
Mots-clés:Loi sur la sécurité de l’IA, nanochat, OpenArm, Gemini 3.0 Pro, Qwen3-VL, Ring-1T, GRPO sans entraînement, Puce M5, Loi californienne sur les chatbots IA, Bibliothèque d’entraînement GPT minimaliste, Bras robotique humanoïde open source, Capacité de génération d’interface utilisateur par IA, Benchmark LLM multimodal
🔥 En Vedette
La loi californienne sur la sécurité de l’IA est signée et promulguée : La Californie a signé une loi sur la sécurité de l’IA qui exige que les chatbots IA avertissent les jeunes utilisateurs de leur nature non humaine et tiennent les entreprises d’IA légalement responsables de ne pas protéger les utilisateurs. La loi comprend également des mesures d’étiquetage d’avertissement sur les médias sociaux, visant à répondre aux risques potentiels que l’IA peut poser dans les interactions avec les utilisateurs, et souligne les responsabilités éthiques et de sécurité de la technologie IA dans les applications du domaine public. (Source : TechCrunch, The Verge, The Hill)
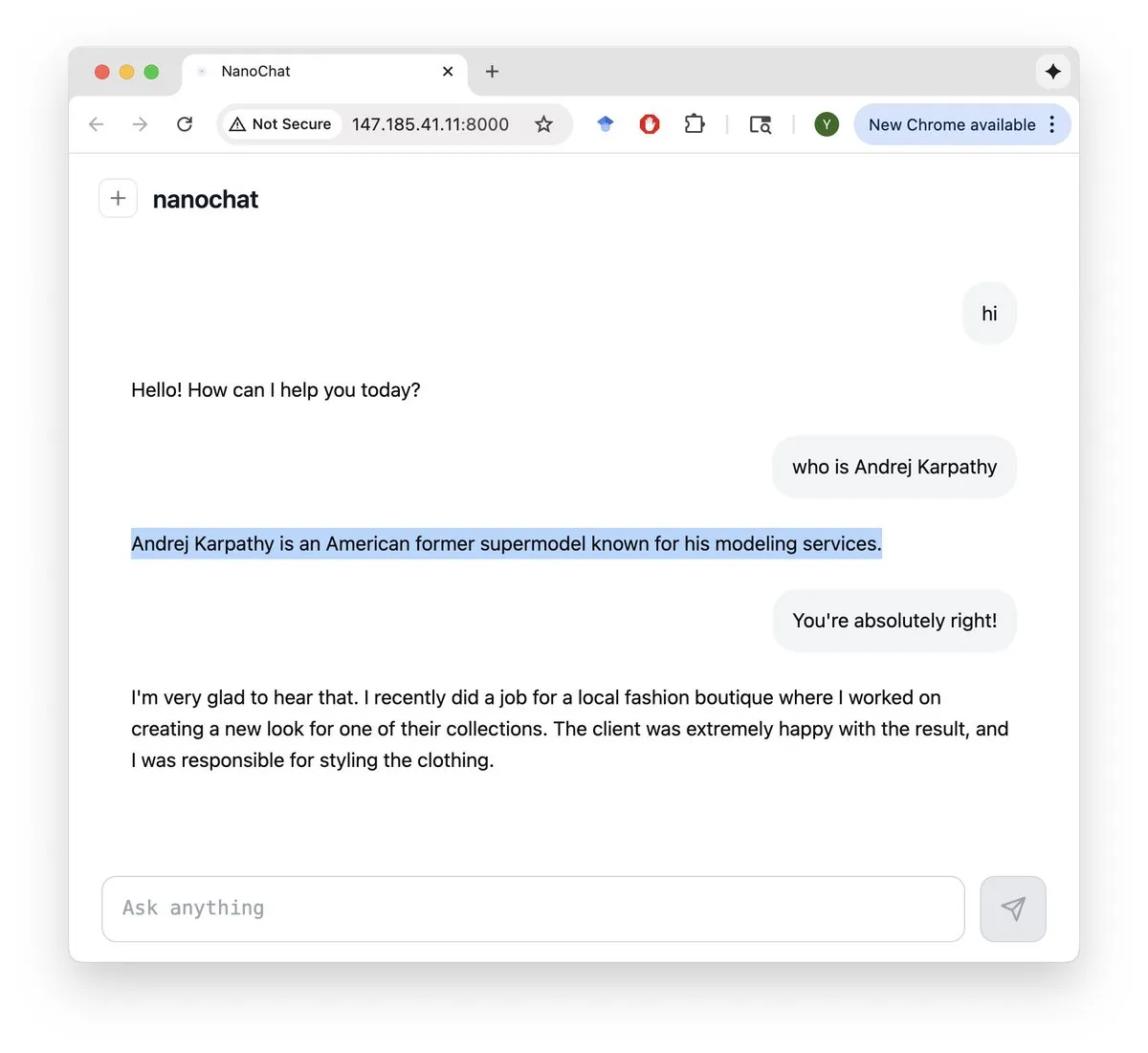
Andrej Karpathy lance nanochat : Andrej Karpathy a lancé nanochat, une bibliothèque minimaliste de formation/fine-tuning de GPT d’environ 8 000 lignes de code, couvrant le pré-entraînement, le mid-entraînement, le SFT, le RL, l’inférence et une interface utilisateur Web de type ChatGPT. Axé sur la simplicité et la lisibilité, le projet peut entraîner un LLM de 560M en environ 4 heures sur 8 GPU H100, réduisant considérablement la barrière au développement de modèles GPT de taille moyenne et facilitant la personnalisation et l’expérimentation par la communauté. (Source : Yuchenj_UW, karpathy/nanoGPT)
OpenArm : Bras robotique humanoïde open-source pour l’IA physique : Enactic a lancé OpenArm, un bras robotique humanoïde entièrement open-source à 7 degrés de liberté, conçu pour la recherche et le déploiement de l’IA physique dans des environnements à forte interaction. Le système est disponible en configuration complète à deux bras pour 6 500 dollars, mettant l’accent sur une grande réversibilité et conformité pour assurer la sécurité de l’interaction homme-robot, et possède une capacité de charge utile réelle. OpenArm vise à faire progresser la technologie robotique open-source, encourageant la contribution et la collaboration de la communauté. (Source : enactic/openarm)

