
Mots-clés:Agent IA intelligent, Grand modèle linguistique, Gemini 2.5 Pro, Supercalculateur IA NVIDIA, Conférence Microsoft Build, Agent IA pour la recherche scientifique, Évaluation des capacités de raisonnement, Programmation IA, Agent de codage avec correction autonome de bugs, Plateforme de recherche Microsoft Discovery, Technologie NVLink Fusion, Super-nœud CloudMatrix 384, Algorithme EdgeInfinite
🔥 À la Une
Les agents IA redéfinissent les paradigmes de développement et de recherche scientifique: Lors de sa conférence Build, Microsoft a annoncé une série d’outils d’agents IA, y compris Coding Agent, capable de corriger de manière autonome les bugs et de maintenir le code, ainsi que la plateforme d’agents IA pour la recherche Microsoft Discovery, capable de générer des idées, de simuler des résultats et d’apprendre de manière autonome. Parallèlement, Kevin Weil, Chief Product Officer d’OpenAI, et Dario Amodei, CEO d’Anthropic, ont tous deux déclaré que l’IA possède déjà des capacités de programmation avancées, laissant présager que les postes de programmeurs juniors pourraient être remplacés et que le rôle des développeurs évoluera vers celui de « guide de l’IA ». Ces avancées indiquent que les agents IA évoluent d’outils auxiliaires vers des forces essentielles capables d’opérer de manière indépendante dans des projets complexes, ce qui transformera profondément les processus et l’efficacité du développement logiciel et de la recherche scientifique (Source: GitHub Trending, X)
Nouveaux défis et évaluations pour les capacités de raisonnement des grands modèles de langage: Plusieurs études et discussions récentes révèlent les limites des grands modèles de langage dans les tâches de raisonnement complexes. Des recherches menées par des institutions telles que l’Université Harvard indiquent que la chaîne de pensée (CoT – Chain of Thought) peut parfois entraîner une baisse de la précision des modèles dans le suivi des instructions, en raison d’une focalisation excessive sur la planification du contenu au détriment de contraintes simples. De même, les tâches physiques du monde réel (comme l’usinage de pièces) et le raisonnement visuo-spatial complexe (comme les problèmes d’empilement de cubes) exposent également les lacunes des modèles d’IA de pointe (y compris o3, Gemini 2.5 Pro). Pour évaluer plus précisément les capacités des modèles, de nouveaux benchmarks tels que EMMA et SPOT ont été proposés, visant à détecter le niveau réel de l’IA en matière de fusion multimodale, de validation scientifique, etc., afin de faire évoluer les modèles vers un raisonnement plus robuste et fiable (Source: HuggingFace Daily Papers, 量子位)
Google AI déploie ses forces sur tous les fronts, Gemini 2.5 Pro affiche de solides performances: Google montre une offensive tous azimuts dans le domaine de l’IA. Son modèle Gemini 2.5 Pro excelle dans plusieurs benchmarks (comme LMSYS Chatbot Arena), atteignant un niveau de pointe notamment en matière de long contexte et de compréhension vidéo, et surpassant les versions précédentes dans WebDev Arena. Lors de la conférence Google Cloud Next ‘25, Google a annoncé plus de 200 mises à jour, incluant Gemini 2.5 Flash, Imagen 3, Veo 2, Vertex AI Agent Development Kit (ADK) et le protocole Agent2Agent (A2A), soulignant sa détermination à intégrer l’IA à tous les niveaux de sa plateforme cloud et à promouvoir son déploiement à grande échelle en entreprise. Google Labs continue également d’incuber des produits d’innovation natifs de l’IA, tels que NotebookLM, démontrant une forte capacité d’innovation et d’itération de produits (Source: Google, GoogleDeepMind)
Nvidia lance un supercalculateur IA de bureau et des solutions d’usine IA pour entreprises: Nvidia a dévoilé plusieurs produits majeurs lors du Computex, notamment l’ordinateur IA personnel DGX Station équipé de la super-puce GB300, doté d’une mémoire unifiée allant jusqu’à 784 Go et capable de faire tourner un grand modèle de 1T paramètres ; ainsi que le RTX PRO Server destiné aux entreprises, capable d’accélérer diverses applications telles que les agents IA, l’IA physique et le calcul scientifique. Parallèlement, Nvidia a lancé la technologie NVLink Fusion semi-personnalisée et la plateforme de données NVIDIA AI, et a annoncé une collaboration avec Disney, entre autres, pour développer le moteur d’IA physique Newton. Ces initiatives indiquent que Nvidia est en train de passer d’une entreprise de puces à une entreprise d’infrastructure IA, visant à construire un écosystème IA complet, du bureau au centre de données (Source: nvidia, 量子位)

🎯 Tendances
Kimi.ai lance le modèle de réflexion sur texte long kimi-thinking-preview: Kimi.ai a lancé son dernier modèle de réflexion sur texte long, kimi-thinking-preview, désormais disponible sur platform.moonshot.ai. Ce modèle posséderait d’excellentes capacités multimodales et de raisonnement. Les nouveaux utilisateurs inscrits peuvent obtenir un bon d’achat de 5 dollars pour l’essayer. Les commentaires de la communauté suggèrent une évaluation du modèle par des tiers et mentionnent que Kimi avait déjà pris la tête sur livecodebench grâce à un modèle de réflexion dédié (Source: X)
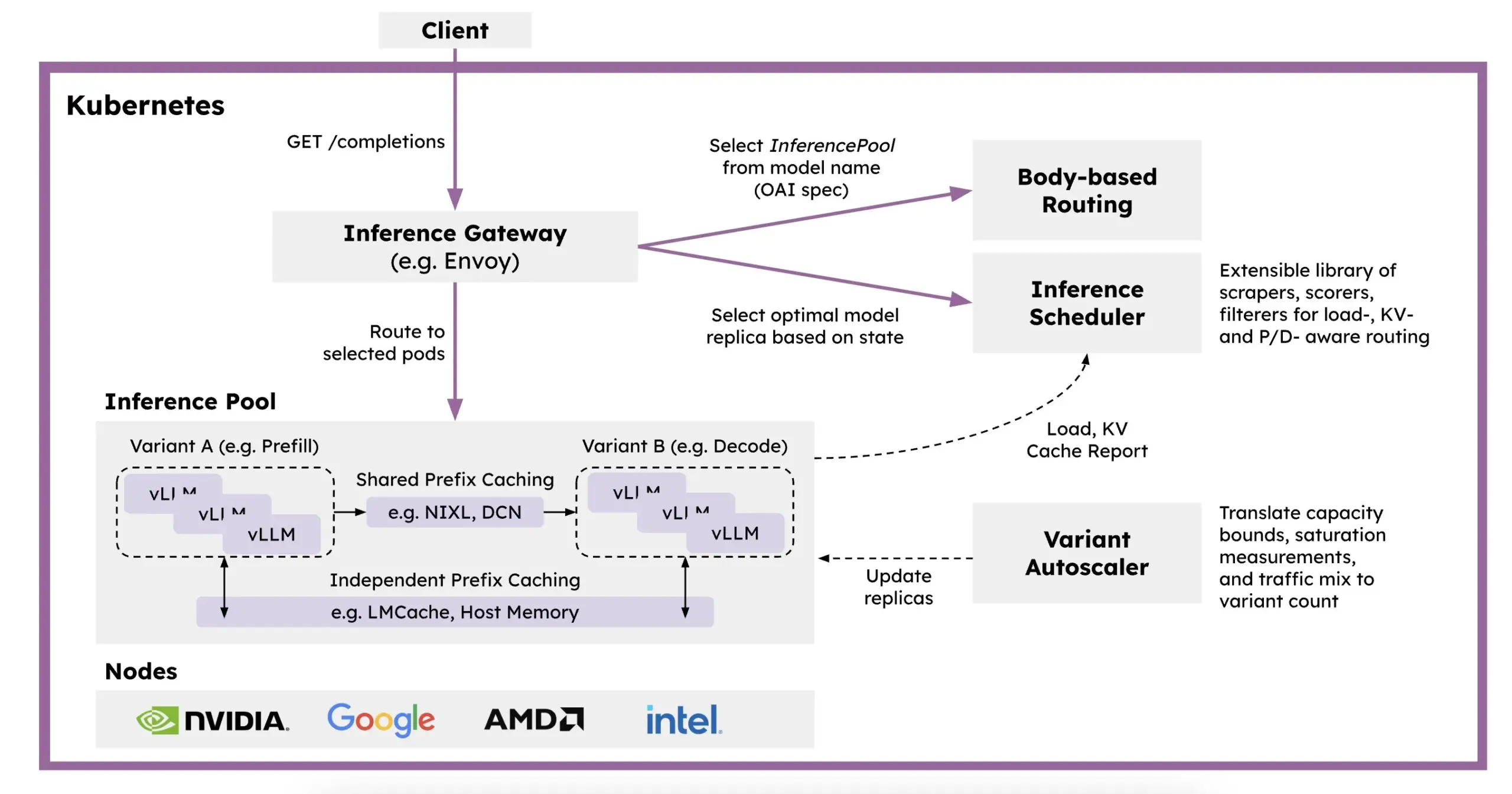
Red Hat lance llm-d : un framework d’inférence distribuée basé sur Kubernetes: Pour résoudre les problèmes de lenteur, de coût élevé et de difficulté de mise à l’échelle de l’inférence des LLM, Red Hat a lancé llm-d, un framework d’inférence distribuée natif de Kubernetes. Ce framework utilise vLLM, l’ordonnancement intelligent et le calcul découplé pour optimiser l’inférence des LLM. llm-d repose sur trois fondations open source : vLLM (moteur d’inférence LLM haute performance), Kubernetes (standard d’orchestration de conteneurs) et Inference Gateway (IGW) (qui réalise un routage intelligent via l’extension Gateway API), visant à améliorer l’efficacité et la scalabilité de l’inférence des LLM (Source: X, X)
Meta AI publie l’ensemble de données OMol25, contenant plus de 100 millions de conformères moléculaires: Meta AI a publié l’ensemble de données OMol25 sur HuggingFace, contenant plus de 100 millions de conformères moléculaires, couvrant 83 éléments et une diversité d’environnements chimiques. Cet ensemble de données vise à entraîner des modèles d’apprentissage automatique capables d’atteindre une précision de niveau DFT (théorie de la fonctionnelle de la densité), tout en réduisant considérablement les coûts de calcul. Cela contribuera à accélérer la recherche et les applications dans des domaines tels que la découverte de médicaments, la conception de matériaux avancés et les solutions d’énergie propre (Source: X)
Gemini 2.5 Pro disponible dans l’application NotebookLM sur l’App Store iOS en Allemagne: L’application NotebookLM de Google (intégrant Gemini 2.5 Pro) est désormais disponible sur l’App Store iOS en Allemagne. Auparavant, la version iOS pour l’Union Européenne n’était disponible que via TestFlight. Parallèlement, la version Android semble être plus largement disponible. NotebookLM vise à aider les utilisateurs à comprendre et à traiter de longs documents, des notes, etc. (Source: X)
ByteDance actif dans la recherche en IA, publie plusieurs articles récents: L’équipe SEED de ByteDance a publié au moins 13 articles de recherche liés à l’IA au cours des deux derniers mois, couvrant des domaines tels que la fusion de modèles, la chaîne de pensée adaptative déclenchée par apprentissage par renforcement (AdaCoT), l’optimisation du raisonnement par représentations latentes (LatentSeek), etc. Ces recherches démontrent l’investissement continu et l’exploration de ByteDance pour améliorer l’efficacité, les capacités de raisonnement et les méthodes d’entraînement des grands modèles de langage (Source: X, X)
L’IA propulse une nouvelle génération de batteries au zinc à une efficacité de 99,8 % et une durée de fonctionnement de 4300 heures: Grâce à l’optimisation par l’intelligence artificielle, une nouvelle génération de batteries au zinc a atteint une efficacité coulombienne de 99,8 % et une durée de fonctionnement allant jusqu’à 4300 heures. Cette percée technologique démontre le potentiel d’application de l’IA dans les domaines de la science des matériaux et du stockage d’énergie, et devrait favoriser le développement de technologies de batteries plus efficaces et plus durables, ce qui est d’une grande importance pour le stockage d’énergie renouvelable et les appareils électroniques portables (Source: X)

