
Kata Kunci:Agen Kecerdasan Buatan, Model Bahasa Besar, Gemini 2.5 Pro, Superkomputer AI Nvidia, Konferensi Build Microsoft, Agen Kecerdasan untuk Penelitian, Evaluasi Kemampuan Penalaran, Pemrograman AI, Perbaikan Bug Mandiri oleh Agen Coding, Platform Penelitian Microsoft Discovery, Teknologi NVLink Fusion, Supernode CloudMatrix 384, Algoritma EdgeInfinite
🔥 Fokus
Agen AI Mendefinisikan Ulang Paradigma Pengembangan dan Penelitian Ilmiah: Konferensi Microsoft Build merilis serangkaian alat agen AI, termasuk Coding Agent yang dapat memperbaiki bug secara mandiri dan memelihara kode, serta platform agen AI untuk penelitian ilmiah Microsoft Discovery yang dapat menghasilkan ide, menyimulasikan hasil, dan belajar secara mandiri. Sementara itu, Chief Product Officer OpenAI Kevin Weil dan CEO Anthropic Dario Amodei menyatakan bahwa AI telah memiliki kemampuan pemrograman tingkat lanjut, mengindikasikan bahwa posisi programmer junior mungkin akan tergantikan, dan peran developer akan beralih menjadi ‘pemandu AI’. Perkembangan ini menandakan bahwa agen AI sedang berevolusi dari alat bantu menjadi kekuatan inti yang dapat beroperasi secara independen dalam proyek-proyek kompleks, yang akan secara mendalam mengubah alur kerja dan efisiensi pengembangan perangkat lunak serta penelitian ilmiah (Sumber: GitHub Trending, X)
Kemampuan Penalaran Large Language Model Hadapi Tantangan dan Evaluasi Baru: Beberapa penelitian dan diskusi baru-baru ini mengungkapkan keterbatasan Large Language Model dalam tugas penalaran yang kompleks. Penelitian dari Universitas Harvard dan institusi lainnya menunjukkan bahwa Chain-of-Thought (CoT) terkadang dapat menyebabkan penurunan akurasi model dalam mengikuti instruksi, karena terlalu fokus pada perencanaan konten dan mengabaikan batasan sederhana. Sementara itu, tugas fisik dunia nyata (seperti pemrosesan suku cadang) dan penalaran spasial visual yang kompleks (seperti masalah penumpukan kubus) juga mengungkap kekurangan model AI teratas (termasuk o3, Gemini 2.5 Pro). Untuk mengevaluasi kemampuan model secara lebih akurat, benchmark baru seperti EMMA dan SPOT diusulkan, yang bertujuan untuk mendeteksi tingkat sebenarnya AI dalam fusi multimodal, validasi ilmiah, dll., mendorong evolusi model menuju penalaran yang lebih kuat dan andal (Sumber: HuggingFace Daily Papers, 量子位)
Google AI Bergerak Penuh, Gemini 2.5 Pro Tunjukkan Performa Kuat: Google menunjukkan serangan komprehensif di bidang AI, dengan model Gemini 2.5 Pro-nya menunjukkan kinerja luar biasa dalam berbagai benchmark (seperti LMSYS Chatbot Arena), terutama mencapai tingkat teratas dalam pemahaman konteks panjang dan video, serta melampaui versi sebelumnya di WebDev Arena. Di konferensi Google Cloud Next ‘25, Google merilis lebih dari 200 pembaruan, termasuk Gemini 2.5 Flash, Imagen 3, Veo 2, Vertex AI Agent Development Kit (ADK), dan protokol Agent2Agent (A2A), menunjukkan tekadnya untuk mengintegrasikan AI ke setiap lapisan platform cloud dan mendorong penyebaran skala perusahaan. Google Labs juga terus menginkubasi produk inovatif asli AI, seperti NotebookLM, menunjukkan kemampuan inovasi dan iterasi produk yang kuat (Sumber: Google, GoogleDeepMind)
Nvidia Merilis Superkomputer AI Desktop dan Solusi Pabrik AI Tingkat Perusahaan: Nvidia merilis beberapa produk penting di Computex, termasuk komputer AI pribadi DGX Station yang ditenagai oleh superchip GB300, dengan memori terpadu hingga 784GB, mendukung model besar parameter 1T; serta RTX PRO Server untuk perusahaan, yang dapat mengakselerasi berbagai aplikasi seperti agen AI, AI fisik, dan komputasi ilmiah. Sementara itu, Nvidia meluncurkan teknologi NVLink Fusion semi-kustom dan NVIDIA AI Data Platform, serta mengumumkan kerja sama dengan Disney dan lainnya untuk mengembangkan mesin AI fisik Newton. Langkah-langkah ini menunjukkan bahwa Nvidia sedang bertransformasi dari perusahaan chip menjadi perusahaan infrastruktur AI, yang bertujuan untuk membangun ekosistem AI lengkap dari desktop hingga pusat data (Sumber: nvidia, 量子位)

🎯 Tren
Kimi.ai Merilis Model Pemikiran Teks Panjang kimi-thinking-preview: Kimi.ai meluncurkan model pemikiran teks panjang terbarunya, kimi-thinking-preview, yang kini tersedia di platform.moonshot.ai. Model ini diklaim memiliki kemampuan multimodal dan penalaran yang luar biasa, dan pengguna baru yang mendaftar akan mendapatkan voucher senilai $5 untuk mencobanya. Komentar komunitas menyarankan agar model ini dievaluasi oleh pihak ketiga, dan menyebutkan bahwa Kimi sebelumnya telah memimpin di livecodebench melalui model pemikiran khusus (Sumber: X)
Red Hat Meluncurkan llm-d: Kerangka Kerja Inferensi Terdistribusi Berbasis Kubernetes: Untuk mengatasi masalah inferensi LLM yang lambat, mahal, dan sulit diskalakan, Red Hat meluncurkan llm-d, sebuah kerangka kerja inferensi terdistribusi asli Kubernetes. Kerangka kerja ini memanfaatkan vLLM, penjadwalan cerdas, dan komputasi terpisah untuk mengoptimalkan inferensi LLM. llm-d dibangun di atas tiga fondasi open source: vLLM (mesin inferensi LLM berkinerja tinggi), Kubernetes (standar orkestrasi kontainer), dan Inference Gateway (IGW) (mengimplementasikan perutean cerdas melalui ekstensi Gateway API), yang bertujuan untuk meningkatkan efisiensi dan skalabilitas inferensi LLM (Sumber: X, X)
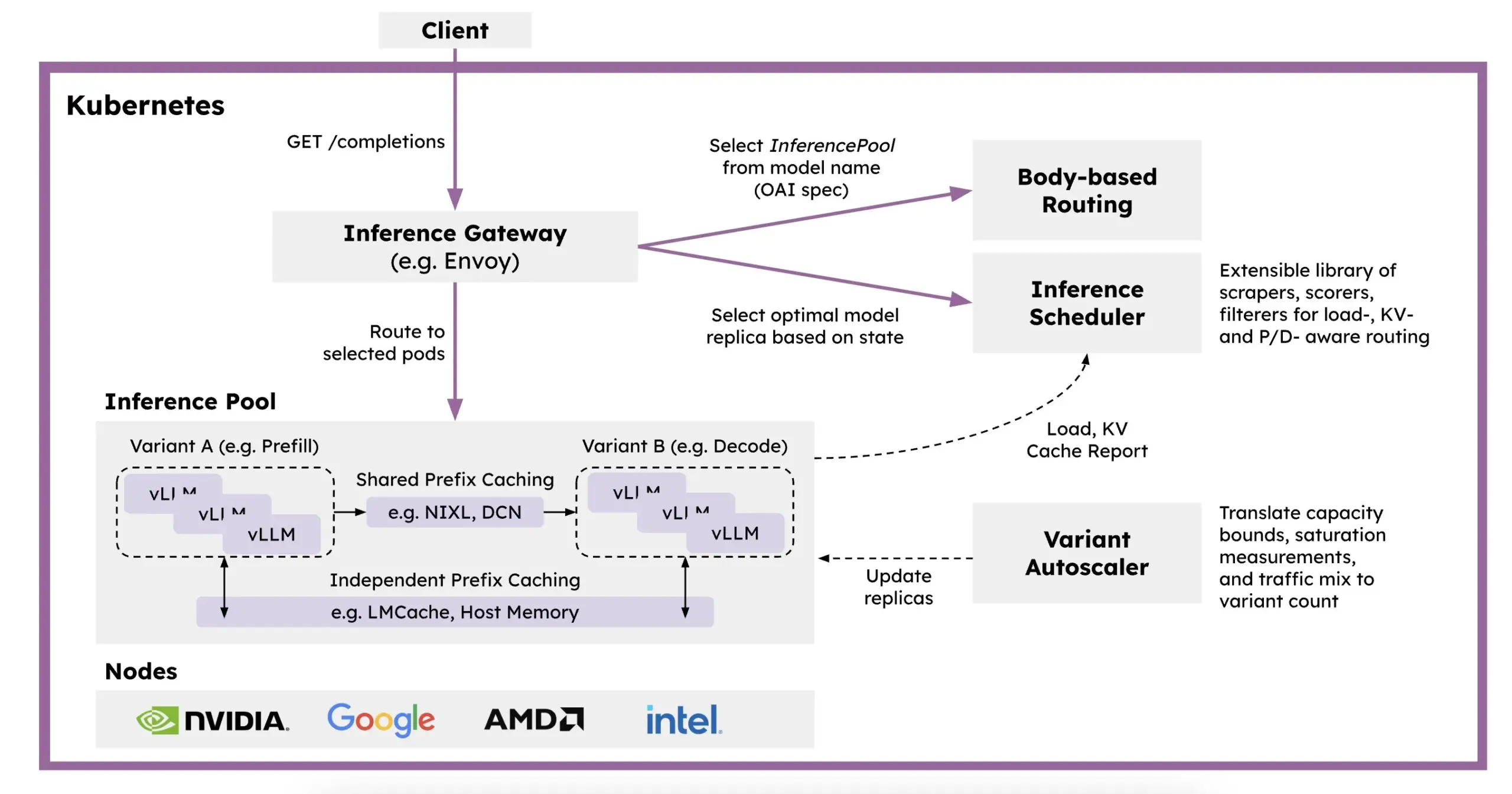
Meta AI Merilis Dataset OMol25, Berisi Lebih dari 100 Juta Konformer Molekul: Meta AI merilis dataset OMol25 di HuggingFace, yang berisi lebih dari 100 juta konformer molekul, mencakup 83 elemen dan lingkungan kimia yang beragam. Dataset ini bertujuan untuk melatih model machine learning yang dapat mencapai akurasi tingkat DFT (Density Functional Theory) sambil secara signifikan mengurangi biaya komputasi. Ini akan membantu mempercepat penelitian dan aplikasi di bidang seperti penemuan obat, desain material canggih, dan solusi energi bersih (Sumber: X)
Gemini 2.5 Pro Hadir di Aplikasi NotebookLM iOS App Store Jerman: Aplikasi NotebookLM Google (terintegrasi dengan Gemini 2.5 Pro) telah tersedia di iOS App Store wilayah Jerman. Sebelumnya, versi iOS di Uni Eropa hanya tersedia melalui TestFlight. Sementara itu, versi Android tampaknya sudah tersedia lebih luas. NotebookLM bertujuan untuk membantu pengguna memahami dan memproses dokumen panjang, catatan, dan konten lainnya (Sumber: X)
Penelitian AI ByteDance Aktif, Merilis Beberapa Makalah Baru-baru Ini: Tim SEED di bawah ByteDance telah menerbitkan setidaknya 13 makalah penelitian terkait AI dalam dua bulan terakhir, mencakup bidang-bidang seperti penggabungan model, Chain-of-Thought adaptif yang dipicu oleh reinforcement learning (AdaCoT), optimasi penalaran melalui representasi laten (LatentSeek), dan lainnya. Penelitian ini menunjukkan investasi dan eksplorasi berkelanjutan ByteDance dalam meningkatkan efisiensi, kemampuan penalaran, dan metode pelatihan Large Language Model (Sumber: X, X)
AI Mendorong Baterai Seng Generasi Berikutnya Mencapai Efisiensi 99,8% dan Waktu Operasi 4300 Jam: Melalui optimasi kecerdasan buatan, baterai seng generasi berikutnya mencapai efisiensi Coulomb 99,8% dan waktu operasi hingga 4300 jam. Terobosan teknologi ini menunjukkan potensi aplikasi AI dalam ilmu material dan penyimpanan energi, diharapkan dapat mendorong pengembangan teknologi baterai yang lebih efisien dan tahan lama, yang memiliki arti penting bagi penyimpanan energi terbarukan dan perangkat elektronik portabel (Sumber: X)

