
Keywords:Engram module, Cowork, Gemini collaboration, Transformer knowledge retrieval mechanism, AI Agent task execution, TTT-E2E test-time training
🔥 Focus
DeepSeek Releases Engram Module, Achieving Decoupling of Storage and Computation: DeepSeek, in collaboration with Peking University, published a paper introducing “Engram,” a conditional memory module. This technology utilizes modernized Hash N-gram embeddings to provide Transformer models with a native “knowledge lookup” mechanism, achieving approximate O(1) deterministic retrieval. Experiments show that Engram-27B significantly outperforms pure MoE models under strict parameter and computation parity. It not only enhances knowledge reserves but also offloads the “rote memorization” burden from shallow attention layers, allowing deep networks to focus on complex reasoning, leading to a massive leap in coding and mathematical capabilities. This engineering route, which offloads massive parameters to host memory (CPU) with inference overhead below 3%, is considered a core primitive for next-generation sparse large models and is highly likely to be integrated into the upcoming DeepSeek-V4. (Source: GitHub)

Anthropic Launches Strategic Product Cowork, Ushering in the “Digital Colleague” Era: Anthropic officially launched Cowork (Research Preview), encapsulating the underlying capabilities of Claude Code into a graphical tool for non-technical users. Cowork allows Claude to directly access local folders with permissions to read, edit, and create files. It is no longer just a chatbot but an intelligent collaborator capable of autonomous step planning and parallel task processing (e.g., organizing download folders, extracting data from screenshots to generate Excel files, and writing report drafts). The product features a built-in virtual machine isolation environment for security and supports browser automation. The community generally believes this marks a paradigm shift for AI from “content generation” to “task execution,” potentially dealing a disruptive blow to many AI startups. (Source: Anthropic)

