
Mots-clés:OpenAI Codex, Développement de logiciels IA, Modèles multimodaux, Génération vocale IA, Filtrage des données, Version préliminaire de recherche Codex, MiniMax Speech-02, Modèle multimodal BLIP3-o, Préselection des données, Série de modèles SWE-1
🔥 À la Une
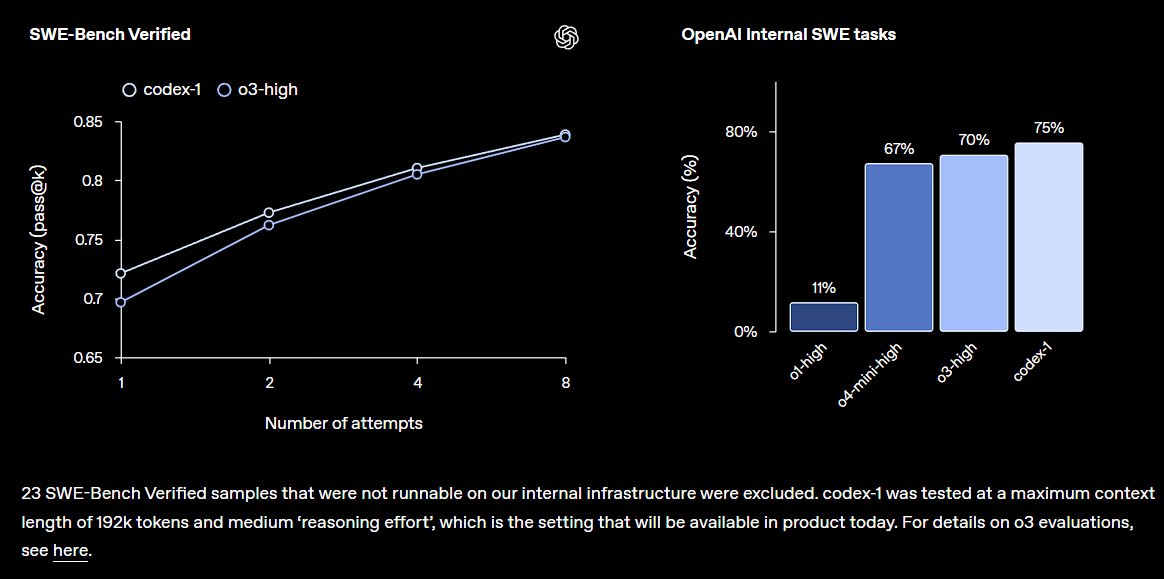
OpenAI publie une préversion de recherche de Codex, intégrée à ChatGPT: OpenAI lance Codex, un agent d’ingénierie logicielle basé sur le cloud, capable de comprendre de vastes bases de code, d’écrire de nouvelles fonctionnalités, de corriger des erreurs et de traiter plusieurs tâches en parallèle. Codex est basé sur le modèle codex-1 affiné par o3 et affiche d’excellentes performances sur SWE-bench. Cette fonctionnalité sera progressivement déployée pour les utilisateurs de ChatGPT Pro, Team et Enterprise, visant à augmenter considérablement la productivité des développeurs et annonçant un rôle plus central pour l’IA dans le domaine du développement logiciel. La communauté a réagi positivement, mais s’interroge également sur son efficacité réelle et ses bugs potentiels (Source: OpenAI, OpenAI Developers, scaling01, dotey)
Les licenciements massifs chez Microsoft secouent l’industrie, la transformation organisationnelle induite par l’IA s’accélère: Microsoft annonce environ 6000 licenciements à l’échelle mondiale, visant à simplifier les niveaux de management et à augmenter la proportion de programmeurs. Parmi les employés licenciés figurent des vétérans avec 25 ans d’ancienneté et des contributions remarquables, ainsi que des développeurs clés de TypeScript. Ces licenciements seraient liés à l’amélioration de l’efficacité par la technologie IA et à l’automatisation de certaines tâches, reflétant la tendance des géants de la technologie à contrôler les coûts et à optimiser la structure des effectifs à l’ère de l’IA. L’événement a suscité un vaste débat sur l’impact de l’IA sur le marché de l’emploi, la fidélité des employés envers l’entreprise et les futurs modèles de travail (Source: WeChat, NeelNanda5)
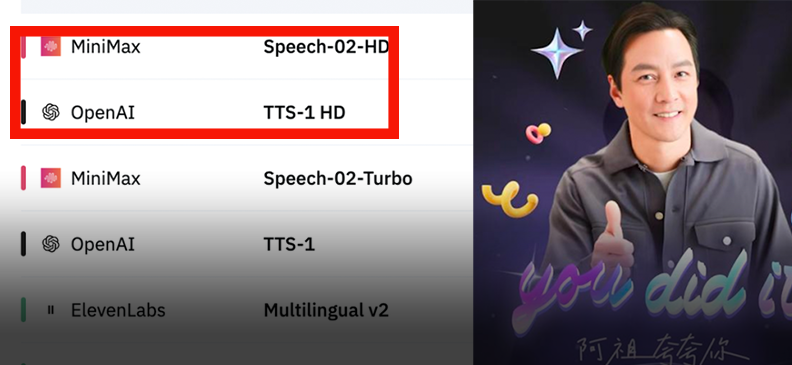
MiniMax lance le modèle vocal Speech-02, qui se hisse au sommet des classements mondiaux: MiniMax a lancé son modèle vocal de nouvelle génération, Speech-02, qui s’est classé premier dans deux évaluations vocales de référence, l’Artificial Analysis Speech Arena et le Hugging Face TTS Arena, surpassant OpenAI et ElevenLabs. Ce modèle excelle en termes d’hyperréalisme, de personnalisation de la tonalité vocale (prenant en charge 32 langues et accents, réplicables en quelques secondes à partir d’un échantillon) et de diversité, et utilise de manière innovante la technologie Flow-VAE pour améliorer les détails du clonage. Sa technologie a déjà été appliquée à des scénarios tels que « AI Azu » apprenant l’anglais et le guide IA de la Cité Interdite, démontrant la position de leader des grands modèles chinois dans le domaine de la génération vocale par IA (Source: WeChat, WeChat)
Salesforce et d’autres institutions publient le modèle multimodal unifié BLIP3-o: Salesforce Research, en collaboration avec plusieurs universités, a publié le modèle multimodal unifié entièrement open source BLIP3-o, qui adopte une stratégie « comprendre d’abord, générer ensuite » et combine les architectures autorégressives et de diffusion. Le modèle utilise de manière innovante les caractéristiques CLIP et l’entraînement Flow Matching, améliorant de manière significative la qualité, la diversité et la capacité d’alignement sur les invites des images générées. BLIP3-o affiche d’excellentes performances dans plusieurs tests de référence et est en cours d’extension à des tâches multimodales complexes telles que l’édition d’images et le dialogue visuel, faisant progresser le développement de la technologie IA multimodale (Source: 36氪)

