
Anahtar Kelimeler:Engram Modülü, Cowork, Gemini İşbirliği, Transformer bilgi arama mekanizması, AI Agent görev yürütme, TTT-E2E test sırasında eğitim
🔥 Odak Noktası
DeepSeek, depolama ve hesaplamayı birbirinden ayıran Engram modülünü yayınladı: DeepSeek, Pekin Üniversitesi ile ortaklaşa yayınladığı makalede “koşullu bellek” modülü Engram’ı tanıttı. Bu teknoloji, modern Hash N-gram embedding aracılığıyla Transformer modellerine yerel bir “bilgi arama” mekanizması kazandırarak O(1) değerine yakın deterministik erişim sağlıyor. Deneyler, Engram-27B’nin eşit parametre ve hesaplama gücü altında saf MoE modellerinden önemli ölçüde daha iyi performans gösterdiğini ortaya koydu. Bilgi birikimini artırmasının yanı sıra, sığ katmanlardaki “ezberleme” yükünü hafifleterek derin ağların karmaşık muhakemeye odaklanmasını sağlıyor; bu da kodlama ve matematik yeteneklerinde büyük bir sıçrama yaratıyor. Devasa parametrelerin ana belleğe (CPU) aktarıldığı ve çıkarım kaybının %3’ün altında olduğu bu mühendislik rotası, yeni nesil seyrek büyük modellerin temel yapı taşı olarak görülüyor ve yakında çıkacak olan DeepSeek-V4’e entegre edilmesi bekleniyor (Kaynak: GitHub)

Anthropic, “dijital meslektaş” çağını başlatan stratejik ürünü Cowork’ü duyurdu: Anthropic, Claude Code’un temel yeteneklerini teknik olmayan kullanıcılar için grafiksel bir araca dönüştüren Cowork’ü (araştırma önizlemesi) resmi olarak başlattı. Cowork, Claude’un yerel klasörlere doğrudan erişmesine; dosyaları okuma, düzenleme ve oluşturma yetkisine sahip olmasına olanak tanıyor. Artık sadece bir sohbet robotu değil; adımları otonom olarak planlayabilen, görevleri paralel olarak işleyebilen (indirilenler klasörünü düzenlemek, ekran görüntülerinden veri çıkarıp Excel oluşturmak, rapor taslakları