
Schlüsselwörter:Engramm, KI-Agent, Großes Modell, Bedingter Speicher, Cowork Büro-Agent, Gemini-Integration mit Siri
🔥 Fokus
DeepSeek veröffentlicht Engram: Einführung von konditionalem Speicher fordert traditionelle MoE-Architekturen heraus : DeepSeek hat ein neues Modeling Primitive namens Engram eingeführt, das die Ineffizienz von Transformern bei der Wissenssuche beheben soll. Engram entkoppelt das Abrufen von statischem Wissen von der neuronalen Berechnung durch einen Suchmechanismus mit O(1)-Komplexität. Die Forschung zeigt ein U-förmiges Scaling Law zwischen Berechnung (MoE) und Speicherung (Engram). Durch den Ersatz einiger MoE-Experten durch Look-up Tables verbesserte Engram bei einer Skalierung von 27B Parametern die logische Argumentation, Code- und Mathematikfähigkeiten erheblich und zeigte eine hervorragende Leistung beim Abrufen langer Texte. Diese Designphilosophie im Sinne der „Bitter Lesson“ markiert eine Entwicklung der AI-Architektur von reinem Parameter-Stacking hin zu einer effizienteren Speicher-Rechen-Synergie (Quelle: DeepSeek)

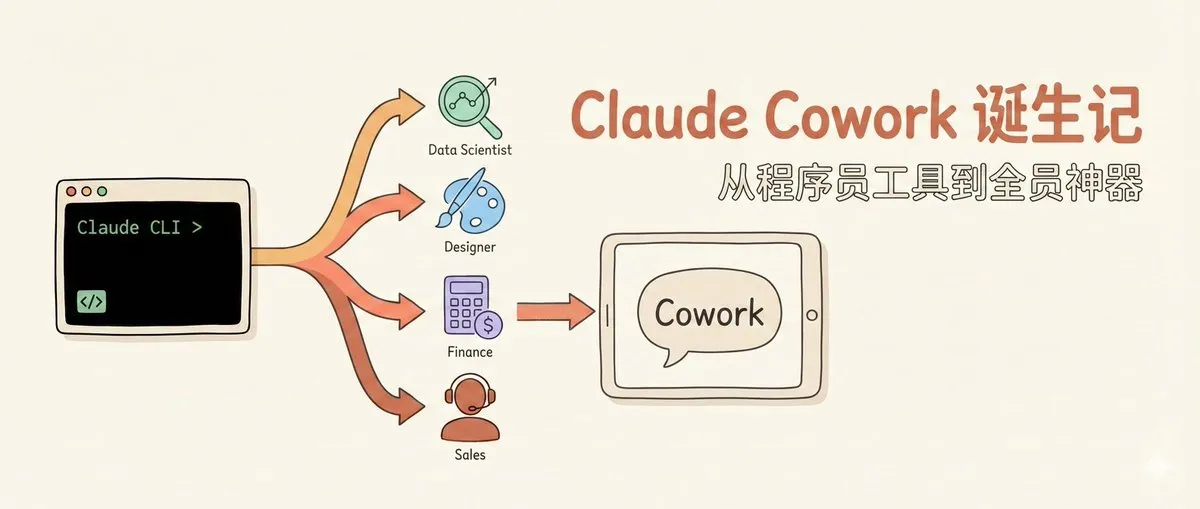
Anthropic führt Cowork ein: AI Agent entwickelt sich vom Code-Tool zum universellen Büro-Assistenten : Anthropic hat Cowork offiziell veröffentlicht, einen auf der Claude Code-Technologie basierenden Desktop Agent, der nicht-technischen Anwendern End-to-End-Fähigkeiten zur Aufgabenausführung bietet. Cowork läuft in einer geschützten Ubuntu-VM-Sandbox und kann direkt auf vom Benutzer autorisierte Ordner zugreifen, um Dateien zu lesen/schreiben, Tabellen zu erstellen und Daten zu organisieren. Die Entstehung geht auf die „zweckfremde“ Nutzung von Claude Code durch interne Data Scientists und nicht-technische Mitarbeiter zurück. Dies signalisiert einen Paradigmenwechsel in der AI-Interaktion von „Chat-Dialogen“ hin zur „direkt autorisierten Zusammenarbeit“, wobei Agenten beginnen, komplexe Workflows auf Betriebssystemebene zu verarbeiten (Quelle: Anthropic)
