
Keywords:AI, Hong Kong stock listing, commercial value, MiniMax and Zhipu AI, China’s AI dual champions, data flywheel
🔥 Focus
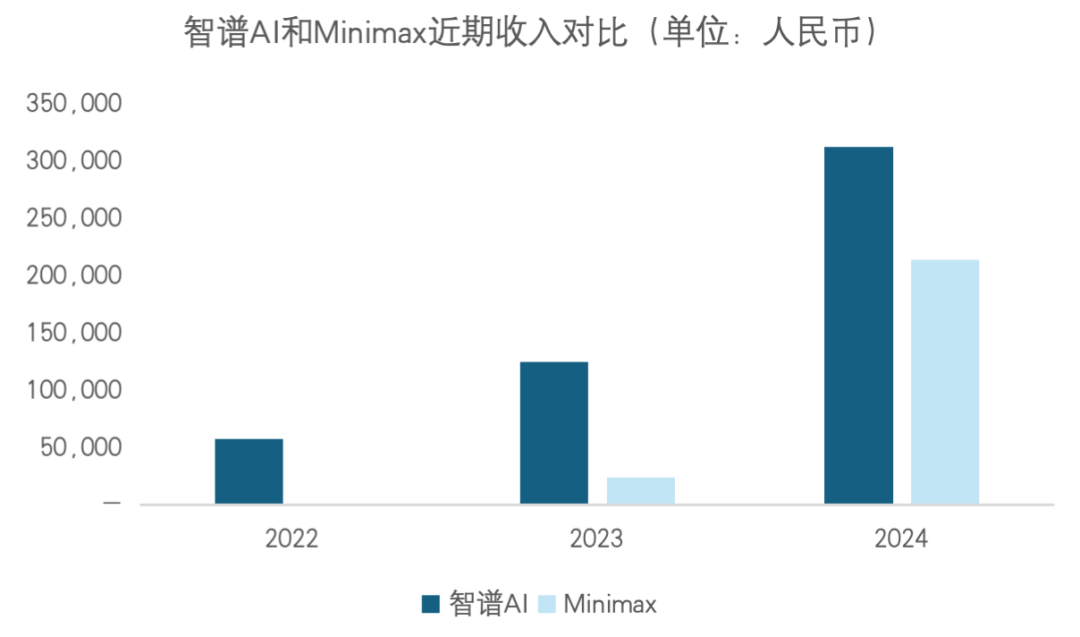
MiniMax and Zhipu AI List in Hong Kong: Differentiated Breakthrough Paths for China’s AI Duo: Zhipu AI and MiniMax have successively listed on the Hong Kong Stock Exchange, with market capitalizations both exceeding the 100-billion-yuan level, showcasing two distinct commercial logics. MiniMax follows an “aggressive” route driven by the C-end, achieving great success in overseas markets with emotional products like Talkie and Xingye, with over 70% of revenue coming from overseas membership fees. In contrast, Zhipu AI is a typical “academic” player, originating from Tsinghua University and focusing on the B-end/G-end route, with over 80% of its revenue derived from local private deployments. The convergence of the two marks a critical stage for domestic AI, shifting from a “burn-rate race” to “realizing commercial value,” where the conversion efficiency of the data flywheel will become the core of future competition (Source: ZhihuFrontier, 36Kr)
CES 2026 Hardware Trends: AI Shifts from “Capability Showcase” to “Physical Implementation”: This year’s CES clearly presented three evolution trends in AI hardware: first, Physical AI and Embodied AI are moving to the main stage, with Atlas robots entering factories marking AI’s start in solving real-world environmental problems; second, on-device AI capabilities are being enhanced, with cross-device synergy becoming the watershed for user experience; finally, the materialization of hyper-personalized services, where AI shifts from passive response to proactive understanding of user health and emotions. AI is no longer isolated software but serves as a “brain” tucked into everyday objects like building blocks, kitchen knives, and rings, changing human-computer interaction in an unobtrusive way (Source: 36Kr, Kling_ai)

Aleph Agent Refreshes Mathematics Benchmark: GPT-5.2 Achieves 99.4% Accuracy on PutnamBench: Driven by OpenAI GPT-5.2, Aleph Agent achieved a staggering score of 668/672 on PutnamBench, currently the most difficult formal mathematics benchmark. The agent demonstrated extremely high efficiency, identifying formal errors in the tests and achieving near-hallucination-free natural language code generation. This breakthrough means AI is approaching top-tier human levels in handling high-difficulty formal logic and mathematical reasoning, which will greatly promote the development of automated scientific discovery and complex system verification (Source: ylecun, markchen90)

