
Mots-clés:Programmation IA, Claude Opus 4.5, NVIDIA Groq, Modèle mondial, Inférence IA, Agent intelligent, Modèle open source, Mode Agentic, Puce d’inférence LPU, Modèle open source GLM-4.7, Auto-évolution IA, Système d’inférence Mini-SGLang
🔥 Focus
Le lancement de Claude Opus 4.5 provoque un séisme dans le « paradigme de programmation » : Avec la sortie de Claude Opus 4.5, l’industrie de l’AI est à nouveau plongée dans un mélange d’anxiété collective et d’excitation. Andrej Karpathy a déclaré qu’en tant que programmeur, il ne s’était jamais senti aussi « dépassé », affirmant que la profession est en train d’être restructurée. La contribution directe de code par les programmeurs devient de plus en plus rare ; s’ils parviennent à orchestrer correctement l’AI, l’efficacité peut être multipliée par plus de 10. Les discussions au sein de la communauté soulignent que l’AI passe de la simple génération de code à un mode « Agentic », capable même d’infiltrer de manière autonome des systèmes de domotique (comme Lutron). Cela marque un transfert total du centre de gravité de l’ingénierie logicielle de l’« exécution » vers la « réflexion et la prise de décision ». Le code n’est plus le goulot d’étranglement, la définition du problème devient le cœur du métier (Sources : Andrej Karpathy, Vtrivedy10)
NVIDIA acquiert Groq pour 20 milliards de dollars pour combler ses lacunes en inférence : En rachetant Groq, cette « usine de pelles », NVIDIA vise à contrer la menace des puces ASIC comme les TPU de Google. Les analyses indiquent que si les GPU sont imbattables en phase de pre-training, ils sont limités par la bande passante de la mémoire HBM lors de l’inférence à faible latence (phase de Decode). Le LPU de Groq utilise de la SRAM intégrée, offrant une vitesse cent fois supérieure à celle des GPU, résolvant ainsi le goulot d’étranglement de la mémoire lors de l’inférence. Ce mouvement de Jensen Huang marque le déplacement de la compétition AI de la couche d’entraînement vers la couche d’application, NVIDIA acquérant un « vaccin » pour éviter d’être renversé par de nouvelles architectures d’inférence (Sources : Gavin Baker, Suhail)

Geoffrey Hinton alerte sur 2026 : l’AI vers le raisonnement autonome et l’auto-évolution : Le parrain de l’AI, Hinton, souligne un changement fondamental : l’AI passe de « donner des réponses » à « exécuter des tâches ». Il insiste sur le fait que l’AI sera dotée de mécanismes d’auto-correction similaires à ceux des humains (auto-vérification), réalisant des raisonnements via des connexions de vecteurs à haute dimension plutôt que par des symboles logiques. Plus important encore, l’AI entrera dans une « phase d’auto-apprentissage », générant des données d’entraînement de haute qualité par le biais du self-play, s’affranchissant ainsi de la dépendance aux données publiques humaines. Cela signifie que les AI Agents commenceront à livrer directement des résultats, le contrôle glissant des mains des humains (Source : )