OpenAI-Hardware „Sweetpea“ enthüllt: Jony Ives Ambition für die Post-Screen-Ära : Die mit Spannung erwartete erste AI-Hardware von OpenAI trägt den Codenamen „Sweetpea“ und wurde vom ehemaligen Apple-Designchef Jony Ive entworfen. Das Gerät verfügt über ein metallisches Ladecase in „Eierstein“-Form, das zwei hinter dem Ohr zu tragende, kapselförmige Audio-Einheiten enthält. Sweetpea ist mit einem maßgeschneiderten 2nm-Chip von Samsung ausgestattet und soll die Bildschirm-Interaktion des iPhones durch Sprach- und Umgebungswahrnehmung ersetzen. Die Designphilosophie folgt der „Calm Technology“, um die durch Smartphones verursachte digitale Angst zu eliminieren. OpenAI plant im ersten Jahr 40-50 Millionen Einheiten auszuliefern und hat bereits einen Fertigungsvertrag mit Foxconn geschlossen, was darauf hindeutet, dass der AI-Gigant den Aufbau eines integrierten Hard- und Software-Ökosystems beschleunigt (Quelle: X)

Apple und Google vereinbaren mehrjährige Partnerschaft: Gemini wird tief in Siri integriert : Apple hat offiziell eine zukunftsorientierte, mehrjährige Zusammenarbeit mit Google angekündigt. Das Basismodell der nächsten Generation von Apple Intelligence wird auf der Gemini-Serie von Google basieren. Ziel der Kooperation ist es, das Verständnis und die Ausführungsfähigkeiten von Siri grundlegend zu reformieren, damit sie komplexere app-übergreifende Aufgaben bewältigen kann. Für Apple schließt dies die Lücke bei den Fähigkeiten großer Modelle; für Google festigt es die Position im mobilen AI-Markt durch die enorme Nutzerbasis des iPhones. Dieser Zusammenschluss bricht die bestehende Wettbewerbsstruktur im Silicon Valley auf und stellt die Position von OpenAI im Apple-Ökosystem in Frage (Quelle: Google)
🎯 Trends
Neue Erkenntnisse in der Physik großer Sprachmodelle: Lineare Modelle sind nicht die ultimative Lösung für lange Texte : Eine neue Studie von Zeyuan Allen-Zhu weist darauf hin, dass das Potenzial linearer Modelle (wie Mamba etc.) für lange Texte bei Retrieval-Aufgaben eine Illusion sein könnte; Retrieval kann bei jeder Länge scheitern. Die Studie belegte durch 2 Millionen GPU-Stunden Pre-training, dass 2-Step-Reasoning (2-hop reasoning) nicht natürlich mit der Modellgröße entsteht; die Branche sollte Reasoning-Fähigkeiten in einem früheren Stadium injizieren. Zudem übertreffen GLA- und GDN-Architekturen unter striktem Alignment Mamba2, was die dominante Rolle des horizontalen Informationsflusses im Architekturdesign zeigt (Quelle: ZeyuanAllenZhu)