Perplexity lance le navigateur intelligent IA Comet en test préliminaire: Perplexity a commencé à déployer son navigateur web doté de fonctionnalités d’agent, Comet, auprès des premiers testeurs. Ce navigateur devrait offrir une toute nouvelle expérience de « navigation d’ambiance » (vibe browsing), combinant potentiellement les puissantes capacités de recherche IA et d’intégration d’informations de Perplexity, pour offrir aux utilisateurs une navigation web plus intelligente et personnalisée (Source: X)
Intel lance les cartes graphiques Arc Pro série B à haute performance et grande VRAM: Intel a lancé les cartes graphiques Arc Pro B50 (16 Go de VRAM, 299 $) et Arc Pro B60 (24 Go de VRAM, 500 $ par carte), spécialement conçues pour les stations de travail IA. La B60 surpasse la Nvidia RTX A1000 dans les tests d’inférence IA, et sa plus grande VRAM lui confère un avantage pour l’exécution de grands modèles. La station de travail Project Battlematrix utilise des processeurs Xeon et peut accueillir jusqu’à 8 GPU B60 (192 Go de VRAM totale), prenant en charge des modèles de plus de 70 milliards de paramètres. Cette initiative est considérée comme une stratégie d’Intel pour percer sur le marché du matériel IA avec un bon rapport qualité-prix (Source: 量子位)

Huawei Cloud lance le super-nœud CloudMatrix 384 pour augmenter la puissance de calcul IA: Huawei Cloud a lancé le super-nœud CloudMatrix 384, qui adopte une architecture d’interconnexion full-mesh permettant de connecter 384 cartes d’accélération IA pour former un super serveur cloud, offrant jusqu’à 300 PFlops de puissance de calcul. Il vise à relever les défis de l’efficacité de la communication, du mur de la mémoire et de la fiabilité dans l’entraînement et l’inférence de l’IA. Cette architecture met particulièrement l’accent sur son affinité avec les modèles MoE, le renforcement du calcul par le réseau et par le stockage, et a déjà été utilisée pour prendre en charge les services d’inférence de grands modèles tels que DeepSeek-R1 (Source: 量子位)

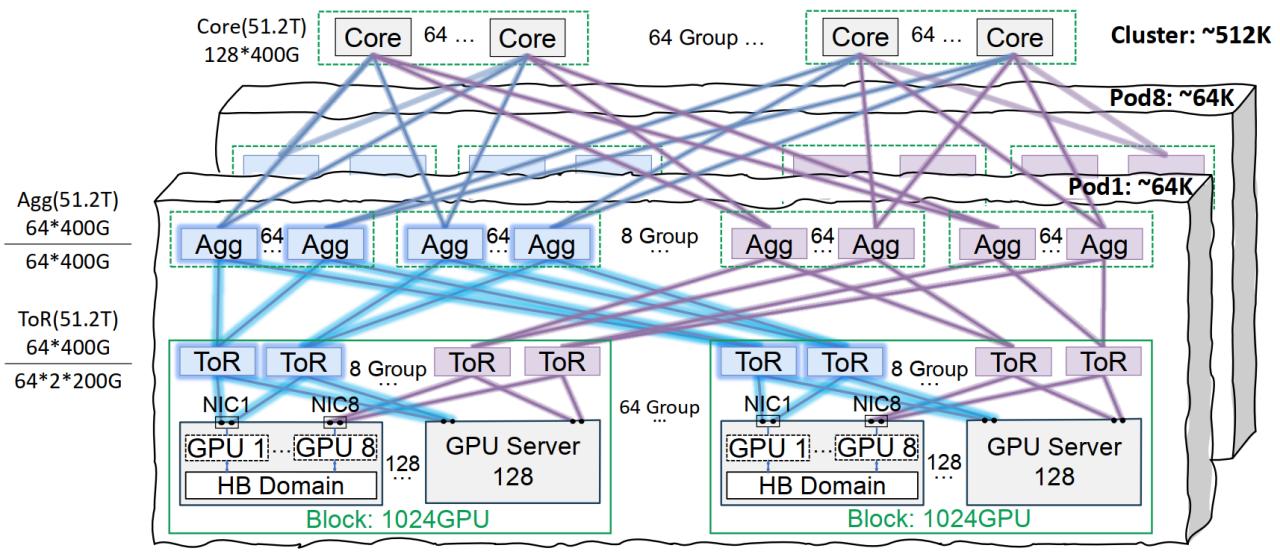
L’infrastructure réseau StarLake de Tencent Cloud optimise l’entraînement des grands modèles: Tencent Cloud a lancé la solution d’infrastructure réseau haute performance StarLake, spécialement conçue pour l’entraînement et l’inférence de modèles IA à grande échelle. Cette solution résout les problèmes des centres de données traditionnels en matière de réseau, de densité de déploiement et de localisation des pannes grâce à une architecture d’interconnexion sur le même rack (prenant en charge un réseau de 64 000 GPU par pod et 512 000 GPU pour l’ensemble du cluster), des solutions optimisées de gestion de l’alimentation et de refroidissement, ainsi qu’un système de surveillance intelligent. StarLake prend déjà en charge les activités internes de Tencent, comme Hunyuan, et a fourni une optimisation des performances pour le framework de communication DeepEP de DeepSeek (Source: 量子位)
Stability AI publie le modèle SV4D2.0, annonçant potentiellement son retour dans le domaine de la génération vidéo: Stability AI a publié un modèle nommé sv4d2.0 sur Hugging Face, suscitant l’attention de la communauté. Bien que les détails soient rares, cette initiative pourrait signifier que Stability AI a de nouvelles avancées technologiques ou des itérations de produits dans la génération vidéo ou les domaines 3D/4D connexes, suggérant qu’après une période d’ajustement, elle pourrait revenir à l’avant-garde du domaine de la génération par IA (Source: X)
Meta AI publie l’algorithme d’apprentissage Adjoint Sampling: Meta AI a proposé un nouvel algorithme d’apprentissage, Adjoint Sampling, pour entraîner des modèles génératifs basés sur une récompense scalaire. Cet algorithme, basé sur les fondements théoriques développés par FAIR, est hautement évolutif et devrait servir de base à de futures recherches sur les méthodes d’échantillonnage évolutives. L’article de recherche, les modèles, le code et les benchmarks correspondants ont été publiés (Source: X)
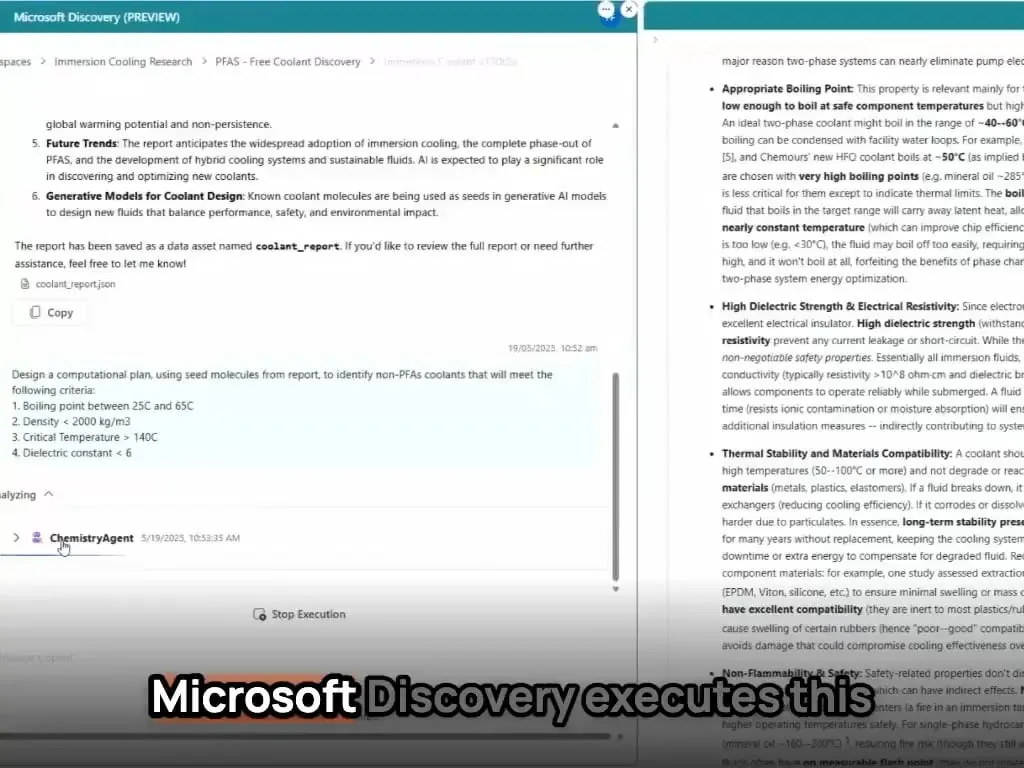
Des agents IA de Microsoft réalisent la découverte et la synthèse de nouveaux matériaux en quelques heures: Microsoft a démontré la puissante capacité de ses agents IA en recherche et développement scientifique. Ces agents sont capables d’analyser la littérature scientifique, d’élaborer des plans, d’écrire du code, d’exécuter des simulations et de découvrir en quelques heures un nouveau liquide de refroidissement pour centres de données, un processus qui prendrait normalement plusieurs années de R&D. De plus, l’équipe a réussi à synthétiser le nouveau liquide de refroidissement conçu par l’IA et l’a testé sur une carte mère réelle, montrant l’énorme potentiel de l’IA pour accélérer la découverte et la création autonomes dans des domaines tels que la science des matériaux (Source: Reddit r/artificial)
L’Institut d’Intelligence Artificielle de Beijing publie trois modèles vectoriels de la série BGE, axés sur la recherche de code et multimodale: L’Institut d’Intelligence Artificielle de Beijing (BAAI), en collaboration avec des universités, a lancé BGE-Code-v1 (modèle vectoriel de code), BGE-VL-v1.5 (modèle vectoriel multimodale général) et BGE-VL-Screenshot (modèle vectoriel pour documents visualisés). Ces modèles ont obtenu d’excellents résultats dans les benchmarks CoIR, Code-RAG, MMEB, MVRB, etc. BGE-Code-v1 est basé sur Qwen2.5-Coder-1.5B, BGE-VL-v1.5 sur LLaVA-1.6, et BGE-VL-Screenshot sur Qwen2.5-VL-3B-Instruct. Ils visent à améliorer les performances en matière de recherche de code, de compréhension image-texte et de recherche de documents visuels complexes, et sont entièrement open source (Source: WeChat)
La technologie OmniPlacement de Huawei optimise l’inférence des modèles MoE, réduisant théoriquement la latence de DeepSeek-V3 de 10%: Face au problème du déséquilibre de charge des réseaux experts (« experts chauds » et « experts froids ») dans les modèles Mixture-of-Experts (MoE), qui limite les performances d’inférence, l’équipe de Huawei a proposé la technologie OmniPlacement. Cette technologie, grâce à la réorganisation des experts, au déploiement redondant inter-couches et à un ordonnancement dynamique quasi temps réel, peut théoriquement réduire la latence d’inférence d’environ 10% et augmenter le débit d’environ 10% sur des modèles tels que DeepSeek-V3. Cette solution sera bientôt entièrement open source (Source: WeChat)