Sakana AI Releases DroPE: Position Encoding Viewed as “Training Wheels” That Can Be Discarded: Sakana AI’s research challenges traditional assumptions of the Transformer architecture, finding that position encodings like RoPE are crucial for convergence in the early stages of training but later become a bottleneck for long-text generalization. By discarding position encoding after pre-training and performing minimal recalibration (the DroPE method), massive context windows can be unlocked at extremely low computational costs. This discovery suggests that the text distribution itself has already encoded sufficient positional information, and removing artificial “training wheels” can instead release the model’s potential to handle ultra-long sequences (Source: hardmaru, SakanaAILabs, machinelearning)

🎯 Trends
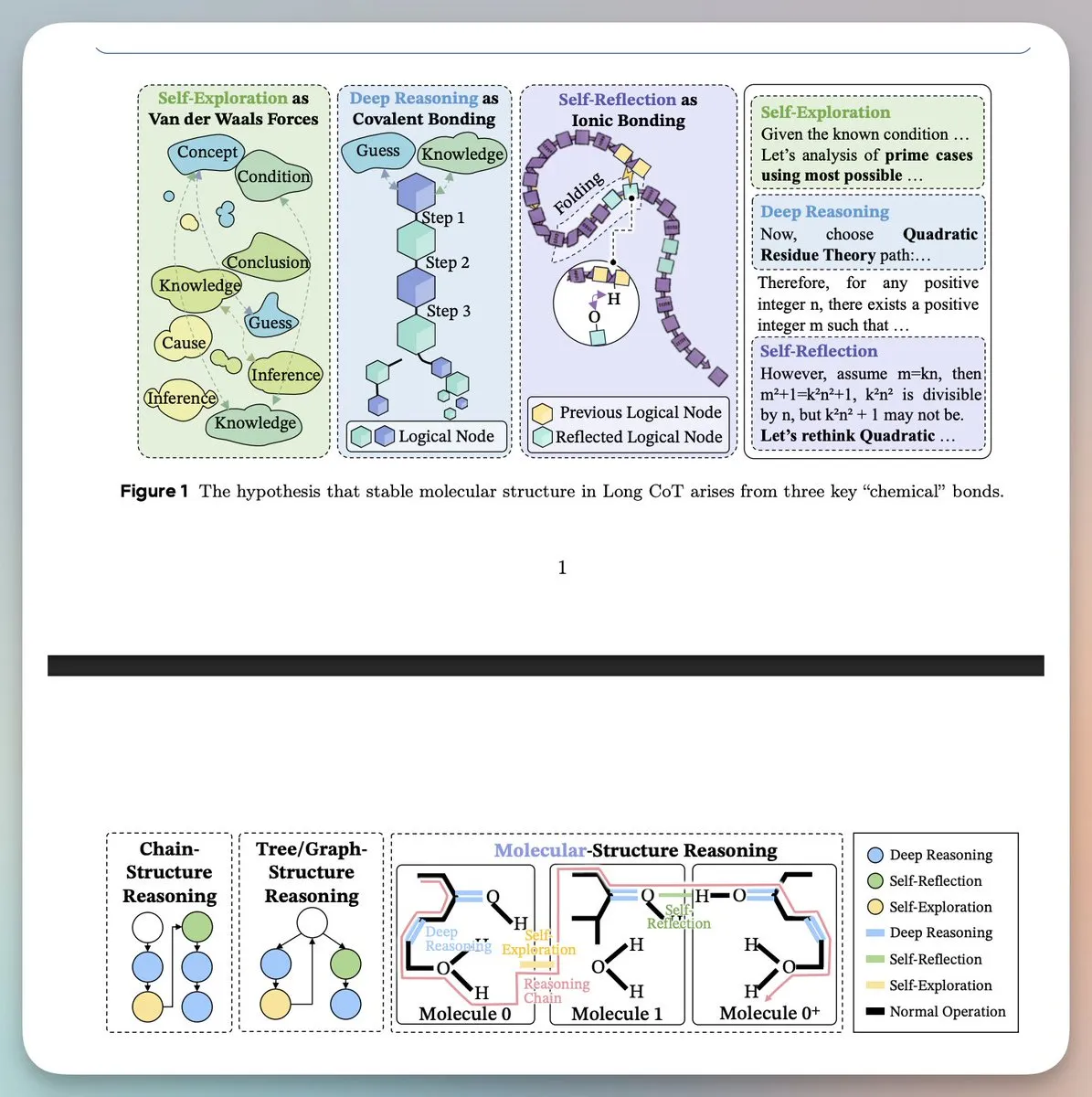
Molecular Structure of Thought: ByteDance Seed Team Reveals Long CoT Reasoning Topology: Research proposes that effective Long Chain of Thought (Long CoT) reasoning possesses a stable structure similar to molecules, composed of three interactions: deep reasoning (covalent bonds), self-reflection (hydrogen bonds), and self-exploration (Van der Waals forces). Experiments prove that models learn this underlying logical topology rather than keyword imitation. By guiding the synthesis of these structures through the Mole-Syn method, the stability and reasoning performance of models in reinforcement learning can be significantly improved. This interdisciplinary perspective provides a brand-new physical model for understanding how LLMs “think” (Source: GeZhang86038849, HuggingFace)
Qwen3-VL Unified Framework: Achieving SOTA Performance in Multimodal Retrieval and Ranking: Alibaba released the Qwen3-VL-Embedding and Reranker series models, supporting unified vector mapping for text, images, videos, and document images. The model ranks first on the MMEB-V2 leaderboard, supporting inputs up to 32k tokens and flexible dimension scaling (Matryoshka learning). This progress solves the challenge of cross-modal semantic alignment in multimodal search, providing powerful infrastructure for building high-precision visual search and RAG systems (Source: HuggingFace)
Google Research Points to LLM Inference Bottlenecks: Memory and Network, Not Compute: A new Google paper analyzes that current LLM inference is limited by memory bandwidth and interconnect latency. Since the Decode stage requires continuous reading of the KV cache, existing hardware optimized for training is inefficient during inference. The study suggests shifting toward High Bandwidth Flash (HBF) and near-memory processing architectures, and promoting low-latency interconnects to reduce inference costs and improve response speeds. This indicates that future AI hardware design will shift from a “compute race” to “storage and transmission optimization” (Source: algo_diver)