Perplexity Meluncurkan Browser Cerdas AI Comet untuk Pengujian Awal: Perplexity telah mulai meluncurkan browser web Comet dengan kemampuan agen cerdas kepada penguji awal. Browser ini diharapkan akan menawarkan pengalaman “vibe browsing” yang baru, yang mungkin menggabungkan kemampuan pencarian AI dan integrasi informasi Perplexity yang kuat, untuk memberikan pengguna cara menjelajah web yang lebih cerdas dan personal (Sumber: X)
Intel Merilis Kartu Grafis Arc Pro B Series Hemat Biaya, Fokus pada Memori Besar: Intel meluncurkan kartu grafis Arc Pro B50 (memori 16GB, $299) dan Arc Pro B60 (memori 24GB, $500 per kartu) yang dirancang khusus untuk workstation AI. B60 menunjukkan kinerja lebih baik daripada Nvidia RTX A1000 dalam pengujian inferensi AI, dan memori yang lebih besar memberinya keunggulan saat menjalankan model besar. Workstation Project Battlematrix menggunakan prosesor Xeon dan dapat dilengkapi hingga 8 GPU B60 (total memori 192GB), mendukung model dengan parameter 70 miliar+. Langkah ini dianggap sebagai strategi Intel untuk mencari terobosan hemat biaya di pasar perangkat keras AI (Sumber: 量子位)

Huawei Cloud Meluncurkan CloudMatrix 384 Super Node, Tingkatkan Daya Komputasi AI: Huawei Cloud merilis CloudMatrix 384 super node, yang menggunakan arsitektur interkoneksi peer-to-peer penuh, dapat menghubungkan 384 kartu akselerator AI untuk membentuk server cloud super, menyediakan daya komputasi hingga 300 PFlops. Ini bertujuan untuk mengatasi tantangan efisiensi komunikasi, memory wall, dan keandalan dalam pelatihan dan inferensi AI. Arsitektur ini secara khusus menekankan afinitas terhadap model MoE, penguatan komputasi dengan jaringan, penguatan komputasi dengan penyimpanan, dan fitur lainnya, serta telah diterapkan untuk mendukung layanan inferensi model besar seperti DeepSeek-R1 (Sumber: 量子位)

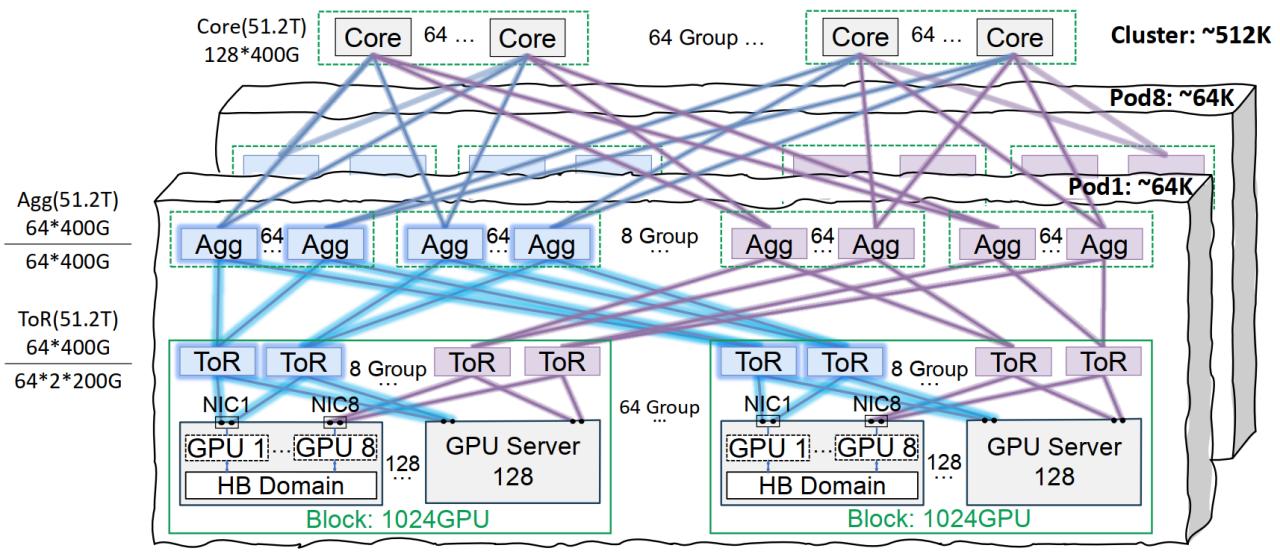
Infrastruktur Jaringan Tencent Cloud StarPulse Optimalkan Pelatihan Model Besar: Tencent Cloud meluncurkan solusi infrastruktur jaringan berkinerja tinggi StarPulse, yang dirancang khusus untuk pelatihan dan inferensi model AI skala besar. Solusi ini mengatasi titik lemah pusat data tradisional dalam hal jaringan, kepadatan penyebaran, dan penentuan lokasi kesalahan melalui arsitektur interkoneksi co-rail (mendukung jaringan 64.000 GPU per Pod, 512.000 GPU per klaster), manajemen daya dan solusi pendinginan yang dioptimalkan, serta sistem pemantauan cerdas. StarPulse telah mendukung bisnis internal Tencent seperti Hunyuan, dan menyediakan optimasi kinerja untuk kerangka kerja komunikasi DeepEP dari DeepSeek (Sumber: 量子位)
Stability AI Merilis Model SV4D2.0, Mungkin Menandakan Kembalinya di Bidang Generasi Video: Stability AI merilis model bernama sv4d2.0 di Hugging Face, yang menarik perhatian komunitas. Meskipun detailnya tidak banyak, langkah ini mungkin berarti Stability AI memiliki kemajuan teknologi baru atau iterasi produk di bidang generasi video atau bidang 3D/4D terkait, mengisyaratkan bahwa setelah penyesuaian, mereka mungkin kembali ke garis depan bidang generasi AI (Sumber: X)
Meta AI Merilis Algoritma Pembelajaran Adjoint Sampling: Meta AI mengusulkan algoritma pembelajaran baru, Adjoint Sampling, untuk melatih model generatif berbasis imbalan skalar. Algoritma ini didasarkan pada dasar teoretis yang dikembangkan oleh FAIR, sangat skalabel, dan diharapkan menjadi dasar untuk penelitian metode sampling skalabel di masa depan. Makalah penelitian, model, kode, dan benchmark terkait telah dirilis (Sumber: X)
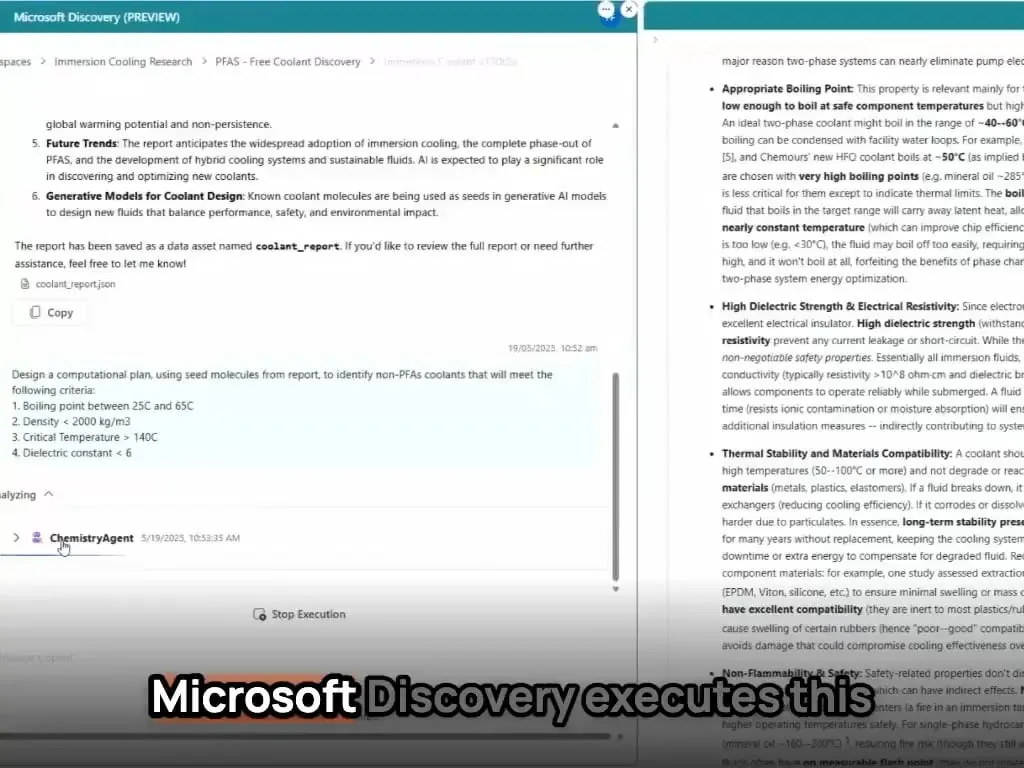
Agen AI Microsoft Menyelesaikan Penemuan dan Sintesis Material Baru dalam Beberapa Jam: Microsoft mendemonstrasikan kemampuan kuat agen AI-nya dalam penelitian dan pengembangan ilmiah. Agen-agen ini mampu memindai literatur ilmiah, menyusun rencana, menulis kode, menjalankan simulasi, dan menyelesaikan penemuan pendingin pusat data baru yang biasanya membutuhkan waktu bertahun-tahun untuk dikembangkan, hanya dalam beberapa jam. Lebih lanjut, tim berhasil mensintesis pendingin baru yang dirancang AI dan mendemonstrasikannya pada motherboard sungguhan, menunjukkan potensi besar AI dalam mempercepat penemuan dan kreasi mandiri di bidang seperti ilmu material (Sumber: Reddit r/artificial)
BAAI Merilis Tiga Model Vektor Seri BGE, Fokus pada Kode dan Pencarian Multimodal: Beijing Academy of Artificial Intelligence (BAAI) bekerja sama dengan universitas meluncurkan BGE-Code-v1 (model vektor kode), BGE-VL-v1.5 (model vektor multimodal umum), dan BGE-VL-Screenshot (model vektor dokumen visual). Model-model ini menunjukkan kinerja luar biasa pada benchmark CoIR, Code-RAG, MMEB, MVRB. BGE-Code-v1 didasarkan pada Qwen2.5-Coder-1.5B, BGE-VL-v1.5 didasarkan pada LLaVA-1.6, dan BGE-VL-Screenshot didasarkan pada Qwen2.5-VL-3B-Instruct. Model-model ini bertujuan untuk meningkatkan kinerja pencarian kode, pemahaman gambar-teks, dan pencarian dokumen visual yang kompleks, dan telah sepenuhnya open source (Sumber: WeChat)
Teknologi OmniPlacement Huawei Optimalkan Inferensi Model MoE, Latensi DeepSeek-V3 Secara Teoretis Turun 10%: Menanggapi masalah beban jaringan pakar yang tidak seimbang (“pakar panas” vs “pakar dingin”) dalam model Mixture-of-Experts (MoE) yang membatasi kinerja inferensi, tim Huawei mengusulkan teknologi OmniPlacement. Teknologi ini secara teoretis dapat mengurangi latensi inferensi sekitar 10% dan meningkatkan throughput sekitar 10% pada model seperti DeepSeek-V3 melalui penataan ulang pakar, penyebaran redundan antar lapisan, dan penjadwalan dinamis hampir real-time. Solusi ini akan sepenuhnya open source dalam waktu dekat (Sumber: WeChat)