Apple and Google Reach Gemini Partnership Agreement, Siri Gains an “External Brain”: Apple and Google released a joint statement confirming that future Apple Foundation Models will be built on Google Gemini models and cloud technology to power the personalized Siri launching later this year. Apple will reportedly pay approximately $1 billion annually. This partnership is viewed as a “transitional concession” by Apple amid delays in its self-developed models. Gemini will handle complex tasks like summarization and planning, while on-device basic functions will still be supported by Apple’s in-house models. This move pushed Google’s market value past $4 trillion for the first time, while also triggering criticism from Elon Musk regarding “excessive concentration of power” and discussions about OpenAI’s potential marginalization within the Apple ecosystem. (Source: Google)

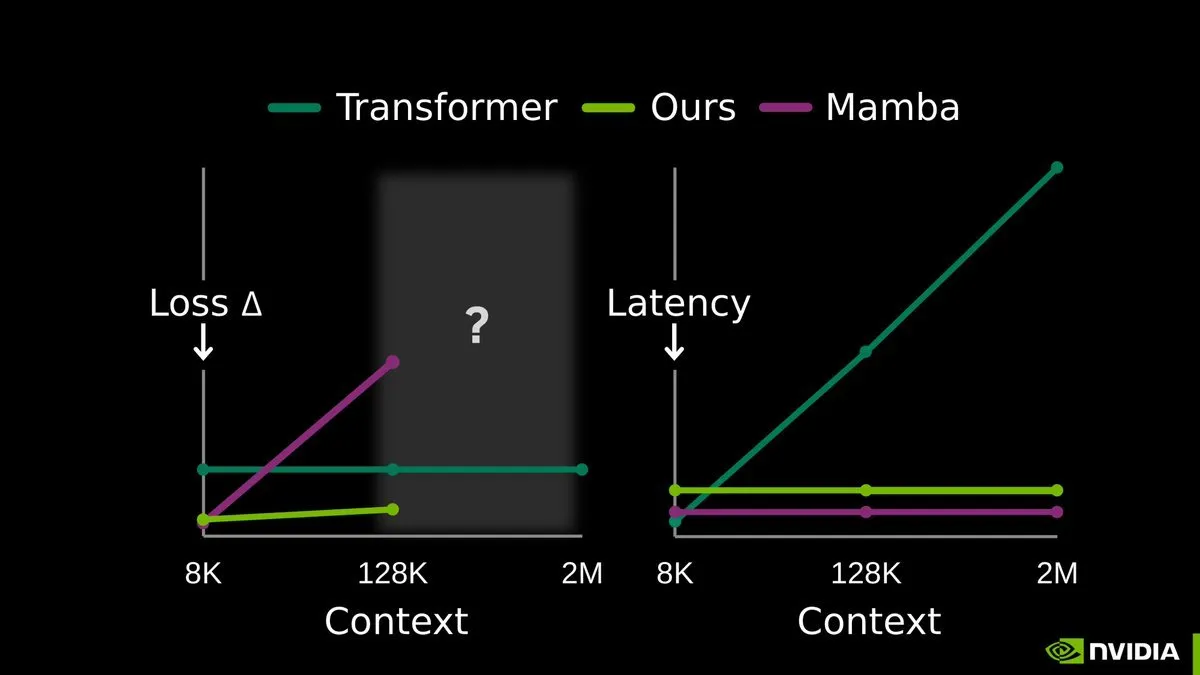
TTT-E2E: End-to-End Test-Time Training Opens a New Era of Long Memory for LLMs: The End-to-End Test-Time Training (TTT-E2E) research, jointly released by NVIDIA, Stanford, and the Astera Institute, has caused a sensation. The technology argues against radical new architectures, instead proposing to use context as training data during the inference phase (test-time) to continuously update model weights via next-token prediction. This approach compresses long-context experiences into model weights, effectively solving the KV cache explosion issue associated with sequence length. TTT makes models true “continuous learners,” demonstrating extreme stability when processing ultra-long sequences of millions of tokens, and is considered the most promising path toward pure sub-quadratic sequence modeling. (Source: arXiv)
🎯 Trends
Sakana AI Introduces DroPE: Dropping Position Embeddings for Long-Text Extrapolation: The team led by Llion Jones, a core author of the Transformer paper, open-sourced DroPE, suggesting that position embeddings are merely “training wheels.” DroPE discards Rotary Position Embeddings (RoPE) during the inference phase and requires less than 1% of the pre-training budget for brief calibration to unlock massive context windows. Experiments show this method significantly outperforms traditional RoPE scaling in LongBench and “Needle In A Haystack” tests, providing a new low-cost approach for extending long-text capabilities. (Source: arXiv)