Agentic Memory (AgeMem): Integrating Memory Management into Agent Strategies: Addressing the disconnect between long-term and short-term memory in current agents, new research proposes the AgeMem framework, which treats operations like storage, retrieval, summarization, and forgetting directly as tool-based actions. Through a three-stage reinforcement learning strategy, agents learn to autonomously manage context based on task requirements. In long-range task benchmarks, AgeMem improved performance by 13%-21% compared to traditional methods, giving agents cognitive memory management capabilities closer to those of humans (Source: omarsar0)

MiniMax M2.1 Introduces Interleaved Thinking: Enhancing Agent Debugging and Reasoning Visibility: MiniMax M2.1 supports “Interleaved Thinking” between tool calls, allowing developers to capture the agent’s reasoning traces between actions. By analyzing these traces, failure modes such as goal abandonment, circular reasoning, or context degradation can be identified, thereby automatically optimizing system prompts. This “white-box” reasoning process provides technical support for agents to shift from “output evaluation” to “process evaluation” (Source: MiniMax_AI)
Grok Visual Generation Upgrade: Supporting Mainstream Aspect Ratios Amid Regulatory Challenges: xAI announced that Grok Imagine now supports five mainstream image and video aspect ratios. Meanwhile, Grok has been blocked in Indonesia and Malaysia due to sensitive content generated by its “digital undressing” feature. This reflects the intense conflict between generative AI’s pursuit of functional diversification and its response to global content regulation and ethical constraints (Source: chaitu, Reddit)
Lumos Launches “Kung Fu Mode” Humanoid Robot: A Breakthrough in Embodied AI Motion: Lumos demonstrated the “Kung Fu Mode” of its child-sized humanoid robot, capable of performing stunning stunts. This marks significant progress for Embodied AI in complex dynamics control and real-time motion planning. The maturity of such technology will drive robots to evolve from simple handling tasks toward more flexible and interactive home companionship scenarios (Source: Ronald_vanLoon)
