 idiomas y acentos, replicable con solo unos segundos de referencia) y diversidad, e innova con la tecnología Flow-VAE para mejorar los detalles de clonación. Su tecnología ya se ha aplicado en escenarios como “AI Azu” aprendiendo inglés y guías de AI para la Ciudad Prohibida, demostrando el liderazgo de los modelos grandes chinos en el campo de la generación de voz por AI (Fuente: WeChat, WeChat)
Salesforce y otras instituciones publican el modelo multimodal unificado BLIP3-o: Salesforce Research, en colaboración con varias universidades, ha lanzado el modelo multimodal unificado de código abierto BLIP3-o, que adopta una estrategia de “comprender primero, luego generar”, combinando arquitecturas autorregresivas y de difusión. El modelo utiliza de forma innovadora características CLIP y Flow Matching para el entrenamiento, mejorando significativamente la calidad, diversidad y capacidad de alineación con las indicaciones de las imágenes generadas. BLIP3-o ha mostrado un rendimiento excelente en múltiples benchmarks y se está expandiendo a tareas multimodales complejas como la edición de imágenes y el diálogo visual, impulsando el desarrollo de la tecnología de AI multimodal (Fuente: 36氪)

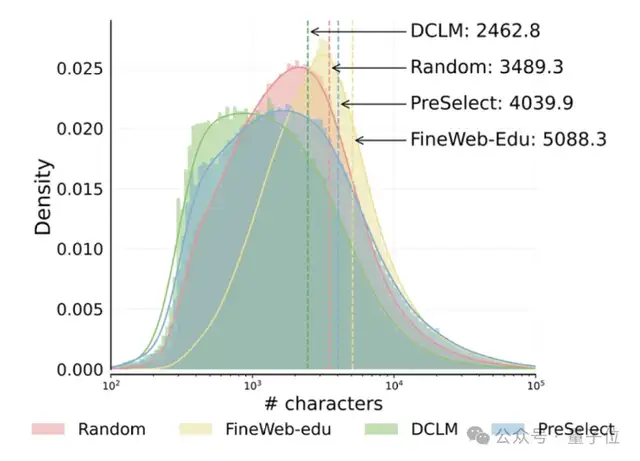
HKUST y vivo proponen la solución de selección de datos PreSelect, multiplicando por 10 la eficiencia del preentrenamiento: La Universidad de Ciencia y Tecnología de Hong Kong (HKUST) y vivo AI Lab han propuesto conjuntamente un método de selección de datos ligero y eficiente llamado PreSelect, que ha sido aceptado en ICML 2025. Este método cuantifica la contribución de los datos a capacidades específicas del modelo mediante un indicador de “fuerza predictiva”, utilizando un clasificador fastText para filtrar el conjunto completo de datos de entrenamiento. Logra una mejora promedio del 3% en el rendimiento del modelo mientras reduce la demanda computacional en 10 veces. PreSelect tiene como objetivo seleccionar datos de alta calidad y diversidad de manera más objetiva y generalizable, superando las limitaciones de los métodos tradicionales de selección basados en reglas o modelos (Fuente: 量子位)
🎯 Tendencias
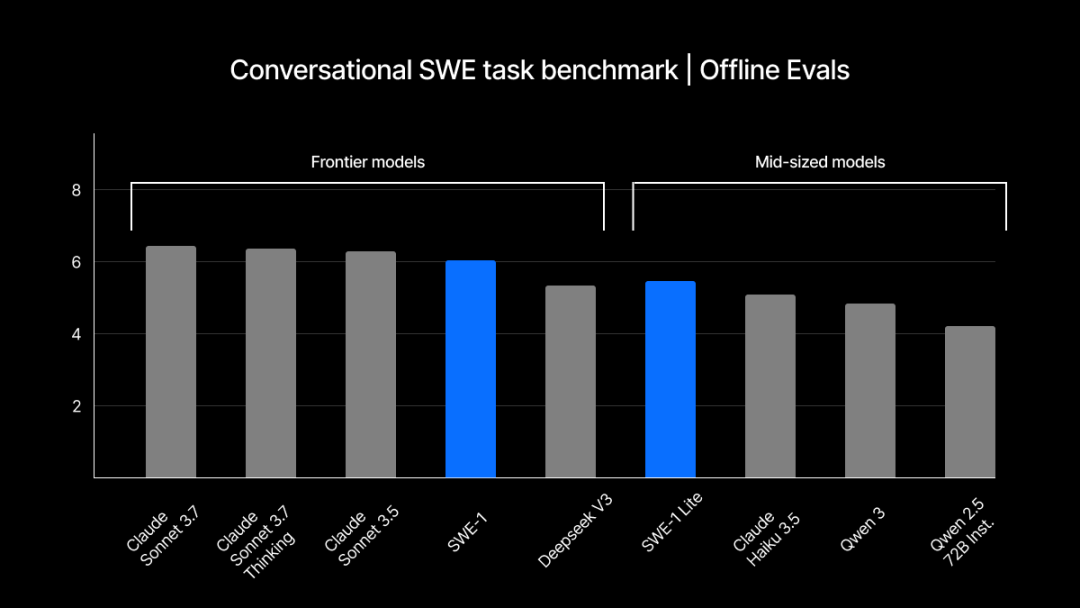
Windsurf lanza su serie de modelos SWE-1 auto-desarrollados, optimizando los procesos de ingeniería de software: Windsurf ha lanzado su primera serie de modelos optimizados para ingeniería de software, SWE-1, con el objetivo de aumentar la eficiencia del desarrollo en un 99%. La serie incluye SWE-1 (con capacidad de llamada a herramientas cercana a Claude 3.5 Sonnet, pero a menor costo), SWE-1-lite (alta calidad, sustituto de Cascade Base) y SWE-1-mini (pequeño y rápido, para escenarios de baja latencia). Su innovación principal radica en el sistema “Flow Awareness”, donde la AI comparte la línea de tiempo operativa con el usuario, logrando una colaboración eficiente y comprensión de los estados incompletos (Fuente: WeChat, WeChat)