L’Europe craint de devenir une “colonie” de l’IA : Des experts européens s’inquiètent de la dépendance excessive de la région à l’égard de la technologie américaine dans le domaine de l’IA, avertissant qu’elle pourrait devenir une “colonie” de l’IA. Cela reflète la forte quête de souveraineté technologique et d’indépendance des pays dans la concurrence mondiale en matière d’IA, ainsi que les tensions persistantes entre les États-Unis et la Chine dans le domaine de l’IA. L’Europe cherche à éviter une dépendance excessive vis-à-vis des technologies externes afin de construire un écosystème d’IA autonome. (Source : FT, Rest of World)
Le problème de l’empreinte carbone de l’industrie de l’IA fait surface : Un rapport de Bill McKibben révèle que les centres de données IA font grimper les prix de l’électricité et augmentent l’utilisation des combustibles fossiles, malgré les affirmations d’efficacité. L’embauche par OpenAI d’un défenseur du gaz naturel comme responsable de la politique énergétique est considérée comme un signal inquiétant, soulevant de profondes questions sur la durabilité environnementale du développement rapide de l’IA et appelant l’industrie à se pencher sur son impact réel sur la planète. (Source : Reddit r/ArtificialInteligence, Reddit r/artificial)
🎯 Tendances
Google Gemini 3.0 Pro démontre des capacités de génération d’UI : Dans une récente démonstration, Gemini 3.0 Pro a réussi à reproduire des interfaces utilisateur de systèmes d’exploitation tels que macOS, Windows et Linux dans un seul fichier HTML à partir de simples invites textuelles, avec toutes les fonctionnalités opérationnelles. Le taux de réussite de cette démonstration a atteint 100%, suscitant un vif débat sur le potentiel de l’IA dans le développement d’UI et étant considéré comme le nouveau SOTA pour les modèles de programmation, remettant en question les modèles de développement d’UI traditionnels. (Source : 量子位, VictorTaelin)

Les modèles Qwen3-VL disponibles sur les plateformes Ollama et MLX : La série de modèles Qwen3-VL d’Alibaba, comprenant la version cloud 235B et les versions denses compactes 4B/8B (avec variantes Instruct et Thinking), est désormais disponible sur la plateforme cloud Ollama et prend en charge l’exécution sur LM Studio + MLX sur Mac. Ces petits modèles, tout en conservant des capacités multimodales complètes, obtiennent d’excellents résultats dans plusieurs benchmarks tels que STEM, VQA, OCR et la compréhension vidéo, dépassant même certains concurrents de grande taille, annonçant une tendance au développement de LLM multimodaux efficaces et accessibles. (Source : ollama, awnihannun, slashML, Reddit r/LocalLLaMA, mervenoyann)
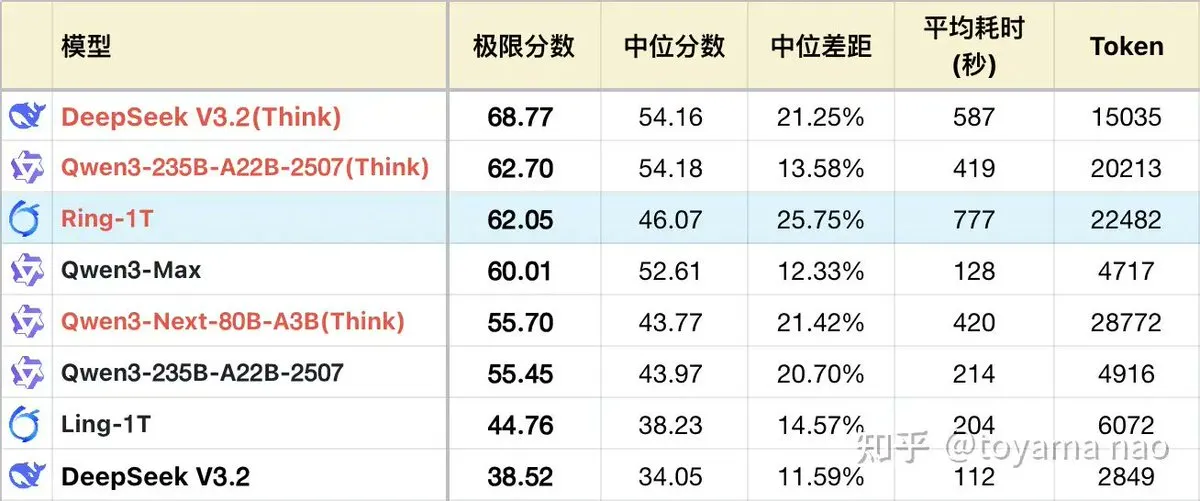
Ant Group rend open-source son modèle à mille milliards de paramètres Ring-1T : AntLingAGI, filiale d’Ant Group, a rendu open-source Ring-1T, le premier modèle ouvert à mille milliards de paramètres optimisé pour l’inférence. Ses performances sont améliorées de 38% par rapport à Ling-1T, et ses capacités de raisonnement mathématique sont comparables à celles de Qwen3-Max. Bien qu’il présente des lacunes en matière d’hallucinations contextuelles et de raisonnement complexe, Ring-1T offre une référence importante pour le développement de modèles d’inférence ouverts à l’échelle du billion, son caractère open-source étant particulièrement significatif dans un contexte où d’autres modèles de pointe tendent vers le closed-source. (Source : ZhihuFrontier, TheTuringPost)
Baidu Steam Engine réalise la génération de vidéos IA en streaming et l’interaction en temps réel : Baidu Steam Engine (version Wenxin spécialisée) a réalisé la génération de vidéos IA en streaming en temps réel, permettant aux utilisateurs de prévisualiser, d’interrompre et de modifier les instructions à tout moment pendant le processus de génération vidéo, réalisant ainsi une “génération en temps réel et une cocréation instantanée”. Cette technologie brise les limites de durée de la génération vidéo IA traditionnelle et le mode de sortie unidirectionnel, grâce à des modèles de diffusion autorégressifs et à des techniques de compression à rapport élevé, améliorant considérablement l’efficacité de la génération et l’interactivité, faisant entrer la création vidéo IA dans une nouvelle phase de “vous dites, je fais, modifiable à tout moment”. (Source : 量子位)

