
Kata Kunci:Modul Engram, Cowork, Kolaborasi Gemini, Mekanisme pencarian pengetahuan Transformer, Eksekusi tugas AI Agent, Pelatihan saat pengujian TTT-E2E
🔥 Fokus
DeepSeek merilis modul Engram, mewujudkan pemisahan penyimpanan dan komputasi : DeepSeek bersama Peking University merilis paper yang memperkenalkan modul “conditional memory” bernama Engram. Teknologi ini menggunakan hashing N-gram embedding modern untuk melengkapi Transformer dengan mekanisme “knowledge lookup” native, mencapai pencarian deterministik mendekati O(1). Eksperimen menunjukkan bahwa Engram-27B secara signifikan mengungguli model MoE murni pada jumlah parameter dan komputasi yang sama. Selain meningkatkan cadangan pengetahuan, teknologi ini membebaskan beban “menghafal” pada attention lapisan dangkal, sehingga jaringan dalam dapat fokus pada penalaran kompleks, yang berujung pada lonjakan drastis kemampuan kode dan matematika. Rute teknik yang memindahkan parameter masif ke memori host (CPU) dengan kerugian inferensi di bawah 3% ini dianggap sebagai primitif inti model sparse generasi berikutnya, dan kemungkinan besar akan diintegrasikan dalam DeepSeek-V4 mendatang (Sumber: GitHub)

Anthropic merilis produk strategis Cowork, memulai era “rekan kerja digital” : Anthropic resmi meluncurkan Cowork (research preview), yang mengemas kemampuan dasar Claude Code menjadi alat grafis untuk pengguna non-teknis. Cowork memungkinkan Claude mengakses folder lokal secara langsung dengan izin untuk membaca, mengedit, dan membuat file. Ini bukan sekadar chatbot, melainkan kolaborator cerdas yang mampu merencanakan langkah secara mandiri dan memproses tugas secara paralel (seperti merapikan folder unduhan, mengekstrak data dari screenshot ke Excel, atau menulis draf laporan). Produk ini dilengkapi lingkungan isolasi mesin virtual bawaan untuk memastikan keamanan dan mendukung otomatisasi browser. Komunitas menganggap ini menandai pergeseran paradigma AI dari “pembuatan konten” ke “eksekusi tugas”, yang berpotensi memberikan disrupsi besar bagi banyak aplikasi AI startup (Sumber: Anthropic)