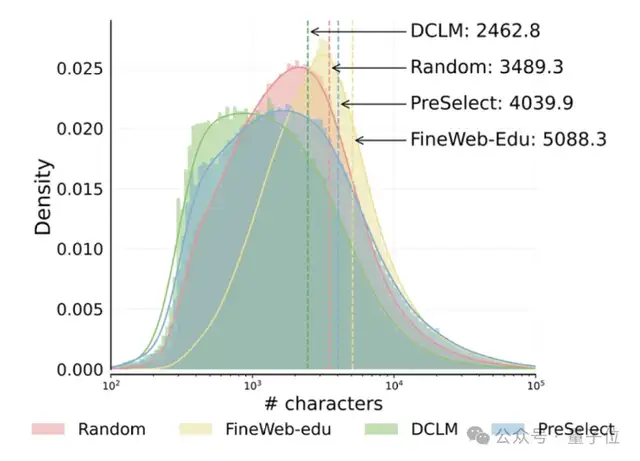
HKUST et vivo proposent la solution de filtrage de données PreSelect, multipliant par 10 l’efficacité du pré-entraînement: L’Université des sciences et technologies de Hong Kong (HKUST) et vivo AI Lab ont conjointement proposé une méthode de sélection de données légère et efficace appelée PreSelect, qui a été acceptée par l’ICML 2025. Cette méthode quantifie la contribution des données aux capacités spécifiques du modèle via un indicateur de « force de prédiction », et utilise un scoreur fastText pour filtrer l’ensemble des données d’entraînement. Elle peut réduire les besoins de calcul d’un facteur 10 tout en améliorant en moyenne de 3 % les performances du modèle. PreSelect vise à filtrer de manière plus objective et généralisable des données de haute qualité et diversifiées, surmontant les limitations des méthodes de filtrage traditionnelles basées sur des règles ou des modèles (Source: 量子位)
🎯 Tendances
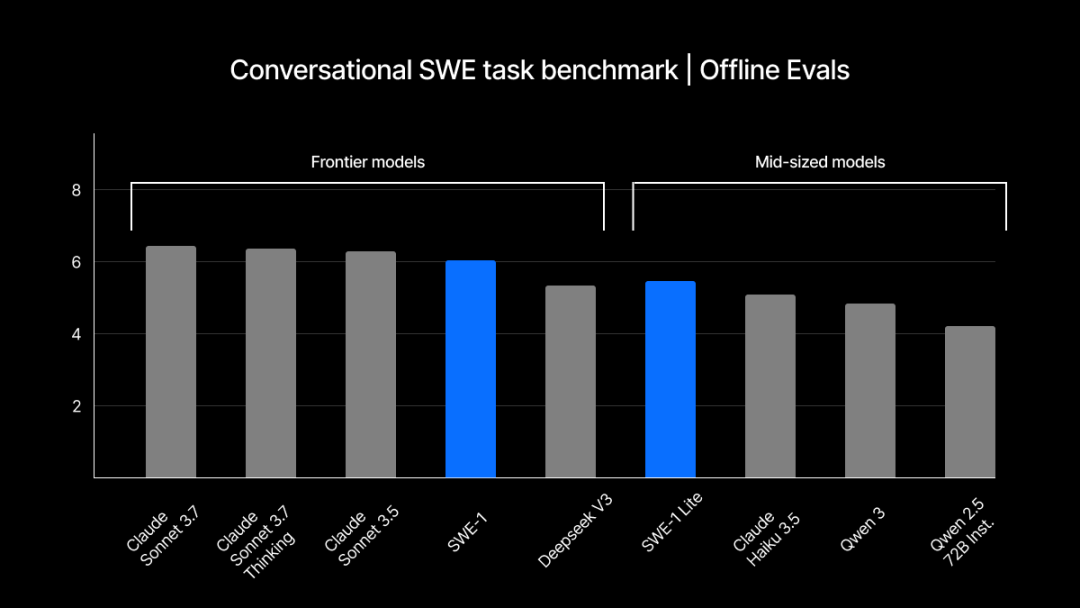
Windsurf lance sa série de modèles auto-développés SWE-1, optimisant les processus d’ingénierie logicielle: Windsurf a lancé sa première série de modèles optimisés pour l’ingénierie logicielle, SWE-1, visant à augmenter l’efficacité du développement de 99 %. La série comprend SWE-1 (capacité d’appel d’outils proche de Claude 3.5 Sonnet, mais à moindre coût), SWE-1-lite (haute qualité, remplaçant Cascade Base) et SWE-1-mini (petit et rapide, pour les scénarios à faible latence). Son innovation principale réside dans le système de « Flow Awareness » (conscience du flux), où l’IA partage la chronologie des opérations avec l’utilisateur, permettant une collaboration efficace et une compréhension des états inachevés (Source: WeChat, WeChat)
Le mécanisme de mémoire de ChatGPT fait l’objet d’une ingénierie inverse, révélant trois sous-systèmes de mémoire: La fonction de mémoire « historique des conversations » introduite par OpenAI pour ChatGPT a été analysée par des passionnés de technologie, révélant qu’elle pourrait comprendre trois sous-systèmes : l’historique de la conversation actuelle, l’historique des conversations (basé sur des résumés et la recherche de contenu) et les informations sur l’utilisateur (générées à partir de l’analyse de plusieurs conversations, avec un score de confiance). Ces mécanismes visent à offrir une expérience d’interaction plus personnalisée et efficace, grâce à des technologies telles que RAG et les espaces vectoriels. Bien qu’OpenAI affirme que cela améliore l’expérience utilisateur, les retours de la communauté sont mitigés, certains utilisateurs signalant une instabilité de la fonction ou des bugs (Source: WeChat, 量子位)
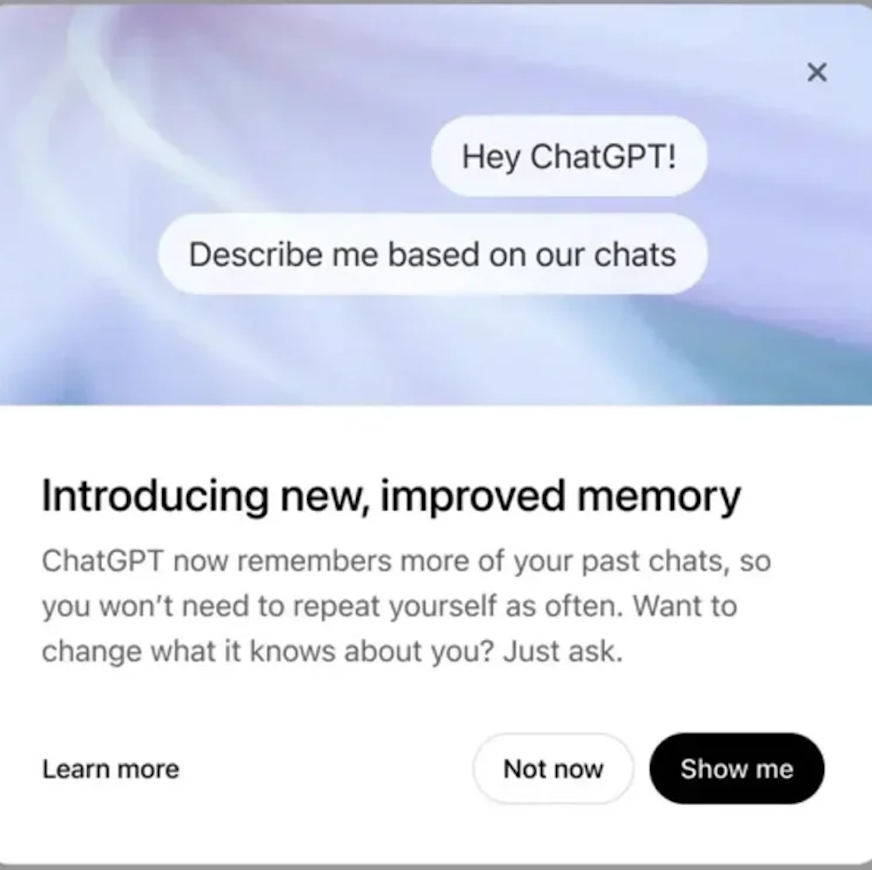
Tencent Hunyuan Image 2.0 est lancé, prenant en charge la génération d’images en temps réel « pendant que vous parlez »: Tencent Hunyuan a lancé le modèle Hunyuan Image 2.0, qui permet une génération de texte en image en temps réel avec une réponse en millisecondes. Lorsque l’utilisateur saisit du texte ou une description vocale, l’image est générée et ajustée en temps réel. Le nouveau modèle prend également en charge un tableau de dessin en temps réel, où les utilisateurs peuvent dessiner des croquis à la main combinés à des descriptions textuelles pour générer des images. Le modèle présente des améliorations significatives en termes de réalisme, de respect de la sémantique (s’adaptant aux grands modèles de langage multimodaux comme encodeurs de texte) et de taux de compression du codec image, et est optimisé par un post-entraînement par apprentissage par renforcement (Source: 量子位)
TII publie la série de modèles BitNet Falcon-Edge et la bibliothèque de fine-tuning onebitllms: TII a lancé Falcon-Edge, une série de modèles de langage compacts avec 1 milliard et 3 milliards de paramètres, d’une taille de seulement 600 Mo et 900 Mo respectivement. Ces modèles utilisent l’architecture BitNet et peuvent être restaurés en bfloat16 sans perte de performance notable. Les résultats préliminaires montrent que leurs performances sont supérieures à celles d’autres petits modèles et comparables à Qwen3-1.7B, tout en n’occupant qu’un quart de sa mémoire. La bibliothèque onebitllms, publiée simultanément, est dédiée au fine-tuning des modèles BitNet (Source: Reddit r/LocalLLaMA, winglian)