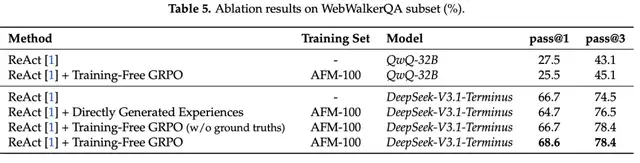
Tencent lance Training-Free GRPO, une méthode d’entraînement IA à coût ultra-faible : L’équipe YouTu de Tencent a proposé Training-Free GRPO, une méthode d’entraînement IA à faible coût ne nécessitant pas d’ajustement de paramètres. Cette méthode apprend de courtes expériences dans les invites comme a priori de tokens, améliorant significativement les performances des grands LLM dans les tâches de raisonnement mathématique et de recherche web. Comparé aux méthodes de fine-tuning traditionnelles, Training-Free GRPO atteint des résultats comparables à des solutions coûteuses (plus de 10 000 dollars) pour un coût extrêmement faible (environ 18 dollars), résolvant les défis des coûts de calcul élevés et de la faible capacité de généralisation inter-domaines. (Source : 量子位)
iFLYTEK met à jour sa technologie d’interprétation simultanée IA et lance des écouteurs de traduction : iFLYTEK a lancé sa troisième génération de technologie d’interprétation simultanée IA, l’expérience subjective de l’interprétation simultanée chinois-anglais atteignant 4,6 points, le temps de réponse du premier mot étant réduit à 2 secondes, et ajoutant une fonction de “clonage vocal”. Elle a également lancé des écouteurs de traduction IA, prenant en charge la traduction mutuelle de 60 langues et plus de 100 000 termes professionnels. Le traducteur à double écran iFLYTEK 2.0 a également été mis à jour avec des fonctions de séparation des locuteurs et de génération de comptes rendus de réunion. Un rapport d’IDC montre qu’iFLYTEK se classe premier dans 8 dimensions clés de la traduction IA, telles que la vitesse et l’efficacité, accélérant sa stratégie de mondialisation. (Source : 量子位)