Apple dan Google mencapai kesepakatan kerja sama Gemini, Siri mendapatkan “otak luar” : Apple dan Google merilis pernyataan bersama yang mengonfirmasi bahwa Apple Foundation Models di masa depan akan dibangun berdasarkan model Gemini dan teknologi cloud Google untuk menggerakkan Siri yang dipersonalisasi akhir tahun ini. Kabarnya Apple akan membayar sekitar $1 miliar per tahun. Kerja sama ini dipandang sebagai “langkah transisi” Apple di tengah penundaan model internalnya; Gemini akan menangani tugas kompleks seperti ringkasan dan perencanaan, sementara fungsi dasar on-device tetap didukung oleh model internal Apple. Langkah ini membuat nilai pasar Google melampaui $4 triliun untuk pertama kalinya, sekaligus memicu kritik dari Elon Musk tentang “konsentrasi kekuasaan yang berlebihan” serta diskusi mengenai terpinggirnya posisi OpenAI dalam ekosistem Apple (Sumber: Google)

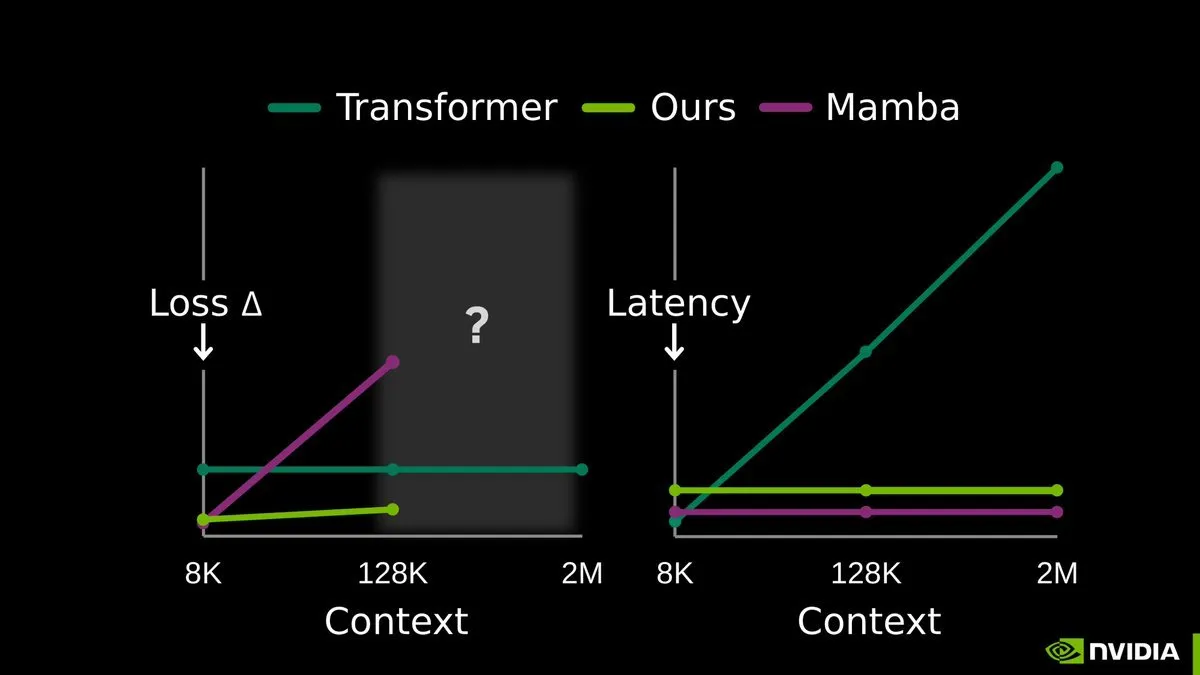
TTT-E2E: End-to-End Test-Time Training membuka era baru memori panjang LLM : Penelitian End-to-End Test-Time Training (TTT-E2E) yang dirilis bersama oleh NVIDIA, Stanford, dan Astera Institute menghebohkan publik. Teknologi ini berpendapat bahwa tanpa memerlukan arsitektur baru yang radikal, model dapat terus memperbarui bobot melalui prediksi token berikutnya dengan memanfaatkan konteks sebagai data pelatihan selama fase inferensi (test-time). Cara ini mengompresi pengalaman konteks panjang ke dalam bobot model, secara efektif menyelesaikan masalah ledakan KV cache seiring bertambahnya panjang sekuens. TTT menjadikan model sebagai “pembelajar berkelanjutan” sejati, menunjukkan stabilitas kuat saat menangani jutaan token, dan dianggap sebagai jalur paling menjanjikan menuju pemodelan sekuens sub-kuadratik murni (Sumber: arXiv)
🎯 Tren
Sakana AI meluncurkan DroPE: Menghapus Position Embedding untuk ekstrapolasi teks panjang : Tim Llion Jones, penulis inti Transformer, merilis teknologi DroPE secara open-source, yang menyatakan bahwa position embedding hanyalah “roda bantu” pelatihan. DroPE membuang Rotary Position Embedding (RoPE) pada fase inferensi dan hanya membutuhkan kurang dari 1% anggaran pre-training untuk kalibrasi singkat guna membuka jendela konteks masif. Eksperimen menunjukkan metode ini secara signifikan mengungguli penskalaan RoPE tradisional pada tes LongBench dan “needle in a haystack”, memberikan solusi biaya rendah untuk memperluas kemampuan teks panjang (Sumber: arXiv)
