
Palabras clave:Módulo Engram, Cowork, Colaboración Gemini, Mecanismo de búsqueda de conocimiento Transformer, Ejecución de tareas de Agente IA, Entrenamiento durante pruebas TTT-E2E
🔥 Focus
DeepSeek lanza el módulo Engram, logrando el desacoplamiento de almacenamiento y computación: DeepSeek, en colaboración con la Universidad de Pekín, ha publicado un artículo presentando el módulo de “memoria condicional” Engram. Esta tecnología, a través de embeddings de hash N-gram modernizados, dota a Transformer de un mecanismo nativo de “búsqueda de conocimiento”, logrando una recuperación determinista cercana a O(1). Los experimentos muestran que Engram-27B supera significativamente a los modelos puros de MoE bajo condiciones estrictas de igualdad de parámetros y cómputo. No solo mejora la reserva de conocimiento, sino que, al liberar a la atención de las capas superficiales de la carga de “memorización mecánica”, permite que las redes profundas se concentren en el razonamiento complejo, disparando las capacidades en código y matemáticas. Esta ruta de ingeniería, que descarga parámetros masivos a la memoria del host (CPU) con una pérdida de inferencia inferior al 3%, es considerada una primitiva central para la próxima generación de modelos grandes dispersos y es muy probable que se integre en el próximo DeepSeek-V4 (Fuente: GitHub)

Anthropic lanza Cowork, un producto estratégico que inicia la era del “colega digital”: Anthropic ha presentado oficialmente Cowork (versión Research Preview), encapsulando las capacidades subyacentes de Claude Code en una herramienta gráfica orientada a personal no técnico. Cowork permite que Claude acceda directamente a carpetas locales, con permisos para leer, editar y crear archivos. Ya no es solo un chatbot, sino un ente colaborativo inteligente capaz de planificar pasos de forma autónoma y procesar tareas en paralelo (como organizar carpetas de descargas, extraer datos de capturas de pantalla para generar Excel o redactar borradores de informes). El producto incluye un entorno de máquina virtual aislado para garantizar la seguridad y admite la automatización del navegador. La comunidad coincide en que esto marca un cambio de paradigma de la IA de “generación de contenido” a “ejecución de tareas”, lo que podría suponer un golpe disruptivo para muchas startups de aplicaciones de IA (Fuente: Anthropic)