Kling 2.6 Motion Control Upgrade: Single Image-to-Video Achieving Viral Spread: Kuaishou’s Kling 2.6 has strengthened its Motion Control feature, enabling the transformation of a single photo into highly dynamic dance videos. Community feedback shows the Motion Brush effect is amazing, achieving precise local motion control. Kling is building an AI-centered creative content ecosystem by lowering the threshold for high-quality video generation (Source: Kling_ai, Minhaa)
🧰 Tools
ChatDev 2.0 (DevAll): Zero-Code Multi-Agent Orchestration Platform Released: ChatDev has evolved from a virtual software company into a comprehensive agent orchestration platform. DevAll allows users to define agents, workflows, and tasks through simple YAML configurations, handling complex scenarios like data visualization, 3D generation, and deep research without coding. It introduces a central orchestrator optimized by reinforcement learning, capable of dynamically activating and serializing agents, significantly improving the efficiency and adaptability of multi-agent collaboration (Source: GitHub)
Claude-Flow v2.7: Enterprise-Grade Agent Platform Integrated with AgentDB: The platform integrates AgentDB v1.3.9, increasing vector search speed by 96-164 times. It supports swarm intelligence, persistent memory, and over 100 MCP tools, featuring 25 skills activated by natural language. Through HNSW indexing and quantization techniques, Claude-Flow achieves millisecond-level semantic retrieval while significantly reducing memory footprint, making it one of the most advanced Claude agent orchestration frameworks currently available (Source: GitHub)
Eva-4B: Professional Financial Evasion Detection Model Based on Qwen3: Eva-4B is a specially designed 4B parameter model used to identify “evasive answers” from executives during corporate earnings calls. In manual annotation tests of 1,000 samples, its accuracy reached 81.3%, surpassing GPT-5.2. This model demonstrates the huge potential of small specialized models against giant general-purpose models in specific vertical fields such as financial auditing (Source: Reddit)

Nanocode: A Minimalist Implementation of Claude Code: A developer released Nanocode, which consists of only about 250 lines of Python code and implements a complete agent loop. It does not rely on external libraries and supports core tools like read/write, edit, and Bash. This minimalist implementation proves that with proper prompt design, Claude’s powerful capabilities can be leveraged to quickly build a fully functional automated programming assistant (Source: imjaredz)