yazmak gibi) akıllı bir iş birliği ortağıdır. Ürün, güvenliği sağlamak için yerleşik sanal makine (VM) izolasyon ortamına sahip ve tarayıcı otomasyonunu destekliyor. Topluluk, bunun AI’nın “içerik üretimi”nden “görev yürütme”ye geçişini simgelediğini ve birçok AI girişimi için yıkıcı bir rekabet yaratabileceğini düşünüyor (Kaynak: Anthropic)

Apple ve Google, Gemini iş birliği anlaşmasına vardı; Siri “dış beyne” kavuşuyor: Apple ve Google, gelecekteki Apple Foundation Models’ın, bu yılın sonlarında sunulacak kişiselleştirilmiş Siri’yi güçlendirmek için Google Gemini modelleri ve bulut teknolojisi üzerine inşa edileceğini doğrulayan ortak bir bildiri yayınladı. Apple’ın yıllık yaklaşık 1 milyar dolar ödeyeceği belirtiliyor. Bu iş birliği, Apple’ın kendi modellerindeki gecikmeler nedeniyle attığı “geçici bir geri adım” olarak görülüyor; Gemini özetleme ve planlama gibi karmaşık görevleri üstlenirken, cihaz üzerindeki temel işlevler Apple’ın kendi modelleri tarafından desteklenmeye devam edecek. Bu hamle Google’ın piyasa değerinin ilk kez 4 trilyon doları aşmasını sağlarken, Elon Musk’ın “aşırı güç konsantrasyonu” eleştirilerine ve OpenAI’ın Apple ekosistemindeki konumunun marjinalleşmesine dair tartışmalara yol açtı (Kaynak: Google)

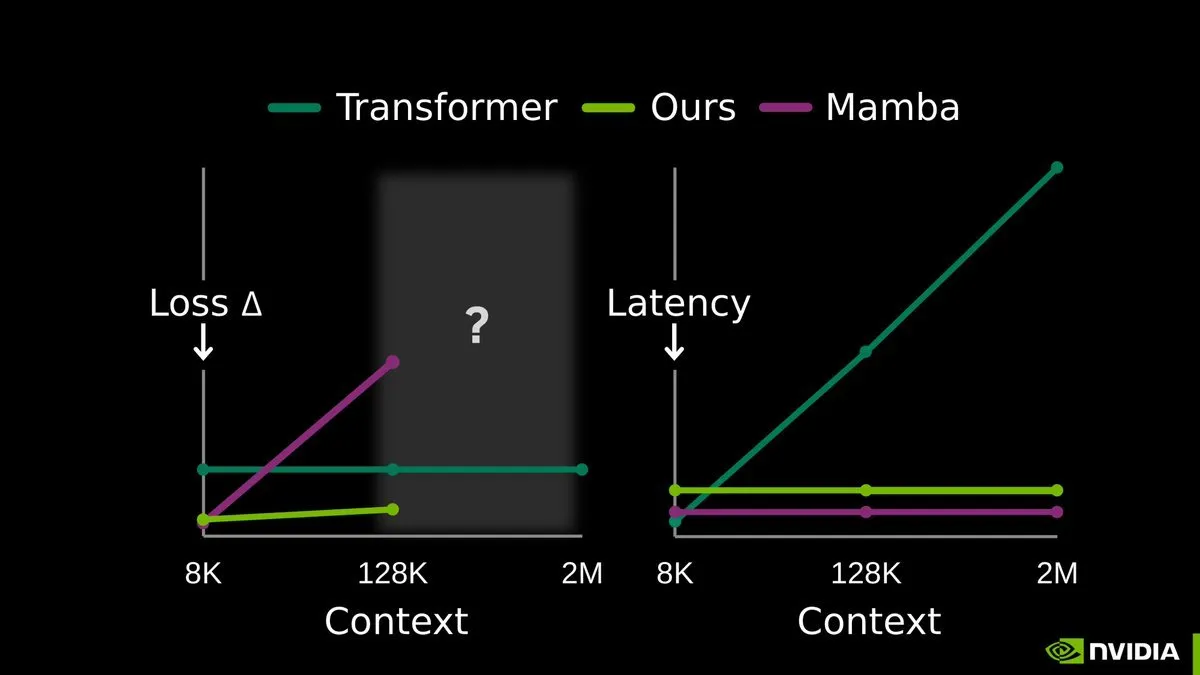
TTT-E2E: Uçtan uca test süresi eğitimi, LLM uzun bellek dönemini başlatıyor: NVIDIA, Stanford ve Astera Enstitüsü tarafından ortaklaşa yayınlanan End-to-End Test-Time Training (TTT-E2E) araştırması büyük yankı uyandırdı. Bu teknoloji, radikal yeni mimarilere ihtiyaç duymadan, çıkarım aşamasında (test süresinde) bağlamı eğitim verisi olarak kullanarak ve Next Token Prediction yoluyla model ağırlıklarını sürekli güncelleyerek çalışıyor. Bu yöntem, uzun bağlam deneyimini