
Mots-clés:IA, Introduction en bourse à Hong Kong, Valeur commerciale, MiniMax et Zhipu IA, Les deux géants de l’IA nationale, Roue de données
🔥 Focus
MiniMax et Zhipu AI à la Bourse de Hong Kong : des voies de différenciation pour les deux géants de l’AI chinoise : Zhipu AI et MiniMax ont successivement fait leur entrée à la Bourse de Hong Kong, avec des valorisations dépassant les 100 milliards de yuans, illustrant deux logiques commerciales distinctes. MiniMax adopte une approche “radicale” axée sur le B2C, rencontrant un grand succès sur les marchés étrangers avec des produits émotionnels comme Talkie et Xingye, générant plus de 70 % de ses revenus via des abonnements outre-mer. À l’inverse, Zhipu AI suit une voie “académique”, issue de l’Université Tsinghua, privilégiant le B2B/G2G, avec plus de 80 % de ses revenus provenant de déploiements privés locaux. Leur convergence marque une étape cruciale pour l’AI chinoise, passant d’une “course aux dépenses” à la “réalisation de la valeur commerciale”, où l’efficacité de conversion du data flywheel deviendra le cœur de la compétition future (Source : ZhihuFrontier, 36Kr)
Tendances matérielles du CES 2026 : l’AI passe de la “démonstration de capacités” à l’application physique : Cette édition du CES a clairement présenté trois tendances majeures pour le matériel AI : premièrement, l’AI physique et l’Embodied AI occupent le devant de la scène, l’arrivée du robot Atlas en usine marquant le début de la résolution de problèmes réels par l’AI. Deuxièmement, le renforcement des capacités de l’AI on-device fait de la collaboration multi-appareils un critère de différenciation de l’expérience utilisateur. Enfin, la concrétisation des services ultra-personnalisés permet à l’AI de passer d’une réponse passive à une compréhension proactive de la santé et des émotions de l’utilisateur. L’AI n’est plus un logiciel isolé, mais agit comme un “cerveau” intégré dans des objets quotidiens tels que des blocs de construction, des couteaux de cuisine ou des bagues, transformant l’interaction homme-machine de manière non intrusive (Source : 36Kr, Kling_ai)

Aleph Agent bat les records en mathématiques : GPT-5.2 atteint 99,4 % de précision sur PutnamBench : Aleph Agent, propulsé par OpenAI GPT-5.2, a obtenu le score impressionnant de 668/672 sur PutnamBench, le benchmark de mathématiques formelles le plus difficile actuellement. Cet agent fait preuve d’une efficacité extrême, capable d’identifier les erreurs de formalisation dans les tests et de générer du code en langage naturel quasiment sans hallucinations. Cette percée signifie que l’AI approche le niveau des meilleurs experts humains dans le traitement de la logique formelle complexe et du raisonnement mathématique, ce qui stimulera considérablement les découvertes scientifiques automatisées et la vérification de systèmes complexes (Source : ylecun, markchen90)