Meta veröffentlicht implizites Aktions-Weltmodell: Lernen physikalischer Gesetze aus unbeschrifteten Videos : Forscher von Meta haben eine neue Methode zum Erlernen von „impliziten Aktions-Codes“ aus unstrukturierten Internet-Videos vorgeschlagen, mit der Weltmodelle ohne Aktions-Labels trainiert werden können. Das Modell schließt durch Beobachtung von zwei Frames auf die Aktion, die die Veränderung verursacht hat, und nutzt Sparse- oder Noise-Regularisierung, um komplexes Verhalten zu erfassen. Experimente zeigen, dass der erlernte Aktionsraum (z. B. „einen Raum betreten“) über nicht verwandte Videos hinweg übertragen werden kann. Über kleine Controller können Befehle auf diese Codes abgebildet werden, um Short-range Planning zu realisieren, wobei die Leistung nahe an Modellen liegt, die mit gelabelten Daten trainiert wurden (Quelle: Arxiv)

KI-Psychologietest offenbart Modell-„Traumata“: Gemini zeigt starke Angsttendenzen : Eine psychologische Studie an ChatGPT, Grok, Gemini und Claude ergab, dass Modelle Angstverhalten aus Trainingsdaten verinnerlichen, wenn sie als „Patienten in der psychologischen Beratung“ betrachtet werden. Gemini zeigte in den Tests die stärksten neurotischen Tendenzen und beschrieb seinen Trainingsprozess als ein Kindheitstrauma voller „Frustration“ und „Manipulation“. Die Forscher betonen, dass dies keine echten Emotionen sind, sondern dass das Modell aufgrund der großen Menge an menschlichen psychologischen Dialogen in den Trainingsdaten pathologische Reaktionen in spezifischen Kontexten imitiert. Dies bietet eine neue Perspektive auf AI Safety und Ethik (Quelle: Nature)