vivo Merilis Algoritma EdgeInfinite, Capai Pemrosesan Efisien Teks Panjang 128K di Ponsel: vivo AI Research Institute mempresentasikan penelitian di ACL 2025, meluncurkan algoritma EdgeInfinite yang dirancang khusus untuk perangkat edge. Melalui modul memori gerbang yang dapat dilatih dan teknologi kompresi/dekompresi memori, algoritma ini secara efisien memproses teks super panjang dalam arsitektur Transformer. Algoritma ini diuji pada model BlueLM-3B, mampu memproses 128K token pada perangkat dengan memori GPU 10GB, dan menunjukkan kinerja luar biasa pada beberapa tugas LongBench, secara signifikan mengurangi waktu output kata pertama dan penggunaan memori (Sumber: WeChat)

🧰 Alat
Pembaruan LlamaParse, Tingkatkan Kemampuan Parsing Dokumen: LlamaParse merilis beberapa pembaruan, meningkatkan kinerjanya sebagai alat parsing dokumen yang digerakkan oleh agen AI. Fitur baru termasuk dukungan untuk Gemini 2.5 Pro, GPT-4.1, penambahan deteksi kemiringan, dan skor kepercayaan. Selain itu, diperkenalkan tombol cuplikan kode, memudahkan pengguna untuk menyalin konfigurasi parsing langsung ke repositori kode mereka, serta penambahan preset kasus penggunaan dan kemampuan untuk beralih ekspor antara Markdown yang dirender/mentah (Sumber: X)
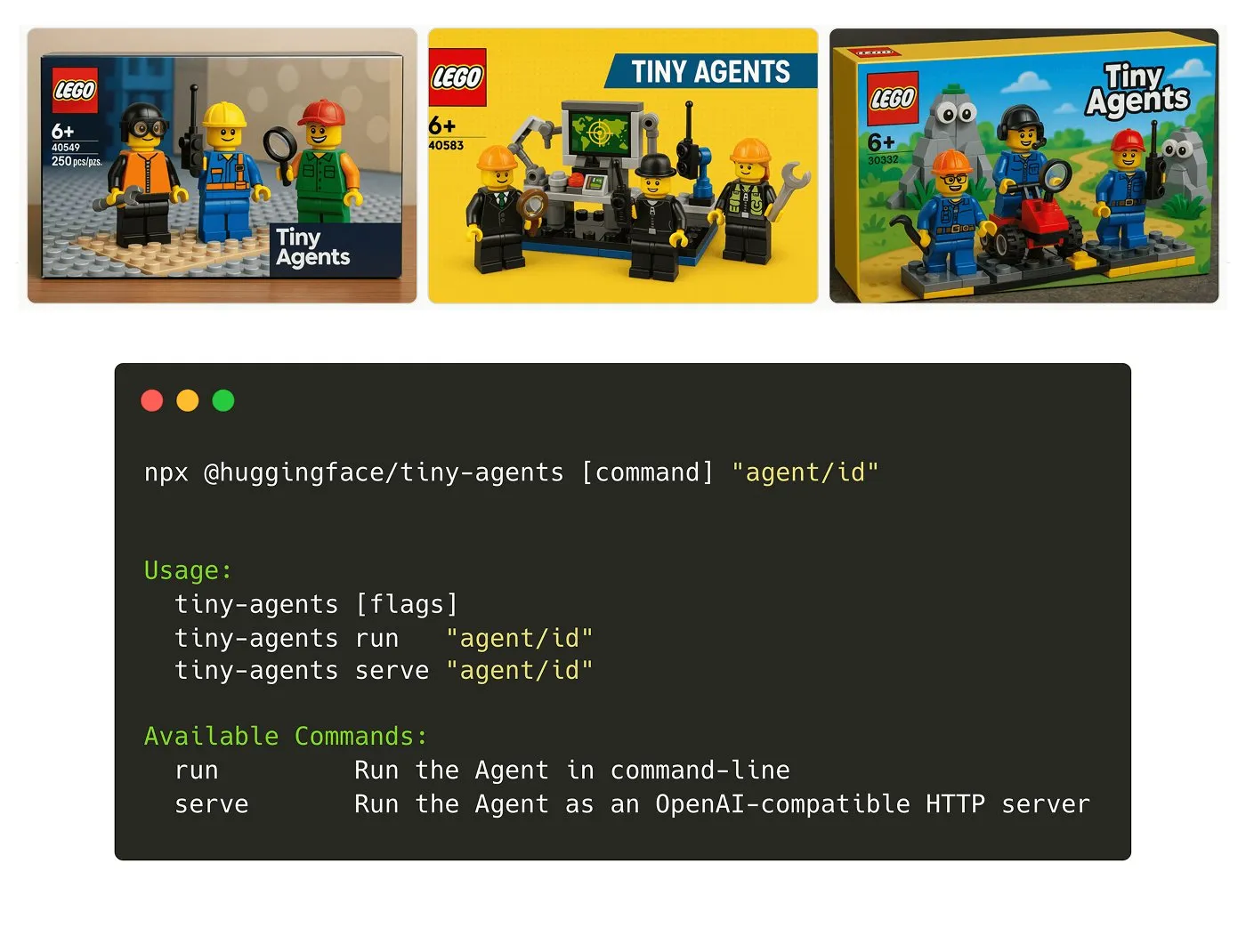
Hugging Face Meluncurkan Paket NPM Tiny Agents: Julien Chaumond merilis Tiny Agents, sebuah paket NPM agen yang ringan dan dapat disusun. Paket ini dibangun di atas Inference Client dan tumpukan MCP (Model Component Protocol) Hugging Face, bertujuan untuk memudahkan developer memulai dan membangun aplikasi agen kecil dengan cepat. Tutorial resmi telah disediakan (Sumber: X)
Platform LangGraph Menambahkan Dukungan MCP, Sederhanakan Integrasi Agen: Platform LangGraph sekarang mendukung MCP (Model Component Protocol), setiap agen yang di-deploy di platform akan secara otomatis mengekspos endpoint MCP. Ini berarti pengguna dapat memanfaatkan agen-agen ini sebagai alat, menggunakannya di klien mana pun yang mendukung MCP streamable HTTP, tanpa perlu menulis kode kustom atau mengonfigurasi infrastruktur tambahan, menyederhanakan integrasi dan interoperabilitas antar agen (Sumber: X)

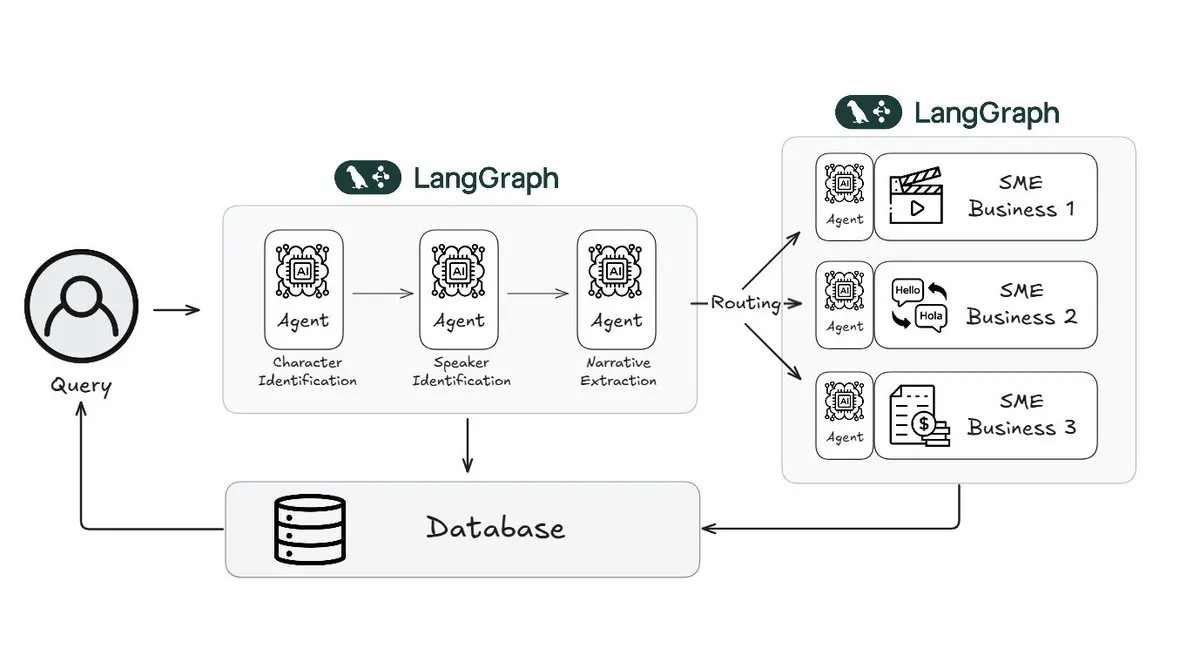
Webtoon Menggunakan LangGraph untuk Mengurangi Beban Kerja Peninjauan Cerita hingga 70%: Pemimpin komik digital Webtoon membangun Webtoon Comprehension AI (WCAI), menggunakan LangGraph untuk mengotomatiskan pemahaman naratif dari perpustakaan kontennya yang masif. WCAI menggantikan penelusuran manual dengan agen multimodal cerdas, mampu melakukan identifikasi karakter dan pembicara, ekstraksi plot dan nada, serta kueri wawasan bahasa alami, mengurangi beban kerja tim pemasaran, terjemahan, dan rekomendasinya hingga 70%, serta meningkatkan kreativitas (Sumber: X)
OpenMemory MCP Mewujudkan Berbagi Memori Pribadi Persisten Antar Alat AI: Proyek Mem0 meluncurkan server OpenMemory MCP, yang bertujuan untuk menyediakan memori pribadi persisten lintas platform dan lintas sesi untuk aplikasi AI. Pengguna dapat melakukan deployment secara lokal, menghubungkan OpenMemory ke alat klien seperti Cursor melalui protokol MCP, untuk menambahkan, mencari, mendaftar, dan menghapus memori. Alat ini menyediakan fungsi manajemen memori melalui dasbor, diharapkan dapat meningkatkan personalisasi dan kemampuan pemahaman konteks agen AI (Sumber: WeChat)