Le nouveau moteur d’Ollama améliore la prise en charge multimodale: Ollama a mis à jour son moteur pour offrir une prise en charge native des modèles multimodaux, permettant des optimisations spécifiques aux modèles et une meilleure gestion de la mémoire. Les utilisateurs peuvent essayer les modèles multimodaux Llama 4, Gemma 3 et d’autres via l’intégration LangChain. Les développeurs de Google AI ont également publié un guide sur l’utilisation d’Ollama et de Gemma 3 pour l’appel de fonctions, afin de réaliser des fonctionnalités telles que la recherche en temps réel (Source: LangChainAI, ollama)
Grok ajoute une fonction de contrôle du rapport d’aspect pour la génération d’images: Le modèle Grok de xAI permet désormais aux utilisateurs de spécifier le rapport d’aspect souhaité lors de la génération d’images, offrant une plus grande flexibilité et un meilleur contrôle sur la création d’images (Source: grok)
Mise à jour de Google AI Studio, ajout d’une page de médias génératifs et d’un tableau de bord d’utilisation: La plateforme ai.studio de Google a fait l’objet d’une série de mises à jour, notamment un nouveau design de la page d’accueil, un tableau de bord d’utilisation intégré et une nouvelle page de médias génératifs (gen media), laissant présager d’autres annonces connexes lors de la prochaine conférence I/O (Source: matvelloso)
LatitudeGames publie un nouveau modèle Harbinger-24B (New Wayfarer): LatitudeGames a publié un nouveau modèle nommé Harbinger-24B sur Hugging Face, sous le nom de code New Wayfarer. La communauté s’y intéresse et discute des raisons pour lesquelles d’autres modèles tels que Qwen3 32B ou Llama 4 Scout n’ont pas été choisis pour le fine-tuning (Source: Reddit r/LocalLLaMA)

🧰 Outils
Adopt AI lève 6 millions de dollars pour réinventer l’interaction logicielle avec des agents IA: La start-up Adopt AI a levé 6 millions de dollars en financement de démarrage, visant à permettre aux logiciels d’entreprise traditionnels d’intégrer rapidement des capacités d’interaction en langage naturel sans code, grâce à ses deux fonctionnalités principales : Agent Builder et Agent Experience. Sa technologie peut apprendre automatiquement la structure des applications et les API, générer des opérations appelables en langage naturel, et garantir la sécurité des données grâce à une architecture Pass-through. L’objectif est d’améliorer le taux d’adoption et l’efficacité des logiciels, et de réduire les coûts pour les entreprises (Source: WeChat)

