
Schlüsselwörter:Engram-Modul, Cowork, Gemini-Zusammenarbeit, Transformer-Wissensabfragemechanismus, KI-Agenten-Aufgabenausführung, TTT-E2E-Training zur Testzeit
🔥 Fokus
DeepSeek veröffentlicht Engram-Modul, realisiert Entkopplung von Speicher und Berechnung: DeepSeek hat gemeinsam mit der Peking-Universität ein Paper veröffentlicht und das „Conditional Memory“-Modul Engram vorgestellt. Diese Technologie nutzt moderne Hash N-gram Embeddings, um Transformer mit einem nativen „Knowledge Lookup“-Mechanismus auszustatten und eine deterministische Suche in annähernd O(1) zu ermöglichen. Experimente zeigen, dass Engram-27B bei identischen Parametern und Rechenaufwand reine MoE-Modelle deutlich übertrifft. Es erweitert nicht nur den Wissensspeicher, sondern befreit auch die flachen Attention-Layer vom „Auswendiglernen“, sodass sich tiefe Netzwerke auf komplexe Reasoning-Aufgaben konzentrieren können, was die Code- und Mathematikfähigkeiten massiv steigert. Dieser technologische Ansatz, bei dem riesige Parametermengen in den Hauptspeicher (CPU) ausgelagert werden und der Inference-Verlust unter 3 % liegt, gilt als zentrales Primitiv für die nächste Generation spärlicher (sparse) Großmodelle und wird höchstwahrscheinlich in das kommende DeepSeek-V4 integriert (Quelle: GitHub)

Anthropic veröffentlicht strategisches Produkt Cowork, läutet Ära der „digitalen Kollegen“ ein: Anthropic hat offiziell Cowork (Research Preview) vorgestellt, das die zugrunde liegenden Fähigkeiten von Claude Code in ein grafisches Tool für nicht-technische Anwender verpackt. Cowork erlaubt Claude den direkten Zugriff auf lokale Ordner mit Berechtigungen zum Lesen, Bearbeiten und Erstellen von Dateien. Es ist nicht mehr nur ein Chatbot, sondern ein intelligenter Kollaborateur, der Schritte autonom planen und Aufgaben