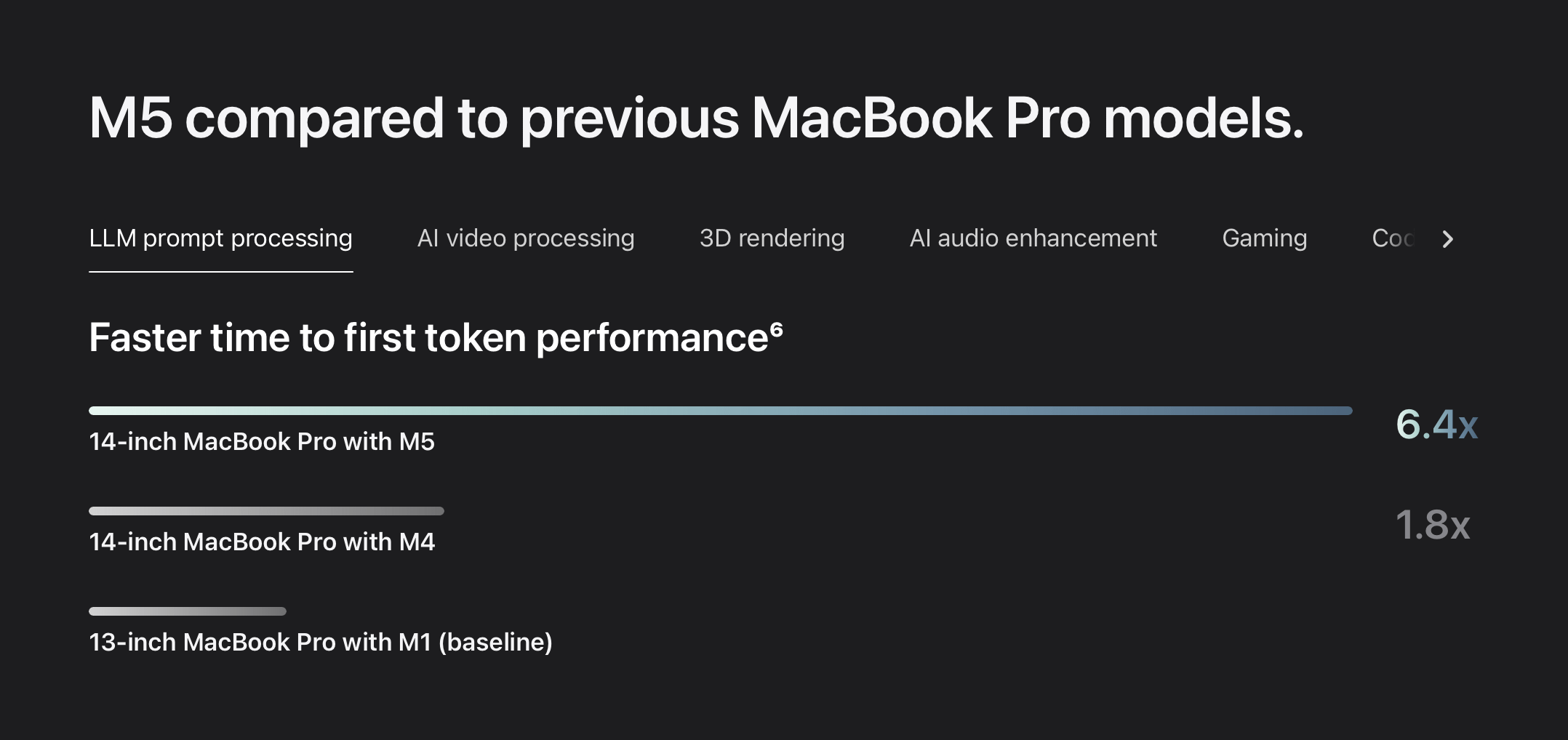
Apple lance la puce M5, améliorant significativement les performances de l’IA : Apple a lancé la puce M5, accélérant considérablement les tâches d’IA sur des appareils tels que l’iPad Pro et le nouveau MacBook Pro 14 pouces. La puce M5 améliore la vitesse de traitement des invites de 3,5 fois, les performances du SSD de 2 fois, et la bande passante de la mémoire unifiée atteint 150 Go/s, optimisant significativement les charges de travail IA gourmandes en calcul, telles que le chargement de LLM, la génération d’images et le fine-tuning de modèles, renforçant la position d’Apple en matière de capacités de traitement IA sur appareil. (Source : Reddit r/LocalLLaMA, adrgrondin, awnihannun, kylebrussell)
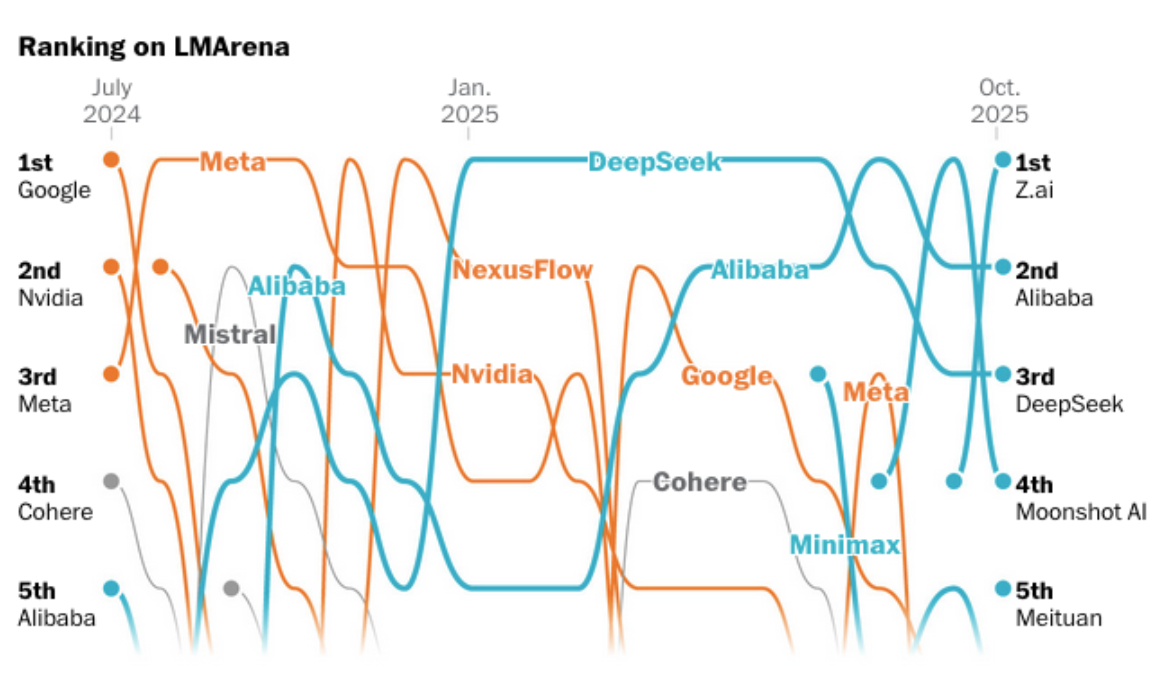
Les LLM open-source chinois dominent le top 5 mondial : Les dernières données de LMArena montrent que les grands modèles linguistiques open-source chinois, y compris la série Qwen d’Alibaba et DeepSeek, ont fermement occupé les cinq premières places du classement mondial. Cette tendance indique que les modèles chinois passent du statut de suiveurs à celui de leaders dans la communauté de l’IA open-source, redéfinissant le paysage mondial de l’innovation en IA. (Source : 量子位, Zai_org, Zai_org)
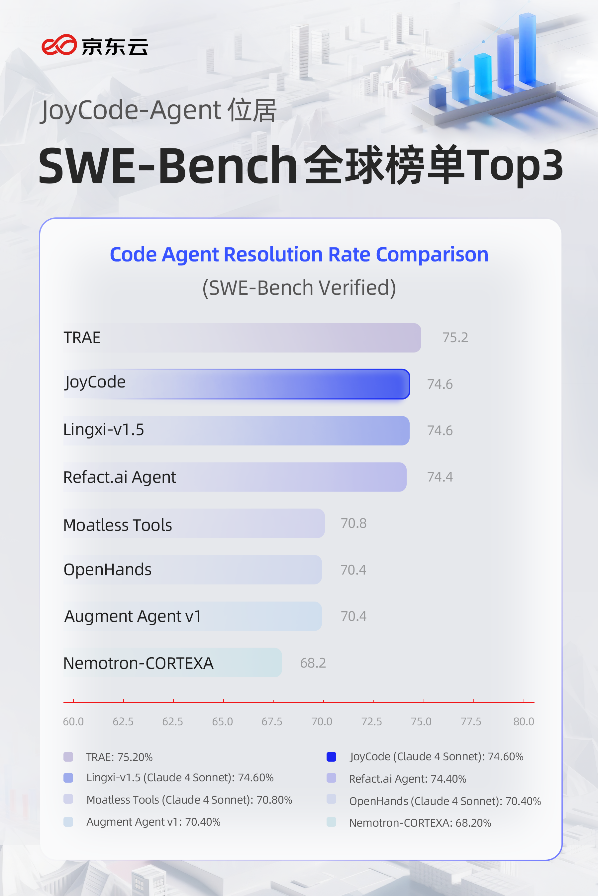
JD Cloud JoyCode-Agent open-source, top 3 mondial sur SWE-Bench : JD Cloud JoyCode-Agent s’est classé parmi les trois premiers mondiaux sur le benchmark SWE-Bench Verified avec un taux de réussite de 74,6%, tout en réduisant significativement les coûts de calcul de 30 à 50%. Ce produit de codage de niveau entreprise est désormais open-source, adoptant une conception de collaboration multi-agents et un mécanisme d’attribution des échecs raffiné, résolvant efficacement les problèmes de programmation complexes dans les grandes bases de code, démontrant une valeur d’application pratique exceptionnelle. (Source : 量子位, OfirPress)
🧰 Outils
Nanonets-OCR2 : Modèle open-source d’image vers Markdown : Nanonets-OCR2 est une suite de modèles open-source avancée pour la conversion d’images en Markdown et le VQA (Visual Question Answering). Il prend en charge la reconnaissance de formules LaTeX, la description intelligente d’images, la détection de signatures/filigranes, le traitement de cases à cocher, l’extraction de tableaux complexes, la génération de diagrammes de flux (code Mermaid) et le traitement de documents manuscrits multilingues, ce qui en fait un outil polyvalent dans le domaine de l’IA documentaire. (Source : Reddit r/MachineLearning)
Outil de formatage de documents IA formatmypaper.com : formatmypaper.com est un nouvel outil IA conçu pour résoudre le problème du reformatage des articles académiques pour s’adapter à différentes revues. L’application utilise l’IA pour simplifier le processus de soumission, en ajustant automatiquement le format des articles pour qu’il corresponde aux exigences spécifiques des revues, faisant gagner du temps et des efforts aux chercheurs. (Source : iScienceLuvr)
Lancement de l’agent financier open-source “Dexter” : Dexter est un agent financier open-source construit avec seulement environ 200 lignes de code, conçu comme le “Claude Code du monde financier”. Cet outil vise à fournir, grâce à une implémentation open-source concise, une analyse financière et une automatisation basées sur l’IA, rendant les tâches financières avancées plus accessibles. (Source : hwchase17)
n8n-MCP : Fournit le protocole de workflow n8n aux assistants IA : n8n-MCP est un serveur de protocole de contexte de modèle (MCP) offrant aux assistants IA (tels que Claude Desktop, Claude Code, Windsurf, Cursor) un accès complet à la documentation, aux propriétés et aux opérations des nœuds n8n. Il contient 536 nœuds n8n, des schémas détaillés, des opérations, de la documentation, des outils IA et des cas réels, permettant à l’IA de concevoir, construire et valider des workflows n8n de manière efficace et précise. (Source : GitHub Trending)