Apple y Google alcanzan un acuerdo de colaboración para Gemini, Siri recibe un “cerebro externo”: Apple y Google emitieron un comunicado conjunto confirmando que los futuros Apple Foundation Models se construirán sobre el modelo Gemini de Google y su tecnología en la nube para potenciar el Siri personalizado que se lanzará a finales de este año. Se informa que Apple pagará aproximadamente 1.000 millones de dólares anuales. Esta colaboración es vista como una “concesión transitoria” de Apple ante el retraso de sus modelos de desarrollo propio; Gemini se encargará de tareas complejas como resúmenes y planificación, mientras que las funciones básicas en el dispositivo seguirán siendo soportadas por los modelos propios de Apple. Este movimiento ha llevado el valor de mercado de Google a superar los 4 billones de dólares por primera vez, al tiempo que ha provocado críticas de Elon Musk sobre la “excesiva concentración de poder” y debates sobre la marginación de OpenAI en el ecosistema de Apple (Fuente: Google)

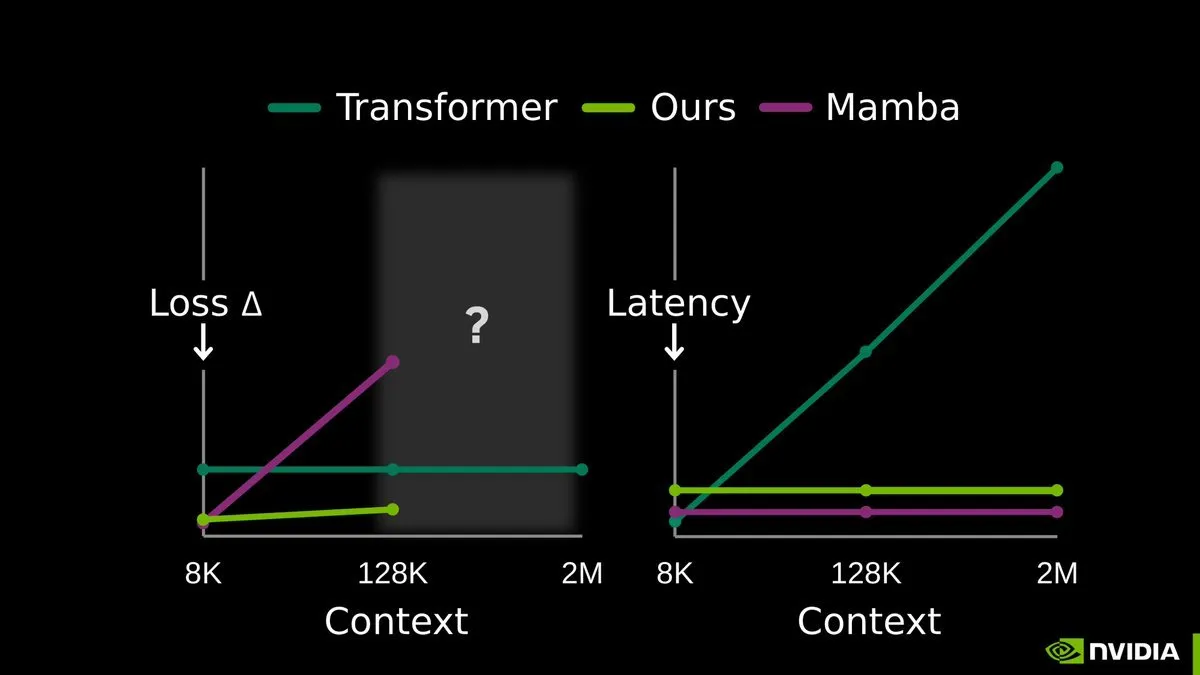
TTT-E2E: El entrenamiento en tiempo de prueba de extremo a extremo abre una nueva era de memoria larga para LLM: La investigación End-to-End Test-Time Training (TTT-E2E), publicada conjuntamente por NVIDIA, Stanford y el Astera Institute, ha causado sensación. Esta tecnología sostiene que no se necesita una arquitectura radicalmente nueva, sino que, mediante el uso del contexto como datos de entrenamiento durante la fase de inferencia (tiempo de prueba), se actualizan continuamente los pesos del modelo a través de la predicción del siguiente Token. Este método comprime la experiencia de contextos largos en los pesos del modelo, resolviendo eficazmente el problema de la explosión de la KV cache con la longitud de la secuencia. TTT convierte al modelo en un verdadero “aprendiz continuo”, mostrando una estabilidad extrema al procesar secuencias ultra largas de millones de Tokens, y es considerada la ruta más prometedora hacia el modelado de secuencias puramente sub-cuadráticas (Fuente: arXiv)
🎯 Tendencias