BabyVision Benchmark: Top Large Models’ Visual Capabilities Fall Short of a 3-Year-Old: The BabyVision evaluation released by Sequoia China xbench and UniPatAI shows that in visual tasks with strictly controlled language dependency, the vast majority of models perform far worse than a 3-year-old child. Even the top-performing Gemini 3 Pro barely passed. The study points out that models’ over-reliance on linguistic reasoning masks their systematic deficiencies in spatial perception, trajectory tracking, and geometric intuition. Future multimodal intelligence must fundamentally rebuild visual capabilities. (Source: 36Kr)

Recursive Language Models (RLM): DeepMind Explores Perfect Memory Without RAG: DeepMind researchers proposed Recursive Language Models (RLM), which allow a model to process millions of tokens by self-introspection, splitting, and recursively calling itself. This mechanism breaks the limitations of traditional context windows; instead of relying on external RAG, the model achieves “perfect memory” of massive information through recursive aggregation of results. This progress suggests a qualitative change in how future AI will handle ultra-long documents. (Source: HuggingFace)

ByteDance’s Global AI Expansion Enters “Efficiency Tool” Phase: ByteDance has recently made intensive moves overseas, launching AnyGen, a workplace Agent targeting Manus, which focuses on high-quality deliverables like document writing and data analysis. Meanwhile, the daily active users of its overseas AI assistant, Dola, have surpassed 10 million. ByteDance is attempting to shift from “outputting happiness” (TikTok) to “selling efficiency,” engaging in close combat with OpenAI and Anthropic in the office Agent track. (Source: 36Kr)

🧰 Tools
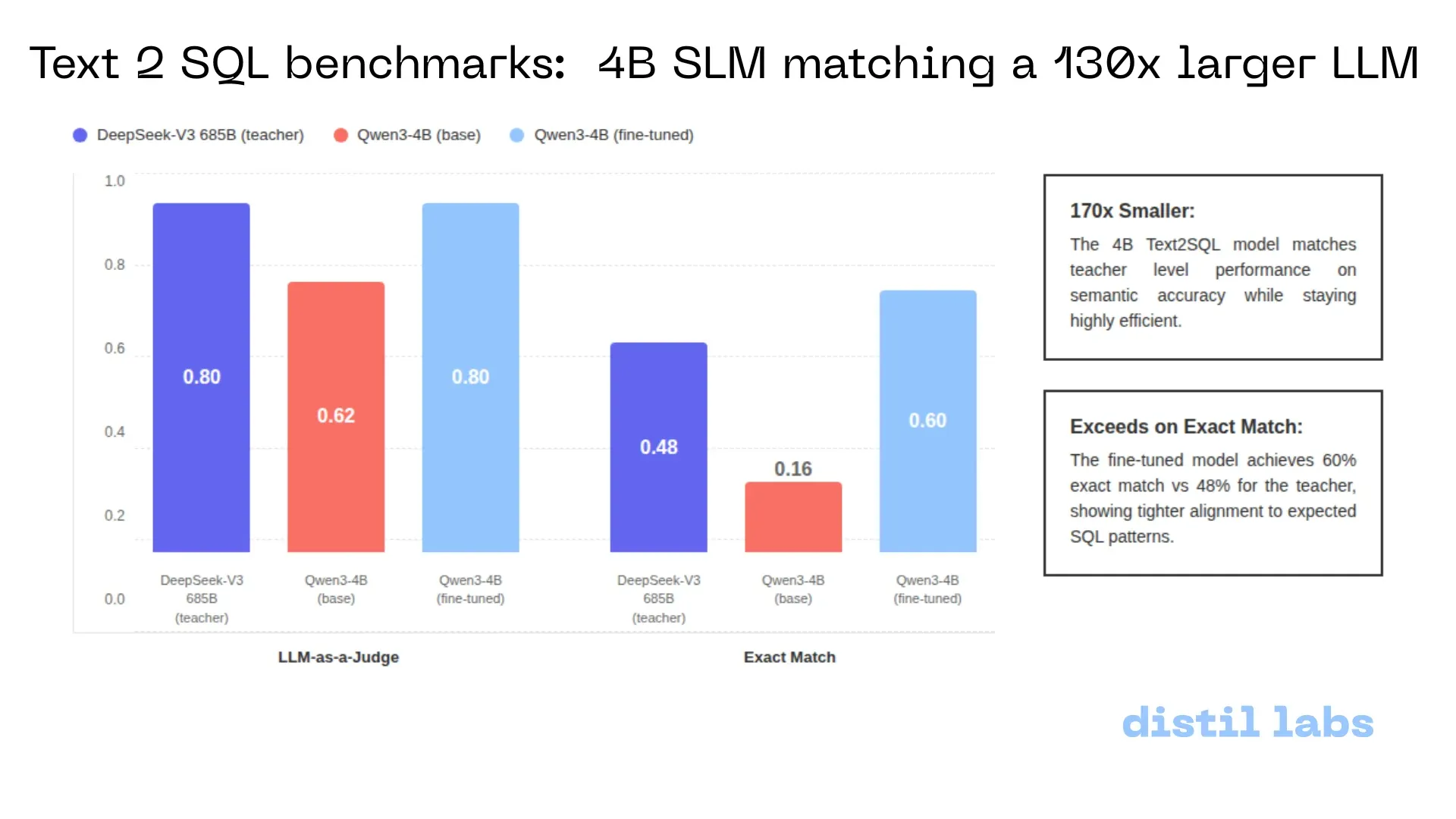
Distil-Text2SQL: 4B Small Model Achieves 685B-Level Accuracy Locally: Distil-labs fine-tuned Qwen3-4B to reach the semantic accuracy of DeepSeek-V3 (685B) on Text2SQL tasks, even surpassing it in “Exact Match” metrics. The model supports local execution, processes CSV data without cloud uploads, and has a response time of under 2 seconds, demonstrating the huge potential of small models to replace ultra-large models in vertical tasks. (Source: GitHub)