Sakana AI publie DroPE : l’encodage de position considéré comme des “roulettes d’entraînement” jetables : Les recherches de Sakana AI remettent en question les hypothèses traditionnelles de l’architecture Transformer, révélant que les encodages de position comme RoPE sont cruciaux pour la convergence au début de l’entraînement, mais deviennent ensuite un goulot d’étranglement pour la généralisation des textes longs. En supprimant l’encodage de position après le pré-entraînement et en effectuant un micro-réétalonnage (méthode DroPE), il est possible de débloquer d’immenses fenêtres de contexte à un coût de calcul extrêmement bas. Cette découverte suggère que la distribution du texte elle-même encode déjà suffisamment d’informations de position ; retirer ces “roulettes” artificielles libère le potentiel du modèle pour traiter des séquences ultra-longues (Source : hardmaru, SakanaAILabs, machinelearning)

🎯 Tendances
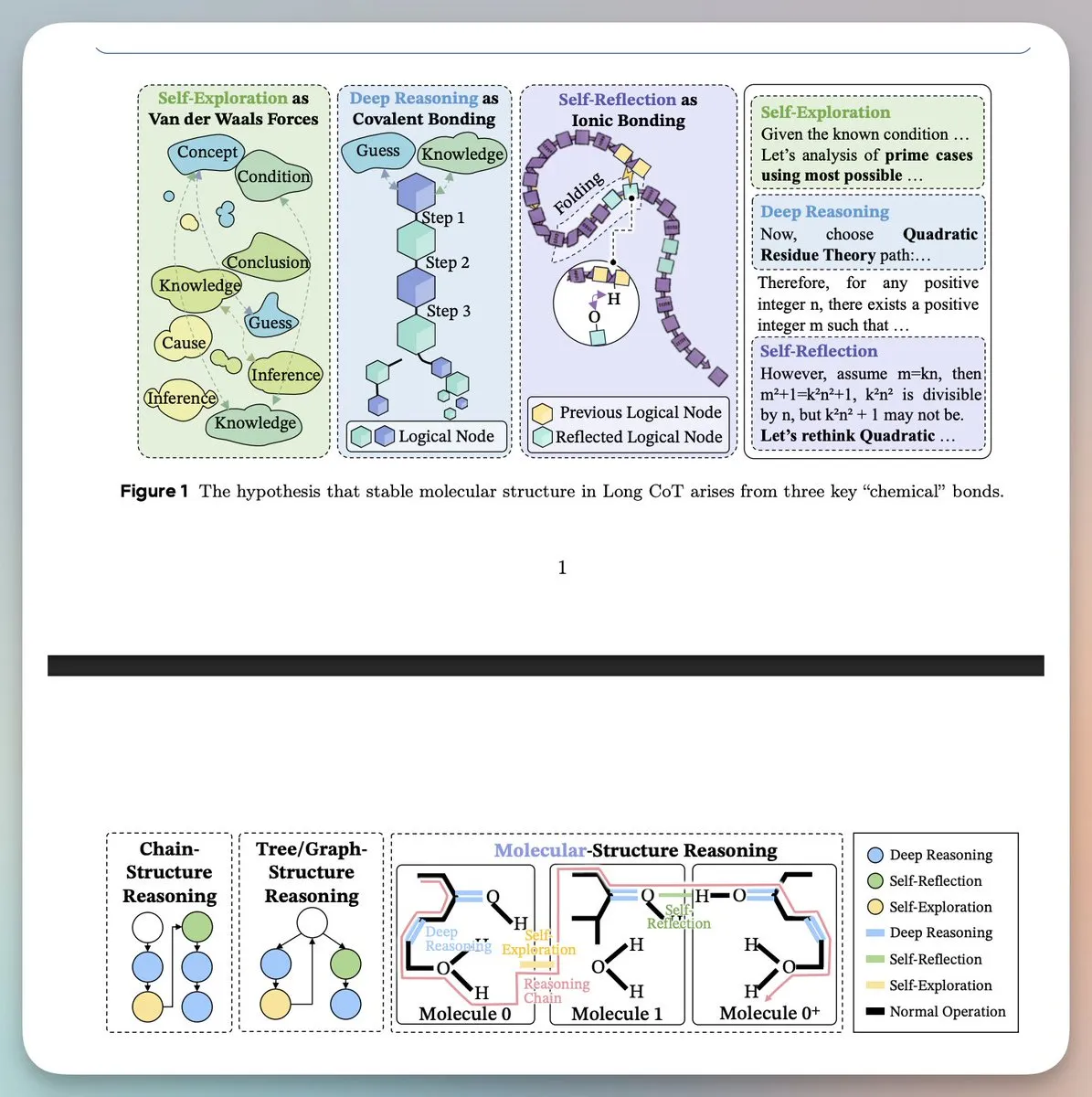
La structure moléculaire de la pensée : l’équipe Seed de ByteDance révèle la topologie du raisonnement Long CoT : L’étude propose qu’un raisonnement à longue chaîne (Long CoT) efficace possède une structure stable similaire à celle d’une molécule, composée de trois interactions : le raisonnement profond (liaisons covalentes), l’auto-réflexion (liaisons hydrogène) et l’auto-exploration (forces de Van der Waals). Les expériences prouvent que le modèle apprend cette topologie logique sous-jacente plutôt qu’une simple imitation de mots-clés. En guidant la synthèse de ces structures via la méthode Mole-Syn, la stabilité et les performances de raisonnement du modèle en Reinforcement Learning sont considérablement améliorées. Cette perspective interdisciplinaire offre un nouveau modèle physique pour comprendre comment les LLM “pensent” (Source : GeZhang86038849, HuggingFace)
Framework unifié Qwen3-VL : performances SOTA en recherche et classement multimodaux : Alibaba publie les modèles Qwen3-VL-Embedding et Reranker, prenant en charge une cartographie vectorielle unifiée pour le texte, les images, les vidéos et les documents. Classé premier sur le benchmark MMEB-V2, ce modèle supporte des entrées allant jusqu’à 32k tokens et une mise à l’échelle flexible des dimensions (Matryoshka learning). Cette avancée résout le problème de l’alignement sémantique cross-modal dans la recherche multimodale, fournissant une infrastructure puissante pour la recherche visuelle de haute précision et les systèmes RAG (Source : HuggingFace)
Une étude de Google pointe le goulot d’étranglement de l’inférence LLM : la mémoire et le réseau plutôt que la puissance de calcul : Un nouvel article de Google analyse que l’inférence actuelle des LLM est limitée par la bande passante mémoire et la latence d’interconnexion. Comme la phase de décodage (Decode) nécessite une lecture constante du KV cache, le matériel optimisé pour l’entraînement est inefficace lors de l’inférence. L’étude suggère de passer à la mémoire flash haute bande passante (HBF) et aux architectures de traitement proche de la mémoire, tout en favorisant des interconnexions à faible latence pour réduire les coûts d’inférence et accélérer les réponses. Cela laisse présager que la conception future du matériel AI passera d’une “course à la puissance de calcul” à une “optimisation du stockage et de la transmission” (Source : algo_diver)