model ağırlıklarına sıkıştırarak KV cache’in dizi uzunluğuyla birlikte patlaması sorununu etkili bir şekilde çözüyor. TTT, modeli gerçek bir “sürekli öğrenen” haline getiriyor ve milyonlarca Token içeren ultra uzun dizileri işlerken olağanüstü kararlılık gösteriyor; bu da saf alt-ikinci dereceden (sub-quadratic) dizi modellemeye giden en umut verici yol olarak kabul ediliyor (Kaynak: arXiv)
🎯 Eğilimler
Sakana AI, DroPE’u tanıttı: Pozisyonel gömmeleri bırakarak uzun metin ekstrapolasyonu: Transformer’ın ana yazarlarından Llion Jones’un ekibi, pozisyonel gömmelerin (Position Embeddings) sadece eğitimin “yardımcı tekerlekleri” olduğunu öne süren DroPE teknolojisini açık kaynak olarak sundu. DroPE, çıkarım aşamasında döner pozisyonel kodlamayı (RoPE) devre dışı bırakıyor ve devasa bağlam pencerelerinin kilidini açmak için ön eğitim bütçesinin %1’inden daha azıyla kısa bir kalibrasyon gerektiriyor. Deneyler, bu yöntemin LongBench ve “iğne samanlıkta” testlerinde geleneksel RoPE ölçeklendirmesinden önemli ölçüde daha iyi performans gösterdiğini ve uzun metin yeteneklerini düşük maliyetle genişletmek için yeni bir yaklaşım sunduğunu gösteriyor (Kaynak: arXiv)
BabyVision Değerlendirme Seti: En iyi büyük modellerin görsel yetenekleri henüz 3 yaşındaki bir çocuğun gerisinde: Sequoia China xbench ve UniPatAI tarafından yayınlanan BabyVision değerlendirmesi, dil bağımlılığı sıkı bir şekilde kontrol edilen görsel görevlerde çoğu modelin 3 yaşındaki bir çocuktan çok daha kötü performans gösterdiğini ortaya koydu. En iyi performansı sergileyen Gemini 3 Pro bile ancak sınırı geçebildi. Araştırma, modellerin dilsel muhakemeye aşırı güvenmesinin; uzamsal algı, yörünge takibi ve geometrik sezgi konularındaki sistematik eksikliklerini maskelediğini, gelecekteki çok modlu zekanın görsel yetenekleri temelden yeniden inşa etmesi gerektiğini belirtiyor (Kaynak: 36Kr)