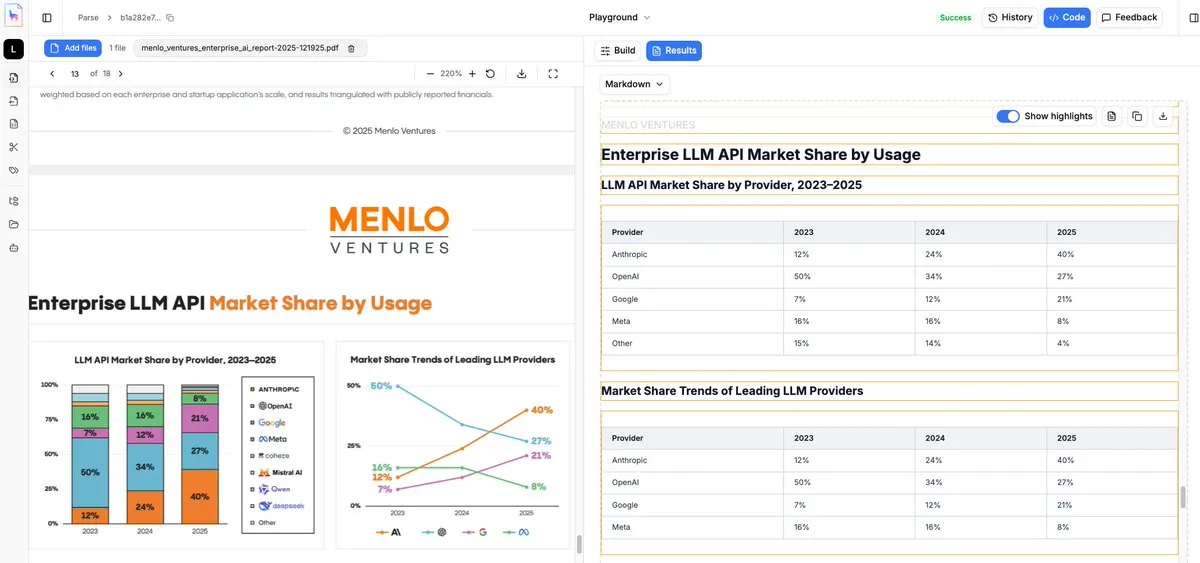
LlamaParse Upgrade: Low-Cost Precise OCR for Charts and Images: LlamaIndex upgraded its parsing tool, LlamaParse, to an Agentic mode, specifically optimized for complex visual elements in documents (e.g., line charts, pie charts, flowcharts). Compared to feeding full-page screenshots directly to a VLM, this tool identifies bounding boxes of sub-elements and extracts numerical logic, converting them into high-quality Markdown. it is currently one of the most cost-effective solutions for handling non-text information in professional documents. (Source: jerryjliu0)
Wobo: An AI Agent-Based “Tinder for Job Seekers”: Wobo is an iOS app that uses AI Agents to automate resume submissions. Users only need to upload their resume once; the AI analyzes their “professional personality” and, when the user “swipes right” on a desired position, automatically navigates complex external official websites, generates personalized cover letters, and answers screening questions. The tool aims to end tedious repetitive form-filling, shortening a 20-minute application process to 2 seconds. (Source: Reddit)
📚 Learning
Stanford CS224N 2026 Returns: New Modules on Agents and Reasoning: The classic Natural Language Processing course CS224N has announced its return. This year’s course is co-taught by Diyi Yang and Yejin Choi. In addition to covering neural network NLP foundations, it will significantly increase focus on AI Agents, tool use, and feature two lectures specifically dedicated to “Reasoning,” keeping pace with the cutting-edge trends of large models. (Source: Stanford)
Andrew Ng Launches “Build with Andrew”: Building Web Apps with Zero Code: Andrew Ng introduced a new course in the latest The Batch newsletter, guiding beginners on how to build and deploy functional web applications using AI tools based solely on natural language descriptions of their ideas. The course emphasizes the “AI as a developer” paradigm, lowering the barrier for ordinary people to enter the software development field. (Source: DeepLearningAI)
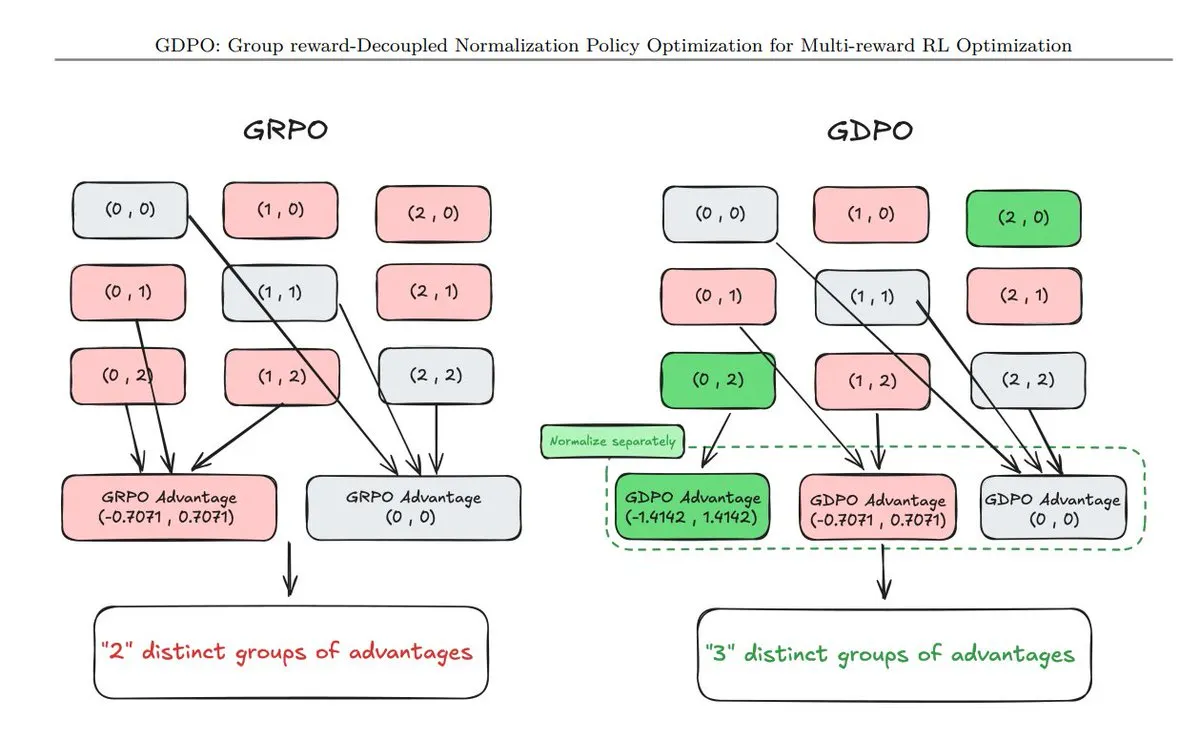