El mecanismo de memoria de ChatGPT es sometido a ingeniería inversa, revelando tres subsistemas de memoria: La función de memoria “historial de chat” introducida por OpenAI para ChatGPT ha sido analizada por entusiastas de la tecnología, revelando que podría constar de tres subsistemas: historial de la conversación actual, historial de conversaciones (basado en resúmenes y recuperación de contenido) y percepciones del usuario (generadas a partir del análisis de múltiples conversaciones, con un grado de confianza). Estos mecanismos tienen como objetivo proporcionar una experiencia de interacción más personalizada y eficiente, utilizando tecnologías como RAG y espacios vectoriales. Aunque OpenAI afirma que mejora la experiencia del usuario, los comentarios de la comunidad son mixtos, y algunos usuarios informan de inestabilidad o bugs en la función (Fuente: WeChat, 量子位)
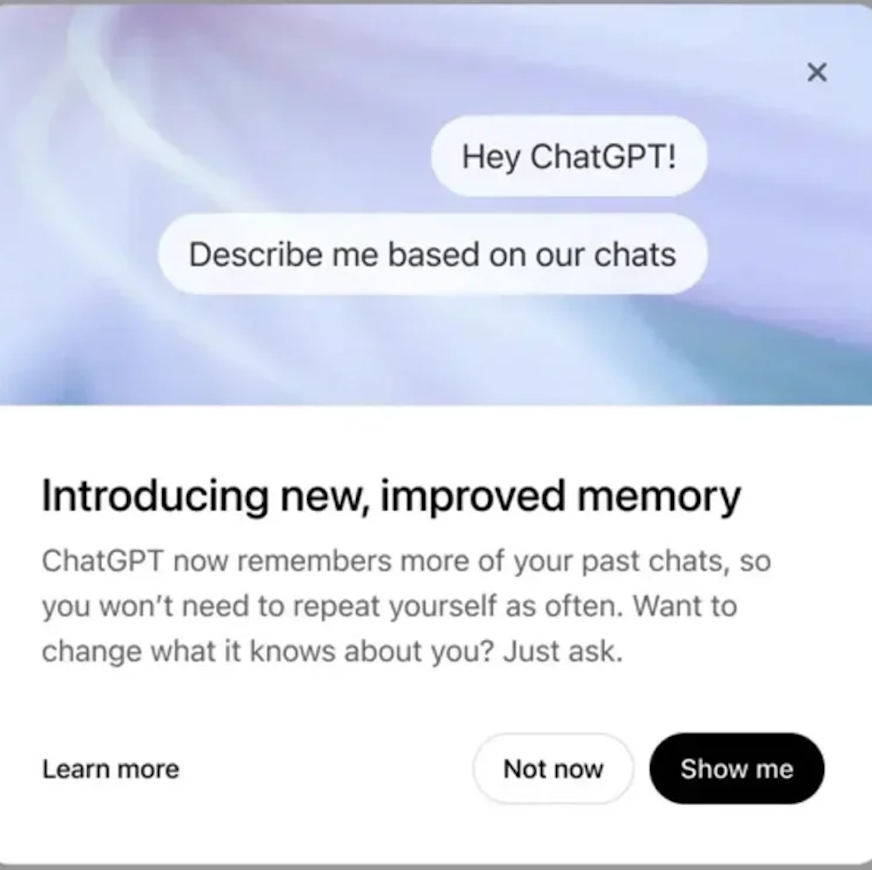
Tencent Hunyuan Image 2.0 lanzado, admite “dibujar mientras se habla” en tiempo real: Tencent Hunyuan ha lanzado el modelo Hunyuan Image 2.0, que logra una función de generación de texto a imagen en tiempo real con respuesta a nivel de milisegundos. A medida que el usuario introduce texto o descripciones de voz, la imagen se genera y ajusta en tiempo real. El nuevo modelo también admite un panel de dibujo en tiempo real, donde los usuarios pueden dibujar bocetos a mano combinados con descripciones de texto para generar imágenes. El modelo ha mejorado significativamente en realismo, cumplimiento semántico (adaptándose a grandes modelos de lenguaje multimodales como codificadores de texto) y tasa de compresión del códec de imagen, y se ha optimizado mediante aprendizaje por refuerzo post-entrenamiento (Fuente: 量子位)
TII lanza la serie de modelos BitNet Falcon-Edge y la biblioteca de ajuste fino onebitllms: TII ha lanzado Falcon-Edge, una serie de modelos de lenguaje compactos con 1B y 3B parámetros, con tamaños de solo 600MB y 900MB respectivamente. Estos modelos utilizan la arquitectura BitNet y pueden restaurarse a bfloat16 casi sin pérdida de rendimiento. Los resultados preliminares muestran un rendimiento superior a otros modelos pequeños y comparable a Qwen3-1.7B, pero con solo 1/4 de la huella de memoria. También se ha lanzado la biblioteca onebitllms, dedicada al ajuste fino de modelos BitNet (Fuente: Reddit r/LocalLLaMA, winglian)