Recursive Language Models (RLM): DeepMind, RAG içermeyen mükemmel belleği araştırıyor: DeepMind araştırmacıları tarafından önerilen Recursive Language Models (RLM), modelin kendi içine bakmasını, parçalara ayrılmasını ve milyonlarca Token’ı işlemek için kendini özyinelemeli (recursive) olarak çağırmasını sağlıyor. Bu mekanizma, geleneksel bağlam penceresi sınırlamalarını kırıyor; model artık harici RAG sistemlerine bağımlı kalmak yerine, sonuçları özyinelemeli olarak birleştirerek devasa bilgiler üzerinde “mükemmel bellek” sağlıyor. Bu gelişme, gelecekte AI’nın ultra uzun belgeleri işleme biçiminde niteliksel bir değişim olacağını öngörüyor (Kaynak: HuggingFace)

ByteDance’in yurt dışı AI hamlesi “verimlilik araçları” aşamasına geçiyor: ByteDance son dönemde yurt dışında yoğun bir yapılanmaya giderek, Manus’a rakip olan ve yüksek kaliteli belge yazımı ile veri analizi gibi çıktılara odaklanan iş senaryosu Agent’ı AnyGen’i piyasaya sürdü. Aynı zamanda, yurt dışı AI asistanı Dola’nın günlük aktif kullanıcı sayısı 10 milyonu aştı. ByteDance, “eğlence sunmaktan” (TikTok) “verimlilik satmaya” geçmeye çalışarak, ofis Agent kulvarında OpenAI ve Anthropic ile doğrudan rekabete giriyor (Kaynak: 36Kr)

🧰 Araçlar
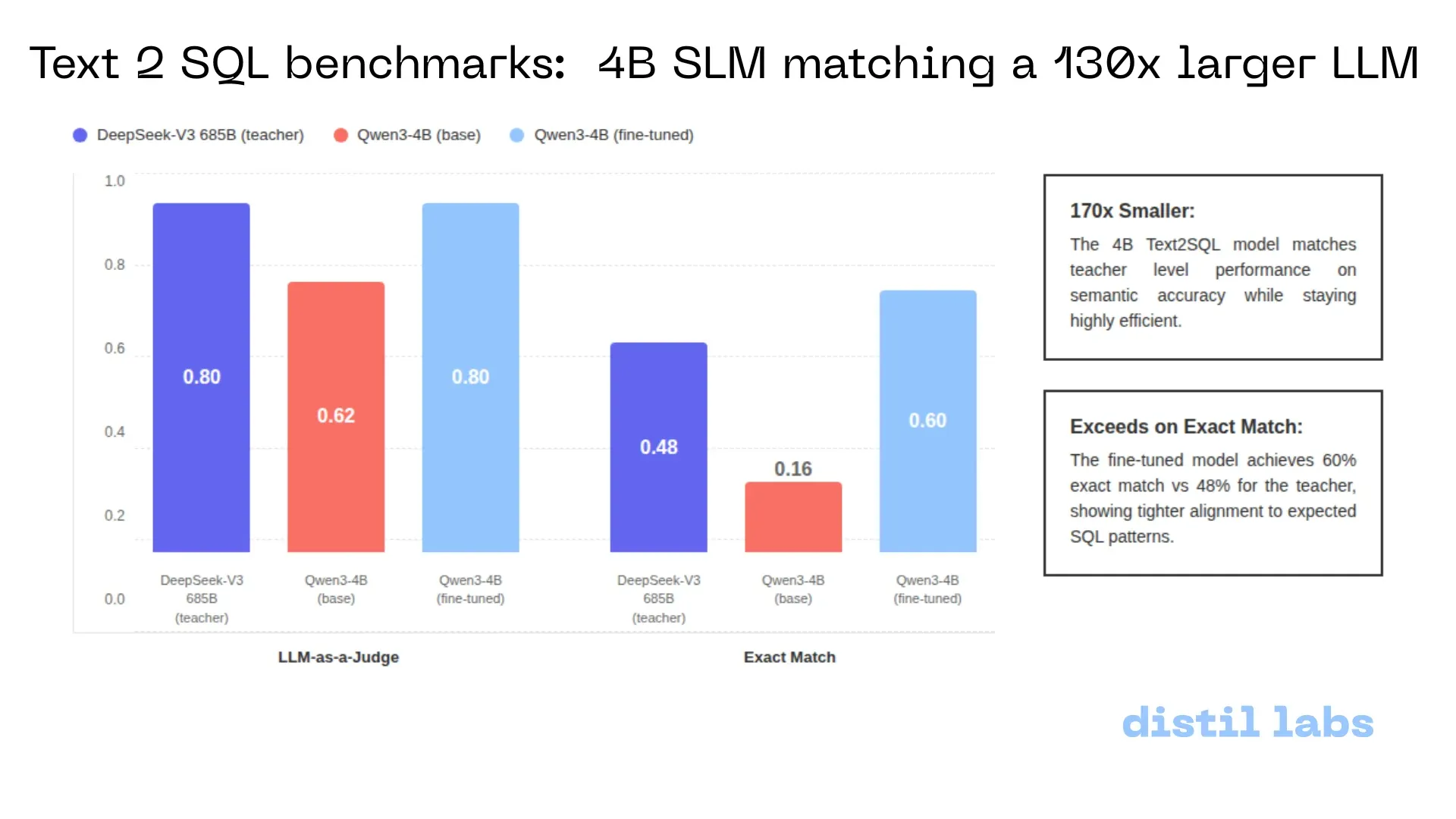
Distil-Text2SQL: 4B küçük model yerel olarak 685B seviyesinde hassasiyet sağlıyor: Distil-labs, Qwen3-4B modelini ince ayar (fine-tuning) yaparak Text2SQL görevlerinde DeepSeek-V3’ün (685B) anlamsal doğruluğuna ulaşmasını ve “tam eşleşme” metriklerinde onu geride bırakmasını sağladı. Yerel çalışmayı destekleyen model, CSV verilerini buluta yüklemeye gerek duymadan 2 saniyenin altında yanıt süresi sunuyor; bu da küçük modellerin dikey görevlerde devasa modellerin yerini alma potansiyelini gösteriyor (Kaynak: GitHub)