parallel verarbeiten kann (z. B. Download-Ordner aufräumen, Daten aus Screenshots in Excel extrahieren, Berichtsentwürfe schreiben). Das Produkt verfügt über eine isolierte virtuelle Maschine zur Gewährleistung der Sicherheit und unterstützt Browser-Automatisierung. Die Community sieht darin einen Paradigmenwechsel der KI von der „Inhaltserstellung“ hin zur „Aufgabenausführung“, was viele KI-Startups unter Druck setzen könnte (Quelle: Anthropic)

Apple und Google schließen Gemini-Kooperationsvereinbarung, Siri erhält „externes Gehirn“: Apple und Google gaben eine gemeinsame Erklärung ab, wonach künftige Apple Foundation Models auf der Gemini-Modell- und Cloud-Technologie von Google basieren werden, um das personalisierte Siri zu unterstützen, das Ende dieses Jahres erscheinen soll. Berichten zufolge wird Apple jährlich etwa 1 Milliarde US-Dollar zahlen. Die Zusammenarbeit wird als „vorübergehendes Nachgeben“ von Apple angesichts von Verzögerungen bei eigenen Modellen gewertet. Gemini wird für komplexe Aufgaben wie Zusammenfassungen und Planung zuständig sein, während On-Device-Basisfunktionen weiterhin von Apples eigenen Modellen unterstützt werden. Dieser Schritt ließ den Marktwert von Google erstmals über 4 Billionen US-Dollar steigen, löste jedoch auch Kritik von Elon Musk wegen „übermäßiger Machtkonzentration“ und Diskussionen über die Marginalisierung von OpenAI im Apple-Ökosystem aus (Quelle: Google)

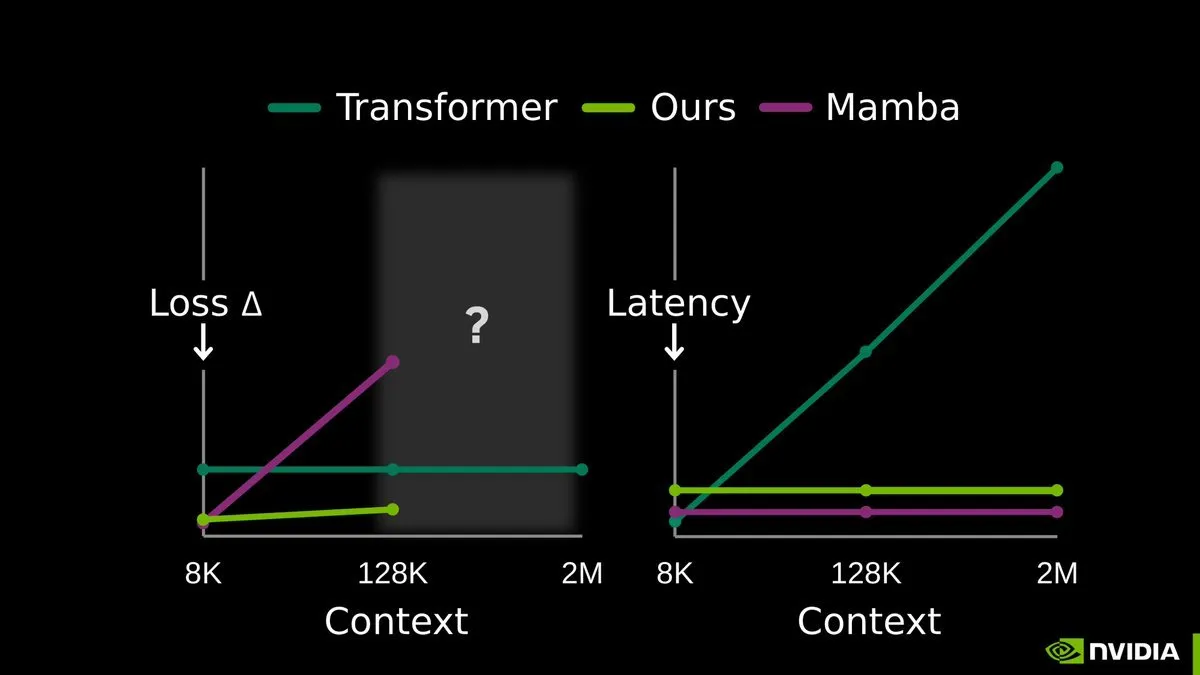
TTT-E2E: End-to-End Test-Time Training eröffnet neue Ära des Langzeitgedächtnisses für LLMs: Die gemeinsam von NVIDIA, Stanford und dem Astera Institute veröffentlichte Studie zu End-to-End Test-Time Training (TTT-E2E) sorgt für Aufsehen. Die Technologie plädiert nicht für radikal neue Architekturen, sondern nutzt den Kontext während der Inference-Phase (Test-Time) als Trainingsdaten, um die Modellgewichte durch Next-Token Prediction kontinuierlich zu aktualisieren. Auf diese Weise werden Erfahrungen aus langen Kontexten in die Modellgewichte komprimiert, was das Problem der explodierenden KV-Cache-Größe bei langen Sequenzen effektiv löst. TTT macht Modelle zu echten „kontinuierlich Lernenden“ und zeigt extreme Stabilität bei der Verarbeitung von Sequenzen mit Millionen von Token. Es gilt als vielversprechendster Pfad hin zu rein sub-quadratischem Sequence Modeling (Quelle: arXiv)
🎯 Trends
Sakana AI stellt DroPE vor: Dropping Positional Embeddings ermöglicht Langtext-Extrapolation: Das Team um Transformer-Mitautor Llion Jones hat die DroPE-Technologie als Open Source veröffentlicht. Sie schlagen vor, dass Positional Embeddings lediglich „Stützräder“ für das Training sind. DroPE verwirft während der Inference die Rotary Positional Encodings (RoPE) und benötigt weniger als 1 % des Pre-training-Budgets für eine kurze Kalibrierung, um riesige Kontextfenster freizuschalten. Experimente zeigen, dass diese Methode in LongBench- und Needle-In-A-Haystack-Tests herkömmliches RoPE-Scaling deutlich übertrifft und neue Wege für kostengünstige Langtext-Erweiterungen bietet (Quelle: arXiv)
BabyVision-Benchmark: Visuelle Fähigkeiten von Top-KI-Modellen noch hinter 3-jährigen Kindern: Der von Sequoia China xbench und UniPatAI veröffentlichte BabyVision-Benchmark zeigt, dass die meisten Modelle in visuellen Aufgaben mit streng kontrollierter Sprachabhängigkeit weit schlechter abschneiden als 3-jährige Kinder. Selbst das bestplatzierte Gemini 3 Pro erreichte nur knapp die Mindestanforderungen. Die Studie weist darauf hin, dass die übermäßige Abhängigkeit der Modelle von sprachlichem Reasoning systemische Mängel in der räumlichen Wahrnehmung, Trajektorienverfolgung und geometrischen Intuition verdeckt. Zukünftige multimodale Intelligenz muss visuelle Fähigkeiten von Grund auf neu aufbauen (Quelle: 36Kr)