Agentboard: A Web Wrapper Optimizing AI Agent TUI: This is a fast tmux-based web wrapper specifically optimized for multiplexing AI agent Terminal User Interfaces (TUI). It particularly supports iOS Safari and Mac shortcuts, allowing developers to monitor and operate Claude or other coding agents more conveniently on mobile devices, solving the pain points of using traditional terminal tools on phones (Source: andersonbcdefg)
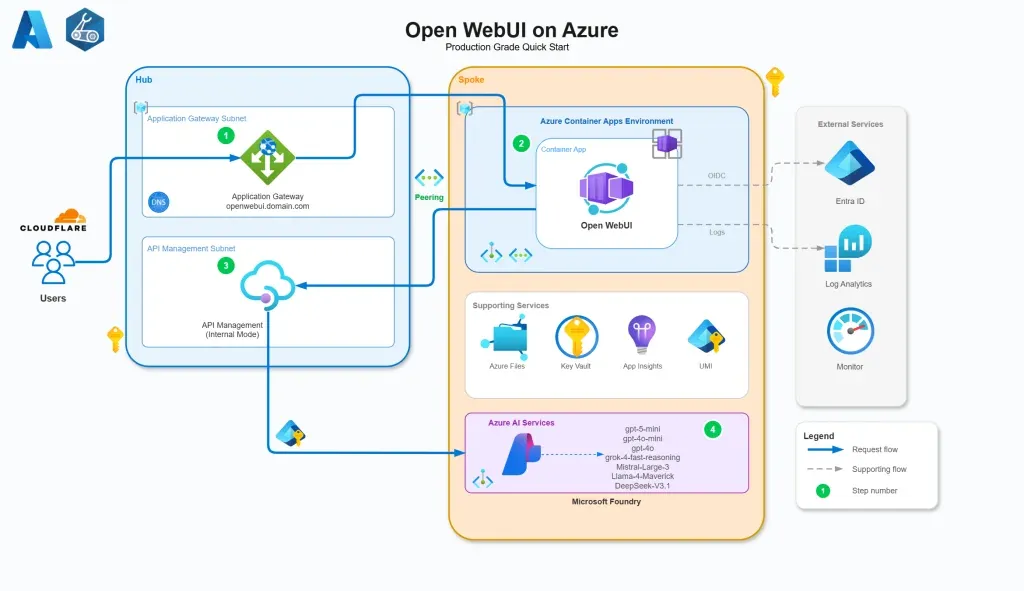
Open WebUI on Azure: Enterprise-Grade AI Gateway Deployment Solution: The community shared a complete architecture for deploying Open WebUI on Azure. The solution utilizes Azure APIM as an AI gateway, covering configuration, policies, authentication flows, and custom LLM metric monitoring. This provides a standardized practical guide for enterprises to build secure and scalable private AI interaction interfaces in the cloud (Source: Reddit)
📚 Learning
ProfTomYeh Visualized Tutorials: Introduction to RAG and Multi-Agent Systems: Renowned educator Tom Yeh shared his hand-drawn style AI tutorial series, covering RAG, vector databases, agents, and multi-agent collaboration. Through intuitive diagrams, he transforms complex algorithmic logic into easy-to-understand visual flows, making it an excellent resource for AI beginners and developers to quickly build system architecture awareness (Source: ProfTomYeh)
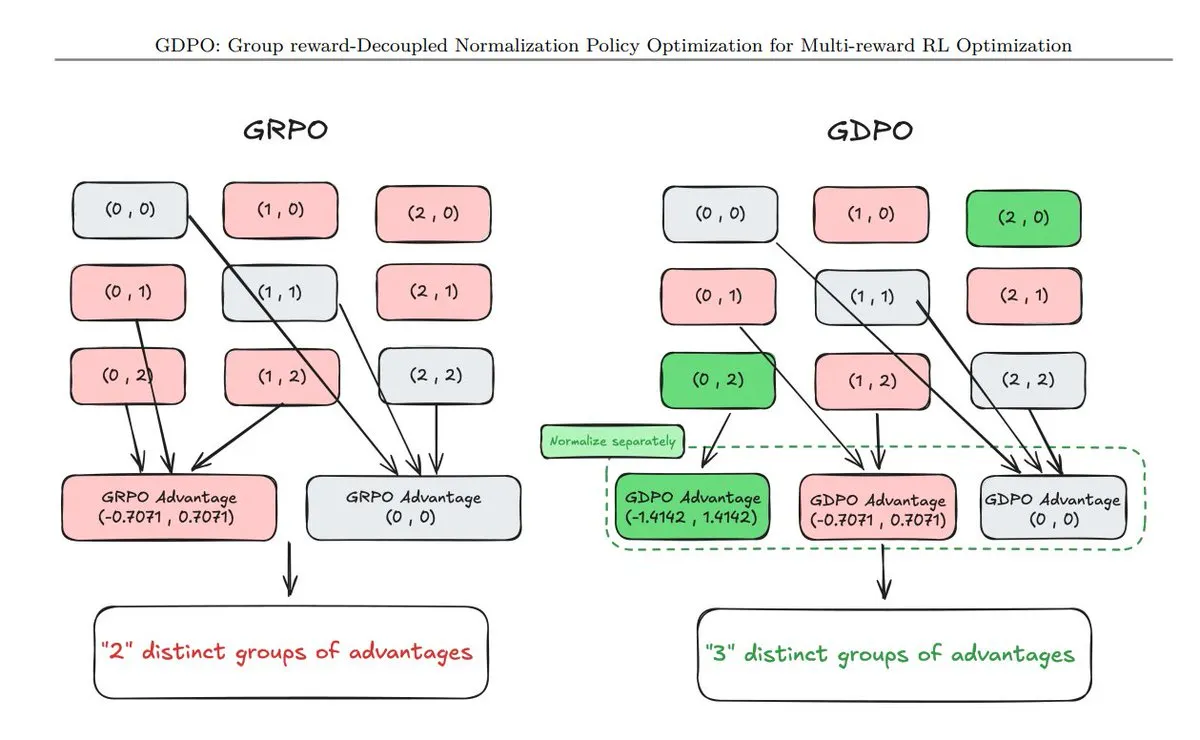
Checklist of 11 New Policy Optimization (PO) Techniques: The community summarized the latest policy optimization techniques, including GDPO (Decoupled Normalization), AT²PO (Agent Turn-based PO based on tree search), and PC-GRPO (Puzzle Curriculum GRPO). These techniques focus on improving agent performance in complex decision-making, tool usage, and self-evolution, representing the frontier of reinforcement learning in the agent field (Source: TheTuringPost)
LLM Fine-Tuning Technology Path: From LoRA to GRPO: A developer compiled 15 fine-tuning techniques essential for customizing LLMs, ranging from basic LoRA/QLoRA and instruction fine-tuning to advanced RLHF, DPO, and GRPO, which is currently gaining significant attention in reasoning models. This list provides a clear learning roadmap for developers wanting to delve into model alignment and reasoning capability enhancement (Source: algo_diver)
ICLR 2026 Recursive Self-Improvement (RSI) Workshop Call for Papers: The workshop aims to explore how AI systems recursively improve themselves, covering theory, algorithms, systems, and evaluation. Invited guests include top scholars from Stanford, CMU, and DeepMind. Recursive self-improvement is seen as one of the core paths to AGI, and this meeting will focus on how models achieve continuous capability leaps through self-play and feedback loops (Source: SchmidhuberAI)