Volcano Engine de ByteDance lance une démo de matériel IA miniature, hautement personnalisable: Volcano Engine a publié une démo d’un matériel IA miniature et a rendu open source son code client/serveur. Ce matériel est hautement personnalisable et peut se connecter aux grands modèles de Volcano Engine, aux agents intelligents Coze, ainsi qu’aux grands modèles tiers compatibles avec l’API OpenAI (comme FastGPT) et à diverses voix TTS (y compris MiniMax). Les utilisateurs peuvent bricoler pour dialoguer avec des personnages spécifiques (comme un jeune Jay Chou, He Jiong) ou créer des applications de service client vocal IA, offrant une riche expérience d’interaction IA (Source: WeChat)

Runway publie l’API Gen-4 References, permettant aux développeurs de créer des applications de génération d’images: Runway met son populaire modèle de génération d’images Gen-4 References à la disposition des développeurs via une API. Ce modèle est réputé pour sa polyvalence et sa flexibilité, capable de générer de nouvelles images stylistiquement cohérentes à partir d’images de référence. La publication de l’API permettra aux développeurs d’intégrer cette puissante capacité de génération d’images dans leurs propres applications et flux de travail (Source: c_valenzuelab)

Zencoder lance la plateforme d’agents IA Zen Agents pour l’optimisation du codage: La start-up IA Zencoder (nom officiel For Good AI Inc.) a lancé une plateforme cloud nommée Zen Agents, utilisée pour créer des agents IA optimisés pour les tâches de codage, visant à améliorer l’efficacité et la qualité du développement logiciel (Source: dl_weekly)
llmbasedos : une distribution Linux minimaliste basée sur MCP, optimisée pour les LLM locaux: Un développeur a créé llmbasedos, une distribution minimaliste basée sur Arch Linux, conçue pour transformer l’environnement local en un citoyen de première classe pour les frontends LLM (tels que Claude Desktop, VS Code). Il expose les capacités locales (fichiers, e-mails, proxies, etc.) via le protocole MCP (Model Context Protocol), prend en charge le mode hors ligne (avec llama.cpp) ou la connexion à des modèles cloud comme GPT-4o, Claude, etc., permettant aux développeurs d’ajouter rapidement de nouvelles fonctionnalités (Source: Reddit r/LocalLLaMA)
L’exécution de LLM et de systèmes Linux dans des fichiers PDF suscite l’attention: Le passionné de technologie Aiden Bai a présenté « llm.pdf », un projet permettant d’exécuter de petits modèles de langage (tels que TinyStories, Pythia, TinyLLM) dans des fichiers PDF, en compilant les modèles en JavaScript et en exploitant la prise en charge de JS par les PDF. Dans les commentaires, certains ont même souligné qu’il existait déjà des précédents d’exécution de systèmes Linux dans des PDF (via un émulateur RISC-V). Cela révèle le potentiel des PDF en tant que conteneurs de contenu dynamique, mais soulève également des discussions sur la sécurité et l’utilité (Source: WeChat)

Mise à jour de l’outil CLI OpenAI Codex, prise en charge de la connexion ChatGPT et du nouveau modèle mini: L’équipe de développeurs d’OpenAI a annoncé des améliorations de l’outil CLI Codex, notamment la prise en charge de la connexion via un compte ChatGPT pour une connexion rapide aux organisations API, et l’ajout du modèle codex-mini, optimisé pour les tâches de questions-réponses et d’édition de code à faible latence (Source: openai, dotey)
La solution tout-en-un de grand modèle de SenseTime recommandée par IDC, prend en charge les modèles SenseNova et DeepSeek: Dans le rapport « Analyse du marché chinois des solutions tout-en-un de grands modèles d’IA et recommandations de marques, 2025 » publié par IDC, la solution tout-en-un de grand modèle de SenseTime a été sélectionnée. Basée sur l’infrastructure IA SenseTime, cette solution est équipée de puces de calcul haute performance et d’un moteur d’accélération de l’inférence. Elle prend en charge le modèle « SenseNova V6 » de SenseTime ainsi que d’autres grands modèles courants tels que DeepSeek, offrant une solution autonome et contrôlable de bout en bout, optimisant le coût total de possession (TCO), et a déjà été déployée dans plusieurs secteurs tels que la santé et la finance (Source: 量子位)

L’outil d’automatisation de flux de travail open source n8n ajoute la prise en charge du chinois: Le populaire outil d’automatisation de flux de travail open source n8n prend désormais en charge une interface en chinois grâce à un pack de localisation fourni par la communauté. Les utilisateurs peuvent télécharger le fichier de localisation correspondant à leur version et, via une simple modification de la configuration Docker, utiliser n8n en chinois, abaissant ainsi la barrière à l’entrée pour les utilisateurs chinois (Source: WeChat)

git-bug : un traqueur de bugs distribué, priorisant le mode hors ligne, intégré à Git: git-bug est un outil open source qui intègre les problèmes, commentaires, etc., en tant qu’objets dans le dépôt Git (plutôt que comme des fichiers ordinaires), réalisant un suivi de bugs distribué et priorisant le mode hors ligne. Il prend en charge la synchronisation des problèmes avec des plateformes comme GitHub, GitLab, etc., via des ponts, et offre des interfaces CLI, TUI et Web (Source: GitHub Trending)
PyLate intègre l’index PLAID, améliorant l’efficacité des tests de référence de modèles sur de grands ensembles de données: Antoine Chaffin a annoncé que PyLate (un écosystème d’entraînement et d’inférence pour les modèles ColBERT) a fusionné l’index PLAID. Cette intégration permet aux utilisateurs d’évaluer efficacement les meilleurs modèles sur leurs très grands ensembles de données, facilitant l’obtention de résultats SOTA sur divers classements de recherche (Source: lateinteraction, tonywu_71)

Neon : base de données PostgreSQL sans serveur open source: Neon est une alternative open source à PostgreSQL sans serveur, qui sépare le stockage et le calcul pour permettre une mise à l’échelle automatique, des branches de base de données en tant que code et une mise à l’échelle jusqu’à zéro. Ce projet suscite l’attention sur GitHub, offrant une nouvelle option aux développeurs d’applications IA et autres nécessitant des solutions de base de données élastiques et évolutives (Source: GitHub Trending)