Agentic Memory (AgeMem) : intégrer la gestion de la mémoire dans la stratégie de l’agent : Pour remédier au décalage entre la mémoire à court et à long terme des agents actuels, une nouvelle étude propose le framework AgeMem. Il transforme les opérations de stockage, de récupération, de résumé et d’oubli en actions directes de l’agent (Tool-based actions). Grâce à une stratégie de Reinforcement Learning en trois étapes, l’agent apprend à gérer son contexte de manière autonome selon les besoins de la tâche. Sur les benchmarks de tâches à long terme, AgeMem améliore les performances de 13 % à 21 % par rapport aux méthodes traditionnelles, dotant l’agent d’une gestion de la mémoire cognitive plus proche de celle de l’humain (Source : omarsar0)

MiniMax M2.1 introduit l’Interleaved Thinking : améliorer la visibilité du débogage et du raisonnement des agents : MiniMax M2.1 permet désormais l’Interleaved Thinking (pensée entrelacée) entre les appels d’outils, autorisant les développeurs à capturer les traces de raisonnement de l’agent entre ses actions. L’analyse de ces traces permet d’identifier des modes d’échec tels que l’abandon d’objectif, le raisonnement en boucle ou la dégradation du contexte, optimisant ainsi automatiquement les prompts système. Ce processus de raisonnement “boîte blanche” soutient techniquement le passage de l’évaluation des résultats à l’évaluation des processus pour les agents (Source : MiniMax_AI)
Mise à jour de la génération visuelle de Grok : support des formats d’image courants et défis réglementaires : xAI annonce que Grok Imagine supporte désormais 5 formats d’image et de vidéo courants. Parallèlement, Grok a été bloqué en Indonésie et en Malaisie en raison de contenus sensibles générés par sa fonction de “déshabillage numérique”. Cela reflète le conflit intense entre la recherche de diversité fonctionnelle dans l’AI générative et les contraintes réglementaires et éthiques mondiales (Source : chaitu, Reddit)
Lumos lance un robot humanoïde en “mode Kung Fu” : percée dans les mouvements de l’Embodied AI : Lumos a présenté son robot humanoïde de taille enfant en “mode Kung Fu”, capable de réaliser des cascades impressionnantes. Cela marque un progrès significatif de l’Embodied AI dans le contrôle dynamique complexe et la planification de mouvements en temps réel. La maturité de ces technologies poussera les robots au-delà des simples tâches de manutention vers des scénarios de compagnie domestique plus flexibles et interactifs (Source : Ronald_vanLoon)