Must-Read Booklist for Machine Learning and Dynamical Systems: For graduate students and researchers, the community recommended a series of classic works on Neural ODEs/PDEs, PINNs, and the application of machine learning in dynamical system modeling. The list includes not only general ML classics like Bishop’s but also advanced monographs at the intersection of applied mathematics and deep learning, serving as a guide to building a solid theoretical foundation (Source: Reddit)
💼 Business
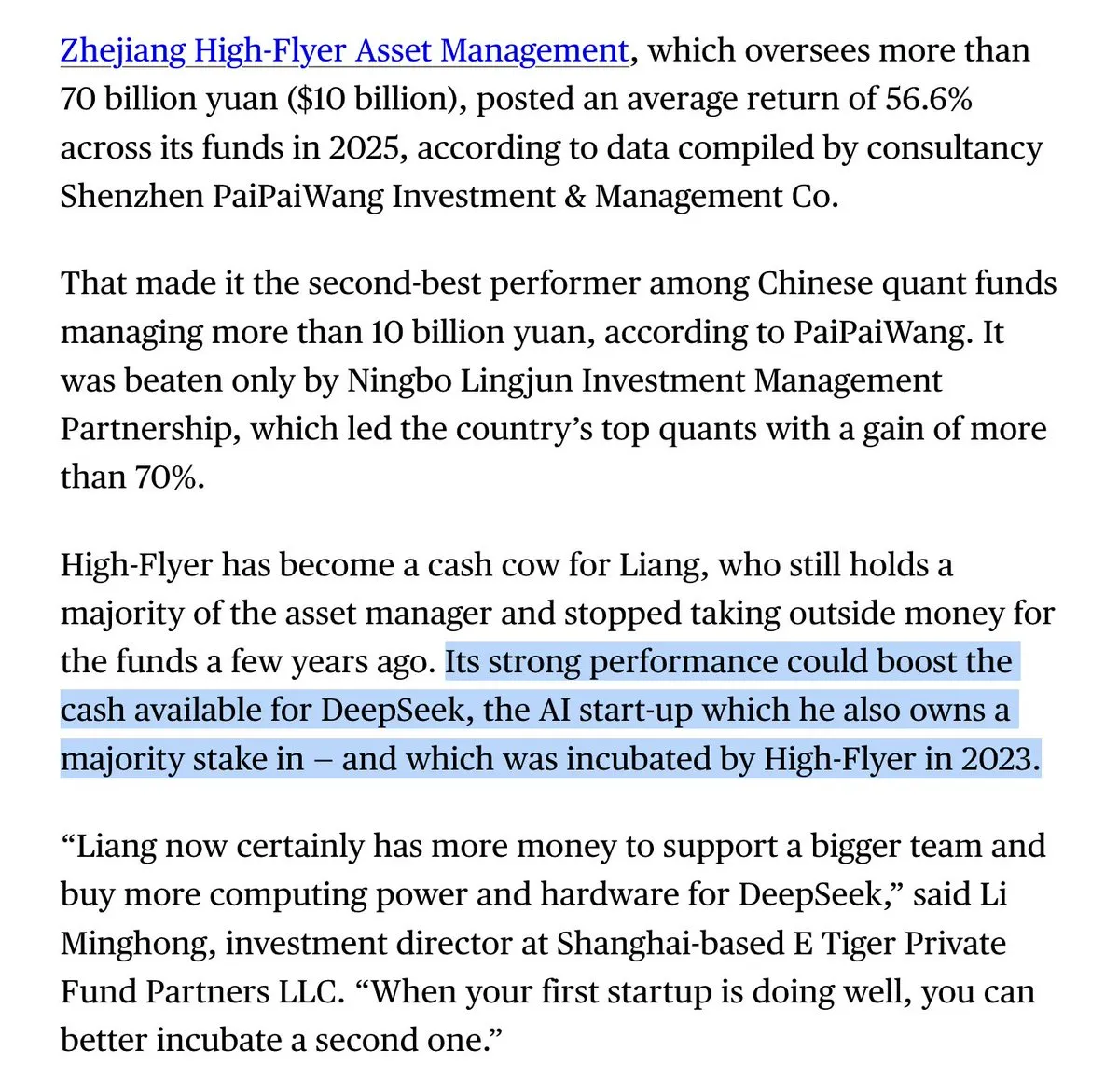
DeepSeek Founder Liang Wenfeng’s Hedge Fund Returns Over 50% Last Year: Bloomberg reported that High-Flyer Quant, the quantitative hedge fund founded by Liang Wenfeng, achieved returns exceeding 50% last year. This massive profit provides DeepSeek with the capability for continuous compute investment without relying on external financing. This “quant-funding-AI” model allows DeepSeek to maintain unique independence and extremely high ROI in the global AI race (Source: teortaxesTex)
Market Performance Differences Between Zhipu AI and MiniMax Post-IPO: MiniMax’s market value growth and valuation multiples on its first day of listing were significantly higher than Zhipu AI’s. Analysts believe the capital market prefers MiniMax’s C-end global platform story (Talkie has 200 million global users), viewing its growth elasticity as greater. Zhipu AI focuses on B-end/G-end infrastructure; while technically solid with stable revenue, its valuation is more cautious due to longer sales cycles and policy sensitivity (Source: ZhihuFrontier)
Runway and Synthesia: Valuation and Expansion in the Video Generation Field: Synthesia recently raised $200 million in a funding round, reaching a valuation of $4 billion with ARR exceeding $100 million. Meanwhile, Runway is hiring art directors and creative developers on a large scale. This indicates that AI video generation has entered a stage of shifting from “technical breakthrough” to “industrial production,” with companies consolidating market positions by building complete creative workflows (Source: synthesiaIO, kylebrussell)
🌟 Community
AI Programming Tool War: Claude Code Blocking OpenCode Sparks Heated Discussion: The community discussed Anthropic’s blocking of OpenCode. Some argue that OpenCode’s experience has been poor since the split and could damage the reputation of Claude models. Claude Code is considered to have more potential due to its deep integration with Bash and “skill” evolution capabilities. Developers are beginning to realize that the quality of agent tools depends not only on the underlying model but also on the degree of engineering integration with the development environment (Source: qnguyen3, dotey)