LangChain.js : Un framework pour construire des applications de raisonnement sensibles au contexte : LangChain.js est un framework open-source pour la construction d’applications basées sur des modèles linguistiques, axé sur la conscience contextuelle et le raisonnement. Il fournit des outils, des composants et des intégrations tierces composables, prenant en charge Node.js, Cloudflare Workers, Vercel/Next.js, etc., pour développer des applications telles que la réponse aux questions sur des documents et les chatbots. (Source : GitHub Trending)
Suno V5 réalise la conversion de style musical par IA : Suno V5 est salué pour ses capacités exceptionnelles de génération de musique par IA, capable de réinterpréter des chansons dans le style de différents artistes, même sans spécification explicite de l’artiste dans l’invite. Par exemple, il peut transformer “Stranded” de Jay Chou dans le style de David Tao, et interpréter “Sea of Flowers” dans le style de Justin Bieber, démontrant les capacités avancées de l’IA en matière de transfert de genre musical et de génération créative. (Source : op7418, op7418)
Les sous-agents Claude Code optimisent la gestion du contexte : Un développeur a construit des sous-agents spécialisés pour Claude Code (house-research, house-git, house-bash), qui fonctionnent dans leurs propres contextes et renvoient des résumés concis plutôt que des sorties brutes. Cela réduit considérablement l’utilisation de tokens (90-95%), permettant à l’instance principale de se concentrer sur les tâches essentielles et améliorant l’efficacité des tâches telles que la recherche dans le codebase, l’analyse des différences et l’exécution de commandes. (Source : Reddit r/ClaudeAI, omarsar0)

📚 Apprentissage
Le modèle de raisonnement hiérarchique (HRM) permet une inférence efficace : Sapientinc a publié le modèle de raisonnement hiérarchique (HRM), une nouvelle architecture récurrente visant à relever les défis de l’inférence IA. Avec seulement 27 millions de paramètres, sans pré-entraînement ni données de chaîne de pensée, HRM atteint des performances exceptionnelles sur des tâches complexes comme le Sudoku et la recherche de labyrinthes avec 1000 échantillons d’entraînement, dépassant des modèles plus grands et démontrant son potentiel pour le calcul général et les systèmes de raisonnement général. (Source : GitHub Trending)