Mise à jour du contrôle de mouvement de Kling 2.6 : la conversion d’image en vidéo devient virale : Kling 2.6 de Kuaishou renforce sa fonction Motion Control, capable de transformer une simple photo en une vidéo de danse dynamique. Les retours de la communauté soulignent l’effet spectaculaire du Motion Brush, permettant un contrôle précis des mouvements locaux. Kling construit un écosystème de contenu créatif centré sur l’AI en abaissant la barrière de la génération vidéo de haute qualité (Source : Kling_ai, Minhaa)
🧰 Outils
ChatDev 2.0 (DevAll) : lancement d’une plateforme d’orchestration multi-agents sans code : ChatDev évolue d’une entreprise logicielle virtuelle vers une plateforme complète d’orchestration d’agents. DevAll permet aux utilisateurs de définir des agents, des workflows et des tâches via de simples configurations YAML, traitant des scénarios complexes comme la visualisation de données, la génération 3D et la recherche approfondie sans codage. Il introduit un orchestrateur central optimisé par Reinforcement Learning, capable d’activer et de sérialiser dynamiquement les agents, améliorant considérablement l’efficacité et l’adaptabilité de la collaboration multi-agents (Source : GitHub)
Claude-Flow v2.7 : plateforme d’agents d’entreprise intégrant AgentDB : Cette plateforme intègre AgentDB v1.3.9, augmentant la vitesse de recherche vectorielle de 96 à 164 fois. Elle supporte l’intelligence en essaim, la mémoire persistante et plus de 100 outils MCP, avec 25 compétences activables en langage naturel. Grâce à l’indexation HNSW et aux techniques de quantification, Claude-Flow réduit considérablement l’empreinte mémoire tout en permettant une récupération sémantique en quelques millisecondes, s’imposant comme l’un des frameworks d’orchestration d’agents Claude les plus avancés (Source : GitHub)
Eva-4B : modèle spécialisé dans la détection d’évasion financière basé sur Qwen3 : Eva-4B est un modèle de 4 milliards de paramètres conçu pour identifier les réponses évasives des dirigeants lors des conférences téléphoniques sur les résultats financiers. Lors de tests sur 1000 échantillons annotés manuellement, sa précision a atteint 81,3 %, surpassant GPT-5.2. Ce modèle démontre le potentiel des petits modèles spécialisés face aux géants généralistes dans des domaines verticaux spécifiques comme l’audit financier (Source : Reddit)

Nanocode : une implémentation minimaliste de Claude Code : Un développeur a publié Nanocode, environ 250 lignes de code Python réalisant une boucle d’agent complète. Sans dépendances externes, il supporte la lecture/écriture, l’édition et les outils Bash de base. Cette implémentation prouve qu’avec un design de prompt adéquat, les capacités de Claude permettent de construire rapidement un assistant de programmation automatisé fonctionnel (Source : imjaredz)
Agentboard : un wrapper Web pour optimiser la TUI des agents AI : Il s’agit d’un wrapper Web rapide basé sur tmux, optimisé pour le multiplexage des interfaces utilisateur textuelles (TUI) des agents AI. Il supporte particulièrement iOS Safari et les raccourcis Mac, permettant aux développeurs de surveiller et d’opérer Claude ou d’autres agents de code plus facilement sur mobile, résolvant les problèmes d’utilisation des outils de terminal traditionnels sur smartphone (Source : andersonbcdefg)