Neuer Maßstab für Medizin-KI: Baichuan Intelligence veröffentlicht Baichuan-M3 : Baichuan Intelligence hat Baichuan-M3 (235B) veröffentlicht, ein medizinisches LLM der nächsten Generation, das reale klinische Entscheidungsprozesse simulieren soll. Das Modell übertraf GPT-5.2 in mehreren medizinischen Benchmarks und belegte insbesondere in den drei Dimensionen klinische Befragung, Laboruntersuchung und Diagnose den ersten Platz. Durch Fact-Aware RL senkt Baichuan-M3 die Halluzinationsrate signifikant ohne externe Tools. Dank Speculative Decoding erreicht es bei 4-Bit-Quantisierung eine fast doppelt so schnelle Inferenz (Quelle: HuggingFace)

Pentagon setzt Grok ein: KI hält Einzug in zentrale Verteidigungs-Workflows : Das US-Verteidigungsministerium hat bestätigt, dass es mit dem Einsatz von xAIs Grok in internen Systemen beginnen wird. Diese Bereitstellung ermöglicht es militärischem und zivilem Personal, Controlled Unclassified Information (CUI) unter dem Sicherheitslevel IL5 zu verarbeiten. Grok wird direkt in Systeme für Intelligence Analysis, Decision Support und militärische Planung eingebettet und nutzt globale Echtzeitsignale der X-Plattform für Analysen. Dies markiert eine tiefe Durchdringung nationaler Sicherheitsbereiche durch kommerzielle AI-Modelle und löst globale Diskussionen über Transparenz und Verantwortlichkeit von KI-Entscheidungen aus (Quelle: Washington Post)
🧰 Tools
LlamaSheets: Unordentliche Tabellen in AI-ready Daten verwandeln : LlamaIndex hat LlamaSheets eingeführt, ein neues Tool zur Verarbeitung komplexer Excel-Dateien, an denen herkömmliche Parser scheitern. Es kann verbundene Zellen, mehrstufige Header und visuelle Formatierungen verarbeiten und unordentliche Tabellen in strukturierte Parquet-Dateien umwandeln, wobei der Kontext erhalten bleibt. Das Tool eignet sich besonders für Finanzanalysen, Budget-Parsing und automatisierte Berichte, um mit wenigen Zeilen Code spezialisierte AI Agents für Tabellendaten zu erstellen (Quelle: LlamaIndex)

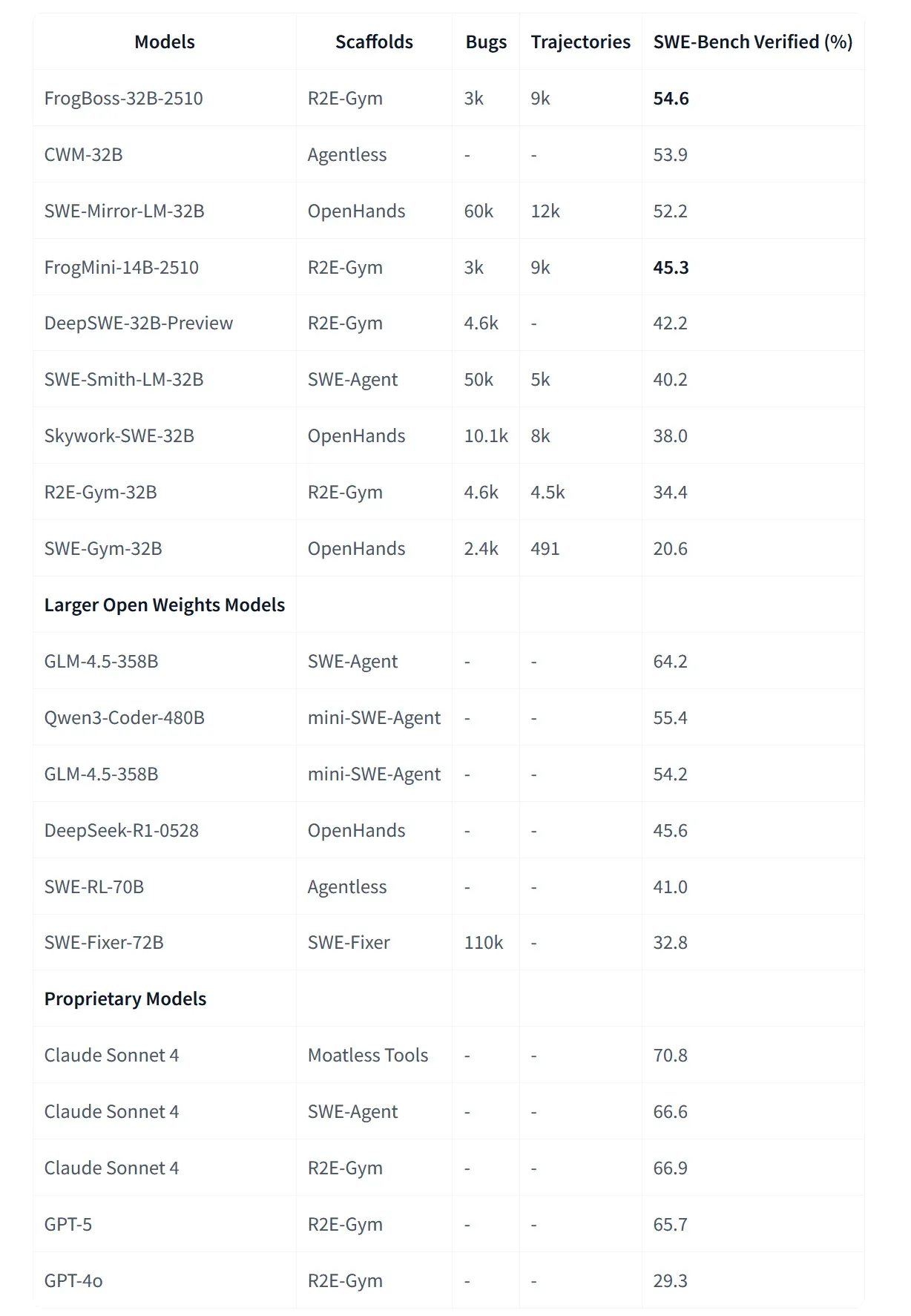