El nuevo motor de Ollama mejora el soporte multimodal: Ollama ha actualizado su motor para ofrecer soporte nativo a modelos multimodales, permitiendo optimizaciones específicas del modelo y una mejor gestión de la memoria. Los usuarios pueden probar modelos multimodales como Llama 4 y Gemma 3 a través de la integración con LangChain. Los desarrolladores de Google AI también han publicado una guía sobre el uso de Ollama y Gemma 3 para la llamada a funciones, con el fin de implementar funcionalidades como la búsqueda en tiempo real (Fuente: LangChainAI, ollama)
Grok añade función de control de relación de aspecto para la generación de imágenes: El modelo Grok de xAI ahora permite a los usuarios especificar la relación de aspecto deseada al generar imágenes, ofreciendo mayor flexibilidad y control en la creación de imágenes (Fuente: grok)
Google AI Studio se actualiza, añade página de generación de medios y panel de uso: La plataforma ai.studio de Google ha recibido una serie de actualizaciones, incluyendo un nuevo diseño de la página de inicio, un panel de control de uso integrado y una nueva página de generación de medios (gen media), lo que sugiere que podría haber más anuncios relacionados en la próxima conferencia I/O (Fuente: matvelloso)
LatitudeGames lanza nuevo modelo Harbinger-24B (New Wayfarer): LatitudeGames ha lanzado un nuevo modelo en Hugging Face llamado Harbinger-24B, con el nombre en clave New Wayfarer. La comunidad ha mostrado interés y debate por qué no se optó por ajustar finamente otros modelos como Qwen3 32B o Llama 4 Scout (Fuente: Reddit r/LocalLLaMA)

🧰 Herramientas
Adopt AI recauda 6 millones de dólares en financiación, con el objetivo de reestructurar la interacción con el software mediante AI Agents: La startup Adopt AI ha obtenido 6 millones de dólares en una ronda de financiación semilla, con el objetivo de permitir que el software empresarial tradicional integre rápidamente capacidades de interacción en lenguaje natural sin necesidad de código, a través de sus dos funciones principales: Agent Builder y Agent Experience. Su tecnología puede aprender automáticamente la estructura de las aplicaciones y las API, generando operaciones que pueden ser invocadas mediante lenguaje natural, y garantiza la seguridad de los datos a través de una arquitectura Pass-through. Su objetivo es mejorar la tasa de adopción y la eficiencia del software, y reducir los costos empresariales (Fuente: WeChat)

Volcano Engine de ByteDance lanza una demo de hardware AI en miniatura, con alta capacidad de personalización (DIY): Volcano Engine ha lanzado una demo de un hardware AI en miniatura y ha hecho público el código de su cliente/servidor. Este hardware permite un alto grado de personalización, pudiendo conectarse a los grandes modelos de Volcano, agentes Coze, así como a grandes modelos de terceros compatibles con la API de OpenAI (como FastGPT) y diversas voces TTS (incluyendo MiniMax). Los usuarios pueden realizar proyectos DIY para conversar con personajes específicos (como un joven Jay Chou o He Jiong) o crear aplicaciones de servicio al cliente por voz con AI, ofreciendo una rica experiencia de interacción con AI (Fuente: WeChat)

Runway lanza la API Gen-4 References, capacitando a los desarrolladores para construir aplicaciones de generación de imágenes: Runway ha abierto su popular modelo de generación de imágenes Gen-4 References a los desarrolladores a través de una API. Este modelo es conocido por su versatilidad y flexibilidad, capaz de generar imágenes nuevas y estilísticamente consistentes basadas en imágenes de referencia. El lanzamiento de la API permitirá a los desarrolladores integrar esta potente capacidad de generación de imágenes en sus propias aplicaciones y flujos de trabajo (Fuente: c_valenzuelab)

Zencoder lanza la plataforma de agentes de IA para optimización de codificación Zen Agents: La startup de IA Zencoder (nombre oficial For Good AI Inc.) ha lanzado una plataforma en la nube llamada Zen Agents, utilizada para crear agentes de IA optimizados para tareas de codificación, con el objetivo de mejorar la eficiencia y calidad del desarrollo de software (Fuente: dl_weekly)
llmbasedos: una distribución Linux minimalista basada en MCP, optimizada para LLM locales: Un desarrollador ha construido llmbasedos, una distribución minimalista basada en Arch Linux, diseñada para convertir el entorno local en un ciudadano de primera clase para frontends de LLM (como Claude Desktop, VS Code). Expone capacidades locales (archivos, correo, proxy, etc.) a través del protocolo MCP (Model Context Protocol), admite modo offline (con llama.cpp) o conexión a modelos en la nube como GPT-4o y Claude, facilitando a los desarrolladores la adición rápida de nuevas funcionalidades (Fuente: Reddit r/LocalLLaMA)
La ejecución de LLM y sistemas Linux en archivos PDF llama la atención: El entusiasta de la tecnología Aiden Bai ha mostrado el proyecto “llm.pdf”, que ejecuta pequeños modelos de lenguaje (como TinyStories, Pythia, TinyLLM) dentro de archivos PDF. Esto se logra compilando el modelo a JavaScript y aprovechando el soporte de PDF para JS. En los comentarios, alguien señaló que ya existía un precedente de ejecutar un sistema Linux en PDF (a través de un emulador RISC-V). Esto revela el potencial de PDF como contenedor de contenido dinámico, pero también plantea debates sobre seguridad y practicidad (Fuente: WeChat)