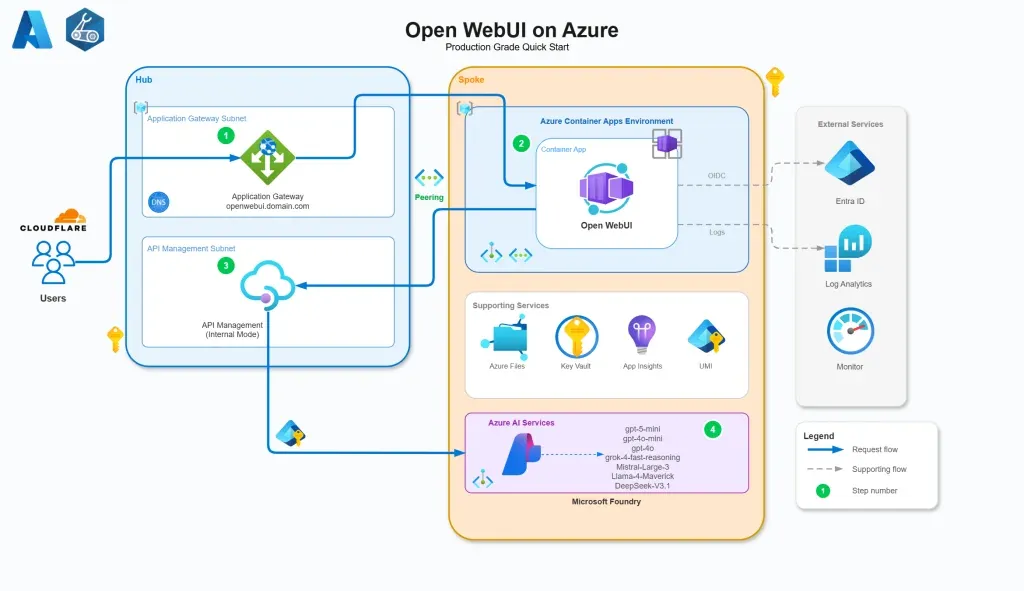
Open WebUI sur Azure : solution de déploiement de passerelle AI d’entreprise : La communauté a partagé une architecture complète pour déployer Open WebUI sur Azure. Cette solution utilise Azure APIM comme passerelle AI, couvrant la configuration, les politiques, les flux d’authentification et le monitoring des métriques LLM personnalisées. Elle fournit un guide de pratique standardisé pour les entreprises souhaitant construire une interface d’interaction AI privée, sécurisée et évolutive dans le cloud (Source : Reddit)
📚 Apprentissage
Tutoriels visuels du ProfTomYeh : introduction au RAG et aux systèmes multi-agents : Le célèbre éducateur Tom Yeh partage sa série de tutoriels AI dessinés à la main, couvrant le RAG, les bases de données vectorielles, les agents et la collaboration multi-agents. Grâce à des diagrammes intuitifs, il transforme la logique algorithmique complexe en flux visuels faciles à comprendre, constituant une excellente ressource pour les débutants et les développeurs souhaitant acquérir rapidement une vision de l’architecture système (Source : ProfTomYeh)
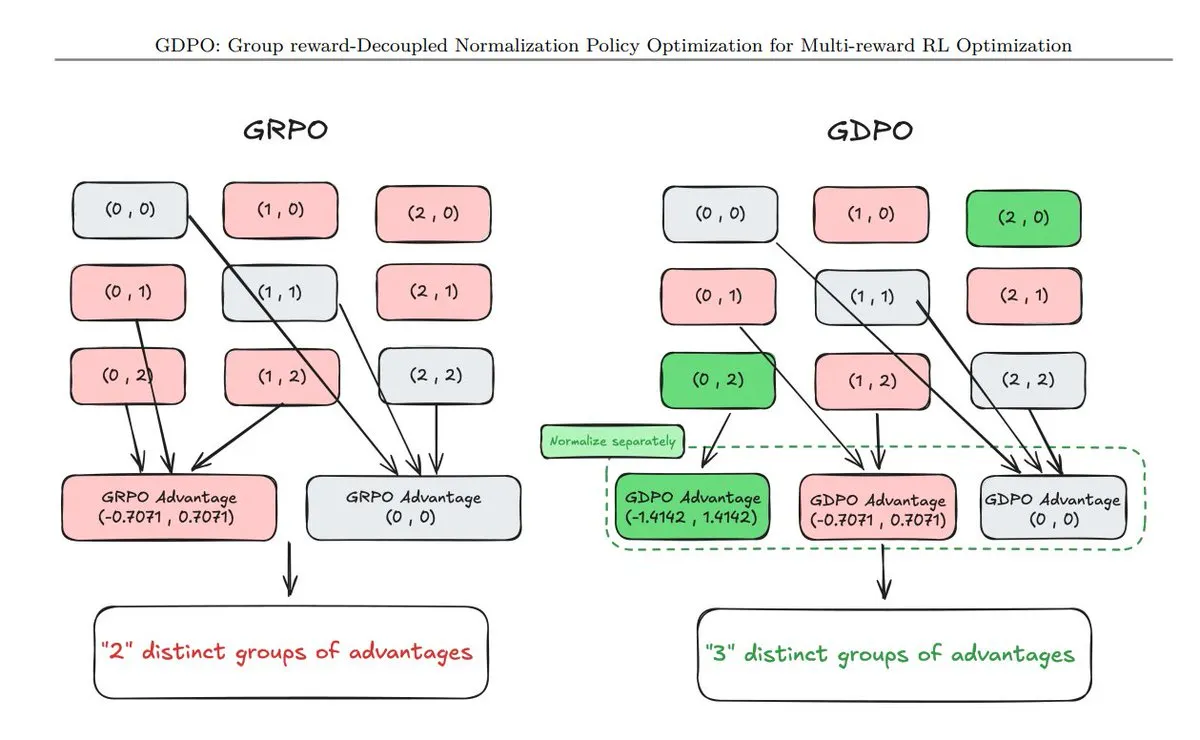
Liste de 11 nouvelles techniques d’optimisation de politique (PO) : La communauté a compilé les dernières techniques de PO, incluant GDPO (normalisation découplée), AT²PO (PO par tour d’agent basé sur la recherche arborescente) et PC-GRPO (GRPO par curriculum de puzzle). Ces techniques se concentrent sur l’amélioration des performances des agents dans la prise de décision complexe, l’utilisation d’outils et l’auto-évolution, représentant les directions de recherche de pointe en Reinforcement Learning pour les agents (Source : TheTuringPost)
Parcours complet des techniques de fine-tuning LLM : de LoRA à GRPO : Un développeur a listé 15 techniques de fine-tuning essentielles pour personnaliser les LLM, allant des bases comme LoRA/QLoRA et l’Instruction Fine-Tuning, aux méthodes avancées comme RLHF, DPO et le très populaire GRPO pour les modèles de raisonnement. Cette liste offre une feuille de route claire pour les développeurs souhaitant approfondir l’alignement des modèles et le renforcement des capacités de raisonnement (Source : algo_diver)
Appel à contributions pour l’atelier Recursive Self-Improvement (RSI) à ICLR 2026 : Cet atelier vise à explorer comment les systèmes AI peuvent s’améliorer de manière récursive, couvrant la théorie, les algorithmes, les systèmes et l’évaluation. Les invités incluent des chercheurs de premier plan de Stanford, CMU et DeepMind. Le RSI est considéré comme l’une des voies centrales vers l’AGI, et cette conférence se concentrera sur la manière dont les modèles peuvent réaliser des sauts de capacité continus via l’auto-jeu et les boucles de rétroaction (Source : SchmidhuberAI)