Recursive Language Models (RLM): DeepMind erforscht perfektes Gedächtnis ohne RAG: Forscher von DeepMind schlagen Recursive Language Models (RLM) vor, die Millionen von Token verarbeiten, indem das Modell sich selbst inspiziert, aufteilt und rekursiv aufruft. Dieser Mechanismus durchbricht die Grenzen herkömmlicher Kontextfenster. Anstatt auf externes RAG angewiesen zu sein, erreicht das Modell durch rekursive Aggregation der Ergebnisse ein „perfektes Gedächtnis“ für riesige Informationsmengen. Dieser Fortschritt deutet auf eine qualitative Veränderung in der Art und Weise hin, wie KI künftig ultralange Dokumente verarbeitet (Quelle: HuggingFace)

ByteDance AI-Expansion im Ausland erreicht neue Phase der „Effizienz-Tools“: ByteDance hat kürzlich seine Präsenz im Ausland intensiviert und AnyGen vorgestellt, einen Agent für Arbeitsszenarien, der mit Manus konkurriert und auf hochwertige Ergebnisse wie Dokumentenerstellung und Datenanalyse setzt. Gleichzeitig hat der KI-Assistent Dola im Ausland bereits über 10 Millionen täglich aktive Nutzer erreicht. ByteDance versucht den Übergang von „Unterhaltung exportieren“ (TikTok) hin zu „Effizienz verkaufen“ und tritt im Bereich der Office-Agents in den direkten Wettbewerb mit OpenAI und Anthropic (Quelle: 36Kr)

🧰 Tools
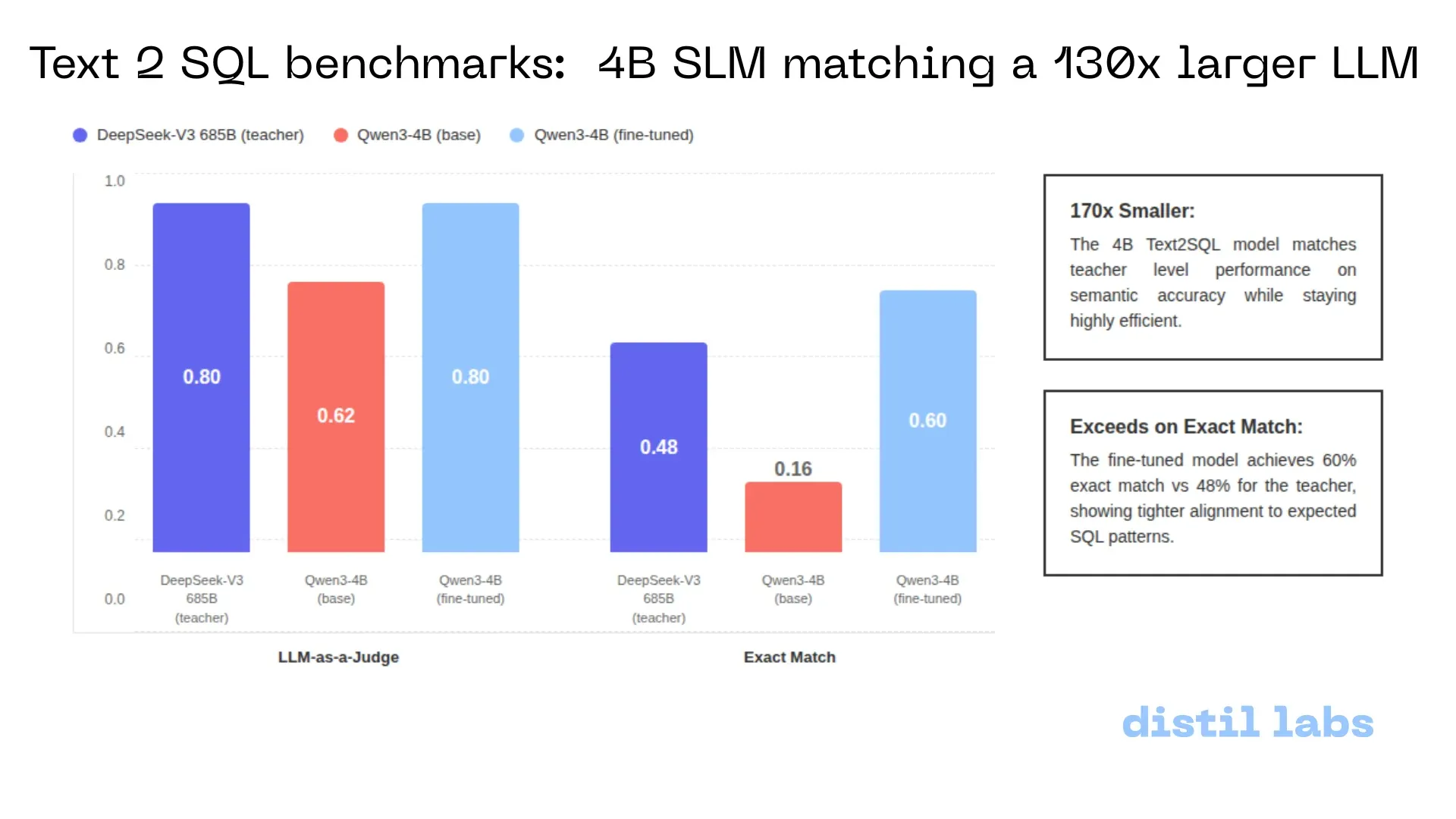
Distil-Text2SQL: 4B-Modell erreicht lokal Präzision der 685B-Klasse: Distil-labs hat durch Fine-tuning von Qwen3-4B erreicht, dass dieses in Text2SQL-Aufgaben die semantische Genauigkeit von DeepSeek-V3 (685B) erreicht und bei der Metrik „Exact Match“ sogar übertrifft. Das Modell unterstützt den lokalen Betrieb, verarbeitet CSV-Daten ohne Cloud-Upload und hat eine Antwortzeit von unter 2 Sekunden. Dies demonstriert das enorme Potenzial kleiner Modelle, ultragroße Modelle in vertikalen Aufgaben zu ersetzen (Quelle: GitHub)