Actualización de la herramienta CLI de OpenAI Codex, admite inicio de sesión con ChatGPT y nuevo modelo mini: El equipo de desarrolladores de OpenAI anunció mejoras en la herramienta CLI de Codex, incluyendo soporte para iniciar sesión con cuentas de ChatGPT para conectar rápidamente con organizaciones API, y la adición del modelo codex-mini, optimizado para tareas de preguntas y respuestas y edición de código de baja latencia (Fuente: openai, dotey)
La máquina todo en uno de IA de SenseTime recibe la recomendación de IDC, admite modelos como SenseNova y DeepSeek: En el informe “Análisis del mercado de máquinas todo en uno de IA de China y recomendación de marcas, 2025” publicado por IDC, la máquina todo en uno de IA de SenseTime fue seleccionada. Esta máquina se basa en la infraestructura de IA SenseTime AI Cloud, está equipada con chips de cómputo de alto rendimiento y motores de aceleración de inferencia, admite el modelo “Ririxin SenseNova V6” de SenseTime y otros modelos grandes convencionales como DeepSeek. Ofrece una solución autónoma y controlable de cadena completa, optimiza el costo total de propiedad (TCO) y ya se ha implementado en múltiples industrias como la médica y financiera (Fuente: 量子位)

La herramienta de automatización de flujos de trabajo de código abierto n8n añade soporte para chino: La popular herramienta de automatización de flujos de trabajo de código abierto n8n ahora admite una interfaz en chino gracias a un paquete de localización contribuido por la comunidad. Los usuarios pueden descargar el archivo de localización correspondiente a su versión y, mediante una simple modificación de la configuración de Docker, utilizar n8n en chino, lo que reduce la barrera de entrada para los usuarios chinos (Fuente: WeChat)

git-bug: Rastreador de bugs distribuido y offline-first incrustado en Git: git-bug es una herramienta de código abierto que incrusta problemas, comentarios, etc., como objetos dentro del repositorio Git (en lugar de archivos comunes), logrando un seguimiento de bugs distribuido y prioritariamente offline. Admite la sincronización de problemas con plataformas como GitHub y GitLab a través de puentes, y ofrece interfaces CLI, TUI y web (Fuente: GitHub Trending)
PyLate integra el índice PLAID, mejorando la eficiencia de las pruebas de referencia de modelos en conjuntos de datos a gran escala: Antoine Chaffin anunció que PyLate (un ecosistema para el entrenamiento e inferencia de modelos ColBERT) ha fusionado el índice PLAID. Esta integración permite a los usuarios realizar pruebas de referencia de los mejores modelos de manera eficiente en sus conjuntos de datos de muy gran escala, facilitando la obtención de resultados SOTA en diversas clasificaciones de recuperación (Fuente: lateinteraction, tonywu_71)

Neon: Base de datos PostgreSQL sin servidor de código abierto: Neon es una alternativa de código abierto y sin servidor a PostgreSQL, que separa el almacenamiento y el cómputo para lograr escalado automático, ramificación de bases de datos como código y escalado a cero. El proyecto ha ganado atención en GitHub, ofreciendo una nueva opción para desarrolladores de IA y otras aplicaciones que necesitan soluciones de bases de datos elásticas y escalables (Fuente: GitHub Trending)

Unmute.sh: Nueva herramienta de chat de voz con IA con prompts y voces personalizables: Unmute.sh es una nueva herramienta de chat de voz con IA que se caracteriza por permitir a los usuarios personalizar los prompts y seleccionar diferentes voces, ofreciendo una experiencia de interacción de voz más personalizada y flexible (Fuente: Reddit r/artificial)
📚 Aprendizaje
Se publica el primer marco de evaluación de modelos multimodales generalistas del mundo, General-Level, y el benchmark General-Bench: Una investigación aceptada en ICML‘25 (Spotlight) propone un nuevo marco de evaluación para grandes modelos multimodales (MLLM) llamado General-Level y su conjunto de datos complementario General-Bench. Este marco introduce un sistema de cinco niveles, centrándose en evaluar el “efecto de generalización sinérgica” (Synergy) del modelo, es decir, la capacidad de transferir y mejorar el conocimiento entre diferentes modalidades o tareas. General-Bench es actualmente el benchmark de evaluación de MLLM más grande y con mayor cobertura, con más de 700 tareas, más de 320,000 datos de prueba, y abarcando cinco modalidades principales (imagen, video, audio, 3D y lenguaje) y 29 dominios. La tabla de clasificación muestra que modelos como GPT-4V actualmente solo alcanzan el Nivel-2 (sin sinergia), y ningún modelo ha alcanzado aún el Nivel-5 (sinergia completa en todas las modalidades) (Fuente: WeChat)