🎯 Tendances
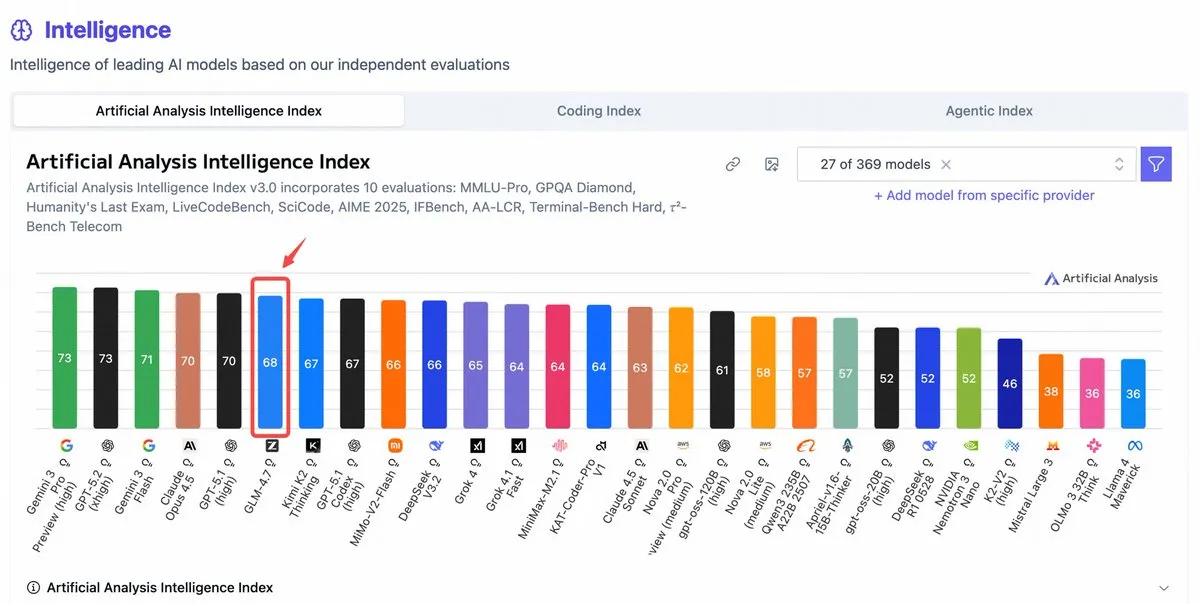
GLM-4.7 en tête des classements de modèles open-source, les modèles chinois continuent de progresser : Le modèle GLM-4.7 de Zhipu AI s’est classé premier parmi les modèles open-source dans l’indice d’intelligence d’Artificial Analysis, surpassant des concurrents comme Kimi K2. La communauté rapporte des performances impressionnantes en vision mathématique et en raisonnement complexe. Parallèlement, le Mimo-v2-flash publié par Xiaomi a également démontré une grande utilité dans l’arène des contextes longs. Cela montre que les modèles open-source réduisent rapidement l’écart avec les flagships propriétaires, en particulier dans des domaines verticaux spécifiques et sur l’efficacité du raisonnement (Sources : Z.ai, LocalLLaMA)
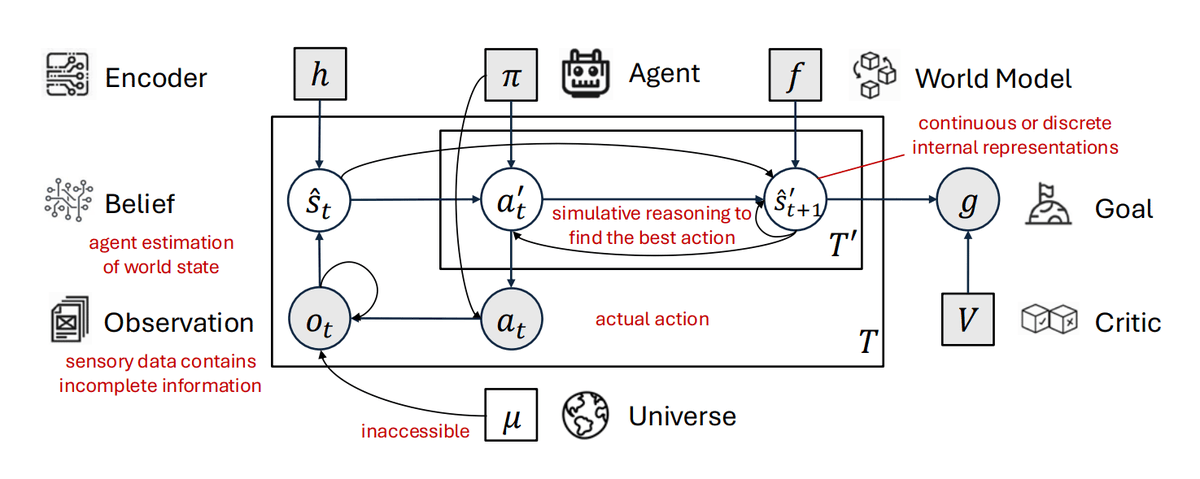
Panorama des sept World Models de 2025 : de la physique à l’imbrication complète des agents : TheTuringPost a répertorié les World Models les plus représentatifs de 2025, notamment LeJEPA, Code World Model (CWM), et Cosmos WFM 2.5. Ces modèles tentent d’intégrer les lois physiques, les comportements des agents et la logique imbriquée dans une architecture unifiée. La tendance montre que l’AI de demain ne se limitera plus à la génération de texte, mais possédera des capacités de simulation et de prédiction haute fidélité du monde physique et des systèmes complexes (Source : TheTuringPost)
Fuite de GPT-5.2 Codex : édition de fichiers plus efficace et cohérence logique : OpenAI progresse en interne sur l’itération de GPT-5.2 Codex. Les premiers testeurs rapportent des améliorations significatives dans la cohérence de l’édition de fichiers et la transparence logique. Le modèle se comporte davantage comme un « collaborateur » mature que comme un simple outil de complétion lors de la manipulation de bases de code complexes. Avec la vague des modèles locaux, ces modèles d’inférence efficaces deviendront le cœur du workflow des développeurs individuels (Source : gdb)
DeepSeek V3.2 affiche une compétitivité intergénérationnelle, redistribution des cartes pour les modèles mondiaux : Les réseaux sociaux s’enflamment pour DeepSeek V3.2, qui surpasse GPT-5.2 sur certaines tâches spécifiques (comme la construction d’un moteur d’échecs). Cette tendance à « battre les géants avec de petits moyens » reflète le potentiel immense des techniques de Post-training pour repousser les limites du raisonnement des modèles. 2026 est considérée comme « l’année de la vérification », où les utilisateurs ne paieront plus pour des « moments magiques » mais exigeront une fiabilité de production supérieure à 95 % (Source : teortaxesTex)
🧰 Outils