Sakana AI lanza DroPE: descartar embeddings de posición para lograr la extrapolación de textos largos: El equipo de Llion Jones, autor principal de Transformer, ha liberado la tecnología DroPE, proponiendo que los embeddings de posición son solo “ruedas de entrenamiento”. DroPE descarta el Rotary Positional Encoding (RoPE) durante la fase de inferencia y solo requiere menos del 1% del presupuesto de pre-entrenamiento para una calibración breve, desbloqueando ventanas de contexto masivas. Los experimentos muestran que este método supera significativamente al escalado tradicional de RoPE en las pruebas LongBench y “Needle In A Haystack”, ofreciendo una nueva vía para expandir la capacidad de textos largos a bajo costo (Fuente: arXiv)
BabyVision: la capacidad visual de los modelos de IA más avanzados es inferior a la de un niño de 3 años: La evaluación BabyVision, publicada por Sequoia China xbench y UniPatAI, muestra que en tareas visuales con dependencia lingüística estrictamente controlada, la gran mayoría de los modelos rinden mucho peor que un niño de 3 años. Incluso Gemini 3 Pro, el de mejor desempeño, apenas logra aprobar. El estudio señala que la excesiva dependencia de los modelos en el razonamiento lingüístico oculta sus deficiencias sistemáticas en percepción espacial, seguimiento de trayectorias e intuición geométrica; la futura inteligencia multimodal debe reconstruir fundamentalmente la capacidad visual (Fuente: 36氪)

Recursive Language Models (RLM): DeepMind explora la memoria perfecta sin RAG: Investigadores de DeepMind han propuesto los Recursive Language Models (RLM), que permiten que el modelo se introspeccione, se divida y se llame a sí mismo de forma recursiva para procesar millones de Tokens. Este mecanismo rompe las limitaciones de las ventanas de contexto tradicionales; el modelo ya no depende de RAG externo, sino que logra una “memoria perfecta” de información masiva mediante la agregación recursiva de resultados. Este avance augura un cambio cualitativo en la forma en que la IA procesará documentos ultra largos en el futuro (Fuente: HuggingFace)