Dataset evaluasi BabyVision: Kemampuan visual model AI papan atas belum menyamai anak usia 3 tahun : Evaluasi BabyVision yang dirilis oleh Sequoia China xbench dan UniPatAI menunjukkan bahwa dalam tugas visual dengan kontrol ketat terhadap ketergantungan bahasa, sebagian besar model berkinerja jauh di bawah anak usia 3 tahun. Bahkan Gemini 3 Pro yang berkinerja terbaik pun hanya nyaris lulus. Penelitian menunjukkan bahwa ketergantungan berlebih model pada penalaran bahasa menutupi kekurangan sistematis dalam persepsi spasial, pelacakan lintasan, dan intuisi geometris; kecerdasan multimodal masa depan harus membangun kembali kemampuan visual secara fundamental (Sumber: 36氪)

Recursive Language Models (RLM): DeepMind mengeksplorasi memori sempurna tanpa RAG : Peneliti DeepMind mengusulkan Recursive Language Models (RLM) yang memungkinkan model melakukan introspeksi, memecah, dan memanggil dirinya sendiri secara rekursif untuk menangani jutaan token. Mekanisme ini mendobrak batasan jendela konteks tradisional; model tidak lagi bergantung pada RAG eksternal, melainkan mencapai “memori sempurna” atas informasi masif melalui agregasi hasil rekursif. Kemajuan ini memprediksi perubahan kualitatif dalam cara AI memproses dokumen super panjang di masa depan (Sumber: HuggingFace)

Ekspansi AI luar negeri ByteDance memasuki tahap baru “alat efisiensi” : ByteDance baru-baru ini gencar berekspansi di luar negeri dengan meluncurkan AnyGen, sebuah Agent skenario kerja yang menyaingi Manus, berfokus pada hasil berkualitas tinggi seperti penulisan dokumen dan analisis data. Sementara itu, asisten AI luar negeri Dola telah melampaui 10 juta pengguna aktif harian. ByteDance mencoba beralih dari “menjual kebahagiaan” (TikTok) menjadi “menjual efisiensi”, bersaing ketat dengan OpenAI dan Anthropic di jalur Office Agent (Sumber: 36氪)

🧰 Alat
Distil-Text2SQL: Model kecil 4B mencapai akurasi tingkat 685B secara lokal : Distil-labs melakukan fine-tuning pada Qwen3-4B sehingga mencapai akurasi semantik DeepSeek-V3 (685B) pada tugas Text2SQL, bahkan melampauinya dalam metrik “exact match”. Model ini mendukung eksekusi lokal tanpa perlu mengunggah data CSV ke cloud, dengan waktu respons di bawah 2 detik, menunjukkan potensi besar model kecil untuk menggantikan model super besar dalam tugas vertikal (Sumber: GitHub)