The Boundary Between “Mediocre” and “Powerful” AI: Is Prompt Engineering Still a Core Skill?: The community is debating why the same model produces vastly different results for different people. One view is that most people use AI like Google, resulting in generic outputs; experts, however, guide it as a “senior intern” through clear goals, constraints, and iterative feedback. Prompt engineering is essentially the ability to clearly define problems; in an era where model capabilities are being “reverse flattened,” this structured thinking remains the key to distinguishing ordinary users from super-individuals (Source: Reddit)
LMSYS Leaderboard Observation: Model Dominance Cycle Shortened to 35 Days: Statistics show that since mid-2023, models topping the LLM leaderboard have only maintained their position for an average of 35 days. Models like Claude 3 Opus, which were once a generation ahead, dropped out of the top 100 in just a few months. This rapid iteration means the speed of improvement in basic model capabilities has exceeded the development cycle of most products, posing a risk of the product layer being “reverse flattened” by model capabilities (Source: dotey)
Redis Founder Rebuts “Anti-AI Hype”: The Joy of Programming Still Exists: Antirez published a post urging people not to fall into anti-AI sentiment. He believes that while code writing can be largely automated, understanding “what to do” and “how to do it” has become more interesting. AI is democratizing the ability to build systems, allowing small teams to compete with giants, much like open-source software in the 90s. He emphasized that the core motivation and joy of building things have not been diminished by AI (Source: swyx, aiamblichus)

Reddit Discussion: The Trust Chain Dilemma in AI Medical Diagnosis: Although AI’s performance in certain cancer detections has surpassed that of radiologists, trust remains difficult to establish due to liability issues and human psychological factors. The community believes that when the cost of error is extremely high, people need explainability and clear accountability, not just high scores. AI is currently positioned more as a “supportive task” rather than a decision-maker (Source: Reddit)
California Wealth Tax Sparks Concern: May Drive Out Top AI Founders: The community discussed the impact of California’s wealth tax on founders like Ilya Sutskever, who hold massive unlisted equity. Since taxes cannot be paid with equity, founders may face huge cash pressures. This policy is seen as driving out AI innovators, potentially leading to a drain of Silicon Valley talent to Texas or other more tax-attractive regions (Source: Yuchenj_UW)