La expansión de la IA de ByteDance en el extranjero entra en una nueva fase de “herramientas de eficiencia”: ByteDance ha intensificado recientemente su presencia en el extranjero con el lanzamiento de AnyGen, un Agent para escenarios de trabajo que compite con Manus, centrado en entregas de alta calidad como redacción de documentos y análisis de datos. Al mismo tiempo, su asistente de IA en el extranjero, Dola, ha superado los diez millones de usuarios activos diarios. ByteDance intenta pasar de “exportar felicidad” (TikTok) a “vender eficiencia”, compitiendo directamente con OpenAI y Anthropic en el sector de los Agent de oficina (Fuente: 36氪)

🧰 Herramientas
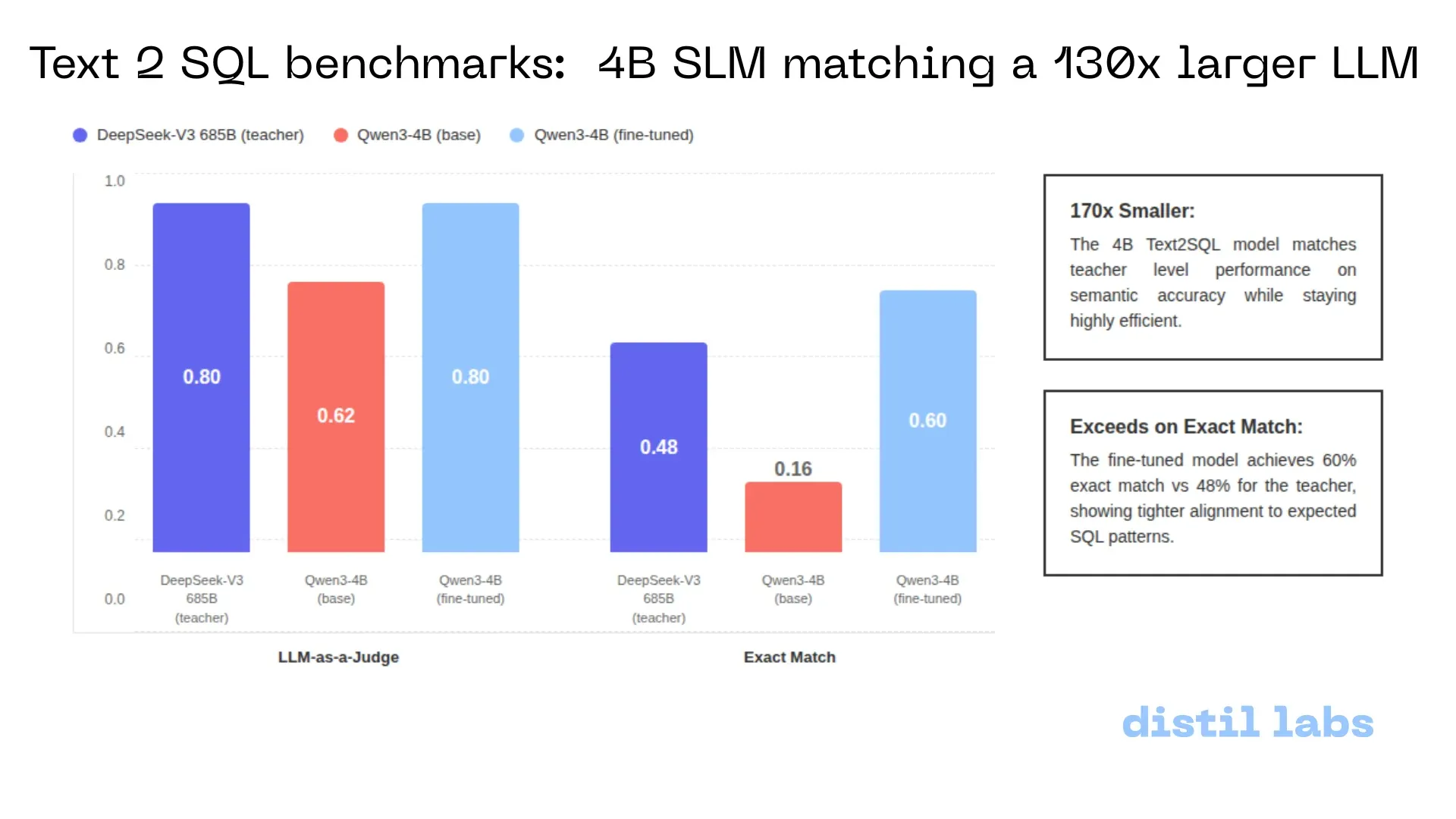
Distil-Text2SQL: un modelo pequeño de 4B logra una precisión de nivel 685B localmente: Distil-labs, mediante el ajuste fino de Qwen3-4B, ha logrado que este alcance la precisión semántica de DeepSeek-V3 (685B) en tareas de Text2SQL, superándolo incluso en la métrica de “coincidencia exacta”. El modelo admite ejecución local, procesa datos CSV sin necesidad de subirlos a la nube y tiene un tiempo de respuesta inferior a 2 segundos, demostrando el enorme potencial de los modelos pequeños para reemplazar a los gigantes en tareas verticales (Fuente: GitHub)
Actualización de LlamaParse: OCR preciso de gráficos e imágenes a bajo costo: LlamaIndex ha actualizado su herramienta de análisis LlamaParse al modo Agentic, optimizándola específicamente para elementos visuales complejos en documentos (como gráficos de líneas, de sectores y diagramas de flujo). En comparación con alimentar una captura de pantalla completa a un VLM, esta herramienta identifica los cuadros delimitadores de los subelementos y extrae la lógica numérica, convirtiéndola en Markdown de alta calidad. Es una de las soluciones más económicas y eficientes para manejar información no textual en documentos profesionales (Fuente: jerryjliu0)
Wobo: el “Tinder para buscar empleo” basado en AI Agent: Wobo es una aplicación para iOS que utiliza un AI Agent para automatizar el envío de currículums. El usuario solo necesita subir su currículum una vez; la IA analiza su “personalidad profesional” y, cuando el usuario desliza a la derecha en un puesto de su interés, navega automáticamente a sitios web externos complejos, genera cartas de presentación personalizadas y responde preguntas de filtrado. La herramienta busca terminar con el tedioso proceso de rellenar formularios repetitivos, reduciendo un proceso de solicitud de 20 minutos a solo 2 segundos (Fuente: Reddit)