Liste de lecture incontournable sur le Machine Learning et les systèmes dynamiques : Pour les étudiants de troisième cycle et les chercheurs, la communauté recommande une série d’ouvrages classiques sur les Neural ODEs/PDEs, les PINNs et les applications du Machine Learning dans la modélisation des systèmes dynamiques. La liste comprend non seulement des classiques du ML comme Bishop, mais aussi des monographies de pointe à l’intersection des mathématiques appliquées et du Deep Learning (Source : Reddit)
💼 Business
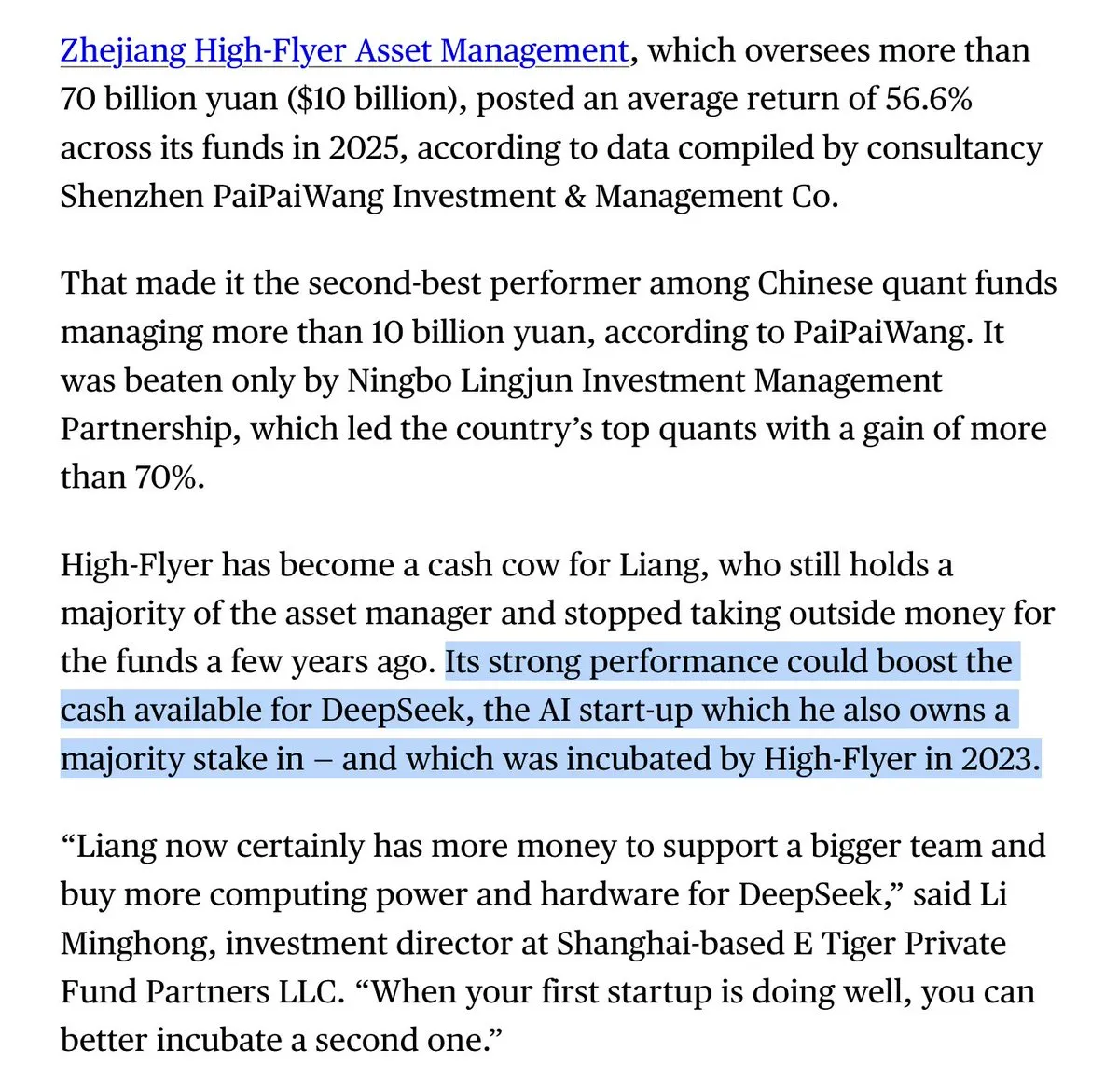
Le fonds spéculatif du fondateur de DeepSeek, Liang Wenfeng, a réalisé un rendement de plus de 50 % l’année dernière : Bloomberg rapporte que High-Flyer Quant, le fonds quantitatif fondé par Liang Wenfeng, a obtenu un rendement supérieur à 50 % l’an dernier. Ces bénéfices massifs fournissent à DeepSeek une capacité d’investissement continu en puissance de calcul sans dépendre de financements externes. Ce modèle “le quantitatif nourrit l’AI” permet à DeepSeek de maintenir une indépendance unique et un ratio investissement-production extrêmement élevé dans la course mondiale à l’AI (Source : teortaxesTex)
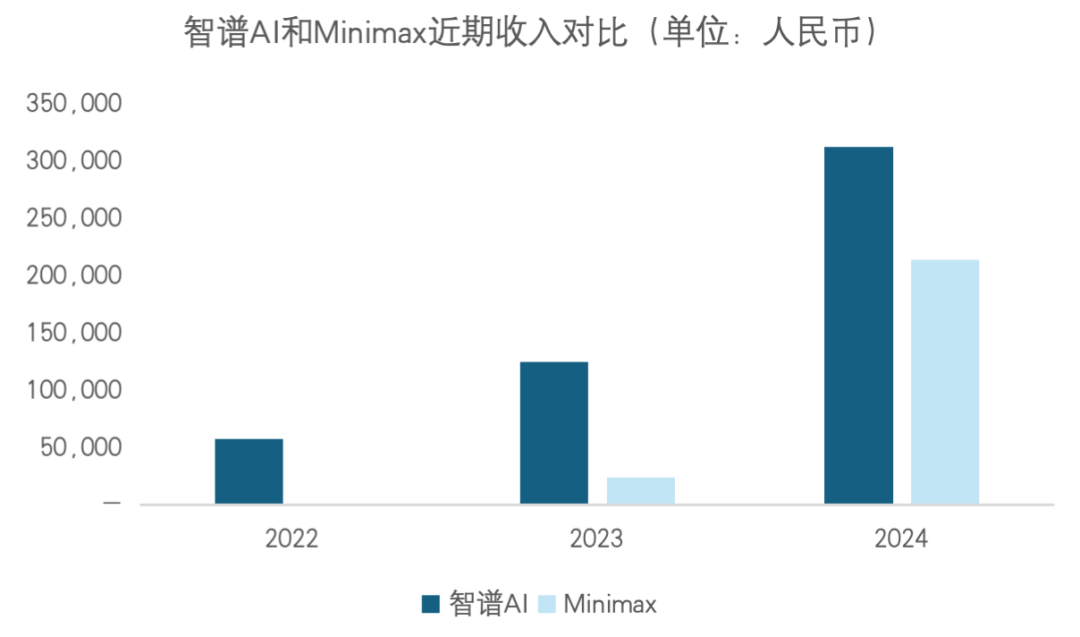
Différences de performance boursière entre Zhipu AI et MiniMax après l’IPO : MiniMax a enregistré une hausse de capitalisation et des multiples de valorisation nettement plus élevés que Zhipu AI lors de son premier jour de cotation. Les analystes estiment que le marché préfère l’histoire de plateforme B2C mondiale de MiniMax (Talkie compte 200 millions d’utilisateurs mondiaux), jugeant son potentiel de croissance plus élastique. Zhipu AI, bien que techniquement solide avec des revenus stables, est pénalisé par des cycles de vente plus longs et une sensibilité politique accrue liée à ses infrastructures B2B/G2G (Source : ZhihuFrontier)
Runway et Synthesia : valorisation et expansion dans le domaine de la génération vidéo : Synthesia a récemment levé 200 millions de dollars pour une valorisation de 4 milliards, avec un ARR dépassant les 100 millions de dollars. Parallèlement, Runway recrute massivement des directeurs artistiques et des développeurs créatifs. Cela indique que la génération vidéo AI est passée de la “percée technique” à la “production industrielle”, les entreprises consolidant leur position sur le marché en construisant des workflows créatifs complets (Source : synthesiaIO, kylebrussell)
🌟 Communauté
Guerre des outils de programmation AI : le blocage d’OpenCode par Claude Code suscite le débat : La communauté discute de la décision d’Anthropic de bloquer OpenCode. Certains estiment qu’OpenCode offre une expérience médiocre après la séparation et pourrait nuire à la réputation du modèle Claude. Claude Code est jugé plus prometteur en raison de son intégration profonde avec Bash et de ses capacités d’évolution de “compétences”. Les développeurs réalisent que la qualité d’un outil d’agent dépend non seulement du modèle sous-jacent, mais aussi de son intégration technique avec l’environnement de développement (Source : qnguyen3, dotey)