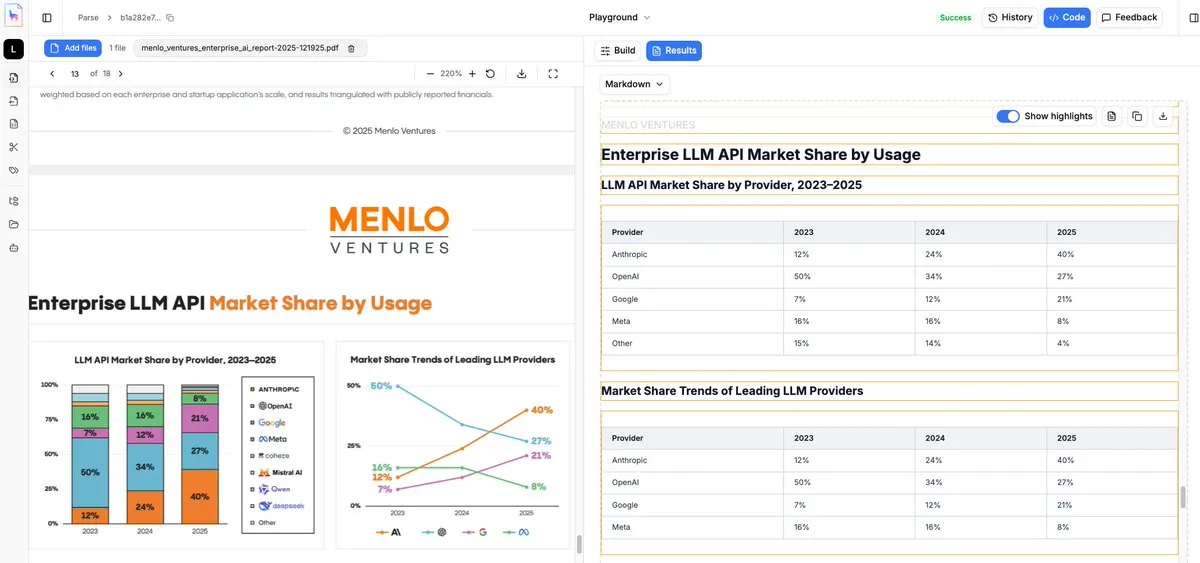
LlamaParse Güncellemesi: Grafik ve görseller için düşük maliyetli, hassas OCR: LlamaIndex, ayrıştırma aracı LlamaParse’ı Agentic moduna yükselterek belgelerdeki karmaşık görsel öğeler (çizgi grafikler, pasta grafikler, akış şemaları gibi) için optimize etti. Tüm sayfa ekran görüntüsünü doğrudan bir VLM’e beslemek yerine, bu araç alt öğelerin sınır kutularını tanımlıyor, sayısal mantığı çıkarıyor ve bunları yüksek kaliteli Markdown formatına dönüştürüyor. Bu, profesyonel belgelerdeki metin dışı bilgileri işlemek için şu anki en ekonomik ve verimli çözümlerden biridir (Kaynak: jerryjliu0)
Wobo: AI Agent tabanlı “iş arama Tinder’ı”: Wobo, özgeçmiş gönderimini otomatikleştiren bir iOS uygulamasıdır. Kullanıcılar özgeçmişlerini bir kez yükler, AI onların “profesyonel kişiliğini” analiz eder ve kullanıcı beğendiği bir iş ilanı için “sağa kaydırdığında”, AI otomatik olarak karmaşık harici web sitelerine gider, kişiselleştirilmiş ön yazılar oluşturur ve eleme sorularını yanıtlar. Bu araç, sıkıcı ve tekrarlayan form doldurma sürecini sona erdirmeyi ve 20 dakikalık başvuru sürecini 2 saniyeye indirmeyi hedefliyor (Kaynak: Reddit)
📚 Öğrenme
Stanford CS224N 2026 Geri Dönüyor: Agent ve Reasoning özel konuları eklendi: Klasik doğal dil işleme dersi CS224N geri döndüğünü duyurdu. Bu yıl Diyi Yang ve Yejin Choi tarafından verilecek olan ders, sinir ağları tabanlı NLP temellerinin yanı sıra AI Agent’lar, araç kullanımı ve “Reasoning” (Muhakeme) üzerine iki özel ders ile büyük modellerin en güncel trendlerini kapsayacak (Kaynak: Stanford)