📚 Aprendizaje
Regreso de Stanford CS224N 2026: se añaden temas especiales sobre Agent y razonamiento: El clásico curso de procesamiento de lenguaje natural CS224N ha anunciado su regreso. El curso de este año será impartido conjuntamente por Diyi Yang y Yejin Choi. Además de cubrir los fundamentos de NLP con redes neuronales, se centrará en añadir contenido sobre AI Agent, uso de herramientas y dos conferencias dedicadas específicamente al “Razonamiento (Reasoning)”, siguiendo las tendencias de vanguardia de los modelos grandes (Fuente: Stanford)
Andrew Ng lanza “Build with Andrew”: construcción de aplicaciones Web sin código: Andrew Ng ha presentado un nuevo curso en su último boletín semanal The Batch, guiando a principiantes sobre cómo construir y publicar aplicaciones Web funcionales utilizando herramientas de IA basándose únicamente en descripciones de ideas en lenguaje natural. El curso enfatiza el paradigma de la “IA como desarrollador”, reduciendo la barrera de entrada al desarrollo de software para el público general (Fuente: DeepLearningAI)
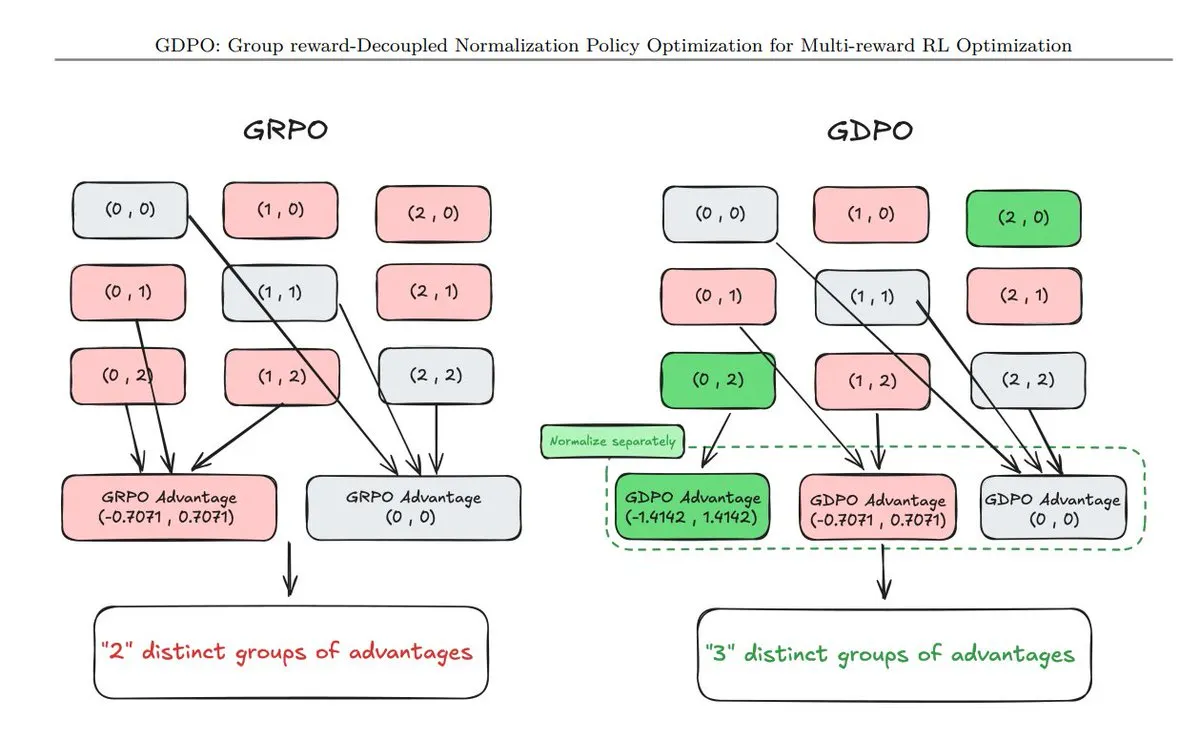
Resumen de 11 nuevas técnicas de optimización de políticas: TuringPost ha recopilado 11 técnicas recientes de optimización de políticas (Policy Optimization), incluyendo GDPO (normalización de desacoplamiento de recompensa), AT²PO (PO por turnos para Agent basado en búsqueda de árboles) y el muy seguido PC-GRPO (GRPO de currículo de rompecabezas). Estas técnicas son fundamentales para mejorar la cadena lógica y la capacidad de alineación de tareas de los modelos grandes (Fuente: TuringPost)
💼 Negocios
OpenAI adquiere la startup médica Torch: OpenAI ha anunciado la adquisición de Torch, una startup de IA médica que integra resultados experimentales, registros de medicamentos y grabaciones de consultas. El equipo de Torch se unirá al departamento de ChatGPT Health. Este movimiento muestra que OpenAI está acelerando la comercialización de la IA en los campos de la gestión de la salud y la asistencia clínica, buscando convertir a ChatGPT en el asistente de salud personal más profesional del mundo (Fuente: OpenAI)