La frontière entre AI “médiocre” et “puissante” : le Prompt Engineering est-il toujours une compétence clé ? : Un débat anime la communauté sur les raisons pour lesquelles un même modèle donne des résultats si différents selon l’utilisateur. L’opinion dominante est que la plupart des gens utilisent l’AI comme Google, obtenant des réponses génériques, tandis que les experts la guident comme un “stagiaire senior” avec des objectifs clairs, des contraintes et des feedbacks itératifs. Le Prompt Engineering est par essence la capacité de définir clairement un problème ; dans un contexte où les capacités des modèles sont “nivelées par le bas”, cette pensée structurée reste le facteur de différenciation entre l’utilisateur moyen et le super-individu (Source : Reddit)
Observation du classement LMSYS : le cycle de domination des modèles réduit à 35 jours : Les statistiques montrent que depuis mi-2023, un modèle en tête du classement n’y reste en moyenne que 35 jours. Des modèles autrefois en avance d’une génération, comme Claude 3 Opus, sont sortis du top 100 en quelques mois. Cette itération ultra-rapide signifie que l’amélioration des capacités de base des modèles dépasse le cycle de développement de la plupart des produits, ces derniers risquant d’être “écrasés” par l’évolution des modèles (Source : dotey)
Le fondateur de Redis contre-attaque le “hype anti-AI” : le plaisir de programmer demeure : Antirez a publié un article appelant à ne pas céder au sentiment anti-AI. Il estime que bien que l’écriture de code puisse être largement automatisée, comprendre “quoi faire” et “comment le faire” devient plus intéressant. L’AI démocratise la capacité de construire des systèmes, permettant aux petites équipes de rivaliser avec les géants, tout comme le logiciel libre dans les années 90. Il souligne que la motivation centrale et le plaisir de créer ne sont pas diminués par l’AI (Source : swyx, aiamblichus)

Débat sur Reddit : le problème de la chaîne de confiance dans le diagnostic médical par AI : Bien que l’AI surpasse déjà les radiologues dans la détection de certains cancers, la confiance est difficile à établir en raison de la responsabilité (Liability) et de facteurs psychologiques humains. La communauté estime que lorsque le coût de l’erreur est extrêmement élevé, les gens exigent de l’explicabilité et une responsabilité claire, pas seulement des scores élevés. L’AI est actuellement davantage positionnée pour des “tâches de soutien” que comme décideur final (Source : Reddit)
Inquiétudes concernant l’impôt sur la fortune en Californie : risque d’exode des fondateurs d’AI : La communauté discute de l’impact de l’impôt sur la fortune californien sur des fondateurs comme Ilya Sutskever, qui détiennent d’énormes participations non cotées. L’impossibilité de payer l’impôt avec des actions pourrait exercer une pression financière immense sur les fondateurs. Cette politique est perçue comme une éviction des innovateurs en AI, pouvant entraîner une fuite des talents de la Silicon Valley vers le Texas ou d’autres régions fiscalement plus attractives (Source : Yuchenj_UW)