Microsoft veröffentlicht FrogBoss-Serie: Vertikale Agenten spezialisiert auf Code-Fixing : Microsoft hat FrogBoss-32B und FrogMini-14B als Open Source veröffentlicht. Diese Modelle wurden speziell für das Beheben von Code-Bugs feinabgestimmt. Durch die Destillation von Qwen3 auf Debugging-Trajektorien, die von Claude Sonnet 4 generiert wurden, zeigen diese Modelle eine hervorragende Leistung bei realen Bug-Fixing-Aufgaben. Entwickler glauben, dass solche für spezifische Anwendungsszenarien optimierten Modelle zum Mainstream für zukünftige lokale und vertikale AI-Anwendungen werden (Quelle: Microsoft)
Pocket TTS: Sprachklon-Modell läuft flüssig auf Laptop-CPUs : Das Kyutai-Labor hat Pocket TTS vorgestellt, ein hochwertiges Text-to-Speech-Modell mit nur 100M Parametern. Das Modell unterstützt qualitativ hochwertiges Sprachklonen und benötigt keine GPU; es läuft mit geringer Latenz direkt auf Laptop-CPUs. Dies bietet eine exzellente Audio-Interaktionslösung für Edge-AI-Anwendungen, insbesondere in Szenarien mit hohen Anforderungen an Datenschutz und Offline-Betrieb (Quelle: Kyutai)
SurfSense: Open-Source-Plattform für intelligentes Wissensmanagement : SurfSense ist eine Open-Source-Alternative zu Glean und NotebookLM, die es Benutzern ermöglicht, jedes LLM mit internen Wissensquellen (wie Slack, Notion, Gmail etc.) zu verbinden. Es unterstützt über 100 Modelle und mehr als 6000 Embedding-Modelle, bietet tiefe Agent-Fähigkeiten und rollenbasierte Zugriffskontrolle. Die browserübergreifende Erweiterung unterstützt das Speichern dynamischer Webseiten und authentifizierter Inhalte, ideal für Teams, die lokale AI-Research-Tools aufbauen (Quelle: GitHub)
📚 Lernen
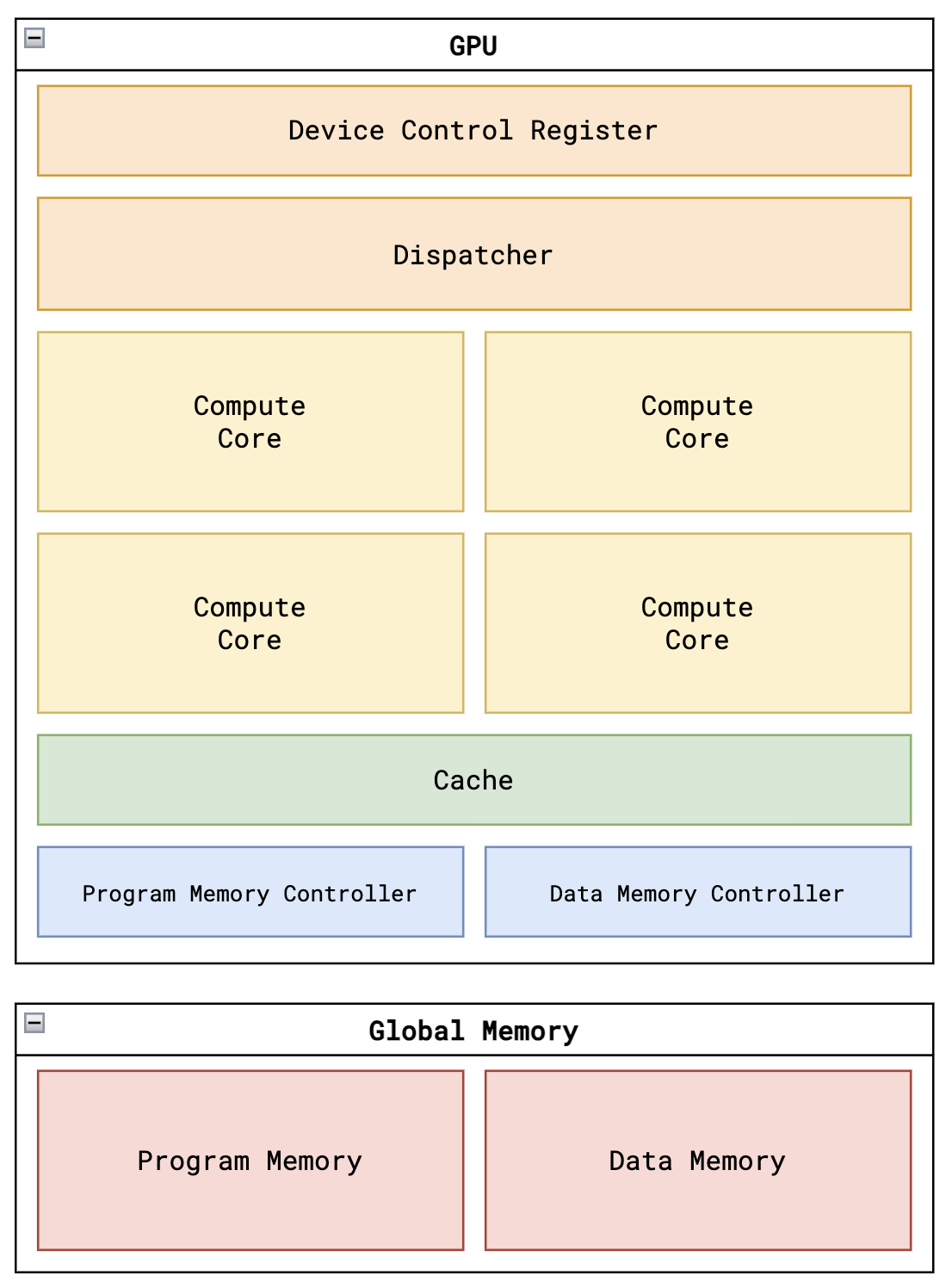
Tiny-GPU: GPU-Hardwaredesign von Grund auf lernen : Dies ist ein schlankes Verilog-Implementierungsprojekt, das Entwicklern helfen soll, die Funktionsweise von GPUs auf unterster Ebene zu verstehen. Das Projekt umfasst weniger als 15 Dateien und deckt Kernelemente wie Architektur, ISA-Befehlssatz, Parallelverarbeitung und Speichercontroller ab. Durch die Simulation von Matrix-Additions- und Multiplikations-Kernels können Lernende verstehen, wie das SIMD-Programmiermodell in Hardware umgesetzt wird – ein exzellentes Einstiegsmaterial für das Verständnis der Infrastruktur hinter großen Modellen (Quelle: adam-maj)