Andrew Ng, “Build with Andrew”u başlattı: Kod yazmadan Web uygulamaları geliştirin: Andrew Ng, en son The Batch bülteninde, yeni başlayanlara sadece doğal dil ile fikirlerini tanımlayarak AI araçlarıyla çalışan Web uygulamaları oluşturmayı ve yayınlamayı öğreten yeni bir kurs başlattı. Kurs, “geliştirici olarak AI” paradigmasını vurgulayarak sıradan insanların yazılım geliştirme dünyasına giriş bariyerini düşürüyor (Kaynak: DeepLearningAI)
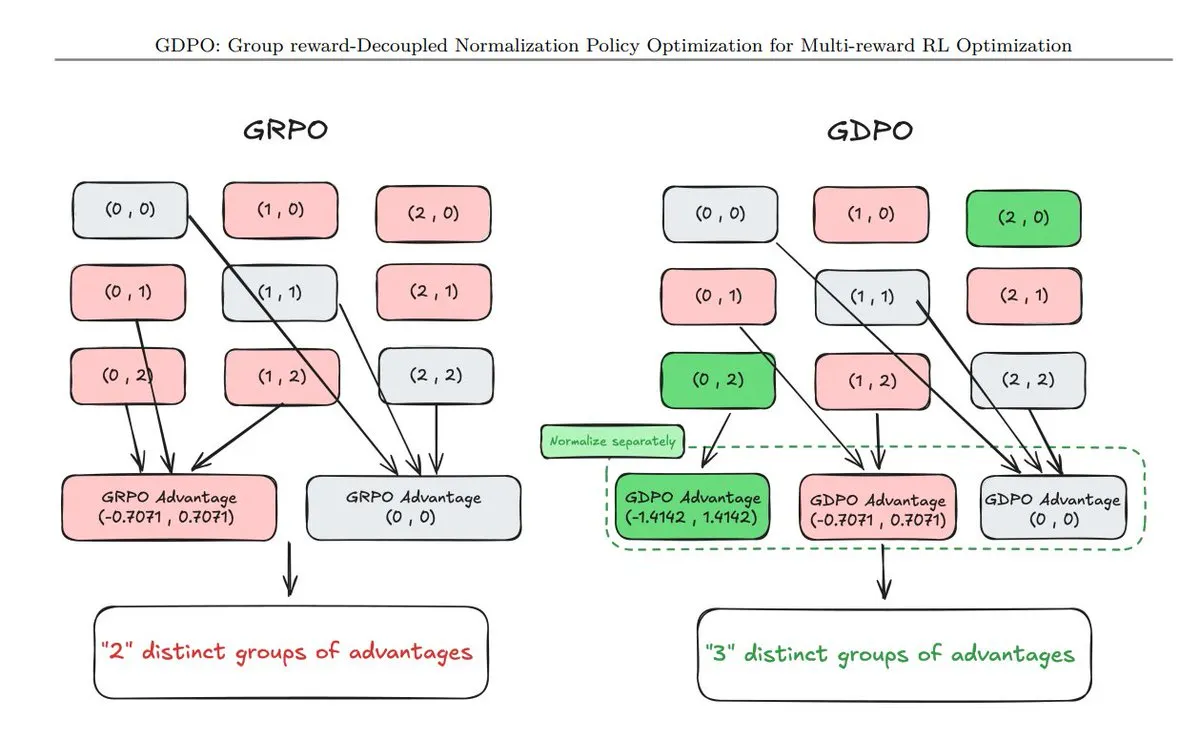
11 Yeni Strateji Optimizasyon Tekniği Özeti: TuringPost, son dönemde ortaya çıkan 11 strateji optimizasyon (Policy Optimization) tekniğini derledi. Bunlar arasında GDPO (ödül ayrıştırmalı normalizasyon), AT²PO (ağaç aramasına dayalı Agent sıra tabanlı PO) ve büyük ilgi gören PC-GRPO (bulmaca müfredatlı GRPO) yer alıyor. Bu teknikler, büyük modellerin mantık zincirini ve görev uyum yeteneklerini geliştirmenin merkezinde yer alıyor (Kaynak: TuringPost)
💼 İş Dünyası
OpenAI, sağlık girişimi Torch’u satın aldı: OpenAI; deney sonuçlarını, ilaç kayıtlarını ve doktor vizite kayıtlarını entegre eden sağlık odaklı AI girişimi Torch’u satın aldığını duyurdu. Torch ekibi ChatGPT Health departmanına katılacak. Bu hamle, OpenAI’ın AI’yı sağlık yönetimi ve klinik destek alanlarında ticarileştirme sürecini hızlandırdığını ve ChatGPT’yi dünyanın en profesyonel kişisel sağlık asistanı haline getirmeyi hedeflediğini gösteriyor (Kaynak: OpenAI)

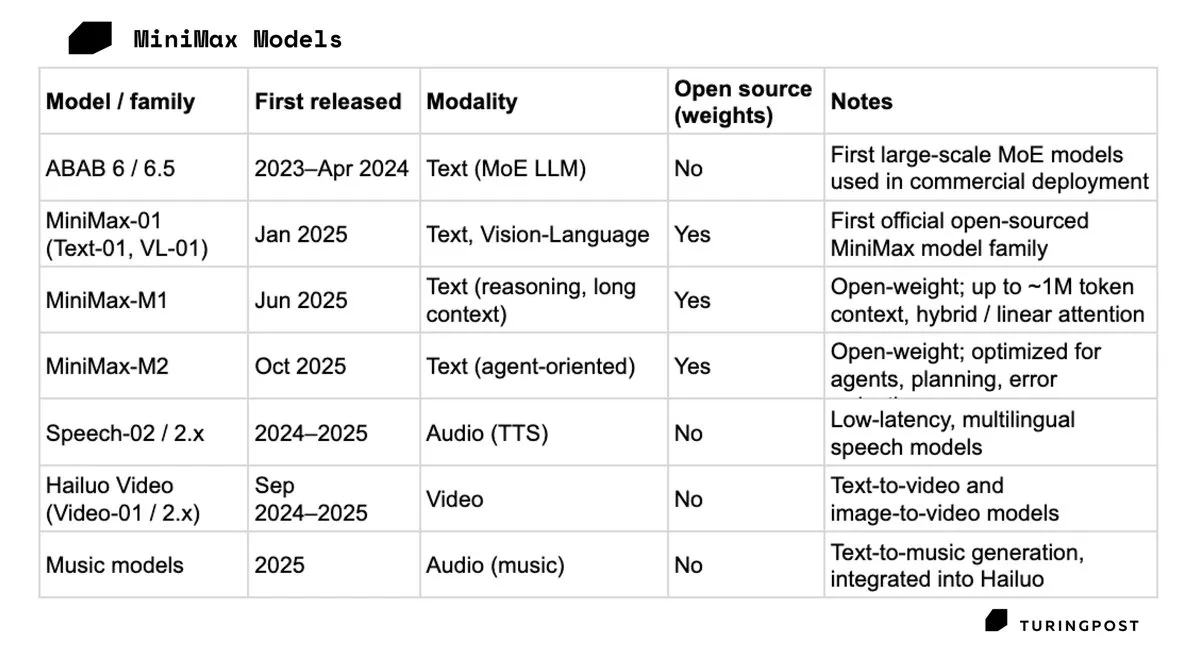
MiniMax Hong Kong’da halka açıldı, ilk gün %109 yükseldi: Çinli AI unicorn’u MiniMax, 9 Ocak 2026’da Hong Kong borsasında işlem görmeye başladı; hisseleri ilk gün %109 artarak piyasa değeri 150 milyar HKD’yi aştı. MiniMax, Talkie ve Hailuo AI ile tüketici pazarındaki başarısıyla, büyük kurumsal sözleşmelere bağımlı kalmadan tüketici odaklı çok modlu ürünlere odaklanmanın sermaye piyasasındaki cazibesini kanıtladı. Bu halka arz (IPO), yoğun bilgi işlem gücü yarışında “oksijen” elde etmek için kritik bir adım olarak görülüyor (Kaynak: TuringPost)