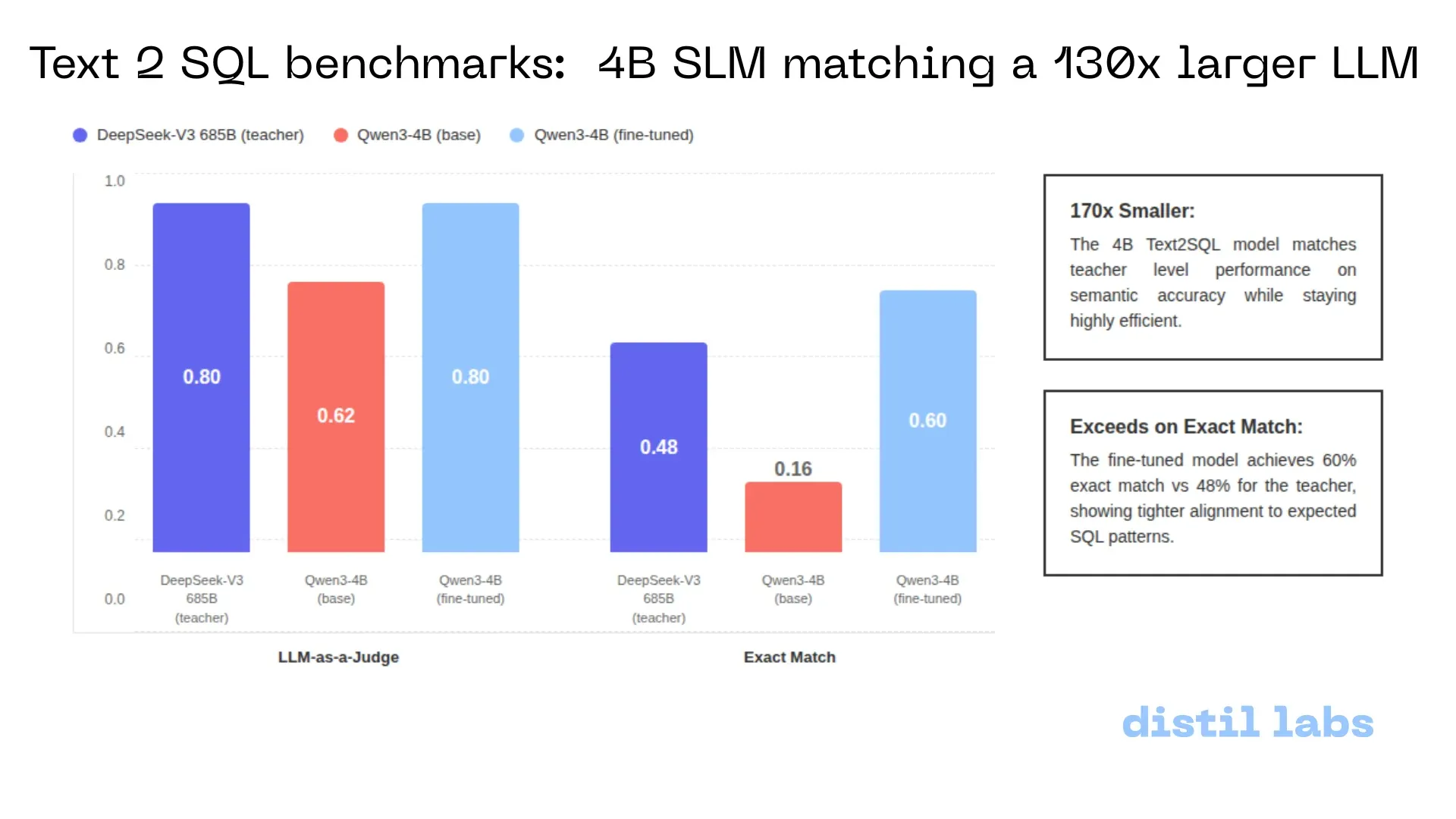
Upgrade LlamaParse: OCR presisi untuk grafik dan gambar dengan biaya rendah : LlamaIndex meningkatkan alat parsing-nya, LlamaParse, ke mode Agentic, yang khusus dioptimalkan untuk elemen visual kompleks dalam dokumen (seperti grafik garis, diagram lingkaran, flowchart). Dibandingkan memberi screenshot halaman penuh ke VLM, alat ini dapat mengidentifikasi kotak pembatas sub-elemen dan mengekstrak logika numerik, mengubahnya menjadi Markdown berkualitas tinggi. Ini adalah salah satu solusi paling ekonomis untuk menangani informasi non-teks dalam dokumen profesional (Sumber: jerryjliu0)
Wobo: “Tinder versi cari kerja” berbasis AI Agent : Wobo adalah aplikasi iOS yang menggunakan AI Agent untuk mengotomatiskan pengiriman resume. Pengguna cukup mengunggah resume sekali, AI akan menganalisis “kepribadian profesional” mereka, dan saat pengguna “swipe kanan” pada pekerjaan yang disukai, AI akan otomatis menavigasi ke situs web eksternal yang kompleks, membuat surat lamaran personal, dan menjawab pertanyaan penyaringan. Alat ini bertujuan mengakhiri proses pengisian formulir yang berulang, mempersingkat proses aplikasi dari 20 menit menjadi 2 detik (Sumber: Reddit)
📚 Pembelajaran
Stanford CS224N 2026 kembali: Menambahkan topik khusus Agent dan Reasoning : Kursus NLP klasik CS224N mengumumkan kembalinya. Tahun ini diajar oleh Diyi Yang dan Yejin Choi. Selain mencakup dasar-dasar NLP jaringan saraf, kursus ini akan menambah fokus pada AI Agent, penggunaan alat, serta dua kuliah khusus tentang “Reasoning”, mengikuti tren terdepan model besar (Sumber: Stanford)
Andrew Ng merilis “Build with Andrew”: Membangun aplikasi Web tanpa kode : Andrew Ng meluncurkan kursus baru dalam buletin mingguan The Batch, membimbing pemula untuk membangun dan merilis aplikasi Web yang berfungsi hanya melalui deskripsi ide dalam bahasa alami menggunakan alat AI. Kursus ini menekankan paradigma “AI sebagai pengembang”, menurunkan hambatan bagi orang awam untuk memasuki bidang pengembangan perangkat lunak (Sumber: DeepLearningAI)