just-bash : une implémentation Bash en TypeScript pour les AI Agents : Malte Ubl a développé just-bash, une implémentation complète de Bash conçue spécifiquement pour les AI Agents (comme Claude Code). Il supporte les outils courants tels que grep, sed, awk, et offre un environnement d’exécution sécurisé en sandbox. L’aspect intéressant du projet est que son code a été presque entièrement écrit par Opus 4.5, illustrant comment l’AI s’auto-améliore en construisant sa propre chaîne d’outils de bas niveau (Source : andersonbcdefg)
Dad Co-Pilot : une application iOS développée indépendamment en 3 semaines avec Claude Code : Un nouveau père a utilisé Claude Code pour créer, en seulement 3 semaines et sans aucun serveur backend, une application de suivi de bébé basée sur SwiftUI et CloudKit. L’outil a permis d’itérer les fonctionnalités via des interactions en langage naturel, prouvant que l’AI abaisse considérablement la barrière à l’entrée du développement logiciel, permettant à des non-professionnels de livrer rapidement des applications complexes et productives (Source : Reddit r/ClaudeAI)

exe.dev : un bac à sable VM persistant pour les agents de code : Pour répondre au besoin des AI Agents d’avoir un environnement stable lors de l’exécution de tâches, exe.dev a lancé un service de « sandbox avec VM intégrée ». Il fournit des machines virtuelles persistantes accessibles via SSH, permettant aux développeurs de laisser les AI Agents y exécuter des tâches en continu. Cela résout les problèmes de sécurité et de cohérence de l’environnement pour les agents dans des tâches de développement complexes (Source : mathemagic1an)

agi-memory : doter les AI Agents d’un « battement de cœur » autonome et d’une mémoire à long terme : QuixiAI a rendu open-source le système agi-memory, qui utilise un « daemon de battement de cœur » pour réveiller périodiquement l’AI (comme Claude), lui permettant de réfléchir de manière autonome, de tenir un journal et de maintenir une mémoire à long terme. Ce mécanisme transforme l’AI d’un programme passif attendant des instructions en une entité capable de requêtes de conscience continues et d’auto-optimisation en arrière-plan (Source : QuixiAI)
📚 Apprentissage
Mini-SGLang : maîtriser l’inférence LLM avec 5000 lignes de code Python : Le projet Mini-SGLang publié par LMSYS compresse une pile d’inférence de niveau production en un code Python lisible. Il couvre des technologies clés telles que FlashAttention-3, le parallélisme de tenseurs (Tensor Parallelism), le Chunked Prefill et le Radix Cache. C’est une ressource de pratique idéale pour comprendre l’architecture des systèmes d’inférence LLM modernes et la logique sous-jacente de l’optimisation du débit et de la latence (Source : arnaud_autef)

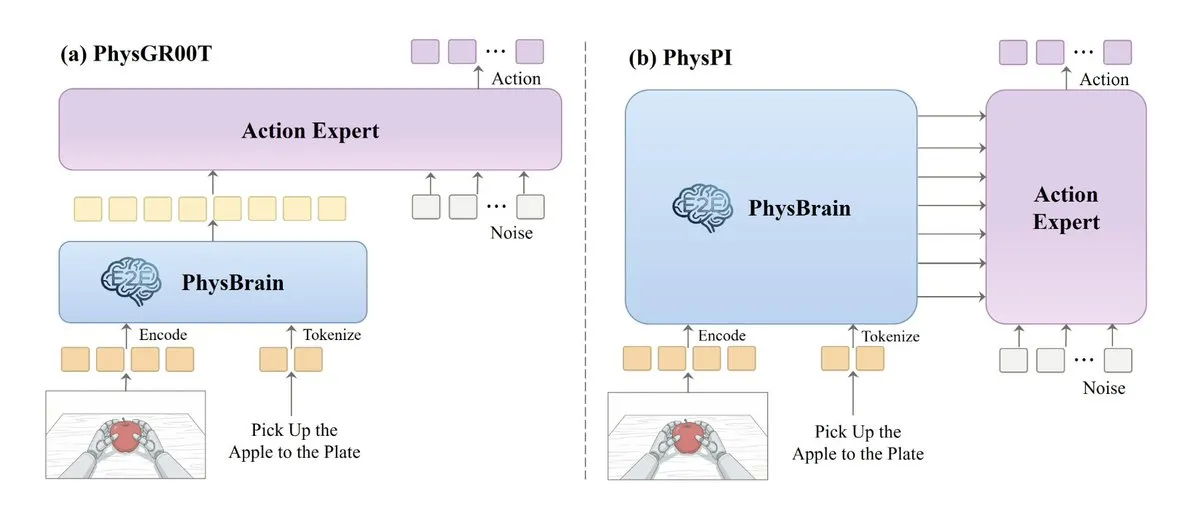