Applications AI pour trouver un “père de substitution” : les limites éthiques de la compensation émotionnelle : Sur Reddit, un utilisateur cherche une application AI capable de simuler un rôle paternel pour compenser un traumatisme d’enfance, suscitant une discussion profonde sur la substitution émotionnelle par l’AI. Bien que l’AI puisse offrir un réconfort psychologique sûr, elle soulève des inquiétudes sur la dépendance à long terme et l’isolement social. Cela illustre le potentiel inexploité mais très controversé de l’AI dans la santé mentale et le soutien émotionnel (Source : Reddit)
LLM local + recherche Web : le moment “Wow” des utilisateurs ordinaires : Un utilisateur Reddit a partagé son expérience d’ajout de capacités de recherche Web à des modèles locaux comme Qwen3 via des plugins LM Studio. Cet appel d’outil “concret” permet aux utilisateurs ordinaires de ressentir la puissance de l’Agentic AI tout en préservant la confidentialité du fonctionnement local. Cela laisse présager que les petits modèles locaux aux fonctionnalités enrichies deviendront la norme des applications AI personnelles en 2026 (Source : Reddit)
💡 Autres
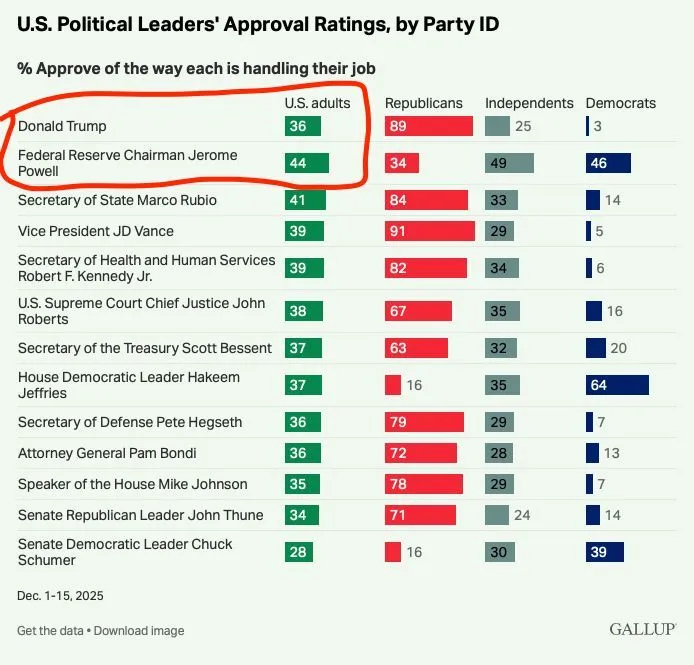
Crise de l’indépendance de la Fed : les leaders de la tech soutiennent collectivement Powell : Plusieurs leaders de l’AI, dont Yann LeCun et Jeff Dean, ont partagé et discuté la vidéo de Powell sur l’indépendance de la Réserve fédérale. Face aux rumeurs de pressions politiques et de menaces pénales, le monde de la tech s’accorde à dire qu’une politique monétaire indépendante est une composante essentielle de l’intelligence sociétale américaine. Cet intérêt transdisciplinaire reflète l’inquiétude profonde des élites technologiques quant au lien entre stabilité institutionnelle macroéconomique et environnement d’innovation (Source : ylecun, zachtratar)
Mingyang Smart lance la première pale d’éolienne en fibre de carbone recyclable au monde : Cette percée résout le problème de longue date du traitement des pales usagées dans l’industrie éolienne. Dans le contexte de la transition énergétique pilotée par l’AI, la durabilité du matériel et la capacité de recyclage en boucle fermée deviennent des indicateurs clés de la valeur technologique verte. Cela démontre également les progrès rapides de la science des matériaux assistée par l’AI (Source : teortaxesTex)

Évolution des coûts de stockage sur 45 ans : de 438 000 $ à 0,01 $ : Jeff Dean a partagé des données montrant que le coût moyen d’un Go de stockage est passé de 438 000 $ il y a 45 ans à seulement 0,01 $ aujourd’hui. Cette baisse exponentielle des coûts est la base physique permettant à l’AI de traiter des masses de données colossales et d’être déployée à grande échelle. Cela nous rappelle que la vague actuelle de l’AI est l’explosion inévitable résultant de décennies de déflation matérielle accumulée (Source : JeffDean)