Unmute.sh : nouvel outil de chat vocal IA avec invites et voix personnalisables: Unmute.sh est un nouvel outil de chat vocal IA qui se distingue par la possibilité pour les utilisateurs de personnaliser les invites (prompt) et de choisir différentes voix, offrant une expérience d’interaction vocale plus personnalisée et flexible (Source: Reddit r/artificial)
📚 Apprentissage
Publication du premier cadre mondial d’évaluation de modèles généralistes multimodaux General-Level et du benchmark General-Bench: Une recherche acceptée à l’ICML‘25 (Spotlight) a proposé un nouveau cadre d’évaluation pour les grands modèles multimodaux (MLLM), General-Level, ainsi que l’ensemble de données associé, General-Bench. Ce cadre introduit un système de classement à cinq niveaux, examinant principalement l’« effet de généralisation synergique » (Synergy) des modèles, c’est-à-dire la capacité de transfert et d’amélioration des connaissances entre différentes modalités ou tâches. General-Bench est actuellement le benchmark d’évaluation MLLM le plus vaste et le plus complet, contenant plus de 700 tâches, plus de 320 000 données de test, couvrant cinq modalités (image, vidéo, audio, 3D et langage) et 29 domaines. Le classement montre que des modèles comme GPT-4V n’atteignent actuellement que le Niveau 2 (pas de synergie), et aucun modèle n’a encore atteint le Niveau 5 (synergie complète sur toutes les modalités) (Source: WeChat)

L’article J1 propose d’inciter les LLM-as-a-Judge à la réflexion via l’apprentissage par renforcement: Un nouvel article intitulé “J1: Incentivizing Thinking in LLM-as-a-Judge via RL” (arxiv:2505.10320) explore comment utiliser l’apprentissage par renforcement (RL) pour inciter les grands modèles de langage agissant comme évaluateurs (LLM-as-a-Judge) à une « réflexion » plus approfondie, plutôt que de simplement donner des jugements superficiels. Cette approche pourrait améliorer la précision et la fiabilité des LLM dans l’évaluation de tâches complexes (Source: jaseweston)

Un nouveau cadre, TREQA, utilise les LLM pour évaluer la qualité de la traduction de textes complexes: Face aux lacunes des indicateurs de traduction automatique (MT) existants pour évaluer les textes complexes, des chercheurs ont proposé le cadre TREQA. Ce cadre utilise des grands modèles de langage (LLM) pour générer des questions sur le texte source et le texte traduit, puis compare les réponses à ces questions pour évaluer si la traduction a conservé les informations clés. Cette méthode vise à mesurer de manière plus complète la qualité de la traduction de textes longs (Source: gneubig)

Découverte d’une méthode de calcul efficace pour le produit d’une matrice par sa transposée: Dmitry Rybin et al. ont découvert un algorithme plus rapide pour calculer le produit d’une matrice par sa transposée (arxiv:2505.09814). Cette avancée fondamentale a des implications profondes pour de nombreux domaines tels que l’analyse de données, la conception de puces, les communications sans fil et l’entraînement des LLM, car ce type de calcul est une opération courante dans ces domaines. Cela prouve une fois de plus que même dans le domaine mature de l’algèbre linéaire computationnelle, il y a encore place à l’amélioration (Source: teortaxesTex, Ar_Douillard)