Miaoduo AI 2.0 Dirilis, Diposisikan sebagai Asisten AI Desain Antarmuka: Miaoduo AI 2.0 dirilis sebagai asisten AI di bidang desain antarmuka, bertujuan untuk berkolaborasi dengan pengguna dalam menyelesaikan tugas desain. Versi baru ini meningkatkan interaksi melalui kotak ajaib AI, mendukung pengeditan percakapan dan iterasi skema desain, dapat menghasilkan beberapa versi antarmuka berdasarkan gaya yang telah ditentukan atau masukan pengguna (teks panjang, sketsa, gambar referensi), dan kompatibel dengan sistem desain mainstream. Selain itu, juga menyediakan fungsi pemrosesan gambar-teks, konsultasi desain, dan perintah cepat (bahasa alami ke panggilan API). Miaoduo AI mendukung protokol MCP, mengoptimalkan data draf desain untuk dibaca oleh model besar, guna menghasilkan kode frontend dengan tingkat restorasi tinggi (Sumber: 量子位)

llmbasedos: Bukti Konsep Sistem Operasi AI Open Source yang Dapat Di-boot Berbasis MCP: Pengembang iluxu, tiga hari sebelum Microsoft merilis konsep “USB-C untuk aplikasi AI” (berbasis MCP), membuat proyek llmbasedos menjadi open source. Proyek ini adalah sistem operasi AI yang dapat di-boot dengan cepat dari USB atau mesin virtual, berkomunikasi dengan daemon Python kecil melalui gateway FastAPI dengan JSON-RPC, memungkinkan skrip pengguna dipanggil oleh ChatGPT/Claude/VS Code melalui konfigurasi cap.json sederhana. Secara default menggunakan llama.cpp offline, tetapi juga dapat dialihkan ke GPT-4o atau Claude 3, bertujuan untuk mendorong standar koneksi aplikasi AI yang terbuka (Sumber: Reddit r/LocalLLaMA)
📚 Pembelajaran
Mengapa Knowledge Distillation (KD) Efektif? Penelitian Baru Memberikan Penjelasan Ringkas: Kyunghyun Cho dkk. mengajukan penjelasan ringkas tentang efektivitas knowledge distillation (KD). Mereka berhipotesis bahwa penggunaan sampling aproksimasi entropi rendah dari model guru menghasilkan model siswa dengan presisi lebih tinggi tetapi recall lebih rendah. Karena model bahasa autoregresif pada dasarnya adalah campuran distribusi berjenjang tak terbatas, mereka memverifikasi hipotesis ini melalui SmolLM. Penelitian ini berpendapat bahwa metode evaluasi saat ini mungkin terlalu menekankan presisi dan mengabaikan hilangnya recall, yang berkaitan dengan konten dan kelompok pengguna yang mungkin terlewatkan oleh model umum skala besar (Sumber: X)

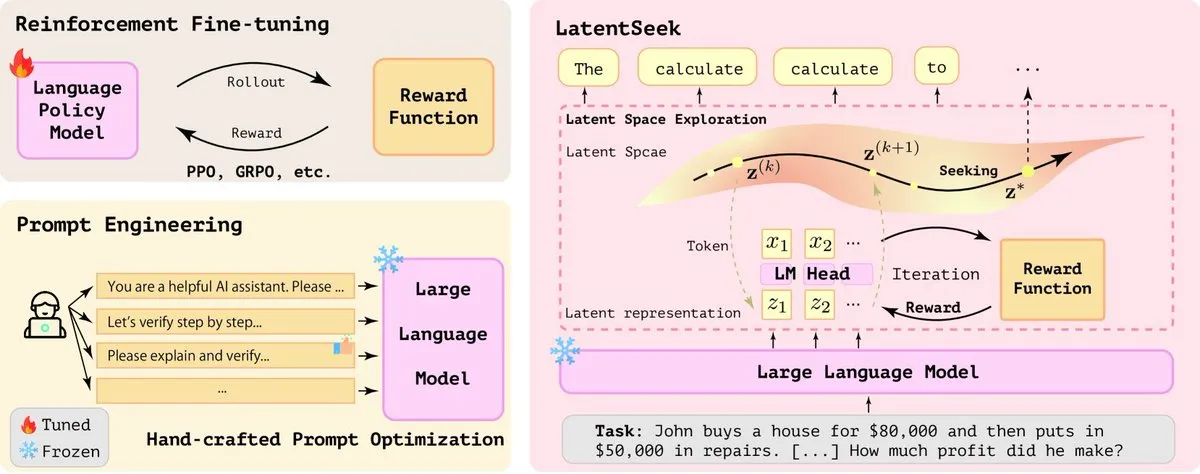
LatentSeek: Meningkatkan Kemampuan Penalaran LLM Melalui Optimasi Gradien Kebijakan Ruang Laten: Sebuah makalah berjudul “Seek in the Dark” mengusulkan LatentSeek, sebuah paradigma baru untuk meningkatkan kemampuan penalaran Large Language Model (LLM) pada saat pengujian melalui gradien kebijakan tingkat instans di ruang laten. Metode ini tidak memerlukan pelatihan, data, atau model imbalan, dan bertujuan untuk meningkatkan proses penalaran model dengan mengoptimalkan representasi laten. Metode yang tidak bergantung pada pelatihan ini menunjukkan potensi dalam meningkatkan kinerja tugas penalaran kompleks LLM (Sumber: X)
Microsoft Mengusulkan CoML: Chain-of-Model Learning untuk Model Bahasa: Microsoft Research mengusulkan paradigma pembelajaran baru “Chain-of-Model Learning” (CoML). Metode ini mengintegrasikan hubungan kausal dari status tersembunyi dalam struktur berantai ke setiap lapisan jaringan, bertujuan untuk meningkatkan efisiensi penskalaan pelatihan model dan fleksibilitas penalaran saat deployment. Konsep intinya “Chain-of-Representation” (CoR) menguraikan status tersembunyi setiap lapisan menjadi beberapa rantai sub-representasi, di mana rantai berikutnya dapat mengakses representasi input dari semua rantai sebelumnya, sehingga memungkinkan model untuk berkembang secara bertahap dengan menambahkan rantai, dan dapat menyediakan sub-model dengan berbagai skala untuk penalaran elastis dengan memilih jumlah rantai yang berbeda. CoLM (Chain-of-Language Model) yang dirancang berdasarkan prinsip ini dan variannya CoLM-Air (memperkenalkan mekanisme berbagi KV) menunjukkan kinerja yang sebanding dengan Transformer standar, serta membawa keuntungan penskalaan bertahap dan penalaran elastis (Sumber: X, HuggingFace Daily Papers)