El paper J1 propone incentivar el pensamiento en LLM-as-a-Judge mediante aprendizaje por refuerzo: Un nuevo paper titulado “J1: Incentivizing Thinking in LLM-as-a-Judge via RL” (arxiv:2505.10320) explora cómo utilizar el aprendizaje por refuerzo (RL) para incentivar a los grandes modelos de lenguaje que actúan como evaluadores (LLM-as-a-Judge) a realizar un “pensamiento” más profundo, en lugar de simplemente emitir juicios superficiales. Este enfoque podría mejorar la precisión y fiabilidad de los LLM al evaluar tareas complejas (Fuente: jaseweston)

Nuevo marco TREQA utiliza LLM para evaluar la calidad de traducción de textos complejos: Ante las deficiencias de las métricas existentes de traducción automática (MT) para evaluar textos complejos, los investigadores han propuesto el marco TREQA. Este marco utiliza grandes modelos de lenguaje (LLM) para generar preguntas sobre el texto fuente y el texto traducido, y compara las respuestas a estas preguntas para evaluar si la traducción ha conservado la información clave. Este método tiene como objetivo medir de manera más integral la calidad de la traducción de textos largos (Fuente: gneubig)

Investigación descubre un método eficiente para calcular el producto de una matriz por su transpuesta: Dmitry Rybin y otros han descubierto un algoritmo más rápido para calcular el producto de una matriz por su transpuesta (arxiv:2505.09814). Este avance fundamental tiene un impacto profundo en múltiples campos como el análisis de datos, el diseño de chips, las comunicaciones inalámbricas y el entrenamiento de LLM, ya que este tipo de cálculo es una operación común en estas áreas. Esto demuestra una vez más que incluso en el campo maduro del álgebra lineal computacional, todavía hay espacio para mejoras (Fuente: teortaxesTex, Ar_Douillard)

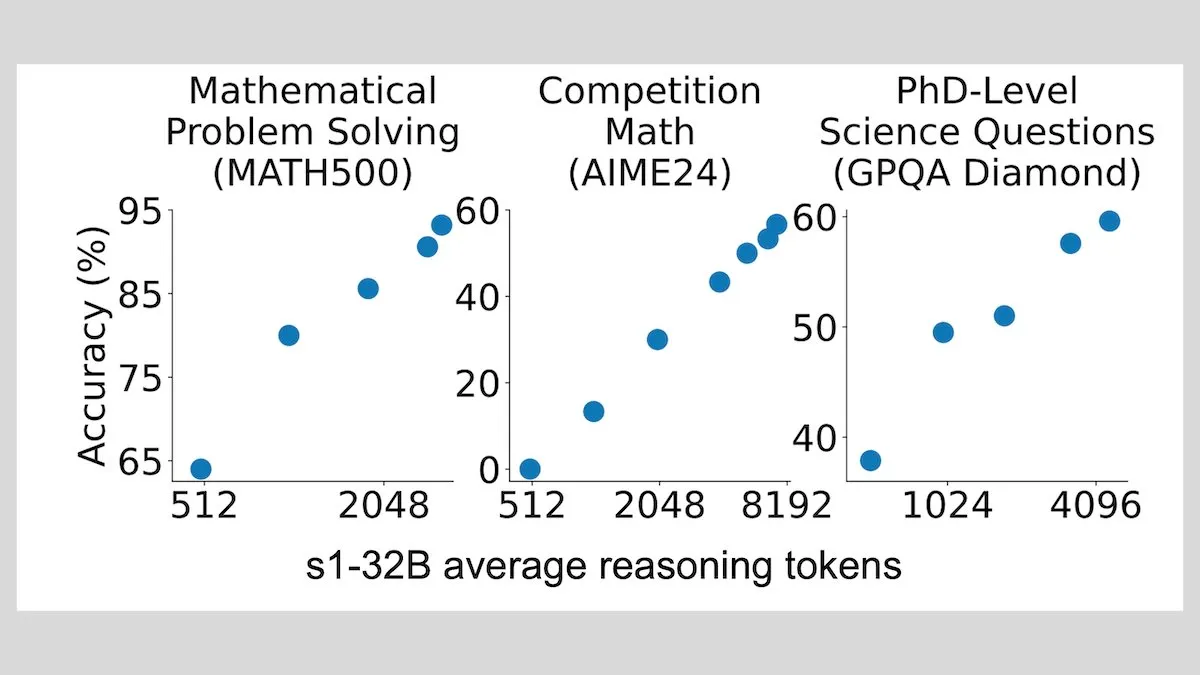
DeepLearningAI: El ajuste fino con pocas muestras puede mejorar significativamente la capacidad de razonamiento de los LLM: Investigaciones muestran que ajustar finamente un gran modelo de lenguaje con solo 1000 muestras puede mejorar significativamente su capacidad de razonamiento. Su modelo experimental s1 extiende el proceso de razonamiento añadiendo la palabra “Wait” durante la inferencia, logrando un buen rendimiento en benchmarks como AIME y MATH 500. Este método de bajos recursos indica que, sin necesidad de aprendizaje por refuerzo, se puede enseñar razonamiento avanzado con pocos datos (Fuente: DeepLearningAI)
Hugging Face lanza curso gratuito de MCP para ayudar a construir aplicaciones de IA con contexto enriquecido: Hugging Face, en colaboración con Anthropic, ha lanzado un curso gratuito titulado “MCP: Build Rich-Context AI Apps with Anthropic”. El curso tiene como objetivo ayudar a los desarrolladores a comprender la arquitectura MCP (Model Context Protocol), aprender a construir y desplegar servidores MCP y aplicaciones compatibles, simplificando así la integración de aplicaciones de IA con herramientas y fuentes de datos. Actualmente, más de 3000 estudiantes se han inscrito (Fuente: DeepLearningAI, huggingface, ClementDelangue)
El proyecto awesome-gpt4o-images recopila ejemplos destacados de generación de imágenes con GPT-4o: El proyecto de GitHub awesome-gpt4o-images, creado por Jamez Bondos, ha obtenido más de 5700 estrellas en 33 días. Este proyecto recopila y muestra excelentes ejemplos de imágenes generadas con GPT-4o y sus prompts, contando actualmente con casi cien ejemplos y planeando continuar actualizándose después de su organización y verificación, proporcionando valiosos recursos creativos para la comunidad AIGC (Fuente: dotey)
Yann LeCun comparte presentación sobre aprendizaje autosupervisado (SSL): Yann LeCun ha compartido el contenido de su presentación sobre aprendizaje autosupervisado (SSL). El SSL, como un paradigma importante del aprendizaje automático, tiene como objetivo permitir que los modelos aprendan representaciones efectivas a partir de datos no etiquetados, lo cual es crucial para reducir la dependencia de datos etiquetados a gran escala y mejorar la capacidad de generalización de los modelos (Fuente: ylecun)
El foro de papers de Hugging Face se convierte en un recurso de calidad para la selección de artículos de IA: Dwarkesh Patel recomienda el foro de papers de Hugging Face, considerándolo un recurso excelente para seleccionar los mejores artículos de IA del último mes. Esta plataforma ofrece a los investigadores un canal conveniente para descubrir y discutir los últimos avances en investigación de IA (Fuente: dwarkesh_sp, huggingface)
Se anuncian los resultados de aceptación de ACL 2025, varios artículos del equipo AIB de Alibaba International seleccionados: La principal conferencia de procesamiento de lenguaje natural, ACL 2025, ha anunciado sus resultados de aceptación. Este año, el número de envíos alcanzó un nuevo récord histórico, lo que refleja una competencia intensa. El equipo de AI Business (AIB) de Alibaba International ha tenido varios artículos aceptados, y algunos de sus logros, como Marco-o1 V2, Marco-Bench-IF y HD-NDEs (ecuaciones diferenciales neuronales para la detección de alucinaciones), han recibido altas valoraciones y han sido aceptados como artículos largos en la conferencia principal. Esto refleja la continua inversión de Alibaba International en el campo de la IA y los primeros frutos de su desarrollo de talento (Fuente: 量子位)