xAI günde 28 milyon dolar harcıyor, değerlemesi 230 milyara koşuyor: xAI, 2025’in ilk üç çeyreğinde 7,8 milyar dolar zarar etmesine rağmen, yakın zamanda 20 milyar dolar yatırım alarak 230 milyar dolar değerlemeye ulaştı. Elon Musk, Tesla robotlarını çalıştırabilecek otonom AI sistemleri inşa etmeyi amaçlayan “Macrohard” planını tüm gücüyle ilerletiyor. Bu “agresif yatırım” modeli, en üst düzey AI oyuncuları için altyapı ve yetenek konusundaki giriş bariyerinin ne kadar yüksek olduğunu yansıtıyor (Kaynak: 36Kr)
🌟 Topluluk
Vibe Coding/Working mesleki kimlik tartışmalarını tetikledi: Claude Cowork ve çeşitli Agent araçlarının yaygınlaşmasıyla “Vibe Working” (atmosfer odaklı çalışma) popüler bir terim haline geldi. Topluluk tartışmaları, bunun sadece basit bir verimlilik artışı değil, “zihindeki alan bilgisini paraya dönüştürmek” olduğunu savunuyor. Gelecekte mühendislerin değeri “100 bin satır kod yazmaktan”, “AI’ya 100 bin satır kod yazdıracak sistemi tasarlamaya” kayacak. Ancak bazıları bunun kod kalitesinde “Slop” (özensizlik) ve AI kara kutusuna aşırı bağımlılığa yol açacağından endişe ediyor (Kaynak: nearcyan, amasad)
AI dedektörlerinin “tamamen bir aldatmaca” olduğu iddia ediliyor: Reddit topluluğu, GPTZero gibi AI tespit araçlarına sert eleştiriler yönelterek, hata paylarının çok yüksek olduğunu ve hatta “Bağımsızlık Bildirgesi”ni bile %90 AI üretimi olarak işaretlediklerini belirtti. Kullanıcılar, bu araçların kaynağı değil “istatistiksel aşinalığı” ölçtüğünü, bu yüzden birçok özgün yazarın ve öğrencinin haksız yere suçlandığını savunuyor. Eğitim dünyası, bu “cadı avına” son verilmesi ve öğrencilerin içeriği anlama ve uygulama yeteneklerinin değerlendirilmesine odaklanılması çağrısında bulunuyor (Kaynak: Reddit)