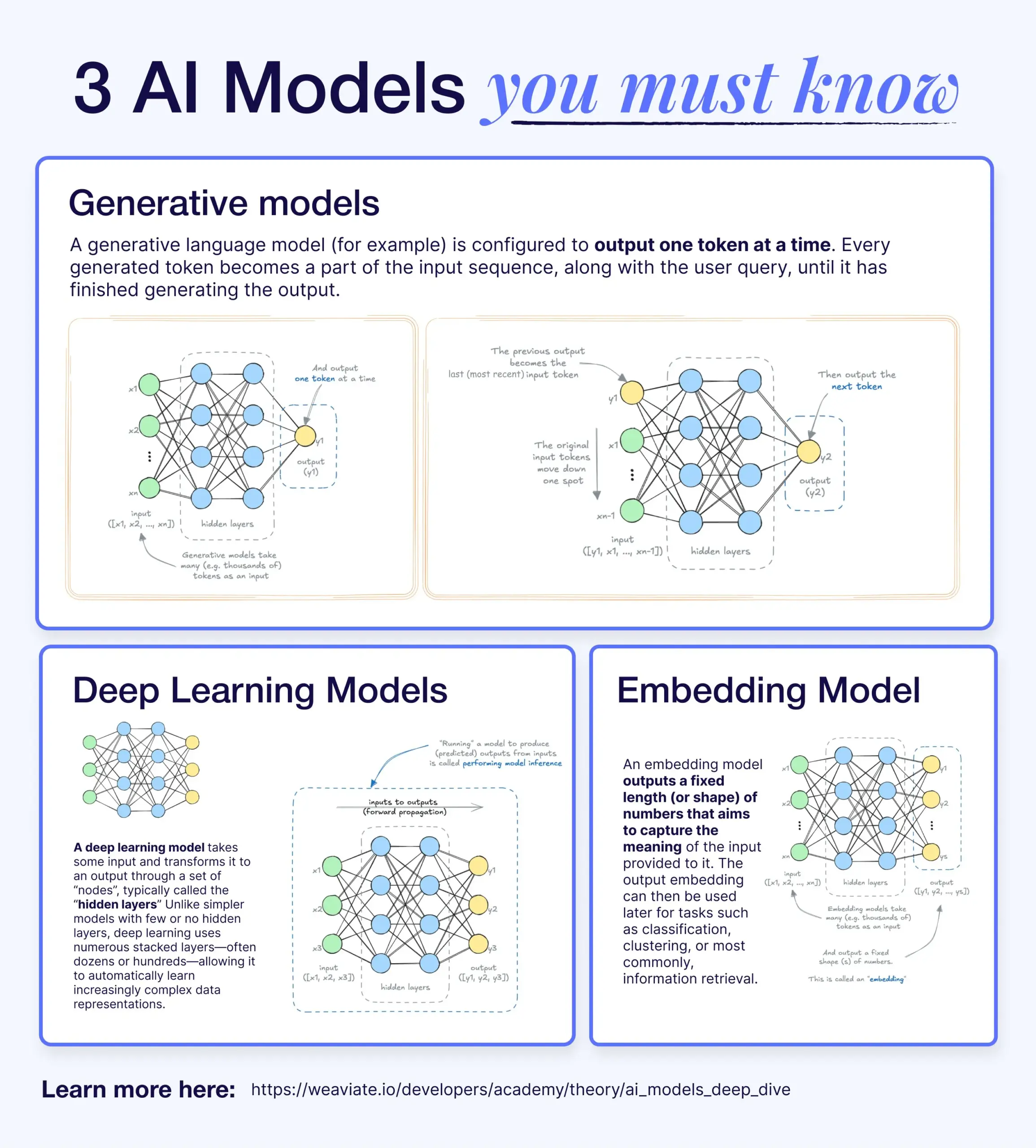
Perbedaan dan Hubungan antara Deep Learning, Model Generatif, dan Model Embedding: Sebuah artikel penjelasan menjelaskan hubungan antara model deep learning, model generatif, dan model embedding. Model deep learning adalah arsitektur dasar, memproses input dan output numerik melalui jaringan saraf berlapis-lapis. Model generatif adalah jenis model deep learning, yang khusus digunakan untuk membuat konten baru yang mirip dengan data pelatihannya (seperti GPT, DALL-E). Model embedding juga merupakan jenis model deep learning, yang digunakan untuk mengubah data (teks, gambar, dll.) menjadi representasi vektor numerik yang menangkap informasi semantik, sering digunakan untuk pencarian kesamaan dan sistem RAG. Dalam banyak sistem AI, model-model ini bekerja sama, misalnya sistem RAG memanfaatkan model embedding untuk pencarian, kemudian model generatif menghasilkan respons (Sumber: X)
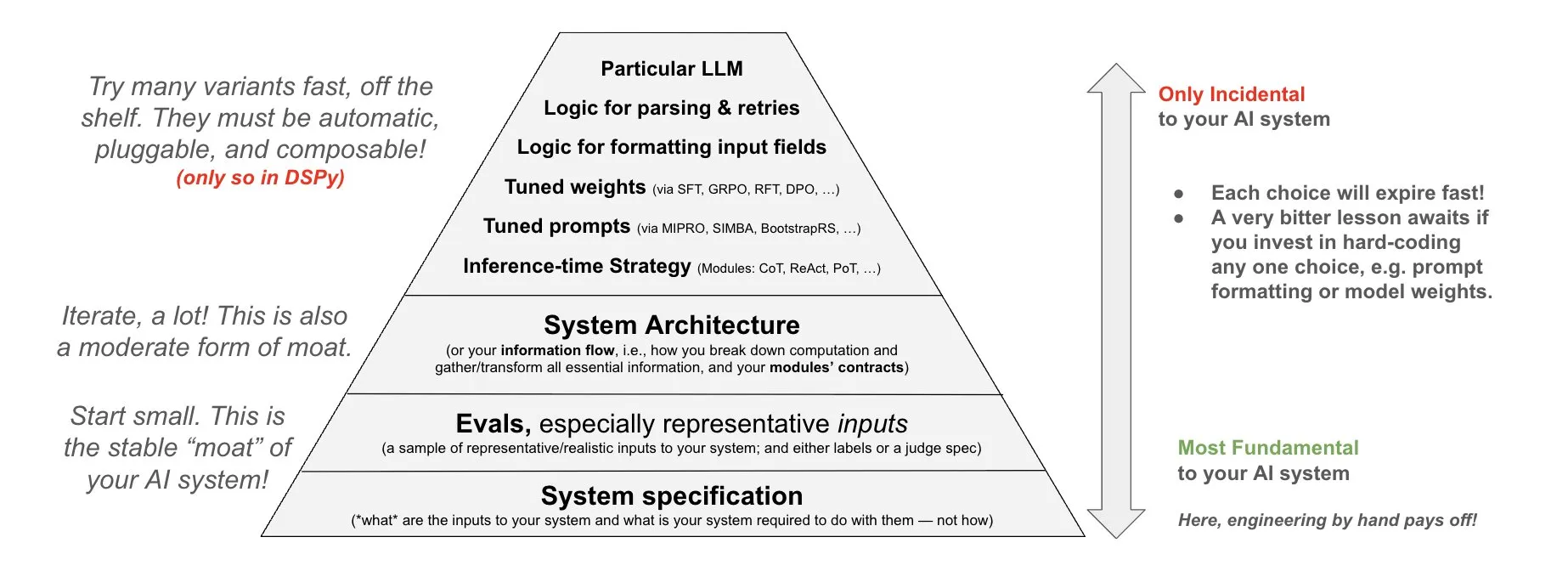
DSPy Mengajukan Filosofi Investasi Sistem AI: DSPy membagikan filosofinya tentang investasi sistem AI, menekankan bahwa upaya harus diinvestasikan dalam tiga lapisan dasar sistem AI: data, model, dan algoritma. Mereka berpendapat bahwa dengan menyediakan modul tingkat atas yang dapat disusun (Prompts, Demonstrations, Optimizers, Metrics, Tools, Agents, Reasoning Modules), developer dapat dengan cepat melakukan iterasi pada ketiga lapisan dasar ini, sehingga membangun sistem AI yang lebih kuat (Sumber: X)
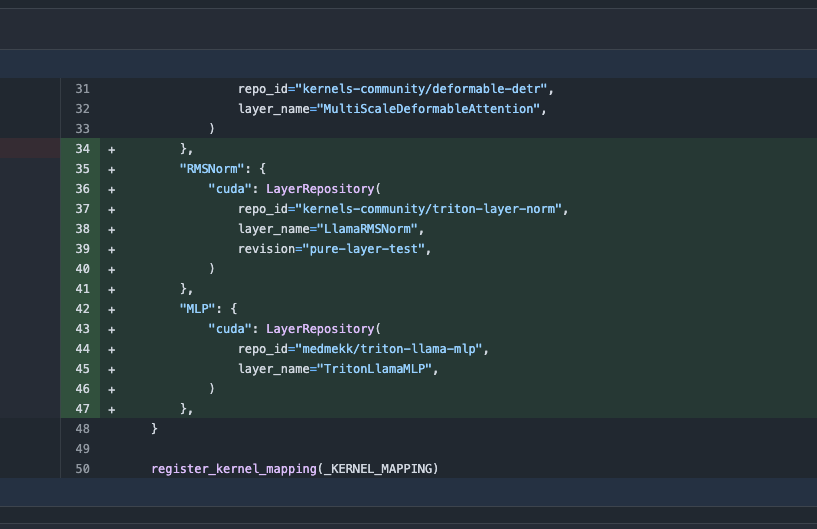
Pembaruan Pustaka Transformers, Beralih Otomatis ke Kernel Teroptimasi untuk Tingkatkan Kinerja: Versi terbaru pustaka Hugging Face Transformers mengimplementasikan peralihan otomatis ke kernel teroptimasi ketika perangkat keras memungkinkan. Pembaruan ini mengintegrasikan pustaka kernels, menargetkan model populer seperti Llama, memanfaatkan kernel komunitas paling populer di Hugging Face Hub, bertujuan untuk meningkatkan efisiensi dan kinerja operasional model pada perangkat keras yang kompatibel (Sumber: X)
Benchmark ARC-AGI-2 Dirilis, Tantang Sistem Penalaran AI Terdepan: François Chollet dkk. merilis makalah tentang benchmark ARC-AGI-2, merinci prinsip desainnya, tantangannya, analisis kinerja manusia, dan kinerja model saat ini. Benchmark ini bertujuan untuk mengevaluasi kemampuan penalaran abstrak AI. Manusia mampu menyelesaikan 100% tugas, sementara skor model AI terdepan saat ini di bawah 5%, menunjukkan masih adanya kesenjangan besar antara AI dan manusia dalam penalaran abstrak tingkat lanjut (Sumber: X)

Terence Tao Merilis Tutorial GitHub Copilot untuk Membantu Pembuktian Limit Fungsi: Matematikawan Terence Tao merilis tutorial video yang mendemonstrasikan cara menggunakan GitHub Copilot untuk membantu membuktikan masalah limit fungsi, termasuk teorema penjumlahan, pengurangan, dan perkalian. Ia menekankan bahwa meskipun Copilot dapat dengan cepat menghasilkan kerangka kode dan menyarankan fungsi pustaka yang ada, intervensi dan penyesuaian manual yang signifikan masih diperlukan untuk detail matematika yang kompleks, penanganan kasus khusus, dan solusi kreatif. Terkadang, menggabungkan penalaran dengan kertas dan pena sebelum melakukan verifikasi formal mungkin lebih efisien (Sumber: 36氪)
Kerangka Kerja PhyT2V Memanfaatkan LLM untuk Meningkatkan Konsistensi Fisik Video yang Dihasilkan Teks: Tim peneliti dari Universitas Pittsburgh mengusulkan kerangka kerja PhyT2V, yang melalui penalaran berantai (CoT) yang dipandu oleh Large Language Model dan mekanisme koreksi diri iteratif, mengoptimalkan prompt teks untuk meningkatkan realisme fisik konten yang dihasilkan oleh model text-to-video (T2V) yang ada. Metode ini tidak memerlukan pelatihan ulang model, melainkan menganalisis ketidaksesuaian semantik antara video yang telah dihasilkan dan prompt, serta menggabungkan aturan fisika untuk koreksi prompt, bertujuan untuk meningkatkan konsistensi fisik model T2V saat menangani skenario di luar distribusi (OOD). Eksperimen menunjukkan bahwa PhyT2V dapat secara signifikan meningkatkan kinerja model seperti CogVideoX dan OpenSora pada benchmark seperti VideoPhy dan PhyGenBench (Sumber: WeChat)