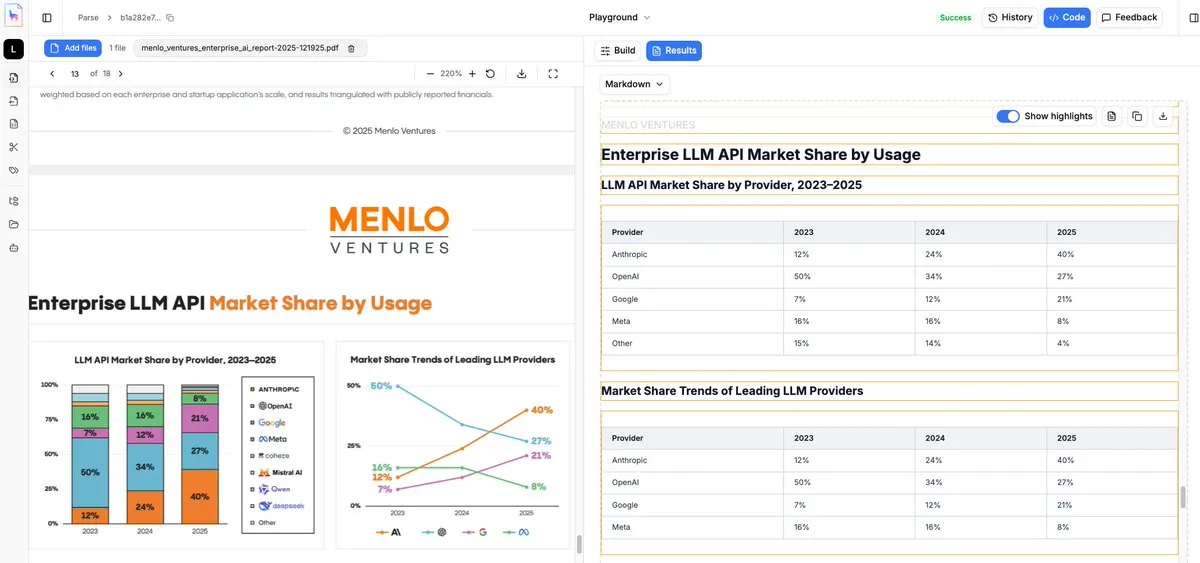
LlamaParse-Upgrade: Kostengünstiges, präzises OCR für Diagramme und Bilder: LlamaIndex hat sein Parsing-Tool LlamaParse auf einen Agentic-Modus aktualisiert, der speziell für komplexe visuelle Elemente in Dokumenten (wie Liniendiagramme, Tortendiagramme, Flussdiagramme) optimiert wurde. Anstatt ganze Seiten-Screenshots an ein VLM zu senden, erkennt das Tool die Bounding Boxes von Unterelementen, extrahiert numerische Logik und wandelt diese in hochwertiges Markdown um. Es ist derzeit eine der wirtschaftlichsten Lösungen für nicht-textuelle Informationen in Fachdokumenten (Quelle: jerryjliu0)
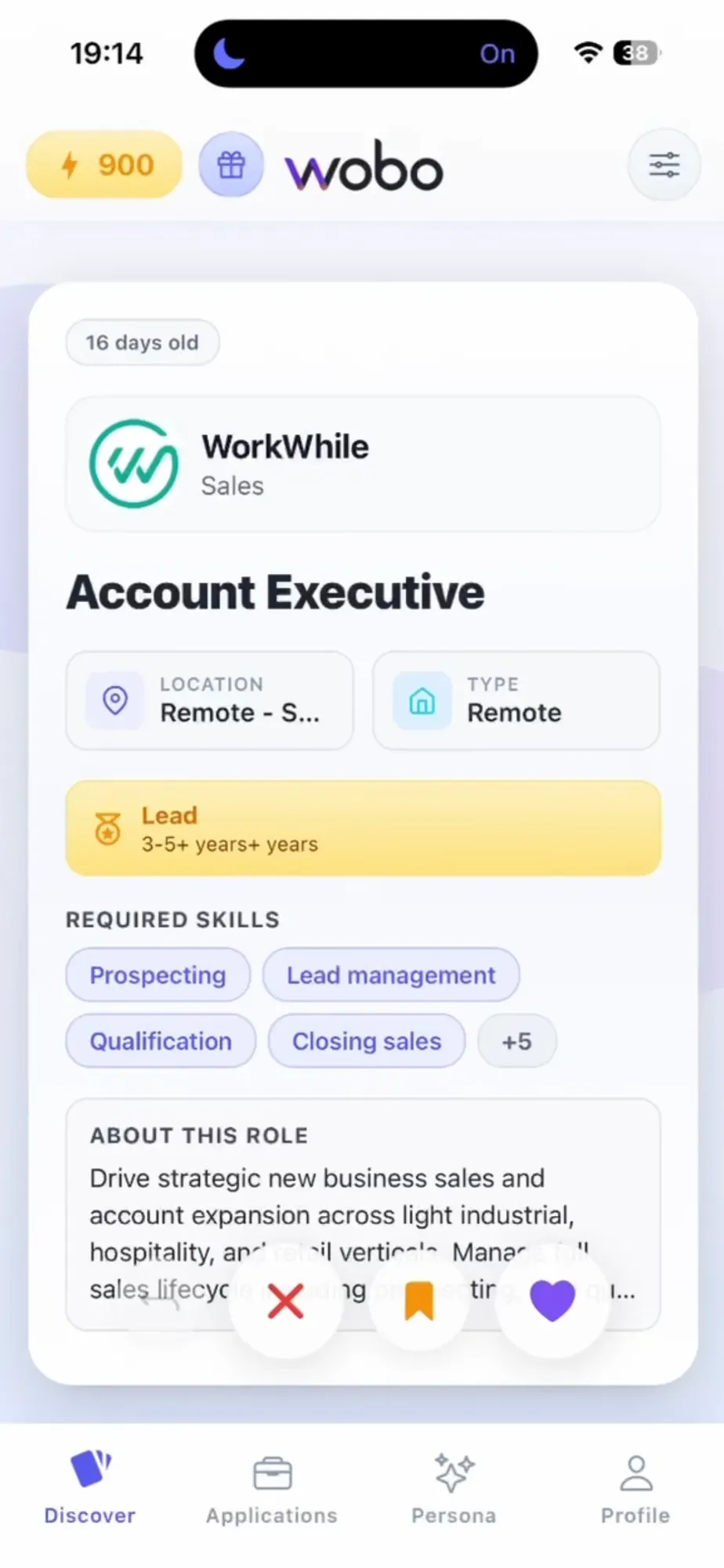
Wobo: Die „Job-Version von Tinder“ basierend auf AI Agents: Wobo ist eine iOS-App, die AI Agents nutzt, um Bewerbungen zu automatisieren. Nutzer laden ihren Lebenslauf einmal hoch, die KI analysiert die „berufliche Persönlichkeit“ und navigiert bei einem „Swipe nach rechts“ für einen Wunschjob automatisch durch komplexe externe Karriereseiten, erstellt personalisierte Anschreiben und beantwortet Screening-Fragen. Das Tool soll mühsame Wiederholungen beim Formularausfüllen beenden und den 20-minütigen Bewerbungsprozess auf 2 Sekunden verkürzen (Quelle: Reddit)
📚 Lernen
Stanford CS224N 2026 Rückkehr: Neue Themen zu Agents und Reasoning: Der klassische NLP-Kurs CS224N kehrt zurück. Der diesjährige Kurs wird von Diyi Yang und Yejin Choi geleitet. Neben den Grundlagen von neuronalem NLP werden Schwerpunkte auf AI Agents, Tool Use sowie zwei spezielle Vorlesungen zu „Reasoning“ gesetzt, um den aktuellen Trends bei Großmodellen gerecht zu werden (Quelle: Stanford)