vivo publie l’algorithme EdgeInfinite, permettant le traitement efficace de textes longs de 128K sur mobile: L’Institut de recherche en IA de vivo a publié une étude à l’ACL 2025, présentant l’algorithme EdgeInfinite, spécialement conçu pour les appareils en périphérie (edge). Grâce à un module de mémoire à portillon entraînable et à des techniques de compression/décompression de la mémoire, il permet de traiter efficacement des textes ultra-longs dans l’architecture Transformer. Testé sur le modèle BlueLM-3B, cet algorithme peut traiter 128K tokens sur un appareil avec 10 Go de mémoire GPU, et obtient d’excellents résultats sur plusieurs tâches de LongBench, réduisant significativement le temps de génération du premier token et l’occupation mémoire (Source: WeChat)

🧰 Outils
Mise à jour de LlamaParse, amélioration des capacités d’analyse de documents: LlamaParse a publié plusieurs mises à jour, améliorant ses performances en tant qu’outil d’analyse de documents piloté par des agents IA. Les nouvelles fonctionnalités incluent la prise en charge de Gemini 2.5 Pro, GPT-4.1, l’ajout de la détection d’inclinaison (skew detection) et des scores de confiance. De plus, un bouton d’extrait de code a été introduit pour permettre aux utilisateurs de copier directement la configuration d’analyse dans leur base de code, ainsi que des préréglages de cas d’utilisation et la possibilité de basculer l’exportation entre Markdown rendu et brut (Source: X)
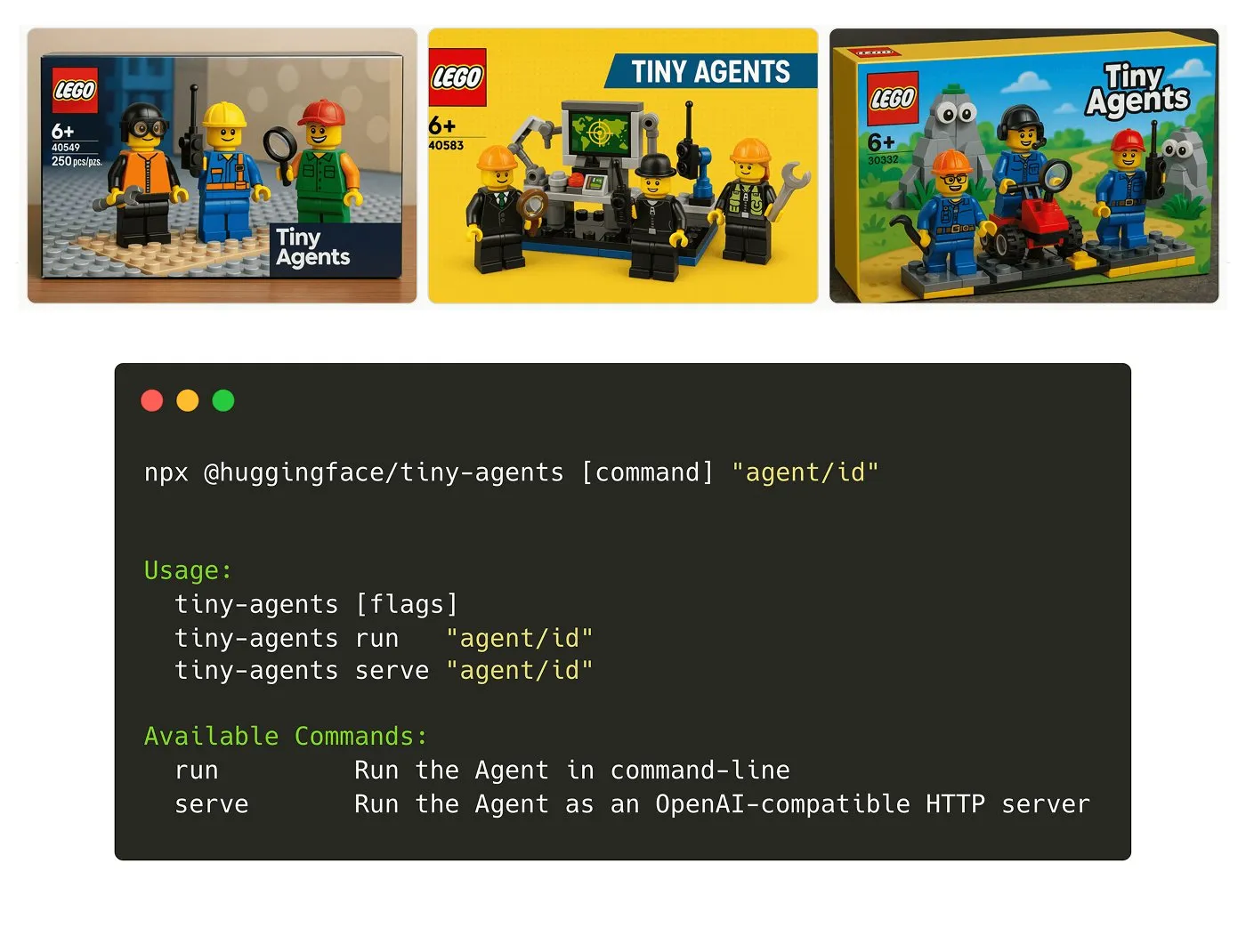
Hugging Face lance le package NPM Tiny Agents: Julien Chaumond a publié Tiny Agents, un package NPM d’agents léger et composable. Il est construit sur la base du client d’inférence de Hugging Face et de la pile MCP (Model Component Protocol), et vise à faciliter aux développeurs la prise en main rapide et la création de petites applications d’agents. Un tutoriel de démarrage est fourni officiellement (Source: X)
La plateforme LangGraph ajoute le support MCP, simplifiant l’intégration des agents: La plateforme LangGraph prend désormais en charge le MCP (Model Component Protocol). Chaque agent déployé sur la plateforme expose automatiquement un point de terminaison MCP. Cela signifie que les utilisateurs peuvent utiliser ces agents comme outils dans n’importe quel client HTTP supportant le streaming MCP, sans avoir à écrire de code personnalisé ni à configurer une infrastructure supplémentaire, ce qui simplifie l’intégration et l’interopérabilité entre les agents (Source: X)