AI App for Finding a “Surrogate Father”: Ethical Boundaries of AI Emotional Compensation: A Reddit user seeking an AI app to simulate a father figure to compensate for childhood trauma sparked a deep discussion on AI emotional substitution. While AI can provide safe psychological comfort, it also raises concerns about long-term dependence and social isolation. This demonstrates AI’s untapped but highly controversial potential in mental health and emotional support (Source: Reddit)
Local LLM + Web Search: A “Wow” Moment for Average Users: A Reddit user shared their experience of adding web search capabilities to local models like Qwen3 via LM Studio plugins. This “down-to-earth” tool calling allows average users to feel the power of Agentic AI while retaining the privacy of local operation. This suggests that localized, functionally enhanced small models will become mainstream for personal AI applications in 2026 (Source: Reddit)
💡 Others
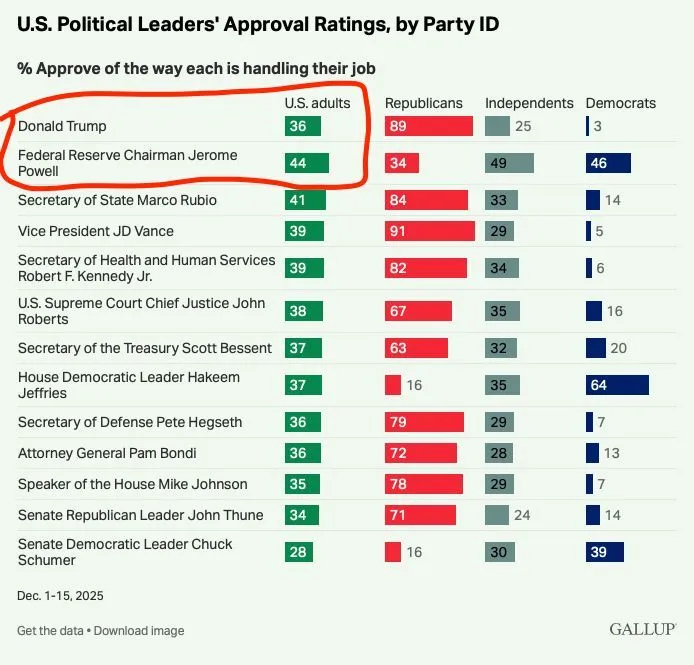
Fed Independence Crisis: Tech Leaders Collectively Speak Out in Support of Powell: Several AI leaders, including Yann LeCun and Jeff Dean, forwarded and discussed a video of Powell regarding the independence of the Federal Reserve. In response to rumors of political pressure or even criminal threats, the tech community generally believes that independent monetary policy is a vital component of American societal intelligence. This cross-sector attention reflects tech elites’ deep concern about the link between macro-institutional stability and the innovation environment (Source: ylecun, zachtratar)
Mingyang Smart Releases World’s First Recyclable Carbon Fiber Wind Turbine Blade: This breakthrough solves the long-standing problem of waste blade disposal in the wind power industry. Against the backdrop of AI-driven energy transition, hardware sustainability and closed-loop recycling capabilities are becoming key indicators of green tech value. This also demonstrates the rapid progress of materials science under AI-assisted design (Source: teortaxesTex)

45-Year Evolution of Storage Costs: From $438,000 to $0.01: Data forwarded by Jeff Dean shows that the average cost of 1GB of storage has plummeted from $438,000 45 years ago to $0.01 today. This exponential cost reduction is the underlying physical foundation that allows AI to process massive amounts of data and achieve large-scale deployment. It reminds us that the current AI wave is an inevitable explosion following decades of cumulative hardware deflation (Source: JeffDean)