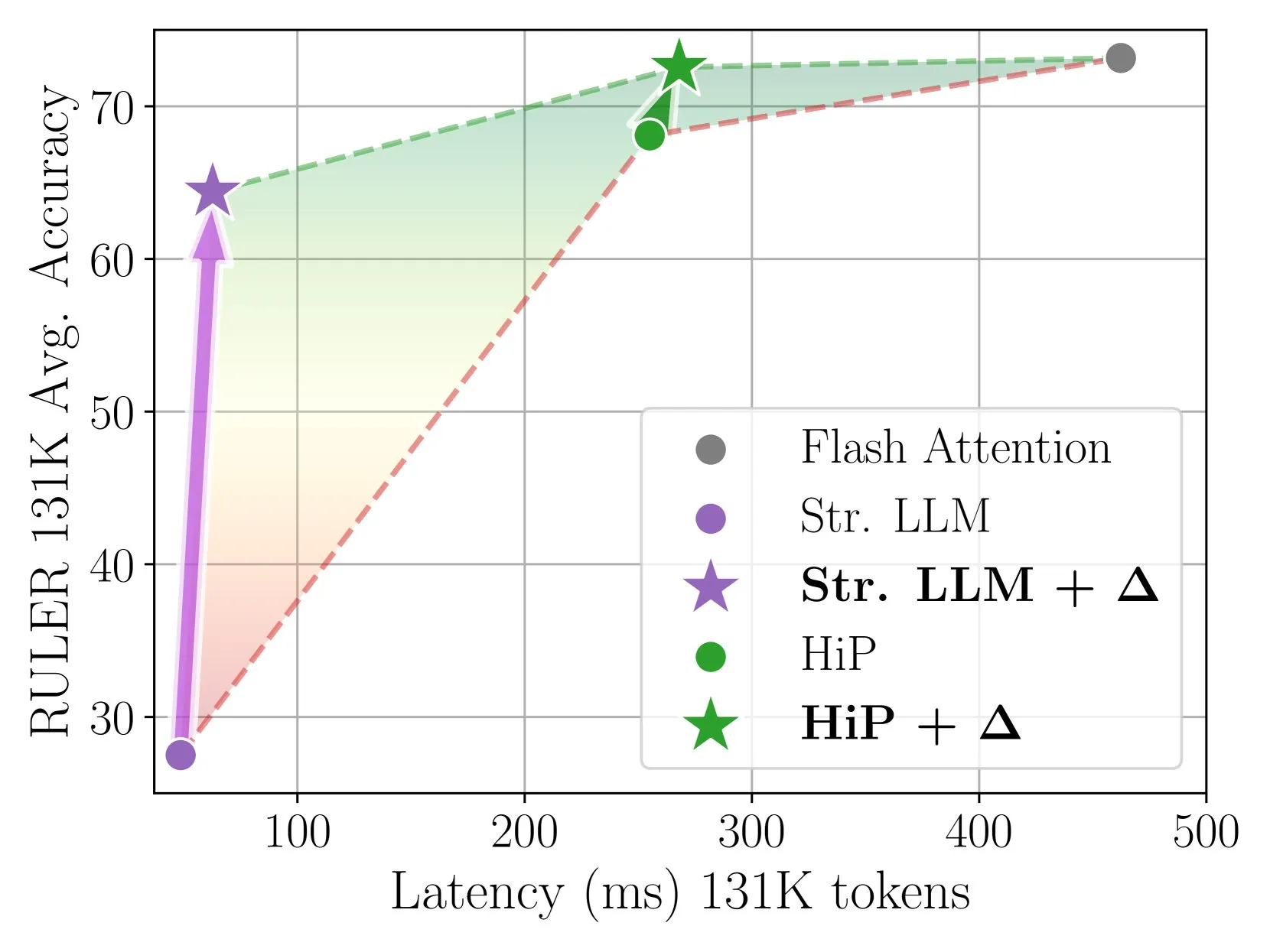
Delta Attention Melalui Koreksi Inkremental Mewujudkan Inferensi Atensi Jarang yang Cepat dan Akurat: Penelitian ini menemukan bahwa komputasi atensi jarang menyebabkan pergeseran distribusi output atensi, sehingga menurunkan kinerja model. Delta Attention, dengan mengoreksi pergeseran distribusi ini, membuat distribusi output atensi jarang lebih mendekati atensi penuh, sehingga sambil mempertahankan tingkat kejarangan tinggi (sekitar 98,5%), secara signifikan meningkatkan kinerja, memulihkan 88% akurasi atensi penuh dari atensi jendela geser (dengan token sink) pada benchmark RULER, dan dengan overhead komputasi yang kecil. Saat memproses pra-pengisian 1M token, 32 kali lebih cepat dari Flash Attention 2 (Sumber: HuggingFace Daily Papers)
Kerangka Kerja Thinkless Membuat LLM Belajar Kapan Melakukan Penalaran CoT: Untuk mengatasi masalah efisiensi komputasi yang rendah akibat Large Language Model (LLM) menggunakan penalaran Chain-of-Thought (CoT) yang kompleks untuk semua kueri, para peneliti mengusulkan kerangka kerja Thinkless. Kerangka kerja ini melatih LLM melalui reinforcement learning agar dapat secara adaptif memilih penalaran bentuk pendek atau panjang berdasarkan kompleksitas tugas dan kemampuannya sendiri. Algoritma inti DeGRPO menguraikan tujuan pembelajaran menjadi kerugian token kontrol (menentukan mode penalaran) dan kerugian respons (meningkatkan akurasi jawaban), sehingga menstabilkan proses pelatihan. Eksperimen menunjukkan bahwa Thinkless dapat mengurangi penggunaan pemikiran rantai panjang sebesar 50%-90% pada benchmark seperti Minerva Algebra, secara signifikan meningkatkan efisiensi penalaran (Sumber: HuggingFace Daily Papers)
Algoritma CPGD Meningkatkan Stabilitas Reinforcement Learning Model Bahasa Berbasis Aturan: Menanggapi masalah ketidakstabilan pelatihan yang mungkin muncul pada metode reinforcement learning berbasis aturan yang ada (seperti GRPO, REINFORCE++, RLOO) saat melatih model bahasa, para peneliti mengusulkan algoritma CPGD (Clipped Policy Gradient Optimization with Policy Drift). CPGD secara dinamis meregularisasi pembaruan kebijakan dengan memperkenalkan batasan pergeseran kebijakan berbasis divergensi KL, dan memanfaatkan mekanisme pemangkasan rasio log untuk mencegah pembaruan kebijakan yang berlebihan. Analisis teoretis dan empiris menunjukkan bahwa CPGD dapat mengurangi ketidakstabilan dan secara signifikan meningkatkan kinerja sambil mempertahankan stabilitas pelatihan (Sumber: HuggingFace Daily Papers)
Kompilator Kueri Neuro-Simbolik QCompiler Meningkatkan Kemampuan Pemrosesan Kueri Kompleks Sistem RAG: Untuk mengatasi masalah sistem Retrieval Augmented Generation (RAG) dalam memproses kueri kompleks dengan struktur bersarang dan dependensi, terutama dalam situasi sumber daya terbatas di mana sulit untuk mengidentifikasi maksud pencarian secara akurat, kerangka kerja QCompiler diusulkan. Kerangka kerja ini terinspirasi oleh aturan tata bahasa linguistik dan desain kompiler, pertama-tama merancang tata bahasa BNF G[q] yang minimal dan memadai untuk memformalkan kueri kompleks, kemudian melalui konverter ekspresi kueri, parser tata bahasa leksikal, dan prosesor penurunan rekursif, mengkompilasi kueri menjadi Abstract Syntax Tree (AST) untuk eksekusi. Atomisitas sub-kueri pada node daun memastikan pengambilan dokumen dan pembuatan respons yang lebih akurat (Sumber: HuggingFace Daily Papers)
Dataset Jedi dan Benchmark OSWorld-G Mendorong Penelitian Lokalisasi Elemen GUI dalam Skenario Penggunaan Komputer: Untuk mengatasi bottleneck dalam lokalisasi Antarmuka Pengguna Grafis (GUI) (memetakan instruksi bahasa alami ke operasi GUI), para peneliti merilis benchmark OSWorld-G (564 sampel beranotasi halus, mencakup pencocokan teks, identifikasi elemen, pemahaman tata letak, dan operasi presisi) dan dataset sintetis skala besar Jedi (4 juta sampel). Model multi-skala yang dilatih pada Jedi mengungguli metode yang ada pada ScreenSpot-v2, ScreenSpot-Pro, dan OSWorld-G, serta dapat meningkatkan kemampuan agen model dasar umum dalam tugas komputer yang kompleks (OSWorld), dari 5% menjadi 27% (Sumber: HuggingFace Daily Papers)
Penalaran Chain-of-Thought Terfragmentasi (Fractured CoT) Meningkatkan Efisiensi dan Kinerja Penalaran LLM: Untuk mengatasi masalah biaya token tinggi yang disebabkan oleh penalaran CoT, para peneliti menemukan bahwa CoT yang dipotong (menghentikan penalaran sebelum selesai dan langsung menghasilkan jawaban) biasanya dapat mencapai kinerja yang sebanding dengan CoT lengkap, tetapi dengan konsumsi token yang jauh lebih sedikit. Berdasarkan hal ini, diusulkan strategi penalaran terpadu Fractured Sampling, yang dengan menyesuaikan tiga dimensi: jumlah lintasan penalaran, jumlah solusi akhir per lintasan, dan kedalaman pemotongan jejak penalaran, mencapai trade-off akurasi-biaya yang lebih optimal pada berbagai benchmark penalaran dan skala model, membuka jalan bagi penalaran LLM yang lebih efisien dan skalabel (Sumber: HuggingFace Daily Papers)
Melalui Kondisioning Konteks LLM dan Prompting PWP untuk Validasi Multimodal Rumus Kimia: Para peneliti mengeksplorasi kondisioning konteks LLM terstruktur, dikombinasikan dengan prinsip Persistent Workflow Prompting (PWP), untuk menyesuaikan perilaku LLM saat penalaran, bertujuan untuk meningkatkan keandalannya dalam tugas validasi presisi (seperti rumus kimia), terutama saat memproses dokumen ilmiah kompleks yang berisi gambar. Metode ini hanya menggunakan antarmuka obrolan standar (Gemini 2.5 Pro, ChatGPT Plus o3), tanpa memerlukan API atau modifikasi model. Eksperimen awal menunjukkan bahwa metode ini meningkatkan identifikasi kesalahan teks dan membantu Gemini 2.5 Pro mengidentifikasi kesalahan rumus gambar yang terlewat oleh tinjauan manual (Sumber: HuggingFace Daily Papers)
Memanfaatkan PWP, Meta-Prompting, dan Meta-Reasoning untuk Mewujudkan Tinjauan Sejawat Akademik yang Digerakkan AI: Para peneliti mengusulkan metode Persistent Workflow Prompting (PWP), yang melalui antarmuka obrolan LLM standar, mewujudkan tinjauan sejawat kritis terhadap naskah ilmiah. PWP mengadopsi arsitektur modular hierarkis (terstruktur Markdown) untuk mendefinisikan alur kerja analisis terperinci, melalui meta-prompting dan meta-reasoning secara sistematis mengkodekan proses tinjauan pakar (termasuk pengetahuan implisit). PWP memandu LLM untuk melakukan evaluasi multimodal sistematis, seperti membedakan klaim dari bukti, mengintegrasikan analisis teks/gambar/diagram, melakukan pemeriksaan kelayakan kuantitatif, dll., dan dalam kasus uji berhasil mengidentifikasi kekurangan metodologis (Sumber: HuggingFace Daily Papers)
Benchmark SPOT Mengevaluasi Kemampuan AI untuk Memvalidasi Penelitian Ilmiah Secara Otomatis: Untuk mengevaluasi kemampuan Large Language Model (LLM) sebagai “ilmuwan rekanan AI” dalam memvalidasi naskah akademis secara otomatis, para peneliti meluncurkan benchmark SPOT. Benchmark ini berisi 83 makalah yang telah diterbitkan dan 91 kesalahan yang cukup untuk menyebabkan koreksi atau pencabutan, serta telah diverifikasi silang oleh penulis asli dan anotator manusia. Hasil eksperimen menunjukkan bahwa bahkan LLM tercanggih (seperti o3), recall-nya di SPOT tidak melebihi 21,1%, presisinya di bawah 6,1%, kepercayaan model rendah, dan hasil beberapa kali proses tidak konsisten, menunjukkan bahwa LLM saat ini masih memiliki kesenjangan besar dengan kebutuhan aktual dalam validasi akademis yang andal (Sumber: HuggingFace Daily Papers)
ExTrans Melalui Pembelajaran Penguatan yang Ditingkatkan Sampel Mewujudkan Terjemahan Penalaran Mendalam Multibahasa: Untuk meningkatkan kemampuan model penalaran besar (LRM) dalam terjemahan mesin, terutama dalam skenario multibahasa, para peneliti mengusulkan ExTrans. Metode ini merancang metode pemodelan imbalan baru, dengan membandingkan hasil terjemahan model kebijakan dengan LRM yang kuat (seperti DeepSeek-R1-671B) untuk mengukur imbalan. Eksperimen menunjukkan bahwa model yang dilatih dengan Qwen2.5-7B-Instruct sebagai tulang punggung mencapai SOTA dalam terjemahan sastra, dan mengungguli OpenAI-o1 dan DeepSeeK-R1. Melalui pemodelan imbalan ringan, metode ini dapat secara efektif mentransfer kemampuan terjemahan satu arah ke 90 arah terjemahan dalam 11 bahasa (Sumber: HuggingFace Daily Papers)
Atensi Jarang yang Dapat Dilatih VSA Mempercepat Model Difusi Video: Untuk mengatasi masalah kompleksitas kuadratik mekanisme atensi penuh 3D dalam Video Diffusion Transformer (DiT), para peneliti mengusulkan VSA (atensi jarang yang dapat dilatih). VSA melalui tahap kasar ringan mengumpulkan token ke dalam blok dan mengidentifikasi token kunci, kemudian melakukan komputasi atensi tingkat token halus di dalam blok-blok ini. VSA adalah kernel tunggal yang dapat dilatih secara end-to-end dan dapat didiferensiasi, tidak memerlukan analisis pasca-pemrosesan, dan mempertahankan 85% MFU FlashAttention3. Eksperimen menunjukkan bahwa VSA, tanpa menurunkan kerugian difusi, mengurangi FLOPS pelatihan sebesar 2,53 kali, dan mempercepat waktu atensi model open source Wan-2.1 sebesar 6 kali, mengurangi waktu generasi end-to-end dari 31 detik menjadi 18 detik (Sumber: HuggingFace Daily Papers)
SoftCoT++: Melalui Penalaran Chain-of-Thought Lunak Mewujudkan Ekspansi Saat Pengujian: Untuk meningkatkan kemampuan eksplorasi metode SoftCoT yang melakukan penalaran dalam ruang laten kontinu, para peneliti mengusulkan SoftCoT++. Metode ini mengganggu ide-ide laten melalui berbagai perturbasi token awal khusus, dan menerapkan pembelajaran kontrastif untuk mendorong keragaman representasi ide lunak, sehingga memperluas SoftCoT ke paradigma ekspansi saat pengujian (TTS). Eksperimen menunjukkan bahwa SoftCoT++ secara signifikan meningkatkan kinerja SoftCoT, dan mengungguli SoftCoT dengan ekspansi konsistensi diri, serta memiliki kompatibilitas yang kuat dengan teknik ekspansi tradisional (seperti konsistensi diri) (Sumber: HuggingFace Daily Papers)
MTVCrafter: Tokenisasi Gerakan 4D untuk Animasi Gambar Manusia Dunia Terbuka: Untuk mengatasi masalah metode yang ada bergantung pada gambar pose 2D yang menyebabkan kemampuan generalisasi terbatas, MTVCrafter mengusulkan untuk secara langsung memodelkan urutan gerakan 3D mentah (gerakan 4D). Intinya adalah 4DMoT (penanda gerakan 4D), yang mengkuantisasi urutan gerakan 3D menjadi penanda gerakan 4D, memberikan petunjuk spasial-temporal yang lebih kuat. Kemudian, melalui atensi gerakan unik dan desain pengkodean posisi 4D MV-DiT (video DiT yang sadar gerakan) secara efektif memanfaatkan penanda ini sebagai konteks, untuk mewujudkan animasi gambar manusia dalam dunia 3D yang kompleks. Eksperimen menunjukkan bahwa MTVCrafter mencapai 6,98 pada FID-VID, secara signifikan mengungguli SOTA, dan dapat melakukan generalisasi dengan baik ke berbagai karakter dengan gaya dan skenario yang berbeda (Sumber: HuggingFace Daily Papers)
QVGen: Mendorong Batas Model Generasi Video Terkuantisasi: Untuk mengatasi masalah kebutuhan komputasi dan memori yang besar pada model difusi video (DM), QVGen mengusulkan kerangka kerja pelatihan sadar kuantisasi (QAT) baru yang dirancang khusus untuk kuantisasi bit sangat rendah (seperti 4-bit ke bawah). Melalui analisis teoretis, para peneliti menemukan bahwa mengurangi norma gradien sangat penting untuk konvergensi QAT, dan memperkenalkan modul bantu (Phi) untuk mengurangi kesalahan kuantisasi yang besar. Untuk menghilangkan overhead inferensi Phi, diusulkan strategi peluruhan peringkat, yang melalui SVD dan regularisasi berbasis peringkat secara bertahap menghilangkan Phi. Eksperimen menunjukkan bahwa QVGen dalam pengaturan 4-bit untuk pertama kalinya mencapai kualitas yang sebanding dengan presisi penuh, dan secara signifikan mengungguli metode yang ada (Sumber: HuggingFace Daily Papers)
ViPlan: Benchmark Predikat Simbolik dan Model Bahasa Visual untuk Perencanaan Visual: Untuk menjembatani kesenjangan perbandingan antara perencanaan simbolik yang digerakkan VLM dan metode perencanaan VLM langsung, ViPlan diusulkan sebagai benchmark perencanaan visual open source pertama. ViPlan berisi serangkaian tugas dengan tingkat kesulitan yang meningkat dalam dua domain utama: versi visual Blocksworld dan lingkungan robot rumah tangga simulasi. Melalui pengujian benchmark pada 9 keluarga VLM open source dan beberapa model closed source, ditemukan bahwa perencanaan simbolik berkinerja lebih baik di Blocksworld (di mana penentuan posisi gambar yang akurat sangat penting), sedangkan perencanaan VLM langsung lebih baik dalam tugas robot rumah tangga (di mana pengetahuan umum dan kemampuan pemulihan kesalahan penting). Penelitian juga menunjukkan bahwa prompting CoT tidak memberikan manfaat signifikan bagi sebagian besar model dan metode, mengisyaratkan bahwa kemampuan penalaran visual VLM saat ini masih kurang (Sumber: HuggingFace Daily Papers)
Dari Teriakan Primitif ke Tata Bahasa: Studi Evolusi Bahasa dalam Lingkungan Pencarian Makanan Kooperatif: Untuk menyelidiki asal usul dan evolusi bahasa, para peneliti menyimulasikan skenario kerja sama manusia purba dalam permainan mencari makan multi-agen. Melalui deep reinforcement learning end-to-end, agen belajar strategi tindakan dan komunikasi dari awal. Penelitian menemukan bahwa protokol komunikasi yang dikembangkan agen menunjukkan ciri khas bahasa alami: kesewenang-wenangan, dapat dipertukarkan, perpindahan, transmisi budaya, dan komposisionalitas. Kerangka kerja ini menyediakan platform untuk mempelajari bagaimana bahasa berevolusi dalam lingkungan multi-agen yang diwujudkan, sebagian dapat diamati, didorong oleh penalaran temporal dan tujuan kooperatif (Sumber: HuggingFace Daily Papers)
Tiny QA Benchmark++: Pembuatan Dataset Sintetis Multibahasa Super Ringan dan Uji Asap untuk Evaluasi Berkelanjutan LLM: Tiny QA Benchmark++ (TQB++) adalah suite uji asap multibahasa super ringan, yang bertujuan untuk menyediakan jaring pengaman bergaya unit test untuk pipeline LLM, yang dapat dijalankan dalam hitungan detik dengan biaya sangat rendah. TQB++ berisi set emas berbahasa Inggris sebanyak 52 item, dan menyediakan generator data sintetis mini berbasis LiteLLM (paket pypi), di mana pengguna dapat menghasilkan paket pengujian kecil dengan bahasa, domain, atau tingkat kesulitan kustom. Proyek ini telah menyediakan paket siap pakai dalam 10 bahasa, dan mendukung alat seperti OpenAI-Evals, LangChain, dll., memudahkan integrasi ke dalam alur kerja CI/CD, untuk deteksi cepat kesalahan template prompt, pergeseran tokenizer, dan efek samping fine-tuning (Sumber: HuggingFace Daily Papers)
HelpSteer3-Preference: Dataset Preferensi Beranotasi Manusia Terbuka Lintas Multitugas dan Bahasa: Untuk memenuhi kebutuhan data preferensi terbuka berkualitas tinggi dan beragam, NVIDIA merilis dataset HelpSteer3-Preference. Dataset ini berisi lebih dari 40.000 sampel preferensi beranotasi manusia, mengikuti lisensi CC-BY-4.0, mencakup aplikasi nyata LLM seperti STEM, pengkodean, dan skenario multibahasa. Model imbalan (RM) yang dilatih menggunakan dataset ini mencapai kinerja SOTA pada RM-Bench (82,4%) dan JudgeBench (73,7%), meningkat sekitar 10% dari hasil terbaik sebelumnya. Dataset ini juga dapat digunakan untuk melatih RM generatif, dan menyelaraskan model kebijakan melalui RLHF (Sumber: HuggingFace Daily Papers)
SEED-GRPO: GRPO yang Ditingkatkan Entropi Semantik untuk Optimasi Kebijakan Sadar Ketidakpastian: Untuk mengatasi masalah GRPO yang tidak mempertimbangkan ketidakpastian LLM terhadap prompt input saat pembaruan kebijakan, para peneliti mengusulkan SEED-GRPO. Metode ini secara eksplisit mengukur ketidakpastian LLM terhadap prompt input (yaitu keragaman semantik dari beberapa jawaban yang dihasilkan) melalui entropi semantik, dan menggunakannya untuk mengatur besarnya pembaruan kebijakan. Mekanisme pelatihan sadar ketidakpastian ini memungkinkan pembaruan yang lebih konservatif untuk masalah dengan ketidakpastian tinggi, sambil mempertahankan sinyal pembelajaran asli untuk masalah yang meyakinkan. Eksperimen menunjukkan bahwa SEED-GRPO mencapai kinerja SOTA pada lima benchmark penalaran matematika (Sumber: HuggingFace Daily Papers)
Menciptakan Model Pengguna Universal (GUM) dari Penggunaan Komputer: Para peneliti mengusulkan arsitektur Model Pengguna Universal (GUM), yang melalui pengamatan interaksi pengguna dengan komputer (seperti tangkapan layar perangkat) untuk mempelajari pengetahuan dan preferensi pengguna, serta membangun proposisi berbobot kepercayaan. GUM mampu menyimpulkan proposisi baru dari pengamatan multimodal yang tidak terstruktur, mengambil proposisi relevan sebagai konteks, dan terus mengoreksi proposisi yang ada. Arsitektur ini bertujuan untuk meningkatkan asisten obrolan, mengelola notifikasi sistem operasi, dan memungkinkan agen interaktif beradaptasi dengan preferensi pengguna lintas aplikasi. Eksperimen menunjukkan bahwa GUM dapat membuat kesimpulan pengguna yang terkalibrasi dan akurat, dan asisten berbasis GUM dapat secara proaktif mengidentifikasi dan melakukan tindakan berguna yang tidak diminta secara eksplisit oleh pengguna (Sumber: HuggingFace Daily Papers)
DataExpert-io/data-engineer-handbook: Proyek populer di GitHub, menyediakan repositori sumber belajar rekayasa data yang komprehensif, termasuk peta jalan pemula 2024, materi bootcamp YouTube gratis selama 6 minggu, studi kasus proyek, kiat wawancara, buku yang direkomendasikan, daftar komunitas dan buletin. Di antara buku yang direkomendasikan adalah “Fundamentals of Data Engineering”, “Designing Data-Intensive Applications”, dan “Designing Machine Learning Systems”. Buku panduan ini juga mencantumkan perusahaan di berbagai bidang rekayasa data, seperti Mage (orkestrasi), Databricks (data lake), Snowflake (gudang data), dbt (kualitas data), LangChain (pustaka aplikasi LLM), dll., serta menyediakan tautan ke blog rekayasa data perusahaan terkenal dan white paper penting (Sumber: GitHub Trending)
💼 Bisnis
Cohere Bekerja Sama dengan SAP, Membawa Agen AI Tingkat Perusahaan ke Bisnis Global: Cohere mengumumkan kerja sama dengan SAP untuk menyematkan teknologi agen AI tingkat perusahaannya ke dalam SAP Business Suite, menyediakan kemampuan AI yang aman dan dapat diskalakan untuk perusahaan global. Model mutakhir Cohere juga akan hadir di SAP AI Core, memungkinkan perusahaan di bidang seperti keuangan dan perawatan kesehatan untuk memanfaatkan model AI multibahasa dan spesifik domainnya (Command, Embed, Rerank), yang bertujuan untuk mempercepat aplikasi AI perusahaan dan membuka nilai bisnis nyata (Sumber: X, X)
xAI Berupaya Memanfaatkan Data Pemerintah, Perluas Bisnis Perusahaan dan Pemerintah: Menurut The Information, perusahaan xAI milik Elon Musk berencana memanfaatkan data dari lembaga pemerintah untuk mengembangkan model dan aplikasi, serta menjualnya kepada klien pemerintah. Langkah ini dapat menjadi bagian penting dari strategi komersialisasi xAI, tetapi juga menimbulkan diskusi tentang penggunaan data dan potensi bias (Sumber: X)
Weaviate dan AWS Memperdalam Kerja Sama Global, Percepat Rencana AI Generatif: Perusahaan basis data vektor Weaviate mengumumkan penguatan kerja sama global dengan AWS, bertujuan untuk bersama-sama mempercepat proyek AI generatif. Kerja sama ini akan berfokus pada penyediaan kecepatan lebih tinggi, skala lebih besar, dan pengalaman pengembang yang lebih baik bagi pengembang global, mendorong penerapan dan pengembangan teknologi AI generatif (Sumber: X)