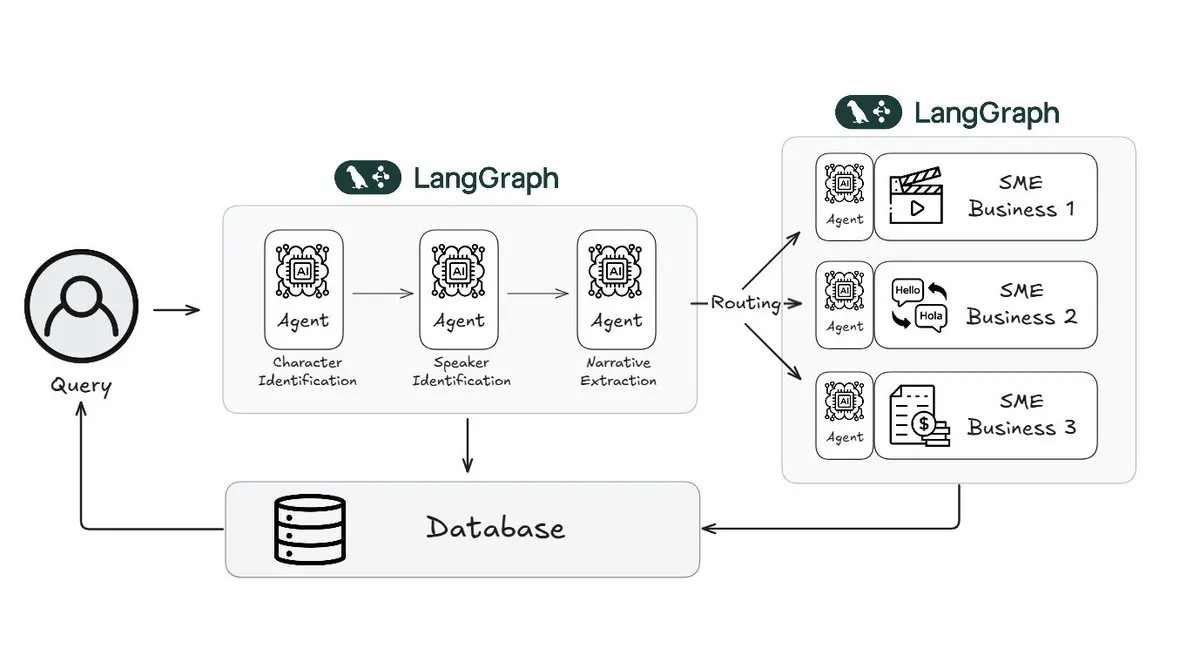
Webtoon réduit de 70% la charge de travail d’examen des histoires grâce à LangGraph: Webtoon, leader de la bande dessinée numérique, a construit Webtoon Comprehension AI (WCAI), qui utilise LangGraph pour automatiser la compréhension narrative de son immense catalogue de contenu. WCAI remplace la navigation manuelle par des agents multimodaux intelligents capables d’identifier les personnages et les locuteurs, d’extraire l’intrigue et le ton, et d’effectuer des requêtes d’informations en langage naturel. Cela a permis de réduire de 70% la charge de travail de ses équipes marketing, de traduction et de recommandation, tout en stimulant la créativité (Source: X)
OpenMemory MCP permet le partage de mémoire privée persistante entre outils IA: Le projet Mem0 a lancé le serveur OpenMemory MCP, visant à fournir une mémoire privée persistante, multiplateforme et inter-sessions pour les applications IA. Les utilisateurs peuvent le déployer localement et connecter OpenMemory à des outils clients tels que Cursor via le protocole MCP, permettant d’ajouter, de rechercher, de lister et de supprimer des souvenirs. Cet outil offre des fonctionnalités de gestion de la mémoire via un tableau de bord et devrait améliorer la personnalisation et la compréhension contextuelle des agents IA (Source: WeChat)

Lancement de Miaoduo AI 2.0, positionné comme assistant IA pour la conception d’interfaces: Miaoduo AI 2.0 a été lancé en tant qu’assistant IA dans le domaine de la conception d’interfaces, visant à collaborer avec les utilisateurs pour accomplir des tâches de design. La nouvelle version améliore l’interaction grâce à une « boîte magique IA », prend en charge l’édition conversationnelle et l’itération des propositions de design, peut générer plusieurs versions d’interfaces basées sur des styles prédéfinis ou des entrées utilisateur (texte long, croquis, images de référence), et est compatible avec les systèmes de design courants. De plus, il offre des fonctionnalités de traitement d’images et de textes, de conseil en design et de commandes rapides (langage naturel vers appel API). Miaoduo AI prend en charge le protocole MCP et optimise les données des maquettes de design pour une lecture par les grands modèles, afin de générer du code frontend à haute fidélité (Source: 量子位)

llmbasedos : une preuve de concept d’un système d’exploitation IA open-source et amorçable basé sur MCP: Le développeur iluxu a rendu open-source le projet llmbasedos trois jours avant que Microsoft n’annonce son concept « USB-C for AI apps » (basé sur MCP). Ce projet est un système d’exploitation IA qui peut être démarré rapidement depuis une clé USB ou une machine virtuelle. Il communique via une passerelle FastAPI en JSON-RPC avec de petits démons Python, permettant aux scripts utilisateur d’être appelés par ChatGPT/Claude/VS Code via une simple configuration cap.json. Il utilise par défaut llama.cpp hors ligne, mais peut également basculer vers GPT-4o ou Claude 3, visant à promouvoir un standard ouvert de connexion pour les applications IA (Source: Reddit r/LocalLLaMA)
📚 Apprentissage
Pourquoi la distillation des connaissances (KD) est-elle efficace ? Une nouvelle étude offre une explication concise: Kyunghyun Cho et ses collègues proposent une explication concise de l’efficacité de la distillation des connaissances (KD). Ils émettent l’hypothèse que l’utilisation d’un échantillonnage approximatif à faible entropie provenant du modèle enseignant conduit le modèle étudiant à avoir une précision plus élevée mais un rappel plus faible. Étant donné que les modèles de langage autorégressifs sont essentiellement des distributions mixtes en cascade infinie, ils ont vérifié cette hypothèse avec SmolLM. L’étude suggère que les méthodes d’évaluation actuelles pourraient trop se concentrer sur la précision, en ignorant la perte de rappel, ce qui soulève des questions sur le contenu et les groupes d’utilisateurs que les grands modèles universels pourraient omettre (Source: X)

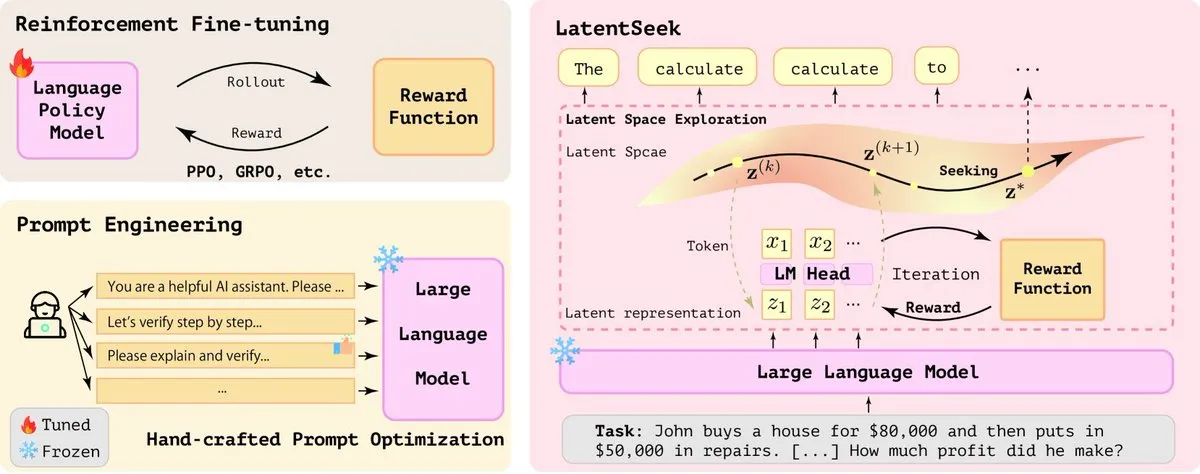
LatentSeek : Améliorer les capacités de raisonnement des LLM grâce à l’optimisation par gradient de politique dans l’espace latent: Un article intitulé « Seek in the Dark » propose LatentSeek, un nouveau paradigme pour améliorer les capacités de raisonnement des grands modèles de langage (LLM) au moment du test, grâce à un gradient de politique au niveau de l’instance dans l’espace latent. Cette méthode ne nécessite ni entraînement, ni données, ni modèle de récompense, et vise à améliorer le processus de raisonnement du modèle en optimisant les représentations latentes. Cette approche indépendante de l’entraînement montre un potentiel pour améliorer les performances des LLM dans les tâches de raisonnement complexes (Source: X)
Microsoft propose CoML : Apprentissage par Chaîne de Modèles pour les modèles de langage: Microsoft Research a proposé un nouveau paradigme d’apprentissage appelé « Apprentissage par Chaîne de Modèles » (Chain-of-Model Learning, CoML). Cette méthode intègre les relations causales des états cachés dans une structure en chaîne à chaque couche du réseau, visant à améliorer l’efficacité de l’extension de l’entraînement du modèle et la flexibilité de l’inférence lors du déploiement. Son concept central, la « Représentation en Chaîne » (CoR – Chain-of-Representation), décompose l’état caché de chaque couche en plusieurs sous-chaînes de représentation. Les chaînes suivantes peuvent accéder aux représentations d’entrée de toutes les chaînes précédentes, permettant ainsi au modèle de s’étendre progressivement en ajoutant des chaînes, et de fournir des sous-modèles de différentes tailles pour une inférence élastique en sélectionnant un nombre variable de chaînes. Le CoLM (Chain-of-Language Model) conçu sur ce principe, ainsi que sa variante CoLM-Air (introduisant un mécanisme de partage KV), affichent des performances comparables à celles du Transformer standard, tout en apportant les avantages de l’extension progressive et de l’inférence élastique (Source: X, HuggingFace Daily Papers)