Summary of 11 New Policy Optimization Techniques: TuringPost summarized 11 recently emerged Policy Optimization techniques, including GDPO (Gradients Decoupled Policy Optimization), AT²PO (Agent Turn-based PO based on tree search), and the highly-watched PC-GRPO (Puzzle Curriculum GRPO). These technologies are core to enhancing the logical chains and task alignment capabilities of large models. (Source: TuringPost)
💼 Business
OpenAI Acquires Healthcare Startup Torch: OpenAI announced the acquisition of Torch, a healthcare AI startup that integrates experimental results, drug records, and clinical recordings. The Torch team will join the ChatGPT Health department. This move indicates OpenAI is accelerating the commercialization of AI in health management and clinical assistance, aiming to build ChatGPT into the world’s most professional personal health assistant. (Source: OpenAI)

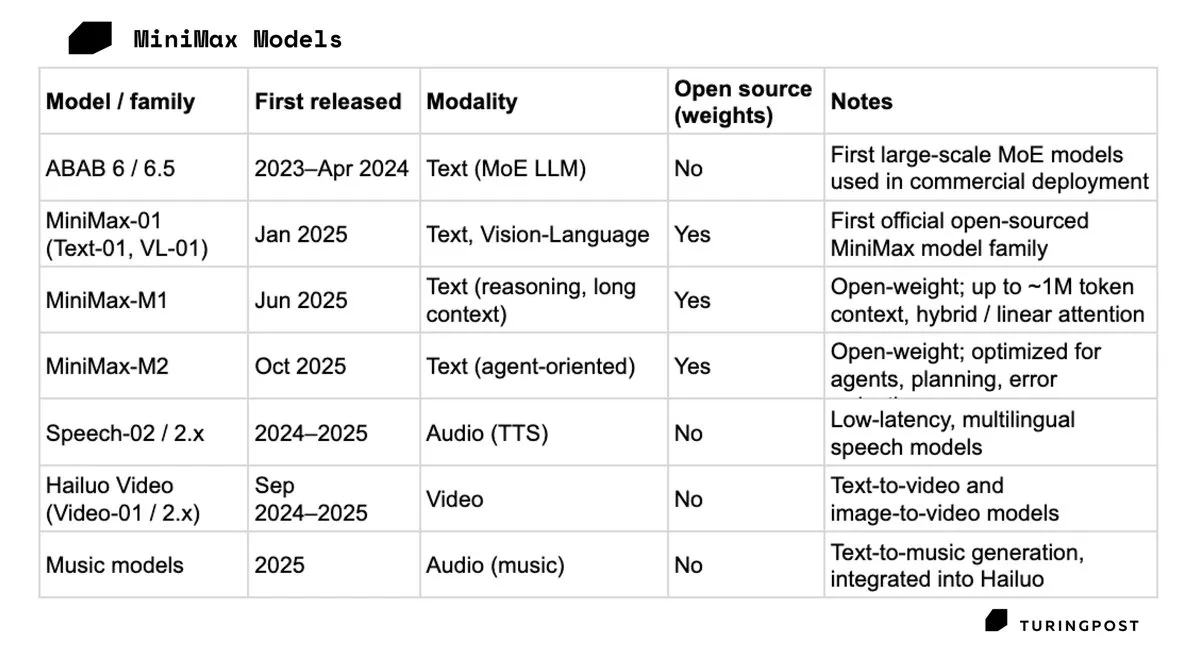
MiniMax Lists in Hong Kong, Surges 109% on First Day: Chinese AI unicorn MiniMax went public in Hong Kong on January 9, 2026, with its stock price soaring 109% on the first day, pushing its market value past HKD 150 billion. With the success of Talkie and HaiLuo AI in the consumer market, MiniMax proved the attractiveness of a path that deepens consumer multimodal products without relying on large enterprise contracts. This IPO is seen as a key step in obtaining “oxygen” in the fierce computing power race. (Source: TuringPost)
xAI Burns $28 Million Daily, Valuation Hits $230 Billion: Despite xAI’s losses reaching $7.8 billion in the first three quarters of 2025, it recently completed a $20 billion funding round at a $230 billion valuation. Elon Musk is fully pushing the “Macrohard” plan, aimed at building autonomous AI systems that can drive Tesla robots. This “brute-force investment” model reflects the extremely high entry barriers for top AI players in terms of infrastructure and talent. (Source: 36Kr)
🌟 Community