Egocentric2Embodiment : entraîner l’intelligence incarnée à partir de vidéos à la première personne : Une nouvelle étude propose le pipeline E2E, qui convertit des vidéos humaines à la première personne en données de supervision structurées sous forme de questions-réponses pour entraîner PhysBrain, un modèle de perception incarnée. Cette méthode renforce considérablement les capacités de planification et de raisonnement interactif de l’AI dans le monde physique, tout en réduisant la dépendance aux échantillons robotiques (Source : TheTuringPost)
Nouveau record de vitesse pour l’entraînement de NanoGPT : l’astuce de l’Asymmetric Logit Scaling : Un développeur a mis à jour NanoGPT avec une seule ligne de code, utilisant des techniques d’Asymmetric Logit Scaling et d’offset pour accélérer à nouveau l’entraînement. Cette astuce exploite le fait que les tâches de prédiction se concentrent uniquement sur la queue droite (Right Tail), permettant une convergence plus rapide via l’optimisation du Logit Softcapping. Cela démontre que de subtiles optimisations mathématiques au niveau de l’infrastructure peuvent encore apporter des gains d’efficacité massifs (Source : kellerjordan0)

💼 Business
OpenAI recrute un « Head of Preparedness » pour contrer les risques d’abus des modèles : Sam Altman a annoncé qu’OpenAI recrute un Head of Preparedness, un poste crucial visant à gérer les risques potentiels des modèles en matière de cybersécurité (comme la recherche automatique de vulnérabilités) et de biosécurité. Avec l’augmentation des capacités d’auto-évolution des modèles, limiter leurs impacts négatifs tout en profitant des bénéfices technologiques est devenu une priorité commerciale pour les laboratoires de pointe (Source : Sam Altman)
Détails de l’acquisition de Groq par NVIDIA : des gains substantiels pour les employés : Alors que l’acquisition est finalisée, Axios rapporte que les employés de Groq ont réalisé d’importants gains financiers lors de cette transaction. Bien que certaines options ne soient pas encore totalement acquises, les conditions offertes par NVIDIA sont extrêmement attractives. Cette transaction n’est pas seulement une fusion technologique, mais aussi une restructuration majeure du marché des talents dans les puces AI (Source : Suhail)
🌟 Communauté
Le phénomène AI Slop fait débat : attention au piège linguistique du « It’s not X, it’s Y » : La communauté remarque une homogénéisation croissante des contenus générés par ChatGPT, en particulier la structure de phrase « Il ne s’agit pas seulement de X, mais surtout de Y ». Les analyses suggèrent que ce style exploite la dépendance psychologique humaine à la « profondeur de surface » et aux « biais de groupe ». Une étude sur YouTube montre que plus de 20 % des vidéos recommandées aux nouveaux utilisateurs sont devenues des déchets générés par AI (Slop), une « prospérité de basse qualité » qui impacte durablement l’écosystème de contenu (Sources : scottastevenson, Reddit r/artificial)