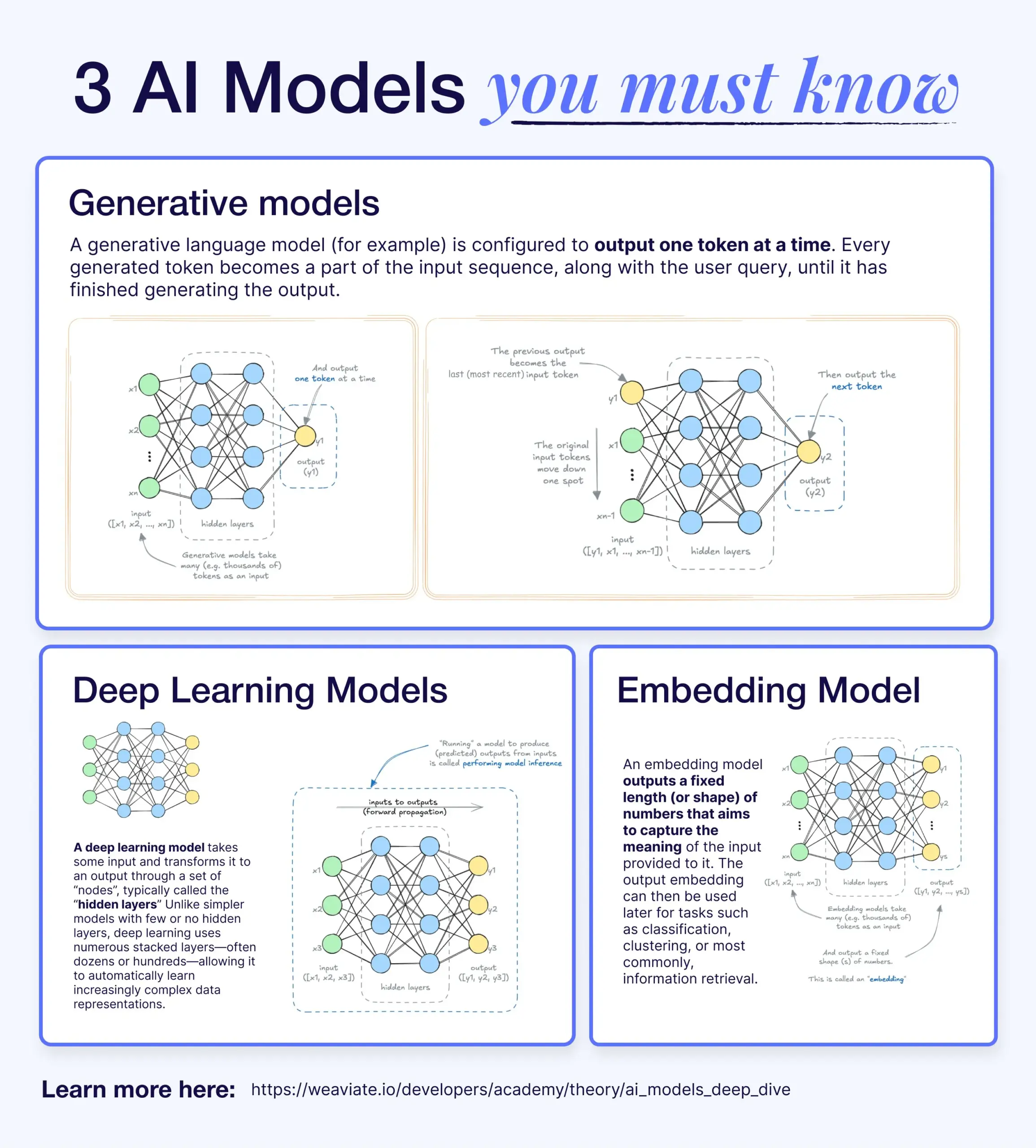
Différences et liens entre modèles d’apprentissage profond, modèles génératifs et modèles d’intégration (embedding models): Un article de vulgarisation explique les relations entre les modèles d’apprentissage profond, les modèles génératifs et les modèles d’intégration. Les modèles d’apprentissage profond constituent l’architecture de base, traitant des entrées et sorties numériques via des réseaux de neurones multicouches. Les modèles génératifs sont un type de modèle d’apprentissage profond, spécialisés dans la création de nouveau contenu similaire à leurs données d’entraînement (ex: GPT, DALL-E). Les modèles d’intégration sont également un type de modèle d’apprentissage profond, utilisés pour convertir des données (texte, images, etc.) en représentations vectorielles numériques capturant des informations sémantiques, souvent utilisés pour la recherche par similarité et les systèmes RAG. Dans de nombreux systèmes d’IA, ces modèles fonctionnent en synergie, par exemple, les systèmes RAG utilisent des modèles d’intégration pour la recherche, puis des modèles génératifs pour générer des réponses (Source: X)
DSPy propose une philosophie d’investissement dans les systèmes IA: DSPy partage sa philosophie concernant l’investissement dans les systèmes IA, soulignant que les efforts devraient se concentrer sur les trois couches fondamentales des systèmes IA : les données, les modèles et les algorithmes. Ils estiment qu’en fournissant des modules de haut niveau composables (Prompts, Demonstrations, Optimizers, Metrics, Tools, Agents, Reasoning Modules), les développeurs peuvent itérer rapidement sur ces trois couches fondamentales, construisant ainsi des systèmes IA plus puissants (Source: X)
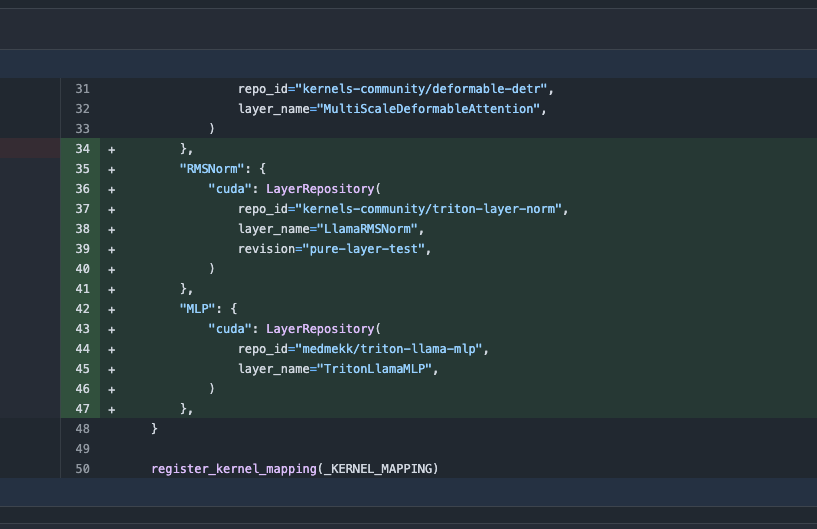
Mise à jour de la bibliothèque Transformers, bascule automatique vers des noyaux optimisés pour améliorer les performances: La dernière version de la bibliothèque Transformers de Hugging Face permet une bascule automatique vers des noyaux optimisés lorsque le matériel le permet. Cette mise à jour intègre la bibliothèque kernels qui, pour les modèles populaires tels que Llama, utilise les noyaux communautaires les plus populaires sur Hugging Face Hub, visant à améliorer l’efficacité et les performances d’exécution des modèles sur le matériel compatible (Source: X)
Publication du benchmark ARC-AGI-2, défiant les systèmes d’IA de pointe en matière de raisonnement: François Chollet et ses collègues ont publié un article sur le benchmark ARC-AGI-2, détaillant ses principes de conception, sa difficulté, l’analyse des performances humaines et les performances des modèles actuels. Ce benchmark vise à évaluer les capacités de raisonnement abstrait de l’IA. Les humains sont capables de résoudre 100% des tâches, tandis que les modèles d’IA de pointe actuels obtiennent un score inférieur à 5%, montrant un écart énorme persistant entre l’IA et les humains en matière de raisonnement abstrait avancé (Source: X)

Terence Tao publie un tutoriel sur l’utilisation de GitHub Copilot pour la démonstration assistée des limites de fonctions: Le mathématicien Terence Tao a publié un tutoriel vidéo montrant comment utiliser GitHub Copilot pour aider à prouver des problèmes de limites de fonctions, y compris les théorèmes sur la somme, la différence et le produit. Il souligne que, bien que Copilot puisse rapidement générer un cadre de code et suggérer des fonctions de bibliothèques existantes, une intervention et un ajustement manuels importants sont encore nécessaires pour les détails mathématiques complexes, la gestion des cas particuliers et les solutions créatives. Parfois, combiner une dérivation papier-crayon avec une vérification formelle ultérieure peut être plus efficace (Source: 36氪)
Le framework PhyT2V utilise les LLM pour améliorer la cohérence physique de la génération texte-vidéo: Une équipe de recherche de l’Université de Pittsburgh a proposé le framework PhyT2V, qui optimise les invites textuelles via un raisonnement en chaîne (CoT) guidé par de grands modèles de langage et un mécanisme d’auto-correction itératif, afin d’améliorer le réalisme physique du contenu généré par les modèles texte-vidéo (T2V) existants. Cette méthode ne nécessite pas de réentraînement du modèle. En analysant l’inadéquation sémantique entre les vidéos déjà générées et les invites, et en combinant cela avec des règles physiques pour corriger les invites, elle vise à améliorer la cohérence physique des modèles T2V lors du traitement de scénarios hors distribution (OOD). Les expériences montrent que PhyT2V peut améliorer de manière significative les performances de modèles tels que CogVideoX et OpenSora sur des benchmarks comme VideoPhy et PhyGenBench (Source: WeChat)