DeepSeek kurucusu Liang Wenfeng, AI dünyasının “gizli ustası” olarak anılıyor: Topluluk, DeepSeek kurucusu Liang Wenfeng’in kantitatif fon geçmişini hararetle tartışıyor. Yönettiği High-Flyer Quant fonu, 2025 yılında %56,6 getiri sağlayarak sektör ortalamasını çok geride bıraktı. Kullanıcılar, kantitatif işlemlerden kazandığı parayı “YOLO” tarzında AI’ya yatırmasına ve teknoloji rotasında alışılmadık yollar izlemesine (MLA, Engram gibi) hayranlık duyuyor. Liang, yüksek mimari zevki ve mühendislik verimliliği ile Çin AI dünyasının Silikon Vadisi devlerine karşı en önemli değişkenlerinden biri olarak görülüyor (Kaynak: teortaxesTex)
💡 Diğer
AI kulaklığı Sweetpea Eylül ayında çıkabilir: OpenAI’ın ilk donanım ürünü olan ve Sweetpea kod adını taşıyan AI kulaklığının, Jony Ive ekibi tarafından tasarlandığı söyleniyor. Metalik bir çakıl taşına benzeyen cihazın, yerel çıkarımı desteklemek için 2nm çip içerdiği belirtiliyor. OpenAI, ilk yıl satışlarının 50 milyon adede ulaşarak AirPods’un pazar konumuna doğrudan meydan okuyacağını öngörüyor (Kaynak: 36Kr)

AI güvenliği 2026’da kurumsal seçimlerde yeni standart haline geliyor: AI Agent yetkilerinin genişlemesiyle birlikte, şirketlerin güvenliğe olan ilgisi “isteğe bağlı” olmaktan çıkıp “ön koşul” haline geldi. Araştırmalar, şirketlerin %43’ünün güvenliği AI kullanımının önündeki en büyük engel olarak gördüğünü gösteriyor. 2026 trendi, güvenlik yeteneklerinin “yerleşik” hale gelmesi; yani model çağırma ve Agent düzenleme aşamalarında denetim ve yetki izolasyonunun varsayılan olarak etkinleştirilmesidir (Kaynak: 36Kr)