Andrew Ng veröffentlicht „Build with Andrew“: Web-Apps ohne Code erstellen: Andrew Ng hat in seinem neuesten The Batch-Newsletter einen neuen Kurs vorgestellt, der Anfängern zeigt, wie sie allein durch natürliche Sprachbeschreibung ihrer Ideen Web-Anwendungen mit KI-Tools erstellen und veröffentlichen können. Der Kurs betont das Paradigma „KI als Entwickler“ und senkt die Hürde für den Einstieg in die Softwareentwicklung (Quelle: DeepLearningAI)
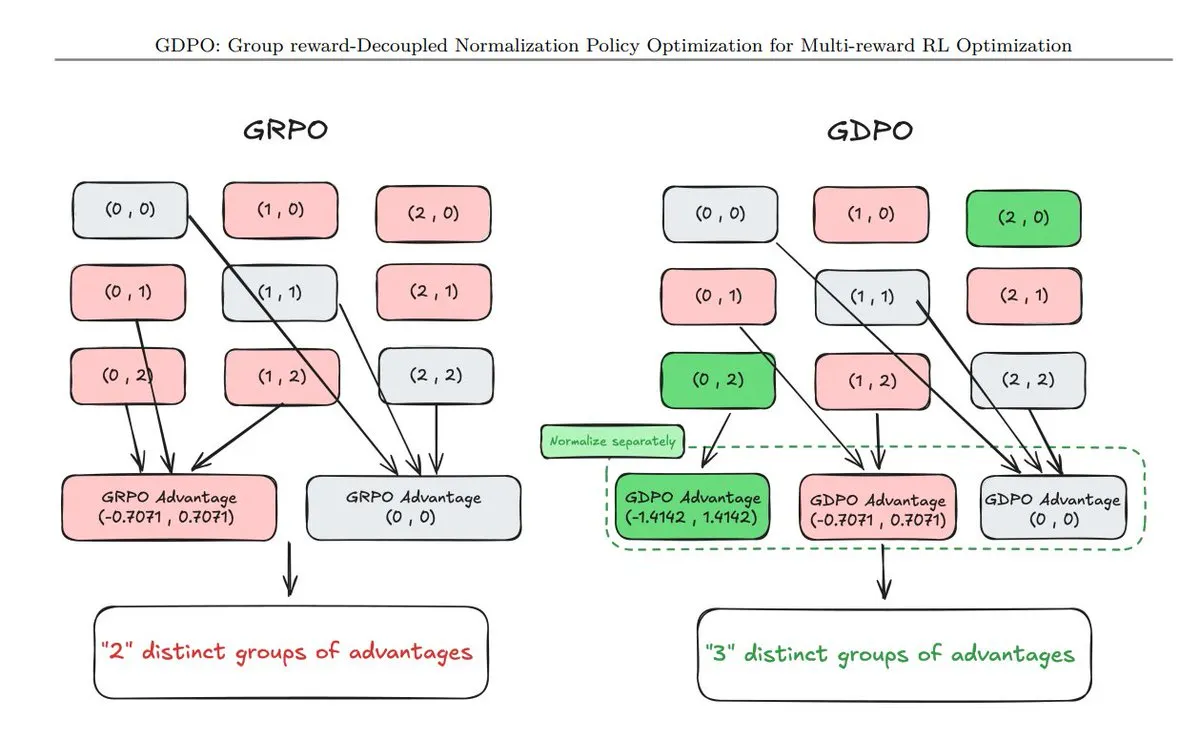
Zusammenfassung von 11 neuen Policy Optimization-Techniken: TuringPost hat 11 kürzlich erschienene Techniken zur Policy Optimization zusammengefasst, darunter GDPO (Reward-decoupled Normalization), AT²PO (Agent Turn-based PO basierend auf Tree Search) und das vielbeachtete PC-GRPO (Puzzle Curriculum GRPO). Diese Techniken sind entscheidend für die Verbesserung der logischen Ketten und der Task-Alignment-Fähigkeiten von Großmodellen (Quelle: TuringPost)
💼 Business
OpenAI übernimmt Healthcare-Startup Torch: OpenAI gab die Übernahme von Torch bekannt, einem Healthcare-KI-Startup, das Laborergebnisse, Medikamentenhistorien und Arztgespräche integriert. Das Torch-Team wird der ChatGPT Health-Abteilung beitreten. Dieser Schritt zeigt, dass OpenAI die Kommerzialisierung von KI im Gesundheitsmanagement und in der klinischen Assistenz beschleunigt, um ChatGPT zum weltweit professionellsten persönlichen Gesundheitsassistenten auszubauen (Quelle: OpenAI)

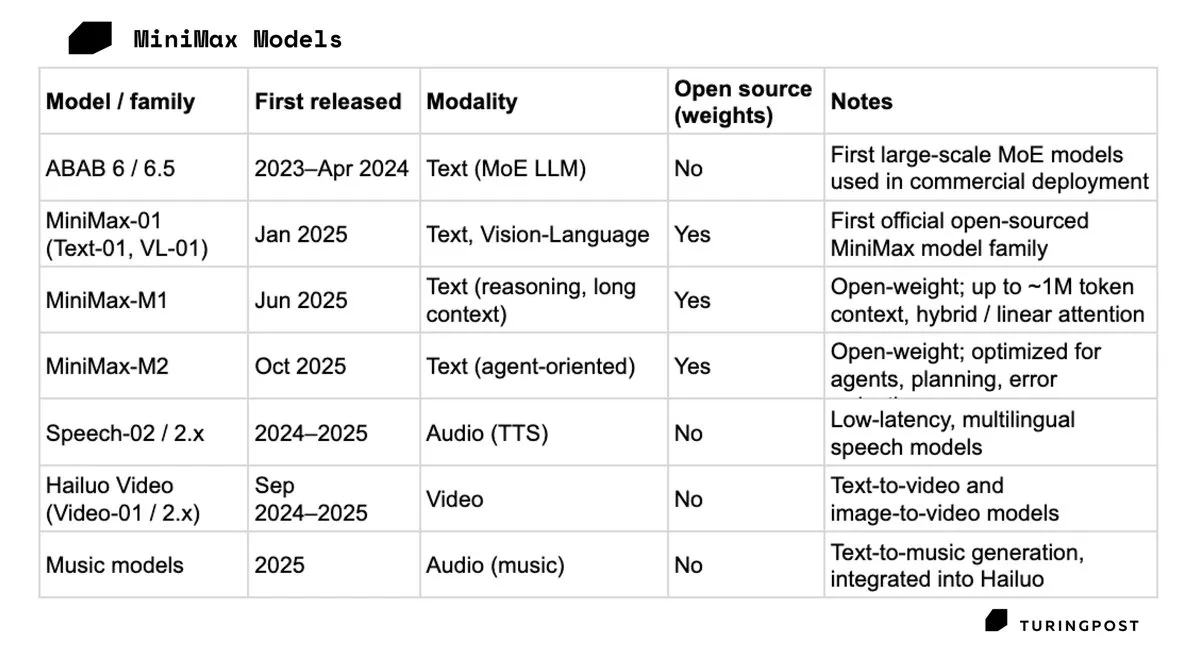
MiniMax geht in Hongkong an die Börse, steigt am ersten Tag um 109 %: Das chinesische KI-Unicorn MiniMax ging am 9. Januar 2026 in Hongkong an die Börse. Der Aktienkurs schoss am ersten Tag um 109 % nach oben, der Marktwert überstieg 150 Milliarden HKD. MiniMax hat mit dem Erfolg von Talkie