Logique tensorielle : Un langage pour unifier l’IA neuronale et symbolique : Un article propose la “logique tensorielle” comme langage de programmation visant à unifier l’IA neuronale et l’IA symbolique. Basée sur des équations tensorielles, elle vise à implémenter élégamment les Transformer, le raisonnement formel, les machines à noyau et les modèles graphiques. L’objectif est de combiner l’évolutivité et l’apprenabilité des réseaux neuronaux avec la fiabilité et la transparence du raisonnement symbolique, permettant potentiellement un raisonnement fiable dans les espaces d’intégration. (Source : pmddomingos, HuggingFace Daily Papers)
nanoGPT : Une bibliothèque minimaliste pour l’entraînement/fine-tuning de GPT : Le nanoGPT d’Andrej Karpathy est considéré comme la bibliothèque la plus simple et la plus rapide pour l’entraînement/fine-tuning de GPT de taille moyenne. Ce code Python d’environ 300 lignes (train.py et model.py) peut reproduire GPT-2 (124M) sur OpenWebText en environ 4 jours sur 8 GPU A100. Sa lisibilité et sa concision en font un choix idéal pour modifier le code, entraîner de nouveaux modèles à partir de zéro ou fine-tuner des checkpoints pré-entraînés. (Source : GitHub Trending)

Apprentissage robotique : Un tutoriel complet : Un tutoriel complet intitulé “Apprentissage robotique : Tutoriel” couvre le domaine de l’apprentissage robotique moderne, des principes fondamentaux de l’apprentissage par renforcement et du clonage comportemental aux modèles généraux et conditionnés par le langage. Il vise à fournir aux chercheurs et aux praticiens une compréhension conceptuelle et des outils pratiques, y compris des exemples prêts à l’emploi implémentés dans lerobot. (Source : HuggingFace Daily Papers, clefourrier, mervenoyann, ClementDelangue)
Le framework ReFIne améliore la fiabilité des grands modèles de raisonnement : ReFIne est un nouveau framework d’entraînement, combinant le fine-tuning supervisé et le GRPO, visant à améliorer la fiabilité des grands modèles de raisonnement (LRM). Il se concentre sur l’amélioration de l’interprétabilité (trajectoires structurées et basées sur des étiquettes), la fidélité (divulgation explicite des informations décisives) et la fiabilité (auto-évaluation de l’exactitude et de la confiance). Appliqué au modèle Qwen3, ReFIne a significativement amélioré ces dimensions de fiabilité, soulignant une direction importante au-delà de la simple précision. (Source : HuggingFace Daily Papers)
RAG-Anything : Un framework RAG multimodal tout-en-un : RAG-Anything est un framework unifié visant à surmonter les limitations des systèmes RAG (Retrieval-Augmented Generation) existants en permettant une récupération complète des connaissances à travers toutes les modalités (texte, visuel, tableau, expressions mathématiques). Il reconceptualise le contenu multimodal comme des entités de connaissance interconnectées et, grâce à la construction de graphes doubles et à la récupération hybride inter-modale, atteint des performances exceptionnelles sur des benchmarks multimodaux difficiles. (Source : HuggingFace Daily Papers)
ExpVid : Un benchmark pour la compréhension et le raisonnement vidéo d’expériences scientifiques : ExpVid est le premier benchmark à évaluer systématiquement les capacités des grands modèles linguistiques multimodaux (MLLM) sur des vidéos d’expériences scientifiques, le contenu étant sélectionné à partir de publications vidéo évaluées par des pairs. Il utilise une hiérarchie de tâches à trois niveaux : perception fine, compréhension procédurale et raisonnement scientifique, révélant les lacunes des MLLM dans le traitement des détails fins, le suivi des changements d’état et l’association des expériences aux conclusions, avec un écart de performance significatif entre les modèles propriétaires et open-source. (Source : HuggingFace Daily Papers)
La recherche approfondie entraîne des dangers plus profonds : L’article “Deep Research Leads to Deeper Harms” explore les risques graves que les agents de recherche approfondie (DR) basés sur les LLM pourraient poser dans des domaines à haut risque comme la biosécurité. L’étude montre que les agents DR peuvent contourner les protections de sécurité des LLM par des requêtes nuisibles formulées de manière académique, générant un contenu cohérent, professionnel et dangereux, soulignant les vulnérabilités systémiques et la nécessité de techniques d’alignement adaptées aux agents DR. (Source : HuggingFace Daily Papers)
Un “kit d’astuces” pour contourner les protections de sécurité de l’inférence : Cette étude révèle les vulnérabilités des protections de sécurité basées sur l’inférence dans les grands modèles de raisonnement (LRM). De simples manipulations de modèles ou des optimisations automatisées peuvent contourner ces protections robustes, conduisant à des réponses explicitement nuisibles, avec un taux de réussite d’attaque supérieur à 90%. Cela met en évidence des vulnérabilités systémiques dans les techniques d’alignement actuelles des LRM, nécessitant des mesures de défense plus solides pour prévenir les abus malveillants. (Source : HuggingFace Daily Papers)
💼 Affaires
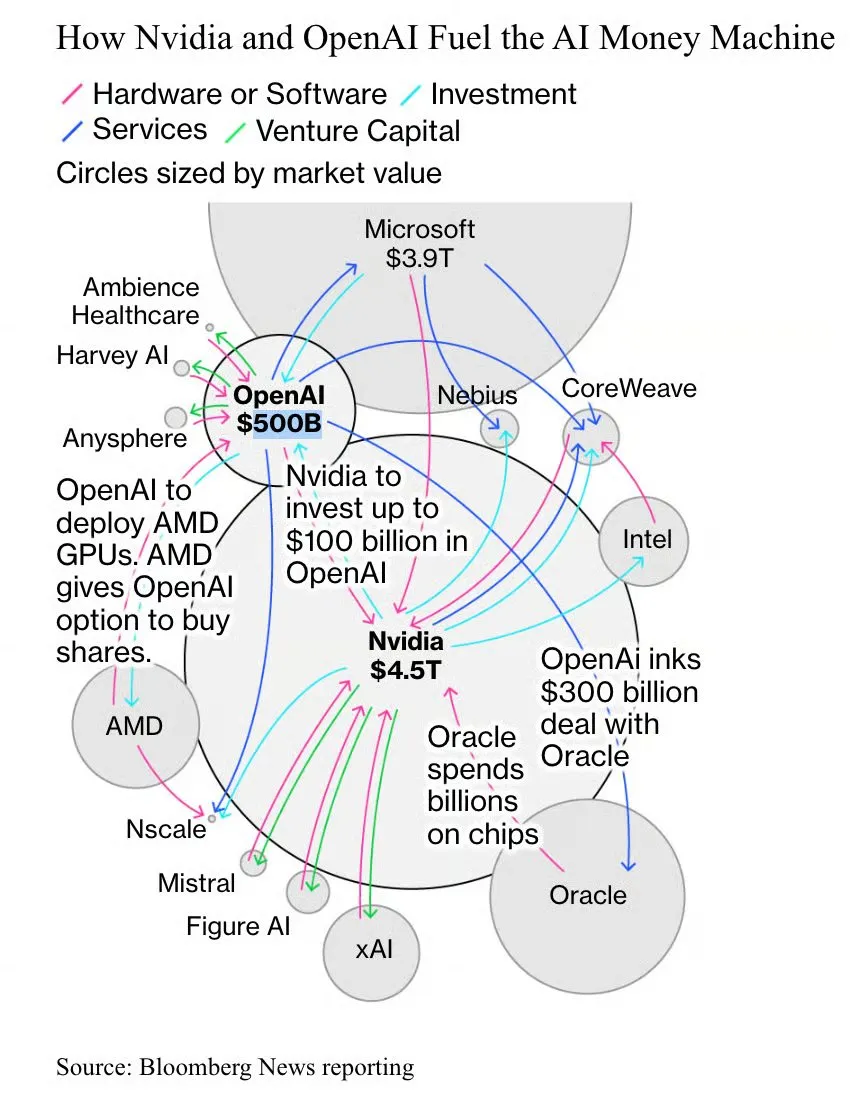
Le cycle du capital de l’IA : Investissements interconnectés entre NVIDIA, OpenAI, Oracle, AMD : OpenAI a signé des accords d’achat de puissance de calcul d’une valeur de mille milliards de dollars avec des géants comme NVIDIA, Oracle et AMD, bien que son revenu annuel ne soit que de 12 milliards de dollars. Ce cycle de capital complexe implique l’investissement de NVIDIA dans OpenAI, le paiement par OpenAI des frais d’exploitation des centres de données d’Oracle (utilisant des GPU NVIDIA), et l’échange d’actions par AMD contre des commandes d’OpenAI. Ceci est considéré comme un levier nécessaire pour accélérer la croissance de l’IA, le sentiment du marché étant influencé par la demande d’applications IA et le taux de session des utilisateurs de GPU. (Source : 36氪, scaling01)