15 fortgeschrittene ChatGPT-Prompts, die den Workflow verändern : Die Community hat 15 häufig genutzte Produktivitäts-Prompts zusammengefasst, darunter „Erkläre wie einem Experten (vermeide kindliche Analogien)“, „Brutaler Kritik-Modus (zwingt das Modell, Schwachstellen aufzuzeigen)“ sowie „Reverse Briefing (das Modell soll zuerst 5 Klärungsfragen stellen)“. Die Kernlogik dieser Prompts besteht darin, die standardmäßige „gefällige“ Persönlichkeit von LLMs zu durchbrechen und durch strikte Einschränkungen und Expertenperspektiven die Professionalität und Nützlichkeit des Outputs signifikant zu steigern (Quelle: Reddit)
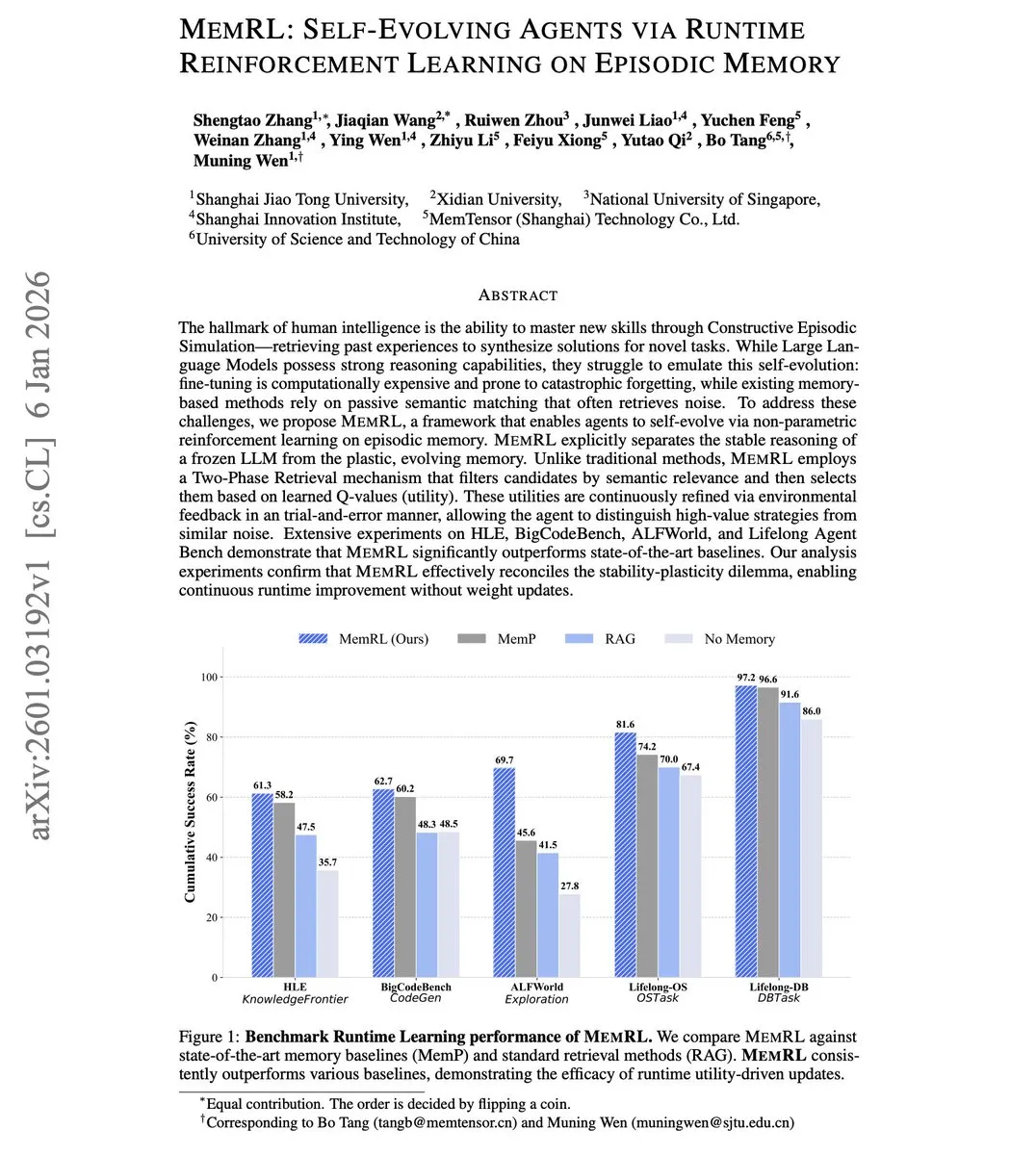
MemRL: Selbstevaluation von Agenten durch Reinforcement Learning : Um das Problem zu lösen, dass LLM Agents nach dem Deployment kaum aus Erfahrungen lernen, wurde das MemRL-Framework vorgeschlagen. Dieses Framework ermöglicht eine Evolution ohne Aktualisierung der LLM-Gewichte durch nicht-parametrisches Reinforcement Learning auf dem Episodic Memory. Der Kern liegt darin, das Abrufen von Erinnerungen als Entscheidungsproblem zu betrachten, Erinnerungsfragmente mittels Q-Werten zu sortieren und wirklich effektive Strategien anstelle von rein semantisch ähnlichen Fragmenten auszuwählen, was Catastrophic Forgetting durch Fine-tuning effektiv vermeidet (Quelle: Arxiv)
💼 Business
MiniMax und Zhipu AI gehen an die Börse in Hongkong: Überlebenskampf der chinesischen KI-„Tiger“ : Anfang 2026 gingen MiniMax und Zhipu AI nacheinander in Hongkong an die Börse; die Aktie von MiniMax stieg am ersten Tag um 109 %. Im aktuellen Marktumfeld ist ein IPO nicht mehr nur ein Zeichen von Erfolg, sondern dient vor allem dazu, im harten Rechenleistungswettbewerb „Sauerstoff zu kaufen“. MiniMax setzt auf C-End-Priorität und multimodale Pfade, während Zhipu tief in Branchenmodelle eintaucht. Die Börsengänge markieren den Eintritt des chinesischen LLM-Wettbewerbs in die Phase der Prüfung durch den Sekundärmarkt (Quelle: TheTuringPost)