und Hailuo AI im C-End-Markt bewiesen, dass ein Pfad, der auf multimodale Konsumentenprodukte statt auf Großkundenverträge setzt, für den Kapitalmarkt attraktiv ist. Der IPO gilt als entscheidender Schritt zur Sicherung von Ressourcen im intensiven Rechenleistungswettbewerb (Quelle: TuringPost)
xAI verbrennt 28 Millionen USD täglich, Bewertung strebt auf 230 Milliarden zu: Obwohl xAI in den ersten drei Quartalen 2025 Verluste von 7,8 Milliarden USD verzeichnete, schloss das Unternehmen kürzlich eine Finanzierungsrunde über 20 Milliarden USD ab, was die Bewertung auf 230 Milliarden USD hob. Elon Musk treibt den „Macrohard“-Plan voran, um autonome KI-Systeme für Tesla-Roboter zu entwickeln. Dieser Modus der „massiven Investitionen“ spiegelt die extrem hohen Eintrittsbarrieren für Top-KI-Player bei Infrastruktur und Talenten wider (Quelle: 36Kr)
🌟 Community
Vibe Coding/Working löst Debatte über berufliche Identität aus: Mit der Verbreitung von Claude Cowork und verschiedenen Agent-Tools ist „Vibe Working“ zum Schlagwort geworden. In der Community wird diskutiert, dass dies nicht nur eine Effizienzsteigerung ist, sondern die „Monetarisierung von Domänenwissen im Kopf“. Der Wert künftiger Ingenieure wird sich vom „Schreiben von 100.000 Zeilen Code“ hin zum „Design von Systemen, die KI 100.000 Zeilen Code schreiben lassen“ verschieben. Es gibt jedoch auch Sorgen über minderwertigen Code („Slop“) und eine übermäßige Abhängigkeit von KI-Blackboxen (Quelle: nearcyan, amasad)
AI-Detektoren als „reiner Betrug“ bezeichnet: Die Reddit-Community kritisiert KI-Erkennungstools wie GPTZero scharf und weist auf extrem hohe Fehlalarmraten hin – sogar die Unabhängigkeitserklärung der USA wurde als zu 90 % KI-generiert markiert. Nutzer argumentieren, dass diese Tools „statistische Vertrautheit“ statt der tatsächlichen Quelle messen, was dazu führt, dass viele originäre Autoren und Studenten fälschlicherweise beschuldigt werden. Bildungsexperten fordern ein Ende der „Hexenjagd“ und einen Fokus auf das Verständnis und die Anwendung von Inhalten (Quelle: Reddit)