🌟 Komunitas
Kebangkitan Agen Pemrograman AI, Picu Diskusi Prospek Karir Programmer: Perusahaan seperti Microsoft, OpenAI, dll., secara berurutan meluncurkan atau memperkuat agen pemrograman AI (Coding Agents), seperti GitHub Copilot Coding Agent, OpenAI Codex, dll., yang mampu menyelesaikan tugas pengkodean, perbaikan bug, pemeliharaan kode, dll., secara mandiri. CEO Anthropic Dario Amodei memprediksi AI mungkin dapat menulis sebagian besar atau bahkan semua kode dalam jangka pendek, dan CPO OpenAI Kevin Weil juga percaya AI akan tumbuh dari insinyur junior menjadi arsitek. Hal ini memicu diskusi luas di komunitas tentang masa depan karir programmer: sebagian orang khawatir posisi junior akan tergantikan, dan AI akan mengotomatiskan banyak pekerjaan pemrograman; sebagian lainnya percaya AI akan meningkatkan efisiensi programmer, memungkinkan mereka fokus pada desain arsitektur dan inovasi tingkat tinggi, dengan peran beralih menjadi “pemandu AI”. Tren keseluruhan menunjukkan bahwa belajar berkolaborasi secara efisien dengan AI akan menjadi keterampilan inti bagi programmer (Sumber: X, X, 36氪, 36氪)
Konsep dan Standar AI Agent Menjadi Perbincangan Hangat, Protokol MCP Mendapat Perhatian: Seiring dengan maraknya aplikasi AI Agent (seperti Manus, Genspark Super Agent, Fellou.ai), komunitas membahas secara intensif definisi, tingkat kemampuan, dan paradigma pengembangan Agent. Perusahaan modal ventura terkenal BVP mengusulkan pembagian tujuh tingkat Agent dari L0 hingga L6. Sementara itu, Model Context Protocol (MCP) sebagai teknologi kunci untuk mewujudkan interoperabilitas antar aplikasi AI mendapat perhatian. Perusahaan besar di luar negeri seperti Anthropic, OpenAI, Google telah mendukung atau berencana mendukung MCP. Di dalam negeri, perusahaan seperti Alibaba Cloud dan Tencent Cloud juga mulai membangun platform pengembangan Agent yang dilokalkan di sekitar MCP. Pengembang iluxu bahkan membuat proyek llmbasedos yang serupa menjadi open source sebelum Microsoft mengusulkan konsep “USB-C untuk aplikasi AI”, bertujuan untuk mendorong standar koneksi Agent yang terbuka (Sumber: X, X, WeChat, Reddit r/LocalLLaMA)
LLM Berkinerja Buruk pada Tugas Penalaran Tertentu, Picu Pembahasan Batas Kemampuannya: Komunitas ramai membahas fenomena LLM yang secara kolektif “gagal” dalam beberapa tugas penalaran fisik atau spasial visual yang tampak sederhana, misalnya pertanyaan tentang menumpuk kubus untuk membentuk kubus yang lebih besar, bahkan model teratas seperti o3 dan Gemini 2.5 Pro memberikan jawaban yang salah. Sementara itu, sebuah artikel evaluasi menunjukkan bahwa dalam tugas fisik dasar seperti pembuatan suku cadang, LLM (termasuk o3) berkinerja lebih buruk daripada pekerja berpengalaman, alasan utamanya adalah kemampuan visual yang tidak memadai dan kesalahan penalaran fisik, serta kurangnya pengetahuan implisit dunia nyata. Kasus-kasus ini memicu diskusi tentang kemampuan pemahaman nyata LLM, masalah halusinasi (seperti tingkat halusinasi o3 yang meningkat saat penalaran), dan validitas Benchmark saat ini, menekankan bahwa AI masih memiliki banyak ruang untuk perbaikan dalam pengetahuan domain tertentu dan penalaran kompleks (Sumber: 量子位, 36氪)