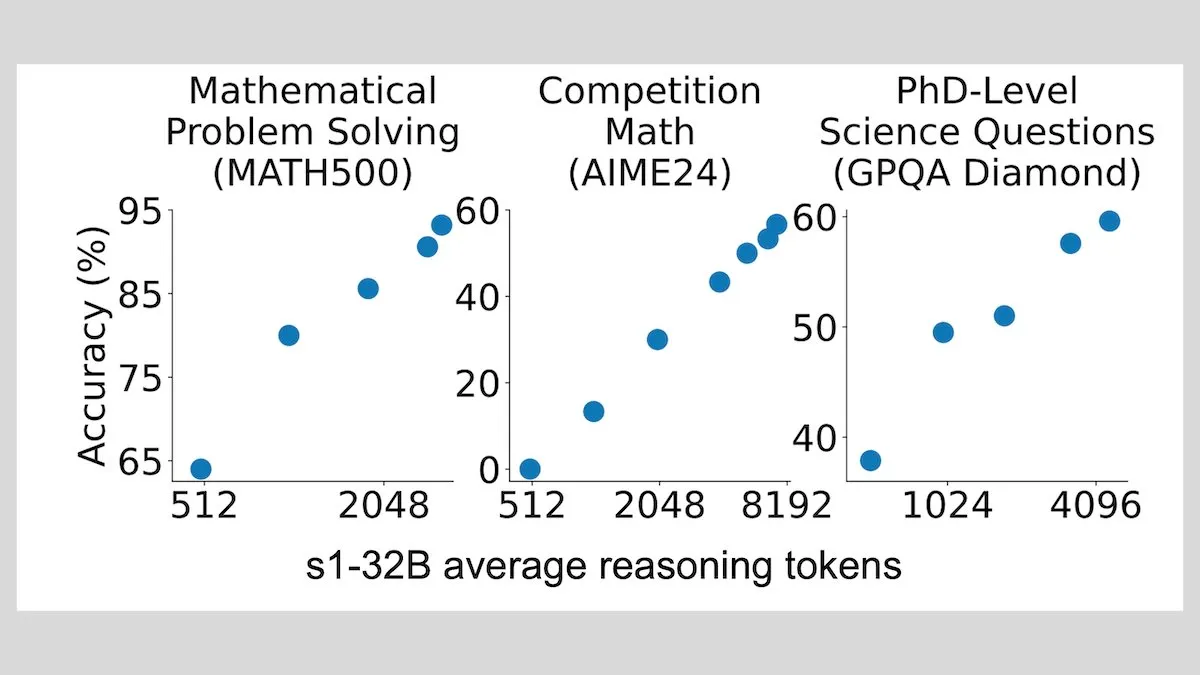
DeepLearningAI : un fine-tuning avec peu d’échantillons peut améliorer significativement la capacité de raisonnement des LLM: Des recherches montrent qu’un fine-tuning d’un grand modèle de langage avec seulement 1000 échantillons peut améliorer significativement sa capacité de raisonnement. Leur modèle expérimental s1, en ajoutant le mot « Wait » pendant le raisonnement pour étendre le processus, a obtenu de bonnes performances sur des benchmarks tels que AIME et MATH 500. Cette approche à faibles ressources suggère qu’il est possible d’enseigner un raisonnement avancé avec peu de données, sans apprentissage par renforcement (Source: DeepLearningAI)
Hugging Face lance un cours MCP gratuit pour aider à créer des applications IA à contexte riche: Hugging Face, en collaboration avec Anthropic, a lancé un cours gratuit intitulé « MCP: Build Rich-Context AI Apps with Anthropic ». Le cours vise à aider les développeurs à comprendre l’architecture MCP (Model Context Protocol), à apprendre comment créer et déployer des serveurs MCP et des applications compatibles, simplifiant ainsi l’intégration des applications IA avec des outils et des sources de données. Plus de 3000 étudiants se sont déjà inscrits (Source: DeepLearningAI, huggingface, ClementDelangue)
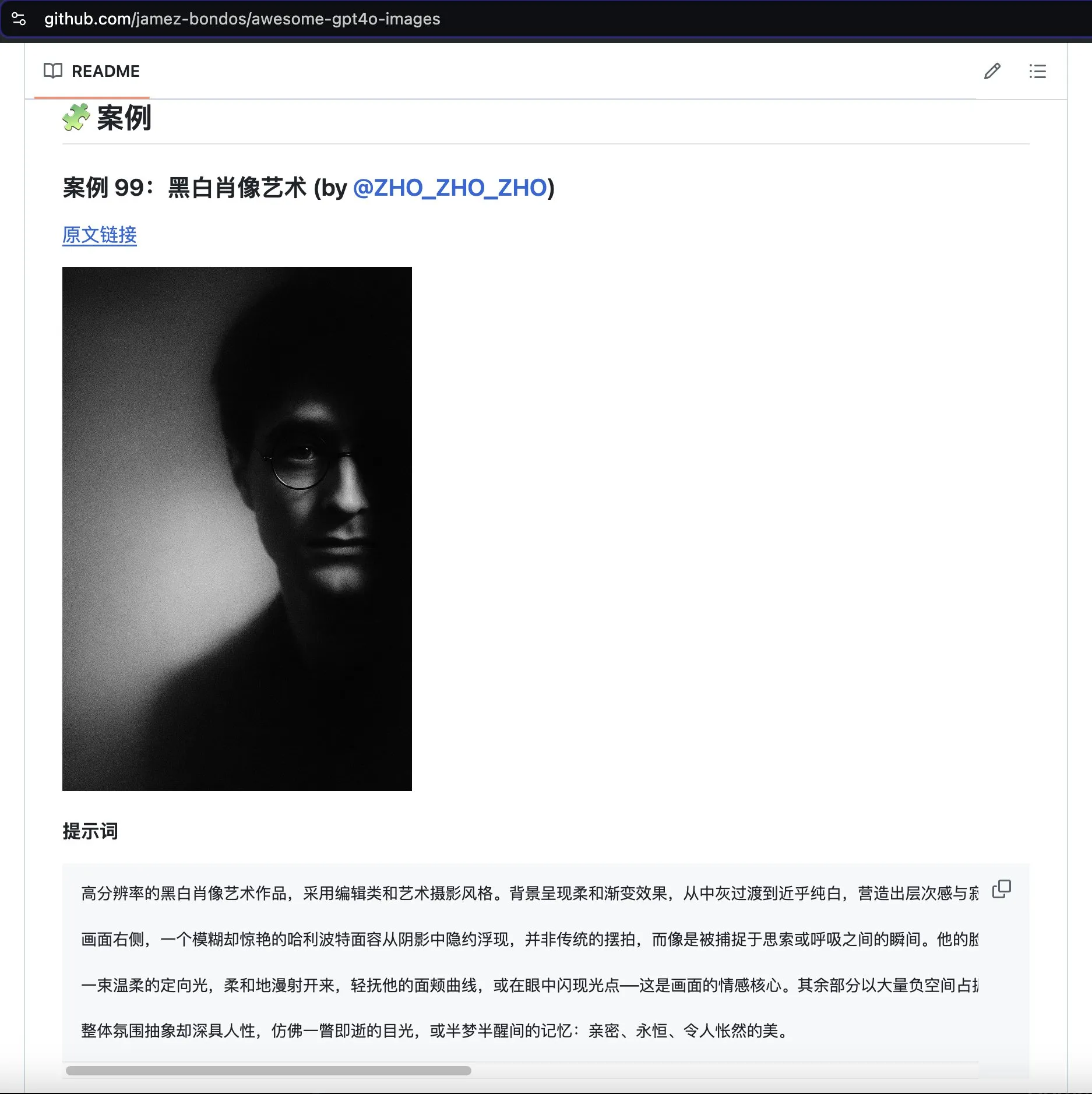
Le projet awesome-gpt4o-images rassemble des exemples remarquables de génération d’images par GPT-4o: Le projet GitHub awesome-gpt4o-images, créé par Jamez Bondos, a obtenu plus de 5700 étoiles en 33 jours. Ce projet collecte et présente d’excellents exemples d’images générées avec GPT-4o ainsi que les invites correspondantes. Il compte actuellement près d’une centaine d’exemples et prévoit de continuer à être mis à jour après organisation et vérification, offrant une ressource créative précieuse à la communauté AIGC (Source: dotey)
Yann LeCun partage une présentation sur l’apprentissage auto-supervisé (SSL): Yann LeCun a partagé le contenu de sa présentation sur l’apprentissage auto-supervisé (SSL). En tant que paradigme important de l’apprentissage automatique, le SSL vise à permettre aux modèles d’apprendre des représentations efficaces à partir de données non étiquetées, ce qui est crucial pour réduire la dépendance aux données étiquetées à grande échelle et améliorer la capacité de généralisation des modèles (Source: ylecun)
Le forum des articles de Hugging Face devient une ressource de qualité pour la sélection d’articles sur l’IA: Dwarkesh Patel recommande le forum des articles de Hugging Face, le considérant comme une excellente ressource pour filtrer les meilleurs articles sur l’IA du mois écoulé. Cette plateforme offre aux chercheurs un moyen pratique de découvrir et de discuter des dernières avancées de la recherche en IA (Source: dwarkesh_sp, huggingface)
Les résultats d’acceptation d’ACL 2025 sont annoncés, plusieurs articles de l’équipe AIB d’Alibaba International sont sélectionnés: La conférence de premier plan en traitement du langage naturel, ACL 2025, a annoncé ses résultats d’acceptation. Le nombre de soumissions a atteint un niveau record cette année, rendant la compétition féroce. Plusieurs articles de l’équipe AI Business (AIB) d’Alibaba International ont été acceptés, et certains résultats tels que Marco-o1 V2, Marco-Bench-IF et HD-NDEs (équations différentielles neuronales pour la détection d’hallucinations) ont été très bien évalués et acceptés comme articles longs pour la conférence principale. Cela reflète les investissements continus d’Alibaba International dans le domaine de l’IA et les premiers succès de sa formation de talents (Source: 量子位)