dstack publica una guía para la configuración rápida de interconexiones en entrenamiento distribuido: dstack ofrece una guía concisa para usuarios que realizan entrenamiento distribuido en clústeres NVIDIA o AMD, explicando cómo configurar interconexiones rápidas mediante dstack. La guía tiene como objetivo ayudar a los usuarios a optimizar el rendimiento de la red al escalar cargas de trabajo de IA en la nube o localmente (Fuente: algo_diver)
AssemblyAI comparte un video con 10 consejos para mejorar las indicaciones (prompts) de LLM: AssemblyAI ha compartido a través de un video de YouTube 10 consejos para mejorar la efectividad de las indicaciones (prompting) en grandes modelos de lenguaje (LLM), con el objetivo de ayudar a los usuarios a interactuar de manera más eficiente con los LLM para obtener los resultados deseados (Fuente: AssemblyAI)
La colección de recursos de aprendizaje de LangGraph.js “awesome-langgraphjs” gana atención: Brace ha creado y mantiene un repositorio de GitHub llamado “awesome-langgraphjs”, que recopila proyectos de código abierto y tutoriales en video de YouTube construidos con LangGraph.js. Este recurso facilita a los desarrolladores que desean aprender y utilizar LangGraph.js para construir diversas aplicaciones, desde sistemas multiagente hasta aplicaciones de chat full-stack (Fuente: LangChainAI)
💼 Negocios
La transformación estratégica de IA de Alibaba muestra efectividad, con un crecimiento significativo en los ingresos de la nube y productos de IA: El informe financiero del cuarto trimestre de 2025 de Alibaba muestra que, excluyendo negocios específicos, los ingresos generales aumentaron un 10% interanual. Los ingresos del negocio de Cloud Intelligence crecieron un 18%, y los ingresos de productos relacionados con la IA mantuvieron un crecimiento interanual de tres dígitos durante 7 trimestres consecutivos. Alibaba considera la IA como una estrategia central y planea invertir más de 380 mil millones de yuanes en los próximos tres años para actualizar su infraestructura de computación en la nube e IA. Su modelo de código abierto Tongyi Qianwen Qwen-3 ha encabezado múltiples listas globales, generando más de 100,000 modelos derivados, lo que demuestra su fortaleza tecnológica y la vitalidad de su ecosistema de código abierto. Alibaba está acelerando la implementación de la IA en industrias como la automotriz, comunicaciones y finanzas (Fuente: 36氪)
La aplicación de edición de video Mojo es adquirida por Dailymotion: La aplicación de edición de video Mojo (@mojo_video_app) ha sido adquirida por Dailymotion. La tecnología de edición de video de Mojo se integrará en la aplicación social y los productos B2B de Dailymotion, con el objetivo conjunto de crear la próxima generación de plataformas de video social en Europa (Fuente: ClementDelangue)
Cohere adquiere Ottogrid, fortaleciendo sus capacidades de IA empresarial: La compañía de IA Cohere anunció la adquisición de la startup Ottogrid. Se espera que esta adquisición mejore las capacidades de Cohere en soluciones de IA a nivel empresarial, aunque no se han revelado detalles específicos de la transacción ni la dirección tecnológica de Ottogrid (Fuente: aidangomez, nickfrosst)