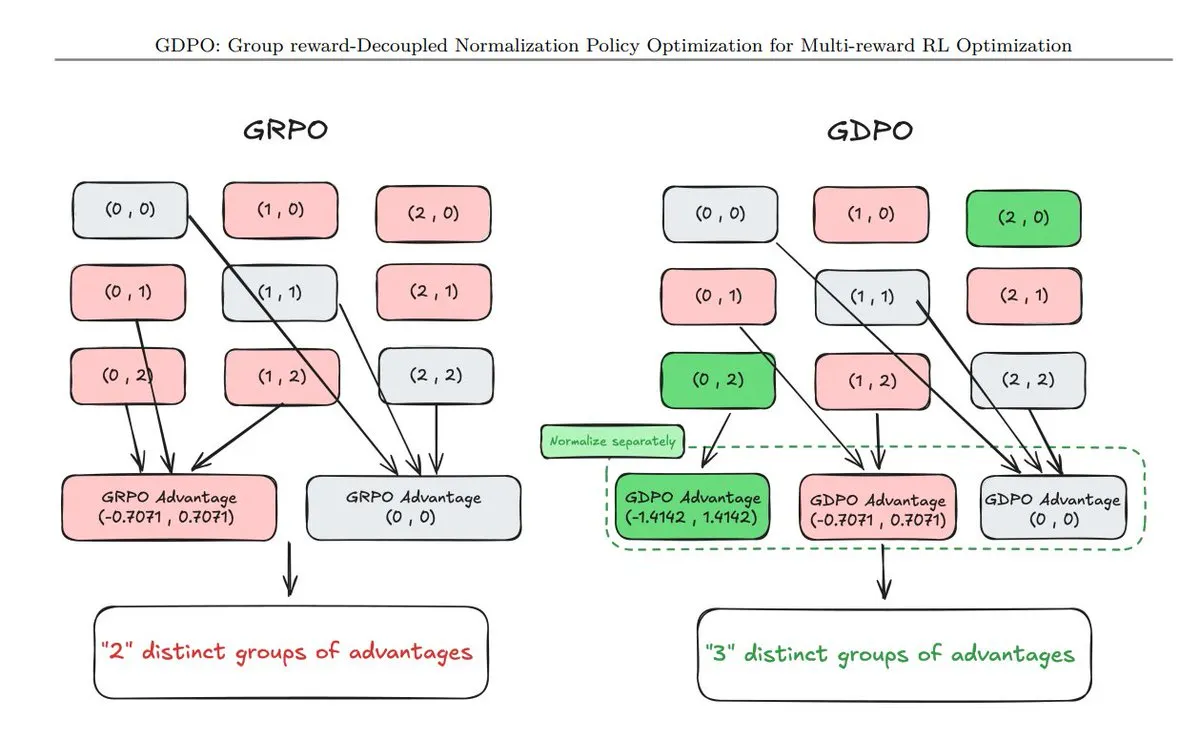
Ringkasan 11 teknik Policy Optimization baru : TuringPost merangkum 11 teknik Policy Optimization yang muncul baru-baru ini, termasuk GDPO (decoupled reward normalization), AT²PO (Agent turn-based PO berbasis tree search), dan PC-GRPO (Pigsaw Curriculum GRPO) yang banyak mendapat perhatian. Teknik-teknik ini adalah inti untuk meningkatkan rantai logika dan kemampuan penyelarasan tugas model besar (Sumber: TuringPost)
💼 Bisnis
OpenAI mengakuisisi startup medis Torch : OpenAI mengumumkan akuisisi Torch, sebuah startup AI medis yang mengintegrasikan hasil eksperimen, catatan obat, dan rekaman kunjungan dokter. Tim Torch akan bergabung dengan departemen ChatGPT Health. Langkah ini menunjukkan percepatan OpenAI dalam komersialisasi AI di bidang manajemen kesehatan dan bantuan klinis, berupaya menjadikan ChatGPT sebagai asisten kesehatan pribadi paling profesional di dunia (Sumber: OpenAI)

MiniMax melantai di bursa Hong Kong, melonjak 109% pada hari pertama : Unicorn AI China, MiniMax, resmi melantai di bursa Hong Kong pada 9 Januari 2026. Harga sahamnya melonjak 109% pada hari pertama dengan nilai pasar melampaui 150 miliar HKD. Keberhasilan MiniMax di pasar C-end melalui Talkie dan HaiLuo AI membuktikan bahwa jalur produk konsumen multimodal tanpa ketergantungan pada kontrak klien besar memiliki daya tarik tinggi di pasar modal (Sumber: TuringPost)
xAI membakar $28 juta per hari, valuasi menuju $230 miliar : Meskipun xAI mengalami kerugian hingga $7,8 miliar pada tiga kuartal pertama 2025, perusahaan baru-baru ini menyelesaikan pendanaan $20 miliar dengan valuasi mencapai $230 miliar. Elon Musk mendorong rencana “Macrohard” untuk membangun sistem AI otonom yang dapat menggerakkan robot Tesla. Model “investasi masif” ini mencerminkan hambatan masuk yang sangat tinggi bagi pemain AI papan atas dalam hal infrastruktur dan talenta (Sumber: 36氪)
🌟 Komunitas