dstack publie un guide de configuration rapide d’interconnexion pour l’entraînement distribué: dstack fournit un guide concis aux utilisateurs effectuant un entraînement distribué sur des clusters NVIDIA ou AMD, expliquant comment configurer une interconnexion rapide via dstack. Ce guide vise à aider les utilisateurs à optimiser les performances réseau lors de la mise à l’échelle des charges de travail IA dans le cloud ou en local (Source: algo_diver)
AssemblyAI partage une vidéo avec 10 astuces pour améliorer les prompts des LLM: AssemblyAI partage, via une vidéo YouTube, 10 astuces pour améliorer l’efficacité des invites (prompting) des grands modèles de langage (LLM), visant à aider les utilisateurs à interagir plus efficacement avec les LLM pour obtenir les résultats souhaités (Source: AssemblyAI)
La collection de ressources d’apprentissage LangGraph.js « awesome-langgraphjs » suscite l’intérêt: Brace a créé et maintient un dépôt GitHub nommé « awesome-langgraphjs », qui rassemble des projets open source et des tutoriels vidéo YouTube utilisant LangGraph.js. Cette ressource facilite la tâche des développeurs souhaitant apprendre et utiliser LangGraph.js pour créer divers types d’applications, des systèmes multi-agents aux applications de chat full-stack (Source: LangChainAI)
💼 Affaires
La transformation stratégique d’Alibaba dans l’IA porte ses fruits, les revenus du cloud et des produits IA en forte croissance: Le rapport financier du T4 2025 d’Alibaba montre une croissance globale des revenus de 10 % après exclusion de certaines activités spécifiques. Les revenus de l’activité Cloud Intelligence ont augmenté de 18 %, dont les revenus des produits liés à l’IA ont maintenu une croissance à trois chiffres pendant 7 trimestres consécutifs. Alibaba considère l’IA comme une stratégie centrale et prévoit d’investir plus de 380 milliards de yuans au cours des trois prochaines années pour moderniser son infrastructure de cloud computing et d’IA. Son modèle open source Qwen-3 (Tongyi Qianwen) s’est hissé en tête de plusieurs classements mondiaux, avec plus de 100 000 modèles dérivés, démontrant sa force technologique et la vitalité de son écosystème open source. Alibaba accélère le déploiement de l’IA dans des secteurs tels que l’automobile, les communications et la finance (Source: 36氪)
L’application de montage vidéo Mojo rachetée par Dailymotion: L’application de montage vidéo Mojo (@mojo_video_app) a été rachetée par Dailymotion. La technologie de montage vidéo de Mojo sera intégrée à l’application sociale et aux produits B2B de Dailymotion, les deux parties visant à créer ensemble la prochaine génération de plateforme vidéo sociale européenne (Source: ClementDelangue)
Cohere acquiert Ottogrid pour renforcer ses capacités en IA d’entreprise: La société d’IA Cohere a annoncé l’acquisition de la start-up Ottogrid. Cette acquisition devrait renforcer les capacités de Cohere en matière de solutions d’IA pour les entreprises, mais les détails spécifiques de la transaction et l’orientation technologique d’Ottogrid n’ont pas été divulgués en détail (Source: aidangomez, nickfrosst)

🌟 Communauté
Les agents IA suscitent des discussions sur la transformation du travail, qui pourrait ressembler à un jeu de stratégie en temps réel: Will Depue suggère que le travail futur pourrait évoluer vers un modèle similaire à StarCraft ou Age of Empires, où les humains commanderaient environ 200 micro-agents intelligents pour traiter des tâches, collecter des informations, concevoir des systèmes, etc. Sam Altman a relayé cette idée en l’approuvant. Fabian Stelzer a plaisanté en qualifiant cela de « Zerg rush coded ». Ce point de vue reflète les réflexions et les discussions de la communauté sur la manière dont les agents IA vont remodeler les flux de travail et les modes de collaboration homme-machine (Source: willdepue, sama, fabianstelzer)
Les réponses du robot Grok de xAI suscitent la controverse, le prompt aurait été modifié sans autorisation: xAI a reconnu que le prompt de son robot de réponse Grok sur la plateforme X avait été modifié sans autorisation le 14 mai au petit matin, ce qui a conduit à des analyses d’événements (comme ceux impliquant Trump) paraissant anormales ou non conformes aux informations grand public. La communauté suit cette affaire de près, et des personnalités comme Clement Delangue appellent à l’ouverture du code de Grok pour plus de transparence. Des utilisateurs comme Colin Fraser tentent de reconstituer l’historique des modifications du prompt système de Grok en comparant ses réponses à différents moments (Source: ClementDelangue, menhguin, colin_fraser)

Des départs massifs seraient survenus au sein de l’équipe Llama4 de Meta, suscitant des inquiétudes dans la communauté quant à l’avenir de l’IA open source: Selon des informations communautaires, environ 80 % des membres de l’équipe Llama4 de Meta (11 départs sur une équipe initiale de 14 personnes) auraient démissionné, et le lancement de son modèle phare Behemoth serait reporté. Cette affaire suscite une large attention, et des personnalités du secteur comme Nat Lambert expriment leurs regrets. Scaling01 commente que Meta pourrait avoir besoin d’un nouveau directeur marketing pour Llama. Des utilisateurs comme TeortaxesTex s’inquiètent des répercussions négatives que cela pourrait avoir sur le développement de l’IA open source, allant même jusqu’à se demander si la Chine deviendra le dernier espoir de l’open source (Source: teortaxesTex, Dorialexander, scaling01)