🌟 Comunidad
Los AI Agents provocan un debate sobre la transformación de las formas de trabajo, el futuro podría ser como un juego de estrategia en tiempo real: Will Depue planteó que el trabajo futuro podría evolucionar hacia un modelo similar a Starcraft o Age of Empires, donde los humanos dirigen alrededor de 200 microagentes inteligentes para procesar tareas, recopilar información, diseñar sistemas, etc. Sam Altman retuiteó mostrando su acuerdo. Fabian Stelzer bromeó llamándolo “codificación estilo Zerg rush”. Esta perspectiva refleja las ideas y discusiones de la comunidad sobre cómo los AI Agents remodelarán los flujos de trabajo y los modelos de colaboración humano-máquina (Fuente: willdepue, sama, fabianstelzer)
Las respuestas del robot Grok de xAI generan controversia, se alega modificación no autorizada de los prompts: xAI admitió que los prompts de su robot de respuesta Grok en la plataforma X fueron modificados sin autorización en la madrugada del 14 de mayo, lo que provocó que sus análisis sobre ciertos eventos (como los relacionados con Trump) parecieran anómalos o no concordaran con la información principal. La comunidad sigue de cerca este asunto, y personalidades como Clement Delangue han pedido que Grok sea de código abierto para aumentar la transparencia. Usuarios como Colin Fraser, comparando las respuestas de Grok en diferentes momentos, intentan realizar ingeniería inversa del historial de modificaciones de sus prompts de sistema (Fuente: ClementDelangue, menhguin, colin_fraser)

Se rumorea una gran cantidad de dimisiones en el equipo Llama4 de Meta, lo que genera preocupación en la comunidad sobre el futuro de la IA de código abierto: Mensajes de la comunidad indican que aproximadamente el 80% de los miembros del equipo Llama4 de Meta (11 de los 14 miembros originales del equipo) han dimitido, y el lanzamiento de su modelo insignia Behemoth se ha retrasado. Este asunto ha generado una amplia atención, y personalidades de la industria como Nat Lambert han expresado su pesar. Scaling01 comentó que Meta podría necesitar un nuevo director de marketing para Llama. Usuarios como TeortaxesTex expresaron su preocupación por el posible impacto negativo en el desarrollo de la IA de código abierto, e incluso discutieron si China se convertiría en la última esperanza para el código abierto (Fuente: teortaxesTex, Dorialexander, scaling01)

El uso de la IA en la guerra y sus cuestiones éticas generan preocupación: La comunidad de Reddit debate sobre la aplicación de la IA en la guerra, señalando que ya se utiliza para la vigilancia y localización de combatientes, proporcionando inteligencia militar mediante el análisis de información. Se menciona que el ejército estadounidense utiliza herramientas de IA como DART desde 1991. Los usuarios temen los riesgos letales que podría conllevar la armamentización de la IA y la amenaza potencial para la humanidad, y siguen de cerca la elaboración de tratados y medidas internacionales al respecto. Las directrices de uso de OpenAI también eliminaron la cláusula que prohibía los usos militares, lo que genera una mayor reflexión (Fuente: Reddit r/ArtificialInteligence)
Los grandes modelos de lenguaje tienen un bajo rendimiento en el concurso de programación CCPC, exponiendo sus limitaciones actuales: En la final del décimo Concurso de Diseño de Programas para Estudiantes Universitarios de China (CCPC), varios grandes modelos de lenguaje conocidos como Seed-Thinking de ByteDance (incluidos o3/o4, Gemini 2.5 pro, DeepSeek R1) tuvieron un rendimiento deficiente, la mayoría solo resolviendo el problema de “check-in” o obteniendo cero puntos. El personal oficial explicó que los modelos intentaron resolver los problemas de forma puramente autónoma, sin intervención humana. La comunidad analiza que esto expone las deficiencias de los grandes modelos actuales para resolver problemas algorítmicos altamente innovadores y complejos, especialmente en modo no agéntico (es decir, sin herramientas auxiliares para ejecución y depuración). Esto contrasta con el o3 de OpenAI, que obtuvo una medalla de oro en la Olimpiada Internacional de Informática (IOI) mediante entrenamiento agéntico (Fuente: WeChat)