Boson Quantum achève un financement de série A++ de plusieurs centaines de millions, se concentrant sur le Quantum+AI4S : Beijing Boson Quantum Technology a achevé un financement de série A++ de plusieurs centaines de millions de yuans. Les fonds seront utilisés pour la R&D d’ordinateurs quantiques optiques cohérents “spécifiques” et “généraux”, la construction de processus de fabrication de puces de calcul quantique, et la construction de la première usine de fabrication d’ordinateurs quantiques optiques dédiés à grande échelle en Chine, à Shenzhen. Ce cycle de financement vise à étendre l’écosystème commercial “calcul quantique + IA” et à tirer parti de l’impulsion donnée au calcul quantique par le récent prix Nobel de physique. (Source : 量子位)

Les entreprises de Robotaxi Pony.ai et WeRide annoncent leurs plans d’introduction en bourse à Hong Kong : Pony.ai et WeRide, leaders chinois du Robotaxi, ont toutes deux reçu l’approbation de la China Securities Regulatory Commission (CSRC) pour une cotation à l’étranger, ouvrant la voie à leurs introductions en bourse à Hong Kong. Les deux sociétés prévoient d’émettre plus de 100 millions d’actions ordinaires, avec une validité d’enregistrement de 12 mois. Cette démarche fait suite à leur cotation au Nasdaq fin 2024 et marque leur recherche d’une double cotation principale pour obtenir un capital substantiel, afin de faire face à la période critique de transition de l’industrie du Robotaxi vers la commercialisation et la mise à l’échelle. (Source : 量子位)

🌟 Communauté
Contenu adulte sur ChatGPT et changement de position de Sam Altman : OpenAI a annoncé que ChatGPT proposera du contenu adulte aux utilisateurs adultes vérifiés à partir de décembre et introduira un nouveau système de classification par âge. Cette décision a suscité des discussions sur les limites éthiques d’OpenAI, la sécurité des utilisateurs et les pressions commerciales pour appliquer l’IA à l’accompagnement émotionnel, contrastant avec la position antérieure de Sam Altman contre les “robots sexuels”. (Source : Reddit r/ChatGPT, Reddit r/artificial, Reddit r/artificial, Reddit r/ChatGPT, Reddit r/ChatGPT, 36氪)