L’application de l’IA dans la guerre et les questions éthiques associées suscitent l’attention: La communauté Reddit discute de l’application de l’IA dans la guerre, soulignant qu’elle est déjà utilisée pour la surveillance et la localisation des combattants, en fournissant des renseignements militaires par l’analyse d’informations. La discussion mentionne que l’armée américaine utilise des outils d’IA tels que DART depuis 1991. Les utilisateurs s’inquiètent des risques mortels que pourrait entraîner l’armement de l’IA et de la menace potentielle pour l’humanité, et suivent l’élaboration de traités et de mesures internationaux pertinents. Les directives d’utilisation d’OpenAI ont également supprimé la clause interdisant les usages militaires, ce qui suscite une réflexion plus approfondie (Source: Reddit r/ArtificialInteligence)
Les grands modèles de langage obtiennent de mauvais résultats au concours de programmation CCPC, révélant leurs limites actuelles: Lors de la finale du 10e Concours chinois de programmation pour étudiants universitaires (CCPC), plusieurs grands modèles de langage renommés (dont o3/o4, Gemini 2.5 pro, DeepSeek R1 et Seed-Thinking de ByteDance) ont obtenu de mauvais résultats, la plupart ne résolvant que le problème d’introduction ou obtenant un score nul. Le personnel officiel a expliqué que les modèles ont tenté de manière purement autonome, sans intervention humaine. L’analyse de la communauté suggère que cela expose les faiblesses des grands modèles actuels dans la résolution de problèmes algorithmiques très innovants et complexes, en particulier en mode non-agentique (c’est-à-dire sans assistance d’outils pour l’exécution et le débogage). Cela contraste avec les performances d’OpenAI o3 au concours IOI, où il a obtenu une médaille d’or grâce à un entraînement agentique (Source: WeChat)

Le framework DSPy et la « leçon amère » suscitent des discussions, soulignant l’importance de la conception normative et de l’automatisation des prompts: Les discussions relatives à DSPy soulignent que, bien que la mise à l’échelle de l’IA (Scaling) puisse contourner de nombreux problèmes d’ingénierie (« la leçon amère »), elle ne peut remplacer une conception minutieuse des spécifications fondamentales du problème (exigences et flux d’informations). Cependant, la mise à l’échelle peut élever le niveau d’abstraction de la définition des problèmes. L’automatisation des prompts (comme les optimiseurs de prompts) est considérée comme une méthode conforme à la « leçon amère » pour exploiter la puissance de calcul, tandis que les prompts manuels peuvent aller à son encontre, car ils injectent l’intuition humaine au lieu de laisser le modèle apprendre (Source: lateinteraction, lateinteraction)
Le coût de calcul de l’auto-vérification/exploration d’outils par les agents IA pendant le raisonnement suscite l’attention: Paul Calcraft s’interroge sur la pratique consistant à investir des ressources de calcul importantes (par exemple, plus de 200 dollars pour résoudre un seul problème) pendant la phase de raisonnement pour que les agents IA effectuent une auto-vérification active, utilisent des outils et explorent des flux de travail. Il note que des acteurs comme Devin et ses concurrents pourraient le faire pour des démonstrations de relations publiques, mais que ce n’est pas clair pour les scénarios recherchant des solutions novatrices (similaires à FunSearch mais avec moins de contraintes) (Source: paul_cal)
Le « Vibe Coding » assisté par IA suscite la discussion: Des outils comme GitHub Copilot rendent possible le « Vibe Coding » (c’est-à-dire une manière de programmer qui repose davantage sur l’intuition et l’assistance de l’IA que sur une planification stricte), au point qu’un élève de 16 ans a utilisé Copilot pour réaliser un projet scolaire. Les avis de la communauté sur ce phénomène sont partagés : certains y voient un nouveau paradigme de programmation, tandis que d’autres soulignent l’importance des bases et de la rigueur (Source: Reddit r/ArtificialInteligence, nrehiew_)
La bibliothèque Transformers de Hugging Face active un nouveau tableau de bord communautaire: Hugging Face a ouvert un nouveau tableau de bord communautaire pour sa bibliothèque principale Transformers, afin de publier des annonces, de présenter de nouvelles fonctionnalités, de mettre à jour la feuille de route, et d’inviter les utilisateurs à poser des questions et à discuter de l’utilisation de la bibliothèque ou des problèmes liés aux modèles. L’objectif est de renforcer l’interaction et le soutien aux développeurs (Source: TheZachMueller, ClementDelangue)
Des développeurs IA appellent les conférences de premier plan à ajouter une section d’articles “Findings”: Étant donné l’augmentation massive du nombre de soumissions aux conférences IA de premier plan comme NeurIPS (par exemple, 25 000 pour NeurIPS), Dan Roy et d’autres appellent à suivre l’exemple de conférences comme ACL en créant une section d’articles de type “Findings”. Cela viserait à offrir une opportunité de publication aux recherches qui, bien que n’atteignant pas les standards de la conférence principale, ont néanmoins de la valeur, allégeant ainsi la pression sur les évaluateurs et favorisant des échanges académiques plus larges. Les propositions incluent une évaluation allégée, axée sur l’amélioration de la clarté des articles, etc. (Source: AndrewLampinen)
💡 Divers
Un exosquelette piloté par IA aide les utilisateurs de fauteuils roulants à se tenir debout et à marcher: Un exosquelette piloté par IA a démontré sa capacité à aider les utilisateurs de fauteuils roulants à se remettre debout et à marcher. Ce type de technologie combine la robotique, les capteurs et les algorithmes d’IA pour percevoir les intentions de l’utilisateur et fournir une assistance motorisée, apportant un espoir de rééducation et d’amélioration de la qualité de vie aux personnes à mobilité réduite (Source: Ronald_vanLoon)
Utilisation de l’IA pour visualiser les idées de noms d’utilisateur: Une petite tendance est apparue sur Reddit et X, où les utilisateurs utilisent des outils de génération d’images par IA (comme DALL-E 3 intégré à ChatGPT) pour créer des images conceptuelles basées sur leurs noms d’utilisateur de médias sociaux, et partagent ces œuvres pleines d’imagination, démontrant l’application ludique de l’IA dans l’expression créative personnalisée (Source: Reddit r/ChatGPT, Reddit r/ChatGPT)

Amazon Ads utilise l’IA pour améliorer l’efficacité du marketing des marques à l’international: Amazon Ads a lancé le concept de « World Screen Lab » pour montrer comment il utilise la technologie IA pour aider les marques chinoises à se développer à l’international. En élargissant la portée des marques grâce à sa matrice médiatique telle que Prime Video, en utilisant des studios de création IA (comme les outils de génération vidéo) pour réduire la barrière à l’entrée de la production de contenu, et en optimisant le placement publicitaire et la conversion via des outils comme Amazon DSP et Performance+. L’IA y joue un rôle de bout en bout, de la génération d’idées créatives à la mesure des performances, visant à aider les propriétaires de marques, en particulier les PME, à construire plus efficacement leur marque à l’échelle mondiale (Source: 36氪)