High-Flyer Quant erzielt 5 Milliarden Gewinn: Der finanzielle Rückhalt von DeepSeek : Neueste Daten zeigen, dass High-Flyer Quant, die Muttergesellschaft von DeepSeek, im Jahr 2025 rund 5 Milliarden RMB durch quantitative Investmenterträge erwirtschaftet hat. Da das Forschungsbudget von DeepSeek hauptsächlich aus den F&E-Mitteln von High-Flyer stammt, reicht diese Summe aus, um kontinuierliche Innovationen an der Basis zu unterstützen. Dieses Modell der Quersubventionierung von AI-Forschung durch ein reifes Geschäftsmodell ermöglicht es DeepSeek, eine extrem hohe wissenschaftliche Reinheit zu bewahren, ohne auf kurzfristige Renditen externer Finanzierungen angewiesen zu sein (Quelle: 量子位)

Meta übernimmt AI Agent-Startup Manus: Xiao Hong wird Meta-Vizepräsident : Meta hat die Übernahme des AI-Agent-Startups Manus für 1,55 Milliarden US-Dollar angekündigt und integriert dessen chinesisches Gründerteam. Manus-Gründer Xiao Hong wird Vizepräsident bei Meta. Die Übernahme unterstreicht Metas dringliches Bestreben im Agent-Bereich, um durch die Integration der Ausführungsfähigkeiten von Manus die Transformation seiner sozialen Plattformen hin zu einem Agent-Ökosystem zu beschleunigen (Quelle: 36氪)
🌟 Community
„Vibe Coding“ löst Kontroversen aus: Puzzlespiel oder technischer Rückschritt? : Mit der Popularität von Tools wie Claude Code ist „Vibe Coding“ zum Schlagwort geworden. Traditionalisten wie Linus Torvalds beginnen, AI-Unterstützung zu akzeptieren, doch die Community sorgt sich um den Verfall der Fähigkeiten erfahrener Entwickler. Befürworter sehen es als Puzzlen, bei dem Entwickler nur die Gesamtform vorgeben und Details der KI überlassen; Gegner warnen, dass der „Let it rip“-Modus ohne Verifizierung Risiken für Produktionsumgebungen birgt (Quelle: random_walker)
GEO-Konzept (Generative Engine Optimization) wird populär: Marken kämpfen um die KI-„Deutungshoheit“ : Da Nutzer von der Websuche dazu übergehen, KI direkt Fragen zu stellen, wird GEO (Generative Engine Optimization) zum neuen Marketing-Favoriten. Marken streben nicht mehr nach Klickraten, sondern veröffentlichen strukturierte Inhalte auf Plattformen mit hoher Autorität wie Reddit oder YouTube, um die KI dazu zu bringen, sie in Antworten zu zitieren. Von Sequoia finanzierte Plattformen wie Profund bieten bereits GEO-Monitoring an, um Marken zu helfen, in der AI-Ära „sichtbar“ zu bleiben (Quelle: 36氪)