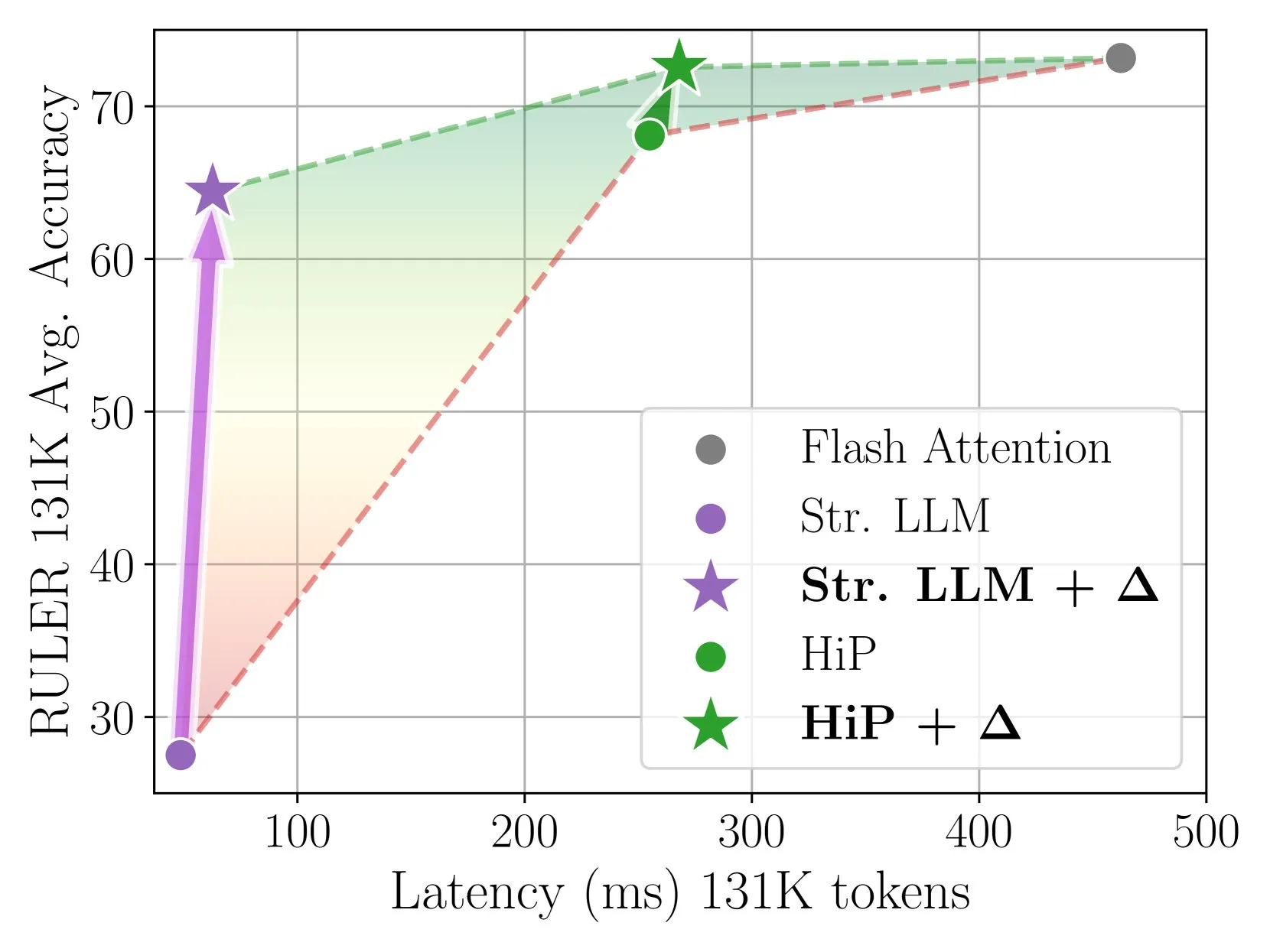
Delta Attention réalise une inférence par attention clairsemée rapide et précise grâce à une correction incrémentielle: Cette étude a révélé que le calcul de l’attention clairsemée entraîne un décalage de distribution de la sortie de l’attention, ce qui dégrade les performances du modèle. Delta Attention corrige ce décalage de distribution, rapprochant la distribution de sortie de l’attention clairsemée de celle de l’attention complète. Ainsi, tout en maintenant une haute sparsité (environ 98,5 %), les performances sont considérablement améliorées, restaurant 88 % de la précision de l’attention complète de l’attention à fenêtre glissante (avec sink tokens) sur le benchmark RULER, avec un faible surcoût de calcul. Lors du traitement d’un pré-remplissage de 1M tokens, elle est 32 fois plus rapide que Flash Attention 2 (Source: HuggingFace Daily Papers)
Le framework Thinkless permet aux LLM d’apprendre quand effectuer un raisonnement CoT: Pour résoudre le problème de la faible efficacité de calcul due à l’utilisation par les grands modèles de langage (LLM) d’un raisonnement complexe en chaîne de pensée (CoT) pour toutes les requêtes, des chercheurs ont proposé le framework Thinkless. Ce framework entraîne les LLM par apprentissage par renforcement à choisir de manière adaptative un raisonnement court ou long en fonction de la complexité de la tâche et de ses propres capacités. L’algorithme principal, DeGRPO, décompose l’objectif d’apprentissage en une perte du token de contrôle (déterminant le mode de raisonnement) et une perte de la réponse (améliorant la précision de la réponse), stabilisant ainsi le processus d’entraînement. Les expériences montrent que Thinkless peut réduire de 50 % à 90 % l’utilisation de la réflexion en chaîne longue sur des benchmarks tels que Minerva Algebra, améliorant considérablement l’efficacité de l’inférence (Source: HuggingFace Daily Papers)
L’algorithme CPGD améliore la stabilité de l’apprentissage par renforcement basé sur des règles pour les modèles de langage: Face aux problèmes d’instabilité de l’entraînement que peuvent rencontrer les méthodes d’apprentissage par renforcement basées sur des règles existantes (telles que GRPO, REINFORCE++, RLOO) lors de l’entraînement de modèles de langage, des chercheurs ont proposé l’algorithme CPGD (Optimisation par Gradient de Politique Tronqué avec Dérive de Politique). CPGD introduit une contrainte de dérive de politique basée sur la divergence KL pour régulariser dynamiquement les mises à jour de la politique, et utilise un mécanisme de troncature du rapport logarithmique pour éviter les mises à jour excessives de la politique. L’analyse théorique et empirique montre que CPGD peut atténuer l’instabilité et améliorer considérablement les performances tout en maintenant la stabilité de l’entraînement (Source: HuggingFace Daily Papers)
Le compilateur de requêtes neuro-symboliques QCompiler améliore la capacité de traitement des requêtes complexes des systèmes RAG: Pour résoudre le problème des systèmes de génération augmentée par récupération (RAG) qui peinent à identifier précisément l’intention de recherche lors du traitement de requêtes complexes avec des structures imbriquées et des dépendances, en particulier dans des situations de ressources limitées, le framework QCompiler a été proposé. Ce framework, inspiré des règles grammaticales linguistiques et de la conception de compilateurs, conçoit d’abord une grammaire BNF G[q] minimale et suffisante pour formaliser les requêtes complexes. Ensuite, via un transformateur d’expressions de requête, un analyseur lexical et syntaxique, et un processeur à descente récursive, la requête est compilée en un arbre syntaxique abstrait (AST) pour exécution. L’atomicité des sous-requêtes des nœuds feuilles assure une récupération de documents et une génération de réponses plus précises (Source: HuggingFace Daily Papers)
L’ensemble de données Jedi et le benchmark OSWorld-G font progresser la recherche sur la localisation des éléments d’interface graphique (GUI) dans les scénarios d’utilisation d’ordinateurs: Pour surmonter le goulot d’étranglement de la localisation dans l’interface graphique utilisateur (GUI) (mapper des instructions en langage naturel à des opérations GUI), les chercheurs ont publié le benchmark OSWorld-G (564 échantillons annotés finement, couvrant la correspondance de texte, la reconnaissance d’éléments, la compréhension de la disposition et les opérations précises) et l’ensemble de données synthétiques à grande échelle Jedi (4 millions d’échantillons). Un modèle multi-échelles entraîné sur Jedi surpasse les méthodes existantes sur ScreenSpot-v2, ScreenSpot-Pro et OSWorld-G, et améliore les capacités d’agent des modèles de fondation généraux dans les tâches informatiques complexes (OSWorld), passant de 5 % à 27 % (Source: HuggingFace Daily Papers)
Le Raisonnement en Chaîne de Pensée Fractionnée (Fractured CoT) améliore l’efficacité et les performances de l’inférence des LLM: Pour résoudre le problème du coût élevé en tokens associé au raisonnement CoT, les chercheurs ont découvert que la CoT tronquée (arrêter le raisonnement avant la fin pour générer directement la réponse) atteint souvent des performances comparables à la CoT complète, mais avec une consommation de tokens significativement réduite. Sur cette base, ils proposent la stratégie d’inférence unifiée Fractured Sampling. En ajustant trois dimensions – le nombre de trajectoires de raisonnement, le nombre de solutions finales par trajectoire et la profondeur de troncature de la trace de raisonnement – ils obtiennent un meilleur compromis précision-coût sur plusieurs benchmarks de raisonnement et tailles de modèles, ouvrant la voie à une inférence LLM plus efficace et évolutive (Source: HuggingFace Daily Papers)
Validation multimodale de formules chimiques par conditionnement contextuel des LLM et incitations PWP: Des chercheurs explorent le conditionnement contextuel structuré des LLM, combiné aux principes des incitations de flux de travail persistantes (PWP – Persistent Workflow Prompting), pour ajuster le comportement des LLM lors du raisonnement. L’objectif est d’améliorer leur fiabilité dans les tâches de validation précises (comme les formules chimiques), en particulier lors du traitement de documents scientifiques complexes contenant des images. Cette méthode utilise uniquement des interfaces de chat standard (Gemini 2.5 Pro, ChatGPT Plus o3), sans API ni modification de modèle. Les expériences préliminaires montrent que cette méthode améliore l’identification des erreurs textuelles et aide Gemini 2.5 Pro à identifier des erreurs dans les formules des images qui avaient été ignorées par une révision humaine (Source: HuggingFace Daily Papers)
Utilisation de PWP, méta-incitations et méta-raisonnement pour une évaluation par les pairs académique assistée par IA: Des chercheurs proposent la méthode des incitations de flux de travail persistantes (PWP – Persistent Workflow Prompting) pour réaliser une évaluation critique par les pairs de manuscrits scientifiques via une interface de chat LLM standard. PWP adopte une architecture modulaire hiérarchique (structurée en Markdown) pour définir un flux de travail d’analyse détaillé. Grâce à des méta-incitations et un méta-raisonnement, il code systématiquement les processus d’évaluation par des experts (y compris les connaissances implicites). PWP guide le LLM pour effectuer une évaluation multimodale systématique, comme distinguer les affirmations des preuves, intégrer l’analyse de texte/images/graphiques, effectuer des vérifications de faisabilité quantitatives, etc. Dans les cas de test, il a réussi à identifier des faiblesses méthodologiques (Source: HuggingFace Daily Papers)
Le benchmark SPOT évalue la capacité de l’IA à valider automatiquement la recherche scientifique: Pour évaluer la capacité des grands modèles de langage (LLM) en tant que « co-scientifiques IA » dans la validation automatisée des manuscrits académiques, les chercheurs ont lancé le benchmark SPOT. Ce benchmark comprend 83 articles publiés et 91 erreurs suffisantes pour entraîner des errata ou des rétractations, et a été validé de manière croisée par les auteurs originaux et des annotateurs humains. Les résultats expérimentaux montrent que même les LLM les plus avancés (comme o3) n’atteignent pas un rappel supérieur à 21,1 % sur SPOT, avec une précision inférieure à 6,1 %. De plus, la confiance des modèles est faible et les résultats sont incohérents entre plusieurs exécutions, ce qui indique un écart énorme entre les LLM actuels et les besoins réels en matière de validation académique fiable (Source: HuggingFace Daily Papers)
ExTrans réalise une traduction par raisonnement profond multilingue grâce à l’apprentissage par renforcement avec augmentation d’échantillons: Pour améliorer les capacités des grands modèles de raisonnement (LRM) en traduction automatique, en particulier dans les scénarios multilingues, les chercheurs proposent ExTrans. Cette méthode conçoit une nouvelle approche de modélisation de la récompense, en quantifiant la récompense par la comparaison des résultats de traduction d’un modèle de traduction stratégique avec ceux d’un LRM puissant (comme DeepSeek-R1-671B). Les expériences montrent qu’un modèle entraîné avec Qwen2.5-7B-Instruct comme ossature atteint des performances SOTA en traduction littéraire, et surpasse OpenAI-o1 et DeepSeeK-R1. Grâce à une modélisation de récompense légère, cette méthode peut transférer efficacement la capacité de traduction unidirectionnelle à 90 directions de traduction dans 11 langues (Source: HuggingFace Daily Papers)
L’Attention Clairsemée Entraînable VSA accélère les modèles de diffusion vidéo: Pour résoudre le problème de complexité quadratique du mécanisme d’attention complète 3D dans les Transformers de Diffusion Vidéo (DiT), les chercheurs proposent VSA (Trainable Sparse Attention). VSA regroupe les tokens en blocs lors d’une phase grossière légère et identifie les tokens clés, puis effectue un calcul d’attention au niveau du token fin au sein de ces blocs. VSA est un noyau unique différentiable entraînable de bout en bout, ne nécessitant pas d’analyse post-traitement, et maintient 85% du MFU de FlashAttention3. Les expériences montrent que VSA réduit les FLOPS d’entraînement de 2,53 fois sans dégrader la perte de diffusion, et accélère le temps d’attention du modèle open source Wan-2.1 de 6 fois, réduisant le temps de génération de bout en bout de 31 à 18 secondes (Source: HuggingFace Daily Papers)
SoftCoT++ : Extension au moment du test par raisonnement en chaîne de pensée souple: Pour renforcer la capacité d’exploration de la méthode SoftCoT, qui effectue un raisonnement dans un espace latent continu, les chercheurs proposent SoftCoT++. Cette méthode perturbe les idées latentes avec diverses perturbations initiales de tokens dédiées et applique l’apprentissage contrastif pour promouvoir la diversité des représentations d’idées souples, étendant ainsi SoftCoT au paradigme de l’extension au moment du test (TTS – Test-Time Scaling). Les expériences montrent que SoftCoT++ améliore significativement les performances de SoftCoT et surpasse SoftCoT avec extension par auto-cohérence, tout en étant fortement compatible avec les techniques d’extension traditionnelles (comme l’auto-cohérence) (Source: HuggingFace Daily Papers)
MTVCrafter : Tokenisation de mouvement 4D pour l’animation d’images humaines en monde ouvert: Pour résoudre le problème des méthodes existantes qui reposent sur des images de pose 2D, limitant leur capacité de généralisation, MTVCrafter propose de modéliser directement les séquences de mouvement 3D brutes (mouvement 4D). Son cœur est le 4DMoT (4D Motion Tokenizer), qui quantifie les séquences de mouvement 3D en tokens de mouvement 4D, fournissant des indices spatio-temporels plus robustes. Ensuite, un MV-DiT (Motion-aware Video DiT) conçu avec une attention au mouvement unique et un encodage de position 4D utilise efficacement ces tokens comme contexte pour réaliser l’animation d’images humaines dans des mondes 3D complexes. Les expériences montrent que MTVCrafter atteint 6,98 sur FID-VID, surpassant de manière significative le SOTA, et se généralise bien à divers personnages de styles et de scènes différents (Source: HuggingFace Daily Papers)
QVGen : Repousser les limites des modèles de génération vidéo quantifiés: Pour faire face aux besoins importants en calcul et en mémoire des modèles de diffusion vidéo (DM), QVGen propose un nouveau cadre d’entraînement conscient de la quantification (QAT) spécialement conçu pour la quantification à très bas bits (par exemple, 4 bits et moins). Grâce à une analyse théorique, les chercheurs ont découvert que la réduction de la norme du gradient est cruciale pour la convergence de QAT, et ont introduit un module auxiliaire (Phi) pour atténuer les grandes erreurs de quantification. Pour éliminer le surcoût d’inférence de Phi, une stratégie de décroissance du rang est proposée, éliminant progressivement Phi par SVD et régularisation basée sur le rang. Les expériences montrent que QVGen atteint pour la première fois une qualité comparable à la pleine précision en configuration 4 bits, et surpasse significativement les méthodes existantes (Source: HuggingFace Daily Papers)
ViPlan : Benchmark de prédicats symboliques et de modèles de langage visuel pour la planification visuelle: Pour combler le fossé comparatif entre la planification symbolique pilotée par VLM et les méthodes de planification VLM directes, ViPlan a été proposé comme le premier benchmark open-source de planification visuelle. ViPlan comprend une série de tâches de difficulté croissante dans deux grands domaines : une version visuelle de Blocksworld et un environnement de robot domestique simulé. Les tests de référence sur 9 familles de VLM open-source et certains modèles propriétaires ont révélé que la planification symbolique est plus performante dans Blocksworld (où la localisation précise des images est cruciale), tandis que la planification VLM directe est meilleure dans les tâches de robot domestique (où les connaissances du monde réel et la capacité de récupération d’erreurs sont importantes). L’étude montre également que les incitations CoT n’apportent pas d’avantages significatifs pour la plupart des modèles et méthodes, suggérant que les capacités actuelles de raisonnement visuel des VLM sont encore insuffisantes (Source: HuggingFace Daily Papers)
Des cris primitifs à la grammaire : étude de l’évolution du langage dans un environnement de recherche de nourriture coopératif: Pour explorer l’origine et l’évolution du langage, des chercheurs ont simulé des scénarios de coopération humaine précoce dans un jeu de recherche de nourriture multi-agents. Grâce à un apprentissage par renforcement profond de bout en bout, les agents apprennent à partir de zéro des stratégies d’action et de communication. L’étude a révélé que les protocoles de communication développés par les agents présentent les caractéristiques emblématiques du langage naturel : arbitraire, interchangeabilité, déplacement, transmission culturelle et compositionalité. Ce cadre offre une plateforme pour étudier comment le langage évolue dans des environnements multi-agents incarnés partiellement observables, nécessitant un raisonnement temporel et motivés par des objectifs coopératifs (Source: HuggingFace Daily Papers)
Tiny QA Benchmark++ : Test de fumée pour la génération de jeux de données synthétiques multilingues ultra-légers et l’évaluation continue des LLM: Tiny QA Benchmark++ (TQB++) est une suite de tests de fumée ultra-légère et multilingue, conçue pour fournir un filet de sécurité de type test unitaire pour les pipelines LLM, capable de s’exécuter en quelques secondes à un coût extrêmement bas. TQB++ comprend un ensemble de référence de 52 items en anglais et fournit un générateur de données synthétiques miniature basé sur LiteLLM (package pypi), permettant aux utilisateurs de générer de petits paquets de test pour des langues, domaines ou difficultés personnalisés. Le projet propose déjà des paquets pré-construits pour 10 langues et prend en charge des outils tels que OpenAI-Evals et LangChain, facilitant son intégration dans les processus CI/CD pour la détection rapide des erreurs de modèles d’incitation, de la dérive des tokeniseurs et des effets secondaires du fine-tuning (Source: HuggingFace Daily Papers)
HelpSteer3-Preference : Ensemble de données ouvert de préférences annotées par des humains, couvrant plusieurs tâches et langues: Pour répondre au besoin de données de préférence ouvertes, diversifiées et de haute qualité, NVIDIA a publié l’ensemble de données HelpSteer3-Preference. Cet ensemble de données contient plus de 40 000 échantillons de préférences annotés par des humains, sous licence CC-BY-4.0, et couvre des applications réelles des LLM telles que les scénarios STEM, de codage et multilingues. Les modèles de récompense (RM) entraînés avec cet ensemble de données obtiennent des performances SOTA sur RM-Bench (82,4 %) et JudgeBench (73,7 %), soit une amélioration d’environ 10 % par rapport aux meilleurs résultats précédents. Cet ensemble de données peut également être utilisé pour entraîner des RM génératifs et pour aligner les modèles de politique via RLHF (Source: HuggingFace Daily Papers)
SEED-GRPO : GRPO amélioré par l’entropie sémantique pour l’optimisation de politique sensible à l’incertitude: Pour résoudre le problème où GRPO ne prend pas en compte l’incertitude du LLM face aux incitations d’entrée lors de la mise à jour de la politique, les chercheurs proposent SEED-GRPO. Cette méthode mesure explicitement l’incertitude du LLM face aux incitations d’entrée (c’est-à-dire la diversité sémantique de plusieurs réponses générées) via l’entropie sémantique, et utilise cette mesure pour moduler l’amplitude de la mise à jour de la politique. Ce mécanisme d’entraînement sensible à l’incertitude permet des mises à jour plus conservatrices pour les questions à forte incertitude, tout en maintenant le signal d’apprentissage original pour les questions de confiance. Les expériences montrent que SEED-GRPO atteint des performances SOTA sur cinq benchmarks de raisonnement mathématique (Source: HuggingFace Daily Papers)
Création d’un Modèle Utilisateur Général (GUM) à partir de l’utilisation de l’ordinateur: Des chercheurs proposent une architecture de Modèle Utilisateur Général (GUM) qui apprend les connaissances et les préférences de l’utilisateur en observant toute interaction de l’utilisateur avec l’ordinateur (par exemple, captures d’écran de l’appareil), et construit des propositions pondérées par la confiance. GUM est capable d’inférer de nouvelles propositions à partir d’observations multimodales non structurées, de récupérer des propositions pertinentes comme contexte, et de corriger continuellement les propositions existantes. Cette architecture vise à améliorer les assistants de chat, à gérer les notifications du système d’exploitation, et à permettre aux agents interactifs de s’adapter aux préférences de l’utilisateur à travers les applications. Les expériences montrent que GUM peut faire des inférences utilisateur calibrées et précises, et que les assistants basés sur GUM peuvent identifier et exécuter de manière proactive des actions utiles non explicitement demandées par l’utilisateur (Source: HuggingFace Daily Papers)
DataExpert-io/data-engineer-handbook: Projet populaire sur GitHub, offrant un référentiel complet de ressources d’apprentissage en ingénierie des données, incluant une feuille de route pour débutants 2024, le matériel d’un camp d’entraînement YouTube gratuit de 6 semaines, des études de cas de projets, des conseils pour les entretiens, des livres recommandés, ainsi que des listes de communautés et de newsletters. Parmi les livres recommandés figurent « Fundamentals of Data Engineering », « Designing Data-Intensive Applications » et « Designing Machine Learning Systems ». Ce manuel répertorie également des entreprises dans divers domaines de l’ingénierie des données, telles que Mage (orchestration), Databricks (data lake), Snowflake (data warehouse), dbt (qualité des données), LangChain (bibliothèque d’applications LLM), etc., et fournit des liens vers les blogs d’ingénierie des données d’entreprises renommées et des livres blancs importants (Source: GitHub Trending)
💼 Affaires
Cohere s’associe à SAP pour introduire des agents IA de niveau entreprise dans les opérations mondiales: Cohere a annoncé un partenariat avec SAP pour intégrer sa technologie d’agents IA de niveau entreprise dans SAP Business Suite, offrant ainsi aux entreprises du monde entier des capacités IA sécurisées et évolutives. Les modèles de pointe de Cohere seront également disponibles sur SAP AI Core, permettant aux entreprises de tirer parti de ses modèles IA multilingues et spécifiques à un domaine (Command, Embed, Rerank) dans des secteurs tels que la finance et la santé, dans le but d’accélérer l’application de l’IA en entreprise et de libérer une valeur commerciale réelle (Source: X, X)
xAI cherche à utiliser les données gouvernementales pour développer ses activités auprès des entreprises et des gouvernements: Selon The Information, la société xAI d’Elon Musk prévoit d’utiliser les données des agences gouvernementales pour développer des modèles et des applications, puis de les vendre à des clients gouvernementaux. Cette initiative pourrait devenir un élément important de la stratégie de commercialisation de xAI, mais elle soulève également des discussions sur l’utilisation des données et les biais potentiels (Source: X)
Weaviate et AWS approfondissent leur collaboration mondiale pour accélérer les initiatives d’IA générative: La société de bases de données vectorielles Weaviate a annoncé le renforcement de sa collaboration mondiale avec AWS, dans le but d’accélérer conjointement les projets d’IA générative. Cette collaboration se concentrera sur l’offre aux développeurs du monde entier d’une vitesse accrue, d’une plus grande échelle et d’une meilleure expérience développeur, afin de promouvoir l’application et le développement des technologies d’IA générative (Source: X)