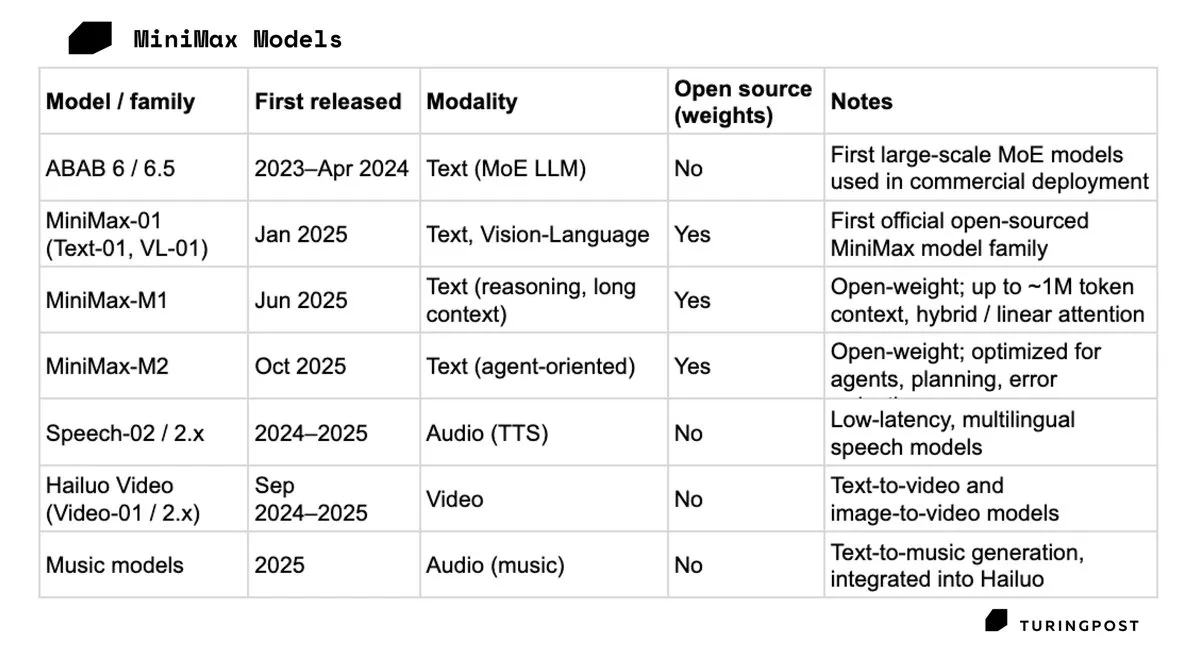
MiniMax sale a bolsa en Hong Kong, subiendo un 109% en su primer día: El unicornio chino de IA MiniMax salió a bolsa en Hong Kong el 9 de enero de 2026, con el precio de sus acciones disparándose un 109% en el primer día, superando una valoración de 150.000 millones de dólares de Hong Kong. MiniMax, gracias al éxito de Talkie y HaiLuo AI en el mercado C-end, ha demostrado el atractivo para el mercado de capitales de una ruta que no depende de contratos con grandes clientes y se profundiza en productos multimodales para el consumidor. Esta IPO se considera un paso clave para obtener “oxígeno” en la feroz competencia por el poder de cómputo (Fuente: TuringPost)
xAI gasta 28 millones de dólares diarios, su valoración se acerca a los 230 mil millones: A pesar de que xAI registró pérdidas de hasta 7.800 millones de dólares en los tres primeros trimestres de 2025, recientemente completó una financiación de 20.000 millones de dólares, alcanzando una valoración de 230.000 millones. Musk está impulsando con todas sus fuerzas el plan “Macrohard”, destinado a construir un sistema de IA autónomo capaz de propulsar a los robots de Tesla. Este modelo de “inversión masiva” refleja las altísimas barreras de entrada en infraestructura y talento para los principales actores de la IA (Fuente: 36氪)
🌟 Comunidad
Vibe Coding/Working provoca un gran debate sobre la identidad profesional: Con la popularización de Claude Cowork y diversas herramientas de Agent, el término “Vibe Working” se ha vuelto viral. La comunidad debate que esto no es una simple mejora de la eficiencia, sino una “monetización del conocimiento de dominio en el cerebro”. El valor de los futuros ingenieros pasará de “escribir 100.000 líneas de código” a “diseñar sistemas que permitan a la IA escribir 100.000 líneas de código”. Sin embargo, a algunos les preocupa que esto lleve a una “producción descuidada (Slop)” de código y a una dependencia excesiva de las cajas negras de la IA (Fuente: nearcyan, amasad)