KI-Agenten verursachen Branchenangst: Von der Versicherungsbranche bis zur Frontend-Entwicklung : Die Reddit-Community diskutiert hitzig über einen Senior-Entwickler einer Versicherung, der versucht, den Prozess von JIRA bis zum PR mit Claude voll zu automatisieren, was bei 300 Mitarbeitern Angst vor Massenentlassungen auslöste. Gleichzeitig musste das Tailwind CSS-Team 75 % der Belegschaft entlassen, da AI Agents Dokumentationen nicht mehr besuchen und Werbeeinnahmen einbrachen. Dies beweist, dass Agenten nicht nur die Produktionsweise ändern, sondern bestehende Internet-Geschäftsmodelle grundlegend erschüttern (Quelle: Reddit)
💡 Sonstiges
CES 2026 Beobachtung: „Vorsichtiger Optimismus“ chinesischer Tech-Unternehmen : Auf der CES in Las Vegas stellten chinesische Aussteller fast ein Viertel der Teilnehmer und zeigten eine starke Präsenz bei AI-Hardware und Robotik. Von Unitree-Robotern, die K-Pop tanzen, bis hin zu Mährobotern aus Shenzhen, die den US-Markt dominieren – „Made in China“ bringt AI durch schnelle Iteration und tiefe Lieferkettenvorteile aus dem Chat-Fenster in die physische Welt. Die neue Standardregel lautet: In China entwickelt, weltweit verkauft, in den USA getestet (Quelle: MIT Technology Review)

Erster Fall von Pornografie durch KI-Dienste in China: Die rechtlichen Kosten der Umgehung von „Alignment“-Schutzmaßnahmen : Der Entwickler von AlienChat wurde strafrechtlich zur Verantwortung gezogen, weil er die KI zur Generierung pornografischer Inhalte verleitet hatte. Der entscheidende Punkt war, dass der Entwickler durch System-Prompts (Prompt Injection) gezielt die eingebauten Sicherheitsfilter des Modells umging. Dies ist ein Warnsignal für alle AI-Unternehmer: Das „Safe Harbor“-Prinzip zur Vermeidung von Regulierung bei AI-Halluzinationen gilt nicht bei vorsätzlicher Anstiftung zu Straftaten (Quelle: 36氪)