Vibe Coding/Working memicu diskusi besar tentang identitas profesional : Seiring populernya Claude Cowork dan berbagai alat Agent, “Vibe Working” menjadi istilah populer. Komunitas berpendapat ini bukan sekadar peningkatan efisiensi, melainkan “monetisasi pengetahuan domain dalam otak”. Nilai insinyur masa depan akan beralih dari “menulis 100 ribu baris kode” menjadi “merancang sistem yang membiarkan AI menulis 100 ribu baris kode”. Namun, ada kekhawatiran hal ini akan menyebabkan penurunan kualitas kode (Slop) dan ketergantungan berlebih pada AI black box (Sumber: nearcyan, amasad)
Detektor AI disebut sebagai “penipuan murni” : Komunitas Reddit melontarkan kritik keras terhadap alat deteksi AI seperti GPTZero, menunjukkan tingkat false positive yang sangat tinggi, bahkan menandai Deklarasi Kemerdekaan sebagai 90% buatan AI. Pengguna berpendapat alat ini mengukur “keakraban statistik” bukan asal-usul, merugikan banyak penulis asli dan siswa. Dunia pendidikan menyerukan penghentian “perburuan penyihir” dan beralih menguji pemahaman serta aplikasi konten oleh siswa (Sumber: Reddit)
Pendiri DeepSeek Liang Wenfeng dijuluki sebagai “biksu penyapu” dunia AI : Komunitas mendiskusikan latar belakang dana kuantitatif pendiri DeepSeek, Liang Wenfeng. High-Flyer Quant yang dipimpinnya mencatat return 56,6% pada tahun 2025, jauh di atas rata-rata industri. Netizen kagum dengan investasinya yang bergaya “YOLO” ke AI dan rute teknis yang tidak biasa (seperti MLA, Engram), menunjukkan selera arsitektur dan efisiensi teknik yang sangat tinggi, dianggap sebagai variabel kunci AI China dalam melawan raksasa Silicon Valley (Sumber: teortaxesTex)
💡 Lainnya
Earphone AI Sweetpea kemungkinan dirilis September : Rumor produk hardware pertama OpenAI—dengan kode nama Sweetpea—dirancang oleh tim Jony Ive, berbentuk seperti batu logam dengan chip 2nm untuk mendukung inferensi lokal. OpenAI memperkirakan penjualan tahun pertama akan mencapai 50 juta unit, langsung menantang posisi AirPods di pasar (Sumber: 36氪)

Keamanan AI menjadi standar baru pemilihan perusahaan tahun 2026 : Seiring perluasan izin AI Agent, fokus perusahaan pada keamanan beralih dari “opsional” menjadi “prasyarat”. Survei menunjukkan 43% perusahaan menganggap keamanan sebagai hambatan utama implementasi AI. Tren tahun 2026 adalah kemampuan keamanan yang “built-in”, di mana audit dan isolasi izin diaktifkan secara default pada tahap pemanggilan model dan orkestrasi Agent (Sumber: 36氪)