Los detectores de IA son señalados como una “estafa pura”: La comunidad de Reddit ha lanzado duras críticas contra herramientas de detección de IA como GPTZero, señalando que su tasa de falsos positivos es extremadamente alta, llegando incluso a marcar la Declaración de Independencia como 90% generada por IA. Los usuarios sostienen que estas herramientas miden la “familiaridad estadística” y no el origen, lo que perjudica injustamente a autores originales y estudiantes. El sector educativo pide detener la “caza de brujas” y centrarse en evaluar la comprensión y aplicación del contenido por parte de los estudiantes (Fuente: Reddit)
El fundador de DeepSeek, Liang Wenfeng, es aclamado como el “monje barrendero” del mundo de la IA: La comunidad comenta con entusiasmo el trasfondo en fondos cuantitativos del fundador de DeepSeek, Liang Wenfeng. Su firma, High-Flyer Quant, obtuvo un rendimiento de hasta el 56,6% en 2025, superando con creces el promedio de la industria. Los internautas admiran cómo invierte el dinero ganado en el sector cuantitativo en la IA al estilo “YOLO”, y cómo sigue rutas tecnológicas poco convencionales (como MLA, Engram), demostrando un alto gusto arquitectónico y eficiencia de ingeniería, siendo visto como una variable clave de la IA china frente a los gigantes de Silicon Valley (Fuente: teortaxesTex)
💡 Otros
Los auriculares de IA Sweetpea podrían lanzarse en septiembre: Rumores indican que el primer producto de hardware de OpenAI, con el nombre en clave Sweetpea, está siendo diseñado por el equipo de Jony Ive. Con una apariencia similar a un guijarro metálico, integraría un chip de 2nm para soportar inferencia local. OpenAI estima que las ventas del primer año alcanzarán los 50 millones de unidades, desafiando directamente la posición de mercado de los AirPods (Fuente: 36氪)

La seguridad de la IA se convierte en el nuevo estándar para la selección de empresas en 2026: Con la expansión de los permisos de los agentes de IA, la preocupación de las empresas por la seguridad ha pasado de ser una “opción” a una “condición previa”. Una encuesta muestra que el 43% de las empresas ven la seguridad como el principal obstáculo para la implementación de la IA. La tendencia para 2026 es la “seguridad integrada”, es decir, habilitar por defecto la auditoría y el aislamiento de permisos durante las llamadas a modelos y la orquestación de Agent (Fuente: 36氪)