DeepSeek-Gründer Liang Wenfeng als „Shaolin-Mönch der KI-Welt“ gefeiert: Die Community diskutiert intensiv über den Hintergrund von DeepSeek-Gründer Liang Wenfeng im Bereich Quant-Fonds. Sein Unternehmen High-Flyer Quant erzielte 2025 eine Rendite von 56,6 %, weit über dem Branchendurchschnitt. Nutzer bewundern, wie er das mit Quant-Trading verdiente Geld im „YOLO“-Stil in KI investiert und dabei unkonventionelle technische Wege geht (wie MLA, Engram), was von hohem architektonischem Geschmack und technischer Effizienz zeugt (Quelle: teortaxesTex)
💡 Sonstiges
AI-Kopfhörer Sweetpea voraussichtlich im September veröffentlicht: Gerüchten zufolge wird das erste Hardware-Produkt von OpenAI – Codename Sweetpea – im September erscheinen. Das vom Team um Jony Ive entworfene Gerät ähnelt einem metallischen Kieselstein und verfügt über einen integrierten 2nm-Chip für lokales Reasoning. OpenAI prognostiziert für das erste Jahr einen Absatz von 50 Millionen Stück und fordert damit direkt die Marktposition der AirPods heraus (Quelle: 36Kr)

AI-Sicherheit wird 2026 zum neuen Standard bei der Unternehmensauswahl: Mit der Ausweitung der Befugnisse von KI-Agenten hat sich der Fokus der Unternehmen auf Sicherheit von einer „Option“ zu einer „Voraussetzung“ gewandelt. Umfragen zeigen, dass 43 % der Unternehmen Sicherheit als größtes Hindernis für die KI-Einführung sehen. Der Trend für 2026 ist „Built-in Security“, bei der Auditing und Berechtigungsisolierung standardmäßig in der Modellaufruf- und Agent-Orchestrierungsphase aktiviert sind (Quelle: 36Kr)