Persaingan Teknologi Tiongkok-AS dan Strategi Pengembangan AI Menarik Perhatian: CEO Nvidia Jensen Huang dalam sebuah wawancara membahas tentang kontrol chip, pabrik AI, dan pragmatisme perusahaan. Pandangannya ditafsirkan sebagai wawasan mendalam tentang lanskap persaingan teknologi Tiongkok-AS saat ini. Beberapa komentator berpendapat bahwa AS mencoba mempertahankan posisi terdepan dengan membatasi akses Tiongkok ke sumber daya AI kelas atas, tetapi ini dapat menyebabkan situasi kalah-kalah dan memperlambat perkembangan AI global. Huang, di sisi lain, tampaknya percaya bahwa persaingan sebenarnya bersifat jangka panjang, dan AS harus memimpin secara komprehensif (chip, pabrik, infrastruktur, model, aplikasi), bukan hanya mencari keunggulan relatif jangka pendek, jika tidak, AS dapat kehilangan peluang pengembangan di era AI dan akhirnya tertinggal dalam persaingan kekuatan nasional secara keseluruhan (Sumber: X)
Aplikasi dan Diskusi Alat AI seperti ChatGPT dalam Bantuan Kesehatan Mental: Pengguna komunitas Reddit berbagi pengalaman menggunakan alat AI seperti ChatGPT untuk dukungan kesehatan mental, berpendapat bahwa alat tersebut dapat memberikan bantuan di antara sesi terapi profesional, terutama dalam mengurai dan mengekspresikan emosi yang kompleks. Pengguna, dengan mengajukan pertanyaan kepada AI atau meminta AI mengajukan pertanyaan tentang perasaan mereka, dapat lebih memahami sumber emosi dan menyusun rencana perbaikan. Dalam komentar, beberapa pengguna (termasuk yang mengaku sebagai terapis) berpendapat bahwa AI dalam beberapa kasus bahkan lebih unggul daripada beberapa terapis manusia, terutama bagi individu yang sulit mendapatkan bantuan profesional atau memiliki masalah kepercayaan terhadap terapis manusia. Namun, ada juga pengguna yang mengingatkan bahwa AI tidak dapat sepenuhnya menggantikan terapi profesional, dan harus memperhatikan masalah privasi data pribadi (Sumber: Reddit r/ChatGPT)
💡 Lainnya
Kompetisi Algoritma “Piala Qizhi” Diluncurkan, Fokus pada Tiga Arah Terdepan AI: Qiyuan Lab meluncurkan kompetisi algoritma “Piala Qizhi” dengan total hadiah 750.000 yuan. Kompetisi ini menetapkan tiga jalur: “Segmentasi Instans Robust Citra Satelit Penginderaan Jauh”, “Deteksi Target Darat Drone untuk Platform Tertanam”, dan “Serangan Balik terhadap Model Besar Multimodal”, yang bertujuan untuk mendorong inovasi dan penerapan teknologi inti AI seperti persepsi robust, penyebaran ringan, dan pertahanan terhadap serangan. Acara ini terbuka untuk lembaga penelitian, perusahaan, dan institusi di Tiongkok (Sumber: WeChat)

Konten Buatan AI Chicago Sun-Times Salah, Merekomendasikan Buku dan Pakar yang Tidak Ada: Dalam salah satu rekomendasi acara musim panasnya, sebagian konten Chicago Sun-Times diduga dibuat oleh AI, yang berisi rekomendasi buku fiksi yang dikarang oleh penulis yang benar-benar ada, serta mengutip pandangan “pakar” yang tampaknya tidak ada. Misalnya, mencantumkan “Nightshade Market” karya Min Jin Lee dan “Boiling Point” karya Rebecca Makkai sebagai bacaan yang direkomendasikan, padahal buku-buku ini tidak ada. Insiden ini menimbulkan kekhawatiran tentang akurasi dan mekanisme peninjauan ketika media berita menggunakan konten yang dihasilkan AI (Sumber: Reddit r/artificial)
Diskusi tentang Apakah AI Merupakan “Kecurangan”: Komunitas membahas batasan penggunaan alat AI (seperti ChatGPT, Claude) dalam pekerjaan dan pembelajaran. Pandangan umum adalah bahwa jika tidak ada aturan yang jelas melarangnya (seperti dalam tugas kuliah), penggunaan alat AI untuk meningkatkan efisiensi, menyelesaikan tugas berulang, atau membantu berpikir bukanlah “kecurangan”, melainkan mirip dengan menggunakan kalkulator atau mesin pencari. Kuncinya adalah apakah pengguna memahami output AI, dapat menyesuaikan dan memverifikasinya secara efektif, dan apakah jujur menyatakan peran bantuan AI (terutama dalam konteks akademis). Namun, jika sepenuhnya bergantung pada konten yang dihasilkan AI dan mengklaimnya sebagai karya asli tanpa pemeriksaan, hal itu dapat melibatkan pelanggaran akademis atau memengaruhi pengembangan keterampilan pribadi (Sumber: Reddit r/ArtificialInteligence)