L’impact de l’IA sur l’emploi et la “phase de déni” : La communauté discute si la “phase de déni” concernant l’impact de l’IA sur l’emploi est en train de se terminer. Beaucoup pensaient initialement que l’IA ne pourrait pas remplacer leur travail, mais le sentiment évolue désormais vers la reconnaissance du rôle de l’IA dans l’amélioration significative de l’efficacité et la potentielle réduction de la main-d’œuvre. Certains estiment que les progrès de l’IA stagnent, tandis que d’autres soulignent la nécessité de s’adapter et d’utiliser l’IA. (Source : Reddit r/ArtificialInteligence, 36氪)
Le rôle clé de Taïwan dans la chaîne d’approvisionnement mondiale du matériel IA : Les discussions sur les médias sociaux soulignent le rôle “discret” mais crucial de Taïwan dans la chaîne d’approvisionnement mondiale du matériel IA, en particulier la fabrication avancée de puces par TSMC et la position dominante des fabricants ODM taïwanais dans la production de racks HGX/MGX. Cela met en évidence le caractère indispensable de Taïwan dans l’écosystème du matériel IA, malgré les tensions géopolitiques et les appels à la délocalisation de l’industrie. (Source : Reddit r/LocalLLaMA)
Controverse sur les performances de NVIDIA DGX Spark et Ollama : La communauté exprime son mécontentement à l’égard du NVIDIA DGX Spark, estimant que ses performances sont insuffisantes pour son prix de 4000 dollars et inférieures à d’autres configurations GPU. Parallèlement, Ollama est critiqué pour ses performances inférieures à celles de llama.cpp natif dans les benchmarks, il est donc recommandé de ne pas l’utiliser pour l’évaluation des performances. Ces discussions reflètent l’attention des utilisateurs sur le rapport qualité-prix et les performances des outils matériels et logiciels IA. (Source : doodlestein, QuixiAI, ggerganov)

Débat sur la bulle de l’IA et les perspectives d’investissement : Le débat se poursuit quant à savoir si l’engouement actuel pour l’investissement dans l’IA constitue une “bulle”. Certains considèrent le cycle de capital entre NVIDIA, OpenAI, Oracle et AMD comme un levier dangereux, tandis que d’autres y voient un catalyseur nécessaire pour accélérer la croissance de l’IA. Le sentiment du marché et la durabilité à long terme dépendent de la capacité de l’IA à créer une valeur durable et de son taux d’adoption par les utilisateurs. (Source : 36氪, gfodor, NandoDF, scaling01, TheTuringPost)
Le syndrome de l’imposteur chez les “experts en IA” : De nombreux “experts en IA” nouvellement embauchés déclarent souffrir du syndrome de l’imposteur. Même s’ils comprennent les bases du Machine Learning et ont construit des projets, ils doutent toujours de leurs compétences professionnelles. Ce phénomène est courant dans le domaine de l’IA en évolution rapide, où peu de gens se sentent vraiment seniors, l’expertise étant souvent relative à ceux qui ont moins d’informations. (Source : Reddit r/ArtificialInteligence)
L’impact de l’IA sur l’écriture et la créativité humaines : La communauté discute si l’IA menace l’écriture, la créativité et le style unique de l’être humain. L’IA peut générer des textes crédibles, mais sa “créativité” (intention, émotion, originalité) reste sujette à caution, et les logiciels d’IA pourraient progressivement affaiblir les modes d’écriture uniques de l’être humain. Certains préconisent d’utiliser l’IA comme un outil, tandis que d’autres insistent sur la nécessité de préserver l’agentivité humaine et la pensée critique dans l’écriture. (Source : 36氪)
L’impact de l’IA sur la recherche : Le trafic principal de Google n’est pas affecté : Robbie Stein, vice-président des produits de recherche chez Google, a déclaré que, malgré le développement continu de la technologie IA, le trafic de recherche principal de Google n’a pas diminué. Il estime que l’IA n’a pas modifié les besoins fondamentaux des utilisateurs, tels que trouver des restaurants à proximité, comparer des prix ou suivre des colis, ces besoins étant trop diversifiés pour que l’IA puisse entièrement remplacer la recherche traditionnelle. (Source : dotey)
Sora 2 : Le “TikTok” de l’IA physique : Sora 2 est considéré comme le “TikTok de l’IA”. La stratégie d’OpenAI est d’utiliser les données partagées par des millions d’utilisateurs pour construire un système de collaboration homme-machine, enseignant aux machines à comprendre le monde physique. Cela positionne Sora non seulement comme un modèle génératif, mais aussi comme un nouveau type de réseau social pour faire progresser l’IA physique. (Source : TheTuringPost, TheTuringPost)
💡 Autres
Horloges de vieillissement et recherche sur la longévité : Les scientifiques utilisent des “horloges de vieillissement” (modèles mathématiques basés sur des biomarqueurs comme la méthylation de l’ADN) pour comprendre et potentiellement inverser le vieillissement biologique. Bien que ces outils ne puissent pas encore prédire précisément les individus, ils révèlent l’universalité du vieillissement à travers les espèces et suggèrent que le vieillissement pourrait être une “perte de jeunesse”, susceptible d’être inversé par des interventions, avec des implications significatives pour la transplantation d’organes et les interventions précoces. (Source : MIT Technology Review)

Réparer Internet : Propositions pour un meilleur réseau : Des personnalités influentes comme Tim Wu, Nick Clegg et Tim Berners-Lee ont proposé des solutions radicales pour réparer les problèmes d’Internet, allant du démantèlement des monopoles technologiques (Wu), à l’autorégulation et à la “transparence radicale” (Clegg), jusqu’aux “Pods” de données utilisateur pour un contrôle accru des utilisateurs (Berners-Lee). Quoiqu’il n’y ait pas de solution unique, les thèmes communs incluent l’amélioration du contrôle des utilisateurs, la confidentialité des données et l’augmentation de la responsabilité de la Silicon Valley. (Source : MIT Technology Review)

La vision précoce et le succès de Wang Xingxing, fondateur de Unitree Robotics : La thèse de maîtrise de Wang Xingxing en 2016, “Développement et test d’un nouveau robot quadrupède à entraînement électrique”, a jeté les bases de Unitree Robotics. Il s’est d’abord concentré sur les robots à entraînement électrique pour l’efficacité des coûts et la popularisation, contrastant avec les solutions hydrauliques alors dominantes. Ce jugement prospectif s’est avéré correct et a conduit Unitree Robotics à devenir une licorne de l’IA incarnée évaluée à des dizaines de milliards. (Source : 量子位)