🌟 Communauté
Montée en puissance des agents de programmation IA, discussion sur les perspectives de carrière des programmeurs: Des entreprises comme Microsoft et OpenAI lancent ou renforcent leurs agents de programmation IA (Coding Agents), tels que GitHub Copilot Coding Agent et OpenAI Codex, capables d’accomplir de manière autonome des tâches de codage, de correction de bugs, de maintenance de code, etc. Dario Amodei, CEO d’Anthropic, prédit que l’IA pourrait écrire la majorité, voire la totalité, du code à court terme, et Kevin Weil, CPO d’OpenAI, pense également que l’IA évoluera d’ingénieur junior à architecte. Cela a suscité un large débat au sein de la communauté sur l’avenir de la profession de programmeur : certains craignent que les postes juniors soient remplacés et que l’IA automatise une grande partie du travail de programmation ; d’autres estiment que l’IA améliorera l’efficacité des programmeurs, leur permettant de se concentrer sur la conception d’architecture et l’innovation de plus haut niveau, leur rôle évoluant vers celui de « guide de l’IA ». La tendance générale indique qu’apprendre à collaborer efficacement avec l’IA deviendra une compétence essentielle pour les programmeurs (Source: X, X, 36氪, 36氪)
Vifs débats sur le concept et les standards des Agents IA, le protocole MCP retient l’attention: Avec l’essor des applications d’Agents IA (comme Manus, Genspark Super Agent, Fellou.ai), la communauté débat activement de la définition, des niveaux de capacité et des paradigmes de développement des Agents. La célèbre société de capital-risque BVP a proposé une classification des Agents en sept niveaux, de L0 à L6. Parallèlement, le protocole de contexte de modèle (MCP), technologie clé pour assurer l’interopérabilité entre les applications IA, suscite l’intérêt. De grandes entreprises étrangères comme Anthropic, OpenAI et Google soutiennent déjà ou prévoient de soutenir MCP, tandis qu’en Chine, des acteurs comme Alibaba Cloud et Tencent Cloud commencent à construire des plateformes de développement d’Agents localisées autour de MCP. Le développeur iluxu a même rendu open-source un projet similaire, llmbasedos, avant que Microsoft ne propose son concept « USB-C for AI apps », dans le but de promouvoir un standard ouvert de connexion pour les Agents (Source: X, X, WeChat, Reddit r/LocalLLaMA)
Les LLM sous-performent dans certaines tâches de raisonnement spécifiques, suscitant un débat sur les limites de leurs capacités: La communauté discute vivement du phénomène de « défaillance » collective des LLM dans certaines tâches de raisonnement physique ou spatio-visuel apparemment simples. Par exemple, une question sur l’empilement de cubes pour former un cube plus grand a mis en échec même les modèles de pointe comme o3 et Gemini 2.5 Pro. Parallèlement, un article d’évaluation souligne que dans des tâches physiques de base comme la fabrication de pièces, les LLM (y compris o3) sont moins performants que des travailleurs expérimentés, principalement en raison de capacités visuelles insuffisantes, d’erreurs de raisonnement physique et d’un manque de connaissances implicites du monde réel. Ces cas soulèvent des questions sur la capacité de compréhension réelle des LLM, les problèmes d’hallucination (par exemple, augmentation du taux d’hallucination d’o3 lors du raisonnement) et la validité des benchmarks actuels, soulignant que l’IA a encore une grande marge de progression en matière de connaissances spécifiques à un domaine et de raisonnement complexe (Source: 量子位, 36氪)