El framework DSPy y las “lecciones amargas” generan debate, enfatizando el diseño normativo y la automatización de prompts: Las discusiones relacionadas con DSPy enfatizan que, aunque el escalado de la IA (Scaling) puede eludir muchos desafíos de ingeniería (las “lecciones amargas”), no puede reemplazar un diseño cuidadoso de la especificación central del problema (requisitos y flujo de información). Sin embargo, el escalado puede elevar el nivel de abstracción en la definición de problemas. La automatización de prompts (como los optimizadores de prompts) se considera una forma de utilizar la capacidad computacional que se alinea con las “lecciones amargas”, mientras que los prompts manuales pueden contravenirlas, ya que inyectan intuición humana en lugar de permitir que el modelo aprenda (Fuente: lateinteraction, lateinteraction)
Se debate el costo computacional de la autoverificación/exploración de herramientas por parte de los AI Agents durante el razonamiento: Paul Calcraft pregunta sobre la práctica de invertir grandes recursos computacionales (como más de 200 dólares para resolver un solo problema) en la fase de inferencia para que los AI Agents realicen una autoverificación activa, uso de herramientas y flujos de trabajo exploratorios. Señala que Devin y sus competidores podrían hacerlo para demostraciones de relaciones públicas, pero no está claro para escenarios que buscan soluciones novedosas (similar a FunSearch pero con menos restricciones) (Fuente: paul_cal)
La “programación por ambiente” (Vibe Coding) asistida por IA genera debate: Herramientas como GitHub Copilot han hecho posible la “programación por ambiente” (Vibe Coding, que se refiere a un estilo de programación que depende más de la intuición y la asistencia de la IA que de una planificación estricta), e incluso estudiantes de 16 años utilizan Copilot para completar proyectos escolares. Las opiniones de la comunidad sobre este fenómeno son diversas: algunos lo consideran un nuevo paradigma de programación, mientras que otros enfatizan la importancia de los fundamentos y la planificación rigurosa (Fuente: Reddit r/ArtificialInteligence, nrehiew_)
La biblioteca Transformers de Hugging Face habilita un nuevo tablero comunitario: Hugging Face ha abierto un nuevo tablero comunitario para su biblioteca principal Transformers, destinado a publicar anuncios, presentar nuevas funciones, actualizar hojas de ruta e invitar a los usuarios a hacer preguntas y discutir sobre el uso de la biblioteca o problemas con los modelos. El objetivo es fortalecer la interacción y el soporte con los desarrolladores (Fuente: TheZachMueller, ClementDelangue)
Desarrolladores de IA piden a las principales conferencias que añadan una vía de artículos “Findings”: Dado el aumento masivo de envíos a las principales conferencias de IA como NeurIPS (que alcanza los 25,000 artículos), Dan Roy y otros piden que se siga el ejemplo de conferencias como ACL y se establezca una vía de artículos tipo “Findings”. Esto tiene como objetivo ofrecer una oportunidad de publicación para investigaciones que, aunque no alcancen el estándar de la conferencia principal, sigan teniendo valor, aliviando la presión sobre los revisores y fomentando un intercambio académico más amplio. La propuesta incluye una revisión ligera, centrada en mejorar la claridad de los artículos, entre otros aspectos (Fuente: AndrewLampinen)
💡 Otros
Exoesqueleto impulsado por IA ayuda a usuarios de sillas de ruedas a ponerse de pie y caminar: Un dispositivo de exoesqueleto impulsado por IA ha demostrado su capacidad para ayudar a los usuarios de sillas de ruedas a volver a ponerse de pie y caminar. Este tipo de tecnología fusiona la robótica, los sensores y los algoritmos de IA, percibiendo la intención del usuario y proporcionando asistencia motorizada, lo que brinda esperanza de rehabilitación y mejora de la calidad de vida a las personas con movilidad reducida (Fuente: Ronald_vanLoon)
Uso de IA para visualizar creativamente nombres de usuario: En Reddit y la comunidad X ha surgido una pequeña tendencia en la que los usuarios utilizan herramientas de generación de imágenes por IA (como DALL-E 3 integrado en ChatGPT) para crear imágenes conceptuales basadas en sus nombres de usuario de redes sociales, compartiendo estas obras llenas de imaginación y demostrando las divertidas aplicaciones de la IA en la expresión creativa personalizada (Fuente: Reddit r/ChatGPT, Reddit r/ChatGPT)

Amazon Ads utiliza IA para mejorar la eficiencia del marketing de marcas en el extranjero: Amazon Ads ha lanzado el concepto “World Screen Lab” para mostrar cómo utiliza la tecnología de IA para potenciar la internacionalización de las marcas chinas. A través de su matriz de medios como Prime Video, amplía el alcance de la marca; utiliza estudios creativos de IA (como herramientas de generación de video) para reducir las barreras de producción de contenido; y optimiza la inversión publicitaria y la conversión mediante herramientas como Amazon DSP y Performance+. La IA desempeña un papel en toda la cadena, desde la generación creativa hasta la medición de resultados, con el objetivo de ayudar a los propietarios de marcas, especialmente a las PYMEs, a construir marcas globales de manera más eficiente (Fuente: 36氪)