Vibe Coding/Working Sparks Discussion on Professional Identity: With the popularity of Claude Cowork and various Agent tools, “Vibe Working” has become a buzzword. The community believes this is not just a simple efficiency boost but “monetizing domain knowledge in the brain.” The value of future engineers will shift from “writing 100,000 lines of code” to “designing systems that let AI write 100,000 lines of code.” However, some worry this will lead to “Slop” (low-quality code) and over-reliance on AI black boxes. (Source: nearcyan, amasad)
AI Detectors Called a “Complete Scam”: The Reddit community launched a fierce attack on AI detection tools like GPTZero, pointing out extremely high false positive rates, even marking the Declaration of Independence as 90% AI-generated. Users argue these tools measure “statistical familiarity” rather than origin, leading to many original creators and students being wrongly accused. The education sector is calling for an end to the “witch hunt” and a shift toward assessing students’ understanding and application of content. (Source: Reddit)
DeepSeek Founder Liang Wenfeng Dubbed the “Hidden Master of AI”: The community is buzzing about DeepSeek founder Liang Wenfeng’s quantitative fund background. His High-Flyer Quant achieved a return of 56.6% in 2025, far exceeding the industry average. Netizens marveled at his “YOLO-style” investment of quant profits into AI and his unconventional technical routes (e.g., MLA, Engram), demonstrating high architectural taste and engineering efficiency. He is seen as a key variable for Chinese AI against Silicon Valley giants. (Source: teortaxesTex)
💡 Others
AI Earphone “Sweetpea” May Launch in September: Rumors suggest OpenAI’s first hardware product—codenamed Sweetpea—is being designed by Jony Ive’s team. Resembling a metallic pebble, it features a built-in 2nm chip to support local inference. OpenAI estimates first-year sales will target 50 million units, directly challenging the market position of AirPods. (Source: 36Kr)

AI Security Becomes the New Standard for Enterprise Selection in 2026: As AI Agent permissions expand, enterprise focus on security has shifted from “optional” to a “precondition.” A survey shows that 43% of enterprises view security as the primary obstacle to AI implementation. The trend for 2026 is “built-in” security, where auditing and permission isolation are enabled by default during model calls and Agent orchestration. (Source: 36Kr)