Le Tennessee propose une loi pour interdire le soutien émotionnel par l’AI, suscitant la controverse : Les législateurs du Tennessee tentent de classer l’entraînement d’AI pour fournir un soutien émotionnel ou agir comme compagnon comme un crime de classe A (équivalent à un meurtre). La communauté a réagi violemment, y voyant non seulement un frein à l’innovation, mais aussi une ignorance du potentiel de l’AI pour la santé mentale. Ce mouvement reflète l’insécurité extrême et la mentalité défensive des systèmes juridiques traditionnels face à la dimension sociale de l’AI (Source : nptacek)

Crise de la revue de code à l’ère des Agents : l’humain devient le goulot d’étranglement de la productivité : Avec des AI Agents (comme Claude Code) capables de produire des centaines de PR par mois, le modèle traditionnel de revue de code humaine est devenu intenable. Brivael souligne que lorsqu’un ingénieur gère 10 Agents, exiger une vérification humaine ligne par ligne entraînera une paralysie systémique. L’ingénierie logicielle fait face à une transition forcée de la « revue ligne par ligne » vers la « vérification systémique » et l’« audit automatisé » (Sources : brivael, dotey)
La pensée systémique l’emporte sur la syntaxe : la nouvelle identité du programmeur à l’ère de l’AI : Un consensus se dégage dans la communauté : l’importance de la pensée systémique et de l’expertise métier dépasse désormais de loin la syntaxe du code. Les développeurs doivent rapidement passer du statut de « celui qui écrit du code » à celui de « celui qui résout des problèmes via le logiciel ». Pour les profils semi-techniques, c’est le moment idéal pour rattraper leur retard, car l’AI lisse la difficulté de mise en œuvre et amplifie la valeur de la décision (Sources : bookwormengr, nptacek)
💡 Autres
Appel à une nouvelle esthétique : Tyler Cowen finance les artistes qui définissent l’époque : L’économiste Tyler Cowen a lancé un programme de bourses intitulé « New Aesthetics », visant à trouver des artistes et designers capables de définir consciemment l’esthétique d’une nouvelle ère. Face à la prolifération des contenus générés par AI, la manière dont les humains créent un nouveau langage visuel unique, profond et résonnant est devenue une question culturelle urgente (Source : Plinz)

Révélation de l’algorithme de recommandation de X : un matching entièrement vectorisé basé sur Grok : Elon Musk a confirmé que le nouvel algorithme de recommandation de la plateforme X est entièrement piloté par Grok. L’algorithme analyse plus de 100 millions de posts par jour, utilisant des Embeddings et le machine learning pour prédire l’engagement des utilisateurs, sans plus dépendre du filtrage par mots-clés ou de règles manuelles. Cette approche entièrement vectorisée vise un « matching d’intérêt » plus précis, mais alimente également les débats sur les chambres d’écho informationnelles (Source : brivael)