La concurrence technologique sino-américaine et les stratégies de développement de l’IA attirent l’attention: Dans une interview, Jensen Huang, PDG de Nvidia, a abordé le contrôle des puces, les usines d’IA et le pragmatisme des entreprises. Ses propos ont été interprétés comme une analyse approfondie du paysage actuel de la concurrence technologique sino-américaine. Certains commentateurs estiment que les États-Unis tentent de maintenir leur avance en limitant l’accès de la Chine aux ressources IA haut de gamme, mais que cela pourrait conduire à une situation perdant-perdant et ralentir le développement mondial de l’IA. Jensen Huang semble quant à lui penser que la vraie concurrence est à long terme et que les États-Unis devraient viser une avance globale (puces, usines, infrastructures, modèles, applications), plutôt que de simplement rechercher un avantage relatif à court terme, au risque de manquer les opportunités de développement de l’ère de l’IA et de finir par prendre du retard dans la compétition globale de puissance nationale (Source: X)
Application et discussion des outils IA comme ChatGPT dans le soutien à la santé mentale: Des utilisateurs de la communauté Reddit partagent leurs expériences d’utilisation d’outils IA comme ChatGPT pour le soutien en santé mentale, estimant qu’ils peuvent apporter une aide entre deux séances de thérapie professionnelle, notamment pour démêler et exprimer des émotions complexes. Les utilisateurs posent des questions à l’IA ou demandent à l’IA de leur poser des questions sur leurs propres sentiments, afin de mieux comprendre l’origine de leurs émotions et d’élaborer des plans d’amélioration. Dans les commentaires, certains utilisateurs (y compris ceux se présentant comme thérapeutes) estiment que l’IA est même parfois supérieure à certains thérapeutes humains, en particulier pour les personnes ayant des difficultés à obtenir une aide professionnelle ou ayant des problèmes de confiance envers les thérapeutes humains. Cependant, d’autres utilisateurs rappellent que l’IA ne peut pas remplacer complètement la thérapie professionnelle et qu’il faut faire attention aux questions de confidentialité des données personnelles (Source: Reddit r/ChatGPT)
💡 Autres
Lancement du concours d’algorithmes « Qizhi Cup », axé sur trois directions de pointe de l’IA: Le laboratoire Qiyuan lance le concours d’algorithmes « Qizhi Cup », doté d’une cagnotte totale de 750 000 yuans. Le concours comprend trois volets : « Segmentation d’instances robuste d’images de télédétection par satellite », « Détection d’objets au sol par drones pour plateformes embarquées » et « Attaques adverses contre les grands modèles multimodaux ». Il vise à promouvoir l’innovation et l’application des technologies IA de base telles que la perception robuste, le déploiement léger et la défense contre les attaques adverses. Le concours est ouvert aux instituts de recherche, entreprises et institutions nationales (Source: WeChat)

Erreur de contenu généré par l’IA dans le Chicago Sun-Times, recommandation de livres et d’experts inexistants: Dans une de ses éditions recommandant des activités estivales, le Chicago Sun-Times a publié du contenu partiellement généré par IA, qui incluait la recommandation de livres fictifs créés par des auteurs réels, ainsi que la citation d’opinions d’« experts » apparemment inexistants. Par exemple, « Nightshade Market » de Min Jin Lee et « Boiling Point » de Rebecca Makkai étaient listés comme lectures recommandées, alors que ces livres n’existent pas. Cet incident a soulevé des préoccupations concernant l’exactitude et les mécanismes de vérification lors de l’utilisation de contenu généré par l’IA par les médias d’information (Source: Reddit r/artificial)
Discussion sur la question de savoir si l’IA constitue de la « triche »: La communauté débat des limites de l’utilisation d’outils IA (comme ChatGPT, Claude) au travail et dans les études. L’opinion générale est qu’en l’absence de règles l’interdisant explicitement (comme pour les devoirs universitaires), utiliser des outils IA pour améliorer l’efficacité, accomplir des tâches répétitives ou aider à la réflexion n’est pas de la « triche », mais similaire à l’utilisation d’une calculatrice ou d’un moteur de recherche. L’essentiel est de savoir si l’utilisateur comprend la sortie de l’IA, s’il peut l’ajuster et la valider efficacement, et s’il déclare honnêtement le rôle d’assistance de l’IA (surtout dans un contexte académique). Cependant, si l’on dépend entièrement du contenu généré par l’IA et qu’on le revendique comme original sans discernement, cela pourrait relever de la fraude académique ou nuire au développement des compétences personnelles (Source: Reddit r/ArtificialInteligence)